Date: Fri, 25 Mar 2022 20:35:54 -0500
Subject: [PATCH 13/16] =?UTF-8?q?0112.=E8=B7=AF=E5=BE=84=E6=80=BB=E5=92=8C?=
=?UTF-8?q?=20python=20113=E6=B7=BB=E5=8A=A0=E8=BF=AD=E4=BB=A3=E6=B3=95?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
0112.路径总和 python 113添加迭代法
---
problems/0112.路径总和.md | 24 ++++++++++++++++++++++++
1 file changed, 24 insertions(+)
diff --git a/problems/0112.路径总和.md b/problems/0112.路径总和.md
index ff682739..1904e92b 100644
--- a/problems/0112.路径总和.md
+++ b/problems/0112.路径总和.md
@@ -519,6 +519,30 @@ class solution:
return result
```
+**迭代法,用第二个队列保存目前的总和与路径**
+```python
+class Solution:
+ def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
+ if not root:
+ return []
+ que, temp = deque([root]), deque([(root.val, [root.val])])
+ result = []
+ while que:
+ for _ in range(len(que)):
+ node = que.popleft()
+ value, path = temp.popleft()
+ if (not node.left) and (not node.right):
+ if value == targetSum:
+ result.append(path)
+ if node.left:
+ que.append(node.left)
+ temp.append((node.left.val+value, path+[node.left.val]))
+ if node.right:
+ que.append(node.right)
+ temp.append((node.right.val+value, path+[node.right.val]))
+ return result
+```
+
## go
112. 路径总和
From 6259a0e31769e1dcba1c54b20af6134ed6107120 Mon Sep 17 00:00:00 2001
From: youngyangyang04 <826123027@qq.com>
Date: Thu, 31 Mar 2022 15:09:10 +0800
Subject: [PATCH 14/16] remote $
---
problems/0005.最长回文子串.md | 10 ++---
problems/0027.移除元素.md | 16 ++++----
problems/0028.实现strStr.md | 4 +-
problems/0042.接雨水.md | 8 ++--
problems/0053.最大子序和.md | 12 +++---
.../0053.最大子序和(动态规划).md | 4 +-
problems/0062.不同路径.md | 14 +++----
problems/0063.不同路径II.md | 4 +-
...�票的最佳时机II(动态规划).md | 8 ++--
problems/0139.单词拆分.md | 10 ++---
problems/0151.翻转字符串里的单词.md | 8 ++--
problems/0189.旋转数组.md | 4 +-
problems/0209.长度最小的子数组.md | 16 ++++----
.../0222.完全二叉树的节点个数.md | 12 +++---
problems/0242.有效的字母异位词.md | 4 +-
problems/0283.移动零.md | 2 +-
problems/0343.整数拆分.md | 4 +-
problems/0349.两个数组的交集.md | 2 +-
problems/0406.根据身高重建队列.md | 10 ++---
problems/0435.无重叠区间.md | 4 +-
problems/0494.目标和.md | 4 +-
problems/0509.斐波那契数.md | 12 +++---
.../0673.最长递增子序列的个数.md | 6 +--
...买卖股票的最佳时机含手续费.md | 12 +++---
problems/0739.每日温度.md | 10 ++---
problems/0746.使用最小花费爬楼梯.md | 8 ++--
problems/0844.比较含退格的字符串.md | 16 ++++----
problems/0922.按奇偶排序数组II.md | 16 ++++----
problems/0925.长按键入.md | 4 +-
problems/0977.有序数组的平方.md | 4 +-
.../1049.最后一块石头的重量II.md | 4 +-
...��时了,此时的n究竟是多大?.md | 18 ++++-----
...杂度,你不知道的都在这里!.md | 40 +++++++++----------
problems/剑指Offer05.替换空格.md | 6 +--
.../动态规划-股票问题总结篇.md | 32 +++++++--------
problems/动态规划理论基础.md | 2 +-
problems/双指针总结.md | 16 ++++----
problems/回溯总结.md | 12 +++---
...溯算法去重问题的另一种写法.md | 6 +--
problems/字符串总结.md | 6 +--
problems/数组总结篇.md | 12 +++---
...高重建队列(vector原理讲解).md | 8 ++--
.../刷力扣用不用库函数.md | 2 +-
.../背包问题理论基础多重背包.md | 4 +-
problems/链表理论基础.md | 4 +-
45 files changed, 210 insertions(+), 210 deletions(-)
diff --git a/problems/0005.最长回文子串.md b/problems/0005.最长回文子串.md
index 8b3af3bb..eaebb5ab 100644
--- a/problems/0005.最长回文子串.md
+++ b/problems/0005.最长回文子串.md
@@ -38,7 +38,7 @@
两层for循环,遍历区间起始位置和终止位置,然后判断这个区间是不是回文。
-时间复杂度:$O(n^3)$
+时间复杂度:O(n^3)
## 动态规划
@@ -205,8 +205,8 @@ public:
```
-* 时间复杂度:$O(n^2)$
-* 空间复杂度:$O(n^2)$
+* 时间复杂度:O(n^2)
+* 空间复杂度:O(n^2)
## 双指针
@@ -253,8 +253,8 @@ public:
```
-* 时间复杂度:$O(n^2)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n^2)
+* 空间复杂度:O(1)
diff --git a/problems/0027.移除元素.md b/problems/0027.移除元素.md
index 3a776837..8d6ca502 100644
--- a/problems/0027.移除元素.md
+++ b/problems/0027.移除元素.md
@@ -11,7 +11,7 @@
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
-不要使用额外的数组空间,你必须仅使用 $O(1)$ 额外空间并**原地**修改输入数组。
+不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并**原地**修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
@@ -42,7 +42,7 @@

-很明显暴力解法的时间复杂度是$O(n^2)$,这道题目暴力解法在leetcode上是可以过的。
+很明显暴力解法的时间复杂度是O(n^2),这道题目暴力解法在leetcode上是可以过的。
代码如下:
@@ -68,8 +68,8 @@ public:
};
```
-* 时间复杂度:$O(n^2)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n^2)
+* 空间复杂度:O(1)
### 双指针法
@@ -101,16 +101,16 @@ public:
```
注意这些实现方法并没有改变元素的相对位置!
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
旧文链接:[数组:就移除个元素很难么?](https://programmercarl.com/0027.移除元素.html)
```CPP
/**
* 相向双指针方法,基于元素顺序可以改变的题目描述改变了元素相对位置,确保了移动最少元素
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
*/
class Solution {
public:
diff --git a/problems/0028.实现strStr.md b/problems/0028.实现strStr.md
index 854789ee..634d8535 100644
--- a/problems/0028.实现strStr.md
+++ b/problems/0028.实现strStr.md
@@ -229,9 +229,9 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
# 时间复杂度分析
-其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是$O(n)$,之前还要单独生成next数组,时间复杂度是$O(m)$。所以整个KMP算法的时间复杂度是$O(n+m)$的。
+其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
-暴力的解法显而易见是$O(n × m)$,所以**KMP在字符串匹配中极大的提高的搜索的效率。**
+暴力的解法显而易见是O(n × m),所以**KMP在字符串匹配中极大的提高的搜索的效率。**
为了和力扣题目28.实现strStr保持一致,方便大家理解,以下文章统称haystack为文本串, needle为模式串。
diff --git a/problems/0042.接雨水.md b/problems/0042.接雨水.md
index 75152eb7..b232ce22 100644
--- a/problems/0042.接雨水.md
+++ b/problems/0042.接雨水.md
@@ -129,8 +129,8 @@ public:
};
```
-因为每次遍历列的时候,还要向两边寻找最高的列,所以时间复杂度为$O(n^2)$。
-空间复杂度为$O(1)$。
+因为每次遍历列的时候,还要向两边寻找最高的列,所以时间复杂度为O(n^2)。
+空间复杂度为O(1)。
@@ -779,8 +779,8 @@ int trap(int* height, int heightSize) {
}
```
-* 时间复杂度 $O(n)$
-* 空间复杂度 $O(1)$
+* 时间复杂度 O(n)
+* 空间复杂度 O(1)
-----------------------
diff --git a/problems/0053.最大子序和.md b/problems/0053.最大子序和.md
index d699d49a..3d11c91e 100644
--- a/problems/0053.最大子序和.md
+++ b/problems/0053.最大子序和.md
@@ -21,8 +21,8 @@
暴力解法的思路,第一层for 就是设置起始位置,第二层for循环遍历数组寻找最大值
-* 时间复杂度:$O(n^2)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n^2)
+* 空间复杂度:O(1)
```CPP
class Solution {
@@ -98,8 +98,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
当然题目没有说如果数组为空,应该返回什么,所以数组为空的话返回啥都可以了。
@@ -128,8 +128,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 总结
diff --git a/problems/0053.最大子序和(动态规划).md b/problems/0053.最大子序和(动态规划).md
index 703e1dd6..4c883cb6 100644
--- a/problems/0053.最大子序和(动态规划).md
+++ b/problems/0053.最大子序和(动态规划).md
@@ -80,8 +80,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 总结
diff --git a/problems/0062.不同路径.md b/problems/0062.不同路径.md
index efa85a03..4a9af129 100644
--- a/problems/0062.不同路径.md
+++ b/problems/0062.不同路径.md
@@ -80,7 +80,7 @@ public:
那二叉树的节点个数就是 2^(m + n - 1) - 1。可以理解深搜的算法就是遍历了整个满二叉树(其实没有遍历整个满二叉树,只是近似而已)
-所以上面深搜代码的时间复杂度为$O(2^{m + n - 1} - 1)$,可以看出,这是指数级别的时间复杂度,是非常大的。
+所以上面深搜代码的时间复杂度为O(2^(m + n - 1) - 1),可以看出,这是指数级别的时间复杂度,是非常大的。
### 动态规划
@@ -143,8 +143,8 @@ public:
};
```
-* 时间复杂度:$O(m × n)$
-* 空间复杂度:$O(m × n)$
+* 时间复杂度:O(m × n)
+* 空间复杂度:O(m × n)
其实用一个一维数组(也可以理解是滚动数组)就可以了,但是不利于理解,可以优化点空间,建议先理解了二维,在理解一维,C++代码如下:
@@ -164,8 +164,8 @@ public:
};
```
-* 时间复杂度:$O(m × n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(m × n)
+* 空间复杂度:O(n)
### 数论方法
@@ -224,8 +224,8 @@ public:
};
```
-* 时间复杂度:$O(m)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(m)
+* 空间复杂度:O(1)
**计算组合问题的代码还是有难度的,特别是处理溢出的情况!**
diff --git a/problems/0063.不同路径II.md b/problems/0063.不同路径II.md
index 8e82007e..34df05d8 100644
--- a/problems/0063.不同路径II.md
+++ b/problems/0063.不同路径II.md
@@ -152,8 +152,8 @@ public:
};
```
-* 时间复杂度:$O(n × m)$,n、m 分别为obstacleGrid 长度和宽度
-* 空间复杂度:$O(n × m)$
+* 时间复杂度:O(n × m),n、m 分别为obstacleGrid 长度和宽度
+* 空间复杂度:O(n × m)
## 总结
diff --git a/problems/0122.买卖股票的最佳时机II(动态规划).md b/problems/0122.买卖股票的最佳时机II(动态规划).md
index e5fdd53d..615d79bb 100644
--- a/problems/0122.买卖股票的最佳时机II(动态规划).md
+++ b/problems/0122.买卖股票的最佳时机II(动态规划).md
@@ -88,8 +88,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
大家可以本题和[121. 买卖股票的最佳时机](https://programmercarl.com/0121.买卖股票的最佳时机.html)的代码几乎一样,唯一的区别在:
@@ -121,8 +121,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
diff --git a/problems/0139.单词拆分.md b/problems/0139.单词拆分.md
index e04cb173..c087183a 100644
--- a/problems/0139.单词拆分.md
+++ b/problems/0139.单词拆分.md
@@ -66,8 +66,8 @@ public:
};
```
-* 时间复杂度:$O(2^n)$,因为每一个单词都有两个状态,切割和不切割
-* 空间复杂度:$O(n)$,算法递归系统调用栈的空间
+* 时间复杂度:O(2^n),因为每一个单词都有两个状态,切割和不切割
+* 空间复杂度:O(n),算法递归系统调用栈的空间
那么以上代码很明显要超时了,超时的数据如下:
@@ -114,7 +114,7 @@ public:
};
```
-这个时间复杂度其实也是:$O(2^n)$。只不过对于上面那个超时测试用例优化效果特别明显。
+这个时间复杂度其实也是:O(2^n)。只不过对于上面那个超时测试用例优化效果特别明显。
**这个代码就可以AC了,当然回溯算法不是本题的主菜,背包才是!**
@@ -207,8 +207,8 @@ public:
};
```
-* 时间复杂度:$O(n^3)$,因为substr返回子串的副本是$O(n)$的复杂度(这里的n是substring的长度)
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n^3),因为substr返回子串的副本是$O(n)$的复杂度(这里的n是substring的长度)
+* 空间复杂度:O(n)
## 总结
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index 7588cbd6..8dfe9bbc 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -36,7 +36,7 @@
一些同学会使用split库函数,分隔单词,然后定义一个新的string字符串,最后再把单词倒序相加,那么这道题题目就是一道水题了,失去了它的意义。
-所以这里我还是提高一下本题的难度:**不要使用辅助空间,空间复杂度要求为$O(1)$。**
+所以这里我还是提高一下本题的难度:**不要使用辅助空间,空间复杂度要求为O(1)。**
不能使用辅助空间之后,那么只能在原字符串上下功夫了。
@@ -81,11 +81,11 @@ void removeExtraSpaces(string& s) {
如果不仔细琢磨一下erase的时间复杂读,还以为以上的代码是$O(n)$的时间复杂度呢。
-想一下真正的时间复杂度是多少,一个erase本来就是$O(n)$的操作,erase实现原理题目:[数组:就移除个元素很难么?](https://programmercarl.com/0027.移除元素.html),最优的算法来移除元素也要$O(n)$。
+想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作,erase实现原理题目:[数组:就移除个元素很难么?](https://programmercarl.com/0027.移除元素.html),最优的算法来移除元素也要O(n)。
-erase操作上面还套了一个for循环,那么以上代码移除冗余空格的代码时间复杂度为$O(n^2)$。
+erase操作上面还套了一个for循环,那么以上代码移除冗余空格的代码时间复杂度为O(n^2)。
-那么使用双指针法来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到$O(n)$的时间复杂度。
+那么使用双指针法来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到O(n)的时间复杂度。
如果对这个操作比较生疏了,可以再看一下这篇文章:[数组:就移除个元素很难么?](https://programmercarl.com/0027.移除元素.html)是如何移除元素的。
diff --git a/problems/0189.旋转数组.md b/problems/0189.旋转数组.md
index bbe152a2..1efe9446 100644
--- a/problems/0189.旋转数组.md
+++ b/problems/0189.旋转数组.md
@@ -12,7 +12,7 @@
进阶:
尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。
-你可以使用空间复杂度为 $O(1)$ 的 原地 算法解决这个问题吗?
+你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
示例 1:
@@ -41,7 +41,7 @@
本题其实和[字符串:剑指Offer58-II.左旋转字符串](https://programmercarl.com/剑指Offer58-II.左旋转字符串.html)就非常像了,剑指offer上左旋转,本题是右旋转。
-注意题目要求是**要求使用空间复杂度为 $O(1)$ 的 原地 算法**
+注意题目要求是**要求使用空间复杂度为 O(1) 的 原地 算法**
那么我来提供一种旋转的方式哈。
diff --git a/problems/0209.长度最小的子数组.md b/problems/0209.长度最小的子数组.md
index dc1d9f18..82a11381 100644
--- a/problems/0209.长度最小的子数组.md
+++ b/problems/0209.长度最小的子数组.md
@@ -20,7 +20,7 @@
## 暴力解法
-这道题目暴力解法当然是 两个for循环,然后不断的寻找符合条件的子序列,时间复杂度很明显是$O(n^2)$。
+这道题目暴力解法当然是 两个for循环,然后不断的寻找符合条件的子序列,时间复杂度很明显是O(n^2)。
代码如下:
@@ -47,8 +47,8 @@ public:
}
};
```
-时间复杂度:$O(n^2)$
-空间复杂度:$O(1)$
+时间复杂度:O(n^2)
+空间复杂度:O(1)
## 滑动窗口
@@ -80,7 +80,7 @@ public:
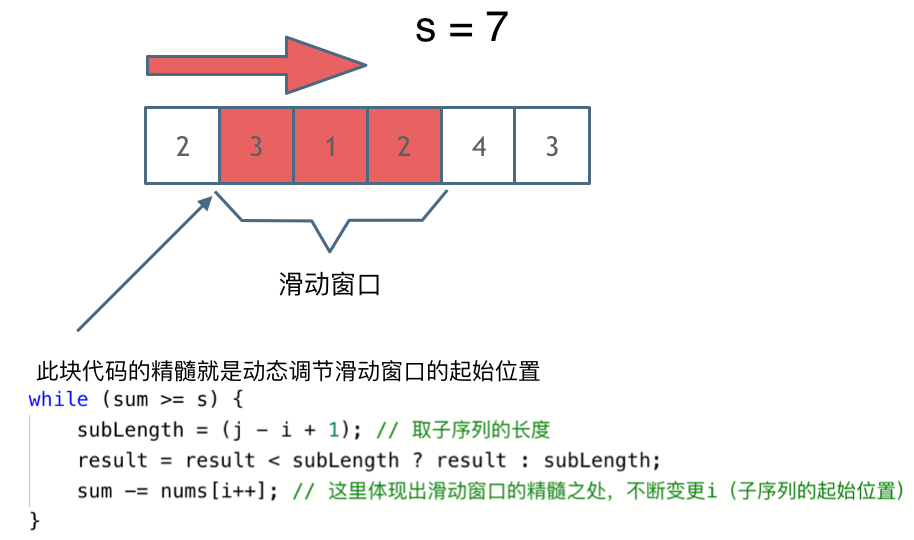
-可以发现**滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将$O(n^2)$的暴力解法降为$O(n)$。**
+可以发现**滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)暴力解法降为O(n)。**
C++代码如下:
@@ -107,12 +107,12 @@ public:
};
```
-时间复杂度:$O(n)$
-空间复杂度:$O(1)$
+时间复杂度:O(n)
+空间复杂度:O(1)
-**一些录友会疑惑为什么时间复杂度是$O(n)$**。
+**一些录友会疑惑为什么时间复杂度是O(n)**。
-不要以为for里放一个while就以为是$O(n^2)$啊, 主要是看每一个元素被操作的次数,每个元素在滑动窗后进来操作一次,出去操作一次,每个元素都是被被操作两次,所以时间复杂度是 2 × n 也就是$O(n)$。
+不要以为for里放一个while就以为是O(n^2)啊, 主要是看每一个元素被操作的次数,每个元素在滑动窗后进来操作一次,出去操作一次,每个元素都是被被操作两次,所以时间复杂度是 2 × n 也就是O(n)。
## 相关题目推荐
diff --git a/problems/0222.完全二叉树的节点个数.md b/problems/0222.完全二叉树的节点个数.md
index ffbc32ff..ba7acc5a 100644
--- a/problems/0222.完全二叉树的节点个数.md
+++ b/problems/0222.完全二叉树的节点个数.md
@@ -105,8 +105,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(\log n)$,算上了递归系统栈占用的空间
+* 时间复杂度:O(n)
+* 空间复杂度:O(log n),算上了递归系统栈占用的空间
**网上基本都是这个精简的代码版本,其实不建议大家照着这个来写,代码确实精简,但隐藏了一些内容,连遍历的顺序都看不出来,所以初学者建议学习版本一的代码,稳稳的打基础**。
@@ -138,8 +138,8 @@ public:
}
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 完全二叉树
@@ -185,8 +185,8 @@ public:
};
```
-* 时间复杂度:$O(\log n × \log n)$
-* 空间复杂度:$O(\log n)$
+* 时间复杂度:O(log n × log n)
+* 空间复杂度:O(log n)
# 其他语言版本
diff --git a/problems/0242.有效的字母异位词.md b/problems/0242.有效的字母异位词.md
index 52f8e667..080166fd 100644
--- a/problems/0242.有效的字母异位词.md
+++ b/problems/0242.有效的字母异位词.md
@@ -27,7 +27,7 @@
## 思路
-先看暴力的解法,两层for循环,同时还要记录字符是否重复出现,很明显时间复杂度是 $O(n^2)$。
+先看暴力的解法,两层for循环,同时还要记录字符是否重复出现,很明显时间复杂度是 O(n^2)。
暴力的方法这里就不做介绍了,直接看一下有没有更优的方式。
@@ -55,7 +55,7 @@
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
-时间复杂度为$O(n)$,空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为$O(1)$。
+时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
C++ 代码如下:
diff --git a/problems/0283.移动零.md b/problems/0283.移动零.md
index bb75a696..ed59d2c4 100644
--- a/problems/0283.移动零.md
+++ b/problems/0283.移动零.md
@@ -30,7 +30,7 @@
好了,我们说一说双指针法,大家如果对双指针还不熟悉,可以看我的这篇总结[双指针法:总结篇!](https://programmercarl.com/双指针总结.html)。
-双指针法在数组移除元素中,可以达到$O(n)$的时间复杂度,在[27.移除元素](https://programmercarl.com/0027.移除元素.html)里已经详细讲解了,那么本题和移除元素其实是一个套路。
+双指针法在数组移除元素中,可以达到O(n)的时间复杂度,在[27.移除元素](https://programmercarl.com/0027.移除元素.html)里已经详细讲解了,那么本题和移除元素其实是一个套路。
**相当于对整个数组移除元素0,然后slowIndex之后都是移除元素0的冗余元素,把这些元素都赋值为0就可以了**。
diff --git a/problems/0343.整数拆分.md b/problems/0343.整数拆分.md
index b6182ed6..777146ba 100644
--- a/problems/0343.整数拆分.md
+++ b/problems/0343.整数拆分.md
@@ -148,8 +148,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
## 总结
diff --git a/problems/0349.两个数组的交集.md b/problems/0349.两个数组的交集.md
index 92342f17..82be1829 100644
--- a/problems/0349.两个数组的交集.md
+++ b/problems/0349.两个数组的交集.md
@@ -28,7 +28,7 @@
注意题目特意说明:**输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序**
-这道题用暴力的解法时间复杂度是$O(n^2)$,那来看看使用哈希法进一步优化。
+这道题用暴力的解法时间复杂度是O(n^2),那来看看使用哈希法进一步优化。
那么用数组来做哈希表也是不错的选择,例如[242. 有效的字母异位词](https://programmercarl.com/0242.有效的字母异位词.html)
diff --git a/problems/0406.根据身高重建队列.md b/problems/0406.根据身高重建队列.md
index 28eb5744..b2354d09 100644
--- a/problems/0406.根据身高重建队列.md
+++ b/problems/0406.根据身高重建队列.md
@@ -116,12 +116,12 @@ public:
}
};
```
-* 时间复杂度:$O(n\log n + n^2)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(nlog n + n^2)
+* 空间复杂度:O(n)
但使用vector是非常费时的,C++中vector(可以理解是一个动态数组,底层是普通数组实现的)如果插入元素大于预先普通数组大小,vector底部会有一个扩容的操作,即申请两倍于原先普通数组的大小,然后把数据拷贝到另一个更大的数组上。
-所以使用vector(动态数组)来insert,是费时的,插入再拷贝的话,单纯一个插入的操作就是$O(n^2)$了,甚至可能拷贝好几次,就不止$O(n^2)$了。
+所以使用vector(动态数组)来insert,是费时的,插入再拷贝的话,单纯一个插入的操作就是O(n^2)了,甚至可能拷贝好几次,就不止O(n^2)了。
改成链表之后,C++代码如下:
@@ -150,8 +150,8 @@ public:
};
```
-* 时间复杂度:$O(n\log n + n^2)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(nlog n + n^2)
+* 空间复杂度:O(n)
大家可以把两个版本的代码提交一下试试,就可以发现其差别了!
diff --git a/problems/0435.无重叠区间.md b/problems/0435.无重叠区间.md
index 389443d1..b24ca024 100644
--- a/problems/0435.无重叠区间.md
+++ b/problems/0435.无重叠区间.md
@@ -92,8 +92,8 @@ public:
}
};
```
-* 时间复杂度:$O(n\log n)$ ,有一个快排
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(nlog n) ,有一个快排
+* 空间复杂度:O(1)
大家此时会发现如此复杂的一个问题,代码实现却这么简单!
diff --git a/problems/0494.目标和.md b/problems/0494.目标和.md
index df667a85..99b76834 100644
--- a/problems/0494.目标和.md
+++ b/problems/0494.目标和.md
@@ -225,8 +225,8 @@ public:
};
```
-* 时间复杂度:$O(n × m)$,n为正数个数,m为背包容量
-* 空间复杂度:$O(m)$,m为背包容量
+* 时间复杂度:O(n × m),n为正数个数,m为背包容量
+* 空间复杂度:O(m),m为背包容量
## 总结
diff --git a/problems/0509.斐波那契数.md b/problems/0509.斐波那契数.md
index c6ce76c0..638bfdfe 100644
--- a/problems/0509.斐波那契数.md
+++ b/problems/0509.斐波那契数.md
@@ -101,8 +101,8 @@ public:
}
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
当然可以发现,我们只需要维护两个数值就可以了,不需要记录整个序列。
@@ -126,8 +126,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
### 递归解法
@@ -145,8 +145,8 @@ public:
};
```
-* 时间复杂度:$O(2^n)$
-* 空间复杂度:$O(n)$,算上了编程语言中实现递归的系统栈所占空间
+* 时间复杂度:O(2^n)
+* 空间复杂度:O(n),算上了编程语言中实现递归的系统栈所占空间
这个递归的时间复杂度大家画一下树形图就知道了,如果不清晰的同学,可以看这篇:[通过一道面试题目,讲一讲递归算法的时间复杂度!](https://programmercarl.com/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.html)
diff --git a/problems/0673.最长递增子序列的个数.md b/problems/0673.最长递增子序列的个数.md
index 7ea91e97..9a2c5db2 100644
--- a/problems/0673.最长递增子序列的个数.md
+++ b/problems/0673.最长递增子序列的个数.md
@@ -216,10 +216,10 @@ public:
};
```
-* 时间复杂度:$O(n^2)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n^2)
+* 空间复杂度:O(n)
-还有$O(n\log n)$的解法,使用树状数组,今天有点忙就先不写了,感兴趣的同学可以自行学习一下,这里有我之前写的树状数组系列博客:https://blog.csdn.net/youngyangyang04/category_871105.html (十年前的陈年老文了)
+还有O(nlog n)的解法,使用树状数组,今天有点忙就先不写了,感兴趣的同学可以自行学习一下,这里有我之前写的树状数组系列博客:https://blog.csdn.net/youngyangyang04/category_871105.html (十年前的陈年老文了)
# 其他语言版本
diff --git a/problems/0714.买卖股票的最佳时机含手续费.md b/problems/0714.买卖股票的最佳时机含手续费.md
index fd42691b..2f27d6ea 100644
--- a/problems/0714.买卖股票的最佳时机含手续费.md
+++ b/problems/0714.买卖股票的最佳时机含手续费.md
@@ -84,8 +84,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
从代码中可以看出对情况一的操作,因为如果还在收获利润的区间里,表示并不是真正的卖出,而计算利润每次都要减去手续费,**所以要让minPrice = prices[i] - fee;,这样在明天收获利润的时候,才不会多减一次手续费!**
@@ -117,8 +117,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
当然可以对空间经行优化,因为当前状态只是依赖前一个状态。
@@ -141,8 +141,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
## 总结
diff --git a/problems/0739.每日温度.md b/problems/0739.每日温度.md
index bdc75b96..710f5eb6 100644
--- a/problems/0739.每日温度.md
+++ b/problems/0739.每日温度.md
@@ -18,7 +18,7 @@
## 思路
-首先想到的当然是暴力解法,两层for循环,把至少需要等待的天数就搜出来了。时间复杂度是$O(n^2)$
+首先想到的当然是暴力解法,两层for循环,把至少需要等待的天数就搜出来了。时间复杂度是O(n^2)
那么接下来在来看看使用单调栈的解法。
@@ -26,13 +26,13 @@
**通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了**。
-时间复杂度为$O(n)$。
+时间复杂度为O(n)。
例如本题其实就是找找到一个元素右边第一个比自己大的元素。
此时就应该想到用单调栈了。
-那么单调栈的原理是什么呢?为什么时间复杂度是$O(n)$就可以找到每一个元素的右边第一个比它大的元素位置呢?
+那么单调栈的原理是什么呢?为什么时间复杂度是O(n)就可以找到每一个元素的右边第一个比它大的元素位置呢?
单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素的元素,优点是只需要遍历一次。
@@ -164,8 +164,8 @@ public:
}
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
精简的代码是直接把情况一二三都合并到了一起,其实这种代码精简是精简,但思路不是很清晰。
diff --git a/problems/0746.使用最小花费爬楼梯.md b/problems/0746.使用最小花费爬楼梯.md
index e94e4d24..c356955a 100644
--- a/problems/0746.使用最小花费爬楼梯.md
+++ b/problems/0746.使用最小花费爬楼梯.md
@@ -113,8 +113,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
还可以优化空间复杂度,因为dp[i]就是由前两位推出来的,那么也不用dp数组了,C++代码如下:
@@ -136,8 +136,8 @@ public:
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
**当然我不建议这么写,能写出版本一就可以了,直观简洁!**
diff --git a/problems/0844.比较含退格的字符串.md b/problems/0844.比较含退格的字符串.md
index 00d52e42..3bbfb73e 100644
--- a/problems/0844.比较含退格的字符串.md
+++ b/problems/0844.比较含退格的字符串.md
@@ -36,7 +36,7 @@
## 思路
-本文将给出 空间复杂度$O(n)$的栈模拟方法 以及空间复杂度是$O(1)$的双指针方法。
+本文将给出 空间复杂度O(n)的栈模拟方法 以及空间复杂度是O(1)的双指针方法。
## 普通方法(使用栈的思路)
@@ -71,8 +71,8 @@ public:
}
};
```
-* 时间复杂度:$O(n + m)$,n为S的长度,m为T的长度 ,也可以理解是$O(n)$的时间复杂度
-* 空间复杂度:$O(n + m)$
+* 时间复杂度:O(n + m),n为S的长度,m为T的长度 ,也可以理解是$O(n)$的时间复杂度
+* 空间复杂度:O(n + m)
当然以上代码,大家可以发现有重复的逻辑处理S,处理T,可以把这块公共逻辑抽离出来,代码精简如下:
@@ -97,12 +97,12 @@ public:
```
性能依然是:
-* 时间复杂度:$O(n + m)$
-* 空间复杂度:$O(n + m)$
+* 时间复杂度:O(n + m)
+* 空间复杂度:O(n + m)
## 优化方法(从后向前双指针)
-当然还可以有使用 $O(1)$ 的空间复杂度来解决该问题。
+当然还可以有使用 O(1) 的空间复杂度来解决该问题。
同时从后向前遍历S和T(i初始为S末尾,j初始为T末尾),记录#的数量,模拟消除的操作,如果#用完了,就开始比较S[i]和S[j]。
@@ -151,8 +151,8 @@ public:
};
```
-* 时间复杂度:$O(n + m)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n + m)
+* 空间复杂度:O(1)
## 其他语言版本
diff --git a/problems/0922.按奇偶排序数组II.md b/problems/0922.按奇偶排序数组II.md
index 19675e7f..4ff419d3 100644
--- a/problems/0922.按奇偶排序数组II.md
+++ b/problems/0922.按奇偶排序数组II.md
@@ -26,11 +26,11 @@
## 思路
-这道题目直接的想法可能是两层for循环再加上used数组表示使用过的元素。这样的的时间复杂度是$O(n^2)$。
+这道题目直接的想法可能是两层for循环再加上used数组表示使用过的元素。这样的的时间复杂度是O(n^2)。
### 方法一
-其实这道题可以用很朴实的方法,时间复杂度就就是$O(n)$了,C++代码如下:
+其实这道题可以用很朴实的方法,时间复杂度就就是O(n)了,C++代码如下:
```CPP
class Solution {
@@ -57,8 +57,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
### 方法二
@@ -86,8 +86,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
### 方法三
@@ -109,8 +109,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
这里时间复杂度并不是$O(n^2)$,因为偶数位和奇数位都只操作一次,不是n/2 * n/2的关系,而是n/2 + n/2的关系!
diff --git a/problems/0925.长按键入.md b/problems/0925.长按键入.md
index 3aacee5c..0ef5a3d7 100644
--- a/problems/0925.长按键入.md
+++ b/problems/0925.长按键入.md
@@ -90,8 +90,8 @@ public:
```
-时间复杂度:$O(n)$
-空间复杂度:$O(1)$
+时间复杂度:O(n)
+空间复杂度:O(1)
## 其他语言版本
diff --git a/problems/0977.有序数组的平方.md b/problems/0977.有序数组的平方.md
index b11fa7ef..24276bcf 100644
--- a/problems/0977.有序数组的平方.md
+++ b/problems/0977.有序数组的平方.md
@@ -40,7 +40,7 @@ public:
};
```
-这个时间复杂度是 $O(n + n\log n)$, 可以说是$O(n\log n)$的时间复杂度,但为了和下面双指针法算法时间复杂度有鲜明对比,我记为 $O(n + n\log n)$。
+这个时间复杂度是 O(n + nlogn), 可以说是O(nlogn)的时间复杂度,但为了和下面双指针法算法时间复杂度有鲜明对比,我记为 O(n + nlog n)。
## 双指针法
@@ -83,7 +83,7 @@ public:
};
```
-此时的时间复杂度为$O(n)$,相对于暴力排序的解法$O(n + n\log n)$还是提升不少的。
+此时的时间复杂度为O(n),相对于暴力排序的解法O(n + nlog n)还是提升不少的。
**这里还是说一下,大家不必太在意leetcode上执行用时,打败多少多少用户,这个就是一个玩具,非常不准确。**
diff --git a/problems/1049.最后一块石头的重量II.md b/problems/1049.最后一块石头的重量II.md
index 7b67b1ac..ee0ddef2 100644
--- a/problems/1049.最后一块石头的重量II.md
+++ b/problems/1049.最后一块石头的重量II.md
@@ -136,8 +136,8 @@ public:
```
-* 时间复杂度:$O(m × n)$ , m是石头总重量(准确的说是总重量的一半),n为石头块数
-* 空间复杂度:$O(m)$
+* 时间复杂度:O(m × n) , m是石头总重量(准确的说是总重量的一半),n为石头块数
+* 空间复杂度:O(m)
## 总结
diff --git a/problems/O(n)的算法居然超时了,此时的n究竟是多大?.md b/problems/O(n)的算法居然超时了,此时的n究竟是多大?.md
index 4de56597..75f441db 100644
--- a/problems/O(n)的算法居然超时了,此时的n究竟是多大?.md
+++ b/problems/O(n)的算法居然超时了,此时的n究竟是多大?.md
@@ -3,7 +3,7 @@

参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 程序提交之后为什么会超时?$O(n)$的算法会超时,n究竟是多大?
+# 程序提交之后为什么会超时?O(n)的算法会超时,n究竟是多大?
一些同学可能对计算机运行的速度还没有概念,就是感觉计算机运行速度应该会很快,那么在leetcode上做算法题目的时候为什么会超时呢?
@@ -18,9 +18,9 @@
也就是说程序运行的时间超过了规定的时间,一般OJ(online judge)的超时时间就是1s,也就是用例数据输入后最多要1s内得到结果,暂时还不清楚leetcode的判题规则,下文为了方便讲解,暂定超时时间就是1s。
-如果写出了一个$O(n)$的算法 ,其实可以估算出来n是多大的时候算法的执行时间就会超过1s了。
+如果写出了一个O(n)的算法 ,其实可以估算出来n是多大的时候算法的执行时间就会超过1s了。
-如果n的规模已经足够让$O(n)$的算法运行时间超过了1s,就应该考虑log(n)的解法了。
+如果n的规模已经足够让O(n)的算法运行时间超过了1s,就应该考虑log(n)的解法了。
# 从硬件配置看计算机的性能
@@ -63,7 +63,7 @@
测试硬件:2015年MacPro,CPU配置:2.7 GHz Dual-Core Intel Core i5
-实现三个函数,时间复杂度分别是 $O(n)$ , $O(n^2)$, $O(n\log n)$,使用加法运算来统一测试。
+实现三个函数,时间复杂度分别是 O(n) , O(n^2), O(nlog n),使用加法运算来统一测试。
```CPP
// O(n)
@@ -128,19 +128,19 @@ int main() {

-O(n)的算法,1s内大概计算机可以运行 5 * (10^8)次计算,可以推测一下$O(n^2)$ 的算法应该1s可以处理的数量级的规模是 5 * (10^8)开根号,实验数据如下。
+O(n)的算法,1s内大概计算机可以运行 5 * (10^8)次计算,可以推测一下O(n^2) 的算法应该1s可以处理的数量级的规模是 5 * (10^8)开根号,实验数据如下。

O(n^2)的算法,1s内大概计算机可以运行 22500次计算,验证了刚刚的推测。
-在推测一下$O(n\log n)$的话, 1s可以处理的数据规模是什么呢?
+在推测一下O(nlogn)的话, 1s可以处理的数据规模是什么呢?
-理论上应该是比 $O(n)$少一个数量级,因为$\log n$的复杂度 其实是很快,看一下实验数据。
+理论上应该是比 O(n)少一个数量级,因为logn的复杂度 其实是很快,看一下实验数据。

-$O(n \logn)$的算法,1s内大概计算机可以运行 2 * (10^7)次计算,符合预期。
+O(nlogn)的算法,1s内大概计算机可以运行 2 * (10^7)次计算,符合预期。
这是在我个人PC上测出来的数据,不能说是十分精确,但数量级是差不多的,大家也可以在自己的计算机上测一下。
@@ -209,7 +209,7 @@ int main() {
# 总结
-本文详细分析了在leetcode上做题程序为什么会有超时,以及从硬件配置上大体知道CPU的执行速度,然后亲自做一个实验来看看$O(n)$的算法,跑一秒钟,这个n究竟是做大,最后给出不同时间复杂度,一秒内可以运算出来的n的大小。
+本文详细分析了在leetcode上做题程序为什么会有超时,以及从硬件配置上大体知道CPU的执行速度,然后亲自做一个实验来看看O(n)的算法,跑一秒钟,这个n究竟是做大,最后给出不同时间复杂度,一秒内可以运算出来的n的大小。
建议录友们也都自己做一做实验,测一测,看看是不是和我的测出来的结果差不多。
diff --git a/problems/关于时间复杂度,你不知道的都在这里!.md b/problems/关于时间复杂度,你不知道的都在这里!.md
index b6477249..77fdacc4 100644
--- a/problems/关于时间复杂度,你不知道的都在这里!.md
+++ b/problems/关于时间复杂度,你不知道的都在这里!.md
@@ -16,21 +16,21 @@
那么该如何估计程序运行时间呢,通常会估算算法的操作单元数量来代表程序消耗的时间,这里默认CPU的每个单元运行消耗的时间都是相同的。
-假设算法的问题规模为n,那么操作单元数量便用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 $O(f(n))$。
+假设算法的问题规模为n,那么操作单元数量便用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 O(f(n))。
## 什么是大O
-这里的大O是指什么呢,说到时间复杂度,**大家都知道$O(n)$,$O(n^2)$,却说不清什么是大O**。
+这里的大O是指什么呢,说到时间复杂度,**大家都知道O(n),O(n^2),却说不清什么是大O**。
算法导论给出的解释:**大O用来表示上界的**,当用它作为算法的最坏情况运行时间的上界,就是对任意数据输入的运行时间的上界。
同样算法导论给出了例子:拿插入排序来说,插入排序的时间复杂度我们都说是$O(n^2)$ 。
-输入数据的形式对程序运算时间是有很大影响的,在数据本来有序的情况下时间复杂度是$O(n)$,但如果数据是逆序的话,插入排序的时间复杂度就是$O(n^2)$,也就对于所有输入情况来说,最坏是$O(n^2)$ 的时间复杂度,所以称插入排序的时间复杂度为$O(n^2)$。
+输入数据的形式对程序运算时间是有很大影响的,在数据本来有序的情况下时间复杂度是O(n),但如果数据是逆序的话,插入排序的时间复杂度就是O(n^2),也就对于所有输入情况来说,最坏是O(n^2) 的时间复杂度,所以称插入排序的时间复杂度为O(n^2)。
-同样的同理再看一下快速排序,都知道快速排序是$O(n\log n)$,但是当数据已经有序情况下,快速排序的时间复杂度是$O(n^2)$ 的,**所以严格从大O的定义来讲,快速排序的时间复杂度应该是$O(n^2)$**。
+同样的同理再看一下快速排序,都知道快速排序是O(nlog n),但是当数据已经有序情况下,快速排序的时间复杂度是O(n^2) 的,**所以严格从大O的定义来讲,快速排序的时间复杂度应该是O(n^2)**。
-**但是我们依然说快速排序是$O(n\log n)$的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界**。如图所示:
+**但是我们依然说快速排序是O(nlog n)的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界**。如图所示:

我们主要关心的还是一般情况下的数据形式。
@@ -46,9 +46,9 @@
在决定使用哪些算法的时候,不是时间复杂越低的越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小甚至可以用$O(n^2)$的算法比$O(n)$的更合适(在有常数项的时候)。
-就像上图中 $O(5n^2)$ 和 $O(100n)$ 在n为20之前 很明显 $O(5n^2)$是更优的,所花费的时间也是最少的。
+就像上图中 O(5n^2) 和 O(100n) 在n为20之前 很明显 O(5n^2)是更优的,所花费的时间也是最少的。
-那为什么在计算时间复杂度的时候要忽略常数项系数呢,也就说$O(100n)$ 就是$O(n)$的时间复杂度,$O(5n^2)$ 就是$O(n^2)$的时间复杂度,而且要默认$O(n)$ 优于$O(n^2)$ 呢 ?
+那为什么在计算时间复杂度的时候要忽略常数项系数呢,也就说O(100n) 就是O(n)的时间复杂度,O(5n^2) 就是O(n^2)的时间复杂度,而且要默认O(n) 优于O(n^2) 呢 ?
这里就又涉及到大O的定义,**因为大O就是数据量级突破一个点且数据量级非常大的情况下所表现出的时间复杂度,这个数据量也就是常数项系数已经不起决定性作用的数据量**。
@@ -56,13 +56,13 @@
**所以我们说的时间复杂度都是省略常数项系数的,是因为一般情况下都是默认数据规模足够的大,基于这样的事实,给出的算法时间复杂的的一个排行如下所示**:
-O(1) 常数阶 < $O(\log n)$ 对数阶 < $O(n)$ 线性阶 < $O(n^2)$ 平方阶 < $O(n^3)$ 立方阶 < $O(2^n)$指数阶
+O(1) 常数阶 < O(\log n) 对数阶 < O(n) 线性阶 < O(n^2) 平方阶 < O(n^3) 立方阶 < O(2^n)指数阶
但是也要注意大常数,如果这个常数非常大,例如10^7 ,10^9 ,那么常数就是不得不考虑的因素了。
## 复杂表达式的化简
-有时候我们去计算时间复杂度的时候发现不是一个简单的$O(n)$ 或者$O(n^2)$, 而是一个复杂的表达式,例如:
+有时候我们去计算时间复杂度的时候发现不是一个简单的O(n) 或者O(n^2), 而是一个复杂的表达式,例如:
```
O(2*n^2 + 10*n + 1000)
@@ -88,19 +88,19 @@ O(n^2 + n)
O(n^2)
```
-如果这一步理解有困难,那也可以做提取n的操作,变成$O(n(n+1))$,省略加法常数项后也就别变成了:
+如果这一步理解有困难,那也可以做提取n的操作,变成O(n(n+1)),省略加法常数项后也就别变成了:
```
O(n^2)
```
-所以最后我们说:这个算法的算法时间复杂度是$O(n^2)$ 。
+所以最后我们说:这个算法的算法时间复杂度是O(n^2) 。
-也可以用另一种简化的思路,其实当n大于40的时候, 这个复杂度会恒小于$O(3 × n^2)$,
-$O(2 × n^2 + 10 × n + 1000)$ < $O(3 × n^2)$,所以说最后省略掉常数项系数最终时间复杂度也是$O(n^2)$。
+也可以用另一种简化的思路,其实当n大于40的时候, 这个复杂度会恒小于O(3 × n^2),
+O(2 × n^2 + 10 × n + 1000) < O(3 × n^2),所以说最后省略掉常数项系数最终时间复杂度也是O(n^2)。
-## $O(\log n)$中的log是以什么为底?
+## O(log n)中的log是以什么为底?
平时说这个算法的时间复杂度是logn的,那么一定是log 以2为底n的对数么?
@@ -123,21 +123,21 @@ $O(2 × n^2 + 10 × n + 1000)$ < $O(3 × n^2)$,所以说最后省略掉常数
通过这道面试题目,来分析一下时间复杂度。题目描述:找出n个字符串中相同的两个字符串(假设这里只有两个相同的字符串)。
-如果是暴力枚举的话,时间复杂度是多少呢,是$O(n^2)$么?
+如果是暴力枚举的话,时间复杂度是多少呢,是O(n^2)么?
-这里一些同学会忽略了字符串比较的时间消耗,这里并不像int 型数字做比较那么简单,除了$n^2$次的遍历次数外,字符串比较依然要消耗m次操作(m也就是字母串的长度),所以时间复杂度是$O(m × n × n)$。
+这里一些同学会忽略了字符串比较的时间消耗,这里并不像int 型数字做比较那么简单,除了n^2次的遍历次数外,字符串比较依然要消耗m次操作(m也就是字母串的长度),所以时间复杂度是$O(m × n × n)$。
接下来再想一下其他解题思路。
先排对n个字符串按字典序来排序,排序后n个字符串就是有序的,意味着两个相同的字符串就是挨在一起,然后在遍历一遍n个字符串,这样就找到两个相同的字符串了。
-那看看这种算法的时间复杂度,快速排序时间复杂度为$O(n\log n)$,依然要考虑字符串的长度是m,那么快速排序每次的比较都要有m次的字符比较的操作,就是$O(m × n × \log n)$。
+那看看这种算法的时间复杂度,快速排序时间复杂度为O(nlog n),依然要考虑字符串的长度是m,那么快速排序每次的比较都要有m次的字符比较的操作,就是O(m × n × log n)。
-之后还要遍历一遍这n个字符串找出两个相同的字符串,别忘了遍历的时候依然要比较字符串,所以总共的时间复杂度是 $O(m × n × \log n + n × m)$。
+之后还要遍历一遍这n个字符串找出两个相同的字符串,别忘了遍历的时候依然要比较字符串,所以总共的时间复杂度是 O(m × n × log n + n × m)。
-我们对$O(m × n × \log n + n × m)$进行简化操作,把$m × n$提取出来变成$O(m × n × (\log n + 1)$),再省略常数项最后的时间复杂度是$O(m × n × \log n)$。
+我们对O(m × n × log n + n × m)进行简化操作,把m × n提取出来变成O(m × n × (log n + 1)),再省略常数项最后的时间复杂度是O(m × n × log n)。
-最后很明显$O(m × n × \log n)$ 要优于$O(m × n × n)$!
+最后很明显O(m × n × log n) 要优于O(m × n × n)!
所以先把字符串集合排序再遍历一遍找到两个相同字符串的方法要比直接暴力枚举的方式更快。
diff --git a/problems/剑指Offer05.替换空格.md b/problems/剑指Offer05.替换空格.md
index 21fc0602..037bd427 100644
--- a/problems/剑指Offer05.替换空格.md
+++ b/problems/剑指Offer05.替换空格.md
@@ -29,7 +29,7 @@ i指向新长度的末尾,j指向旧长度的末尾。
有同学问了,为什么要从后向前填充,从前向后填充不行么?
-从前向后填充就是$O(n^2)$的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
+从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
**其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。**
@@ -74,8 +74,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
此时算上本题,我们已经做了七道双指针相关的题目了分别是:
diff --git a/problems/动态规划-股票问题总结篇.md b/problems/动态规划-股票问题总结篇.md
index e1fb477b..47a9b34b 100644
--- a/problems/动态规划-股票问题总结篇.md
+++ b/problems/动态规划-股票问题总结篇.md
@@ -72,8 +72,8 @@ public:
}
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
使用滚动数组,代码如下:
@@ -95,8 +95,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
## 买卖股票的最佳时机II
@@ -121,8 +121,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
【动态规划】
@@ -162,8 +162,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 买卖股票的最佳时机III
@@ -226,8 +226,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n × 5)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n × 5)
当然,大家可以看到力扣官方题解里的一种优化空间写法,我这里给出对应的C++版本:
@@ -251,8 +251,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
**这种写法看上去简单,其实思路很绕,不建议大家这么写,这么思考,很容易把自己绕进去!** 对于本题,把版本一的写法研究明白,足以!
@@ -404,8 +404,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 买卖股票的最佳时机含手续费
@@ -456,8 +456,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 总结
diff --git a/problems/动态规划理论基础.md b/problems/动态规划理论基础.md
index e94295a5..66971fce 100644
--- a/problems/动态规划理论基础.md
+++ b/problems/动态规划理论基础.md
@@ -16,7 +16,7 @@
所以动态规划中每一个状态一定是由上一个状态推导出来的,**这一点就区分于贪心**,贪心没有状态推导,而是从局部直接选最优的,
-在[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/A9MHJi1a5uugFaqp8QJFWg)中我举了一个背包问题的例子。
+在[关于贪心算法,你该了解这些!](https://programmercarl.com/%E8%B4%AA%E5%BF%83%E7%AE%97%E6%B3%95%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html)中我举了一个背包问题的例子。
例如:有N件物品和一个最多能背重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。**每件物品只能用一次**,求解将哪些物品装入背包里物品价值总和最大。
diff --git a/problems/双指针总结.md b/problems/双指针总结.md
index e866aa66..39096ff7 100644
--- a/problems/双指针总结.md
+++ b/problems/双指针总结.md
@@ -22,7 +22,7 @@ for (int i = 0; i < array.size(); i++) {
}
```
-这个代码看上去好像是$O(n)$的时间复杂度,其实是$O(n^2)$的时间复杂度,因为erase操作也是$O(n)$的操作。
+这个代码看上去好像是O(n)的时间复杂度,其实是O(n^2)的时间复杂度,因为erase操作也是O(n)的操作。
所以此时使用双指针法才展现出效率的优势:**通过两个指针在一个for循环下完成两个for循环的工作。**
@@ -30,7 +30,7 @@ for (int i = 0; i < array.size(); i++) {
在[字符串:这道题目,使用库函数一行代码搞定](https://programmercarl.com/0344.反转字符串.html)中讲解了反转字符串,注意这里强调要原地反转,要不然就失去了题目的意义。
-使用双指针法,**定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。**,时间复杂度是$O(n)$。
+使用双指针法,**定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。**,时间复杂度是O(n)。
在[替换空格](https://programmercarl.com/剑指Offer05.替换空格.html) 中介绍使用双指针填充字符串的方法,如果想把这道题目做到极致,就不要只用额外的辅助空间了!
@@ -38,13 +38,13 @@ for (int i = 0; i < array.size(); i++) {
有同学问了,为什么要从后向前填充,从前向后填充不行么?
-从前向后填充就是$O(n^2)$的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
+从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
**其实很多数组(字符串)填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。**
-那么在[字符串:花式反转还不够!](https://programmercarl.com/0151.翻转字符串里的单词.html)中,我们使用双指针法,用$O(n)$的时间复杂度完成字符串删除类的操作,因为题目要产出冗余空格。
+那么在[字符串:花式反转还不够!](https://programmercarl.com/0151.翻转字符串里的单词.html)中,我们使用双指针法,用O(n)的时间复杂度完成字符串删除类的操作,因为题目要产出冗余空格。
-**在删除冗余空格的过程中,如果不注意代码效率,很容易写成了$O(n^2)$的时间复杂度。其实使用双指针法$O(n)$就可以搞定。**
+**在删除冗余空格的过程中,如果不注意代码效率,很容易写成了O(n^2)的时间复杂度。其实使用双指针法O(n)就可以搞定。**
**主要还是大家用erase用的比较随意,一定要注意for循环下用erase的情况,一般可以用双指针写效率更高!**
@@ -74,15 +74,15 @@ for (int i = 0; i < array.size(); i++) {
去重的过程不好处理,有很多小细节,如果在面试中很难想到位。
-时间复杂度可以做到$O(n^2)$,但还是比较费时的,因为不好做剪枝操作。
+时间复杂度可以做到O(n^2),但还是比较费时的,因为不好做剪枝操作。
所以这道题目使用双指针法才是最为合适的,用双指针做这道题目才能就能真正体会到,**通过前后两个指针不算向中间逼近,在一个for循环下完成两个for循环的工作。**
-只用双指针法时间复杂度为$O(n^2)$,但比哈希法的$O(n^2)$效率高得多,哈希法在使用两层for循环的时候,能做的剪枝操作很有限。
+只用双指针法时间复杂度为O(n^2),但比哈希法的O(n^2)效率高得多,哈希法在使用两层for循环的时候,能做的剪枝操作很有限。
在[双指针法:一样的道理,能解决四数之和](https://programmercarl.com/0018.四数之和.html)中,讲到了四数之和,其实思路是一样的,**在三数之和的基础上再套一层for循环,依然是使用双指针法。**
-对于三数之和使用双指针法就是将原本暴力$O(n^3)$的解法,降为$O(n^2)$的解法,四数之和的双指针解法就是将原本暴力$O(n^4)$的解法,降为$O(n^3)$的解法。
+对于三数之和使用双指针法就是将原本暴力O(n^3)的解法,降为O(n^2)的解法,四数之和的双指针解法就是将原本暴力O(n^4)的解法,降为O(n^3)的解法。
同样的道理,五数之和,n数之和都是在这个基础上累加。
diff --git a/problems/回溯总结.md b/problems/回溯总结.md
index bd0db575..5b8e2276 100644
--- a/problems/回溯总结.md
+++ b/problems/回溯总结.md
@@ -302,11 +302,11 @@ if (startIndex >= nums.size()) { // 终止条件可以不加
**而使用used数组在时间复杂度上几乎没有额外负担!**
-**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是$O(n)$,但如果使用set去重,空间复杂度就变成了$O(n^2)$,因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
+**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了$O(n^2)$,因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
-那有同学可能疑惑 用used数组也是占用$O(n)$的空间啊?
+那有同学可能疑惑 用used数组也是占用O(n)的空间啊?
-used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是$O(n + n)$,最终空间复杂度还是$O(n)$。
+used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是O(n + n),最终空间复杂度还是O(n)。
# 重新安排行程(图论额外拓展)
@@ -380,8 +380,8 @@ used数组可是全局变量,每层与每层之间公用一个used数组,所
以下在计算空间复杂度的时候我都把系统栈(不是数据结构里的栈)所占空间算进去。
子集问题分析:
-* 时间复杂度:O(2^n),因为每一个元素的状态无外乎取与不取,所以时间复杂度为$O(2^n)$
-* 空间复杂度:O(n),递归深度为n,所以系统栈所用空间为$O(n)$,每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为$O(n)$
+* 时间复杂度:O(2^n),因为每一个元素的状态无外乎取与不取,所以时间复杂度为O(2^n)
+* 空间复杂度:O(n),递归深度为n,所以系统栈所用空间为O(n),每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为O(n)
排列问题分析:
* 时间复杂度:O(n!),这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!。
@@ -392,7 +392,7 @@ used数组可是全局变量,每层与每层之间公用一个used数组,所
* 空间复杂度:O(n),和子集问题同理。
N皇后问题分析:
-* 时间复杂度:O(n!) ,其实如果看树形图的话,直觉上是$O(n^n)$,但皇后之间不能见面所以在搜索的过程中是有剪枝的,最差也就是O(n!),n!表示n * (n-1) * .... * 1。
+* 时间复杂度:O(n!) ,其实如果看树形图的话,直觉上是O(n^n),但皇后之间不能见面所以在搜索的过程中是有剪枝的,最差也就是O(n!),n!表示n * (n-1) * .... * 1。
* 空间复杂度:O(n),和子集问题同理。
解数独问题分析:
diff --git a/problems/回溯算法去重问题的另一种写法.md b/problems/回溯算法去重问题的另一种写法.md
index 7a601493..b4bdda00 100644
--- a/problems/回溯算法去重问题的另一种写法.md
+++ b/problems/回溯算法去重问题的另一种写法.md
@@ -226,11 +226,11 @@ public:
**而使用used数组在时间复杂度上几乎没有额外负担!**
-**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是$O(n)$,但如果使用set去重,空间复杂度就变成了$O(n^2)$,因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
+**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了O(n^2),因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
-那有同学可能疑惑 用used数组也是占用$O(n)$的空间啊?
+那有同学可能疑惑 用used数组也是占用O(n)的空间啊?
-used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是$O(n + n)$,最终空间复杂度还是$O(n)$。
+used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是O(n + n),最终空间复杂度还是O(n)。
## 总结
diff --git a/problems/字符串总结.md b/problems/字符串总结.md
index 469cb743..1993b44b 100644
--- a/problems/字符串总结.md
+++ b/problems/字符串总结.md
@@ -57,15 +57,15 @@ for (int i = 0; i < a.size(); i++) {
在[344.反转字符串](https://programmercarl.com/0344.反转字符串.html) ,我们使用双指针法实现了反转字符串的操作,**双指针法在数组,链表和字符串中很常用。**
-接着在[字符串:替换空格](https://programmercarl.com/剑指Offer05.替换空格.html),同样还是使用双指针法在时间复杂度$O(n)$的情况下完成替换空格。
+接着在[字符串:替换空格](https://programmercarl.com/剑指Offer05.替换空格.html),同样还是使用双指针法在时间复杂度O(n)的情况下完成替换空格。
**其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。**
那么针对数组删除操作的问题,其实在[27. 移除元素](https://programmercarl.com/0027.移除元素.html)中就已经提到了使用双指针法进行移除操作。
-同样的道理在[151.翻转字符串里的单词](https://programmercarl.com/0151.翻转字符串里的单词.html)中我们使用$O(n)$的时间复杂度,完成了删除冗余空格。
+同样的道理在[151.翻转字符串里的单词](https://programmercarl.com/0151.翻转字符串里的单词.html)中我们使用O(n)的时间复杂度,完成了删除冗余空格。
-一些同学会使用for循环里调用库函数erase来移除元素,这其实是$O(n^2)$的操作,因为erase就是$O(n)$的操作,所以这也是典型的不知道库函数的时间复杂度,上来就用的案例了。
+一些同学会使用for循环里调用库函数erase来移除元素,这其实是O(n^2)的操作,因为erase就是O(n)的操作,所以这也是典型的不知道库函数的时间复杂度,上来就用的案例了。
# 反转系列
diff --git a/problems/数组总结篇.md b/problems/数组总结篇.md
index d3d4a1e2..242c1498 100644
--- a/problems/数组总结篇.md
+++ b/problems/数组总结篇.md
@@ -67,8 +67,8 @@
可以使用暴力解法,通过这道题目,如果追求更优的算法,建议试一试用二分法,来解决这道题目
-* 暴力解法时间复杂度:$O(n)$
-* 二分法时间复杂度:$O(\log n)$
+* 暴力解法时间复杂度:O(n)
+* 二分法时间复杂度:O(logn)
在这道题目中我们讲到了**循环不变量原则**,只有在循环中坚持对区间的定义,才能清楚的把握循环中的各种细节。
@@ -81,8 +81,8 @@
双指针法(快慢指针法):**通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。**
-* 暴力解法时间复杂度:$O(n^2)$
-* 双指针时间复杂度:$O(n)$
+* 暴力解法时间复杂度:O(n^2)
+* 双指针时间复杂度:O(n)
这道题目迷惑了不少同学,纠结于数组中的元素为什么不能删除,主要是因为以下两点:
@@ -97,8 +97,8 @@
本题介绍了数组操作中的另一个重要思想:滑动窗口。
-* 暴力解法时间复杂度:$O(n^2)$
-* 滑动窗口时间复杂度:$O(n)$
+* 暴力解法时间复杂度:O(n^2)
+* 滑动窗口时间复杂度:O(n)
本题中,主要要理解滑动窗口如何移动 窗口起始位置,达到动态更新窗口大小的,从而得出长度最小的符合条件的长度。
diff --git a/problems/根据身高重建队列(vector原理讲解).md b/problems/根据身高重建队列(vector原理讲解).md
index 11a72e2d..6d248c40 100644
--- a/problems/根据身高重建队列(vector原理讲解).md
+++ b/problems/根据身高重建队列(vector原理讲解).md
@@ -33,7 +33,7 @@ public:
耗时如下:

-其直观上来看数组的insert操作是$O(n)$的,整体代码的时间复杂度是$O(n^2)$。
+其直观上来看数组的insert操作是O(n)的,整体代码的时间复杂度是O(n^2)。
这么一分析好像和版本二链表实现的时间复杂度是一样的啊,为什么提交之后效率会差距这么大呢?
```CPP
@@ -97,7 +97,7 @@ for (int i = 0; i < vec.size(); i++) {
**同时也注意此时capicity和size的变化,关键的地方我都标红了**。
-而在[贪心算法:根据身高重建队列](https://programmercarl.com/0406.根据身高重建队列.html)中,我们使用vector来做insert的操作,此时大家可会发现,**虽然表面上复杂度是$O(n^2)$,但是其底层都不知道额外做了多少次全量拷贝了,所以算上vector的底层拷贝,整体时间复杂度可以认为是$O(n^2 + t × n)$级别的,t是底层拷贝的次数**。
+而在[贪心算法:根据身高重建队列](https://programmercarl.com/0406.根据身高重建队列.html)中,我们使用vector来做insert的操作,此时大家可会发现,**虽然表面上复杂度是O(n^2),但是其底层都不知道额外做了多少次全量拷贝了,所以算上vector的底层拷贝,整体时间复杂度可以认为是O(n^2 + t × n)级别的,t是底层拷贝的次数**。
那么是不是可以直接确定好vector的大小,不让它在动态扩容了,例如在[贪心算法:根据身高重建队列](https://programmercarl.com/0406.根据身高重建队列.html)中已经给出了有people.size这么多的人,可以定义好一个固定大小的vector,这样我们就可以控制vector,不让它底层动态扩容。
@@ -133,7 +133,7 @@ public:

-这份代码就是不让vector动态扩容,全程我们自己模拟insert的操作,大家也可以直观的看出是一个$O(n^2)$的方法了。
+这份代码就是不让vector动态扩容,全程我们自己模拟insert的操作,大家也可以直观的看出是一个O(n^2)的方法了。
但这份代码在leetcode上统计的耗时甚至比版本一的还高,我们都不让它动态扩容了,为什么耗时更高了呢?
@@ -151,7 +151,7 @@ public:
大家应该发现了,编程语言中一个普通容器的insert,delete的使用,都可能对写出来的算法的有很大影响!
-如果抛开语言谈算法,除非从来不用代码写算法纯分析,**否则的话,语言功底不到位$O(n)$的算法可以写出$O(n^2)$的性能**,哈哈。
+如果抛开语言谈算法,除非从来不用代码写算法纯分析,**否则的话,语言功底不到位O(n)的算法可以写出$O(n^2)$的性能**,哈哈。
相信在这里学习算法的录友们,都是想在软件行业长远发展的,都是要从事编程的工作,那么一定要深耕好一门编程语言,这个非常重要!
diff --git a/problems/知识星球精选/刷力扣用不用库函数.md b/problems/知识星球精选/刷力扣用不用库函数.md
index b52e4d03..c8e2f5c6 100644
--- a/problems/知识星球精选/刷力扣用不用库函数.md
+++ b/problems/知识星球精选/刷力扣用不用库函数.md
@@ -27,7 +27,7 @@
使用库函数最大的忌讳就是不知道这个库函数怎么实现的,也不知道其时间复杂度,上来就用,这样写出来的算法,时间复杂度自己都掌握不好的。
-例如for循环里套一个字符串的insert,erase之类的操作,你说时间复杂度是多少呢,很明显是$O(n^2)$的时间复杂度了。
+例如for循环里套一个字符串的insert,erase之类的操作,你说时间复杂度是多少呢,很明显是O(n^2)的时间复杂度了。
在刷题的时候本着我说的标准来使用库函数,详细对大家回有所帮助!
diff --git a/problems/背包问题理论基础多重背包.md b/problems/背包问题理论基础多重背包.md
index d05c3445..a988db2c 100644
--- a/problems/背包问题理论基础多重背包.md
+++ b/problems/背包问题理论基础多重背包.md
@@ -89,7 +89,7 @@ int main() {
```
-* 时间复杂度:$O(m × n × k)$,m:物品种类个数,n背包容量,k单类物品数量
+* 时间复杂度:O(m × n × k),m:物品种类个数,n背包容量,k单类物品数量
也有另一种实现方式,就是把每种商品遍历的个数放在01背包里面在遍历一遍。
@@ -125,7 +125,7 @@ int main() {
}
```
-* 时间复杂度:$O(m × n × k)$,m:物品种类个数,n背包容量,k单类物品数量
+* 时间复杂度:O(m × n × k),m:物品种类个数,n背包容量,k单类物品数量
从代码里可以看出是01背包里面在加一个for循环遍历一个每种商品的数量。 和01背包还是如出一辙的。
diff --git a/problems/链表理论基础.md b/problems/链表理论基础.md
index a4fefa2b..095282f5 100644
--- a/problems/链表理论基础.md
+++ b/problems/链表理论基础.md
@@ -120,9 +120,9 @@ head->val = 5;
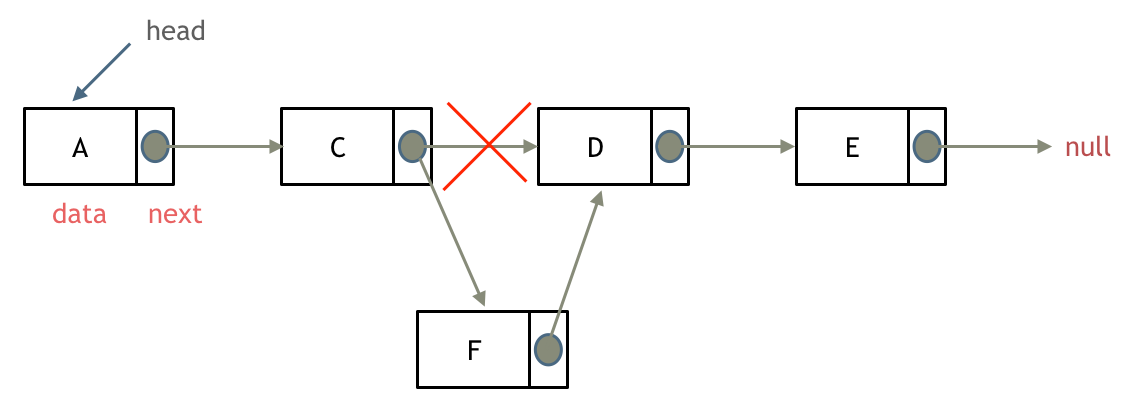
-可以看出链表的增添和删除都是$O(1)$操作,也不会影响到其他节点。
+可以看出链表的增添和删除都是O(1)操作,也不会影响到其他节点。
-但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是$O(n)$。
+但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
# 性能分析
From 9b9a37b92c20fc616b7808317ba05ff03c6d8633 Mon Sep 17 00:00:00 2001
From: SianXiaoCHN
Date: Sat, 2 Apr 2022 00:03:08 -0500
Subject: [PATCH 15/16] 0455 typo
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
0455思路多打了一个“了”
---
problems/0455.分发饼干.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/problems/0455.分发饼干.md b/problems/0455.分发饼干.md
index 210b492d..5c86e478 100644
--- a/problems/0455.分发饼干.md
+++ b/problems/0455.分发饼干.md
@@ -32,7 +32,7 @@
## 思路
-为了了满足更多的小孩,就不要造成饼干尺寸的浪费。
+为了满足更多的小孩,就不要造成饼干尺寸的浪费。
大尺寸的饼干既可以满足胃口大的孩子也可以满足胃口小的孩子,那么就应该优先满足胃口大的。
From 69a9316bebce0fc3f43835bb9245f124076f105f Mon Sep 17 00:00:00 2001
From: SianXiaoCHN
Date: Sun, 3 Apr 2022 23:42:04 -0500
Subject: [PATCH 16/16] =?UTF-8?q?python=200860.=E6=9F=A0=E6=AA=AC=E6=B0=B4?=
=?UTF-8?q?=E6=89=BE=E9=9B=B6=20=E5=8E=BB=E9=99=A4=E6=97=A0=E7=94=A8?=
=?UTF-8?q?=E5=8F=98=E9=87=8F?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
python 0860.柠檬水找零 去除无用变量:在本题中,20的数量是无用的,因为不需要用来找零,可以不用维护这个变量。
---
problems/0860.柠檬水找零.md | 4 +---
1 file changed, 1 insertion(+), 3 deletions(-)
diff --git a/problems/0860.柠檬水找零.md b/problems/0860.柠檬水找零.md
index f48ecf4d..ffd5490d 100644
--- a/problems/0860.柠檬水找零.md
+++ b/problems/0860.柠檬水找零.md
@@ -157,7 +157,7 @@ class Solution {
```python
class Solution:
def lemonadeChange(self, bills: List[int]) -> bool:
- five, ten, twenty = 0, 0, 0
+ five, ten = 0, 0
for bill in bills:
if bill == 5:
five += 1
@@ -169,10 +169,8 @@ class Solution:
if ten > 0 and five > 0:
ten -= 1
five -= 1
- twenty += 1
elif five > 2:
five -= 3
- twenty += 1
else:
return False
return True
