mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-09 03:34:02 +08:00
Merge branch 'master' into master
This commit is contained in:
@ -1,4 +1,4 @@
|
||||
👉 推荐 [在线阅读](http://programmercarl.com/) (Github在国内访问经常不稳定)
|
||||
👉 推荐 [在线阅读](http://programmercarl.com/) (Github在国内访问经常不稳定)
|
||||
👉 推荐 [Gitee同步](https://gitee.com/programmercarl/leetcode-master)
|
||||
|
||||
> 1. **介绍**:本项目是一套完整的刷题计划,旨在帮助大家少走弯路,循序渐进学算法,[关注作者](#关于作者)
|
||||
@ -494,6 +494,7 @@
|
||||
## 图论
|
||||
* [463.岛屿的周长](./problems/0463.岛屿的周长.md) (模拟)
|
||||
* [841.钥匙和房间](./problems/0841.钥匙和房间.md) 【有向图】dfs,bfs都可以
|
||||
* [127.单词接龙](./problems/0127.单词接龙.md) 广搜
|
||||
|
||||
## 并查集
|
||||
* [684.冗余连接](./problems/0684.冗余连接.md) 【并查集基础题目】
|
||||
|
||||
@ -191,33 +191,48 @@ class Solution {
|
||||
|
||||
python:
|
||||
|
||||
```python
|
||||
```python3
|
||||
class Solution:
|
||||
|
||||
def generateMatrix(self, n: int) -> List[List[int]]:
|
||||
left, right, up, down = 0, n-1, 0, n-1
|
||||
matrix = [ [0]*n for _ in range(n)]
|
||||
num = 1
|
||||
while left<=right and up<=down:
|
||||
# 填充左到右
|
||||
for i in range(left, right+1):
|
||||
matrix[up][i] = num
|
||||
num += 1
|
||||
up += 1
|
||||
# 填充上到下
|
||||
for i in range(up, down+1):
|
||||
matrix[i][right] = num
|
||||
num += 1
|
||||
right -= 1
|
||||
# 填充右到左
|
||||
for i in range(right, left-1, -1):
|
||||
matrix[down][i] = num
|
||||
num += 1
|
||||
down -= 1
|
||||
# 填充下到上
|
||||
for i in range(down, up-1, -1):
|
||||
matrix[i][left] = num
|
||||
num += 1
|
||||
# 初始化要填充的正方形
|
||||
matrix = [[0] * n for _ in range(n)]
|
||||
|
||||
left, right, up, down = 0, n - 1, 0, n - 1
|
||||
number = 1 # 要填充的数字
|
||||
|
||||
while left < right and up < down:
|
||||
|
||||
# 从左到右填充上边
|
||||
for x in range(left, right):
|
||||
matrix[up][x] = number
|
||||
number += 1
|
||||
|
||||
# 从上到下填充右边
|
||||
for y in range(up, down):
|
||||
matrix[y][right] = number
|
||||
number += 1
|
||||
|
||||
# 从右到左填充下边
|
||||
for x in range(right, left, -1):
|
||||
matrix[down][x] = number
|
||||
number += 1
|
||||
|
||||
# 从下到上填充左边
|
||||
for y in range(down, up, -1):
|
||||
matrix[y][left] = number
|
||||
number += 1
|
||||
|
||||
# 缩小要填充的范围
|
||||
left += 1
|
||||
right -= 1
|
||||
up += 1
|
||||
down -= 1
|
||||
|
||||
# 如果阶数为奇数,额外填充一次中心
|
||||
if n % 2:
|
||||
matrix[n // 2][n // 2] = number
|
||||
|
||||
return matrix
|
||||
```
|
||||
|
||||
|
||||
150
problems/0127.单词接龙.md
Normal file
150
problems/0127.单词接龙.md
Normal file
@ -0,0 +1,150 @@
|
||||
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/RsdcQ9umo09R6cfnwXZlrQ"><img src="https://img.shields.io/badge/PDF下载-代码随想录-blueviolet" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw"><img src="https://img.shields.io/badge/刷题-微信群-green" alt=""></a>
|
||||
<a href="https://space.bilibili.com/525438321"><img src="https://img.shields.io/badge/B站-代码随想录-orange" alt=""></a>
|
||||
<a href="https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ"><img src="https://img.shields.io/badge/知识星球-代码随想录-blue" alt=""></a>
|
||||
</p>
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
|
||||
# 127. 单词接龙
|
||||
|
||||
[力扣题目链接](https://leetcode-cn.com/problems/word-ladder/)
|
||||
|
||||
|
||||
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
|
||||
* 序列中第一个单词是 beginWord 。
|
||||
* 序列中最后一个单词是 endWord 。
|
||||
* 每次转换只能改变一个字母。
|
||||
* 转换过程中的中间单词必须是字典 wordList 中的单词。
|
||||
* 给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
|
||||
|
||||
|
||||
示例 1:
|
||||
|
||||
* 输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
|
||||
* 输出:5
|
||||
* 解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
|
||||
|
||||
示例 2:
|
||||
* 输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
|
||||
* 输出:0
|
||||
* 解释:endWord "cog" 不在字典中,所以无法进行转换。
|
||||
|
||||
|
||||
# 思路
|
||||
|
||||
以示例1为例,从这个图中可以看出 hit 到 cog的路线,不止一条,有三条,两条是最短的长度为5,一条长度为6。
|
||||
|
||||
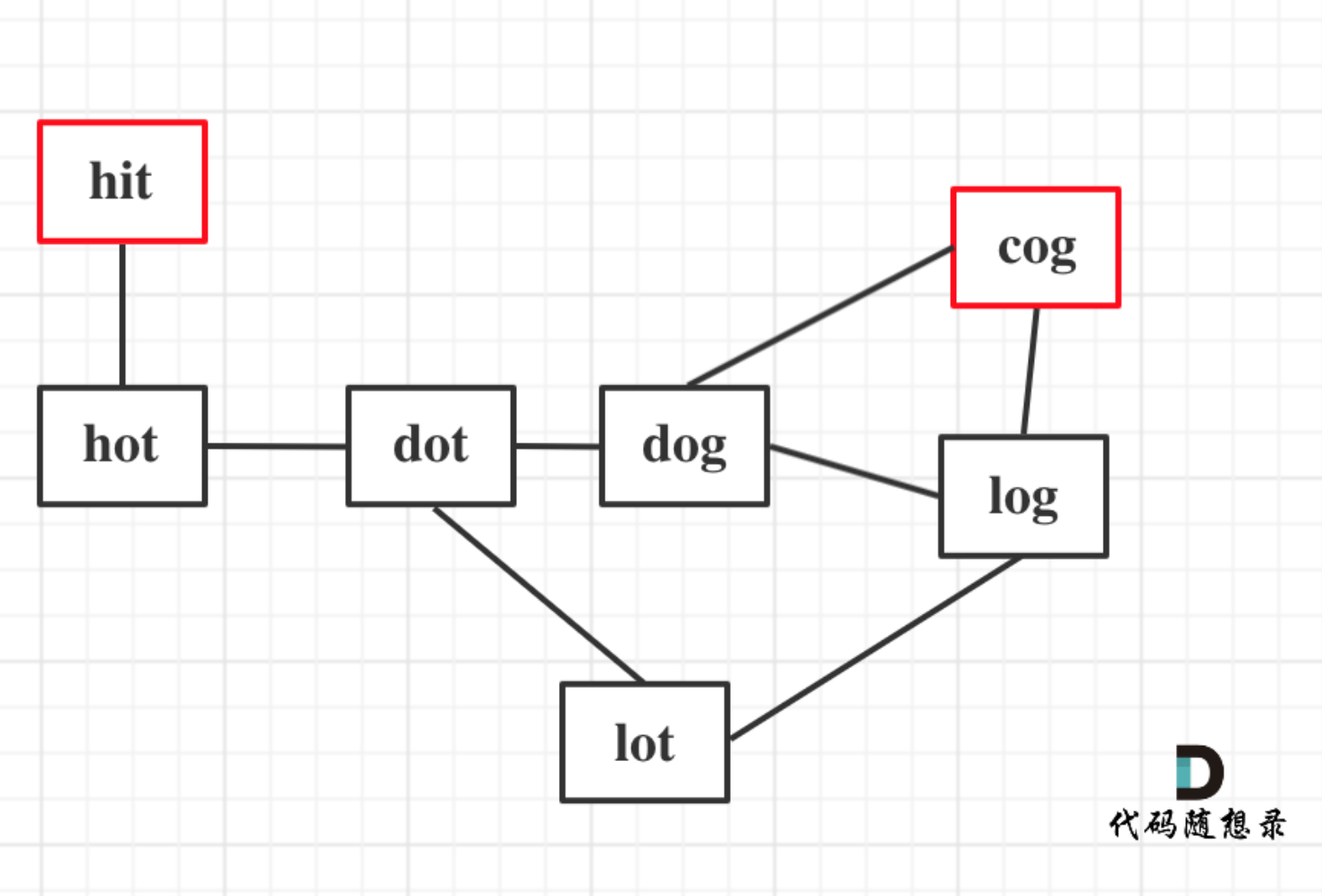
|
||||
|
||||
本题只需要求出最短长度就可以了,不用找出路径。
|
||||
|
||||
所以这道题要解决两个问题:
|
||||
|
||||
* 图中的线是如何连在一起的
|
||||
* 起点和终点的最短路径长度
|
||||
|
||||
|
||||
首先题目中并没有给出点与点之间的连线,而是要我们自己去连,条件是字符只能差一个,所以判断点与点之间的关系,要自己判断是不是差一个字符,如果差一个字符,那就是有链接。
|
||||
|
||||
然后就是求起点和终点的最短路径长度,**这里无向图求最短路,广搜最为合适,广搜只要搜到了终点,那么一定是最短的路径**。因为广搜就是以起点中心向四周扩散的搜索。
|
||||
|
||||
本题如果用深搜,会非常麻烦。
|
||||
|
||||
另外需要有一个注意点:
|
||||
|
||||
* 本题是一个无向图,需要用标记位,标记着节点是否走过,否则就会死循环!
|
||||
* 本题给出集合是数组型的,可以转成set结构,查找更快一些
|
||||
|
||||
C++代码如下:(详细注释)
|
||||
|
||||
```CPP
|
||||
class Solution {
|
||||
public:
|
||||
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
|
||||
// 将vector转成unordered_set,提高查询速度
|
||||
unordered_set<string> wordSet(wordList.begin(), wordList.end());
|
||||
// 如果endWord没有在wordSet出现,直接返回0
|
||||
if (wordSet.find(endWord) == wordSet.end()) return 0;
|
||||
// 记录word是否访问过
|
||||
unordered_map<string, int> visitMap; // <word, 查询到这个word路径长度>
|
||||
// 初始化队列
|
||||
queue<string> que;
|
||||
que.push(beginWord);
|
||||
// 初始化visitMap
|
||||
visitMap.insert(pair<string, int>(beginWord, 1));
|
||||
|
||||
while(!que.empty()) {
|
||||
string word = que.front();
|
||||
que.pop();
|
||||
int path = visitMap[word]; // 这个word的路径长度
|
||||
for (int i = 0; i < word.size(); i++) {
|
||||
string newWord = word; // 用一个新单词替换word,因为每次置换一个字母
|
||||
for (int j = 0 ; j < 26; j++) {
|
||||
newWord[i] = j + 'a';
|
||||
if (newWord == endWord) return path + 1; // 找到了end,返回path+1
|
||||
// wordSet出现了newWord,并且newWord没有被访问过
|
||||
if (wordSet.find(newWord) != wordSet.end()
|
||||
&& visitMap.find(newWord) == visitMap.end()) {
|
||||
// 添加访问信息
|
||||
visitMap.insert(pair<string, int>(newWord, path + 1));
|
||||
que.push(newWord);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
# 其他语言版本
|
||||
|
||||
## Java
|
||||
|
||||
```java
|
||||
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
|
||||
HashSet<String> wordSet = new HashSet<>(wordList); //转换为hashset 加快速度
|
||||
if (wordSet.size() == 0 || !wordSet.contains(endWord)) { //特殊情况判断
|
||||
return 0;
|
||||
}
|
||||
Queue<String> queue = new LinkedList<>(); //bfs 队列
|
||||
queue.offer(beginWord);
|
||||
Map<String, Integer> map = new HashMap<>(); //记录单词对应路径长度
|
||||
map.put(beginWord, 1);
|
||||
|
||||
while (!queue.isEmpty()) {
|
||||
String word = queue.poll(); //取出队头单词
|
||||
int path = map.get(word); //获取到该单词的路径长度
|
||||
for (int i = 0; i < word.length(); i++) { //遍历单词的每个字符
|
||||
char[] chars = word.toCharArray(); //将单词转换为char array,方便替换
|
||||
for (char k = 'a'; k <= 'z'; k++) { //从'a' 到 'z' 遍历替换
|
||||
chars[i] = k; //替换第i个字符
|
||||
String newWord = String.valueOf(chars); //得到新的字符串
|
||||
if (newWord.equals(endWord)) { //如果新的字符串值与endWord一致,返回当前长度+1
|
||||
return path + 1;
|
||||
}
|
||||
if (wordSet.contains(newWord) && !map.containsKey(newWord)) { //如果新单词在set中,但是没有访问过
|
||||
map.put(newWord, path + 1); //记录单词对应的路径长度
|
||||
queue.offer(newWord);//加入队尾
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return 0; //未找到
|
||||
}
|
||||
```
|
||||
|
||||
## Python
|
||||
|
||||
## Go
|
||||
|
||||
## JavaScript
|
||||
|
||||
|
||||
-----------------------
|
||||
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
|
||||
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
|
||||
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
|
||||
<div align="center"><img src=https://code-thinking.cdn.bcebos.com/pics/01二维码.jpg width=450> </img></div>
|
||||
@ -9,7 +9,7 @@
|
||||
|
||||
> 本来是打算将二叉树和二叉搜索树的公共祖先问题一起讲,后来发现篇幅过长了,只能先说一说二叉树的公共祖先问题。
|
||||
|
||||
## 236. 二叉树的最近公共祖先
|
||||
# 236. 二叉树的最近公共祖先
|
||||
|
||||
[力扣题目链接](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/)
|
||||
|
||||
@ -35,7 +35,7 @@
|
||||
* 所有节点的值都是唯一的。
|
||||
* p、q 为不同节点且均存在于给定的二叉树中。
|
||||
|
||||
## 思路
|
||||
# 思路
|
||||
|
||||
遇到这个题目首先想的是要是能自底向上查找就好了,这样就可以找到公共祖先了。
|
||||
|
||||
@ -202,7 +202,7 @@ public:
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
# 总结
|
||||
|
||||
这道题目刷过的同学未必真正了解这里面回溯的过程,以及结果是如何一层一层传上去的。
|
||||
|
||||
@ -219,10 +219,10 @@ public:
|
||||
本题没有给出迭代法,因为迭代法不适合模拟回溯的过程。理解递归的解法就够了。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
# 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
## Java
|
||||
```Java
|
||||
class Solution {
|
||||
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
|
||||
@ -261,14 +261,9 @@ class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
## Python
|
||||
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, x):
|
||||
# self.val = x
|
||||
# self.left = None
|
||||
# self.right = None
|
||||
//递归
|
||||
class Solution:
|
||||
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
|
||||
@ -280,7 +275,9 @@ class Solution:
|
||||
elif not left and right: return right //目标节点是通过right返回的
|
||||
else: return None //没找到
|
||||
```
|
||||
Go:
|
||||
|
||||
## Go
|
||||
|
||||
```Go
|
||||
func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
|
||||
// check
|
||||
@ -310,7 +307,8 @@ func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript版本:
|
||||
## JavaScript
|
||||
|
||||
```javascript
|
||||
var lowestCommonAncestor = function(root, p, q) {
|
||||
// 使用递归的方法
|
||||
|
||||
@ -29,7 +29,7 @@
|
||||
|
||||
与198.打家劫舍,213.打家劫舍II一样,关键是要讨论当前节点抢还是不抢。
|
||||
|
||||
如果抢了当前节点,两个孩子就不是动,如果没抢当前节点,就可以考虑抢左右孩子(**注意这里说的是“考虑”**)
|
||||
如果抢了当前节点,两个孩子就不能动,如果没抢当前节点,就可以考虑抢左右孩子(**注意这里说的是“考虑”**)
|
||||
|
||||
### 暴力递归
|
||||
|
||||
@ -91,7 +91,7 @@ public:
|
||||
|
||||
### 动态规划
|
||||
|
||||
在上面两种方法,其实对一个节点 投与不投得到的最大金钱都没有做记录,而是需要实时计算。
|
||||
在上面两种方法,其实对一个节点 偷与不偷得到的最大金钱都没有做记录,而是需要实时计算。
|
||||
|
||||
而动态规划其实就是使用状态转移容器来记录状态的变化,这里可以使用一个长度为2的数组,记录当前节点偷与不偷所得到的的最大金钱。
|
||||
|
||||
@ -121,7 +121,7 @@ vector<int> robTree(TreeNode* cur) {
|
||||
|
||||
2. 确定终止条件
|
||||
|
||||
在遍历的过程中,如果遇到空间点的话,很明显,无论偷还是不偷都是0,所以就返回
|
||||
在遍历的过程中,如果遇到空节点的话,很明显,无论偷还是不偷都是0,所以就返回
|
||||
```
|
||||
if (cur == NULL) return vector<int>{0, 0};
|
||||
```
|
||||
|
||||
@ -128,7 +128,10 @@ x = (S + sum) / 2
|
||||
if ((S + sum) % 2 == 1) return 0; // 此时没有方案
|
||||
```
|
||||
|
||||
**看到这种表达式,应该本能的反应,两个int相加数值可能溢出的问题,当然本题并没有溢出**。
|
||||
同时如果 S的绝对值已经大于sum,那么也是没有方案的。
|
||||
```CPP
|
||||
if (abs(S) > sum) return 0; // 此时没有方案
|
||||
```
|
||||
|
||||
再回归到01背包问题,为什么是01背包呢?
|
||||
|
||||
@ -200,7 +203,7 @@ public:
|
||||
int findTargetSumWays(vector<int>& nums, int S) {
|
||||
int sum = 0;
|
||||
for (int i = 0; i < nums.size(); i++) sum += nums[i];
|
||||
if (S > sum) return 0; // 此时没有方案
|
||||
if (abs(S) > sum) return 0; // 此时没有方案
|
||||
if ((S + sum) % 2 == 1) return 0; // 此时没有方案
|
||||
int bagSize = (S + sum) / 2;
|
||||
vector<int> dp(bagSize + 1, 0);
|
||||
|
||||
@ -9,7 +9,7 @@
|
||||
|
||||
> 二叉树上应该怎么求,二叉搜索树上又应该怎么求?
|
||||
|
||||
## 501.二叉搜索树中的众数
|
||||
# 501.二叉搜索树中的众数
|
||||
|
||||
[力扣题目链接](https://leetcode-cn.com/problems/find-mode-in-binary-search-tree/solution/)
|
||||
|
||||
@ -33,7 +33,7 @@
|
||||
|
||||
进阶:你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
|
||||
|
||||
## 思路
|
||||
# 思路
|
||||
|
||||
这道题目呢,递归法我从两个维度来讲。
|
||||
|
||||
@ -321,7 +321,7 @@ public:
|
||||
};
|
||||
```
|
||||
|
||||
## 总结
|
||||
# 总结
|
||||
|
||||
本题在递归法中,我给出了如果是普通二叉树,应该怎么求众数。
|
||||
|
||||
@ -340,12 +340,13 @@ public:
|
||||
> **需要强调的是 leetcode上的耗时统计是非常不准确的,看个大概就行,一样的代码耗时可以差百分之50以上**,所以leetcode的耗时统计别太当回事,知道理论上的效率优劣就行了。
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
# 其他语言版本
|
||||
|
||||
|
||||
Java:
|
||||
## Java
|
||||
|
||||
暴力法
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int[] findMode(FindModeInBinarySearchTree.TreeNode root) {
|
||||
@ -379,6 +380,8 @@ class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
中序遍历-不使用额外空间,利用二叉搜索树特性
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
ArrayList<Integer> resList;
|
||||
@ -427,15 +430,11 @@ class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
## Python
|
||||
|
||||
递归法
|
||||
|
||||
```python
|
||||
# Definition for a binary tree node.
|
||||
# class TreeNode:
|
||||
# def __init__(self, val=0, left=None, right=None):
|
||||
# self.val = val
|
||||
# self.left = left
|
||||
# self.right = right
|
||||
# 递归法
|
||||
class Solution:
|
||||
def findMode(self, root: TreeNode) -> List[int]:
|
||||
if not root: return
|
||||
@ -460,36 +459,11 @@ class Solution:
|
||||
return
|
||||
findNumber(root)
|
||||
return self.res
|
||||
```
|
||||
|
||||
|
||||
# 迭代法-中序遍历-使用额外空间map的方法:
|
||||
class Solution:
|
||||
def findMode(self, root: TreeNode) -> List[int]:
|
||||
stack = []
|
||||
cur = root
|
||||
pre = None
|
||||
dist = {}
|
||||
while cur or stack:
|
||||
if cur: # 指针来访问节点,访问到最底层
|
||||
stack.append(cur)
|
||||
cur = cur.left
|
||||
else: # 逐一处理节点
|
||||
cur = stack.pop()
|
||||
if cur.val in dist:
|
||||
dist[cur.val] += 1
|
||||
else:
|
||||
dist[cur.val] = 1
|
||||
pre = cur
|
||||
cur = cur.right
|
||||
|
||||
# 找出字典中最大的key
|
||||
res = []
|
||||
for key, value in dist.items():
|
||||
if (value == max(dist.values())):
|
||||
res.append(key)
|
||||
return res
|
||||
|
||||
# 迭代法-中序遍历-不使用额外空间,利用二叉搜索树特性:
|
||||
迭代法-中序遍历-不使用额外空间,利用二叉搜索树特性
|
||||
```python
|
||||
class Solution:
|
||||
def findMode(self, root: TreeNode) -> List[int]:
|
||||
stack = []
|
||||
@ -521,18 +495,11 @@ class Solution:
|
||||
return res
|
||||
|
||||
```
|
||||
Go:
|
||||
## Go
|
||||
|
||||
暴力法(非BSL)
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func findMode(root *TreeNode) []int {
|
||||
var history map[int]int
|
||||
var maxValue int
|
||||
@ -571,15 +538,7 @@ func traversal(root *TreeNode,history map[int]int){
|
||||
计数法,不使用额外空间,利用二叉树性质,中序遍历
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func findMode(root *TreeNode) []int {
|
||||
func findMode(root *TreeNode) []int {
|
||||
res := make([]int, 0)
|
||||
count := 1
|
||||
max := 1
|
||||
@ -611,8 +570,9 @@ func traversal(root *TreeNode,history map[int]int){
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript版本:
|
||||
使用额外空间map的方法:
|
||||
## JavaScript
|
||||
|
||||
使用额外空间map的方法
|
||||
```javascript
|
||||
var findMode = function(root) {
|
||||
// 使用递归中序遍历
|
||||
@ -649,8 +609,10 @@ var findMode = function(root) {
|
||||
}
|
||||
return res;
|
||||
};
|
||||
```
|
||||
```
|
||||
|
||||
不使用额外空间,利用二叉树性质,中序遍历(有序):
|
||||
|
||||
```javascript
|
||||
var findMode = function(root) {
|
||||
// 不使用额外空间,使用中序遍历,设置出现最大次数初始值为1
|
||||
|
||||
@ -9,6 +9,10 @@
|
||||
|
||||
# 673.最长递增子序列的个数
|
||||
|
||||
|
||||
[力扣题目链接](https://leetcode-cn.com/problems/number-of-longest-increasing-subsequence/)
|
||||
|
||||
|
||||
给定一个未排序的整数数组,找到最长递增子序列的个数。
|
||||
|
||||
示例 1:
|
||||
@ -224,16 +228,110 @@ public:
|
||||
## Java
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int findNumberOfLIS(int[] nums) {
|
||||
if (nums.length <= 1) return nums.length;
|
||||
int[] dp = new int[nums.length];
|
||||
for(int i = 0; i < dp.length; i++) dp[i] = 1;
|
||||
int[] count = new int[nums.length];
|
||||
for(int i = 0; i < count.length; i++) count[i] = 1;
|
||||
|
||||
int maxCount = 0;
|
||||
for (int i = 1; i < nums.length; i++) {
|
||||
for (int j = 0; j < i; j++) {
|
||||
if (nums[i] > nums[j]) {
|
||||
if (dp[j] + 1 > dp[i]) {
|
||||
dp[i] = dp[j] + 1;
|
||||
count[i] = count[j];
|
||||
} else if (dp[j] + 1 == dp[i]) {
|
||||
count[i] += count[j];
|
||||
}
|
||||
}
|
||||
if (dp[i] > maxCount) maxCount = dp[i];
|
||||
}
|
||||
}
|
||||
int result = 0;
|
||||
for (int i = 0; i < nums.length; i++) {
|
||||
if (maxCount == dp[i]) result += count[i];
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Python
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def findNumberOfLIS(self, nums: List[int]) -> int:
|
||||
size = len(nums)
|
||||
if size<= 1: return size
|
||||
|
||||
dp = [1 for i in range(size)]
|
||||
count = [1 for i in range(size)]
|
||||
|
||||
maxCount = 0
|
||||
for i in range(1, size):
|
||||
for j in range(i):
|
||||
if nums[i] > nums[j]:
|
||||
if dp[j] + 1 > dp[i] :
|
||||
dp[i] = dp[j] + 1
|
||||
count[i] = count[j]
|
||||
elif dp[j] + 1 == dp[i] :
|
||||
count[i] += count[j]
|
||||
if dp[i] > maxCount:
|
||||
maxCount = dp[i];
|
||||
result = 0
|
||||
for i in range(size):
|
||||
if maxCount == dp[i]:
|
||||
result += count[i]
|
||||
return result;
|
||||
```
|
||||
|
||||
## Go
|
||||
|
||||
```go
|
||||
|
||||
func findNumberOfLIS(nums []int) int {
|
||||
size := len(nums)
|
||||
if size <= 1 {
|
||||
return size
|
||||
}
|
||||
|
||||
dp := make([]int, size);
|
||||
for i, _ := range dp {
|
||||
dp[i] = 1
|
||||
}
|
||||
count := make([]int, size);
|
||||
for i, _ := range count {
|
||||
count[i] = 1
|
||||
}
|
||||
|
||||
maxCount := 0
|
||||
for i := 1; i < size; i++ {
|
||||
for j := 0; j < i; j++ {
|
||||
if nums[i] > nums[j] {
|
||||
if dp[j] + 1 > dp[i] {
|
||||
dp[i] = dp[j] + 1
|
||||
count[i] = count[j]
|
||||
} else if dp[j] + 1 == dp[i] {
|
||||
count[i] += count[j]
|
||||
}
|
||||
}
|
||||
if dp[i] > maxCount {
|
||||
maxCount = dp[i]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
result := 0
|
||||
for i := 0; i < size; i++ {
|
||||
if maxCount == dp[i] {
|
||||
result += count[i]
|
||||
}
|
||||
}
|
||||
return result
|
||||
}
|
||||
```
|
||||
|
||||
## JavaScript
|
||||
|
||||
@ -116,12 +116,10 @@ class Solution {
|
||||
}
|
||||
}
|
||||
// 如果K还大于0,那么反复转变数值最小的元素,将K用完
|
||||
|
||||
if (K % 2 == 1) nums[len - 1] = -nums[len - 1];
|
||||
int result = 0;
|
||||
for (int a : nums) {
|
||||
result += a;
|
||||
}
|
||||
return result;
|
||||
return Arrays.stream(nums).sum();
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@ -5,3 +5,7 @@
|
||||
**push代码之前 一定要 先pull最新代码**,否则提交的pr可能会有删除其他录友代码的操作。
|
||||
|
||||
一个pr 不要修改过多文件,因为一旦有一个 文件修改有问题,就不能合入,影响其他文件的合入了。
|
||||
|
||||
git add之前,要git diff 查看一下,本次提交所修改的代码是不是 自己修改的,是否 误删,或者误加的文件。
|
||||
|
||||
提交代码,不要使用git push -f 这种命令,要足够了解 -f 意味着什么。
|
||||
|
||||
@ -230,7 +230,7 @@ void test_2_wei_bag_problem1() {
|
||||
int bagWeight = 4;
|
||||
|
||||
// 二维数组
|
||||
vector<vector<int>> dp(weight.size() + 1, vector<int>(bagWeight + 1, 0));
|
||||
vector<vector<int>> dp(weight.size(), vector<int>(bagWeight + 1, 0));
|
||||
|
||||
// 初始化
|
||||
for (int j = weight[0]; j <= bagWeight; j++) {
|
||||
|
||||
@ -80,7 +80,7 @@ dp状态图如下:
|
||||
* [动态规划:关于01背包问题,你该了解这些!](https://programmercarl.com/背包理论基础01背包-1.html)
|
||||
* [动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://programmercarl.com/背包理论基础01背包-2.html)
|
||||
|
||||
就知道了,01背包中二维dp数组的两个for遍历的先后循序是可以颠倒了,一位dp数组的两个for循环先后循序一定是先遍历物品,再遍历背包容量。
|
||||
就知道了,01背包中二维dp数组的两个for遍历的先后循序是可以颠倒了,一维dp数组的两个for循环先后循序一定是先遍历物品,再遍历背包容量。
|
||||
|
||||
**在完全背包中,对于一维dp数组来说,其实两个for循环嵌套顺序同样无所谓!**
|
||||
|
||||
|
||||
Reference in New Issue
Block a user