mirror of
https://github.com/VHellendoorn/Code-LMs.git
synced 2026-03-13 10:00:47 +08:00
Update README.md
This commit is contained in:
committed by
 GitHub
GitHub
parent
0658ad9409
commit
ebbe1c61a8
11
README.md
11
README.md
@@ -2,10 +2,10 @@
|
||||
I occasionally train and publicly release large neural language models on programs. Here, I describe how to use these.
|
||||
|
||||
## 2.7B Model of Assorted Languages
|
||||
This is a 32 layer, 2,560 dimensional Transformer model trained for 100K steps on a [large corpus](#data-characteristics) of code from across 11 programming languages using the [GPT-neox](https://github.com/EleutherAI/gpt-neox) toolkit.
|
||||
This is a 32 layer, 2,560 dimensional Transformer model on a [large corpus](#data-characteristics) of code from across 11 programming languages, trained for 100K steps using the [GPT-neox](https://github.com/EleutherAI/gpt-neox) toolkit.
|
||||
|
||||
### Availability & Usage
|
||||
**Via DockerHub (recommended):** A public image containing a slightly modified version of the [gpt-neox repository](https://github.com/EleutherAI/gpt-neox) with the final checkpoint has been [pushed to DockerHub](https://hub.docker.com/repository/docker/vhellendoorn/neox-2-7b-code). The image size is 15GB and the model will require 6GB of GPU memory to run (running on CPU is neither tested nor recommended). Acquire and run it with the following commands (substituting another GPU device index if needed):
|
||||
**Via DockerHub (recommended):** A public image containing a slightly modified version of the [gpt-neox repository](https://github.com/EleutherAI/gpt-neox) containing the final model checkpoint has been [pushed to DockerHub](https://hub.docker.com/repository/docker/vhellendoorn/neox-2-7b-code). The image size is 15GB and the model will require 6GB of GPU memory to run (running on CPU is neither tested nor recommended). Acquire and run it with the following commands (substituting another GPU device index if needed):
|
||||
```
|
||||
nvidia-docker run --rm -it -e NVIDIA_VISIBLE_DEVICES=0 --shm-size=1g --ulimit memlock=-1 vhellendoorn/neox-2-7b-code:trained100K
|
||||
cd /gpt-neox
|
||||
@@ -43,15 +43,18 @@ Very large (>1MB) and very short (<100 tokens) files were filtered out. Files we
|
||||
|
||||
Training took ca. 3 weeks on 8 NVIDIA RTX 8000 GPUs, largely following the standard [2-7B.yml](https://github.com/EleutherAI/gpt-neox/blob/main/configs/2-7B.yml) values except also enabling "scaled-upper-triang-masked-softmax-fusion" and "bias-gelu-fusion" for performance and slightly changing the batch size, data split, initial loss scale, and print/eval intervals.
|
||||
|
||||
The below image shows the loss curve of the training process on validation data.
|
||||
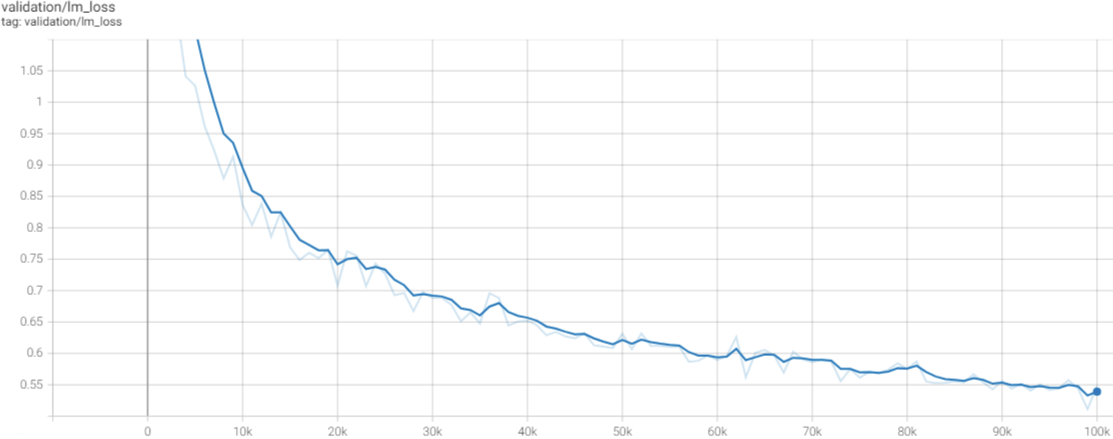
|
||||
|
||||
### Caveats
|
||||
The trained model has a few minor known limitations:
|
||||
- This model was not trained to solve programming problems, and may not perform well on a benchmark such as [HumanEval](https://github.com/openai/human-eval). Models like Codex (powering Copilot) are pretrained on natural language, which may boost their ability to interpret NL prompts; this model only learned language from comments in code.
|
||||
- The model appears to start generating a random new file once it reaches the (predicted) end of the current one. It is possible that the end-of-document token was not properly added to the training data.
|
||||
- Whitespace is **very important** to the model, since no preprocessing was done on the input files. For instance, the following snippet will yield poor predictions, because in Java we would never expect an instance-method at the top-level, as is indicated by the single level of indentation of the lines within this method:
|
||||
- Whitespace is **very important** to the model, since no preprocessing was done on the input files. For instance, the following snippet will yield poor predictions, because in Java we would never expect an instance-method at the top-level, as is indicated by the single level of (`\t`) indentation of the two lines within this method:
|
||||
```
|
||||
public int getTotalWeight(List<Integer> weights) {\n\t// Sum weights in parallel.\n\treturn
|
||||
```
|
||||
Adjusting the indentation makes it predict more reasonable results:
|
||||
Adjusting the indentation makes it predict more reasonable continuations:
|
||||
```
|
||||
public int getTotalWeight(List<Integer> weights) {\n\t\t// Sum weights in parallel.\n\t\treturn
|
||||
```
|
||||
|
||||
Reference in New Issue
Block a user