mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-08 08:50:15 +08:00
Update
This commit is contained in:
11
README.md
11
README.md
@ -47,10 +47,10 @@
|
|||||||
* 求职
|
* 求职
|
||||||
* [程序员的简历应该这么写!!(附简历模板)](https://mp.weixin.qq.com/s/nCTUzuRTBo1_R_xagVszsA)
|
* [程序员的简历应该这么写!!(附简历模板)](https://mp.weixin.qq.com/s/nCTUzuRTBo1_R_xagVszsA)
|
||||||
* [BAT级别技术面试流程和注意事项都在这里了](https://mp.weixin.qq.com/s/815qCyFGVIxwut9I_7PNFw)
|
* [BAT级别技术面试流程和注意事项都在这里了](https://mp.weixin.qq.com/s/815qCyFGVIxwut9I_7PNFw)
|
||||||
* [深圳原来有这么多互联网公司,你都知道么?](https://mp.weixin.qq.com/s/Yzrkim-5bY0Df66Ao-hoqA)
|
* [深圳原来有这么多互联网公司,你都知道么?](https://mp.weixin.qq.com/s/3VJHF2zNohBwDBxARFIn-Q)
|
||||||
* [北京有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/FQTzoZtqXQ2rlS1UthGrag)
|
* [北京有这些互联网公司,你都知道么?]()
|
||||||
* [上海有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/msqbX6eR2-JBQOYFfec4sg)
|
* [上海有这些互联网公司,你都知道么?]()
|
||||||
* [成都有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/Y9Qg22WEsBngs8B-K8acqQ)
|
* [成都有这些互联网公司,你都知道么?]()
|
||||||
|
|
||||||
* 算法性能分析
|
* 算法性能分析
|
||||||
* [关于时间复杂度,你不知道的都在这里!](https://mp.weixin.qq.com/s/LWBfehW1gMuEnXtQjJo-sw)
|
* [关于时间复杂度,你不知道的都在这里!](https://mp.weixin.qq.com/s/LWBfehW1gMuEnXtQjJo-sw)
|
||||||
@ -196,6 +196,8 @@
|
|||||||
* [贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)
|
* [贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)
|
||||||
* [贪心算法:跳跃游戏II](https://mp.weixin.qq.com/s/kJBcsJ46DKCSjT19pxrNYg)
|
* [贪心算法:跳跃游戏II](https://mp.weixin.qq.com/s/kJBcsJ46DKCSjT19pxrNYg)
|
||||||
* [贪心算法:K次取反后最大化的数组和](https://mp.weixin.qq.com/s/dMTzBBVllRm_Z0aaWvYazA)
|
* [贪心算法:K次取反后最大化的数组和](https://mp.weixin.qq.com/s/dMTzBBVllRm_Z0aaWvYazA)
|
||||||
|
* [本周小结!(贪心算法系列二)](https://mp.weixin.qq.com/s/RiQri-4rP9abFmq_mlXNiQ)
|
||||||
|
* [贪心算法:加油站](https://mp.weixin.qq.com/s/aDbiNuEZIhy6YKgQXvKELw)
|
||||||
|
|
||||||
|
|
||||||
* 动态规划
|
* 动态规划
|
||||||
@ -359,6 +361,7 @@
|
|||||||
|[0705.设计哈希集合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0705.设计哈希集合.md) |哈希表 |简单|**模拟**|
|
|[0705.设计哈希集合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0705.设计哈希集合.md) |哈希表 |简单|**模拟**|
|
||||||
|[0707.设计链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0707.设计链表.md) |链表 |中等|**模拟**|
|
|[0707.设计链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0707.设计链表.md) |链表 |中等|**模拟**|
|
||||||
|[0763.划分字母区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0763.划分字母区间.md) |贪心 |中等|**双指针/贪心** 体现贪心尽可能多的思想|
|
|[0763.划分字母区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0763.划分字母区间.md) |贪心 |中等|**双指针/贪心** 体现贪心尽可能多的思想|
|
||||||
|
|[0738.单调递增的数字](https://github.com/youngyangyang04/leetcode/blob/master/problems/0738.单调递增的数字.md) |贪心算法 |中等|**贪心算法** 思路不错,贪心好题|
|
||||||
|[0739.每日温度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0739.每日温度.md) |栈 |中等|**单调栈** 适合单调栈入门|
|
|[0739.每日温度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0739.每日温度.md) |栈 |中等|**单调栈** 适合单调栈入门|
|
||||||
|[0767.重构字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0767.重构字符串.md) |字符串 |中等|**字符串** + 排序+一点贪心|
|
|[0767.重构字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0767.重构字符串.md) |字符串 |中等|**字符串** + 排序+一点贪心|
|
||||||
|[0841.钥匙和房间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0841.钥匙和房间.md) |孤岛问题 |中等|**bfs** **dfs**|
|
|[0841.钥匙和房间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0841.钥匙和房间.md) |孤岛问题 |中等|**bfs** **dfs**|
|
||||||
|
|||||||
@ -1,11 +1,41 @@
|
|||||||
|
> 好了
|
||||||
|
|
||||||
## 思路
|
|
||||||
|
|
||||||
这道题目一定是要确定一边之后,再确定另一边,例如比较每一个孩子的左边,然后再比较右边,如果两边一起考虑就会顾此失彼。
|
# 135. 分发糖果
|
||||||
|
|
||||||
本题贪心贪在哪里呢?
|
链接:https://leetcode-cn.com/problems/candy/
|
||||||
|
|
||||||
先确定每个孩子左边的情况(也就是从前向后遍历)
|
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
|
||||||
|
|
||||||
|
你需要按照以下要求,帮助老师给这些孩子分发糖果:
|
||||||
|
|
||||||
|
* 每个孩子至少分配到 1 个糖果。
|
||||||
|
* 相邻的孩子中,评分高的孩子必须获得更多的糖果。
|
||||||
|
|
||||||
|
那么这样下来,老师至少需要准备多少颗糖果呢?
|
||||||
|
|
||||||
|
示例 1:
|
||||||
|
输入: [1,0,2]
|
||||||
|
输出: 5
|
||||||
|
解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。
|
||||||
|
|
||||||
|
示例 2:
|
||||||
|
输入: [1,2,2]
|
||||||
|
输出: 4
|
||||||
|
解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。
|
||||||
|
第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
|
||||||
|
|
||||||
|
|
||||||
|
# 思路
|
||||||
|
|
||||||
|
这道题目一定是要确定一边之后,再确定另一边,例如比较每一个孩子的左边,然后再比较右边,**如果两边一起考虑一定会顾此失彼**。
|
||||||
|
|
||||||
|
|
||||||
|
先确定右边评分大于左边的情况(也就是从前向后遍历)
|
||||||
|
|
||||||
|
此时局部最优:只要右边评分比左边大,右边的孩子就多一个糖果,全局最优:相邻的孩子中,评分高的右孩子获得比左边孩子更多的糖果
|
||||||
|
|
||||||
|
局部最优可以推出全局最优。
|
||||||
|
|
||||||
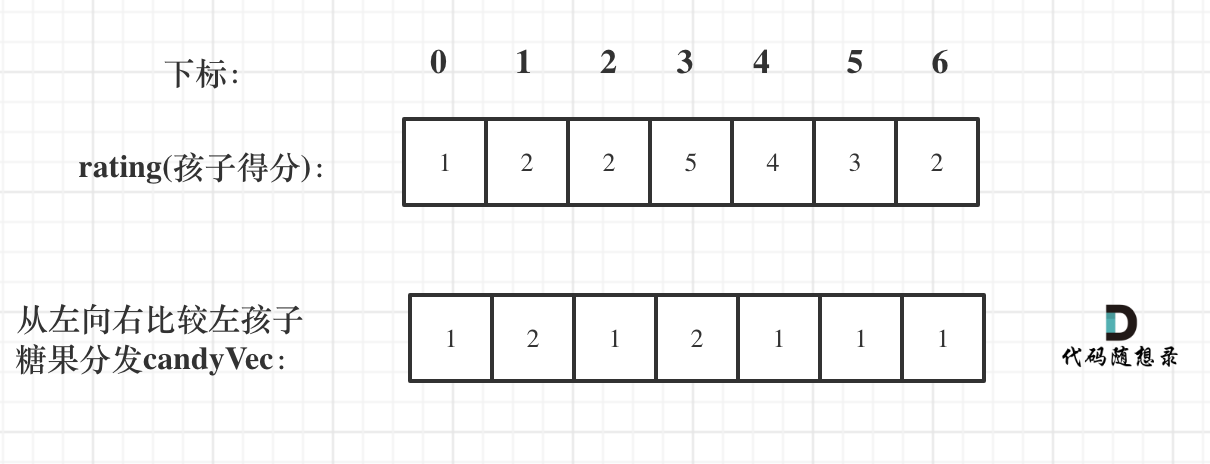
如果ratings[i] > ratings[i - 1] 那么[i]的糖 一定要比[i - 1]的糖多一个,所以贪心:candyVec[i] = candyVec[i - 1] + 1
|
如果ratings[i] > ratings[i - 1] 那么[i]的糖 一定要比[i - 1]的糖多一个,所以贪心:candyVec[i] = candyVec[i - 1] + 1
|
||||||
|
|
||||||
@ -22,20 +52,27 @@ for (int i = 1; i < ratings.size(); i++) {
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
再确定每个孩子右边的情况(从后向前遍历)
|
再确定左孩子大于右孩子的情况(从后向前遍历)
|
||||||
|
|
||||||
遍历顺序这里有同学可能会有疑问,为什么不能从前向后遍历呢?
|
遍历顺序这里有同学可能会有疑问,为什么不能从前向后遍历呢?
|
||||||
|
|
||||||
因为如果从前向后遍历,根据 ratings[i + 1] 来确定 ratings[i] 对应的糖果,那么每次都不能利用上前一次的比较结果了。
|
因为如果从前向后遍历,根据 ratings[i + 1] 来确定 ratings[i] 对应的糖果,那么每次都不能利用上前一次的比较结果了。
|
||||||
**所以确定每个孩子右边的情况一定要从后向前遍历!**
|
|
||||||
|
|
||||||
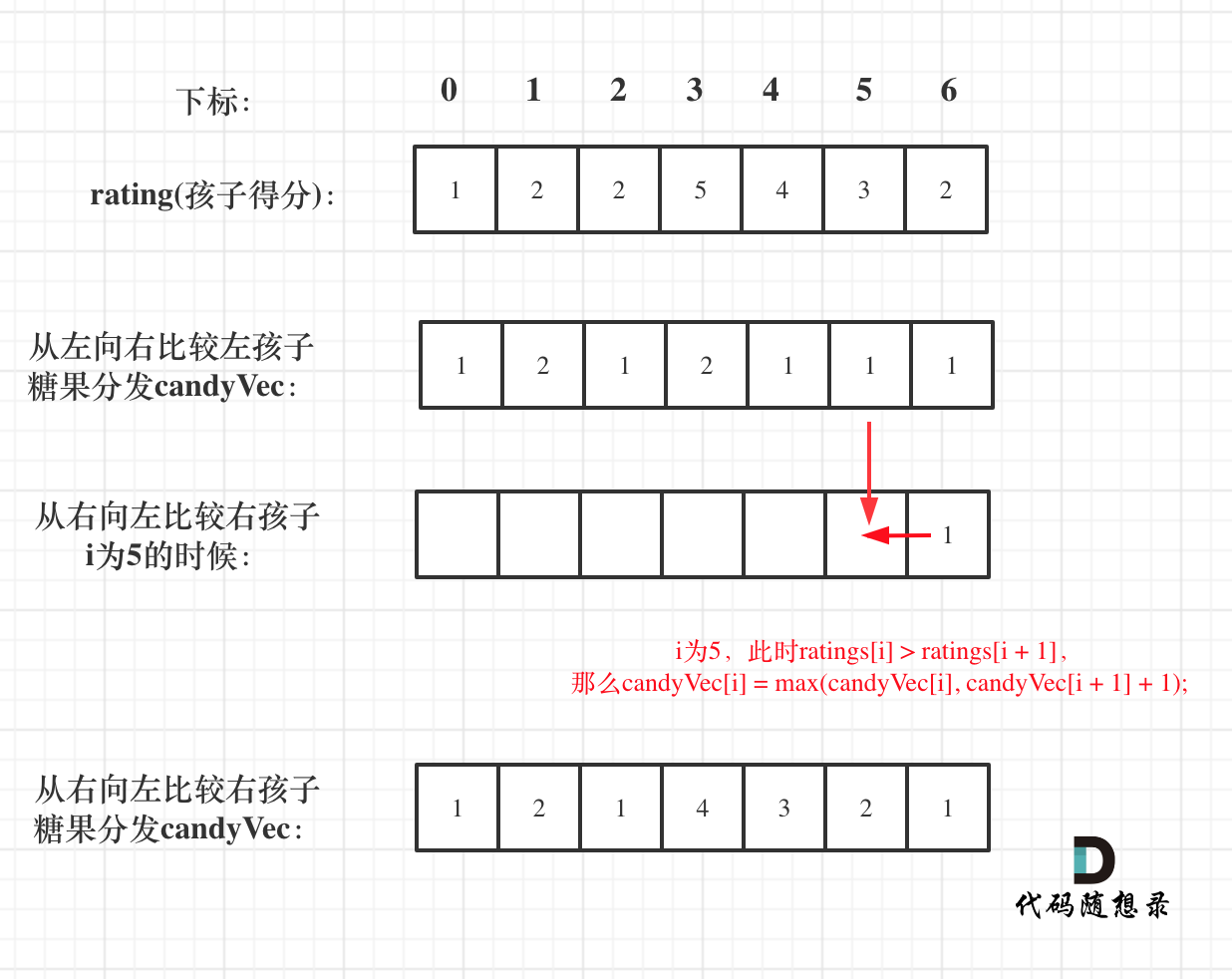
此时又要开始贪心,如果 ratings[i] > ratings[i + 1],就取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,**因为candyVec[i]只有取最大的才能既保持对左边candyVec[i - 1]的糖果多,也比右边candyVec[i + 1]的糖果多**。
|
**所以确定左孩子大于右孩子的情况一定要从后向前遍历!**
|
||||||
|
|
||||||
|
如果 ratings[i] > ratings[i + 1],此时candyVec[i](第i个小孩的糖果数量)就有两个选择了,一个是candyVec[i + 1] + 1(从右边这个加1得到的糖果数量),一个是candyVec[i](之前比较右孩子大于左孩子得到的糖果数量)。
|
||||||
|
|
||||||
|
那么又要贪心了,局部最优:取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,保证第i个小孩的糖果数量即大于左边的也大于右边的。全局最优:相邻的孩子中,评分高的孩子获得更多的糖果。
|
||||||
|
|
||||||
|
局部最优可以推出全局最优。
|
||||||
|
|
||||||
|
所以就取candyVec[i + 1] + 1 和 candyVec[i] 最大的糖果数量,**candyVec[i]只有取最大的才能既保持对左边candyVec[i - 1]的糖果多,也比右边candyVec[i + 1]的糖果多**。
|
||||||
|
|
||||||
如图:
|
如图:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
所以代码如下:
|
所以该过程代码如下:
|
||||||
|
|
||||||
```C++
|
```C++
|
||||||
// 从后向前
|
// 从后向前
|
||||||
@ -70,7 +107,22 @@ public:
|
|||||||
};
|
};
|
||||||
```
|
```
|
||||||
|
|
||||||
|
# 总结
|
||||||
|
|
||||||
|
这在leetcode上是一道困难的题目,其难点就在于贪心的策略,如果在考虑局部的时候想两边兼顾,就会顾此失彼。
|
||||||
|
|
||||||
|
那么本题我采用了两次贪心的策略:
|
||||||
|
|
||||||
|
* 一次是从左到右遍历,只比较右边孩子评分比左边大的情况。
|
||||||
|
* 一次是从右到左遍历,只比较左边孩子评分比右边大的情况。
|
||||||
|
|
||||||
|
这样从局部最优推出了全局最优,即:相邻的孩子中,评分高的孩子获得更多的糖果。
|
||||||
|
|
||||||
|
就酱,如果感觉「代码随想录」干货满满,就推荐给身边的朋友同学们吧,关注后就会发现相见恨晚!
|
||||||
|
|
||||||
|
|
||||||
> **我是[程序员Carl](https://github.com/youngyangyang04),[组队刷题](https://img-blog.csdnimg.cn/20201115103410182.png)可以找我,本文[leetcode刷题攻略](https://github.com/youngyangyang04/leetcode-master)已收录,更多[精彩算法文章](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzUxNjY5NTYxNA==&action=getalbum&album_id=1485825793120387074&scene=173#wechat_redirect)尽在:[代码随想录](https://img-blog.csdnimg.cn/20200815195519696.png),关注后就会发现和「代码随想录」相见恨晚!**
|
> **我是[程序员Carl](https://github.com/youngyangyang04),[组队刷题](https://img-blog.csdnimg.cn/20201115103410182.png)可以找我,本文[leetcode刷题攻略](https://github.com/youngyangyang04/leetcode-master)已收录,更多[精彩算法文章](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzUxNjY5NTYxNA==&action=getalbum&album_id=1485825793120387074&scene=173#wechat_redirect)尽在:[代码随想录](https://img-blog.csdnimg.cn/20200815195519696.png),关注后就会发现和「代码随想录」相见恨晚!**
|
||||||
|
|
||||||
**如果感觉题解对你有帮助,不要吝啬给一个👍吧!**
|
**如果感觉题解对你有帮助,不要吝啬给一个👍吧!**
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -60,7 +60,7 @@
|
|||||||
|
|
||||||
针对以上情形,result初始为1(默认最右面有一个峰值),此时curDiff > 0 && preDiff <= 0,那么result++(计算了左面的峰值),最后得到的result就是2(峰值个数为2即摆动序列长度为2)
|
针对以上情形,result初始为1(默认最右面有一个峰值),此时curDiff > 0 && preDiff <= 0,那么result++(计算了左面的峰值),最后得到的result就是2(峰值个数为2即摆动序列长度为2)
|
||||||
|
|
||||||
C++代码如下:
|
C++代码如下(和上图是对应的逻辑):
|
||||||
|
|
||||||
```C++
|
```C++
|
||||||
class Solution {
|
class Solution {
|
||||||
@ -70,8 +70,8 @@ public:
|
|||||||
int curDiff = 0; // 当前一对差值
|
int curDiff = 0; // 当前一对差值
|
||||||
int preDiff = 0; // 前一对差值
|
int preDiff = 0; // 前一对差值
|
||||||
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
|
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
|
||||||
for (int i = 1; i < nums.size(); i++) {
|
for (int i = 0; i < nums.size() - 1; i++) {
|
||||||
curDiff = nums[i] - nums[i - 1];
|
curDiff = nums[i + 1] - nums[i];
|
||||||
// 出现峰值
|
// 出现峰值
|
||||||
if ((curDiff > 0 && preDiff <= 0) || (preDiff >= 0 && curDiff < 0)) {
|
if ((curDiff > 0 && preDiff <= 0) || (preDiff >= 0 && curDiff < 0)) {
|
||||||
result++;
|
result++;
|
||||||
|
|||||||
82
problems/0738.单调递增的数字.md
Normal file
82
problems/0738.单调递增的数字.md
Normal file
@ -0,0 +1,82 @@
|
|||||||
|
|
||||||
|
# 思路
|
||||||
|
|
||||||
|
## 暴力解法
|
||||||
|
|
||||||
|
暴力一波 果然超时了
|
||||||
|
|
||||||
|
```C++
|
||||||
|
class Solution {
|
||||||
|
private:
|
||||||
|
bool checkNum(int num) {
|
||||||
|
int max = 10;
|
||||||
|
while (num) {
|
||||||
|
int t = num % 10;
|
||||||
|
if (max >= t) max = t;
|
||||||
|
else return false;
|
||||||
|
num = num / 10;
|
||||||
|
}
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
public:
|
||||||
|
int monotoneIncreasingDigits(int N) {
|
||||||
|
for (int i = N; i > 0; i--) {
|
||||||
|
if (checkNum(i)) return i;
|
||||||
|
}
|
||||||
|
return 0;
|
||||||
|
}
|
||||||
|
};
|
||||||
|
```
|
||||||
|
## 贪心算法
|
||||||
|
|
||||||
|
题目要求小于等于N的最大单调递增的整数,那么拿一个两位的数字来举例。
|
||||||
|
|
||||||
|
例如:98,一旦出现strNum[i - 1] > strNum[i]的情况(非单调递增),首先想让strNum[i - 1]--,然后strNum[i]给为9,这样这个整数就是89,即小于98的最大的单调递增整数。
|
||||||
|
|
||||||
|
这一点如果想清楚了,这道题就好办了。
|
||||||
|
|
||||||
|
**局部最优:遇到strNum[i - 1] > strNum[i]的情况,让strNum[i - 1]--,然后strNum[i]给为9,可以保证这两位变成最大单调递增整数**。
|
||||||
|
|
||||||
|
**全局最优:得到小于等于N的最大单调递增的整数**。
|
||||||
|
|
||||||
|
**但这里局部最优推出全局最优,还需要其他条件,即遍历顺序,和标记从哪一位开始统一改成9**。
|
||||||
|
|
||||||
|
此时是从前向后遍历还是从后向前遍历呢?
|
||||||
|
|
||||||
|
这里其实还有一个贪心选择,对于“遇到strNum[i - 1] > strNum[i]的情况,让strNum[i - 1]--,然后strNum[i]给为9”的情况,这个strNum[i - 1]--的操作应该是越靠后越好。
|
||||||
|
|
||||||
|
因为这样才能让这个单调递增整数尽可能的大。例如:对于5486,第一位的5能不减一尽量不减一,因为这个减一对整体损失最大。
|
||||||
|
|
||||||
|
所以要从后向前遍历,遇到strNum[i - 1] > strNum[i]的情况,让strNum[i - 1]--,然后strNum[i]给为9,这样保证这个减一的操作尽可能在后面进行(即整数的尽可能小的位数上进行)。
|
||||||
|
|
||||||
|
|
||||||
|
确定了遍历顺序之后,那么此时局部最优就可以推出全局,找不出反例,试试贪心。
|
||||||
|
|
||||||
|
C++代码如下:
|
||||||
|
|
||||||
|
```C++
|
||||||
|
class Solution {
|
||||||
|
public:
|
||||||
|
int monotoneIncreasingDigits(int N) {
|
||||||
|
string strNum = to_string(N);
|
||||||
|
// flag用来标记赋值9从哪里开始
|
||||||
|
// 设置为这个默认值,为了防止第二个for循环在flag没有被赋值的情况下执行
|
||||||
|
int flag = strNum.size();
|
||||||
|
for (int i = strNum.size() - 1; i > 0; i--) {
|
||||||
|
if (strNum[i - 1] > strNum[i] ) {
|
||||||
|
flag = i;
|
||||||
|
strNum[i - 1]--;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
for (int i = flag; i < strNum.size(); i++) {
|
||||||
|
strNum[i] = '9';
|
||||||
|
}
|
||||||
|
return stoi(strNum);
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
||||||
|
```
|
||||||
|
> **我是[程序员Carl](https://github.com/youngyangyang04),可以找我[组队刷题](https://img-blog.csdnimg.cn/20201115103410182.png),也可以在[B站上找到我](https://space.bilibili.com/525438321),本文[leetcode刷题攻略](https://github.com/youngyangyang04/leetcode-master)已收录,更多[精彩算法文章](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzUxNjY5NTYxNA==&action=getalbum&album_id=1485825793120387074&scene=173#wechat_redirect)尽在公众号:[代码随想录](https://img-blog.csdnimg.cn/20201124161234338.png),关注后就会发现和「代码随想录」相见恨晚!**
|
||||||
|
|
||||||
|
**如果感觉题解对你有帮助,不要吝啬给一个👍吧!**
|
||||||
|
|
||||||
39
problems/0879.盈利计划.md
Normal file
39
problems/0879.盈利计划.md
Normal file
@ -0,0 +1,39 @@
|
|||||||
|
|
||||||
|
(待完整)
|
||||||
|
https://www.cnblogs.com/grandyang/p/11108205.html
|
||||||
|
|
||||||
|
* 如果g >= group[k - 1],则说明犯罪k可以执行,因为人数已经足够了
|
||||||
|
* 如果profit[k - 1] >= p,则说明只执行犯罪k就能达到利润p,可以单独执行,接着我们考虑必须执行犯罪k,然后加上前面的利润不低于p - profit[k - 1]的方案,这样凑出的方案利润也会超过p
|
||||||
|
* 否则犯罪k不能执行,此时只能直接将前面 dp[k - 1][g][p]利润超过p的方案搬过来
|
||||||
|
|
||||||
|
```
|
||||||
|
class Solution {
|
||||||
|
public:
|
||||||
|
int profitableSchemes(int G, int P, vector<int>& group, vector<int>& profit) {
|
||||||
|
int K = group.size(), MOD = 1e9 + 7;
|
||||||
|
//dp[k][g][p]使用计划[1,2,3,... k],最多g个人,盈利不少于p个方案个数
|
||||||
|
vector<vector<vector<int> > > dp(K + 1, vector<vector<int> >(G + 1, vector<int>(P + 1, 0)));
|
||||||
|
for (int k = 1; k <= K; ++k){
|
||||||
|
for (int g = 1; g <= G; ++g){
|
||||||
|
for (int p = 0; p <= P; ++p){
|
||||||
|
//如果人数g能够执行第k种犯罪(人数g >= 第k种犯罪需要的人数group[k - 1])
|
||||||
|
if (g >= group[k - 1]){
|
||||||
|
if (profit[k - 1] >= p){
|
||||||
|
//如果执行第k种犯罪获得的利润profit[k - 1]不小于p,则可以单独执行该犯罪
|
||||||
|
dp[k][g][p] += 1;
|
||||||
|
}
|
||||||
|
//将第k个方案产生的利润profit[k]与之前方案产生的利润凑出不少于p
|
||||||
|
//dp[k - 1][g - group[k]][p > profit[k] ? p - profit[k] : 0]表示在使用[1, k - 1]这些犯罪,使用人数不超过g - group[k],获得路润不少于p - profit[k]
|
||||||
|
//这样前面的产生p - profit[k]的利润再加上执行第k个犯罪的利润profit[k]就能到达到利润不少于p(注意p 可能大于 profit[k],所以不能为负数)
|
||||||
|
dp[k][g][p] = (dp[k][g][p] + dp[k - 1][g - group[k - 1]][p > profit[k - 1] ? p - profit[k - 1] : 0]) % MOD;
|
||||||
|
}
|
||||||
|
//不执行第k个犯罪,直接将前面的利润超过p的方案搬过来
|
||||||
|
dp[k][g][p] = (dp[k][g][p] + dp[k - 1][g][p]) % MOD;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return dp[K][G][P];
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
||||||
|
```
|
||||||
@ -19,9 +19,9 @@
|
|||||||
* [程序员的简历应该这么写!!(附简历模板)](https://mp.weixin.qq.com/s/nCTUzuRTBo1_R_xagVszsA)
|
* [程序员的简历应该这么写!!(附简历模板)](https://mp.weixin.qq.com/s/nCTUzuRTBo1_R_xagVszsA)
|
||||||
* [BAT级别技术面试流程和注意事项都在这里了](https://mp.weixin.qq.com/s/815qCyFGVIxwut9I_7PNFw)
|
* [BAT级别技术面试流程和注意事项都在这里了](https://mp.weixin.qq.com/s/815qCyFGVIxwut9I_7PNFw)
|
||||||
* [深圳原来有这么多互联网公司,你都知道么?](https://mp.weixin.qq.com/s/Yzrkim-5bY0Df66Ao-hoqA)
|
* [深圳原来有这么多互联网公司,你都知道么?](https://mp.weixin.qq.com/s/Yzrkim-5bY0Df66Ao-hoqA)
|
||||||
* [北京有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/FQTzoZtqXQ2rlS1UthGrag)
|
* [北京有这些互联网公司,你都知道么?]()
|
||||||
* [上海有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/msqbX6eR2-JBQOYFfec4sg)
|
* [上海有这些互联网公司,你都知道么?]()
|
||||||
* [成都有这些互联网公司,你都知道么?](https://mp.weixin.qq.com/s/Y9Qg22WEsBngs8B-K8acqQ)
|
* [成都有这些互联网公司,你都知道么?]()
|
||||||
|
|
||||||
* 算法性能分析
|
* 算法性能分析
|
||||||
* [关于时间复杂度,你不知道的都在这里!](https://mp.weixin.qq.com/s/LWBfehW1gMuEnXtQjJo-sw)
|
* [关于时间复杂度,你不知道的都在这里!](https://mp.weixin.qq.com/s/LWBfehW1gMuEnXtQjJo-sw)
|
||||||
@ -166,6 +166,8 @@
|
|||||||
* [贪心算法:跳跃游戏II](https://mp.weixin.qq.com/s/kJBcsJ46DKCSjT19pxrNYg)
|
* [贪心算法:跳跃游戏II](https://mp.weixin.qq.com/s/kJBcsJ46DKCSjT19pxrNYg)
|
||||||
* [贪心算法:K次取反后最大化的数组和](https://mp.weixin.qq.com/s/dMTzBBVllRm_Z0aaWvYazA)
|
* [贪心算法:K次取反后最大化的数组和](https://mp.weixin.qq.com/s/dMTzBBVllRm_Z0aaWvYazA)
|
||||||
* [本周小结!(贪心算法系列二)](https://mp.weixin.qq.com/s/RiQri-4rP9abFmq_mlXNiQ)
|
* [本周小结!(贪心算法系列二)](https://mp.weixin.qq.com/s/RiQri-4rP9abFmq_mlXNiQ)
|
||||||
|
* [贪心算法:加油站](https://mp.weixin.qq.com/s/aDbiNuEZIhy6YKgQXvKELw)
|
||||||
|
|
||||||
|
|
||||||
(持续更新.....)
|
(持续更新.....)
|
||||||
|
|
||||||
|
|||||||
125
problems/数组总结篇.md
Normal file
125
problems/数组总结篇.md
Normal file
@ -0,0 +1,125 @@
|
|||||||
|
> 这个周末我们对数组做一个总结
|
||||||
|
|
||||||
|
# 数组理论基础
|
||||||
|
|
||||||
|
数组是非常基础的数据结构,在面试中,考察数组的题目一般在思维上都不难,主要是考察对代码的掌控能力
|
||||||
|
|
||||||
|
也就是说,想法很简单,但实现起来 可能就不是那么回事了。
|
||||||
|
|
||||||
|
首先要知道数组在内存中的存储方式,这样才能真正理解数组相关的面试题
|
||||||
|
|
||||||
|
**数组是存放在连续内存空间上的相同类型数据的集合。**
|
||||||
|
|
||||||
|
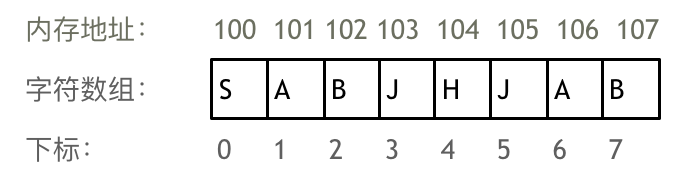
数组可以方便的通过下表索引的方式获取到下表下对应的数据。
|
||||||
|
|
||||||
|
举一个字符数组的例子,如图所示:
|
||||||
|
|
||||||
|
<img src='../../media/pics/算法通关数组.png' width=600> </img></div>
|
||||||
|
|
||||||
|
需要两点注意的是
|
||||||
|
|
||||||
|
* **数组下表都是从0开始的。**
|
||||||
|
* **数组内存空间的地址是连续的**
|
||||||
|
|
||||||
|
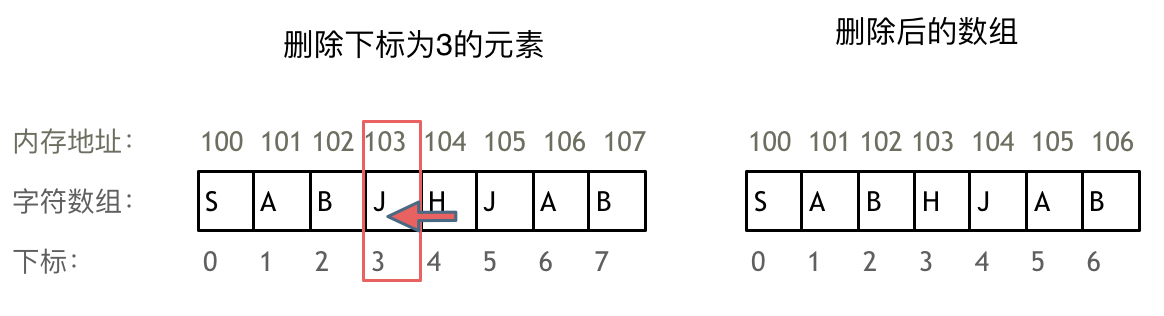
正是**因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。**
|
||||||
|
|
||||||
|
例如删除下表为3的元素,需要对下表为3的元素后面的所有元素都要做移动操作,如图所示:
|
||||||
|
|
||||||
|
<img src='../../media/pics/算法通关数组1.png' width=600> </img></div>
|
||||||
|
|
||||||
|
而且大家如果使用C++的话,要注意vector 和 array的区别,vector的底层实现是array,严格来讲vector是容器,不是数组。
|
||||||
|
|
||||||
|
**数组的元素是不能删的,只能覆盖。**
|
||||||
|
|
||||||
|
那么二维数组直接上图,大家应该就知道怎么回事了
|
||||||
|
|
||||||
|
<img src='../../media/pics/算法通关数组2.png' width=600> </img></div>
|
||||||
|
|
||||||
|
**那么二维数组在内存的空间地址是连续的么?**
|
||||||
|
|
||||||
|
我们来举一个例子,例如: `int[][] rating = new int[3][4];` , 这个二维数据在内存空间可不是一个 `3*4` 的连续地址空间
|
||||||
|
|
||||||
|
看了下图,就应该明白了:
|
||||||
|
|
||||||
|
<img src='../../media/pics/算法通关数组3.png' width=600> </img></div>
|
||||||
|
|
||||||
|
所以**二维数据在内存中不是 `3*4` 的连续地址空间,而是四条连续的地址空间组成!**
|
||||||
|
|
||||||
|
# 数组的经典题目
|
||||||
|
|
||||||
|
在面试中,数组是必考的基础数据结构。
|
||||||
|
|
||||||
|
其实数据的题目在思想上一般比较简单的,但是如果想高效,并不容易。
|
||||||
|
|
||||||
|
我们之前一共讲解了四道经典数组题目,每一道题目都代表一个类型,一种思想。
|
||||||
|
|
||||||
|
## 二分法
|
||||||
|
|
||||||
|
[数组:每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)
|
||||||
|
|
||||||
|
这道题目呢,考察的数据的基本操作,思路很简单,但是在通过率在简单题里并不高,不要轻敌。
|
||||||
|
|
||||||
|
可以使用暴力解法,通过这道题目,如果准求更优的算法,建议试一试用二分法,来解决这道题目
|
||||||
|
|
||||||
|
暴力解法时间复杂度:O(n)
|
||||||
|
二分法时间复杂度:O(logn)
|
||||||
|
|
||||||
|
在这道题目中我们讲到了**循环不变量原则**,只有在循环中坚持对区间的定义,才能清楚的把握循环中的各种细节。
|
||||||
|
|
||||||
|
**二分法是算法面试中的常考题,建议通过这道题目,锻炼自己手撕二分的能力**。
|
||||||
|
|
||||||
|
|
||||||
|
## 双指针法
|
||||||
|
|
||||||
|
* [数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
|
||||||
|
|
||||||
|
双指针法(快慢指针法):**通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。**
|
||||||
|
|
||||||
|
暴力解法时间复杂度:O(n^2)
|
||||||
|
双指针时间复杂度:O(n)
|
||||||
|
|
||||||
|
这道题目迷惑了不少同学,纠结于数组中的元素为什么不能删除,主要是因为一下两点:
|
||||||
|
|
||||||
|
* 数组在内存中是连续的地址空间,不能释放单一元素,如果要释放,就是全释放(程序运行结束,回收内存栈空间)。
|
||||||
|
* C++中vector和array的区别一定要弄清楚,vector的底层实现是array,所以vector展现出友好的一些都是因为经过包装了。
|
||||||
|
|
||||||
|
双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法。
|
||||||
|
|
||||||
|
## 滑动窗口
|
||||||
|
|
||||||
|
* [数组:滑动窗口拯救了你](https://mp.weixin.qq.com/s/UrZynlqi4QpyLlLhBPglyg)
|
||||||
|
|
||||||
|
本题介绍了数组操作中的另一个重要思想:滑动窗口。
|
||||||
|
|
||||||
|
暴力解法时间复杂度:O(n^2)
|
||||||
|
滑动窗口时间复杂度:O(n)
|
||||||
|
|
||||||
|
本题中,主要要理解滑动窗口如何移动 窗口起始位置,达到动态更新窗口大小的,从而得出长度最小的符合条件的长度。
|
||||||
|
|
||||||
|
**滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)的暴力解法降为O(n)。**
|
||||||
|
|
||||||
|
如果没有接触过这一类的方法,很难想到类似的解题思路,滑动窗口方法还是很巧妙的。
|
||||||
|
|
||||||
|
|
||||||
|
## 模拟行为
|
||||||
|
|
||||||
|
* [数组:这个循环可以转懵很多人!](https://mp.weixin.qq.com/s/KTPhaeqxbMK9CxHUUgFDmg)
|
||||||
|
|
||||||
|
模拟类的题目在数组中很常见,不涉及到什么算法,就是单纯的模拟,十分考察大家对代码的掌控能力。
|
||||||
|
|
||||||
|
在这道题目中,我们再一次介绍到了**循环不变量原则**,其实这也是写程序中的重要原则。
|
||||||
|
|
||||||
|
相信大家又遇到过这种情况: 感觉题目的边界调节超多,一波接着一波的判断,找边界,踩了东墙补西墙,好不容易运行通过了,代码写的十分冗余,毫无章法,其实**真正解决题目的代码都是简洁的,或者有原则性的**,大家可以在这道题目中体会到这一点。
|
||||||
|
|
||||||
|
|
||||||
|
# 总结
|
||||||
|
|
||||||
|
从二分法到双指针,从滑动窗口到螺旋矩阵,相信如果大家真的认真做了「代码随想录」每日推荐的题目,定会有所收获。
|
||||||
|
|
||||||
|
推荐的题目即使大家之前做过了,再读一遍的文章,也会帮助你提炼出解题的精髓所在。
|
||||||
|
|
||||||
|
如果感觉有所收获,希望大家多多支持,打卡转发,点赞在看 都是对我最大的鼓励!
|
||||||
|
|
||||||
|
最后,大家周末愉快!
|
||||||
|
|
||||||
|
|
||||||
52
problems/数组理论基础.md
Normal file
52
problems/数组理论基础.md
Normal file
@ -0,0 +1,52 @@
|
|||||||
|
|
||||||
|
# 数组理论基础
|
||||||
|
|
||||||
|
数组是非常基础的数据结构,在面试中,考察数组的题目一般在思维上都不难,主要是考察对代码的掌控能力
|
||||||
|
|
||||||
|
也就是说,想法很简单,但实现起来 可能就不是那么回事了。
|
||||||
|
|
||||||
|
首先要知道数组在内存中的存储方式,这样才能真正理解数组相关的面试题
|
||||||
|
|
||||||
|
**数组是存放在连续内存空间上的相同类型数据的集合。**
|
||||||
|
|
||||||
|
数组可以方便的通过下表索引的方式获取到下表下对应的数据。
|
||||||
|
|
||||||
|
举一个字符数组的例子,如图所示:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
需要两点注意的是
|
||||||
|
|
||||||
|
* **数组下表都是从0开始的。**
|
||||||
|
* **数组内存空间的地址是连续的**
|
||||||
|
|
||||||
|
正是**因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。**
|
||||||
|
|
||||||
|
例如删除下表为3的元素,需要对下表为3的元素后面的所有元素都要做移动操作,如图所示:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
而且大家如果使用C++的话,要注意vector 和 array的区别,vector的底层实现是array,严格来讲vector是容器,不是数组。
|
||||||
|
|
||||||
|
**数组的元素是不能删的,只能覆盖。**
|
||||||
|
|
||||||
|
那么二维数组直接上图,大家应该就知道怎么回事了
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**那么二维数组在内存的空间地址是连续的么?**
|
||||||
|
|
||||||
|
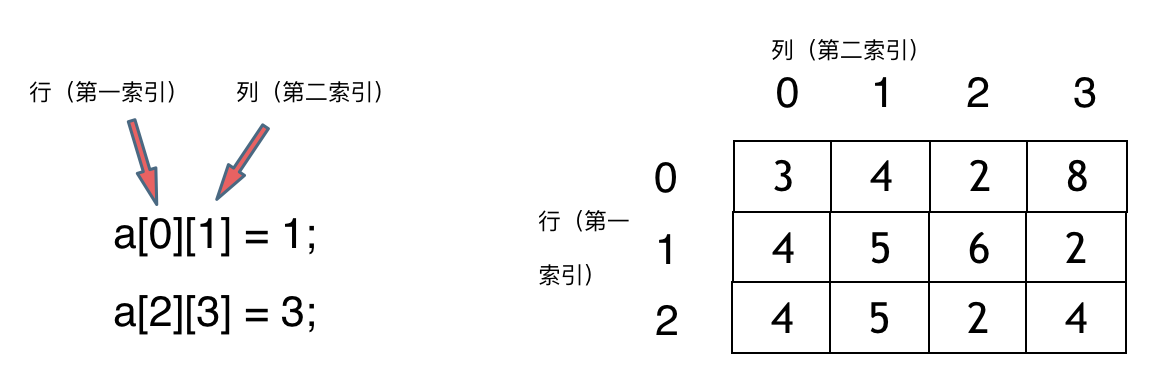
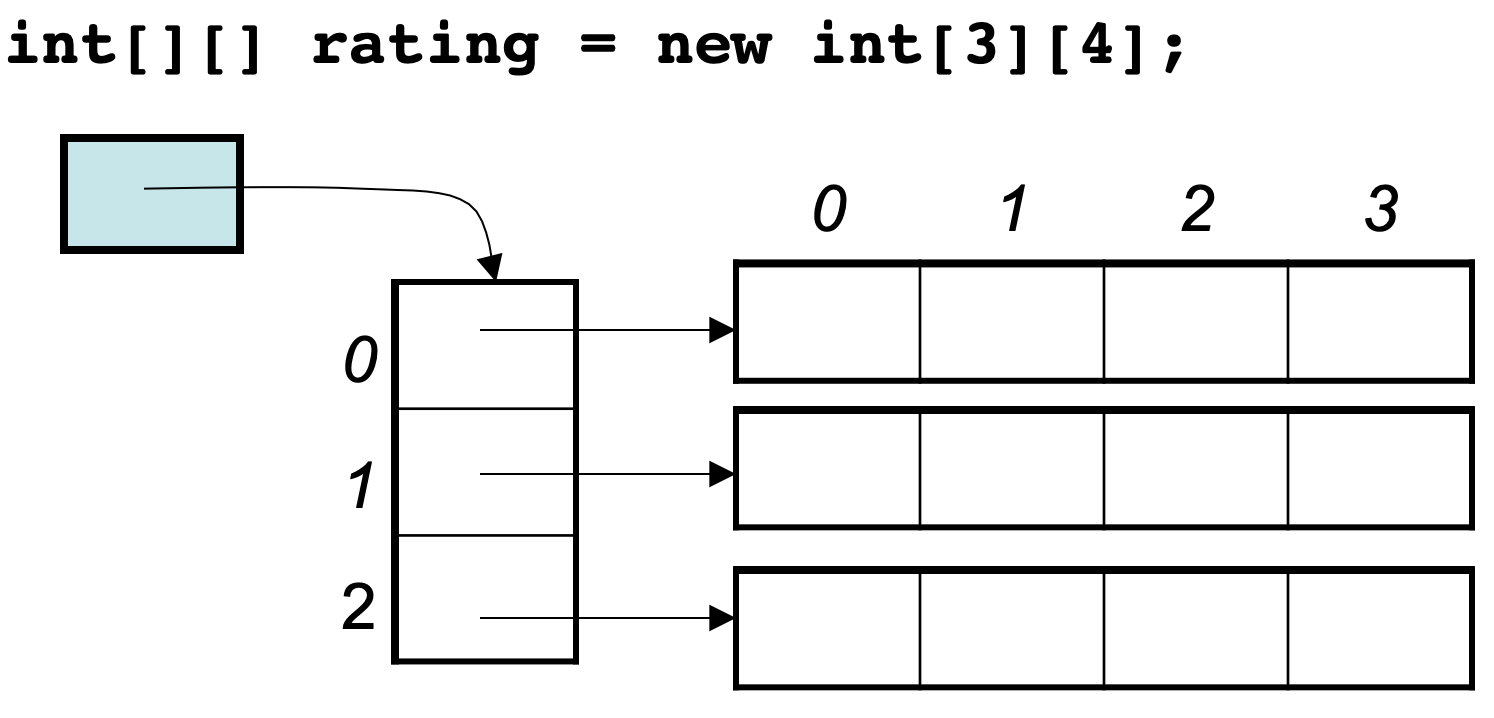
我们来举一个例子,例如: `int[][] rating = new int[3][4];` , 这个二维数据在内存空间可不是一个 `3*4` 的连续地址空间
|
||||||
|
|
||||||
|
看了下图,就应该明白了:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
所以**二维数据在内存中不是 `3*4` 的连续地址空间,而是四条连续的地址空间组成!**
|
||||||
|
|
||||||
|
很多同学会以为二维数组在内存中是一片连续的地址,其实并不是。
|
||||||
|
|
||||||
|
这里面试中数组相关的理论知识就介绍完了。
|
||||||
|
|
||||||
|
后续我将介绍面试中数组相关的五道经典面试题目,敬请期待!
|
||||||
Reference in New Issue
Block a user