Update
@ -69,6 +69,7 @@
|
||||
|
||||
* 双指针法
|
||||
* [数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
|
||||
* [数组:977. 有序数组的平方]()
|
||||
* [字符串:这道题目,使用库函数一行代码搞定](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)
|
||||
* [字符串:替换空格](https://mp.weixin.qq.com/s/t0A9C44zgM-RysAQV3GZpg)
|
||||
* [字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)
|
||||
@ -129,6 +130,7 @@
|
||||
* [0035.搜索插入位置](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)
|
||||
* [0027.移除元素](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
|
||||
* [0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md)
|
||||
* [0977.有序数组的平方](https://github.com/youngyangyang04/leetcode/blob/master/problems/0977.有序数组的平方.md)
|
||||
* [0209.长度最小的子数组](https://mp.weixin.qq.com/s/UrZynlqi4QpyLlLhBPglyg)
|
||||
* [0059.螺旋矩阵II](https://mp.weixin.qq.com/s/KTPhaeqxbMK9CxHUUgFDmg)
|
||||
|
||||
@ -230,7 +232,7 @@
|
||||
# LeetCode 最强题解:
|
||||
|
||||
|题目 | 类型 | 难度 | 解题方法 |
|
||||
|---|---| ---| --- |
|
||||
|---|---| ---| --- |
|
||||
|[0001.两数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0001.两数之和.md) | 数组|简单|**暴力** **哈希**|
|
||||
|[0015.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md) | 数组 |中等|**双指针** **哈希**|
|
||||
|[0017.电话号码的字母组合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0017.电话号码的字母组合.md) | 回溯 |中等|**回溯**|
|
||||
@ -332,6 +334,7 @@
|
||||
|[0705.设计哈希集合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0705.设计哈希集合.md) |哈希表 |简单|**模拟**|
|
||||
|[0707.设计链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0707.设计链表.md) |链表 |中等|**模拟**|
|
||||
|[0841.钥匙和房间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0841.钥匙和房间.md) |孤岛问题 |中等|**bfs** **dfs**|
|
||||
|[0977.有序数组的平方](https://github.com/youngyangyang04/leetcode/blob/master/problems/0977.有序数组的平方.md) |数组 |中等|**双指针**|
|
||||
|[1002.查找常用字符](https://github.com/youngyangyang04/leetcode/blob/master/problems/1002.查找常用字符.md) |栈 |简单|**栈**|
|
||||
|[1047.删除字符串中的所有相邻重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/1047.删除字符串中的所有相邻重复项.md) |哈希表 |简单|**哈希表/数组**|
|
||||
|[剑指Offer05.替换空格](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md) |字符串 |简单|**双指针**|
|
||||
|
||||
BIN
pics/236.二叉树的最近公共祖先.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 111 KiB |
BIN
pics/236.二叉树的最近公共祖先1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 123 KiB |
BIN
pics/236.二叉树的最近公共祖先2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
BIN
pics/42.接雨水4.png
{kind=link}
|
Before Width: | Height: | Size: 37 KiB After Width: | Height: | Size: 45 KiB |
BIN
pics/977.有序数组的平方.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 45 KiB |
@ -1,12 +1,15 @@
|
||||
# 题目链接
|
||||
|
||||
# 思路
|
||||
// 只要一个柱子的
|
||||
// 暴力的解法 都不好写啊
|
||||
// 找左面最大的, 找右边最大的,找左右边际的时候容易迷糊。我已开始还找左大于右的。 (还不够)
|
||||
// 每次记录单条,不要记录整个面积
|
||||
|
||||
## 暴力解法
|
||||
接雨水问题在面试中还是常见题目的,有必要好好讲一讲。
|
||||
|
||||
本文深度讲解如下三种方法:
|
||||
* 双指针法
|
||||
* 动态规划
|
||||
* 单调栈
|
||||
|
||||
## 双指针解法
|
||||
|
||||
这道题目暴力解法并不简单,我们来看一下思路。
|
||||
|
||||
@ -100,29 +103,93 @@ public:
|
||||
因为每次遍历列的时候,还要向两边寻找最高的列,所以时间复杂度为O(n^2)。
|
||||
空间复杂度为O(1)。
|
||||
|
||||
## 动态规划解法
|
||||
|
||||
# 单调栈
|
||||
在上面的双指针解法,我们可以看到,只要知道左边柱子的最高高度 和 记录右边柱子的最高高度,就可以计算当前位置的雨水面积,这也是也列来计算的。
|
||||
|
||||
单调栈究竟如何做呢,得画一个图,不太好理解
|
||||
即,当前列雨水面积:min(左边柱子的最高高度,记录右边柱子的最高高度) - 当前柱子高度
|
||||
|
||||
## 使用单调栈内元素的顺序
|
||||
为了的到两边的最高高度,使用了双指针来遍历,每到一个柱子都向两边遍历一波。
|
||||
|
||||
从打到小还是从小打到呢
|
||||
这其实是有重复计算的。
|
||||
|
||||
从栈底到栈头(元素从栈头弹出)是从大到小的顺序,因为一旦发现添加的柱子高度大于栈头元素了,此时就出现凹槽了,栈头元素就是凹槽底部的柱子,栈头第二个元素就是凹槽左边的柱子,而添加的元素就是凹槽右边的柱子。
|
||||
我们把每一个位置的左边最高高度记录在一个数组上(maxLeft),右边最高高度记录在一个数组上(maxRight)。
|
||||
|
||||
避免的重复计算,者就用到了动态规划。
|
||||
|
||||
当前位置,左边的最高高度,是前一个位置的最高高度和本高度的最大值。
|
||||
|
||||
即从左向右遍历:maxLeft[i] = max(height[i], maxLeft[i - 1]);
|
||||
|
||||
从右向左遍历:maxRight[i] = max(height[i], maxRight[i + 1]);
|
||||
|
||||
这样就找到递推公式。
|
||||
|
||||
是不是地推公式还挺简单的,其实动态规划就是这样,只要想到了递推公式,其实就比较简单了。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
int trap(vector<int>& height) {
|
||||
if (height.size() <= 2) return 0;
|
||||
vector<int> maxLeft(height.size(), 0);
|
||||
vector<int> maxRight(height.size(), 0);
|
||||
int size = maxRight.size();
|
||||
|
||||
// 记录每个柱子左边柱子最大高度
|
||||
maxLeft[0] = height[0];
|
||||
for (int i = 1; i < size; i++) {
|
||||
maxLeft[i] = max(height[i], maxLeft[i - 1]);
|
||||
}
|
||||
// 记录每个柱子右边柱子最大高度
|
||||
maxRight[size - 1] = height[size - 1];
|
||||
for (int i = size - 2; i >= 0; i--) {
|
||||
maxRight[i] = max(height[i], maxRight[i + 1]);
|
||||
}
|
||||
// 求和
|
||||
int sum = 0;
|
||||
for (int i = 0; i < size; i++) {
|
||||
int count = min(maxLeft[i], maxRight[i]) - height[i];
|
||||
if (count > 0) sum += count;
|
||||
}
|
||||
return sum;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
## 单调栈解法
|
||||
|
||||
这个解法可以说是最不好理解的了,所以下面我花了大量的篇幅来介绍这种方法。
|
||||
|
||||
单调栈就是保持栈内元素有序。和[栈与队列:单调队列](https://mp.weixin.qq.com/s/8c6l2bO74xyMjph09gQtpA)一样,需要我们自己维持顺序,没有现成的容器可以用。
|
||||
|
||||
|
||||
### 准备工作
|
||||
|
||||
那么本题使用单调栈有如下几个问题:
|
||||
|
||||
1. 使用单调栈内元素的顺序
|
||||
|
||||
从大到小还是从小打到呢?
|
||||
|
||||
要从栈底到栈头(元素从栈头弹出)是从大到小的顺序。
|
||||
|
||||
因为一旦发现添加的柱子高度大于栈头元素了,此时就出现凹槽了,栈头元素就是凹槽底部的柱子,栈头第二个元素就是凹槽左边的柱子,而添加的元素就是凹槽右边的柱子。
|
||||
|
||||
如图:
|
||||
|
||||
<img src='../pics/42.接雨水4.png' width=600> </img></div>
|
||||
|
||||
|
||||
## 遇到相同高度的柱子怎么办。
|
||||
2. 遇到相同高度的柱子怎么办。
|
||||
|
||||
遇到相同的元素,更新栈内下表,就是将栈里元素(旧下标)弹出,讲新元素(新下标)加入栈中。
|
||||
遇到相同的元素,更新栈内下表,就是将栈里元素(旧下标)弹出,将新元素(新下标)加入栈中。
|
||||
|
||||
例如 5 5 1 3 这种情况。如果添加第二个5的时候就应该将第一个5的下标弹出,把第二个5添加到栈中。
|
||||
|
||||
因为我们要求宽度的时候 如果遇到相容高度的柱子,需要使用最右边的柱子来计算宽度。
|
||||
因为我们要求宽度的时候 如果遇到相同高度的柱子,需要使用最右边的柱子来计算宽度。
|
||||
|
||||
如图所示:
|
||||
|
||||
@ -130,37 +197,102 @@ public:
|
||||
<img src='../pics/42.接雨水5.png' width=600> </img></div>
|
||||
|
||||
|
||||
3. 栈里要保存什么数值
|
||||
|
||||
是用单调栈,其实是通过 长 * 宽 来计算雨水面积的。
|
||||
|
||||
长就是通过柱子的高度来计算,宽是通过柱子之间的下表来计算,
|
||||
|
||||
没有必要 stack<pair<int, int>> st; // 高度,下表
|
||||
那么栈里有没有必要存一个pair<int, int>类型的元素,保存柱子的高度和下表呢。
|
||||
|
||||
其实不用,栈里就存放int类型的元素就行了,表示下表,想要知道对应的高度,通过height[stack.top()] 就知道弹出的下表对应的高度了。
|
||||
|
||||
放进去元素,相同怎么办,相同也没事,放里面就行,计算结果也是0
|
||||
所以栈的定义如下:
|
||||
|
||||
**真的难**
|
||||
```
|
||||
stack<int> st; // 存着下标,计算的时候用下标对应的柱子高度
|
||||
```
|
||||
|
||||
明确了如上几点,我们再来看处理逻辑。
|
||||
|
||||
### 单调栈处理逻辑
|
||||
|
||||
先将下表0的柱子加入到栈中,`st.push(0);`。
|
||||
|
||||
然后开始从下表1开始遍历所有的柱子,`for (int i = 1; i < height.size(); i++)`。
|
||||
|
||||
如果当前遍历的元素(柱子)高度小于栈顶元素的高度,就把这个元素加入栈中,因为栈里本来就要保持从大到小的顺序(从栈底到栈头)。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (height[i] < height[st.top()]) st.push(i);
|
||||
```
|
||||
|
||||
如果当前遍历的元素(柱子)高度等于栈顶元素的高度,要跟更新栈顶元素,因为遇到相相同高度的柱子,需要使用最右边的柱子来计算宽度。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (height[i] == height[st.top()]) { // 例如 5 5 1 7 这种情况
|
||||
st.pop();
|
||||
st.push(i);
|
||||
}
|
||||
```
|
||||
|
||||
如果当前遍历的元素(柱子)高度大于栈顶元素的高度,此时就出现凹槽了,如图所示:
|
||||
|
||||
<img src='../pics/42.接雨水4.png' width=600> </img></div>
|
||||
|
||||
取栈顶元素,将栈顶元素弹出,这个就是凹槽的底部,也就是中间位置,下表记为mid,对应的高度为height[mid](就是图中的高度1)。
|
||||
|
||||
栈顶元素st.top(),就是凹槽的左边位置,下表为st.top(),对应的高度为height[st.top()](就是图中的高度2)。
|
||||
|
||||
当前遍历的元素i,就是凹槽右边的位置,下表为i,对应的高度为height[i](就是图中的高度3)。
|
||||
|
||||
那么雨水高度是 min(凹槽左边高度, 凹槽右边高度) - 凹槽底部高度,代码为:`int h = min(height[st.top()], height[i]) - height[mid];`
|
||||
|
||||
雨水的宽度是 凹槽右边的下表 - 凹槽左边的下表 - 1(因为只求中间宽度),代码为:`int w = i - st.top() - 1 ;`
|
||||
|
||||
当前凹槽雨水的体积就是:`h * w`。
|
||||
|
||||
求当前凹槽雨水的体积代码如下:
|
||||
|
||||
```
|
||||
while (!st.empty() && height[i] > height[st.top()]) { // 注意这里是while,持续跟新栈顶元素
|
||||
int mid = st.top();
|
||||
st.pop();
|
||||
if (!st.empty()) {
|
||||
int h = min(height[st.top()], height[i]) - height[mid];
|
||||
int w = i - st.top() - 1; // 注意减一,只求中间宽度
|
||||
sum += h * w;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
关键部分讲完了,整体代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
int trap(vector<int>& height) {
|
||||
if (height.size() <= 2) return 0;
|
||||
if (height.size() <= 2) return 0; // 可以不加
|
||||
stack<int> st; // 存着下标,计算的时候用下标对应的柱子高度
|
||||
st.push(0);
|
||||
int sum = 0;
|
||||
for (int i = 1; i < height.size(); i++) {
|
||||
if (height[i] < height[st.top()]) {
|
||||
if (height[i] < height[st.top()]) { // 情况一
|
||||
st.push(i);
|
||||
} if (height[i] == height[st.top()]) { // 如果相等则更新栈内下表,例如 5 5 1 7 这种情况
|
||||
st.pop();
|
||||
} if (height[i] == height[st.top()]) { // 情况二
|
||||
st.pop(); // 其实这一句可以不加,效果是一样的,但处理相同的情况的思路却变了。
|
||||
st.push(i);
|
||||
} else {
|
||||
} else { // 情况三
|
||||
while (!st.empty() && height[i] > height[st.top()]) { // 注意这里是while
|
||||
int mid = st.top();
|
||||
st.pop();
|
||||
if (!st.empty()) {
|
||||
int h = min(height[st.top()], height[i]) - height[mid];
|
||||
int w = i - st.top() - 1 ; // 注意求宽度这里不加1,而是减一
|
||||
int w = i - st.top() - 1; // 注意减一,只求中间宽度
|
||||
sum += h * w;
|
||||
}
|
||||
}
|
||||
@ -171,3 +303,32 @@ public:
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
以上代码冗余了一些,但是思路是清晰的,下面我将代码精简一下,如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
int trap(vector<int>& height) {
|
||||
stack<int> st;
|
||||
st.push(0);
|
||||
int sum = 0;
|
||||
for (int i = 1; i < height.size(); i++) {
|
||||
while (!st.empty() && height[i] > height[st.top()]) {
|
||||
int mid = st.top();
|
||||
st.pop();
|
||||
if (!st.empty()) {
|
||||
int h = min(height[st.top()], height[i]) - height[mid];
|
||||
int w = i - st.top() - 1;
|
||||
sum += h * w;
|
||||
}
|
||||
}
|
||||
st.push(i);
|
||||
}
|
||||
return sum;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
精简之后的代码,大家就看不出去三种情况的处理了,貌似好像只处理的情况三,其实是把情况一和情况二融合了。 这样的代码不太利于理解。
|
||||
|
||||
|
||||
@ -2,6 +2,13 @@
|
||||
|
||||
> 递归函数什么时候需要返回值
|
||||
|
||||
相信很多同学都会疑惑,递归函数什么时候要有返回值,什么时候没有返回值,特别是有的时候递归函数返回类型为bool类型。那么
|
||||
|
||||
接下来我通过详细讲解如下两道题,来回答这个问题:
|
||||
|
||||
* 112. 路径总和
|
||||
* 113. 路径总和II
|
||||
|
||||
# 112. 路径总和
|
||||
|
||||
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
|
||||
@ -17,6 +24,7 @@
|
||||
|
||||
# 思路
|
||||
|
||||
|
||||
这道题我们要遍历从根节点到叶子节点的的路径看看总和是不是目标和。
|
||||
|
||||
## 递归
|
||||
|
||||
@ -1,17 +1,184 @@
|
||||
## 链接
|
||||
https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/
|
||||
|
||||
> 本来是打算将二叉树和二叉搜索树的公共祖先问题一起讲,后来发现篇幅过长了,只能先说一说二叉树的公共祖先问题。
|
||||
|
||||
# 236. 二叉树的最近公共祖先
|
||||
|
||||
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
|
||||
|
||||
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
|
||||
|
||||
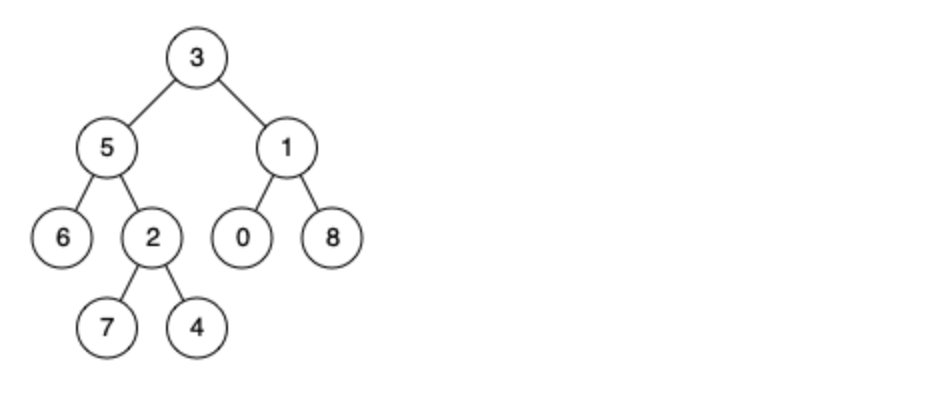
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
|
||||
|
||||
|
||||
|
||||
示例 1:
|
||||
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
|
||||
输出: 3
|
||||
解释: 节点 5 和节点 1 的最近公共祖先是节点 3。
|
||||
|
||||
示例 2:
|
||||
输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
|
||||
输出: 5
|
||||
解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。
|
||||
|
||||
说明:
|
||||
* 所有节点的值都是唯一的。
|
||||
* p、q 为不同节点且均存在于给定的二叉树中。
|
||||
|
||||
## 思路
|
||||
|
||||
与其说是递归,不如说是回溯。(要好好讲讲回溯)
|
||||
遇到这个题目首先想的是要是能自底向上查找就好了,这样就可以找到公共祖先了。
|
||||
|
||||
如果左孩子出现在左子树,右孩子出现在右子树,那么该节点为最近公共祖先。
|
||||
那么二叉树如何可以自底向上查找呢?
|
||||
|
||||
最后如果
|
||||
回溯啊,二叉树回溯的过程就是从低到上。
|
||||
|
||||
后序遍历就是天然的回溯过程,最先处理的一定是叶子节点。
|
||||
|
||||
接下来就看如何判断一个节点是节点q和节点p的公共公共祖先呢。
|
||||
|
||||
**如果找到一个节点,发现左子树出现结点p,右子树出现节点q,或者 左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先。**
|
||||
|
||||
使用后序遍历,回溯的过程,就是从低向上遍历节点,一旦发现如何这个条件的节点,就是最近公共节点了。
|
||||
|
||||
递归三部曲:
|
||||
|
||||
* 确定递归函数返回值以及参数
|
||||
|
||||
需要递归函数返回值,来告诉我们是否找到节点q或者p,那么返回值为bool类型就可以了。
|
||||
|
||||
但我们还要返回最近公共节点,可以利用上题目中返回值是TreeNode * ,那么如果遇到p或者q,就把q或者p返回,返回值不为空,就说明找到了q或者p。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
|
||||
```
|
||||
|
||||
* 确定终止条件
|
||||
|
||||
如果找到了 节点p或者q,或者遇到空节点,就返回。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (root == q || root == p || root == NULL) return root;
|
||||
```
|
||||
|
||||
* 确定单层递归逻辑
|
||||
|
||||
值得注意的是 本题函数有返回值,是因为回溯的过程需要递归函数的返回值做判断,但本题我们依然要遍历树的所有节点。
|
||||
|
||||
我们在[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)中说了 递归函数有返回值就是要遍历某一条边,但有返回值也要看如何处理返回值!
|
||||
|
||||
如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树呢?
|
||||
|
||||
搜索一条边的写法:
|
||||
|
||||
```
|
||||
if (递归函数(root->left)) return ;
|
||||
|
||||
if (递归函数(root->right)) return ;
|
||||
```
|
||||
|
||||
搜索整个树写法:
|
||||
|
||||
```
|
||||
left = 递归函数(root->left);
|
||||
right = 递归函数(root->right);
|
||||
left与right的逻辑处理;
|
||||
```
|
||||
|
||||
看出区别了没?
|
||||
|
||||
**在递归函数有返回值的情况下:如果要搜索一条边,递归函数返回值不为空的时候,立刻返回,如果搜索整个树,直接用一个变量left、right接住返回值,这个left、right后序还有逻辑处理的需要,也就是后序遍历中处理中间节点的逻辑(也是回溯)**。
|
||||
|
||||
那么为什么要遍历整颗树呢?直观上来看,找到最近公共祖先,直接一路返回就可以了。
|
||||
|
||||
如图:
|
||||
|
||||
<img src='../pics/236.二叉树的最近公共祖先.png' width=600> </img></div>
|
||||
|
||||
就像图中一样直接返回7,多美滋滋。
|
||||
|
||||
但事实上还要遍历根节点右子树(即使此时已经找到了目标节点了),也就是图中的节点4、15、20。
|
||||
|
||||
因为在如下代码的后序遍历中,如果想利用left和right做逻辑处理, 不能立刻返回,而是要等left与right逻辑处理完之后才能返回。
|
||||
|
||||
```
|
||||
left = 递归函数(root->left);
|
||||
right = 递归函数(root->right);
|
||||
left与right的逻辑处理;
|
||||
```
|
||||
|
||||
所以此时大家要知道我们要遍历整棵树。知道这一点,对本题就有一定深度的理解了。
|
||||
|
||||
|
||||
那么先用left和right接住左子树和右子树的返回值,代码如下:
|
||||
|
||||
## C++代码
|
||||
```
|
||||
TreeNode* left = lowestCommonAncestor(root->left, p, q);
|
||||
TreeNode* right = lowestCommonAncestor(root->right, p, q);
|
||||
|
||||
```
|
||||
|
||||
**如果left 和 right都不为空,说明此时root就是最近公共节点。这个比较好理解**
|
||||
|
||||
**如果left为空,right不为空,就返回right,说明目标节点是通过right返回的,反之依然**。
|
||||
|
||||
这里有的同学就理解不了了,为什么left为空,right不为空,目标节点通过right返回呢?
|
||||
|
||||
如图:
|
||||
|
||||
<img src='../pics/236.二叉树的最近公共祖先1.png' width=600> </img></div>
|
||||
|
||||
图中节点10的左子树返回null,右子树返回目标值7,那么此时节点10的处理逻辑就是把右子树的返回值(最近公共祖先7)返回上去!
|
||||
|
||||
这里点也很重要,可能刷过这道题目的同学,都不清楚结果究竟是如何从底层一层一层传到头结点的。
|
||||
|
||||
那么如果left和right都为空,则返回left或者right都是可以的,也就是返回空。
|
||||
|
||||
代码如下:
|
||||
|
||||
```
|
||||
if (left == NULL && right != NULL) return right;
|
||||
else if (left != NULL && right == NULL) return left;
|
||||
else { // (left == NULL && right == NULL)
|
||||
return NULL;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
那么寻找最小公共祖先,完整流程图如下:
|
||||
|
||||
<img src='../pics/236.二叉树的最近公共祖先2.png' width=600> </img></div>
|
||||
|
||||
**从图中,大家可以看到,我们是如何回溯遍历整颗二叉树,将结果返回给头结点的!**
|
||||
|
||||
整体代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
|
||||
if (root == q || root == p || root == NULL) return root;
|
||||
TreeNode* left = lowestCommonAncestor(root->left, p, q);
|
||||
TreeNode* right = lowestCommonAncestor(root->right, p, q);
|
||||
if (left != NULL && right != NULL) return root;
|
||||
|
||||
if (left == NULL && right != NULL) return right;
|
||||
else if (left != NULL && right == NULL) return left;
|
||||
else { // (left == NULL && right == NULL)
|
||||
return NULL;
|
||||
}
|
||||
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
稍加精简,代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
@ -26,3 +193,21 @@ public:
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 总结
|
||||
|
||||
这道题目刷过的同学未必真正了解这里面回溯的过程,以及结果是如何一层一层传上去的。
|
||||
|
||||
**那么我给大家归纳如下三点**:
|
||||
|
||||
1. 求最小公共祖先,需要从底向上遍历,那么二叉树,只能通过后序遍历(即:回溯)实现从低向上的遍历方式。
|
||||
|
||||
2. 在回溯的过程中,必然要遍历整颗二叉树,即使已经找到结果了,依然要把其他节点遍历完,因为要使用递归函数的返回值(也就是代码中的left和right)做逻辑判断。
|
||||
|
||||
3. 要理解如果返回值left为空,right不为空为什么要返回right,为什么可以用返回right传给上一层结果。
|
||||
|
||||
可以说这里每一步,都是有难度的,都需要对二叉树,递归和回溯有一定的理解。
|
||||
|
||||
本题没有给出迭代法,因为迭代法不适合模拟回溯的过程。理解递归的解法就够了。
|
||||
|
||||
**就酱,转发给身边需要学习的同学吧!**
|
||||
|
||||
75
problems/0977.有序数组的平方.md
Normal file
@ -0,0 +1,75 @@
|
||||
|
||||
## 思路
|
||||
|
||||
### 暴力排序
|
||||
|
||||
最直观的相反,莫过于:每个数平方之后,排个序,美滋滋,代码如下:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
vector<int> sortedSquares(vector<int>& A) {
|
||||
for (int i = 0; i < A.size(); i++) {
|
||||
A[i] *= A[i];
|
||||
}
|
||||
sort(A.begin(), A.end()); // 快速排序
|
||||
return A;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
这个时间复杂度是 O(n + nlogn), 可以说是O(nlogn)的时间复杂度,但为了和下面双指针法算法时间复杂度有鲜明对比,我记为 O(n + nlogn)。
|
||||
|
||||
### 双指针法
|
||||
|
||||
数组其实是有序的, 只不过负数平方之后可能成为最大数了。
|
||||
|
||||
那么数组平方的最大值就在数组的两端,不是最左边就是最右边,不可能是中间。
|
||||
|
||||
此时可以考虑双指针法了,i指向其实位置,j指向终止位置。
|
||||
|
||||
定义一个新数组result,和A数组一样的大小,让k指向result数组终止位置。
|
||||
|
||||
如果`A[i] * A[i] < A[j] * A[j]` 那么`result[k--] = A[j] * A[j];` 。
|
||||
|
||||
如果`A[i] * A[i] >= A[j] * A[j]` 那么`result[k--] = A[i] * A[i];` 。
|
||||
|
||||
如动画所示:
|
||||
|
||||
<img src='../video/977.有序数组的平方.gif' width=600> </img></div>
|
||||
|
||||
不难写出如下代码:
|
||||
|
||||
```
|
||||
class Solution {
|
||||
public:
|
||||
vector<int> sortedSquares(vector<int>& A) {
|
||||
int k = A.size() - 1;
|
||||
vector<int> result(A.size(), 0);
|
||||
for (int i = 0, j = A.size() - 1; i <= j;) { // 注意这里要i <= j,因为最后要处理两个元素
|
||||
if (A[i] * A[i] < A[j] * A[j]) {
|
||||
result[k--] = A[j] * A[j];
|
||||
j--;
|
||||
}
|
||||
else {
|
||||
result[k--] = A[i] * A[i];
|
||||
i++;
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
此时的时间复杂度为O(n),相对于暴力排序的解法O(n + nlogn)还是提升不少的。
|
||||
|
||||
效率如下:
|
||||
|
||||
<img src='../pics/977.有序数组的平方.png' width=600> </img></div>
|
||||
|
||||
**这里还是说一下,大家不必太在意leetcode上执行用时,打败多少多少用户,这个就是一个玩具,非常不准确。**
|
||||
|
||||
做题的时候自己能分析出来时间复杂度就可以了,至于leetcode上执行用时,大概看一下就行,只要达到最优的时间复杂度就可以了,
|
||||
|
||||
一样的代码多提交几次可能就击败百分之百了.....
|
||||
|
||||
BIN
video/977.有序数组的平方.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.3 MiB |