mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-06 15:09:40 +08:00
Merge branch 'youngyangyang04:master' into master
This commit is contained in:
@ -256,7 +256,60 @@ public:
|
||||
* 时间复杂度:O(n^2)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
### Manacher 算法
|
||||
|
||||
Manacher 算法的关键在于高效利用回文的对称性,通过插入分隔符和维护中心、边界等信息,在线性时间内找到最长回文子串。这种方法避免了重复计算,是处理回文问题的最优解。
|
||||
|
||||
```c++
|
||||
//Manacher 算法
|
||||
class Solution {
|
||||
public:
|
||||
string longestPalindrome(string s) {
|
||||
// 预处理字符串,在每个字符之间插入 '#'
|
||||
string t = "#";
|
||||
for (char c : s) {
|
||||
t += c; // 添加字符
|
||||
t += '#';// 添加分隔符
|
||||
}
|
||||
int n = t.size();// 新字符串的长度
|
||||
vector<int> p(n, 0);// p[i] 表示以 t[i] 为中心的回文半径
|
||||
int center = 0, right = 0;// 当前回文的中心和右边界
|
||||
|
||||
|
||||
// 遍历预处理后的字符串
|
||||
for (int i = 0; i < n; i++) {
|
||||
// 如果当前索引在右边界内,利用对称性初始化 p[i]
|
||||
if (i < right) {
|
||||
p[i] = min(right - i, p[2 * center - i]);
|
||||
}
|
||||
// 尝试扩展回文
|
||||
while (i - p[i] - 1 >= 0 && i + p[i] + 1 < n && t[i - p[i] - 1] == t[i + p[i] + 1]) {
|
||||
p[i]++;// 增加回文半径
|
||||
}
|
||||
// 如果当前回文扩展超出右边界,更新中心和右边界
|
||||
if (i + p[i] > right) {
|
||||
center = i;// 更新中心
|
||||
right = i + p[i];// 更新右边界
|
||||
}
|
||||
}
|
||||
// 找到最大回文半径和对应的中心
|
||||
int maxLen = 0, centerIndex = 0;
|
||||
for (int i = 0; i < n; i++) {
|
||||
if (p[i] > maxLen) {
|
||||
maxLen = p[i];// 更新最大回文长度
|
||||
centerIndex = i;// 更新中心索引
|
||||
}
|
||||
}
|
||||
// 计算原字符串中回文子串的起始位置并返回
|
||||
return s.substr((centerIndex - maxLen) / 2, maxLen);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
@ -682,3 +735,4 @@ public class Solution {
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -201,6 +201,7 @@ class Solution {
|
||||
public void backtrack(int[] nums, LinkedList<Integer> path) {
|
||||
if (path.size() == nums.length) {
|
||||
result.add(new ArrayList<>(path));
|
||||
return;
|
||||
}
|
||||
for (int i =0; i < nums.length; i++) {
|
||||
// 如果path中已有,则跳过
|
||||
@ -524,3 +525,4 @@ public class Solution
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -214,6 +214,7 @@ class Solution:
|
||||
return result
|
||||
|
||||
```
|
||||
贪心法
|
||||
```python
|
||||
class Solution:
|
||||
def maxSubArray(self, nums):
|
||||
@ -226,9 +227,55 @@ class Solution:
|
||||
if count <= 0: # 相当于重置最大子序起始位置,因为遇到负数一定是拉低总和
|
||||
count = 0
|
||||
return result
|
||||
|
||||
|
||||
```
|
||||
动态规划
|
||||
```python
|
||||
class Solution:
|
||||
def maxSubArray(self, nums: List[int]) -> int:
|
||||
dp = [0] * len(nums)
|
||||
dp[0] = nums[0]
|
||||
res = nums[0]
|
||||
for i in range(1, len(nums)):
|
||||
dp[i] = max(dp[i-1] + nums[i], nums[i])
|
||||
res = max(res, dp[i])
|
||||
return res
|
||||
```
|
||||
|
||||
动态规划
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def maxSubArray(self, nums):
|
||||
if not nums:
|
||||
return 0
|
||||
dp = [0] * len(nums) # dp[i]表示包括i之前的最大连续子序列和
|
||||
dp[0] = nums[0]
|
||||
result = dp[0]
|
||||
for i in range(1, len(nums)):
|
||||
dp[i] = max(dp[i-1]+nums[i], nums[i]) # 状态转移公式
|
||||
if dp[i] > result:
|
||||
result = dp[i] # result 保存dp[i]的最大值
|
||||
return result
|
||||
```
|
||||
|
||||
动态规划优化
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def maxSubArray(self, nums: List[int]) -> int:
|
||||
max_sum = float("-inf") # 初始化结果为负无穷大,方便比较取最大值
|
||||
current_sum = 0 # 初始化当前连续和
|
||||
|
||||
for num in nums:
|
||||
|
||||
# 更新当前连续和
|
||||
# 如果原本的连续和加上当前数字之后没有当前数字大,说明原本的连续和是负数,那么就直接从当前数字开始重新计算连续和
|
||||
current_sum = max(current_sum+num, num)
|
||||
max_sum = max(max_sum, current_sum) # 更新结果
|
||||
|
||||
return max_sum
|
||||
```
|
||||
|
||||
### Go
|
||||
贪心法
|
||||
```go
|
||||
|
||||
@ -143,6 +143,23 @@ class Solution:
|
||||
return False
|
||||
```
|
||||
|
||||
```python
|
||||
## 基于当前最远可到达位置判断
|
||||
class Solution:
|
||||
def canJump(self, nums: List[int]) -> bool:
|
||||
far = nums[0]
|
||||
for i in range(len(nums)):
|
||||
# 要考虑两个情况
|
||||
# 1. i <= far - 表示 当前位置i 可以到达
|
||||
# 2. i > far - 表示 当前位置i 无法到达
|
||||
if i > far:
|
||||
return False
|
||||
far = max(far, nums[i]+i)
|
||||
# 如果循环正常结束,表示最后一个位置也可以到达,否则会在中途直接退出
|
||||
# 关键点在于,要想明白其实列表中的每个位置都是需要验证能否到达的
|
||||
return True
|
||||
```
|
||||
|
||||
### Go
|
||||
|
||||
```go
|
||||
|
||||
@ -184,6 +184,16 @@ if __name__ == '__main__':
|
||||
|
||||
### Go:
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"fmt"
|
||||
"os"
|
||||
"strconv"
|
||||
"strings"
|
||||
)
|
||||
|
||||
func climbStairs(n int, m int) int {
|
||||
dp := make([]int, n+1)
|
||||
dp[0] = 1
|
||||
|
||||
@ -467,9 +467,37 @@ class Solution:
|
||||
num = int(s[start:end+1])
|
||||
return 0 <= num <= 255
|
||||
|
||||
回溯(版本三)
|
||||
|
||||
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def restoreIpAddresses(self, s: str) -> List[str]:
|
||||
result = []
|
||||
self.backtracking(s, 0, [], result)
|
||||
return result
|
||||
|
||||
def backtracking(self, s, startIndex, path, result):
|
||||
if startIndex == len(s):
|
||||
result.append('.'.join(path[:]))
|
||||
return
|
||||
|
||||
for i in range(startIndex, min(startIndex+3, len(s))):
|
||||
# 如果 i 往后遍历了,并且当前地址的第一个元素是 0 ,就直接退出
|
||||
if i > startIndex and s[startIndex] == '0':
|
||||
break
|
||||
# 比如 s 长度为 5,当前遍历到 i = 3 这个元素
|
||||
# 因为还没有执行任何操作,所以此时剩下的元素数量就是 5 - 3 = 2 ,即包括当前的 i 本身
|
||||
# path 里面是当前包含的子串,所以有几个元素就表示储存了几个地址
|
||||
# 所以 (4 - len(path)) * 3 表示当前路径至多能存放的元素个数
|
||||
# 4 - len(path) 表示至少要存放的元素个数
|
||||
if (4 - len(path)) * 3 < len(s) - i or 4 - len(path) > len(s) - i:
|
||||
break
|
||||
if i - startIndex == 2:
|
||||
if not int(s[startIndex:i+1]) <= 255:
|
||||
break
|
||||
path.append(s[startIndex:i+1])
|
||||
self.backtracking(s, i+1, path, result)
|
||||
path.pop()
|
||||
```
|
||||
|
||||
### Go
|
||||
|
||||
@ -609,10 +609,13 @@ class Solution:
|
||||
while stack:
|
||||
node = stack.pop()
|
||||
if node:
|
||||
stack.append(node)
|
||||
stack.append(node) # 中
|
||||
stack.append(None)
|
||||
if node.left: stack.append(node.left)
|
||||
if node.right: stack.append(node.right)
|
||||
# 采用数组进行迭代,先将右节点加入,保证左节点能够先出栈
|
||||
if node.right: # 右
|
||||
stack.append(node.right)
|
||||
if node.left: # 左
|
||||
stack.append(node.left)
|
||||
else:
|
||||
real_node = stack.pop()
|
||||
left, right = height_map.get(real_node.left, 0), height_map.get(real_node.right, 0)
|
||||
|
||||
@ -158,7 +158,7 @@ i从0开始累加rest[i],和记为curSum,一旦curSum小于零,说明[0, i
|
||||
|
||||
如果 curSum<0 说明 区间和1 + 区间和2 < 0, 那么 假设从上图中的位置开始计数curSum不会小于0的话,就是 区间和2>0。
|
||||
|
||||
区间和1 + 区间和2 < 0 同时 区间和2>0,只能说明区间和1 < 0, 那么就会从假设的箭头初就开始从新选择其实位置了。
|
||||
区间和1 + 区间和2 < 0 同时 区间和2>0,只能说明区间和1 < 0, 那么就会从假设的箭头初就开始从新选择起始位置了。
|
||||
|
||||
|
||||
**那么局部最优:当前累加rest[i]的和curSum一旦小于0,起始位置至少要是i+1,因为从i之前开始一定不行。全局最优:找到可以跑一圈的起始位置**。
|
||||
|
||||
@ -177,21 +177,20 @@ class Solution {
|
||||
```python
|
||||
class Solution:
|
||||
def candy(self, ratings: List[int]) -> int:
|
||||
candyVec = [1] * len(ratings)
|
||||
n = len(ratings)
|
||||
candies = [1] * n
|
||||
|
||||
# 从前向后遍历,处理右侧比左侧评分高的情况
|
||||
for i in range(1, len(ratings)):
|
||||
# Forward pass: handle cases where right rating is higher than left
|
||||
for i in range(1, n):
|
||||
if ratings[i] > ratings[i - 1]:
|
||||
candyVec[i] = candyVec[i - 1] + 1
|
||||
candies[i] = candies[i - 1] + 1
|
||||
|
||||
# 从后向前遍历,处理左侧比右侧评分高的情况
|
||||
for i in range(len(ratings) - 2, -1, -1):
|
||||
# Backward pass: handle cases where left rating is higher than right
|
||||
for i in range(n - 2, -1, -1):
|
||||
if ratings[i] > ratings[i + 1]:
|
||||
candyVec[i] = max(candyVec[i], candyVec[i + 1] + 1)
|
||||
candies[i] = max(candies[i], candies[i + 1] + 1)
|
||||
|
||||
# 统计结果
|
||||
result = sum(candyVec)
|
||||
return result
|
||||
return sum(candies)
|
||||
|
||||
```
|
||||
|
||||
|
||||
@ -108,7 +108,7 @@ public:
|
||||
}
|
||||
}
|
||||
|
||||
int result = st.top();
|
||||
long long result = st.top();
|
||||
st.pop(); // 把栈里最后一个元素弹出(其实不弹出也没事)
|
||||
return result;
|
||||
}
|
||||
|
||||
@ -440,11 +440,10 @@ class Solution {
|
||||
```Python
|
||||
class Solution:
|
||||
def reverseWords(self, s: str) -> str:
|
||||
# 删除前后空白
|
||||
s = s.strip()
|
||||
# 反转整个字符串
|
||||
s = s[::-1]
|
||||
# 将字符串拆分为单词,并反转每个单词
|
||||
# split()函数能够自动忽略多余的空白字符
|
||||
s = ' '.join(word[::-1] for word in s.split())
|
||||
return s
|
||||
|
||||
@ -475,7 +474,45 @@ class Solution:
|
||||
words = words[::-1] # 反转单词
|
||||
return ' '.join(words) #列表转换成字符串
|
||||
```
|
||||
(版本四) 将字符串转换为列表后,使用双指针去除空格
|
||||
```python
|
||||
class Solution:
|
||||
def single_reverse(self, s, start: int, end: int):
|
||||
while start < end:
|
||||
s[start], s[end] = s[end], s[start]
|
||||
start += 1
|
||||
end -= 1
|
||||
|
||||
def reverseWords(self, s: str) -> str:
|
||||
result = ""
|
||||
fast = 0
|
||||
# 1. 首先将原字符串反转并且除掉空格, 并且加入到新的字符串当中
|
||||
# 由于Python字符串的不可变性,因此只能转换为列表进行处理
|
||||
s = list(s)
|
||||
s.reverse()
|
||||
while fast < len(s):
|
||||
if s[fast] != " ":
|
||||
if len(result) != 0:
|
||||
result += " "
|
||||
while s[fast] != " " and fast < len(s):
|
||||
result += s[fast]
|
||||
fast += 1
|
||||
else:
|
||||
fast += 1
|
||||
# 2.其次将每个单词进行翻转操作
|
||||
slow = 0
|
||||
fast = 0
|
||||
result = list(result)
|
||||
while fast <= len(result):
|
||||
if fast == len(result) or result[fast] == " ":
|
||||
self.single_reverse(result, slow, fast - 1)
|
||||
slow = fast + 1
|
||||
fast += 1
|
||||
else:
|
||||
fast += 1
|
||||
|
||||
return "".join(result)
|
||||
```
|
||||
### Go:
|
||||
|
||||
版本一:
|
||||
@ -991,3 +1028,4 @@ public string ReverseWords(string s) {
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -534,6 +534,30 @@ public class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
### Ruby:
|
||||
|
||||
```ruby
|
||||
# @param {Integer} n
|
||||
# @return {Boolean}
|
||||
def is_happy(n)
|
||||
@occurred_nums = Set.new
|
||||
|
||||
while true
|
||||
n = next_value(n)
|
||||
|
||||
return true if n == 1
|
||||
|
||||
return false if @occurred_nums.include?(n)
|
||||
|
||||
@occurred_nums << n
|
||||
end
|
||||
end
|
||||
|
||||
def next_value(n)
|
||||
n.to_s.chars.sum { |char| char.to_i ** 2 }
|
||||
end
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -459,11 +459,10 @@ class Solution:
|
||||
|
||||
queue = collections.deque([root])
|
||||
while queue:
|
||||
for i in range(len(queue)):
|
||||
node = queue.popleft()
|
||||
node.left, node.right = node.right, node.left
|
||||
if node.left: queue.append(node.left)
|
||||
if node.right: queue.append(node.right)
|
||||
node = queue.popleft()
|
||||
node.left, node.right = node.right, node.left
|
||||
if node.left: queue.append(node.left)
|
||||
if node.right: queue.append(node.right)
|
||||
return root
|
||||
|
||||
```
|
||||
@ -1033,4 +1032,3 @@ public TreeNode InvertTree(TreeNode root) {
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -454,7 +454,11 @@ impl Solution {
|
||||
p: Option<Rc<RefCell<TreeNode>>>,
|
||||
q: Option<Rc<RefCell<TreeNode>>>,
|
||||
) -> Option<Rc<RefCell<TreeNode>>> {
|
||||
if root == p || root == q || root.is_none() {
|
||||
if root.is_none() {
|
||||
return root;
|
||||
}
|
||||
if Rc::ptr_eq(root.as_ref().unwrap(), p.as_ref().unwrap())
|
||||
|| Rc::ptr_eq(root.as_ref().unwrap(), q.as_ref().unwrap()) {
|
||||
return root;
|
||||
}
|
||||
let left = Self::lowest_common_ancestor(
|
||||
|
||||
@ -337,6 +337,29 @@ pub fn length_of_lis(nums: Vec<i32>) -> i32 {
|
||||
}
|
||||
```
|
||||
|
||||
### Cangjie:
|
||||
|
||||
```cangjie
|
||||
func lengthOfLIS(nums: Array<Int64>): Int64 {
|
||||
let n = nums.size
|
||||
if (n <= 1) {
|
||||
return n
|
||||
}
|
||||
|
||||
let dp = Array(n, item: 1)
|
||||
var res = 0
|
||||
for (i in 1..n) {
|
||||
for (j in 0..i) {
|
||||
if (nums[i] > nums[j]) {
|
||||
dp[i] = max(dp[i], dp[j] + 1)
|
||||
}
|
||||
}
|
||||
res = max(dp[i], res)
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
@ -388,6 +388,90 @@ class Solution:
|
||||
|
||||
### Go
|
||||
|
||||
暴力递归
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
func rob(root *TreeNode) int {
|
||||
if root == nil {
|
||||
return 0
|
||||
}
|
||||
if root.Left == nil && root.Right == nil {
|
||||
return root.Val
|
||||
}
|
||||
// 偷父节点
|
||||
val1 := root.Val
|
||||
if root.Left != nil {
|
||||
val1 += rob(root.Left.Left) + rob(root.Left.Right) // 跳过root->left,相当于不考虑左孩子了
|
||||
}
|
||||
if root.Right != nil {
|
||||
val1 += rob(root.Right.Left) + rob(root.Right.Right) // 跳过root->right,相当于不考虑右孩子了
|
||||
}
|
||||
// 不偷父节点
|
||||
val2 := rob(root.Left) + rob(root.Right) // 考虑root的左右孩子
|
||||
return max(val1, val2)
|
||||
}
|
||||
|
||||
func max(x, y int) int {
|
||||
if x > y {
|
||||
return x
|
||||
}
|
||||
return y
|
||||
}
|
||||
```
|
||||
|
||||
记忆化递推
|
||||
|
||||
```go
|
||||
/**
|
||||
* Definition for a binary tree node.
|
||||
* type TreeNode struct {
|
||||
* Val int
|
||||
* Left *TreeNode
|
||||
* Right *TreeNode
|
||||
* }
|
||||
*/
|
||||
var umap = make(map[*TreeNode]int)
|
||||
|
||||
func rob(root *TreeNode) int {
|
||||
if root == nil {
|
||||
return 0
|
||||
}
|
||||
if root.Left == nil && root.Right == nil {
|
||||
return root.Val
|
||||
}
|
||||
if val, ok := umap[root]; ok {
|
||||
return val // 如果umap里已经有记录则直接返回
|
||||
}
|
||||
// 偷父节点
|
||||
val1 := root.Val
|
||||
if root.Left != nil {
|
||||
val1 += rob(root.Left.Left) + rob(root.Left.Right) // 跳过root->left,相当于不考虑左孩子了
|
||||
}
|
||||
if root.Right != nil {
|
||||
val1 += rob(root.Right.Left) + rob(root.Right.Right) // 跳过root->right,相当于不考虑右孩子了
|
||||
}
|
||||
// 不偷父节点
|
||||
val2 := rob(root.Left) + rob(root.Right) // 考虑root的左右孩子
|
||||
umap[root] = max(val1, val2) // umap记录一下结果
|
||||
return max(val1, val2)
|
||||
}
|
||||
|
||||
func max(x, y int) int {
|
||||
if x > y {
|
||||
return x
|
||||
}
|
||||
return y
|
||||
}
|
||||
```
|
||||
|
||||
动态规划
|
||||
|
||||
```go
|
||||
|
||||
@ -243,6 +243,29 @@ class Solution {
|
||||
}
|
||||
}
|
||||
```
|
||||
贪心
|
||||
```Java
|
||||
class Solution {
|
||||
public int integerBreak(int n) {
|
||||
// with 贪心
|
||||
// 通过数学原理拆出更多的3乘积越大,则
|
||||
/**
|
||||
@Param: an int, the integer we need to break.
|
||||
@Return: an int, the maximum integer after breaking
|
||||
@Method: Using math principle to solve this problem
|
||||
@Time complexity: O(1)
|
||||
**/
|
||||
if(n == 2) return 1;
|
||||
if(n == 3) return 2;
|
||||
int result = 1;
|
||||
while(n > 4) {
|
||||
n-=3;
|
||||
result *=3;
|
||||
}
|
||||
return result*n;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Python
|
||||
动态规划(版本一)
|
||||
|
||||
@ -26,7 +26,7 @@
|
||||
|
||||
## 算法公开课
|
||||
|
||||
**[《代码随想录》算法视频公开课](https://programmercarl.com/other/gongkaike.html):[调整二叉树的结构最难!| LeetCode:450.删除二叉搜索树中的节点](https://www.bilibili.com/video/BV1tP41177us?share_source=copy_web),相信结合视频在看本篇题解,更有助于大家对本题的理解**。
|
||||
**[《代码随想录》算法视频公开课](https://programmercarl.com/other/gongkaike.html):[调整二叉树的结构最难!| LeetCode:450.删除二叉搜索树中的节点](https://www.bilibili.com/video/BV1tP41177us?share_source=copy_web),相信结合视频再看本篇题解,更有助于大家对本题的理解**。
|
||||
|
||||
## 思路
|
||||
|
||||
|
||||
@ -110,7 +110,7 @@ public:
|
||||
```
|
||||
|
||||
* 时间复杂度:O(nlog n),因为有一个快排
|
||||
* 空间复杂度:O(1),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
|
||||
* 空间复杂度:O(n),有一个快排,最差情况(倒序)时,需要n次递归调用。因此确实需要O(n)的栈空间
|
||||
|
||||
可以看出代码并不复杂。
|
||||
|
||||
@ -180,19 +180,25 @@ class Solution:
|
||||
```python
|
||||
class Solution: # 不改变原数组
|
||||
def findMinArrowShots(self, points: List[List[int]]) -> int:
|
||||
if len(points) == 0:
|
||||
return 0
|
||||
|
||||
points.sort(key = lambda x: x[0])
|
||||
sl,sr = points[0][0],points[0][1]
|
||||
|
||||
# points已经按照第一个坐标正序排列,因此只需要设置一个变量,记录右侧坐标(阈值)
|
||||
# 考虑一个气球范围包含两个不相交气球的情况:气球1: [1, 10], 气球2: [2, 5], 气球3: [6, 10]
|
||||
curr_min_right = points[0][1]
|
||||
count = 1
|
||||
|
||||
for i in points:
|
||||
if i[0]>sr:
|
||||
count+=1
|
||||
sl,sr = i[0],i[1]
|
||||
if i[0] > curr_min_right:
|
||||
# 当气球左侧大于这个阈值,那么一定就需要在发射一只箭,并且将阈值更新为当前气球的右侧
|
||||
count += 1
|
||||
curr_min_right = i[1]
|
||||
else:
|
||||
sl = max(sl,i[0])
|
||||
sr = min(sr,i[1])
|
||||
# 否则的话,我们只需要求阈值和当前气球的右侧的较小值来更新阈值
|
||||
curr_min_right = min(curr_min_right, i[1])
|
||||
return count
|
||||
|
||||
|
||||
```
|
||||
### Go
|
||||
```go
|
||||
|
||||
@ -488,6 +488,44 @@ int fourSumCount(int* nums1, int nums1Size, int* nums2, int nums2Size, int* nums
|
||||
}
|
||||
```
|
||||
|
||||
### Ruby:
|
||||
|
||||
```ruby
|
||||
# @param {Integer[]} nums1
|
||||
# @param {Integer[]} nums2
|
||||
# @param {Integer[]} nums3
|
||||
# @param {Integer[]} nums4
|
||||
# @return {Integer}
|
||||
# 新思路:和版主的思路基本相同,只是对后面两个数组的二重循环,用一个方法调用外加一重循环替代,简化了一点。
|
||||
# 简单的说,就是把四数和变成了两个两数和的统计(结果放到两个 hash 中),然后再来一次两数和为0.
|
||||
# 把四个数分成两组两个数,然后分别计算每组可能的和情况,分别存入 hash 中,key 是 和,value 是 数量;
|
||||
# 最后,得到的两个 hash 只需要遍历一次,符合和为零的 value 相乘并加总。
|
||||
def four_sum_count(nums1, nums2, nums3, nums4)
|
||||
num_to_count_1 = two_sum_mapping(nums1, nums2)
|
||||
num_to_count_2 = two_sum_mapping(nums3, nums4)
|
||||
|
||||
count_sum = 0
|
||||
|
||||
num_to_count_1.each do |num, count|
|
||||
count_sum += num_to_count_2[-num] * count # 反查另一个 hash,看有没有匹配的,没有的话,hash 默认值为 0,不影响加总;有匹配的,乘积就是可能的情况
|
||||
end
|
||||
|
||||
count_sum
|
||||
end
|
||||
|
||||
def two_sum_mapping(nums1, nums2)
|
||||
num_to_count = Hash.new(0)
|
||||
|
||||
nums1.each do |num1|
|
||||
nums2.each do |nums2|
|
||||
num_to_count[num1 + nums2] += 1 # 统计和为 num1 + nums2 的有几个
|
||||
end
|
||||
end
|
||||
|
||||
num_to_count
|
||||
end
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -64,7 +64,7 @@
|
||||
|
||||
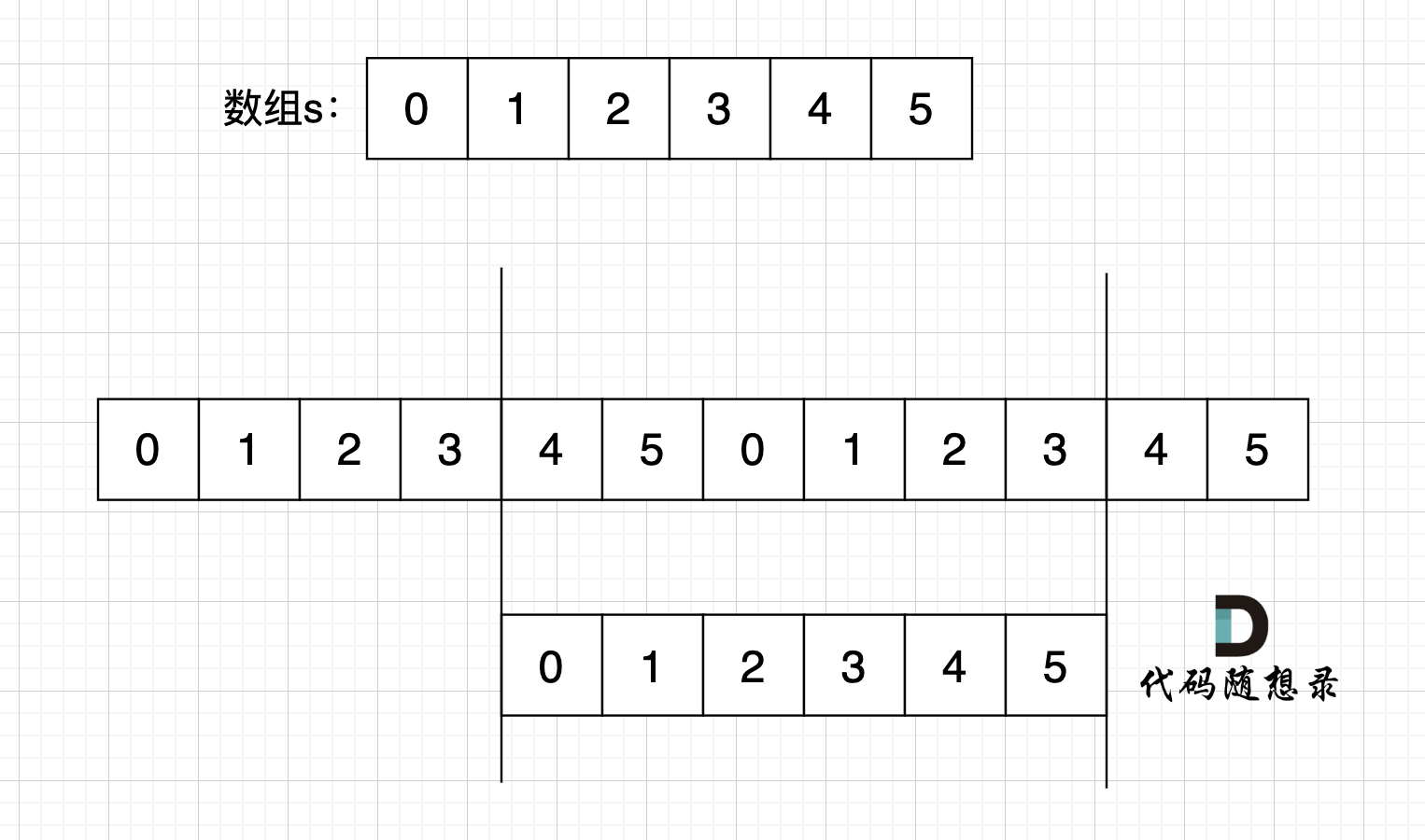
如果有一个字符串s,在 s + s 拼接后, 不算首尾字符,如果能凑成s字符串,说明s 一定是重复子串组成。
|
||||
|
||||
如图,字符串s,图中数字为数组下标,在 s + s 拼接后, 不算首尾字符,中间凑成s字符串。
|
||||
如图,字符串s,图中数字为数组下标,在 s + s 拼接后, 不算首尾字符,中间凑成s字符串。 (图中数字为数组下标)
|
||||
|
||||
|
||||
|
||||
@ -163,9 +163,7 @@ KMP算法中next数组为什么遇到字符不匹配的时候可以找到上一
|
||||
|
||||
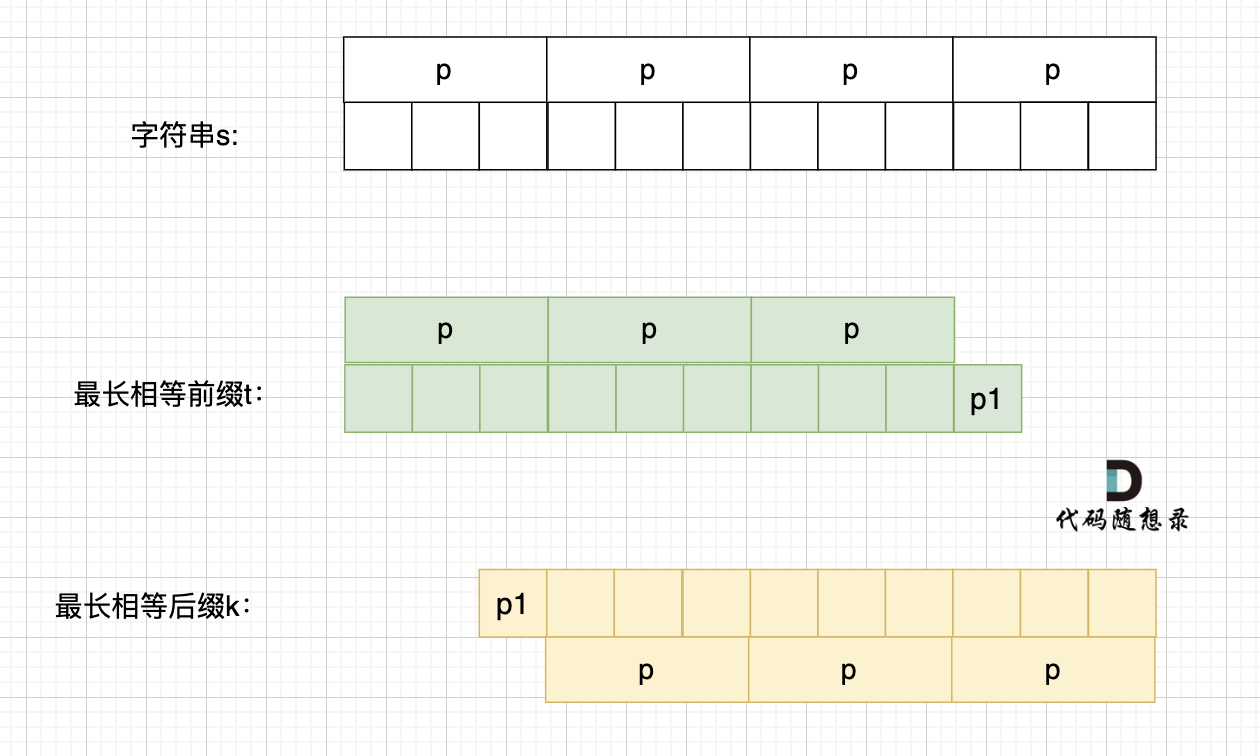
如果一个字符串s是由重复子串组成,那么 最长相等前后缀不包含的子串一定是字符串s的最小重复子串。
|
||||
|
||||
证明: 如果s 是有是有最小重复子串p组成。
|
||||
|
||||
即 s = n * p
|
||||
如果s 是由最小重复子串p组成,即 s = n * p
|
||||
|
||||
那么相同前后缀可以是这样:
|
||||
|
||||
@ -179,7 +177,7 @@ KMP算法中next数组为什么遇到字符不匹配的时候可以找到上一
|
||||
|
||||

|
||||
|
||||
这里有录友就想:如果字符串s 是有是有最小重复子串p组成,最长相等前后缀就不能更长一些? 例如这样:
|
||||
这里有录友就想:如果字符串s 是由最小重复子串p组成,最长相等前后缀就不能更长一些? 例如这样:
|
||||
|
||||
|
||||
|
||||
@ -203,12 +201,14 @@ p2 = p1,p3 = p2 即: p1 = p2 = p3
|
||||
|
||||
最长相等前后缀不包含的子串已经是字符串s的最小重复子串,那么字符串s一定由重复子串组成,这个不需要证明了。
|
||||
|
||||
关键是要要证明:最长相等前后缀不包含的子串什么时候才是字符串s的最小重复子串呢。
|
||||
关键是要证明:最长相等前后缀不包含的子串什么时候才是字符串s的最小重复子串呢。
|
||||
|
||||
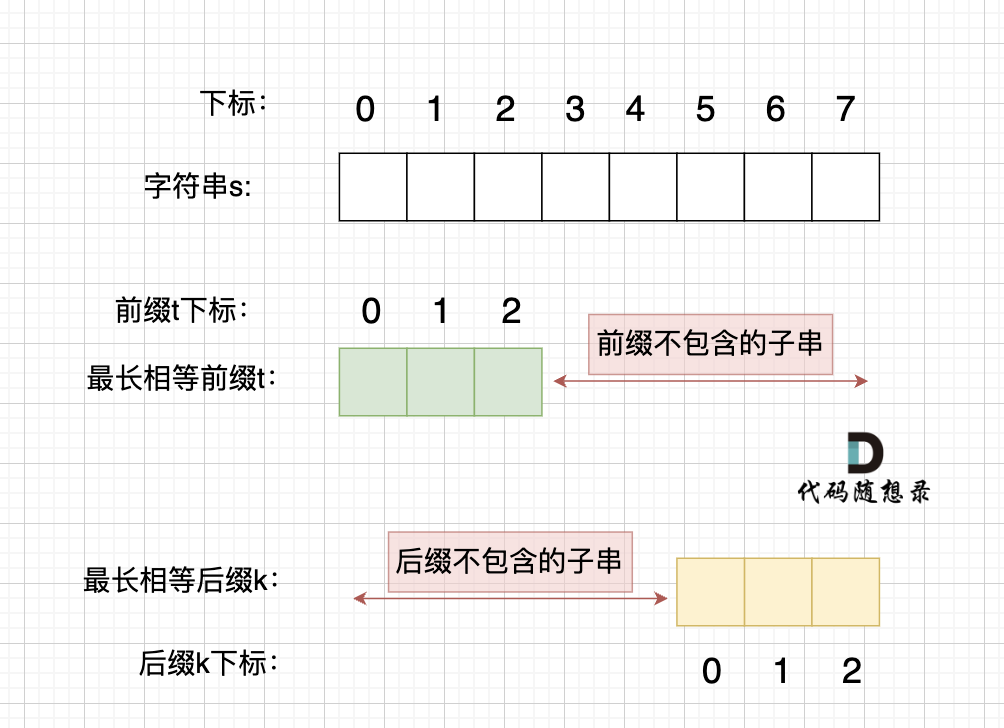
情况一, 最长相等前后缀不包含的子串的长度 比 字符串s的一半的长度还大,那一定不是字符串s的重复子串
|
||||
情况一, 最长相等前后缀不包含的子串的长度 比 字符串s的一半的长度还大,那一定不是字符串s的重复子串,如图:
|
||||
|
||||
|
||||
|
||||
图中:前后缀不包含的子串的长度 大于 字符串s的长度的 二分之一
|
||||
|
||||
--------------
|
||||
|
||||
情况二,最长相等前后缀不包含的子串的长度 可以被 字符串s的长度整除,如图:
|
||||
@ -230,7 +230,7 @@ p2 = p1,p3 = p2 即: p1 = p2 = p3
|
||||
即 s[0]s[1] 是最小重复子串
|
||||
|
||||
|
||||
以上推导中,录友可能想,你怎么知道 s[0] 和 s[1] 就不相同呢? s[0] 为什么就不能使最小重复子串。
|
||||
以上推导中,录友可能想,你怎么知道 s[0] 和 s[1] 就不相同呢? s[0] 为什么就不能是最小重复子串。
|
||||
|
||||
如果 s[0] 和 s[1] 也相同,同时 s[0]s[1]与s[2]s[3]相同,s[2]s[3] 与 s[4]s[5]相同,s[4]s[5] 与 s[6]s[7] 相同,那么这个字符串就是有一个字符构成的字符串。
|
||||
|
||||
@ -246,7 +246,7 @@ p2 = p1,p3 = p2 即: p1 = p2 = p3
|
||||
|
||||
或者说,自己举个例子,`aaaaaa`,这个字符串,他的最长相等前后缀是什么?
|
||||
|
||||
同上以上推导,最长相等前后缀不包含的子串的长度只要被 字符串s的长度整除,就是一定是最小重复子串。
|
||||
同上以上推导,最长相等前后缀不包含的子串的长度只要被 字符串s的长度整除,最长相等前后缀不包含的子串一定是最小重复子串。
|
||||
|
||||
----------------
|
||||
|
||||
@ -267,7 +267,7 @@ p2 = p1,p3 = p2 即: p1 = p2 = p3
|
||||
|
||||
以上推导,可以得出 s[0],s[1],s[2] 与 s[3],s[4],s[5] 相同,s[3]s[4] 与 s[6]s[7]相同。
|
||||
|
||||
那么 最长相等前后缀不包含的子串的长度 不被 字符串s的长度整除 ,就不是s的重复子串
|
||||
那么 最长相等前后缀不包含的子串的长度 不被 字符串s的长度整除 ,最长相等前后缀不包含的子串就不是s的重复子串
|
||||
|
||||
-----------
|
||||
|
||||
@ -277,7 +277,7 @@ p2 = p1,p3 = p2 即: p1 = p2 = p3
|
||||
|
||||
在必要条件,这个是 显而易见的,都已经假设 最长相等前后缀不包含的子串 是 s的最小重复子串了,那s必然是重复子串。
|
||||
|
||||
关键是需要证明, 字符串s的最长相等前后缀不包含的子串 什么时候才是 s最小重复子串。
|
||||
**关键是需要证明, 字符串s的最长相等前后缀不包含的子串 什么时候才是 s最小重复子串**。
|
||||
|
||||
同上我们证明了,当 最长相等前后缀不包含的子串的长度 可以被 字符串s的长度整除,那么不包含的子串 就是s的最小重复子串。
|
||||
|
||||
@ -312,7 +312,7 @@ next 数组记录的就是最长相同前后缀( [字符串:KMP算法精讲]
|
||||
|
||||
4可以被 12(字符串的长度) 整除,所以说明有重复的子字符串(asdf)。
|
||||
|
||||
### 打码实现
|
||||
### 代码实现
|
||||
|
||||
C++代码如下:(这里使用了前缀表统一减一的实现方式)
|
||||
|
||||
@ -884,3 +884,4 @@ public int[] GetNext(string s)
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -706,6 +706,57 @@ class Solution:
|
||||
```
|
||||
|
||||
### Go
|
||||
二维dp
|
||||
```go
|
||||
func findTargetSumWays(nums []int, target int) int {
|
||||
sum := 0
|
||||
for _, v := range nums {
|
||||
sum += v
|
||||
}
|
||||
if math.Abs(float64(target)) > float64(sum) {
|
||||
return 0 // 此时没有方案
|
||||
}
|
||||
if (target + sum) % 2 == 1 {
|
||||
return 0 // 此时没有方案
|
||||
}
|
||||
bagSize := (target + sum) / 2
|
||||
|
||||
dp := make([][]int, len(nums))
|
||||
for i := range dp {
|
||||
dp[i] = make([]int, bagSize + 1)
|
||||
}
|
||||
|
||||
// 初始化最上行
|
||||
if nums[0] <= bagSize {
|
||||
dp[0][nums[0]] = 1
|
||||
}
|
||||
|
||||
// 初始化最左列,最左列其他数值在递推公式中就完成了赋值
|
||||
dp[0][0] = 1
|
||||
|
||||
var numZero float64
|
||||
for i := range nums {
|
||||
if nums[i] == 0 {
|
||||
numZero++
|
||||
}
|
||||
dp[i][0] = int(math.Pow(2, numZero))
|
||||
}
|
||||
|
||||
// 以下遍历顺序行列可以颠倒
|
||||
for i := 1; i < len(nums); i++ { // 行,遍历物品
|
||||
for j := 0; j <= bagSize; j++ { // 列,遍历背包
|
||||
if nums[i] > j {
|
||||
dp[i][j] = dp[i-1][j]
|
||||
} else {
|
||||
dp[i][j] = dp[i-1][j] + dp[i-1][j-nums[i]]
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[len(nums)-1][bagSize]
|
||||
}
|
||||
```
|
||||
|
||||
一维dp
|
||||
```go
|
||||
func findTargetSumWays(nums []int, target int) int {
|
||||
sum := 0
|
||||
|
||||
@ -168,23 +168,43 @@ for (int j = 0; j <= amount; j++) { // 遍历背包容量
|
||||
class Solution {
|
||||
public:
|
||||
int change(int amount, vector<int>& coins) {
|
||||
vector<int> dp(amount + 1, 0);
|
||||
dp[0] = 1;
|
||||
vector<uint64_t> dp(amount + 1, 0); // 防止相加数据超int
|
||||
dp[0] = 1; // 只有一种方式达到0
|
||||
for (int i = 0; i < coins.size(); i++) { // 遍历物品
|
||||
for (int j = coins[i]; j <= amount; j++) { // 遍历背包
|
||||
dp[j] += dp[j - coins[i]];
|
||||
}
|
||||
}
|
||||
return dp[amount];
|
||||
return dp[amount]; // 返回组合数
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
C++测试用例有两个数相加超过int的数据,所以需要在if里加上dp[i] < INT_MAX - dp[i - num]。
|
||||
|
||||
* 时间复杂度: O(mn),其中 m 是amount,n 是 coins 的长度
|
||||
* 空间复杂度: O(m)
|
||||
|
||||
为了防止相加的数据 超int 也可以这么写:
|
||||
|
||||
```CPP
|
||||
class Solution {
|
||||
public:
|
||||
int change(int amount, vector<int>& coins) {
|
||||
vector<int> dp(amount + 1, 0);
|
||||
dp[0] = 1; // 只有一种方式达到0
|
||||
for (int i = 0; i < coins.size(); i++) { // 遍历物品
|
||||
for (int j = coins[i]; j <= amount; j++) { // 遍历背包
|
||||
if (dp[j] < INT_MAX - dp[j - coins[i]]) { //防止相加数据超int
|
||||
dp[j] += dp[j - coins[i]];
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[amount]; // 返回组合数
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
是不是发现代码如此精简
|
||||
|
||||
## 总结
|
||||
|
||||
@ -268,6 +288,7 @@ class Solution:
|
||||
|
||||
### Go:
|
||||
|
||||
一维dp
|
||||
```go
|
||||
func change(amount int, coins []int) int {
|
||||
// 定义dp数组
|
||||
@ -286,6 +307,29 @@ func change(amount int, coins []int) int {
|
||||
return dp[amount]
|
||||
}
|
||||
```
|
||||
二维dp
|
||||
```go
|
||||
func change(amount int, coins []int) int {
|
||||
dp := make([][]int, len(coins))
|
||||
for i := range dp {
|
||||
dp[i] = make([]int, amount + 1)
|
||||
dp[i][0] = 1
|
||||
}
|
||||
for j := coins[0]; j <= amount; j++ {
|
||||
dp[0][j] += dp[0][j-coins[0]]
|
||||
}
|
||||
for i := 1; i < len(coins); i++ {
|
||||
for j := 1; j <= amount; j++ {
|
||||
if j < coins[i] {
|
||||
dp[i][j] = dp[i-1][j]
|
||||
} else {
|
||||
dp[i][j] = dp[i][j-coins[i]] + dp[i-1][j]
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[len(coins)-1][amount]
|
||||
}
|
||||
```
|
||||
|
||||
### Rust:
|
||||
|
||||
|
||||
@ -37,7 +37,7 @@
|
||||
|
||||
因为要找的也就是每2 * k 区间的起点,这样写,程序会高效很多。
|
||||
|
||||
**所以当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。**
|
||||
**所以当需要固定规律一段一段去处理字符串的时候,要想想在for循环的表达式上做做文章。**
|
||||
|
||||
性能如下:
|
||||
<img src='https://code-thinking.cdn.bcebos.com/pics/541_反转字符串II.png' width=600> </img></div>
|
||||
@ -505,3 +505,4 @@ impl Solution {
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
@ -492,6 +492,25 @@ int findLengthOfLCIS(int* nums, int numsSize) {
|
||||
}
|
||||
```
|
||||
|
||||
### Cangjie
|
||||
|
||||
```cangjie
|
||||
func findLengthOfLCIS(nums: Array<Int64>): Int64 {
|
||||
let n = nums.size
|
||||
if (n <= 1) {
|
||||
return n
|
||||
}
|
||||
let dp = Array(n, repeat: 1)
|
||||
var res = 0
|
||||
for (i in 1..n) {
|
||||
if (nums[i] > nums[i - 1]) {
|
||||
dp[i] = dp[i - 1] + 1
|
||||
}
|
||||
res = max(res, dp[i])
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
@ -43,7 +43,7 @@
|
||||
|
||||
在[贪心算法:122.买卖股票的最佳时机II](https://programmercarl.com/0122.买卖股票的最佳时机II.html)中使用贪心策略不用关心具体什么时候买卖,只要收集每天的正利润,最后稳稳的就是最大利润了。
|
||||
|
||||
而本题有了手续费,就要关系什么时候买卖了,因为计算所获得利润,需要考虑买卖利润可能不足以手续费的情况。
|
||||
而本题有了手续费,就要关心什么时候买卖了,因为计算所获得利润,需要考虑买卖利润可能不足以扣减手续费的情况。
|
||||
|
||||
如果使用贪心策略,就是最低值买,最高值(如果算上手续费还盈利)就卖。
|
||||
|
||||
@ -122,7 +122,7 @@ public:
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(n)
|
||||
|
||||
当然可以对空间经行优化,因为当前状态只是依赖前一个状态。
|
||||
当然可以对空间进行优化,因为当前状态只是依赖前一个状态。
|
||||
|
||||
C++ 代码如下:
|
||||
|
||||
|
||||
@ -46,7 +46,7 @@
|
||||
* 时间复杂度:O(n)
|
||||
* 空间复杂度:O(1)
|
||||
|
||||
本题使用贪心算法并不好理解,也很容易出错,那么我们再来看看是使用动规的方法如何解题。
|
||||
本题使用贪心算法并不好理解,也很容易出错,那么我们再来看看使用动规的方法如何解题。
|
||||
|
||||
相对于[动态规划:122.买卖股票的最佳时机II](https://programmercarl.com/0122.买卖股票的最佳时机II(动态规划).html),本题只需要在计算卖出操作的时候减去手续费就可以了,代码几乎是一样的。
|
||||
|
||||
@ -54,7 +54,7 @@
|
||||
|
||||
这里重申一下dp数组的含义:
|
||||
|
||||
dp[i][0] 表示第i天持有股票所省最多现金。
|
||||
dp[i][0] 表示第i天持有股票所得最多现金。
|
||||
dp[i][1] 表示第i天不持有股票所得最多现金
|
||||
|
||||
|
||||
|
||||
@ -581,6 +581,25 @@ int findLength(int* nums1, int nums1Size, int* nums2, int nums2Size) {
|
||||
}
|
||||
```
|
||||
|
||||
### Cangjie
|
||||
|
||||
```cangjie
|
||||
func findLength(nums1: Array<Int64>, nums2: Array<Int64>): Int64 {
|
||||
let n = nums1.size
|
||||
let m = nums2.size
|
||||
let dp = Array(n + 1, {_ => Array(m + 1, item: 0)})
|
||||
var res = 0
|
||||
for (i in 1..=n) {
|
||||
for (j in 1..=m) {
|
||||
if (nums1[i - 1] == nums2[j - 1]) {
|
||||
dp[i][j] = dp[i - 1][j - 1] + 1
|
||||
}
|
||||
res = max(res, dp[i][j])
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
|
||||
@ -100,6 +100,7 @@ public:
|
||||
## 其他语言版本
|
||||
|
||||
### Java:
|
||||
|
||||
排序法
|
||||
```Java
|
||||
class Solution {
|
||||
@ -209,6 +210,43 @@ class Solution:
|
||||
return new_list[::-1]
|
||||
```
|
||||
|
||||
```python3
|
||||
(双指针优化版本) 三步优化
|
||||
class Solution:
|
||||
def sortedSquares(self, nums: List[int]) -> List[int]:
|
||||
"""
|
||||
整体思想:有序数组的绝对值最大值永远在两头,比较两头,平方大的插到新数组的最后
|
||||
优 化:1. 优化所有元素为非正或非负的情况
|
||||
2. 头尾平方的大小比较直接将头尾相加与0进行比较即可
|
||||
3. 新的平方排序数组的插入索引可以用倒序插入实现(针对for循环,while循环不适用)
|
||||
"""
|
||||
|
||||
# 特殊情况, 元素都非负(优化1)
|
||||
if nums[0] >= 0:
|
||||
return [num ** 2 for num in nums] # 按顺序平方即可
|
||||
# 最后一个非正,全负有序的
|
||||
if nums[-1] <= 0:
|
||||
return [x ** 2 for x in nums[::-1]] # 倒序平方后的数组
|
||||
|
||||
# 一般情况, 有正有负
|
||||
i = 0 # 原数组头索引
|
||||
j = len(nums) - 1 # 原数组尾部索引
|
||||
new_nums = [0] * len(nums) # 新建一个等长数组用于保存排序后的结果
|
||||
# end_index = len(nums) - 1 # 新的排序数组(是新数组)尾插索引, 每次需要减一(优化3优化了)
|
||||
|
||||
for end_index in range(len(nums)-1, -1, -1): # (优化3,倒序,不用单独创建变量)
|
||||
# if nums[i] ** 2 >= nums[j] ** 2:
|
||||
if nums[i] + nums[j] <= 0: # (优化2)
|
||||
new_nums[end_index] = nums[i] ** 2
|
||||
i += 1
|
||||
# end_index -= 1 (优化3)
|
||||
else:
|
||||
new_nums[end_index] = nums[j] ** 2
|
||||
j -= 1
|
||||
# end_index -= 1 (优化3)
|
||||
return new_nums
|
||||
```
|
||||
|
||||
### Go:
|
||||
|
||||
```Go
|
||||
|
||||
@ -164,7 +164,7 @@ class Solution {
|
||||
int top = -1;
|
||||
for (int i = 0; i < s.length(); i++) {
|
||||
char c = s.charAt(i);
|
||||
// 当 top > 0,即栈中有字符时,当前字符如果和栈中字符相等,弹出栈顶字符,同时 top--
|
||||
// 当 top >= 0,即栈中有字符时,当前字符如果和栈中字符相等,弹出栈顶字符,同时 top--
|
||||
if (top >= 0 && res.charAt(top) == c) {
|
||||
res.deleteCharAt(top);
|
||||
top--;
|
||||
|
||||
@ -399,6 +399,25 @@ int longestCommonSubsequence(char* text1, char* text2) {
|
||||
}
|
||||
```
|
||||
|
||||
### Cangjie
|
||||
|
||||
```cangjie
|
||||
func longestCommonSubsequence(text1: String, text2: String): Int64 {
|
||||
let n = text1.size
|
||||
let m = text2.size
|
||||
let dp = Array(n + 1, {_ => Array(m + 1, repeat: 0)})
|
||||
for (i in 1..=n) {
|
||||
for (j in 1..=m) {
|
||||
if (text1[i - 1] == text2[j - 1]) {
|
||||
dp[i][j] = dp[i - 1][j - 1] + 1
|
||||
} else {
|
||||
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
|
||||
}
|
||||
}
|
||||
}
|
||||
return dp[n][m]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
|
||||
@ -869,6 +869,65 @@ if __name__ == "__main__":
|
||||
|
||||
### Javascript
|
||||
|
||||
```js
|
||||
function dijkstra(grid, start, end) {
|
||||
const visited = Array.from({length: end + 1}, () => false)
|
||||
const minDist = Array.from({length: end + 1}, () => Number.MAX_VALUE)
|
||||
minDist[start] = 0
|
||||
|
||||
for (let i = 1 ; i < end + 1 ; i++) {
|
||||
let cur = -1
|
||||
let tempMinDist = Number.MAX_VALUE
|
||||
// 1. 找尋與起始點距離最近且未被訪的節點
|
||||
for (let j = 1 ; j < end + 1 ; j++) {
|
||||
if (!visited[j] && minDist[j] < tempMinDist) {
|
||||
cur = j
|
||||
tempMinDist = minDist[j]
|
||||
}
|
||||
}
|
||||
if (cur === -1) break;
|
||||
|
||||
// 2. 更新節點狀態為已拜訪
|
||||
visited[cur] = true
|
||||
|
||||
// 3. 更新未拜訪節點與起始點的最短距離
|
||||
for (let j = 1 ; j < end + 1 ; j++) {
|
||||
if(!visited[j] && grid[cur][j] != Number.MAX_VALUE
|
||||
&& grid[cur][j] + minDist[cur] < minDist[j]
|
||||
) {
|
||||
minDist[j] = grid[cur][j] + minDist[cur]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return minDist[end] === Number.MAX_VALUE ? -1 : minDist[end]
|
||||
}
|
||||
|
||||
|
||||
async function main() {
|
||||
// 輸入
|
||||
const rl = require('readline').createInterface({ input: process.stdin })
|
||||
const iter = rl[Symbol.asyncIterator]()
|
||||
const readline = async () => (await iter.next()).value
|
||||
const [n, m] = (await readline()).split(" ").map(Number)
|
||||
const grid = Array.from({length: n + 1},
|
||||
() => Array.from({length:n + 1}, () => Number.MAX_VALUE))
|
||||
for (let i = 0 ; i < m ; i++) {
|
||||
const [s, e, w] = (await readline()).split(" ").map(Number)
|
||||
grid[s][e] = w
|
||||
}
|
||||
|
||||
// dijkstra
|
||||
const result = dijkstra(grid, 1, n)
|
||||
|
||||
// 輸出
|
||||
console.log(result)
|
||||
}
|
||||
|
||||
|
||||
main()
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
### PhP
|
||||
|
||||
@ -549,6 +549,62 @@ if __name__ == "__main__":
|
||||
|
||||
### Javascript
|
||||
|
||||
```js
|
||||
function kruskal(v, edges) {
|
||||
const father = Array.from({ length: v + 1 }, (_, i) => i)
|
||||
|
||||
function find(u){
|
||||
if (u === father[u]) {
|
||||
return u
|
||||
} else {
|
||||
father[u] = find(father[u])
|
||||
return father[u]
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
function isSame(u, v) {
|
||||
let s = find(u)
|
||||
let t = find(v)
|
||||
return s === t
|
||||
}
|
||||
|
||||
function join(u, v) {
|
||||
let s = find(u)
|
||||
let t = find(v)
|
||||
if (s !== t) {
|
||||
father[s] = t
|
||||
}
|
||||
}
|
||||
|
||||
edges.sort((a, b) => a[2] - b[2])
|
||||
let result = 0
|
||||
for (const [v1, v2, w] of edges) {
|
||||
if (!isSame(v1, v2)) {
|
||||
result += w
|
||||
join(v1 ,v2)
|
||||
}
|
||||
}
|
||||
console.log(result)
|
||||
}
|
||||
|
||||
|
||||
async function main() {
|
||||
const rl = require('readline').createInterface({ input: process.stdin })
|
||||
const iter = rl[Symbol.asyncIterator]()
|
||||
const readline = async () => (await iter.next()).value
|
||||
const [v, e] = (await readline()).split(" ").map(Number)
|
||||
const edges = []
|
||||
for (let i = 0 ; i < e ; i++) {
|
||||
edges.push((await readline()).split(" ").map(Number))
|
||||
}
|
||||
kruskal(v, edges)
|
||||
}
|
||||
|
||||
|
||||
main()
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
### PhP
|
||||
|
||||
@ -693,6 +693,55 @@ if __name__ == "__main__":
|
||||
### Rust
|
||||
|
||||
### Javascript
|
||||
```js
|
||||
function prim(v, edges) {
|
||||
const grid = Array.from({ length: v + 1 }, () => new Array(v + 1).fill(10001)); // Fixed grid initialization
|
||||
const minDist = new Array(v + 1).fill(10001)
|
||||
const isInTree = new Array(v + 1).fill(false)
|
||||
// 建構鄰接矩陣
|
||||
for(const [v1, v2, w] of edges) {
|
||||
grid[v1][v2] = w
|
||||
grid[v2][v1] = w
|
||||
}
|
||||
// prim 演算法
|
||||
for (let i = 1 ; i < v ; i++) {
|
||||
let cur = -1
|
||||
let tempMinDist = Number.MAX_VALUE
|
||||
// 1. 尋找距離生成樹最近的節點
|
||||
for (let j = 1 ; j < v + 1 ; j++) {
|
||||
if (!isInTree[j] && minDist[j] < tempMinDist) {
|
||||
tempMinDist = minDist[j]
|
||||
cur = j
|
||||
}
|
||||
}
|
||||
// 2. 將節點放入生成樹
|
||||
isInTree[cur] = true
|
||||
// 3. 更新非生成樹節點與生成樹的最短距離
|
||||
for (let j = 1 ; j < v + 1 ; j++) {
|
||||
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
|
||||
minDist[j] = grid[cur][j]
|
||||
}
|
||||
}
|
||||
}
|
||||
console.log(minDist.slice(2).reduce((acc, cur) => acc + cur, 0))
|
||||
}
|
||||
|
||||
|
||||
async function main() {
|
||||
const rl = require('readline').createInterface({ input: process.stdin })
|
||||
const iter = rl[Symbol.asyncIterator]()
|
||||
const readline = async () => (await iter.next()).value
|
||||
const [v, e] = (await readline()).split(" ").map(Number)
|
||||
const edges = []
|
||||
for (let i = 0 ; i < e ; i++) {
|
||||
edges.push((await readline()).split(" ").map(Number))
|
||||
}
|
||||
prim(v, edges)
|
||||
}
|
||||
|
||||
|
||||
main()
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
|
||||
@ -464,6 +464,60 @@ if __name__ == "__main__":
|
||||
|
||||
### Javascript
|
||||
|
||||
```js
|
||||
async function main() {
|
||||
// 輸入
|
||||
const rl = require('readline').createInterface({ input: process.stdin })
|
||||
const iter = rl[Symbol.asyncIterator]()
|
||||
const readline = async () => (await iter.next()).value
|
||||
const [n, m] = (await readline()).split(" ").map(Number)
|
||||
const grid = {}
|
||||
for (let i = 0 ; i < m ; i++) {
|
||||
const [src, desc, w] = (await readline()).split(" ").map(Number)
|
||||
if (grid.hasOwnProperty(src)) {
|
||||
grid[src].push([desc, w])
|
||||
} else {
|
||||
grid[src] = [[desc, w]]
|
||||
}
|
||||
}
|
||||
const minDist = Array.from({length: n + 1}, () => Number.MAX_VALUE)
|
||||
|
||||
// 起始點
|
||||
minDist[1] = 0
|
||||
|
||||
const q = [1]
|
||||
const visited = Array.from({length: n + 1}, () => false)
|
||||
|
||||
while (q.length) {
|
||||
const src = q.shift()
|
||||
const neighbors = grid[src]
|
||||
visited[src] = false
|
||||
if (neighbors) {
|
||||
for (const [desc, w] of neighbors) {
|
||||
if (minDist[src] !== Number.MAX_VALUE
|
||||
&& minDist[src] + w < minDist[desc]) {
|
||||
minDist[desc] = minDist[src] + w
|
||||
if (!visited[desc]) {
|
||||
q.push(desc)
|
||||
visited[desc] = true
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 輸出
|
||||
if (minDist[n] === Number.MAX_VALUE) {
|
||||
console.log('unconnected')
|
||||
} else {
|
||||
console.log(minDist[n])
|
||||
}
|
||||
}
|
||||
|
||||
main()
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
### PhP
|
||||
|
||||
@ -485,6 +485,45 @@ if __name__ == "__main__":
|
||||
|
||||
### Javascript
|
||||
|
||||
```js
|
||||
async function main() {
|
||||
// 輸入
|
||||
const rl = require('readline').createInterface({ input: process.stdin })
|
||||
const iter = rl[Symbol.asyncIterator]()
|
||||
const readline = async () => (await iter.next()).value
|
||||
const [n, m] = (await readline()).split(" ").map(Number)
|
||||
const edges = []
|
||||
for (let i = 0 ; i < m ; i++) {
|
||||
edges.push((await readline()).split(" ").map(Number))
|
||||
}
|
||||
const minDist = Array.from({length: n + 1}, () => Number.MAX_VALUE)
|
||||
// 起始點
|
||||
minDist[1] = 0
|
||||
|
||||
for (let i = 1 ; i < n ; i++) {
|
||||
let update = false
|
||||
for (const [src, desc, w] of edges) {
|
||||
if (minDist[src] !== Number.MAX_VALUE && minDist[src] + w < minDist[desc]) {
|
||||
minDist[desc] = minDist[src] + w
|
||||
update = true
|
||||
}
|
||||
}
|
||||
if (!update) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
// 輸出
|
||||
if (minDist[n] === Number.MAX_VALUE) {
|
||||
console.log('unconnected')
|
||||
} else {
|
||||
console.log(minDist[n])
|
||||
}
|
||||
}
|
||||
|
||||
main()
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
### PhP
|
||||
|
||||
@ -54,7 +54,7 @@ circle
|
||||
|
||||
## 思路
|
||||
|
||||
本题是 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 延伸题目。
|
||||
本题是 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) 延伸题目。
|
||||
|
||||
本题是要我们判断 负权回路,也就是图中出现环且环上的边总权值为负数。
|
||||
|
||||
@ -64,7 +64,7 @@ circle
|
||||
|
||||
接下来我们来看 如何使用 bellman_ford 算法来判断 负权回路。
|
||||
|
||||
在 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 中 我们讲了 bellman_ford 算法的核心就是一句话:对 所有边 进行 n-1 次松弛。 同时文中的 【拓展】部分, 我们也讲了 松弛n次以上 会怎么样?
|
||||
在 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) 中 我们讲了 bellman_ford 算法的核心就是一句话:对 所有边 进行 n-1 次松弛。 同时文中的 【拓展】部分, 我们也讲了 松弛n次以上 会怎么样?
|
||||
|
||||
在没有负权回路的图中,松弛 n 次以上 ,结果不会有变化。
|
||||
|
||||
@ -72,7 +72,7 @@ circle
|
||||
|
||||
那么每松弛一次,都会更新最短路径,所以结果会一直有变化。
|
||||
|
||||
(如果对于 bellman_ford 不了解的录友,建议详细看这里:[kama94.城市间货物运输I](./kama94.城市间货物运输I.md))
|
||||
(如果对于 bellman_ford 不了解的录友,建议详细看这里:[kama94.城市间货物运输I](./0094.城市间货物运输I.md))
|
||||
|
||||
以上为理论分析,接下来我们再画图举例。
|
||||
|
||||
@ -94,13 +94,13 @@ circle
|
||||
|
||||
如果在负权回路多绕两圈,三圈,无穷圈,那么我们的总成本就会无限小, 如果要求最小成本的话,你会发现本题就无解了。
|
||||
|
||||
在 bellman_ford 算法中,松弛 n-1 次所有的边 就可以求得 起点到任何节点的最短路径,松弛 n 次以上,minDist数组(记录起到到其他节点的最短距离)中的结果也不会有改变 (如果对 bellman_ford 算法 不了解,也不知道 minDist 是什么,建议详看上篇讲解[kama94.城市间货物运输I](./kama94.城市间货物运输I.md))
|
||||
在 bellman_ford 算法中,松弛 n-1 次所有的边 就可以求得 起点到任何节点的最短路径,松弛 n 次以上,minDist数组(记录起到到其他节点的最短距离)中的结果也不会有改变 (如果对 bellman_ford 算法 不了解,也不知道 minDist 是什么,建议详看上篇讲解[kama94.城市间货物运输I](./0094.城市间货物运输I.md))
|
||||
|
||||
而本题有负权回路的情况下,一直都会有更短的最短路,所以 松弛 第n次,minDist数组 也会发生改变。
|
||||
|
||||
那么解决本题的 核心思路,就是在 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 的基础上,再多松弛一次,看minDist数组 是否发生变化。
|
||||
那么解决本题的 核心思路,就是在 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) 的基础上,再多松弛一次,看minDist数组 是否发生变化。
|
||||
|
||||
代码和 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 基本是一样的,如下:(关键地方已注释)
|
||||
代码和 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) 基本是一样的,如下:(关键地方已注释)
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
|
||||
@ -51,15 +51,15 @@
|
||||
|
||||
## 思路
|
||||
|
||||
本题为单源有限最短路问题,同样是 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 延伸题目。
|
||||
本题为单源有限最短路问题,同样是 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) 延伸题目。
|
||||
|
||||
注意题目中描述是 **最多经过 k 个城市的条件下,而不是一定经过k个城市,也可以经过的城市数量比k小,但要最短的路径**。
|
||||
|
||||
在 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 中我们讲了:**对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离**。
|
||||
在 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) 中我们讲了:**对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离**。
|
||||
|
||||
节点数量为n,起点到终点,最多是 n-1 条边相连。 那么对所有边松弛 n-1 次 就一定能得到 起点到达 终点的最短距离。
|
||||
|
||||
(如果对以上讲解看不懂,建议详看 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) )
|
||||
(如果对以上讲解看不懂,建议详看 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) )
|
||||
|
||||
本题是最多经过 k 个城市, 那么是 k + 1条边相连的节点。 这里可能有录友想不懂为什么是k + 1,来看这个图:
|
||||
|
||||
@ -71,7 +71,7 @@
|
||||
|
||||
对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离,那么对所有边松弛 k + 1次,就是求 起点到达 与起点k + 1条边相连的节点的 最短距离。
|
||||
|
||||
**注意**: 本题是 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 的拓展题,如果对 bellman_ford 没有深入了解,强烈建议先看 [kama94.城市间货物运输I](./kama94.城市间货物运输I.md) 再做本题。
|
||||
**注意**: 本题是 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) 的拓展题,如果对 bellman_ford 没有深入了解,强烈建议先看 [kama94.城市间货物运输I](./0094.城市间货物运输I.md) 再做本题。
|
||||
|
||||
理解以上内容,其实本题代码就很容易了,bellman_ford 标准写法是松弛 n-1 次,本题就松弛 k + 1次就好。
|
||||
|
||||
@ -366,19 +366,19 @@ int main() {
|
||||
|
||||
## 拓展二(本题本质)
|
||||
|
||||
那么前面讲解过的 [94.城市间货物运输I](./kama94.城市间货物运输I.md) 和 [95.城市间货物运输II](./kama95.城市间货物运输II.md) 也是bellman_ford经典算法,也没使用 minDist_copy,怎么就没问题呢?
|
||||
那么前面讲解过的 [94.城市间货物运输I](./0094.城市间货物运输I.md) 和 [95.城市间货物运输II](./0095.城市间货物运输II.md) 也是bellman_ford经典算法,也没使用 minDist_copy,怎么就没问题呢?
|
||||
|
||||
> 如果没看过我上面这两篇讲解的话,建议详细学习上面两篇,再看我下面讲的区别,否则容易看不懂。
|
||||
|
||||
[94.城市间货物运输I](./kama94.城市间货物运输I.md), 是没有 负权回路的,那么 多松弛多少次,对结果都没有影响。
|
||||
[94.城市间货物运输I](./0094.城市间货物运输I.md), 是没有 负权回路的,那么 多松弛多少次,对结果都没有影响。
|
||||
|
||||
求 节点1 到 节点n 的最短路径,松弛n-1 次就够了,松弛 大于 n-1次,结果也不会变。
|
||||
|
||||
那么在对所有边进行第一次松弛的时候,如果基于 本次计算的 minDist 来计算 minDist (相当于多做松弛了),也是对最终结果没影响。
|
||||
|
||||
[95.城市间货物运输II](./kama95.城市间货物运输II.md) 是判断是否有 负权回路,一旦有负权回路, 对所有边松弛 n-1 次以后,在做松弛 minDist 数值一定会变,根据这一点来判断是否有负权回路。
|
||||
[95.城市间货物运输II](./0095.城市间货物运输II.md) 是判断是否有 负权回路,一旦有负权回路, 对所有边松弛 n-1 次以后,在做松弛 minDist 数值一定会变,根据这一点来判断是否有负权回路。
|
||||
|
||||
所以,[95.城市间货物运输II](./kama95.城市间货物运输II.md) 只需要判断minDist数值变化了就行,而 minDist 的数值对不对,并不是我们关心的。
|
||||
所以,[95.城市间货物运输II](./0095.城市间货物运输II.md) 只需要判断minDist数值变化了就行,而 minDist 的数值对不对,并不是我们关心的。
|
||||
|
||||
那么本题 为什么计算minDist 一定要基于上次 的 minDist 数值。
|
||||
|
||||
@ -703,6 +703,42 @@ public class Main {
|
||||
```
|
||||
|
||||
### Python
|
||||
```python
|
||||
def main():
|
||||
# 輸入
|
||||
n, m = map(int, input().split())
|
||||
edges = list()
|
||||
for _ in range(m):
|
||||
edges.append(list(map(int, input().split() )))
|
||||
|
||||
start, end, k = map(int, input().split())
|
||||
min_dist = [float('inf') for _ in range(n + 1)]
|
||||
min_dist[start] = 0
|
||||
|
||||
# 只能經過k個城市,所以從起始點到中間有(k + 1)個邊連接
|
||||
# 需要鬆弛(k + 1)次
|
||||
|
||||
for _ in range(k + 1):
|
||||
update = False
|
||||
min_dist_copy = min_dist.copy()
|
||||
for src, desc, w in edges:
|
||||
if (min_dist_copy[src] != float('inf') and
|
||||
min_dist_copy[src] + w < min_dist[desc]):
|
||||
min_dist[desc] = min_dist_copy[src] + w
|
||||
update = True
|
||||
if not update:
|
||||
break
|
||||
# 輸出
|
||||
if min_dist[end] == float('inf'):
|
||||
print('unreachable')
|
||||
else:
|
||||
print(min_dist[end])
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
### Go
|
||||
|
||||
|
||||
@ -277,7 +277,7 @@ ACM格式大家在输出结果的时候,要关注看看格式问题,特别
|
||||
|
||||
有录友可能会想,ACM格式就是麻烦,有空格没有空格有什么影响,结果对了不就行了?
|
||||
|
||||
ACM模式相对于核心代码模式(力扣) 更考验大家对代码的掌控能力。 例如工程代码里,输出输出都是要自己控制的。这也是为什么大公司笔试,都是ACM模式。
|
||||
ACM模式相对于核心代码模式(力扣) 更考验大家对代码的掌控能力。 例如工程代码里,输入输出都是要自己控制的。这也是为什么大公司笔试,都是ACM模式。
|
||||
|
||||
以上代码中,结果都存在了 result数组里(二维数组,每一行是一个结果),最后将其打印出来。(重点看注释)
|
||||
|
||||
|
||||
@ -499,6 +499,55 @@ main();
|
||||
### Swift
|
||||
|
||||
### Scala
|
||||
```scala
|
||||
import scala.collection.mutable.Queue
|
||||
import util.control.Breaks._
|
||||
|
||||
// Dev on LeetCode: https://leetcode.cn/problems/number-of-islands/description/
|
||||
object Solution {
|
||||
def numIslands(grid: Array[Array[Char]]): Int = {
|
||||
val row = grid.length
|
||||
val col = grid(0).length
|
||||
val dir = List((-1,0), (0,-1), (1,0), (0,1)) // 四个方向
|
||||
var visited = Array.fill(row)(Array.fill(col)(false))
|
||||
var counter = 0
|
||||
var que = Queue.empty[Tuple2[Int, Int]]
|
||||
|
||||
(0 until row).map{ r =>
|
||||
(0 until col).map{ c =>
|
||||
breakable {
|
||||
if (!visited(r)(c) && grid(r)(c) == '1') {
|
||||
que.enqueue((r, c))
|
||||
visited(r)(c) // 只要加入队列,立刻标记
|
||||
} else break // 不是岛屿不进入queue,也不记录
|
||||
|
||||
while (!que.isEmpty) {
|
||||
val cur = que.head
|
||||
que.dequeue()
|
||||
val x = cur(0)
|
||||
val y = cur(1)
|
||||
dir.map{ d =>
|
||||
val nextX = x + d(0)
|
||||
val nextY = y + d(1)
|
||||
breakable {
|
||||
// 越界就跳过
|
||||
if (nextX < 0 || nextX >= row || nextY < 0 || nextY >= col) break
|
||||
if (!visited(nextX)(nextY) && grid(nextX)(nextY) == '1') {
|
||||
visited(nextX)(nextY) = true // 只要加入队列,立刻标记
|
||||
que.enqueue((nextX, nextY))
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
counter = counter + 1 // 找完一个岛屿后记录一下
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
counter
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### C#
|
||||
|
||||
|
||||
@ -412,6 +412,46 @@ const dfs = (graph, visited, x, y) => {
|
||||
### Swift
|
||||
|
||||
### Scala
|
||||
```scala
|
||||
import util.control.Breaks._
|
||||
|
||||
object Solution {
|
||||
val dir = List((-1,0), (0,-1), (1,0), (0,1)) // 四个方向
|
||||
|
||||
def dfs(grid: Array[Array[Char]], visited: Array[Array[Boolean]], row: Int, col: Int): Unit = {
|
||||
(0 until 4).map { x =>
|
||||
val nextR = row + dir(x)(0)
|
||||
val nextC = col + dir(x)(1)
|
||||
breakable {
|
||||
if(nextR < 0 || nextR >= grid.length || nextC < 0 || nextC >= grid(0).length) break
|
||||
if (!visited(nextR)(nextC) && grid(nextR)(nextC) == '1') {
|
||||
visited(nextR)(nextC) = true // 经过就记录
|
||||
dfs(grid, visited, nextR, nextC)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
def numIslands(grid: Array[Array[Char]]): Int = {
|
||||
val row = grid.length
|
||||
val col = grid(0).length
|
||||
var visited = Array.fill(row)(Array.fill(col)(false))
|
||||
var counter = 0
|
||||
|
||||
(0 until row).map{ r =>
|
||||
(0 until col).map{ c =>
|
||||
if (!visited(r)(c) && grid(r)(c) == '1') {
|
||||
visited(r)(c) = true // 经过就记录
|
||||
dfs(grid, visited, r, c)
|
||||
counter += 1
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
counter
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### C#
|
||||
|
||||
|
||||
@ -222,8 +222,128 @@ public:
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
### Java
|
||||
### Java
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
import java.math.*;
|
||||
|
||||
/**
|
||||
* DFS版
|
||||
*/
|
||||
public class Main{
|
||||
|
||||
static final int[][] dir={{0,1},{1,0},{0,-1},{-1,0}};
|
||||
static int result=0;
|
||||
static int count=0;
|
||||
|
||||
public static void main(String[] args){
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
int n = scanner.nextInt();
|
||||
int m = scanner.nextInt();
|
||||
int[][] map = new int[n][m];
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
map[i][j]=scanner.nextInt();
|
||||
}
|
||||
}
|
||||
boolean[][] visited = new boolean[n][m];
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
if(!visited[i][j]&&map[i][j]==1){
|
||||
count=0;
|
||||
dfs(map,visited,i,j);
|
||||
result= Math.max(count, result);
|
||||
}
|
||||
}
|
||||
}
|
||||
System.out.println(result);
|
||||
}
|
||||
|
||||
static void dfs(int[][] map,boolean[][] visited,int x,int y){
|
||||
count++;
|
||||
visited[x][y]=true;
|
||||
for (int i = 0; i < 4; i++) {
|
||||
int nextX=x+dir[i][0];
|
||||
int nextY=y+dir[i][1];
|
||||
//水或者已经访问过的跳过
|
||||
if(nextX<0||nextY<0
|
||||
||nextX>=map.length||nextY>=map[0].length
|
||||
||visited[nextX][nextY]||map[nextX][nextY]==0)continue;
|
||||
|
||||
dfs(map,visited,nextX,nextY);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
import java.math.*;
|
||||
|
||||
/**
|
||||
* BFS版
|
||||
*/
|
||||
public class Main {
|
||||
static class Node {
|
||||
int x;
|
||||
int y;
|
||||
|
||||
public Node(int x, int y) {
|
||||
this.x = x;
|
||||
this.y = y;
|
||||
}
|
||||
}
|
||||
|
||||
static final int[][] dir = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
|
||||
static int result = 0;
|
||||
static int count = 0;
|
||||
|
||||
public static void main(String[] args) {
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
int n = scanner.nextInt();
|
||||
int m = scanner.nextInt();
|
||||
int[][] map = new int[n][m];
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
map[i][j] = scanner.nextInt();
|
||||
}
|
||||
}
|
||||
boolean[][] visited = new boolean[n][m];
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
if (!visited[i][j] && map[i][j] == 1) {
|
||||
count = 0;
|
||||
bfs(map, visited, i, j);
|
||||
result = Math.max(count, result);
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
System.out.println(result);
|
||||
}
|
||||
|
||||
static void bfs(int[][] map, boolean[][] visited, int x, int y) {
|
||||
Queue<Node> q = new LinkedList<>();
|
||||
q.add(new Node(x, y));
|
||||
visited[x][y] = true;
|
||||
count++;
|
||||
while (!q.isEmpty()) {
|
||||
Node node = q.remove();
|
||||
for (int i = 0; i < 4; i++) {
|
||||
int nextX = node.x + dir[i][0];
|
||||
int nextY = node.y + dir[i][1];
|
||||
if (nextX < 0 || nextY < 0 || nextX >= map.length || nextY >= map[0].length || visited[nextX][nextY] || map[nextX][nextY] == 0)
|
||||
continue;
|
||||
q.add(new Node(nextX, nextY));
|
||||
visited[nextX][nextY] = true;
|
||||
count++;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
### Python
|
||||
|
||||
DFS
|
||||
@ -389,6 +509,144 @@ func main() {
|
||||
|
||||
|
||||
### Rust
|
||||
DFS
|
||||
|
||||
``` rust
|
||||
use std::io;
|
||||
use std::cmp;
|
||||
|
||||
// 定义四个方向
|
||||
const DIRECTIONS: [(i32, i32); 4] = [(0, 1), (1, 0), (-1, 0), (0, -1)];
|
||||
|
||||
fn dfs(grid: &Vec<Vec<i32>>, visited: &mut Vec<Vec<bool>>, x: usize, y: usize, count: &mut i32) {
|
||||
if visited[x][y] || grid[x][y] == 0 {
|
||||
return; // 终止条件:已访问或者遇到海水
|
||||
}
|
||||
visited[x][y] = true; // 标记已访问
|
||||
*count += 1;
|
||||
|
||||
for &(dx, dy) in DIRECTIONS.iter() {
|
||||
let new_x = x as i32 + dx;
|
||||
let new_y = y as i32 + dy;
|
||||
|
||||
// 检查边界条件
|
||||
if new_x >= 0 && new_x < grid.len() as i32 && new_y >= 0 && new_y < grid[0].len() as i32 {
|
||||
dfs(grid, visited, new_x as usize, new_y as usize, count);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fn main() {
|
||||
let mut input = String::new();
|
||||
|
||||
// 读取 n 和 m
|
||||
io::stdin().read_line(&mut input);
|
||||
let dims: Vec<usize> = input.trim().split_whitespace().map(|s| s.parse().unwrap()).collect();
|
||||
let (n, m) = (dims[0], dims[1]);
|
||||
|
||||
// 读取 grid
|
||||
let mut grid = vec![];
|
||||
for _ in 0..n {
|
||||
input.clear();
|
||||
io::stdin().read_line(&mut input);
|
||||
let row: Vec<i32> = input.trim().split_whitespace().map(|s| s.parse().unwrap()).collect();
|
||||
grid.push(row);
|
||||
}
|
||||
|
||||
// 初始化访问记录
|
||||
let mut visited = vec![vec![false; m]; n];
|
||||
let mut result = 0;
|
||||
|
||||
// 遍历所有格子
|
||||
for i in 0..n {
|
||||
for j in 0..m {
|
||||
if !visited[i][j] && grid[i][j] == 1 {
|
||||
let mut count = 0;
|
||||
dfs(&grid, &mut visited, i, j, &mut count);
|
||||
result = cmp::max(result, count);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 输出结果
|
||||
println!("{}", result);
|
||||
}
|
||||
|
||||
```
|
||||
BFS
|
||||
```rust
|
||||
use std::io;
|
||||
use std::collections::VecDeque;
|
||||
|
||||
// 定义四个方向
|
||||
const DIRECTIONS: [(i32, i32); 4] = [(0, 1), (1, 0), (-1, 0), (0, -1)];
|
||||
|
||||
fn bfs(grid: &Vec<Vec<i32>>, visited: &mut Vec<Vec<bool>>, x: usize, y: usize) -> i32 {
|
||||
let mut count = 0;
|
||||
let mut queue = VecDeque::new();
|
||||
queue.push_back((x, y));
|
||||
visited[x][y] = true; // 标记已访问
|
||||
|
||||
while let Some((cur_x, cur_y)) = queue.pop_front() {
|
||||
count += 1; // 增加计数
|
||||
|
||||
for &(dx, dy) in DIRECTIONS.iter() {
|
||||
let new_x = cur_x as i32 + dx;
|
||||
let new_y = cur_y as i32 + dy;
|
||||
|
||||
// 检查边界条件
|
||||
if new_x >= 0 && new_x < grid.len() as i32 && new_y >= 0 && new_y < grid[0].len() as i32 {
|
||||
let new_x_usize = new_x as usize;
|
||||
let new_y_usize = new_y as usize;
|
||||
|
||||
// 如果未访问且是陆地,加入队列
|
||||
if !visited[new_x_usize][new_y_usize] && grid[new_x_usize][new_y_usize] == 1 {
|
||||
visited[new_x_usize][new_y_usize] = true; // 标记已访问
|
||||
queue.push_back((new_x_usize, new_y_usize));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
count
|
||||
}
|
||||
|
||||
fn main() {
|
||||
let mut input = String::new();
|
||||
|
||||
// 读取 n 和 m
|
||||
io::stdin().read_line(&mut input).expect("Failed to read line");
|
||||
let dims: Vec<usize> = input.trim().split_whitespace().map(|s| s.parse().unwrap()).collect();
|
||||
let (n, m) = (dims[0], dims[1]);
|
||||
|
||||
// 读取 grid
|
||||
let mut grid = vec![];
|
||||
for _ in 0..n {
|
||||
input.clear();
|
||||
io::stdin().read_line(&mut input).expect("Failed to read line");
|
||||
let row: Vec<i32> = input.trim().split_whitespace().map(|s| s.parse().unwrap()).collect();
|
||||
grid.push(row);
|
||||
}
|
||||
|
||||
// 初始化访问记录
|
||||
let mut visited = vec![vec![false; m]; n];
|
||||
let mut result = 0;
|
||||
|
||||
// 遍历所有格子
|
||||
for i in 0..n {
|
||||
for j in 0..m {
|
||||
if !visited[i][j] && grid[i][j] == 1 {
|
||||
let count = bfs(&grid, &mut visited, i, j);
|
||||
result = result.max(count);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 输出结果
|
||||
println!("{}", result);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### Javascript
|
||||
|
||||
@ -480,7 +738,84 @@ const bfs = (graph, visited, x, y) => {
|
||||
})()
|
||||
```
|
||||
|
||||
```javascript
|
||||
|
||||
// 深搜版
|
||||
|
||||
const r1 = require('readline').createInterface({ input: process.stdin });
|
||||
// 创建readline接口
|
||||
let iter = r1[Symbol.asyncIterator]();
|
||||
// 创建异步迭代器
|
||||
const readline = async () => (await iter.next()).value;
|
||||
|
||||
let graph // 地图
|
||||
let N, M // 地图大小
|
||||
let visited // 访问过的节点
|
||||
let result = 0 // 最大岛屿面积
|
||||
let count = 0 // 岛屿内节点数
|
||||
const dir = [[0, 1], [1, 0], [0, -1], [-1, 0]] //方向
|
||||
|
||||
// 读取输入,初始化地图
|
||||
const initGraph = async () => {
|
||||
let line = await readline();
|
||||
[N, M] = line.split(' ').map(Number);
|
||||
graph = new Array(N).fill(0).map(() => new Array(M).fill(0))
|
||||
visited = new Array(N).fill(false).map(() => new Array(M).fill(false))
|
||||
|
||||
for (let i = 0; i < N; i++) {
|
||||
line = await readline()
|
||||
line = line.split(' ').map(Number)
|
||||
for (let j = 0; j < M; j++) {
|
||||
graph[i][j] = line[j]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* @description: 从(x, y)开始深度优先遍历
|
||||
* @param {*} graph 地图
|
||||
* @param {*} visited 访问过的节点
|
||||
* @param {*} x 开始搜索节点的下标
|
||||
* @param {*} y 开始搜索节点的下标
|
||||
* @return {*}
|
||||
*/
|
||||
const dfs = (graph, visited, x, y) => {
|
||||
for (let i = 0; i < 4; i++) {
|
||||
let nextx = x + dir[i][0]
|
||||
let nexty = y + dir[i][1]
|
||||
if(nextx < 0 || nextx >= N || nexty < 0 || nexty >= M) continue
|
||||
if(!visited[nextx][nexty] && graph[nextx][nexty] === 1){
|
||||
count++
|
||||
visited[nextx][nexty] = true
|
||||
dfs(graph, visited, nextx, nexty)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
(async function () {
|
||||
|
||||
// 读取输入,初始化地图
|
||||
await initGraph()
|
||||
|
||||
// 统计最大岛屿面积
|
||||
for (let i = 0; i < N; i++) {
|
||||
for (let j = 0; j < M; j++) {
|
||||
if (!visited[i][j] && graph[i][j] === 1) { //遇到没有访问过的陆地
|
||||
// 重新计算面积
|
||||
count = 1
|
||||
visited[i][j] = true
|
||||
|
||||
// 深度优先遍历,统计岛屿内节点数,并将岛屿标记为已访问
|
||||
dfs(graph, visited, i, j)
|
||||
|
||||
// 更新最大岛屿面积
|
||||
result = Math.max(result, count)
|
||||
}
|
||||
}
|
||||
}
|
||||
console.log(result);
|
||||
})()
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
|
||||
@ -360,6 +360,71 @@ for i in range(n):
|
||||
|
||||
print(count)
|
||||
```
|
||||
|
||||
```python
|
||||
direction = [[1, 0], [-1, 0], [0, 1], [0, -1]]
|
||||
result = 0
|
||||
|
||||
# 深度搜尋
|
||||
def dfs(grid, y, x):
|
||||
grid[y][x] = 0
|
||||
global result
|
||||
result += 1
|
||||
|
||||
for i, j in direction:
|
||||
next_x = x + j
|
||||
next_y = y + i
|
||||
if (next_x < 0 or next_y < 0 or
|
||||
next_x >= len(grid[0]) or next_y >= len(grid)
|
||||
):
|
||||
continue
|
||||
if grid[next_y][next_x] == 1 and not visited[next_y][next_x]:
|
||||
visited[next_y][next_x] = True
|
||||
dfs(grid, next_y, next_x)
|
||||
|
||||
|
||||
# 讀取輸入值
|
||||
n, m = map(int, input().split())
|
||||
grid = []
|
||||
visited = [[False] * m for _ in range(n)]
|
||||
|
||||
for i in range(n):
|
||||
grid.append(list(map(int, input().split())))
|
||||
|
||||
# 處理邊界
|
||||
for j in range(m):
|
||||
# 上邊界
|
||||
if grid[0][j] == 1 and not visited[0][j]:
|
||||
visited[0][j] = True
|
||||
dfs(grid, 0, j)
|
||||
# 下邊界
|
||||
if grid[n - 1][j] == 1 and not visited[n - 1][j]:
|
||||
visited[n - 1][j] = True
|
||||
dfs(grid, n - 1, j)
|
||||
|
||||
for i in range(n):
|
||||
# 左邊界
|
||||
if grid[i][0] == 1 and not visited[i][0]:
|
||||
visited[i][0] = True
|
||||
dfs(grid, i, 0)
|
||||
# 右邊界
|
||||
if grid[i][m - 1] == 1 and not visited[i][m - 1]:
|
||||
visited[i][m - 1] = True
|
||||
dfs(grid, i, m - 1)
|
||||
|
||||
# 計算孤島總面積
|
||||
result = 0 # 初始化,避免使用到處理邊界時所產生的累加值
|
||||
|
||||
for i in range(n):
|
||||
for j in range(m):
|
||||
if grid[i][j] == 1 and not visited[i][j]:
|
||||
visited[i][j] = True
|
||||
dfs(grid, i, j)
|
||||
|
||||
# 輸出孤島的總面積
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Go
|
||||
|
||||
``` go
|
||||
|
||||
@ -178,6 +178,45 @@ int main() {
|
||||
|
||||
### Python
|
||||
|
||||
```python
|
||||
father = list()
|
||||
|
||||
def find(u):
|
||||
if u == father[u]:
|
||||
return u
|
||||
else:
|
||||
father[u] = find(father[u])
|
||||
return father[u]
|
||||
|
||||
def is_same(u, v):
|
||||
u = find(u)
|
||||
v = find(v)
|
||||
return u == v
|
||||
|
||||
def join(u, v):
|
||||
u = find(u)
|
||||
v = find(v)
|
||||
if u != v:
|
||||
father[u] = v
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 輸入
|
||||
n = int(input())
|
||||
for i in range(n + 1):
|
||||
father.append(i)
|
||||
# 尋找冗余邊
|
||||
result = None
|
||||
for i in range(n):
|
||||
s, t = map(int, input().split())
|
||||
if is_same(s, t):
|
||||
result = str(s) + ' ' + str(t)
|
||||
else:
|
||||
join(s, t)
|
||||
|
||||
# 輸出
|
||||
print(result)
|
||||
```
|
||||
|
||||
### Go
|
||||
|
||||
### Rust
|
||||
|
||||
@ -251,8 +251,218 @@ int main() {
|
||||
|
||||
### Java
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
|
||||
/*
|
||||
* 冗余连接II。主要问题是存在入度为2或者成环,也可能两个问题同时存在。
|
||||
* 1.判断入度为2的边
|
||||
* 2.判断是否成环(并查集)
|
||||
*/
|
||||
|
||||
public class Main {
|
||||
/**
|
||||
* 并查集模板
|
||||
*/
|
||||
static class Disjoint {
|
||||
|
||||
private final int[] father;
|
||||
|
||||
public Disjoint(int n) {
|
||||
father = new int[n];
|
||||
for (int i = 0; i < n; i++) {
|
||||
father[i] = i;
|
||||
}
|
||||
}
|
||||
|
||||
public void join(int n, int m) {
|
||||
n = find(n);
|
||||
m = find(m);
|
||||
if (n == m) return;
|
||||
father[n] = m;
|
||||
}
|
||||
|
||||
public int find(int n) {
|
||||
return father[n] == n ? n : (father[n] = find(father[n]));
|
||||
}
|
||||
|
||||
public boolean isSame(int n, int m) {
|
||||
return find(n) == find(m);
|
||||
}
|
||||
}
|
||||
|
||||
static class Edge {
|
||||
int s;
|
||||
int t;
|
||||
|
||||
public Edge(int s, int t) {
|
||||
this.s = s;
|
||||
this.t = t;
|
||||
}
|
||||
}
|
||||
|
||||
static class Node {
|
||||
int id;
|
||||
int in;
|
||||
int out;
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
int n = scanner.nextInt();
|
||||
List<Edge> edges = new ArrayList<>();
|
||||
Node[] nodeMap = new Node[n + 1];
|
||||
for (int i = 1; i <= n; i++) {
|
||||
nodeMap[i] = new Node();
|
||||
}
|
||||
Integer doubleIn = null;
|
||||
for (int i = 0; i < n; i++) {
|
||||
int s = scanner.nextInt();
|
||||
int t = scanner.nextInt();
|
||||
//记录入度
|
||||
nodeMap[t].in++;
|
||||
if (!(nodeMap[t].in < 2)) doubleIn = t;
|
||||
Edge edge = new Edge(s, t);
|
||||
edges.add(edge);
|
||||
}
|
||||
Edge result = null;
|
||||
//存在入度为2的节点,既要消除入度为2的问题同时解除可能存在的环
|
||||
if (doubleIn != null) {
|
||||
List<Edge> doubleInEdges = new ArrayList<>();
|
||||
for (Edge edge : edges) {
|
||||
if (edge.t == doubleIn) doubleInEdges.add(edge);
|
||||
if (doubleInEdges.size() == 2) break;
|
||||
}
|
||||
Edge edge = doubleInEdges.get(1);
|
||||
if (isTreeWithExclude(edges, edge, nodeMap)) {
|
||||
result = edge;
|
||||
} else {
|
||||
result = doubleInEdges.get(0);
|
||||
}
|
||||
} else {
|
||||
//不存在入度为2的节点,则只需要解除环即可
|
||||
result = getRemoveEdge(edges, nodeMap);
|
||||
}
|
||||
|
||||
System.out.println(result.s + " " + result.t);
|
||||
}
|
||||
|
||||
public static boolean isTreeWithExclude(List<Edge> edges, Edge exculdEdge, Node[] nodeMap) {
|
||||
Disjoint disjoint = new Disjoint(nodeMap.length + 1);
|
||||
for (Edge edge : edges) {
|
||||
if (edge == exculdEdge) continue;
|
||||
//成环则不是树
|
||||
if (disjoint.isSame(edge.s, edge.t)) {
|
||||
return false;
|
||||
}
|
||||
disjoint.join(edge.s, edge.t);
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
public static Edge getRemoveEdge(List<Edge> edges, Node[] nodeMap) {
|
||||
int length = nodeMap.length;
|
||||
Disjoint disjoint = new Disjoint(length);
|
||||
|
||||
for (Edge edge : edges) {
|
||||
if (disjoint.isSame(edge.s, edge.t)) return edge;
|
||||
disjoint.join(edge.s, edge.t);
|
||||
}
|
||||
return null;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### Python
|
||||
|
||||
```python
|
||||
from collections import defaultdict
|
||||
|
||||
father = list()
|
||||
|
||||
|
||||
def find(u):
|
||||
if u == father[u]:
|
||||
return u
|
||||
else:
|
||||
father[u] = find(father[u])
|
||||
return father[u]
|
||||
|
||||
|
||||
def is_same(u, v):
|
||||
u = find(u)
|
||||
v = find(v)
|
||||
return u == v
|
||||
|
||||
|
||||
def join(u, v):
|
||||
u = find(u)
|
||||
v = find(v)
|
||||
if u != v:
|
||||
father[u] = v
|
||||
|
||||
|
||||
def is_tree_after_remove_edge(edges, edge, n):
|
||||
# 初始化并查集
|
||||
global father
|
||||
father = [i for i in range(n + 1)]
|
||||
|
||||
for i in range(len(edges)):
|
||||
if i == edge:
|
||||
continue
|
||||
s, t = edges[i]
|
||||
if is_same(s, t): # 成環,即不是有向樹
|
||||
return False
|
||||
else: # 將s,t放入集合中
|
||||
join(s, t)
|
||||
return True
|
||||
|
||||
|
||||
def get_remove_edge(edges):
|
||||
# 初始化并查集
|
||||
global father
|
||||
father = [i for i in range(n + 1)]
|
||||
|
||||
for s, t in edges:
|
||||
if is_same(s, t):
|
||||
print(s, t)
|
||||
return
|
||||
else:
|
||||
join(s, t)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 輸入
|
||||
n = int(input())
|
||||
edges = list()
|
||||
in_degree = defaultdict(int)
|
||||
|
||||
for i in range(n):
|
||||
s, t = map(int, input().split())
|
||||
in_degree[t] += 1
|
||||
edges.append([s, t])
|
||||
|
||||
# 尋找入度為2的邊,並紀錄其下標(index)
|
||||
vec = list()
|
||||
for i in range(n - 1, -1, -1):
|
||||
if in_degree[edges[i][1]] == 2:
|
||||
vec.append(i)
|
||||
|
||||
# 輸出
|
||||
if len(vec) > 0:
|
||||
# 情況一:刪除輸出順序靠後的邊
|
||||
if is_tree_after_remove_edge(edges, vec[0], n):
|
||||
print(edges[vec[0]][0], edges[vec[0]][1])
|
||||
# 情況二:只能刪除特定的邊
|
||||
else:
|
||||
print(edges[vec[1]][0], edges[vec[1]][1])
|
||||
else:
|
||||
# 情況三: 原圖有環
|
||||
get_remove_edge(edges)
|
||||
```
|
||||
|
||||
### Go
|
||||
|
||||
### Rust
|
||||
|
||||
@ -152,66 +152,70 @@ int main() {
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
### Java
|
||||
### Java
|
||||
|
||||
```Java
|
||||
import java.util.*;
|
||||
|
||||
public class Main {
|
||||
// BFS方法
|
||||
public static int ladderLength(String beginWord, String endWord, List<String> wordList) {
|
||||
// 使用set作为查询容器,效率更高
|
||||
HashSet<String> set = new HashSet<>(wordList);
|
||||
|
||||
// 声明一个queue存储每次变更一个字符得到的且存在于容器中的新字符串
|
||||
Queue<String> queue = new LinkedList<>();
|
||||
|
||||
// 声明一个hashMap存储遍历到的字符串以及所走过的路径path
|
||||
HashMap<String, Integer> visitMap = new HashMap<>();
|
||||
queue.offer(beginWord);
|
||||
visitMap.put(beginWord, 1);
|
||||
|
||||
while (!queue.isEmpty()) {
|
||||
String curWord = queue.poll();
|
||||
int path = visitMap.get(curWord);
|
||||
public static void main(String[] args) {
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
int n = scanner.nextInt();
|
||||
scanner.nextLine();
|
||||
String beginStr = scanner.next();
|
||||
String endStr = scanner.next();
|
||||
scanner.nextLine();
|
||||
List<String> wordList = new ArrayList<>();
|
||||
wordList.add(beginStr);
|
||||
wordList.add(endStr);
|
||||
for (int i = 0; i < n; i++) {
|
||||
wordList.add(scanner.nextLine());
|
||||
}
|
||||
int count = bfs(beginStr, endStr, wordList);
|
||||
System.out.println(count);
|
||||
}
|
||||
|
||||
for (int i = 0; i < curWord.length(); i++) {
|
||||
char[] ch = curWord.toCharArray();
|
||||
// 每个位置尝试26个字母
|
||||
for (char k = 'a'; k <= 'z'; k++) {
|
||||
ch[i] = k;
|
||||
|
||||
String newWord = new String(ch);
|
||||
if (newWord.equals(endWord)) return path + 1;
|
||||
|
||||
// 如果这个新字符串存在于容器且之前未被访问到
|
||||
if (set.contains(newWord) && !visitMap.containsKey(newWord)) {
|
||||
visitMap.put(newWord, path + 1);
|
||||
queue.offer(newWord);
|
||||
/**
|
||||
* 广度优先搜索-寻找最短路径
|
||||
*/
|
||||
public static int bfs(String beginStr, String endStr, List<String> wordList) {
|
||||
int len = 1;
|
||||
Set<String> set = new HashSet<>(wordList);
|
||||
Set<String> visited = new HashSet<>();
|
||||
Queue<String> q = new LinkedList<>();
|
||||
visited.add(beginStr);
|
||||
q.add(beginStr);
|
||||
q.add(null);
|
||||
while (!q.isEmpty()) {
|
||||
String node = q.remove();
|
||||
//上一层结束,若下一层还有节点进入下一层
|
||||
if (node == null) {
|
||||
if (!q.isEmpty()) {
|
||||
len++;
|
||||
q.add(null);
|
||||
}
|
||||
continue;
|
||||
}
|
||||
char[] charArray = node.toCharArray();
|
||||
//寻找邻接节点
|
||||
for (int i = 0; i < charArray.length; i++) {
|
||||
//记录旧值,用于回滚修改
|
||||
char old = charArray[i];
|
||||
for (char j = 'a'; j <= 'z'; j++) {
|
||||
charArray[i] = j;
|
||||
String newWord = new String(charArray);
|
||||
if (set.contains(newWord) && !visited.contains(newWord)) {
|
||||
q.add(newWord);
|
||||
visited.add(newWord);
|
||||
//找到结尾
|
||||
if (newWord.equals(endStr)) return len + 1;
|
||||
}
|
||||
}
|
||||
charArray[i] = old;
|
||||
}
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
public static void main (String[] args) {
|
||||
/* code */
|
||||
// 接收输入
|
||||
Scanner sc = new Scanner(System.in);
|
||||
int N = sc.nextInt();
|
||||
sc.nextLine();
|
||||
String[] strs = sc.nextLine().split(" ");
|
||||
|
||||
List<String> wordList = new ArrayList<>();
|
||||
for (int i = 0; i < N; i++) {
|
||||
wordList.add(sc.nextLine());
|
||||
}
|
||||
|
||||
// wordList.add(strs[1]);
|
||||
|
||||
// 打印结果
|
||||
int result = ladderLength(strs[0], strs[1], wordList);
|
||||
System.out.println(result);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
@ -375,6 +375,131 @@ for _ in range(n):
|
||||
|
||||
### Javascript
|
||||
|
||||
```js
|
||||
class MinHeap {
|
||||
constructor() {
|
||||
this.val = []
|
||||
}
|
||||
push(val) {
|
||||
this.val.push(val)
|
||||
if (this.val.length > 1) {
|
||||
this.bubbleUp()
|
||||
}
|
||||
}
|
||||
bubbleUp() {
|
||||
let pi = this.val.length - 1
|
||||
let pp = Math.floor((pi - 1) / 2)
|
||||
while (pi > 0 && this.val[pp][0] > this.val[pi][0]) {
|
||||
;[this.val[pi], this.val[pp]] = [this.val[pp], this.val[pi]]
|
||||
pi = pp
|
||||
pp = Math.floor((pi - 1) / 2)
|
||||
}
|
||||
}
|
||||
pop() {
|
||||
if (this.val.length > 1) {
|
||||
let pp = 0
|
||||
let pi = this.val.length - 1
|
||||
;[this.val[pi], this.val[pp]] = [this.val[pp], this.val[pi]]
|
||||
const min = this.val.pop()
|
||||
if (this.val.length > 1) {
|
||||
this.sinkDown(0)
|
||||
}
|
||||
return min
|
||||
} else if (this.val.length == 1) {
|
||||
return this.val.pop()
|
||||
}
|
||||
|
||||
}
|
||||
sinkDown(parentIdx) {
|
||||
let pp = parentIdx
|
||||
let plc = pp * 2 + 1
|
||||
let prc = pp * 2 + 2
|
||||
let pt = pp // temp pointer
|
||||
if (plc < this.val.length && this.val[pp][0] > this.val[plc][0]) {
|
||||
pt = plc
|
||||
}
|
||||
if (prc < this.val.length && this.val[pt][0] > this.val[prc][0]) {
|
||||
pt = prc
|
||||
}
|
||||
if (pt != pp) {
|
||||
;[this.val[pp], this.val[pt]] = [this.val[pt], this.val[pp]]
|
||||
this.sinkDown(pt)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const moves = [
|
||||
[1, 2],
|
||||
[2, 1],
|
||||
[-1, -2],
|
||||
[-2, -1],
|
||||
[-1, 2],
|
||||
[-2, 1],
|
||||
[1, -2],
|
||||
[2, -1]
|
||||
]
|
||||
|
||||
function dist(a, b) {
|
||||
return ((a[0] - b[0])**2 + (a[1] - b[1])**2)**0.5
|
||||
}
|
||||
|
||||
function isValid(x, y) {
|
||||
return x >= 1 && y >= 1 && x < 1001 && y < 1001
|
||||
}
|
||||
|
||||
function bfs(start, end) {
|
||||
const step = new Map()
|
||||
step.set(start.join(" "), 0)
|
||||
const q = new MinHeap()
|
||||
q.push([dist(start, end), start[0], start[1]])
|
||||
|
||||
while(q.val.length) {
|
||||
const [d, x, y] = q.pop()
|
||||
// if x and y correspond to end position output result
|
||||
if (x == end[0] && y == end[1]) {
|
||||
console.log(step.get(end.join(" ")))
|
||||
break;
|
||||
}
|
||||
for (const [dx, dy] of moves) {
|
||||
const nx = dx + x
|
||||
const ny = dy + y
|
||||
if (isValid(nx, ny)) {
|
||||
const newStep = step.get([x, y].join(" ")) + 1
|
||||
const newDist = dist([nx, ny], [...end])
|
||||
const s = step.get([nx, ny].join(" ")) ?
|
||||
step.get([nx, ny]) :
|
||||
Number.MAX_VALUE
|
||||
if (newStep < s) {
|
||||
q.push(
|
||||
[
|
||||
newStep + newDist,
|
||||
nx,
|
||||
ny
|
||||
]
|
||||
)
|
||||
step.set([nx, ny].join(" "), newStep)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
async function main() {
|
||||
const rl = require('readline').createInterface({ input: process.stdin })
|
||||
const iter = rl[Symbol.asyncIterator]()
|
||||
const readline = async () => (await iter.next()).value
|
||||
const n = Number((await readline()))
|
||||
|
||||
// find min step
|
||||
for (let i = 0 ; i < n ; i++) {
|
||||
const [s1, s2, t1, t2] = (await readline()).split(" ").map(Number)
|
||||
bfs([s1, s2], [t1, t2])
|
||||
}
|
||||
}
|
||||
|
||||
main()
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
### PhP
|
||||
|
||||
Reference in New Issue
Block a user