mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-08 16:54:50 +08:00
update 0028.实现strStr:改错字,优化python代码格式
This commit is contained in:
@ -94,7 +94,7 @@ next数组就是一个前缀表(prefix table)。
|
||||
|
||||
**前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。**
|
||||
|
||||
为了清楚的了解前缀表的来历,我们来举一个例子:
|
||||
为了清楚地了解前缀表的来历,我们来举一个例子:
|
||||
|
||||
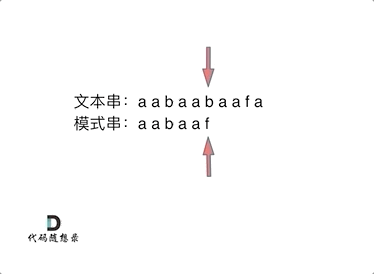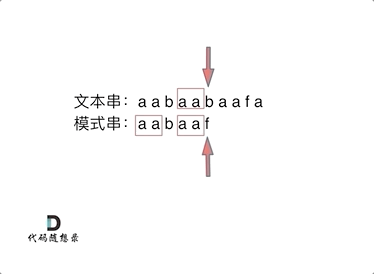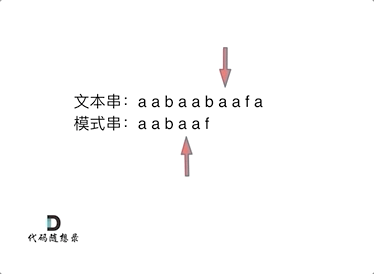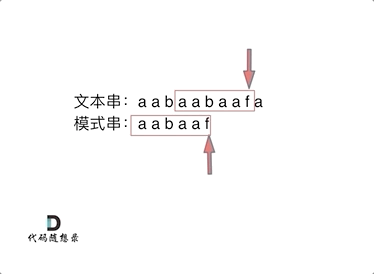
要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
|
||||
|
||||
@ -110,9 +110,9 @@ next数组就是一个前缀表(prefix table)。
|
||||
|
||||
|
||||
|
||||
动画里,我特意把 子串`aa` 标记上了,这是有原因的,大家先注意一下,后面还会说道。
|
||||
动画里,我特意把 子串`aa` 标记上了,这是有原因的,大家先注意一下,后面还会说到。
|
||||
|
||||
可以看出,文本串中第六个字符b 和 模式串的第六个字符f,不匹配了。如果暴力匹配,会发现不匹配,此时就要从头匹配了。
|
||||
可以看出,文本串中第六个字符b 和 模式串的第六个字符f,不匹配了。如果暴力匹配,发现不匹配,此时就要从头匹配了。
|
||||
|
||||
但如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容开始匹配,找到了模式串中第三个字符b继续开始匹配。
|
||||
|
||||
@ -157,7 +157,7 @@ next数组就是一个前缀表(prefix table)。
|
||||
|
||||
以下这句话,对于理解为什么使用前缀表可以告诉我们匹配失败之后跳到哪里重新匹配 非常重要!
|
||||
|
||||
**下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面从新匹配就可以了。**
|
||||
**下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。**
|
||||
|
||||
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
|
||||
|
||||
@ -199,7 +199,7 @@ next数组就是一个前缀表(prefix table)。
|
||||
|
||||
所以要看前一位的 前缀表的数值。
|
||||
|
||||
前一个字符的前缀表的数值是2, 所有把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
|
||||
前一个字符的前缀表的数值是2, 所以把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
|
||||
|
||||
最后就在文本串中找到了和模式串匹配的子串了。
|
||||
|
||||
@ -211,7 +211,7 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
|
||||
|
||||
为什么这么做呢,其实也是很多文章视频没有解释清楚的地方。
|
||||
|
||||
其实**这并不涉及到KMP的原理,而是具体实现,next数组即可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。**
|
||||
其实**这并不涉及到KMP的原理,而是具体实现,next数组既可以就是前缀表,也可以是前缀表统一减一(右移一位,初始位置为-1)。**
|
||||
|
||||
后面我会提供两种不同的实现代码,大家就明白了。
|
||||
|
||||
@ -231,7 +231,7 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
|
||||
|
||||
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
|
||||
|
||||
暴力的解法显而易见是O(n × m),所以**KMP在字符串匹配中极大的提高的搜索的效率。**
|
||||
暴力的解法显而易见是O(n × m),所以**KMP在字符串匹配中极大地提高了搜索的效率。**
|
||||
|
||||
为了和力扣题目28.实现strStr保持一致,方便大家理解,以下文章统称haystack为文本串, needle为模式串。
|
||||
|
||||
@ -251,7 +251,7 @@ void getNext(int* next, const string& s)
|
||||
2. 处理前后缀不相同的情况
|
||||
3. 处理前后缀相同的情况
|
||||
|
||||
接下来我们详解详解一下。
|
||||
接下来我们详解一下。
|
||||
|
||||
1. 初始化:
|
||||
|
||||
|
||||
Reference in New Issue
Block a user