+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + +# 5.最长回文子串 + +题目链接:https://leetcode-cn.com/problems/longest-palindromic-substring/ + +给你一个字符串 s,找到 s 中最长的回文子串。 + +示例 1: +* 输入:s = "babad" +* 输出:"bab" +* 解释:"aba" 同样是符合题意的答案。 + +示例 2: +* 输入:s = "cbbd" +* 输出:"bb" + +示例 3: +* 输入:s = "a" +* 输出:"a" + +示例 4: +* 输入:s = "ac" +* 输出:"a" + + +# 思路 + +本题和[647.回文子串](https://mp.weixin.qq.com/s/2WetyP6IYQ6VotegepVpEw) 差不多是一样的,但647.回文子串更基本一点,建议可以先做647.回文子串 + +## 暴力解法 + +两层for循环,遍历区间起始位置和终止位置,然后判断这个区间是不是回文。 + +时间复杂度:O(n^3) + +## 动态规划 + +动规五部曲: + +1. 确定dp数组(dp table)以及下标的含义 + +布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。 + + +2. 确定递推公式 + +在确定递推公式时,就要分析如下几种情况。 + +整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。 + +当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。 + +当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况 + +* 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串 +* 情况二:下标i 与 j相差为1,例如aa,也是文子串 +* 情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。 + +以上三种情况分析完了,那么递归公式如下: + +```C++ +if (s[i] == s[j]) { + if (j - i <= 1) { // 情况一 和 情况二 + dp[i][j] = true; + } else if (dp[i + 1][j - 1]) { // 情况三 + dp[i][j] = true; + } +} +``` + +注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。 + +在得到[i,j]区间是否是回文子串的时候,直接保存最长回文子串的左边界和右边界,代码如下: + +```C++ +if (s[i] == s[j]) { + if (j - i <= 1) { // 情况一 和 情况二 + dp[i][j] = true; + } else if (dp[i + 1][j - 1]) { // 情况三 + dp[i][j] = true; + } +} +if (dp[i][j] && j - i + 1 > maxlenth) { + maxlenth = j - i + 1; + left = i; + right = j; +} +``` + +3. dp数组如何初始化 + +dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。 + +所以dp[i][j]初始化为false。 + +4. 确定遍历顺序 + +遍历顺序可有有点讲究了。 + +首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。 + +dp[i + 1][j - 1] 在 dp[i][j]的左下角,如图: + +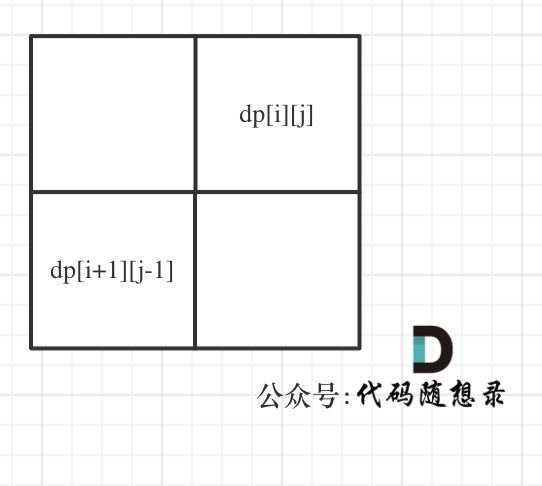 + +如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。 + +**所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的**。 + +有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。 + +代码如下: + +```C++ +for (int i = s.size() - 1; i >= 0; i--) { // 注意遍历顺序 + for (int j = i; j < s.size(); j++) { + if (s[i] == s[j]) { + if (j - i <= 1) { // 情况一 和 情况二 + dp[i][j] = true; + } else if (dp[i + 1][j - 1]) { // 情况三 + dp[i][j] = true; + } + } + if (dp[i][j] && j - i + 1 > maxlenth) { + maxlenth = j - i + 1; + left = i; + right = j; + } + } + +} +``` + +5. 举例推导dp数组 + +举例,输入:"aaa",dp[i][j]状态如下: + + + +**注意因为dp[i][j]的定义,所以j一定是大于等于i的,那么在填充dp[i][j]的时候一定是只填充右上半部分**。 + +以上分析完毕,C++代码如下: + +```C++ +class Solution { +public: + string longestPalindrome(string s) { + vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + + +# 31.下一个排列 + +链接:https://leetcode-cn.com/problems/next-permutation/ + +实现获取 下一个排列 的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。 + +如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。 + +必须 原地 修改,只允许使用额外常数空间。 + +示例 1: +* 输入:nums = [1,2,3] +* 输出:[1,3,2] + +示例 2: +* 输入:nums = [3,2,1] +* 输出:[1,2,3] + +示例 3: +* 输入:nums = [1,1,5] +* 输出:[1,5,1] + +示例 4: +* 输入:nums = [1] +* 输出:[1] + + +# 思路 + +一些同学可能手动写排列的顺序,都没有写对,那么写程序的话思路一定是有问题的了,我这里以1234为例子,把全排列都列出来。可以参考一下规律所在: + +``` +1 2 3 4 +1 2 4 3 +1 3 2 4 +1 3 4 2 +1 4 2 3 +1 4 3 2 +2 1 3 4 +2 1 4 3 +2 3 1 4 +2 3 4 1 +2 4 1 3 +2 4 3 1 +3 1 2 4 +3 1 4 2 +3 2 1 4 +3 2 4 1 +3 4 1 2 +3 4 2 1 +4 1 2 3 +4 1 3 2 +4 2 1 3 +4 2 3 1 +4 3 1 2 +4 3 2 1 +``` + +如图: + +以求1243为例,流程如图: + +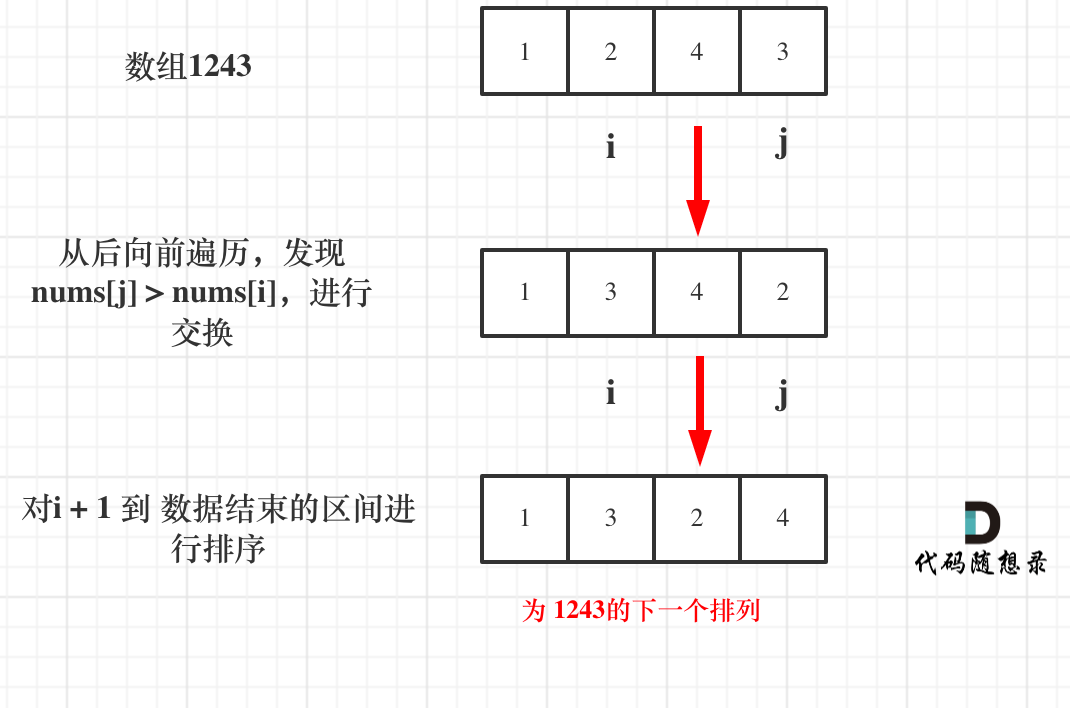 +
+对应的C++代码如下:
+
+```C++
+class Solution {
+public:
+ void nextPermutation(vector
+
+对应的C++代码如下:
+
+```C++
+class Solution {
+public:
+ void nextPermutation(vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 34. 在排序数组中查找元素的第一个和最后一个位置 + +给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。 + +如果数组中不存在目标值 target,返回 [-1, -1]。 + +进阶:你可以设计并实现时间复杂度为 O(log n) 的算法解决此问题吗? + + +示例 1: +* 输入:nums = [5,7,7,8,8,10], target = 8 +* 输出:[3,4] + +示例 2: +* 输入:nums = [5,7,7,8,8,10], target = 6 +* 输出:[-1,-1] + +示例 3: +* 输入:nums = [], target = 0 +* 输出:[-1,-1] + + +# 思路 + +这道题目如果基础不是很好,不建议大家看简短的代码,简短的代码隐藏了太多逻辑,结果就是稀里糊涂把题AC了,但是没有想清楚具体细节! + +对二分还不了解的同学先做这两题: + +* [704.二分查找](https://mp.weixin.qq.com/s/4X-8VRgnYRGd5LYGZ33m4w) +* [35.搜索插入位置](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q) + +下面我来把所有情况都讨论一下。 + +寻找target在数组里的左右边界,有如下三种情况: + +* 情况一:target 在数组范围的右边或者左边,例如数组{3, 4, 5},target为2或者数组{3, 4, 5},target为6,此时应该返回{-1, -1} +* 情况二:target 在数组范围中,且数组中不存在target,例如数组{3,6,7},target为5,此时应该返回{-1, -1} +* 情况三:target 在数组范围中,且数组中存在target,例如数组{3,6,7},target为6,此时应该返回{1, 1} + +这三种情况都考虑到,说明就想的很清楚了。 + +接下来,在去寻找左边界,和右边界了。 + +采用二分法来取寻找左右边界,为了让代码清晰,我分别写两个二分来寻找左边界和右边界。 + +**刚刚接触二分搜索的同学不建议上来就像如果用一个二分来查找左右边界,很容易把自己绕进去,建议扎扎实实的写两个二分分别找左边界和右边界** + +## 寻找右边界 + +先来寻找右边界,至于二分查找,如果看过[为什么每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)就会知道,二分查找中什么时候用while (left <= right),有什么时候用while (left < right),其实只要清楚**循环不变量**,很容易区分两种写法。 + +那么这里我采用while (left <= right)的写法,区间定义为[left, right],即左闭又闭的区间(如果这里有点看不懂了,强烈建议把[为什么每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)这篇文章先看了,在把「leetcode:35.搜索插入位置」做了之后在做这道题目就好很多了) + +确定好:计算出来的右边界是不包好target的右边界,左边界同理。 + +可以写出如下代码 + +```C++ +// 二分查找,寻找target的右边界(不包括target) +// 如果rightBorder为没有被赋值(即target在数组范围的左边,例如数组[3,3],target为2),为了处理情况一 +int getRightBorder(vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + +# 100. 相同的树 + +题目地址:https://leetcode-cn.com/problems/same-tree/ + +给定两个二叉树,编写一个函数来检验它们是否相同。 + +如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。 + + + + + + +# 思路 + +在[101.对称二叉树](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)中,我们讲到对于二叉树是否对称,要比较的是根节点的左子树与右子树是不是相互翻转的,理解这一点就知道了**其实我们要比较的是两个树(这两个树是根节点的左右子树)**,所以在递归遍历的过程中,也是要同时遍历两棵树。 + +理解这一本质之后,就会发现,求二叉树是否对称,和求二叉树是否相同几乎是同一道题目。 + +**如果没有读过[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)这一篇,请认真读完再做这道题,就会有感觉了。** + +递归三部曲中: + +1. 确定递归函数的参数和返回值 + +我们要比较的是两个树是否是相互相同的,参数也就是两个树的根节点。 + +返回值自然是bool类型。 + +代码如下: +``` +bool compare(TreeNode* tree1, TreeNode* tree2) +``` + +分析过程同[101.对称二叉树](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)。 + +2. 确定终止条件 + +**要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。** + +节点为空的情况有: + +* tree1为空,tree2不为空,不对称,return false +* tree1不为空,tree2为空,不对称 return false +* tree1,tree2都为空,对称,返回true + +此时已经排除掉了节点为空的情况,那么剩下的就是tree1和tree2不为空的时候: + +* tree1、tree2都不为空,比较节点数值,不相同就return false + +此时tree1、tree2节点不为空,且数值也不相同的情况我们也处理了。 + +代码如下: +```C++ +if (tree1 == NULL && tree2 != NULL) return false; +else if (tree1 != NULL && tree2 == NULL) return false; +else if (tree1 == NULL && tree2 == NULL) return true; +else if (tree1->val != tree2->val) return false; // 注意这里我没有使用else +``` + +分析过程同[101.对称二叉树](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg) + +3. 确定单层递归的逻辑 + +* 比较二叉树是否相同 :传入的是tree1的左孩子,tree2的右孩子。 +* 如果左右都相同就返回true ,有一侧不相同就返回false 。 + +代码如下: + +```C++ +bool left = compare(tree1->left, tree2->left); // 左子树:左、 右子树:左 +bool right = compare(tree1->right, tree2->right); // 左子树:右、 右子树:右 +bool isSame = left && right; // 左子树:中、 右子树:中(逻辑处理) +return isSame; +``` +最后递归的C++整体代码如下: + +```C++ +class Solution { +public: + bool compare(TreeNode* tree1, TreeNode* tree2) { + if (tree1 == NULL && tree2 != NULL) return false; + else if (tree1 != NULL && tree2 == NULL) return false; + else if (tree1 == NULL && tree2 == NULL) return true; + else if (tree1->val != tree2->val) return false; // 注意这里我没有使用else + + // 此时就是:左右节点都不为空,且数值相同的情况 + // 此时才做递归,做下一层的判断 + bool left = compare(tree1->left, tree2->left); // 左子树:左、 右子树:左 + bool right = compare(tree1->right, tree2->right); // 左子树:右、 右子树:右 + bool isSame = left && right; // 左子树:中、 右子树:中(逻辑处理) + return isSame; + + } + bool isSameTree(TreeNode* p, TreeNode* q) { + return compare(p, q); + } +}; +``` + + +**我给出的代码并不简洁,但是把每一步判断的逻辑都清楚的描绘出来了。** + +如果上来就看网上各种简洁的代码,看起来真的很简单,但是很多逻辑都掩盖掉了,而题解可能也没有把掩盖掉的逻辑说清楚。 + +**盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。** + +当然我可以把如上代码整理如下: + +## 递归 + +```C++ +class Solution { +public: + bool compare(TreeNode* left, TreeNode* right) { + if (left == NULL && right != NULL) return false; + else if (left != NULL && right == NULL) return false; + else if (left == NULL && right == NULL) return true; + else if (left->val != right->val) return false; + else return compare(left->left, right->left) && compare(left->right, right->right); + + } + bool isSameTree(TreeNode* p, TreeNode* q) { + return compare(p, q); + } +}; +``` + +## 迭代法 + +```C++ +lass Solution { +public: + + bool isSameTree(TreeNode* p, TreeNode* q) { + if (p == NULL && q == NULL) return true; + if (p == NULL || q == NULL) return false; + queue
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 116. 填充每个节点的下一个右侧节点指针 + +链接:https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node/ + +给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下: + +``` +struct Node { + int val; + Node *left; + Node *right; + Node *next; +} +``` + +填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。 + +初始状态下,所有 next 指针都被设置为 NULL。 + +进阶: +* 你只能使用常量级额外空间。 +* 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。 + +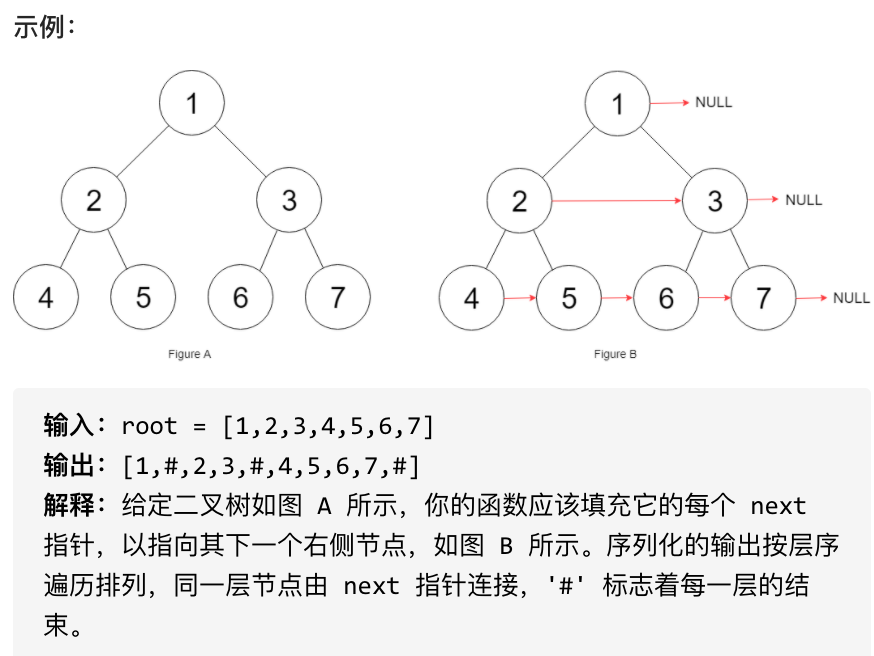 + +# 思路 + +注意题目提示内容,: +* 你只能使用常量级额外空间。 +* 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。 + +基本上就是要求使用递归了,迭代的方式一定会用到栈或者队列。 + +## 递归 + +一想用递归怎么做呢,虽然层序遍历是最直观的,但是递归的方式确实不好想。 + +如图,假如当前操作的节点是cur: + + +
+最关键的点是可以通过上一层递归 搭出来的线,进行本次搭线。
+
+图中cur节点为元素4,那么搭线的逻辑代码:(**注意注释中操作1和操作2和图中的对应关系**)
+
+```C++
+if (cur->left) cur->left->next = cur->right; // 操作1
+if (cur->right) {
+ if (cur->next) cur->right->next = cur->next->left; // 操作2
+ else cur->right->next = NULL;
+}
+```
+
+理解到这里,使用前序遍历,那么不难写出如下代码:
+
+
+```C++
+class Solution {
+private:
+ void traversal(Node* cur) {
+ if (cur == NULL) return;
+ // 中
+ if (cur->left) cur->left->next = cur->right; // 操作1
+ if (cur->right) {
+ if (cur->next) cur->right->next = cur->next->left; // 操作2
+ else cur->right->next = NULL;
+ }
+ traversal(cur->left); // 左
+ traversal(cur->right); // 右
+ }
+public:
+ Node* connect(Node* root) {
+ traversal(root);
+ return root;
+ }
+};
+```
+
+## 迭代(层序遍历)
+
+本题使用层序遍历是最为直观的,如果对层序遍历不了解,看这篇:[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)。
+
+层序遍历本来就是一层一层的去遍历,记录一层的头结点(nodePre),然后让nodePre指向当前遍历的节点就可以了。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ Node* connect(Node* root) {
+ queue
+
+最关键的点是可以通过上一层递归 搭出来的线,进行本次搭线。
+
+图中cur节点为元素4,那么搭线的逻辑代码:(**注意注释中操作1和操作2和图中的对应关系**)
+
+```C++
+if (cur->left) cur->left->next = cur->right; // 操作1
+if (cur->right) {
+ if (cur->next) cur->right->next = cur->next->left; // 操作2
+ else cur->right->next = NULL;
+}
+```
+
+理解到这里,使用前序遍历,那么不难写出如下代码:
+
+
+```C++
+class Solution {
+private:
+ void traversal(Node* cur) {
+ if (cur == NULL) return;
+ // 中
+ if (cur->left) cur->left->next = cur->right; // 操作1
+ if (cur->right) {
+ if (cur->next) cur->right->next = cur->next->left; // 操作2
+ else cur->right->next = NULL;
+ }
+ traversal(cur->left); // 左
+ traversal(cur->right); // 右
+ }
+public:
+ Node* connect(Node* root) {
+ traversal(root);
+ return root;
+ }
+};
+```
+
+## 迭代(层序遍历)
+
+本题使用层序遍历是最为直观的,如果对层序遍历不了解,看这篇:[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)。
+
+层序遍历本来就是一层一层的去遍历,记录一层的头结点(nodePre),然后让nodePre指向当前遍历的节点就可以了。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ Node* connect(Node* root) {
+ queue
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + +# 132. 分割回文串 II + +链接:https://leetcode-cn.com/problems/palindrome-partitioning-ii/ + +给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。 + +返回符合要求的 最少分割次数 。 + +示例 1: + +输入:s = "aab" +输出:1 +解释:只需一次分割就可将 s 分割成 ["aa","b"] 这样两个回文子串。 + +示例 2: +输入:s = "a" +输出:0 + +示例 3: +输入:s = "ab" +输出:1 + + +提示: + +* 1 <= s.length <= 2000 +* s 仅由小写英文字母组成 + +# 思路 + +我们在讲解回溯法系列的时候,讲过了这道题目[回溯算法:131.分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)。 + +本题呢其实也可以使用回溯法,只不过会超时!(通过记忆化回溯,也可以过,感兴趣的同学可以自行研究一下) + +我们来讲一讲如何使用动态规划,来解决这道题目。 + +关于回文子串,两道题目题目大家是一定要掌握的。 + +* [动态规划:647. 回文子串](https://mp.weixin.qq.com/s/2WetyP6IYQ6VotegepVpEw) +* 5.最长回文子串 和 647.回文子串基本一样的 + +这两道题目是回文子串的基础题目,本题也要用到相关的知识点。 + +动规五部曲分析如下: + +1. 确定dp数组(dp table)以及下标的含义 + +dp[i]:范围是[0, i]的回文子串,最少分割次数是dp[i]。 + +2. 确定递推公式 + +来看一下由什么可以推出dp[i]。 + +如果要对长度为[0, i]的子串进行分割,分割点为j。 + +那么如果分割后,区间[j + 1, i]是回文子串,那么dp[i] 就等于 dp[j] + 1。 + +这里可能有同学就不明白了,为什么只看[j + 1, i]区间,不看[0, j]区间是不是回文子串呢? + +那么在回顾一下dp[i]的定义: 范围是[0, i]的回文子串,最少分割次数是dp[i]。 + +[0, j]区间的最小切割数量,我们已经知道了就是dp[j]。 + +此时就找到了递推关系,当切割点j在[0, i] 之间时候,dp[i] = dp[j] + 1; + +本题是要找到最少分割次数,所以遍历j的时候要取最小的dp[i]。 + +**所以最后递推公式为:dp[i] = min(dp[i], dp[j] + 1);** + +注意这里不是要 dp[j] + 1 和 dp[i]去比较,而是要在遍历j的过程中取最小的dp[i]! + +可以有dp[j] + 1推出,当[j + 1, i] 为回文子串 + +3. dp数组如何初始化 + +首先来看一下dp[0]应该是多少。 + +dp[i]: 范围是[0, i]的回文子串,最少分割次数是dp[i]。 + +那么dp[0]一定是0,长度为1的字符串最小分割次数就是0。这个是比较直观的。 + +在看一下非零下标的dp[i]应该初始化为多少? + +在递推公式dp[i] = min(dp[i], dp[j] + 1) 中我们可以看出每次要取最小的dp[i]。 + +那么非零下标的dp[i]就应该初始化为一个最大数,这样递推公式在计算结果的时候才不会被初始值覆盖! + +如果非零下标的dp[i]初始化为0,在那么在递推公式中,所有数值将都是零。 + +非零下标的dp[i]初始化为一个最大数。 + +代码如下: + +```C++ +vector 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 动态规划:单词拆分 + + ## 139.单词拆分 diff --git a/problems/0141.环形链表.md b/problems/0141.环形链表.md new file mode 100644 index 00000000..4a40f953 --- /dev/null +++ b/problems/0141.环形链表.md @@ -0,0 +1,109 @@ + +
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 141. 环形链表 + +给定一个链表,判断链表中是否有环。 + +如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。 + +如果链表中存在环,则返回 true 。 否则,返回 false 。 + + + +# 思路 + +可以使用快慢指针法, 分别定义 fast 和 slow指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。 + +为什么fast 走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢? + +首先第一点: **fast指针一定先进入环中,如果fast 指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。** + +那么来看一下,**为什么fast指针和slow指针一定会相遇呢?** + +可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。 + +会发现最终都是这种情况, 如下图: + +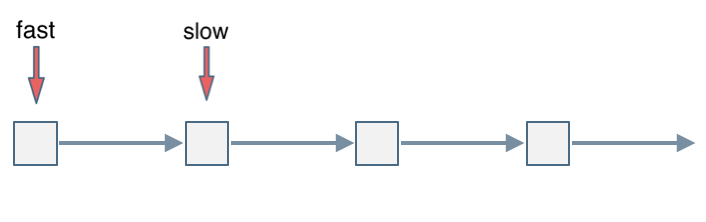 +
+fast和slow各自再走一步, fast和slow就相遇了
+
+这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
+
+动画如下:
+
+
+
+
+
+C++代码如下
+
+```C++
+class Solution {
+public:
+ bool hasCycle(ListNode *head) {
+ ListNode* fast = head;
+ ListNode* slow = head;
+ while(fast != NULL && fast->next != NULL) {
+ slow = slow->next;
+ fast = fast->next->next;
+ // 快慢指针相遇,说明有环
+ if (slow == fast) return true;
+ }
+ return false;
+ }
+};
+```
+
+# 扩展
+
+做完这道题目,可以在做做142.环形链表II,不仅仅要找环,还要找环的入口。
+
+142.环形链表II题解:[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/gt_VH3hQTqNxyWcl1ECSbQ)
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+class Solution:
+ def hasCycle(self, head: ListNode) -> bool:
+ if not head: return False
+ slow, fast = head, head
+ while fast and fast.next:
+ slow = slow.next
+ fast = fast.next.next
+ if fast == slow:
+ return True
+ return False
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+fast和slow各自再走一步, fast和slow就相遇了
+
+这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
+
+动画如下:
+
+
+
+
+
+C++代码如下
+
+```C++
+class Solution {
+public:
+ bool hasCycle(ListNode *head) {
+ ListNode* fast = head;
+ ListNode* slow = head;
+ while(fast != NULL && fast->next != NULL) {
+ slow = slow->next;
+ fast = fast->next->next;
+ // 快慢指针相遇,说明有环
+ if (slow == fast) return true;
+ }
+ return false;
+ }
+};
+```
+
+# 扩展
+
+做完这道题目,可以在做做142.环形链表II,不仅仅要找环,还要找环的入口。
+
+142.环形链表II题解:[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/gt_VH3hQTqNxyWcl1ECSbQ)
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+class Solution:
+ def hasCycle(self, head: ListNode) -> bool:
+ if not head: return False
+ slow, fast = head, head
+ while fast and fast.next:
+ slow = slow.next
+ fast = fast.next.next
+ if fast == slow:
+ return True
+ return False
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 143.重排链表 + +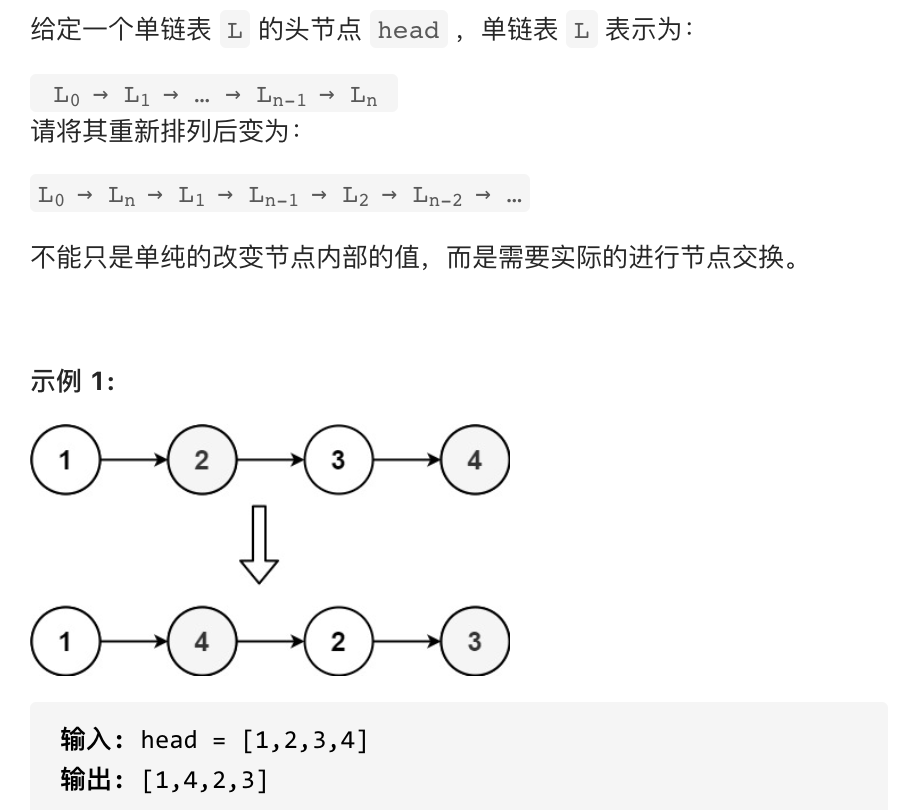 + +# 思路 + +本篇将给出三种C++实现的方法 + +* 数组模拟 +* 双向队列模拟 +* 直接分割链表 + +## 方法一 + +把链表放进数组中,然后通过双指针法,一前一后,来遍历数组,构造链表。 + +代码如下: + +```C++ +class Solution { +public: + void reorderList(ListNode* head) { + vector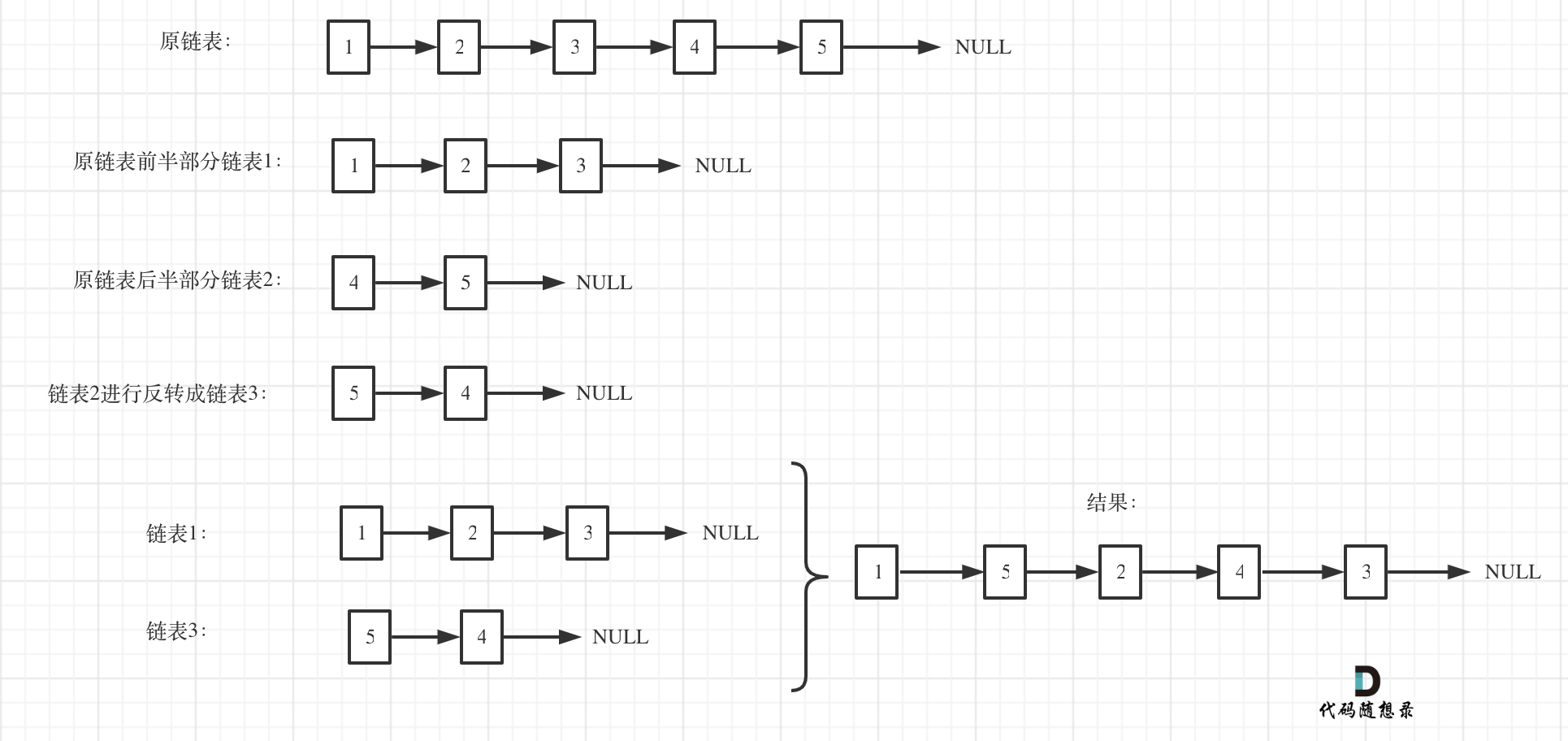 +
+这种方法,比较难,平均切割链表,看上去很简单,真正代码写的时候有很多细节,同时两个链表最后拼装整一个新的链表也有一些细节需要注意!
+
+代码如下:
+
+```C++
+class Solution {
+private:
+ // 反转链表
+ ListNode* reverseList(ListNode* head) {
+ ListNode* temp; // 保存cur的下一个节点
+ ListNode* cur = head;
+ ListNode* pre = NULL;
+ while(cur) {
+ temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
+ cur->next = pre; // 翻转操作
+ // 更新pre 和 cur指针
+ pre = cur;
+ cur = temp;
+ }
+ return pre;
+ }
+
+public:
+ void reorderList(ListNode* head) {
+ if (head == nullptr) return;
+ // 使用快慢指针法,将链表分成长度均等的两个链表head1和head2
+ // 如果总链表长度为奇数,则head1相对head2多一个节点
+ ListNode* fast = head;
+ ListNode* slow = head;
+ while (fast && fast->next && fast->next->next) {
+ fast = fast->next->next;
+ slow = slow->next;
+ }
+ ListNode* head1 = head;
+ ListNode* head2;
+ head2 = slow->next;
+ slow->next = nullptr;
+
+ // 对head2进行翻转
+ head2 = reverseList(head2);
+
+ // 将head1和head2交替生成新的链表head
+ ListNode* cur1 = head1;
+ ListNode* cur2 = head2;
+ ListNode* cur = head;
+ cur1 = cur1->next;
+ int count = 0; // 偶数取head2的元素,奇数取head1的元素
+ while (cur1 && cur2) {
+ if (count % 2 == 0) {
+ cur->next = cur2;
+ cur2 = cur2->next;
+ } else {
+ cur->next = cur1;
+ cur1 = cur1->next;
+ }
+ count++;
+ cur = cur->next;
+ }
+ if (cur2 != nullptr) { // 处理结尾
+ cur->next = cur2;
+ }
+ if (cur1 != nullptr) {
+ cur->next = cur1;
+ }
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+这种方法,比较难,平均切割链表,看上去很简单,真正代码写的时候有很多细节,同时两个链表最后拼装整一个新的链表也有一些细节需要注意!
+
+代码如下:
+
+```C++
+class Solution {
+private:
+ // 反转链表
+ ListNode* reverseList(ListNode* head) {
+ ListNode* temp; // 保存cur的下一个节点
+ ListNode* cur = head;
+ ListNode* pre = NULL;
+ while(cur) {
+ temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
+ cur->next = pre; // 翻转操作
+ // 更新pre 和 cur指针
+ pre = cur;
+ cur = temp;
+ }
+ return pre;
+ }
+
+public:
+ void reorderList(ListNode* head) {
+ if (head == nullptr) return;
+ // 使用快慢指针法,将链表分成长度均等的两个链表head1和head2
+ // 如果总链表长度为奇数,则head1相对head2多一个节点
+ ListNode* fast = head;
+ ListNode* slow = head;
+ while (fast && fast->next && fast->next->next) {
+ fast = fast->next->next;
+ slow = slow->next;
+ }
+ ListNode* head1 = head;
+ ListNode* head2;
+ head2 = slow->next;
+ slow->next = nullptr;
+
+ // 对head2进行翻转
+ head2 = reverseList(head2);
+
+ // 将head1和head2交替生成新的链表head
+ ListNode* cur1 = head1;
+ ListNode* cur2 = head2;
+ ListNode* cur = head;
+ cur1 = cur1->next;
+ int count = 0; // 偶数取head2的元素,奇数取head1的元素
+ while (cur1 && cur2) {
+ if (count % 2 == 0) {
+ cur->next = cur2;
+ cur2 = cur2->next;
+ } else {
+ cur->next = cur1;
+ cur1 = cur1->next;
+ }
+ count++;
+ cur = cur->next;
+ }
+ if (cur2 != nullptr) { // 处理结尾
+ cur->next = cur2;
+ }
+ if (cur1 != nullptr) {
+ cur->next = cur1;
+ }
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 189. 旋转数组 + +给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。 + +进阶: + +尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。 +你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗? + +示例 1: + +* 输入: nums = [1,2,3,4,5,6,7], k = 3 +* 输出: [5,6,7,1,2,3,4] +* 解释: +向右旋转 1 步: [7,1,2,3,4,5,6]。 +向右旋转 2 步: [6,7,1,2,3,4,5]。 +向右旋转 3 步: [5,6,7,1,2,3,4]。 + +示例 2: +* 输入:nums = [-1,-100,3,99], k = 2 +* 输出:[3,99,-1,-100] +* 解释: +向右旋转 1 步: [99,-1,-100,3]。 +向右旋转 2 步: [3,99,-1,-100]。 + + +# 思路 + +这道题目在字符串里其实很常见,我把字符串反转相关的题目列一下: + +* [字符串:力扣541.反转字符串II](https://mp.weixin.qq.com/s/pzXt6PQ029y7bJ9YZB2mVQ) +* [字符串:力扣151.翻转字符串里的单词](https://mp.weixin.qq.com/s/4j6vPFHkFAXnQhmSkq2X9g) +* [字符串:剑指Offer58-II.左旋转字符串](https://mp.weixin.qq.com/s/Px_L-RfT2b_jXKcNmccPsw) + +本题其实和[字符串:剑指Offer58-II.左旋转字符串](https://mp.weixin.qq.com/s/Px_L-RfT2b_jXKcNmccPsw)就非常像了,剑指offer上左旋转,本题是右旋转。 + +注意题目要求是**要求使用空间复杂度为 O(1) 的 原地 算法** + +那么我来提供一种旋转的方式哈。 + +在[字符串:剑指Offer58-II.左旋转字符串](https://mp.weixin.qq.com/s/Px_L-RfT2b_jXKcNmccPsw)中,我们提到,如下步骤就可以坐旋转字符串: + +1. 反转区间为前n的子串 +2. 反转区间为n到末尾的子串 +3. 反转整个字符串 + +本题是右旋转,其实就是反转的顺序改动一下,优先反转整个字符串,步骤如下: + +1. 反转整个字符串 +2. 反转区间为前k的子串 +3. 反转区间为k到末尾的子串 + +**需要注意的是,本题还有一个小陷阱,题目输入中,如果k大于nums.size了应该怎么办?** + +举个例子,比较容易想, + +例如,1,2,3,4,5,6,7 如果右移动15次的话,是 7 1 2 3 4 5 6 。 + +所以其实就是右移 k % nums.size() 次,即:15 % 7 = 1 + +C++代码如下: + +```C++ +class Solution { +public: + void rotate(vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 205. 同构字符串 + +题目地址:https://leetcode-cn.com/problems/isomorphic-strings/ + +给定两个字符串 s 和 t,判断它们是否是同构的。 + +如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。 + +每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。 + +示例 1: +* 输入:s = "egg", t = "add" +* 输出:true + +示例 2: +* 输入:s = "foo", t = "bar" +* 输出:false + +示例 3: +* 输入:s = "paper", t = "title" +* 输出:true + +提示:可以假设 s 和 t 长度相同。 + +# 思路 + +字符串没有说都是小写字母之类的,所以用数组不合适了,用map来做映射。 + +使用两个map 保存 s[i] 到 t[j] 和 t[j] 到 s[i] 的映射关系,如果发现对应不上,立刻返回 false + +C++代码 如下: + +```C++ +class Solution { +public: + bool isIsomorphic(string s, string t) { + unordered_map
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 234.回文链表 + +题目链接:https://leetcode-cn.com/problems/palindrome-linked-list/ + +请判断一个链表是否为回文链表。 + +示例 1: +* 输入: 1->2 +* 输出: false + +示例 2: +* 输入: 1->2->2->1 +* 输出: true + + +# 思路 + +## 数组模拟 + +最直接的想法,就是把链表装成数组,然后再判断是否回文。 + +代码也比较简单。如下: + +```C++ +class Solution { +public: + bool isPalindrome(ListNode* head) { + vector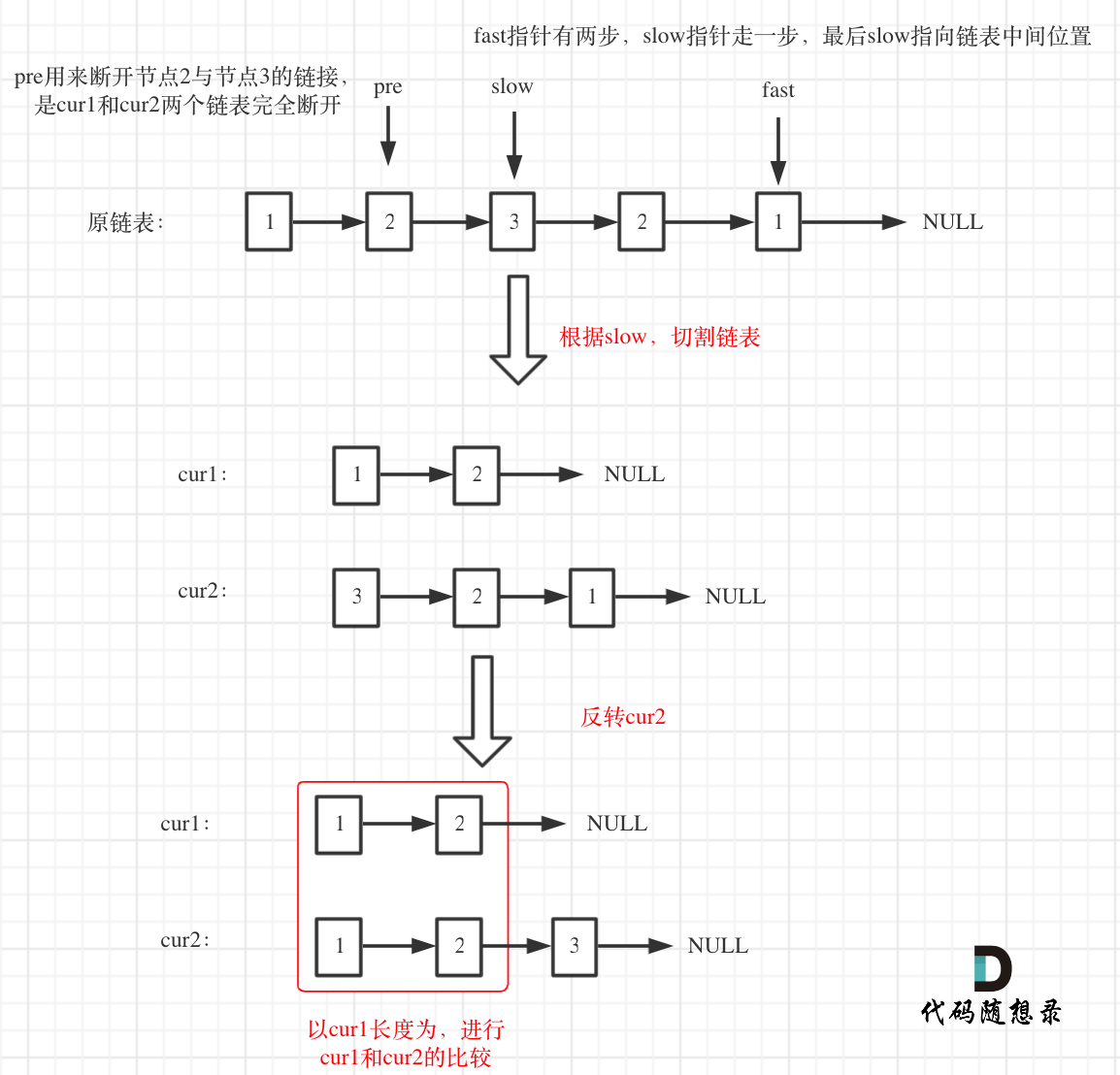 +
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool isPalindrome(ListNode* head) {
+ if (head == nullptr || head->next == nullptr) return true;
+ ListNode* slow = head; // 慢指针,找到链表中间分位置,作为分割
+ ListNode* fast = head;
+ ListNode* pre = head; // 记录慢指针的前一个节点,用来分割链表
+ while (fast && fast->next) {
+ pre = slow;
+ slow = slow->next;
+ fast = fast->next->next;
+ }
+ pre->next = nullptr; // 分割链表
+
+ ListNode* cur1 = head; // 前半部分
+ ListNode* cur2 = reverseList(slow); // 反转后半部分,总链表长度如果是奇数,cur2比cur1多一个节点
+
+ // 开始两个链表的比较
+ while (cur1) {
+ if (cur1->val != cur2->val) return false;
+ cur1 = cur1->next;
+ cur2 = cur2->next;
+ }
+ return true;
+ }
+ // 反转链表
+ ListNode* reverseList(ListNode* head) {
+ ListNode* temp; // 保存cur的下一个节点
+ ListNode* cur = head;
+ ListNode* pre = nullptr;
+ while(cur) {
+ temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
+ cur->next = pre; // 翻转操作
+ // 更新pre 和 cur指针
+ pre = cur;
+ cur = temp;
+ }
+ return pre;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool isPalindrome(ListNode* head) {
+ if (head == nullptr || head->next == nullptr) return true;
+ ListNode* slow = head; // 慢指针,找到链表中间分位置,作为分割
+ ListNode* fast = head;
+ ListNode* pre = head; // 记录慢指针的前一个节点,用来分割链表
+ while (fast && fast->next) {
+ pre = slow;
+ slow = slow->next;
+ fast = fast->next->next;
+ }
+ pre->next = nullptr; // 分割链表
+
+ ListNode* cur1 = head; // 前半部分
+ ListNode* cur2 = reverseList(slow); // 反转后半部分,总链表长度如果是奇数,cur2比cur1多一个节点
+
+ // 开始两个链表的比较
+ while (cur1) {
+ if (cur1->val != cur2->val) return false;
+ cur1 = cur1->next;
+ cur2 = cur2->next;
+ }
+ return true;
+ }
+ // 反转链表
+ ListNode* reverseList(ListNode* head) {
+ ListNode* temp; // 保存cur的下一个节点
+ ListNode* cur = head;
+ ListNode* pre = nullptr;
+ while(cur) {
+ temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
+ cur->next = pre; // 翻转操作
+ // 更新pre 和 cur指针
+ pre = cur;
+ cur = temp;
+ }
+ return pre;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+# 动态规划:一样的套路,再求一次完全平方数 + +# 283. 移动零 + +题目链接:https://leetcode-cn.com/problems/move-zeroes/ + +给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 + +示例: + +输入: [0,1,0,3,12] +输出: [1,3,12,0,0] +说明: + +必须在原数组上操作,不能拷贝额外的数组。 +尽量减少操作次数。 + + +# 思路 + +做这道题目之前,大家可以做一做[27.移除元素](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww) + +这道题目,使用暴力的解法,可以两层for循环,模拟数组删除元素(也就是向前覆盖)的过程。 + +好了,我们说一说双指针法,大家如果对双指针还不熟悉,可以看我的这篇总结[双指针法:总结篇!](https://mp.weixin.qq.com/s/PLfYLuUIGDR6xVRQ_jTrmg)。 + +双指针法在数组移除元素中,可以达到O(n)的时间复杂度,在[27.移除元素](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)里已经详细讲解了,那么本题和移除元素其实是一个套路。 + +**相当于对整个数组移除元素0,然后slowIndex之后都是移除元素0的冗余元素,把这些元素都赋值为0就可以了**。 + +如动画所示: + + + +C++代码如下: + +```C++ +class Solution { +public: + void moveZeroes(vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + +# 649. Dota2 参议院 + +Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇) + +Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的一项: + +1. 禁止一名参议员的权利:参议员可以让另一位参议员在这一轮和随后的几轮中丧失所有的权利。 + +2. 宣布胜利:如果参议员发现有权利投票的参议员都是同一个阵营的,他可以宣布胜利并决定在游戏中的有关变化。 + +给定一个字符串代表每个参议员的阵营。字母 “R” 和 “D” 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。 + +以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。 + +假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 Radiant 或 Dire。 + + + +示例 1: +* 输入:"RD" +* 输出:"Radiant" +* 解释:第一个参议员来自 Radiant 阵营并且他可以使用第一项权利让第二个参议员失去权力,因此第二个参议员将被跳过因为他没有任何权利。然后在第二轮的时候,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人 + +示例 2: +* 输入:"RDD" +* 输出:"Dire" +* 解释: +第一轮中,第一个来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利, +第二个来自 Dire 阵营的参议员会被跳过因为他的权利被禁止, +第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利, +因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利。 + + +# 思路 + +这道题 题意太绕了,我举一个更形象的例子给大家捋顺一下。 + +例如输入"RRDDD",执行过程应该是什么样呢? + +* 第一轮:senate[0]的R消灭senate[2]的D,senate[1]的R消灭senate[3]的D,senate[4]的D消灭senate[0]的R,此时剩下"RD",第一轮结束! +* 第二轮:senate[0]的R消灭senate[1]的D,第二轮结束 +* 第三轮:只有R了,R胜利 + +估计不少同学都困惑,R和D数量相同怎么办,究竟谁赢,**其实这是一个持续消灭的过程!** 即:如果同时存在R和D就继续进行下一轮消灭,轮数直到只剩下R或者D为止! + +那么每一轮消灭的策略应该是什么呢? + +例如:RDDRD + +第一轮:senate[0]的R消灭senate[1]的D,那么senate[2]的D,是消灭senate[0]的R还是消灭senate[3]的R呢? + +当然是消灭senate[3]的R,因为当轮到这个R的时候,它可以消灭senate[4]的D。 + +**所以消灭的策略是,尽量消灭自己后面的对手,因为前面的对手已经使用过权利了,而后序的对手依然可以使用权利消灭自己的同伴!** + +那么局部最优:有一次权利机会,就消灭自己后面的对手。全局最优:为自己的阵营赢取最大利益。 + +局部最优可以退出全局最优,举不出反例,那么试试贪心。 + +如果对贪心算法理论基础还不了解的话,可以看看这篇:[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg) ,相信看完之后对贪心就有基本的了解了。 + +# 代码实现 + +实现代码,在每一轮循环的过程中,去过模拟优先消灭身后的对手,其实是比较麻烦的。 + +这里有一个技巧,就是用一个变量记录当前参议员之前有几个敌对对手了,进而判断自己是否被消灭了。这个变量我用flag来表示。 + +C++代码如下: + + +```C++ +class Solution { +public: + string predictPartyVictory(string senate) { + // R = true表示本轮循环结束后,字符串里依然有R。D同理 + bool R = true, D = true; + // 当flag大于0时,R在D前出现,R可以消灭D。当flag小于0时,D在R前出现,D可以消灭R + int flag = 0; + while (R && D) { // 一旦R或者D为false,就结束循环,说明本轮结束后只剩下R或者D了 + R = false; + D = false; + for (int i = 0; i < senate.size(); i++) { + if (senate[i] == 'R') { + if (flag < 0) senate[i] = 0; // 消灭R,R此时为false + else R = true; // 如果没被消灭,本轮循环结束有R + flag++; + } + if (senate[i] == 'D') { + if (flag > 0) senate[i] = 0; + else D = true; + flag--; + } + } + } + // 循环结束之后,R和D只能有一个为true + return R == true ? "Radiant" : "Dire"; + } +}; +``` + + + +# 其他语言版本 + +## Java + +```java +``` + +## Python + +```python +``` + +## Go + +```go +``` + +## JavaScript + +```js +``` + +----------------------- +* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw) +* B站视频:[代码随想录](https://space.bilibili.com/525438321) +* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) +
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 657. 机器人能否返回原点 + +题目地址:https://leetcode-cn.com/problems/robot-return-to-origin/ + +在二维平面上,有一个机器人从原点 (0, 0) 开始。给出它的移动顺序,判断这个机器人在完成移动后是否在 (0, 0) 处结束。 + +移动顺序由字符串表示。字符 move[i] 表示其第 i 次移动。机器人的有效动作有 R(右),L(左),U(上)和 D(下)。如果机器人在完成所有动作后返回原点,则返回 true。否则,返回 false。 + +注意:机器人“面朝”的方向无关紧要。 “R” 将始终使机器人向右移动一次,“L” 将始终向左移动等。此外,假设每次移动机器人的移动幅度相同。 + + + +示例 1: +* 输入: "UD" +* 输出: true +* 解释:机器人向上移动一次,然后向下移动一次。所有动作都具有相同的幅度,因此它最终回到它开始的原点。因此,我们返回 true。 + +示例 2: +* 输入: "LL" +* 输出: false +* 解释:机器人向左移动两次。它最终位于原点的左侧,距原点有两次 “移动” 的距离。我们返回 false,因为它在移动结束时没有返回原点。 + + + +# 思路 + +这道题目还是挺简单的,大家不要想复杂了,一波哈希法又一波图论算法啥的,哈哈。 + +其实就是,x,y坐标,初始为0,然后: +* if (moves[i] == 'U') y++; +* if (moves[i] == 'D') y--; +* if (moves[i] == 'L') x--; +* if (moves[i] == 'R') x++; + +最后判断一下x,y是否回到了(0, 0)位置就可以了。 + +如图所示: +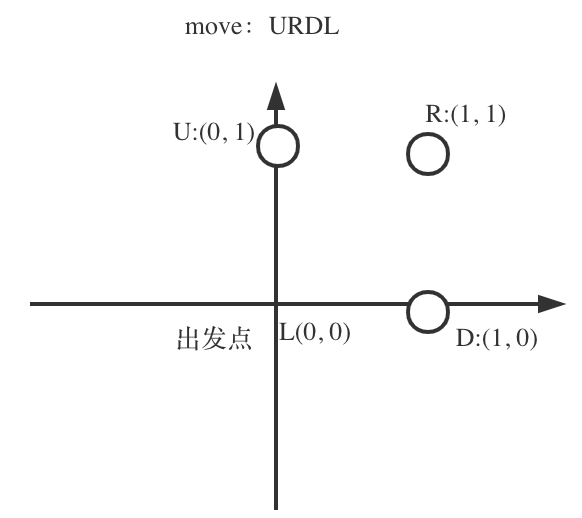 +
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ bool judgeCircle(string moves) {
+ int x = 0, y = 0;
+ for (int i = 0; i < moves.size(); i++) {
+ if (moves[i] == 'U') y++;
+ if (moves[i] == 'D') y--;
+ if (moves[i] == 'L') x--;
+ if (moves[i] == 'R') x++;
+ }
+ if (x == 0 && y == 0) return true;
+ return false;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ bool judgeCircle(string moves) {
+ int x = 0, y = 0;
+ for (int i = 0; i < moves.size(); i++) {
+ if (moves[i] == 'U') y++;
+ if (moves[i] == 'D') y--;
+ if (moves[i] == 'L') x--;
+ if (moves[i] == 'R') x++;
+ }
+ if (x == 0 && y == 0) return true;
+ return false;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 673.最长递增子序列的个数 + +给定一个未排序的整数数组,找到最长递增子序列的个数。 + +示例 1: +* 输入: [1,3,5,4,7] +* 输出: 2 +* 解释: 有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, 3, 5, 7]。 + +示例 2: +* 输入: [2,2,2,2,2] +* 输出: 5 +* 解释: 最长递增子序列的长度是1,并且存在5个子序列的长度为1,因此输出5。 + + +# 思路 + +这道题可以说是 300.最长上升子序列 的进阶版本 + +1. 确定dp数组(dp table)以及下标的含义 + +这道题目我们要一起维护两个数组。 + +dp[i]:i之前(包括i)最长递增子序列的长度为dp[i] + +count[i]:以nums[i]为结尾的字符串,最长递增子序列的个数为count[i] + +2. 确定递推公式 + +在300.最长上升子序列 中,我们给出的状态转移是: + +if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1); + +即:位置i的最长递增子序列长度 等于j从0到i-1各个位置的最长升序子序列 + 1的最大值。 + +本题就没那么简单了,我们要考虑两个维度,一个是dp[i]的更新,一个是count[i]的更新。 + +那么如何更新count[i]呢? + +以nums[i]为结尾的字符串,最长递增子序列的个数为count[i]。 + +那么在nums[i] > nums[j]前提下,如果在[0, i-1]的范围内,找到了j,使得dp[j] + 1 > dp[i],说明找到了一个更长的递增子序列。 + +那么以j为结尾的子串的最长递增子序列的个数,就是最新的以i为结尾的子串的最长递增子序列的个数,即:count[i] = count[j]。 + +在nums[i] > nums[j]前提下,如果在[0, i-1]的范围内,找到了j,使得dp[j] + 1 == dp[i],说明找到了两个相同长度的递增子序列。 + +那么以i为结尾的子串的最长递增子序列的个数 就应该加上以j为结尾的子串的最长递增子序列的个数,即:count[i] += count[j]; + +代码如下: + +```C++ +if (nums[i] > nums[j]) { + if (dp[j] + 1 > dp[i]) { + count[i] = count[j]; + } else if (dp[j] + 1 == dp[i]) { + count[i] += count[j]; + } + dp[i] = max(dp[i], dp[j] + 1); +} +``` + +当然也可以这么写: + +```C++ +if (nums[i] > nums[j]) { + if (dp[j] + 1 > dp[i]) { + dp[i] = dp[j] + 1; // 更新dp[i]放在这里,就不用max了 + count[i] = count[j]; + } else if (dp[j] + 1 == dp[i]) { + count[i] += count[j]; + } +} +``` + +这里count[i]记录了以nums[i]为结尾的字符串,最长递增子序列的个数。dp[i]记录了i之前(包括i)最长递增序列的长度。 + +题目要求最长递增序列的长度的个数,我们应该把最长长度记录下来。 + +代码如下: + +```C++ +for (int i = 1; i < nums.size(); i++) { + for (int j = 0; j < i; j++) { + if (nums[i] > nums[j]) { + if (dp[j] + 1 > dp[i]) { + count[i] = count[j]; + } else if (dp[j] + 1 == dp[i]) { + count[i] += count[j]; + } + dp[i] = max(dp[i], dp[j] + 1); + } + if (dp[i] > maxCount) maxCount = dp[i]; // 记录最长长度 + } +} +``` + +3. dp数组如何初始化 + +再回顾一下dp[i]和count[i]的定义 + +count[i]记录了以nums[i]为结尾的字符串,最长递增子序列的个数。 + +那么最少也就是1个,所以count[i]初始为1。 + +dp[i]记录了i之前(包括i)最长递增序列的长度。 + +最小的长度也是1,所以dp[i]初始为1。 + +代码如下: + +``` +vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + +# 684.冗余连接 + +树可以看成是一个连通且 无环 的 无向 图。 + +给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。 + +请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的边。 + +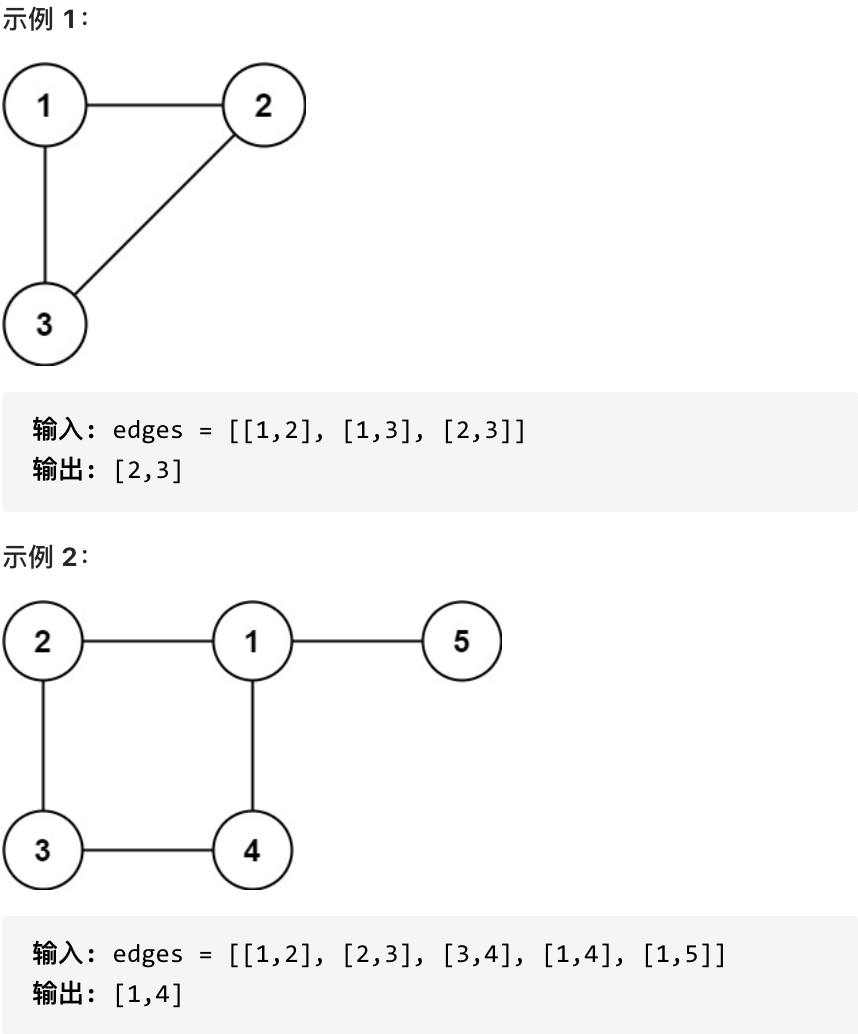 + +提示: +* n == edges.length +* 3 <= n <= 1000 +* edges[i].length == 2 +* 1 <= ai < bi <= edges.length +* ai != bi +* edges 中无重复元素 +* 给定的图是连通的 + +# 思路 + +这道题目也是并查集基础题目。 + +首先要知道并查集可以解决什么问题呢? + +主要就是集合问题,两个节点在不在一个集合,也可以将两个节点添加到一个集合中。 + +这里整理出我的并查集模板如下: + +```C++ +int n = 1005; // 节点数量3 到 1000 +int father[1005]; + +// 并查集初始化 +void init() { + for (int i = 0; i < n; ++i) { + father[i] = i; + } +} +// 并查集里寻根的过程 +int find(int u) { + return u == father[u] ? u : father[u] = find(father[u]); +} +// 将v->u 这条边加入并查集 +void join(int u, int v) { + u = find(u); + v = find(v); + if (u == v) return ; + father[v] = u; +} +// 判断 u 和 v是否找到同一个根 +bool same(int u, int v) { + u = find(u); + v = find(v); + return u == v; +} +``` + +以上模板汇总,只要修改 n 和father数组的大小就可以了。 + +并查集主要有三个功能。 + +1. 寻找根节点,函数:find(int u),也就是判断这个节点的祖先节点是哪个 +2. 将两个节点接入到同一个集合,函数:join(int u, int v),将两个节点连在同一个根节点上 +3. 判断两个节点是否在同一个集合,函数:same(int u, int v),就是判断两个节点是不是同一个根节点 + +简单介绍并查集之后,我们再来看一下这道题目。 + +题目说是无向图,返回一条可以删去的边,使得结果图是一个有着N个节点的树。 + +如果有多个答案,则返回二维数组中最后出现的边。 + +那么我们就可以从前向后遍历每一条边,边的两个节点如果不在同一个集合,就加入集合(即:同一个根节点)。 + +如果边的两个节点已经出现在同一个集合里,说明着边的两个节点已经连在一起了,如果再加入这条边一定就出现环了。 + +这个思路清晰之后,代码就很好写了。 + +并查集C++代码如下: + +```C++ +class Solution { +private: + int n = 1005; // 节点数量3 到 1000 + int father[1005]; + + // 并查集初始化 + void init() { + for (int i = 0; i < n; ++i) { + father[i] = i; + } + } + // 并查集里寻根的过程 + int find(int u) { + return u == father[u] ? u : father[u] = find(father[u]); + } + // 将v->u 这条边加入并查集 + void join(int u, int v) { + u = find(u); + v = find(v); + if (u == v) return ; + father[v] = u; + } + // 判断 u 和 v是否找到同一个根,本题用不上 + bool same(int u, int v) { + u = find(u); + v = find(v); + return u == v; + } +public: + vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
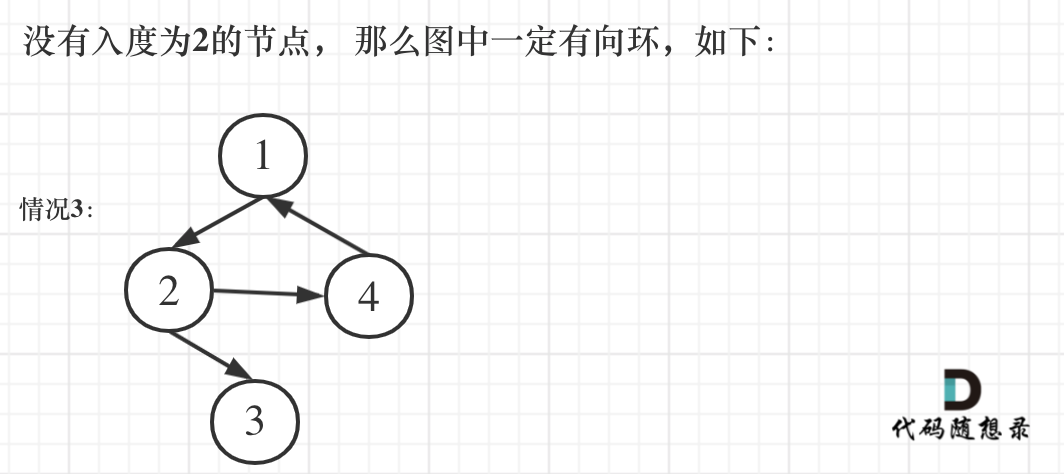
+ + +# 685.冗余连接II + +题目地址:https://leetcode-cn.com/problems/redundant-connection-ii/ + +在本问题中,有根树指满足以下条件的 有向 图。该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。 + +输入一个有向图,该图由一个有着 n 个节点(节点值不重复,从 1 到 n)的树及一条附加的有向边构成。附加的边包含在 1 到 n 中的两个不同顶点间,这条附加的边不属于树中已存在的边。 + +结果图是一个以边组成的二维数组 edges 。 每个元素是一对 [ui, vi],用以表示 有向 图中连接顶点 ui 和顶点 vi 的边,其中 ui 是 vi 的一个父节点。 + +返回一条能删除的边,使得剩下的图是有 n 个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。 + + +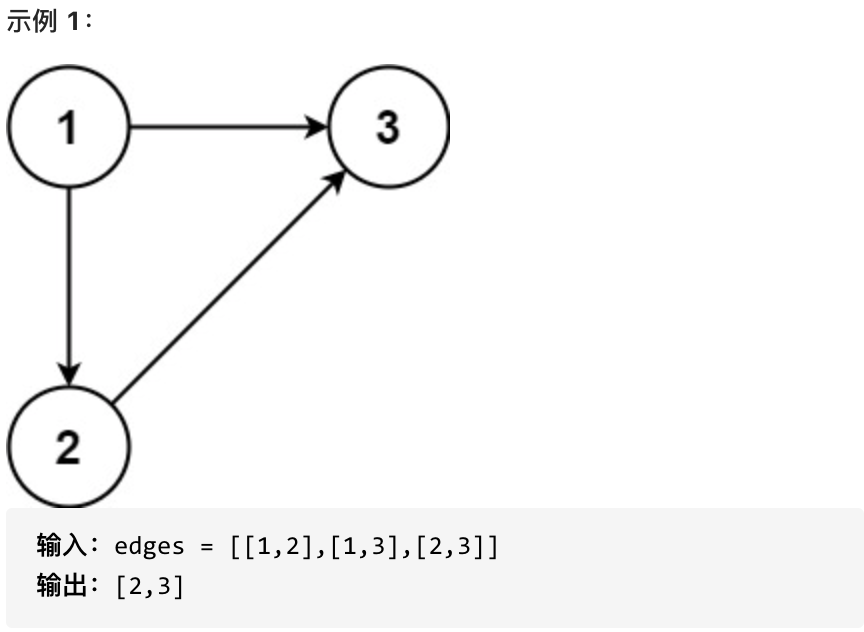 + +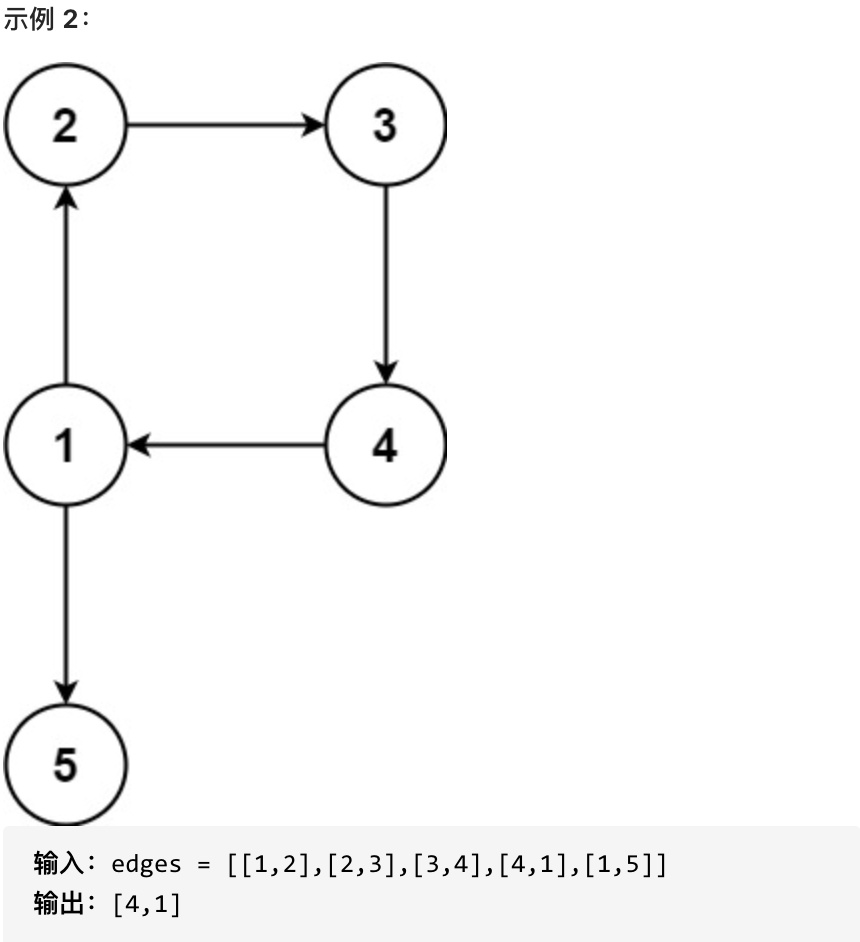 + +提示: + +* n == edges.length +* 3 <= n <= 1000 +* edges[i].length == 2 +* 1 <= ui, vi <= n + +## 思路 + +先重点读懂题目中的这句**该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。** + +**这说明题目中的图原本是是一棵树,只不过在不增加节点的情况下多加了一条边!** + +还有**若有多个答案,返回最后出现在给定二维数组的答案。**这说明在两天边都可以删除的情况下,要删顺序靠后的! + + +那么有如下三种情况,前两种情况是出现入度为2的点,如图: + + +
+且只有一个节点入度为2,为什么不看出度呢,出度没有意义,一颗树中随便一个父节点就有多个出度。
+
+
+第三种情况是没有入度为2的点,那么图中一定出现了有向环(**注意这里强调是有向环!**)
+
+如图:
+
+
+
+且只有一个节点入度为2,为什么不看出度呢,出度没有意义,一颗树中随便一个父节点就有多个出度。
+
+
+第三种情况是没有入度为2的点,那么图中一定出现了有向环(**注意这里强调是有向环!**)
+
+如图:
+
+ +
+
+首先先计算节点的入度,代码如下:
+
+```C++
+int inDegree[N] = {0}; // 记录节点入度
+n = edges.size(); // 边的数量
+for (int i = 0; i < n; i++) {
+ inDegree[edges[i][1]]++; // 统计入度
+}
+```
+
+前两种入度为2的情况,一定是删除指向入度为2的节点的两条边其中的一条,如果删了一条,判断这个图是一个树,那么这条边就是答案,同时注意要从后向前遍历,因为如果两天边删哪一条都可以成为树,就删最后那一条。
+
+代码如下:
+
+```C++
+vector
+
+
+首先先计算节点的入度,代码如下:
+
+```C++
+int inDegree[N] = {0}; // 记录节点入度
+n = edges.size(); // 边的数量
+for (int i = 0; i < n; i++) {
+ inDegree[edges[i][1]]++; // 统计入度
+}
+```
+
+前两种入度为2的情况,一定是删除指向入度为2的节点的两条边其中的一条,如果删了一条,判断这个图是一个树,那么这条边就是答案,同时注意要从后向前遍历,因为如果两天边删哪一条都可以成为树,就删最后那一条。
+
+代码如下:
+
+```C++
+vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 724.寻找数组的中心下标 + +给你一个整数数组 nums ,请计算数组的 中心下标 。 + +数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。 + +如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。 + +如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。 + +示例 1: +* 输入:nums = [1, 7, 3, 6, 5, 6] +* 输出:3 +* 解释:中心下标是 3。左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 ,右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。 + +示例 2: +* 输入:nums = [1, 2, 3] +* 输出:-1 +* 解释:数组中不存在满足此条件的中心下标。 + +示例 3: +* 输入:nums = [2, 1, -1] +* 输出:0 +* 解释:中心下标是 0。左侧数之和 sum = 0 ,(下标 0 左侧不存在元素),右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。 + + +# 思路 + +这道题目还是比较简单直接啊哈哈 + +1. 遍历一遍求出总和sum +2. 遍历第二遍求中心索引左半和leftSum + * 同时根据sum和leftSum 计算中心索引右半和rightSum + * 判断leftSum和rightSum是否相同 + +C++代码如下: +```C++ +class Solution { +public: + int pivotIndex(vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + +# 841.钥匙和房间 + +题目地址:https://leetcode-cn.com/problems/keys-and-rooms/ + +有 N 个房间,开始时你位于 0 号房间。每个房间有不同的号码:0,1,2,...,N-1,并且房间里可能有一些钥匙能使你进入下一个房间。 + +在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i],每个钥匙 rooms[i][j] 由 [0,1,...,N-1] 中的一个整数表示,其中 N = rooms.length。 钥匙 rooms[i][j] = v 可以打开编号为 v 的房间。 + +最初,除 0 号房间外的其余所有房间都被锁住。 + +你可以自由地在房间之间来回走动。 + +如果能进入每个房间返回 true,否则返回 false。 + +示例 1: +* 输入: [[1],[2],[3],[]] +* 输出: true +* 解释: +我们从 0 号房间开始,拿到钥匙 1。 +之后我们去 1 号房间,拿到钥匙 2。 +然后我们去 2 号房间,拿到钥匙 3。 +最后我们去了 3 号房间。 +由于我们能够进入每个房间,我们返回 true。 + +示例 2: +* 输入:[[1,3],[3,0,1],[2],[0]] +* 输出:false +* 解释:我们不能进入 2 号房间。 + + +## 思 + +其实这道题的本质就是判断各个房间所连成的有向图,说明不用访问所有的房间。 + +如图所示: + + +
+示例1就可以访问所有的房间,因为通过房间里的key将房间连在了一起。
+
+示例2中,就不能访问所有房间,从图中就可以看出,房间2是一个孤岛,我们从0出发,无论怎么遍历,都访问不到房间2。
+
+认清本质问题之后,**使用 广度优先搜索(BFS) 还是 深度优先搜索(DFS) 都是可以的。**
+
+BFS C++代码代码如下:
+
+```C++
+class Solution {
+bool bfs(const vector
+
+示例1就可以访问所有的房间,因为通过房间里的key将房间连在了一起。
+
+示例2中,就不能访问所有房间,从图中就可以看出,房间2是一个孤岛,我们从0出发,无论怎么遍历,都访问不到房间2。
+
+认清本质问题之后,**使用 广度优先搜索(BFS) 还是 深度优先搜索(DFS) 都是可以的。**
+
+BFS C++代码代码如下:
+
+```C++
+class Solution {
+bool bfs(const vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 844.比较含退格的字符串 + +题目链接:https://leetcode-cn.com/problems/backspace-string-compare/ + +给定 S 和 T 两个字符串,当它们分别被输入到空白的文本编辑器后,判断二者是否相等,并返回结果。 # 代表退格字符。 + +注意:如果对空文本输入退格字符,文本继续为空。 + +示例 1: +* 输入:S = "ab#c", T = "ad#c" +* 输出:true +* 解释:S 和 T 都会变成 “ac”。 + +示例 2: +* 输入:S = "ab##", T = "c#d#" +* 输出:true +* 解释:S 和 T 都会变成 “”。 + +示例 3: +* 输入:S = "a##c", T = "#a#c" +* 输出:true +* 解释:S 和 T 都会变成 “c”。 + +示例 4: +* 输入:S = "a#c", T = "b" +* 输出:false +* 解释:S 会变成 “c”,但 T 仍然是 “b”。 + + +# 思路 + +本文将给出 空间复杂度O(n)的栈模拟方法 以及空间复杂度是O(1)的双指针方法。 + +## 普通方法(使用栈的思路) + +这道题目一看就是要使用栈的节奏,这种匹配(消除)问题也是栈的擅长所在,跟着一起刷题的同学应该知道,在[栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/1-x6r1wGA9mqIHW5LrMvBg),我就已经提过了一次使用栈来做类似的事情了。 + +**那么本题,确实可以使用栈的思路,但是没有必要使用栈,因为最后比较的时候还要比较栈里的元素,有点麻烦**。 + +这里直接使用字符串string,来作为栈,末尾添加和弹出,string都有相应的接口,最后比较的时候,只要比较两个字符串就可以了,比比较栈里的元素方便一些。 + +代码如下: + +```C++ +class Solution { +public: + bool backspaceCompare(string S, string T) { + string s; // 当栈来用 + string t; // 当栈来用 + for (int i = 0; i < S.size(); i++) { + if (S[i] != '#') s += S[i]; + else if (!s.empty()) { + s.pop_back(); + + } + for (int i = 0; i < T.size(); i++) { + if (T[i] != '#') t += T[i]; + else if (!t.empty()) { + t.pop_back(); + } + } + if (s == t) return true; // 直接比较两个字符串是否相等,比用栈来比较方便多了 + return false; + } +}; +``` +* 时间复杂度:O(n + m), n为S的长度,m为T的长度 ,也可以理解是O(n)的时间复杂度 +* 空间复杂度:O(n + m) + +当然以上代码,大家可以发现有重复的逻辑处理S,处理T,可以把这块公共逻辑抽离出来,代码精简如下: + +```C++ +class Solution { +private: +string getString(const string& S) { + string s; + for (int i = 0; i < S.size(); i++) { + if (S[i] != '#') s += S[i]; + else if (!s.empty()) { + s.pop_back(); + } + } + return s; +} +public: + bool backspaceCompare(string S, string T) { + return getString(S) == getString(T); + } +}; +``` +性能依然是: +* 时间复杂度:O(n + m) +* 空间复杂度:O(n + m) + +## 优化方法(从后向前双指针) + +当然还可以有使用 O(1) 的空间复杂度来解决该问题。 + +同时从后向前遍历S和T(i初始为S末尾,j初始为T末尾),记录#的数量,模拟消除的操作,如果#用完了,就开始比较S[i]和S[j]。 + +动画如下: + +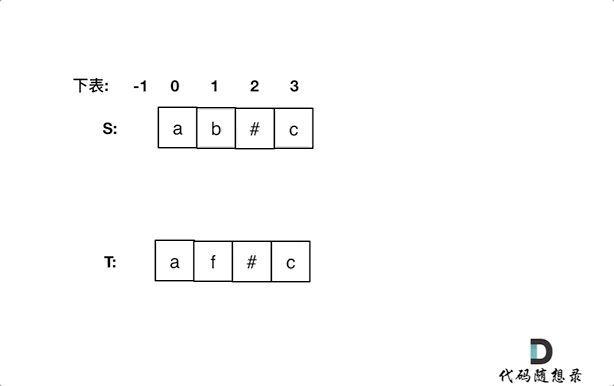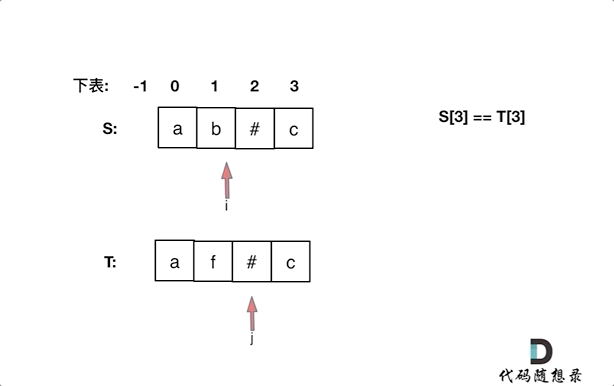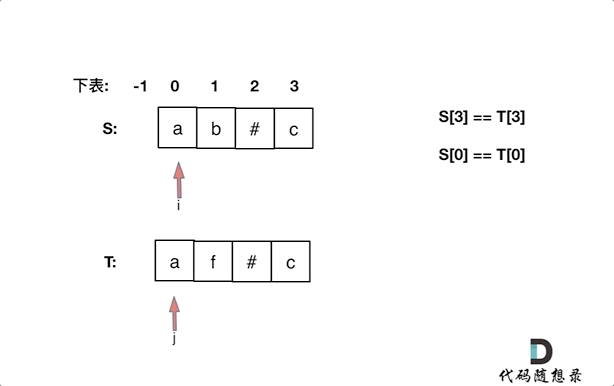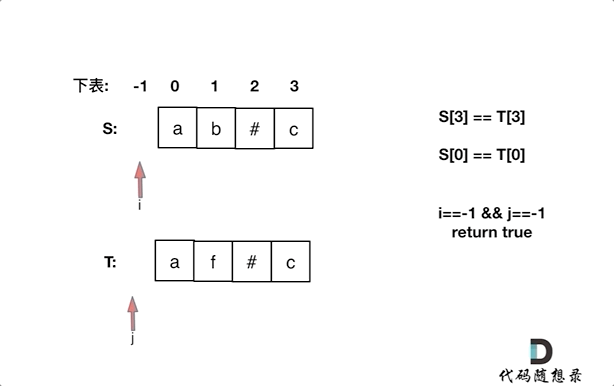 +
+如果S[i]和S[j]不相同返回false,如果有一个指针(i或者j)先走到的字符串头部位置,也返回false。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool backspaceCompare(string S, string T) {
+ int sSkipNum = 0; // 记录S的#数量
+ int tSkipNum = 0; // 记录T的#数量
+ int i = S.size() - 1;
+ int j = T.size() - 1;
+ while (1) {
+ while (i >= 0) { // 从后向前,消除S的#
+ if (S[i] == '#') sSkipNum++;
+ else {
+ if (sSkipNum > 0) sSkipNum--;
+ else break;
+ }
+ i--;
+ }
+ while (j >= 0) { // 从后向前,消除T的#
+ if (T[j] == '#') tSkipNum++;
+ else {
+ if (tSkipNum > 0) tSkipNum--;
+ else break;
+ }
+ j--;
+ }
+ // 后半部分#消除完了,接下来比较S[i] != T[j]
+ if (i < 0 || j < 0) break; // S 或者T 遍历到头了
+ if (S[i] != T[j]) return false;
+ i--;j--;
+ }
+ // 说明S和T同时遍历完毕
+ if (i == -1 && j == -1) return true;
+ return false;
+ }
+};
+```
+
+* 时间复杂度:O(n + m)
+* 空间复杂度:O(1)
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+如果S[i]和S[j]不相同返回false,如果有一个指针(i或者j)先走到的字符串头部位置,也返回false。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool backspaceCompare(string S, string T) {
+ int sSkipNum = 0; // 记录S的#数量
+ int tSkipNum = 0; // 记录T的#数量
+ int i = S.size() - 1;
+ int j = T.size() - 1;
+ while (1) {
+ while (i >= 0) { // 从后向前,消除S的#
+ if (S[i] == '#') sSkipNum++;
+ else {
+ if (sSkipNum > 0) sSkipNum--;
+ else break;
+ }
+ i--;
+ }
+ while (j >= 0) { // 从后向前,消除T的#
+ if (T[j] == '#') tSkipNum++;
+ else {
+ if (tSkipNum > 0) tSkipNum--;
+ else break;
+ }
+ j--;
+ }
+ // 后半部分#消除完了,接下来比较S[i] != T[j]
+ if (i < 0 || j < 0) break; // S 或者T 遍历到头了
+ if (S[i] != T[j]) return false;
+ i--;j--;
+ }
+ // 说明S和T同时遍历完毕
+ if (i == -1 && j == -1) return true;
+ return false;
+ }
+};
+```
+
+* 时间复杂度:O(n + m)
+* 空间复杂度:O(1)
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + + +# 922. 按奇偶排序数组II + +给定一个非负整数数组 A, A 中一半整数是奇数,一半整数是偶数。 + +对数组进行排序,以便当 A[i] 为奇数时,i 也是奇数;当 A[i] 为偶数时, i 也是偶数。 + +你可以返回任何满足上述条件的数组作为答案。 + +示例: + +* 输入:[4,2,5,7] +* 输出:[4,5,2,7] +* 解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。 + + +# 思路 + +这道题目直接的想法可能是两层for循环再加上used数组表示使用过的元素。这样的的时间复杂度是O(n^2)。 + +## 方法一 + +其实这道题可以用很朴实的方法,时间复杂度就就是O(n)了,C++代码如下: + +```C++ +class Solution { +public: + vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 925.长按键入 + +你的朋友正在使用键盘输入他的名字 name。偶尔,在键入字符 c 时,按键可能会被长按,而字符可能被输入 1 次或多次。 + +你将会检查键盘输入的字符 typed。如果它对应的可能是你的朋友的名字(其中一些字符可能被长按),那么就返回 True。 + +示例 1: +* 输入:name = "alex", typed = "aaleex" +* 输出:true +* 解释:'alex' 中的 'a' 和 'e' 被长按。 + +示例 2: +* 输入:name = "saeed", typed = "ssaaedd" +* 输出:false +* 解释:'e' 一定需要被键入两次,但在 typed 的输出中不是这样。 + + +示例 3: + +* 输入:name = "leelee", typed = "lleeelee" +* 输出:true + +示例 4: + +* 输入:name = "laiden", typed = "laiden" +* 输出:true +* 解释:长按名字中的字符并不是必要的。 + +# 思路 + +这道题目一看以为是哈希,仔细一看不行,要有顺序。 + +所以模拟同时遍历两个数组,进行对比就可以了。 + +对比的时候需要一下几点: + +* name[i] 和 typed[j]相同,则i++,j++ (继续向后对比) +* name[i] 和 typed[j]不相同 + * 看是不是第一位就不相同了,也就是j如果等于0,那么直接返回false + * 不是第一位不相同,就让j跨越重复项,移动到重复项之后的位置,再次比较name[i] 和typed[j] + * 如果 name[i] 和 typed[j]相同,则i++,j++ (继续向后对比) + * 不相同,返回false +* 对比完之后有两种情况 + * name没有匹配完,例如name:"pyplrzzzzdsfa" type:"ppyypllr" + * type没有匹配完,例如name:"alex" type:"alexxrrrrssda" + +动画如下: + +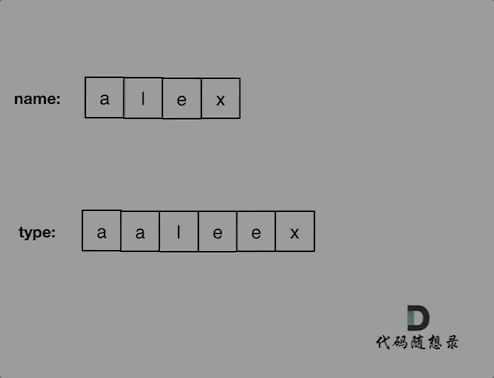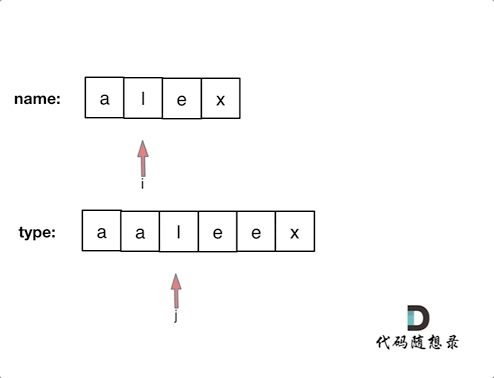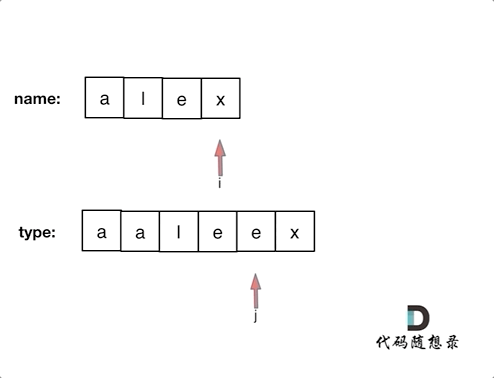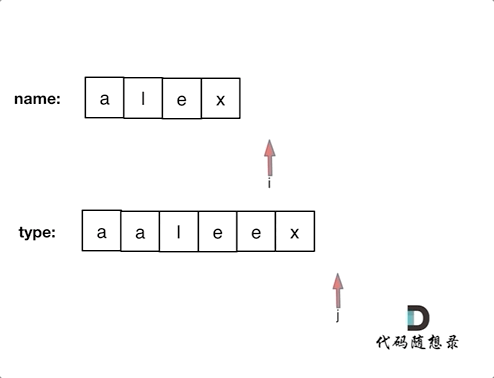 +
+上面的逻辑想清楚了,不难写出如下C++代码:
+
+```C++
+class Solution {
+public:
+ bool isLongPressedName(string name, string typed) {
+ int i = 0, j = 0;
+ while (i < name.size() && j < typed.size()) {
+ if (name[i] == typed[j]) { // 相同则同时向后匹配
+ j++; i++;
+ } else { // 不相同
+ if (j == 0) return false; // 如果是第一位就不相同直接返回false
+ // j跨越重复项,向后移动,同时防止j越界
+ while(j < typed.size() && typed[j] == typed[j - 1]) j++;
+ if (name[i] == typed[j]) { // j跨越重复项之后再次和name[i]匹配
+ j++; i++; // 相同则同时向后匹配
+ }
+ else return false;
+ }
+ }
+ // 说明name没有匹配完,例如 name:"pyplrzzzzdsfa" type:"ppyypllr"
+ if (i < name.size()) return false;
+
+ // 说明type没有匹配完,例如 name:"alex" type:"alexxrrrrssda"
+ while (j < typed.size()) {
+ if (typed[j] == typed[j - 1]) j++;
+ else return false;
+ }
+ return true;
+ }
+};
+
+```
+
+时间复杂度:O(n)
+空间复杂度:O(1)
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+上面的逻辑想清楚了,不难写出如下C++代码:
+
+```C++
+class Solution {
+public:
+ bool isLongPressedName(string name, string typed) {
+ int i = 0, j = 0;
+ while (i < name.size() && j < typed.size()) {
+ if (name[i] == typed[j]) { // 相同则同时向后匹配
+ j++; i++;
+ } else { // 不相同
+ if (j == 0) return false; // 如果是第一位就不相同直接返回false
+ // j跨越重复项,向后移动,同时防止j越界
+ while(j < typed.size() && typed[j] == typed[j - 1]) j++;
+ if (name[i] == typed[j]) { // j跨越重复项之后再次和name[i]匹配
+ j++; i++; // 相同则同时向后匹配
+ }
+ else return false;
+ }
+ }
+ // 说明name没有匹配完,例如 name:"pyplrzzzzdsfa" type:"ppyypllr"
+ if (i < name.size()) return false;
+
+ // 说明type没有匹配完,例如 name:"alex" type:"alexxrrrrssda"
+ while (j < typed.size()) {
+ if (typed[j] == typed[j - 1]) j++;
+ else return false;
+ }
+ return true;
+ }
+};
+
+```
+
+时间复杂度:O(n)
+空间复杂度:O(1)
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 1207.独一无二的出现次数 + +链接:https://leetcode-cn.com/problems/unique-number-of-occurrences/ + +给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。 + +如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。 + +示例 1: +* 输入:arr = [1,2,2,1,1,3] +* 输出:true +* 解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。 + +示例 2: +* 输入:arr = [1,2] +* 输出:false + +示例 3: +* 输入:arr = [-3,0,1,-3,1,1,1,-3,10,0] +* 输出:true + +提示: + +* 1 <= arr.length <= 1000 +* -1000 <= arr[i] <= 1000 + + +# 思路 + +这道题目数组在是哈希法中的经典应用,如果对数组在哈希法中的使用还不熟悉的同学可以看这两篇:[数组在哈希法中的应用](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)和[哈希法:383. 赎金信](https://mp.weixin.qq.com/s/qAXqv--UERmiJNNpuphOUQ) + +进而可以学习一下[set在哈希法中的应用](https://mp.weixin.qq.com/s/aMSA5zrp3jJcLjuSB0Es2Q),以及[map在哈希法中的应用](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ) + +回归本题,**本题强调了-1000 <= arr[i] <= 1000**,那么就可以用数组来做哈希,arr[i]作为哈希表(数组)的下标,那么arr[i]可以是负数,怎么办?负数不能做数组下标。 + + +**此时可以定义一个2000大小的数组,例如int count[2002];**,统计的时候,将arr[i]统一加1000,这样就可以统计arr[i]的出现频率了。 + +题目中要求的是是否有相同的频率出现,那么需要再定义一个哈希表(数组)用来记录频率是否重复出现过,bool fre[1002]; 定义布尔类型的就可以了,**因为题目中强调1 <= arr.length <= 1000,所以哈希表大小为1000就可以了**。 + +如图所示: + + +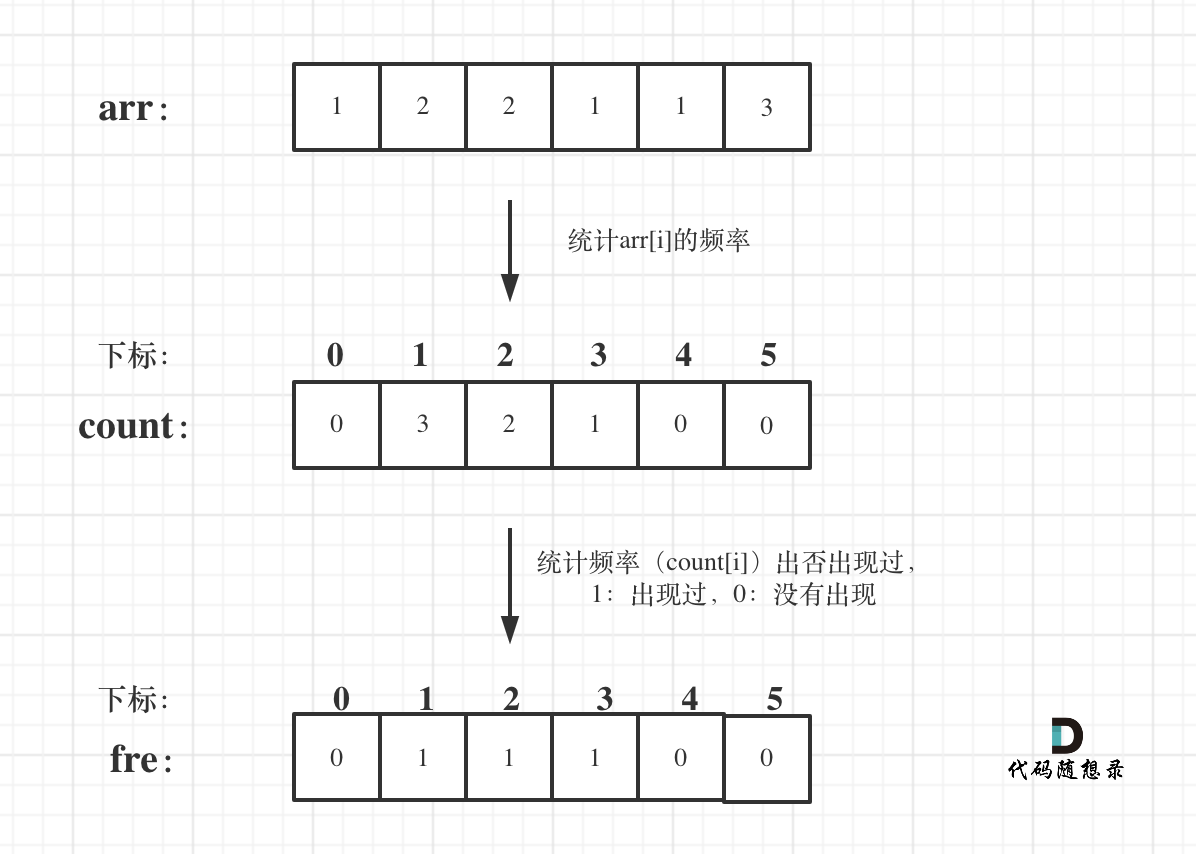 +
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ bool uniqueOccurrences(vector
+
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ bool uniqueOccurrences(vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
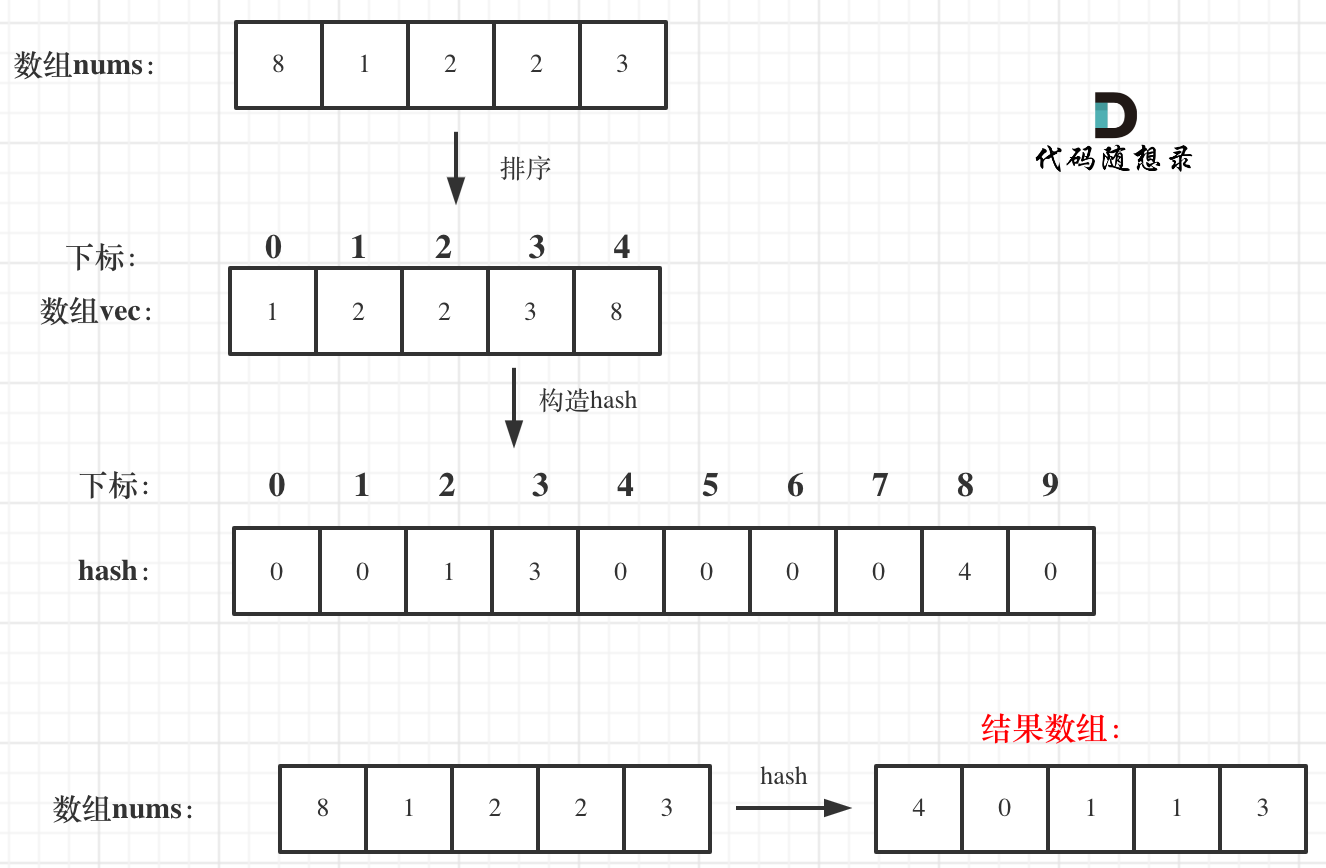
-## 思路 +# 1365.有多少小于当前数字的数字 -这道题其实是考察如何计算一个数的二进制中1的数量。 +题目链接:https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/ -我提供两种方法: +给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。 -* 方法一: +换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。 -朴实无华挨个计算1的数量,最多就是循环n的二进制位数,32位。 +以数组形式返回答案。 + + +示例 1: +输入:nums = [8,1,2,2,3] +输出:[4,0,1,1,3] +解释: +对于 nums[0]=8 存在四个比它小的数字:(1,2,2 和 3)。 +对于 nums[1]=1 不存在比它小的数字。 +对于 nums[2]=2 存在一个比它小的数字:(1)。 +对于 nums[3]=2 存在一个比它小的数字:(1)。 +对于 nums[4]=3 存在三个比它小的数字:(1,2 和 2)。 + +示例 2: +输入:nums = [6,5,4,8] +输出:[2,1,0,3] + +示例 3: +输入:nums = [7,7,7,7] +输出:[0,0,0,0] + +提示: +* 2 <= nums.length <= 500 +* 0 <= nums[i] <= 100 + +# 思路 + +两层for循环暴力查找,时间复杂度明显为O(n^2)。 + +那么我们来看一下如何优化。 + +首先要找小于当前数字的数字,那么从小到大排序之后,该数字之前的数字就都是比它小的了。 + +所以可以定义一个新数组,将数组排个序。 + +**排序之后,其实每一个数值的下标就代表这前面有几个比它小的了**。 + +代码如下: + +``` +vector +流程如图:
-下面我就使用方法二,来做这道题目:
+
+流程如图:
-下面我就使用方法二,来做这道题目:
+ -## C++代码
+关键地方讲完了,整体C++代码如下:
```C++
class Solution {
-private:
- static int bitCount(int n) { // 计算n的二进制中1的数量
- int count = 0;
- while(n) {
- n &= (n -1); // 清除最低位的1
- count++;
- }
- return count;
- }
- static bool cmp(int a, int b) {
- int bitA = bitCount(a);
- int bitB = bitCount(b);
- if (bitA == bitB) return a < b; // 如果bit中1数量相同,比较数值大小
- return bitA < bitB; // 否则比较bit中1数量大小
- }
public:
- vector
-## C++代码
+关键地方讲完了,整体C++代码如下:
```C++
class Solution {
-private:
- static int bitCount(int n) { // 计算n的二进制中1的数量
- int count = 0;
- while(n) {
- n &= (n -1); // 清除最低位的1
- count++;
- }
- return count;
- }
- static bool cmp(int a, int b) {
- int bitA = bitCount(a);
- int bitB = bitCount(b);
- if (bitA == bitB) return a < b; // 如果bit中1数量相同,比较数值大小
- return bitA < bitB; // 否则比较bit中1数量大小
- }
public:
- vector
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
# 1365.有多少小于当前数字的数字 -题目链接:https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/ +题目链接:https://leetcode-cn.com/problems/how-many-numbers-are-smaller-than-the-current-number/ 给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。 diff --git a/problems/1382.将二叉搜索树变平衡.md b/problems/1382.将二叉搜索树变平衡.md new file mode 100644 index 00000000..268f21c5 --- /dev/null +++ b/problems/1382.将二叉搜索树变平衡.md @@ -0,0 +1,92 @@ + +
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +# 1382.将二叉搜索树变平衡 + +题目地址:https://leetcode-cn.com/problems/balance-a-binary-search-tree/ + +给你一棵二叉搜索树,请你返回一棵 平衡后 的二叉搜索树,新生成的树应该与原来的树有着相同的节点值。 + +如果一棵二叉搜索树中,每个节点的两棵子树高度差不超过 1 ,我们就称这棵二叉搜索树是 平衡的 。 + +如果有多种构造方法,请你返回任意一种。 + +示例: + +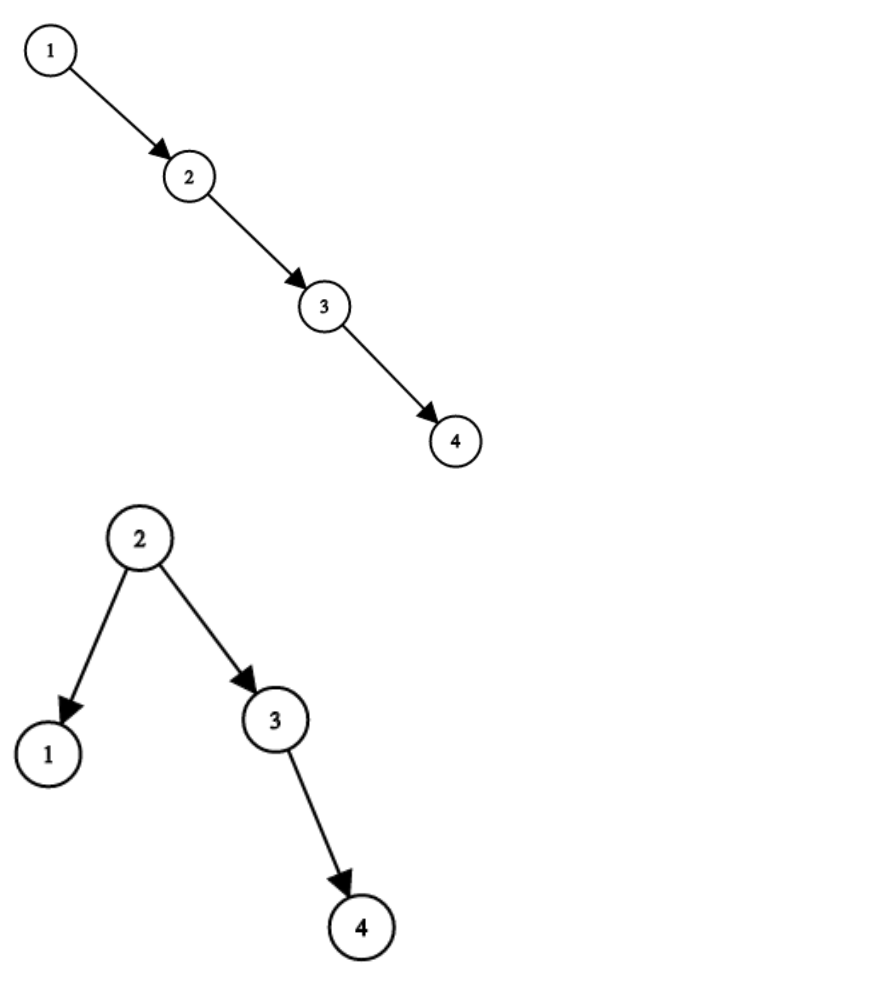 + +* 输入:root = [1,null,2,null,3,null,4,null,null] +* 输出:[2,1,3,null,null,null,4] +* 解释:这不是唯一的正确答案,[3,1,4,null,2,null,null] 也是一个可行的构造方案。 + +提示: + +* 树节点的数目在 1 到 10^4 之间。 +* 树节点的值互不相同,且在 1 到 10^5 之间。 + +# 思路 + +这道题目,可以中序遍历把二叉树转变为有序数组,然后在根据有序数组构造平衡二叉搜索树。 + +建议做这道题之前,先看如下两篇题解: +* [98.验证二叉搜索树](https://mp.weixin.qq.com/s/8odY9iUX5eSi0eRFSXFD4Q) 学习二叉搜索树的特性 +* [108.将有序数组转换为二叉搜索树](https://mp.weixin.qq.com/s/sy3ygnouaZVJs8lhFgl9mw) 学习如何通过有序数组构造二叉搜索树 + +这两道题目做过之后,本题分分钟就可以做出来了。 + +代码如下: + +```C++ +class Solution { +private: + vector