mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-09 19:44:45 +08:00
Merge pull request #1781 from juguagua/leetcode-modify-the-code-of-the-string-part
完善字符串部分代码和文本
This commit is contained in:
@ -94,7 +94,7 @@ next数组就是一个前缀表(prefix table)。
|
|||||||
|
|
||||||
**前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。**
|
**前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。**
|
||||||
|
|
||||||
为了清楚的了解前缀表的来历,我们来举一个例子:
|
为了清楚地了解前缀表的来历,我们来举一个例子:
|
||||||
|
|
||||||
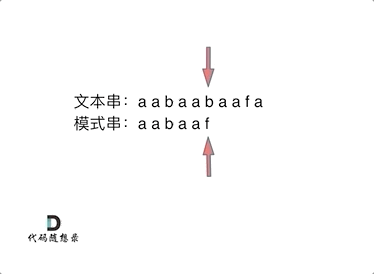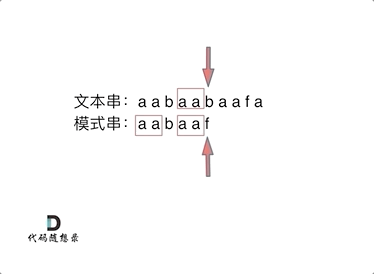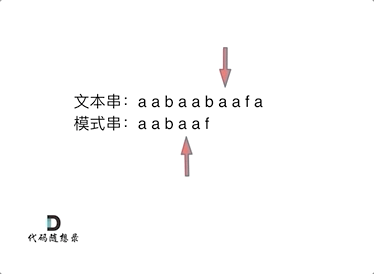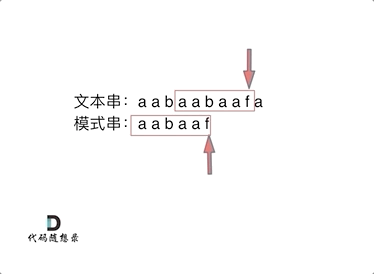
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
|
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
|
||||||
|
|
||||||
@ -110,9 +110,9 @@ next数组就是一个前缀表(prefix table)。
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
动画里,我特意把 子串`aa` 标记上了,这是有原因的,大家先注意一下,后面还会说道。
|
动画里,我特意把 子串`aa` 标记上了,这是有原因的,大家先注意一下,后面还会说到。
|
||||||
|
|
||||||
可以看出,文本串中第六个字符b 和 模式串的第六个字符f,不匹配了。如果暴力匹配,会发现不匹配,此时就要从头匹配了。
|
可以看出,文本串中第六个字符b 和 模式串的第六个字符f,不匹配了。如果暴力匹配,发现不匹配,此时就要从头匹配了。
|
||||||
|
|
||||||
但如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容开始匹配,找到了模式串中第三个字符b继续开始匹配。
|
但如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容开始匹配,找到了模式串中第三个字符b继续开始匹配。
|
||||||
|
|
||||||
@ -157,7 +157,7 @@ next数组就是一个前缀表(prefix table)。
|
|||||||
|
|
||||||
以下这句话,对于理解为什么使用前缀表可以告诉我们匹配失败之后跳到哪里重新匹配 非常重要!
|
以下这句话,对于理解为什么使用前缀表可以告诉我们匹配失败之后跳到哪里重新匹配 非常重要!
|
||||||
|
|
||||||
**下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面从新匹配就可以了。**
|
**下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。**
|
||||||
|
|
||||||
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
|
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
|
||||||
|
|
||||||
@ -199,7 +199,7 @@ next数组就是一个前缀表(prefix table)。
|
|||||||
|
|
||||||
所以要看前一位的 前缀表的数值。
|
所以要看前一位的 前缀表的数值。
|
||||||
|
|
||||||
前一个字符的前缀表的数值是2, 所有把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
|
前一个字符的前缀表的数值是2, 所以把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
|
||||||
|
|
||||||
最后就在文本串中找到了和模式串匹配的子串了。
|
最后就在文本串中找到了和模式串匹配的子串了。
|
||||||
|
|
||||||
@ -211,7 +211,7 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
|
|||||||
|
|
||||||
为什么这么做呢,其实也是很多文章视频没有解释清楚的地方。
|
为什么这么做呢,其实也是很多文章视频没有解释清楚的地方。
|
||||||
|
|
||||||
其实**这并不涉及到KMP的原理,而是具体实现,next数组即可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。**
|
其实**这并不涉及到KMP的原理,而是具体实现,next数组既可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。**
|
||||||
|
|
||||||
后面我会提供两种不同的实现代码,大家就明白了。
|
后面我会提供两种不同的实现代码,大家就明白了。
|
||||||
|
|
||||||
@ -231,7 +231,7 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
|
|||||||
|
|
||||||
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
|
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
|
||||||
|
|
||||||
暴力的解法显而易见是O(n × m),所以**KMP在字符串匹配中极大的提高的搜索的效率。**
|
暴力的解法显而易见是O(n × m),所以**KMP在字符串匹配中极大地提高了搜索的效率。**
|
||||||
|
|
||||||
为了和力扣题目28.实现strStr保持一致,方便大家理解,以下文章统称haystack为文本串, needle为模式串。
|
为了和力扣题目28.实现strStr保持一致,方便大家理解,以下文章统称haystack为文本串, needle为模式串。
|
||||||
|
|
||||||
@ -251,7 +251,7 @@ void getNext(int* next, const string& s)
|
|||||||
2. 处理前后缀不相同的情况
|
2. 处理前后缀不相同的情况
|
||||||
3. 处理前后缀相同的情况
|
3. 处理前后缀相同的情况
|
||||||
|
|
||||||
接下来我们详解详解一下。
|
接下来我们详解一下。
|
||||||
|
|
||||||
1. 初始化:
|
1. 初始化:
|
||||||
|
|
||||||
|
|||||||
@ -119,7 +119,7 @@ void removeExtraSpaces(string& s) {
|
|||||||
1. leetcode上的测试集里,字符串的长度不够长,如果足够长,性能差距会非常明显。
|
1. leetcode上的测试集里,字符串的长度不够长,如果足够长,性能差距会非常明显。
|
||||||
2. leetcode的测程序耗时不是很准确的。
|
2. leetcode的测程序耗时不是很准确的。
|
||||||
|
|
||||||
版本一的代码是比较如何一般思考过程,就是 先移除字符串钱的空格,在移除中间的,在移除后面部分。
|
版本一的代码是一般的思考过程,就是 先移除字符串前的空格,再移除中间的,再移除后面部分。
|
||||||
|
|
||||||
不过其实还可以优化,这部分和[27.移除元素](https://programmercarl.com/0027.移除元素.html)的逻辑是一样一样的,本题是移除空格,而 27.移除元素 就是移除元素。
|
不过其实还可以优化,这部分和[27.移除元素](https://programmercarl.com/0027.移除元素.html)的逻辑是一样一样的,本题是移除空格,而 27.移除元素 就是移除元素。
|
||||||
|
|
||||||
@ -145,7 +145,7 @@ void removeExtraSpaces(string& s) {//去除所有空格并在相邻单词之间
|
|||||||
|
|
||||||
此时我们已经实现了removeExtraSpaces函数来移除冗余空格。
|
此时我们已经实现了removeExtraSpaces函数来移除冗余空格。
|
||||||
|
|
||||||
还做实现反转字符串的功能,支持反转字符串子区间,这个实现我们分别在[344.反转字符串](https://programmercarl.com/0344.反转字符串.html)和[541.反转字符串II](https://programmercarl.com/0541.反转字符串II.html)里已经讲过了。
|
还要实现反转字符串的功能,支持反转字符串子区间,这个实现我们分别在[344.反转字符串](https://programmercarl.com/0344.反转字符串.html)和[541.反转字符串II](https://programmercarl.com/0541.反转字符串II.html)里已经讲过了。
|
||||||
|
|
||||||
代码如下:
|
代码如下:
|
||||||
|
|
||||||
@ -451,6 +451,7 @@ class Solution:
|
|||||||
tmp.append(s[left])
|
tmp.append(s[left])
|
||||||
left += 1
|
left += 1
|
||||||
return tmp
|
return tmp
|
||||||
|
|
||||||
#2.翻转字符数组
|
#2.翻转字符数组
|
||||||
def reverse_string(self, nums, left, right):
|
def reverse_string(self, nums, left, right):
|
||||||
while left < right:
|
while left < right:
|
||||||
@ -458,6 +459,7 @@ class Solution:
|
|||||||
left += 1
|
left += 1
|
||||||
right -= 1
|
right -= 1
|
||||||
return None
|
return None
|
||||||
|
|
||||||
#3.翻转每个单词
|
#3.翻转每个单词
|
||||||
def reverse_each_word(self, nums):
|
def reverse_each_word(self, nums):
|
||||||
start = 0
|
start = 0
|
||||||
|
|||||||
@ -46,17 +46,17 @@
|
|||||||
|
|
||||||
## 移动匹配
|
## 移动匹配
|
||||||
|
|
||||||
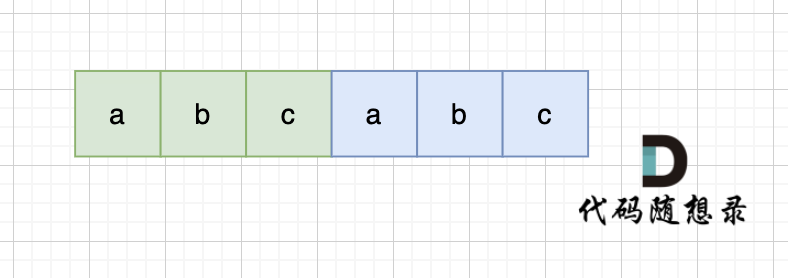
当一个字符串s:abcabc,内部又重复的子串组成,那么这个字符串的结构一定是这样的:
|
当一个字符串s:abcabc,内部由重复的子串组成,那么这个字符串的结构一定是这样的:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
也就是又前后又相同的子串组成。
|
也就是由前后相同的子串组成。
|
||||||
|
|
||||||
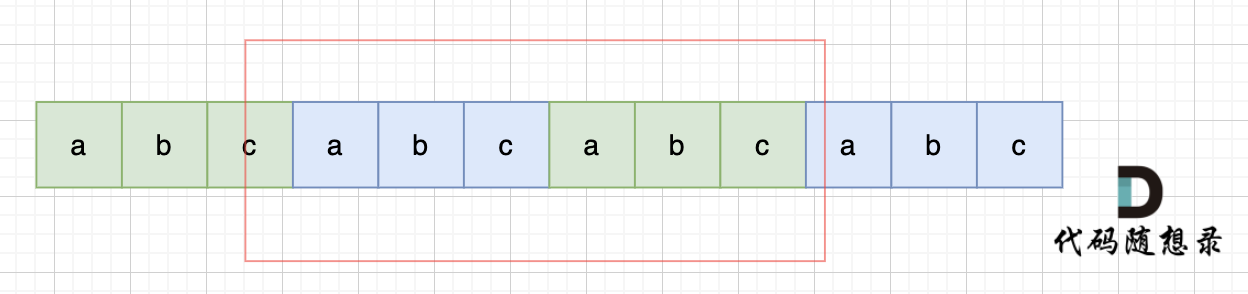
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前后的子串做后串,就一定还能组成一个s,如图:
|
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前后的子串做后串,就一定还能组成一个s,如图:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
所以判断字符串s是否有重复子串组成,只要两个s拼接在一起,里面还出现一个s的话,就说明是又重复子串组成。
|
所以判断字符串s是否由重复子串组成,只要两个s拼接在一起,里面还出现一个s的话,就说明是由重复子串组成。
|
||||||
|
|
||||||
当然,我们在判断 s + s 拼接的字符串里是否出现一个s的的时候,**要刨除 s + s 的首字符和尾字符**,这样避免在s+s中搜索出原来的s,我们要搜索的是中间拼接出来的s。
|
当然,我们在判断 s + s 拼接的字符串里是否出现一个s的的时候,**要刨除 s + s 的首字符和尾字符**,这样避免在s+s中搜索出原来的s,我们要搜索的是中间拼接出来的s。
|
||||||
|
|
||||||
@ -81,7 +81,7 @@ public:
|
|||||||
## KMP
|
## KMP
|
||||||
|
|
||||||
### 为什么会使用KMP
|
### 为什么会使用KMP
|
||||||
以下使用KMP方式讲解,强烈建议大家先把一下两个视频看了,理解KMP算法,在来看下面讲解,否则会很懵。
|
以下使用KMP方式讲解,强烈建议大家先把以下两个视频看了,理解KMP算法,再来看下面讲解,否则会很懵。
|
||||||
|
|
||||||
* [视频讲解版:帮你把KMP算法学个通透!(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd/)
|
* [视频讲解版:帮你把KMP算法学个通透!(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd/)
|
||||||
* [视频讲解版:帮你把KMP算法学个通透!(求next数组代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
|
* [视频讲解版:帮你把KMP算法学个通透!(求next数组代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
|
||||||
@ -93,12 +93,12 @@ KMP算法中next数组为什么遇到字符不匹配的时候可以找到上一
|
|||||||
|
|
||||||
那么 最长相同前后缀和重复子串的关系又有什么关系呢。
|
那么 最长相同前后缀和重复子串的关系又有什么关系呢。
|
||||||
|
|
||||||
可能很多录友又忘了 前缀和后缀的定义,在回顾一下:
|
可能很多录友又忘了 前缀和后缀的定义,再回顾一下:
|
||||||
|
|
||||||
* 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
|
* 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
|
||||||
* 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
|
* 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串
|
||||||
|
|
||||||
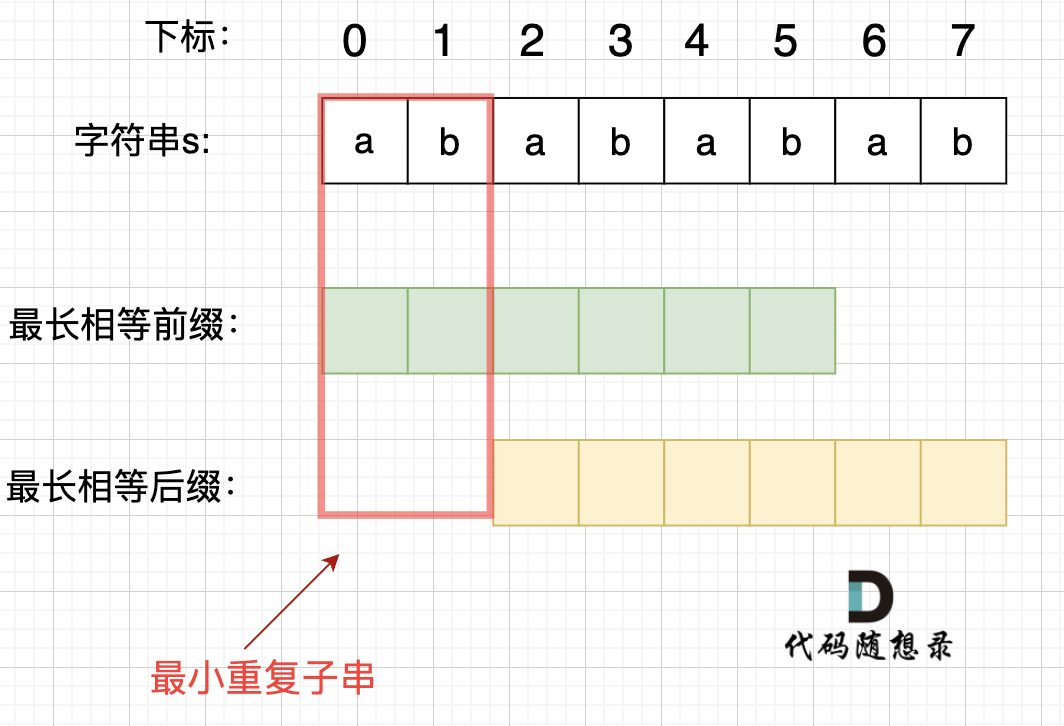
在由重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串,这里那字符串s:abababab 来举例,ab就是最小重复单位,如图所示:
|
在由重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串,这里拿字符串s:abababab 来举例,ab就是最小重复单位,如图所示:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -123,11 +123,11 @@ KMP算法中next数组为什么遇到字符不匹配的时候可以找到上一
|
|||||||
|
|
||||||
### 简单推理
|
### 简单推理
|
||||||
|
|
||||||
这里在给出一个数推导,就容易理解很多。
|
这里再给出一个数学推导,就容易理解很多。
|
||||||
|
|
||||||
假设字符串s使用多个重复子串构成(这个子串是最小重复单位),重复出现的子字符串长度是x,所以s是由n * x组成。
|
假设字符串s使用多个重复子串构成(这个子串是最小重复单位),重复出现的子字符串长度是x,所以s是由n * x组成。
|
||||||
|
|
||||||
因为字符串s的最长相同前后缀的的长度一定是不包含s本身,所以 最长相同前后缀长度必然是m * x,而且 n - m = 1,(这里如果不懂,看上面的推理)
|
因为字符串s的最长相同前后缀的长度一定是不包含s本身,所以 最长相同前后缀长度必然是m * x,而且 n - m = 1,(这里如果不懂,看上面的推理)
|
||||||
|
|
||||||
所以如果 nx % (n - m)x = 0,就可以判定有重复出现的子字符串。
|
所以如果 nx % (n - m)x = 0,就可以判定有重复出现的子字符串。
|
||||||
|
|
||||||
|
|||||||
@ -294,6 +294,8 @@ func reverseStr(s string, k int) string {
|
|||||||
ss := []byte(s)
|
ss := []byte(s)
|
||||||
length := len(s)
|
length := len(s)
|
||||||
for i := 0; i < length; i += 2 * k {
|
for i := 0; i < length; i += 2 * k {
|
||||||
|
// 1. 每隔 2k 个字符的前 k 个字符进行反转
|
||||||
|
// 2. 剩余字符小于 2k 但大于或等于 k 个,则反转前 k 个字符
|
||||||
if i + k <= length {
|
if i + k <= length {
|
||||||
reverse(ss[i:i+k])
|
reverse(ss[i:i+k])
|
||||||
} else {
|
} else {
|
||||||
@ -326,7 +328,7 @@ javaScript:
|
|||||||
var reverseStr = function(s, k) {
|
var reverseStr = function(s, k) {
|
||||||
const len = s.length;
|
const len = s.length;
|
||||||
let resArr = s.split("");
|
let resArr = s.split("");
|
||||||
for(let i = 0; i < len; i += 2 * k) {
|
for(let i = 0; i < len; i += 2 * k) { // 每隔 2k 个字符的前 k 个字符进行反转
|
||||||
let l = i - 1, r = i + k > len ? len : i + k;
|
let l = i - 1, r = i + k > len ? len : i + k;
|
||||||
while(++l < --r) [resArr[l], resArr[r]] = [resArr[r], resArr[l]];
|
while(++l < --r) [resArr[l], resArr[r]] = [resArr[r], resArr[l]];
|
||||||
}
|
}
|
||||||
|
|||||||
@ -36,7 +36,7 @@ i指向新长度的末尾,j指向旧长度的末尾。
|
|||||||
这么做有两个好处:
|
这么做有两个好处:
|
||||||
|
|
||||||
1. 不用申请新数组。
|
1. 不用申请新数组。
|
||||||
2. 从后向前填充元素,避免了从前先后填充元素要来的 每次添加元素都要将添加元素之后的所有元素向后移动。
|
2. 从后向前填充元素,避免了从前向后填充元素时,每次添加元素都要将添加元素之后的所有元素向后移动的问题。
|
||||||
|
|
||||||
时间复杂度,空间复杂度均超过100%的用户。
|
时间复杂度,空间复杂度均超过100%的用户。
|
||||||
|
|
||||||
|
|||||||
@ -31,7 +31,7 @@
|
|||||||
不能使用额外空间的话,模拟在本串操作要实现左旋转字符串的功能还是有点困难的。
|
不能使用额外空间的话,模拟在本串操作要实现左旋转字符串的功能还是有点困难的。
|
||||||
|
|
||||||
|
|
||||||
那么我们可以想一下上一题目[字符串:花式反转还不够!](https://programmercarl.com/0151.翻转字符串里的单词.html)中讲过,使用整体反转+局部反转就可以实现,反转单词顺序的目的。
|
那么我们可以想一下上一题目[字符串:花式反转还不够!](https://programmercarl.com/0151.翻转字符串里的单词.html)中讲过,使用整体反转+局部反转就可以实现反转单词顺序的目的。
|
||||||
|
|
||||||
这道题目也非常类似,依然可以通过局部反转+整体反转 达到左旋转的目的。
|
这道题目也非常类似,依然可以通过局部反转+整体反转 达到左旋转的目的。
|
||||||
|
|
||||||
@ -41,7 +41,7 @@
|
|||||||
2. 反转区间为n到末尾的子串
|
2. 反转区间为n到末尾的子串
|
||||||
3. 反转整个字符串
|
3. 反转整个字符串
|
||||||
|
|
||||||
最后就可以得到左旋n的目的,而不用定义新的字符串,完全在本串上操作。
|
最后就可以达到左旋n的目的,而不用定义新的字符串,完全在本串上操作。
|
||||||
|
|
||||||
例如 :示例1中 输入:字符串abcdefg,n=2
|
例如 :示例1中 输入:字符串abcdefg,n=2
|
||||||
|
|
||||||
@ -75,7 +75,7 @@ public:
|
|||||||
|
|
||||||
在这篇文章[344.反转字符串](https://programmercarl.com/0344.反转字符串.html),第一次讲到反转一个字符串应该怎么做,使用了双指针法。
|
在这篇文章[344.反转字符串](https://programmercarl.com/0344.反转字符串.html),第一次讲到反转一个字符串应该怎么做,使用了双指针法。
|
||||||
|
|
||||||
然后发现[541. 反转字符串II](https://programmercarl.com/0541.反转字符串II.html),这里开始给反转加上了一些条件,当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
|
然后发现[541. 反转字符串II](https://programmercarl.com/0541.反转字符串II.html),这里开始给反转加上了一些条件,当需要固定规律一段一段去处理字符串的时候,要想想在for循环的表达式上做做文章。
|
||||||
|
|
||||||
后来在[151.翻转字符串里的单词](https://programmercarl.com/0151.翻转字符串里的单词.html)中,要对一句话里的单词顺序进行反转,发现先整体反转再局部反转 是一个很妙的思路。
|
后来在[151.翻转字符串里的单词](https://programmercarl.com/0151.翻转字符串里的单词.html)中,要对一句话里的单词顺序进行反转,发现先整体反转再局部反转 是一个很妙的思路。
|
||||||
|
|
||||||
|
|||||||
Reference in New Issue
Block a user