mirror of
https://github.com/labmlai/annotated_deep_learning_paper_implementations.git
synced 2025-08-14 01:13:00 +08:00
131 lines
4.9 KiB
Python
131 lines
4.9 KiB
Python
"""
|
|
# [labml.ai Annotated PyTorch Paper Implementations](index.html)
|
|
|
|
This is a collection of simple PyTorch implementations of
|
|
neural networks and related algorithms.
|
|
[These implementations](https://github.com/labmlai/annotated_deep_learning_paper_implementations) are documented with explanations,
|
|
and the [website](index.html)
|
|
renders these as side-by-side formatted notes.
|
|
We believe these would help you understand these algorithms better.
|
|
|
|
|
|
|
|
We are actively maintaining this repo and adding new
|
|
implementations.
|
|
[](https://twitter.com/labmlai) for updates.
|
|
|
|
## Modules
|
|
|
|
#### ✨ [Transformers](transformers/index.html)
|
|
|
|
* [Multi-headed attention](transformers/mha.html)
|
|
* [Transformer building blocks](transformers/models.html)
|
|
* [Transformer XL](transformers/xl/index.html)
|
|
* [Relative multi-headed attention](transformers/xl/relative_mha.html)
|
|
* [Compressive Transformer](transformers/compressive/index.html)
|
|
* [GPT Architecture](transformers/gpt/index.html)
|
|
* [GLU Variants](transformers/glu_variants/simple.html)
|
|
* [kNN-LM: Generalization through Memorization](transformers/knn/index.html)
|
|
* [Feedback Transformer](transformers/feedback/index.html)
|
|
* [Switch Transformer](transformers/switch/index.html)
|
|
* [Fast Weights Transformer](transformers/fast_weights/index.html)
|
|
* [FNet](transformers/fnet/index.html)
|
|
* [Attention Free Transformer](transformers/aft/index.html)
|
|
* [Masked Language Model](transformers/mlm/index.html)
|
|
* [MLP-Mixer: An all-MLP Architecture for Vision](transformers/mlp_mixer/index.html)
|
|
* [Pay Attention to MLPs (gMLP)](transformers/gmlp/index.html)
|
|
* [Vision Transformer (ViT)](transformers/vit/index.html)
|
|
* [Primer EZ](transformers/primer_ez/index.html)
|
|
* [Hourglass](transformers/hourglass/index.html)
|
|
|
|
#### ✨ [Recurrent Highway Networks](recurrent_highway_networks/index.html)
|
|
|
|
#### ✨ [LSTM](lstm/index.html)
|
|
|
|
#### ✨ [HyperNetworks - HyperLSTM](hypernetworks/hyper_lstm.html)
|
|
|
|
#### ✨ [ResNet](resnet/index.html)
|
|
|
|
#### ✨ [ConvMixer](conv_mixer/index.html)
|
|
|
|
#### ✨ [Capsule Networks](capsule_networks/index.html)
|
|
|
|
#### ✨ [Generative Adversarial Networks](gan/index.html)
|
|
* [Original GAN](gan/original/index.html)
|
|
* [GAN with deep convolutional network](gan/dcgan/index.html)
|
|
* [Cycle GAN](gan/cycle_gan/index.html)
|
|
* [Wasserstein GAN](gan/wasserstein/index.html)
|
|
* [Wasserstein GAN with Gradient Penalty](gan/wasserstein/gradient_penalty/index.html)
|
|
* [StyleGAN 2](gan/stylegan/index.html)
|
|
|
|
#### ✨ [Diffusion models](diffusion/index.html)
|
|
|
|
* [Denoising Diffusion Probabilistic Models (DDPM)](diffusion/ddpm/index.html)
|
|
|
|
#### ✨ [Sketch RNN](sketch_rnn/index.html)
|
|
|
|
#### ✨ Graph Neural Networks
|
|
|
|
* [Graph Attention Networks (GAT)](graphs/gat/index.html)
|
|
* [Graph Attention Networks v2 (GATv2)](graphs/gatv2/index.html)
|
|
|
|
#### ✨ [Counterfactual Regret Minimization (CFR)](cfr/index.html)
|
|
|
|
Solving games with incomplete information such as poker with CFR.
|
|
|
|
* [Kuhn Poker](cfr/kuhn/index.html)
|
|
|
|
#### ✨ [Reinforcement Learning](rl/index.html)
|
|
* [Proximal Policy Optimization](rl/ppo/index.html) with
|
|
[Generalized Advantage Estimation](rl/ppo/gae.html)
|
|
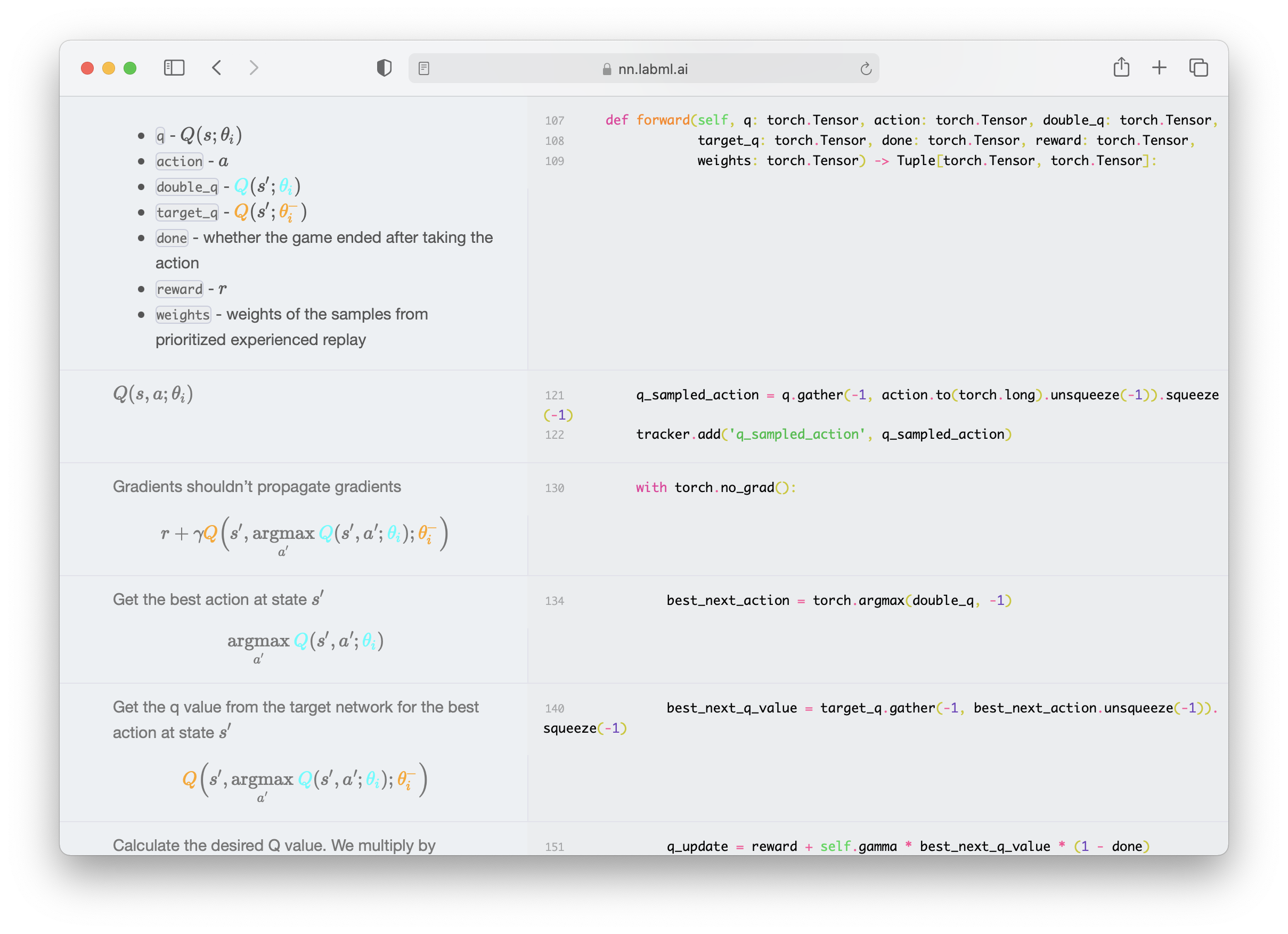
* [Deep Q Networks](rl/dqn/index.html) with
|
|
with [Dueling Network](rl/dqn/model.html),
|
|
[Prioritized Replay](rl/dqn/replay_buffer.html)
|
|
and Double Q Network.
|
|
|
|
#### ✨ [Optimizers](optimizers/index.html)
|
|
* [Adam](optimizers/adam.html)
|
|
* [AMSGrad](optimizers/amsgrad.html)
|
|
* [Adam Optimizer with warmup](optimizers/adam_warmup.html)
|
|
* [Noam Optimizer](optimizers/noam.html)
|
|
* [Rectified Adam Optimizer](optimizers/radam.html)
|
|
* [AdaBelief Optimizer](optimizers/ada_belief.html)
|
|
|
|
#### ✨ [Normalization Layers](https://nn.labml.ai/normalization/index.html)
|
|
* [Batch Normalization](https://nn.labml.ai/normalization/batch_norm/index.html)
|
|
* [Layer Normalization](https://nn.labml.ai/normalization/layer_norm/index.html)
|
|
* [Instance Normalization](https://nn.labml.ai/normalization/instance_norm/index.html)
|
|
* [Group Normalization](https://nn.labml.ai/normalization/group_norm/index.html)
|
|
* [Weight Standardization](https://nn.labml.ai/normalization/weight_standardization/index.html)
|
|
* [Batch-Channel Normalization](https://nn.labml.ai/normalization/batch_channel_norm/index.html)
|
|
|
|
#### ✨ [Distillation](distillation/index.html)
|
|
|
|
#### ✨ [Adaptive Computation](adaptive_computation/index.html)
|
|
|
|
* [PonderNet](adaptive_computation/ponder_net/index.html)
|
|
|
|
#### ✨ [Uncertainty](uncertainty/index.html)
|
|
|
|
* [Evidential Deep Learning to Quantify Classification Uncertainty](uncertainty/evidence/index.html)
|
|
|
|
### Installation
|
|
|
|
```bash
|
|
pip install labml-nn
|
|
```
|
|
|
|
### Citing LabML
|
|
|
|
If you use this for academic research, please cite it using the following BibTeX entry.
|
|
|
|
```bibtex
|
|
@misc{labml,
|
|
author = {Varuna Jayasiri, Nipun Wijerathne},
|
|
title = {labml.ai Annotated Paper Implementations},
|
|
year = {2020},
|
|
url = {https://nn.labml.ai/},
|
|
}
|
|
```
|
|
"""
|