mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-08 08:50:15 +08:00
Merge branch 'master' into my-contribution
This commit is contained in:
@ -131,7 +131,7 @@
|
||||
1. [数组过于简单,但你该了解这些!](./problems/数组理论基础.md)
|
||||
2. [数组:二分查找](./problems/0704.二分查找.md)
|
||||
3. [数组:移除元素](./problems/0027.移除元素.md)
|
||||
4. [数组:序数组的平方](./problems/0977.有序数组的平方.md)
|
||||
4. [数组:有序数组的平方](./problems/0977.有序数组的平方.md)
|
||||
5. [数组:长度最小的子数组](./problems/0209.长度最小的子数组.md)
|
||||
6. [数组:螺旋矩阵II](./problems/0059.螺旋矩阵II.md)
|
||||
7. [数组:总结篇](./problems/数组总结篇.md)
|
||||
|
||||
BIN
problems/.DS_Store
vendored
Normal file
BIN
problems/.DS_Store
vendored
Normal file
Binary file not shown.
@ -455,42 +455,31 @@ function letterCombinations(digits: string): string[] {
|
||||
## Rust
|
||||
|
||||
```Rust
|
||||
const map: [&str; 10] = [
|
||||
"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz",
|
||||
];
|
||||
impl Solution {
|
||||
fn backtracking(result: &mut Vec<String>, s: &mut String, map: &[&str; 10], digits: &String, index: usize) {
|
||||
fn back_trace(result: &mut Vec<String>, s: &mut String, digits: &String, index: usize) {
|
||||
let len = digits.len();
|
||||
if len == index {
|
||||
result.push(s.to_string());
|
||||
return;
|
||||
}
|
||||
// 在保证不会越界的情况下使用unwrap()将Some()中的值提取出来
|
||||
let digit= digits.chars().nth(index).unwrap().to_digit(10).unwrap() as usize;
|
||||
let letters = map[digit];
|
||||
for i in letters.chars() {
|
||||
let digit = (digits.as_bytes()[index] - b'0') as usize;
|
||||
for i in map[digit].chars() {
|
||||
s.push(i);
|
||||
Self::backtracking(result, s, &map, &digits, index+1);
|
||||
Self::back_trace(result, s, digits, index + 1);
|
||||
s.pop();
|
||||
}
|
||||
}
|
||||
pub fn letter_combinations(digits: String) -> Vec<String> {
|
||||
if digits.len() == 0 {
|
||||
if digits.is_empty() {
|
||||
return vec![];
|
||||
}
|
||||
const MAP: [&str; 10] = [
|
||||
"",
|
||||
"",
|
||||
"abc",
|
||||
"def",
|
||||
"ghi",
|
||||
"jkl",
|
||||
"mno",
|
||||
"pqrs",
|
||||
"tuv",
|
||||
"wxyz"
|
||||
];
|
||||
let mut result: Vec<String> = Vec::new();
|
||||
let mut s: String = String::new();
|
||||
Self::backtracking(&mut result, &mut s, &MAP, &digits, 0);
|
||||
result
|
||||
let mut res = vec![];
|
||||
let mut s = String::new();
|
||||
Self::back_trace(&mut res, &mut s, &digits, 0);
|
||||
res
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@ -42,7 +42,7 @@
|
||||
|
||||
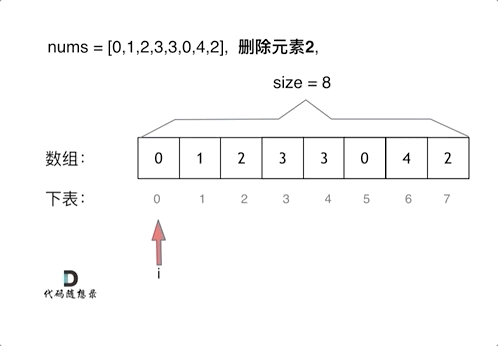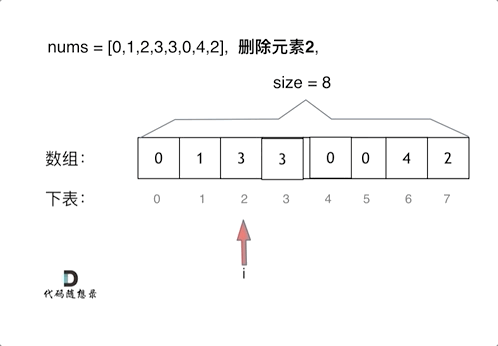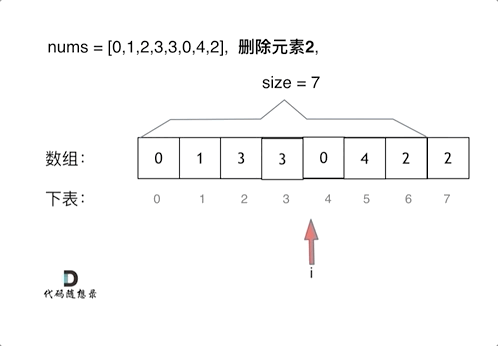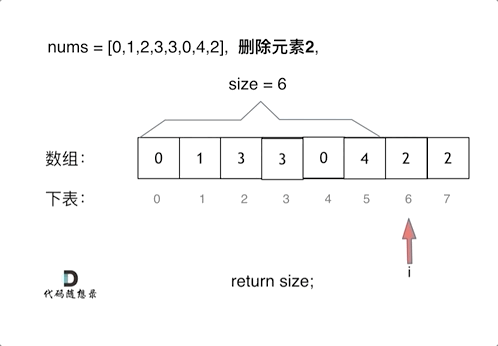
删除过程如下:
|
||||
|
||||

|
||||
|
||||
|
||||
很明显暴力解法的时间复杂度是O(n^2),这道题目暴力解法在leetcode上是可以过的。
|
||||
|
||||
@ -86,7 +86,7 @@ public:
|
||||
|
||||
删除过程如下:
|
||||
|
||||

|
||||
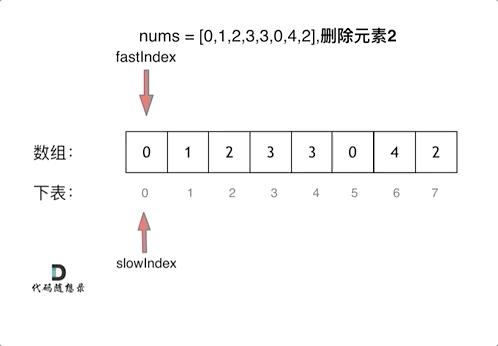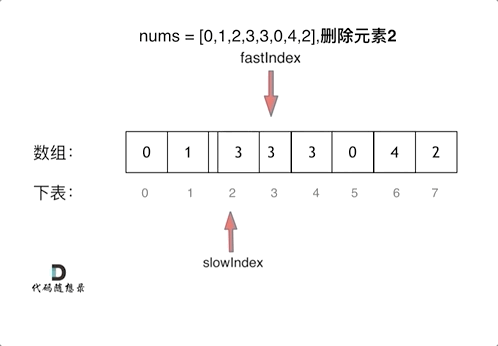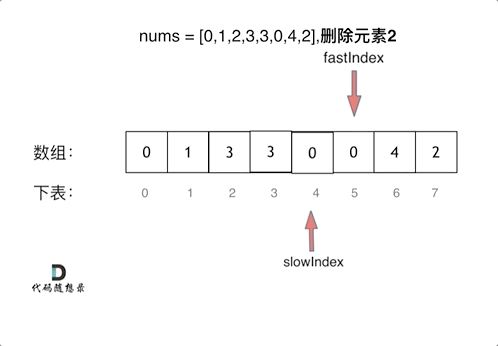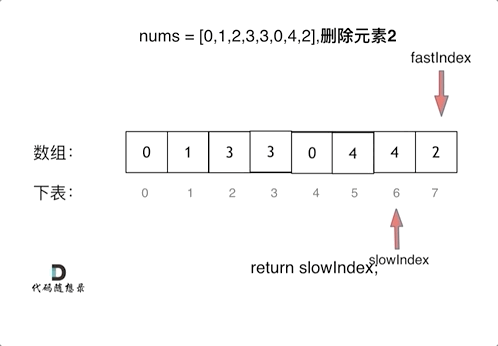
|
||||
|
||||
很多同学不了解
|
||||
|
||||
|
||||
@ -174,9 +174,11 @@ next数组就是一个前缀表(prefix table)。
|
||||
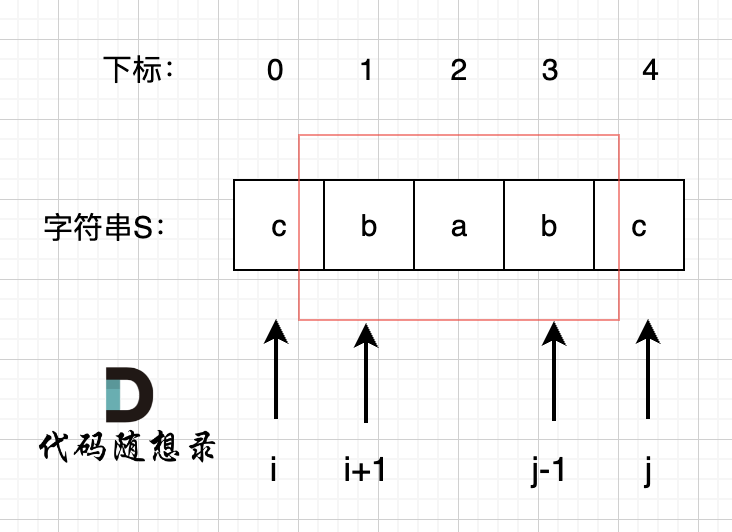
长度为前1个字符的子串`a`,最长相同前后缀的长度为0。(注意字符串的**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串**;**后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串**。)
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/KMP%E7%B2%BE%E8%AE%B26.png' width=600 alt='KMP精讲6'> </img></div>
|
||||
|
||||
长度为前2个字符的子串`aa`,最长相同前后缀的长度为1。
|
||||
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/KMP%E7%B2%BE%E8%AE%B27.png' width=600 alt='KMP精讲7'> </img></div>
|
||||
|
||||
长度为前3个字符的子串`aab`,最长相同前后缀的长度为0。
|
||||
|
||||
以此类推:
|
||||
|
||||
@ -16,31 +16,39 @@
|
||||
candidates 中的每个数字在每个组合中只能使用一次。
|
||||
|
||||
说明:
|
||||
所有数字(包括目标数)都是正整数。
|
||||
解集不能包含重复的组合。
|
||||
所有数字(包括目标数)都是正整数。解集不能包含重复的组合。
|
||||
|
||||
示例 1:
|
||||
输入: candidates = [10,1,2,7,6,1,5], target = 8,
|
||||
所求解集为:
|
||||
* 示例 1:
|
||||
* 输入: candidates = [10,1,2,7,6,1,5], target = 8,
|
||||
* 所求解集为:
|
||||
```
|
||||
[
|
||||
[1, 7],
|
||||
[1, 2, 5],
|
||||
[2, 6],
|
||||
[1, 1, 6]
|
||||
]
|
||||
```
|
||||
|
||||
示例 2:
|
||||
输入: candidates = [2,5,2,1,2], target = 5,
|
||||
所求解集为:
|
||||
* 示例 2:
|
||||
* 输入: candidates = [2,5,2,1,2], target = 5,
|
||||
* 所求解集为:
|
||||
|
||||
```
|
||||
[
|
||||
[1,2,2],
|
||||
[5]
|
||||
]
|
||||
```
|
||||
|
||||
# 算法公开课
|
||||
|
||||
**《代码随想录》算法视频公开课:[回溯算法中的去重,树层去重树枝去重,你弄清楚了没?| LeetCode:40.组合总和II](https://www.bilibili.com/video/BV12V4y1V73A),相信结合视频再看本篇题解,更有助于大家对本题的理解**。
|
||||
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
**如果对回溯算法基础还不了解的话,我还特意录制了一期视频:[带你学透回溯算法(理论篇)](https://www.bilibili.com/video/BV1cy4y167mM/)** 可以结合题解和视频一起看,希望对大家理解回溯算法有所帮助。
|
||||
|
||||
|
||||
这道题目和[39.组合总和](https://programmercarl.com/0039.组合总和.html)如下区别:
|
||||
|
||||
|
||||
@ -471,7 +471,7 @@ class Solution {
|
||||
### Python:
|
||||
|
||||
双指针法
|
||||
```python3
|
||||
```Python
|
||||
class Solution:
|
||||
def trap(self, height: List[int]) -> int:
|
||||
res = 0
|
||||
@ -510,7 +510,7 @@ class Solution:
|
||||
return result
|
||||
```
|
||||
单调栈
|
||||
```python3
|
||||
```Python
|
||||
class Solution:
|
||||
def trap(self, height: List[int]) -> int:
|
||||
# 单调栈
|
||||
|
||||
@ -73,11 +73,11 @@ public:
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
nextDistance = max(nums[i] + i, nextDistance); // 更新下一步覆盖最远距离下标
|
||||
if (i == curDistance) { // 遇到当前覆盖最远距离下标
|
||||
if (curDistance != nums.size() - 1) { // 如果当前覆盖最远距离下标不是终点
|
||||
if (curDistance < nums.size() - 1) { // 如果当前覆盖最远距离下标不是终点
|
||||
ans++; // 需要走下一步
|
||||
curDistance = nextDistance; // 更新当前覆盖最远距离下标(相当于加油了)
|
||||
if (nextDistance >= nums.size() - 1) break; // 下一步的覆盖范围已经可以达到终点,结束循环
|
||||
} else break; // 当前覆盖最远距离下标是集合终点,不用做ans++操作了,直接结束
|
||||
} else break; // 当前覆盖最远距到达集合终点,不用做ans++操作了,直接结束
|
||||
}
|
||||
}
|
||||
return ans;
|
||||
@ -126,7 +126,7 @@ public:
|
||||
|
||||
可以看出版本二的代码相对于版本一简化了不少!
|
||||
|
||||
其精髓在于控制移动下标i只移动到nums.size() - 2的位置,所以移动下标只要遇到当前覆盖最远距离的下标,直接步数加一,不用考虑别的了。
|
||||
**其精髓在于控制移动下标i只移动到nums.size() - 2的位置**,所以移动下标只要遇到当前覆盖最远距离的下标,直接步数加一,不用考虑别的了。
|
||||
|
||||
## 总结
|
||||
|
||||
|
||||
@ -12,9 +12,9 @@
|
||||
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
|
||||
|
||||
示例:
|
||||
输入: [-2,1,-3,4,-1,2,1,-5,4]
|
||||
输出: 6
|
||||
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
|
||||
* 输入: [-2,1,-3,4,-1,2,1,-5,4]
|
||||
* 输出: 6
|
||||
* 解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
|
||||
|
||||
|
||||
## 暴力解法
|
||||
@ -103,8 +103,28 @@ public:
|
||||
|
||||
当然题目没有说如果数组为空,应该返回什么,所以数组为空的话返回啥都可以了。
|
||||
|
||||
|
||||
## 常见误区
|
||||
|
||||
误区一:
|
||||
|
||||
不少同学认为 如果输入用例都是-1,或者 都是负数,这个贪心算法跑出来的结果是0, 这是**又一次证明脑洞模拟不靠谱的经典案例**,建议大家把代码运行一下试一试,就知道了,也会理解 为什么 result 要初始化为最小负数了。
|
||||
|
||||
|
||||
误区二:
|
||||
|
||||
大家在使用贪心算法求解本题,经常陷入的误区,就是分不清,是遇到 负数就选择起始位置,还是连续和为负选择起始位置。
|
||||
|
||||
在动画演示用,大家可以发现, 4,遇到 -1 的时候,我们依然累加了,为什么呢?
|
||||
|
||||
因为和为3,只要连续和还是正数就会 对后面的元素 起到增大总和的作用。 所以只要连续和为正数我们就保留。
|
||||
|
||||
这里也会有录友疑惑,那 4 + -1 之后 不就变小了吗? 会不会错过 4 成为最大连续和的可能性?
|
||||
|
||||
其实并不会,因为还有一个变量result 一直在更新 最大的连续和,只要有更大的连续和出现,result就更新了,那么result已经把4更新了,后面 连续和变成3,也不会对最后结果有影响。
|
||||
|
||||
|
||||
|
||||
## 动态规划
|
||||
|
||||
当然本题还可以用动态规划来做,当前[「代码随想录」](https://img-blog.csdnimg.cn/20201124161234338.png)主要讲解贪心系列,后续到动态规划系列的时候会详细讲解本题的dp方法。
|
||||
@ -135,7 +155,7 @@ public:
|
||||
|
||||
本题的贪心思路其实并不好想,这也进一步验证了,别看贪心理论很直白,有时候看似是常识,但贪心的题目一点都不简单!
|
||||
|
||||
后续将介绍的贪心题目都挺难的,哈哈,所以贪心很有意思,别小看贪心!
|
||||
后续将介绍的贪心题目都挺难的,所以贪心很有意思,别小看贪心!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
@ -78,7 +78,7 @@ public:
|
||||
|
||||
一些同学可能感觉,我在讲贪心系列的时候,题目和题目之间貌似没有什么联系?
|
||||
|
||||
**是真的就是没什么联系,因为贪心无套路!**没有个整体的贪心框架解决一系列问题,只能是接触各种类型的题目锻炼自己的贪心思维!
|
||||
**是真的就是没什么联系,因为贪心无套路**!没有个整体的贪心框架解决一系列问题,只能是接触各种类型的题目锻炼自己的贪心思维!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
|
||||
@ -16,25 +16,25 @@
|
||||
* 删除一个字符
|
||||
* 替换一个字符
|
||||
|
||||
示例 1:
|
||||
输入:word1 = "horse", word2 = "ros"
|
||||
输出:3
|
||||
解释:
|
||||
* 示例 1:
|
||||
* 输入:word1 = "horse", word2 = "ros"
|
||||
* 输出:3
|
||||
* 解释:
|
||||
horse -> rorse (将 'h' 替换为 'r')
|
||||
rorse -> rose (删除 'r')
|
||||
rose -> ros (删除 'e')
|
||||
|
||||
示例 2:
|
||||
输入:word1 = "intention", word2 = "execution"
|
||||
输出:5
|
||||
解释:
|
||||
|
||||
* 示例 2:
|
||||
* 输入:word1 = "intention", word2 = "execution"
|
||||
* 输出:5
|
||||
* 解释:
|
||||
intention -> inention (删除 't')
|
||||
inention -> enention (将 'i' 替换为 'e')
|
||||
enention -> exention (将 'n' 替换为 'x')
|
||||
exention -> exection (将 'n' 替换为 'c')
|
||||
exection -> execution (插入 'u')
|
||||
|
||||
|
||||
提示:
|
||||
|
||||
* 0 <= word1.length, word2.length <= 500
|
||||
@ -54,10 +54,11 @@ exection -> execution (插入 'u')
|
||||
|
||||
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
|
||||
|
||||
这里在强调一下:为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
|
||||
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
|
||||
|
||||
用i来表示也可以! 但我统一以下标i-1为结尾的字符串,在下面的递归公式中会容易理解一点。
|
||||
为什么这么定义我在 [718. 最长重复子数组](https://programmercarl.com/0718.最长重复子数组.html) 中做了详细的讲解。
|
||||
|
||||
其实用i来表示也可以! 用i-1就是为了方便后面dp数组初始化的。
|
||||
|
||||
### 2. 确定递推公式
|
||||
|
||||
@ -111,9 +112,13 @@ if (word1[i - 1] != word2[j - 1])
|
||||
+-----+-----+
|
||||
```
|
||||
|
||||
操作三:替换元素,`word1`替换`word1[i - 1]`,使其与`word2[j - 1]`相同,此时不用增加元素,那么以下标`i-2`为结尾的`word1` 与 `j-2`为结尾的`word2`的最近编辑距离 加上一个替换元素的操作。
|
||||
操作三:替换元素,`word1`替换`word1[i - 1]`,使其与`word2[j - 1]`相同,此时不用增删加元素。
|
||||
|
||||
即 `dp[i][j] = dp[i - 1][j - 1] + 1;`
|
||||
可以回顾一下,`if (word1[i - 1] == word2[j - 1])`的时候我们的操作 是 `dp[i][j] = dp[i - 1][j - 1]` 对吧。
|
||||
|
||||
那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。
|
||||
|
||||
所以 `dp[i][j] = dp[i - 1][j - 1] + 1;`
|
||||
|
||||
综上,当 `if (word1[i - 1] != word2[j - 1])` 时取最小的,即:`dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;`
|
||||
|
||||
|
||||
@ -267,22 +267,22 @@ Rust:
|
||||
|
||||
```Rust
|
||||
impl Solution {
|
||||
fn backtracking(result: &mut Vec<Vec<i32>>, path: &mut Vec<i32>, n: i32, k: i32, startIndex: i32) {
|
||||
fn backtracking(result: &mut Vec<Vec<i32>>, path: &mut Vec<i32>, n: i32, k: i32, start_index: i32) {
|
||||
let len= path.len() as i32;
|
||||
if len == k{
|
||||
result.push(path.to_vec());
|
||||
return;
|
||||
}
|
||||
// 此处剪枝
|
||||
for i in startIndex..= n - (k - len) + 1 {
|
||||
for i in start_index..= n - (k - len) + 1 {
|
||||
path.push(i);
|
||||
Self::backtracking(result, path, n, k, i+1);
|
||||
path.pop();
|
||||
}
|
||||
}
|
||||
pub fn combine(n: i32, k: i32) -> Vec<Vec<i32>> {
|
||||
let mut result: Vec<Vec<i32>> = Vec::new();
|
||||
let mut path: Vec<i32> = Vec::new();
|
||||
let mut result = vec![];
|
||||
let mut path = vec![];
|
||||
Self::backtracking(&mut result, &mut path, n, k, 1);
|
||||
result
|
||||
}
|
||||
|
||||
@ -392,7 +392,26 @@ class Solution:
|
||||
return is_left_valid and is_right_valid
|
||||
return __isValidBST(root)
|
||||
```
|
||||
|
||||
**递归** - 避免初始化最小值做法:
|
||||
```python
|
||||
class Solution:
|
||||
def isValidBST(self, root: TreeNode) -> bool:
|
||||
# 规律: BST的中序遍历节点数值是从小到大.
|
||||
pre = None
|
||||
def __isValidBST(root: TreeNode) -> bool:
|
||||
nonlocal pre
|
||||
|
||||
if not root:
|
||||
return True
|
||||
|
||||
is_left_valid = __isValidBST(root.left)
|
||||
if pre and pre.val>=root.val: return False
|
||||
pre = root
|
||||
is_right_valid = __isValidBST(root.right)
|
||||
|
||||
return is_left_valid and is_right_valid
|
||||
return __isValidBST(root)
|
||||
```
|
||||
```python
|
||||
迭代-中序遍历
|
||||
class Solution:
|
||||
|
||||
@ -169,7 +169,7 @@ public:
|
||||
|
||||
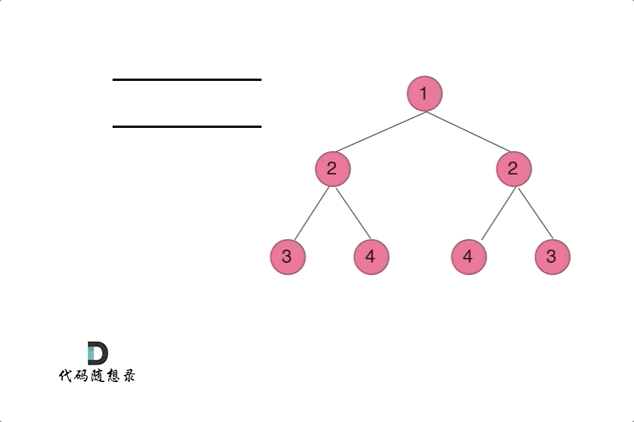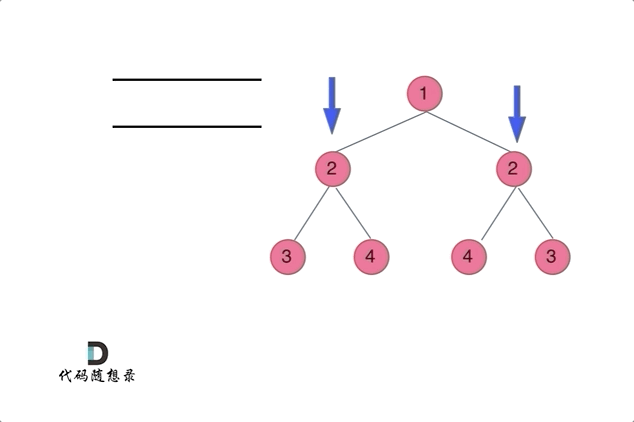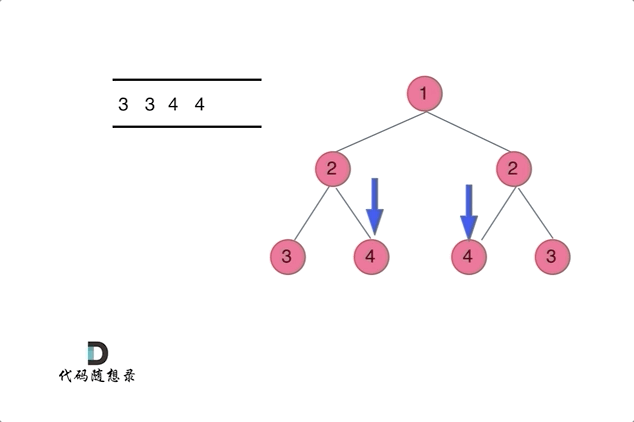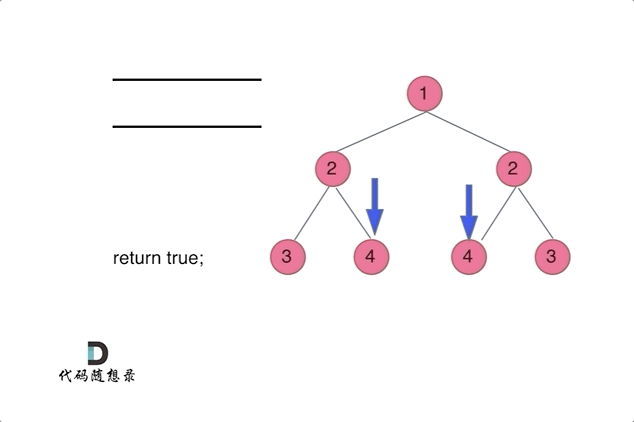
通过队列来判断根节点的左子树和右子树的内侧和外侧是否相等,如动画所示:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -23,7 +23,9 @@
|
||||
* 111.二叉树的最小深度
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@ -53,7 +55,7 @@
|
||||
|
||||
使用队列实现二叉树广度优先遍历,动画如下:
|
||||
|
||||

|
||||
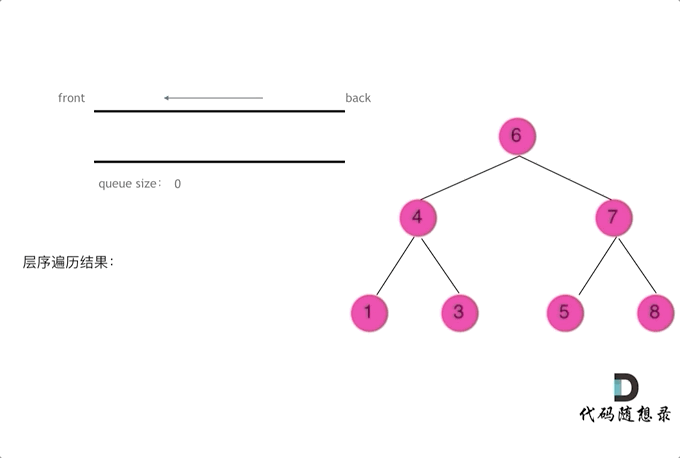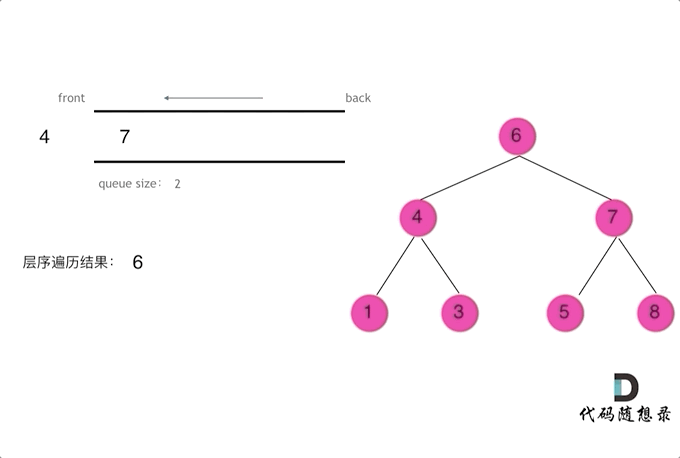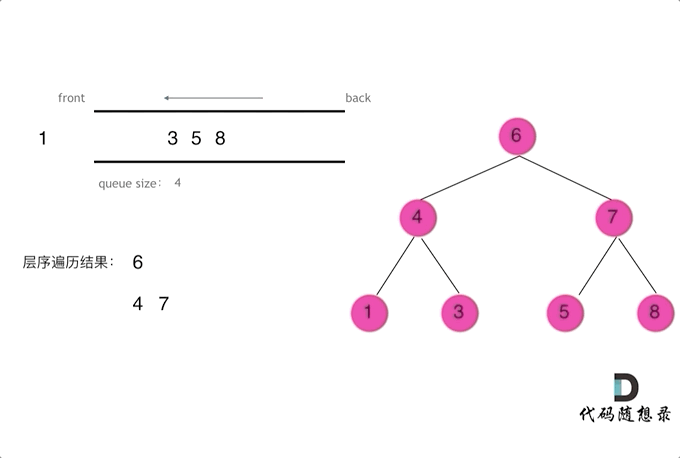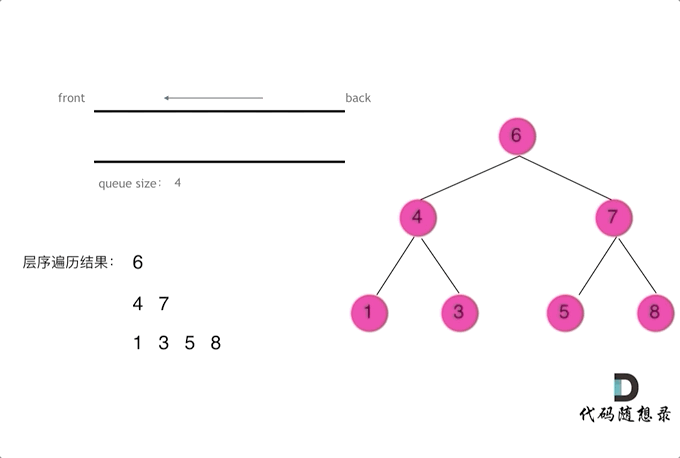
|
||||
|
||||
这样就实现了层序从左到右遍历二叉树。
|
||||
|
||||
@ -2532,20 +2534,18 @@ class Solution:
|
||||
return 0
|
||||
|
||||
queue_ = [root]
|
||||
result = []
|
||||
depth = 0
|
||||
while queue_:
|
||||
length = len(queue_)
|
||||
sub = []
|
||||
for i in range(length):
|
||||
cur = queue_.pop(0)
|
||||
sub.append(cur.val)
|
||||
#子节点入队列
|
||||
if cur.left: queue_.append(cur.left)
|
||||
if cur.right: queue_.append(cur.right)
|
||||
result.append(sub)
|
||||
depth += 1
|
||||
|
||||
|
||||
return len(result)
|
||||
return depth
|
||||
```
|
||||
|
||||
Go:
|
||||
|
||||
@ -83,6 +83,7 @@ public:
|
||||
```
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -23,11 +23,13 @@
|
||||
["a","a","b"]
|
||||
]
|
||||
|
||||
# 算法公开课
|
||||
|
||||
**《代码随想录》算法视频公开课:[131.分割回文串](https://www.bilibili.com/video/BV1c54y1e7k6),相信结合视频再看本篇题解,更有助于大家对本题的理解**。
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
关于本题,大家也可以看我在B站的视频讲解:[131.分割回文串(B站视频)](https://www.bilibili.com/video/BV1c54y1e7k6)
|
||||
|
||||
本题这涉及到两个关键问题:
|
||||
|
||||
1. 切割问题,有不同的切割方式
|
||||
|
||||
@ -40,7 +40,7 @@ fast和slow各自再走一步, fast和slow就相遇了
|
||||
动画如下:
|
||||
|
||||
|
||||

|
||||
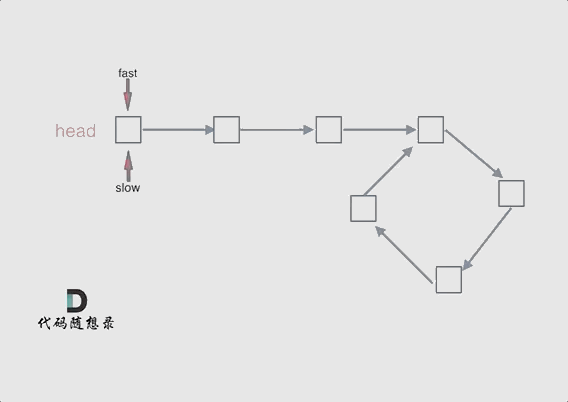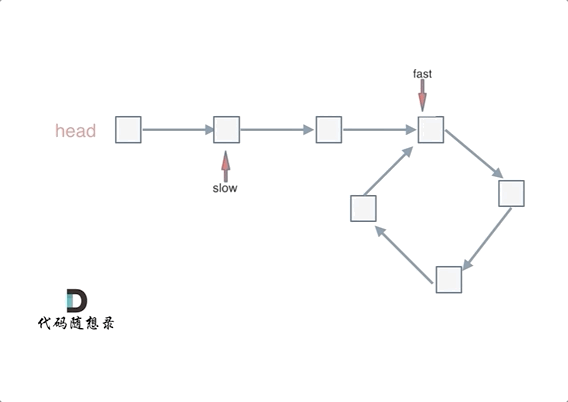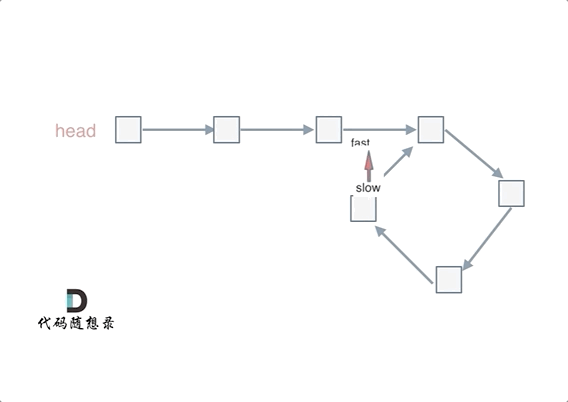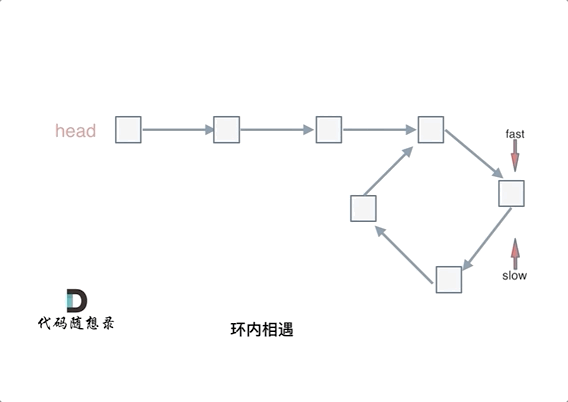
|
||||
|
||||
|
||||
C++代码如下
|
||||
@ -64,7 +64,7 @@ public:
|
||||
|
||||
## 扩展
|
||||
|
||||
做完这道题目,可以在做做[142.环形链表II](https://mp.weixin.qq.com/s/gt_VH3hQTqNxyWcl1ECSbQ),不仅仅要找环,还要找环的入口。
|
||||
做完这道题目,可以在做做[142.环形链表II](https://programmercarl.com/0142.%E7%8E%AF%E5%BD%A2%E9%93%BE%E8%A1%A8II.html),不仅仅要找环,还要找环的入口。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -57,7 +57,7 @@ fast和slow各自再走一步, fast和slow就相遇了
|
||||
|
||||
动画如下:
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
### 如果有环,如何找到这个环的入口
|
||||
@ -101,7 +101,7 @@ fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走
|
||||
|
||||
动画如下:
|
||||
|
||||

|
||||
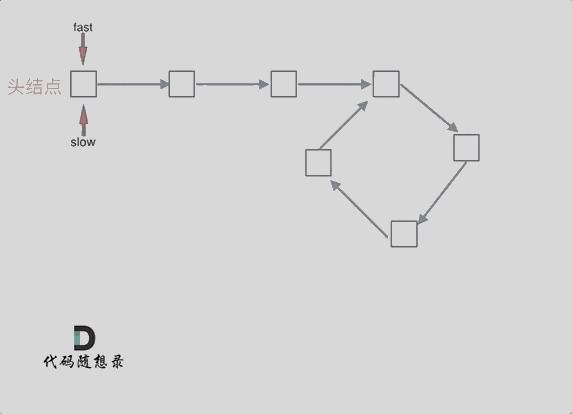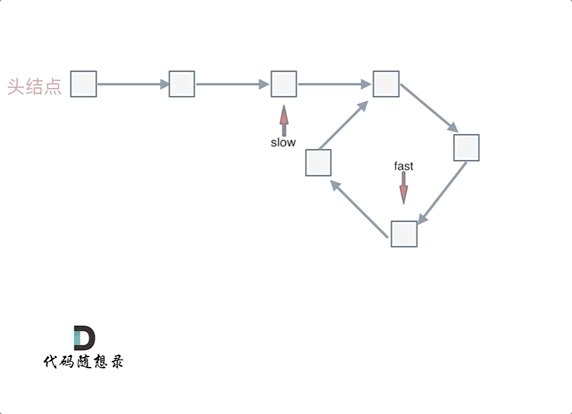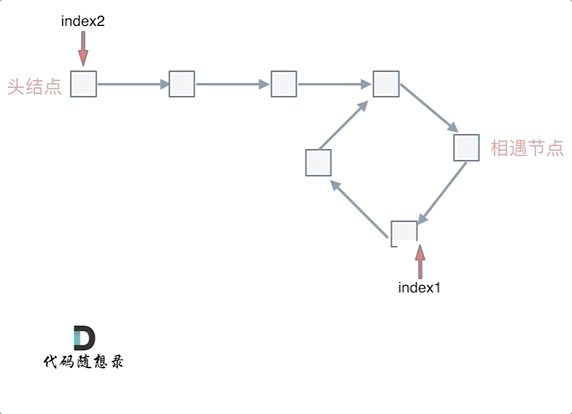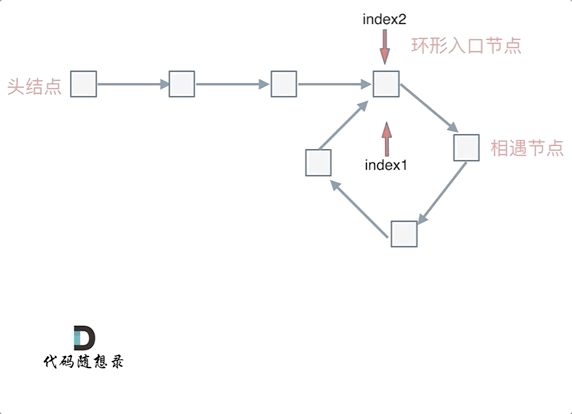
|
||||
|
||||
|
||||
那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
|
||||
|
||||
@ -163,6 +163,25 @@ class Solution {
|
||||
|
||||
python3
|
||||
|
||||
```python
|
||||
from operator import add, sub, mul
|
||||
|
||||
class Solution:
|
||||
op_map = {'+': add, '-': sub, '*': mul, '/': lambda x, y: int(x / y)}
|
||||
|
||||
def evalRPN(self, tokens: List[str]) -> int:
|
||||
stack = []
|
||||
for token in tokens:
|
||||
if token not in {'+', '-', '*', '/'}:
|
||||
stack.append(int(token))
|
||||
else:
|
||||
op2 = stack.pop()
|
||||
op1 = stack.pop()
|
||||
stack.append(self.op_map[token](op1, op2)) # 第一个出来的在运算符后面
|
||||
return stack.pop()
|
||||
```
|
||||
|
||||
另一种可行,但因为使用eval相对较慢的方法:
|
||||
```python
|
||||
class Solution:
|
||||
def evalRPN(self, tokens: List[str]) -> int:
|
||||
|
||||
@ -323,40 +323,6 @@ func max(a, b int) int {
|
||||
}
|
||||
```
|
||||
|
||||
```go
|
||||
func maxProfit(k int, prices []int) int {
|
||||
if len(prices)==0{
|
||||
return 0
|
||||
}
|
||||
dp:=make([][]int,len(prices))
|
||||
for i:=0;i<len(prices);i++{
|
||||
dp[i]=make([]int,2*k+1)
|
||||
}
|
||||
for i:=1;i<len(dp[0]);i++{
|
||||
if i%2!=0{
|
||||
dp[0][i]=-prices[0]
|
||||
}
|
||||
}
|
||||
for i:=1;i<len(prices);i++{
|
||||
dp[i][0]=dp[i-1][0]
|
||||
for j:=1;j<len(dp[0]);j++{
|
||||
if j%2!=0{
|
||||
dp[i][j]=max(dp[i-1][j],dp[i-1][j-1]-prices[i])
|
||||
}else {
|
||||
dp[i][j]=max(dp[i-1][j],dp[i-1][j-1]+prices[i])
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[len(prices)-1][2*k]
|
||||
}
|
||||
func max(a,b int)int{
|
||||
if a>b{
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
|
||||
```javascript
|
||||
|
||||
@ -103,7 +103,7 @@ void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y
|
||||
}
|
||||
```
|
||||
|
||||
以上两个版本其实,其实只有细微区别,就是 `visited[x][y] = true;` 放在的地方,着去取决于我们对 代码中队列的定义,队列中的节点就表示已经走过的节点。 **所以只要加入队列,理解标记该节点走过**。
|
||||
以上两个版本其实,其实只有细微区别,就是 `visited[x][y] = true;` 放在的地方,着去取决于我们对 代码中队列的定义,队列中的节点就表示已经走过的节点。 **所以只要加入队列,立即标记该节点走过**。
|
||||
|
||||
本题完整广搜代码:
|
||||
|
||||
|
||||
@ -33,7 +33,7 @@
|
||||
|
||||
我们拿有示例中的链表来举例,如动画所示:(纠正:动画应该是先移动pre,在移动cur)
|
||||
|
||||

|
||||
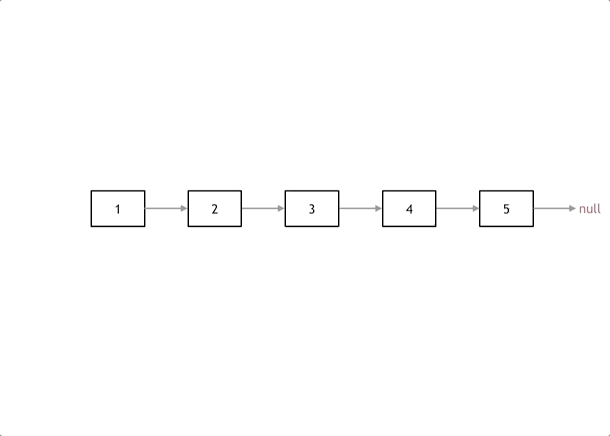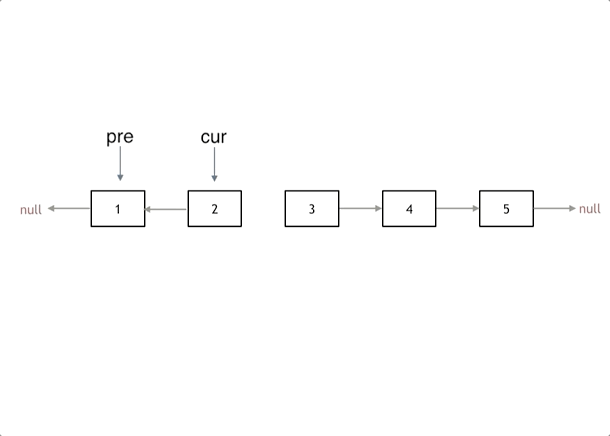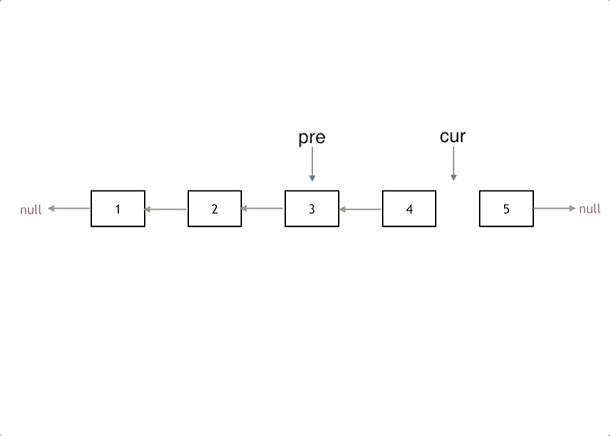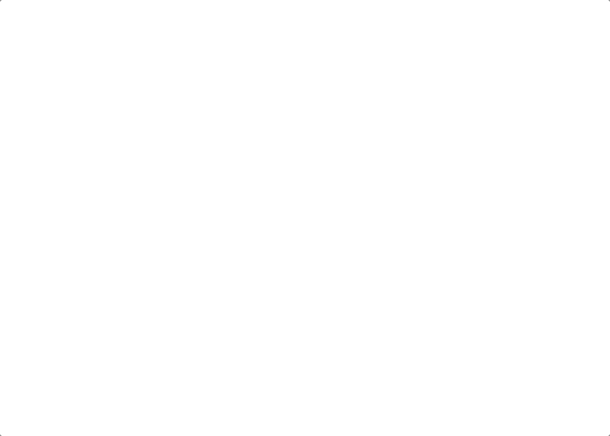
|
||||
|
||||
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
|
||||
|
||||
|
||||
@ -131,7 +131,7 @@ class Solution:
|
||||
val2=self.roblist(nums[:-1])#不偷最后一间房
|
||||
return max(val1,val2)
|
||||
|
||||
def robRange(self,nums):
|
||||
def roblist(self,nums):
|
||||
l=len(nums)
|
||||
dp=[0]*l
|
||||
dp[0]=nums[0]
|
||||
|
||||
@ -479,28 +479,36 @@ function combinationSum3(k: number, n: number): number[][] {
|
||||
|
||||
```Rust
|
||||
impl Solution {
|
||||
fn backtracking(result: &mut Vec<Vec<i32>>, path:&mut Vec<i32>, targetSum:i32, k: i32, mut sum: i32, startIndex: i32) {
|
||||
pub fn combination_sum3(k: i32, n: i32) -> Vec<Vec<i32>> {
|
||||
let mut result = vec![];
|
||||
let mut path = vec![];
|
||||
Self::backtrace(&mut result, &mut path, n, k, 0, 1);
|
||||
result
|
||||
}
|
||||
pub fn backtrace(
|
||||
result: &mut Vec<Vec<i32>>,
|
||||
path: &mut Vec<i32>,
|
||||
target_sum: i32,
|
||||
k: i32,
|
||||
sum: i32,
|
||||
start_index: i32,
|
||||
) {
|
||||
if sum > target_sum {
|
||||
return;
|
||||
}
|
||||
let len = path.len() as i32;
|
||||
if len == k {
|
||||
if sum == targetSum {
|
||||
if sum == target_sum {
|
||||
result.push(path.to_vec());
|
||||
}
|
||||
return;
|
||||
}
|
||||
for i in startIndex..=9 {
|
||||
sum += i;
|
||||
for i in start_index..=9 - (k - len) + 1 {
|
||||
path.push(i);
|
||||
Self::backtracking(result, path, targetSum, k, sum, i+1);
|
||||
sum -= i;
|
||||
Self::backtrace(result, path, target_sum, k, sum + i, i + 1);
|
||||
path.pop();
|
||||
}
|
||||
}
|
||||
pub fn combination_sum3(k: i32, n: i32) -> Vec<Vec<i32>> {
|
||||
let mut result: Vec<Vec<i32>> = Vec::new();
|
||||
let mut path: Vec<i32> = Vec::new();
|
||||
Self::backtracking(&mut result, &mut path, n, k, 0, 1);
|
||||
result
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -188,7 +188,7 @@ public:
|
||||
|
||||
```CPP
|
||||
if (root == nullptr) return 0;
|
||||
// 开始根据做深度和有深度是否相同来判断该子树是不是满二叉树
|
||||
// 开始根据左深度和右深度是否相同来判断该子树是不是满二叉树
|
||||
TreeNode* left = root->left;
|
||||
TreeNode* right = root->right;
|
||||
int leftDepth = 0, rightDepth = 0; // 这里初始为0是有目的的,为了下面求指数方便
|
||||
@ -843,3 +843,4 @@ impl Solution {
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -53,7 +53,7 @@
|
||||
|
||||
我们下文以前序遍历为例,通过动画来看一下翻转的过程:
|
||||
|
||||

|
||||
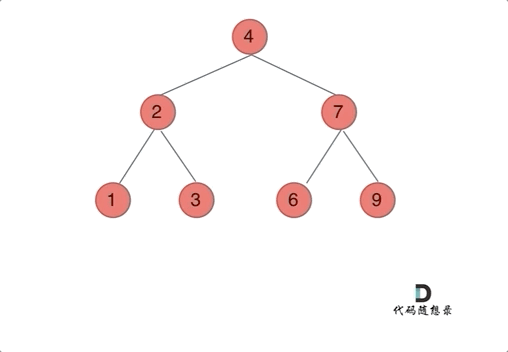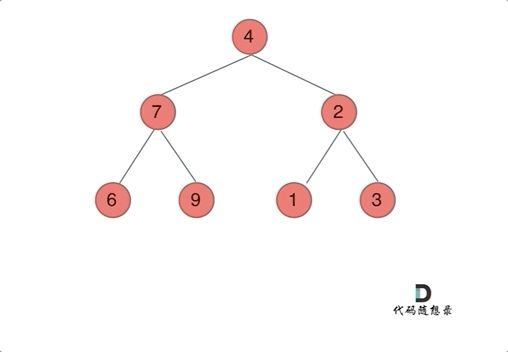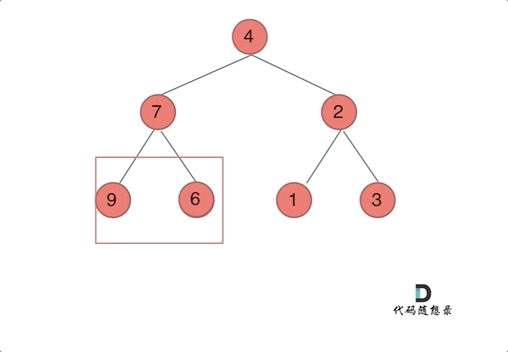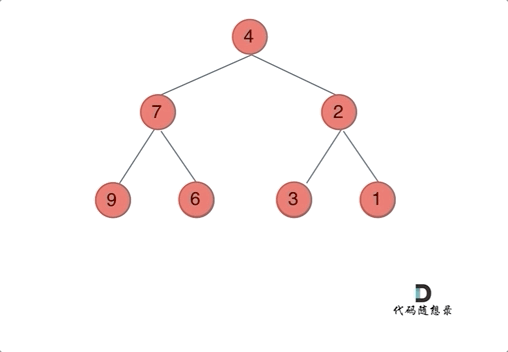
|
||||
|
||||
我们来看一下递归三部曲:
|
||||
|
||||
@ -371,7 +371,22 @@ class Solution:
|
||||
queue.append(node.right)
|
||||
return root
|
||||
```
|
||||
|
||||
迭代法:广度优先遍历(层序遍历),和之前的层序遍历写法一致:
|
||||
```python
|
||||
class Solution:
|
||||
def invertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
|
||||
if not root: return root
|
||||
from collections import deque
|
||||
que=deque([root])
|
||||
while que:
|
||||
size=len(que)
|
||||
for i in range(size):
|
||||
cur=que.popleft()
|
||||
cur.left, cur.right = cur.right, cur.left
|
||||
if cur.left: que.append(cur.left)
|
||||
if cur.right: que.append(cur.right)
|
||||
return root
|
||||
```
|
||||
### Go
|
||||
|
||||
递归版本的前序遍历
|
||||
|
||||
@ -38,7 +38,7 @@ queue.empty(); // 返回 false
|
||||
|
||||
## 思路
|
||||
|
||||
《代码随想录》算法公开课:[栈的基本操作! | LeetCode:232.用栈实现队列](https://www.bilibili.com/video/BV1nY4y1w7VC),相信结合视频再看本篇题解,更有助于大家对链表的理解。
|
||||
《代码随想录》算法公开课:[栈的基本操作! | LeetCode:232.用栈实现队列](https://www.bilibili.com/video/BV1nY4y1w7VC),相信结合视频再看本篇题解,更有助于大家对栈和队列的理解。
|
||||
|
||||
|
||||
这是一道模拟题,不涉及到具体算法,考察的就是对栈和队列的掌握程度。
|
||||
@ -662,3 +662,4 @@ impl MyQueue {
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -43,7 +43,7 @@
|
||||
|
||||
操作动画如下:
|
||||
|
||||

|
||||

|
||||
|
||||
定义一个数组叫做record用来上记录字符串s里字符出现的次数。
|
||||
|
||||
|
||||
@ -468,7 +468,7 @@ class Solution {
|
||||
---
|
||||
## Python:
|
||||
递归法+隐形回溯
|
||||
```Python3
|
||||
```Python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
@ -499,7 +499,7 @@ class Solution:
|
||||
|
||||
迭代法:
|
||||
|
||||
```python3
|
||||
```Python
|
||||
from collections import deque
|
||||
|
||||
|
||||
|
||||
@ -36,7 +36,7 @@
|
||||
|
||||
如动画所示:
|
||||
|
||||

|
||||

|
||||
|
||||
C++代码如下:
|
||||
|
||||
|
||||
@ -36,9 +36,9 @@
|
||||
首先通过本题大家要明确什么是子序列,“子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序”。
|
||||
|
||||
本题也是代码随想录中子序列问题的第一题,如果没接触过这种题目的话,本题还是很难的,甚至想暴力去搜索也不知道怎么搜。
|
||||
子序列问题是动态规划解决的经典问题,当前下标i的递增子序列长度,其实和i之前的下表j的子序列长度有关系,那那又是什么样的关系呢。
|
||||
子序列问题是动态规划解决的经典问题,当前下标i的递增子序列长度,其实和i之前的下表j的子序列长度有关系,那又是什么样的关系呢。
|
||||
|
||||
接下来,我们依然用动规五部曲来分析详细一波:
|
||||
接下来,我们依然用动规五部曲来详细分析一波:
|
||||
|
||||
1. dp[i]的定义
|
||||
|
||||
@ -46,7 +46,7 @@
|
||||
|
||||
**dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度**
|
||||
|
||||
为什么一定表示 “以nums[i]结尾的最长递增子序” ,因为我们在 做 递增比较的时候,如果比较 nums[j] 和 nums[i] 的大小,那么两个递增子序列一定分别以nums[j]为结尾 和 nums[i]为结尾, 要不然这个比较就没有意义了,不是尾部元素的比较那么 如果算递增呢。
|
||||
为什么一定表示 “以nums[i]结尾的最长递增子序” ,因为我们在 做 递增比较的时候,如果比较 nums[j] 和 nums[i] 的大小,那么两个递增子序列一定分别以nums[j]为结尾 和 nums[i]为结尾, 要不然这个比较就没有意义了,不是尾部元素的比较那么 如何算递增呢。
|
||||
|
||||
|
||||
2. 状态转移方程
|
||||
@ -155,31 +155,6 @@ class Solution:
|
||||
```
|
||||
|
||||
Go:
|
||||
```go
|
||||
func lengthOfLIS(nums []int ) int {
|
||||
dp := []int{}
|
||||
for _, num := range nums {
|
||||
if len(dp) ==0 || dp[len(dp) - 1] < num {
|
||||
dp = append(dp, num)
|
||||
} else {
|
||||
l, r := 0, len(dp) - 1
|
||||
pos := r
|
||||
for l <= r {
|
||||
mid := (l + r) >> 1
|
||||
if dp[mid] >= num {
|
||||
pos = mid;
|
||||
r = mid - 1
|
||||
} else {
|
||||
l = mid + 1
|
||||
}
|
||||
}
|
||||
dp[pos] = num
|
||||
}//二分查找
|
||||
}
|
||||
return len(dp)
|
||||
}
|
||||
```
|
||||
|
||||
```go
|
||||
// 动态规划求解
|
||||
func lengthOfLIS(nums []int) int {
|
||||
@ -212,21 +187,29 @@ func max(x, y int) int {
|
||||
return y
|
||||
}
|
||||
```
|
||||
|
||||
Rust:
|
||||
```rust
|
||||
pub fn length_of_lis(nums: Vec<i32>) -> i32 {
|
||||
let mut dp = vec![1; nums.len() + 1];
|
||||
let mut result = 1;
|
||||
for i in 1..nums.len() {
|
||||
for j in 0..i {
|
||||
if nums[j] < nums[i] {
|
||||
dp[i] = dp[i].max(dp[j] + 1);
|
||||
}
|
||||
result = result.max(dp[i]);
|
||||
}
|
||||
}
|
||||
result
|
||||
贪心+二分 优化
|
||||
```go
|
||||
func lengthOfLIS(nums []int ) int {
|
||||
dp := []int{}
|
||||
for _, num := range nums {
|
||||
if len(dp) == 0 || dp[len(dp) - 1] < num {
|
||||
dp = append(dp, num)
|
||||
} else {
|
||||
l, r := 0, len(dp) - 1
|
||||
pos := r
|
||||
for l <= r {
|
||||
mid := (l + r) >> 1
|
||||
if dp[mid] >= num {
|
||||
pos = mid;
|
||||
r = mid - 1
|
||||
} else {
|
||||
l = mid + 1
|
||||
}
|
||||
}
|
||||
dp[pos] = num
|
||||
}//二分查找
|
||||
}
|
||||
return len(dp)
|
||||
}
|
||||
```
|
||||
|
||||
@ -270,6 +253,22 @@ function lengthOfLIS(nums: number[]): number {
|
||||
};
|
||||
```
|
||||
|
||||
Rust:
|
||||
```rust
|
||||
pub fn length_of_lis(nums: Vec<i32>) -> i32 {
|
||||
let mut dp = vec![1; nums.len() + 1];
|
||||
let mut result = 1;
|
||||
for i in 1..nums.len() {
|
||||
for j in 0..i {
|
||||
if nums[j] < nums[i] {
|
||||
dp[i] = dp[i].max(dp[j] + 1);
|
||||
}
|
||||
result = result.max(dp[i]);
|
||||
}
|
||||
}
|
||||
result
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
@ -69,7 +69,7 @@
|
||||
|
||||
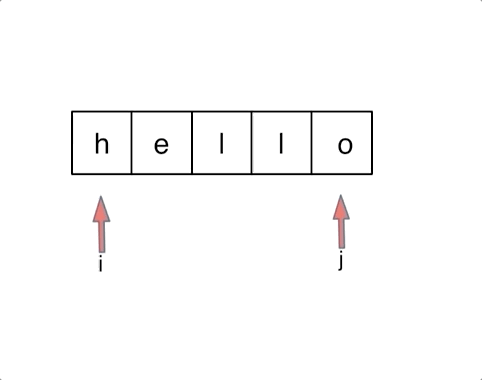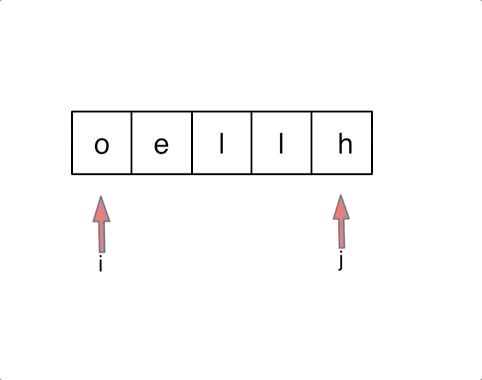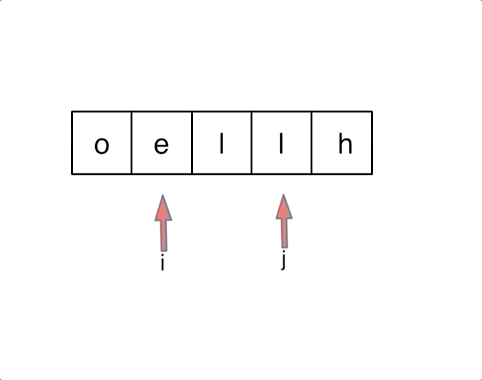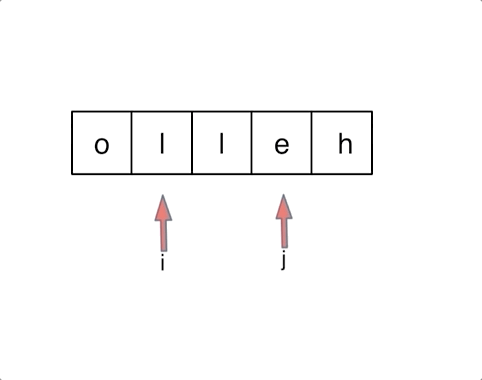
以字符串`hello`为例,过程如下:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
不难写出如下C++代码:
|
||||
|
||||
@ -137,8 +137,18 @@ class Solution {
|
||||
resSet.add(i);
|
||||
}
|
||||
}
|
||||
//将结果几何转为数组
|
||||
|
||||
//方法1:直接将结果几何转为数组
|
||||
return resSet.stream().mapToInt(x -> x).toArray();
|
||||
|
||||
//方法2:另外申请一个数组存放setRes中的元素,最后返回数组
|
||||
int[] arr = new int[setRes.size()];
|
||||
int j = 0;
|
||||
for(int i : setRes){
|
||||
arr[j++] = i;
|
||||
}
|
||||
|
||||
return arr;
|
||||
}
|
||||
}
|
||||
```
|
||||
@ -423,3 +433,4 @@ C#:
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -53,21 +53,64 @@
|
||||
|
||||
**实际操作上,其实连删除的操作都不用做,因为题目要求的是最长摆动子序列的长度,所以只需要统计数组的峰值数量就可以了(相当于是删除单一坡度上的节点,然后统计长度)**
|
||||
|
||||
**这就是贪心所贪的地方,让峰值尽可能的保持峰值,然后删除单一坡度上的节点**。
|
||||
**这就是贪心所贪的地方,让峰值尽可能的保持峰值,然后删除单一坡度上的节点**
|
||||
|
||||
本题代码实现中,还有一些技巧,例如统计峰值的时候,数组最左面和最右面是最不好统计的。
|
||||
在计算是否有峰值的时候,大家知道遍历的下标i ,计算prediff(nums[i] - nums[i-1]) 和 curdiff(nums[i+1] - nums[i]),如果`prediff < 0 && curdiff > 0` 或者 `prediff > 0 && curdiff < 0` 此时就有波动就需要统计。
|
||||
|
||||
例如序列[2,5],它的峰值数量是2,如果靠统计差值来计算峰值个数就需要考虑数组最左面和最右面的特殊情况。
|
||||
这是我们思考本题的一个大题思路,但本题要考虑三种情况:
|
||||
|
||||
所以可以针对序列[2,5],可以假设为[2,2,5],这样它就有坡度了即preDiff = 0,如图:
|
||||
1. 情况一:上下坡中有平坡
|
||||
2. 情况二:数组首尾两端
|
||||
3. 情况三:单调坡中有平坡
|
||||
|
||||
### 情况一:上下坡中有平坡
|
||||
|
||||
例如 [1,2,2,2,1]这样的数组,如图:
|
||||
|
||||
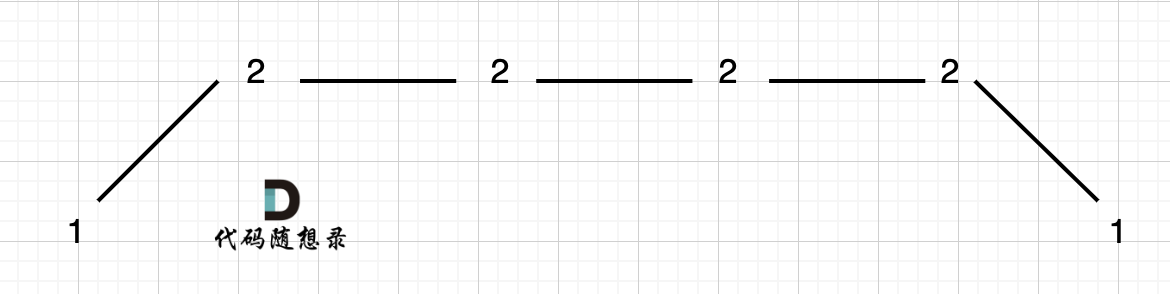
|
||||
|
||||
它的摇摆序列长度是多少呢? **其实是长度是3**,也就是我们在删除的时候 要不删除左面的三个2,要不就删除右边的三个2。
|
||||
|
||||
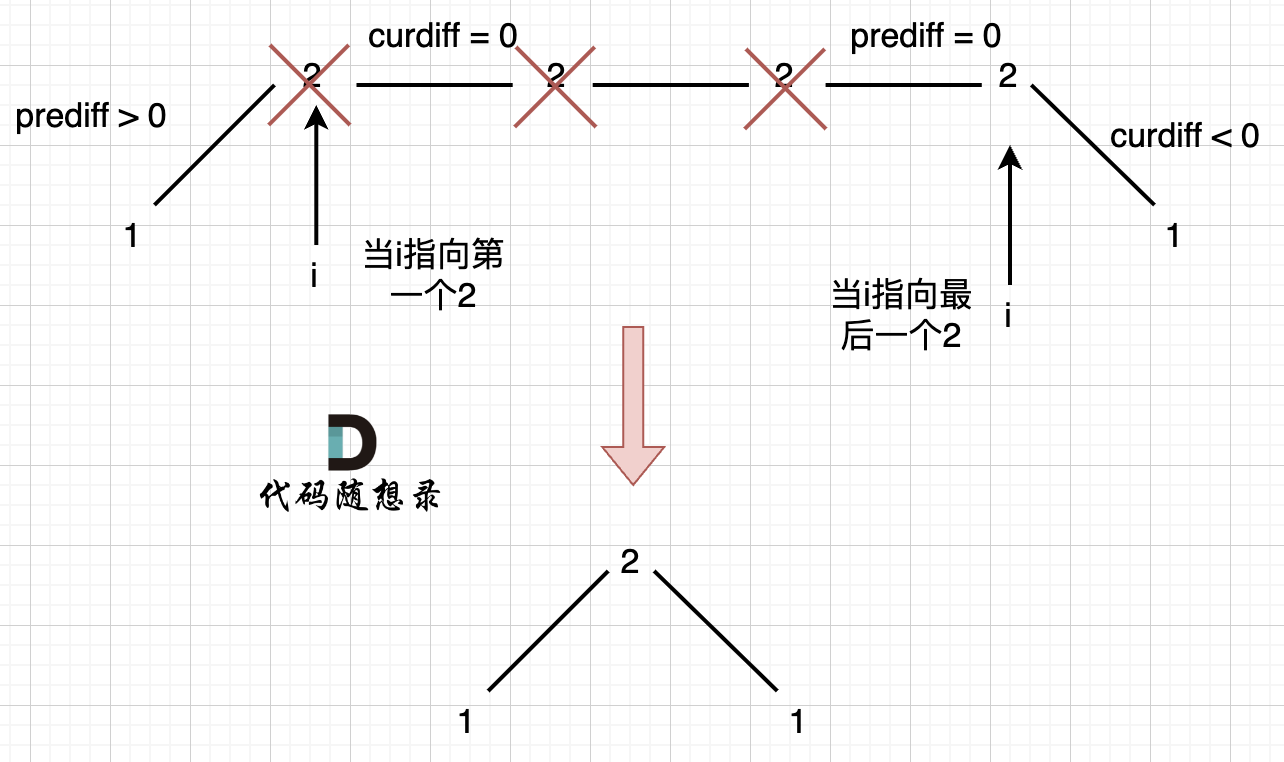
如图,可以统一规则,删除左边的三个2:
|
||||
|
||||
|
||||
|
||||
在图中,当i指向第一个2的时候,`prediff > 0 && curdiff = 0` ,当 i 指向最后一个2的时候 `prediff = 0 && curdiff < 0`。
|
||||
|
||||
如果我们采用,删左面三个2的规则,那么 当 `prediff = 0 && curdiff < 0` 也要记录一个峰值,因为他是把之前相同的元素都删掉留下的峰值。
|
||||
|
||||
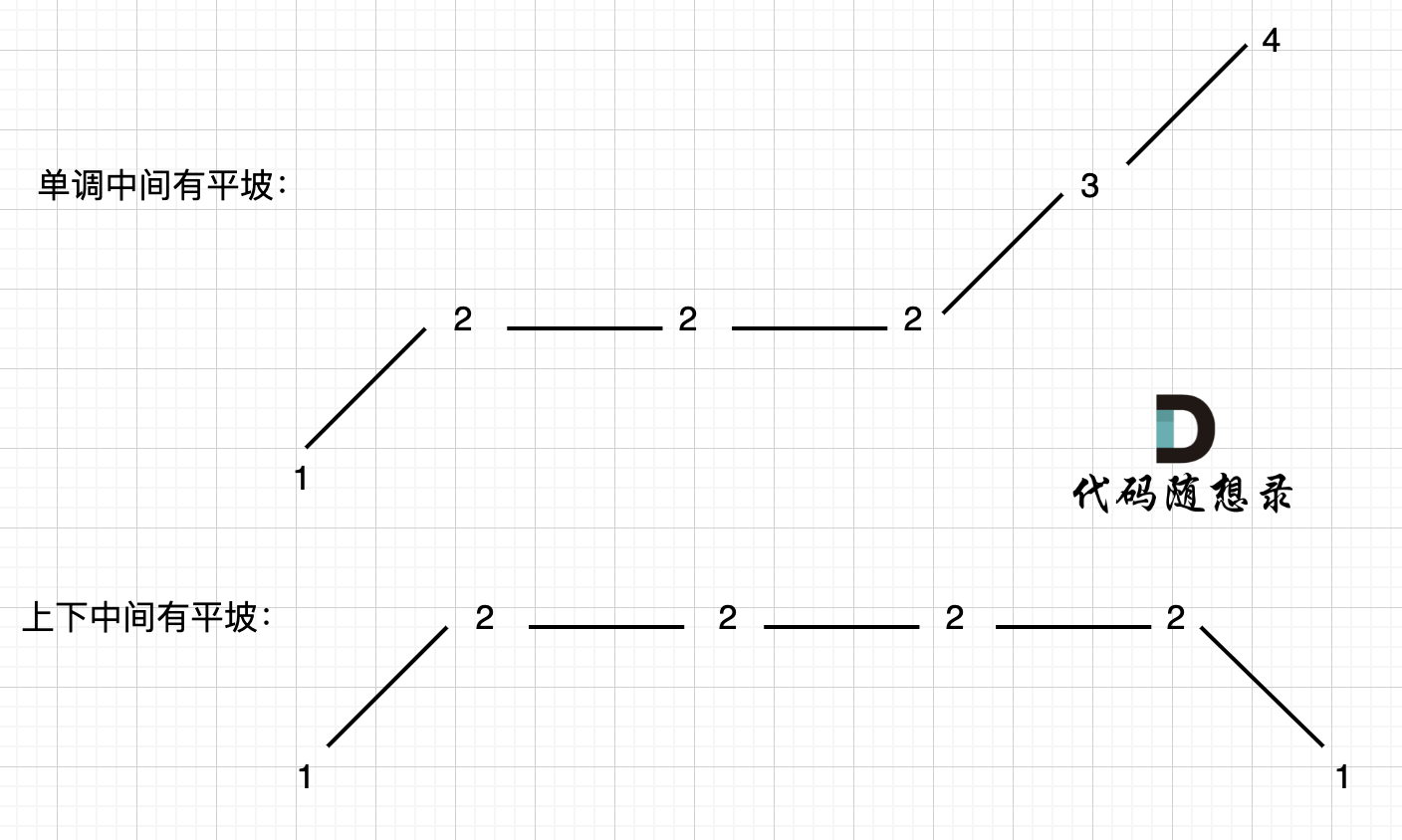
所以我们记录峰值的条件应该是: `(preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)`,为什么这里允许 prediff == 0 ,就是为了 上面我说的这种情况。
|
||||
|
||||
|
||||
### 情况二:数组首尾两端
|
||||
|
||||
|
||||
所以本题统计峰值的时候,数组最左面和最右面如果统计呢?
|
||||
|
||||
题目中说了,如果只有两个不同的元素,那摆动序列也是2。
|
||||
|
||||
例如序列[2,5],如果靠统计差值来计算峰值个数就需要考虑数组最左面和最右面的特殊情况。
|
||||
|
||||
因为我们在计算 prediff(nums[i] - nums[i-1]) 和 curdiff(nums[i+1] - nums[i])的时候,至少需要三个数字才能计算,而数组只有两个数字。
|
||||
|
||||
这里我们可以写死,就是 如果只有两个元素,且元素不同,那么结果为2。
|
||||
|
||||
不写死的话,如果和我们的判断规则结合在一起呢?
|
||||
|
||||
可以假设,数组最前面还有一个数字,那这个数字应该是什么呢?
|
||||
|
||||
之前我们在 讨论 情况一:相同数字连续 的时候, prediff = 0 ,curdiff < 0 或者 >0 也记为波谷。
|
||||
|
||||
那么为了规则统一,针对序列[2,5],可以假设为[2,2,5],这样它就有坡度了即preDiff = 0,如图:
|
||||
|
||||
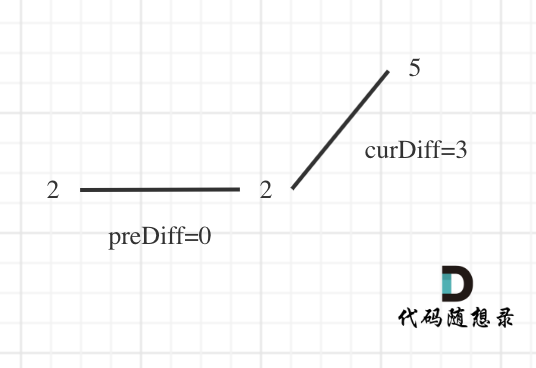
|
||||
|
||||
针对以上情形,result初始为1(默认最右面有一个峰值),此时curDiff > 0 && preDiff <= 0,那么result++(计算了左面的峰值),最后得到的result就是2(峰值个数为2即摆动序列长度为2)
|
||||
|
||||
C++代码如下(和上图是对应的逻辑):
|
||||
经过以上分析后,我们可以写出如下代码:
|
||||
|
||||
```CPP
|
||||
```CPP
|
||||
// 版本一
|
||||
class Solution {
|
||||
public:
|
||||
int wiggleMaxLength(vector<int>& nums) {
|
||||
@ -78,9 +121,54 @@ public:
|
||||
for (int i = 0; i < nums.size() - 1; i++) {
|
||||
curDiff = nums[i + 1] - nums[i];
|
||||
// 出现峰值
|
||||
if ((curDiff > 0 && preDiff <= 0) || (preDiff >= 0 && curDiff < 0)) {
|
||||
if ((preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)) {
|
||||
result++;
|
||||
preDiff = curDiff;
|
||||
}
|
||||
preDiff = curDiff;
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
此时大家是不是发现 以上代码提交也不能通过本题?
|
||||
|
||||
所以此时我们要讨论情况三!
|
||||
|
||||
### 情况三:单调坡度有平坡
|
||||
|
||||
在版本一中,我们忽略了一种情况,即 如果在一个单调坡度上有平坡,例如[1,2,2,2,3,4],如图:
|
||||
|
||||
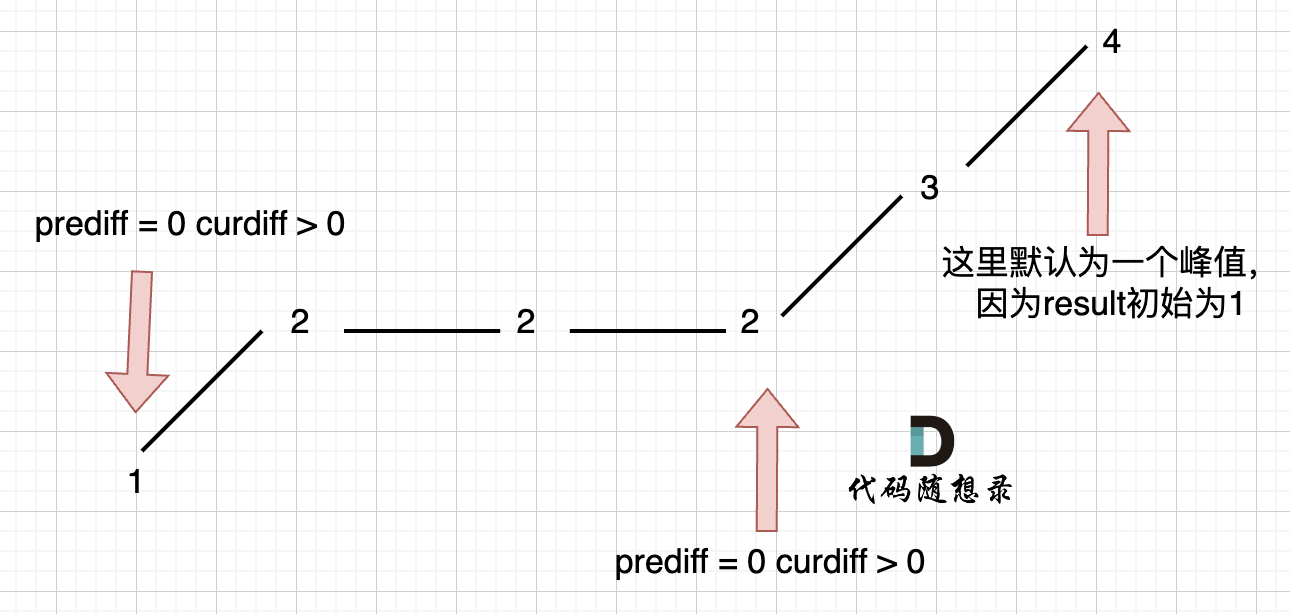
|
||||
|
||||
图中,我们可以看出,版本一的代码在三个地方记录峰值,但其实结果因为是2,因为 单调中的平坡 不能算峰值(即摆动)。
|
||||
|
||||
之所以版本一会出问题,是因为我们实时更新了 prediff。
|
||||
|
||||
那么我们应该什么时候更新prediff呢?
|
||||
|
||||
我们只需要在 这个坡度 摆动变化的时候,更新prediff就行,这样prediff在 单调区间有平坡的时候 就不会发生变化,造成我们的误判。
|
||||
|
||||
所以本题的最终代码为:
|
||||
|
||||
```CPP
|
||||
|
||||
// 版本二
|
||||
class Solution {
|
||||
public:
|
||||
int wiggleMaxLength(vector<int>& nums) {
|
||||
if (nums.size() <= 1) return nums.size();
|
||||
int curDiff = 0; // 当前一对差值
|
||||
int preDiff = 0; // 前一对差值
|
||||
int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值
|
||||
for (int i = 0; i < nums.size() - 1; i++) {
|
||||
curDiff = nums[i + 1] - nums[i];
|
||||
// 出现峰值
|
||||
if ((preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)) {
|
||||
result++;
|
||||
preDiff = curDiff; // 注意这里,只在摆动变化的时候更新prediff
|
||||
}
|
||||
}
|
||||
return result;
|
||||
@ -88,8 +176,11 @@ public:
|
||||
};
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
其实本题看起来好像简单,但需要考虑的情况还是很复杂的,而且很难一次性想到位。
|
||||
|
||||
**本题异常情况的本质,就是要考虑平坡**, 平坡分两种,一个是 上下中间有平坡,一个是单调有平坡,如图:
|
||||
|
||||
|
||||
|
||||
## 思路2(动态规划)
|
||||
|
||||
@ -111,25 +202,19 @@ public:
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```c++
|
||||
```CPP
|
||||
class Solution {
|
||||
public:
|
||||
int dp[1005][2];
|
||||
int wiggleMaxLength(vector<int>& nums) {
|
||||
memset(dp, 0, sizeof dp);
|
||||
dp[0][0] = dp[0][1] = 1;
|
||||
|
||||
for (int i = 1; i < nums.size(); ++i)
|
||||
{
|
||||
for (int i = 1; i < nums.size(); ++i) {
|
||||
dp[i][0] = dp[i][1] = 1;
|
||||
|
||||
for (int j = 0; j < i; ++j)
|
||||
{
|
||||
for (int j = 0; j < i; ++j) {
|
||||
if (nums[j] > nums[i]) dp[i][1] = max(dp[i][1], dp[j][0] + 1);
|
||||
}
|
||||
|
||||
for (int j = 0; j < i; ++j)
|
||||
{
|
||||
for (int j = 0; j < i; ++j) {
|
||||
if (nums[j] < nums[i]) dp[i][0] = max(dp[i][0], dp[j][1] + 1);
|
||||
}
|
||||
}
|
||||
@ -153,17 +238,6 @@ public:
|
||||
|
||||
空间复杂度:O(n)
|
||||
|
||||
## 总结
|
||||
|
||||
**贪心的题目说简单有的时候就是常识,说难就难在都不知道该怎么用贪心**。
|
||||
|
||||
本题大家如果要去模拟删除元素达到最长摆动子序列的过程,那指定绕里面去了,一时半会拔不出来。
|
||||
|
||||
而这道题目有什么技巧说一下子能想到贪心么?
|
||||
|
||||
其实也没有,类似的题目做过了就会想到。
|
||||
|
||||
此时大家就应该了解了:保持区间波动,只需要把单调区间上的元素移除就可以了。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -68,7 +68,7 @@ if (root == nullptr) return root;
|
||||
|
||||
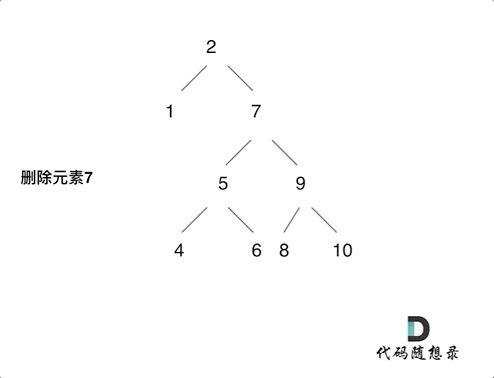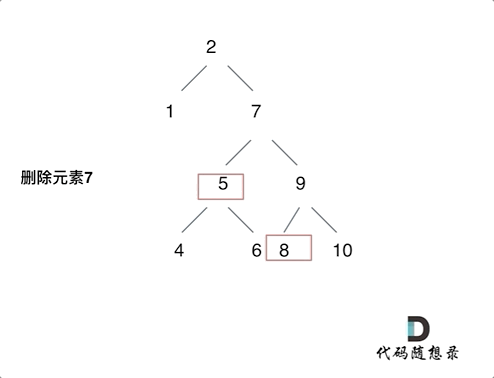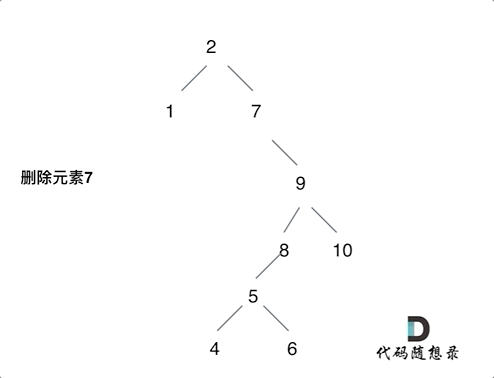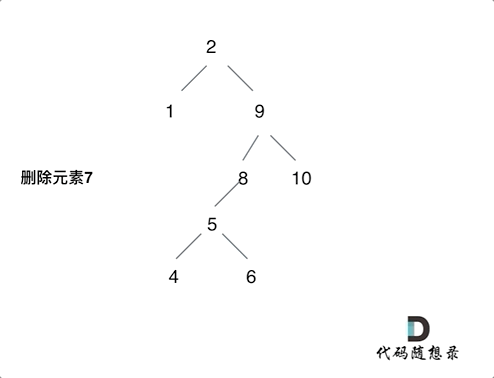
第五种情况有点难以理解,看下面动画:
|
||||
|
||||

|
||||
|
||||
|
||||
动画中的二叉搜索树中,删除元素7, 那么删除节点(元素7)的左孩子就是5,删除节点(元素7)的右子树的最左面节点是元素8。
|
||||
|
||||
|
||||
@ -52,6 +52,7 @@
|
||||
C++代码整体如下:
|
||||
|
||||
```CPP
|
||||
// 版本一
|
||||
// 时间复杂度:O(nlogn)
|
||||
// 空间复杂度:O(1)
|
||||
class Solution {
|
||||
@ -61,8 +62,8 @@ public:
|
||||
sort(s.begin(), s.end());
|
||||
int index = s.size() - 1; // 饼干数组的下标
|
||||
int result = 0;
|
||||
for (int i = g.size() - 1; i >= 0; i--) {
|
||||
if (index >= 0 && s[index] >= g[i]) {
|
||||
for (int i = g.size() - 1; i >= 0; i--) { // 遍历胃口
|
||||
if (index >= 0 && s[index] >= g[i]) { // 遍历饼干
|
||||
result++;
|
||||
index--;
|
||||
}
|
||||
@ -76,6 +77,26 @@ public:
|
||||
|
||||
有的同学看到要遍历两个数组,就想到用两个for循环,那样逻辑其实就复杂了。
|
||||
|
||||
|
||||
### 注意事项
|
||||
|
||||
注意版本一的代码中,可以看出来,是先遍历的胃口,在遍历的饼干,那么可不可以 先遍历 饼干,在遍历胃口呢?
|
||||
|
||||
其实是不可以的。
|
||||
|
||||
外面的for 是里的下标i 是固定移动的,而if里面的下标 index 是符合条件才移动的。
|
||||
|
||||
如果 for 控制的是饼干, if 控制胃口,就是出现如下情况 :
|
||||
|
||||
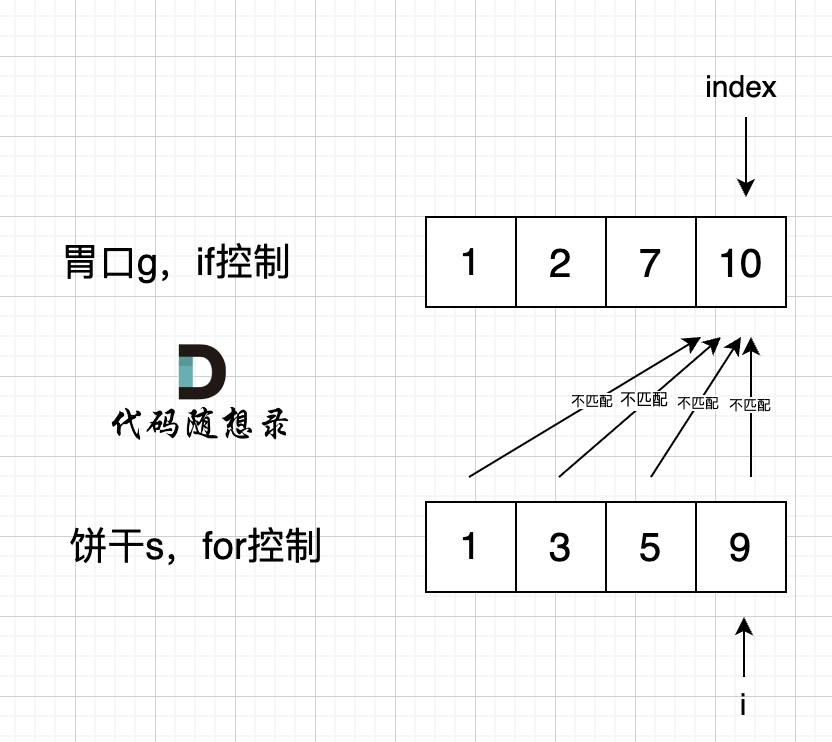
|
||||
|
||||
if 里的 index 指向 胃口 10, for里的i指向饼干9,因为 饼干9 满足不了 胃口10,所以 i 持续向前移动,而index 走不到` s[index] >= g[i]` 的逻辑,所以index不会移动,那么当i 持续向前移动,最后所有的饼干都匹配不上。
|
||||
|
||||
所以 一定要for 控制 胃口,里面的if控制饼干。
|
||||
|
||||
|
||||
### 其他思路
|
||||
|
||||
**也可以换一个思路,小饼干先喂饱小胃口**
|
||||
|
||||
代码如下:
|
||||
@ -87,15 +108,19 @@ public:
|
||||
sort(g.begin(),g.end());
|
||||
sort(s.begin(),s.end());
|
||||
int index = 0;
|
||||
for(int i = 0;i < s.size();++i){
|
||||
if(index < g.size() && g[index] <= s[i]){
|
||||
for(int i = 0; i < s.size(); i++) { // 饼干
|
||||
if(index < g.size() && g[index] <= s[i]){ // 胃口
|
||||
index++;
|
||||
}
|
||||
}
|
||||
return index;
|
||||
}
|
||||
};
|
||||
```
|
||||
```
|
||||
|
||||
细心的录友可以发现,这种写法,两个循环的顺序改变了,先遍历的饼干,在遍历的胃口,这是因为遍历顺序变了,我们是从小到大遍历。
|
||||
|
||||
理由在上面 “注意事项”中 已经讲过。
|
||||
|
||||
## 总结
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@
|
||||
|
||||
# 491.递增子序列
|
||||
|
||||
[力扣题目链接](https://leetcode.cn/problems/increasing-subsequences/)
|
||||
[力扣题目链接](https://leetcode.cn/problems/non-decreasing-subsequences/)
|
||||
|
||||
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
|
||||
|
||||
@ -614,3 +614,4 @@ object Solution {
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -270,6 +270,8 @@ class Solution {
|
||||
public int findTargetSumWays(int[] nums, int target) {
|
||||
int sum = 0;
|
||||
for (int i = 0; i < nums.length; i++) sum += nums[i];
|
||||
//如果target过大 sum将无法满足
|
||||
if ( target < 0 && sum < -target) return 0;
|
||||
if ((target + sum) % 2 != 0) return 0;
|
||||
int size = (target + sum) / 2;
|
||||
if(size < 0) size = -size;
|
||||
|
||||
@ -56,7 +56,7 @@
|
||||
|
||||
(如果这里看不懂,回忆一下dp[i][j]的定义)
|
||||
|
||||
如果s[i]与s[j]不相同,说明s[i]和s[j]的同时加入 并不能增加[i,j]区间回文子串的长度,那么分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。
|
||||
如果s[i]与s[j]不相同,说明s[i]和s[j]的同时加入 并不能增加[i,j]区间回文子序列的长度,那么分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。
|
||||
|
||||
加入s[j]的回文子序列长度为dp[i + 1][j]。
|
||||
|
||||
@ -91,13 +91,13 @@ for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
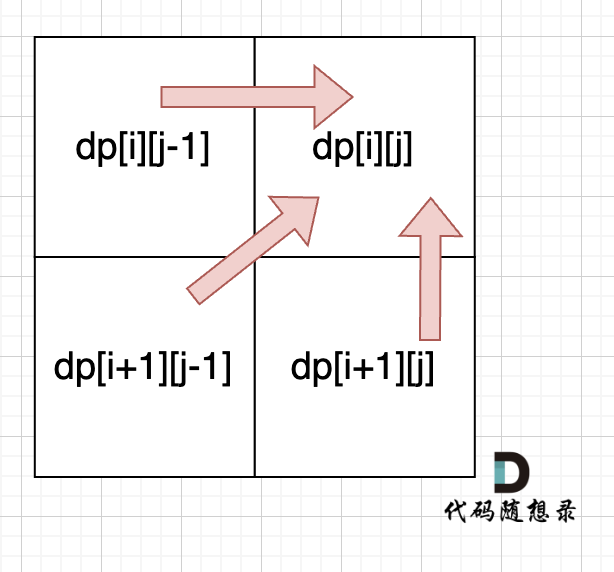
从递推公式dp[i][j] = dp[i + 1][j - 1] + 2 和 dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]) 可以看出,dp[i][j]是依赖于dp[i + 1][j - 1] 和 dp[i + 1][j],
|
||||
从递归公式中,可以看出,dp[i][j] 依赖于 dp[i + 1][j - 1] ,dp[i + 1][j] 和 dp[i][j - 1],如图:
|
||||
|
||||
也就是从矩阵的角度来说,dp[i][j] 下一行的数据。 **所以遍历i的时候一定要从下到上遍历,这样才能保证,下一行的数据是经过计算的**。
|
||||
|
||||
|
||||
递推公式:dp[i][j] = dp[i + 1][j - 1] + 2,dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]) 分别对应着下图中的红色箭头方向,如图:
|
||||
**所以遍历i的时候一定要从下到上遍历,这样才能保证下一行的数据是经过计算的**。
|
||||
|
||||
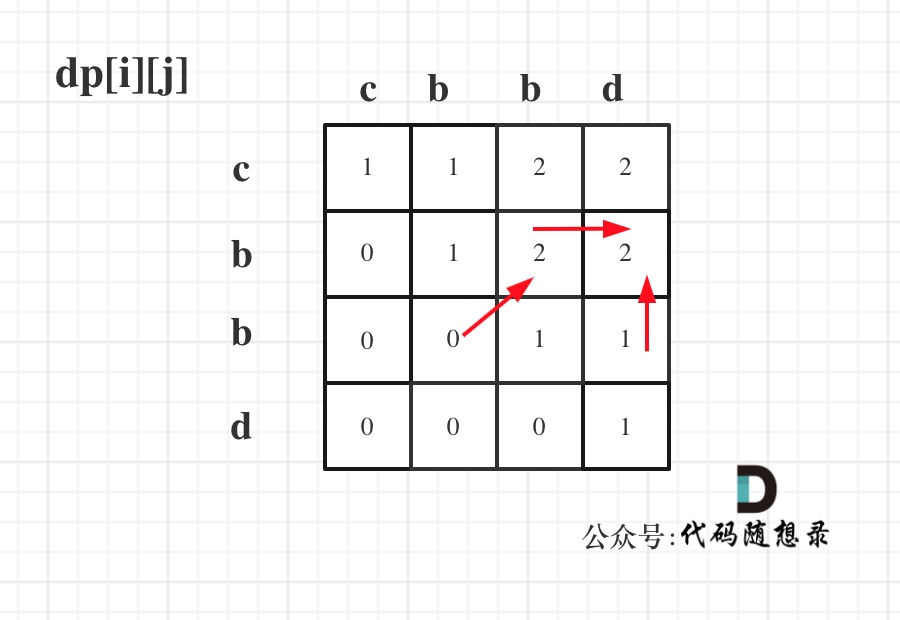
|
||||
j的话,可以正常从左向右遍历。
|
||||
|
||||
代码如下:
|
||||
|
||||
|
||||
@ -95,6 +95,8 @@ dp[j] 就是所有的dp[j - coins[i]](考虑coins[i]的情况)相加。
|
||||
|
||||
下标非0的dp[j]初始化为0,这样累计加dp[j - coins[i]]的时候才不会影响真正的dp[j]
|
||||
|
||||
dp[0]=1还说明了一种情况:如果正好选了coins[i]后,也就是j-coins[i] == 0的情况表示这个硬币刚好能选,此时dp[0]为1表示只选coins[i]存在这样的一种选法。
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
本题中我们是外层for循环遍历物品(钱币),内层for遍历背包(金钱总额),还是外层for遍历背包(金钱总额),内层for循环遍历物品(钱币)呢?
|
||||
@ -316,3 +318,4 @@ object Solution {
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -374,6 +374,55 @@ object Solution {
|
||||
}
|
||||
```
|
||||
|
||||
## rust
|
||||
|
||||
递归:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn convert_bst(root: Option<Rc<RefCell<TreeNode>>>) -> Option<Rc<RefCell<TreeNode>>> {
|
||||
let mut pre = 0;
|
||||
Self::traversal(&root, &mut pre);
|
||||
root
|
||||
}
|
||||
|
||||
pub fn traversal(cur: &Option<Rc<RefCell<TreeNode>>>, pre: &mut i32) {
|
||||
if cur.is_none() {
|
||||
return;
|
||||
}
|
||||
let mut node = cur.as_ref().unwrap().borrow_mut();
|
||||
Self::traversal(&node.right, pre);
|
||||
*pre += node.val;
|
||||
node.val = *pre;
|
||||
Self::traversal(&node.left, pre);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
迭代:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn convert_bst(root: Option<Rc<RefCell<TreeNode>>>) -> Option<Rc<RefCell<TreeNode>>> {
|
||||
let mut cur = root.clone();
|
||||
let mut stack = vec![];
|
||||
let mut pre = 0;
|
||||
while !stack.is_empty() || cur.is_some() {
|
||||
while let Some(node) = cur {
|
||||
cur = node.borrow().right.clone();
|
||||
stack.push(node);
|
||||
}
|
||||
if let Some(node) = stack.pop() {
|
||||
pre += node.borrow().val;
|
||||
node.borrow_mut().val = pre;
|
||||
cur = node.borrow().left.clone();
|
||||
}
|
||||
}
|
||||
root
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
@ -12,9 +12,9 @@
|
||||
|
||||
示例:
|
||||
|
||||
输入: "sea", "eat"
|
||||
输出: 2
|
||||
解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"
|
||||
* 输入: "sea", "eat"
|
||||
* 输出: 2
|
||||
* 解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"
|
||||
|
||||
## 思路
|
||||
|
||||
@ -47,7 +47,10 @@ dp[i][j]:以i-1为结尾的字符串word1,和以j-1位结尾的字符串word
|
||||
|
||||
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
|
||||
|
||||
因为dp[i - 1][j - 1] + 1等于 dp[i - 1][j] 或 dp[i][j - 1],所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
|
||||
|
||||
因为 dp[i][j - 1] + 1 = dp[i - 1][j - 1] + 2,所以递推公式可简化为:dp[i][j] = min(dp[i - 1][j] + 1, dp[i][j - 1] + 1);
|
||||
|
||||
这里可能不少录友有点迷糊,从字面上理解 就是 当 同时删word1[i - 1]和word2[j - 1],dp[i][j-1] 本来就不考虑 word2[j - 1]了,那么我在删 word1[i - 1],是不是就达到两个元素都删除的效果,即 dp[i][j-1] + 1。
|
||||
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
@ -40,7 +40,7 @@
|
||||
|
||||
动画如下:
|
||||
|
||||

|
||||
|
||||
|
||||
那么我们来按照递归三部曲来解决:
|
||||
|
||||
|
||||
@ -14,25 +14,21 @@
|
||||
|
||||
示例 1:
|
||||
|
||||
输入:"abc"
|
||||
输出:3
|
||||
解释:三个回文子串: "a", "b", "c"
|
||||
* 输入:"abc"
|
||||
* 输出:3
|
||||
* 解释:三个回文子串: "a", "b", "c"
|
||||
|
||||
示例 2:
|
||||
|
||||
输入:"aaa"
|
||||
输出:6
|
||||
解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"
|
||||
* 输入:"aaa"
|
||||
* 输出:6
|
||||
* 解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"
|
||||
|
||||
提示:
|
||||
|
||||
输入的字符串长度不会超过 1000 。
|
||||
提示:输入的字符串长度不会超过 1000 。
|
||||
|
||||
## 暴力解法
|
||||
|
||||
两层for循环,遍历区间起始位置和终止位置,然后判断这个区间是不是回文。
|
||||
|
||||
时间复杂度:O(n^3)
|
||||
两层for循环,遍历区间起始位置和终止位置,然后还需要一层遍历判断这个区间是不是回文。所以时间复杂度:O(n^3)
|
||||
|
||||
## 动态规划
|
||||
|
||||
@ -40,6 +36,23 @@
|
||||
|
||||
1. 确定dp数组(dp table)以及下标的含义
|
||||
|
||||
如果大家做了很多这种子序列相关的题目,在定义dp数组的时候 很自然就会想题目求什么,我们就如何定义dp数组。
|
||||
|
||||
绝大多数题目确实是这样,不过本题如果我们定义,dp[i] 为 下标i结尾的字符串有 dp[i]个回文串的话,我们会发现很难找到递归关系。
|
||||
|
||||
dp[i] 和 dp[i-1] ,dp[i + 1] 看上去都没啥关系。
|
||||
|
||||
所以我们要看回文串的性质。 如图:
|
||||
|
||||
|
||||
|
||||
我们在判断字符串S是否是回文,那么如果我们知道 s[1],s[2],s[3] 这个子串是回文的,那么只需要比较 s[0]和s[4]这两个元素是否相同,如果相同的话,这个字符串s 就是回文串。
|
||||
|
||||
|
||||
那么此时我们是不是能找到一种递归关系,也就是判断一个子字符串(字符串的下表范围[i,j])是否回文,依赖于,子字符串(下表范围[i + 1, j - 1])) 是否是回文。
|
||||
|
||||
所以为了明确这种递归关系,我们的dp数组是要定义成一位二维dp数组。
|
||||
|
||||
布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
|
||||
|
||||
|
||||
|
||||
@ -34,7 +34,7 @@
|
||||
|
||||
最大二叉树的构建过程如下:
|
||||
|
||||

|
||||

|
||||
|
||||
构造树一般采用的是前序遍历,因为先构造中间节点,然后递归构造左子树和右子树。
|
||||
|
||||
|
||||
@ -3,8 +3,11 @@
|
||||
<img src="../pics/训练营.png" width="1000"/>
|
||||
</a>
|
||||
<p align="center"><strong><a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
# 695. 岛屿的最大面积
|
||||
|
||||
[力扣题目链接](https://leetcode.cn/problems/max-area-of-island/)
|
||||
|
||||
给你一个大小为 m x n 的二进制矩阵 grid 。
|
||||
|
||||
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
|
||||
@ -15,9 +18,9 @@
|
||||
|
||||
|
||||
|
||||
输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]]
|
||||
输出:6
|
||||
解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1 。
|
||||
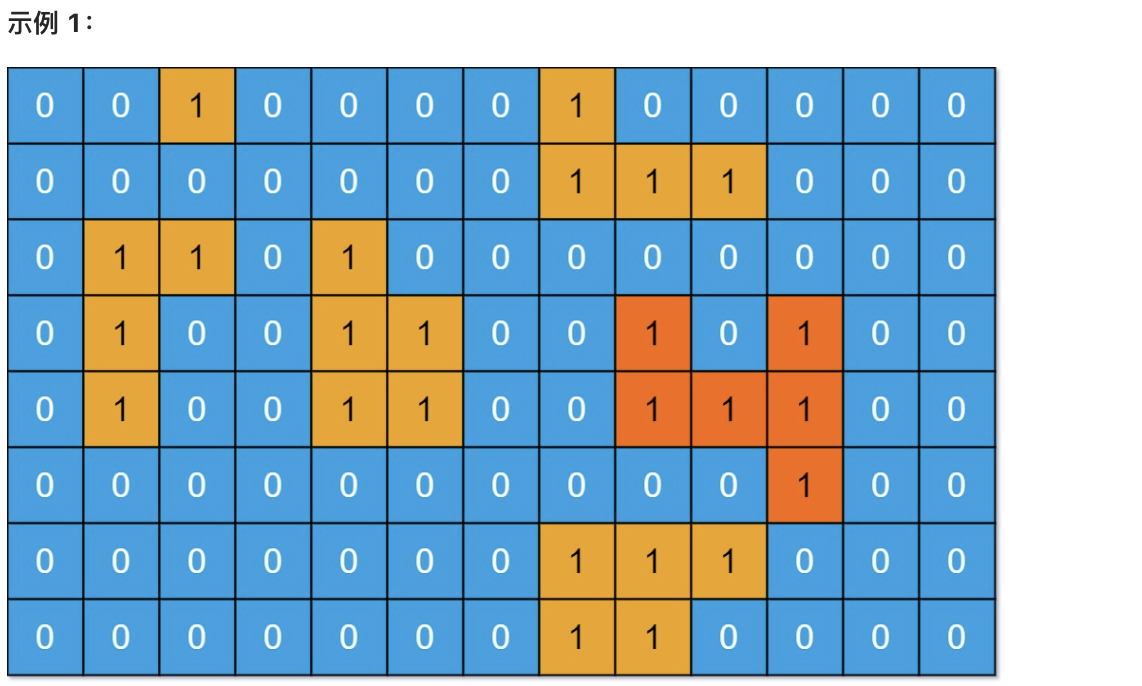
* 输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]]
|
||||
* 输出:6
|
||||
* 解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1 。
|
||||
|
||||
# 思路
|
||||
|
||||
@ -28,18 +31,23 @@
|
||||
|
||||

|
||||
|
||||
这道题目也是 dfs bfs基础类题目。
|
||||
这道题目也是 dfs bfs基础类题目,就是搜索每个岛屿上“1”的数量,然后取一个最大的。
|
||||
|
||||
本题思路上比较简单,难点其实都是 dfs 和 bfs的理论基础,关于理论基础我在这里都有详细讲解 :
|
||||
|
||||
* [DFS理论基础](https://leetcode.cn/problems/all-paths-from-source-to-target/solution/by-carlsun-2-66pf/)
|
||||
* [BFS理论基础](https://leetcode.cn/circle/discuss/V3FulB/)
|
||||
|
||||
## DFS
|
||||
|
||||
很多同学,写dfs其实也是凭感觉来,有的时候dfs函数中写终止条件才能过,有的时候 dfs函数不写终止添加也能过!
|
||||
|
||||
这里其实涉及到dfs的两种写法,
|
||||
这里其实涉及到dfs的两种写法。
|
||||
|
||||
以下代码使用dfs实现,如果对dfs不太了解的话,建议先看这篇题解:[797.所有可能的路径](https://leetcode.cn/problems/all-paths-from-source-to-target/solution/by-carlsun-2-66pf/),
|
||||
写法一,dfs只处理下一个节点,即在主函数遇到岛屿就计数为1,dfs处理接下来的相邻陆地
|
||||
|
||||
写法一,dfs只处理下一个节点
|
||||
```CPP
|
||||
// 版本一
|
||||
class Solution {
|
||||
private:
|
||||
int count;
|
||||
@ -67,7 +75,7 @@ public:
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
if (!visited[i][j] && grid[i][j] == 1) {
|
||||
count = 1;
|
||||
count = 1; // 因为dfs处理下一个节点,所以这里遇到陆地了就先计数,dfs处理接下来的相邻陆地
|
||||
visited[i][j] = true;
|
||||
dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
|
||||
result = max(result, count);
|
||||
@ -79,9 +87,11 @@ public:
|
||||
};
|
||||
```
|
||||
|
||||
写法二,dfs处理当前节点
|
||||
写法二,dfs处理当前节点,即即在主函数遇到岛屿就计数为0,dfs处理接下来的全部陆地
|
||||
|
||||
dfs
|
||||
```CPP
|
||||
// 版本二
|
||||
class Solution {
|
||||
private:
|
||||
int count;
|
||||
@ -106,7 +116,7 @@ public:
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
if (!visited[i][j] && grid[i][j] == 1) {
|
||||
count = 0;
|
||||
count = 0; // 因为dfs处理当前节点,所以遇到陆地计数为0,进dfs之后在开始从1计数
|
||||
dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
|
||||
result = max(result, count);
|
||||
}
|
||||
@ -117,8 +127,13 @@ public:
|
||||
};
|
||||
```
|
||||
|
||||
大家通过注释可以发现,两种写法,版本一,在主函数遇到陆地就计数为1,接下来的相邻陆地都在dfs中计算。 版本二 在主函数遇到陆地 计数为0,也就是不计数,陆地数量都去dfs里做计算。
|
||||
|
||||
这也是为什么大家看了很多,dfs的写法,发现写法怎么都不一样呢? 其实这就是根本原因。
|
||||
|
||||
以上两种写法的区别,我在题解: [DFS,BDF 你没注意的细节都给你列出来了!LeetCode:200. 岛屿数量](https://leetcode.cn/problems/number-of-islands/solution/by-carlsun-2-n72a/)做了详细介绍。
|
||||
|
||||
|
||||
## BFS
|
||||
|
||||
关于广度优先搜索,如果大家还不了解的话,看这里:[广度优先搜索精讲](https://leetcode.cn/circle/discuss/V3FulB/)
|
||||
|
||||
@ -34,7 +34,7 @@
|
||||
|
||||
如下演示视频中可以看出:只要按照二叉搜索树的规则去遍历,遇到空节点就插入节点就可以了。
|
||||
|
||||

|
||||
|
||||
|
||||
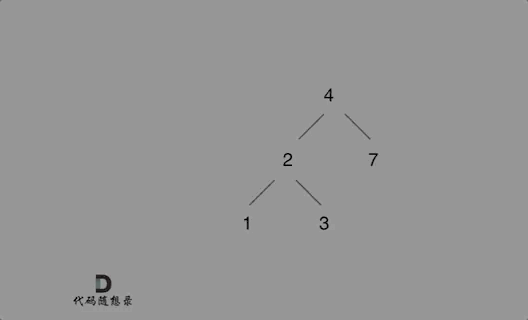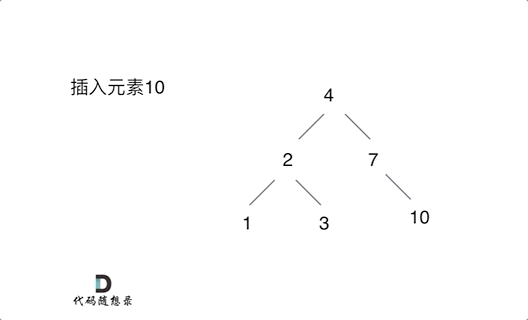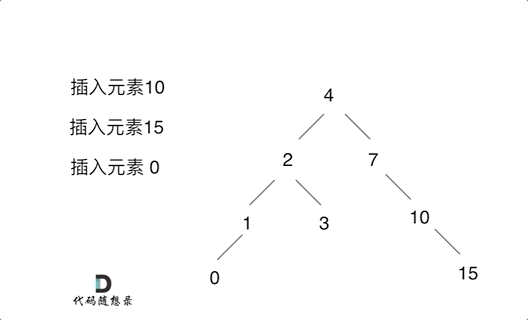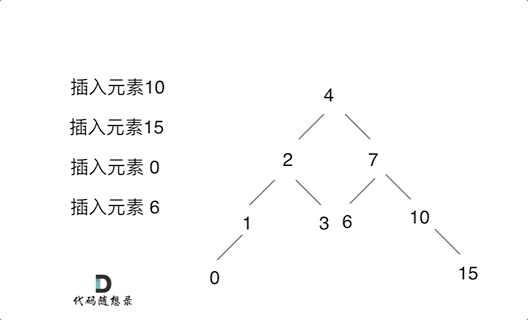
例如插入元素10 ,需要找到末尾节点插入便可,一样的道理来插入元素15,插入元素0,插入元素6,**需要调整二叉树的结构么? 并不需要。**。
|
||||
|
||||
|
||||
@ -157,7 +157,7 @@ private:
|
||||
## 其他语言版本
|
||||
C:
|
||||
```C
|
||||
typedef struct {
|
||||
typedef struct MyLinkedList {
|
||||
int val;
|
||||
struct MyLinkedList* next;
|
||||
}MyLinkedList;
|
||||
@ -233,7 +233,7 @@ void myLinkedListDeleteAtIndex(MyLinkedList* obj, int index) {
|
||||
MyLinkedList *tmp = obj->next;
|
||||
if (tmp != NULL){
|
||||
obj->next = tmp->next;
|
||||
free(tmp)
|
||||
free(tmp);
|
||||
}
|
||||
return;
|
||||
}
|
||||
|
||||
@ -28,7 +28,7 @@
|
||||
|
||||
注意题目中说的子数组,其实就是连续子序列。
|
||||
|
||||
要求两个数组中最长重复子数组,如果是暴力的解法 只要需要先两层for循环确定两个数组起始位置,然后在来一个循环可以是for或者while,来从两个起始位置开始比较,取得重复子数组的长度。
|
||||
要求两个数组中最长重复子数组,如果是暴力的解法 只需要先两层for循环确定两个数组起始位置,然后再来一个循环可以是for或者while,来从两个起始位置开始比较,取得重复子数组的长度。
|
||||
|
||||
本题其实是动规解决的经典题目,我们只要想到 用二维数组可以记录两个字符串的所有比较情况,这样就比较好推 递推公式了。
|
||||
动规五部曲分析如下:
|
||||
@ -163,7 +163,7 @@ public:
|
||||
|
||||
当然可以,就是实现起来麻烦一些。
|
||||
|
||||
如果定义 dp[i][j]为 以下标i为结尾的A,和以下标j 为结尾的B,那么 第一行和第一列毕竟要经行初始化,如果nums1[i] 与 nums2[0] 相同的话,对应的 dp[i][0]就要初始为1, 因为此时最长重复子数组为1。 nums2[j] 与 nums1[0]相同的话,同理。
|
||||
如果定义 dp[i][j]为 以下标i为结尾的A,和以下标j 为结尾的B,那么 第一行和第一列毕竟要进行初始化,如果nums1[i] 与 nums2[0] 相同的话,对应的 dp[i][0]就要初始为1, 因为此时最长重复子数组为1。 nums2[j] 与 nums1[0]相同的话,同理。
|
||||
|
||||
所以代码如下:
|
||||
|
||||
@ -298,6 +298,29 @@ func findLength(A []int, B []int) int {
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
// 滚动数组
|
||||
func findLength(nums1 []int, nums2 []int) int {
|
||||
n, m, res := len(nums1), len(nums2), 0
|
||||
dp := make([]int, m+1)
|
||||
for i := 1; i <= n; i++ {
|
||||
for j := m; j >= 1; j-- {
|
||||
if nums1[i-1] == nums2[j-1] {
|
||||
dp[j] = dp[j-1] + 1
|
||||
} else {
|
||||
dp[j] = 0 // 注意这里不相等要赋值为0,供下一层使用
|
||||
}
|
||||
res = max(res, dp[j])
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
func max(a, b int) int {
|
||||
if a > b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript:
|
||||
|
||||
@ -3,8 +3,11 @@
|
||||
<img src="../pics/训练营.png" width="1000"/>
|
||||
</a>
|
||||
<p align="center"><strong><a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
# 827. 最大人工岛
|
||||
|
||||
[力扣链接](https://leetcode.cn/problems/making-a-large-island/)
|
||||
|
||||
给你一个大小为 n x n 二进制矩阵 grid 。最多 只能将一格 0 变成 1 。
|
||||
|
||||
返回执行此操作后,grid 中最大的岛屿面积是多少?
|
||||
@ -30,7 +33,9 @@
|
||||
|
||||
本题的一个暴力想法,应该是遍历地图尝试 将每一个 0 改成1,然后去搜索地图中的最大的岛屿面积。
|
||||
|
||||
计算地图的最大面积:遍历地图 + 深搜岛屿,时间复杂度为 n * n
|
||||
计算地图的最大面积:遍历地图 + 深搜岛屿,时间复杂度为 n * n。
|
||||
|
||||
(其实使用深搜还是广搜都是可以的,其目的就是遍历岛屿做一个标记,相当于染色,那么使用哪个遍历方式都行,以下我用深搜来讲解)
|
||||
|
||||
每改变一个0的方格,都需要重新计算一个地图的最大面积,所以 整体时间复杂度为:n^4。
|
||||
|
||||
@ -41,7 +46,7 @@
|
||||
|
||||
其实每次深搜遍历计算最大岛屿面积,我们都做了很多重复的工作。
|
||||
|
||||
只要把深搜就可以并每个岛屿的面积记录下来就好。
|
||||
只要用一次深搜把每个岛屿的面积记录下来就好。
|
||||
|
||||
第一步:一次遍历地图,得出各个岛屿的面积,并做编号记录。可以使用map记录,key为岛屿编号,value为岛屿面积
|
||||
第二步:在遍历地图,遍历0的方格(因为要将0变成1),并统计该1(由0变成的1)周边岛屿面积,将其相邻面积相加在一起,遍历所有 0 之后,就可以得出 选一个0变成1 之后的最大面积。
|
||||
@ -74,7 +79,7 @@ void dfs(vector<vector<int>>& grid, vector<vector<bool>>& visited, int x, int y,
|
||||
|
||||
int largestIsland(vector<vector<int>>& grid) {
|
||||
int n = grid.size(), m = grid[0].size();
|
||||
vector<vector<bool>> visited = vector<vector<bool>>(n, vector<bool>(m, false));
|
||||
vector<vector<bool>> visited = vector<vector<bool>>(n, vector<bool>(m, false)); // 标记访问过的点
|
||||
unordered_map<int ,int> gridNum;
|
||||
int mark = 2; // 记录每个岛屿的编号
|
||||
bool isAllGrid = true; // 标记是否整个地图都是陆地
|
||||
@ -92,9 +97,10 @@ int largestIsland(vector<vector<int>>& grid) {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
这个过程时间复杂度 n * n 。可能有录友想:分明是两个for循环下面套这一个dfs,时间复杂度怎么回事 n * n呢?
|
||||
|
||||
其实大家可以自己看代码的时候,**n * n这个方格地图中,每个节点我们就遍历一次,并不会重复遍历**。
|
||||
其实大家可以仔细看一下代码,**n * n这个方格地图中,每个节点我们就遍历一次,并不会重复遍历**。
|
||||
|
||||
第二步过程如图所示:
|
||||
|
||||
@ -106,6 +112,47 @@ int largestIsland(vector<vector<int>>& grid) {
|
||||
|
||||
所以整个解法的时间复杂度,为 n * n + n * n 也就是 n^2。
|
||||
|
||||
当然这里还有一个优化的点,就是 可以不用 visited数组,因为有mark来标记,所以遍历过的grid[i][j]是不等于1的。
|
||||
|
||||
代码如下:
|
||||
|
||||
```CPP
|
||||
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
|
||||
void dfs(vector<vector<int>>& grid, int x, int y, int mark) {
|
||||
if (grid[x][y] != 1 || grid[x][y] == 0) return; // 终止条件:访问过的节点 或者 遇到海水
|
||||
grid[x][y] = mark; // 给陆地标记新标签
|
||||
count++;
|
||||
for (int i = 0; i < 4; i++) {
|
||||
int nextx = x + dir[i][0];
|
||||
int nexty = y + dir[i][1];
|
||||
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
|
||||
dfs(grid, nextx, nexty, mark);
|
||||
}
|
||||
}
|
||||
|
||||
public:
|
||||
int largestIsland(vector<vector<int>>& grid) {
|
||||
int n = grid.size(), m = grid[0].size();
|
||||
unordered_map<int ,int> gridNum;
|
||||
int mark = 2; // 记录每个岛屿的编号
|
||||
bool isAllGrid = true; // 标记是否整个地图都是陆地
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
if (grid[i][j] == 0) isAllGrid = false;
|
||||
if (grid[i][j] == 1) {
|
||||
count = 0;
|
||||
dfs(grid, i, j, mark); // 将与其链接的陆地都标记上 true
|
||||
gridNum[mark] = count; // 记录每一个岛屿的面积
|
||||
mark++; // 记录下一个岛屿编号
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
不过为了让各个变量各司其事,代码清晰一些,完整代码还是使用visited数组来标记。
|
||||
|
||||
最后,整体代码如下:
|
||||
|
||||
```CPP
|
||||
@ -129,7 +176,7 @@ private:
|
||||
public:
|
||||
int largestIsland(vector<vector<int>>& grid) {
|
||||
int n = grid.size(), m = grid[0].size();
|
||||
vector<vector<bool>> visited = vector<vector<bool>>(n, vector<bool>(m, false));
|
||||
vector<vector<bool>> visited = vector<vector<bool>>(n, vector<bool>(m, false)); // 标记访问过的点
|
||||
unordered_map<int ,int> gridNum;
|
||||
int mark = 2; // 记录每个岛屿的编号
|
||||
bool isAllGrid = true; // 标记是否整个地图都是陆地
|
||||
@ -171,6 +218,7 @@ public:
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -577,6 +577,91 @@ object Solution {
|
||||
result
|
||||
}
|
||||
}
|
||||
```
|
||||
### Rust
|
||||
```Rust
|
||||
/// 版本一
|
||||
impl Solution {
|
||||
pub fn min_camera_cover(root: Option<Rc<RefCell<TreeNode>>>) -> i32 {
|
||||
let mut res = 0;
|
||||
if Self::traversal(&root, &mut res) == 0 {
|
||||
res += 1;
|
||||
}
|
||||
res
|
||||
}
|
||||
|
||||
pub fn traversal(cur: &Option<Rc<RefCell<TreeNode>>>, ans: &mut i32) -> i32 {
|
||||
// 0 未覆盖 1 节点已设置摄像头 2 节点已覆盖
|
||||
if let Some(node) = cur {
|
||||
let node = node.borrow();
|
||||
|
||||
let left = Self::traversal(&node.left, ans);
|
||||
let right = Self::traversal(&node.right, ans);
|
||||
|
||||
// 左右节点都被覆盖
|
||||
if left == 2 && right == 2 {
|
||||
return 0; // 无覆盖
|
||||
}
|
||||
|
||||
// left == 0 right == 0 左右无覆盖
|
||||
// left == 0 right == 1 左节点无覆盖 右节点有摄像头
|
||||
// left == 1 right == 0 左节点有摄像头 左节点无覆盖
|
||||
// left == 0 right == 2 左节点无覆盖 右节点有覆盖
|
||||
// left == 2 right == 0 左节点有覆盖 右节点无覆盖
|
||||
if left == 0 || right == 0 {
|
||||
*ans += 1;
|
||||
return 1;
|
||||
}
|
||||
|
||||
// left == 1 right == 1 左节点有摄像头 右节点有摄像头
|
||||
// left == 1 right == 2 左节点有摄像头 右节点覆盖
|
||||
// left == 2 right == 1 左节点覆盖 右节点有摄像头
|
||||
if left == 1 || right == 1 {
|
||||
return 2; // 已覆盖
|
||||
}
|
||||
} else {
|
||||
return 2;
|
||||
}
|
||||
-1
|
||||
}
|
||||
}
|
||||
|
||||
/// 版本二
|
||||
enum NodeState {
|
||||
NoCover = 0,
|
||||
Camera = 1,
|
||||
Covered = 2,
|
||||
}
|
||||
|
||||
impl Solution {
|
||||
pub fn min_camera_cover(root: Option<Rc<RefCell<TreeNode>>>) -> i32 {
|
||||
let mut res = 0;
|
||||
let state = Self::traversal(&root, &mut res);
|
||||
match state {
|
||||
NodeState::NoCover => res + 1,
|
||||
_ => res,
|
||||
}
|
||||
}
|
||||
|
||||
pub fn traversal(cur: &Option<Rc<RefCell<TreeNode>>>, ans: &mut i32) -> NodeState {
|
||||
if let Some(node) = cur {
|
||||
let node = node.borrow();
|
||||
let left_state = Self::traversal(&node.left, ans);
|
||||
let right_state = Self::traversal(&node.right, ans);
|
||||
match (left_state, right_state) {
|
||||
(NodeState::NoCover, _) | (_, NodeState::NoCover) => {
|
||||
*ans += 1;
|
||||
NodeState::Camera
|
||||
}
|
||||
(NodeState::Camera, _) | (_, NodeState::Camera) => NodeState::Covered,
|
||||
(_, _) => NodeState::NoCover,
|
||||
}
|
||||
} else {
|
||||
NodeState::Covered
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
|
||||
@ -44,7 +44,7 @@
|
||||
|
||||
那么如果将负数都转变为正数了,K依然大于0,此时的问题是一个有序正整数序列,如何转变K次正负,让 数组和 达到最大。
|
||||
|
||||
那么又是一个贪心:局部最优:只找数值最小的正整数进行反转,当前数值可以达到最大(例如正整数数组{5, 3, 1},反转1 得到-1 比 反转5得到的-5 大多了),全局最优:整个 数组和 达到最大。
|
||||
那么又是一个贪心:局部最优:只找数值最小的正整数进行反转,当前数值和可以达到最大(例如正整数数组{5, 3, 1},反转1 得到-1 比 反转5得到的-5 大多了),全局最优:整个 数组和 达到最大。
|
||||
|
||||
虽然这道题目大家做的时候,可能都不会去想什么贪心算法,一鼓作气,就AC了。
|
||||
|
||||
|
||||
@ -6,6 +6,8 @@
|
||||
|
||||
# 1020. 飞地的数量
|
||||
|
||||
[力扣链接](https://leetcode.cn/problems/number-of-enclaves/description/)
|
||||
|
||||
给你一个大小为 m x n 的二进制矩阵 grid ,其中 0 表示一个海洋单元格、1 表示一个陆地单元格。
|
||||
|
||||
一次 移动 是指从一个陆地单元格走到另一个相邻(上、下、左、右)的陆地单元格或跨过 grid 的边界。
|
||||
@ -26,7 +28,7 @@
|
||||
|
||||
## 思路
|
||||
|
||||
本题使用dfs,bfs,并查集都是可以的。 本题和 417. 太平洋大西洋水流问题 很像。
|
||||
本题使用dfs,bfs,并查集都是可以的。
|
||||
|
||||
本题要求找到不靠边的陆地面积,那么我们只要从周边找到陆地然后 通过 dfs或者bfs 将周边靠陆地且相邻的陆地都变成海洋,然后再去重新遍历地图的时候,统计此时还剩下的陆地就可以了。
|
||||
|
||||
@ -142,6 +144,11 @@ public:
|
||||
}
|
||||
};
|
||||
```
|
||||
## 类似题目
|
||||
|
||||
* 1254. 统计封闭岛屿的数目
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -49,7 +49,7 @@ dp[i][j]:长度为[0, i - 1]的字符串text1与长度为[0, j - 1]的字符
|
||||
|
||||
有同学会问:为什么要定义长度为[0, i - 1]的字符串text1,定义为长度为[0, i]的字符串text1不香么?
|
||||
|
||||
这样定义是为了后面代码实现方便,如果非要定义为为长度为[0, i]的字符串text1也可以,我在 [动态规划:718. 最长重复子数组](https://programmercarl.com/0718.最长重复子数组.html) 中的「拓展」里 详细讲解了区别所在,其实就是简化了dp数组第一行和第一列的初始化逻辑。
|
||||
这样定义是为了后面代码实现方便,如果非要定义为长度为[0, i]的字符串text1也可以,我在 [动态规划:718. 最长重复子数组](https://programmercarl.com/0718.最长重复子数组.html) 中的「拓展」里 详细讲解了区别所在,其实就是简化了dp数组第一行和第一列的初始化逻辑。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
@ -240,27 +240,6 @@ func max(a,b int)int {
|
||||
|
||||
```
|
||||
|
||||
Rust:
|
||||
```rust
|
||||
pub fn longest_common_subsequence(text1: String, text2: String) -> i32 {
|
||||
let (n, m) = (text1.len(), text2.len());
|
||||
let (s1, s2) = (text1.as_bytes(), text2.as_bytes());
|
||||
let mut dp = vec![0; m + 1];
|
||||
let mut last = vec![0; m + 1];
|
||||
for i in 1..=n {
|
||||
dp.swap_with_slice(&mut last);
|
||||
for j in 1..=m {
|
||||
dp[j] = if s1[i - 1] == s2[j - 1] {
|
||||
last[j - 1] + 1
|
||||
} else {
|
||||
last[j].max(dp[j - 1])
|
||||
};
|
||||
}
|
||||
}
|
||||
dp[m]
|
||||
}
|
||||
```
|
||||
|
||||
Javascript:
|
||||
```javascript
|
||||
const longestCommonSubsequence = (text1, text2) => {
|
||||
@ -304,6 +283,26 @@ function longestCommonSubsequence(text1: string, text2: string): number {
|
||||
};
|
||||
```
|
||||
|
||||
Rust:
|
||||
```rust
|
||||
pub fn longest_common_subsequence(text1: String, text2: String) -> i32 {
|
||||
let (n, m) = (text1.len(), text2.len());
|
||||
let (s1, s2) = (text1.as_bytes(), text2.as_bytes());
|
||||
let mut dp = vec![0; m + 1];
|
||||
let mut last = vec![0; m + 1];
|
||||
for i in 1..=n {
|
||||
dp.swap_with_slice(&mut last);
|
||||
for j in 1..=m {
|
||||
dp[j] = if s1[i - 1] == s2[j - 1] {
|
||||
last[j - 1] + 1
|
||||
} else {
|
||||
last[j].max(dp[j - 1])
|
||||
};
|
||||
}
|
||||
}
|
||||
dp[m]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
@ -63,7 +63,7 @@ public:
|
||||
|
||||
看代码有点抽象我们来看一下动画(中序遍历):
|
||||
|
||||

|
||||
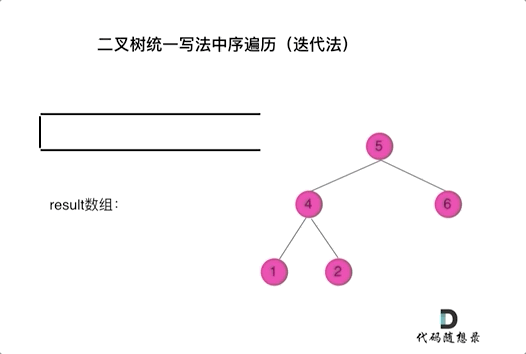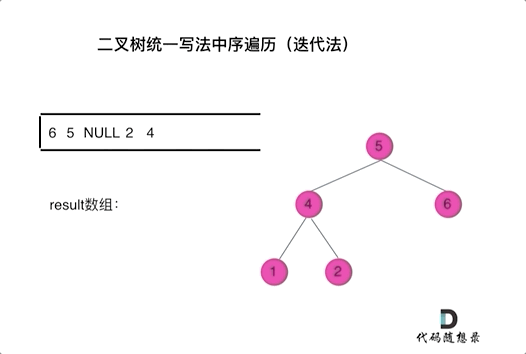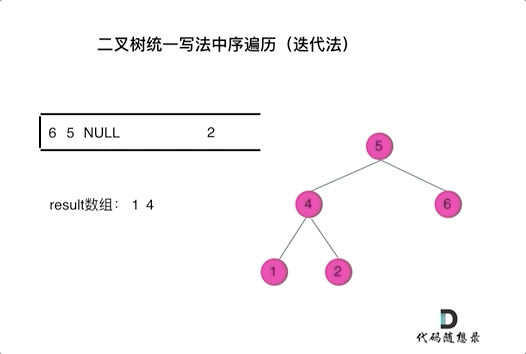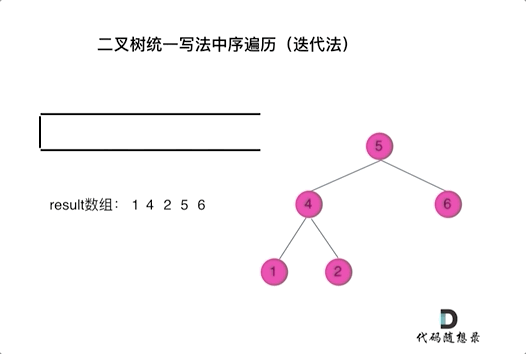
|
||||
|
||||
动画中,result数组就是最终结果集。
|
||||
|
||||
|
||||
@ -37,7 +37,7 @@
|
||||
|
||||
动画如下:
|
||||
|
||||

|
||||

|
||||
|
||||
不难写出如下代码: (**注意代码中空节点不入栈**)
|
||||
|
||||
@ -84,7 +84,7 @@ public:
|
||||
|
||||
动画如下:
|
||||
|
||||

|
||||
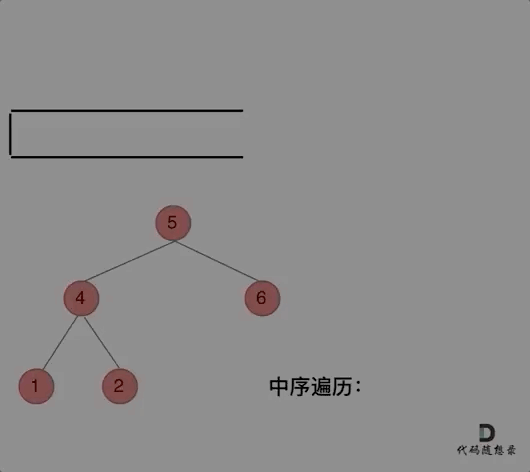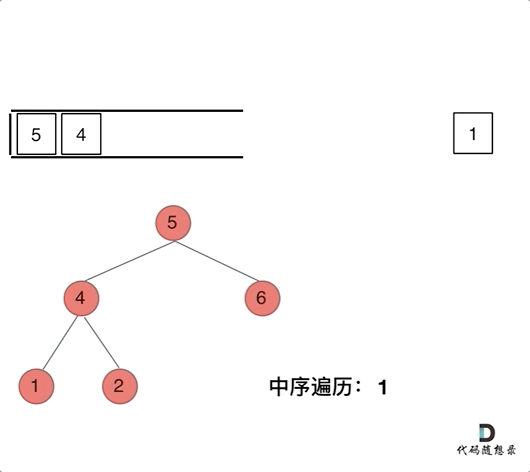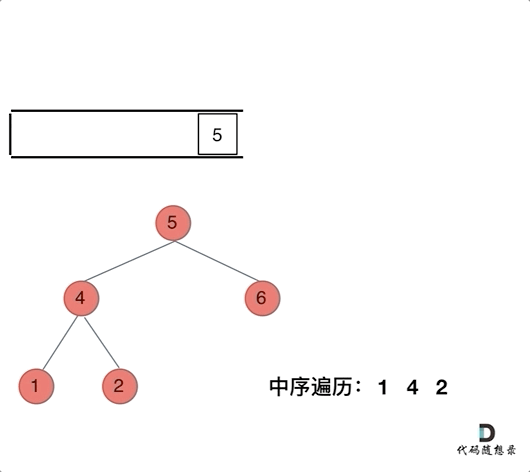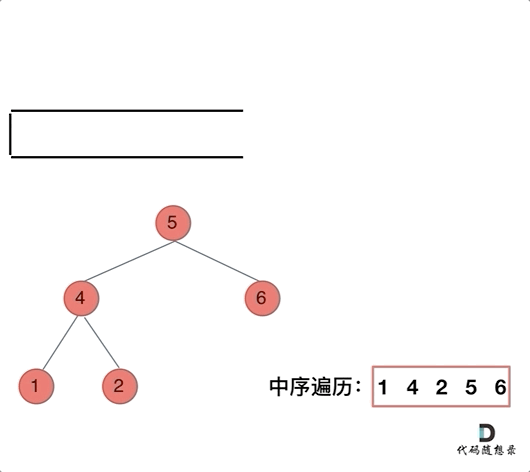
|
||||
|
||||
**中序遍历,可以写出如下代码:**
|
||||
|
||||
|
||||
@ -280,7 +280,7 @@ public class Solution {
|
||||
|
||||
## Python
|
||||
|
||||
```Python3
|
||||
```Python
|
||||
class TreeNode:
|
||||
def __init__(self, val = 0, left = None, right = None):
|
||||
self.val = val
|
||||
|
||||
@ -25,7 +25,7 @@
|
||||
|
||||
i指向新长度的末尾,j指向旧长度的末尾。
|
||||
|
||||

|
||||

|
||||
|
||||
有同学问了,为什么要从后向前填充,从前向后填充不行么?
|
||||
|
||||
|
||||
@ -26,6 +26,7 @@
|
||||
|
||||
再举一个例子如果是 有一堆盒子,你有一个背包体积为n,如何把背包尽可能装满,如果还每次选最大的盒子,就不行了。这时候就需要动态规划。动态规划的问题在下一个系列会详细讲解。
|
||||
|
||||
|
||||
## 贪心的套路(什么时候用贪心)
|
||||
|
||||
很多同学做贪心的题目的时候,想不出来是贪心,想知道有没有什么套路可以一看就看出来是贪心。
|
||||
@ -74,7 +75,10 @@
|
||||
* 求解每一个子问题的最优解
|
||||
* 将局部最优解堆叠成全局最优解
|
||||
|
||||
其实这个分的有点细了,真正做题的时候很难分出这么详细的解题步骤,可能就是因为贪心的题目往往还和其他方面的知识混在一起。
|
||||
这个四步其实过于理论化了,我们平时在做贪心类的题目 很难去按照这四步去思考,真是有点“鸡肋”。
|
||||
|
||||
做题的时候,只要想清楚 局部最优 是什么,如果推导出全局最优,其实就够了。
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
@ -84,9 +88,6 @@
|
||||
|
||||
最后给出贪心的一般解题步骤,大家可以发现这个解题步骤也是比较抽象的,不像是二叉树,回溯算法,给出了那么具体的解题套路和模板。
|
||||
|
||||
本篇没有配图,其实可以找一些动漫周边或者搞笑的图配一配(符合大多数公众号文章的作风),但这不是我的风格,所以本篇文字描述足以!
|
||||
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
Reference in New Issue
Block a user