mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-08 00:43:04 +08:00
Merge branch 'master' of github.com:jinbudaily/leetcode-master
This commit is contained in:
@ -37,20 +37,20 @@
|
||||
[242. 有效的字母异位词](https://www.programmercarl.com/0242.有效的字母异位词.html) 这道题目是用数组作为哈希表来解决哈希问题,[349. 两个数组的交集](https://www.programmercarl.com/0349.两个数组的交集.html)这道题目是通过set作为哈希表来解决哈希问题。
|
||||
|
||||
|
||||
首先我在强调一下 **什么时候使用哈希法**,当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
|
||||
首先我再强调一下 **什么时候使用哈希法**,当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
|
||||
|
||||
本题呢,我就需要一个集合来存放我们遍历过的元素,然后在遍历数组的时候去询问这个集合,某元素是否遍历过,也就是 是否出现在这个集合。
|
||||
|
||||
那么我们就应该想到使用哈希法了。
|
||||
|
||||
因为本地,我们不仅要知道元素有没有遍历过,还要知道这个元素对应的下标,**需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适**。
|
||||
因为本题,我们不仅要知道元素有没有遍历过,还要知道这个元素对应的下标,**需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适**。
|
||||
|
||||
再来看一下使用数组和set来做哈希法的局限。
|
||||
|
||||
* 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
|
||||
* set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
|
||||
|
||||
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value在保存数值所在的下标。
|
||||
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value再保存数值所在的下标。
|
||||
|
||||
C++中map,有三种类型:
|
||||
|
||||
|
||||
@ -171,7 +171,7 @@ public:
|
||||
|
||||
#### a的去重
|
||||
|
||||
说道去重,其实主要考虑三个数的去重。 a, b ,c, 对应的就是 nums[i],nums[left],nums[right]
|
||||
说到去重,其实主要考虑三个数的去重。 a, b ,c, 对应的就是 nums[i],nums[left],nums[right]
|
||||
|
||||
a 如果重复了怎么办,a是nums里遍历的元素,那么应该直接跳过去。
|
||||
|
||||
@ -181,7 +181,7 @@ a 如果重复了怎么办,a是nums里遍历的元素,那么应该直接跳
|
||||
|
||||
其实不一样!
|
||||
|
||||
都是和 nums[i]进行比较,是比较它的前一个,还是比较他的后一个。
|
||||
都是和 nums[i]进行比较,是比较它的前一个,还是比较它的后一个。
|
||||
|
||||
如果我们的写法是 这样:
|
||||
|
||||
@ -191,7 +191,7 @@ if (nums[i] == nums[i + 1]) { // 去重操作
|
||||
}
|
||||
```
|
||||
|
||||
那就我们就把 三元组中出现重复元素的情况直接pass掉了。 例如{-1, -1 ,2} 这组数据,当遍历到第一个-1 的时候,判断 下一个也是-1,那这组数据就pass了。
|
||||
那我们就把 三元组中出现重复元素的情况直接pass掉了。 例如{-1, -1 ,2} 这组数据,当遍历到第一个-1 的时候,判断 下一个也是-1,那这组数据就pass了。
|
||||
|
||||
**我们要做的是 不能有重复的三元组,但三元组内的元素是可以重复的!**
|
||||
|
||||
|
||||
@ -649,6 +649,54 @@ object Solution {
|
||||
}
|
||||
}
|
||||
```
|
||||
### Ruby:
|
||||
|
||||
```ruby
|
||||
def four_sum(nums, target)
|
||||
#结果集
|
||||
result = []
|
||||
nums = nums.sort!
|
||||
|
||||
for i in 0..nums.size - 1
|
||||
return result if i > 0 && nums[i] > target && nums[i] >= 0
|
||||
#对a进行去重
|
||||
next if i > 0 && nums[i] == nums[i - 1]
|
||||
|
||||
for j in i + 1..nums.size - 1
|
||||
break if nums[i] + nums[j] > target && nums[i] + nums[j] >= 0
|
||||
#对b进行去重
|
||||
next if j > i + 1 && nums[j] == nums[j - 1]
|
||||
left = j + 1
|
||||
right = nums.size - 1
|
||||
while left < right
|
||||
sum = nums[i] + nums[j] + nums[left] + nums[right]
|
||||
if sum > target
|
||||
right -= 1
|
||||
elsif sum < target
|
||||
left += 1
|
||||
else
|
||||
result << [nums[i], nums[j], nums[left], nums[right]]
|
||||
|
||||
#对c进行去重
|
||||
while left < right && nums[left] == nums[left + 1]
|
||||
left += 1
|
||||
end
|
||||
|
||||
#对d进行去重
|
||||
while left < right && nums[right] == nums[right - 1]
|
||||
right -= 1
|
||||
end
|
||||
|
||||
right -= 1
|
||||
left += 1
|
||||
end
|
||||
end
|
||||
end
|
||||
end
|
||||
|
||||
return result
|
||||
end
|
||||
```
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -73,7 +73,7 @@ candidates 中的数字可以无限制重复被选取。
|
||||
|
||||
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:[17.电话号码的字母组合](https://programmercarl.com/0017.电话号码的字母组合.html)
|
||||
|
||||
**注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我再讲解排列的时候就重点介绍**。
|
||||
**注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我在讲解排列的时候会重点介绍**。
|
||||
|
||||
代码如下:
|
||||
|
||||
@ -311,7 +311,7 @@ class Solution:
|
||||
|
||||
for i in range(startIndex, len(candidates)):
|
||||
if total + candidates[i] > target:
|
||||
break
|
||||
continue
|
||||
total += candidates[i]
|
||||
path.append(candidates[i])
|
||||
self.backtracking(candidates, target, total, i, path, result)
|
||||
|
||||
@ -200,6 +200,58 @@ class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
### Javascript
|
||||
```
|
||||
/**
|
||||
* @param {number[][]} matrix
|
||||
* @return {number[]}
|
||||
*/
|
||||
var spiralOrder = function(matrix) {
|
||||
let m = matrix.length
|
||||
let n = matrix[0].length
|
||||
|
||||
let startX = startY = 0
|
||||
let i = 0
|
||||
let arr = new Array(m*n).fill(0)
|
||||
let offset = 1
|
||||
let loop = mid = Math.floor(Math.min(m,n) / 2)
|
||||
while (loop--) {
|
||||
let row = startX
|
||||
let col = startY
|
||||
// -->
|
||||
for (; col < n + startY - offset; col++) {
|
||||
arr[i++] = matrix[row][col]
|
||||
}
|
||||
// down
|
||||
for (; row < m + startX - offset; row++) {
|
||||
arr[i++] = matrix[row][col]
|
||||
}
|
||||
// <--
|
||||
for (; col > startY; col--) {
|
||||
arr[i++] = matrix[row][col]
|
||||
}
|
||||
for (; row > startX; row--) {
|
||||
arr[i++] = matrix[row][col]
|
||||
}
|
||||
startX++
|
||||
startY++
|
||||
offset += 2
|
||||
}
|
||||
if (Math.min(m, n) % 2 === 1) {
|
||||
if (n > m) {
|
||||
for (let j = mid; j < mid + n - m + 1; j++) {
|
||||
arr[i++] = matrix[mid][j]
|
||||
}
|
||||
} else {
|
||||
for (let j = mid; j < mid + m - n + 1; j++) {
|
||||
arr[i++] = matrix[j][mid]
|
||||
}
|
||||
}
|
||||
}
|
||||
return arr
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
<p align="center">
|
||||
|
||||
@ -403,6 +403,64 @@ int minDistance(char * word1, char * word2){
|
||||
}
|
||||
```
|
||||
|
||||
Rust:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn min_distance(word1: String, word2: String) -> i32 {
|
||||
let mut dp = vec![vec![0; word2.len() + 1]; word1.len() + 1];
|
||||
for i in 1..=word2.len() {
|
||||
dp[0][i] = i;
|
||||
}
|
||||
|
||||
for (j, v) in dp.iter_mut().enumerate().skip(1) {
|
||||
v[0] = j;
|
||||
}
|
||||
for (i, char1) in word1.chars().enumerate() {
|
||||
for (j, char2) in word2.chars().enumerate() {
|
||||
if char1 == char2 {
|
||||
dp[i + 1][j + 1] = dp[i][j];
|
||||
continue;
|
||||
}
|
||||
dp[i + 1][j + 1] = dp[i][j + 1].min(dp[i + 1][j]).min(dp[i][j]) + 1;
|
||||
}
|
||||
}
|
||||
|
||||
dp[word1.len()][word2.len()] as i32
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> 一维 dp
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn min_distance(word1: String, word2: String) -> i32 {
|
||||
let mut dp = vec![0; word1.len() + 1];
|
||||
for (i, v) in dp.iter_mut().enumerate().skip(1) {
|
||||
*v = i;
|
||||
}
|
||||
|
||||
for char2 in word2.chars() {
|
||||
// 相当于 dp[i][0] 的初始化
|
||||
let mut pre = dp[0];
|
||||
dp[0] += 1; // j = 0, 将前 i 个字符变成空串的个数
|
||||
for (j, char1) in word1.chars().enumerate() {
|
||||
let temp = dp[j + 1];
|
||||
if char1 == char2 {
|
||||
dp[j + 1] = pre;
|
||||
} else {
|
||||
dp[j + 1] = dp[j + 1].min(dp[j]).min(pre) + 1;
|
||||
}
|
||||
pre = temp;
|
||||
}
|
||||
}
|
||||
|
||||
dp[word1.len()] as i32
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -729,62 +729,6 @@ impl Solution {
|
||||
}
|
||||
```
|
||||
|
||||
Rust
|
||||
|
||||
双指针预处理
|
||||
```rust
|
||||
|
||||
impl Solution {
|
||||
pub fn largest_rectangle_area(v: Vec<i32>) -> i32 {
|
||||
let n = v.len();
|
||||
let mut left_smaller_idx = vec![-1; n];
|
||||
let mut right_smaller_idx = vec![n as i32; n];
|
||||
for i in 1..n {
|
||||
let mut mid = i as i32 - 1;
|
||||
while mid >= 0 && v[mid as usize] >= v[i] {
|
||||
mid = left_smaller_idx[mid as usize];
|
||||
}
|
||||
left_smaller_idx[i] = mid;
|
||||
}
|
||||
for i in (0..n-1).rev() {
|
||||
let mut mid = i + 1;
|
||||
while mid < n && v[mid] >= v[i] {
|
||||
mid = right_smaller_idx[mid] as usize;
|
||||
}
|
||||
right_smaller_idx[i] = mid as i32;
|
||||
}
|
||||
let mut res = 0;
|
||||
for (idx, &e) in v.iter().enumerate() {
|
||||
res = res.max((right_smaller_idx[idx] - left_smaller_idx[idx] - 1) * e);
|
||||
}
|
||||
dbg!(res)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
单调栈
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn largest_rectangle_area1(mut v: Vec<i32>) -> i32 {
|
||||
v.insert(0, 0); // 便于使第一个元素能够有左侧<=它的值
|
||||
v.push(0); // 便于在结束处理最后一个元素后清空残留在栈中的值
|
||||
let mut res = 0;
|
||||
let mut stack = vec![]; // 递增的栈
|
||||
for (idx, &e) in v.iter().enumerate() {
|
||||
while !stack.is_empty() && v[*stack.last().unwrap()] > e {
|
||||
let pos = stack.pop().unwrap();
|
||||
let prev_pos = *stack.last().unwrap();
|
||||
let s = (idx - prev_pos - 1) as i32 * v[pos];
|
||||
res = res.max(s);
|
||||
}
|
||||
stack.push(idx);
|
||||
}
|
||||
res
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -18,7 +18,7 @@
|
||||
* [102.二叉树的层序遍历](https://leetcode.cn/problems/binary-tree-level-order-traversal/)
|
||||
* [107.二叉树的层次遍历II](https://leetcode.cn/problems/binary-tree-level-order-traversal-ii/)
|
||||
* [199.二叉树的右视图](https://leetcode.cn/problems/binary-tree-right-side-view/)
|
||||
* [637.二叉树的层平均值](https://leetcode.cn/problems/binary-tree-right-side-view/)
|
||||
* [637.二叉树的层平均值](https://leetcode.cn/problems/average-of-levels-in-binary-tree/)
|
||||
* [429.N叉树的层序遍历](https://leetcode.cn/problems/n-ary-tree-level-order-traversal/)
|
||||
* [515.在每个树行中找最大值](https://leetcode.cn/problems/find-largest-value-in-each-tree-row/)
|
||||
* [116.填充每个节点的下一个右侧节点指针](https://leetcode.cn/problems/populating-next-right-pointers-in-each-node/)
|
||||
|
||||
@ -317,6 +317,63 @@ function numDistinct(s: string, t: string): number {
|
||||
};
|
||||
```
|
||||
|
||||
### Rust:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn num_distinct(s: String, t: String) -> i32 {
|
||||
if s.len() < t.len() {
|
||||
return 0;
|
||||
}
|
||||
let mut dp = vec![vec![0; s.len() + 1]; t.len() + 1];
|
||||
// i = 0, t 为空字符串,s 作为子序列的个数为 1(删除 s 所有元素)
|
||||
dp[0] = vec![1; s.len() + 1];
|
||||
for (i, char_t) in t.chars().enumerate() {
|
||||
for (j, char_s) in s.chars().enumerate() {
|
||||
if char_t == char_s {
|
||||
// t 的前 i 个字符在 s 的前 j 个字符中作为子序列的个数
|
||||
dp[i + 1][j + 1] = dp[i][j] + dp[i + 1][j];
|
||||
continue;
|
||||
}
|
||||
dp[i + 1][j + 1] = dp[i + 1][j];
|
||||
}
|
||||
}
|
||||
dp[t.len()][s.len()]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> 滚动数组
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn num_distinct(s: String, t: String) -> i32 {
|
||||
if s.len() < t.len() {
|
||||
return 0;
|
||||
}
|
||||
let (s, t) = (s.into_bytes(), t.into_bytes());
|
||||
// 对于 t 为空字符串,s 作为子序列的个数为 1(删除 s 所有元素)
|
||||
let mut dp = vec![1; s.len() + 1];
|
||||
for char_t in t {
|
||||
// dp[i - 1][j - 1],dp[j + 1] 更新之前的值
|
||||
let mut pre = dp[0];
|
||||
// 当开始遍历 t,s 的前 0 个字符无法包含任意子序列
|
||||
dp[0] = 0;
|
||||
for (j, &char_s) in s.iter().enumerate() {
|
||||
let temp = dp[j + 1];
|
||||
if char_t == char_s {
|
||||
dp[j + 1] = pre + dp[j];
|
||||
} else {
|
||||
dp[j + 1] = dp[j];
|
||||
}
|
||||
pre = temp;
|
||||
}
|
||||
}
|
||||
dp[s.len()]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
@ -385,6 +385,55 @@ class Solution {
|
||||
}
|
||||
}
|
||||
```
|
||||
### Python3
|
||||
|
||||
```Python
|
||||
// 深度优先遍历
|
||||
class Solution:
|
||||
dir_list = [(0, 1), (0, -1), (1, 0), (-1, 0)]
|
||||
def solve(self, board: List[List[str]]) -> None:
|
||||
"""
|
||||
Do not return anything, modify board in-place instead.
|
||||
"""
|
||||
row_size = len(board)
|
||||
column_size = len(board[0])
|
||||
visited = [[False] * column_size for _ in range(row_size)]
|
||||
# 从边缘开始,将边缘相连的O改成A。然后遍历所有,将A改成O,O改成X
|
||||
# 第一行和最后一行
|
||||
for i in range(column_size):
|
||||
if board[0][i] == "O" and not visited[0][i]:
|
||||
self.dfs(board, 0, i, visited)
|
||||
if board[row_size-1][i] == "O" and not visited[row_size-1][i]:
|
||||
self.dfs(board, row_size-1, i, visited)
|
||||
|
||||
# 第一列和最后一列
|
||||
for i in range(1, row_size-1):
|
||||
if board[i][0] == "O" and not visited[i][0]:
|
||||
self.dfs(board, i, 0, visited)
|
||||
if board[i][column_size-1] == "O" and not visited[i][column_size-1]:
|
||||
self.dfs(board, i, column_size-1, visited)
|
||||
|
||||
for i in range(row_size):
|
||||
for j in range(column_size):
|
||||
if board[i][j] == "A":
|
||||
board[i][j] = "O"
|
||||
elif board[i][j] == "O":
|
||||
board[i][j] = "X"
|
||||
|
||||
|
||||
def dfs(self, board, x, y, visited):
|
||||
if visited[x][y] or board[x][y] == "X":
|
||||
return
|
||||
visited[x][y] = True
|
||||
board[x][y] = "A"
|
||||
for i in range(4):
|
||||
new_x = x + self.dir_list[i][0]
|
||||
new_y = y + self.dir_list[i][1]
|
||||
if new_x >= len(board) or new_y >= len(board[0]) or new_x < 0 or new_y < 0:
|
||||
continue
|
||||
self.dfs(board, new_x, new_y, visited)
|
||||
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
@ -197,6 +197,7 @@ class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Python
|
||||
BFS solution
|
||||
```python
|
||||
@ -236,6 +237,7 @@ class Solution:
|
||||
continue
|
||||
q.append((next_i, next_j))
|
||||
visited[next_i][next_j] = True
|
||||
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
|
||||
@ -218,6 +218,67 @@ class Solution {
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Python:
|
||||
|
||||
```python
|
||||
# 版本一
|
||||
class Solution:
|
||||
def numIslands(self, grid: List[List[str]]) -> int:
|
||||
m, n = len(grid), len(grid[0])
|
||||
visited = [[False] * n for _ in range(m)]
|
||||
dirs = [(-1, 0), (0, 1), (1, 0), (0, -1)] # 四个方向
|
||||
result = 0
|
||||
|
||||
def dfs(x, y):
|
||||
for d in dirs:
|
||||
nextx = x + d[0]
|
||||
nexty = y + d[1]
|
||||
if nextx < 0 or nextx >= m or nexty < 0 or nexty >= n: # 越界了,直接跳过
|
||||
continue
|
||||
if not visited[nextx][nexty] and grid[nextx][nexty] == '1': # 没有访问过的同时是陆地的
|
||||
visited[nextx][nexty] = True
|
||||
dfs(nextx, nexty)
|
||||
|
||||
for i in range(m):
|
||||
for j in range(n):
|
||||
if not visited[i][j] and grid[i][j] == '1':
|
||||
visited[i][j] = True
|
||||
result += 1 # 遇到没访问过的陆地,+1
|
||||
dfs(i, j) # 将与其链接的陆地都标记上 true
|
||||
|
||||
return result
|
||||
```
|
||||
|
||||
```python
|
||||
# 版本二
|
||||
class Solution:
|
||||
def numIslands(self, grid: List[List[str]]) -> int:
|
||||
m, n = len(grid), len(grid[0])
|
||||
visited = [[False] * n for _ in range(m)]
|
||||
dirs = [(-1, 0), (0, 1), (1, 0), (0, -1)] # 四个方向
|
||||
result = 0
|
||||
|
||||
def dfs(x, y):
|
||||
if visited[x][y] or grid[x][y] == '0':
|
||||
return # 终止条件:访问过的节点 或者 遇到海水
|
||||
visited[x][y] = True
|
||||
for d in dirs:
|
||||
nextx = x + d[0]
|
||||
nexty = y + d[1]
|
||||
if nextx < 0 or nextx >= m or nexty < 0 or nexty >= n: # 越界了,直接跳过
|
||||
continue
|
||||
dfs(nextx, nexty)
|
||||
|
||||
for i in range(m):
|
||||
for j in range(n):
|
||||
if not visited[i][j] and grid[i][j] == '1':
|
||||
result += 1 # 遇到没访问过的陆地,+1
|
||||
dfs(i, j) # 将与其链接的陆地都标记上 true
|
||||
|
||||
return result
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -423,29 +423,61 @@ impl Solution {
|
||||
### C:
|
||||
|
||||
```C
|
||||
typedef struct HashNodeTag {
|
||||
int key; /* num */
|
||||
struct HashNodeTag *next;
|
||||
}HashNode;
|
||||
|
||||
/* Calcualte the hash key */
|
||||
static inline int hash(int key, int size) {
|
||||
int index = key % size;
|
||||
return (index > 0) ? (index) : (-index);
|
||||
}
|
||||
|
||||
/* Calculate the sum of the squares of its digits*/
|
||||
static inline int calcSquareSum(int num) {
|
||||
unsigned int sum = 0;
|
||||
while(num > 0) {
|
||||
sum += (num % 10) * (num % 10);
|
||||
num = num/10;
|
||||
int get_sum(int n) {
|
||||
int sum = 0;
|
||||
div_t n_div = { .quot = n };
|
||||
while (n_div.quot != 0) {
|
||||
n_div = div(n_div.quot, 10);
|
||||
sum += n_div.rem * n_div.rem;
|
||||
}
|
||||
return sum;
|
||||
}
|
||||
|
||||
// (版本1)使用数组
|
||||
bool isHappy(int n) {
|
||||
// sum = a1^2 + a2^2 + ... ak^2
|
||||
// first round:
|
||||
// 1 <= k <= 10
|
||||
// 1 <= sum <= 1 + 81 * 9 = 730
|
||||
// second round:
|
||||
// 1 <= k <= 3
|
||||
// 1 <= sum <= 36 + 81 * 2 = 198
|
||||
// third round:
|
||||
// 1 <= sum <= 81 * 2 = 162
|
||||
// fourth round:
|
||||
// 1 <= sum <= 81 * 2 = 162
|
||||
|
||||
Scala:
|
||||
uint8_t visited[163] = { 0 };
|
||||
int sum = get_sum(get_sum(n));
|
||||
int next_n = sum;
|
||||
|
||||
while (next_n != 1) {
|
||||
sum = get_sum(next_n);
|
||||
|
||||
if (visited[sum]) return false;
|
||||
|
||||
visited[sum] = 1;
|
||||
next_n = sum;
|
||||
};
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
// (版本2)使用快慢指针
|
||||
bool isHappy(int n) {
|
||||
int slow = n;
|
||||
int fast = n;
|
||||
|
||||
do {
|
||||
slow = get_sum(slow);
|
||||
fast = get_sum(get_sum(fast));
|
||||
} while (slow != fast);
|
||||
|
||||
return (fast == 1);
|
||||
}
|
||||
```
|
||||
|
||||
### Scala:
|
||||
```scala
|
||||
object Solution {
|
||||
// 引入mutable
|
||||
|
||||
@ -133,7 +133,7 @@ left与right的逻辑处理; // 中
|
||||
|
||||
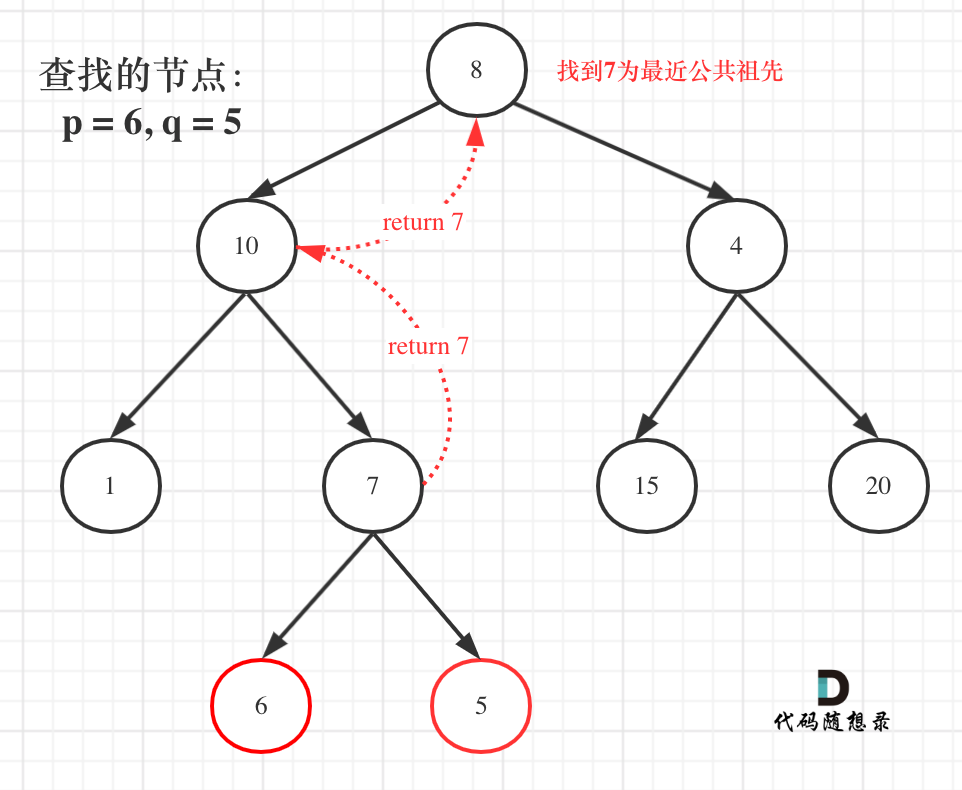
|
||||
|
||||
就像图中一样直接返回7,多美滋滋。
|
||||
就像图中一样直接返回7。
|
||||
|
||||
但事实上还要遍历根节点右子树(即使此时已经找到了目标节点了),也就是图中的节点4、15、20。
|
||||
|
||||
|
||||
@ -130,18 +130,16 @@ public:
|
||||
class Solution {
|
||||
public int lengthOfLIS(int[] nums) {
|
||||
int[] dp = new int[nums.length];
|
||||
int res = 0;
|
||||
Arrays.fill(dp, 1);
|
||||
for (int i = 0; i < dp.length; i++) {
|
||||
for (int i = 1; i < dp.length; i++) {
|
||||
for (int j = 0; j < i; j++) {
|
||||
if (nums[i] > nums[j]) {
|
||||
dp[i] = Math.max(dp[i], dp[j] + 1);
|
||||
}
|
||||
}
|
||||
}
|
||||
int res = 0;
|
||||
for (int i = 0; i < dp.length; i++) {
|
||||
res = Math.max(res, dp[i]);
|
||||
}
|
||||
}
|
||||
return res;
|
||||
}
|
||||
}
|
||||
@ -294,7 +292,7 @@ function lengthOfLIS(nums: number[]): number {
|
||||
|
||||
```rust
|
||||
pub fn length_of_lis(nums: Vec<i32>) -> i32 {
|
||||
let mut dp = vec![1; nums.len() + 1];
|
||||
let mut dp = vec![1; nums.len()];
|
||||
let mut result = 1;
|
||||
for i in 1..nums.len() {
|
||||
for j in 0..i {
|
||||
@ -309,7 +307,6 @@ pub fn length_of_lis(nums: Vec<i32>) -> i32 {
|
||||
```
|
||||
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -237,13 +237,10 @@ public:
|
||||
```cpp
|
||||
for (pair<const string, int>& target : targets[result[result.size() - 1]])
|
||||
```
|
||||
pair里要有const,因为map中的key是不可修改的,所以是`pair<const string, int>`。
|
||||
|
||||
如果不加const,也可以复制一份pair,例如这么写:
|
||||
一定要加上引用即 `& target`,因为后面有对 target.second 做减减操作,如果没有引用,单纯复制,这个结果就没记录下来,那最后的结果就不对了。
|
||||
|
||||
```cpp
|
||||
for (pair<string, int>target : targets[result[result.size() - 1]])
|
||||
```
|
||||
加上引用之后,就必须在 string 前面加上 const,因为map中的key 是不可修改了,这就是语法规定了。
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
@ -465,6 +465,25 @@ object Solution {
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
###Ruby
|
||||
```ruby
|
||||
def intersection(nums1, nums2)
|
||||
hash = {}
|
||||
result = {}
|
||||
|
||||
nums1.each do |num|
|
||||
hash[num] = 1 if hash[num].nil?
|
||||
end
|
||||
|
||||
nums2.each do |num|
|
||||
#取nums1和nums2交集
|
||||
result[num] = 1 if hash[num] != nil
|
||||
end
|
||||
|
||||
return result.keys
|
||||
end
|
||||
```
|
||||
## 相关题目
|
||||
|
||||
* [350.两个数组的交集 II](https://leetcode.cn/problems/intersection-of-two-arrays-ii/)
|
||||
|
||||
@ -68,7 +68,7 @@ public:
|
||||
|
||||
### 哈希解法
|
||||
|
||||
因为题目所只有小写字母,那可以采用空间换取时间的哈希策略, 用一个长度为26的数组还记录magazine里字母出现的次数。
|
||||
因为题目说只有小写字母,那可以采用空间换取时间的哈希策略,用一个长度为26的数组来记录magazine里字母出现的次数。
|
||||
|
||||
然后再用ransomNote去验证这个数组是否包含了ransomNote所需要的所有字母。
|
||||
|
||||
|
||||
@ -259,9 +259,49 @@ func isSubsequence(s string, t string) bool {
|
||||
}
|
||||
```
|
||||
|
||||
Rust:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn is_subsequence(s: String, t: String) -> bool {
|
||||
let mut dp = vec![vec![0; t.len() + 1]; s.len() + 1];
|
||||
for (i, char_s) in s.chars().enumerate() {
|
||||
for (j, char_t) in t.chars().enumerate() {
|
||||
if char_s == char_t {
|
||||
dp[i + 1][j + 1] = dp[i][j] + 1;
|
||||
continue;
|
||||
}
|
||||
dp[i + 1][j + 1] = dp[i + 1][j]
|
||||
}
|
||||
}
|
||||
dp[s.len()][t.len()] == s.len()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> 滚动数组
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn is_subsequence(s: String, t: String) -> bool {
|
||||
let mut dp = vec![0; t.len() + 1];
|
||||
let (s, t) = (s.as_bytes(), t.as_bytes());
|
||||
for &byte_s in s {
|
||||
let mut pre = 0;
|
||||
for j in 0..t.len() {
|
||||
let temp = dp[j + 1];
|
||||
if byte_s == t[j] {
|
||||
dp[j + 1] = pre + 1;
|
||||
} else {
|
||||
dp[j + 1] = dp[j];
|
||||
}
|
||||
pre = temp;
|
||||
}
|
||||
}
|
||||
dp[t.len()] == s.len()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
@ -41,7 +41,7 @@
|
||||
|
||||
## 思路
|
||||
|
||||
本题咋眼一看好像和[0015.三数之和](https://programmercarl.com/0015.三数之和.html),[0018.四数之和](https://programmercarl.com/0018.四数之和.html)差不多,其实差很多。
|
||||
本题乍眼一看好像和[0015.三数之和](https://programmercarl.com/0015.三数之和.html),[0018.四数之和](https://programmercarl.com/0018.四数之和.html)差不多,其实差很多。
|
||||
|
||||
**本题是使用哈希法的经典题目,而[0015.三数之和](https://programmercarl.com/0015.三数之和.html),[0018.四数之和](https://programmercarl.com/0018.四数之和.html)并不合适使用哈希法**,因为三数之和和四数之和这两道题目使用哈希法在不超时的情况下做到对结果去重是很困难的,很有多细节需要处理。
|
||||
|
||||
|
||||
@ -52,7 +52,7 @@
|
||||
|
||||
也就是由前后相同的子串组成。
|
||||
|
||||
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前后的子串做后串,就一定还能组成一个s,如图:
|
||||
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前面的子串做后串,就一定还能组成一个s,如图:
|
||||
|
||||
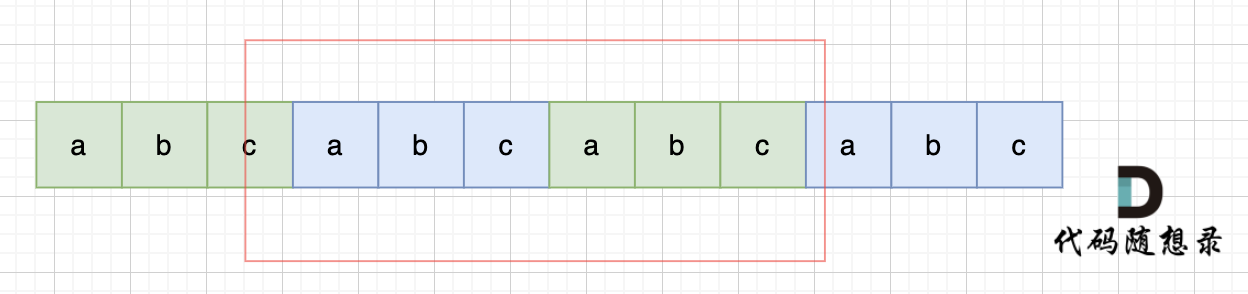
|
||||
|
||||
|
||||
@ -302,6 +302,104 @@ var islandPerimeter = function(grid) {
|
||||
};
|
||||
```
|
||||
|
||||
TypeScript:
|
||||
|
||||
```typescript
|
||||
/**
|
||||
* 方法一:深度优先搜索(DFS)
|
||||
* @param grid 二维网格地图,其中 grid[i][j] = 1 表示陆地, grid[i][j] = 0 表示水域
|
||||
* @returns 岛屿的周长
|
||||
*/
|
||||
function islandPerimeter(grid: number[][]): number {
|
||||
// 处理特殊情况:网格为空或行列数为 0,直接返回 0
|
||||
if (!grid || grid.length === 0 || grid[0].length === 0) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
// 获取网格的行数和列数
|
||||
const rows = grid.length;
|
||||
const cols = grid[0].length;
|
||||
let perimeter = 0; // 岛屿的周长
|
||||
|
||||
/**
|
||||
* 深度优先搜索函数
|
||||
* @param i 当前格子的行索引
|
||||
* @param j 当前格子的列索引
|
||||
*/
|
||||
const dfs = (i: number, j: number) => {
|
||||
// 如果当前位置超出网格范围,或者当前位置是水域(grid[i][j] === 0),则周长增加1
|
||||
if (i < 0 || i >= rows || j < 0 || j >= cols || grid[i][j] === 0) {
|
||||
perimeter++;
|
||||
return;
|
||||
}
|
||||
|
||||
// 如果当前位置已经访问过(grid[i][j] === -1),则直接返回
|
||||
if (grid[i][j] === -1) {
|
||||
return;
|
||||
}
|
||||
|
||||
// 标记当前位置为已访问(-1),避免重复计算
|
||||
grid[i][j] = -1;
|
||||
|
||||
// 继续搜索上、下、左、右四个方向
|
||||
dfs(i + 1, j);
|
||||
dfs(i - 1, j);
|
||||
dfs(i, j + 1);
|
||||
dfs(i, j - 1);
|
||||
};
|
||||
|
||||
// 遍历整个网格,找到第一个陆地格子(grid[i][j] === 1),并以此为起点进行深度优先搜索
|
||||
for (let i = 0; i < rows; i++) {
|
||||
for (let j = 0; j < cols; j++) {
|
||||
if (grid[i][j] === 1) {
|
||||
dfs(i, j);
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return perimeter;
|
||||
}
|
||||
|
||||
/**
|
||||
* 方法二:遍历每个陆地格子,统计周长
|
||||
* @param grid 二维网格地图,其中 grid[i][j] = 1 表示陆地, grid[i][j] = 0 表示水域
|
||||
* @returns 岛屿的周长
|
||||
*/
|
||||
function islandPerimeter(grid: number[][]): number {
|
||||
// 处理特殊情况:网格为空或行列数为 0,直接返回 0
|
||||
if (!grid || grid.length === 0 || grid[0].length === 0) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
// 获取网格的行数和列数
|
||||
const rows = grid.length;
|
||||
const cols = grid[0].length;
|
||||
let perimeter = 0; // 岛屿的周长
|
||||
|
||||
// 遍历整个网格
|
||||
for (let i = 0; i < rows; i++) {
|
||||
for (let j = 0; j < cols; j++) {
|
||||
// 如果当前格子是陆地(grid[i][j] === 1)
|
||||
if (grid[i][j] === 1) {
|
||||
perimeter += 4; // 周长先加上4个边
|
||||
|
||||
// 判断当前格子的上方是否也是陆地,如果是,则周长减去2个边
|
||||
if (i > 0 && grid[i - 1][j] === 1) {
|
||||
perimeter -= 2;
|
||||
}
|
||||
|
||||
// 判断当前格子的左方是否也是陆地,如果是,则周长减去2个边
|
||||
if (j > 0 && grid[i][j - 1] === 1) {
|
||||
perimeter -= 2;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return perimeter;
|
||||
}
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
@ -276,7 +276,26 @@ function longestPalindromeSubseq(s: string): number {
|
||||
};
|
||||
```
|
||||
|
||||
Rust:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn longest_palindrome_subseq(s: String) -> i32 {
|
||||
let mut dp = vec![vec![0; s.len()]; s.len()];
|
||||
for i in (0..s.len()).rev() {
|
||||
dp[i][i] = 1;
|
||||
for j in i + 1..s.len() {
|
||||
if s[i..=i] == s[j..=j] {
|
||||
dp[i][j] = dp[i + 1][j - 1] + 2;
|
||||
continue;
|
||||
}
|
||||
dp[i][j] = dp[i + 1][j].max(dp[i][j - 1]);
|
||||
}
|
||||
}
|
||||
dp[0][s.len() - 1]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
|
||||
@ -370,7 +370,51 @@ function minDistance(word1: string, word2: string): number {
|
||||
};
|
||||
```
|
||||
|
||||
Rust:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn min_distance(word1: String, word2: String) -> i32 {
|
||||
let mut dp = vec![vec![0; word2.len() + 1]; word1.len() + 1];
|
||||
for i in 0..word1.len() {
|
||||
dp[i + 1][0] = i + 1;
|
||||
}
|
||||
for j in 0..word2.len() {
|
||||
dp[0][j + 1] = j + 1;
|
||||
}
|
||||
for (i, char1) in word1.chars().enumerate() {
|
||||
for (j, char2) in word2.chars().enumerate() {
|
||||
if char1 == char2 {
|
||||
dp[i + 1][j + 1] = dp[i][j];
|
||||
continue;
|
||||
}
|
||||
dp[i + 1][j + 1] = dp[i][j + 1].min(dp[i + 1][j]) + 1;
|
||||
}
|
||||
}
|
||||
dp[word1.len()][word2.len()] as i32
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> 版本 2
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn min_distance(word1: String, word2: String) -> i32 {
|
||||
let mut dp = vec![vec![0; word2.len() + 1]; word1.len() + 1];
|
||||
for (i, char1) in word1.chars().enumerate() {
|
||||
for (j, char2) in word2.chars().enumerate() {
|
||||
if char1 == char2 {
|
||||
dp[i + 1][j + 1] = dp[i][j] + 1;
|
||||
continue;
|
||||
}
|
||||
dp[i + 1][j + 1] = dp[i][j + 1].max(dp[i + 1][j]);
|
||||
}
|
||||
}
|
||||
(word1.len() + word2.len() - 2 * dp[word1.len()][word2.len()]) as i32
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
|
||||
@ -525,8 +525,51 @@ function expandRange(s: string, left: number, right: number): number {
|
||||
}
|
||||
```
|
||||
|
||||
Rust:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn count_substrings(s: String) -> i32 {
|
||||
let mut dp = vec![vec![false; s.len()]; s.len()];
|
||||
let mut res = 0;
|
||||
|
||||
for i in (0..s.len()).rev() {
|
||||
for j in i..s.len() {
|
||||
if s[i..=i] == s[j..=j] && (j - i <= 1 || dp[i + 1][j - 1]) {
|
||||
dp[i][j] = true;
|
||||
res += 1;
|
||||
}
|
||||
}
|
||||
}
|
||||
res
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> 双指针
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn count_substrings(s: String) -> i32 {
|
||||
let mut res = 0;
|
||||
for i in 0..s.len() {
|
||||
res += Self::extend(&s, i, i, s.len());
|
||||
res += Self::extend(&s, i, i + 1, s.len());
|
||||
}
|
||||
res
|
||||
}
|
||||
|
||||
fn extend(s: &str, mut i: usize, mut j: usize, len: usize) -> i32 {
|
||||
let mut res = 0;
|
||||
while i < len && j < len && s[i..=i] == s[j..=j] {
|
||||
res += 1;
|
||||
i = i.wrapping_sub(1);
|
||||
j += 1;
|
||||
}
|
||||
res
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
@ -302,8 +302,9 @@ func findLengthOfLCIS(nums []int) int {
|
||||
}
|
||||
```
|
||||
|
||||
### Rust:
|
||||
|
||||
### Rust:
|
||||
>动态规划
|
||||
```rust
|
||||
pub fn find_length_of_lcis(nums: Vec<i32>) -> i32 {
|
||||
if nums.is_empty() {
|
||||
@ -321,6 +322,27 @@ pub fn find_length_of_lcis(nums: Vec<i32>) -> i32 {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
> 贪心
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn find_length_of_lcis(nums: Vec<i32>) -> i32 {
|
||||
let (mut res, mut count) = (1, 1);
|
||||
for i in 1..nums.len() {
|
||||
if nums[i] > nums[i - 1] {
|
||||
count += 1;
|
||||
res = res.max(count);
|
||||
continue;
|
||||
}
|
||||
count = 1;
|
||||
}
|
||||
res
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Javascript:
|
||||
|
||||
> 动态规划:
|
||||
|
||||
@ -536,6 +536,29 @@ function findLength(nums1: number[], nums2: number[]): number {
|
||||
};
|
||||
```
|
||||
|
||||
Rust:
|
||||
|
||||
> 滚动数组
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn find_length(nums1: Vec<i32>, nums2: Vec<i32>) -> i32 {
|
||||
let (mut res, mut dp) = (0, vec![0; nums2.len()]);
|
||||
|
||||
for n1 in nums1 {
|
||||
for j in (0..nums2.len()).rev() {
|
||||
if n1 == nums2[j] {
|
||||
dp[j] = if j == 0 { 1 } else { dp[j - 1] + 1 };
|
||||
res = res.max(dp[j]);
|
||||
} else {
|
||||
dp[j] = 0;
|
||||
}
|
||||
}
|
||||
}
|
||||
res
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
@ -30,7 +30,7 @@
|
||||
|
||||
### 暴力排序
|
||||
|
||||
最直观的想法,莫过于:每个数平方之后,排个序,美滋滋,代码如下:
|
||||
最直观的想法,莫过于:每个数平方之后,排个序,代码如下:
|
||||
|
||||
```CPP
|
||||
class Solution {
|
||||
|
||||
@ -525,6 +525,54 @@ impl Solution {
|
||||
}
|
||||
```
|
||||
|
||||
Ruby:
|
||||
```ruby
|
||||
def common_chars(words)
|
||||
result = []
|
||||
#统计所有字符串里字符出现的最小频率
|
||||
hash = {}
|
||||
#初始化标识
|
||||
is_first = true
|
||||
|
||||
words.each do |word|
|
||||
#记录共同字符
|
||||
chars = []
|
||||
word.split('').each do |chr|
|
||||
#第一个字符串初始化
|
||||
if is_first
|
||||
chars << chr
|
||||
else
|
||||
#字母之前出现过的最小次数
|
||||
if hash[chr] != nil && hash[chr] > 0
|
||||
hash[chr] -= 1
|
||||
chars << chr
|
||||
end
|
||||
end
|
||||
end
|
||||
|
||||
is_first = false
|
||||
#清除hash,更新字符最小频率
|
||||
hash.clear
|
||||
chars.each do |chr|
|
||||
if hash[chr] != nil
|
||||
hash[chr] += 1
|
||||
else
|
||||
hash[chr] = 1
|
||||
end
|
||||
end
|
||||
end
|
||||
|
||||
#字符最小频率hash转换为字符数组
|
||||
hash.keys.each do |key|
|
||||
for i in 0..hash[key] - 1
|
||||
result << key
|
||||
end
|
||||
end
|
||||
|
||||
return result
|
||||
end
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -155,21 +155,44 @@ func max(a, b int) int {
|
||||
### Rust:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn max_uncrossed_lines(nums1: Vec<i32>, nums2: Vec<i32>) -> i32 {
|
||||
let (n, m) = (nums1.len(), nums2.len());
|
||||
let mut last = vec![0; m + 1]; // 记录滚动数组
|
||||
let mut dp = vec![0; m + 1];
|
||||
for i in 1..=n {
|
||||
dp.swap_with_slice(&mut last);
|
||||
for j in 1..=m {
|
||||
if nums1[i - 1] == nums2[j - 1] {
|
||||
dp[j] = last[j - 1] + 1;
|
||||
let mut dp = vec![vec![0; nums2.len() + 1]; nums1.len() + 1];
|
||||
for (i, num1) in nums1.iter().enumerate() {
|
||||
for (j, num2) in nums2.iter().enumerate() {
|
||||
if num1 == num2 {
|
||||
dp[i + 1][j + 1] = dp[i][j] + 1;
|
||||
} else {
|
||||
dp[j] = last[j].max(dp[j - 1]);
|
||||
dp[i + 1][j + 1] = dp[i][j + 1].max(dp[i + 1][j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
dp[m]
|
||||
dp[nums1.len()][nums2.len()]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> 滚动数组
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn max_uncrossed_lines(nums1: Vec<i32>, nums2: Vec<i32>) -> i32 {
|
||||
let mut dp = vec![0; nums2.len() + 1];
|
||||
for num1 in nums1 {
|
||||
let mut prev = 0;
|
||||
for (j, &num2) in nums2.iter().enumerate() {
|
||||
let temp = dp[j + 1];
|
||||
if num1 == num2 {
|
||||
// 使用上一次的状态,防止重复计算
|
||||
dp[j + 1] = prev + 1;
|
||||
} else {
|
||||
dp[j + 1] = dp[j + 1].max(dp[j]);
|
||||
}
|
||||
prev = temp;
|
||||
}
|
||||
}
|
||||
dp[nums2.len()]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -475,6 +475,26 @@ impl Solution {
|
||||
}
|
||||
```
|
||||
|
||||
### Ruby
|
||||
|
||||
```ruby
|
||||
def remove_duplicates(s)
|
||||
#数组模拟栈
|
||||
stack = []
|
||||
s.each_char do |chr|
|
||||
if stack.empty?
|
||||
stack.push chr
|
||||
else
|
||||
head = stack.pop
|
||||
#重新进栈
|
||||
stack.push head, chr if head != chr
|
||||
end
|
||||
end
|
||||
|
||||
return stack.join
|
||||
end
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
|
||||
@ -329,25 +329,50 @@ function longestCommonSubsequence(text1: string, text2: string): number {
|
||||
};
|
||||
```
|
||||
|
||||
### Rust:
|
||||
### Rust
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn longest_common_subsequence(text1: String, text2: String) -> i32 {
|
||||
let (n, m) = (text1.len(), text2.len());
|
||||
let (s1, s2) = (text1.as_bytes(), text2.as_bytes());
|
||||
let mut dp = vec![0; m + 1];
|
||||
let mut last = vec![0; m + 1];
|
||||
for i in 1..=n {
|
||||
dp.swap_with_slice(&mut last);
|
||||
for j in 1..=m {
|
||||
dp[j] = if s1[i - 1] == s2[j - 1] {
|
||||
last[j - 1] + 1
|
||||
let mut dp = vec![vec![0; text2.len() + 1]; text1.len() + 1];
|
||||
for (i, c1) in text1.chars().enumerate() {
|
||||
for (j, c2) in text2.chars().enumerate() {
|
||||
if c1 == c2 {
|
||||
dp[i + 1][j + 1] = dp[i][j] + 1;
|
||||
} else {
|
||||
last[j].max(dp[j - 1])
|
||||
};
|
||||
dp[i + 1][j + 1] = dp[i][j + 1].max(dp[i + 1][j]);
|
||||
}
|
||||
}
|
||||
dp[m]
|
||||
}
|
||||
dp[text1.len()][text2.len()]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
一维:
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn longest_common_subsequence(text1: String, text2: String) -> i32 {
|
||||
let mut dp = vec![0; text2.len() + 1];
|
||||
for c1 in text1.chars() {
|
||||
// 初始化 prev
|
||||
let mut prev = 0;
|
||||
|
||||
for (j, c2) in text2.chars().enumerate() {
|
||||
let temp = dp[j + 1];
|
||||
if c1 == c2 {
|
||||
// 使用上一次的状态,防止重复计算
|
||||
dp[j + 1] = prev + 1;
|
||||
} else {
|
||||
dp[j + 1] = dp[j + 1].max(dp[j]);
|
||||
}
|
||||
// 使用上一次的状态更新 prev
|
||||
prev = temp;
|
||||
}
|
||||
}
|
||||
dp[text2.len()]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -203,6 +203,26 @@ function uniqueOccurrences(arr: number[]): boolean {
|
||||
```
|
||||
|
||||
|
||||
### Go:
|
||||
```Go
|
||||
func uniqueOccurrences(arr []int) bool {
|
||||
count := make(map[int]int) // 统计数字出现的频率
|
||||
for _, v := range arr {
|
||||
count[v] += 1
|
||||
}
|
||||
fre := make(map[int]struct{}) // 看相同频率是否重复出现
|
||||
for _, v := range count {
|
||||
if _, ok := fre[v]; ok {
|
||||
return false
|
||||
}
|
||||
fre[v] = struct{}{}
|
||||
}
|
||||
return true
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
|
||||
89
problems/qita/acm.md
Normal file
89
problems/qita/acm.md
Normal file
@ -0,0 +1,89 @@
|
||||
|
||||
# 如何练习ACM模式输入输入模式 | 如何准备笔试 | 卡码网
|
||||
|
||||
卡码网地址:[https://kamacoder.com](https://kamacoder.com)
|
||||
|
||||
## 为什么卡码网
|
||||
|
||||
录友们在求职的时候会发现,很多公司的笔试题和面试题都是ACM模式, 而大家习惯去力扣刷题,力扣是核心代码模式。
|
||||
|
||||
当大家在做ACM模式的算法题的时候,需要自己处理数据的输入输出,**如果没有接触过的话,还是挺难的**。
|
||||
|
||||
[知识星球](https://programmercarl.com/other/kstar.html)里很多录友的日常打卡中,都表示被 ACM模式折磨过:
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727163624.png' width=500 alt=''></img></div>
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727163938.png' width=500 alt=''></img></div>
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164042.png' width=500 alt=''></img></div>
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164151.png' width=500 alt=''></img></div>
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727164459.png' width=500 alt=''></img></div>
|
||||
|
||||
所以我正式推出:**卡码网**([https://kamacoder.com](https://kamacoder.com)),**专门帮助大家练习ACM模式**。
|
||||
|
||||
那么之前大家去哪里练习ACM模式呢?
|
||||
|
||||
去牛客做笔试真题,结果发现 ACM模式没练出来,题目倒是巨难,一点思路都没有,代码更没有写,ACM模式无从练起。
|
||||
|
||||
去洛谷,POJ上练习? 结果发现 题目超多,不知道从哪里开始刷,也没有一个循序渐进的刷题顺序。
|
||||
|
||||
**而卡码网上有我精选+制作的25道题目**!我还把25题的后台测试数据制作了一遍,保证大家练习的效果。
|
||||
|
||||
为什么题目不多,只有25道?
|
||||
|
||||
因为大家练习ACM模式不需要那么多题目,有一个循序渐进的练习过程就好了。
|
||||
|
||||
这25道题目包含了数组、链表、哈希表、字符串、二叉树、动态规划以及图的的题目,常见的输入输出方式都覆盖了。
|
||||
|
||||
**这是最精华的25道题目**!。
|
||||
|
||||
## 卡码网长什么样
|
||||
|
||||
来看看这极简的界面,没有烂七八糟的功能,只有刷题!
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727171535.png' width=500 alt=''></img></div>
|
||||
|
||||
在「状态」这里可以看到 大家提交的代码和判题记录,目前卡码网([https://kamacoder.com](https://kamacoder.com))几乎无时无刻都有卡友在提交代码。
|
||||
看看大家周六晚上都在做什么,刷哪些题目。
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230730200451.png' width=500 alt=''></img></div>
|
||||
|
||||
|
||||
提交代码的界面是这样的,**目前支持所有主流刷题语言**。
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230727172727.png' width=500 alt=''></img></div>
|
||||
|
||||
## 题解
|
||||
|
||||
基本大家来卡码网([https://kamacoder.com](https://kamacoder.com))练习ACM模式,都是对输入输出不够了解的,所以想看现成的题解,看看究竟是怎么处理的。
|
||||
|
||||
所以我用C++把卡码网上25道题目的题解都写了,并发布到Github上:
|
||||
|
||||
[https://github.com/youngyangyang04/kamacoder-solutions](https://github.com/youngyangyang04/kamacoder-solutions)
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230730200709.png' width=500 alt=''></img></div>
|
||||
|
||||
**欢迎去Github上star,欢迎fork,也欢迎来Github仓库贡献其他语言版本,成为contributor**。
|
||||
|
||||
如果不懂如何和开源项目提交代码,[可以看这里](https://www.programmercarl.com/qita/join.html)
|
||||
|
||||
目前已经有两位录友贡献C和Java版本了。
|
||||
|
||||
<div align="center"><img src='https://code-thinking-1253855093.file.myqcloud.com/pics/20230730195613.png' width=500 alt=''></img></div>
|
||||
|
||||
期待在Github(https://github.com/youngyangyang04/kamacoder-solutions) 的contributors上也出现你的头像。
|
||||
|
||||
目前题解只有C++代码吗?
|
||||
|
||||
当然不是,大多数题目已经有了 Java、python、C版本。 **其他语言版本,就给录友们成为contributor的机会了**。
|
||||
|
||||
## 最后
|
||||
|
||||
卡码网地址:[https://kamacoder.com](https://kamacoder.com)
|
||||
|
||||
快去体验吧,笔试之前最好 把卡码网25道题目都刷完。
|
||||
|
||||
期待录友们成为最早一批把卡码网刷爆的coder!
|
||||
|
||||
@ -150,7 +150,7 @@
|
||||
|
||||
最后再说一说二叉树中深度优先和广度优先遍历实现方式,我们做二叉树相关题目,经常会使用递归的方式来实现深度优先遍历,也就是实现前中后序遍历,使用递归是比较方便的。
|
||||
|
||||
**之前我们讲栈与队列的时候,就说过栈其实就是递归的一种实现结构**,也就说前中后序遍历的逻辑其实都是可以借助栈使用非递归的方式来实现的。
|
||||
**之前我们讲栈与队列的时候,就说过栈其实就是递归的一种实现结构**,也就说前中后序遍历的逻辑其实都是可以借助栈使用递归的方式来实现的。
|
||||
|
||||
而广度优先遍历的实现一般使用队列来实现,这也是队列先进先出的特点所决定的,因为需要先进先出的结构,才能一层一层的来遍历二叉树。
|
||||
|
||||
|
||||
@ -17,7 +17,7 @@
|
||||
|
||||
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:[回溯算法:电话号码的字母组合](https://programmercarl.com/0017.电话号码的字母组合.html)
|
||||
|
||||
**注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我再讲解排列的时候就重点介绍**。
|
||||
**注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路,后面我在讲解排列的时候会重点介绍**。
|
||||
|
||||
最后还给出了本题的剪枝优化,如下:
|
||||
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
**一般来说哈希表都是用来快速判断一个元素是否出现集合里**。
|
||||
|
||||
对于哈希表,要知道**哈希函数**和**哈希碰撞**在哈希表中的作用.
|
||||
对于哈希表,要知道**哈希函数**和**哈希碰撞**在哈希表中的作用。
|
||||
|
||||
哈希函数是把传入的key映射到符号表的索引上。
|
||||
|
||||
@ -88,7 +88,7 @@ std::set和std::multiset底层实现都是红黑树,std::unordered_set的底
|
||||
|
||||
map是一种`<key, value>`的结构,本题可以用key保存数值,用value在保存数值所在的下标。所以使用map最为合适。
|
||||
|
||||
C++提供如下三种map::(详情请看[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html))
|
||||
C++提供如下三种map:(详情请看[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html))
|
||||
|
||||
* std::map
|
||||
* std::multimap
|
||||
|
||||
@ -28,7 +28,7 @@
|
||||
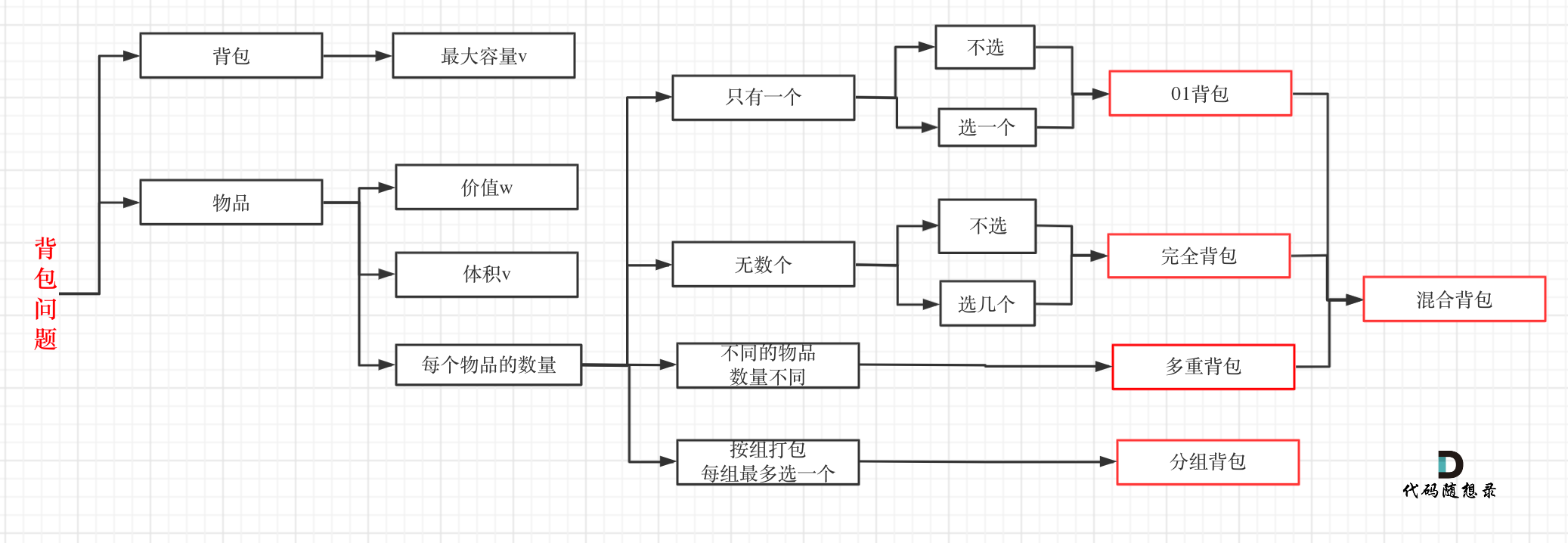
|
||||
|
||||
|
||||
至于背包九讲其其他背包,面试几乎不会问,都是竞赛级别的了,leetcode上连多重背包的题目都没有,所以题库也告诉我们,01背包和完全背包就够用了。
|
||||
至于背包九讲其他背包,面试几乎不会问,都是竞赛级别的了,leetcode上连多重背包的题目都没有,所以题库也告诉我们,01背包和完全背包就够用了。
|
||||
|
||||
而完全背包又是也是01背包稍作变化而来,即:完全背包的物品数量是无限的。
|
||||
|
||||
|
||||
Reference in New Issue
Block a user