mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-06 07:06:42 +08:00
Merge branch 'master' of github.com:youngyangyang04/leetcode-master
This commit is contained in:
@ -152,6 +152,24 @@ public int[] twoSum(int[] nums, int target) {
|
||||
return res;
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
//使用哈希表方法2
|
||||
public int[] twoSum(int[] nums, int target) {
|
||||
Map<Integer, Integer> indexMap = new HashMap<>();
|
||||
|
||||
for(int i = 0; i < nums.length; i++){
|
||||
int balance = target - nums[i]; // 记录当前的目标值的余数
|
||||
if(indexMap.containsKey(balance)){ // 查找当前的map中是否有满足要求的值
|
||||
return new int []{i, indexMap.get(balance)}; // 如果有,返回目标值
|
||||
} else{
|
||||
indexMap.put(nums[i], i); // 如果没有,把访问过的元素和下标加入map中
|
||||
}
|
||||
}
|
||||
return null;
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
//使用双指针
|
||||
public int[] twoSum(int[] nums, int target) {
|
||||
|
||||
@ -262,6 +262,11 @@ class Solution {
|
||||
|
||||
for (int j = i + 1; j < nums.length; j++) {
|
||||
|
||||
// nums[i]+nums[j] > target 直接返回, 剪枝操作
|
||||
if (nums[i]+nums[j] > 0 && nums[i]+nums[j] > target) {
|
||||
return result;
|
||||
}
|
||||
|
||||
if (j > i + 1 && nums[j - 1] == nums[j]) { // 对nums[j]去重
|
||||
continue;
|
||||
}
|
||||
|
||||
@ -287,6 +287,7 @@ function subsets(nums: number[]): number[][] {
|
||||
|
||||
### Rust
|
||||
|
||||
思路一:使用本题的标准解法,递归回溯。
|
||||
```Rust
|
||||
impl Solution {
|
||||
fn backtracking(result: &mut Vec<Vec<i32>>, path: &mut Vec<i32>, nums: &Vec<i32>, start_index: usize) {
|
||||
@ -308,6 +309,30 @@ impl Solution {
|
||||
}
|
||||
}
|
||||
```
|
||||
思路二:使用二进制枚举,n个元素的子集问题一共是$2^n$种情况。如果我们使用一个二进制数字,每一位根据0和1来决定是选取该元素与否,那么一共也是$2^n$的情况,正好可以一一对应,所以我们可以不使用递归,直接利用循环枚举完成子集问题。
|
||||
这种方法的优点在于效率高,不需要递归调用,并且代码容易编写。缺点则是过滤某些非法情况时会比递归方法难写一点,不过在子集问题中不存在这个问题。
|
||||
```Rust
|
||||
impl Solution {
|
||||
pub fn subsets(nums: Vec<i32>) -> Vec<Vec<i32>> {
|
||||
let n = nums.len();
|
||||
// 预分配2^n空间
|
||||
let mut result = Vec::with_capacity(1 << n);
|
||||
// 二进制枚举,2^n种情况
|
||||
for i in 0..(1 << n) {
|
||||
let mut subset = Vec::new();
|
||||
for j in 0..n {
|
||||
// 枚举该二进制数字的每一位
|
||||
// 如果该位是1,对应位置上的元素加入子集,否则跳过
|
||||
if i & (1 << j) != 0 {
|
||||
subset.push(nums[j]);
|
||||
}
|
||||
}
|
||||
result.push(subset);
|
||||
}
|
||||
result
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### C
|
||||
|
||||
|
||||
@ -265,7 +265,7 @@ func levelOrder(root *TreeNode) [][]int {
|
||||
|
||||
```go
|
||||
/**
|
||||
102. 二叉树的层序遍历
|
||||
102. 二叉树的层序遍历 使用container包
|
||||
*/
|
||||
func levelOrder(root *TreeNode) [][]int {
|
||||
res := [][]int{}
|
||||
@ -296,6 +296,35 @@ func levelOrder(root *TreeNode) [][]int {
|
||||
return res
|
||||
}
|
||||
|
||||
/**
|
||||
102. 二叉树的层序遍历 使用切片
|
||||
*/
|
||||
func levelOrder(root *TreeNode) [][]int {
|
||||
res := make([][]int, 0)
|
||||
if root == nil {
|
||||
return res
|
||||
}
|
||||
queue := make([]*TreeNode, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
level := make([]int, 0)
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[0]
|
||||
queue = queue[1:]
|
||||
level = append(level, node.Val)
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
}
|
||||
res = append(res, level)
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
/**
|
||||
102. 二叉树的层序遍历:使用切片模拟队列,易理解
|
||||
*/
|
||||
@ -695,6 +724,41 @@ func levelOrderBottom(root *TreeNode) [][]int {
|
||||
}
|
||||
```
|
||||
|
||||
```GO
|
||||
// 使用切片作为队列
|
||||
func levelOrderBottom(root *TreeNode) [][]int {
|
||||
res := make([][]int, 0)
|
||||
if root == nil {
|
||||
return res
|
||||
}
|
||||
queue := make([]*TreeNode, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
level := make([]int, 0)
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[0]
|
||||
queue = queue[1:]
|
||||
level = append(level, node.Val)
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
}
|
||||
res = append(res, level)
|
||||
}
|
||||
l, r := 0, len(res)-1
|
||||
for l < r {
|
||||
res[l], res[r] = res[r], res[l]
|
||||
l++
|
||||
r--
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
#### Javascript:
|
||||
|
||||
```javascript
|
||||
@ -1008,6 +1072,35 @@ func rightSideView(root *TreeNode) []int {
|
||||
}
|
||||
```
|
||||
|
||||
```GO
|
||||
// 使用切片作为队列
|
||||
func rightSideView(root *TreeNode) []int {
|
||||
res := make([]int, 0)
|
||||
if root == nil {
|
||||
return res
|
||||
}
|
||||
queue := make([]*TreeNode, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[0]
|
||||
queue = queue[1:]
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
if i == size-1 {
|
||||
res = append(res, node.Val)
|
||||
}
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
#### Javascript:
|
||||
|
||||
```javascript
|
||||
@ -1299,6 +1392,35 @@ func averageOfLevels(root *TreeNode) []float64 {
|
||||
}
|
||||
```
|
||||
|
||||
```GO
|
||||
// 使用切片作为队列
|
||||
func averageOfLevels(root *TreeNode) []float64 {
|
||||
res := make([]float64, 0)
|
||||
if root == nil {
|
||||
return res
|
||||
}
|
||||
queue := make([]*TreeNode, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
sum := 0
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[0]
|
||||
queue = queue[1:]
|
||||
sum += node.Val
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
}
|
||||
res = append(res, float64(sum)/float64(size))
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
#### Javascript:
|
||||
|
||||
```javascript
|
||||
@ -1631,6 +1753,32 @@ func levelOrder(root *Node) [][]int {
|
||||
}
|
||||
```
|
||||
|
||||
```GO
|
||||
// 使用切片作为队列
|
||||
func levelOrder(root *Node) [][]int {
|
||||
res := make([][]int, 0)
|
||||
if root == nil {
|
||||
return res
|
||||
}
|
||||
queue := make([]*Node, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
level := make([]int, 0)
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[0]
|
||||
queue = queue[1:]
|
||||
level = append(level, node.Val)
|
||||
if len(node.Children) > 0 {
|
||||
queue = append(queue, node.Children...)
|
||||
}
|
||||
}
|
||||
res = append(res, level)
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
#### JavaScript:
|
||||
|
||||
```JavaScript
|
||||
@ -1930,6 +2078,37 @@ func max(x, y int) int {
|
||||
}
|
||||
```
|
||||
|
||||
```GO
|
||||
// 使用切片作为队列
|
||||
func largestValues(root *TreeNode) []int {
|
||||
res := make([]int, 0)
|
||||
if root == nil {
|
||||
return res
|
||||
}
|
||||
queue := make([]*TreeNode, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
maxValue := math.MinInt64
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[0]
|
||||
queue = queue[1:]
|
||||
if node.Val > maxValue {
|
||||
maxValue = node.Val
|
||||
}
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
}
|
||||
res = append(res, maxValue)
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
#### Javascript:
|
||||
|
||||
```javascript
|
||||
@ -2243,6 +2422,34 @@ func connect(root *Node) *Node {
|
||||
|
||||
```
|
||||
|
||||
```GO
|
||||
// 使用切片作为队列
|
||||
func connect(root *Node) *Node {
|
||||
if root == nil {
|
||||
return root
|
||||
}
|
||||
queue := make([]*Node, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[i]
|
||||
if i != size - 1 {
|
||||
queue[i].Next = queue[i+1]
|
||||
}
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
}
|
||||
queue = queue[size:]
|
||||
}
|
||||
return root
|
||||
}
|
||||
```
|
||||
|
||||
#### JavaScript:
|
||||
|
||||
```javascript
|
||||
@ -2531,6 +2738,34 @@ func connect(root *Node) *Node {
|
||||
}
|
||||
```
|
||||
|
||||
```GO
|
||||
// 使用切片作为队列
|
||||
func connect(root *Node) *Node {
|
||||
if root == nil {
|
||||
return root
|
||||
}
|
||||
queue := make([]*Node, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[i]
|
||||
if i != size - 1 {
|
||||
queue[i].Next = queue[i+1]
|
||||
}
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
}
|
||||
queue = queue[size:]
|
||||
}
|
||||
return root
|
||||
}
|
||||
```
|
||||
|
||||
#### JavaScript:
|
||||
|
||||
```javascript
|
||||
@ -2800,6 +3035,33 @@ func maxDepth(root *TreeNode) int {
|
||||
}
|
||||
```
|
||||
|
||||
```go
|
||||
// 使用切片作为队列
|
||||
func maxDepth(root *TreeNode) int {
|
||||
if root == nil {
|
||||
return 0
|
||||
}
|
||||
depth := 0
|
||||
queue := make([]*TreeNode, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[0]
|
||||
queue = queue[1:]
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
}
|
||||
depth++
|
||||
}
|
||||
return depth
|
||||
}
|
||||
```
|
||||
|
||||
#### JavaScript:
|
||||
|
||||
```javascript
|
||||
@ -3073,7 +3335,37 @@ func minDepth(root *TreeNode) int {
|
||||
ans++//记录层数
|
||||
}
|
||||
|
||||
return ans+1
|
||||
return ans
|
||||
}
|
||||
```
|
||||
|
||||
```go
|
||||
// 使用切片作为队列
|
||||
func minDepth(root *TreeNode) int {
|
||||
if root == nil {
|
||||
return 0
|
||||
}
|
||||
depth := 0
|
||||
queue := make([]*TreeNode, 0)
|
||||
queue = append(queue, root)
|
||||
for len(queue) > 0 {
|
||||
size := len(queue)
|
||||
depth++
|
||||
for i := 0; i < size; i++ {
|
||||
node := queue[0]
|
||||
queue = queue[1:]
|
||||
if node.Left != nil {
|
||||
queue = append(queue, node.Left)
|
||||
}
|
||||
if node.Right != nil {
|
||||
queue = append(queue, node.Right)
|
||||
}
|
||||
if node.Left == nil && node.Right == nil {
|
||||
return depth
|
||||
}
|
||||
}
|
||||
}
|
||||
return depth
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -82,7 +82,7 @@
|
||||
如动画所示:
|
||||
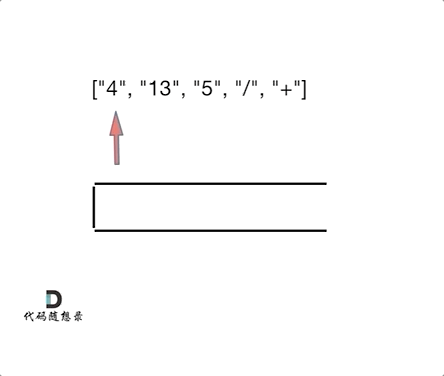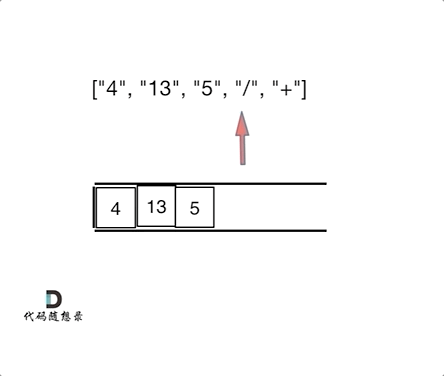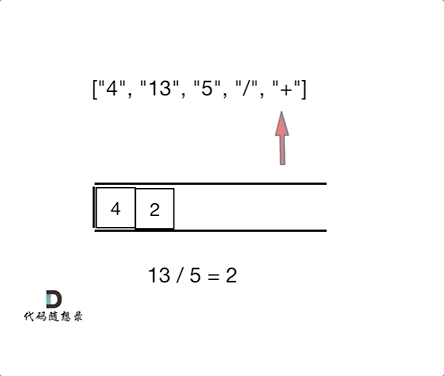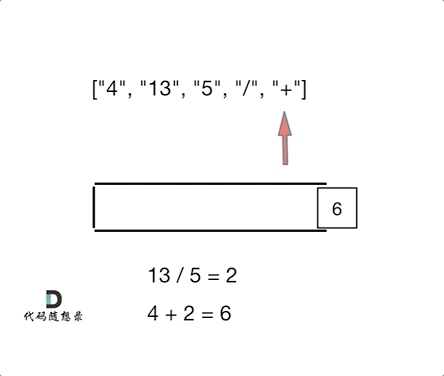
|
||||
|
||||
相信看完动画大家应该知道,这和[1047. 删除字符串中的所有相邻重复项](https://programmercarl.com/1047.删除字符串中的所有相邻重复项.html)是差不错的,只不过本题不要相邻元素做消除了,而是做运算!
|
||||
相信看完动画大家应该知道,这和[1047. 删除字符串中的所有相邻重复项](https://programmercarl.com/1047.删除字符串中的所有相邻重复项.html)是差不多的,只不过本题不要相邻元素做消除了,而是做运算!
|
||||
|
||||
C++代码如下:
|
||||
|
||||
|
||||
@ -224,9 +224,10 @@ struct ListNode* removeElements(struct ListNode* head, int val){
|
||||
|
||||
### Java:
|
||||
|
||||
用原来的链表操作:
|
||||
```java
|
||||
/**
|
||||
* 添加虚节点方式
|
||||
* 方法1
|
||||
* 时间复杂度 O(n)
|
||||
* 空间复杂度 O(1)
|
||||
* @param head
|
||||
@ -234,25 +235,22 @@ struct ListNode* removeElements(struct ListNode* head, int val){
|
||||
* @return
|
||||
*/
|
||||
public ListNode removeElements(ListNode head, int val) {
|
||||
if (head == null) {
|
||||
return head;
|
||||
while(head!=null && head.val==val) {
|
||||
head = head.next;
|
||||
}
|
||||
// 因为删除可能涉及到头节点,所以设置dummy节点,统一操作
|
||||
ListNode dummy = new ListNode(-1, head);
|
||||
ListNode pre = dummy;
|
||||
ListNode cur = head;
|
||||
while (cur != null) {
|
||||
if (cur.val == val) {
|
||||
pre.next = cur.next;
|
||||
ListNode curr = head;
|
||||
while(curr!=null && curr.next !=null) {
|
||||
if(curr.next.val == val){
|
||||
curr.next = curr.next.next;
|
||||
} else {
|
||||
pre = cur;
|
||||
curr = curr.next;
|
||||
}
|
||||
cur = cur.next;
|
||||
}
|
||||
return dummy.next;
|
||||
return head;
|
||||
}
|
||||
|
||||
/**
|
||||
* 不添加虚拟节点方式
|
||||
* 方法1
|
||||
* 时间复杂度 O(n)
|
||||
* 空间复杂度 O(1)
|
||||
* @param head
|
||||
@ -280,8 +278,13 @@ public ListNode removeElements(ListNode head, int val) {
|
||||
}
|
||||
return head;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
设置一个虚拟头结点:
|
||||
|
||||
```java
|
||||
/**
|
||||
* 不添加虚拟节点and pre Node方式
|
||||
* 时间复杂度 O(n)
|
||||
* 空间复杂度 O(1)
|
||||
* @param head
|
||||
@ -289,18 +292,21 @@ public ListNode removeElements(ListNode head, int val) {
|
||||
* @return
|
||||
*/
|
||||
public ListNode removeElements(ListNode head, int val) {
|
||||
while(head!=null && head.val==val){
|
||||
head = head.next;
|
||||
}
|
||||
ListNode curr = head;
|
||||
while(curr!=null){
|
||||
while(curr.next!=null && curr.next.val == val){
|
||||
curr.next = curr.next.next;
|
||||
// 设置一个虚拟的头结点
|
||||
ListNode dummy = new ListNode();
|
||||
dummy.next = head;
|
||||
|
||||
ListNode cur = dummy;
|
||||
while (cur.next != null) {
|
||||
if (cur.next.val == val) {
|
||||
cur.next = cur.next.next;
|
||||
} else {
|
||||
cur = cur.next;
|
||||
}
|
||||
curr = curr.next;
|
||||
}
|
||||
return head;
|
||||
return dummy.next;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### Python:
|
||||
|
||||
@ -72,6 +72,7 @@ class MyStack {
|
||||
public:
|
||||
queue<int> que1;
|
||||
queue<int> que2; // 辅助队列,用来备份
|
||||
|
||||
/** Initialize your data structure here. */
|
||||
MyStack() {
|
||||
|
||||
@ -100,9 +101,28 @@ public:
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Get the top element. */
|
||||
int top() {
|
||||
return que1.back();
|
||||
/** Get the top element.
|
||||
** Can not use back() direactly.
|
||||
*/
|
||||
int top(){
|
||||
int size = que1.size();
|
||||
size--;
|
||||
while (size--){
|
||||
// 将que1 导入que2,但要留下最后一个元素
|
||||
que2.push(que1.front());
|
||||
que1.pop();
|
||||
}
|
||||
|
||||
int result = que1.front(); // 留下的最后一个元素就是要回返的值
|
||||
que2.push(que1.front()); // 获取值后将最后一个元素也加入que2中,保持原本的结构不变
|
||||
que1.pop();
|
||||
|
||||
que1 = que2; // 再将que2赋值给que1
|
||||
while (!que2.empty()){
|
||||
// 清空que2
|
||||
que2.pop();
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Returns whether the stack is empty. */
|
||||
@ -126,14 +146,17 @@ C++优化代码
|
||||
class MyStack {
|
||||
public:
|
||||
queue<int> que;
|
||||
|
||||
/** Initialize your data structure here. */
|
||||
MyStack() {
|
||||
|
||||
}
|
||||
|
||||
/** Push element x onto stack. */
|
||||
void push(int x) {
|
||||
que.push(x);
|
||||
}
|
||||
|
||||
/** Removes the element on top of the stack and returns that element. */
|
||||
int pop() {
|
||||
int size = que.size();
|
||||
@ -147,9 +170,21 @@ public:
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Get the top element. */
|
||||
int top() {
|
||||
return que.back();
|
||||
/** Get the top element.
|
||||
** Can not use back() direactly.
|
||||
*/
|
||||
int top(){
|
||||
int size = que.size();
|
||||
size--;
|
||||
while (size--){
|
||||
// 将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部
|
||||
que.push(que.front());
|
||||
que.pop();
|
||||
}
|
||||
int result = que.front(); // 此时获得的元素就是栈顶的元素了
|
||||
que.push(que.front()); // 将获取完的元素也重新添加到队列尾部,保证数据结构没有变化
|
||||
que.pop();
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Returns whether the stack is empty. */
|
||||
|
||||
@ -41,7 +41,7 @@
|
||||
首先通过本题大家要明确什么是子序列,“子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序”。
|
||||
|
||||
本题也是代码随想录中子序列问题的第一题,如果没接触过这种题目的话,本题还是很难的,甚至想暴力去搜索也不知道怎么搜。
|
||||
子序列问题是动态规划解决的经典问题,当前下标i的递增子序列长度,其实和i之前的下表j的子序列长度有关系,那又是什么样的关系呢。
|
||||
子序列问题是动态规划解决的经典问题,当前下标i的递增子序列长度,其实和i之前的下标j的子序列长度有关系,那又是什么样的关系呢。
|
||||
|
||||
接下来,我们依然用动规五部曲来详细分析一波:
|
||||
|
||||
|
||||
@ -55,7 +55,7 @@ dp[i] 和 dp[i-1] ,dp[i + 1] 看上去都没啥关系。
|
||||
我们在判断字符串S是否是回文,那么如果我们知道 s[1],s[2],s[3] 这个子串是回文的,那么只需要比较 s[0]和s[4]这两个元素是否相同,如果相同的话,这个字符串s 就是回文串。
|
||||
|
||||
|
||||
那么此时我们是不是能找到一种递归关系,也就是判断一个子字符串(字符串的下表范围[i,j])是否回文,依赖于,子字符串(下表范围[i + 1, j - 1])) 是否是回文。
|
||||
那么此时我们是不是能找到一种递归关系,也就是判断一个子字符串(字符串下标范围[i,j])是否回文,依赖于,子字符串(下标范围[i + 1, j - 1])) 是否是回文。
|
||||
|
||||
所以为了明确这种递归关系,我们的dp数组是要定义成一位二维dp数组。
|
||||
|
||||
|
||||
@ -328,14 +328,29 @@ class MyLinkedList {
|
||||
return currentNode.val;
|
||||
}
|
||||
|
||||
//在链表最前面插入一个节点,等价于在第0个元素前添加
|
||||
public void addAtHead(int val) {
|
||||
addAtIndex(0, val);
|
||||
ListNode newNode = new ListNode(val);
|
||||
newNode.next = head.next;
|
||||
head.next = newNode;
|
||||
size++;
|
||||
|
||||
// 在链表最前面插入一个节点,等价于在第0个元素前添加
|
||||
// addAtIndex(0, val);
|
||||
}
|
||||
|
||||
//在链表的最后插入一个节点,等价于在(末尾+1)个元素前添加
|
||||
|
||||
public void addAtTail(int val) {
|
||||
addAtIndex(size, val);
|
||||
ListNode newNode = new ListNode(val);
|
||||
ListNode cur = head;
|
||||
while (cur.next != null) {
|
||||
cur = cur.next;
|
||||
}
|
||||
|
||||
cur.next = newNode;
|
||||
size++;
|
||||
|
||||
// 在链表的最后插入一个节点,等价于在(末尾+1)个元素前添加
|
||||
// addAtIndex(size, val);
|
||||
}
|
||||
|
||||
// 在第 index 个节点之前插入一个新节点,例如index为0,那么新插入的节点为链表的新头节点。
|
||||
@ -365,10 +380,7 @@ class MyLinkedList {
|
||||
return;
|
||||
}
|
||||
size--;
|
||||
if (index == 0) {
|
||||
head = head.next;
|
||||
return;
|
||||
}
|
||||
//因为有虚拟头节点,所以不用对Index=0的情况进行特殊处理
|
||||
ListNode pred = head;
|
||||
for (int i = 0; i < index ; i++) {
|
||||
pred = pred.next;
|
||||
@ -407,7 +419,7 @@ class MyLinkedList {
|
||||
|
||||
public int get(int index) {
|
||||
//判断index是否有效
|
||||
if(index<0 || index>=size){
|
||||
if(index>=size){
|
||||
return -1;
|
||||
}
|
||||
ListNode cur = this.head;
|
||||
@ -441,10 +453,7 @@ class MyLinkedList {
|
||||
if(index>size){
|
||||
return;
|
||||
}
|
||||
//index小于0
|
||||
if(index<0){
|
||||
index = 0;
|
||||
}
|
||||
|
||||
size++;
|
||||
//找到前驱
|
||||
ListNode pre = this.head;
|
||||
@ -462,7 +471,7 @@ class MyLinkedList {
|
||||
|
||||
public void deleteAtIndex(int index) {
|
||||
//判断索引是否有效
|
||||
if(index<0 || index>=size){
|
||||
if(index>=size){
|
||||
return;
|
||||
}
|
||||
//删除操作
|
||||
|
||||
@ -588,6 +588,40 @@ public class Main {
|
||||
```
|
||||
|
||||
### Python
|
||||
```python
|
||||
# 接收输入
|
||||
v, e = list(map(int, input().strip().split()))
|
||||
# 按照常规的邻接矩阵存储图信息,不可达的初始化为10001
|
||||
graph = [[10001] * (v+1) for _ in range(v+1)]
|
||||
for _ in range(e):
|
||||
x, y, w = list(map(int, input().strip().split()))
|
||||
graph[x][y] = w
|
||||
graph[y][x] = w
|
||||
|
||||
# 定义加入生成树的标记数组和未加入生成树的最近距离
|
||||
visited = [False] * (v + 1)
|
||||
minDist = [10001] * (v + 1)
|
||||
|
||||
# 循环 n - 1 次,建立 n - 1 条边
|
||||
# 从节点视角来看:每次选中一个节点加入树,更新剩余的节点到树的最短距离,
|
||||
# 这一步其实蕴含了确定下一条选取的边,计入总路程 ans 的计算
|
||||
for _ in range(1, v + 1):
|
||||
min_val = 10002
|
||||
cur = -1
|
||||
for j in range(1, v + 1):
|
||||
if visited[j] == False and minDist[j] < min_val:
|
||||
cur = j
|
||||
min_val = minDist[j]
|
||||
visited[cur] = True
|
||||
for j in range(1, v + 1):
|
||||
if visited[j] == False and minDist[j] > graph[cur][j]:
|
||||
minDist[j] = graph[cur][j]
|
||||
|
||||
ans = 0
|
||||
for i in range(2, v + 1):
|
||||
ans += minDist[i]
|
||||
print(ans)
|
||||
```
|
||||
|
||||
```python
|
||||
def prim(v, e, edges):
|
||||
|
||||
@ -422,9 +422,186 @@ int main() {
|
||||
## 其他语言版本
|
||||
|
||||
### Java
|
||||
#### 邻接矩阵写法
|
||||
```java
|
||||
import java.util.ArrayList;
|
||||
import java.util.List;
|
||||
import java.util.Scanner;
|
||||
|
||||
public class Main {
|
||||
static List<List<Integer>> result = new ArrayList<>(); // 收集符合条件的路径
|
||||
static List<Integer> path = new ArrayList<>(); // 1节点到终点的路径
|
||||
|
||||
public static void dfs(int[][] graph, int x, int n) {
|
||||
// 当前遍历的节点x 到达节点n
|
||||
if (x == n) { // 找到符合条件的一条路径
|
||||
result.add(new ArrayList<>(path));
|
||||
return;
|
||||
}
|
||||
for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点
|
||||
if (graph[x][i] == 1) { // 找到 x链接的节点
|
||||
path.add(i); // 遍历到的节点加入到路径中来
|
||||
dfs(graph, i, n); // 进入下一层递归
|
||||
path.remove(path.size() - 1); // 回溯,撤销本节点
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
int n = scanner.nextInt();
|
||||
int m = scanner.nextInt();
|
||||
|
||||
// 节点编号从1到n,所以申请 n+1 这么大的数组
|
||||
int[][] graph = new int[n + 1][n + 1];
|
||||
|
||||
for (int i = 0; i < m; i++) {
|
||||
int s = scanner.nextInt();
|
||||
int t = scanner.nextInt();
|
||||
// 使用邻接矩阵表示无向图,1 表示 s 与 t 是相连的
|
||||
graph[s][t] = 1;
|
||||
}
|
||||
|
||||
path.add(1); // 无论什么路径已经是从1节点出发
|
||||
dfs(graph, 1, n); // 开始遍历
|
||||
|
||||
// 输出结果
|
||||
if (result.isEmpty()) System.out.println(-1);
|
||||
for (List<Integer> pa : result) {
|
||||
for (int i = 0; i < pa.size() - 1; i++) {
|
||||
System.out.print(pa.get(i) + " ");
|
||||
}
|
||||
System.out.println(pa.get(pa.size() - 1));
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 邻接表写法
|
||||
```java
|
||||
import java.util.ArrayList;
|
||||
import java.util.LinkedList;
|
||||
import java.util.List;
|
||||
import java.util.Scanner;
|
||||
|
||||
public class Main {
|
||||
static List<List<Integer>> result = new ArrayList<>(); // 收集符合条件的路径
|
||||
static List<Integer> path = new ArrayList<>(); // 1节点到终点的路径
|
||||
|
||||
public static void dfs(List<LinkedList<Integer>> graph, int x, int n) {
|
||||
if (x == n) { // 找到符合条件的一条路径
|
||||
result.add(new ArrayList<>(path));
|
||||
return;
|
||||
}
|
||||
for (int i : graph.get(x)) { // 找到 x指向的节点
|
||||
path.add(i); // 遍历到的节点加入到路径中来
|
||||
dfs(graph, i, n); // 进入下一层递归
|
||||
path.remove(path.size() - 1); // 回溯,撤销本节点
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
int n = scanner.nextInt();
|
||||
int m = scanner.nextInt();
|
||||
|
||||
// 节点编号从1到n,所以申请 n+1 这么大的数组
|
||||
List<LinkedList<Integer>> graph = new ArrayList<>(n + 1);
|
||||
for (int i = 0; i <= n; i++) {
|
||||
graph.add(new LinkedList<>());
|
||||
}
|
||||
|
||||
while (m-- > 0) {
|
||||
int s = scanner.nextInt();
|
||||
int t = scanner.nextInt();
|
||||
// 使用邻接表表示 s -> t 是相连的
|
||||
graph.get(s).add(t);
|
||||
}
|
||||
|
||||
path.add(1); // 无论什么路径已经是从1节点出发
|
||||
dfs(graph, 1, n); // 开始遍历
|
||||
|
||||
// 输出结果
|
||||
if (result.isEmpty()) System.out.println(-1);
|
||||
for (List<Integer> pa : result) {
|
||||
for (int i = 0; i < pa.size() - 1; i++) {
|
||||
System.out.print(pa.get(i) + " ");
|
||||
}
|
||||
System.out.println(pa.get(pa.size() - 1));
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
### Python
|
||||
#### 邻接矩阵写法
|
||||
``` python
|
||||
def dfs(graph, x, n, path, result):
|
||||
if x == n:
|
||||
result.append(path.copy())
|
||||
return
|
||||
for i in range(1, n + 1):
|
||||
if graph[x][i] == 1:
|
||||
path.append(i)
|
||||
dfs(graph, i, n, path, result)
|
||||
path.pop()
|
||||
|
||||
def main():
|
||||
n, m = map(int, input().split())
|
||||
graph = [[0] * (n + 1) for _ in range(n + 1)]
|
||||
|
||||
for _ in range(m):
|
||||
s, t = map(int, input().split())
|
||||
graph[s][t] = 1
|
||||
|
||||
result = []
|
||||
dfs(graph, 1, n, [1], result)
|
||||
|
||||
if not result:
|
||||
print(-1)
|
||||
else:
|
||||
for path in result:
|
||||
print(' '.join(map(str, path)))
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
#### 邻接表写法
|
||||
``` python
|
||||
from collections import defaultdict
|
||||
|
||||
result = [] # 收集符合条件的路径
|
||||
path = [] # 1节点到终点的路径
|
||||
|
||||
def dfs(graph, x, n):
|
||||
if x == n: # 找到符合条件的一条路径
|
||||
result.append(path.copy())
|
||||
return
|
||||
for i in graph[x]: # 找到 x指向的节点
|
||||
path.append(i) # 遍历到的节点加入到路径中来
|
||||
dfs(graph, i, n) # 进入下一层递归
|
||||
path.pop() # 回溯,撤销本节点
|
||||
|
||||
def main():
|
||||
n, m = map(int, input().split())
|
||||
|
||||
graph = defaultdict(list) # 邻接表
|
||||
for _ in range(m):
|
||||
s, t = map(int, input().split())
|
||||
graph[s].append(t)
|
||||
|
||||
path.append(1) # 无论什么路径已经是从1节点出发
|
||||
dfs(graph, 1, n) # 开始遍历
|
||||
|
||||
# 输出结果
|
||||
if not result:
|
||||
print(-1)
|
||||
for pa in result:
|
||||
print(' '.join(map(str, pa)))
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
### Go
|
||||
|
||||
### Rust
|
||||
|
||||
@ -167,7 +167,7 @@
|
||||
|
||||

|
||||
|
||||
--------------
|
||||
--------------
|
||||
|
||||
后面的过程一样的,节点3 和 节点4,入度都为0,选哪个都行。
|
||||
|
||||
@ -344,8 +344,107 @@ int main() {
|
||||
|
||||
### Java
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
|
||||
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
int n = scanner.nextInt();
|
||||
int m = scanner.nextInt();
|
||||
|
||||
List<List<Integer>> umap = new ArrayList<>(); // 记录文件依赖关系
|
||||
int[] inDegree = new int[n]; // 记录每个文件的入度
|
||||
|
||||
for (int i = 0; i < n; i++)
|
||||
umap.add(new ArrayList<>());
|
||||
|
||||
for (int i = 0; i < m; i++) {
|
||||
int s = scanner.nextInt();
|
||||
int t = scanner.nextInt();
|
||||
umap.get(s).add(t); // 记录s指向哪些文件
|
||||
inDegree[t]++; // t的入度加一
|
||||
}
|
||||
|
||||
Queue<Integer> queue = new LinkedList<>();
|
||||
for (int i = 0; i < n; i++) {
|
||||
if (inDegree[i] == 0) {
|
||||
// 入度为0的文件,可以作为开头,先加入队列
|
||||
queue.add(i);
|
||||
}
|
||||
}
|
||||
|
||||
List<Integer> result = new ArrayList<>();
|
||||
|
||||
// 拓扑排序
|
||||
while (!queue.isEmpty()) {
|
||||
int cur = queue.poll(); // 当前选中的文件
|
||||
result.add(cur);
|
||||
for (int file : umap.get(cur)) {
|
||||
inDegree[file]--; // cur的指向的文件入度-1
|
||||
if (inDegree[file] == 0) {
|
||||
queue.add(file);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (result.size() == n) {
|
||||
for (int i = 0; i < result.size(); i++) {
|
||||
System.out.print(result.get(i));
|
||||
if (i < result.size() - 1) {
|
||||
System.out.print(" ");
|
||||
}
|
||||
}
|
||||
} else {
|
||||
System.out.println(-1);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Python
|
||||
|
||||
```python
|
||||
from collections import deque, defaultdict
|
||||
|
||||
def topological_sort(n, edges):
|
||||
inDegree = [0] * n # inDegree 记录每个文件的入度
|
||||
umap = defaultdict(list) # 记录文件依赖关系
|
||||
|
||||
# 构建图和入度表
|
||||
for s, t in edges:
|
||||
inDegree[t] += 1
|
||||
umap[s].append(t)
|
||||
|
||||
# 初始化队列,加入所有入度为0的节点
|
||||
queue = deque([i for i in range(n) if inDegree[i] == 0])
|
||||
result = []
|
||||
|
||||
while queue:
|
||||
cur = queue.popleft() # 当前选中的文件
|
||||
result.append(cur)
|
||||
for file in umap[cur]: # 获取该文件指向的文件
|
||||
inDegree[file] -= 1 # cur的指向的文件入度-1
|
||||
if inDegree[file] == 0:
|
||||
queue.append(file)
|
||||
|
||||
if len(result) == n:
|
||||
print(" ".join(map(str, result)))
|
||||
else:
|
||||
print(-1)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
n, m = map(int, input().split())
|
||||
edges = [tuple(map(int, input().split())) for _ in range(m)]
|
||||
topological_sort(n, edges)
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Go
|
||||
|
||||
### Rust
|
||||
|
||||
@ -25,7 +25,7 @@
|
||||
index_{left}=(\sum_{i=0}^{i=k}2^i)+2*m-1-1=2^{k+1}+2m-3
|
||||
$$
|
||||
|
||||
- 故左孩子的下表为$index_{left}=index_{father}\times2+1$,同理可得到右子孩子的索引关系。也可以直接在左子孩子的基础上`+1`。
|
||||
- 故左孩子的下标为$index_{left}=index_{father}\times2+1$,同理可得到右子孩子的索引关系。也可以直接在左子孩子的基础上`+1`。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -55,7 +55,7 @@
|
||||
|
||||
**构造二叉树有三个注意的点:**
|
||||
|
||||
* 分割时候,坚持区间不变量原则,左闭右开,或者左闭又闭。
|
||||
* 分割时候,坚持区间不变量原则,左闭右开,或者左闭右闭。
|
||||
* 分割的时候,注意后序 或者 前序已经有一个节点作为中间节点了,不能继续使用了。
|
||||
* 如何使用切割后的后序数组来切合中序数组?利用中序数组大小一定是和后序数组的大小相同这一特点来进行切割。
|
||||
|
||||
|
||||
Reference in New Issue
Block a user