diff --git a/problems/0042.接雨水.md b/problems/0042.接雨水.md
index 70a4e07c..b0af2c26 100644
--- a/problems/0042.接雨水.md
+++ b/problems/0042.接雨水.md
@@ -364,6 +364,14 @@ public:
## 其他语言版本
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/0101.对称二叉树.md b/problems/0101.对称二叉树.md
index 9717588a..241564e9 100644
--- a/problems/0101.对称二叉树.md
+++ b/problems/0101.对称二叉树.md
@@ -7,7 +7,7 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 101. 对称二叉树
+# 101. 对称二叉树
题目地址:https://leetcode-cn.com/problems/symmetric-tree/
@@ -15,7 +15,7 @@

-## 思路
+# 思路
**首先想清楚,判断对称二叉树要比较的是哪两个节点,要比较的可不是左右节点!**
@@ -73,7 +73,7 @@ bool compare(TreeNode* left, TreeNode* right)
此时左右节点不为空,且数值也不相同的情况我们也处理了。
代码如下:
-```
+```C++
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
@@ -84,7 +84,7 @@ else if (left->val != right->val) return false; // 注意这里我没有
3. 确定单层递归的逻辑
-此时才进入单层递归的逻辑,单层递归的逻辑就是处理 右节点都不为空,且数值相同的情况。
+此时才进入单层递归的逻辑,单层递归的逻辑就是处理 左右节点都不为空,且数值相同的情况。
* 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
@@ -93,7 +93,7 @@ else if (left->val != right->val) return false; // 注意这里我没有
代码如下:
-```
+```C++
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
bool isSame = outside && inside; // 左子树:中、 右子树:中(逻辑处理)
@@ -104,7 +104,7 @@ return isSame;
最后递归的C++整体代码如下:
-```
+```C++
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
@@ -137,7 +137,7 @@ public:
**盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。**
当然我可以把如上代码整理如下:
-```
+```C++
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
@@ -177,7 +177,7 @@ public:
代码如下:
-```
+```C++
class Solution {
public:
bool isSymmetric(TreeNode* root) {
@@ -212,7 +212,7 @@ public:
只要把队列原封不动的改成栈就可以了,我下面也给出了代码。
-```
+```C++
class Solution {
public:
bool isSymmetric(TreeNode* root) {
@@ -239,7 +239,7 @@ public:
};
```
-## 总结
+# 总结
这次我们又深度剖析了一道二叉树的“简单题”,大家会发现,真正的把题目搞清楚其实并不简单,leetcode上accept了和真正掌握了还是有距离的。
@@ -249,11 +249,14 @@ public:
如果已经做过这道题目的同学,读完文章可以再去看看这道题目,思考一下,会有不一样的发现!
+# 相关题目推荐
+* 100.相同的树
+* 572.另一个树的子树
-## 其他语言版本
+# 其他语言版本
-Java:
+## Java
```Java
/**
@@ -358,9 +361,9 @@ Java:
```
-Python:
+## Python
-> 递归法
+递归法:
```python
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
@@ -384,7 +387,7 @@ class Solution:
return isSame
```
-> 迭代法: 使用队列
+迭代法: 使用队列
```python
import collections
class Solution:
@@ -410,7 +413,7 @@ class Solution:
return True
```
-> 迭代法:使用栈
+迭代法:使用栈
```python
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
@@ -433,7 +436,7 @@ class Solution:
return True
```
-Go:
+## Go
```go
/**
@@ -484,22 +487,7 @@ func isSymmetric(root *TreeNode) bool {
```
-JavaScript
-```javascript
-var isSymmetric = function(root) {
- return check(root, root)
-};
-
-const check = (leftPtr, rightPtr) => {
- // 如果只有根节点,返回true
- if (!leftPtr && !rightPtr) return true
- // 如果左右节点只存在一个,则返回false
- if (!leftPtr || !rightPtr) return false
-
- return leftPtr.val === rightPtr.val && check(leftPtr.left, rightPtr.right) && check(leftPtr.right, rightPtr.left)
-}
-```
-JavaScript:
+## JavaScript
递归判断是否为对称二叉树:
```javascript
@@ -526,6 +514,7 @@ var isSymmetric = function(root) {
return compareNode(root.left,root.right);
};
```
+
队列实现迭代判断是否为对称二叉树:
```javascript
var isSymmetric = function(root) {
@@ -554,6 +543,7 @@ var isSymmetric = function(root) {
return true;
};
```
+
栈实现迭代判断是否为对称二叉树:
```javascript
var isSymmetric = function(root) {
diff --git a/problems/0104.二叉树的最大深度.md b/problems/0104.二叉树的最大深度.md
index 463b55d9..218a966c 100644
--- a/problems/0104.二叉树的最大深度.md
+++ b/problems/0104.二叉树的最大深度.md
@@ -30,9 +30,13 @@
### 递归法
-本题其实也要后序遍历(左右中),依然是因为要通过递归函数的返回值做计算树的高度。
+本题可以使用前序(中左右),也可以使用后序遍历(左右中),使用前序求的就是深度,使用后序求的是高度。
-按照递归三部曲,来看看如何来写。
+**而根节点的高度就是二叉树的最大深度**,所以本题中我们通过后序求的根节点高度来求的二叉树最大深度。
+
+这一点其实是很多同学没有想清楚的,很多题解同样没有讲清楚。
+
+我先用后序遍历(左右中)来计算树的高度。
1. 确定递归函数的参数和返回值:参数就是传入树的根节点,返回就返回这棵树的深度,所以返回值为int类型。
@@ -92,6 +96,66 @@ public:
**精简之后的代码根本看不出是哪种遍历方式,也看不出递归三部曲的步骤,所以如果对二叉树的操作还不熟练,尽量不要直接照着精简代码来学。**
+本题当然也可以使用前序,代码如下:(**充分表现出求深度回溯的过程**)
+
+```C++
+class Solution {
+public:
+ int result;
+ void getDepth(TreeNode* node, int depth) {
+ result = depth > result ? depth : result; // 中
+
+ if (node->left == NULL && node->right == NULL) return ;
+
+ if (node->left) { // 左
+ depth++; // 深度+1
+ getDepth(node->left, depth);
+ depth--; // 回溯,深度-1
+ }
+ if (node->right) { // 右
+ depth++; // 深度+1
+ getDepth(node->right, depth);
+ depth--; // 回溯,深度-1
+ }
+ return ;
+ }
+ int maxDepth(TreeNode* root) {
+ result = 0;
+ if (root == 0) return result;
+ getDepth(root, 1);
+ return result;
+ }
+};
+```
+
+**可以看出使用了前序(中左右)的遍历顺序,这才是真正求深度的逻辑!**
+
+注意以上代码是为了把细节体现出来,简化一下代码如下:
+
+```C++
+class Solution {
+public:
+ int result;
+ void getDepth(TreeNode* node, int depth) {
+ result = depth > result ? depth : result; // 中
+ if (node->left == NULL && node->right == NULL) return ;
+ if (node->left) { // 左
+ getDepth(node->left, depth + 1);
+ }
+ if (node->right) { // 右
+ getDepth(node->right, depth + 1);
+ }
+ return ;
+ }
+ int maxDepth(TreeNode* root) {
+ result = 0;
+ if (root == 0) return result;
+ getDepth(root, 1);
+ return result;
+ }
+};
+```
+
### 迭代法
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
diff --git a/problems/0129.求根到叶子节点数字之和.md b/problems/0129.求根到叶子节点数字之和.md
index a54ebf59..f8c93382 100644
--- a/problems/0129.求根到叶子节点数字之和.md
+++ b/problems/0129.求根到叶子节点数字之和.md
@@ -1,10 +1,9 @@
-
-## 链接
+## 链接
https://leetcode-cn.com/problems/sum-root-to-leaf-numbers/
## 思路
-本题和[113.路径总和II](https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0113.%E8%B7%AF%E5%BE%84%E6%80%BB%E5%92%8CII.md)是类似的思路,做完这道题,可以顺便把[113.路径总和II](https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0113.%E8%B7%AF%E5%BE%84%E6%80%BB%E5%92%8CII.md) 和 [112.路径总和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0112.路径总和.md) 做了。
+本题和[113.路径总和II](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)是类似的思路,做完这道题,可以顺便把[113.路径总和II](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg) 和 [112.路径总和](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg) 做了。
结合112.路径总和 和 113.路径总和II,我在讲了[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg),如果大家对二叉树递归函数什么时候需要返回值很迷茫,可以看一下。
@@ -26,19 +25,19 @@ https://leetcode-cn.com/problems/sum-root-to-leaf-numbers/
参数只需要把根节点传入,此时还需要定义两个全局遍历,一个是result,记录最终结果,一个是vector path。
-**为什么用vector类型(就是数组)呢? 因为用vector方便我们做回溯!**
+**为什么用vector类型(就是数组)呢? 因为用vector方便我们做回溯!**
所以代码如下:
```
int result;
vector path;
-void traversal(TreeNode* cur)
+void traversal(TreeNode* cur)
```
-* 确定终止条件
+* 确定终止条件
-递归什么时候终止呢?
+递归什么时候终止呢?
当然是遇到叶子节点,此时要收集结果了,通知返回本层递归,因为单条路径的结果使用vector,我们需要一个函数vectorToInt把vector转成int。
@@ -154,12 +153,13 @@ public:
};
```
-## 总结
+# 总结
过于简洁的代码,很容易让初学者忽视了本题中回溯的精髓,甚至作者本身都没有想清楚自己用了回溯。
**我这里提供的代码把整个回溯过程充分体现出来,希望可以帮助大家看的明明白白!**
+
## 其他语言版本
Java:
diff --git a/problems/1365.有多少小于当前数字的数字.md b/problems/1365.有多少小于当前数字的数字.md
new file mode 100644
index 00000000..3026dfca
--- /dev/null
+++ b/problems/1365.有多少小于当前数字的数字.md
@@ -0,0 +1,146 @@
+
+
+
+# 1365.有多少小于当前数字的数字
+
+题目链接:https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
+
+给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
+
+换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。
+
+以数组形式返回答案。
+
+
+示例 1:
+* 输入:nums = [8,1,2,2,3]
+* 输出:[4,0,1,1,3]
+* 解释:
+对于 nums[0]=8 存在四个比它小的数字:(1,2,2 和 3)。
+对于 nums[1]=1 不存在比它小的数字。
+对于 nums[2]=2 存在一个比它小的数字:(1)。
+对于 nums[3]=2 存在一个比它小的数字:(1)。
+对于 nums[4]=3 存在三个比它小的数字:(1,2 和 2)。
+
+示例 2:
+* 输入:nums = [6,5,4,8]
+* 输出:[2,1,0,3]
+
+示例 3:
+* 输入:nums = [7,7,7,7]
+* 输出:[0,0,0,0]
+
+提示:
+* 2 <= nums.length <= 500
+* 0 <= nums[i] <= 100
+
+# 思路
+
+两层for循环暴力查找,时间复杂度明显为O(n^2)。
+
+那么我们来看一下如何优化。
+
+首先要找小于当前数字的数字,那么从小到大排序之后,该数字之前的数字就都是比它小的了。
+
+所以可以定义一个新数组,将数组排个序。
+
+**排序之后,其实每一个数值的下标就代表这前面有几个比它小的了**。
+
+代码如下:
+
+```
+vector vec = nums;
+sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+```
+
+用一个哈希表hash(本题可以就用一个数组)来做数值和下标的映射。这样就可以通过数值快速知道下标(也就是前面有几个比它小的)。
+
+此时有一个情况,就是数值相同怎么办?
+
+例如,数组:1 2 3 4 4 4 ,第一个数值4的下标是3,第二个数值4的下标是4了。
+
+这里就需要一个技巧了,**在构造数组hash的时候,从后向前遍历,这样hash里存放的就是相同元素最左面的数值和下标了**。
+代码如下:
+
+```C++
+int hash[101];
+for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+}
+```
+
+最后在遍历原数组nums,用hash快速找到每一个数值 对应的 小于这个数值的个数。存放在将结果存放在另一个数组中。
+
+代码如下:
+
+```C++
+// 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+}
+```
+
+流程如图:
+
+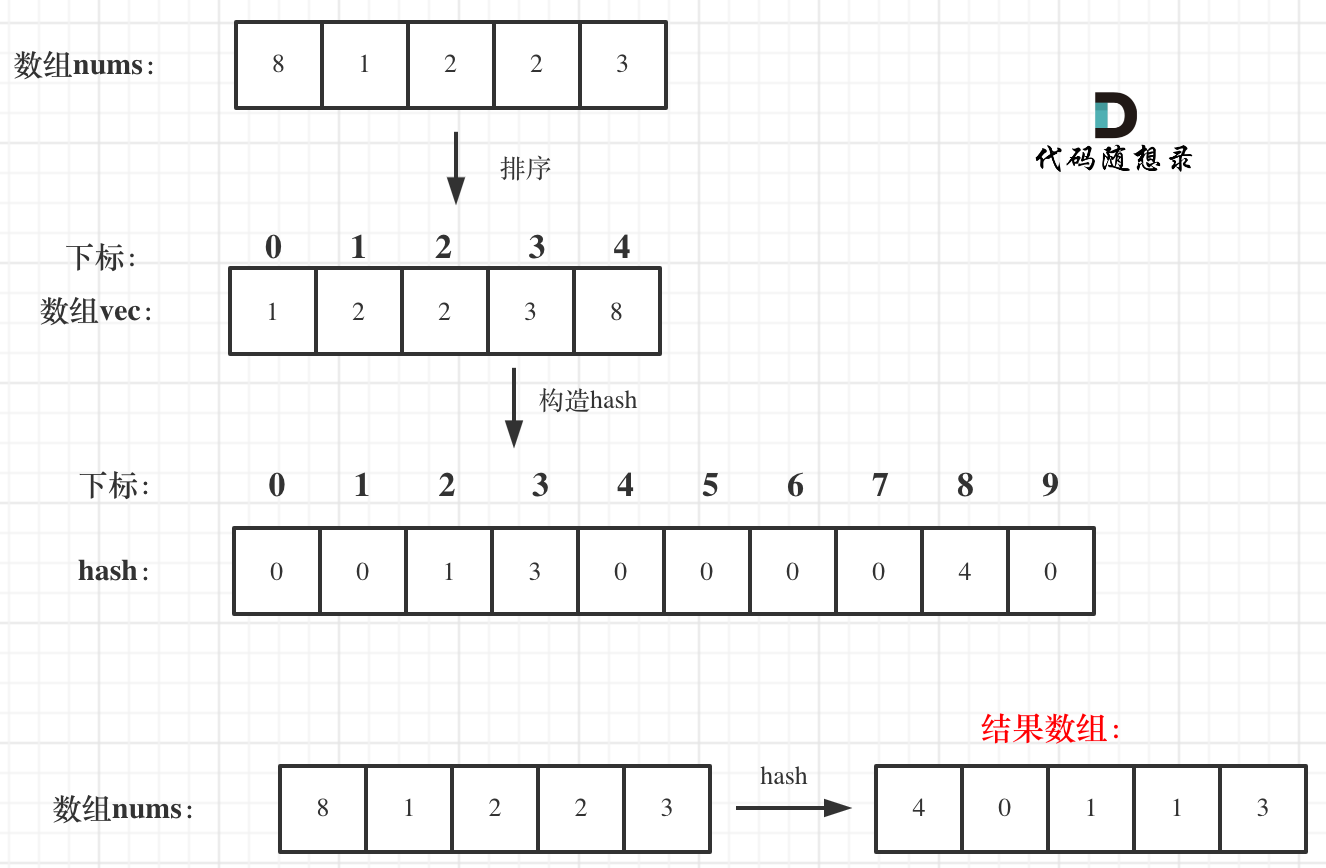 +
+关键地方讲完了,整体C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector smallerNumbersThanCurrent(vector& nums) {
+ vector vec = nums;
+ sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+ int hash[101];
+ for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+ }
+ // 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+ for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+ }
+ return vec;
+ }
+};
+```
+
+可以排序之后加哈希,时间复杂度为O(nlogn)
+
+
+# 其他语言版本
+
+Java:
+
+```Java
+public int[] smallerNumbersThanCurrent(int[] nums) {
+ Map map = new HashMap<>(); // 记录数字 nums[i] 有多少个比它小的数字
+ int[] res = Arrays.copyOf(nums, nums.length);
+ Arrays.sort(res);
+ for (int i = 0; i < res.length; i++) {
+ if (!map.containsKey(res[i])) { // 遇到了相同的数字,那么不需要更新该 number 的情况
+ map.put(res[i], i);
+ }
+ }
+
+ for (int i = 0; i < nums.length; i++) {
+ res[i] = map.get(nums[i]);
+ }
+
+ return res;
+ }
+```
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+关键地方讲完了,整体C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector smallerNumbersThanCurrent(vector& nums) {
+ vector vec = nums;
+ sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+ int hash[101];
+ for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+ }
+ // 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+ for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+ }
+ return vec;
+ }
+};
+```
+
+可以排序之后加哈希,时间复杂度为O(nlogn)
+
+
+# 其他语言版本
+
+Java:
+
+```Java
+public int[] smallerNumbersThanCurrent(int[] nums) {
+ Map map = new HashMap<>(); // 记录数字 nums[i] 有多少个比它小的数字
+ int[] res = Arrays.copyOf(nums, nums.length);
+ Arrays.sort(res);
+ for (int i = 0; i < res.length; i++) {
+ if (!map.containsKey(res[i])) { // 遇到了相同的数字,那么不需要更新该 number 的情况
+ map.put(res[i], i);
+ }
+ }
+
+ for (int i = 0; i < nums.length; i++) {
+ res[i] = map.get(nums[i]);
+ }
+
+ return res;
+ }
+```
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+