mirror of
https://github.com/halfrost/LeetCode-Go.git
synced 2025-07-07 18:10:29 +08:00
Compare commits
196 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| b012a1f9d5 | |||
| c28e1c0267 | |||
| fe99f9d7d5 | |||
| eb5eb51233 | |||
| 4d91e41bef | |||
| 7a90f3713d | |||
| 555737bcff | |||
| 5cf1b806b1 | |||
| 48cb642554 | |||
| fe13c6dc18 | |||
| b2a4f39401 | |||
| 259eba0c84 | |||
| aa8912611f | |||
| dbdc464dee | |||
| 640dc700a6 | |||
| d0c6f905f6 | |||
| 295504eb45 | |||
| cc78fdd0ef | |||
| c0191c235d | |||
| 60d3b04030 | |||
| 2104d8f332 | |||
| ec597e285d | |||
| d61a0226b8 | |||
| 135754159e | |||
| 9e357544d1 | |||
| 3dac8b9e82 | |||
| 9fb39146b7 | |||
| e256d74761 | |||
| 5cd43244e9 | |||
| cff768e63c | |||
| ad3dfff270 | |||
| 7ca6279850 | |||
| 44eddae9d0 | |||
| 95eddf7a24 | |||
| 889e495992 | |||
| 22e9be3663 | |||
| 11f3e13688 | |||
| 315d4fa8d8 | |||
| 7a3fe1fed2 | |||
| 00b6d1a6ca | |||
| 38875b19fb | |||
| 44c68a333a | |||
| 6d2d38e124 | |||
| 851e0eaad5 | |||
| d5aacae9d2 | |||
| 58f6f7fedb | |||
| 9dbefba7cd | |||
| 991cb6e3d7 | |||
| 4330393c9b | |||
| cd5572f250 | |||
| 776fe07932 | |||
| 36f3a4c757 | |||
| 86370c1ac5 | |||
| bb50f33fec | |||
| be276a58dc | |||
| 0d64196cf1 | |||
| 5e77733f1a | |||
| 851946dc9a | |||
| e72e4cb599 | |||
| 40201dceb1 | |||
| e3304f5a83 | |||
| 3c1176be43 | |||
| 012999a33b | |||
| 2a164310be | |||
| 9347140480 | |||
| 87c5b40454 | |||
| 9a30c0094e | |||
| 09c6e478e1 | |||
| 98c5414092 | |||
| 76753e8ca6 | |||
| a10cebc033 | |||
| 5f6ea09570 | |||
| 2a115eccc3 | |||
| 2450cf4dd0 | |||
| 1835b6dd45 | |||
| 24829288bb | |||
| 624a9ae9e6 | |||
| 70aafb68d4 | |||
| 0c817666f5 | |||
| 99fe55c7df | |||
| 65f4c4f060 | |||
| 1071ae0455 | |||
| 3d5df51382 | |||
| 4abb13e6ca | |||
| 9c0603ea84 | |||
| dd99c2c7e1 | |||
| bff8947a8b | |||
| 678bc75719 | |||
| 86856f687a | |||
| 1eb4bf698a | |||
| 594af3f4d8 | |||
| 0f1bb00e62 | |||
| 01ce0fd9b1 | |||
| 099e31ea64 | |||
| 97b5aaf1c2 | |||
| 87c8048afb | |||
| 2d5005a24a | |||
| 263ca6e3b7 | |||
| 8f1f1db6f2 | |||
| 0a614a0e79 | |||
| d27ca9bd0a | |||
| 6fcc9ec669 | |||
| 0a87bb5a02 | |||
| f92ac03f8f | |||
| 4be7d82168 | |||
| 45fb40ee7f | |||
| 1cdbefdc9c | |||
| fd409dcbd1 | |||
| 8a14f2c734 | |||
| 732095c59a | |||
| d4d5a20eb1 | |||
| e0aed6a035 | |||
| 19e5c7e9c9 | |||
| ebd8951db4 | |||
| 4e6a1e3287 | |||
| 370ec68c76 | |||
| 8ee289c17c | |||
| 5fbca5f096 | |||
| 4c59f10469 | |||
| 18e6d08e93 | |||
| 784e731c77 | |||
| 09463eee6f | |||
| ec4cc41102 | |||
| d3c556bb5d | |||
| 86fac4e139 | |||
| 7f0a3b514f | |||
| 7cbef318e1 | |||
| 541ec13f70 | |||
| 8b5785532a | |||
| 858198e385 | |||
| d47c2ec4c3 | |||
| 8ded561341 | |||
| a8f9bfb98c | |||
| 1376328b0b | |||
| dab1f90a2f | |||
| ce600d6822 | |||
| f376eaf316 | |||
| a15f91f029 | |||
| a6ee37ebef | |||
| eb2331edb6 | |||
| c5a6ac4b11 | |||
| 58dcf6b469 | |||
| ce93f89531 | |||
| 6d37f59f97 | |||
| 9bd6121476 | |||
| 99cea18cc6 | |||
| d798338426 | |||
| 3fc7e9c543 | |||
| 984b06f29c | |||
| 417635f58c | |||
| aa5bccb403 | |||
| b4d7a80343 | |||
| e10eaa99f8 | |||
| 427b25d4b7 | |||
| 1781d4e7a5 | |||
| 0c519027d4 | |||
| fec98dba7f | |||
| 613fa9aa92 | |||
| fe7d9845bd | |||
| 23a0f0a2b4 | |||
| 031d96b369 | |||
| 1cd9cec988 | |||
| 89af12786a | |||
| c92b576018 | |||
| 096f514b66 | |||
| 6cbaad13b1 | |||
| c30c6c7f41 | |||
| 943d558ca8 | |||
| 53e10a59c1 | |||
| 8bb84f2edc | |||
| a841eac968 | |||
| 1eac64966f | |||
| 2e7dd977c4 | |||
| 11e38a651e | |||
| 21fda4f75f | |||
| 3f3026ca05 | |||
| 66e690a277 | |||
| 87c1060ef5 | |||
| ee741232d4 | |||
| f0c5270f84 | |||
| a7a40da0aa | |||
| b4eab90b74 | |||
| c839a96874 | |||
| cf841b821b | |||
| fd62b9f721 | |||
| d12dde092f | |||
| 075d7ba884 | |||
| 4dc97cd730 | |||
| 6c7d4fb59a | |||
| 28b422f87f | |||
| 8e01a1c176 | |||
| 2af901862f | |||
| 5a2331afd4 | |||
| be7fe42dcd | |||
| 86e61e9dc6 | |||
| 917d613465 |
1
.gitignore
vendored
1
.gitignore
vendored
@ -1 +1,2 @@
|
||||
*.toml
|
||||
.idea
|
||||
|
||||
15
ctl/label.go
15
ctl/label.go
@ -4,18 +4,19 @@ import (
|
||||
"bufio"
|
||||
"errors"
|
||||
"fmt"
|
||||
"github.com/halfrost/LeetCode-Go/ctl/util"
|
||||
"github.com/spf13/cobra"
|
||||
"io"
|
||||
"io/ioutil"
|
||||
"os"
|
||||
"regexp"
|
||||
"strings"
|
||||
|
||||
"github.com/halfrost/LeetCode-Go/ctl/util"
|
||||
"github.com/spf13/cobra"
|
||||
)
|
||||
|
||||
var (
|
||||
chapterOneFileOrder = []string{"_index", "Data_Structure", "Algorithm"}
|
||||
chapterOneMenuOrder = []string{"_index", "#关于作者", "Data_Structure", "Algorithm"}
|
||||
chapterOneFileOrder = []string{"_index", "Data_Structure", "Algorithm", "Time_Complexity"}
|
||||
chapterOneMenuOrder = []string{"_index", "#关于作者", "Data_Structure", "Algorithm", "Time_Complexity"}
|
||||
chapterTwoFileOrder = []string{"_index", "Array", "String", "Two_Pointers", "Linked_List", "Stack", "Tree", "Dynamic_Programming", "Backtracking", "Depth_First_Search", "Breadth_First_Search",
|
||||
"Binary_Search", "Math", "Hash_Table", "Sort", "Bit_Manipulation", "Union_Find", "Sliding_Window", "Segment_Tree", "Binary_Indexed_Tree"}
|
||||
chapterThreeFileOrder = []string{"_index", "Segment_Tree", "UnionFind", "LRUCache", "LFUCache"}
|
||||
@ -35,9 +36,9 @@ var (
|
||||
chapterMap = map[string]map[string]string{
|
||||
"ChapterOne": {
|
||||
"_index": "第一章 序章",
|
||||
"#关于作者": "1.1 关于作者",
|
||||
"Data_Structure": "1.2 数据结构知识",
|
||||
"Algorithm": "1.3 算法知识",
|
||||
"Data_Structure": "1.1 数据结构知识",
|
||||
"Algorithm": "1.2 算法知识",
|
||||
"Time_Complexity": "1.3 时间复杂度",
|
||||
},
|
||||
"ChapterTwo": {
|
||||
"_index": "第二章 算法专题",
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
|56. Merge Intervals | [Go]({{< relref "/ChapterFour/0056.Merge-Intervals.md" >}})| Medium | O(n log n)| O(log n)||
|
||||
|57. Insert Interval | [Go]({{< relref "/ChapterFour/0057.Insert-Interval.md" >}})| Hard | O(n)| O(1)||
|
||||
|75. Sort Colors | [Go]({{< relref "/ChapterFour/0075.Sort-Colors.md" >}})| Medium| O(n)| O(1)|❤️|
|
||||
|147. Insertion Sort List | [Go]({{< relref "/ChapterFour/0147.Insertion-Sort-List.md" >}})| Medium | O(n)| O(1) |❤️|
|
||||
|147. Insertion Sort List | [Go]({{< relref "/ChapterFour/0147.Insertion-Sort-List.md" >}})| Medium | O(n^2)| O(1) |❤️|
|
||||
|148. Sort List | [Go]({{< relref "/ChapterFour/0148.Sort-List.md" >}})| Medium |O(n log n)| O(log n)|❤️|
|
||||
|164. Maximum Gap | [Go]({{< relref "/ChapterFour/0164.Maximum-Gap.md" >}})| Hard | O(n log n)| O(log n) |❤️|
|
||||
|179. Largest Number | [Go]({{< relref "/ChapterFour/0179.Largest-Number.md" >}})| Medium | O(n log n)| O(log n) |❤️|
|
||||
|
||||
@ -18,15 +18,38 @@ type Mdrow struct {
|
||||
|
||||
// GenerateMdRows define
|
||||
func GenerateMdRows(solutionIds []int, mdrows []Mdrow) {
|
||||
mdMap := map[int]Mdrow{}
|
||||
for _, row := range mdrows {
|
||||
mdMap[int(row.FrontendQuestionID)] = row
|
||||
}
|
||||
for i := 0; i < len(solutionIds); i++ {
|
||||
id := mdrows[solutionIds[i]-1].FrontendQuestionID
|
||||
if solutionIds[i] == int(id) {
|
||||
//fmt.Printf("id = %v i = %v solutionIds = %v\n", id, i, solutionIds[i])
|
||||
mdrows[id-1].SolutionPath = fmt.Sprintf("[Go](https://github.com/halfrost/LeetCode-Go/tree/master/leetcode/%v)", fmt.Sprintf("%04d.%v", id, strings.Replace(strings.TrimSpace(mdrows[id-1].QuestionTitle), " ", "-", -1)))
|
||||
if row, ok := mdMap[solutionIds[i]]; ok {
|
||||
s7 := standardizedTitle(row.QuestionTitle, row.FrontendQuestionID)
|
||||
mdMap[solutionIds[i]] = Mdrow{
|
||||
FrontendQuestionID: row.FrontendQuestionID,
|
||||
QuestionTitle: strings.TrimSpace(row.QuestionTitle),
|
||||
QuestionTitleSlug: row.QuestionTitleSlug,
|
||||
SolutionPath: fmt.Sprintf("[Go](https://github.com/halfrost/LeetCode-Go/tree/master/leetcode/%v)", fmt.Sprintf("%04d.%v", solutionIds[i], s7)),
|
||||
Acceptance: row.Acceptance,
|
||||
Difficulty: row.Difficulty,
|
||||
Frequency: row.Frequency,
|
||||
}
|
||||
} else {
|
||||
fmt.Printf("序号出错了 solutionIds = %v id = %v\n", solutionIds[i], id)
|
||||
fmt.Printf("序号不存在 len(solutionIds) = %v len(mdrows) = %v len(solutionIds) = %v solutionIds[i] = %v QuestionTitle = %v\n", len(solutionIds), len(mdrows), len(solutionIds), solutionIds[i], mdrows[solutionIds[i]-1].QuestionTitle)
|
||||
}
|
||||
}
|
||||
for i := range mdrows {
|
||||
mdrows[i] = Mdrow{
|
||||
FrontendQuestionID: mdrows[i].FrontendQuestionID,
|
||||
QuestionTitle: strings.TrimSpace(mdrows[i].QuestionTitle),
|
||||
QuestionTitleSlug: mdrows[i].QuestionTitleSlug,
|
||||
SolutionPath: mdMap[int(mdrows[i].FrontendQuestionID)].SolutionPath,
|
||||
Acceptance: mdrows[i].Acceptance,
|
||||
Difficulty: mdrows[i].Difficulty,
|
||||
Frequency: mdrows[i].Frequency,
|
||||
}
|
||||
}
|
||||
// fmt.Printf("mdrows = %v\n\n", mdrows)
|
||||
}
|
||||
|
||||
// | 0001 | Two Sum | [Go](https://github.com/halfrost/LeetCode-Go/tree/master/leetcode/0001.Two-Sum)| 45.6% | Easy | |
|
||||
|
||||
@ -115,6 +115,41 @@ func (t TagList) tableLine() string {
|
||||
return fmt.Sprintf("|%04d|%v|%v|%v|%v|%v|%v|%v|\n", t.FrontendQuestionID, t.QuestionTitle, t.SolutionPath, t.Difficulty, t.TimeComplexity, t.SpaceComplexity, t.Favorite, t.Acceptance)
|
||||
}
|
||||
|
||||
func standardizedTitle(orig string, frontendQuestionID int32) string {
|
||||
s0 := strings.TrimSpace(orig)
|
||||
s1 := strings.Replace(s0, " ", "-", -1)
|
||||
s2 := strings.Replace(s1, "'", "", -1)
|
||||
s3 := strings.Replace(s2, "%", "", -1)
|
||||
s4 := strings.Replace(s3, "(", "", -1)
|
||||
s5 := strings.Replace(s4, ")", "", -1)
|
||||
s6 := strings.Replace(s5, ",", "", -1)
|
||||
s7 := strings.Replace(s6, "?", "", -1)
|
||||
count := 0
|
||||
// 去掉 --- 这种情况,这种情况是由于题目标题中包含 - ,左右有空格,左右一填充,造成了 ---,3 个 -
|
||||
for i := 0; i < len(s7)-2; i++ {
|
||||
if s7[i] == '-' && s7[i+1] == '-' && s7[i+2] == '-' {
|
||||
fmt.Printf("【需要修正 --- 的标题是 %v】\n", fmt.Sprintf("%04d.%v", int(frontendQuestionID), s7))
|
||||
s7 = s7[:i+1] + s7[i+3:]
|
||||
count++
|
||||
}
|
||||
}
|
||||
if count > 0 {
|
||||
fmt.Printf("总共修正了 %v 个标题\n", count)
|
||||
}
|
||||
// 去掉 -- 这种情况,这种情况是由于题目标题中包含负号 -
|
||||
for i := 0; i < len(s7)-2; i++ {
|
||||
if s7[i] == '-' && s7[i+1] == '-' {
|
||||
fmt.Printf("【需要修正 -- 的标题是 %v】\n", fmt.Sprintf("%04d.%v", int(frontendQuestionID), s7))
|
||||
s7 = s7[:i+1] + s7[i+2:]
|
||||
count++
|
||||
}
|
||||
}
|
||||
if count > 0 {
|
||||
fmt.Printf("总共修正了 %v 个标题\n", count)
|
||||
}
|
||||
return s7
|
||||
}
|
||||
|
||||
// GenerateTagMdRows define
|
||||
func GenerateTagMdRows(solutionIds []int, metaMap map[int]TagList, mdrows []Mdrow, internal bool) []TagList {
|
||||
tl := []TagList{}
|
||||
@ -123,13 +158,7 @@ func GenerateTagMdRows(solutionIds []int, metaMap map[int]TagList, mdrows []Mdro
|
||||
tmp := TagList{}
|
||||
tmp.FrontendQuestionID = row.FrontendQuestionID
|
||||
tmp.QuestionTitle = strings.TrimSpace(row.QuestionTitle)
|
||||
s1 := strings.Replace(tmp.QuestionTitle, " ", "-", -1)
|
||||
s2 := strings.Replace(s1, "'", "", -1)
|
||||
s3 := strings.Replace(s2, "%", "", -1)
|
||||
s4 := strings.Replace(s3, "(", "", -1)
|
||||
s5 := strings.Replace(s4, ")", "", -1)
|
||||
s6 := strings.Replace(s5, ",", "", -1)
|
||||
s7 := strings.Replace(s6, "?", "", -1)
|
||||
s7 := standardizedTitle(row.QuestionTitle, row.FrontendQuestionID)
|
||||
if internal {
|
||||
tmp.SolutionPath = fmt.Sprintf("[Go]({{< relref \"/ChapterFour/%v/%v.md\" >}})", util.GetChpaterFourFileNum(int(row.FrontendQuestionID)), fmt.Sprintf("%04d.%v", int(row.FrontendQuestionID), s7))
|
||||
} else {
|
||||
|
||||
@ -16,6 +16,7 @@
|
||||
<a href="https://travis-ci.org/github/halfrost/LeetCode-Go" rel="nofollow"><img src="https://travis-ci.org/halfrost/LeetCode-Go.svg?branch=master"></a>
|
||||
<a href="https://goreportcard.com/report/github.com/halfrost/LeetCode-Go" rel="nofollow"><img src="https://goreportcard.com/badge/github.com/halfrost/LeetCode-Go"></a>
|
||||
<img src="https://img.shields.io/badge/runtime%20beats-100%25-success">
|
||||
<a href="https://codecov.io/gh/halfrost/LeetCode-Go"><img src="https://codecov.io/gh/halfrost/LeetCode-Go/branch/master/graph/badge.svg" /></a>
|
||||
<!--<img alt="GitHub go.mod Go version" src="https://img.shields.io/github/go-mod/go-version/halfrost/LeetCode-Go?color=26C2F0">-->
|
||||
<img alt="Support Go version" src="https://img.shields.io/badge/Go-v1.15-26C2F0">
|
||||
<img src="https://visitor-badge.laobi.icu/badge?page_id=halfrost.LeetCode-Go">
|
||||
|
||||
@ -27,7 +27,7 @@ func lengthOfLongestSubstring(s string) int {
|
||||
}
|
||||
|
||||
// 解法二 滑动窗口
|
||||
func lengthOfLongestSubstring_(s string) int {
|
||||
func lengthOfLongestSubstring1(s string) int {
|
||||
if len(s) == 0 {
|
||||
return 0
|
||||
}
|
||||
@ -47,6 +47,21 @@ func lengthOfLongestSubstring_(s string) int {
|
||||
return result
|
||||
}
|
||||
|
||||
// 解法三 滑动窗口-哈希桶
|
||||
func lengthOfLongestSubstring2(s string) int {
|
||||
right, left, res := 0, 0, 0
|
||||
indexes := make(map[byte]int, len(s))
|
||||
for left < len(s) {
|
||||
if idx, ok := indexes[s[left]]; ok && idx >= right {
|
||||
right = idx + 1
|
||||
}
|
||||
indexes[s[left]] = left
|
||||
left++
|
||||
res = max(res, left-right)
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func max(a int, b int) int {
|
||||
if a > b {
|
||||
return a
|
||||
|
||||
@ -51,7 +51,7 @@ func Test_Problem3(t *testing.T) {
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans3, q.para3
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, lengthOfLongestSubstring_(p.s))
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, lengthOfLongestSubstring(p.s))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
|
||||
@ -39,7 +39,7 @@ You may assume **nums1** and **nums2** cannot be both empty.
|
||||
|
||||
|
||||
- 给出两个有序数组,要求找出这两个数组合并以后的有序数组中的中位数。要求时间复杂度为 O(log (m+n))。
|
||||
- 这一题最容易想到的办法是把两个数组合并,然后取出中位数。但是合并有序数组的操作是 `O(max(n,m))` 的,不符合题意。看到题目给的 `log` 的时间复杂度,很容易联想到二分搜索。
|
||||
- 这一题最容易想到的办法是把两个数组合并,然后取出中位数。但是合并有序数组的操作是 `O(m+n)` 的,不符合题意。看到题目给的 `log` 的时间复杂度,很容易联想到二分搜索。
|
||||
- 由于要找到最终合并以后数组的中位数,两个数组的总大小也知道,所以中间这个位置也是知道的。只需要二分搜索一个数组中切分的位置,另一个数组中切分的位置也能得到。为了使得时间复杂度最小,所以二分搜索两个数组中长度较小的那个数组。
|
||||
- 关键的问题是如何切分数组 1 和数组 2 。其实就是如何切分数组 1 。先随便二分产生一个 `midA`,切分的线何时算满足了中位数的条件呢?即,线左边的数都小于右边的数,即,`nums1[midA-1] ≤ nums2[midB] && nums2[midB-1] ≤ nums1[midA]` 。如果这些条件都不满足,切分线就需要调整。如果 `nums1[midA] < nums2[midB-1]`,说明 `midA` 这条线划分出来左边的数小了,切分线应该右移;如果 `nums1[midA-1] > nums2[midB]`,说明 midA 这条线划分出来左边的数大了,切分线应该左移。经过多次调整以后,切分线总能找到满足条件的解。
|
||||
- 假设现在找到了切分的两条线了,`数组 1` 在切分线两边的下标分别是 `midA - 1` 和 `midA`。`数组 2` 在切分线两边的下标分别是 `midB - 1` 和 `midB`。最终合并成最终数组,如果数组长度是奇数,那么中位数就是 `max(nums1[midA-1], nums2[midB-1])`。如果数组长度是偶数,那么中间位置的两个数依次是:`max(nums1[midA-1], nums2[midB-1])` 和 `min(nums1[midA], nums2[midB])`,那么中位数就是 `(max(nums1[midA-1], nums2[midB-1]) + min(nums1[midA], nums2[midB])) / 2`。图示见下图:
|
||||
|
||||
@ -0,0 +1,117 @@
|
||||
package leetcode
|
||||
|
||||
// 解法一 Manacher's algorithm,时间复杂度 O(n),空间复杂度 O(n)
|
||||
func longestPalindrome(s string) string {
|
||||
if len(s) < 2 {
|
||||
return s
|
||||
}
|
||||
newS := make([]rune, 0)
|
||||
newS = append(newS, '#')
|
||||
for _, c := range s {
|
||||
newS = append(newS, c)
|
||||
newS = append(newS, '#')
|
||||
}
|
||||
// dp[i]: 以预处理字符串下标 i 为中心的回文半径(奇数长度时不包括中心)
|
||||
// maxRight: 通过中心扩散的方式能够扩散的最右边的下标
|
||||
// center: 与 maxRight 对应的中心字符的下标
|
||||
// maxLen: 记录最长回文串的半径
|
||||
// begin: 记录最长回文串在起始串 s 中的起始下标
|
||||
dp, maxRight, center, maxLen, begin := make([]int, len(newS)), 0, 0, 1, 0
|
||||
for i := 0; i < len(newS); i++ {
|
||||
if i < maxRight {
|
||||
// 这一行代码是 Manacher 算法的关键所在
|
||||
dp[i] = min(maxRight-i, dp[2*center-i])
|
||||
}
|
||||
// 中心扩散法更新 dp[i]
|
||||
left, right := i-(1+dp[i]), i+(1+dp[i])
|
||||
for left >= 0 && right < len(newS) && newS[left] == newS[right] {
|
||||
dp[i]++
|
||||
left--
|
||||
right++
|
||||
}
|
||||
// 更新 maxRight,它是遍历过的 i 的 i + dp[i] 的最大者
|
||||
if i+dp[i] > maxRight {
|
||||
maxRight = i + dp[i]
|
||||
center = i
|
||||
}
|
||||
// 记录最长回文子串的长度和相应它在原始字符串中的起点
|
||||
if dp[i] > maxLen {
|
||||
maxLen = dp[i]
|
||||
begin = (i - maxLen) / 2 // 这里要除以 2 因为有我们插入的辅助字符 #
|
||||
}
|
||||
}
|
||||
return s[begin : begin+maxLen]
|
||||
}
|
||||
|
||||
func min(x, y int) int {
|
||||
if x < y {
|
||||
return x
|
||||
}
|
||||
return y
|
||||
}
|
||||
|
||||
// 解法二 滑动窗口,时间复杂度 O(n^2),空间复杂度 O(1)
|
||||
func longestPalindrome1(s string) string {
|
||||
if len(s) == 0 {
|
||||
return ""
|
||||
}
|
||||
left, right, pl, pr := 0, -1, 0, 0
|
||||
for left < len(s) {
|
||||
// 移动到相同字母的最右边(如果有相同字母)
|
||||
for right+1 < len(s) && s[left] == s[right+1] {
|
||||
right++
|
||||
}
|
||||
// 找到回文的边界
|
||||
for left-1 >= 0 && right+1 < len(s) && s[left-1] == s[right+1] {
|
||||
left--
|
||||
right++
|
||||
}
|
||||
if right-left > pr-pl {
|
||||
pl, pr = left, right
|
||||
}
|
||||
// 重置到下一次寻找回文的中心
|
||||
left = (left+right)/2 + 1
|
||||
right = left
|
||||
}
|
||||
return s[pl : pr+1]
|
||||
}
|
||||
|
||||
// 解法三 中心扩散法,时间复杂度 O(n^2),空间复杂度 O(1)
|
||||
func longestPalindrome2(s string) string {
|
||||
res := ""
|
||||
for i := 0; i < len(s); i++ {
|
||||
res = maxPalindrome(s, i, i, res)
|
||||
res = maxPalindrome(s, i, i+1, res)
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func maxPalindrome(s string, i, j int, res string) string {
|
||||
sub := ""
|
||||
for i >= 0 && j < len(s) && s[i] == s[j] {
|
||||
sub = s[i : j+1]
|
||||
i--
|
||||
j++
|
||||
}
|
||||
if len(res) < len(sub) {
|
||||
return sub
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
// 解法四 DP,时间复杂度 O(n^2),空间复杂度 O(n^2)
|
||||
func longestPalindrome3(s string) string {
|
||||
res, dp := "", make([][]bool, len(s))
|
||||
for i := 0; i < len(s); i++ {
|
||||
dp[i] = make([]bool, len(s))
|
||||
}
|
||||
for i := len(s) - 1; i >= 0; i-- {
|
||||
for j := i; j < len(s); j++ {
|
||||
dp[i][j] = (s[i] == s[j]) && ((j-i < 3) || dp[i+1][j-1])
|
||||
if dp[i][j] && (res == "" || j-i+1 > len(res)) {
|
||||
res = s[i : j+1]
|
||||
}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
@ -0,0 +1,67 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question5 struct {
|
||||
para5
|
||||
ans5
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para5 struct {
|
||||
s string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans5 struct {
|
||||
one string
|
||||
}
|
||||
|
||||
func Test_Problem5(t *testing.T) {
|
||||
|
||||
qs := []question5{
|
||||
|
||||
{
|
||||
para5{"babad"},
|
||||
ans5{"bab"},
|
||||
},
|
||||
|
||||
{
|
||||
para5{"cbbd"},
|
||||
ans5{"bb"},
|
||||
},
|
||||
|
||||
{
|
||||
para5{"a"},
|
||||
ans5{"a"},
|
||||
},
|
||||
|
||||
{
|
||||
para5{"ac"},
|
||||
ans5{"a"},
|
||||
},
|
||||
|
||||
{
|
||||
para5{"aa"},
|
||||
ans5{"aa"},
|
||||
},
|
||||
|
||||
{
|
||||
para5{"ajgiljtperkvubjmdsefcylksrxtftqrehoitdgdtttswwttmfuvwgwrruuqmxttzsbmuhgfaoueumvbhajqsaxkkihjwevzzedizmrsmpxqavyryklbotwzngxscvyuqjkkaotitddlhhnutmotupwuwyltebtsdfssbwayuxrbgihmtphshdslktvsjadaykyjivbzhwujcdvzdxxfiixnzrmusqvwujjmxhbqbdpauacnzojnzxxgrkmupadfcsujkcwajsgintahwgbjnvjqubcxajdyyapposrkpqtpqfjcvbhlmwfutgognqxgaukpmdyaxghgoqkqnigcllachmwzrazwhpppmsodvxilrccfqgpkmdqhoorxpyjsrtbeeidsinpeyxxpsjnymxkouskyhenzgieybwkgzrhhrzgkwbyeigznehyksuokxmynjspxxyepnisdieebtrsjypxroohqdmkpgqfccrlixvdosmppphwzarzwmhcallcginqkqoghgxaydmpkuagxqngogtufwmlhbvcjfqptqpkrsoppayydjaxcbuqjvnjbgwhatnigsjawckjuscfdapumkrgxxznjozncauapdbqbhxmjjuwvqsumrznxiifxxdzvdcjuwhzbvijykyadajsvtklsdhshptmhigbrxuyawbssfdstbetlywuwputomtunhhlddtitoakkjquyvcsxgnzwtoblkyryvaqxpmsrmzidezzvewjhikkxasqjahbvmueuoafghumbszttxmquurrwgwvufmttwwstttdgdtioherqtftxrsklycfesdmjbuvkreptjligja"},
|
||||
ans5{"ajgiljtperkvubjmdsefcylksrxtftqrehoitdgdtttswwttmfuvwgwrruuqmxttzsbmuhgfaoueumvbhajqsaxkkihjwevzzedizmrsmpxqavyryklbotwzngxscvyuqjkkaotitddlhhnutmotupwuwyltebtsdfssbwayuxrbgihmtphshdslktvsjadaykyjivbzhwujcdvzdxxfiixnzrmusqvwujjmxhbqbdpauacnzojnzxxgrkmupadfcsujkcwajsgintahwgbjnvjqubcxajdyyapposrkpqtpqfjcvbhlmwfutgognqxgaukpmdyaxghgoqkqnigcllachmwzrazwhpppmsodvxilrccfqgpkmdqhoorxpyjsrtbeeidsinpeyxxpsjnymxkouskyhenzgieybwkgzrhhrzgkwbyeigznehyksuokxmynjspxxyepnisdieebtrsjypxroohqdmkpgqfccrlixvdosmppphwzarzwmhcallcginqkqoghgxaydmpkuagxqngogtufwmlhbvcjfqptqpkrsoppayydjaxcbuqjvnjbgwhatnigsjawckjuscfdapumkrgxxznjozncauapdbqbhxmjjuwvqsumrznxiifxxdzvdcjuwhzbvijykyadajsvtklsdhshptmhigbrxuyawbssfdstbetlywuwputomtunhhlddtitoakkjquyvcsxgnzwtoblkyryvaqxpmsrmzidezzvewjhikkxasqjahbvmueuoafghumbszttxmquurrwgwvufmttwwstttdgdtioherqtftxrsklycfesdmjbuvkreptjligja"},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 5------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans5, q.para5
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, longestPalindrome(p.s))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
186
leetcode/0005.Longest-Palindromic-Substring/README.md
Normal file
186
leetcode/0005.Longest-Palindromic-Substring/README.md
Normal file
@ -0,0 +1,186 @@
|
||||
# [5. Longest Palindromic Substring](https://leetcode.com/problems/longest-palindromic-substring/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given a string `s`, return *the longest palindromic substring* in `s`.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: s = "babad"
|
||||
Output: "bab"
|
||||
Note: "aba" is also a valid answer.
|
||||
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: s = "cbbd"
|
||||
Output: "bb"
|
||||
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: s = "a"
|
||||
Output: "a"
|
||||
|
||||
```
|
||||
|
||||
**Example 4:**
|
||||
|
||||
```
|
||||
Input: s = "ac"
|
||||
Output: "a"
|
||||
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= s.length <= 1000`
|
||||
- `s` consist of only digits and English letters (lower-case and/or upper-case),
|
||||
|
||||
## 题目大意
|
||||
|
||||
给你一个字符串 `s`,找到 `s` 中最长的回文子串。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 此题非常经典,并且有多种解法。
|
||||
- 解法一,动态规划。定义 `dp[i][j]` 表示从字符串第 `i` 个字符到第 `j` 个字符这一段子串是否是回文串。由回文串的性质可以得知,回文串去掉一头一尾相同的字符以后,剩下的还是回文串。所以状态转移方程是 `dp[i][j] = (s[i] == s[j]) && ((j-i < 3) || dp[i+1][j-1])`,注意特殊的情况,`j - i == 1` 的时候,即只有 2 个字符的情况,只需要判断这 2 个字符是否相同即可。`j - i == 2` 的时候,即只有 3 个字符的情况,只需要判断除去中心以外对称的 2 个字符是否相等。每次循环动态维护保存最长回文串即可。时间复杂度 O(n^2),空间复杂度 O(n^2)。
|
||||
- 解法二,中心扩散法。动态规划的方法中,我们将任意起始,终止范围内的字符串都判断了一遍。其实没有这个必要,如果不是最长回文串,无需判断并保存结果。所以动态规划的方法在空间复杂度上还有优化空间。判断回文有一个核心问题是找到“轴心”。如果长度是偶数,那么轴心是中心虚拟的,如果长度是奇数,那么轴心正好是正中心的那个字母。中心扩散法的思想是枚举每个轴心的位置。然后做两次假设,假设最长回文串是偶数,那么以虚拟中心往 2 边扩散;假设最长回文串是奇数,那么以正中心的字符往 2 边扩散。扩散的过程就是对称判断两边字符是否相等的过程。这个方法时间复杂度和动态规划是一样的,但是空间复杂度降低了。时间复杂度 O(n^2),空间复杂度 O(1)。
|
||||
- 解法三,滑动窗口。这个写法其实就是中心扩散法变了一个写法。中心扩散是依次枚举每一个轴心。滑动窗口的方法稍微优化了一点,有些轴心两边字符不相等,下次就不会枚举这些不可能形成回文子串的轴心了。不过这点优化并没有优化时间复杂度,时间复杂度 O(n^2),空间复杂度 O(1)。
|
||||
- 解法四,马拉车算法。这个算法是本题的最优解,也是最复杂的解法。时间复杂度 O(n),空间复杂度 O(n)。中心扩散法有 2 处有重复判断,第一处是每次都往两边扩散,不同中心扩散多次,实际上有很多重复判断的字符,能否不重复判断?第二处,中心能否跳跃选择,不是每次都枚举,是否可以利用前一次的信息,跳跃选择下一次的中心?马拉车算法针对重复判断的问题做了优化,增加了一个辅助数组,将时间复杂度从 O(n^2) 优化到了 O(n),空间换了时间,空间复杂度增加到 O(n)。
|
||||
|
||||
|
||||
|
||||
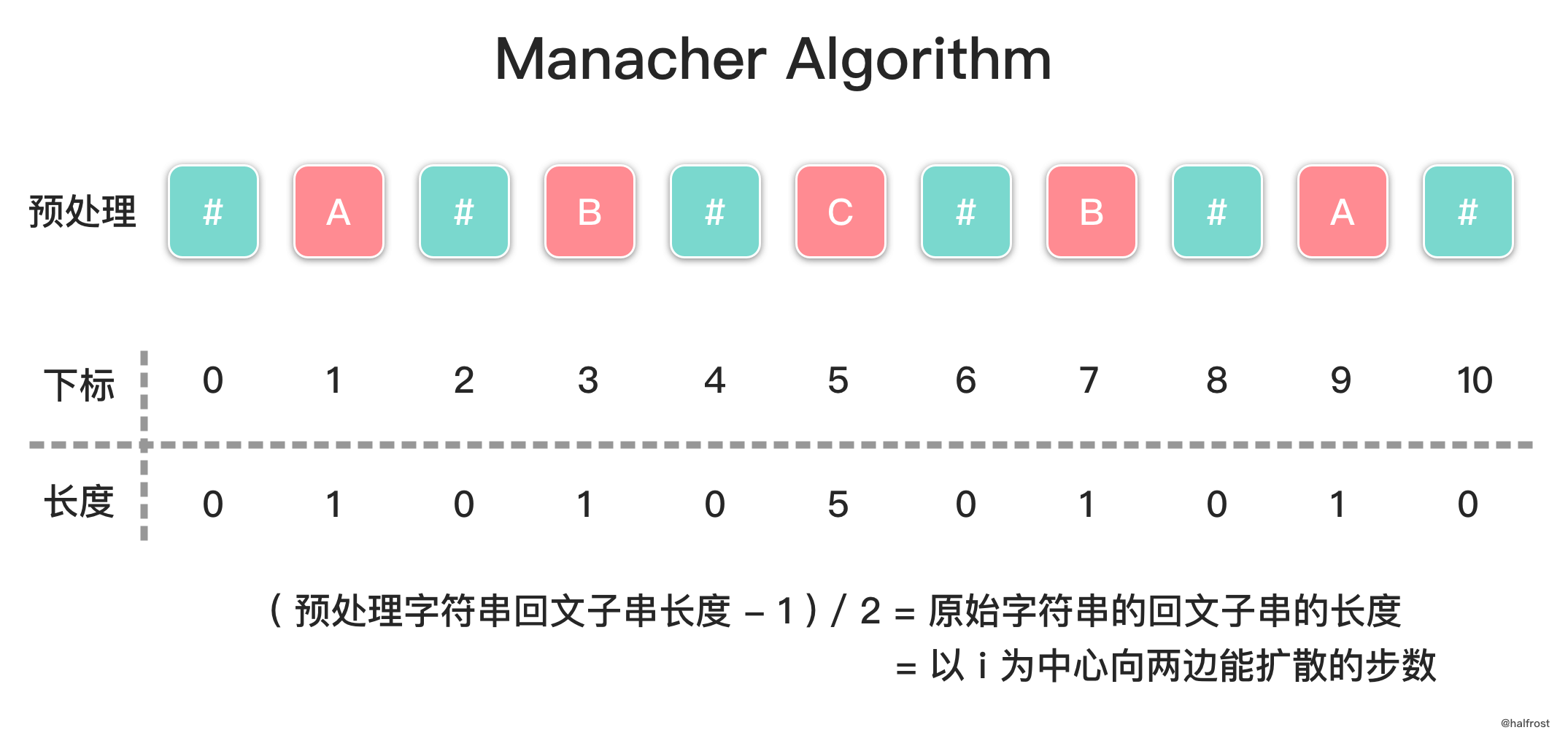
- 首先是预处理,向字符串的头尾以及每两个字符中间添加一个特殊字符 `#`,比如字符串 `aaba` 处理后会变成 `#a#a#b#a#`。那么原先长度为偶数的回文字符串 `aa` 会变成长度为奇数的回文字符串 `#a#a#`,而长度为奇数的回文字符串 `aba` 会变成长度仍然为奇数的回文字符串 `#a#b#a#`,经过预处理以后,都会变成长度为奇数的字符串。**注意这里的特殊字符不需要是没有出现过的字母,也可以使用任何一个字符来作为这个特殊字符。**这是因为,当我们只考虑长度为奇数的回文字符串时,每次我们比较的两个字符奇偶性一定是相同的,所以原来字符串中的字符不会与插入的特殊字符互相比较,不会因此产生问题。**预处理以后,以某个中心扩散的步数和实际字符串长度是相等的。**因为半径里面包含了插入的特殊字符,又由于左右对称的性质,所以扩散半径就等于原来回文子串的长度。
|
||||
|
||||
|
||||
|
||||
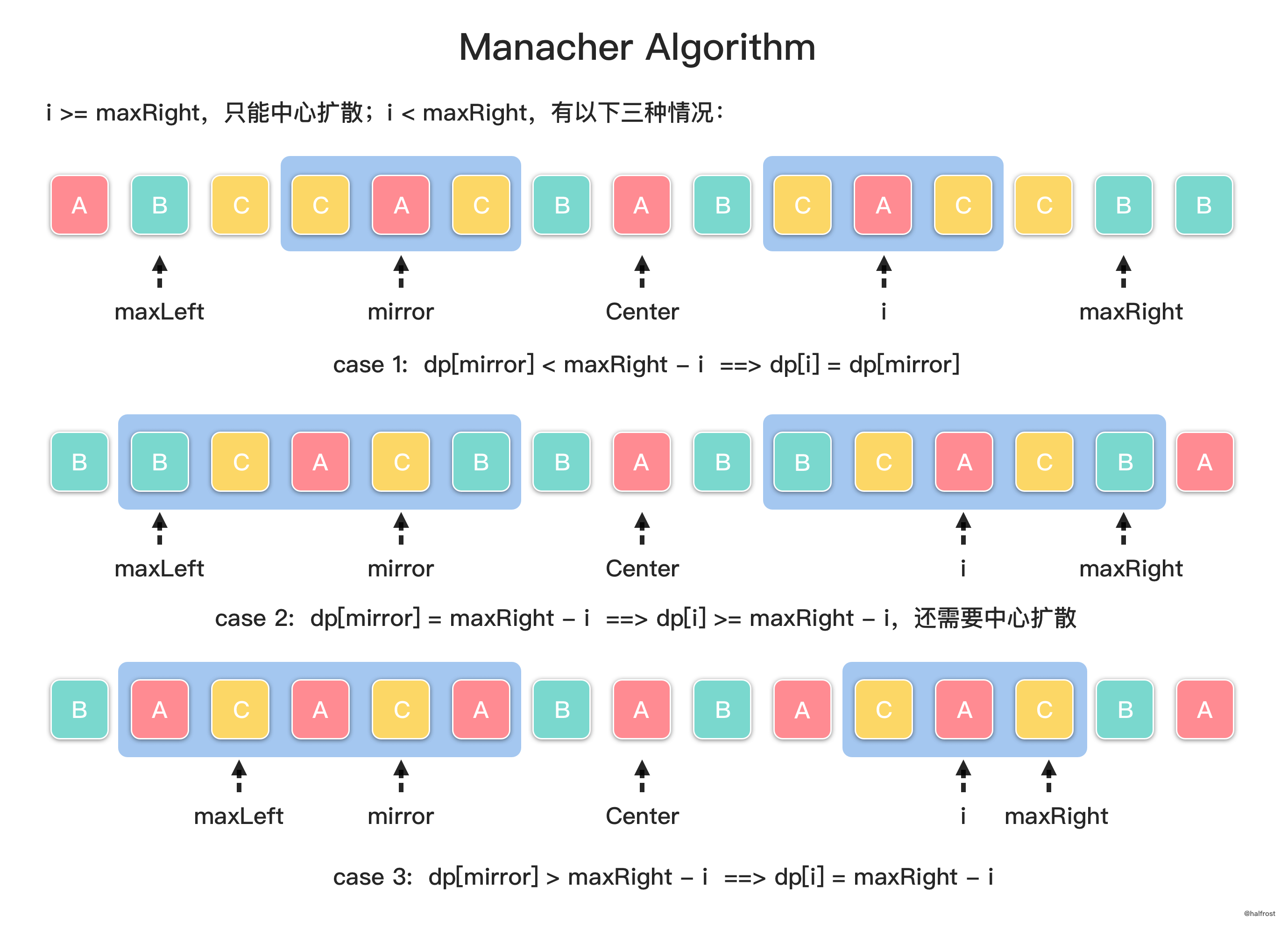
- 核心部分是如何通过左边已经扫描过的数据推出右边下一次要扩散的中心。这里定义下一次要扩散的中心下标是 `i`。如果 `i` 比 `maxRight` 要小,只能继续中心扩散。如果 `i` 比 `maxRight` 大,这是又分为 3 种情况。三种情况见上图。将上述 3 种情况总结起来,就是 :`dp[i] = min(maxRight-i, dp[2*center-i])`,其中,`mirror` 相对于 `center` 是和 `i` 中心对称的,所以它的下标可以计算出来是 `2*center-i`。更新完 `dp[i]` 以后,就要进行中心扩散了。中心扩散以后动态维护最长回文串并相应的更新 `center`,`maxRight`,并且记录下原始字符串的起始位置 `begin` 和 `maxLen`。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
// 解法一 Manacher's algorithm,时间复杂度 O(n),空间复杂度 O(n)
|
||||
func longestPalindrome(s string) string {
|
||||
if len(s) < 2 {
|
||||
return s
|
||||
}
|
||||
newS := make([]rune, 0)
|
||||
newS = append(newS, '#')
|
||||
for _, c := range s {
|
||||
newS = append(newS, c)
|
||||
newS = append(newS, '#')
|
||||
}
|
||||
// dp[i]: 以预处理字符串下标 i 为中心的回文半径(奇数长度时不包括中心)
|
||||
// maxRight: 通过中心扩散的方式能够扩散的最右边的下标
|
||||
// center: 与 maxRight 对应的中心字符的下标
|
||||
// maxLen: 记录最长回文串的半径
|
||||
// begin: 记录最长回文串在起始串 s 中的起始下标
|
||||
dp, maxRight, center, maxLen, begin := make([]int, len(newS)), 0, 0, 1, 0
|
||||
for i := 0; i < len(newS); i++ {
|
||||
if i < maxRight {
|
||||
// 这一行代码是 Manacher 算法的关键所在
|
||||
dp[i] = min(maxRight-i, dp[2*center-i])
|
||||
}
|
||||
// 中心扩散法更新 dp[i]
|
||||
left, right := i-(1+dp[i]), i+(1+dp[i])
|
||||
for left >= 0 && right < len(newS) && newS[left] == newS[right] {
|
||||
dp[i]++
|
||||
left--
|
||||
right++
|
||||
}
|
||||
// 更新 maxRight,它是遍历过的 i 的 i + dp[i] 的最大者
|
||||
if i+dp[i] > maxRight {
|
||||
maxRight = i + dp[i]
|
||||
center = i
|
||||
}
|
||||
// 记录最长回文子串的长度和相应它在原始字符串中的起点
|
||||
if dp[i] > maxLen {
|
||||
maxLen = dp[i]
|
||||
begin = (i - maxLen) / 2 // 这里要除以 2 因为有我们插入的辅助字符 #
|
||||
}
|
||||
}
|
||||
return s[begin : begin+maxLen]
|
||||
}
|
||||
|
||||
func min(x, y int) int {
|
||||
if x < y {
|
||||
return x
|
||||
}
|
||||
return y
|
||||
}
|
||||
|
||||
// 解法二 滑动窗口,时间复杂度 O(n^2),空间复杂度 O(1)
|
||||
func longestPalindrome1(s string) string {
|
||||
if len(s) == 0 {
|
||||
return ""
|
||||
}
|
||||
left, right, pl, pr := 0, -1, 0, 0
|
||||
for left < len(s) {
|
||||
// 移动到相同字母的最右边(如果有相同字母)
|
||||
for right+1 < len(s) && s[left] == s[right+1] {
|
||||
right++
|
||||
}
|
||||
// 找到回文的边界
|
||||
for left-1 >= 0 && right+1 < len(s) && s[left-1] == s[right+1] {
|
||||
left--
|
||||
right++
|
||||
}
|
||||
if right-left > pr-pl {
|
||||
pl, pr = left, right
|
||||
}
|
||||
// 重置到下一次寻找回文的中心
|
||||
left = (left+right)/2 + 1
|
||||
right = left
|
||||
}
|
||||
return s[pl : pr+1]
|
||||
}
|
||||
|
||||
// 解法三 中心扩散法,时间复杂度 O(n^2),空间复杂度 O(1)
|
||||
func longestPalindrome2(s string) string {
|
||||
res := ""
|
||||
for i := 0; i < len(s); i++ {
|
||||
res = maxPalindrome(s, i, i, res)
|
||||
res = maxPalindrome(s, i, i+1, res)
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func maxPalindrome(s string, i, j int, res string) string {
|
||||
sub := ""
|
||||
for i >= 0 && j < len(s) && s[i] == s[j] {
|
||||
sub = s[i : j+1]
|
||||
i--
|
||||
j++
|
||||
}
|
||||
if len(res) < len(sub) {
|
||||
return sub
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
// 解法四 DP,时间复杂度 O(n^2),空间复杂度 O(n^2)
|
||||
func longestPalindrome3(s string) string {
|
||||
res, dp := "", make([][]bool, len(s))
|
||||
for i := 0; i < len(s); i++ {
|
||||
dp[i] = make([]bool, len(s))
|
||||
}
|
||||
for i := len(s) - 1; i >= 0; i-- {
|
||||
for j := i; j < len(s); j++ {
|
||||
dp[i][j] = (s[i] == s[j]) && ((j-i < 3) || dp[i+1][j-1])
|
||||
if dp[i][j] && (res == "" || j-i+1 > len(res)) {
|
||||
res = s[i : j+1]
|
||||
}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
26
leetcode/0006.ZigZag-Conversion/6. ZigZag Conversion.go
Normal file
26
leetcode/0006.ZigZag-Conversion/6. ZigZag Conversion.go
Normal file
@ -0,0 +1,26 @@
|
||||
package leetcode
|
||||
|
||||
func convert(s string, numRows int) string {
|
||||
matrix, down, up := make([][]byte, numRows, numRows), 0, numRows-2
|
||||
for i := 0; i != len(s); {
|
||||
if down != numRows {
|
||||
matrix[down] = append(matrix[down], byte(s[i]))
|
||||
down++
|
||||
i++
|
||||
} else if up > 0 {
|
||||
matrix[up] = append(matrix[up], byte(s[i]))
|
||||
up--
|
||||
i++
|
||||
} else {
|
||||
up = numRows - 2
|
||||
down = 0
|
||||
}
|
||||
}
|
||||
solution := make([]byte, 0, len(s))
|
||||
for _, row := range matrix {
|
||||
for _, item := range row {
|
||||
solution = append(solution, item)
|
||||
}
|
||||
}
|
||||
return string(solution)
|
||||
}
|
||||
53
leetcode/0006.ZigZag-Conversion/6. ZigZag Conversion_test.go
Normal file
53
leetcode/0006.ZigZag-Conversion/6. ZigZag Conversion_test.go
Normal file
@ -0,0 +1,53 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question6 struct {
|
||||
para6
|
||||
ans6
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para6 struct {
|
||||
s string
|
||||
numRows int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans6 struct {
|
||||
one string
|
||||
}
|
||||
|
||||
func Test_Problem6(t *testing.T) {
|
||||
|
||||
qs := []question6{
|
||||
|
||||
{
|
||||
para6{"PAYPALISHIRING", 3},
|
||||
ans6{"PAHNAPLSIIGYIR"},
|
||||
},
|
||||
|
||||
{
|
||||
para6{"PAYPALISHIRING", 4},
|
||||
ans6{"PINALSIGYAHRPI"},
|
||||
},
|
||||
|
||||
{
|
||||
para6{"A", 1},
|
||||
ans6{"A"},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 6------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans6, q.para6
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, convert(p.s, p.numRows))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
107
leetcode/0006.ZigZag-Conversion/README.md
Normal file
107
leetcode/0006.ZigZag-Conversion/README.md
Normal file
@ -0,0 +1,107 @@
|
||||
# [6. ZigZag Conversion](https://leetcode.com/problems/zigzag-conversion/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
The string `"PAYPALISHIRING"` is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
|
||||
|
||||
```
|
||||
P A H N
|
||||
A P L S I I G
|
||||
Y I R
|
||||
```
|
||||
|
||||
And then read line by line: `"PAHNAPLSIIGYIR"`
|
||||
|
||||
Write the code that will take a string and make this conversion given a number of rows:
|
||||
|
||||
```
|
||||
string convert(string s, int numRows);
|
||||
```
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: s = "PAYPALISHIRING", numRows = 3
|
||||
Output: "PAHNAPLSIIGYIR"
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: s = "PAYPALISHIRING", numRows = 4
|
||||
Output: "PINALSIGYAHRPI"
|
||||
Explanation:
|
||||
P I N
|
||||
A L S I G
|
||||
Y A H R
|
||||
P I
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: s = "A", numRows = 1
|
||||
Output: "A"
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= s.length <= 1000`
|
||||
- `s` consists of English letters (lower-case and upper-case), `','` and `'.'`.
|
||||
- `1 <= numRows <= 1000`
|
||||
|
||||
## 题目大意
|
||||
|
||||
将一个给定字符串 `s` 根据给定的行数 `numRows` ,以从上往下、从左到右进行 Z 字形排列。
|
||||
|
||||
比如输入字符串为 `"PAYPALISHIRING"` 行数为 3 时,排列如下:
|
||||
|
||||
```go
|
||||
P A H N
|
||||
A P L S I I G
|
||||
Y I R
|
||||
```
|
||||
|
||||
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:`"PAHNAPLSIIGYIR"`。
|
||||
|
||||
请你实现这个将字符串进行指定行数变换的函数:
|
||||
|
||||
```go
|
||||
string convert(string s, int numRows);
|
||||
```
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 这一题没有什么算法思想,考察的是对程序控制的能力。用 2 个变量保存方向,当垂直输出的行数达到了规定的目标行数以后,需要从下往上转折到第一行,循环中控制好方向ji
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func convert(s string, numRows int) string {
|
||||
matrix, down, up := make([][]byte, numRows, numRows), 0, numRows-2
|
||||
for i := 0; i != len(s); {
|
||||
if down != numRows {
|
||||
matrix[down] = append(matrix[down], byte(s[i]))
|
||||
down++
|
||||
i++
|
||||
} else if up > 0 {
|
||||
matrix[up] = append(matrix[up], byte(s[i]))
|
||||
up--
|
||||
i++
|
||||
} else {
|
||||
up = numRows - 2
|
||||
down = 0
|
||||
}
|
||||
}
|
||||
solution := make([]byte, 0, len(s))
|
||||
for _, row := range matrix {
|
||||
for _, item := range row {
|
||||
solution = append(solution, item)
|
||||
}
|
||||
}
|
||||
return string(solution)
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,56 @@
|
||||
package leetcode
|
||||
|
||||
func myAtoi(s string) int {
|
||||
maxInt, signAllowed, whitespaceAllowed, sign, digits := int64(2<<30), true, true, 1, []int{}
|
||||
for _, c := range s {
|
||||
if c == ' ' && whitespaceAllowed {
|
||||
continue
|
||||
}
|
||||
if signAllowed {
|
||||
if c == '+' {
|
||||
signAllowed = false
|
||||
whitespaceAllowed = false
|
||||
continue
|
||||
} else if c == '-' {
|
||||
sign = -1
|
||||
signAllowed = false
|
||||
whitespaceAllowed = false
|
||||
continue
|
||||
}
|
||||
}
|
||||
if c < '0' || c > '9' {
|
||||
break
|
||||
}
|
||||
whitespaceAllowed, signAllowed = false, false
|
||||
digits = append(digits, int(c-48))
|
||||
}
|
||||
var num, place int64
|
||||
place, num = 1, 0
|
||||
lastLeading0Index := -1
|
||||
for i, d := range digits {
|
||||
if d == 0 {
|
||||
lastLeading0Index = i
|
||||
} else {
|
||||
break
|
||||
}
|
||||
}
|
||||
if lastLeading0Index > -1 {
|
||||
digits = digits[lastLeading0Index+1:]
|
||||
}
|
||||
var rtnMax int64
|
||||
if sign > 0 {
|
||||
rtnMax = maxInt - 1
|
||||
} else {
|
||||
rtnMax = maxInt
|
||||
}
|
||||
digitsCount := len(digits)
|
||||
for i := digitsCount - 1; i >= 0; i-- {
|
||||
num += int64(digits[i]) * place
|
||||
place *= 10
|
||||
if digitsCount-i > 10 || num > rtnMax {
|
||||
return int(int64(sign) * rtnMax)
|
||||
}
|
||||
}
|
||||
num *= int64(sign)
|
||||
return int(num)
|
||||
}
|
||||
@ -0,0 +1,62 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question8 struct {
|
||||
para8
|
||||
ans8
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para8 struct {
|
||||
one string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans8 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem8(t *testing.T) {
|
||||
|
||||
qs := []question8{
|
||||
|
||||
{
|
||||
para8{"42"},
|
||||
ans8{42},
|
||||
},
|
||||
|
||||
{
|
||||
para8{" -42"},
|
||||
ans8{-42},
|
||||
},
|
||||
|
||||
{
|
||||
para8{"4193 with words"},
|
||||
ans8{4193},
|
||||
},
|
||||
|
||||
{
|
||||
para8{"words and 987"},
|
||||
ans8{0},
|
||||
},
|
||||
|
||||
{
|
||||
para8{"-91283472332"},
|
||||
ans8{-2147483648},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 8------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans8, q.para8
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p.one, myAtoi(p.one))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
192
leetcode/0008.String-to-Integer-atoi/README.md
Normal file
192
leetcode/0008.String-to-Integer-atoi/README.md
Normal file
@ -0,0 +1,192 @@
|
||||
# [8. String to Integer (atoi)](https://leetcode.com/problems/string-to-integer-atoi/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Implement the `myAtoi(string s)` function, which converts a string to a 32-bit signed integer (similar to C/C++'s `atoi` function).
|
||||
|
||||
The algorithm for `myAtoi(string s)` is as follows:
|
||||
|
||||
1. Read in and ignore any leading whitespace.
|
||||
2. Check if the next character (if not already at the end of the string) is `'-'` or `'+'`. Read this character in if it is either. This determines if the final result is negative or positive respectively. Assume the result is positive if neither is present.
|
||||
3. Read in next the characters until the next non-digit charcter or the end of the input is reached. The rest of the string is ignored.
|
||||
4. Convert these digits into an integer (i.e. `"123" -> 123`, `"0032" -> 32`). If no digits were read, then the integer is `0`. Change the sign as necessary (from step 2).
|
||||
5. If the integer is out of the 32-bit signed integer range `[-231, 231 - 1]`, then clamp the integer so that it remains in the range. Specifically, integers less than `231` should be clamped to `231`, and integers greater than `231 - 1` should be clamped to `231 - 1`.
|
||||
6. Return the integer as the final result.
|
||||
|
||||
**Note:**
|
||||
|
||||
- Only the space character `' '` is considered a whitespace character.
|
||||
- **Do not ignore** any characters other than the leading whitespace or the rest of the string after the digits.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: s = "42"
|
||||
Output: 42
|
||||
Explanation: The underlined characters are what is read in, the caret is the current reader position.
|
||||
Step 1: "42" (no characters read because there is no leading whitespace)
|
||||
^
|
||||
Step 2: "42" (no characters read because there is neither a '-' nor '+')
|
||||
^
|
||||
Step 3: "42" ("42" is read in)
|
||||
^
|
||||
The parsed integer is 42.
|
||||
Since 42 is in the range [-231, 231 - 1], the final result is 42.
|
||||
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: s = " -42"
|
||||
Output: -42
|
||||
Explanation:
|
||||
Step 1: " -42" (leading whitespace is read and ignored)
|
||||
^
|
||||
Step 2: " -42" ('-' is read, so the result should be negative)
|
||||
^
|
||||
Step 3: " -42" ("42" is read in)
|
||||
^
|
||||
The parsed integer is -42.
|
||||
Since -42 is in the range [-231, 231 - 1], the final result is -42.
|
||||
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: s = "4193 with words"
|
||||
Output: 4193
|
||||
Explanation:
|
||||
Step 1: "4193 with words" (no characters read because there is no leading whitespace)
|
||||
^
|
||||
Step 2: "4193 with words" (no characters read because there is neither a '-' nor '+')
|
||||
^
|
||||
Step 3: "4193 with words" ("4193" is read in; reading stops because the next character is a non-digit)
|
||||
^
|
||||
The parsed integer is 4193.
|
||||
Since 4193 is in the range [-231, 231 - 1], the final result is 4193.
|
||||
|
||||
```
|
||||
|
||||
**Example 4:**
|
||||
|
||||
```
|
||||
Input: s = "words and 987"
|
||||
Output: 0
|
||||
Explanation:
|
||||
Step 1: "words and 987" (no characters read because there is no leading whitespace)
|
||||
^
|
||||
Step 2: "words and 987" (no characters read because there is neither a '-' nor '+')
|
||||
^
|
||||
Step 3: "words and 987" (reading stops immediately because there is a non-digit 'w')
|
||||
^
|
||||
The parsed integer is 0 because no digits were read.
|
||||
Since 0 is in the range [-231, 231 - 1], the final result is 0.
|
||||
|
||||
```
|
||||
|
||||
**Example 5:**
|
||||
|
||||
```
|
||||
Input: s = "-91283472332"
|
||||
Output: -2147483648
|
||||
Explanation:
|
||||
Step 1: "-91283472332" (no characters read because there is no leading whitespace)
|
||||
^
|
||||
Step 2: "-91283472332" ('-' is read, so the result should be negative)
|
||||
^
|
||||
Step 3: "-91283472332" ("91283472332" is read in)
|
||||
^
|
||||
The parsed integer is -91283472332.
|
||||
Since -91283472332 is less than the lower bound of the range [-231, 231 - 1], the final result is clamped to -231 = -2147483648.
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `0 <= s.length <= 200`
|
||||
- `s` consists of English letters (lower-case and upper-case), digits (`0-9`), `' '`, `'+'`
|
||||
|
||||
## 题目大意
|
||||
|
||||
请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C++ 中的 atoi 函数)。
|
||||
|
||||
函数 myAtoi(string s) 的算法如下:
|
||||
|
||||
- 读入字符串并丢弃无用的前导空格
|
||||
- 检查下一个字符(假设还未到字符末尾)为正还是负号,读取该字符(如果有)。 确定最终结果是负数还是正数。 如果两者都不存在,则假定结果为正。
|
||||
- 读入下一个字符,直到到达下一个非数字字符或到达输入的结尾。字符串的其余部分将被忽略。
|
||||
- 将前面步骤读入的这些数字转换为整数(即,"123" -> 123, "0032" -> 32)。如果没有读入数字,则整数为 0 。必要时更改符号(从步骤 2 开始)。
|
||||
- 如果整数数超过 32 位有符号整数范围 [−231, 231 − 1] ,需要截断这个整数,使其保持在这个范围内。具体来说,小于 −231 的整数应该被固定为 −231 ,大于 231 − 1 的整数应该被固定为 231 − 1 。
|
||||
- 返回整数作为最终结果。
|
||||
|
||||
注意:
|
||||
|
||||
- 本题中的空白字符只包括空格字符 ' ' 。
|
||||
- 除前导空格或数字后的其余字符串外,请勿忽略 任何其他字符。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 这题是简单题。题目要求实现类似 `C++` 中 `atoi` 函数的功能。这个函数功能是将字符串类型的数字转成 `int` 类型数字。先去除字符串中的前导空格,并判断记录数字的符号。数字需要去掉前导 `0` 。最后将数字转换成数字类型,判断是否超过 `int` 类型的上限 `[-2^31, 2^31 - 1]`,如果超过上限,需要输出边界,即 `-2^31`,或者 `2^31 - 1`。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func myAtoi(s string) int {
|
||||
maxInt, signAllowed, whitespaceAllowed, sign, digits := int64(2<<30), true, true, 1, []int{}
|
||||
for _, c := range s {
|
||||
if c == ' ' && whitespaceAllowed {
|
||||
continue
|
||||
}
|
||||
if signAllowed {
|
||||
if c == '+' {
|
||||
signAllowed = false
|
||||
whitespaceAllowed = false
|
||||
continue
|
||||
} else if c == '-' {
|
||||
sign = -1
|
||||
signAllowed = false
|
||||
whitespaceAllowed = false
|
||||
continue
|
||||
}
|
||||
}
|
||||
if c < '0' || c > '9' {
|
||||
break
|
||||
}
|
||||
whitespaceAllowed, signAllowed = false, false
|
||||
digits = append(digits, int(c-48))
|
||||
}
|
||||
var num, place int64
|
||||
place, num = 1, 0
|
||||
lastLeading0Index := -1
|
||||
for i, d := range digits {
|
||||
if d == 0 {
|
||||
lastLeading0Index = i
|
||||
} else {
|
||||
break
|
||||
}
|
||||
}
|
||||
if lastLeading0Index > -1 {
|
||||
digits = digits[lastLeading0Index+1:]
|
||||
}
|
||||
var rtnMax int64
|
||||
if sign > 0 {
|
||||
rtnMax = maxInt - 1
|
||||
} else {
|
||||
rtnMax = maxInt
|
||||
}
|
||||
digitsCount := len(digits)
|
||||
for i := digitsCount - 1; i >= 0; i-- {
|
||||
num += int64(digits[i]) * place
|
||||
place *= 10
|
||||
if digitsCount-i > 10 || num > rtnMax {
|
||||
return int(int64(sign) * rtnMax)
|
||||
}
|
||||
}
|
||||
num *= int64(sign)
|
||||
return int(num)
|
||||
}
|
||||
```
|
||||
@ -2,7 +2,33 @@ package leetcode
|
||||
|
||||
import "strconv"
|
||||
|
||||
// 解法一
|
||||
func isPalindrome(x int) bool {
|
||||
if x < 0 {
|
||||
return false
|
||||
}
|
||||
if x == 0 {
|
||||
return true
|
||||
}
|
||||
if x%10 == 0 {
|
||||
return false
|
||||
}
|
||||
arr := make([]int, 0, 32)
|
||||
for x > 0 {
|
||||
arr = append(arr, x%10)
|
||||
x = x / 10
|
||||
}
|
||||
sz := len(arr)
|
||||
for i, j := 0, sz-1; i <= j; i, j = i+1, j-1 {
|
||||
if arr[i] != arr[j] {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
// 解法二 数字转字符串
|
||||
func isPalindrome1(x int) bool {
|
||||
if x < 0 {
|
||||
return false
|
||||
}
|
||||
|
||||
@ -49,7 +49,33 @@ package leetcode
|
||||
|
||||
import "strconv"
|
||||
|
||||
// 解法一
|
||||
func isPalindrome(x int) bool {
|
||||
if x < 0 {
|
||||
return false
|
||||
}
|
||||
if x == 0 {
|
||||
return true
|
||||
}
|
||||
if x%10 == 0 {
|
||||
return false
|
||||
}
|
||||
arr := make([]int, 0, 32)
|
||||
for x > 0 {
|
||||
arr = append(arr, x%10)
|
||||
x = x / 10
|
||||
}
|
||||
sz := len(arr)
|
||||
for i, j := 0, sz-1; i <= j; i, j = i+1, j-1 {
|
||||
if arr[i] != arr[j] {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
// 解法二 数字转字符串
|
||||
func isPalindrome1(x int) bool {
|
||||
if x < 0 {
|
||||
return false
|
||||
}
|
||||
@ -66,4 +92,5 @@ func isPalindrome(x int) bool {
|
||||
return true
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
15
leetcode/0012.Integer-to-Roman/12. Integer to Roman.go
Normal file
15
leetcode/0012.Integer-to-Roman/12. Integer to Roman.go
Normal file
@ -0,0 +1,15 @@
|
||||
package leetcode
|
||||
|
||||
func intToRoman(num int) string {
|
||||
values := []int{1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1}
|
||||
symbols := []string{"M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"}
|
||||
res, i := "", 0
|
||||
for num != 0 {
|
||||
for values[i] > num {
|
||||
i++
|
||||
}
|
||||
num -= values[i]
|
||||
res += symbols[i]
|
||||
}
|
||||
return res
|
||||
}
|
||||
71
leetcode/0012.Integer-to-Roman/12. Integer to Roman_test.go
Normal file
71
leetcode/0012.Integer-to-Roman/12. Integer to Roman_test.go
Normal file
@ -0,0 +1,71 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question12 struct {
|
||||
para12
|
||||
ans12
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para12 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans12 struct {
|
||||
one string
|
||||
}
|
||||
|
||||
func Test_Problem12(t *testing.T) {
|
||||
|
||||
qs := []question12{
|
||||
|
||||
{
|
||||
para12{3},
|
||||
ans12{"III"},
|
||||
},
|
||||
|
||||
{
|
||||
para12{4},
|
||||
ans12{"IV"},
|
||||
},
|
||||
|
||||
{
|
||||
para12{9},
|
||||
ans12{"IX"},
|
||||
},
|
||||
|
||||
{
|
||||
para12{58},
|
||||
ans12{"LVIII"},
|
||||
},
|
||||
|
||||
{
|
||||
para12{1994},
|
||||
ans12{"MCMXCIV"},
|
||||
},
|
||||
{
|
||||
para12{123},
|
||||
ans12{"CXXIII"},
|
||||
},
|
||||
|
||||
{
|
||||
para12{120},
|
||||
ans12{"CXX"},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 12------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans12, q.para12
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p.one, intToRoman(p.one))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
102
leetcode/0012.Integer-to-Roman/README.md
Normal file
102
leetcode/0012.Integer-to-Roman/README.md
Normal file
@ -0,0 +1,102 @@
|
||||
# [12. Integer to Roman](https://leetcode.com/problems/integer-to-roman/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Roman numerals are represented by seven different symbols: `I`, `V`, `X`, `L`, `C`, `D` and `M`.
|
||||
|
||||
```
|
||||
Symbol Value
|
||||
I 1
|
||||
V 5
|
||||
X 10
|
||||
L 50
|
||||
C 100
|
||||
D 500
|
||||
M 1000
|
||||
```
|
||||
|
||||
For example, `2` is written as `II` in Roman numeral, just two one's added together. `12` is written as `XII`, which is simply `X + II`. The number `27` is written as `XXVII`, which is `XX + V + II`.
|
||||
|
||||
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not `IIII`. Instead, the number four is written as `IV`. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as `IX`. There are six instances where subtraction is used:
|
||||
|
||||
- `I` can be placed before `V` (5) and `X` (10) to make 4 and 9.
|
||||
- `X` can be placed before `L` (50) and `C` (100) to make 40 and 90.
|
||||
- `C` can be placed before `D` (500) and `M` (1000) to make 400 and 900.
|
||||
|
||||
Given an integer, convert it to a roman numeral.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: num = 3
|
||||
Output: "III"
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: num = 4
|
||||
Output: "IV"
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: num = 9
|
||||
Output: "IX"
|
||||
```
|
||||
|
||||
**Example 4:**
|
||||
|
||||
```
|
||||
Input: num = 58
|
||||
Output: "LVIII"
|
||||
Explanation: L = 50, V = 5, III = 3.
|
||||
```
|
||||
|
||||
**Example 5:**
|
||||
|
||||
```
|
||||
Input: num = 1994
|
||||
Output: "MCMXCIV"
|
||||
Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= num <= 3999`
|
||||
|
||||
## 题目大意
|
||||
|
||||
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
|
||||
|
||||
- I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
|
||||
- X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
|
||||
- C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
|
||||
|
||||
给定一个整数,将其转为罗马数字。输入确保在 1 到 3999 的范围内。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 依照题意,优先选择大的数字,解题思路采用贪心算法。将 1-3999 范围内的罗马数字从大到小放在数组中,从头选择到尾,即可把整数转成罗马数字。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func intToRoman(num int) string {
|
||||
values := []int{1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1}
|
||||
symbols := []string{"M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"}
|
||||
res, i := "", 0
|
||||
for num != 0 {
|
||||
for values[i] > num {
|
||||
i++
|
||||
}
|
||||
num -= values[i]
|
||||
res += symbols[i]
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
@ -17,22 +17,18 @@ type ListNode = structures.ListNode
|
||||
|
||||
// 解法一
|
||||
func removeNthFromEnd(head *ListNode, n int) *ListNode {
|
||||
var fast, slow *ListNode
|
||||
fast = head
|
||||
slow = head
|
||||
for i := 0; i < n; i++ {
|
||||
fast = fast.Next
|
||||
}
|
||||
if fast == nil {
|
||||
head = head.Next
|
||||
return head
|
||||
}
|
||||
for fast.Next != nil {
|
||||
fast = fast.Next
|
||||
dummyHead := &ListNode{Next: head}
|
||||
preSlow, slow, fast := dummyHead, head, head
|
||||
for fast != nil {
|
||||
if n <= 0 {
|
||||
preSlow = slow
|
||||
slow = slow.Next
|
||||
}
|
||||
slow.Next = slow.Next.Next
|
||||
return head
|
||||
n--
|
||||
fast = fast.Next
|
||||
}
|
||||
preSlow.Next = slow.Next
|
||||
return dummyHead.Next
|
||||
}
|
||||
|
||||
// 解法二
|
||||
|
||||
@ -29,6 +29,26 @@ func Test_Problem19(t *testing.T) {
|
||||
|
||||
qs := []question19{
|
||||
|
||||
{
|
||||
para19{[]int{1}, 3},
|
||||
ans19{[]int{1}},
|
||||
},
|
||||
|
||||
{
|
||||
para19{[]int{1, 2}, 2},
|
||||
ans19{[]int{2}},
|
||||
},
|
||||
|
||||
{
|
||||
para19{[]int{1}, 1},
|
||||
ans19{[]int{}},
|
||||
},
|
||||
|
||||
{
|
||||
para19{[]int{1, 2, 3, 4, 5}, 10},
|
||||
ans19{[]int{1, 2, 3, 4, 5}},
|
||||
},
|
||||
|
||||
{
|
||||
para19{[]int{1, 2, 3, 4, 5}, 1},
|
||||
ans19{[]int{1, 2, 3, 4}},
|
||||
|
||||
@ -2,16 +2,44 @@
|
||||
|
||||
## 题目
|
||||
|
||||
Given a linked list, remove the n-th node from the end of list and return its head.
|
||||
Given the `head` of a linked list, remove the `nth` node from the end of the list and return its head.
|
||||
|
||||
Example:
|
||||
**Follow up:** Could you do this in one pass?
|
||||
|
||||
**Example 1:**
|
||||
|
||||

|
||||
|
||||
```
|
||||
Given linked list: 1->2->3->4->5, and n = 2.
|
||||
Input: head = [1,2,3,4,5], n = 2
|
||||
Output: [1,2,3,5]
|
||||
|
||||
After removing the second node from the end, the linked list becomes 1->2->3->5.
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: head = [1], n = 1
|
||||
Output: []
|
||||
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: head = [1,2], n = 1
|
||||
Output: [1]
|
||||
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- The number of nodes in the list is `sz`.
|
||||
- `1 <= sz <= 30`
|
||||
- `0 <= Node.val <= 100`
|
||||
- `1 <= n <= sz`
|
||||
|
||||
|
||||
## 题目大意
|
||||
|
||||
删除链表中倒数第 n 个结点。
|
||||
|
||||
@ -16,30 +16,9 @@ type ListNode = structures.ListNode
|
||||
*/
|
||||
|
||||
func swapPairs(head *ListNode) *ListNode {
|
||||
if head == nil || head.Next == nil {
|
||||
return head
|
||||
dummy := &ListNode{Next: head}
|
||||
for pt := dummy; pt != nil && pt.Next != nil && pt.Next.Next != nil; {
|
||||
pt, pt.Next, pt.Next.Next, pt.Next.Next.Next = pt.Next, pt.Next.Next, pt.Next.Next.Next, pt.Next
|
||||
}
|
||||
s := head.Next
|
||||
var behind *ListNode
|
||||
for head.Next != nil {
|
||||
headNext := head.Next
|
||||
if behind != nil && behind.Next != nil {
|
||||
behind.Next = headNext
|
||||
}
|
||||
var next *ListNode
|
||||
if head.Next.Next != nil {
|
||||
next = head.Next.Next
|
||||
}
|
||||
if head.Next.Next != nil {
|
||||
head.Next = next
|
||||
} else {
|
||||
head.Next = nil
|
||||
}
|
||||
headNext.Next = head
|
||||
behind = head
|
||||
if head.Next != nil {
|
||||
head = next
|
||||
}
|
||||
}
|
||||
return s
|
||||
return dummy.Next
|
||||
}
|
||||
|
||||
@ -0,0 +1,58 @@
|
||||
package leetcode
|
||||
|
||||
// 解法一 栈
|
||||
func longestValidParentheses(s string) int {
|
||||
stack, res := []int{}, 0
|
||||
stack = append(stack, -1)
|
||||
for i := 0; i < len(s); i++ {
|
||||
if s[i] == '(' {
|
||||
stack = append(stack, i)
|
||||
} else {
|
||||
stack = stack[:len(stack)-1]
|
||||
if len(stack) == 0 {
|
||||
stack = append(stack, i)
|
||||
} else {
|
||||
res = max(res, i-stack[len(stack)-1])
|
||||
}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func max(a, b int) int {
|
||||
if a > b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
|
||||
// 解法二 双指针
|
||||
func longestValidParentheses1(s string) int {
|
||||
left, right, maxLength := 0, 0, 0
|
||||
for i := 0; i < len(s); i++ {
|
||||
if s[i] == '(' {
|
||||
left++
|
||||
} else {
|
||||
right++
|
||||
}
|
||||
if left == right {
|
||||
maxLength = max(maxLength, 2*right)
|
||||
} else if right > left {
|
||||
left, right = 0, 0
|
||||
}
|
||||
}
|
||||
left, right = 0, 0
|
||||
for i := len(s) - 1; i >= 0; i-- {
|
||||
if s[i] == '(' {
|
||||
left++
|
||||
} else {
|
||||
right++
|
||||
}
|
||||
if left == right {
|
||||
maxLength = max(maxLength, 2*left)
|
||||
} else if left > right {
|
||||
left, right = 0, 0
|
||||
}
|
||||
}
|
||||
return maxLength
|
||||
}
|
||||
@ -0,0 +1,61 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question32 struct {
|
||||
para32
|
||||
ans32
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para32 struct {
|
||||
s string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans32 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem32(t *testing.T) {
|
||||
|
||||
qs := []question32{
|
||||
|
||||
{
|
||||
para32{"(()"},
|
||||
ans32{2},
|
||||
},
|
||||
|
||||
{
|
||||
para32{")()())"},
|
||||
ans32{4},
|
||||
},
|
||||
|
||||
{
|
||||
para32{"()(())"},
|
||||
ans32{6},
|
||||
},
|
||||
|
||||
{
|
||||
para32{"()(())))"},
|
||||
ans32{6},
|
||||
},
|
||||
|
||||
{
|
||||
para32{"()(()"},
|
||||
ans32{2},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 32------------------------\n")
|
||||
for _, q := range qs {
|
||||
_, p := q.ans32, q.para32
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, longestValidParentheses(p.s))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
108
leetcode/0032.Longest-Valid-Parentheses/README.md
Normal file
108
leetcode/0032.Longest-Valid-Parentheses/README.md
Normal file
@ -0,0 +1,108 @@
|
||||
# [32. Longest Valid Parentheses](https://leetcode.com/problems/longest-valid-parentheses/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given a string containing just the characters `'('` and `')'`, find the length of the longest valid (well-formed) parentheses substring.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: s = "(()"
|
||||
Output: 2
|
||||
Explanation: The longest valid parentheses substring is "()".
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: s = ")()())"
|
||||
Output: 4
|
||||
Explanation: The longest valid parentheses substring is "()()".
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: s = ""
|
||||
Output: 0
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `0 <= s.length <= 3 * 104`
|
||||
- `s[i]` is `'('`, or `')'`.
|
||||
|
||||
## 题目大意
|
||||
|
||||
给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 提到括号匹配,第一时间能让人想到的就是利用栈。这里需要计算嵌套括号的总长度,所以栈里面不能单纯的存左括号,而应该存左括号在原字符串的下标,这样通过下标相减可以获取长度。那么栈如果是非空,栈底永远存的是当前遍历过的字符串中**上一个没有被匹配的右括号的下标**。**上一个没有被匹配的右括号的下标**可以理解为每段括号匹配之间的“隔板”。例如,`())((()))`,第三个右括号,即为左右 2 段正确的括号匹配中间的“隔板”。“隔板”的存在影响计算最长括号长度。如果不存在“隔板”,前后 2 段正确的括号匹配应该“融合”在一起,最长长度为 `2 + 6 = 8`,但是这里存在了“隔板”,所以最长长度仅为 `6`。
|
||||
- 具体算法实现,遇到每个 `'('` ,将它的下标压入栈中。对于遇到的每个 `')'`,先弹出栈顶元素表示匹配了当前右括号。如果栈为空,说明当前的右括号为没有被匹配的右括号,于是将其下标放入栈中来更新**上一个没有被匹配的右括号的下标**。如果栈不为空,当前右括号的下标减去栈顶元素即为以该右括号为结尾的最长有效括号的长度。需要注意初始化时,不存在**上一个没有被匹配的右括号的下标**,那么将 `-1` 放入栈中,充当下标为 `0` 的“隔板”。时间复杂度 O(n),空间复杂度 O(n)。
|
||||
- 在栈的方法中,实际用到的元素仅仅是栈底的**上一个没有被匹配的右括号的下标**。那么考虑能否把这个值存在一个变量中,这样可以省去栈 O(n) 的时间复杂度。利用两个计数器 left 和 right 。首先,从左到右遍历字符串,每当遇到 `'('`,增加 left 计数器,每当遇到 `')'` ,增加 right 计数器。每当 left 计数器与 right 计数器相等时,计算当前有效字符串的长度,并且记录目前为止找到的最长子字符串。当 right 计数器比 left 计数器大时,说明括号不匹配,于是将 left 和 right 计数器同时变回 0。这样的做法利用了贪心的思想,考虑了以当前字符下标结尾的有效括号长度,每次当右括号数量多于左括号数量的时候之前的字符就扔掉不再考虑,重新从下一个字符开始计算。
|
||||
- 但上面的做法会漏掉一种情况,就是遍历的时候左括号的数量始终大于右括号的数量,即 `(()` ,这种时候最长有效括号是求不出来的。解决办法是反向再计算一遍,如果从右往左计算,`(()` 先计算匹配的括号,最后只剩下 `'('`,这样依旧可以算出最长匹配的括号长度。反过来计算的方法和上述从左往右计算的方法一致:当 left 计数器比 right 计数器大时,将 left 和 right 计数器同时变回 0;当 left 计数器与 right 计数器相等时,计算当前有效字符串的长度,并且记录目前为止找到的最长子字符串。这种方法的时间复杂度是 O(n),空间复杂度 O(1)。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
// 解法一 栈
|
||||
func longestValidParentheses(s string) int {
|
||||
stack, res := []int{}, 0
|
||||
stack = append(stack, -1)
|
||||
for i := 0; i < len(s); i++ {
|
||||
if s[i] == '(' {
|
||||
stack = append(stack, i)
|
||||
} else {
|
||||
stack = stack[:len(stack)-1]
|
||||
if len(stack) == 0 {
|
||||
stack = append(stack, i)
|
||||
} else {
|
||||
res = max(res, i-stack[len(stack)-1])
|
||||
}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func max(a, b int) int {
|
||||
if a > b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
|
||||
// 解法二 双指针
|
||||
func longestValidParentheses1(s string) int {
|
||||
left, right, maxLength := 0, 0, 0
|
||||
for i := 0; i < len(s); i++ {
|
||||
if s[i] == '(' {
|
||||
left++
|
||||
} else {
|
||||
right++
|
||||
}
|
||||
if left == right {
|
||||
maxLength = max(maxLength, 2*right)
|
||||
} else if right > left {
|
||||
left, right = 0, 0
|
||||
}
|
||||
}
|
||||
left, right = 0, 0
|
||||
for i := len(s) - 1; i >= 0; i-- {
|
||||
if s[i] == '(' {
|
||||
left++
|
||||
} else {
|
||||
right++
|
||||
}
|
||||
if left == right {
|
||||
maxLength = max(maxLength, 2*left)
|
||||
} else if left > right {
|
||||
left, right = 0, 0
|
||||
}
|
||||
}
|
||||
return maxLength
|
||||
}
|
||||
```
|
||||
25
leetcode/0043.Multiply-Strings/43. Multiply Strings.go
Normal file
25
leetcode/0043.Multiply-Strings/43. Multiply Strings.go
Normal file
@ -0,0 +1,25 @@
|
||||
package leetcode
|
||||
|
||||
func multiply(num1 string, num2 string) string {
|
||||
if num1 == "0" || num2 == "0" {
|
||||
return "0"
|
||||
}
|
||||
b1, b2, tmp := []byte(num1), []byte(num2), make([]int, len(num1)+len(num2))
|
||||
for i := 0; i < len(b1); i++ {
|
||||
for j := 0; j < len(b2); j++ {
|
||||
tmp[i+j+1] += int(b1[i]-'0') * int(b2[j]-'0')
|
||||
}
|
||||
}
|
||||
for i := len(tmp) - 1; i > 0; i-- {
|
||||
tmp[i-1] += tmp[i] / 10
|
||||
tmp[i] = tmp[i] % 10
|
||||
}
|
||||
if tmp[0] == 0 {
|
||||
tmp = tmp[1:]
|
||||
}
|
||||
res := make([]byte, len(tmp))
|
||||
for i := 0; i < len(tmp); i++ {
|
||||
res[i] = '0' + byte(tmp[i])
|
||||
}
|
||||
return string(res)
|
||||
}
|
||||
48
leetcode/0043.Multiply-Strings/43. Multiply Strings_test.go
Normal file
48
leetcode/0043.Multiply-Strings/43. Multiply Strings_test.go
Normal file
@ -0,0 +1,48 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question43 struct {
|
||||
para43
|
||||
ans43
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para43 struct {
|
||||
num1 string
|
||||
num2 string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans43 struct {
|
||||
one string
|
||||
}
|
||||
|
||||
func Test_Problem43(t *testing.T) {
|
||||
|
||||
qs := []question43{
|
||||
|
||||
{
|
||||
para43{"2", "3"},
|
||||
ans43{"6"},
|
||||
},
|
||||
|
||||
{
|
||||
para43{"123", "456"},
|
||||
ans43{"56088"},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 43------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans43, q.para43
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, multiply(p.num1, p.num2))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
66
leetcode/0043.Multiply-Strings/README.md
Normal file
66
leetcode/0043.Multiply-Strings/README.md
Normal file
@ -0,0 +1,66 @@
|
||||
# [43. Multiply Strings](https://leetcode.com/problems/multiply-strings/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given two non-negative integers `num1` and `num2` represented as strings, return the product of `num1` and `num2`, also represented as a string.
|
||||
|
||||
**Note:** You must not use any built-in BigInteger library or convert the inputs to integer directly.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: num1 = "2", num2 = "3"
|
||||
Output: "6"
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: num1 = "123", num2 = "456"
|
||||
Output: "56088"
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= num1.length, num2.length <= 200`
|
||||
- `num1` and `num2` consist of digits only.
|
||||
- Both `num1` and `num2` do not contain any leading zero, except the number `0` itself.
|
||||
|
||||
## 题目大意
|
||||
|
||||
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 用数组模拟乘法。创建一个数组长度为 `len(num1) + len(num2)` 的数组用于存储乘积。对于任意 `0 ≤ i < len(num1)`,`0 ≤ j < len(num2)`,`num1[i] * num2[j]` 的结果位于 `tmp[i+j+1]`,如果 `tmp[i+j+1]≥10`,则将进位部分加到 `tmp[i+j]`。最后,将数组 `tmp` 转成字符串,如果最高位是 0 则舍弃最高位。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func multiply(num1 string, num2 string) string {
|
||||
if num1 == "0" || num2 == "0" {
|
||||
return "0"
|
||||
}
|
||||
b1, b2, tmp := []byte(num1), []byte(num2), make([]int, len(num1)+len(num2))
|
||||
for i := 0; i < len(b1); i++ {
|
||||
for j := 0; j < len(b2); j++ {
|
||||
tmp[i+j+1] += int(b1[i]-'0') * int(b2[j]-'0')
|
||||
}
|
||||
}
|
||||
for i := len(tmp) - 1; i > 0; i-- {
|
||||
tmp[i-1] += tmp[i] / 10
|
||||
tmp[i] = tmp[i] % 10
|
||||
}
|
||||
if tmp[0] == 0 {
|
||||
tmp = tmp[1:]
|
||||
}
|
||||
res := make([]byte, len(tmp))
|
||||
for i := 0; i < len(tmp); i++ {
|
||||
res[i] = '0' + byte(tmp[i])
|
||||
}
|
||||
return string(res)
|
||||
}
|
||||
```
|
||||
21
leetcode/0045.Jump-Game-II/45. Jump Game II.go
Normal file
21
leetcode/0045.Jump-Game-II/45. Jump Game II.go
Normal file
@ -0,0 +1,21 @@
|
||||
package leetcode
|
||||
|
||||
func jump(nums []int) int {
|
||||
if len(nums) == 1 {
|
||||
return 0
|
||||
}
|
||||
needChoose, canReach, step := 0, 0, 0
|
||||
for i, x := range nums {
|
||||
if i+x > canReach {
|
||||
canReach = i + x
|
||||
if canReach >= len(nums)-1 {
|
||||
return step + 1
|
||||
}
|
||||
}
|
||||
if i == needChoose {
|
||||
needChoose = canReach
|
||||
step++
|
||||
}
|
||||
}
|
||||
return step
|
||||
}
|
||||
47
leetcode/0045.Jump-Game-II/45. Jump Game II_test.go
Normal file
47
leetcode/0045.Jump-Game-II/45. Jump Game II_test.go
Normal file
@ -0,0 +1,47 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question45 struct {
|
||||
para45
|
||||
ans45
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para45 struct {
|
||||
nums []int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans45 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem45(t *testing.T) {
|
||||
|
||||
qs := []question45{
|
||||
|
||||
{
|
||||
para45{[]int{2, 3, 1, 1, 4}},
|
||||
ans45{2},
|
||||
},
|
||||
|
||||
{
|
||||
para45{[]int{2, 3, 0, 1, 4}},
|
||||
ans45{2},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 45------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans45, q.para45
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, jump(p.nums))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
67
leetcode/0045.Jump-Game-II/README.md
Normal file
67
leetcode/0045.Jump-Game-II/README.md
Normal file
@ -0,0 +1,67 @@
|
||||
# [45. Jump Game II](https://leetcode.com/problems/jump-game-ii/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given an array of non-negative integers `nums`, you are initially positioned at the first index of the array.
|
||||
|
||||
Each element in the array represents your maximum jump length at that position.
|
||||
|
||||
Your goal is to reach the last index in the minimum number of jumps.
|
||||
|
||||
You can assume that you can always reach the last index.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: nums = [2,3,1,1,4]
|
||||
Output: 2
|
||||
Explanation: The minimum number of jumps to reach the last index is 2. Jump 1 step from index 0 to 1, then 3 steps to the last index.
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: nums = [2,3,0,1,4]
|
||||
Output: 2
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= nums.length <= 1000`
|
||||
- `0 <= nums[i] <= 10^5`
|
||||
|
||||
## 题目大意
|
||||
|
||||
给定一个非负整数数组,你最初位于数组的第一个位置。数组中的每个元素代表你在该位置可以跳跃的最大长度。你的目标是使用最少的跳跃次数到达数组的最后一个位置。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 要求找到最少跳跃次数,顺理成章的会想到用贪心算法解题。扫描步数数组,维护当前能够到达最大下标的位置,记为能到达的最远边界,如果扫描过程中到达了最远边界,更新边界并将跳跃次数 + 1。
|
||||
- 扫描数组的时候,其实不需要扫描最后一个元素,因为在跳到最后一个元素之前,能到达的最远边界一定大于等于最后一个元素的位置,不然就跳不到最后一个元素,到达不了终点了;如果遍历到最后一个元素,说明边界正好为最后一个位置,最终跳跃次数直接 + 1 即可,也不需要访问最后一个元素。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func jump(nums []int) int {
|
||||
if len(nums) == 1 {
|
||||
return 0
|
||||
}
|
||||
needChoose, canReach, step := 0, 0, 0
|
||||
for i, x := range nums {
|
||||
if i+x > canReach {
|
||||
canReach = i + x
|
||||
if canReach >= len(nums)-1 {
|
||||
return step + 1
|
||||
}
|
||||
}
|
||||
if i == needChoose {
|
||||
needChoose = canReach
|
||||
step++
|
||||
}
|
||||
}
|
||||
return step
|
||||
}
|
||||
```
|
||||
@ -1,26 +1,17 @@
|
||||
package leetcode
|
||||
|
||||
func rotate(matrix [][]int) {
|
||||
row := len(matrix)
|
||||
if row <= 0 {
|
||||
return
|
||||
}
|
||||
column := len(matrix[0])
|
||||
length := len(matrix)
|
||||
// rotate by diagonal 对角线变换
|
||||
for i := 0; i < row; i++ {
|
||||
for j := i + 1; j < column; j++ {
|
||||
tmp := matrix[i][j]
|
||||
matrix[i][j] = matrix[j][i]
|
||||
matrix[j][i] = tmp
|
||||
for i := 0; i < length; i++ {
|
||||
for j := i + 1; j < length; j++ {
|
||||
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
|
||||
}
|
||||
}
|
||||
// rotate by vertical centerline 竖直轴对称翻转
|
||||
halfColumn := column / 2
|
||||
for i := 0; i < row; i++ {
|
||||
for j := 0; j < halfColumn; j++ {
|
||||
tmp := matrix[i][j]
|
||||
matrix[i][j] = matrix[i][column-j-1]
|
||||
matrix[i][column-j-1] = tmp
|
||||
for i := 0; i < length; i++ {
|
||||
for j := 0; j < length/2; j++ {
|
||||
matrix[i][j], matrix[i][length-j-1] = matrix[i][length-j-1], matrix[i][j]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@ -10,8 +10,9 @@ Rotate the image by 90 degrees (clockwise).
|
||||
|
||||
You have to rotate the image **[in-place](https://en.wikipedia.org/wiki/In-place_algorithm)**, which means you have to modify the input 2D matrix directly. **DO NOT** allocate another 2D matrix and do the rotation.
|
||||
|
||||
**Example 1:**
|
||||
**Example 1**:
|
||||
|
||||
|
||||
|
||||
Given input matrix =
|
||||
[
|
||||
@ -28,8 +29,9 @@ You have to rotate the image **[in-place](https://en.wikipedia.org/wiki/In-plac
|
||||
]
|
||||
|
||||
|
||||
**Example 2:**
|
||||
**Example 2**:
|
||||
|
||||
|
||||
|
||||
Given input matrix =
|
||||
[
|
||||
|
||||
@ -47,39 +47,45 @@ func generateBoard(n int, row *[]int) []string {
|
||||
return board
|
||||
}
|
||||
|
||||
// 解法二 二进制操作法
|
||||
// class Solution
|
||||
// {
|
||||
// int n;
|
||||
// string getNq(int p)
|
||||
// {
|
||||
// string s(n, '.');
|
||||
// s[p] = 'Q';
|
||||
// return s;
|
||||
// }
|
||||
// void nQueens(int p, int l, int m, int r, vector<vector<string>> &res)
|
||||
// {
|
||||
// static vector<string> ans;
|
||||
// if (p >= n)
|
||||
// {
|
||||
// res.push_back(ans);
|
||||
// return ;
|
||||
// }
|
||||
// int mask = l | m | r;
|
||||
// for (int i = 0, b = 1; i < n; ++ i, b <<= 1)
|
||||
// if (!(mask & b))
|
||||
// {
|
||||
// ans.push_back(getNq(i));
|
||||
// nQueens(p + 1, (l | b) >> 1, m | b, (r | b) << 1, res);
|
||||
// ans.pop_back();
|
||||
// }
|
||||
// }
|
||||
// public:
|
||||
// vector<vector<string> > solveNQueens(int n)
|
||||
// {
|
||||
// this->n = n;
|
||||
// vector<vector<string>> res;
|
||||
// nQueens(0, 0, 0, 0, res);
|
||||
// return res;
|
||||
// }
|
||||
// };
|
||||
// 解法二 二进制操作法 Signed-off-by: Hanlin Shi shihanlin9@gmail.com
|
||||
func solveNQueens2(n int) (res [][]string) {
|
||||
placements := make([]string, n)
|
||||
for i := range placements {
|
||||
buf := make([]byte, n)
|
||||
for j := range placements {
|
||||
if i == j {
|
||||
buf[j] = 'Q'
|
||||
} else {
|
||||
buf[j] = '.'
|
||||
}
|
||||
}
|
||||
placements[i] = string(buf)
|
||||
}
|
||||
var construct func(prev []int)
|
||||
construct = func(prev []int) {
|
||||
if len(prev) == n {
|
||||
plan := make([]string, n)
|
||||
for i := 0; i < n; i++ {
|
||||
plan[i] = placements[prev[i]]
|
||||
}
|
||||
res = append(res, plan)
|
||||
return
|
||||
}
|
||||
occupied := 0
|
||||
for i := range prev {
|
||||
dist := len(prev) - i
|
||||
bit := 1 << prev[i]
|
||||
occupied |= bit | bit<<dist | bit>>dist
|
||||
}
|
||||
prev = append(prev, -1)
|
||||
for i := 0; i < n; i++ {
|
||||
if (occupied>>i)&1 != 0 {
|
||||
continue
|
||||
}
|
||||
prev[len(prev)-1] = i
|
||||
construct(prev)
|
||||
}
|
||||
}
|
||||
construct(make([]int, 0, n))
|
||||
return
|
||||
}
|
||||
|
||||
@ -40,4 +40,5 @@ Each solution contains a distinct board configuration of the *n*-queens' placem
|
||||
- 利用 col 数组记录列信息,col 有 `n` 列。用 dia1,dia2 记录从左下到右上的对角线,从左上到右下的对角线的信息,dia1 和 dia2 分别都有 `2*n-1` 个。
|
||||
- dia1 对角线的规律是 `i + j 是定值`,例如[0,0],为 0;[1,0]、[0,1] 为 1;[2,0]、[1,1]、[0,2] 为 2;
|
||||
- dia2 对角线的规律是 `i - j 是定值`,例如[0,7],为 -7;[0,6]、[1,7] 为 -6;[0,5]、[1,6]、[2,7] 为 -5;为了使他们从 0 开始,i - j + n - 1 偏移到 0 开始,所以 dia2 的规律是 `i - j + n - 1 为定值`。
|
||||
- 还有一个位运算的方法,每行只能选一个位置放皇后,那么对每行遍历可能放皇后的位置。如何高效判断哪些点不能放皇后呢?这里的做法毕竟巧妙,把所有之前选过的点按照顺序存下来,然后根据之前选的点到当前行的距离,就可以快速判断是不是会有冲突。举个例子: 假如在 4 皇后问题中,如果第一二行已经选择了位置 [1, 3],那么在第三行选择时,首先不能再选 1, 3 列了,而对于第三行, 1 距离长度为2,所以它会影响到 -1, 3 两个列。同理,3 在第二行,距离第三行为 1,所以 3 会影响到列 2, 4。由上面的结果,我们知道 -1, 4 超出边界了不用去管,别的不能选的点是 1, 2, 3,所以第三行就只能选 0。在代码实现中,可以在每次遍历前根据之前选择的情况生成一个 occupied 用来记录当前这一行,已经被选了的和由于之前皇后攻击范围所以不能选的位置,然后只选择合法的位置进入到下一层递归。另外就是预处理了一个皇后放不同位置的字符串,这样这些字符串在返回结果的时候是可以在内存中复用的,省一点内存。
|
||||
|
||||
|
||||
@ -5,14 +5,12 @@ func uniquePaths(m int, n int) int {
|
||||
for i := 0; i < n; i++ {
|
||||
dp[i] = make([]int, m)
|
||||
}
|
||||
for i := 0; i < m; i++ {
|
||||
dp[0][i] = 1
|
||||
}
|
||||
for i := 0; i < n; i++ {
|
||||
dp[i][0] = 1
|
||||
for j := 0; j < m; j++ {
|
||||
if i == 0 || j == 0 {
|
||||
dp[i][j] = 1
|
||||
continue
|
||||
}
|
||||
for i := 1; i < n; i++ {
|
||||
for j := 1; j < m; j++ {
|
||||
dp[i][j] = dp[i-1][j] + dp[i][j-1]
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,21 +1,17 @@
|
||||
package leetcode
|
||||
|
||||
func plusOne(digits []int) []int {
|
||||
if len(digits) == 0 {
|
||||
return []int{}
|
||||
}
|
||||
carry := 1
|
||||
for i := len(digits) - 1; i >= 0; i-- {
|
||||
if digits[i]+carry > 9 {
|
||||
digits[i] = 0
|
||||
carry = 1
|
||||
} else {
|
||||
digits[i] += carry
|
||||
carry = 0
|
||||
}
|
||||
}
|
||||
if digits[0] == 0 && carry == 1 {
|
||||
digits = append([]int{1}, digits...)
|
||||
}
|
||||
digits[i]++
|
||||
if digits[i] != 10 {
|
||||
// no carry
|
||||
return digits
|
||||
}
|
||||
// carry
|
||||
digits[i] = 0
|
||||
}
|
||||
// all carry
|
||||
digits[0] = 1
|
||||
digits = append(digits, 0)
|
||||
return digits
|
||||
}
|
||||
|
||||
@ -1,23 +1,17 @@
|
||||
package leetcode
|
||||
|
||||
// 解法一 二分
|
||||
// 解法一 二分, 找到最后一个满足 n^2 <= x 的整数n
|
||||
func mySqrt(x int) int {
|
||||
if x == 0 {
|
||||
return 0
|
||||
}
|
||||
left, right, res := 1, x, 0
|
||||
for left <= right {
|
||||
mid := left + ((right - left) >> 1)
|
||||
if mid < x/mid {
|
||||
left = mid + 1
|
||||
res = mid
|
||||
} else if mid == x/mid {
|
||||
return mid
|
||||
l, r := 0, x
|
||||
for l < r {
|
||||
mid := (l + r + 1) / 2
|
||||
if mid*mid > x {
|
||||
r = mid - 1
|
||||
} else {
|
||||
right = mid - 1
|
||||
l = mid
|
||||
}
|
||||
}
|
||||
return res
|
||||
return l
|
||||
}
|
||||
|
||||
// 解法二 牛顿迭代法 https://en.wikipedia.org/wiki/Integer_square_root
|
||||
|
||||
54
leetcode/0073.Set-Matrix-Zeroes/73. Set Matrix Zeroes.go
Normal file
54
leetcode/0073.Set-Matrix-Zeroes/73. Set Matrix Zeroes.go
Normal file
@ -0,0 +1,54 @@
|
||||
package leetcode
|
||||
|
||||
func setZeroes(matrix [][]int) {
|
||||
if len(matrix) == 0 || len(matrix[0]) == 0 {
|
||||
return
|
||||
}
|
||||
isFirstRowExistZero, isFirstColExistZero := false, false
|
||||
for i := 0; i < len(matrix); i++ {
|
||||
if matrix[i][0] == 0 {
|
||||
isFirstColExistZero = true
|
||||
break
|
||||
}
|
||||
}
|
||||
for j := 0; j < len(matrix[0]); j++ {
|
||||
if matrix[0][j] == 0 {
|
||||
isFirstRowExistZero = true
|
||||
break
|
||||
}
|
||||
}
|
||||
for i := 1; i < len(matrix); i++ {
|
||||
for j := 1; j < len(matrix[0]); j++ {
|
||||
if matrix[i][j] == 0 {
|
||||
matrix[i][0] = 0
|
||||
matrix[0][j] = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
// 处理[1:]行全部置 0
|
||||
for i := 1; i < len(matrix); i++ {
|
||||
if matrix[i][0] == 0 {
|
||||
for j := 1; j < len(matrix[0]); j++ {
|
||||
matrix[i][j] = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
// 处理[1:]列全部置 0
|
||||
for j := 1; j < len(matrix[0]); j++ {
|
||||
if matrix[0][j] == 0 {
|
||||
for i := 1; i < len(matrix); i++ {
|
||||
matrix[i][j] = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
if isFirstRowExistZero {
|
||||
for j := 0; j < len(matrix[0]); j++ {
|
||||
matrix[0][j] = 0
|
||||
}
|
||||
}
|
||||
if isFirstColExistZero {
|
||||
for i := 0; i < len(matrix); i++ {
|
||||
matrix[i][0] = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,47 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question73 struct {
|
||||
para73
|
||||
ans73
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para73 struct {
|
||||
matrix [][]int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans73 struct {
|
||||
}
|
||||
|
||||
func Test_Problem73(t *testing.T) {
|
||||
|
||||
qs := []question73{
|
||||
|
||||
{
|
||||
para73{[][]int{
|
||||
{0, 1, 2, 0},
|
||||
{3, 4, 5, 2},
|
||||
{1, 3, 1, 5},
|
||||
}},
|
||||
ans73{},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 73------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans73, q.para73
|
||||
fmt.Printf("【input】:%v ", p)
|
||||
setZeroes(p.matrix)
|
||||
fmt.Printf("【output】:%v\n", p)
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
104
leetcode/0073.Set-Matrix-Zeroes/README.md
Normal file
104
leetcode/0073.Set-Matrix-Zeroes/README.md
Normal file
@ -0,0 +1,104 @@
|
||||
# [73. Set Matrix Zeroes](https://leetcode.com/problems/set-matrix-zeroes/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given an *`m* x *n*` matrix. If an element is **0**, set its entire row and column to **0**. Do it **[in-place](https://en.wikipedia.org/wiki/In-place_algorithm)**.
|
||||
|
||||
**Follow up:**
|
||||
|
||||
- A straight forward solution using O(*mn*) space is probably a bad idea.
|
||||
- A simple improvement uses O(*m* + *n*) space, but still not the best solution.
|
||||
- Could you devise a constant space solution?
|
||||
|
||||
**Example 1:**
|
||||
|
||||
|
||||
|
||||
```
|
||||
Input: matrix = [[1,1,1],[1,0,1],[1,1,1]]
|
||||
Output: [[1,0,1],[0,0,0],[1,0,1]]
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
|
||||
|
||||
```
|
||||
Input: matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
|
||||
Output: [[0,0,0,0],[0,4,5,0],[0,3,1,0]]
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `m == matrix.length`
|
||||
- `n == matrix[0].length`
|
||||
- `1 <= m, n <= 200`
|
||||
- `2^31 <= matrix[i][j] <= 2^31 - 1`
|
||||
|
||||
## 题目大意
|
||||
|
||||
给定一个 `m x n` 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 此题考查对程序的控制能力,无算法思想。题目要求采用原地的算法,所有修改即在原二维数组上进行。在二维数组中有 2 个特殊位置,一个是第一行,一个是第一列。它们的特殊性在于,它们之间只要有一个 0,它们都会变为全 0 。先用 2 个变量记录这一行和这一列中是否有 0,防止之后的修改覆盖了这 2 个地方。然后除去这一行和这一列以外的部分判断是否有 0,如果有 0,将它们所在的行第一个元素标记为 0,所在列的第一个元素标记为 0 。最后通过标记,将对应的行列置 0 即可。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func setZeroes(matrix [][]int) {
|
||||
if len(matrix) == 0 || len(matrix[0]) == 0 {
|
||||
return
|
||||
}
|
||||
isFirstRowExistZero, isFirstColExistZero := false, false
|
||||
for i := 0; i < len(matrix); i++ {
|
||||
if matrix[i][0] == 0 {
|
||||
isFirstColExistZero = true
|
||||
break
|
||||
}
|
||||
}
|
||||
for j := 0; j < len(matrix[0]); j++ {
|
||||
if matrix[0][j] == 0 {
|
||||
isFirstRowExistZero = true
|
||||
break
|
||||
}
|
||||
}
|
||||
for i := 1; i < len(matrix); i++ {
|
||||
for j := 1; j < len(matrix[0]); j++ {
|
||||
if matrix[i][j] == 0 {
|
||||
matrix[i][0] = 0
|
||||
matrix[0][j] = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
// 处理[1:]行全部置 0
|
||||
for i := 1; i < len(matrix); i++ {
|
||||
if matrix[i][0] == 0 {
|
||||
for j := 1; j < len(matrix[0]); j++ {
|
||||
matrix[i][j] = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
// 处理[1:]列全部置 0
|
||||
for j := 1; j < len(matrix[0]); j++ {
|
||||
if matrix[0][j] == 0 {
|
||||
for i := 1; i < len(matrix); i++ {
|
||||
matrix[i][j] = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
if isFirstRowExistZero {
|
||||
for j := 0; j < len(matrix[0]); j++ {
|
||||
matrix[0][j] = 0
|
||||
}
|
||||
}
|
||||
if isFirstColExistZero {
|
||||
for i := 0; i < len(matrix); i++ {
|
||||
matrix[i][0] = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
@ -1,28 +1,16 @@
|
||||
package leetcode
|
||||
|
||||
func sortColors(nums []int) {
|
||||
if len(nums) == 0 {
|
||||
return
|
||||
zero, one := 0, 0
|
||||
for i, n := range nums {
|
||||
nums[i] = 2
|
||||
if n <= 1 {
|
||||
nums[one] = 1
|
||||
one++
|
||||
}
|
||||
|
||||
r := 0
|
||||
w := 0
|
||||
b := 0 // label the end of different colors;
|
||||
for _, num := range nums {
|
||||
if num == 0 {
|
||||
nums[b] = 2
|
||||
b++
|
||||
nums[w] = 1
|
||||
w++
|
||||
nums[r] = 0
|
||||
r++
|
||||
} else if num == 1 {
|
||||
nums[b] = 2
|
||||
b++
|
||||
nums[w] = 1
|
||||
w++
|
||||
} else if num == 2 {
|
||||
b++
|
||||
if n == 0 {
|
||||
nums[zero] = 0
|
||||
zero++
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@ -32,9 +32,7 @@ func minWindow(s string, t string) string {
|
||||
}
|
||||
}
|
||||
if finalLeft != -1 {
|
||||
for i := finalLeft; i < finalRight+1; i++ {
|
||||
result += string(s[i])
|
||||
}
|
||||
result = string(s[finalLeft : finalRight+1])
|
||||
}
|
||||
return result
|
||||
}
|
||||
|
||||
@ -1,35 +1,12 @@
|
||||
package leetcode
|
||||
|
||||
func removeDuplicates80(nums []int) int {
|
||||
if len(nums) == 0 {
|
||||
return 0
|
||||
}
|
||||
last, finder := 0, 0
|
||||
for last < len(nums)-1 {
|
||||
startFinder := -1
|
||||
for nums[finder] == nums[last] {
|
||||
if startFinder == -1 || startFinder > finder {
|
||||
startFinder = finder
|
||||
}
|
||||
if finder == len(nums)-1 {
|
||||
break
|
||||
}
|
||||
finder++
|
||||
}
|
||||
if finder-startFinder >= 2 && nums[finder-1] == nums[last] && nums[finder] != nums[last] {
|
||||
nums[last+1] = nums[finder-1]
|
||||
nums[last+2] = nums[finder]
|
||||
last += 2
|
||||
} else {
|
||||
nums[last+1] = nums[finder]
|
||||
last++
|
||||
}
|
||||
if finder == len(nums)-1 {
|
||||
if nums[finder] != nums[last-1] {
|
||||
nums[last] = nums[finder]
|
||||
}
|
||||
return last + 1
|
||||
func removeDuplicates(nums []int) int {
|
||||
slow := 0
|
||||
for fast, v := range nums {
|
||||
if fast < 2 || nums[slow-2] != v {
|
||||
nums[slow] = v
|
||||
slow++
|
||||
}
|
||||
}
|
||||
return last + 1
|
||||
return slow
|
||||
}
|
||||
|
||||
@ -61,7 +61,7 @@ func Test_Problem80(t *testing.T) {
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans80, q.para80
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p.one, removeDuplicates80(p.one))
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p.one, removeDuplicates(p.one))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
|
||||
@ -51,6 +51,6 @@ for (int i = 0; i < len; i++) {
|
||||
|
||||
## 解题思路
|
||||
|
||||
这道题和第 26 题很像。是第 26 题的加强版。这道题和第 283 题,第 27 题基本一致,283 题是删除 0,27 题是删除指定元素,这一题是删除重复元素,实质是一样的。
|
||||
|
||||
这里数组的删除并不是真的删除,只是将删除的元素移动到数组后面的空间内,然后返回数组实际剩余的元素个数,OJ 最终判断题目的时候会读取数组剩余个数的元素进行输出。
|
||||
- 问题提示有序数组,一般最容易想到使用双指针的解法,双指针的关键点:移动两个指针的条件。
|
||||
- 在该题中移动的条件:快指针从头遍历数组,慢指针指向修改后的数组的末端,当慢指针指向倒数第二个数与快指针指向的数不相等时,才移动慢指针,同时赋值慢指针。
|
||||
- 处理边界条件:当数组小于两个元素时,不做处理。
|
||||
|
||||
@ -1,32 +1,25 @@
|
||||
package leetcode
|
||||
|
||||
import "fmt"
|
||||
|
||||
func largestRectangleArea(heights []int) int {
|
||||
maxArea, stack, height := 0, []int{}, 0
|
||||
for i := 0; i <= len(heights); i++ {
|
||||
if i == len(heights) {
|
||||
height = 0
|
||||
} else {
|
||||
height = heights[i]
|
||||
maxArea := 0
|
||||
n := len(heights) + 2
|
||||
// Add a sentry at the beginning and the end
|
||||
getHeight := func(i int) int {
|
||||
if i == 0 || n-1 == i {
|
||||
return 0
|
||||
}
|
||||
if len(stack) == 0 || height >= heights[stack[len(stack)-1]] {
|
||||
stack = append(stack, i)
|
||||
} else {
|
||||
tmp := stack[len(stack)-1]
|
||||
fmt.Printf("1. tmp = %v stack = %v\n", tmp, stack)
|
||||
stack = stack[:len(stack)-1]
|
||||
length := 0
|
||||
if len(stack) == 0 {
|
||||
length = i
|
||||
} else {
|
||||
length = i - 1 - stack[len(stack)-1]
|
||||
fmt.Printf("2. length = %v stack = %v i = %v\n", length, stack, i)
|
||||
return heights[i-1]
|
||||
}
|
||||
maxArea = max(maxArea, heights[tmp]*length)
|
||||
fmt.Printf("3. maxArea = %v heights[tmp]*length = %v\n", maxArea, heights[tmp]*length)
|
||||
i--
|
||||
st := make([]int, 0, n/2)
|
||||
for i := 0; i < n; i++ {
|
||||
for len(st) > 0 && getHeight(st[len(st)-1]) > getHeight(i) {
|
||||
// pop stack
|
||||
idx := st[len(st)-1]
|
||||
st = st[:len(st)-1]
|
||||
maxArea = max(maxArea, getHeight(idx)*(i-st[len(st)-1]-1))
|
||||
}
|
||||
// push stack
|
||||
st = append(st, i)
|
||||
}
|
||||
return maxArea
|
||||
}
|
||||
|
||||
@ -40,6 +40,10 @@ func Test_Problem84(t *testing.T) {
|
||||
para84{[]int{1, 1}},
|
||||
ans84{2},
|
||||
},
|
||||
{
|
||||
para84{[]int{2, 1, 2}},
|
||||
ans84{3},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 84------------------------\n")
|
||||
|
||||
@ -1,29 +1,16 @@
|
||||
package leetcode
|
||||
|
||||
func merge(nums1 []int, m int, nums2 []int, n int) {
|
||||
if m == 0 {
|
||||
copy(nums1, nums2)
|
||||
return
|
||||
}
|
||||
// 这里不需要,因为测试数据考虑到了第一个数组的空间问题
|
||||
// for index := 0; index < n; index++ {
|
||||
// nums1 = append(nums1, nums2[index])
|
||||
// }
|
||||
i := m - 1
|
||||
j := n - 1
|
||||
k := m + n - 1
|
||||
// 从后面往前放,只需要循环一次即可
|
||||
for ; i >= 0 && j >= 0; k-- {
|
||||
if nums1[i] > nums2[j] {
|
||||
nums1[k] = nums1[i]
|
||||
i--
|
||||
for p := m + n; m > 0 && n > 0; p-- {
|
||||
if nums1[m-1] <= nums2[n-1] {
|
||||
nums1[p-1] = nums2[n-1]
|
||||
n--
|
||||
} else {
|
||||
nums1[k] = nums2[j]
|
||||
j--
|
||||
nums1[p-1] = nums1[m-1]
|
||||
m--
|
||||
}
|
||||
}
|
||||
for ; j >= 0; k-- {
|
||||
nums1[k] = nums2[j]
|
||||
j--
|
||||
for ; n > 0; n-- {
|
||||
nums1[n-1] = nums2[n-1]
|
||||
}
|
||||
}
|
||||
|
||||
@ -29,20 +29,10 @@ func Test_Problem88(t *testing.T) {
|
||||
|
||||
qs := []question88{
|
||||
|
||||
// question{
|
||||
// para{[]int{0}, 0, []int{1}, 1},
|
||||
// ans{[]int{1}},
|
||||
// },
|
||||
//
|
||||
// question{
|
||||
// para{[]int{1, 3, 5, 7}, 4, []int{2, 4}, 2},
|
||||
// ans{[]int{1, 2, 3, 4}},
|
||||
// },
|
||||
//
|
||||
// question{
|
||||
// para{[]int{1, 3, 5, 7}, 4, []int{2, 2}, 2},
|
||||
// ans{[]int{1, 2, 2, 3}},
|
||||
// },
|
||||
{
|
||||
para88{[]int{0}, 0, []int{1}, 1},
|
||||
ans88{[]int{1}},
|
||||
},
|
||||
|
||||
{
|
||||
para88{[]int{1, 2, 3, 0, 0, 0}, 3, []int{2, 5, 6}, 3},
|
||||
|
||||
@ -1,29 +1,16 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"strconv"
|
||||
)
|
||||
|
||||
func numDecodings(s string) int {
|
||||
if len(s) == 0 {
|
||||
return 0
|
||||
}
|
||||
dp := make([]int, len(s)+1)
|
||||
n := len(s)
|
||||
dp := make([]int, n+1)
|
||||
dp[0] = 1
|
||||
if s[:1] == "0" {
|
||||
dp[1] = 0
|
||||
} else {
|
||||
dp[1] = 1
|
||||
}
|
||||
for i := 2; i <= len(s); i++ {
|
||||
lastNum, _ := strconv.Atoi(s[i-1 : i])
|
||||
if lastNum >= 1 && lastNum <= 9 {
|
||||
for i := 1; i <= n; i++ {
|
||||
if s[i-1] != '0' {
|
||||
dp[i] += dp[i-1]
|
||||
}
|
||||
lastNum, _ = strconv.Atoi(s[i-2 : i])
|
||||
if lastNum >= 10 && lastNum <= 26 {
|
||||
if i > 1 && s[i-2] != '0' && (s[i-2]-'0')*10+(s[i-1]-'0') <= 26 {
|
||||
dp[i] += dp[i-2]
|
||||
}
|
||||
}
|
||||
return dp[len(s)]
|
||||
return dp[n]
|
||||
}
|
||||
|
||||
35
leetcode/0097.Interleaving-String/97. Interleaving String.go
Normal file
35
leetcode/0097.Interleaving-String/97. Interleaving String.go
Normal file
@ -0,0 +1,35 @@
|
||||
package leetcode
|
||||
|
||||
func isInterleave(s1 string, s2 string, s3 string) bool {
|
||||
if len(s1)+len(s2) != len(s3) {
|
||||
return false
|
||||
}
|
||||
visited := make(map[int]bool)
|
||||
return dfs(s1, s2, s3, 0, 0, visited)
|
||||
}
|
||||
|
||||
func dfs(s1, s2, s3 string, p1, p2 int, visited map[int]bool) bool {
|
||||
if p1+p2 == len(s3) {
|
||||
return true
|
||||
}
|
||||
if _, ok := visited[(p1*len(s3))+p2]; ok {
|
||||
return false
|
||||
}
|
||||
visited[(p1*len(s3))+p2] = true
|
||||
var match1, match2 bool
|
||||
if p1 < len(s1) && s3[p1+p2] == s1[p1] {
|
||||
match1 = true
|
||||
}
|
||||
if p2 < len(s2) && s3[p1+p2] == s2[p2] {
|
||||
match2 = true
|
||||
}
|
||||
if match1 && match2 {
|
||||
return dfs(s1, s2, s3, p1+1, p2, visited) || dfs(s1, s2, s3, p1, p2+1, visited)
|
||||
} else if match1 {
|
||||
return dfs(s1, s2, s3, p1+1, p2, visited)
|
||||
} else if match2 {
|
||||
return dfs(s1, s2, s3, p1, p2+1, visited)
|
||||
} else {
|
||||
return false
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,54 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question97 struct {
|
||||
para97
|
||||
ans97
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para97 struct {
|
||||
s1 string
|
||||
s2 string
|
||||
s3 string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans97 struct {
|
||||
one bool
|
||||
}
|
||||
|
||||
func Test_Problem97(t *testing.T) {
|
||||
|
||||
qs := []question97{
|
||||
|
||||
{
|
||||
para97{"aabcc", "dbbca", "aadbbcbcac"},
|
||||
ans97{true},
|
||||
},
|
||||
|
||||
{
|
||||
para97{"aabcc", "dbbca", "aadbbbaccc"},
|
||||
ans97{false},
|
||||
},
|
||||
|
||||
{
|
||||
para97{"", "", ""},
|
||||
ans97{true},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 97------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans97, q.para97
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, isInterleave(p.s1, p.s2, p.s3))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
104
leetcode/0097.Interleaving-String/README.md
Normal file
104
leetcode/0097.Interleaving-String/README.md
Normal file
@ -0,0 +1,104 @@
|
||||
# [97. Interleaving String](https://leetcode.com/problems/interleaving-string/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given strings `s1`, `s2`, and `s3`, find whether `s3` is formed by an **interleaving** of `s1` and `s2`.
|
||||
|
||||
An **interleaving** of two strings `s` and `t` is a configuration where they are divided into **non-empty** substrings such that:
|
||||
|
||||
- `s = s1 + s2 + ... + sn`
|
||||
- `t = t1 + t2 + ... + tm`
|
||||
- `|n - m| <= 1`
|
||||
- The **interleaving** is `s1 + t1 + s2 + t2 + s3 + t3 + ...` or `t1 + s1 + t2 + s2 + t3 + s3 + ...`
|
||||
|
||||
**Note:** `a + b` is the concatenation of strings `a` and `b`.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
|
||||
|
||||
```
|
||||
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac"
|
||||
Output: true
|
||||
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc"
|
||||
Output: false
|
||||
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: s1 = "", s2 = "", s3 = ""
|
||||
Output: true
|
||||
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `0 <= s1.length, s2.length <= 100`
|
||||
- `0 <= s3.length <= 200`
|
||||
- `s1`, `s2`, and `s3` consist of lowercase English letters.
|
||||
|
||||
**Follow up:** Could you solve it using only `O(s2.length)` additional memory space?
|
||||
|
||||
## 题目大意
|
||||
|
||||
给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串:
|
||||
|
||||
- s = s1 + s2 + ... + sn
|
||||
- t = t1 + t2 + ... + tm
|
||||
- |n - m| <= 1
|
||||
- 交错 是 s1 + t1 + s2 + t2 + s3 + t3 + ... 或者 t1 + s1 + t2 + s2 + t3 + s3 + ...
|
||||
|
||||
提示:a + b 意味着字符串 a 和 b 连接。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 深搜或者广搜暴力解题。笔者用深搜实现的。记录 s1 和 s2 串当前比较的位置 p1 和 p2。如果 s3[p1+p2] 的位置上等于 s1[p1] 或者 s2[p2] 代表能匹配上,那么继续往后移动 p1 和 p2 相应的位置。因为是交错字符串,所以判断匹配的位置是 s3[p1+p2] 的位置。如果仅仅这么写,会超时,s1 和 s2 两个字符串重复交叉判断的位置太多了。需要加上记忆化搜索。可以用 visited[i][j] 这样的二维数组来记录是否搜索过了。笔者为了压缩空间,将 i 和 j 编码压缩到一维数组了。i * len(s3) + j 是唯一下标,所以可以用这种方式存储是否搜索过。具体代码见下面的实现。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func isInterleave(s1 string, s2 string, s3 string) bool {
|
||||
if len(s1)+len(s2) != len(s3) {
|
||||
return false
|
||||
}
|
||||
visited := make(map[int]bool)
|
||||
return dfs(s1, s2, s3, 0, 0, visited)
|
||||
}
|
||||
|
||||
func dfs(s1, s2, s3 string, p1, p2 int, visited map[int]bool) bool {
|
||||
if p1+p2 == len(s3) {
|
||||
return true
|
||||
}
|
||||
if _, ok := visited[(p1*len(s3))+p2]; ok {
|
||||
return false
|
||||
}
|
||||
visited[(p1*len(s3))+p2] = true
|
||||
var match1, match2 bool
|
||||
if p1 < len(s1) && s3[p1+p2] == s1[p1] {
|
||||
match1 = true
|
||||
}
|
||||
if p2 < len(s2) && s3[p1+p2] == s2[p2] {
|
||||
match2 = true
|
||||
}
|
||||
if match1 && match2 {
|
||||
return dfs(s1, s2, s3, p1+1, p2, visited) || dfs(s1, s2, s3, p1, p2+1, visited)
|
||||
} else if match1 {
|
||||
return dfs(s1, s2, s3, p1+1, p2, visited)
|
||||
} else if match2 {
|
||||
return dfs(s1, s2, s3, p1, p2+1, visited)
|
||||
} else {
|
||||
return false
|
||||
}
|
||||
}
|
||||
```
|
||||
@ -16,7 +16,26 @@ type TreeNode = structures.TreeNode
|
||||
* }
|
||||
*/
|
||||
|
||||
// 解法一 dfs
|
||||
func isSymmetric(root *TreeNode) bool {
|
||||
return root == nil || dfs(root.Left, root.Right)
|
||||
}
|
||||
|
||||
func dfs(rootLeft, rootRight *TreeNode) bool {
|
||||
if rootLeft == nil && rootRight == nil {
|
||||
return true
|
||||
}
|
||||
if rootLeft == nil || rootRight == nil {
|
||||
return false
|
||||
}
|
||||
if rootLeft.Val != rootRight.Val {
|
||||
return false
|
||||
}
|
||||
return dfs(rootLeft.Left, rootRight.Right) && dfs(rootLeft.Right, rootRight.Left)
|
||||
}
|
||||
|
||||
// 解法二
|
||||
func isSymmetric1(root *TreeNode) bool {
|
||||
if root == nil {
|
||||
return true
|
||||
}
|
||||
|
||||
@ -21,50 +21,42 @@ func levelOrder(root *TreeNode) [][]int {
|
||||
if root == nil {
|
||||
return [][]int{}
|
||||
}
|
||||
queue := []*TreeNode{}
|
||||
queue = append(queue, root)
|
||||
curNum, nextLevelNum, res, tmp := 1, 0, [][]int{}, []int{}
|
||||
for len(queue) != 0 {
|
||||
if curNum > 0 {
|
||||
node := queue[0]
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
nextLevelNum++
|
||||
queue := []*TreeNode{root}
|
||||
res := make([][]int, 0)
|
||||
for len(queue) > 0 {
|
||||
l := len(queue)
|
||||
tmp := make([]int, 0, l)
|
||||
for i := 0; i < l; i++ {
|
||||
if queue[i].Left != nil {
|
||||
queue = append(queue, queue[i].Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
nextLevelNum++
|
||||
if queue[i].Right != nil {
|
||||
queue = append(queue, queue[i].Right)
|
||||
}
|
||||
curNum--
|
||||
tmp = append(tmp, node.Val)
|
||||
queue = queue[1:]
|
||||
tmp = append(tmp, queue[i].Val)
|
||||
}
|
||||
if curNum == 0 {
|
||||
queue = queue[l:]
|
||||
res = append(res, tmp)
|
||||
curNum = nextLevelNum
|
||||
nextLevelNum = 0
|
||||
tmp = []int{}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
// 解法二 DFS
|
||||
func levelOrder1(root *TreeNode) [][]int {
|
||||
levels := [][]int{}
|
||||
dfsLevel(root, -1, &levels)
|
||||
return levels
|
||||
}
|
||||
|
||||
func dfsLevel(node *TreeNode, level int, res *[][]int) {
|
||||
var res [][]int
|
||||
var dfsLevel func(node *TreeNode, level int)
|
||||
dfsLevel = func(node *TreeNode, level int) {
|
||||
if node == nil {
|
||||
return
|
||||
}
|
||||
currLevel := level + 1
|
||||
for len(*res) <= currLevel {
|
||||
*res = append(*res, []int{})
|
||||
if len(res) == level {
|
||||
res = append(res, []int{node.Val})
|
||||
} else {
|
||||
res[level] = append(res[level], node.Val)
|
||||
}
|
||||
(*res)[currLevel] = append((*res)[currLevel], node.Val)
|
||||
dfsLevel(node.Left, currLevel, res)
|
||||
dfsLevel(node.Right, currLevel, res)
|
||||
dfsLevel(node.Left, level+1)
|
||||
dfsLevel(node.Right, level+1)
|
||||
}
|
||||
dfsLevel(root, 0)
|
||||
return res
|
||||
}
|
||||
|
||||
@ -81,3 +81,40 @@ func search(root *TreeNode, depth int, res *[][]int) {
|
||||
search(root.Left, depth+1, res)
|
||||
search(root.Right, depth+1, res)
|
||||
}
|
||||
|
||||
// 解法三 BFS
|
||||
func zigzagLevelOrder1(root *TreeNode) [][]int {
|
||||
res := [][]int{}
|
||||
if root == nil {
|
||||
return res
|
||||
}
|
||||
q := []*TreeNode{root}
|
||||
size, i, j, lay, tmp, flag := 0, 0, 0, []int{}, []*TreeNode{}, false
|
||||
for len(q) > 0 {
|
||||
size = len(q)
|
||||
tmp = []*TreeNode{}
|
||||
lay = make([]int, size)
|
||||
j = size - 1
|
||||
for i = 0; i < size; i++ {
|
||||
root = q[0]
|
||||
q = q[1:]
|
||||
if !flag {
|
||||
lay[i] = root.Val
|
||||
} else {
|
||||
lay[j] = root.Val
|
||||
j--
|
||||
}
|
||||
if root.Left != nil {
|
||||
tmp = append(tmp, root.Left)
|
||||
}
|
||||
if root.Right != nil {
|
||||
tmp = append(tmp, root.Right)
|
||||
}
|
||||
|
||||
}
|
||||
res = append(res, lay)
|
||||
flag = !flag
|
||||
q = tmp
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
@ -0,0 +1,45 @@
|
||||
package leetcode
|
||||
|
||||
// 解法一 压缩版 DP
|
||||
func numDistinct(s string, t string) int {
|
||||
dp := make([]int, len(s)+1)
|
||||
for i, curT := range t {
|
||||
pre := 0
|
||||
for j, curS := range s {
|
||||
if i == 0 {
|
||||
pre = 1
|
||||
}
|
||||
newDP := dp[j+1]
|
||||
if curT == curS {
|
||||
dp[j+1] = dp[j] + pre
|
||||
} else {
|
||||
dp[j+1] = dp[j]
|
||||
}
|
||||
pre = newDP
|
||||
}
|
||||
}
|
||||
return dp[len(s)]
|
||||
}
|
||||
|
||||
// 解法二 普通 DP
|
||||
func numDistinct1(s, t string) int {
|
||||
m, n := len(s), len(t)
|
||||
if m < n {
|
||||
return 0
|
||||
}
|
||||
dp := make([][]int, m+1)
|
||||
for i := range dp {
|
||||
dp[i] = make([]int, n+1)
|
||||
dp[i][n] = 1
|
||||
}
|
||||
for i := m - 1; i >= 0; i-- {
|
||||
for j := n - 1; j >= 0; j-- {
|
||||
if s[i] == t[j] {
|
||||
dp[i][j] = dp[i+1][j+1] + dp[i+1][j]
|
||||
} else {
|
||||
dp[i][j] = dp[i+1][j]
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[0][0]
|
||||
}
|
||||
@ -0,0 +1,48 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question115 struct {
|
||||
para115
|
||||
ans115
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para115 struct {
|
||||
s string
|
||||
t string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans115 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem115(t *testing.T) {
|
||||
|
||||
qs := []question115{
|
||||
|
||||
{
|
||||
para115{"rabbbit", "rabbit"},
|
||||
ans115{3},
|
||||
},
|
||||
|
||||
{
|
||||
para115{"babgbag", "bag"},
|
||||
ans115{5},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 115------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans115, q.para115
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, numDistinct(p.s, p.t))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
99
leetcode/0115.Distinct-Subsequences/README.md
Normal file
99
leetcode/0115.Distinct-Subsequences/README.md
Normal file
@ -0,0 +1,99 @@
|
||||
# [115. Distinct Subsequences](https://leetcode.com/problems/distinct-subsequences/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given two strings `s` and `t`, return *the number of distinct subsequences of `s` which equals `t`*.
|
||||
|
||||
A string's **subsequence** is a new string formed from the original string by deleting some (can be none) of the characters without disturbing the remaining characters' relative positions. (i.e., `"ACE"` is a subsequence of `"ABCDE"` while `"AEC"` is not).
|
||||
|
||||
It is guaranteed the answer fits on a 32-bit signed integer.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: s = "rabbbit", t = "rabbit"
|
||||
Output: 3
|
||||
Explanation:
|
||||
As shown below, there are 3 ways you can generate "rabbit" from S.
|
||||
rabbbitrabbbitrabbbit
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: s = "babgbag", t = "bag"
|
||||
Output: 5
|
||||
Explanation:
|
||||
As shown below, there are 5 ways you can generate "bag" from S.
|
||||
babgbagbabgbagbabgbagbabgbagbabgbag
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `0 <= s.length, t.length <= 1000`
|
||||
- `s` and `t` consist of English letters.
|
||||
|
||||
## 题目大意
|
||||
|
||||
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)题目数据保证答案符合 32 位带符号整数范围。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 在字符串 `s` 中最多包含多少个字符串 `t`。这里面包含很多重叠子问题,所以尝试用动态规划解决这个问题。定义 `dp[i][j]` 代表 `s[i:]` 的子序列中 `t[j:]` 出现的个数。初始化先判断边界条件。当 `i = len(s)` 且 `0≤ j < len(t)` 的时候,`s[i:]` 为空字符串,`t[j:]` 不为空,所以 `dp[len(s)][j] = 0`。当 `j = len(t)` 且 `0 ≤ i < len(s)` 的时候,`t[j:]` 不为空字符串,空字符串是任何字符串的子序列。所以 `dp[i][n] = 1`。
|
||||
- 当 `i < len(s)` 且 `j < len(t)` 的时候,如果 `s[i] == t[j]`,有 2 种匹配方式,第一种将 `s[i]` 与 `t[j]` 匹配,那么 `t[j+1:]` 匹配 `s[i+1:]` 的子序列,子序列数为 `dp[i+1][j+1]`;第二种将 `s[i]` 不与 `t[j]` 匹配,`t[j:]` 作为 `s[i+1:]` 的子序列,子序列数为 `dp[i+1][j]`。综合 2 种情况,当 `s[i] == t[j]` 时,`dp[i][j] = dp[i+1][j+1] + dp[i+1][j]`。
|
||||
- 如果 `s[i] != t[j]`,此时 `t[j:]` 只能作为 `s[i+1:]` 的子序列,子序列数为 `dp[i+1][j]`。所以当 `s[i] != t[j]` 时,`dp[i][j] = dp[i+1][j]`。综上分析得:
|
||||
|
||||
$$dp[i][j] = \left\{\begin{matrix}dp[i+1][j+1]+dp[i+1][j]&,s[i]=t[j]\\ dp[i+1][j]&,s[i]!=t[j]\end{matrix}\right.$$
|
||||
|
||||
- 最后是优化版本。写出上述代码以后,可以发现填表的过程是从右下角一直填到左上角。填表顺序是 从下往上一行一行的填。行内从右往左填。于是可以将这个二维数据压缩到一维。因为填充当前行只需要用到它的下一行信息即可,更进一步,用到的是下一行中右边元素的信息。于是可以每次更新该行时,先将旧的值存起来,计算更新该行的时候从右往左更新。这样做即可减少一维空间,将原来的二维数组压缩到一维数组。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
// 解法一 压缩版 DP
|
||||
func numDistinct(s string, t string) int {
|
||||
dp := make([]int, len(s)+1)
|
||||
for i, curT := range t {
|
||||
pre := 0
|
||||
for j, curS := range s {
|
||||
if i == 0 {
|
||||
pre = 1
|
||||
}
|
||||
newDP := dp[j+1]
|
||||
if curT == curS {
|
||||
dp[j+1] = dp[j] + pre
|
||||
} else {
|
||||
dp[j+1] = dp[j]
|
||||
}
|
||||
pre = newDP
|
||||
}
|
||||
}
|
||||
return dp[len(s)]
|
||||
}
|
||||
|
||||
// 解法二 普通 DP
|
||||
func numDistinct1(s, t string) int {
|
||||
m, n := len(s), len(t)
|
||||
if m < n {
|
||||
return 0
|
||||
}
|
||||
dp := make([][]int, m+1)
|
||||
for i := range dp {
|
||||
dp[i] = make([]int, n+1)
|
||||
dp[i][n] = 1
|
||||
}
|
||||
for i := m - 1; i >= 0; i-- {
|
||||
for j := n - 1; j >= 0; j-- {
|
||||
if s[i] == t[j] {
|
||||
dp[i][j] = dp[i+1][j+1] + dp[i+1][j]
|
||||
} else {
|
||||
dp[i][j] = dp[i+1][j]
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[0][0]
|
||||
}
|
||||
```
|
||||
@ -1,9 +1,5 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"strconv"
|
||||
)
|
||||
|
||||
import (
|
||||
"github.com/halfrost/LeetCode-Go/structures"
|
||||
)
|
||||
@ -21,29 +17,20 @@ type TreeNode = structures.TreeNode
|
||||
*/
|
||||
|
||||
func sumNumbers(root *TreeNode) int {
|
||||
res, nums := 0, binaryTreeNums(root)
|
||||
for _, n := range nums {
|
||||
num, _ := strconv.Atoi(n)
|
||||
res += num
|
||||
}
|
||||
res := 0
|
||||
dfs(root, 0, &res)
|
||||
return res
|
||||
}
|
||||
|
||||
func binaryTreeNums(root *TreeNode) []string {
|
||||
func dfs(root *TreeNode, sum int, res *int) {
|
||||
if root == nil {
|
||||
return []string{}
|
||||
return
|
||||
}
|
||||
res := []string{}
|
||||
sum = sum*10 + root.Val
|
||||
if root.Left == nil && root.Right == nil {
|
||||
return []string{strconv.Itoa(root.Val)}
|
||||
*res += sum
|
||||
return
|
||||
}
|
||||
tmpLeft := binaryTreeNums(root.Left)
|
||||
for i := 0; i < len(tmpLeft); i++ {
|
||||
res = append(res, strconv.Itoa(root.Val)+tmpLeft[i])
|
||||
}
|
||||
tmpRight := binaryTreeNums(root.Right)
|
||||
for i := 0; i < len(tmpRight); i++ {
|
||||
res = append(res, strconv.Itoa(root.Val)+tmpRight[i])
|
||||
}
|
||||
return res
|
||||
dfs(root.Left, sum, res)
|
||||
dfs(root.Right, sum, res)
|
||||
}
|
||||
|
||||
@ -45,4 +45,4 @@ Find the total sum of all root-to-leaf numbers.
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 这一题是第 257 题的变形题,第 257 题要求输出每条从根节点到叶子节点的路径,这一题变成了把每一个从根节点到叶子节点的数字都串联起来,再累加每条路径,求出最后的总和。实际做题思路基本没变
|
||||
- 运用前序遍历的思想,当从根节点出发一直加到叶子节点,每个叶子节点汇总一次。
|
||||
@ -30,7 +30,7 @@ Your algorithm should have a linear runtime complexity. Could you implement it w
|
||||
## 解题思路
|
||||
|
||||
- 这一题是第 136 题的加强版。这类题也可以扩展,在数组中每个元素都出现 5 次,找出只出现 1 次的数。
|
||||
- 本题中要求找出只出现 1 次的数,出现 3 次的数都要被消除。第 136 题是消除出现 2 次的数。这一题也会相当相同的解法,出现 3 次的数也要被消除。定义状态,00、10、01,这 3 个状态。当一个数出现 3 次,那么它每个位置上的 1 出现的次数肯定是 3 的倍数,所以当 1 出现 3 次以后,就归零清除。如何能做到这点呢?仿造`三进制(00,10,01)` 就可以做到。
|
||||
- 本题中要求找出只出现 1 次的数,出现 3 次的数都要被消除。第 136 题是消除出现 2 次的数。这一题也会相当相同的解法,出现 3 次的数也要被消除。定义状态,00、10、01,这 3 个状态。当一个数出现 3 次,那么它每个位置上的 1 出现的次数肯定是 3 的倍数,所以当 1 出现 3 次以后,就归零清除。如何能做到这点呢?仿造`三进制(00,01,10)` 就可以做到。
|
||||
- 变量 ones 中记录遍历中每个位上出现 1 的个数。将它与 A[i] 进行异或,目的是:
|
||||
- 每位上两者都是 1 的,表示历史统计结果 ones 出现1次、A[i]中又出现 1 次,则是出现 2 次,需要进位到 twos 变量中。
|
||||
- 每位上两者分别为 0、1 的,加入到 ones 统计结果中。
|
||||
@ -41,6 +41,31 @@ Your algorithm should have a linear runtime complexity. Could you implement it w
|
||||
|
||||
> 在 golang 中没有 Java 中的 ~ 位操作运算符,Java 中的 ~ 运算符代表按位取反。这个操作就想当于 golang 中的 ^ 运算符当做一元运算符使用的效果。
|
||||
|
||||
|(twos,ones)|xi|(twos'',ones')|ones'|
|
||||
|:----:|:----:|:----:|:----:|
|
||||
|00|0|00|0|
|
||||
|00|1|01|1|
|
||||
|01|0|01|1|
|
||||
|01|1|10|0|
|
||||
|10|0|10|0|
|
||||
|10|1|00|0|
|
||||
|
||||
- 第一步,先将 ones -> ones'。通过观察可以看出 ones = (ones ^ nums[i]) & ^twos
|
||||
|
||||
|(twos,ones')|xi|twos'|
|
||||
|:----:|:----:|:----:|
|
||||
|00|0|0|
|
||||
|01|1|0|
|
||||
|01|0|0|
|
||||
|00|1|1|
|
||||
|10|0|1|
|
||||
|10|1|0|
|
||||
|
||||
|
||||
- 第二步,再将 twos -> twos'。这一步需要用到前一步的 ones。通过观察可以看出 twos = (twos ^ nums[i]) & ^ones。
|
||||
|
||||
--------------------------
|
||||
|
||||
这一题还可以继续扩展,在数组中每个元素都出现 5 次,找出只出现 1 次的数。那该怎么做呢?思路还是一样的,模拟一个五进制,5 次就会消除。代码如下:
|
||||
|
||||
// 解法一
|
||||
|
||||
@ -5,46 +5,23 @@ import (
|
||||
)
|
||||
|
||||
func evalRPN(tokens []string) int {
|
||||
if len(tokens) == 1 {
|
||||
i, _ := strconv.Atoi(tokens[0])
|
||||
return i
|
||||
}
|
||||
stack, top := []int{}, 0
|
||||
for _, v := range tokens {
|
||||
switch v {
|
||||
stack := make([]int, 0, len(tokens))
|
||||
for _, token := range tokens {
|
||||
v, err := strconv.Atoi(token)
|
||||
if err == nil {
|
||||
stack = append(stack, v)
|
||||
} else {
|
||||
num1, num2 := stack[len(stack)-2], stack[len(stack)-1]
|
||||
stack = stack[:len(stack)-2]
|
||||
switch token {
|
||||
case "+":
|
||||
{
|
||||
sum := stack[top-2] + stack[top-1]
|
||||
stack = stack[:top-2]
|
||||
stack = append(stack, sum)
|
||||
top--
|
||||
}
|
||||
stack = append(stack, num1+num2)
|
||||
case "-":
|
||||
{
|
||||
sub := stack[top-2] - stack[top-1]
|
||||
stack = stack[:top-2]
|
||||
stack = append(stack, sub)
|
||||
top--
|
||||
}
|
||||
stack = append(stack, num1-num2)
|
||||
case "*":
|
||||
{
|
||||
mul := stack[top-2] * stack[top-1]
|
||||
stack = stack[:top-2]
|
||||
stack = append(stack, mul)
|
||||
top--
|
||||
}
|
||||
stack = append(stack, num1*num2)
|
||||
case "/":
|
||||
{
|
||||
div := stack[top-2] / stack[top-1]
|
||||
stack = stack[:top-2]
|
||||
stack = append(stack, div)
|
||||
top--
|
||||
}
|
||||
default:
|
||||
{
|
||||
i, _ := strconv.Atoi(v)
|
||||
stack = append(stack, i)
|
||||
top++
|
||||
stack = append(stack, num1/num2)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@ -6,13 +6,14 @@ func twoSum167(numbers []int, target int) []int {
|
||||
for i < j {
|
||||
if numbers[i]+numbers[j] == target {
|
||||
return []int{i + 1, j + 1}
|
||||
} else if numbers[i]+numbers[j] < target {
|
||||
}
|
||||
if numbers[i]+numbers[j] < target {
|
||||
i++
|
||||
} else {
|
||||
j--
|
||||
}
|
||||
}
|
||||
return []int{-1, -1}
|
||||
return nil
|
||||
}
|
||||
|
||||
// 解法二 不管数组是否有序,空间复杂度比上一种解法要多 O(n)
|
||||
@ -20,8 +21,8 @@ func twoSum167_1(numbers []int, target int) []int {
|
||||
m := make(map[int]int)
|
||||
for i := 0; i < len(numbers); i++ {
|
||||
another := target - numbers[i]
|
||||
if _, ok := m[another]; ok {
|
||||
return []int{m[another] + 1, i + 1}
|
||||
if idx, ok := m[another]; ok {
|
||||
return []int{idx + 1, i + 1}
|
||||
}
|
||||
m[numbers[i]] = i
|
||||
}
|
||||
@ -17,33 +17,23 @@ type TreeNode = structures.TreeNode
|
||||
*/
|
||||
|
||||
func rightSideView(root *TreeNode) []int {
|
||||
res := []int{}
|
||||
if root == nil {
|
||||
return []int{}
|
||||
return res
|
||||
}
|
||||
queue := []*TreeNode{}
|
||||
queue = append(queue, root)
|
||||
curNum, nextLevelNum, res, tmp := 1, 0, []int{}, []int{}
|
||||
for len(queue) != 0 {
|
||||
if curNum > 0 {
|
||||
node := queue[0]
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
nextLevelNum++
|
||||
queue := []*TreeNode{root}
|
||||
for len(queue) > 0 {
|
||||
n := len(queue)
|
||||
for i := 0; i < n; i++ {
|
||||
if queue[i].Left != nil {
|
||||
queue = append(queue, queue[i].Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
nextLevelNum++
|
||||
if queue[i].Right != nil {
|
||||
queue = append(queue, queue[i].Right)
|
||||
}
|
||||
curNum--
|
||||
tmp = append(tmp, node.Val)
|
||||
queue = queue[1:]
|
||||
}
|
||||
if curNum == 0 {
|
||||
res = append(res, tmp[len(tmp)-1])
|
||||
curNum = nextLevelNum
|
||||
nextLevelNum = 0
|
||||
tmp = []int{}
|
||||
}
|
||||
res = append(res, queue[n-1].Val)
|
||||
queue = queue[n:]
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
@ -1,24 +1,16 @@
|
||||
package leetcode
|
||||
|
||||
func minSubArrayLen(s int, nums []int) int {
|
||||
n := len(nums)
|
||||
if n == 0 {
|
||||
return 0
|
||||
}
|
||||
left, right, res, sum := 0, -1, n+1, 0
|
||||
for left < n {
|
||||
if (right+1) < n && sum < s {
|
||||
right++
|
||||
sum += nums[right]
|
||||
} else {
|
||||
func minSubArrayLen(target int, nums []int) int {
|
||||
left, sum, res := 0, 0, len(nums)+1
|
||||
for right, v := range nums {
|
||||
sum += v
|
||||
for sum >= target {
|
||||
res = min(res, right-left+1)
|
||||
sum -= nums[left]
|
||||
left++
|
||||
}
|
||||
if sum >= s {
|
||||
res = min(res, right-left+1)
|
||||
}
|
||||
}
|
||||
if res == n+1 {
|
||||
if res == len(nums)+1 {
|
||||
return 0
|
||||
}
|
||||
return res
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
package leetcode
|
||||
|
||||
import "sort"
|
||||
import (
|
||||
"math/rand"
|
||||
"sort"
|
||||
)
|
||||
|
||||
// 解法一 排序,排序的方法反而速度是最快的
|
||||
func findKthLargest1(nums []int, k int) int {
|
||||
@ -9,36 +12,62 @@ func findKthLargest1(nums []int, k int) int {
|
||||
}
|
||||
|
||||
// 解法二 这个方法的理论依据是 partition 得到的点的下标就是最终排序之后的下标,根据这个下标,我们可以判断第 K 大的数在哪里
|
||||
// 时间复杂度 O(n),空间复杂度 O(log n),最坏时间复杂度为 O(n^2),空间复杂度 O(n)
|
||||
func findKthLargest(nums []int, k int) int {
|
||||
if len(nums) == 0 {
|
||||
return 0
|
||||
}
|
||||
return selection(nums, 0, len(nums)-1, len(nums)-k)
|
||||
m := len(nums) - k + 1 // mth smallest, from 1..len(nums)
|
||||
return selectSmallest(nums, 0, len(nums)-1, m)
|
||||
}
|
||||
|
||||
func selection(arr []int, l, r, k int) int {
|
||||
if l == r {
|
||||
return arr[l]
|
||||
func selectSmallest(nums []int, l, r, i int) int {
|
||||
if l >= r {
|
||||
return nums[l]
|
||||
}
|
||||
p := partition164(arr, l, r)
|
||||
if k == p {
|
||||
return arr[p]
|
||||
} else if k < p {
|
||||
return selection(arr, l, p-1, k)
|
||||
q := partition(nums, l, r)
|
||||
k := q - l + 1
|
||||
if k == i {
|
||||
return nums[q]
|
||||
}
|
||||
if i < k {
|
||||
return selectSmallest(nums, l, q-1, i)
|
||||
} else {
|
||||
return selection(arr, p+1, r, k)
|
||||
return selectSmallest(nums, q+1, r, i-k)
|
||||
}
|
||||
}
|
||||
|
||||
func partition164(a []int, lo, hi int) int {
|
||||
pivot := a[hi]
|
||||
i := lo - 1
|
||||
for j := lo; j < hi; j++ {
|
||||
if a[j] < pivot {
|
||||
func partition(nums []int, l, r int) int {
|
||||
k := l + rand.Intn(r-l+1) // 此处为优化,使得时间复杂度期望降为 O(n),最坏时间复杂度为 O(n^2)
|
||||
nums[k], nums[r] = nums[r], nums[k]
|
||||
i := l - 1
|
||||
// nums[l..i] <= nums[r]
|
||||
// nums[i+1..j-1] > nums[r]
|
||||
for j := l; j < r; j++ {
|
||||
if nums[j] <= nums[r] {
|
||||
i++
|
||||
a[j], a[i] = a[i], a[j]
|
||||
nums[i], nums[j] = nums[j], nums[i]
|
||||
}
|
||||
}
|
||||
a[i+1], a[hi] = a[hi], a[i+1]
|
||||
nums[i+1], nums[r] = nums[r], nums[i+1]
|
||||
return i + 1
|
||||
}
|
||||
|
||||
// 扩展题 剑指 Offer 40. 最小的 k 个数
|
||||
func getLeastNumbers(arr []int, k int) []int {
|
||||
return selectSmallest1(arr, 0, len(arr)-1, k)[:k]
|
||||
}
|
||||
|
||||
// 和 selectSmallest 实现完全一致,只是返回值不用再截取了,直接返回 nums 即可
|
||||
func selectSmallest1(nums []int, l, r, i int) []int {
|
||||
if l >= r {
|
||||
return nums
|
||||
}
|
||||
q := partition(nums, l, r)
|
||||
k := q - l + 1
|
||||
if k == i {
|
||||
return nums
|
||||
}
|
||||
if i < k {
|
||||
return selectSmallest1(nums, l, q-1, i)
|
||||
} else {
|
||||
return selectSmallest1(nums, q+1, r, i-k)
|
||||
}
|
||||
}
|
||||
|
||||
@ -27,6 +27,11 @@ func Test_Problem215(t *testing.T) {
|
||||
|
||||
qs := []question215{
|
||||
|
||||
{
|
||||
para215{[]int{3, 2, 1}, 2},
|
||||
ans215{2},
|
||||
},
|
||||
|
||||
{
|
||||
para215{[]int{3, 2, 1, 5, 6, 4}, 2},
|
||||
ans215{5},
|
||||
|
||||
@ -6,8 +6,83 @@ import (
|
||||
"github.com/halfrost/LeetCode-Go/template"
|
||||
)
|
||||
|
||||
// 解法一 线段树 Segment Tree,时间复杂度 O(n log n)
|
||||
// 解法一 树状数组,时间复杂度 O(n log n)
|
||||
const LEFTSIDE = 1
|
||||
const RIGHTSIDE = 2
|
||||
|
||||
type Point struct {
|
||||
xAxis int
|
||||
side int
|
||||
index int
|
||||
}
|
||||
|
||||
func getSkyline(buildings [][]int) [][]int {
|
||||
res := [][]int{}
|
||||
if len(buildings) == 0 {
|
||||
return res
|
||||
}
|
||||
allPoints, bit := make([]Point, 0), BinaryIndexedTree{}
|
||||
// [x-axis (value), [1 (left) | 2 (right)], index (building number)]
|
||||
for i, b := range buildings {
|
||||
allPoints = append(allPoints, Point{xAxis: b[0], side: LEFTSIDE, index: i})
|
||||
allPoints = append(allPoints, Point{xAxis: b[1], side: RIGHTSIDE, index: i})
|
||||
}
|
||||
sort.Slice(allPoints, func(i, j int) bool {
|
||||
if allPoints[i].xAxis == allPoints[j].xAxis {
|
||||
return allPoints[i].side < allPoints[j].side
|
||||
}
|
||||
return allPoints[i].xAxis < allPoints[j].xAxis
|
||||
})
|
||||
bit.Init(len(allPoints))
|
||||
kth := make(map[Point]int)
|
||||
for i := 0; i < len(allPoints); i++ {
|
||||
kth[allPoints[i]] = i
|
||||
}
|
||||
for i := 0; i < len(allPoints); i++ {
|
||||
pt := allPoints[i]
|
||||
if pt.side == LEFTSIDE {
|
||||
bit.Add(kth[Point{xAxis: buildings[pt.index][1], side: RIGHTSIDE, index: pt.index}], buildings[pt.index][2])
|
||||
}
|
||||
currHeight := bit.Query(kth[pt] + 1)
|
||||
if len(res) == 0 || res[len(res)-1][1] != currHeight {
|
||||
if len(res) > 0 && res[len(res)-1][0] == pt.xAxis {
|
||||
res[len(res)-1][1] = currHeight
|
||||
} else {
|
||||
res = append(res, []int{pt.xAxis, currHeight})
|
||||
}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
type BinaryIndexedTree struct {
|
||||
tree []int
|
||||
capacity int
|
||||
}
|
||||
|
||||
// Init define
|
||||
func (bit *BinaryIndexedTree) Init(capacity int) {
|
||||
bit.tree, bit.capacity = make([]int, capacity+1), capacity
|
||||
}
|
||||
|
||||
// Add define
|
||||
func (bit *BinaryIndexedTree) Add(index int, val int) {
|
||||
for ; index > 0; index -= index & -index {
|
||||
bit.tree[index] = max(bit.tree[index], val)
|
||||
}
|
||||
}
|
||||
|
||||
// Query define
|
||||
func (bit *BinaryIndexedTree) Query(index int) int {
|
||||
sum := 0
|
||||
for ; index <= bit.capacity; index += index & -index {
|
||||
sum = max(sum, bit.tree[index])
|
||||
}
|
||||
return sum
|
||||
}
|
||||
|
||||
// 解法三 线段树 Segment Tree,时间复杂度 O(n log n)
|
||||
func getSkyline1(buildings [][]int) [][]int {
|
||||
st, ans, lastHeight, check := template.SegmentTree{}, [][]int{}, 0, false
|
||||
posMap, pos := discretization218(buildings)
|
||||
tmp := make([]int, len(posMap))
|
||||
@ -54,8 +129,8 @@ func max(a int, b int) int {
|
||||
return b
|
||||
}
|
||||
|
||||
// 解法二 扫描线 Sweep Line,时间复杂度 O(n log n)
|
||||
func getSkyline1(buildings [][]int) [][]int {
|
||||
// 解法三 扫描线 Sweep Line,时间复杂度 O(n log n)
|
||||
func getSkyline2(buildings [][]int) [][]int {
|
||||
size := len(buildings)
|
||||
es := make([]E, 0)
|
||||
for i, b := range buildings {
|
||||
|
||||
@ -30,6 +30,16 @@ func Test_Problem218(t *testing.T) {
|
||||
para218{[][]int{{2, 9, 10}, {3, 7, 15}, {5, 12, 12}, {15, 20, 10}, {19, 24, 8}}},
|
||||
ans218{[][]int{{2, 10}, {3, 15}, {7, 12}, {12, 0}, {15, 10}, {20, 8}, {24, 0}}},
|
||||
},
|
||||
|
||||
{
|
||||
para218{[][]int{{1, 2, 1}, {1, 2, 2}, {1, 2, 3}, {2, 3, 1}, {2, 3, 2}, {2, 3, 3}}},
|
||||
ans218{[][]int{{1, 3}, {3, 0}}},
|
||||
},
|
||||
|
||||
{
|
||||
para218{[][]int{{4, 9, 10}, {4, 9, 15}, {4, 9, 12}, {10, 12, 10}, {10, 12, 8}}},
|
||||
ans218{[][]int{{4, 15}, {9, 0}, {10, 10}, {12, 0}}},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 218------------------------\n")
|
||||
|
||||
@ -50,7 +50,7 @@ func Test_Problem226(t *testing.T) {
|
||||
_, p := q.ans226, q.para226
|
||||
fmt.Printf("【input】:%v ", p)
|
||||
root := structures.Ints2TreeNode(p.one)
|
||||
fmt.Printf("【output】:%v \n", structures.Tree2Preorder(invertTree(root)))
|
||||
fmt.Printf("【output】:%v \n", structures.Tree2ints(invertTree(root)))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
|
||||
@ -0,0 +1,29 @@
|
||||
package leetcode
|
||||
|
||||
func calculate(s string) int {
|
||||
stack, preSign, num, res := []int{}, '+', 0, 0
|
||||
for i, ch := range s {
|
||||
isDigit := '0' <= ch && ch <= '9'
|
||||
if isDigit {
|
||||
num = num*10 + int(ch-'0')
|
||||
}
|
||||
if !isDigit && ch != ' ' || i == len(s)-1 {
|
||||
switch preSign {
|
||||
case '+':
|
||||
stack = append(stack, num)
|
||||
case '-':
|
||||
stack = append(stack, -num)
|
||||
case '*':
|
||||
stack[len(stack)-1] *= num
|
||||
default:
|
||||
stack[len(stack)-1] /= num
|
||||
}
|
||||
preSign = ch
|
||||
num = 0
|
||||
}
|
||||
}
|
||||
for _, v := range stack {
|
||||
res += v
|
||||
}
|
||||
return res
|
||||
}
|
||||
@ -0,0 +1,66 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question227 struct {
|
||||
para227
|
||||
ans227
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para227 struct {
|
||||
one string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans227 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem227(t *testing.T) {
|
||||
|
||||
qs := []question227{
|
||||
|
||||
{
|
||||
para227{"3+2*2"},
|
||||
ans227{7},
|
||||
},
|
||||
|
||||
{
|
||||
para227{"3/2"},
|
||||
ans227{1},
|
||||
},
|
||||
|
||||
{
|
||||
para227{" 3+5 / 2 "},
|
||||
ans227{5},
|
||||
},
|
||||
|
||||
{
|
||||
para227{"1 + 1"},
|
||||
ans227{2},
|
||||
},
|
||||
{
|
||||
para227{" 2-1 + 2 "},
|
||||
ans227{3},
|
||||
},
|
||||
|
||||
{
|
||||
para227{"2-5/6"},
|
||||
ans227{2},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 227------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans227, q.para227
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, calculate(p.one))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
80
leetcode/0227.Basic-Calculator-II/README.md
Normal file
80
leetcode/0227.Basic-Calculator-II/README.md
Normal file
@ -0,0 +1,80 @@
|
||||
# [227. Basic Calculator II](https://leetcode.com/problems/basic-calculator-ii/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given a string `s` which represents an expression, *evaluate this expression and return its value*.
|
||||
|
||||
The integer division should truncate toward zero.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: s = "3+2*2"
|
||||
Output: 7
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: s = " 3/2 "
|
||||
Output: 1
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: s = " 3+5 / 2 "
|
||||
Output: 5
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= s.length <= 3 * 10^5`
|
||||
- `s` consists of integers and operators `('+', '-', '*', '/')` separated by some number of spaces.
|
||||
- `s` represents **a valid expression**.
|
||||
- All the integers in the expression are non-negative integers in the range `[0, 2^31 - 1]`.
|
||||
- The answer is **guaranteed** to fit in a **32-bit integer**.
|
||||
|
||||
## 题目大意
|
||||
|
||||
给你一个字符串表达式 `s` ,请你实现一个基本计算器来计算并返回它的值。整数除法仅保留整数部分。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 这道题是第 224 题的加强版。第 224 题中只有加减运算和括号,这一题增加了乘除运算。由于乘除运算的优先级高于加减。所以先计算乘除运算,将算出来的结果再替换回原来的算式中。最后只剩下加减运算,于是题目降级成了第 224 题。
|
||||
- 把加减运算符号后面的数字压入栈中,遇到乘除运算,直接将它与栈顶的元素计算,并将计算后的结果放入栈顶。若读到一个运算符,或者遍历到字符串末尾,即认为是遍历到了数字末尾。处理完该数字后,更新 `preSign` 为当前遍历的字符。遍历完字符串 `s` 后,将栈中元素累加,即为该字符串表达式的值。时间复杂度 O(n),空间复杂度 O(n)。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func calculate(s string) int {
|
||||
stack, preSign, num, res := []int{}, '+', 0, 0
|
||||
for i, ch := range s {
|
||||
isDigit := '0' <= ch && ch <= '9'
|
||||
if isDigit {
|
||||
num = num*10 + int(ch-'0')
|
||||
}
|
||||
if !isDigit && ch != ' ' || i == len(s)-1 {
|
||||
switch preSign {
|
||||
case '+':
|
||||
stack = append(stack, num)
|
||||
case '-':
|
||||
stack = append(stack, -num)
|
||||
case '*':
|
||||
stack[len(stack)-1] *= num
|
||||
default:
|
||||
stack[len(stack)-1] /= num
|
||||
}
|
||||
preSign = ch
|
||||
num = 0
|
||||
}
|
||||
}
|
||||
for _, v := range stack {
|
||||
res += v
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
@ -1,10 +1,12 @@
|
||||
package leetcode
|
||||
|
||||
func isUgly(num int) bool {
|
||||
for i := 2; i < 6 && num > 0; i++ {
|
||||
if num > 0 {
|
||||
for _, i := range []int{2, 3, 5} {
|
||||
for num%i == 0 {
|
||||
num /= i
|
||||
}
|
||||
}
|
||||
}
|
||||
return num == 1
|
||||
}
|
||||
|
||||
27
leetcode/0264.Ugly-Number-II/264. Ugly Number II.go
Normal file
27
leetcode/0264.Ugly-Number-II/264. Ugly Number II.go
Normal file
@ -0,0 +1,27 @@
|
||||
package leetcode
|
||||
|
||||
func nthUglyNumber(n int) int {
|
||||
dp, p2, p3, p5 := make([]int, n+1), 1, 1, 1
|
||||
dp[0], dp[1] = 0, 1
|
||||
for i := 2; i <= n; i++ {
|
||||
x2, x3, x5 := dp[p2]*2, dp[p3]*3, dp[p5]*5
|
||||
dp[i] = min(min(x2, x3), x5)
|
||||
if dp[i] == x2 {
|
||||
p2++
|
||||
}
|
||||
if dp[i] == x3 {
|
||||
p3++
|
||||
}
|
||||
if dp[i] == x5 {
|
||||
p5++
|
||||
}
|
||||
}
|
||||
return dp[n]
|
||||
}
|
||||
|
||||
func min(a, b int) int {
|
||||
if a < b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
62
leetcode/0264.Ugly-Number-II/264. Ugly Number II_test.go
Normal file
62
leetcode/0264.Ugly-Number-II/264. Ugly Number II_test.go
Normal file
@ -0,0 +1,62 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question264 struct {
|
||||
para264
|
||||
ans264
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para264 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans264 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem264(t *testing.T) {
|
||||
|
||||
qs := []question264{
|
||||
|
||||
{
|
||||
para264{10},
|
||||
ans264{12},
|
||||
},
|
||||
|
||||
{
|
||||
para264{1},
|
||||
ans264{1},
|
||||
},
|
||||
|
||||
{
|
||||
para264{6},
|
||||
ans264{6},
|
||||
},
|
||||
|
||||
{
|
||||
para264{8},
|
||||
ans264{9},
|
||||
},
|
||||
|
||||
{
|
||||
para264{14},
|
||||
ans264{20},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 264------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans264, q.para264
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, nthUglyNumber(p.one))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
69
leetcode/0264.Ugly-Number-II/README.md
Normal file
69
leetcode/0264.Ugly-Number-II/README.md
Normal file
@ -0,0 +1,69 @@
|
||||
# [264. Ugly Number II](https://leetcode.com/problems/ugly-number-ii/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given an integer `n`, return *the* `nth` ***ugly number***.
|
||||
|
||||
**Ugly number** is a positive number whose prime factors only include `2`, `3`, and/or `5`.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: n = 10
|
||||
Output: 12
|
||||
Explanation: [1, 2, 3, 4, 5, 6, 8, 9, 10, 12] is the sequence of the first 10 ugly numbers.
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: n = 1
|
||||
Output: 1
|
||||
Explanation: 1 is typically treated as an ugly number.
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= n <= 1690`
|
||||
|
||||
## 题目大意
|
||||
|
||||
给你一个整数 `n` ,请你找出并返回第 `n` 个 **丑数** 。**丑数** 就是只包含质因数 `2`、`3` 和/或 `5` 的正整数。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 解法一,生成丑数的方法:先用最小质因数 1,分别和 2,3,5 相乘,得到的数是丑数,不断的将这些数分别和 2,3,5 相乘,得到的数去重以后,从小到大排列,第 n 个数即为所求。排序可用最小堆实现,去重用 map 去重。时间复杂度 O(n log n),空间复杂度 O(n)
|
||||
- 上面的解法耗时在排序中,需要排序的根源是小的丑数乘以 5 大于了大的丑数乘以 2 。如何保证每次乘积以后,找出有序的丑数,是去掉排序,提升时间复杂度的关键。举个例子很容易想通:初始状态丑数只有 {1},乘以 2,3,5 以后,将最小的结果存入集合中 {1,2}。下一轮再相乘,由于上一轮 1 已经和 2 相乘过了,1 不要再和 2 相乘了,所以这一轮 1 和 3,5 相乘。2 和 2,3,5 相乘。将最小的结果存入集合中 {1,2,3},按照这样的策略往下比较,每轮选出的丑数是有序且不重复的。具体实现利用 3 个指针和一个数组即可实现。时间复杂度 O(n),空间复杂度 O(n)。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func nthUglyNumber(n int) int {
|
||||
dp, p2, p3, p5 := make([]int, n+1), 1, 1, 1
|
||||
dp[0], dp[1] = 0, 1
|
||||
for i := 2; i <= n; i++ {
|
||||
x2, x3, x5 := dp[p2]*2, dp[p3]*3, dp[p5]*5
|
||||
dp[i] = min(min(x2, x3), x5)
|
||||
if dp[i] == x2 {
|
||||
p2++
|
||||
}
|
||||
if dp[i] == x3 {
|
||||
p3++
|
||||
}
|
||||
if dp[i] == x5 {
|
||||
p5++
|
||||
}
|
||||
}
|
||||
return dp[n]
|
||||
}
|
||||
|
||||
func min(a, b int) int {
|
||||
if a < b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
```
|
||||
19
leetcode/0278.First-Bad-Version/278. First Bad Version.go
Normal file
19
leetcode/0278.First-Bad-Version/278. First Bad Version.go
Normal file
@ -0,0 +1,19 @@
|
||||
package leetcode
|
||||
|
||||
import "sort"
|
||||
|
||||
/**
|
||||
* Forward declaration of isBadVersion API.
|
||||
* @param version your guess about first bad version
|
||||
* @return true if current version is bad
|
||||
* false if current version is good
|
||||
* func isBadVersion(version int) bool;
|
||||
*/
|
||||
|
||||
func firstBadVersion(n int) int {
|
||||
return sort.Search(n, func(version int) bool { return isBadVersion(version) })
|
||||
}
|
||||
|
||||
func isBadVersion(version int) bool {
|
||||
return true
|
||||
}
|
||||
@ -0,0 +1,46 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question278 struct {
|
||||
para278
|
||||
ans278
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para278 struct {
|
||||
n int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans278 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem278(t *testing.T) {
|
||||
|
||||
qs := []question278{
|
||||
|
||||
{
|
||||
para278{5},
|
||||
ans278{4},
|
||||
},
|
||||
{
|
||||
para278{1},
|
||||
ans278{1},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 278------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans278, q.para278
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, firstBadVersion(p.n))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
62
leetcode/0278.First-Bad-Version/README.md
Normal file
62
leetcode/0278.First-Bad-Version/README.md
Normal file
@ -0,0 +1,62 @@
|
||||
# [278. First Bad Version](https://leetcode.com/problems/first-bad-version/)
|
||||
|
||||
## 题目
|
||||
|
||||
You are a product manager and currently leading a team to develop a new product. Unfortunately, the latest version of your product fails the quality check. Since each version is developed based on the previous version, all the versions after a bad version are also bad.
|
||||
|
||||
Suppose you have `n` versions `[1, 2, ..., n]` and you want to find out the first bad one, which causes all the following ones to be bad.
|
||||
|
||||
You are given an API `bool isBadVersion(version)` which returns whether `version` is bad. Implement a function to find the first bad version. You should minimize the number of calls to the API.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: n = 5, bad = 4
|
||||
Output: 4
|
||||
Explanation:
|
||||
call isBadVersion(3) -> false
|
||||
call isBadVersion(5) -> true
|
||||
call isBadVersion(4) -> true
|
||||
Then 4 is the first bad version.
|
||||
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: n = 1, bad = 1
|
||||
Output: 1
|
||||
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= bad <= n <= 231 - 1`
|
||||
|
||||
## 题目大意
|
||||
|
||||
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。假设你有 n 个版本 [1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 我们知道开发产品迭代的版本,如果当一个版本为正确版本,则该版本之前的所有版本均为正确版本;当一个版本为错误版本,则该版本之后的所有版本均为错误版本。利用这个性质就可以进行二分查找。利用二分搜索,也可以满足减少对调用 API 的次数的要求。时间复杂度:O(logn),其中 n 是给定版本的数量。空间复杂度:O(1)。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
import "sort"
|
||||
|
||||
/**
|
||||
* Forward declaration of isBadVersion API.
|
||||
* @param version your guess about first bad version
|
||||
* @return true if current version is bad
|
||||
* false if current version is good
|
||||
* func isBadVersion(version int) bool;
|
||||
*/
|
||||
|
||||
func firstBadVersion(n int) int {
|
||||
return sort.Search(n, func(version int) bool { return isBadVersion(version) })
|
||||
}
|
||||
```
|
||||
33
leetcode/0279.Perfect-Squares/279. Perfect Squares.go
Normal file
33
leetcode/0279.Perfect-Squares/279. Perfect Squares.go
Normal file
@ -0,0 +1,33 @@
|
||||
package leetcode
|
||||
|
||||
import "math"
|
||||
|
||||
func numSquares(n int) int {
|
||||
if isPerfectSquare(n) {
|
||||
return 1
|
||||
}
|
||||
if checkAnswer4(n) {
|
||||
return 4
|
||||
}
|
||||
for i := 1; i*i <= n; i++ {
|
||||
j := n - i*i
|
||||
if isPerfectSquare(j) {
|
||||
return 2
|
||||
}
|
||||
}
|
||||
return 3
|
||||
}
|
||||
|
||||
// 判断是否为完全平方数
|
||||
func isPerfectSquare(n int) bool {
|
||||
sq := int(math.Floor(math.Sqrt(float64(n))))
|
||||
return sq*sq == n
|
||||
}
|
||||
|
||||
// 判断是否能表示为 4^k*(8m+7)
|
||||
func checkAnswer4(x int) bool {
|
||||
for x%4 == 0 {
|
||||
x /= 4
|
||||
}
|
||||
return x%8 == 7
|
||||
}
|
||||
46
leetcode/0279.Perfect-Squares/279. Perfect Squares_test.go
Normal file
46
leetcode/0279.Perfect-Squares/279. Perfect Squares_test.go
Normal file
@ -0,0 +1,46 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question279 struct {
|
||||
para279
|
||||
ans279
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para279 struct {
|
||||
n int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans279 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem279(t *testing.T) {
|
||||
|
||||
qs := []question279{
|
||||
|
||||
{
|
||||
para279{13},
|
||||
ans279{2},
|
||||
},
|
||||
{
|
||||
para279{12},
|
||||
ans279{3},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 279------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans279, q.para279
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, numSquares(p.n))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
78
leetcode/0279.Perfect-Squares/README.md
Normal file
78
leetcode/0279.Perfect-Squares/README.md
Normal file
@ -0,0 +1,78 @@
|
||||
# [279. Perfect Squares](https://leetcode.com/problems/perfect-squares/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given an integer `n`, return *the least number of perfect square numbers that sum to* `n`.
|
||||
|
||||
A **perfect square** is an integer that is the square of an integer; in other words, it is the product of some integer with itself. For example, `1`, `4`, `9`, and `16` are perfect squares while `3` and `11` are not.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: n = 12
|
||||
Output: 3
|
||||
Explanation: 12 = 4 + 4 + 4.
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: n = 13
|
||||
Output: 2
|
||||
Explanation: 13 = 4 + 9.
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= n <= 104`
|
||||
|
||||
## 题目大意
|
||||
|
||||
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。给你一个整数 n ,返回和为 n 的完全平方数的 最少数量 。
|
||||
|
||||
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 由拉格朗日的四平方定理可得,每个自然数都可以表示为四个整数平方之和。 其中四个数字是整数。四平方和定理证明了任意一个正整数都可以被表示为至多四个正整数的平方和。这给出了本题的答案的上界。
|
||||
- 四平方和定理可以推出三平方和推论:当且仅当 {{< katex >}} n \neq 4^{k} \times (8*m + 7){{< /katex >}} 时,n 可以被表示为至多三个正整数的平方和。所以当 {{< katex >}} n = 4^{k} * (8*m + 7){{< /katex >}} 时,n 只能被表示为四个正整数的平方和。此时我们可以直接返回 4。
|
||||
- 当 {{< katex >}} n \neq 4^{k} \times (8*m + 7){{< /katex >}} 时,需要判断 n 到底可以分解成几个完全平方数之和。答案肯定是 1,2,3 中的一个。题目要求我们求最小的,所以从 1 开始一个个判断是否满足。如果答案为 1,代表 n 为完全平方数,这很好判断。如果答案为 2,代表 {{< katex >}} n = a^{2} + b^{2} {{< /katex >}},枚举 {{< katex >}} 1 \leqslant a \leqslant \sqrt{n} {{< /katex >}},判断 {{< katex >}} n - a^{2} {{< /katex >}} 是否为完全平方数。当 1 和 2 都排除了,剩下的答案只能为 3 了。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
import "math"
|
||||
|
||||
func numSquares(n int) int {
|
||||
if isPerfectSquare(n) {
|
||||
return 1
|
||||
}
|
||||
if checkAnswer4(n) {
|
||||
return 4
|
||||
}
|
||||
for i := 1; i*i <= n; i++ {
|
||||
j := n - i*i
|
||||
if isPerfectSquare(j) {
|
||||
return 2
|
||||
}
|
||||
}
|
||||
return 3
|
||||
}
|
||||
|
||||
// 判断是否为完全平方数
|
||||
func isPerfectSquare(n int) bool {
|
||||
sq := int(math.Floor(math.Sqrt(float64(n))))
|
||||
return sq*sq == n
|
||||
}
|
||||
|
||||
// 判断是否能表示为 4^k*(8m+7)
|
||||
func checkAnswer4(x int) bool {
|
||||
for x%4 == 0 {
|
||||
x /= 4
|
||||
}
|
||||
return x%8 == 7
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,54 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"strconv"
|
||||
"strings"
|
||||
|
||||
"github.com/halfrost/LeetCode-Go/structures"
|
||||
)
|
||||
|
||||
type TreeNode = structures.TreeNode
|
||||
|
||||
type Codec struct {
|
||||
builder strings.Builder
|
||||
input []string
|
||||
}
|
||||
|
||||
func Constructor() Codec {
|
||||
return Codec{}
|
||||
}
|
||||
|
||||
// Serializes a tree to a single string.
|
||||
func (this *Codec) serialize(root *TreeNode) string {
|
||||
if root == nil {
|
||||
this.builder.WriteString("#,")
|
||||
return ""
|
||||
}
|
||||
this.builder.WriteString(strconv.Itoa(root.Val) + ",")
|
||||
this.serialize(root.Left)
|
||||
this.serialize(root.Right)
|
||||
return this.builder.String()
|
||||
}
|
||||
|
||||
// Deserializes your encoded data to tree.
|
||||
func (this *Codec) deserialize(data string) *TreeNode {
|
||||
if len(data) == 0 {
|
||||
return nil
|
||||
}
|
||||
this.input = strings.Split(data, ",")
|
||||
return this.deserializeHelper()
|
||||
}
|
||||
|
||||
func (this *Codec) deserializeHelper() *TreeNode {
|
||||
if this.input[0] == "#" {
|
||||
this.input = this.input[1:]
|
||||
return nil
|
||||
}
|
||||
val, _ := strconv.Atoi(this.input[0])
|
||||
this.input = this.input[1:]
|
||||
return &TreeNode{
|
||||
Val: val,
|
||||
Left: this.deserializeHelper(),
|
||||
Right: this.deserializeHelper(),
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,55 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
|
||||
"github.com/halfrost/LeetCode-Go/structures"
|
||||
)
|
||||
|
||||
type question297 struct {
|
||||
para297
|
||||
ans297
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para297 struct {
|
||||
one []int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans297 struct {
|
||||
one []int
|
||||
}
|
||||
|
||||
func Test_Problem297(t *testing.T) {
|
||||
qs := []question297{
|
||||
{
|
||||
para297{[]int{}},
|
||||
ans297{[]int{}},
|
||||
},
|
||||
{
|
||||
para297{[]int{1,2,3,-1,-1,4,5}},
|
||||
ans297{[]int{1,2,3,-1,-1,4,5}},
|
||||
},
|
||||
{
|
||||
para297{[]int{1,2}},
|
||||
ans297{[]int{1,2}},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 297------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans297, q.para297
|
||||
fmt.Printf("【input】:%v ", p)
|
||||
root := structures.Ints2TreeNode(p.one)
|
||||
|
||||
tree297 := Constructor()
|
||||
serialized := tree297.serialize(root)
|
||||
fmt.Printf("【output】:%v \n", structures.Tree2Preorder(tree297.deserialize(serialized)))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
113
leetcode/0297.Serialize-and-Deserialize-Binary-Tree/README.md
Normal file
113
leetcode/0297.Serialize-and-Deserialize-Binary-Tree/README.md
Normal file
@ -0,0 +1,113 @@
|
||||
# [297. Serialize and Deserialize Binary Tree](https://leetcode.com/problems/serialize-and-deserialize-binary-tree/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
|
||||
|
||||
Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
|
||||
|
||||
**Clarification:** The input/output format is the same as [how LeetCode serializes a binary tree](https://leetcode.com/faq/#binary-tree). You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
|
||||
|
||||
```
|
||||
Input: root = [1,2,3,null,null,4,5]
|
||||
Output: [1,2,3,null,null,4,5]
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: root = []
|
||||
Output: []
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: root = [1]
|
||||
Output: [1]
|
||||
```
|
||||
|
||||
**Example 4:**
|
||||
|
||||
```
|
||||
Input: root = [1,2]
|
||||
Output: [1,2]
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- The number of nodes in the tree is in the range `[0, 104]`.
|
||||
- `1000 <= Node.val <= 1000`
|
||||
|
||||
## 题目大意
|
||||
|
||||
设计一个算法,来序列化和反序列化二叉树。并不限制如何进行序列化和反序列化,但是你需要保证二叉树可以序列化为字符串,并且这个字符串可以被反序列化成原有的二叉树。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 1. 将给定的二叉树想象成一颗满二叉树(不存在的结点用 null 填充)。
|
||||
- 2. 通过前序遍历,可以得到一个第一个结点为根的序列,然后递归进行序列化/反序列化即可。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"strconv"
|
||||
"strings"
|
||||
|
||||
"github.com/halfrost/LeetCode-Go/structures"
|
||||
)
|
||||
|
||||
type TreeNode = structures.TreeNode
|
||||
|
||||
type Codec struct {
|
||||
builder strings.Builder
|
||||
input []string
|
||||
}
|
||||
|
||||
func Constructor() Codec {
|
||||
return Codec{}
|
||||
}
|
||||
|
||||
// Serializes a tree to a single string.
|
||||
func (this *Codec) serialize(root *TreeNode) string {
|
||||
if root == nil {
|
||||
this.builder.WriteString("#,")
|
||||
return ""
|
||||
}
|
||||
this.builder.WriteString(strconv.Itoa(root.Val) + ",")
|
||||
this.serialize(root.Left)
|
||||
this.serialize(root.Right)
|
||||
return this.builder.String()
|
||||
}
|
||||
|
||||
// Deserializes your encoded data to tree.
|
||||
func (this *Codec) deserialize(data string) *TreeNode {
|
||||
if len(data) == 0 {
|
||||
return nil
|
||||
}
|
||||
this.input = strings.Split(data, ",")
|
||||
return this.deserializeHelper()
|
||||
}
|
||||
|
||||
func (this *Codec) deserializeHelper() *TreeNode {
|
||||
if this.input[0] == "#" {
|
||||
this.input = this.input[1:]
|
||||
return nil
|
||||
}
|
||||
val, _ := strconv.Atoi(this.input[0])
|
||||
this.input = this.input[1:]
|
||||
return &TreeNode{
|
||||
Val: val,
|
||||
Left: this.deserializeHelper(),
|
||||
Right: this.deserializeHelper(),
|
||||
}
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,31 @@
|
||||
package leetcode
|
||||
|
||||
type NumMatrix struct {
|
||||
cumsum [][]int
|
||||
}
|
||||
|
||||
func Constructor(matrix [][]int) NumMatrix {
|
||||
if len(matrix) == 0 {
|
||||
return NumMatrix{nil}
|
||||
}
|
||||
cumsum := make([][]int, len(matrix)+1)
|
||||
cumsum[0] = make([]int, len(matrix[0])+1)
|
||||
for i := range matrix {
|
||||
cumsum[i+1] = make([]int, len(matrix[i])+1)
|
||||
for j := range matrix[i] {
|
||||
cumsum[i+1][j+1] = matrix[i][j] + cumsum[i][j+1] + cumsum[i+1][j] - cumsum[i][j]
|
||||
}
|
||||
}
|
||||
return NumMatrix{cumsum}
|
||||
}
|
||||
|
||||
func (this *NumMatrix) SumRegion(row1 int, col1 int, row2 int, col2 int) int {
|
||||
cumsum := this.cumsum
|
||||
return cumsum[row2+1][col2+1] - cumsum[row1][col2+1] - cumsum[row2+1][col1] + cumsum[row1][col1]
|
||||
}
|
||||
|
||||
/**
|
||||
* Your NumMatrix object will be instantiated and called as such:
|
||||
* obj := Constructor(matrix);
|
||||
* param_1 := obj.SumRegion(row1,col1,row2,col2);
|
||||
*/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user