mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-08 16:54:50 +08:00
Update
This commit is contained in:
@ -59,7 +59,7 @@ KMP的经典思想就是:**当出现字符串不匹配时,可以记录一部
|
|||||||
* 总结
|
* 总结
|
||||||
|
|
||||||
|
|
||||||
读完本篇可以顺便,把leetcode上28.实现strStr()题目做了。
|
读完本篇可以顺便把leetcode上28.实现strStr()题目做了。
|
||||||
|
|
||||||
|
|
||||||
# 什么是KMP
|
# 什么是KMP
|
||||||
@ -126,16 +126,15 @@ next数组就是一个前缀表(prefix table)。
|
|||||||
|
|
||||||
# 最长公共前后缀?
|
# 最长公共前后缀?
|
||||||
|
|
||||||
文章中字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
|
文章中字符串的**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串**。
|
||||||
|
|
||||||
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
|
**后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串**。
|
||||||
|
|
||||||
**正确理解什么是前缀什么是后缀很重要。**
|
**正确理解什么是前缀什么是后缀很重要**!
|
||||||
|
|
||||||
那么网上清一色都说 “kmp 最长公共前后缀” 又是什么回事呢?
|
那么网上清一色都说 “kmp 最长公共前后缀” 又是什么回事呢?
|
||||||
|
|
||||||
|
我查了一遍 算法导论 和 算法4里KMP的章节,都没有提到 “最长公共前后缀”这个词,也不知道从哪里来了,我理解是用“最长相等前后缀” 更准确一些。
|
||||||
我查了一遍 算法导论 和 算法4里KMP的章节,都没有提到 “最长公共前后缀”这个词,也不知道从哪里来了,我理解是用“最长相等前后缀” 准确一些。
|
|
||||||
|
|
||||||
**因为前缀表要求的就是相同前后缀的长度。**
|
**因为前缀表要求的就是相同前后缀的长度。**
|
||||||
|
|
||||||
@ -220,7 +219,7 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
|
|||||||
|
|
||||||
# 使用next数组来匹配
|
# 使用next数组来匹配
|
||||||
|
|
||||||
以下我们以前缀表统一减一之后的next数组来做演示。
|
**以下我们以前缀表统一减一之后的next数组来做演示**。
|
||||||
|
|
||||||
有了next数组,就可以根据next数组来 匹配文本串s,和模式串t了。
|
有了next数组,就可以根据next数组来 匹配文本串s,和模式串t了。
|
||||||
|
|
||||||
@ -236,7 +235,7 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
|
|||||||
|
|
||||||
暴力的解法显而易见是O(n * m),所以**KMP在字符串匹配中极大的提高的搜索的效率。**
|
暴力的解法显而易见是O(n * m),所以**KMP在字符串匹配中极大的提高的搜索的效率。**
|
||||||
|
|
||||||
为了和[字符串:KMP是时候上场了(一文读懂系列)](https://mp.weixin.qq.com/s/70OXnZ4Ez29CKRrUpVJmug)字符串命名统一,方便大家理解,以下文章统称haystack为文本串, needle为模式串。
|
为了和力扣题目28.实现strStr保持一致,方便大家理解,以下文章统称haystack为文本串, needle为模式串。
|
||||||
|
|
||||||
都知道使用KMP算法,一定要构造next数组。
|
都知道使用KMP算法,一定要构造next数组。
|
||||||
|
|
||||||
@ -402,7 +401,7 @@ for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
此时所有逻辑的代码都已经写出来了,本题整体代码如下:
|
此时所有逻辑的代码都已经写出来了,力扣 28.实现strStr 题目的整体代码如下:
|
||||||
|
|
||||||
# 前缀表统一减一 C++代码实现
|
# 前缀表统一减一 C++代码实现
|
||||||
|
|
||||||
@ -448,7 +447,9 @@ public:
|
|||||||
|
|
||||||
# 前缀表(不减一)C++实现
|
# 前缀表(不减一)C++实现
|
||||||
|
|
||||||
那么前缀表就不减一了,也不右移的,到底行不行呢?行!
|
那么前缀表就不减一了,也不右移的,到底行不行呢?
|
||||||
|
|
||||||
|
**行!**
|
||||||
|
|
||||||
我之前说过,这仅仅是KMP算法实现上的问题,如果就直接使用前缀表可以换一种回退方式,找j=next[j-1] 来进行回退。
|
我之前说过,这仅仅是KMP算法实现上的问题,如果就直接使用前缀表可以换一种回退方式,找j=next[j-1] 来进行回退。
|
||||||
|
|
||||||
@ -544,7 +545,7 @@ public:
|
|||||||
|
|
||||||
我们介绍了什么是KMP,KMP可以解决什么问题,然后分析KMP算法里的next数组,知道了next数组就是前缀表,再分析为什么要是前缀表而不是什么其他表。
|
我们介绍了什么是KMP,KMP可以解决什么问题,然后分析KMP算法里的next数组,知道了next数组就是前缀表,再分析为什么要是前缀表而不是什么其他表。
|
||||||
|
|
||||||
接着从给出的模式串中,我们一步一步的推导出了前缀表,得出前缀表无论是统一减一还是不同意减一得到的next数组仅仅是kmp的实现方式的不同。
|
接着从给出的模式串中,我们一步一步的推导出了前缀表,得出前缀表无论是统一减一还是不减一得到的next数组仅仅是kmp的实现方式的不同。
|
||||||
|
|
||||||
其中还分析了KMP算法的时间复杂度,并且和暴力方法做了对比。
|
其中还分析了KMP算法的时间复杂度,并且和暴力方法做了对比。
|
||||||
|
|
||||||
|
|||||||
@ -57,7 +57,7 @@ queue.pop();**注意此时的输出栈的操作**
|
|||||||
queue.pop();
|
queue.pop();
|
||||||
queue.empty();
|
queue.empty();
|
||||||
|
|
||||||
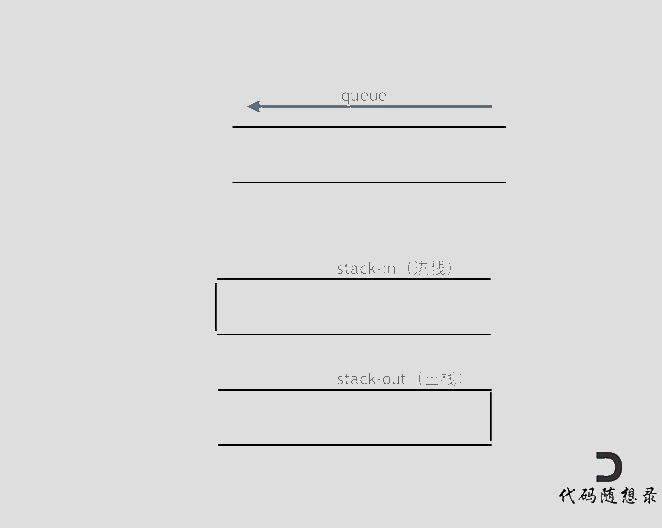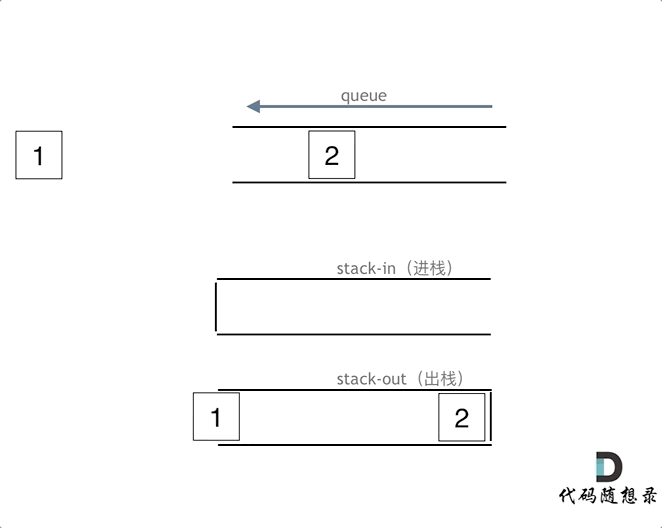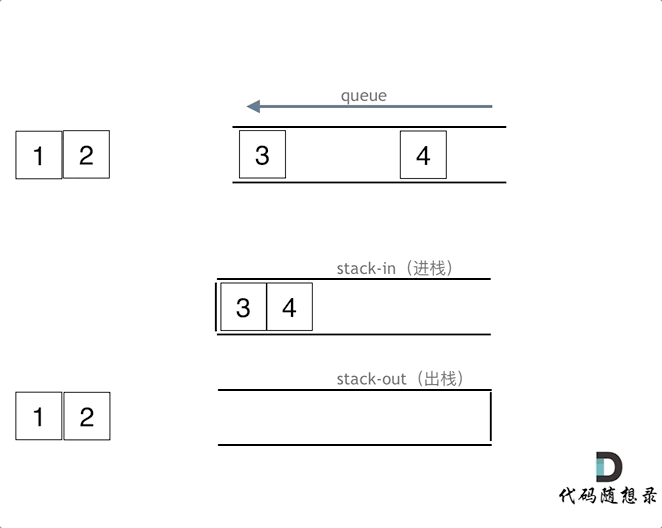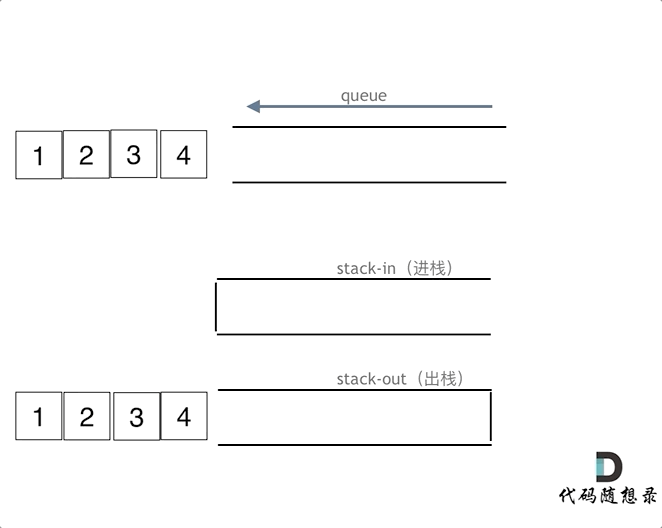
|
|
||||||
|
|
||||||
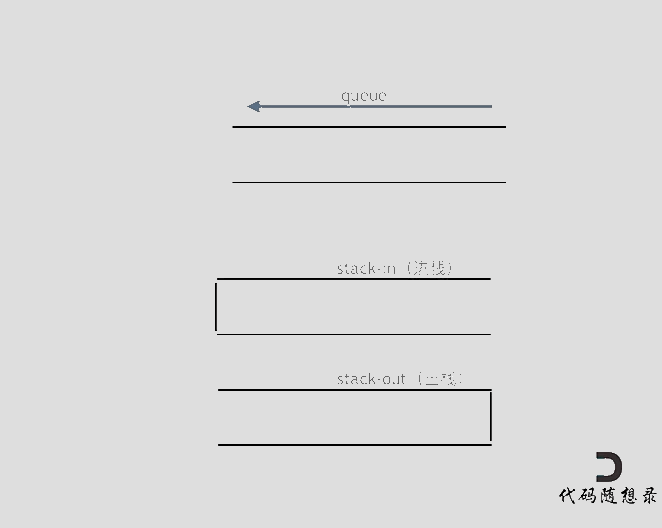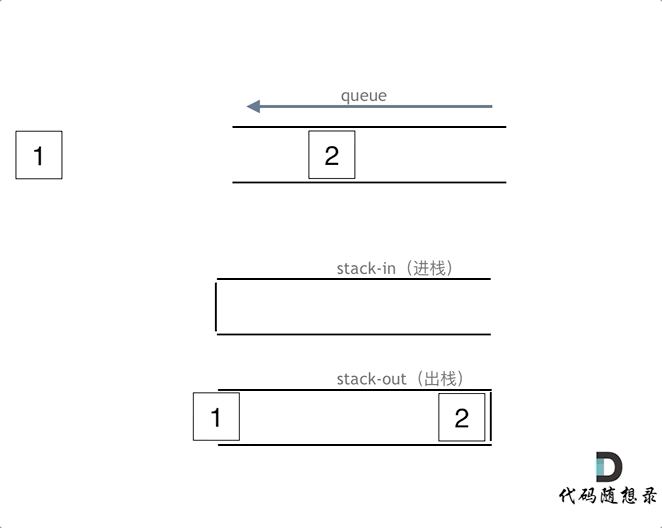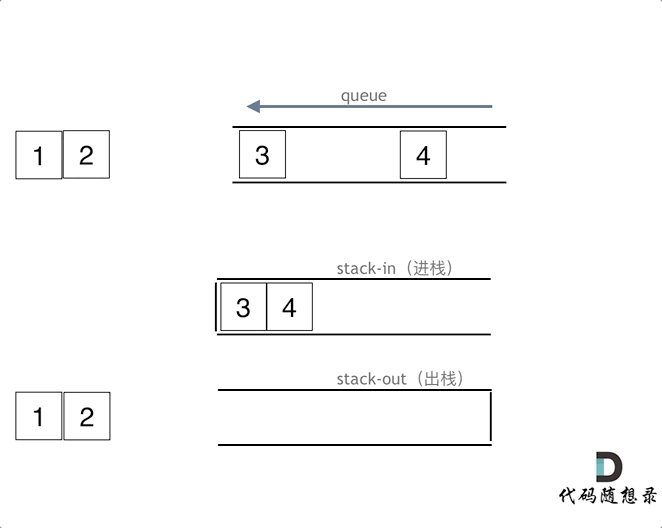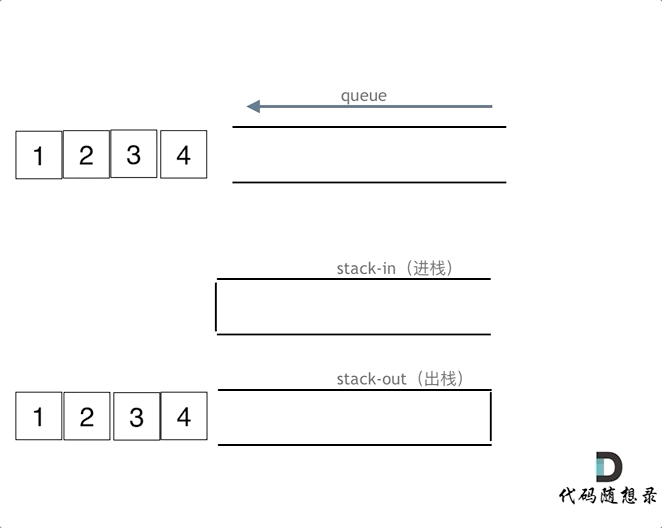
在push数据的时候,只要数据放进输入栈就好,**但在pop的时候,操作就复杂一些,输出栈如果为空,就把进栈数据全部导入进来(注意是全部导入)**,再从出栈弹出数据,如果输出栈不为空,则直接从出栈弹出数据就可以了。
|
在push数据的时候,只要数据放进输入栈就好,**但在pop的时候,操作就复杂一些,输出栈如果为空,就把进栈数据全部导入进来(注意是全部导入)**,再从出栈弹出数据,如果输出栈不为空,则直接从出栈弹出数据就可以了。
|
||||||
|
|
||||||
@ -125,8 +125,6 @@ public:
|
|||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 其他语言版本
|
## 其他语言版本
|
||||||
|
|
||||||
Java:
|
Java:
|
||||||
|
|||||||
@ -26,7 +26,8 @@
|
|||||||
|
|
||||||
拿示例一A = [1,4,2], B = [1,2,4]为例,相交情况如图:
|
拿示例一A = [1,4,2], B = [1,2,4]为例,相交情况如图:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
其实也就是说A和B的最长公共子序列是[1,4],长度为2。 这个公共子序列指的是相对顺序不变(即数字4在字符串A中数字1的后面,那么数字4也应该在字符串B数字1的后面)
|
其实也就是说A和B的最长公共子序列是[1,4],长度为2。 这个公共子序列指的是相对顺序不变(即数字4在字符串A中数字1的后面,那么数字4也应该在字符串B数字1的后面)
|
||||||
|
|
||||||
|
|||||||
Reference in New Issue
Block a user