Update
21
README.md
@ -28,6 +28,13 @@
|
||||
* [算法分析中的空间复杂度,你真的会了么?](https://mp.weixin.qq.com/s/sXjjnOUEQ4Gf5F9QCRzy7g)
|
||||
* [刷leetcode的时候,究竟什么时候可以使用库函数,什么时候不要使用库函数,过来人来说一说](https://leetcode-cn.com/circle/article/E1Kjzn/)
|
||||
|
||||
* 数组
|
||||
* [必须掌握的数组理论知识](https://mp.weixin.qq.com/s/X7R55wSENyY62le0Fiawsg)
|
||||
* [数组:每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)
|
||||
* [数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
|
||||
* [数组:滑动窗口拯救了你](https://mp.weixin.qq.com/s/UrZynlqi4QpyLlLhBPglyg)
|
||||
* [数组:这个循环可以转懵很多人!](https://mp.weixin.qq.com/s/KTPhaeqxbMK9CxHUUgFDmg)
|
||||
* [数组:总结篇](https://mp.weixin.qq.com/s/LIfQFRJBH5ENTZpvixHEmg)
|
||||
* 链表
|
||||
* [关于链表,你该了解这些!](https://mp.weixin.qq.com/s/ntlZbEdKgnFQKZkSUAOSpQ)
|
||||
* [链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/slM1CH5Ew9XzK93YOQYSjA)
|
||||
@ -46,13 +53,6 @@
|
||||
* [哈希表:解决了两数之和,那么能解决三数之和么?](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)
|
||||
* [双指针法:一样的道理,能解决四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)
|
||||
|
||||
* 数组
|
||||
* [必须掌握的数组理论知识](https://mp.weixin.qq.com/s/X7R55wSENyY62le0Fiawsg)
|
||||
* [数组:每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)
|
||||
* [数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
|
||||
* [数组:滑动窗口拯救了你](https://mp.weixin.qq.com/s/UrZynlqi4QpyLlLhBPglyg)
|
||||
* [数组:这个循环可以转懵很多人!](https://mp.weixin.qq.com/s/KTPhaeqxbMK9CxHUUgFDmg)
|
||||
* [数组:总结篇](https://mp.weixin.qq.com/s/LIfQFRJBH5ENTZpvixHEmg)
|
||||
|
||||
* 字符串
|
||||
* [字符串:这道题目,使用库函数一行代码搞定](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)
|
||||
@ -110,6 +110,9 @@
|
||||
* [二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)
|
||||
* [二叉树:构造二叉树登场!](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg)
|
||||
* [二叉树:构造一棵最大的二叉树](https://mp.weixin.qq.com/s/1iWJV6Aov23A7xCF4nV88w)
|
||||
* [本周小结!(二叉树系列三)](https://mp.weixin.qq.com/s/JLLpx3a_8jurXcz6ovgxtg)
|
||||
* [二叉树:合并两个二叉树](https://mp.weixin.qq.com/s/3f5fbjOFaOX_4MXzZ97LsQ)
|
||||
* [二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)
|
||||
|
||||
|
||||
|
||||
@ -233,6 +236,7 @@
|
||||
|[0018.四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md) | 数组 |中等|**双指针**|
|
||||
|[0020.有效的括号](https://github.com/youngyangyang04/leetcode/blob/master/problems/0020.有效的括号.md) | 栈 |简单|**栈**|
|
||||
|[0021.合并两个有序链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0021.合并两个有序链表.md) |链表 |简单|**模拟** |
|
||||
|[0024.两两交换链表中的节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0024.两两交换链表中的节点.md) |链表 |中等|**模拟** |
|
||||
|[0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md) |数组 |简单|**暴力** **快慢指针/快慢指针** |
|
||||
|[0027.移除元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0027.移除元素.md) |数组 |简单| **暴力** **双指针/快慢指针/双指针**|
|
||||
|[0028.实现strStr()](https://github.com/youngyangyang04/leetcode/blob/master/problems/0028.实现strStr().md) |字符串 |简单| **KMP** |
|
||||
@ -326,7 +330,8 @@
|
||||
|[0705.设计哈希集合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0705.设计哈希集合.md) |哈希表 |简单|**模拟**|
|
||||
|[0707.设计链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0707.设计链表.md) |链表 |中等|**模拟**|
|
||||
|[0841.钥匙和房间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0841.钥匙和房间.md) |孤岛问题 |中等|**bfs** **dfs**|
|
||||
|[1047.删除字符串中的所有相邻重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/1047.删除字符串中的所有相邻重复项.md) |栈 |简单|**栈**|
|
||||
|[1002.查找常用字符](https://github.com/youngyangyang04/leetcode/blob/master/problems/1002.查找常用字符.md) |栈 |简单|**栈**|
|
||||
|[1047.删除字符串中的所有相邻重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/1047.删除字符串中的所有相邻重复项.md) |哈希表 |简单|**哈希表/数组**|
|
||||
|[剑指Offer05.替换空格](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md) |字符串 |简单|**双指针**|
|
||||
|[ 剑指Offer58-I.翻转单词顺序](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md) |字符串 |简单|**模拟/双指针**|
|
||||
|[剑指Offer58-II.左旋转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer58-II.左旋转字符串.md) |字符串 |简单|**反转操作**|
|
||||
|
||||
BIN
pics/1002.查找常用字符.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 118 KiB |
BIN
pics/24.两两交换链表中的节点.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 44 KiB |
BIN
pics/24.两两交换链表中的节点1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 62 KiB |
BIN
pics/24.两两交换链表中的节点2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 60 KiB |
BIN
pics/24.两两交换链表中的节点3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 36 KiB |
BIN
pics/42.接雨水4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 37 KiB |
BIN
pics/42.接雨水5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
BIN
pics/98.验证二叉搜索树.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 51 KiB |
@ -22,6 +22,8 @@ https://leetcode-cn.com/problems/3sum/
|
||||
|
||||
# 思路
|
||||
|
||||
**注意[0, 0, 0, 0] 这组数据**
|
||||
|
||||
## 哈希解法
|
||||
|
||||
两层for循环就可以确定 a 和b 的数值了,可以使用哈希法来确定 0-(a+b) 是否在 数组里出现过,其实这个思路是正确的,但是我们有一个非常棘手的问题,就是题目中说的不可以包含重复的三元组。
|
||||
|
||||
70
problems/0024.两两交换链表中的节点.md
Normal file
@ -0,0 +1,70 @@
|
||||
|
||||
|
||||
## 题目地址
|
||||
|
||||
## 思路
|
||||
|
||||
这道题目正常模拟就可以了。
|
||||
|
||||
建议使用虚拟头结点,这样会方便很多,要不然每次针对头结点(没有前一个指针指向头结点),还要单独处理。
|
||||
|
||||
对虚拟头结点的操作,还不熟悉的话,可以看这篇[链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/slM1CH5Ew9XzK93YOQYSjA)。
|
||||
|
||||
接下来就是交换相邻两个元素了,**此时一定要画图,不画图,操作多个指针很容易乱,而且要操作的先后顺序**
|
||||
|
||||
初始时,cur指向虚拟头结点,然后进行如下三步:
|
||||
|
||||
<img src='../pics/24.两两交换链表中的节点1.png' width=600> </img></div>
|
||||
|
||||
操作之后,链表如下:
|
||||
|
||||
|
||||
<img src='../pics/24.两两交换链表中的节点2.png' width=600> </img></div>
|
||||
|
||||
看这个可能就更直观一些了:
|
||||
|
||||
|
||||
<img src='../pics/24.两两交换链表中的节点3.png' width=600> </img></div>
|
||||
|
||||
对应的C++代码实现如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
ListNode* swapPairs(ListNode* head) {
|
||||
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
|
||||
dummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作
|
||||
ListNode* cur = dummyHead;
|
||||
while(cur->next != nullptr && cur->next->next != nullptr) {
|
||||
ListNode* tmp = cur->next; // 记录临时节点
|
||||
ListNode* tmp1 = cur->next->next->next; // 记录临时节点
|
||||
|
||||
cur->next = cur->next->next; // 步骤一
|
||||
cur->next->next = tmp; // 步骤二
|
||||
cur->next->next->next = tmp1; // 步骤三
|
||||
|
||||
cur = cur->next->next; // cur移动两位,准备下一轮交换
|
||||
}
|
||||
return dummyHead->next;
|
||||
}
|
||||
};
|
||||
```
|
||||
时间复杂度:O(n)
|
||||
空间复杂度:O(1)
|
||||
|
||||
## 拓展
|
||||
|
||||
**这里还是说一下,大家不必太在意leetcode上执行用时,打败多少多少用户,这个就是一个玩具,非常不准确。**
|
||||
|
||||
做题的时候自己能分析出来时间复杂度就可以了,至于leetcode上执行用时,大概看一下就行。
|
||||
|
||||
上面的代码我第一次提交执行用时8ms,打败6.5%的用户,差点吓到我了。
|
||||
|
||||
心想应该没有更好的方法了吧,也就O(n)的时间复杂度,重复提交几次,这样了:
|
||||
|
||||
<img src='../pics/24.两两交换链表中的节点.png' width=600> </img></div>
|
||||
|
||||
所以,不必过于在意leetcode上这个统计。
|
||||
|
||||
|
||||
|
||||
@ -108,7 +108,7 @@ next数组就是一个前缀表(prefix table)。
|
||||
|
||||
如动画所示:
|
||||
|
||||
<img src='../../media/video/KMP精讲1.gif' width=600> </img></div>
|
||||
<img src='../video/KMP详解1.gif' width=600> </img></div>
|
||||
|
||||
动画里,我特意把 子串`aa` 标记上了,这是有原因的,大家先注意一下,后面还会说道。
|
||||
|
||||
@ -169,7 +169,7 @@ next数组就是一个前缀表(prefix table)。
|
||||
|
||||
再来看一下如何利用 前缀表找到 当字符不匹配的时候应该指针应该移动的位置。如动画所示:
|
||||
|
||||
<img src='../../media/video/KMP精讲2.gif' width=600> </img></div>
|
||||
<img src='../video/KMP精讲2.gif' width=600> </img></div>
|
||||
|
||||
找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
|
||||
|
||||
@ -311,7 +311,7 @@ void getNext(int* next, const string& s){
|
||||
|
||||
代码构造next数组的逻辑流程动画如下:
|
||||
|
||||
<img src='../../media/video/KMP精讲3.gif' width=600> </img></div>
|
||||
<img src='../video/KMP精讲3.gif' width=600> </img></div>
|
||||
|
||||
|
||||
得到了next数组之后,就要用这个来做匹配了。
|
||||
|
||||
@ -105,4 +105,69 @@ public:
|
||||
|
||||
单调栈究竟如何做呢,得画一个图,不太好理解
|
||||
|
||||
按照列来算的,遇到相同的怎么办。
|
||||
## 使用单调栈内元素的顺序
|
||||
|
||||
从打到小还是从小打到呢
|
||||
|
||||
从栈底到栈头(元素从栈头弹出)是从大到小的顺序,因为一旦发现添加的柱子高度大于栈头元素了,此时就出现凹槽了,栈头元素就是凹槽底部的柱子,栈头第二个元素就是凹槽左边的柱子,而添加的元素就是凹槽右边的柱子。
|
||||
|
||||
如图:
|
||||
|
||||
<img src='../pics/42.接雨水4.png' width=600> </img></div>
|
||||
|
||||
|
||||
## 遇到相同高度的柱子怎么办。
|
||||
|
||||
遇到相同的元素,更新栈内下表,就是将栈里元素(旧下标)弹出,讲新元素(新下标)加入栈中。
|
||||
|
||||
例如 5 5 1 3 这种情况。如果添加第二个5的时候就应该将第一个5的下标弹出,把第二个5添加到栈中。
|
||||
|
||||
因为我们要求宽度的时候 如果遇到相容高度的柱子,需要使用最右边的柱子来计算宽度。
|
||||
|
||||
如图所示:
|
||||
|
||||
|
||||
<img src='../pics/42.接雨水5.png' width=600> </img></div>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
没有必要 stack<pair<int, int>> st; // 高度,下表
|
||||
|
||||
|
||||
放进去元素,相同怎么办,相同也没事,放里面就行,计算结果也是0
|
||||
|
||||
**真的难**
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
int trap(vector<int>& height) {
|
||||
if (height.size() <= 2) return 0;
|
||||
stack<int> st; // 存着下标,计算的时候用下标对应的柱子高度
|
||||
st.push(0);
|
||||
int sum = 0;
|
||||
for (int i = 1; i < height.size(); i++) {
|
||||
if (height[i] < height[st.top()]) {
|
||||
st.push(i);
|
||||
} if (height[i] == height[st.top()]) { // 如果相等则更新栈内下表,例如 5 5 1 7 这种情况
|
||||
st.pop();
|
||||
st.push(i);
|
||||
} else {
|
||||
while (!st.empty() && height[i] > height[st.top()]) { // 注意这里是while
|
||||
int mid = st.top();
|
||||
st.pop();
|
||||
if (!st.empty()) {
|
||||
int h = min(height[st.top()], height[i]) - height[mid];
|
||||
int w = i - st.top() - 1 ; // 注意求宽度这里不加1,而是减一
|
||||
sum += h * w;
|
||||
}
|
||||
}
|
||||
st.push(i);
|
||||
}
|
||||
}
|
||||
return sum;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
@ -1,65 +1,246 @@
|
||||
## 题目地址
|
||||
|
||||
## 思路
|
||||
> 学习完二叉搜索树的特性了,那么就验证一波
|
||||
|
||||
中序遍历下,输出的二叉搜索树节点的数值是有序序列,有了这个特性,**验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。**
|
||||
# 98.验证二叉搜索树
|
||||
|
||||
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
|
||||
|
||||
假设一个二叉搜索树具有如下特征:
|
||||
|
||||
* 节点的左子树只包含小于当前节点的数。
|
||||
* 节点的右子树只包含大于当前节点的数。
|
||||
* 所有左子树和右子树自身必须也是二叉搜索树。
|
||||
|
||||
<img src='../pics/98.验证二叉搜索树.png' width=600> </img></div>
|
||||
|
||||
# 思路
|
||||
|
||||
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
|
||||
|
||||
有了这个特性,**验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。**
|
||||
|
||||
## 递归法
|
||||
|
||||
可以递归中序遍历将二叉搜索树转变成一个数组,代码如下:
|
||||
|
||||
```
|
||||
vector<int> vec;
|
||||
void traversal(TreeNode* root) {
|
||||
if (root == NULL) return;
|
||||
traversal(root->left);
|
||||
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
|
||||
traversal(root->right);
|
||||
}
|
||||
```
|
||||
|
||||
然后只要比较一下,这个数组是否是有序的,**注意二叉搜索树中不能有重复元素**。
|
||||
|
||||
```
|
||||
traversal(root);
|
||||
for (int i = 1; i < vec.size(); i++) {
|
||||
// 注意要小于等于,搜索树里不能有相同元素
|
||||
if (vec[i] <= vec[i - 1]) return false;
|
||||
}
|
||||
return true;
|
||||
```
|
||||
|
||||
整体代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
private:
|
||||
vector<int> vec;
|
||||
void traversal(TreeNode* root) {
|
||||
if (root == NULL) return;
|
||||
traversal(root->left);
|
||||
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
|
||||
traversal(root->right);
|
||||
}
|
||||
public:
|
||||
bool isValidBST(TreeNode* root) {
|
||||
vec.clear(); // 不加这句在leetcode上也可以过,但最好加上
|
||||
traversal(root);
|
||||
for (int i = 1; i < vec.size(); i++) {
|
||||
// 注意要小于等于,搜索树里不能有相同元素
|
||||
if (vec[i] <= vec[i - 1]) return false;
|
||||
}
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
以上代码中,我们把二叉树转变为数组来判断,是最直观的,但其实不用转变成数组,可以在递归遍历的过程中直接判断是否有序。
|
||||
|
||||
所以代码实现上,我们就使用递归法来中序遍历,遍历的过程中判断节点上的数值是不是递增的就可以了。
|
||||
|
||||
这道题目比较容易陷入两个陷阱:
|
||||
|
||||
* 陷阱1 :[10,5,15,null,null,6,20] 这个case 要考虑道
|
||||
* 陷阱1
|
||||
|
||||
**不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了**。
|
||||
|
||||
写出了类似这样的代码:
|
||||
|
||||
```
|
||||
if (root->val > root->left->val && root->val < root->right->val) {
|
||||
return true;
|
||||
} else {
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
**我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。**所以以上代码的判断逻辑是错误的。
|
||||
|
||||
例如: [10,5,15,null,null,6,20] 这个case:
|
||||
|
||||
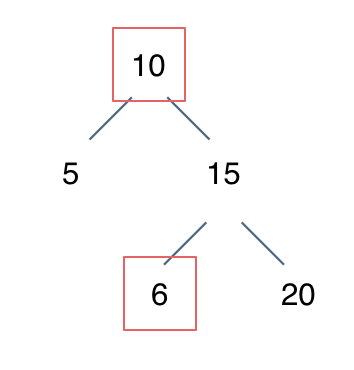
|
||||
|
||||
10的右子树只能包含大于当前节点的数,而右面出现了一个6 这就不符合了!
|
||||
节点10小于左节点5,大于右节点15,但右子树里出现了一个6 这就不符合了!
|
||||
|
||||
* 陷阱2:样例中根节点的val 可能是int的最小值
|
||||
* 陷阱2
|
||||
|
||||
问题可以进一步演进:如果样例中根节点的val 可能是longlong的最小值 又要怎么办呢?看下文解答!
|
||||
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
|
||||
|
||||
## C++代码
|
||||
此时可以初始化比较元素为longlong的最小值。
|
||||
|
||||
定于全局变量初始化为long long最小值
|
||||
问题可以进一步演进:如果样例中根节点的val 可能是longlong的最小值 又要怎么办呢?文中会解答。
|
||||
|
||||
了解这些陷阱之后我们来看一下代码应该怎么写:
|
||||
|
||||
递归三部曲:
|
||||
|
||||
* 确定递归函数,返回值以及参数
|
||||
|
||||
要定义一个longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。
|
||||
|
||||
注意递归函数要有bool类型的返回值, 我们在[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg) 中讲了,只有寻找某一条边(或者一个节点)的时候,递归函数会有bool类型的返回值。
|
||||
|
||||
其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
|
||||
bool isValidBST(TreeNode* root)
|
||||
```
|
||||
|
||||
* 确定终止条件
|
||||
|
||||
如果是空节点 是不是二叉搜索树呢?
|
||||
|
||||
是的,二叉搜索树也可以为空!
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (root == NULL) return true;
|
||||
```
|
||||
|
||||
* 确定单层递归的逻辑
|
||||
|
||||
中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
bool left = isValidBST(root->left); // 左
|
||||
|
||||
// 中序遍历,验证遍历的元素是不是从小到大
|
||||
if (maxVal < root->val) maxVal = root->val; // 中
|
||||
else return false;
|
||||
|
||||
bool right = isValidBST(root->right); // 右
|
||||
return left && right;
|
||||
```
|
||||
|
||||
整体代码如下:
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
long long maxVal = LONG_MIN;
|
||||
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
|
||||
bool isValidBST(TreeNode* root) {
|
||||
if (root == NULL) return true;
|
||||
|
||||
bool left = isValidBST(root->left);
|
||||
// 中序遍历,验证遍历的元素是不是从小到大
|
||||
if (maxVal < root->val) maxVal = root->val;
|
||||
else return false;
|
||||
bool right = isValidBST(root->right);
|
||||
|
||||
return left && right;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
其实因为后台数据有int最小值测试用例,所以都改成了longlong最小值。
|
||||
以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
|
||||
|
||||
如果测试数据中有 longlong的最小值,怎么办?不可能在初始化一个更小的值了吧。 建议避免 初始化最小值,如下方法取到最左面的数值:
|
||||
如果测试数据中有 longlong的最小值,怎么办?
|
||||
|
||||
不可能在初始化一个更小的值了吧。 建议避免 初始化最小值,如下方法取到最左面节点的数值来比较。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
long long maxVal = 0; // 记录中序遍历的过程中出现过的最大值
|
||||
bool flag = false; // 标记是否取到了最左面节点的数值
|
||||
TreeNode* pre = NULL; // 用来记录前一个节点
|
||||
bool isValidBST(TreeNode* root) {
|
||||
if (root == NULL) return true;
|
||||
bool left = isValidBST(root->left);
|
||||
if (!flag) {
|
||||
maxVal = root->val;
|
||||
flag = true;
|
||||
} else {
|
||||
// 中序遍历,这里相当于从大到小进行比较
|
||||
if (maxVal < root->val) maxVal = root->val;
|
||||
else return false;
|
||||
}
|
||||
|
||||
if (pre != NULL && pre->val >= root->val) return false;
|
||||
pre = root; // 记录前一个节点
|
||||
|
||||
bool right = isValidBST(root->right);
|
||||
return left && right;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
最后这份代码看上去整洁一些,思路也清晰。
|
||||
|
||||
## 迭代法
|
||||
|
||||
可以用迭代法模拟二叉树中序遍历,对前中后序迭代法生疏的同学可以看这两篇[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg),[二叉树:前中后序迭代方式统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)
|
||||
|
||||
迭代法中序遍历稍加改动就可以了,代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
bool isValidBST(TreeNode* root) {
|
||||
stack<TreeNode*> st;
|
||||
TreeNode* cur = root;
|
||||
TreeNode* pre = NULL; // 记录前一个节点
|
||||
while (cur != NULL || !st.empty()) {
|
||||
if (cur != NULL) {
|
||||
st.push(cur);
|
||||
cur = cur->left; // 左
|
||||
} else {
|
||||
cur = st.top(); // 中
|
||||
st.pop();
|
||||
if (pre != NULL && cur->val <= pre->val)
|
||||
return false;
|
||||
pre = cur; //保存前一个访问的结点
|
||||
|
||||
cur = cur->right; // 右
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
在[二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)中我们分明写出了痛哭流涕的简洁迭代法,怎么在这里不行了呢,因为本题是要验证二叉搜索树啊。
|
||||
|
||||
# 总结
|
||||
|
||||
这道题目是一个简单题,但对于没接触过的同学还是有难度的。
|
||||
|
||||
所以初学者刚开始学习算法的时候,看到简单题目没有思路很正常,千万别怀疑自己智商,学习过程都是这样的,大家智商都差不多,哈哈。
|
||||
|
||||
只要把基本类型的题目都做过,总结过之后,思路自然就开阔了。
|
||||
|
||||
**就酱,学到了的话,就转发给身边需要的同学吧!**
|
||||
|
||||
> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
|
||||
|
||||
@ -74,12 +74,15 @@ return NULL;
|
||||
整体代码如下:
|
||||
|
||||
```
|
||||
TreeNode* searchBST(TreeNode* root, int val) {
|
||||
if (root == NULL || root->val == val) return root;
|
||||
if (root->val > val) return searchBST(root->left, val);
|
||||
if (root->val < val) return searchBST(root->right, val);
|
||||
return NULL;
|
||||
}
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* searchBST(TreeNode* root, int val) {
|
||||
if (root == NULL || root->val == val) return root;
|
||||
if (root->val > val) return searchBST(root->left, val);
|
||||
if (root->val < val) return searchBST(root->right, val);
|
||||
return NULL;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 迭代法
|
||||
|
||||
110
problems/1002.查找常用字符.md
Normal file
@ -0,0 +1,110 @@
|
||||
# 题目地址
|
||||
https://leetcode-cn.com/problems/find-common-characters/
|
||||
|
||||
## 思路
|
||||
|
||||
这道题意一起就有点绕,不是那么容易懂,其实就是26个小写字符中有字符 在所有字符串里都出现的话,就输出,重复的也算。
|
||||
|
||||
例如:
|
||||
|
||||
输入:["ll","ll","ll"]
|
||||
输出:["l","l"]
|
||||
|
||||
这道题目一眼看上去,就是用哈希法,**“小写字符”,“出现频率”, 这些关键字都是为哈希法量身定做的啊**
|
||||
|
||||
首先可以想到的是暴力解法,一个字符串一个字符串去搜,时间复杂度是O(n^m),n是字符串长度,m是有几个字符串。
|
||||
|
||||
可以看出这是指数级别的时间复杂度,非常高,而且代码实现也不容易,因为要统计 重复的字符,还要适当的替换或者去重。
|
||||
|
||||
那我们还是哈希法吧。如果对哈希法不了解,可以这这篇文章:[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/g8N6WmoQmsCUw3_BaWxHZA)。
|
||||
|
||||
如果对用数组来做哈希法不了解的话,可以看这篇:[哈希表:可以拿数组当哈希表来用,但哈希值不要太大](https://mp.weixin.qq.com/s/vM6OszkM6L1Mx2Ralm9Dig)。
|
||||
|
||||
了解了哈希法,理解了数组在哈希法中的应用之后,可以来看解题思路了。
|
||||
|
||||
整体思路就是统计出搜索字符串里26个字符的出现的频率,然后取每个字符频率最小值,最后转成输出格式就可以了。
|
||||
|
||||
如图:
|
||||
|
||||
<img src='../pics/1002.查找常用字符.png' width=600> </img></div>
|
||||
|
||||
先统计第一个字符串所有字符出现的次数,代码如下:
|
||||
|
||||
```
|
||||
int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
|
||||
for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
|
||||
hash[A[0][i] - 'a']++;
|
||||
}
|
||||
```
|
||||
|
||||
接下来,把其他字符串里字符的出现次数也统计出来一次放在hashOtherStr中。
|
||||
|
||||
然后hash 和 hashOtherStr 取最小值,这是本题关键所在,此时取最小值,就是 一个字符在所有字符串里出现的最小次数了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
|
||||
for (int i = 1; i < A.size(); i++) {
|
||||
memset(hashOtherStr, 0, 26 * sizeof(int));
|
||||
for (int j = 0; j < A[i].size(); j++) {
|
||||
hashOtherStr[A[i][j] - 'a']++;
|
||||
}
|
||||
// 这是关键所在
|
||||
for (int k = 0; k < 26; k++) { // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
|
||||
hash[k] = min(hash[k], hashOtherStr[k]);
|
||||
}
|
||||
}
|
||||
```
|
||||
此时hash里统计着字符在所有字符串里出现的最小次数,那么把hash转正题目要求的输出格式就可以了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
// 将hash统计的字符次数,转成输出形式
|
||||
for (int i = 0; i < 26; i++) {
|
||||
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
|
||||
string s(1, i + 'a'); // char -> string
|
||||
result.push_back(s);
|
||||
hash[i]--;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
整体C++代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
vector<string> commonChars(vector<string>& A) {
|
||||
vector<string> result;
|
||||
if (A.size() == 0) return result;
|
||||
int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
|
||||
for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
|
||||
hash[A[0][i] - 'a']++;
|
||||
}
|
||||
|
||||
int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
|
||||
for (int i = 1; i < A.size(); i++) {
|
||||
memset(hashOtherStr, 0, 26 * sizeof(int));
|
||||
for (int j = 0; j < A[i].size(); j++) {
|
||||
hashOtherStr[A[i][j] - 'a']++;
|
||||
}
|
||||
// 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
|
||||
for (int k = 0; k < 26; k++) {
|
||||
hash[k] = min(hash[k], hashOtherStr[k]);
|
||||
}
|
||||
}
|
||||
// 将hash统计的字符次数,转成输出形式
|
||||
for (int i = 0; i < 26; i++) {
|
||||
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
|
||||
string s(1, i + 'a'); // char -> string
|
||||
result.push_back(s);
|
||||
hash[i]--;
|
||||
}
|
||||
}
|
||||
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
{kind=link}
|
Before Width: | Height: | Size: 687 KiB After Width: | Height: | Size: 687 KiB |
BIN
video/KMP精讲2.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.9 MiB |
BIN
video/KMP精讲4.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.5 MiB |