diff --git a/README.md b/README.md
index 58f71049..b9ee3a9e 100644
--- a/README.md
+++ b/README.md
@@ -17,6 +17,11 @@

 +
+
+
+  +
+
# LeetCode 刷题攻略
@@ -120,6 +125,10 @@
4. [马上秋招了,慌得很!](https://mp.weixin.qq.com/s/7q7W8Cb2-a5U5atZdOnOFA)
5. [Carl看了上百份简历,总结了这些!](https://mp.weixin.qq.com/s/sJa87MZD28piCOVMFkIbwQ)
6. [面试中遇到了发散性问题.....](https://mp.weixin.qq.com/s/SSonDxi2pjkSVwHNzZswng)
+7. [英语到底重不重要!](https://mp.weixin.qq.com/s/1PRZiyF_-TVA-ipwDNjdKw)
+8. [计算机专业要不要读研!](https://mp.weixin.qq.com/s/c9v1L3IjqiXtkNH7sOMAdg)
+9. [秋招和提前批都越来越提前了....](https://mp.weixin.qq.com/s/SNFiRDx8CKyjhTPlys6ywQ)
+
## 数组
@@ -379,9 +388,12 @@
54. [动态规划:最长回文子序列](./problems/0516.最长回文子序列.md)
55. [动态规划总结篇](./problems/动态规划总结篇.md)
-
(持续更新中....)
+## 单调栈
+
+1. [每日温度](./problems/0739.每日温度.md)
+
## 图论
## 十大排序
diff --git a/problems/0001.两数之和.md b/problems/0001.两数之和.md
index 02e9996f..31a808b0 100644
--- a/problems/0001.两数之和.md
+++ b/problems/0001.两数之和.md
@@ -107,7 +107,7 @@ public int[] twoSum(int[] nums, int target) {
Python:
-```python3
+```python
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hashmap={}
diff --git a/problems/0037.解数独.md b/problems/0037.解数独.md
index 4eb60704..e43708b8 100644
--- a/problems/0037.解数独.md
+++ b/problems/0037.解数独.md
@@ -321,6 +321,59 @@ class Solution:
backtrack(board)
```
+Python3:
+
+```python3
+class Solution:
+ def __init__(self) -> None:
+ self.board = []
+
+ def isValid(self, row: int, col: int, target: int) -> bool:
+ for idx in range(len(self.board)):
+ # 同列是否重复
+ if self.board[idx][col] == str(target):
+ return False
+ # 同行是否重复
+ if self.board[row][idx] == str(target):
+ return False
+ # 9宫格里是否重复
+ box_row, box_col = (row // 3) * 3 + idx // 3, (col // 3) * 3 + idx % 3
+ if self.board[box_row][box_col] == str(target):
+ return False
+ return True
+
+ def getPlace(self) -> List[int]:
+ for row in range(len(self.board)):
+ for col in range(len(self.board)):
+ if self.board[row][col] == ".":
+ return [row, col]
+ return [-1, -1]
+
+ def isSolved(self) -> bool:
+ row, col = self.getPlace() # 找个空位置
+
+ if row == -1 and col == -1: # 没有空位置,棋盘被填满的
+ return True
+
+ for i in range(1, 10):
+ if self.isValid(row, col, i): # 检查这个空位置放i,是否合适
+ self.board[row][col] = str(i) # 放i
+ if self.isSolved(): # 合适,立刻返回, 填下一个空位置。
+ return True
+ self.board[row][col] = "." # 不合适,回溯
+
+ return False # 空位置没法解决
+
+ def solveSudoku(self, board: List[List[str]]) -> None:
+ """
+ Do not return anything, modify board in-place instead.
+ """
+ if board is None or len(board) == 0:
+ return
+ self.board = board
+ self.isSolved()
+```
+
Go:
Javascript:
diff --git a/problems/0051.N皇后.md b/problems/0051.N皇后.md
index 5242fce2..fd2c7d0f 100644
--- a/problems/0051.N皇后.md
+++ b/problems/0051.N皇后.md
@@ -353,14 +353,6 @@ class Solution {
}
```
-## 其他语言版本
-
-
-Java:
-
-
-Python:
-
Go:
```Go
diff --git a/problems/0053.最大子序和(动态规划).md b/problems/0053.最大子序和(动态规划).md
index 3cd687a6..dd0e513b 100644
--- a/problems/0053.最大子序和(动态规划).md
+++ b/problems/0053.最大子序和(动态规划).md
@@ -95,10 +95,47 @@ public:
Java:
+```java
+ /**
+ * 1.dp[i]代表当前下标对应的最大值
+ * 2.递推公式 dp[i] = max (dp[i-1]+nums[i],nums[i]) res = max(res,dp[i])
+ * 3.初始化 都为 0
+ * 4.遍历方向,从前往后
+ * 5.举例推导结果。。。
+ *
+ * @param nums
+ * @return
+ */
+ public static int maxSubArray(int[] nums) {
+ if (nums.length == 0) {
+ return 0;
+ }
+ int res = nums[0];
+ int[] dp = new int[nums.length];
+ dp[0] = nums[0];
+ for (int i = 1; i < nums.length; i++) {
+ dp[i] = Math.max(dp[i - 1] + nums[i], nums[i]);
+ res = res > dp[i] ? res : dp[i];
+ }
+ return res;
+ }
+```
Python:
-
+```python
+class Solution:
+ def maxSubArray(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+ dp = [0] * len(nums)
+ dp[0] = nums[0]
+ result = dp[0]
+ for i in range(1, len(nums)):
+ dp[i] = max(dp[i-1] + nums[i], nums[i]) #状态转移公式
+ result = max(result, dp[i]) #result 保存dp[i]的最大值
+ return result
+```
Go:
diff --git a/problems/0062.不同路径.md b/problems/0062.不同路径.md
index 60b65818..47cb41af 100644
--- a/problems/0062.不同路径.md
+++ b/problems/0062.不同路径.md
@@ -308,6 +308,27 @@ func uniquePaths(m int, n int) int {
}
```
+Javascript:
+```Javascript
+var uniquePaths = function(m, n) {
+ const dp = Array(m).fill().map(item => Array(n))
+
+ for (let i = 0; i < m; ++i) {
+ dp[i][0] = 1
+ }
+
+ for (let i = 0; i < n; ++i) {
+ dp[0][i] = 1
+ }
+
+ for (let i = 1; i < m; ++i) {
+ for (let j = 1; j < n; ++j) {
+ dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
+ }
+ }
+ return dp[m - 1][n - 1]
+};
+```
-----------------------
diff --git a/problems/0063.不同路径II.md b/problems/0063.不同路径II.md
index eeecad70..52f00322 100644
--- a/problems/0063.不同路径II.md
+++ b/problems/0063.不同路径II.md
@@ -279,6 +279,30 @@ func uniquePathsWithObstacles(obstacleGrid [][]int) int {
```
+Javascript
+``` Javascript
+var uniquePathsWithObstacles = function(obstacleGrid) {
+ const m = obstacleGrid.length
+ const n = obstacleGrid[0].length
+ const dp = Array(m).fill().map(item => Array(n).fill(0))
+
+ for (let i = 0; i < m && obstacleGrid[i][0] === 0; ++i) {
+ dp[i][0] = 1
+ }
+
+ for (let i = 0; i < n && obstacleGrid[0][i] === 0; ++i) {
+ dp[0][i] = 1
+ }
+
+ for (let i = 1; i < m; ++i) {
+ for (let j = 1; j < n; ++j) {
+ dp[i][j] = obstacleGrid[i][j] === 1 ? 0 : dp[i - 1][j] + dp[i][j - 1]
+ }
+ }
+
+ return dp[m - 1][n - 1]
+};
+```
-----------------------
diff --git a/problems/0070.爬楼梯完全背包版本.md b/problems/0070.爬楼梯完全背包版本.md
index 69750f8f..5c8270b6 100644
--- a/problems/0070.爬楼梯完全背包版本.md
+++ b/problems/0070.爬楼梯完全背包版本.md
@@ -148,9 +148,44 @@ class Solution {
Python:
-Go:
+```python3
+class Solution:
+ def climbStairs(self, n: int) -> int:
+ dp = [0]*(n + 1)
+ dp[0] = 1
+ m = 2
+ # 遍历背包
+ for j in range(n + 1):
+ # 遍历物品
+ for step in range(1, m + 1):
+ if j >= step:
+ dp[j] += dp[j - step]
+ return dp[n]
+```
+Go:
+```go
+func climbStairs(n int) int {
+ //定义
+ dp := make([]int, n+1)
+ //初始化
+ dp[0] = 1
+ // 本题物品只有两个1,2
+ m := 2
+ // 遍历顺序
+ for j := 1; j <= n; j++ { //先遍历背包
+ for i := 1; i <= m; i++ { //再遍历物品
+ if j >= i {
+ dp[j] += dp[j-i]
+ }
+ //fmt.Println(dp)
+ }
+ }
+ return dp[n]
+}
+```
+
-----------------------
diff --git a/problems/0072.编辑距离.md b/problems/0072.编辑距离.md
index 824c74af..26f080fe 100644
--- a/problems/0072.编辑距离.md
+++ b/problems/0072.编辑距离.md
@@ -8,7 +8,7 @@
## 72. 编辑距离
-https://leetcode-cn.com/problems/edit-distance/
+https://leetcode-cn.com/problems/edit-distance/
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
@@ -18,23 +18,23 @@ https://leetcode-cn.com/problems/edit-distance/
* 删除一个字符
* 替换一个字符
-示例 1:
-输入:word1 = "horse", word2 = "ros"
-输出:3
-解释:
-horse -> rorse (将 'h' 替换为 'r')
-rorse -> rose (删除 'r')
-rose -> ros (删除 'e')
+示例 1:
+输入:word1 = "horse", word2 = "ros"
+输出:3
+解释:
+horse -> rorse (将 'h' 替换为 'r')
+rorse -> rose (删除 'r')
+rose -> ros (删除 'e')
-示例 2:
-输入:word1 = "intention", word2 = "execution"
-输出:5
-解释:
-intention -> inention (删除 't')
-inention -> enention (将 'i' 替换为 'e')
-enention -> exention (将 'n' 替换为 'x')
-exention -> exection (将 'n' 替换为 'c')
-exection -> execution (插入 'u')
+示例 2:
+输入:word1 = "intention", word2 = "execution"
+输出:5
+解释:
+intention -> inention (删除 't')
+inention -> enention (将 'i' 替换为 'e')
+enention -> exention (将 'n' 替换为 'x')
+exention -> exection (将 'n' 替换为 'c')
+exection -> execution (插入 'u')
提示:
@@ -51,7 +51,9 @@ exection -> execution (插入 'u')
接下来我依然使用动规五部曲,对本题做一个详细的分析:
-1. 确定dp数组(dp table)以及下标的含义
+-----------------------
+
+### 1. 确定dp数组(dp table)以及下标的含义
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
@@ -59,49 +61,65 @@ exection -> execution (插入 'u')
用i来表示也可以! 但我统一以下标i-1为结尾的字符串,在下面的递归公式中会容易理解一点。
-2. 确定递推公式
+-----------------------
+
+### 2. 确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
-* if (word1[i - 1] == word2[j - 1])
- * 不操作
-* if (word1[i - 1] != word2[j - 1])
- * 增
- * 删
- * 换
+```
+if (word1[i - 1] == word2[j - 1])
+ 不操作
+if (word1[i - 1] != word2[j - 1])
+ 增
+ 删
+ 换
+```
-也就是如上四种情况。
+也就是如上4种情况。
-if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
+`if (word1[i - 1] == word2[j - 1])` 那么说明不用任何编辑,`dp[i][j]` 就应该是 `dp[i - 1][j - 1]`,即`dp[i][j] = dp[i - 1][j - 1];`
-此时可能有同学有点不明白,为啥要即dp[i][j] = dp[i - 1][j - 1]呢?
+此时可能有同学有点不明白,为啥要即`dp[i][j] = dp[i - 1][j - 1]`呢?
-那么就在回顾上面讲过的dp[i][j]的定义,word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1] 就是 dp[i][j]了。
+那么就在回顾上面讲过的`dp[i][j]`的定义,`word1[i - 1]` 与 `word2[j - 1]`相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串`word2`的最近编辑距离`dp[i - 1][j - 1]`就是 `dp[i][j]`了。
-在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。
+在下面的讲解中,如果哪里看不懂,就回想一下`dp[i][j]`的定义,就明白了。
-**在整个动规的过程中,最为关键就是正确理解dp[i][j]的定义!**
+**在整个动规的过程中,最为关键就是正确理解`dp[i][j]`的定义!**
-if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢?
-操作一:word1增加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-2为结尾的word1 与 i-1为结尾的word2的最近编辑距离 加上一个增加元素的操作。
+`if (word1[i - 1] != word2[j - 1])`,此时就需要编辑了,如何编辑呢?
-即 dp[i][j] = dp[i - 1][j] + 1;
+操作一:word1增加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 加上一个增加元素的操作。
+
+即 `dp[i][j] = dp[i - 1][j] + 1;`
操作二:word2添加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个增加元素的操作。
-即 dp[i][j] = dp[i][j - 1] + 1;
+即 `dp[i][j] = dp[i][j - 1] + 1;`
这里有同学发现了,怎么都是添加元素,删除元素去哪了。
-**word2添加一个元素,相当于word1删除一个元素**,例如 word1 = "ad" ,word2 = "a",word2添加一个元素d,也就是相当于word1删除一个元素d,操作数是一样!
+**word2添加一个元素,相当于word1删除一个元素**,例如 `word1 = "ad" ,word2 = "a"`,`word1`删除元素`'d'`,`word2`添加一个元素`'d'`,变成`word1="a", word2="ad"`, 最终的操作数是一样! dp数组如下图所示意的:
-操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增加元素,那么以下标i-2为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个替换元素的操作。
+```
+ a a d
+ +-----+-----+ +-----+-----+-----+
+ | 0 | 1 | | 0 | 1 | 2 |
+ +-----+-----+ ===> +-----+-----+-----+
+ a | 1 | 0 | a | 1 | 0 | 1 |
+ +-----+-----+ +-----+-----+-----+
+ d | 2 | 1 |
+ +-----+-----+
+```
-即 dp[i][j] = dp[i - 1][j - 1] + 1;
+操作三:替换元素,`word1`替换`word1[i - 1]`,使其与`word2[j - 1]`相同,此时不用增加元素,那么以下标`i-2`为结尾的`word1` 与 `j-2`为结尾的`word2`的最近编辑距离 加上一个替换元素的操作。
-综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
+即 `dp[i][j] = dp[i - 1][j - 1] + 1;`
+
+综上,当 `if (word1[i - 1] != word2[j - 1])` 时取最小的,即:`dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;`
递归公式代码如下:
@@ -114,9 +132,12 @@ else {
}
```
-3. dp数组如何初始化
+---
-在回顾一下dp[i][j]的定义。
+### 3. dp数组如何初始化
+
+
+再回顾一下dp[i][j]的定义:
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
@@ -135,14 +156,16 @@ for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
```
-4. 确定遍历顺序
+-----------------------
+
+### 4. 确定遍历顺序
从如下四个递推公式:
-* dp[i][j] = dp[i - 1][j - 1]
-* dp[i][j] = dp[i - 1][j - 1] + 1
-* dp[i][j] = dp[i][j - 1] + 1
-* dp[i][j] = dp[i - 1][j] + 1
+* `dp[i][j] = dp[i - 1][j - 1]`
+* `dp[i][j] = dp[i - 1][j - 1] + 1`
+* `dp[i][j] = dp[i][j - 1] + 1`
+* `dp[i][j] = dp[i - 1][j] + 1`
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:
@@ -164,10 +187,12 @@ for (int i = 1; i <= word1.size(); i++) {
}
}
```
+-----------------------
-5. 举例推导dp数组
+### 5. 举例推导dp数组
-以示例1,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下:
+
+以示例1为例,输入:`word1 = "horse", word2 = "ros"`为例,dp矩阵状态图如下:
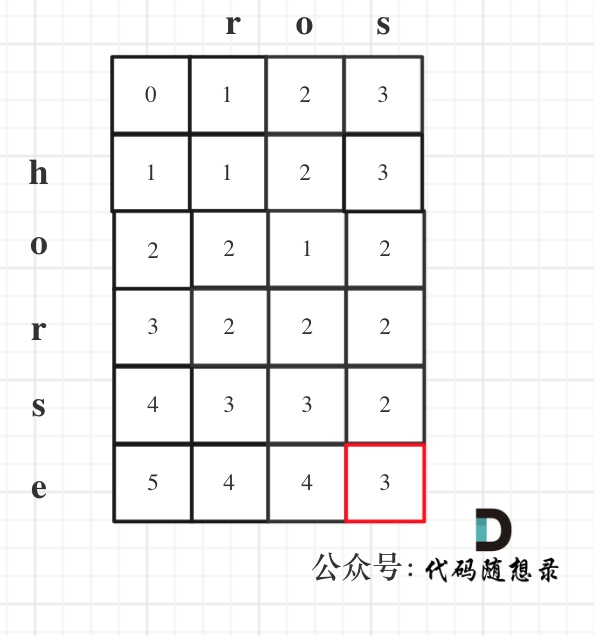
@@ -195,7 +220,7 @@ public:
};
```
-
+-----------------------
## 其他语言版本
@@ -228,7 +253,22 @@ public int minDistance(String word1, String word2) {
```
Python:
-
+```python
+class Solution:
+ def minDistance(self, word1: str, word2: str) -> int:
+ dp = [[0] * (len(word2)+1) for _ in range(len(word1)+1)]
+ for i in range(len(word1)+1):
+ dp[i][0] = i
+ for j in range(len(word2)+1):
+ dp[0][j] = j
+ for i in range(1, len(word1)+1):
+ for j in range(1, len(word2)+1):
+ if word1[i-1] == word2[j-1]:
+ dp[i][j] = dp[i-1][j-1]
+ else:
+ dp[i][j] = min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1]) + 1
+ return dp[-1][-1]
+```
Go:
```Go
diff --git a/problems/0093.复原IP地址.md b/problems/0093.复原IP地址.md
index a8b9a215..c47896d9 100644
--- a/problems/0093.复原IP地址.md
+++ b/problems/0093.复原IP地址.md
@@ -338,6 +338,46 @@ class Solution(object):
return ans```
```
+```python3
+class Solution:
+ def __init__(self) -> None:
+ self.s = ""
+ self.res = []
+
+ def isVaild(self, s: str) -> bool:
+ if len(s) > 1 and s[0] == "0":
+ return False
+
+ if 0 <= int(s) <= 255:
+ return True
+
+ return False
+
+ def backTrack(self, path: List[str], start: int) -> None:
+ if start == len(self.s) and len(path) == 4:
+ self.res.append(".".join(path))
+ return
+
+ for end in range(start + 1, len(self.s) + 1):
+ # 剪枝
+ # 保证切割完,s没有剩余的字符。
+ if len(self.s) - end > 3 * (4 - len(path) - 1):
+ continue
+ if self.isVaild(self.s[start:end]):
+ # 在参数处,更新状态,实则创建一个新的变量
+ # 不会影响当前的状态,当前的path变量没有改变
+ # 因此递归完不用path.pop()
+ self.backTrack(path + [self.s[start:end]], end)
+
+ def restoreIpAddresses(self, s: str) -> List[str]:
+ # prune
+ if len(s) > 3 * 4:
+ return []
+ self.s = s
+ self.backTrack([], 0)
+ return self.res
+```
+
JavaScript:
```js
diff --git a/problems/0102.二叉树的层序遍历.md b/problems/0102.二叉树的层序遍历.md
index c7fdf776..341f4ba5 100644
--- a/problems/0102.二叉树的层序遍历.md
+++ b/problems/0102.二叉树的层序遍历.md
@@ -98,15 +98,13 @@ class Solution:
out_list = []
while quene:
+ length = len(queue)
in_list = []
- for _ in range(len(quene)):
- node = quene.pop(0)
- in_list.append(node.val)
- if node.left:
- quene.append(node.left)
- if node.right:
- quene.append(node.right)
-
+ for _ in range(length):
+ curnode = queue.pop(0) # (默认移除列表最后一个元素)这里需要移除队列最头上的那个
+ in_list.append(curnode.val)
+ if curnode.left: queue.append(curnode.left)
+ if curnode.right: queue.append(curnode.right)
out_list.append(in_list)
return out_list
@@ -629,6 +627,27 @@ public:
}
};
```
+python代码:
+
+```python
+class Solution:
+ def largestValues(self, root: TreeNode) -> List[int]:
+ if root is None:
+ return []
+ queue = [root]
+ out_list = []
+ while queue:
+ length = len(queue)
+ in_list = []
+ for _ in range(length):
+ curnode = queue.pop(0)
+ in_list.append(curnode.val)
+ if curnode.left: queue.append(curnode.left)
+ if curnode.right: queue.append(curnode.right)
+ out_list.append(max(in_list))
+ return out_list
+```
+
javascript代码:
```javascript
@@ -714,6 +733,42 @@ public:
};
```
+python代码:
+
+```python
+# 层序遍历解法
+class Solution:
+ def connect(self, root: 'Node') -> 'Node':
+ if not root:
+ return None
+ queue = [root]
+ while queue:
+ n = len(queue)
+ for i in range(n):
+ node = queue.pop(0)
+ if node.left:
+ queue.append(node.left)
+ if node.right:
+ queue.append(node.right)
+ if i == n - 1:
+ break
+ node.next = queue[0]
+ return root
+
+# 链表解法
+class Solution:
+ def connect(self, root: 'Node') -> 'Node':
+ first = root
+ while first:
+ cur = first
+ while cur: # 遍历每一层的节点
+ if cur.left: cur.left.next = cur.right # 找左节点的next
+ if cur.right and cur.next: cur.right.next = cur.next.left # 找右节点的next
+ cur = cur.next # cur同层移动到下一节点
+ first = first.left # 从本层扩展到下一层
+ return root
+```
+
## 117.填充每个节点的下一个右侧节点指针II
题目地址:https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node-ii/
@@ -755,7 +810,48 @@ public:
}
};
```
+python代码:
+```python
+# 层序遍历解法
+class Solution:
+ def connect(self, root: 'Node') -> 'Node':
+ if not root:
+ return None
+ queue = [root]
+ while queue: # 遍历每一层
+ length = len(queue)
+ tail = None # 每一层维护一个尾节点
+ for i in range(length): # 遍历当前层
+ curnode = queue.pop(0)
+ if tail:
+ tail.next = curnode # 让尾节点指向当前节点
+ tail = curnode # 让当前节点成为尾节点
+ if curnode.left : queue.append(curnode.left)
+ if curnode.right: queue.append(curnode.right)
+ return root
+
+# 链表解法
+class Solution:
+ def connect(self, root: 'Node') -> 'Node':
+ if not root:
+ return None
+ first = root
+ while first: # 遍历每一层
+ dummyHead = Node(None) # 为下一行创建一个虚拟头节点,相当于下一行所有节点链表的头结点(每一层都会创建);
+ tail = dummyHead # 为下一行维护一个尾节点指针(初始化是虚拟节点)
+ cur = first
+ while cur: # 遍历当前层的节点
+ if cur.left: # 链接下一行的节点
+ tail.next = cur.left
+ tail = tail.next
+ if cur.right:
+ tail.next = cur.right
+ tail = tail.next
+ cur = cur.next # cur同层移动到下一节点
+ first = dummyHead.next # 此处为换行操作,更新到下一行
+ return root
+```
## 总结
diff --git a/problems/0104.二叉树的最大深度.md b/problems/0104.二叉树的最大深度.md
index 812c58ca..463b55d9 100644
--- a/problems/0104.二叉树的最大深度.md
+++ b/problems/0104.二叉树的最大深度.md
@@ -193,40 +193,6 @@ public:
};
```
-使用栈来模拟后序遍历依然可以
-
-```C++
-class Solution {
-public:
- int maxDepth(TreeNode* root) {
- stack st;
- if (root != NULL) st.push(root);
- int depth = 0;
- int result = 0;
- while (!st.empty()) {
- TreeNode* node = st.top();
- if (node != NULL) {
- st.pop();
- st.push(node); // 中
- st.push(NULL);
- depth++;
- if (node->right) st.push(node->right); // 右
- if (node->left) st.push(node->left); // 左
-
- } else {
- st.pop();
- node = st.top();
- st.pop();
- depth--;
- }
- result = result > depth ? result : depth;
- }
- return result;
-
- }
-};
-```
-
## 其他语言版本
diff --git a/problems/0106.从中序与后序遍历序列构造二叉树.md b/problems/0106.从中序与后序遍历序列构造二叉树.md
index ba2d46a1..4c5a70a0 100644
--- a/problems/0106.从中序与后序遍历序列构造二叉树.md
+++ b/problems/0106.从中序与后序遍历序列构造二叉树.md
@@ -693,6 +693,70 @@ class Solution:
return root
```
Go:
+> 106 从中序与后序遍历序列构造二叉树
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func buildTree(inorder []int, postorder []int) *TreeNode {
+ if len(inorder)<1||len(postorder)<1{return nil}
+ //先找到根节点(后续遍历的最后一个就是根节点)
+ nodeValue:=postorder[len(postorder)-1]
+ //从中序遍历中找到一分为二的点,左边为左子树,右边为右子树
+ left:=findRootIndex(inorder,nodeValue)
+ //构造root
+ root:=&TreeNode{Val: nodeValue,
+ Left: buildTree(inorder[:left],postorder[:left]),//将后续遍历一分为二,左边为左子树,右边为右子树
+ Right: buildTree(inorder[left+1:],postorder[left:len(postorder)-1])}
+ return root
+}
+func findRootIndex(inorder []int,target int) (index int){
+ for i:=0;i 105 从前序与中序遍历序列构造二叉树
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func buildTree(preorder []int, inorder []int) *TreeNode {
+ if len(preorder)<1||len(inorder)<1{return nil}
+ left:=findRootIndex(preorder[0],inorder)
+ root:=&TreeNode{
+ Val: preorder[0],
+ Left: buildTree(preorder[1:left+1],inorder[:left]),
+ Right: buildTree(preorder[left+1:],inorder[left+1:])}
+ return root
+}
+func findRootIndex(target int,inorder []int) int{
+ for i:=0;i number === root.val);
+ root.left = buildTree(preorder.slice(1, mid + 1), inorder.slice(0, mid));
+ root.right = buildTree(preorder.slice(mid + 1, preorder.length), inorder.slice(mid + 1, inorder.length));
+ return root;
+};
+```
+
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
diff --git a/problems/0112.路径总和.md b/problems/0112.路径总和.md
index d810a046..54f79d1d 100644
--- a/problems/0112.路径总和.md
+++ b/problems/0112.路径总和.md
@@ -486,6 +486,92 @@ class Solution:
Go:
+> 112. 路径总和
+
+```go
+//递归法
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func hasPathSum(root *TreeNode, targetSum int) bool {
+ var flage bool //找没找到的标志
+ if root==nil{
+ return flage
+ }
+ pathSum(root,0,targetSum,&flage)
+ return flage
+}
+func pathSum(root *TreeNode, sum int,targetSum int,flage *bool){
+ sum+=root.Val
+ if root.Left==nil&&root.Right==nil&&sum==targetSum{
+ *flage=true
+ return
+ }
+ if root.Left!=nil&&!(*flage){//左节点不为空且还没找到
+ pathSum(root.Left,sum,targetSum,flage)
+ }
+ if root.Right!=nil&&!(*flage){//右节点不为空且没找到
+ pathSum(root.Right,sum,targetSum,flage)
+ }
+}
+```
+
+
+
+> 113 递归法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func pathSum(root *TreeNode, targetSum int) [][]int {
+ var result [][]int//最终结果
+ if root==nil{
+ return result
+ }
+ var sumNodes []int//经过路径的节点集合
+ hasPathSum(root,&sumNodes,targetSum,&result)
+ return result
+}
+func hasPathSum(root *TreeNode,sumNodes *[]int,targetSum int,result *[][]int){
+ *sumNodes=append(*sumNodes,root.Val)
+ if root.Left==nil&&root.Right==nil{//叶子节点
+ fmt.Println(*sumNodes)
+ var sum int
+ var number int
+ for k,v:=range *sumNodes{//求该路径节点的和
+ sum+=v
+ number=k
+ }
+ tempNodes:=make([]int,number+1)//新的nodes接受指针里的值,防止最终指针里的值发生变动,导致最后的结果都是最后一个sumNodes的值
+ for k,v:=range *sumNodes{
+ tempNodes[k]=v
+ }
+ if sum==targetSum{
+ *result=append(*result,tempNodes)
+ }
+ }
+ if root.Left!=nil{
+ hasPathSum(root.Left,sumNodes,targetSum,result)
+ *sumNodes=(*sumNodes)[:len(*sumNodes)-1]//回溯
+ }
+ if root.Right!=nil{
+ hasPathSum(root.Right,sumNodes,targetSum,result)
+ *sumNodes=(*sumNodes)[:len(*sumNodes)-1]//回溯
+ }
+}
+```
+
JavaScript:
0112.路径总和
diff --git a/problems/0115.不同的子序列.md b/problems/0115.不同的子序列.md
index 1661acf8..d3bc6d97 100644
--- a/problems/0115.不同的子序列.md
+++ b/problems/0115.不同的子序列.md
@@ -145,10 +145,46 @@ public:
Java:
-
+```java
+class Solution {
+ public int numDistinct(String s, String t) {
+ int[][] dp = new int[s.length() + 1][t.length() + 1];
+ for (int i = 0; i < s.length() + 1; i++) {
+ dp[i][0] = 1;
+ }
+
+ for (int i = 1; i < s.length() + 1; i++) {
+ for (int j = 1; j < t.length() + 1; j++) {
+ if (s.charAt(i - 1) == t.charAt(j - 1)) {
+ dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
+ }else{
+ dp[i][j] = dp[i - 1][j];
+ }
+ }
+ }
+
+ return dp[s.length()][t.length()];
+ }
+}
+```
Python:
-
+```python
+class Solution:
+ def numDistinct(self, s: str, t: str) -> int:
+ dp = [[0] * (len(t)+1) for _ in range(len(s)+1)]
+ for i in range(len(s)):
+ dp[i][0] = 1
+ for j in range(1, len(t)):
+ dp[0][j] = 0
+ for i in range(1, len(s)+1):
+ for j in range(1, len(t)+1):
+ if s[i-1] == t[j-1]:
+ dp[i][j] = dp[i-1][j-1] + dp[i-1][j]
+ else:
+ dp[i][j] = dp[i-1][j]
+ return dp[-1][-1]
+```
Go:
diff --git a/problems/0121.买卖股票的最佳时机.md b/problems/0121.买卖股票的最佳时机.md
index d018efb7..259fff34 100644
--- a/problems/0121.买卖股票的最佳时机.md
+++ b/problems/0121.买卖股票的最佳时机.md
@@ -244,6 +244,47 @@ class Solution { // 动态规划解法
Python:
+> 贪心法:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ low = float("inf")
+ result = 0
+ for i in range(len(prices)):
+ low = min(low, prices[i]) #取最左最小价格
+ result = max(result, prices[i] - low) #直接取最大区间利润
+ return result
+```
+
+> 动态规划:版本一
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ length = len(prices)
+ if len == 0:
+ return 0
+ dp = [[0] * 2 for _ in range(length)]
+ dp[0][0] = -prices[0]
+ dp[0][1] = 0
+ for i in range(1, length):
+ dp[i][0] = max(dp[i-1][0], -prices[i])
+ dp[i][1] = max(dp[i-1][1], prices[i] + dp[i-1][0])
+ return dp[-1][1]
+```
+
+> 动态规划:版本二
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ length = len(prices)
+ dp = [[0] * 2 for _ in range(2)] #注意这里只开辟了一个2 * 2大小的二维数组
+ dp[0][0] = -prices[0]
+ dp[0][1] = 0
+ for i in range(1, length):
+ dp[i % 2][0] = max(dp[(i-1) % 2][0], -prices[i])
+ dp[i % 2][1] = max(dp[(i-1) % 2][1], prices[i] + dp[(i-1) % 2][0])
+ return dp[(length-1) % 2][1]
+```
Go:
```Go
diff --git a/problems/0122.买卖股票的最佳时机II(动态规划).md b/problems/0122.买卖股票的最佳时机II(动态规划).md
index ba277fdc..1215025e 100644
--- a/problems/0122.买卖股票的最佳时机II(动态规划).md
+++ b/problems/0122.买卖股票的最佳时机II(动态规划).md
@@ -171,6 +171,33 @@ class Solution
Python:
+> 版本一:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ length = len(prices)
+ dp = [[0] * 2 for _ in range(length)]
+ dp[0][0] = -prices[0]
+ dp[0][1] = 0
+ for i in range(1, length):
+ dp[i][0] = max(dp[i-1][0], dp[i-1][1] - prices[i]) #注意这里是和121. 买卖股票的最佳时机唯一不同的地方
+ dp[i][1] = max(dp[i-1][1], dp[i-1][0] + prices[i])
+ return dp[-1][1]
+```
+
+> 版本二:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ length = len(prices)
+ dp = [[0] * 2 for _ in range(2)] #注意这里只开辟了一个2 * 2大小的二维数组
+ dp[0][0] = -prices[0]
+ dp[0][1] = 0
+ for i in range(1, length):
+ dp[i % 2][0] = max(dp[(i-1) % 2][0], dp[(i-1) % 2][1] - prices[i])
+ dp[i % 2][1] = max(dp[(i-1) % 2][1], dp[(i-1) % 2][0] + prices[i])
+ return dp[(length-1) % 2][1]
+```
Go:
diff --git a/problems/0123.买卖股票的最佳时机III.md b/problems/0123.买卖股票的最佳时机III.md
index 24370d38..fccb187d 100644
--- a/problems/0123.买卖股票的最佳时机III.md
+++ b/problems/0123.买卖股票的最佳时机III.md
@@ -229,6 +229,40 @@ class Solution { // 动态规划
Python:
+> 版本一:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ if len(prices) == 0:
+ return 0
+ dp = [[0] * 5 for _ in range(len(prices))]
+ dp[0][1] = -prices[0]
+ dp[0][3] = -prices[0]
+ for i in range(1, len(prices)):
+ dp[i][0] = dp[i-1][0]
+ dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i])
+ dp[i][2] = max(dp[i-1][2], dp[i-1][1] + prices[i])
+ dp[i][3] = max(dp[i-1][3], dp[i-1][2] - prices[i])
+ dp[i][4] = max(dp[i-1][4], dp[i-1][3] + prices[i])
+ return dp[-1][4]
+```
+
+> 版本二:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ if len(prices) == 0:
+ return 0
+ dp = [0] * 5
+ dp[1] = -prices[0]
+ dp[3] = -prices[0]
+ for i in range(1, len(prices)):
+ dp[1] = max(dp[1], dp[0] - prices[i])
+ dp[2] = max(dp[2], dp[1] + prices[i])
+ dp[3] = max(dp[3], dp[2] - prices[i])
+ dp[4] = max(dp[4], dp[3] + prices[i])
+ return dp[4]
+```
Go:
diff --git a/problems/0134.加油站.md b/problems/0134.加油站.md
index dfed2d96..9b660ea0 100644
--- a/problems/0134.加油站.md
+++ b/problems/0134.加油站.md
@@ -240,6 +240,25 @@ class Solution:
```
Go:
+```go
+func canCompleteCircuit(gas []int, cost []int) int {
+ curSum := 0
+ totalSum := 0
+ start := 0
+ for i := 0; i < len(gas); i++ {
+ curSum += gas[i] - cost[i]
+ totalSum += gas[i] - cost[i]
+ if curSum < 0 {
+ start = i+1
+ curSum = 0
+ }
+ }
+ if totalSum < 0 {
+ return -1
+ }
+ return start
+}
+```
Javascript:
```Javascript
diff --git a/problems/0139.单词拆分.md b/problems/0139.单词拆分.md
index aa729e02..b6a6242e 100644
--- a/problems/0139.单词拆分.md
+++ b/problems/0139.单词拆分.md
@@ -252,6 +252,23 @@ class Solution {
Python:
+```python3
+class Solution:
+ def wordBreak(self, s: str, wordDict: List[str]) -> bool:
+ '''排列'''
+ dp = [False]*(len(s) + 1)
+ dp[0] = True
+ # 遍历背包
+ for j in range(1, len(s) + 1):
+ # 遍历单词
+ for word in wordDict:
+ if j >= len(word):
+ dp[j] = dp[j] or (dp[j - len(word)] and word == s[j - len(word):j])
+ return dp[len(s)]
+```
+
+
+
Go:
```Go
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index 63499b71..ffa3446a 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -16,19 +16,19 @@ https://leetcode-cn.com/problems/reverse-words-in-a-string/
给定一个字符串,逐个翻转字符串中的每个单词。
-示例 1:
-输入: "the sky is blue"
-输出: "blue is sky the"
+示例 1:
+输入: "the sky is blue"
+输出: "blue is sky the"
-示例 2:
-输入: " hello world! "
-输出: "world! hello"
-解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
+示例 2:
+输入: " hello world! "
+输出: "world! hello"
+解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
-示例 3:
-输入: "a good example"
-输出: "example good a"
-解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
+示例 3:
+输入: "a good example"
+输出: "example good a"
+解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
# 思路
@@ -50,12 +50,15 @@ https://leetcode-cn.com/problems/reverse-words-in-a-string/
* 将整个字符串反转
* 将每个单词反转
-如动画所示:
+举个例子,源字符串为:"the sky is blue "
-
+* 移除多余空格 : "the sky is blue"
+* 字符串反转:"eulb si yks eht"
+* 单词反转:"blue is sky the"
这样我们就完成了翻转字符串里的单词。
+
思路很明确了,我们说一说代码的实现细节,就拿移除多余空格来说,一些同学会上来写如下代码:
```C++
@@ -80,13 +83,13 @@ void removeExtraSpaces(string& s) {
如果不仔细琢磨一下erase的时间复杂读,还以为以上的代码是O(n)的时间复杂度呢。
-想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作,erase实现原理题目:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA),最优的算法来移除元素也要O(n)。
+想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作,erase实现原理题目:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww),最优的算法来移除元素也要O(n)。
erase操作上面还套了一个for循环,那么以上代码移除冗余空格的代码时间复杂度为O(n^2)。
那么使用双指针法来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到O(n)的时间复杂度。
-如果对这个操作比较生疏了,可以再看一下这篇文章:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)是如何移除元素的。
+如果对这个操作比较生疏了,可以再看一下这篇文章:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)是如何移除元素的。
那么使用双指针来移除冗余空格代码如下: fastIndex走的快,slowIndex走的慢,最后slowIndex就标记着移除多余空格后新字符串的长度。
@@ -122,7 +125,7 @@ void removeExtraSpaces(string& s) {
此时我们已经实现了removeExtraSpaces函数来移除冗余空格。
-还做实现反转字符串的功能,支持反转字符串子区间,这个实现我们分别在[字符串:这道题目,使用库函数一行代码搞定](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)和[字符串:简单的反转还不够!](https://mp.weixin.qq.com/s/XGSk1GyPWhfqj2g7Cb1Vgw)里已经讲过了。
+还做实现反转字符串的功能,支持反转字符串子区间,这个实现我们分别在[344.反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w)和[541.反转字符串II](https://mp.weixin.qq.com/s/pzXt6PQ029y7bJ9YZB2mVQ)里已经讲过了。
代码如下:
@@ -135,11 +138,8 @@ void reverse(string& s, int start, int end) {
}
```
-## 本题C++整体代码
+本题C++整体代码
-效率:
-
-
+
+
# LeetCode 刷题攻略
@@ -120,6 +125,10 @@
4. [马上秋招了,慌得很!](https://mp.weixin.qq.com/s/7q7W8Cb2-a5U5atZdOnOFA)
5. [Carl看了上百份简历,总结了这些!](https://mp.weixin.qq.com/s/sJa87MZD28piCOVMFkIbwQ)
6. [面试中遇到了发散性问题.....](https://mp.weixin.qq.com/s/SSonDxi2pjkSVwHNzZswng)
+7. [英语到底重不重要!](https://mp.weixin.qq.com/s/1PRZiyF_-TVA-ipwDNjdKw)
+8. [计算机专业要不要读研!](https://mp.weixin.qq.com/s/c9v1L3IjqiXtkNH7sOMAdg)
+9. [秋招和提前批都越来越提前了....](https://mp.weixin.qq.com/s/SNFiRDx8CKyjhTPlys6ywQ)
+
## 数组
@@ -379,9 +388,12 @@
54. [动态规划:最长回文子序列](./problems/0516.最长回文子序列.md)
55. [动态规划总结篇](./problems/动态规划总结篇.md)
-
(持续更新中....)
+## 单调栈
+
+1. [每日温度](./problems/0739.每日温度.md)
+
## 图论
## 十大排序
diff --git a/problems/0001.两数之和.md b/problems/0001.两数之和.md
index 02e9996f..31a808b0 100644
--- a/problems/0001.两数之和.md
+++ b/problems/0001.两数之和.md
@@ -107,7 +107,7 @@ public int[] twoSum(int[] nums, int target) {
Python:
-```python3
+```python
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hashmap={}
diff --git a/problems/0037.解数独.md b/problems/0037.解数独.md
index 4eb60704..e43708b8 100644
--- a/problems/0037.解数独.md
+++ b/problems/0037.解数独.md
@@ -321,6 +321,59 @@ class Solution:
backtrack(board)
```
+Python3:
+
+```python3
+class Solution:
+ def __init__(self) -> None:
+ self.board = []
+
+ def isValid(self, row: int, col: int, target: int) -> bool:
+ for idx in range(len(self.board)):
+ # 同列是否重复
+ if self.board[idx][col] == str(target):
+ return False
+ # 同行是否重复
+ if self.board[row][idx] == str(target):
+ return False
+ # 9宫格里是否重复
+ box_row, box_col = (row // 3) * 3 + idx // 3, (col // 3) * 3 + idx % 3
+ if self.board[box_row][box_col] == str(target):
+ return False
+ return True
+
+ def getPlace(self) -> List[int]:
+ for row in range(len(self.board)):
+ for col in range(len(self.board)):
+ if self.board[row][col] == ".":
+ return [row, col]
+ return [-1, -1]
+
+ def isSolved(self) -> bool:
+ row, col = self.getPlace() # 找个空位置
+
+ if row == -1 and col == -1: # 没有空位置,棋盘被填满的
+ return True
+
+ for i in range(1, 10):
+ if self.isValid(row, col, i): # 检查这个空位置放i,是否合适
+ self.board[row][col] = str(i) # 放i
+ if self.isSolved(): # 合适,立刻返回, 填下一个空位置。
+ return True
+ self.board[row][col] = "." # 不合适,回溯
+
+ return False # 空位置没法解决
+
+ def solveSudoku(self, board: List[List[str]]) -> None:
+ """
+ Do not return anything, modify board in-place instead.
+ """
+ if board is None or len(board) == 0:
+ return
+ self.board = board
+ self.isSolved()
+```
+
Go:
Javascript:
diff --git a/problems/0051.N皇后.md b/problems/0051.N皇后.md
index 5242fce2..fd2c7d0f 100644
--- a/problems/0051.N皇后.md
+++ b/problems/0051.N皇后.md
@@ -353,14 +353,6 @@ class Solution {
}
```
-## 其他语言版本
-
-
-Java:
-
-
-Python:
-
Go:
```Go
diff --git a/problems/0053.最大子序和(动态规划).md b/problems/0053.最大子序和(动态规划).md
index 3cd687a6..dd0e513b 100644
--- a/problems/0053.最大子序和(动态规划).md
+++ b/problems/0053.最大子序和(动态规划).md
@@ -95,10 +95,47 @@ public:
Java:
+```java
+ /**
+ * 1.dp[i]代表当前下标对应的最大值
+ * 2.递推公式 dp[i] = max (dp[i-1]+nums[i],nums[i]) res = max(res,dp[i])
+ * 3.初始化 都为 0
+ * 4.遍历方向,从前往后
+ * 5.举例推导结果。。。
+ *
+ * @param nums
+ * @return
+ */
+ public static int maxSubArray(int[] nums) {
+ if (nums.length == 0) {
+ return 0;
+ }
+ int res = nums[0];
+ int[] dp = new int[nums.length];
+ dp[0] = nums[0];
+ for (int i = 1; i < nums.length; i++) {
+ dp[i] = Math.max(dp[i - 1] + nums[i], nums[i]);
+ res = res > dp[i] ? res : dp[i];
+ }
+ return res;
+ }
+```
Python:
-
+```python
+class Solution:
+ def maxSubArray(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+ dp = [0] * len(nums)
+ dp[0] = nums[0]
+ result = dp[0]
+ for i in range(1, len(nums)):
+ dp[i] = max(dp[i-1] + nums[i], nums[i]) #状态转移公式
+ result = max(result, dp[i]) #result 保存dp[i]的最大值
+ return result
+```
Go:
diff --git a/problems/0062.不同路径.md b/problems/0062.不同路径.md
index 60b65818..47cb41af 100644
--- a/problems/0062.不同路径.md
+++ b/problems/0062.不同路径.md
@@ -308,6 +308,27 @@ func uniquePaths(m int, n int) int {
}
```
+Javascript:
+```Javascript
+var uniquePaths = function(m, n) {
+ const dp = Array(m).fill().map(item => Array(n))
+
+ for (let i = 0; i < m; ++i) {
+ dp[i][0] = 1
+ }
+
+ for (let i = 0; i < n; ++i) {
+ dp[0][i] = 1
+ }
+
+ for (let i = 1; i < m; ++i) {
+ for (let j = 1; j < n; ++j) {
+ dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
+ }
+ }
+ return dp[m - 1][n - 1]
+};
+```
-----------------------
diff --git a/problems/0063.不同路径II.md b/problems/0063.不同路径II.md
index eeecad70..52f00322 100644
--- a/problems/0063.不同路径II.md
+++ b/problems/0063.不同路径II.md
@@ -279,6 +279,30 @@ func uniquePathsWithObstacles(obstacleGrid [][]int) int {
```
+Javascript
+``` Javascript
+var uniquePathsWithObstacles = function(obstacleGrid) {
+ const m = obstacleGrid.length
+ const n = obstacleGrid[0].length
+ const dp = Array(m).fill().map(item => Array(n).fill(0))
+
+ for (let i = 0; i < m && obstacleGrid[i][0] === 0; ++i) {
+ dp[i][0] = 1
+ }
+
+ for (let i = 0; i < n && obstacleGrid[0][i] === 0; ++i) {
+ dp[0][i] = 1
+ }
+
+ for (let i = 1; i < m; ++i) {
+ for (let j = 1; j < n; ++j) {
+ dp[i][j] = obstacleGrid[i][j] === 1 ? 0 : dp[i - 1][j] + dp[i][j - 1]
+ }
+ }
+
+ return dp[m - 1][n - 1]
+};
+```
-----------------------
diff --git a/problems/0070.爬楼梯完全背包版本.md b/problems/0070.爬楼梯完全背包版本.md
index 69750f8f..5c8270b6 100644
--- a/problems/0070.爬楼梯完全背包版本.md
+++ b/problems/0070.爬楼梯完全背包版本.md
@@ -148,9 +148,44 @@ class Solution {
Python:
-Go:
+```python3
+class Solution:
+ def climbStairs(self, n: int) -> int:
+ dp = [0]*(n + 1)
+ dp[0] = 1
+ m = 2
+ # 遍历背包
+ for j in range(n + 1):
+ # 遍历物品
+ for step in range(1, m + 1):
+ if j >= step:
+ dp[j] += dp[j - step]
+ return dp[n]
+```
+Go:
+```go
+func climbStairs(n int) int {
+ //定义
+ dp := make([]int, n+1)
+ //初始化
+ dp[0] = 1
+ // 本题物品只有两个1,2
+ m := 2
+ // 遍历顺序
+ for j := 1; j <= n; j++ { //先遍历背包
+ for i := 1; i <= m; i++ { //再遍历物品
+ if j >= i {
+ dp[j] += dp[j-i]
+ }
+ //fmt.Println(dp)
+ }
+ }
+ return dp[n]
+}
+```
+
-----------------------
diff --git a/problems/0072.编辑距离.md b/problems/0072.编辑距离.md
index 824c74af..26f080fe 100644
--- a/problems/0072.编辑距离.md
+++ b/problems/0072.编辑距离.md
@@ -8,7 +8,7 @@
## 72. 编辑距离
-https://leetcode-cn.com/problems/edit-distance/
+https://leetcode-cn.com/problems/edit-distance/
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
@@ -18,23 +18,23 @@ https://leetcode-cn.com/problems/edit-distance/
* 删除一个字符
* 替换一个字符
-示例 1:
-输入:word1 = "horse", word2 = "ros"
-输出:3
-解释:
-horse -> rorse (将 'h' 替换为 'r')
-rorse -> rose (删除 'r')
-rose -> ros (删除 'e')
+示例 1:
+输入:word1 = "horse", word2 = "ros"
+输出:3
+解释:
+horse -> rorse (将 'h' 替换为 'r')
+rorse -> rose (删除 'r')
+rose -> ros (删除 'e')
-示例 2:
-输入:word1 = "intention", word2 = "execution"
-输出:5
-解释:
-intention -> inention (删除 't')
-inention -> enention (将 'i' 替换为 'e')
-enention -> exention (将 'n' 替换为 'x')
-exention -> exection (将 'n' 替换为 'c')
-exection -> execution (插入 'u')
+示例 2:
+输入:word1 = "intention", word2 = "execution"
+输出:5
+解释:
+intention -> inention (删除 't')
+inention -> enention (将 'i' 替换为 'e')
+enention -> exention (将 'n' 替换为 'x')
+exention -> exection (将 'n' 替换为 'c')
+exection -> execution (插入 'u')
提示:
@@ -51,7 +51,9 @@ exection -> execution (插入 'u')
接下来我依然使用动规五部曲,对本题做一个详细的分析:
-1. 确定dp数组(dp table)以及下标的含义
+-----------------------
+
+### 1. 确定dp数组(dp table)以及下标的含义
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
@@ -59,49 +61,65 @@ exection -> execution (插入 'u')
用i来表示也可以! 但我统一以下标i-1为结尾的字符串,在下面的递归公式中会容易理解一点。
-2. 确定递推公式
+-----------------------
+
+### 2. 确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
-* if (word1[i - 1] == word2[j - 1])
- * 不操作
-* if (word1[i - 1] != word2[j - 1])
- * 增
- * 删
- * 换
+```
+if (word1[i - 1] == word2[j - 1])
+ 不操作
+if (word1[i - 1] != word2[j - 1])
+ 增
+ 删
+ 换
+```
-也就是如上四种情况。
+也就是如上4种情况。
-if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
+`if (word1[i - 1] == word2[j - 1])` 那么说明不用任何编辑,`dp[i][j]` 就应该是 `dp[i - 1][j - 1]`,即`dp[i][j] = dp[i - 1][j - 1];`
-此时可能有同学有点不明白,为啥要即dp[i][j] = dp[i - 1][j - 1]呢?
+此时可能有同学有点不明白,为啥要即`dp[i][j] = dp[i - 1][j - 1]`呢?
-那么就在回顾上面讲过的dp[i][j]的定义,word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1] 就是 dp[i][j]了。
+那么就在回顾上面讲过的`dp[i][j]`的定义,`word1[i - 1]` 与 `word2[j - 1]`相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串`word2`的最近编辑距离`dp[i - 1][j - 1]`就是 `dp[i][j]`了。
-在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。
+在下面的讲解中,如果哪里看不懂,就回想一下`dp[i][j]`的定义,就明白了。
-**在整个动规的过程中,最为关键就是正确理解dp[i][j]的定义!**
+**在整个动规的过程中,最为关键就是正确理解`dp[i][j]`的定义!**
-if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢?
-操作一:word1增加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-2为结尾的word1 与 i-1为结尾的word2的最近编辑距离 加上一个增加元素的操作。
+`if (word1[i - 1] != word2[j - 1])`,此时就需要编辑了,如何编辑呢?
-即 dp[i][j] = dp[i - 1][j] + 1;
+操作一:word1增加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 加上一个增加元素的操作。
+
+即 `dp[i][j] = dp[i - 1][j] + 1;`
操作二:word2添加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个增加元素的操作。
-即 dp[i][j] = dp[i][j - 1] + 1;
+即 `dp[i][j] = dp[i][j - 1] + 1;`
这里有同学发现了,怎么都是添加元素,删除元素去哪了。
-**word2添加一个元素,相当于word1删除一个元素**,例如 word1 = "ad" ,word2 = "a",word2添加一个元素d,也就是相当于word1删除一个元素d,操作数是一样!
+**word2添加一个元素,相当于word1删除一个元素**,例如 `word1 = "ad" ,word2 = "a"`,`word1`删除元素`'d'`,`word2`添加一个元素`'d'`,变成`word1="a", word2="ad"`, 最终的操作数是一样! dp数组如下图所示意的:
-操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增加元素,那么以下标i-2为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个替换元素的操作。
+```
+ a a d
+ +-----+-----+ +-----+-----+-----+
+ | 0 | 1 | | 0 | 1 | 2 |
+ +-----+-----+ ===> +-----+-----+-----+
+ a | 1 | 0 | a | 1 | 0 | 1 |
+ +-----+-----+ +-----+-----+-----+
+ d | 2 | 1 |
+ +-----+-----+
+```
-即 dp[i][j] = dp[i - 1][j - 1] + 1;
+操作三:替换元素,`word1`替换`word1[i - 1]`,使其与`word2[j - 1]`相同,此时不用增加元素,那么以下标`i-2`为结尾的`word1` 与 `j-2`为结尾的`word2`的最近编辑距离 加上一个替换元素的操作。
-综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
+即 `dp[i][j] = dp[i - 1][j - 1] + 1;`
+
+综上,当 `if (word1[i - 1] != word2[j - 1])` 时取最小的,即:`dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;`
递归公式代码如下:
@@ -114,9 +132,12 @@ else {
}
```
-3. dp数组如何初始化
+---
-在回顾一下dp[i][j]的定义。
+### 3. dp数组如何初始化
+
+
+再回顾一下dp[i][j]的定义:
**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。
@@ -135,14 +156,16 @@ for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
```
-4. 确定遍历顺序
+-----------------------
+
+### 4. 确定遍历顺序
从如下四个递推公式:
-* dp[i][j] = dp[i - 1][j - 1]
-* dp[i][j] = dp[i - 1][j - 1] + 1
-* dp[i][j] = dp[i][j - 1] + 1
-* dp[i][j] = dp[i - 1][j] + 1
+* `dp[i][j] = dp[i - 1][j - 1]`
+* `dp[i][j] = dp[i - 1][j - 1] + 1`
+* `dp[i][j] = dp[i][j - 1] + 1`
+* `dp[i][j] = dp[i - 1][j] + 1`
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:
@@ -164,10 +187,12 @@ for (int i = 1; i <= word1.size(); i++) {
}
}
```
+-----------------------
-5. 举例推导dp数组
+### 5. 举例推导dp数组
-以示例1,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下:
+
+以示例1为例,输入:`word1 = "horse", word2 = "ros"`为例,dp矩阵状态图如下:

@@ -195,7 +220,7 @@ public:
};
```
-
+-----------------------
## 其他语言版本
@@ -228,7 +253,22 @@ public int minDistance(String word1, String word2) {
```
Python:
-
+```python
+class Solution:
+ def minDistance(self, word1: str, word2: str) -> int:
+ dp = [[0] * (len(word2)+1) for _ in range(len(word1)+1)]
+ for i in range(len(word1)+1):
+ dp[i][0] = i
+ for j in range(len(word2)+1):
+ dp[0][j] = j
+ for i in range(1, len(word1)+1):
+ for j in range(1, len(word2)+1):
+ if word1[i-1] == word2[j-1]:
+ dp[i][j] = dp[i-1][j-1]
+ else:
+ dp[i][j] = min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1]) + 1
+ return dp[-1][-1]
+```
Go:
```Go
diff --git a/problems/0093.复原IP地址.md b/problems/0093.复原IP地址.md
index a8b9a215..c47896d9 100644
--- a/problems/0093.复原IP地址.md
+++ b/problems/0093.复原IP地址.md
@@ -338,6 +338,46 @@ class Solution(object):
return ans```
```
+```python3
+class Solution:
+ def __init__(self) -> None:
+ self.s = ""
+ self.res = []
+
+ def isVaild(self, s: str) -> bool:
+ if len(s) > 1 and s[0] == "0":
+ return False
+
+ if 0 <= int(s) <= 255:
+ return True
+
+ return False
+
+ def backTrack(self, path: List[str], start: int) -> None:
+ if start == len(self.s) and len(path) == 4:
+ self.res.append(".".join(path))
+ return
+
+ for end in range(start + 1, len(self.s) + 1):
+ # 剪枝
+ # 保证切割完,s没有剩余的字符。
+ if len(self.s) - end > 3 * (4 - len(path) - 1):
+ continue
+ if self.isVaild(self.s[start:end]):
+ # 在参数处,更新状态,实则创建一个新的变量
+ # 不会影响当前的状态,当前的path变量没有改变
+ # 因此递归完不用path.pop()
+ self.backTrack(path + [self.s[start:end]], end)
+
+ def restoreIpAddresses(self, s: str) -> List[str]:
+ # prune
+ if len(s) > 3 * 4:
+ return []
+ self.s = s
+ self.backTrack([], 0)
+ return self.res
+```
+
JavaScript:
```js
diff --git a/problems/0102.二叉树的层序遍历.md b/problems/0102.二叉树的层序遍历.md
index c7fdf776..341f4ba5 100644
--- a/problems/0102.二叉树的层序遍历.md
+++ b/problems/0102.二叉树的层序遍历.md
@@ -98,15 +98,13 @@ class Solution:
out_list = []
while quene:
+ length = len(queue)
in_list = []
- for _ in range(len(quene)):
- node = quene.pop(0)
- in_list.append(node.val)
- if node.left:
- quene.append(node.left)
- if node.right:
- quene.append(node.right)
-
+ for _ in range(length):
+ curnode = queue.pop(0) # (默认移除列表最后一个元素)这里需要移除队列最头上的那个
+ in_list.append(curnode.val)
+ if curnode.left: queue.append(curnode.left)
+ if curnode.right: queue.append(curnode.right)
out_list.append(in_list)
return out_list
@@ -629,6 +627,27 @@ public:
}
};
```
+python代码:
+
+```python
+class Solution:
+ def largestValues(self, root: TreeNode) -> List[int]:
+ if root is None:
+ return []
+ queue = [root]
+ out_list = []
+ while queue:
+ length = len(queue)
+ in_list = []
+ for _ in range(length):
+ curnode = queue.pop(0)
+ in_list.append(curnode.val)
+ if curnode.left: queue.append(curnode.left)
+ if curnode.right: queue.append(curnode.right)
+ out_list.append(max(in_list))
+ return out_list
+```
+
javascript代码:
```javascript
@@ -714,6 +733,42 @@ public:
};
```
+python代码:
+
+```python
+# 层序遍历解法
+class Solution:
+ def connect(self, root: 'Node') -> 'Node':
+ if not root:
+ return None
+ queue = [root]
+ while queue:
+ n = len(queue)
+ for i in range(n):
+ node = queue.pop(0)
+ if node.left:
+ queue.append(node.left)
+ if node.right:
+ queue.append(node.right)
+ if i == n - 1:
+ break
+ node.next = queue[0]
+ return root
+
+# 链表解法
+class Solution:
+ def connect(self, root: 'Node') -> 'Node':
+ first = root
+ while first:
+ cur = first
+ while cur: # 遍历每一层的节点
+ if cur.left: cur.left.next = cur.right # 找左节点的next
+ if cur.right and cur.next: cur.right.next = cur.next.left # 找右节点的next
+ cur = cur.next # cur同层移动到下一节点
+ first = first.left # 从本层扩展到下一层
+ return root
+```
+
## 117.填充每个节点的下一个右侧节点指针II
题目地址:https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node-ii/
@@ -755,7 +810,48 @@ public:
}
};
```
+python代码:
+```python
+# 层序遍历解法
+class Solution:
+ def connect(self, root: 'Node') -> 'Node':
+ if not root:
+ return None
+ queue = [root]
+ while queue: # 遍历每一层
+ length = len(queue)
+ tail = None # 每一层维护一个尾节点
+ for i in range(length): # 遍历当前层
+ curnode = queue.pop(0)
+ if tail:
+ tail.next = curnode # 让尾节点指向当前节点
+ tail = curnode # 让当前节点成为尾节点
+ if curnode.left : queue.append(curnode.left)
+ if curnode.right: queue.append(curnode.right)
+ return root
+
+# 链表解法
+class Solution:
+ def connect(self, root: 'Node') -> 'Node':
+ if not root:
+ return None
+ first = root
+ while first: # 遍历每一层
+ dummyHead = Node(None) # 为下一行创建一个虚拟头节点,相当于下一行所有节点链表的头结点(每一层都会创建);
+ tail = dummyHead # 为下一行维护一个尾节点指针(初始化是虚拟节点)
+ cur = first
+ while cur: # 遍历当前层的节点
+ if cur.left: # 链接下一行的节点
+ tail.next = cur.left
+ tail = tail.next
+ if cur.right:
+ tail.next = cur.right
+ tail = tail.next
+ cur = cur.next # cur同层移动到下一节点
+ first = dummyHead.next # 此处为换行操作,更新到下一行
+ return root
+```
## 总结
diff --git a/problems/0104.二叉树的最大深度.md b/problems/0104.二叉树的最大深度.md
index 812c58ca..463b55d9 100644
--- a/problems/0104.二叉树的最大深度.md
+++ b/problems/0104.二叉树的最大深度.md
@@ -193,40 +193,6 @@ public:
};
```
-使用栈来模拟后序遍历依然可以
-
-```C++
-class Solution {
-public:
- int maxDepth(TreeNode* root) {
- stack st;
- if (root != NULL) st.push(root);
- int depth = 0;
- int result = 0;
- while (!st.empty()) {
- TreeNode* node = st.top();
- if (node != NULL) {
- st.pop();
- st.push(node); // 中
- st.push(NULL);
- depth++;
- if (node->right) st.push(node->right); // 右
- if (node->left) st.push(node->left); // 左
-
- } else {
- st.pop();
- node = st.top();
- st.pop();
- depth--;
- }
- result = result > depth ? result : depth;
- }
- return result;
-
- }
-};
-```
-
## 其他语言版本
diff --git a/problems/0106.从中序与后序遍历序列构造二叉树.md b/problems/0106.从中序与后序遍历序列构造二叉树.md
index ba2d46a1..4c5a70a0 100644
--- a/problems/0106.从中序与后序遍历序列构造二叉树.md
+++ b/problems/0106.从中序与后序遍历序列构造二叉树.md
@@ -693,6 +693,70 @@ class Solution:
return root
```
Go:
+> 106 从中序与后序遍历序列构造二叉树
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func buildTree(inorder []int, postorder []int) *TreeNode {
+ if len(inorder)<1||len(postorder)<1{return nil}
+ //先找到根节点(后续遍历的最后一个就是根节点)
+ nodeValue:=postorder[len(postorder)-1]
+ //从中序遍历中找到一分为二的点,左边为左子树,右边为右子树
+ left:=findRootIndex(inorder,nodeValue)
+ //构造root
+ root:=&TreeNode{Val: nodeValue,
+ Left: buildTree(inorder[:left],postorder[:left]),//将后续遍历一分为二,左边为左子树,右边为右子树
+ Right: buildTree(inorder[left+1:],postorder[left:len(postorder)-1])}
+ return root
+}
+func findRootIndex(inorder []int,target int) (index int){
+ for i:=0;i 105 从前序与中序遍历序列构造二叉树
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func buildTree(preorder []int, inorder []int) *TreeNode {
+ if len(preorder)<1||len(inorder)<1{return nil}
+ left:=findRootIndex(preorder[0],inorder)
+ root:=&TreeNode{
+ Val: preorder[0],
+ Left: buildTree(preorder[1:left+1],inorder[:left]),
+ Right: buildTree(preorder[left+1:],inorder[left+1:])}
+ return root
+}
+func findRootIndex(target int,inorder []int) int{
+ for i:=0;i number === root.val);
+ root.left = buildTree(preorder.slice(1, mid + 1), inorder.slice(0, mid));
+ root.right = buildTree(preorder.slice(mid + 1, preorder.length), inorder.slice(mid + 1, inorder.length));
+ return root;
+};
+```
+
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
diff --git a/problems/0112.路径总和.md b/problems/0112.路径总和.md
index d810a046..54f79d1d 100644
--- a/problems/0112.路径总和.md
+++ b/problems/0112.路径总和.md
@@ -486,6 +486,92 @@ class Solution:
Go:
+> 112. 路径总和
+
+```go
+//递归法
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func hasPathSum(root *TreeNode, targetSum int) bool {
+ var flage bool //找没找到的标志
+ if root==nil{
+ return flage
+ }
+ pathSum(root,0,targetSum,&flage)
+ return flage
+}
+func pathSum(root *TreeNode, sum int,targetSum int,flage *bool){
+ sum+=root.Val
+ if root.Left==nil&&root.Right==nil&&sum==targetSum{
+ *flage=true
+ return
+ }
+ if root.Left!=nil&&!(*flage){//左节点不为空且还没找到
+ pathSum(root.Left,sum,targetSum,flage)
+ }
+ if root.Right!=nil&&!(*flage){//右节点不为空且没找到
+ pathSum(root.Right,sum,targetSum,flage)
+ }
+}
+```
+
+
+
+> 113 递归法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func pathSum(root *TreeNode, targetSum int) [][]int {
+ var result [][]int//最终结果
+ if root==nil{
+ return result
+ }
+ var sumNodes []int//经过路径的节点集合
+ hasPathSum(root,&sumNodes,targetSum,&result)
+ return result
+}
+func hasPathSum(root *TreeNode,sumNodes *[]int,targetSum int,result *[][]int){
+ *sumNodes=append(*sumNodes,root.Val)
+ if root.Left==nil&&root.Right==nil{//叶子节点
+ fmt.Println(*sumNodes)
+ var sum int
+ var number int
+ for k,v:=range *sumNodes{//求该路径节点的和
+ sum+=v
+ number=k
+ }
+ tempNodes:=make([]int,number+1)//新的nodes接受指针里的值,防止最终指针里的值发生变动,导致最后的结果都是最后一个sumNodes的值
+ for k,v:=range *sumNodes{
+ tempNodes[k]=v
+ }
+ if sum==targetSum{
+ *result=append(*result,tempNodes)
+ }
+ }
+ if root.Left!=nil{
+ hasPathSum(root.Left,sumNodes,targetSum,result)
+ *sumNodes=(*sumNodes)[:len(*sumNodes)-1]//回溯
+ }
+ if root.Right!=nil{
+ hasPathSum(root.Right,sumNodes,targetSum,result)
+ *sumNodes=(*sumNodes)[:len(*sumNodes)-1]//回溯
+ }
+}
+```
+
JavaScript:
0112.路径总和
diff --git a/problems/0115.不同的子序列.md b/problems/0115.不同的子序列.md
index 1661acf8..d3bc6d97 100644
--- a/problems/0115.不同的子序列.md
+++ b/problems/0115.不同的子序列.md
@@ -145,10 +145,46 @@ public:
Java:
-
+```java
+class Solution {
+ public int numDistinct(String s, String t) {
+ int[][] dp = new int[s.length() + 1][t.length() + 1];
+ for (int i = 0; i < s.length() + 1; i++) {
+ dp[i][0] = 1;
+ }
+
+ for (int i = 1; i < s.length() + 1; i++) {
+ for (int j = 1; j < t.length() + 1; j++) {
+ if (s.charAt(i - 1) == t.charAt(j - 1)) {
+ dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
+ }else{
+ dp[i][j] = dp[i - 1][j];
+ }
+ }
+ }
+
+ return dp[s.length()][t.length()];
+ }
+}
+```
Python:
-
+```python
+class Solution:
+ def numDistinct(self, s: str, t: str) -> int:
+ dp = [[0] * (len(t)+1) for _ in range(len(s)+1)]
+ for i in range(len(s)):
+ dp[i][0] = 1
+ for j in range(1, len(t)):
+ dp[0][j] = 0
+ for i in range(1, len(s)+1):
+ for j in range(1, len(t)+1):
+ if s[i-1] == t[j-1]:
+ dp[i][j] = dp[i-1][j-1] + dp[i-1][j]
+ else:
+ dp[i][j] = dp[i-1][j]
+ return dp[-1][-1]
+```
Go:
diff --git a/problems/0121.买卖股票的最佳时机.md b/problems/0121.买卖股票的最佳时机.md
index d018efb7..259fff34 100644
--- a/problems/0121.买卖股票的最佳时机.md
+++ b/problems/0121.买卖股票的最佳时机.md
@@ -244,6 +244,47 @@ class Solution { // 动态规划解法
Python:
+> 贪心法:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ low = float("inf")
+ result = 0
+ for i in range(len(prices)):
+ low = min(low, prices[i]) #取最左最小价格
+ result = max(result, prices[i] - low) #直接取最大区间利润
+ return result
+```
+
+> 动态规划:版本一
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ length = len(prices)
+ if len == 0:
+ return 0
+ dp = [[0] * 2 for _ in range(length)]
+ dp[0][0] = -prices[0]
+ dp[0][1] = 0
+ for i in range(1, length):
+ dp[i][0] = max(dp[i-1][0], -prices[i])
+ dp[i][1] = max(dp[i-1][1], prices[i] + dp[i-1][0])
+ return dp[-1][1]
+```
+
+> 动态规划:版本二
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ length = len(prices)
+ dp = [[0] * 2 for _ in range(2)] #注意这里只开辟了一个2 * 2大小的二维数组
+ dp[0][0] = -prices[0]
+ dp[0][1] = 0
+ for i in range(1, length):
+ dp[i % 2][0] = max(dp[(i-1) % 2][0], -prices[i])
+ dp[i % 2][1] = max(dp[(i-1) % 2][1], prices[i] + dp[(i-1) % 2][0])
+ return dp[(length-1) % 2][1]
+```
Go:
```Go
diff --git a/problems/0122.买卖股票的最佳时机II(动态规划).md b/problems/0122.买卖股票的最佳时机II(动态规划).md
index ba277fdc..1215025e 100644
--- a/problems/0122.买卖股票的最佳时机II(动态规划).md
+++ b/problems/0122.买卖股票的最佳时机II(动态规划).md
@@ -171,6 +171,33 @@ class Solution
Python:
+> 版本一:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ length = len(prices)
+ dp = [[0] * 2 for _ in range(length)]
+ dp[0][0] = -prices[0]
+ dp[0][1] = 0
+ for i in range(1, length):
+ dp[i][0] = max(dp[i-1][0], dp[i-1][1] - prices[i]) #注意这里是和121. 买卖股票的最佳时机唯一不同的地方
+ dp[i][1] = max(dp[i-1][1], dp[i-1][0] + prices[i])
+ return dp[-1][1]
+```
+
+> 版本二:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ length = len(prices)
+ dp = [[0] * 2 for _ in range(2)] #注意这里只开辟了一个2 * 2大小的二维数组
+ dp[0][0] = -prices[0]
+ dp[0][1] = 0
+ for i in range(1, length):
+ dp[i % 2][0] = max(dp[(i-1) % 2][0], dp[(i-1) % 2][1] - prices[i])
+ dp[i % 2][1] = max(dp[(i-1) % 2][1], dp[(i-1) % 2][0] + prices[i])
+ return dp[(length-1) % 2][1]
+```
Go:
diff --git a/problems/0123.买卖股票的最佳时机III.md b/problems/0123.买卖股票的最佳时机III.md
index 24370d38..fccb187d 100644
--- a/problems/0123.买卖股票的最佳时机III.md
+++ b/problems/0123.买卖股票的最佳时机III.md
@@ -229,6 +229,40 @@ class Solution { // 动态规划
Python:
+> 版本一:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ if len(prices) == 0:
+ return 0
+ dp = [[0] * 5 for _ in range(len(prices))]
+ dp[0][1] = -prices[0]
+ dp[0][3] = -prices[0]
+ for i in range(1, len(prices)):
+ dp[i][0] = dp[i-1][0]
+ dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i])
+ dp[i][2] = max(dp[i-1][2], dp[i-1][1] + prices[i])
+ dp[i][3] = max(dp[i-1][3], dp[i-1][2] - prices[i])
+ dp[i][4] = max(dp[i-1][4], dp[i-1][3] + prices[i])
+ return dp[-1][4]
+```
+
+> 版本二:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ if len(prices) == 0:
+ return 0
+ dp = [0] * 5
+ dp[1] = -prices[0]
+ dp[3] = -prices[0]
+ for i in range(1, len(prices)):
+ dp[1] = max(dp[1], dp[0] - prices[i])
+ dp[2] = max(dp[2], dp[1] + prices[i])
+ dp[3] = max(dp[3], dp[2] - prices[i])
+ dp[4] = max(dp[4], dp[3] + prices[i])
+ return dp[4]
+```
Go:
diff --git a/problems/0134.加油站.md b/problems/0134.加油站.md
index dfed2d96..9b660ea0 100644
--- a/problems/0134.加油站.md
+++ b/problems/0134.加油站.md
@@ -240,6 +240,25 @@ class Solution:
```
Go:
+```go
+func canCompleteCircuit(gas []int, cost []int) int {
+ curSum := 0
+ totalSum := 0
+ start := 0
+ for i := 0; i < len(gas); i++ {
+ curSum += gas[i] - cost[i]
+ totalSum += gas[i] - cost[i]
+ if curSum < 0 {
+ start = i+1
+ curSum = 0
+ }
+ }
+ if totalSum < 0 {
+ return -1
+ }
+ return start
+}
+```
Javascript:
```Javascript
diff --git a/problems/0139.单词拆分.md b/problems/0139.单词拆分.md
index aa729e02..b6a6242e 100644
--- a/problems/0139.单词拆分.md
+++ b/problems/0139.单词拆分.md
@@ -252,6 +252,23 @@ class Solution {
Python:
+```python3
+class Solution:
+ def wordBreak(self, s: str, wordDict: List[str]) -> bool:
+ '''排列'''
+ dp = [False]*(len(s) + 1)
+ dp[0] = True
+ # 遍历背包
+ for j in range(1, len(s) + 1):
+ # 遍历单词
+ for word in wordDict:
+ if j >= len(word):
+ dp[j] = dp[j] or (dp[j - len(word)] and word == s[j - len(word):j])
+ return dp[len(s)]
+```
+
+
+
Go:
```Go
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index 63499b71..ffa3446a 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -16,19 +16,19 @@ https://leetcode-cn.com/problems/reverse-words-in-a-string/
给定一个字符串,逐个翻转字符串中的每个单词。
-示例 1:
-输入: "the sky is blue"
-输出: "blue is sky the"
+示例 1:
+输入: "the sky is blue"
+输出: "blue is sky the"
-示例 2:
-输入: " hello world! "
-输出: "world! hello"
-解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
+示例 2:
+输入: " hello world! "
+输出: "world! hello"
+解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
-示例 3:
-输入: "a good example"
-输出: "example good a"
-解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
+示例 3:
+输入: "a good example"
+输出: "example good a"
+解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
# 思路
@@ -50,12 +50,15 @@ https://leetcode-cn.com/problems/reverse-words-in-a-string/
* 将整个字符串反转
* 将每个单词反转
-如动画所示:
+举个例子,源字符串为:"the sky is blue "
-
+* 移除多余空格 : "the sky is blue"
+* 字符串反转:"eulb si yks eht"
+* 单词反转:"blue is sky the"
这样我们就完成了翻转字符串里的单词。
+
思路很明确了,我们说一说代码的实现细节,就拿移除多余空格来说,一些同学会上来写如下代码:
```C++
@@ -80,13 +83,13 @@ void removeExtraSpaces(string& s) {
如果不仔细琢磨一下erase的时间复杂读,还以为以上的代码是O(n)的时间复杂度呢。
-想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作,erase实现原理题目:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA),最优的算法来移除元素也要O(n)。
+想一下真正的时间复杂度是多少,一个erase本来就是O(n)的操作,erase实现原理题目:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww),最优的算法来移除元素也要O(n)。
erase操作上面还套了一个for循环,那么以上代码移除冗余空格的代码时间复杂度为O(n^2)。
那么使用双指针法来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到O(n)的时间复杂度。
-如果对这个操作比较生疏了,可以再看一下这篇文章:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)是如何移除元素的。
+如果对这个操作比较生疏了,可以再看一下这篇文章:[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)是如何移除元素的。
那么使用双指针来移除冗余空格代码如下: fastIndex走的快,slowIndex走的慢,最后slowIndex就标记着移除多余空格后新字符串的长度。
@@ -122,7 +125,7 @@ void removeExtraSpaces(string& s) {
此时我们已经实现了removeExtraSpaces函数来移除冗余空格。
-还做实现反转字符串的功能,支持反转字符串子区间,这个实现我们分别在[字符串:这道题目,使用库函数一行代码搞定](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)和[字符串:简单的反转还不够!](https://mp.weixin.qq.com/s/XGSk1GyPWhfqj2g7Cb1Vgw)里已经讲过了。
+还做实现反转字符串的功能,支持反转字符串子区间,这个实现我们分别在[344.反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w)和[541.反转字符串II](https://mp.weixin.qq.com/s/pzXt6PQ029y7bJ9YZB2mVQ)里已经讲过了。
代码如下:
@@ -135,11 +138,8 @@ void reverse(string& s, int start, int end) {
}
```
-## 本题C++整体代码
+本题C++整体代码
-效率:
-
- ```C++
// 版本一
@@ -183,7 +183,7 @@ public:
int end = 0; // 反转的单词在字符串里终止位置
bool entry = false; // 标记枚举字符串的过程中是否已经进入了单词区间
for (int i = 0; i < s.size(); i++) { // 开始反转单词
- if ((!entry))) {
+ if (!entry) {
start = i; // 确定单词起始位置
entry = true; // 进入单词区间
}
@@ -203,6 +203,7 @@ public:
return s;
}
+ // 当然这里的主函数reverseWords写的有一些冗余的,可以精简一些,精简之后的主函数为:
/* 主函数简单写法
string reverseWords(string s) {
removeExtraSpaces(s);
@@ -220,25 +221,8 @@ public:
};
```
-当然这里的主函数reverseWords写的有一些冗余的,可以精简一些,精简之后的主函数为:
-
-```C++
-// 注意这里仅仅是主函数,其他函数和版本一一致
-string reverseWords(string s) {
- removeExtraSpaces(s);
- reverse(s, 0, s.size() - 1);
- for(int i = 0; i < s.size(); i++) {
- int j = i;
- // 查找单词间的空格,翻转单词
- while(j < s.size() && s[j] != ' ') j++;
- reverse(s, i, j - 1);
- i = j;
- }
- return s;
-}
-```
-
-
+效率:
+
```C++
// 版本一
@@ -183,7 +183,7 @@ public:
int end = 0; // 反转的单词在字符串里终止位置
bool entry = false; // 标记枚举字符串的过程中是否已经进入了单词区间
for (int i = 0; i < s.size(); i++) { // 开始反转单词
- if ((!entry))) {
+ if (!entry) {
start = i; // 确定单词起始位置
entry = true; // 进入单词区间
}
@@ -203,6 +203,7 @@ public:
return s;
}
+ // 当然这里的主函数reverseWords写的有一些冗余的,可以精简一些,精简之后的主函数为:
/* 主函数简单写法
string reverseWords(string s) {
removeExtraSpaces(s);
@@ -220,25 +221,8 @@ public:
};
```
-当然这里的主函数reverseWords写的有一些冗余的,可以精简一些,精简之后的主函数为:
-
-```C++
-// 注意这里仅仅是主函数,其他函数和版本一一致
-string reverseWords(string s) {
- removeExtraSpaces(s);
- reverse(s, 0, s.size() - 1);
- for(int i = 0; i < s.size(); i++) {
- int j = i;
- // 查找单词间的空格,翻转单词
- while(j < s.size() && s[j] != ' ') j++;
- reverse(s, i, j - 1);
- i = j;
- }
- return s;
-}
-```
-
-
+效率:
+ @@ -316,7 +300,57 @@ class Solution {
}
```
-Python:
+
+```Python3
+class Solution:
+ #1.去除多余的空格
+ def trim_spaces(self,s):
+ n=len(s)
+ left=0
+ right=n-1
+
+ while left<=right and s[left]==' ': #去除开头的空格
+ left+=1
+ while left<=right and s[right]==' ': #去除结尾的空格
+ right=right-1
+ tmp=[]
+ while left<=right: #去除单词中间多余的空格
+ if s[left]!=' ':
+ tmp.append(s[left])
+ elif tmp[-1]!=' ': #当前位置是空格,但是相邻的上一个位置不是空格,则该空格是合理的
+ tmp.append(s[left])
+ left+=1
+ return tmp
+#2.翻转字符数组
+ def reverse_string(self,nums,left,right):
+ while left
@@ -316,7 +300,57 @@ class Solution {
}
```
-Python:
+
+```Python3
+class Solution:
+ #1.去除多余的空格
+ def trim_spaces(self,s):
+ n=len(s)
+ left=0
+ right=n-1
+
+ while left<=right and s[left]==' ': #去除开头的空格
+ left+=1
+ while left<=right and s[right]==' ': #去除结尾的空格
+ right=right-1
+ tmp=[]
+ while left<=right: #去除单词中间多余的空格
+ if s[left]!=' ':
+ tmp.append(s[left])
+ elif tmp[-1]!=' ': #当前位置是空格,但是相邻的上一个位置不是空格,则该空格是合理的
+ tmp.append(s[left])
+ left+=1
+ return tmp
+#2.翻转字符数组
+ def reverse_string(self,nums,left,right):
+ while left \ No newline at end of file
+
\ No newline at end of file
+
diff --git a/problems/0160.相交链表.md b/problems/0160.相交链表.md
new file mode 100644
index 00000000..d26f66fd
--- /dev/null
+++ b/problems/0160.相交链表.md
@@ -0,0 +1,2 @@
+
+同:[链表:链表相交](./面试题02.07.链表相交.md)
diff --git a/problems/0188.买卖股票的最佳时机IV.md b/problems/0188.买卖股票的最佳时机IV.md
index f0adc237..431c292b 100644
--- a/problems/0188.买卖股票的最佳时机IV.md
+++ b/problems/0188.买卖股票的最佳时机IV.md
@@ -212,6 +212,20 @@ class Solution { //动态规划
Python:
+```python
+class Solution:
+ def maxProfit(self, k: int, prices: List[int]) -> int:
+ if len(prices) == 0:
+ return 0
+ dp = [[0] * (2*k+1) for _ in range(len(prices))]
+ for j in range(1, 2*k, 2):
+ dp[0][j] = -prices[0]
+ for i in range(1, len(prices)):
+ for j in range(0, 2*k-1, 2):
+ dp[i][j+1] = max(dp[i-1][j+1], dp[i-1][j] - prices[i])
+ dp[i][j+2] = max(dp[i-1][j+2], dp[i-1][j+1] + prices[i])
+ return dp[-1][2*k]
+```
Go:
diff --git a/problems/0198.打家劫舍.md b/problems/0198.打家劫舍.md
index 8b46a784..63a68c36 100644
--- a/problems/0198.打家劫舍.md
+++ b/problems/0198.打家劫舍.md
@@ -118,7 +118,7 @@ class Solution {
if (nums == null || nums.length == 0) return 0;
if (nums.length == 1) return nums[0];
- int[] dp = new int[nums.length + 1];
+ int[] dp = new int[nums.length];
dp[0] = nums[0];
dp[1] = Math.max(dp[0], nums[1]);
for (int i = 2; i < nums.length; i++) {
@@ -131,7 +131,20 @@ class Solution {
```
Python:
-
+```python
+class Solution:
+ def rob(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+ if len(nums) == 1:
+ return nums[0]
+ dp = [0] * len(nums)
+ dp[0] = nums[0]
+ dp[1] = max(nums[0], nums[1])
+ for i in range(2, len(nums)):
+ dp[i] = max(dp[i-2]+nums[i], dp[i-1])
+ return dp[-1]
+```
Go:
```Go
diff --git a/problems/0209.长度最小的子数组.md b/problems/0209.长度最小的子数组.md
index 90280451..42687514 100644
--- a/problems/0209.长度最小的子数组.md
+++ b/problems/0209.长度最小的子数组.md
@@ -109,7 +109,7 @@ public:
};
```
-时间复杂度:$O(n)$
+时间复杂度:$O(n)$
空间复杂度:$O(1)$
**一些录友会疑惑为什么时间复杂度是O(n)**。
@@ -118,8 +118,8 @@ public:
## 相关题目推荐
-* 904.水果成篮
-* 76.最小覆盖子串
+* [904.水果成篮](https://leetcode-cn.com/problems/fruit-into-baskets/)
+* [76.最小覆盖子串](https://leetcode-cn.com/problems/minimum-window-substring/)
diff --git a/problems/0222.完全二叉树的节点个数.md b/problems/0222.完全二叉树的节点个数.md
index 91e24247..998e22f3 100644
--- a/problems/0222.完全二叉树的节点个数.md
+++ b/problems/0222.完全二叉树的节点个数.md
@@ -308,6 +308,35 @@ class Solution:
Go:
+递归版本
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+//本题直接就是求有多少个节点,无脑存进数组算长度就行了。
+func countNodes(root *TreeNode) int {
+ if root == nil {
+ return 0
+ }
+ res := 1
+ if root.Right != nil {
+ res += countNodes(root.Right)
+ }
+ if root.Left != nil {
+ res += countNodes(root.Left)
+ }
+ return res
+}
+```
+
+
+
JavaScript:
递归版本
diff --git a/problems/0235.二叉搜索树的最近公共祖先.md b/problems/0235.二叉搜索树的最近公共祖先.md
index 15ff7af4..d78db42a 100644
--- a/problems/0235.二叉搜索树的最近公共祖先.md
+++ b/problems/0235.二叉搜索树的最近公共祖先.md
@@ -265,6 +265,54 @@ class Solution:
else: return root
```
Go:
+> BSL法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+//利用BSL的性质(前序遍历有序)
+func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
+ if root==nil{return nil}
+ if root.Val>p.Val&&root.Val>q.Val{//当前节点的值大于给定的值,则说明满足条件的在左边
+ return lowestCommonAncestor(root.Left,p,q)
+ }else if root.Val 普通法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+//递归会将值层层返回
+func lowestCommonAncestor(root, p, q *TreeNode) *TreeNode {
+ //终止条件
+ if root==nil||root.Val==p.Val||root.Val==q.Val{return root}//最后为空或者找到一个值时,就返回这个值
+ //后序遍历
+ findLeft:=lowestCommonAncestor(root.Left,p,q)
+ findRight:=lowestCommonAncestor(root.Right,p,q)
+ //处理单层逻辑
+ if findLeft!=nil&&findRight!=nil{return root}//说明在root节点的两边
+ if findLeft==nil{//左边没找到,就说明在右边找到了
+ return findRight
+ }else {return findLeft}
+}
+```
+
diff --git a/problems/0239.滑动窗口最大值.md b/problems/0239.滑动窗口最大值.md
index 47383a47..d108335b 100644
--- a/problems/0239.滑动窗口最大值.md
+++ b/problems/0239.滑动窗口最大值.md
@@ -332,6 +332,66 @@ func maxSlidingWindow(nums []int, k int) []int {
```
+```go
+// 封装单调队列的方式解题
+type MyQueue struct {
+ queue []int
+}
+
+func NewMyQueue() *MyQueue {
+ return &MyQueue{
+ queue: make([]int, 0),
+ }
+}
+
+func (m *MyQueue) Front() int {
+ return m.queue[0]
+}
+
+func (m *MyQueue) Back() int {
+ return m.queue[len(m.queue)-1]
+}
+
+func (m *MyQueue) Empty() bool {
+ return len(m.queue) == 0
+}
+
+func (m *MyQueue) Push(val int) {
+ for !m.Empty() && val > m.Back() {
+ m.queue = m.queue[:len(m.queue)-1]
+ }
+ m.queue = append(m.queue, val)
+}
+
+func (m *MyQueue) Pop(val int) {
+ if !m.Empty() && val == m.Front() {
+ m.queue = m.queue[1:]
+ }
+}
+
+func maxSlidingWindow(nums []int, k int) []int {
+ queue := NewMyQueue()
+ length := len(nums)
+ res := make([]int, 0)
+ // 先将前k个元素放入队列
+ for i := 0; i < k; i++ {
+ queue.Push(nums[i])
+ }
+ // 记录前k个元素的最大值
+ res = append(res, queue.Front())
+
+ for i := k; i < length; i++ {
+ // 滑动窗口移除最前面的元素
+ queue.Pop(nums[i-k])
+ // 滑动窗口添加最后面的元素
+ queue.Push(nums[i])
+ // 记录最大值
+ res = append(res, queue.Front())
+ }
+ return res
+}
+```
+
Javascript:
```javascript
var maxSlidingWindow = function (nums, k) {
diff --git a/problems/0242.有效的字母异位词.md b/problems/0242.有效的字母异位词.md
index ba942f70..93bba44c 100644
--- a/problems/0242.有效的字母异位词.md
+++ b/problems/0242.有效的字母异位词.md
@@ -130,7 +130,27 @@ class Solution:
return True
```
+Python写法二(没有使用数组作为哈希表,只是介绍defaultdict这样一种解题思路):
+
+```python
+class Solution:
+ def isAnagram(self, s: str, t: str) -> bool:
+ from collections import defaultdict
+
+ s_dict = defaultdict(int)
+ t_dict = defaultdict(int)
+
+ for x in s:
+ s_dict[x] += 1
+
+ for x in t:
+ t_dict[x] += 1
+
+ return s_dict == t_dict
+```
+
Go:
+
```go
func isAnagram(s string, t string) bool {
if len(s)!=len(t){
diff --git a/problems/0279.完全平方数.md b/problems/0279.完全平方数.md
index 8d8c1f48..60d6d165 100644
--- a/problems/0279.完全平方数.md
+++ b/problems/0279.完全平方数.md
@@ -26,7 +26,7 @@
输入:n = 13
输出:2
解释:13 = 4 + 9
-
+
提示:
* 1 <= n <= 10^4
@@ -184,9 +184,89 @@ class Solution {
Python:
+```python3
+class Solution:
+ def numSquares(self, n: int) -> int:
+ '''版本一'''
+ # 初始化
+ nums = [i**2 for i in range(1, n + 1) if i**2 <= n]
+ dp = [10**4]*(n + 1)
+ dp[0] = 0
+ # 遍历背包
+ for j in range(1, n + 1):
+ # 遍历物品
+ for num in nums:
+ if j >= num:
+ dp[j] = min(dp[j], dp[j - num] + 1)
+ return dp[n]
+
+ def numSquares1(self, n: int) -> int:
+ '''版本二'''
+ # 初始化
+ nums = [i**2 for i in range(1, n + 1) if i**2 <= n]
+ dp = [10**4]*(n + 1)
+ dp[0] = 0
+ # 遍历物品
+ for num in nums:
+ # 遍历背包
+ for j in range(num, n + 1)
+ dp[j] = min(dp[j], dp[j - num] + 1)
+ return dp[n]
+```
+
+
+
Go:
+```go
+// 版本一,先遍历物品, 再遍历背包
+func numSquares1(n int) int {
+ //定义
+ dp := make([]int, n+1)
+ // 初始化
+ dp[0] = 0
+ for i := 1; i <= n; i++ {
+ dp[i] = math.MaxInt32
+ }
+ // 遍历物品
+ for i := 1; i <= n; i++ {
+ // 遍历背包
+ for j := i*i; j <= n; j++ {
+ dp[j] = min(dp[j], dp[j-i*i]+1)
+ }
+ }
+ return dp[n]
+}
+
+// 版本二,先遍历背包, 再遍历物品
+func numSquares2(n int) int {
+ //定义
+ dp := make([]int, n+1)
+ // 初始化
+ dp[0] = 0
+ // 遍历背包
+ for j := 1; j <= n; j++ {
+ //初始化
+ dp[j] = math.MaxInt32
+ // 遍历物品
+ for i := 1; i <= n; i++ {
+ if j >= i*i {
+ dp[j] = min(dp[j], dp[j-i*i]+1)
+ }
+ }
+ }
+
+ return dp[n]
+}
+
+func min(a, b int) int {
+ if a < b {
+ return a
+ }
+ return b
+}
+```
diff --git a/problems/0300.最长上升子序列.md b/problems/0300.最长上升子序列.md
index 02105a7c..8b4ad5b1 100644
--- a/problems/0300.最长上升子序列.md
+++ b/problems/0300.最长上升子序列.md
@@ -130,7 +130,20 @@ class Solution {
```
Python:
-
+```python
+class Solution:
+ def lengthOfLIS(self, nums: List[int]) -> int:
+ if len(nums) <= 1:
+ return len(nums)
+ dp = [1] * len(nums)
+ result = 0
+ for i in range(1, len(nums)):
+ for j in range(0, i):
+ if nums[i] > nums[j]:
+ dp[i] = max(dp[i], dp[j] + 1)
+ result = max(result, dp[i]) #取长的子序列
+ return result
+```
Go:
```go
diff --git a/problems/0309.最佳买卖股票时机含冷冻期.md b/problems/0309.最佳买卖股票时机含冷冻期.md
index 44ca2b26..4667c122 100644
--- a/problems/0309.最佳买卖股票时机含冷冻期.md
+++ b/problems/0309.最佳买卖股票时机含冷冻期.md
@@ -189,6 +189,21 @@ class Solution {
Python:
+```python
+class Solution:
+ def maxProfit(self, prices: List[int]) -> int:
+ n = len(prices)
+ if n == 0:
+ return 0
+ dp = [[0] * 4 for _ in range(n)]
+ dp[0][0] = -prices[0] #持股票
+ for i in range(1, n):
+ dp[i][0] = max(dp[i-1][0], max(dp[i-1][3], dp[i-1][1]) - prices[i])
+ dp[i][1] = max(dp[i-1][1], dp[i-1][3])
+ dp[i][2] = dp[i-1][0] + prices[i]
+ dp[i][3] = dp[i-1][2]
+ return max(dp[n-1][3], dp[n-1][1], dp[n-1][2])
+```
Go:
diff --git a/problems/0322.零钱兑换.md b/problems/0322.零钱兑换.md
index ddcd739b..cf537088 100644
--- a/problems/0322.零钱兑换.md
+++ b/problems/0322.零钱兑换.md
@@ -35,7 +35,7 @@
示例 5:
输入:coins = [1], amount = 2
输出:2
-
+
提示:
* 1 <= coins.length <= 12
@@ -209,9 +209,100 @@ class Solution {
Python:
+```python3
+class Solution:
+ def coinChange(self, coins: List[int], amount: int) -> int:
+ '''版本一'''
+ # 初始化
+ dp = [amount + 1]*(amount + 1)
+ dp[0] = 0
+ # 遍历物品
+ for coin in coins:
+ # 遍历背包
+ for j in range(coin, amount + 1):
+ dp[j] = min(dp[j], dp[j - coin] + 1)
+ return dp[amount] if dp[amount] < amount + 1 else -1
+
+ def coinChange1(self, coins: List[int], amount: int) -> int:
+ '''版本二'''
+ # 初始化
+ dp = [amount + 1]*(amount + 1)
+ dp[0] = 0
+ # 遍历物品
+ for j in range(1, amount + 1):
+ # 遍历背包
+ for coin in coins:
+ if j >= coin:
+ dp[j] = min(dp[j], dp[j - coin] + 1)
+ return dp[amount] if dp[amount] < amount + 1 else -1
+```
+
+
+
Go:
+```go
+// 版本一, 先遍历物品,再遍历背包
+func coinChange1(coins []int, amount int) int {
+ dp := make([]int, amount+1)
+ // 初始化dp[0]
+ dp[0] = 0
+ // 初始化为math.MaxInt32
+ for j := 1; j <= amount; j++ {
+ dp[j] = math.MaxInt32
+ }
+ // 遍历物品
+ for i := 0; i < len(coins); i++ {
+ // 遍历背包
+ for j := coins[i]; j <= amount; j++ {
+ if dp[j-coins[i]] != math.MaxInt32 {
+ // 推导公式
+ dp[j] = min(dp[j], dp[j-coins[i]]+1)
+ //fmt.Println(dp,j,i)
+ }
+ }
+ }
+ // 没找到能装满背包的, 就返回-1
+ if dp[amount] == math.MaxInt32 {
+ return -1
+ }
+ return dp[amount]
+}
+
+// 版本二,先遍历背包,再遍历物品
+func coinChange2(coins []int, amount int) int {
+ dp := make([]int, amount+1)
+ // 初始化dp[0]
+ dp[0] = 0
+ // 遍历背包,从1开始
+ for j := 1; j <= amount; j++ {
+ // 初始化为math.MaxInt32
+ dp[j] = math.MaxInt32
+ // 遍历物品
+ for i := 0; i < len(coins); i++ {
+ if j >= coins[i] && dp[j-coins[i]] != math.MaxInt32 {
+ // 推导公式
+ dp[j] = min(dp[j], dp[j-coins[i]]+1)
+ //fmt.Println(dp)
+ }
+ }
+ }
+ // 没找到能装满背包的, 就返回-1
+ if dp[amount] == math.MaxInt32 {
+ return -1
+ }
+ return dp[amount]
+}
+
+func min(a, b int) int {
+ if a < b {
+ return a
+ }
+ return b
+}
+
+```
diff --git a/problems/0337.打家劫舍III.md b/problems/0337.打家劫舍III.md
index 58d0e640..0a4b752b 100644
--- a/problems/0337.打家劫舍III.md
+++ b/problems/0337.打家劫舍III.md
@@ -287,6 +287,25 @@ class Solution {
Python:
+> 动态规划
+```python
+class Solution:
+ def rob(self, root: TreeNode) -> int:
+ result = self.robTree(root)
+ return max(result[0], result[1])
+
+ #长度为2的数组,0:不偷,1:偷
+ def robTree(self, cur):
+ if not cur:
+ return (0, 0) #这里返回tuple, 也可以返回list
+ left = self.robTree(cur.left)
+ right = self.robTree(cur.right)
+ #偷cur
+ val1 = cur.val + left[0] + right[0]
+ #不偷cur
+ val2 = max(left[0], left[1]) + max(right[0], right[1])
+ return (val2, val1)
+```
Go:
diff --git a/problems/0343.整数拆分.md b/problems/0343.整数拆分.md
index fefaa293..cf60575f 100644
--- a/problems/0343.整数拆分.md
+++ b/problems/0343.整数拆分.md
@@ -218,7 +218,7 @@ class Solution:
# 假设对正整数 i 拆分出的第一个正整数是 j(1 <= j < i),则有以下两种方案:
# 1) 将 i 拆分成 j 和 i−j 的和,且 i−j 不再拆分成多个正整数,此时的乘积是 j * (i-j)
# 2) 将 i 拆分成 j 和 i−j 的和,且 i−j 继续拆分成多个正整数,此时的乘积是 j * dp[i-j]
- for j in range(1, i):
+ for j in range(1, i - 1):
dp[i] = max(dp[i], max(j * (i - j), j * dp[i - j]))
return dp[n]
```
diff --git a/problems/0344.反转字符串.md b/problems/0344.反转字符串.md
index 1b86e847..fd395ce6 100644
--- a/problems/0344.反转字符串.md
+++ b/problems/0344.反转字符串.md
@@ -20,14 +20,13 @@ https://leetcode-cn.com/problems/reverse-string/
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
-示例 1:
+示例 1:
+输入:["h","e","l","l","o"]
+输出:["o","l","l","e","h"]
-输入:["h","e","l","l","o"]
-输出:["o","l","l","e","h"]
-示例 2:
-
-输入:["H","a","n","n","a","h"]
-输出:["h","a","n","n","a","H"]
+示例 2:
+输入:["H","a","n","n","a","h"]
+输出:["h","a","n","n","a","H"]
# 思路
@@ -56,7 +55,7 @@ https://leetcode-cn.com/problems/reverse-string/
接下来再来讲一下如何解决反转字符串的问题。
-大家应该还记得,我们已经讲过了[206.反转链表](https://mp.weixin.qq.com/s/pnvVP-0ZM7epB8y3w_Njwg)。
+大家应该还记得,我们已经讲过了[206.反转链表](https://mp.weixin.qq.com/s/ckEvIVGcNLfrz6OLOMoT0A)。
在反转链表中,使用了双指针的方法。
@@ -64,7 +63,7 @@ https://leetcode-cn.com/problems/reverse-string/
因为字符串也是一种数组,所以元素在内存中是连续分布,这就决定了反转链表和反转字符串方式上还是有所差异的。
-如果对数组和链表原理不清楚的同学,可以看这两篇,[关于链表,你该了解这些!](https://mp.weixin.qq.com/s/ntlZbEdKgnFQKZkSUAOSpQ),[必须掌握的数组理论知识](https://mp.weixin.qq.com/s/X7R55wSENyY62le0Fiawsg)。
+如果对数组和链表原理不清楚的同学,可以看这两篇,[关于链表,你该了解这些!](https://mp.weixin.qq.com/s/fDGMmLrW7ZHlzkzlf_dZkw),[必须掌握的数组理论知识](https://mp.weixin.qq.com/s/c2KABb-Qgg66HrGf8z-8Og)。
对于字符串,我们定义两个指针(也可以说是索引下表),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。
@@ -119,8 +118,7 @@ s[i] ^= s[j];
相信大家本着我所讲述的原则来做字符串相关的题目,在选择库函数的角度上会有所原则,也会有所收获。
-
-## C++代码
+C++代码如下:
```C++
class Solution {
diff --git a/problems/0349.两个数组的交集.md b/problems/0349.两个数组的交集.md
index 090480a4..5c635d39 100644
--- a/problems/0349.两个数组的交集.md
+++ b/problems/0349.两个数组的交集.md
@@ -118,7 +118,7 @@ class Solution {
```
Python:
-```python3
+```python
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
result_set = set()
diff --git a/problems/0376.摆动序列.md b/problems/0376.摆动序列.md
index bbca5ea0..4d283eb0 100644
--- a/problems/0376.摆动序列.md
+++ b/problems/0376.摆动序列.md
@@ -138,20 +138,16 @@ class Solution {
```
Python:
-```python
+```python3
class Solution:
def wiggleMaxLength(self, nums: List[int]) -> int:
- #贪心 求波峰数量 + 波谷数量
- if len(nums)<=1:
- return len(nums)
- cur, pre = 0,0 #当前一对差值,前一对差值
- count = 1#默认最右边有一个峰值
- for i in range(len(nums)-1):
- cur = nums[i+1] - nums[i]
- if((cur>0 and pre<=0) or (cur<0 and pre>=0)):
- count += 1
- pre = cur
- return count
+ preC,curC,res = 0,0,1 #题目里nums长度大于等于1,当长度为1时,其实到不了for循环里去,所以不用考虑nums长度
+ for i in range(len(nums) - 1):
+ curC = nums[i + 1] - nums[i]
+ if curC * preC <= 0 and curC !=0: #差值为0时,不算摆动
+ res += 1
+ preC = curC #如果当前差值和上一个差值为一正一负时,才需要用当前差值替代上一个差值
+ return res
```
Go:
diff --git a/problems/0377.组合总和Ⅳ.md b/problems/0377.组合总和Ⅳ.md
index c6dc3d42..d0394706 100644
--- a/problems/0377.组合总和Ⅳ.md
+++ b/problems/0377.组合总和Ⅳ.md
@@ -183,7 +183,23 @@ class Solution:
Go:
-
+```go
+func combinationSum4(nums []int, target int) int {
+ //定义dp数组
+ dp := make([]int, target+1)
+ // 初始化
+ dp[0] = 1
+ // 遍历顺序, 先遍历背包,再循环遍历物品
+ for j:=0;j<=target;j++ {
+ for i:=0 ;i < len(nums);i++ {
+ if j >= nums[i] {
+ dp[j] += dp[j-nums[i]]
+ }
+ }
+ }
+ return dp[target]
+}
+```
diff --git a/problems/0383.赎金信.md b/problems/0383.赎金信.md
index 23e2c5fd..a5315b0e 100644
--- a/problems/0383.赎金信.md
+++ b/problems/0383.赎金信.md
@@ -22,13 +22,13 @@ https://leetcode-cn.com/problems/ransom-note/
你可以假设两个字符串均只含有小写字母。
-canConstruct("a", "b") -> false
-canConstruct("aa", "ab") -> false
-canConstruct("aa", "aab") -> true
+canConstruct("a", "b") -> false
+canConstruct("aa", "ab") -> false
+canConstruct("aa", "aab") -> true
## 思路
-这道题目和[242.有效的字母异位词](https://mp.weixin.qq.com/s/vM6OszkM6L1Mx2Ralm9Dig)很像,[242.有效的字母异位词](https://mp.weixin.qq.com/s/vM6OszkM6L1Mx2Ralm9Dig)相当于求 字符串a 和 字符串b 是否可以相互组成 ,而这道题目是求 字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
+这道题目和[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)很像,[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)相当于求 字符串a 和 字符串b 是否可以相互组成 ,而这道题目是求 字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
本题判断第一个字符串ransom能不能由第二个字符串magazines里面的字符构成,但是这里需要注意两点。
@@ -75,7 +75,7 @@ public:
依然是数组在哈希法中的应用。
-一些同学可能想,用数组干啥,都用map完事了,**其实在本题的情况下,使用map的空间消耗要比数组大一些的,因为map要维护红黑树或者哈希表,而且还要做哈希函数。 所以数组更加简单直接有效!**
+一些同学可能想,用数组干啥,都用map完事了,**其实在本题的情况下,使用map的空间消耗要比数组大一些的,因为map要维护红黑树或者哈希表,而且还要做哈希函数,是费时的!数据量大的话就能体现出来差别了。 所以数组更加简单直接有效!**
代码如下:
@@ -135,8 +135,52 @@ class Solution {
```
-Python:
-```py
+Python写法一(使用数组作为哈希表):
+
+```python
+class Solution:
+ def canConstruct(self, ransomNote: str, magazine: str) -> bool:
+
+ arr = [0] * 26
+
+ for x in magazine:
+ arr[ord(x) - ord('a')] += 1
+
+ for x in ransomNote:
+ if arr[ord(x) - ord('a')] == 0:
+ return False
+ else:
+ arr[ord(x) - ord('a')] -= 1
+
+ return True
+```
+
+Python写法二(使用defaultdict):
+
+```python
+class Solution:
+ def canConstruct(self, ransomNote: str, magazine: str) -> bool:
+
+ from collections import defaultdict
+
+ hashmap = defaultdict(int)
+
+ for x in magazine:
+ hashmap[x] += 1
+
+ for x in ransomNote:
+ value = hashmap.get(x)
+ if value is None or value == 0:
+ return False
+ else:
+ hashmap[x] -= 1
+
+ return True
+```
+
+Python写法三:
+
+```python
class Solution(object):
def canConstruct(self, ransomNote, magazine):
"""
@@ -166,6 +210,7 @@ class Solution(object):
```
Go:
+
```go
func canConstruct(ransomNote string, magazine string) bool {
record := make([]int, 26)
diff --git a/problems/0392.判断子序列.md b/problems/0392.判断子序列.md
index 512ebc82..9048ac44 100644
--- a/problems/0392.判断子序列.md
+++ b/problems/0392.判断子序列.md
@@ -144,7 +144,20 @@ Java:
Python:
-
+```python
+class Solution:
+ def isSubsequence(self, s: str, t: str) -> bool:
+ dp = [[0] * (len(t)+1) for _ in range(len(s)+1)]
+ for i in range(1, len(s)+1):
+ for j in range(1, len(t)+1):
+ if s[i-1] == t[j-1]:
+ dp[i][j] = dp[i-1][j-1] + 1
+ else:
+ dp[i][j] = dp[i][j-1]
+ if dp[-1][-1] == len(s):
+ return True
+ return False
+```
Go:
diff --git a/problems/0404.左叶子之和.md b/problems/0404.左叶子之和.md
index e5daa9db..aa758367 100644
--- a/problems/0404.左叶子之和.md
+++ b/problems/0404.左叶子之和.md
@@ -226,6 +226,71 @@ class Solution:
```
Go:
+> 递归法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func sumOfLeftLeaves(root *TreeNode) int {
+ var res int
+ findLeft(root,&res)
+ return res
+}
+func findLeft(root *TreeNode,res *int){
+ //左节点
+ if root.Left!=nil&&root.Left.Left==nil&&root.Left.Right==nil{
+ *res=*res+root.Left.Val
+ }
+ if root.Left!=nil{
+ findLeft(root.Left,res)
+ }
+ if root.Right!=nil{
+ findLeft(root.Right,res)
+ }
+}
+```
+
+> 迭代法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func sumOfLeftLeaves(root *TreeNode) int {
+ var res int
+ queue:=list.New()
+ queue.PushBack(root)
+ for queue.Len()>0{
+ length:=queue.Len()
+ for i:=0;i {
+ if(b[0] !== a[0]) {
+ return b[0] - a[0]
+ } else {
+ return a[1] - b[1]
+ }
+
+ })
+ for(let i = 0; i < people.length; i++) {
+ queue.splice(people[i][1], 0, people[i])
+ }
+ return queue
+};
+```
-----------------------
diff --git a/problems/0435.无重叠区间.md b/problems/0435.无重叠区间.md
index 248526a1..23ee9f94 100644
--- a/problems/0435.无重叠区间.md
+++ b/problems/0435.无重叠区间.md
@@ -228,7 +228,27 @@ class Solution:
Go:
+Javascript:
+```Javascript
+var eraseOverlapIntervals = function(intervals) {
+ intervals.sort((a, b) => {
+ return a[1] - b[1]
+ })
+ let count = 1
+ let end = intervals[0][1]
+
+ for(let i = 1; i < intervals.length; i++) {
+ let interval = intervals[i]
+ if(interval[0] >= right) {
+ end = interval[1]
+ count += 1
+ }
+ }
+
+ return intervals.length - count
+};
+```
-----------------------
diff --git a/problems/0452.用最少数量的箭引爆气球.md b/problems/0452.用最少数量的箭引爆气球.md
index 9b0cc925..bb3ebbdc 100644
--- a/problems/0452.用最少数量的箭引爆气球.md
+++ b/problems/0452.用最少数量的箭引爆气球.md
@@ -175,7 +175,24 @@ class Solution:
Go:
+Javascript:
+```Javascript
+var findMinArrowShots = function(points) {
+ points.sort((a, b) => {
+ return a[0] - b[0]
+ })
+ let result = 1
+ for(let i = 1; i < points.length; i++) {
+ if(points[i][0] > points[i - 1][1]) {
+ result++
+ } else {
+ points[i][1] = Math.min(points[i - 1][1], points[i][1])
+ }
+ }
+ return result
+};
+```
-----------------------
diff --git a/problems/0454.四数相加II.md b/problems/0454.四数相加II.md
index 835178dd..0621ab5b 100644
--- a/problems/0454.四数相加II.md
+++ b/problems/0454.四数相加II.md
@@ -120,7 +120,7 @@ class Solution {
Python:
-```
+```python
class Solution(object):
def fourSumCount(self, nums1, nums2, nums3, nums4):
"""
@@ -147,7 +147,31 @@ class Solution(object):
if key in hashmap:
count += hashmap[key]
return count
+
+# 下面这个写法更为简洁,但是表达的是同样的算法
+# class Solution:
+# def fourSumCount(self, nums1: List[int], nums2: List[int], nums3: List[int], nums4: List[int]) -> int:
+# from collections import defaultdict
+
+# hashmap = defaultdict(int)
+
+# for x1 in nums1:
+# for x2 in nums2:
+# hashmap[x1+x2] += 1
+
+# count=0
+# for x3 in nums3:
+# for x4 in nums4:
+# key = -x3-x4
+# value = hashmap.get(key)
+
+ # dict的get方法会返回None(key不存在)或者key对应的value
+ # 所以如果value==0,就会继续执行or,count+0,否则就会直接加value
+ # 这样就不用去写if判断了
+
+# count += value or 0
+# return count
```
diff --git a/problems/0455.分发饼干.md b/problems/0455.分发饼干.md
index ecf7f132..4814d414 100644
--- a/problems/0455.分发饼干.md
+++ b/problems/0455.分发饼干.md
@@ -134,22 +134,17 @@ class Solution {
```
Python:
-```python
+```python3
class Solution:
def findContentChildren(self, g: List[int], s: List[int]) -> int:
- #先考虑胃口小的孩子
g.sort()
s.sort()
- i=j=0
- count = 0
- while(i= g[res]: #小饼干先喂饱小胃口
+ res += 1
+ return res
```
-
Go:
Javascript:
diff --git a/problems/0474.一和零.md b/problems/0474.一和零.md
index d60faa98..fd925f76 100644
--- a/problems/0474.一和零.md
+++ b/problems/0474.一和零.md
@@ -206,7 +206,43 @@ class Solution:
```
Go:
+```go
+func findMaxForm(strs []string, m int, n int) int {
+ // 定义数组
+ dp := make([][]int, m+1)
+ for i,_ := range dp {
+ dp[i] = make([]int, n+1 )
+ }
+ // 遍历
+ for i:=0;i= zeroNum;j-- {
+ for k:=n ; k >= oneNum;k-- {
+ // 推导公式
+ dp[j][k] = max(dp[j][k],dp[j-zeroNum][k-oneNum]+1)
+ }
+ }
+ //fmt.Println(dp)
+ }
+ return dp[m][n]
+}
+func max(a,b int) int {
+ if a > b {
+ return a
+ }
+ return b
+}
+```
diff --git a/problems/0501.二叉搜索树中的众数.md b/problems/0501.二叉搜索树中的众数.md
index dfd589ce..3ca7d892 100644
--- a/problems/0501.二叉搜索树中的众数.md
+++ b/problems/0501.二叉搜索树中的众数.md
@@ -428,7 +428,100 @@ class Solution:
return self.res
```
Go:
+暴力法(非BSL)
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func findMode(root *TreeNode) []int {
+ var history map[int]int
+ var maxValue int
+ var maxIndex int
+ var result []int
+ history=make(map[int]int)
+ traversal(root,history)
+ for k,value:=range history{
+ if value>maxValue{
+ maxValue=value
+ maxIndex=k
+ }
+ }
+ for k,value:=range history{
+ if value==history[maxIndex]{
+ result=append(result,k)
+ }
+ }
+ return result
+}
+func traversal(root *TreeNode,history map[int]int){
+ if root.Left!=nil{
+ traversal(root.Left,history)
+ }
+ if value,ok:=history[root.Val];ok{
+ history[root.Val]=value+1
+ }else{
+ history[root.Val]=1
+ }
+ if root.Right!=nil{
+ traversal(root.Right,history)
+ }
+}
+```
+
+计数法BSL(此代码在执行代码里能执行,但提交后报错,不知为何,思路是对的)
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+ var count,maxCount int //统计计数
+func findMode(root *TreeNode) []int {
+ var result []int
+ var pre *TreeNode //前指针
+ if root.Left==nil&&root.Right==nil{
+ result=append(result,root.Val)
+ return result
+ }
+ traversal(root,&result,pre)
+ return result
+}
+func traversal(root *TreeNode,result *[]int,pre *TreeNode){//遍历统计
+ //如果BSL中序遍历相邻的两个节点值相同,则统计频率;如果不相同,依据BSL中序遍历排好序的性质,重新计数
+ if pre==nil{
+ count=1
+ }else if pre.Val==root.Val{
+ count++
+ }else {
+ count=1
+ }
+ //如果统计的频率等于最大频率,则加入结果集;如果统计的频率大于最大频率,更新最大频率且重新将结果加入新的结果集中
+ if count==maxCount{
+ *result=append(*result,root.Val)
+ }else if count>maxCount{
+ maxCount=count//重新赋值maxCount
+ *result=[]int{}//清空result中的内容
+ *result=append(*result,root.Val)
+ }
+ pre=root//保存上一个的节点
+ if root.Left!=nil{
+ traversal(root.Left,result,pre)
+ }
+ if root.Right!=nil{
+ traversal(root.Right,result,pre)
+ }
+}
+```
diff --git a/problems/0513.找树左下角的值.md b/problems/0513.找树左下角的值.md
index 97464e3d..e252ccd3 100644
--- a/problems/0513.找树左下角的值.md
+++ b/problems/0513.找树左下角的值.md
@@ -298,6 +298,80 @@ class Solution:
```
Go:
+> 递归法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+ var maxDeep int // 全局变量 深度
+ var value int //全局变量 最终值
+func findBottomLeftValue(root *TreeNode) int {
+ if root.Left==nil&&root.Right==nil{//需要提前判断一下(不要这个if的话提交结果会出错,但执行代码不会。防止这种情况出现,故先判断是否只有一个节点)
+ return root.Val
+ }
+ findLeftValue (root,maxDeep)
+ return value
+}
+func findLeftValue (root *TreeNode,deep int){
+ //最左边的值在左边
+ if root.Left==nil&&root.Right==nil{
+ if deep>maxDeep{
+ value=root.Val
+ maxDeep=deep
+ }
+ }
+ //递归
+ if root.Left!=nil{
+ deep++
+ findLeftValue(root.Left,deep)
+ deep--//回溯
+ }
+ if root.Right!=nil{
+ deep++
+ findLeftValue(root.Right,deep)
+ deep--//回溯
+ }
+}
+```
+
+> 迭代法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func findBottomLeftValue(root *TreeNode) int {
+ queue:=list.New()
+ var gradation int
+ queue.PushBack(root)
+ for queue.Len()>0{
+ length:=queue.Len()
+ for i:=0;i int:
+ dp = [[0] * len(s) for _ in range(len(s))]
+ for i in range(len(s)):
+ dp[i][i] = 1
+ for i in range(len(s)-1, -1, -1):
+ for j in range(i+1, len(s)):
+ if s[i] == s[j]:
+ dp[i][j] = dp[i+1][j-1] + 2
+ else:
+ dp[i][j] = max(dp[i+1][j], dp[i][j-1])
+ return dp[0][-1]
+```
Go:
```Go
diff --git a/problems/0518.零钱兑换II.md b/problems/0518.零钱兑换II.md
index 2dee030c..08043ea3 100644
--- a/problems/0518.零钱兑换II.md
+++ b/problems/0518.零钱兑换II.md
@@ -33,7 +33,7 @@
示例 3:
输入: amount = 10, coins = [10]
输出: 1
-
+
注意,你可以假设:
* 0 <= amount (总金额) <= 5000
@@ -101,7 +101,7 @@ dp[j] (考虑coins[i]的组合总和) 就是所有的dp[j - coins[i]](不
而本题要求凑成总和的组合数,元素之间要求没有顺序。
-所以纯完全背包是能凑成总结就行,不用管怎么凑的。
+所以纯完全背包是能凑成总和就行,不用管怎么凑的。
本题是求凑出来的方案个数,且每个方案个数是为组合数。
@@ -208,10 +208,42 @@ class Solution {
Python:
-Go:
+```python3
+class Solution:
+ def change(self, amount: int, coins: List[int]) -> int:
+ dp = [0]*(amount + 1)
+ dp[0] = 1
+ # 遍历物品
+ for i in range(len(coins)):
+ # 遍历背包
+ for j in range(coins[i], amount + 1):
+ dp[j] += dp[j - coins[i]]
+ return dp[amount]
+```
+Go:
+```go
+func change(amount int, coins []int) int {
+ // 定义dp数组
+ dp := make([]int, amount+1)
+ // 初始化,0大小的背包, 当然是不装任何东西了, 就是1种方法
+ dp[0] = 1
+ // 遍历顺序
+ // 遍历物品
+ for i := 0 ;i < len(coins);i++ {
+ // 遍历背包
+ for j:= coins[i] ; j <= amount ;j++ {
+ // 推导公式
+ dp[j] += dp[j-coins[i]]
+ }
+ }
+ return dp[amount]
+}
+```
+
+
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/0530.二叉搜索树的最小绝对差.md b/problems/0530.二叉搜索树的最小绝对差.md
index 143bd053..0bbc4908 100644
--- a/problems/0530.二叉搜索树的最小绝对差.md
+++ b/problems/0530.二叉搜索树的最小绝对差.md
@@ -151,7 +151,30 @@ public:
Java:
-
+递归
+```java
+class Solution {
+ TreeNode pre;// 记录上一个遍历的结点
+ int result = Integer.MAX_VALUE;
+ public int getMinimumDifference(TreeNode root) {
+ if(root==null)return 0;
+ traversal(root);
+ return result;
+ }
+ public void traversal(TreeNode root){
+ if(root==null)return;
+ //左
+ traversal(root.left);
+ //中
+ if(pre!=null){
+ result = Math.min(result,root.val-pre.val);
+ }
+ pre = root;
+ //右
+ traversal(root.right);
+ }
+}
+```
```Java
class Solution {
TreeNode pre;// 记录上一个遍历的结点
@@ -201,8 +224,37 @@ class Solution:
return r
```
Go:
+> 中序遍历,然后计算最小差值
-
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func getMinimumDifference(root *TreeNode) int {
+ var res []int
+ findMIn(root,&res)
+ min:=1000000//一个比较大的值
+ for i:=1;i
+ 那么这里具体反转的逻辑我们要不要使用库函数呢,其实用不用都可以,使用reverse来实现反转也没毛病,毕竟不是解题关键部分。
@@ -65,7 +65,7 @@ public:
};
```
-那么我们也可以实现自己的reverse函数,其实和题目[344. 反转字符串](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)道理是一样的。
+那么我们也可以实现自己的reverse函数,其实和题目[344. 反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w)道理是一样的。
下面我实现的reverse函数区间是左闭右闭区间,代码如下:
@@ -103,6 +103,7 @@ public:
Java:
```Java
+//解法一
class Solution {
public String reverseStr(String s, int k) {
StringBuffer res = new StringBuffer();
@@ -128,6 +129,28 @@ class Solution {
return res.toString();
}
}
+
+//解法二(似乎更容易理解点)
+//题目的意思其实概括为 每隔2k个反转前k个,尾数不够k个时候全部反转
+class Solution {
+ public String reverseStr(String s, int k) {
+ char[] ch = s.toCharArray();
+ for(int i = 0; i < ch.length; i += 2 * k){
+ int start = i;
+ //这里是判断尾数够不够k个来取决end指针的位置
+ int end = Math.min(ch.length - 1, start + k - 1);
+ //用异或运算反转
+ while(start < end){
+ ch[start] ^= ch[end];
+ ch[end] ^= ch[start];
+ ch[start] ^= ch[end];
+ start++;
+ end--;
+ }
+ }
+ return new String(ch);
+ }
+}
```
Python:
diff --git a/problems/0583.两个字符串的删除操作.md b/problems/0583.两个字符串的删除操作.md
index cd550d65..ee1fbc5f 100644
--- a/problems/0583.两个字符串的删除操作.md
+++ b/problems/0583.两个字符串的删除操作.md
@@ -104,10 +104,47 @@ public:
Java:
+```java
+class Solution {
+ public int minDistance(String word1, String word2) {
+ int[][] dp = new int[word1.length() + 1][word2.length() + 1];
+ for (int i = 0; i < word1.length() + 1; i++) dp[i][0] = i;
+ for (int j = 0; j < word2.length() + 1; j++) dp[0][j] = j;
+
+ for (int i = 1; i < word1.length() + 1; i++) {
+ for (int j = 1; j < word2.length() + 1; j++) {
+ if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
+ dp[i][j] = dp[i - 1][j - 1];
+ }else{
+ dp[i][j] = Math.min(dp[i - 1][j - 1] + 2,
+ Math.min(dp[i - 1][j] + 1, dp[i][j - 1] + 1));
+ }
+ }
+ }
+
+ return dp[word1.length()][word2.length()];
+ }
+}
+```
Python:
-
+```python
+class Solution:
+ def minDistance(self, word1: str, word2: str) -> int:
+ dp = [[0] * (len(word2)+1) for _ in range(len(word1)+1)]
+ for i in range(len(word1)+1):
+ dp[i][0] = i
+ for j in range(len(word2)+1):
+ dp[0][j] = j
+ for i in range(1, len(word1)+1):
+ for j in range(1, len(word2)+1):
+ if word1[i-1] == word2[j-1]:
+ dp[i][j] = dp[i-1][j-1]
+ else:
+ dp[i][j] = min(dp[i-1][j-1] + 2, dp[i-1][j] + 1, dp[i][j-1] + 1)
+ return dp[-1][-1]
+```
Go:
diff --git a/problems/0617.合并二叉树.md b/problems/0617.合并二叉树.md
index d65275f0..be6bb425 100644
--- a/problems/0617.合并二叉树.md
+++ b/problems/0617.合并二叉树.md
@@ -332,6 +332,43 @@ class Solution:
Go:
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+ //前序遍历(递归遍历,跟105 106差不多的思路)
+func mergeTrees(t1 *TreeNode, t2 *TreeNode) *TreeNode {
+ var value int
+ var nullNode *TreeNode//空node,便于遍历
+ nullNode=&TreeNode{
+ Val:0,
+ Left:nil,
+ Right:nil}
+ switch {
+ case t1==nil&&t2==nil: return nil//终止条件
+ default : //如果其中一个节点为空,则将该节点置为nullNode,方便下次遍历
+ if t1==nil{
+ value=t2.Val
+ t1=nullNode
+ }else if t2==nil{
+ value=t1.Val
+ t2=nullNode
+ }else {
+ value=t1.Val+t2.Val
+ }
+ }
+ root:=&TreeNode{//构造新的二叉树
+ Val: value,
+ Left: mergeTrees(t1.Left,t2.Left),
+ Right: mergeTrees(t1.Right,t2.Right)}
+ return root
+}
+```
diff --git a/problems/0647.回文子串.md b/problems/0647.回文子串.md
index 58949571..31734bbc 100644
--- a/problems/0647.回文子串.md
+++ b/problems/0647.回文子串.md
@@ -284,6 +284,56 @@ class Solution {
Python:
+> 动态规划:
+```python
+class Solution:
+ def countSubstrings(self, s: str) -> int:
+ dp = [[False] * len(s) for _ in range(len(s))]
+ result = 0
+ for i in range(len(s)-1, -1, -1): #注意遍历顺序
+ for j in range(i, len(s)):
+ if s[i] == s[j]:
+ if j - i <= 1: #情况一 和 情况二
+ result += 1
+ dp[i][j] = True
+ elif dp[i+1][j-1]: #情况三
+ result += 1
+ dp[i][j] = True
+ return result
+```
+
+> 动态规划:简洁版
+```python
+class Solution:
+ def countSubstrings(self, s: str) -> int:
+ dp = [[False] * len(s) for _ in range(len(s))]
+ result = 0
+ for i in range(len(s)-1, -1, -1): #注意遍历顺序
+ for j in range(i, len(s)):
+ if s[i] == s[j] and (j - i <= 1 or dp[i+1][j-1]):
+ result += 1
+ dp[i][j] = True
+ return result
+```
+
+> 双指针法:
+```python
+class Solution:
+ def countSubstrings(self, s: str) -> int:
+ result = 0
+ for i in range(len(s)):
+ result += self.extend(s, i, i, len(s)) #以i为中心
+ result += self.extend(s, i, i+1, len(s)) #以i和i+1为中心
+ return result
+
+ def extend(self, s, i, j, n):
+ res = 0
+ while i >= 0 and j < n and s[i] == s[j]:
+ i -= 1
+ j += 1
+ res += 1
+ return res
+```
Go:
```Go
diff --git a/problems/0654.最大二叉树.md b/problems/0654.最大二叉树.md
index ea8c15cd..4e1e7a72 100644
--- a/problems/0654.最大二叉树.md
+++ b/problems/0654.最大二叉树.md
@@ -278,6 +278,75 @@ class Solution:
Go:
+> 654. 最大二叉树
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func constructMaximumBinaryTree(nums []int) *TreeNode {
+ if len(nums)<1{return nil}
+ //首选找到最大值
+ index:=findMax(nums)
+ //其次构造二叉树
+ root:=&TreeNode{
+ Val: nums[index],
+ Left:constructMaximumBinaryTree(nums[:index]),//左半边
+ Right:constructMaximumBinaryTree(nums[index+1:]),//右半边
+ }
+ return root
+}
+func findMax(nums []int) (index int){
+ for i:=0;inums[index]{
+ index=i
+ }
+ }
+ return
+}
+```
+
+JavaScript版本
+
+```javascript
+/**
+ * Definition for a binary tree node.
+ * function TreeNode(val, left, right) {
+ * this.val = (val===undefined ? 0 : val)
+ * this.left = (left===undefined ? null : left)
+ * this.right = (right===undefined ? null : right)
+ * }
+ */
+/**
+ * @param {number[]} nums
+ * @return {TreeNode}
+ */
+var constructMaximumBinaryTree = function (nums) {
+ const BuildTree = (arr, left, right) => {
+ if (left > right)
+ return null;
+ let maxValue = -1;
+ let maxIndex = -1;
+ for (let i = left; i <= right; ++i) {
+ if (arr[i] > maxValue) {
+ maxValue = arr[i];
+ maxIndex = i;
+ }
+ }
+ let root = new TreeNode(maxValue);
+ root.left = BuildTree(arr, left, maxIndex - 1);
+ root.right = BuildTree(arr, maxIndex + 1, right);
+ return root;
+ }
+ let root = BuildTree(nums, 0, nums.length - 1);
+ return root;
+};
+```
diff --git a/problems/0674.最长连续递增序列.md b/problems/0674.最长连续递增序列.md
index 46413d98..31ab6b0e 100644
--- a/problems/0674.最长连续递增序列.md
+++ b/problems/0674.最长连续递增序列.md
@@ -156,10 +156,65 @@ public:
Java:
-
+```java
+ /**
+ * 1.dp[i] 代表当前下表最大连续值
+ * 2.递推公式 if(nums[i+1]>nums[i]) dp[i+1] = dp[i]+1
+ * 3.初始化 都为1
+ * 4.遍历方向,从其那往后
+ * 5.结果推导 。。。。
+ * @param nums
+ * @return
+ */
+ public static int findLengthOfLCIS(int[] nums) {
+ int[] dp = new int[nums.length];
+ for (int i = 0; i < dp.length; i++) {
+ dp[i] = 1;
+ }
+ int res = 1;
+ for (int i = 0; i < nums.length - 1; i++) {
+ if (nums[i + 1] > nums[i]) {
+ dp[i + 1] = dp[i] + 1;
+ }
+ res = res > dp[i + 1] ? res : dp[i + 1];
+ }
+ return res;
+ }
+```
Python:
+> 动态规划:
+```python
+class Solution:
+ def findLengthOfLCIS(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+ result = 1
+ dp = [1] * len(nums)
+ for i in range(len(nums)-1):
+ if nums[i+1] > nums[i]: #连续记录
+ dp[i+1] = dp[i] + 1
+ result = max(result, dp[i+1])
+ return result
+```
+
+> 贪心法:
+```python
+class Solution:
+ def findLengthOfLCIS(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+ result = 1 #连续子序列最少也是1
+ count = 1
+ for i in range(len(nums)-1):
+ if nums[i+1] > nums[i]: #连续记录
+ count += 1
+ else: #不连续,count从头开始
+ count = 1
+ result = max(result, count)
+ return result
+```
Go:
diff --git a/problems/0700.二叉搜索树中的搜索.md b/problems/0700.二叉搜索树中的搜索.md
index 25a06617..16b21f26 100644
--- a/problems/0700.二叉搜索树中的搜索.md
+++ b/problems/0700.二叉搜索树中的搜索.md
@@ -241,6 +241,56 @@ class Solution:
Go:
+> 递归法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+ //递归法
+func searchBST(root *TreeNode, val int) *TreeNode {
+ if root==nil||root.Val==val{
+ return root
+ }
+ if root.Val>val{
+ return searchBST(root.Left,val)
+ }
+ return searchBST(root.Right,val)
+}
+```
+
+> 迭代法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+ //迭代法
+func searchBST(root *TreeNode, val int) *TreeNode {
+ for root!=nil{
+ if root.Val>val{
+ root=root.Left
+ }else if root.Val int:
left, right = 0, len(nums) - 1
@@ -211,8 +218,26 @@ class Solution:
return -1
```
+(版本二)左闭右开区间
-Go:
+```python
+class Solution:
+ def search(self, nums: List[int], target: int) -> int:
+ left,right =0, len(nums)
+ while left < right:
+ mid = (left + right) // 2
+ if nums[mid] < target:
+ left = mid+1
+ elif nums[mid] > target:
+ right = mid
+ else:
+ return mid
+ return -1
+```
+
+
+
+**Go:**
(版本一)左闭右闭区间
@@ -254,7 +279,7 @@ func search(nums []int, target int) int {
}
```
-javaScript
+**javaScript:**
```js
diff --git a/problems/0707.设计链表.md b/problems/0707.设计链表.md
index 2fa1af29..b67a36eb 100644
--- a/problems/0707.设计链表.md
+++ b/problems/0707.设计链表.md
@@ -158,6 +158,7 @@ private:
Java:
```Java
+//单链表
class ListNode {
int val;
ListNode next;
@@ -236,10 +237,110 @@ class MyLinkedList {
pred.next = pred.next.next;
}
}
+
+//双链表
+class MyLinkedList {
+ class ListNode {
+ int val;
+ ListNode next,prev;
+ ListNode(int x) {val = x;}
+ }
+
+ int size;
+ ListNode head,tail;//Sentinel node
+
+ /** Initialize your data structure here. */
+ public MyLinkedList() {
+ size = 0;
+ head = new ListNode(0);
+ tail = new ListNode(0);
+ head.next = tail;
+ tail.prev = head;
+ }
+
+ /** Get the value of the index-th node in the linked list. If the index is invalid, return -1. */
+ public int get(int index) {
+ if(index < 0 || index >= size){return -1;}
+ ListNode cur = head;
+
+ // 通过判断 index < (size - 1) / 2 来决定是从头结点还是尾节点遍历,提高效率
+ if(index < (size - 1) / 2){
+ for(int i = 0; i <= index; i++){
+ cur = cur.next;
+ }
+ }else{
+ cur = tail;
+ for(int i = 0; i <= size - index - 1; i++){
+ cur = cur.prev;
+ }
+ }
+ return cur.val;
+ }
+
+ /** Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list. */
+ public void addAtHead(int val) {
+ ListNode cur = head;
+ ListNode newNode = new ListNode(val);
+ newNode.next = cur.next;
+ cur.next.prev = newNode;
+ cur.next = newNode;
+ newNode.prev = cur;
+ size++;
+ }
+
+ /** Append a node of value val to the last element of the linked list. */
+ public void addAtTail(int val) {
+ ListNode cur = tail;
+ ListNode newNode = new ListNode(val);
+ newNode.next = tail;
+ newNode.prev = cur.prev;
+ cur.prev.next = newNode;
+ cur.prev = newNode;
+ size++;
+ }
+
+ /** Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted. */
+ public void addAtIndex(int index, int val) {
+ if(index > size){return;}
+ if(index < 0){index = 0;}
+ ListNode cur = head;
+ for(int i = 0; i < index; i++){
+ cur = cur.next;
+ }
+ ListNode newNode = new ListNode(val);
+ newNode.next = cur.next;
+ cur.next.prev = newNode;
+ newNode.prev = cur;
+ cur.next = newNode;
+ size++;
+ }
+
+ /** Delete the index-th node in the linked list, if the index is valid. */
+ public void deleteAtIndex(int index) {
+ if(index >= size || index < 0){return;}
+ ListNode cur = head;
+ for(int i = 0; i < index; i++){
+ cur = cur.next;
+ }
+ cur.next.next.prev = cur;
+ cur.next = cur.next.next;
+ size--;
+ }
+}
+
+/**
+ * Your MyLinkedList object will be instantiated and called as such:
+ * MyLinkedList obj = new MyLinkedList();
+ * int param_1 = obj.get(index);
+ * obj.addAtHead(val);
+ * obj.addAtTail(val);
+ * obj.addAtIndex(index,val);
+ * obj.deleteAtIndex(index);
+ */
```
Python:
-```python3
+```python
# 单链表
class Node:
diff --git a/problems/0714.买卖股票的最佳时机含手续费.md b/problems/0714.买卖股票的最佳时机含手续费.md
index abd20625..2e8f9208 100644
--- a/problems/0714.买卖股票的最佳时机含手续费.md
+++ b/problems/0714.买卖股票的最佳时机含手续费.md
@@ -217,7 +217,29 @@ class Solution: # 贪心思路
Go:
+Javascript:
+```Javascript
+// 贪心思路
+var maxProfit = function(prices, fee) {
+ let result = 0
+ let minPrice = prices[0]
+ for(let i = 1; i < prices.length; i++) {
+ if(prices[i] < minPrice) {
+ minPrice = prices[i]
+ }
+ if(prices[i] >= minPrice && prices[i] <= minPrice + fee) {
+ continue
+ }
+ if(prices[i] > minPrice + fee) {
+ result += prices[i] - minPrice - fee
+ // 买入和卖出只需要支付一次手续费
+ minPrice = prices[i] -fee
+ }
+ }
+ return result
+};
+```
-----------------------
diff --git a/problems/0714.买卖股票的最佳时机含手续费(动态规划).md b/problems/0714.买卖股票的最佳时机含手续费(动态规划).md
index 14b5859b..5eb3453b 100644
--- a/problems/0714.买卖股票的最佳时机含手续费(动态规划).md
+++ b/problems/0714.买卖股票的最佳时机含手续费(动态规划).md
@@ -139,7 +139,17 @@ public int maxProfit(int[] prices, int fee) {
```
Python:
-
+```python
+class Solution:
+ def maxProfit(self, prices: List[int], fee: int) -> int:
+ n = len(prices)
+ dp = [[0] * 2 for _ in range(n)]
+ dp[0][0] = -prices[0] #持股票
+ for i in range(1, n):
+ dp[i][0] = max(dp[i-1][0], dp[i-1][1] - prices[i])
+ dp[i][1] = max(dp[i-1][1], dp[i-1][0] + prices[i] - fee)
+ return max(dp[-1][0], dp[-1][1])
+```
Go:
diff --git a/problems/0718.最长重复子数组.md b/problems/0718.最长重复子数组.md
index be9109b2..bef616d3 100644
--- a/problems/0718.最长重复子数组.md
+++ b/problems/0718.最长重复子数组.md
@@ -154,10 +154,58 @@ public:
Java:
-
+```java
+class Solution {
+ public int findLength(int[] nums1, int[] nums2) {
+ int result = 0;
+ int[][] dp = new int[nums1.length + 1][nums2.length + 1];
+
+ for (int i = 1; i < nums1.length + 1; i++) {
+ for (int j = 1; j < nums2.length + 1; j++) {
+ if (nums1[i - 1] == nums2[j - 1]) {
+ dp[i][j] = dp[i - 1][j - 1] + 1;
+ max = Math.max(max, dp[i][j]);
+ }
+ }
+ }
+
+ return result;
+ }
+}
+```
Python:
+> 动态规划:
+```python
+class Solution:
+ def findLength(self, A: List[int], B: List[int]) -> int:
+ dp = [[0] * (len(B)+1) for _ in range(len(A)+1)]
+ result = 0
+ for i in range(1, len(A)+1):
+ for j in range(1, len(B)+1):
+ if A[i-1] == B[j-1]:
+ dp[i][j] = dp[i-1][j-1] + 1
+ result = max(result, dp[i][j])
+ return result
+```
+
+> 动态规划:滚动数组
+```python
+class Solution:
+ def findLength(self, A: List[int], B: List[int]) -> int:
+ dp = [0] * (len(B) + 1)
+ result = 0
+ for i in range(1, len(A)+1):
+ for j in range(len(B), 0, -1):
+ if A[i-1] == B[j-1]:
+ dp[j] = dp[j-1] + 1
+ else:
+ dp[j] = 0 #注意这里不相等的时候要有赋0的操作
+ result = max(result, dp[j])
+ return result
+```
+
Go:
```Go
diff --git a/problems/0738.单调递增的数字.md b/problems/0738.单调递增的数字.md
index 5bddb234..75c7f250 100644
--- a/problems/0738.单调递增的数字.md
+++ b/problems/0738.单调递增的数字.md
@@ -147,23 +147,43 @@ class Solution {
Python:
-```python
+```python3
class Solution:
def monotoneIncreasingDigits(self, n: int) -> int:
- strNum = list(str(n))
- flag = len(strNum)
- for i in range(len(strNum) - 1, 0, -1):
- if int(strNum[i]) < int(strNum[i - 1]):
- strNum[i - 1] = str(int(strNum[i - 1]) - 1)
- flag = i
- for i in range(flag, len(strNum)):
- strNum[i] = '9'
- return int("".join(strNum))
+ a = list(str(n))
+ for i in range(len(a)-1,0,-1):
+ if int(a[i]) < int(a[i-1]):
+ a[i-1] = str(int(a[i-1]) - 1)
+ a[i:] = '9' * (len(a) - i) #python不需要设置flag值,直接按长度给9就好了
+ return int("".join(a))
```
Go:
+Javascript:
+```Javascript
+var monotoneIncreasingDigits = function(n) {
+ n = n.toString()
+ n = n.split('').map(item => {
+ return +item
+ })
+ let flag = Infinity
+ for(let i = n.length - 1; i > 0; i--) {
+ if(n [i - 1] > n[i]) {
+ flag = i
+ n[i - 1] = n[i - 1] - 1
+ n[i] = 9
+ }
+ }
+ for(let i = flag; i < n.length; i++) {
+ n[i] = 9
+ }
+
+ n = n.join('')
+ return +n
+};
+```
-----------------------
diff --git a/problems/0739.每日温度.md b/problems/0739.每日温度.md
new file mode 100644
index 00000000..eeea6ead
--- /dev/null
+++ b/problems/0739.每日温度.md
@@ -0,0 +1,271 @@
+
+
那么这里具体反转的逻辑我们要不要使用库函数呢,其实用不用都可以,使用reverse来实现反转也没毛病,毕竟不是解题关键部分。
@@ -65,7 +65,7 @@ public:
};
```
-那么我们也可以实现自己的reverse函数,其实和题目[344. 反转字符串](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)道理是一样的。
+那么我们也可以实现自己的reverse函数,其实和题目[344. 反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w)道理是一样的。
下面我实现的reverse函数区间是左闭右闭区间,代码如下:
@@ -103,6 +103,7 @@ public:
Java:
```Java
+//解法一
class Solution {
public String reverseStr(String s, int k) {
StringBuffer res = new StringBuffer();
@@ -128,6 +129,28 @@ class Solution {
return res.toString();
}
}
+
+//解法二(似乎更容易理解点)
+//题目的意思其实概括为 每隔2k个反转前k个,尾数不够k个时候全部反转
+class Solution {
+ public String reverseStr(String s, int k) {
+ char[] ch = s.toCharArray();
+ for(int i = 0; i < ch.length; i += 2 * k){
+ int start = i;
+ //这里是判断尾数够不够k个来取决end指针的位置
+ int end = Math.min(ch.length - 1, start + k - 1);
+ //用异或运算反转
+ while(start < end){
+ ch[start] ^= ch[end];
+ ch[end] ^= ch[start];
+ ch[start] ^= ch[end];
+ start++;
+ end--;
+ }
+ }
+ return new String(ch);
+ }
+}
```
Python:
diff --git a/problems/0583.两个字符串的删除操作.md b/problems/0583.两个字符串的删除操作.md
index cd550d65..ee1fbc5f 100644
--- a/problems/0583.两个字符串的删除操作.md
+++ b/problems/0583.两个字符串的删除操作.md
@@ -104,10 +104,47 @@ public:
Java:
+```java
+class Solution {
+ public int minDistance(String word1, String word2) {
+ int[][] dp = new int[word1.length() + 1][word2.length() + 1];
+ for (int i = 0; i < word1.length() + 1; i++) dp[i][0] = i;
+ for (int j = 0; j < word2.length() + 1; j++) dp[0][j] = j;
+
+ for (int i = 1; i < word1.length() + 1; i++) {
+ for (int j = 1; j < word2.length() + 1; j++) {
+ if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
+ dp[i][j] = dp[i - 1][j - 1];
+ }else{
+ dp[i][j] = Math.min(dp[i - 1][j - 1] + 2,
+ Math.min(dp[i - 1][j] + 1, dp[i][j - 1] + 1));
+ }
+ }
+ }
+
+ return dp[word1.length()][word2.length()];
+ }
+}
+```
Python:
-
+```python
+class Solution:
+ def minDistance(self, word1: str, word2: str) -> int:
+ dp = [[0] * (len(word2)+1) for _ in range(len(word1)+1)]
+ for i in range(len(word1)+1):
+ dp[i][0] = i
+ for j in range(len(word2)+1):
+ dp[0][j] = j
+ for i in range(1, len(word1)+1):
+ for j in range(1, len(word2)+1):
+ if word1[i-1] == word2[j-1]:
+ dp[i][j] = dp[i-1][j-1]
+ else:
+ dp[i][j] = min(dp[i-1][j-1] + 2, dp[i-1][j] + 1, dp[i][j-1] + 1)
+ return dp[-1][-1]
+```
Go:
diff --git a/problems/0617.合并二叉树.md b/problems/0617.合并二叉树.md
index d65275f0..be6bb425 100644
--- a/problems/0617.合并二叉树.md
+++ b/problems/0617.合并二叉树.md
@@ -332,6 +332,43 @@ class Solution:
Go:
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+ //前序遍历(递归遍历,跟105 106差不多的思路)
+func mergeTrees(t1 *TreeNode, t2 *TreeNode) *TreeNode {
+ var value int
+ var nullNode *TreeNode//空node,便于遍历
+ nullNode=&TreeNode{
+ Val:0,
+ Left:nil,
+ Right:nil}
+ switch {
+ case t1==nil&&t2==nil: return nil//终止条件
+ default : //如果其中一个节点为空,则将该节点置为nullNode,方便下次遍历
+ if t1==nil{
+ value=t2.Val
+ t1=nullNode
+ }else if t2==nil{
+ value=t1.Val
+ t2=nullNode
+ }else {
+ value=t1.Val+t2.Val
+ }
+ }
+ root:=&TreeNode{//构造新的二叉树
+ Val: value,
+ Left: mergeTrees(t1.Left,t2.Left),
+ Right: mergeTrees(t1.Right,t2.Right)}
+ return root
+}
+```
diff --git a/problems/0647.回文子串.md b/problems/0647.回文子串.md
index 58949571..31734bbc 100644
--- a/problems/0647.回文子串.md
+++ b/problems/0647.回文子串.md
@@ -284,6 +284,56 @@ class Solution {
Python:
+> 动态规划:
+```python
+class Solution:
+ def countSubstrings(self, s: str) -> int:
+ dp = [[False] * len(s) for _ in range(len(s))]
+ result = 0
+ for i in range(len(s)-1, -1, -1): #注意遍历顺序
+ for j in range(i, len(s)):
+ if s[i] == s[j]:
+ if j - i <= 1: #情况一 和 情况二
+ result += 1
+ dp[i][j] = True
+ elif dp[i+1][j-1]: #情况三
+ result += 1
+ dp[i][j] = True
+ return result
+```
+
+> 动态规划:简洁版
+```python
+class Solution:
+ def countSubstrings(self, s: str) -> int:
+ dp = [[False] * len(s) for _ in range(len(s))]
+ result = 0
+ for i in range(len(s)-1, -1, -1): #注意遍历顺序
+ for j in range(i, len(s)):
+ if s[i] == s[j] and (j - i <= 1 or dp[i+1][j-1]):
+ result += 1
+ dp[i][j] = True
+ return result
+```
+
+> 双指针法:
+```python
+class Solution:
+ def countSubstrings(self, s: str) -> int:
+ result = 0
+ for i in range(len(s)):
+ result += self.extend(s, i, i, len(s)) #以i为中心
+ result += self.extend(s, i, i+1, len(s)) #以i和i+1为中心
+ return result
+
+ def extend(self, s, i, j, n):
+ res = 0
+ while i >= 0 and j < n and s[i] == s[j]:
+ i -= 1
+ j += 1
+ res += 1
+ return res
+```
Go:
```Go
diff --git a/problems/0654.最大二叉树.md b/problems/0654.最大二叉树.md
index ea8c15cd..4e1e7a72 100644
--- a/problems/0654.最大二叉树.md
+++ b/problems/0654.最大二叉树.md
@@ -278,6 +278,75 @@ class Solution:
Go:
+> 654. 最大二叉树
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func constructMaximumBinaryTree(nums []int) *TreeNode {
+ if len(nums)<1{return nil}
+ //首选找到最大值
+ index:=findMax(nums)
+ //其次构造二叉树
+ root:=&TreeNode{
+ Val: nums[index],
+ Left:constructMaximumBinaryTree(nums[:index]),//左半边
+ Right:constructMaximumBinaryTree(nums[index+1:]),//右半边
+ }
+ return root
+}
+func findMax(nums []int) (index int){
+ for i:=0;inums[index]{
+ index=i
+ }
+ }
+ return
+}
+```
+
+JavaScript版本
+
+```javascript
+/**
+ * Definition for a binary tree node.
+ * function TreeNode(val, left, right) {
+ * this.val = (val===undefined ? 0 : val)
+ * this.left = (left===undefined ? null : left)
+ * this.right = (right===undefined ? null : right)
+ * }
+ */
+/**
+ * @param {number[]} nums
+ * @return {TreeNode}
+ */
+var constructMaximumBinaryTree = function (nums) {
+ const BuildTree = (arr, left, right) => {
+ if (left > right)
+ return null;
+ let maxValue = -1;
+ let maxIndex = -1;
+ for (let i = left; i <= right; ++i) {
+ if (arr[i] > maxValue) {
+ maxValue = arr[i];
+ maxIndex = i;
+ }
+ }
+ let root = new TreeNode(maxValue);
+ root.left = BuildTree(arr, left, maxIndex - 1);
+ root.right = BuildTree(arr, maxIndex + 1, right);
+ return root;
+ }
+ let root = BuildTree(nums, 0, nums.length - 1);
+ return root;
+};
+```
diff --git a/problems/0674.最长连续递增序列.md b/problems/0674.最长连续递增序列.md
index 46413d98..31ab6b0e 100644
--- a/problems/0674.最长连续递增序列.md
+++ b/problems/0674.最长连续递增序列.md
@@ -156,10 +156,65 @@ public:
Java:
-
+```java
+ /**
+ * 1.dp[i] 代表当前下表最大连续值
+ * 2.递推公式 if(nums[i+1]>nums[i]) dp[i+1] = dp[i]+1
+ * 3.初始化 都为1
+ * 4.遍历方向,从其那往后
+ * 5.结果推导 。。。。
+ * @param nums
+ * @return
+ */
+ public static int findLengthOfLCIS(int[] nums) {
+ int[] dp = new int[nums.length];
+ for (int i = 0; i < dp.length; i++) {
+ dp[i] = 1;
+ }
+ int res = 1;
+ for (int i = 0; i < nums.length - 1; i++) {
+ if (nums[i + 1] > nums[i]) {
+ dp[i + 1] = dp[i] + 1;
+ }
+ res = res > dp[i + 1] ? res : dp[i + 1];
+ }
+ return res;
+ }
+```
Python:
+> 动态规划:
+```python
+class Solution:
+ def findLengthOfLCIS(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+ result = 1
+ dp = [1] * len(nums)
+ for i in range(len(nums)-1):
+ if nums[i+1] > nums[i]: #连续记录
+ dp[i+1] = dp[i] + 1
+ result = max(result, dp[i+1])
+ return result
+```
+
+> 贪心法:
+```python
+class Solution:
+ def findLengthOfLCIS(self, nums: List[int]) -> int:
+ if len(nums) == 0:
+ return 0
+ result = 1 #连续子序列最少也是1
+ count = 1
+ for i in range(len(nums)-1):
+ if nums[i+1] > nums[i]: #连续记录
+ count += 1
+ else: #不连续,count从头开始
+ count = 1
+ result = max(result, count)
+ return result
+```
Go:
diff --git a/problems/0700.二叉搜索树中的搜索.md b/problems/0700.二叉搜索树中的搜索.md
index 25a06617..16b21f26 100644
--- a/problems/0700.二叉搜索树中的搜索.md
+++ b/problems/0700.二叉搜索树中的搜索.md
@@ -241,6 +241,56 @@ class Solution:
Go:
+> 递归法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+ //递归法
+func searchBST(root *TreeNode, val int) *TreeNode {
+ if root==nil||root.Val==val{
+ return root
+ }
+ if root.Val>val{
+ return searchBST(root.Left,val)
+ }
+ return searchBST(root.Right,val)
+}
+```
+
+> 迭代法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+ //迭代法
+func searchBST(root *TreeNode, val int) *TreeNode {
+ for root!=nil{
+ if root.Val>val{
+ root=root.Left
+ }else if root.Val int:
left, right = 0, len(nums) - 1
@@ -211,8 +218,26 @@ class Solution:
return -1
```
+(版本二)左闭右开区间
-Go:
+```python
+class Solution:
+ def search(self, nums: List[int], target: int) -> int:
+ left,right =0, len(nums)
+ while left < right:
+ mid = (left + right) // 2
+ if nums[mid] < target:
+ left = mid+1
+ elif nums[mid] > target:
+ right = mid
+ else:
+ return mid
+ return -1
+```
+
+
+
+**Go:**
(版本一)左闭右闭区间
@@ -254,7 +279,7 @@ func search(nums []int, target int) int {
}
```
-javaScript
+**javaScript:**
```js
diff --git a/problems/0707.设计链表.md b/problems/0707.设计链表.md
index 2fa1af29..b67a36eb 100644
--- a/problems/0707.设计链表.md
+++ b/problems/0707.设计链表.md
@@ -158,6 +158,7 @@ private:
Java:
```Java
+//单链表
class ListNode {
int val;
ListNode next;
@@ -236,10 +237,110 @@ class MyLinkedList {
pred.next = pred.next.next;
}
}
+
+//双链表
+class MyLinkedList {
+ class ListNode {
+ int val;
+ ListNode next,prev;
+ ListNode(int x) {val = x;}
+ }
+
+ int size;
+ ListNode head,tail;//Sentinel node
+
+ /** Initialize your data structure here. */
+ public MyLinkedList() {
+ size = 0;
+ head = new ListNode(0);
+ tail = new ListNode(0);
+ head.next = tail;
+ tail.prev = head;
+ }
+
+ /** Get the value of the index-th node in the linked list. If the index is invalid, return -1. */
+ public int get(int index) {
+ if(index < 0 || index >= size){return -1;}
+ ListNode cur = head;
+
+ // 通过判断 index < (size - 1) / 2 来决定是从头结点还是尾节点遍历,提高效率
+ if(index < (size - 1) / 2){
+ for(int i = 0; i <= index; i++){
+ cur = cur.next;
+ }
+ }else{
+ cur = tail;
+ for(int i = 0; i <= size - index - 1; i++){
+ cur = cur.prev;
+ }
+ }
+ return cur.val;
+ }
+
+ /** Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list. */
+ public void addAtHead(int val) {
+ ListNode cur = head;
+ ListNode newNode = new ListNode(val);
+ newNode.next = cur.next;
+ cur.next.prev = newNode;
+ cur.next = newNode;
+ newNode.prev = cur;
+ size++;
+ }
+
+ /** Append a node of value val to the last element of the linked list. */
+ public void addAtTail(int val) {
+ ListNode cur = tail;
+ ListNode newNode = new ListNode(val);
+ newNode.next = tail;
+ newNode.prev = cur.prev;
+ cur.prev.next = newNode;
+ cur.prev = newNode;
+ size++;
+ }
+
+ /** Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted. */
+ public void addAtIndex(int index, int val) {
+ if(index > size){return;}
+ if(index < 0){index = 0;}
+ ListNode cur = head;
+ for(int i = 0; i < index; i++){
+ cur = cur.next;
+ }
+ ListNode newNode = new ListNode(val);
+ newNode.next = cur.next;
+ cur.next.prev = newNode;
+ newNode.prev = cur;
+ cur.next = newNode;
+ size++;
+ }
+
+ /** Delete the index-th node in the linked list, if the index is valid. */
+ public void deleteAtIndex(int index) {
+ if(index >= size || index < 0){return;}
+ ListNode cur = head;
+ for(int i = 0; i < index; i++){
+ cur = cur.next;
+ }
+ cur.next.next.prev = cur;
+ cur.next = cur.next.next;
+ size--;
+ }
+}
+
+/**
+ * Your MyLinkedList object will be instantiated and called as such:
+ * MyLinkedList obj = new MyLinkedList();
+ * int param_1 = obj.get(index);
+ * obj.addAtHead(val);
+ * obj.addAtTail(val);
+ * obj.addAtIndex(index,val);
+ * obj.deleteAtIndex(index);
+ */
```
Python:
-```python3
+```python
# 单链表
class Node:
diff --git a/problems/0714.买卖股票的最佳时机含手续费.md b/problems/0714.买卖股票的最佳时机含手续费.md
index abd20625..2e8f9208 100644
--- a/problems/0714.买卖股票的最佳时机含手续费.md
+++ b/problems/0714.买卖股票的最佳时机含手续费.md
@@ -217,7 +217,29 @@ class Solution: # 贪心思路
Go:
+Javascript:
+```Javascript
+// 贪心思路
+var maxProfit = function(prices, fee) {
+ let result = 0
+ let minPrice = prices[0]
+ for(let i = 1; i < prices.length; i++) {
+ if(prices[i] < minPrice) {
+ minPrice = prices[i]
+ }
+ if(prices[i] >= minPrice && prices[i] <= minPrice + fee) {
+ continue
+ }
+ if(prices[i] > minPrice + fee) {
+ result += prices[i] - minPrice - fee
+ // 买入和卖出只需要支付一次手续费
+ minPrice = prices[i] -fee
+ }
+ }
+ return result
+};
+```
-----------------------
diff --git a/problems/0714.买卖股票的最佳时机含手续费(动态规划).md b/problems/0714.买卖股票的最佳时机含手续费(动态规划).md
index 14b5859b..5eb3453b 100644
--- a/problems/0714.买卖股票的最佳时机含手续费(动态规划).md
+++ b/problems/0714.买卖股票的最佳时机含手续费(动态规划).md
@@ -139,7 +139,17 @@ public int maxProfit(int[] prices, int fee) {
```
Python:
-
+```python
+class Solution:
+ def maxProfit(self, prices: List[int], fee: int) -> int:
+ n = len(prices)
+ dp = [[0] * 2 for _ in range(n)]
+ dp[0][0] = -prices[0] #持股票
+ for i in range(1, n):
+ dp[i][0] = max(dp[i-1][0], dp[i-1][1] - prices[i])
+ dp[i][1] = max(dp[i-1][1], dp[i-1][0] + prices[i] - fee)
+ return max(dp[-1][0], dp[-1][1])
+```
Go:
diff --git a/problems/0718.最长重复子数组.md b/problems/0718.最长重复子数组.md
index be9109b2..bef616d3 100644
--- a/problems/0718.最长重复子数组.md
+++ b/problems/0718.最长重复子数组.md
@@ -154,10 +154,58 @@ public:
Java:
-
+```java
+class Solution {
+ public int findLength(int[] nums1, int[] nums2) {
+ int result = 0;
+ int[][] dp = new int[nums1.length + 1][nums2.length + 1];
+
+ for (int i = 1; i < nums1.length + 1; i++) {
+ for (int j = 1; j < nums2.length + 1; j++) {
+ if (nums1[i - 1] == nums2[j - 1]) {
+ dp[i][j] = dp[i - 1][j - 1] + 1;
+ max = Math.max(max, dp[i][j]);
+ }
+ }
+ }
+
+ return result;
+ }
+}
+```
Python:
+> 动态规划:
+```python
+class Solution:
+ def findLength(self, A: List[int], B: List[int]) -> int:
+ dp = [[0] * (len(B)+1) for _ in range(len(A)+1)]
+ result = 0
+ for i in range(1, len(A)+1):
+ for j in range(1, len(B)+1):
+ if A[i-1] == B[j-1]:
+ dp[i][j] = dp[i-1][j-1] + 1
+ result = max(result, dp[i][j])
+ return result
+```
+
+> 动态规划:滚动数组
+```python
+class Solution:
+ def findLength(self, A: List[int], B: List[int]) -> int:
+ dp = [0] * (len(B) + 1)
+ result = 0
+ for i in range(1, len(A)+1):
+ for j in range(len(B), 0, -1):
+ if A[i-1] == B[j-1]:
+ dp[j] = dp[j-1] + 1
+ else:
+ dp[j] = 0 #注意这里不相等的时候要有赋0的操作
+ result = max(result, dp[j])
+ return result
+```
+
Go:
```Go
diff --git a/problems/0738.单调递增的数字.md b/problems/0738.单调递增的数字.md
index 5bddb234..75c7f250 100644
--- a/problems/0738.单调递增的数字.md
+++ b/problems/0738.单调递增的数字.md
@@ -147,23 +147,43 @@ class Solution {
Python:
-```python
+```python3
class Solution:
def monotoneIncreasingDigits(self, n: int) -> int:
- strNum = list(str(n))
- flag = len(strNum)
- for i in range(len(strNum) - 1, 0, -1):
- if int(strNum[i]) < int(strNum[i - 1]):
- strNum[i - 1] = str(int(strNum[i - 1]) - 1)
- flag = i
- for i in range(flag, len(strNum)):
- strNum[i] = '9'
- return int("".join(strNum))
+ a = list(str(n))
+ for i in range(len(a)-1,0,-1):
+ if int(a[i]) < int(a[i-1]):
+ a[i-1] = str(int(a[i-1]) - 1)
+ a[i:] = '9' * (len(a) - i) #python不需要设置flag值,直接按长度给9就好了
+ return int("".join(a))
```
Go:
+Javascript:
+```Javascript
+var monotoneIncreasingDigits = function(n) {
+ n = n.toString()
+ n = n.split('').map(item => {
+ return +item
+ })
+ let flag = Infinity
+ for(let i = n.length - 1; i > 0; i--) {
+ if(n [i - 1] > n[i]) {
+ flag = i
+ n[i - 1] = n[i - 1] - 1
+ n[i] = 9
+ }
+ }
+ for(let i = flag; i < n.length; i++) {
+ n[i] = 9
+ }
+
+ n = n.join('')
+ return +n
+};
+```
-----------------------
diff --git a/problems/0739.每日温度.md b/problems/0739.每日温度.md
new file mode 100644
index 00000000..eeea6ead
--- /dev/null
+++ b/problems/0739.每日温度.md
@@ -0,0 +1,271 @@
+
+
+  +
+  +
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 739. 每日温度
+
+
+https://leetcode-cn.com/problems/daily-temperatures/
+
+请根据每日 气温 列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用 0 来代替。
+
+例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
+
+提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
+
+
+## 思路
+
+首先想到的当然是暴力解法,两层for循环,把至少需要等待的天数就搜出来了。时间复杂度是O(n^2)
+
+那么接下来在来看看使用单调栈的解法。
+
+那有同学就问了,我怎么能想到用单调栈呢? 什么时候用单调栈呢?
+
+**通常是一维数组,要寻找任一个元素的右边或者左边第一个比自己大或者小的元素的位置,此时我们就要想到可以用单调栈了**。
+
+时间复杂度为O(n)。
+
+例如本题其实就是找找到一个元素右边第一个比自己大的元素。
+
+此时就应该想到用单调栈了。
+
+那么单调栈的原理是什么呢?为什么时间复杂度是O(n)就可以找到每一个元素的右边第一个比它大的元素位置呢?
+
+单调栈的本质是空间换时间,因为在遍历的过程中需要用一个栈来记录右边第一个比当前元素的元素,优点是只需要遍历一次。
+
+
+在使用单调栈的时候首先要明确如下几点:
+
+1. 单调栈里存放的元素是什么?
+
+单调栈里只需要存放元素的下标i就可以了,如果需要使用对应的元素,直接T[i]就可以获取。
+
+2. 单调栈里元素是递增呢? 还是递减呢?
+
+**注意一下顺序为 从栈头到栈底的顺序**,因为单纯的说从左到右或者从前到后,不说栈头朝哪个方向的话,大家一定会越看越懵。
+
+
+这里我们要使用递增循序(再强调一下是指从栈头到栈底的顺序),因为只有递增的时候,加入一个元素i,才知道栈顶元素在数组中右面第一个比栈顶元素大的元素是i。
+
+文字描述理解起来有点费劲,接下来我画了一系列的图,来讲解单调栈的工作过程。
+
+使用单调栈主要有三个判断条件。
+
+* 当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
+* 当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
+* 当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
+
+**把这三种情况分析清楚了,也就理解透彻了**。
+
+接下来我们用temperatures = [73, 74, 75, 71, 71, 72, 76, 73]为例来逐步分析,输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
+
+首先先将第一个遍历元素加入单调栈
+
+
+加入T[1] = 74,因为T[1] > T[0](当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况),而我们要保持一个递增单调栈(从栈头到栈底),所以将T[0]弹出,T[1]加入,此时result数组可以记录了,result[0] = 1,即T[0]右面第一个比T[0]大的元素是T[1]。
+
+
+加入T[2],同理,T[1]弹出
+
+
+
+加入T[3],T[3] < T[2] (当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况),加T[3]加入单调栈。
+
+
+
+加入T[4],T[4] == T[3] (当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况),此时依然要加入栈,不用计算距离,因为我们要求的是右面第一个大于本元素的位置,而不是大于等于!
+
+
+加入T[5],T[5] > T[4] (当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况),将T[4]弹出,同时计算距离,更新result
+
+
+T[4]弹出之后, T[5] > T[3] (当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况),将T[3]继续弹出,同时计算距离,更新result
+
+
+直到发现T[5]小于T[st.top()],终止弹出,将T[5]加入单调栈
+
+
+加入T[6],同理,需要将栈里的T[5],T[2]弹出
+
+
+同理,继续弹出
+
+
+此时栈里只剩下了T[6]
+
+
+
+加入T[7], T[7] < T[6] 直接入栈,这就是最后的情况,result数组也更新完了。
+
+
+
+此时有同学可能就疑惑了,那result[6] , result[7]怎么没更新啊,元素也一直在栈里。
+
+其实定义result数组的时候,就应该直接初始化为0,如果result没有更新,说明这个元素右面没有更大的了,也就是为0。
+
+以上在图解的时候,已经把,这三种情况都做了详细的分析。
+
+* 情况一:当前遍历的元素T[i]小于栈顶元素T[st.top()]的情况
+* 情况二:当前遍历的元素T[i]等于栈顶元素T[st.top()]的情况
+* 情况三:当前遍历的元素T[i]大于栈顶元素T[st.top()]的情况
+
+C++代码如下:
+
+```C++
+// 版本一
+class Solution {
+public:
+ vector dailyTemperatures(vector& T) {
+ // 递减栈
+ stack st;
+ vector result(T.size(), 0);
+ st.push(0);
+ for (int i = 1; i < T.size(); i++) {
+ if (T[i] < T[st.top()]) { // 情况一
+ st.push(i);
+ } else if (T[i] == T[st.top()]) { // 情况二
+ st.push(i);
+ } else {
+ while (!st.empty() && T[i] > T[st.top()]) { // 情况三
+ result[st.top()] = i - st.top();
+ st.pop();
+ }
+ st.push(i);
+ }
+ }
+ return result;
+ }
+};
+```
+
+**建议一开始 都把每种情况分析好,不要上来看简短的代码,关键逻辑都被隐藏了**。
+
+精简代码如下:
+
+```C++
+// 版本二
+class Solution {
+public:
+ vector dailyTemperatures(vector& T) {
+ stack st; // 递减栈
+ vector result(T.size(), 0);
+ st.push(0);
+ for (int i = 1; i < T.size(); i++) {
+ while (!st.empty() && T[i] > T[st.top()]) { // 注意栈不能为空
+ result[st.top()] = i - st.top();
+ st.pop();
+ }
+ st.push(i);
+
+ }
+ return result;
+ }
+};
+```
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
+
+精简的代码是直接把情况一二三都合并到了一起,其实这种代码精简是精简,但思路不是很清晰。
+
+建议大家把情况一二三想清楚了,先写出版本一的代码,然后在其基础上在做精简!
+
+
+## 其他语言版本
+
+
+Java:
+```java
+/**
+ * 单调栈,栈内顺序要么从大到小 要么从小到大,本题从大到笑
+ *
+ * 入站元素要和当前栈内栈首元素进行比较
+ * 若大于栈首则 则与元素下标做差
+ * 若大于等于则放入
+ *
+ * @param temperatures
+ * @return
+ */
+ public static int[] dailyTemperatures(int[] temperatures) {
+ Stack stack = new Stack<>();
+ int[] res = new int[temperatures.length];
+ for (int i = 0; i < temperatures.length; i++) {
+ /**
+ * 取出下标进行元素值的比较
+ */
+ while (!stack.isEmpty() && temperatures[i] > temperatures[stack.peek()]) {
+ int preIndex = stack.pop();
+ res[preIndex] = i - preIndex;
+ }
+ /**
+ * 注意 放入的是元素位置
+ */
+ stack.push(i);
+ }
+ return res;
+ }
+```
+Python:
+
+Go:
+
+> 暴力法
+
+```go
+func dailyTemperatures(temperatures []int) []int {
+ length:=len(temperatures)
+ res:=make([]int,length)
+ for i:=0;i=temperatures[j]{//大于等于
+ j++
+ }
+ if j 单调栈法
+
+```go
+func dailyTemperatures(temperatures []int) []int {
+ length:=len(temperatures)
+ res:=make([]int,length)
+ stack:=[]int{}
+ for i:=0;i0&&temperatures[i]>temperatures[stack[len(stack)-1]]{
+ res[stack[len(stack)-1]]=i-stack[len(stack)-1]//存放结果集
+ stack=stack[:len(stack)-1]//删除stack[len(stack)-1]的元素
+ }
+ //如果栈顶元素大于等于新来的元素,则加入到栈中。当栈内元素个数为0时,直接入栈
+ if len(stack)==0||temperatures[i]<=temperatures[stack[len(stack)-1]]{
+ stack = append(stack, i)
+ }
+ }
+ return res
+}
+```
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0746.使用最小花费爬楼梯.md b/problems/0746.使用最小花费爬楼梯.md
index 1e8e8038..4238a389 100644
--- a/problems/0746.使用最小花费爬楼梯.md
+++ b/problems/0746.使用最小花费爬楼梯.md
@@ -255,7 +255,18 @@ func min(a, b int) int {
}
```
-
+Javascript:
+```Javascript
+var minCostClimbingStairs = function(cost) {
+ const dp = [ cost[0], cost[1] ]
+
+ for (let i = 2; i < cost.length; ++i) {
+ dp[i] = Math.min(dp[i -1] + cost[i], dp[i - 2] + cost[i])
+ }
+
+ return Math.min(dp[cost.length - 1], dp[cost.length - 2])
+};
+```
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/0763.划分字母区间.md b/problems/0763.划分字母区间.md
index bcdd71dc..1e2fcc03 100644
--- a/problems/0763.划分字母区间.md
+++ b/problems/0763.划分字母区间.md
@@ -128,7 +128,26 @@ class Solution:
Go:
-
+Javascript:
+```Javascript
+var partitionLabels = function(s) {
+ let hash = {}
+ for(let i = 0; i < s.length; i++) {
+ hash[s[i]] = i
+ }
+ let result = []
+ let left = 0
+ let right = 0
+ for(let i = 0; i < s.length; i++) {
+ right = Math.max(right, hash[s[i]])
+ if(right === i) {
+ result.push(right - left + 1)
+ left = i + 1
+ }
+ }
+ return result
+};
+```
-----------------------
diff --git a/problems/0860.柠檬水找零.md b/problems/0860.柠檬水找零.md
index faee2e56..a18c008d 100644
--- a/problems/0860.柠檬水找零.md
+++ b/problems/0860.柠檬水找零.md
@@ -184,7 +184,38 @@ class Solution:
Go:
+Javascript:
+```Javascript
+var lemonadeChange = function(bills) {
+ let fiveCount = 0
+ let tenCount = 0
+ for(let i = 0; i < bills.length; i++) {
+ let bill = bills[i]
+ if(bill === 5) {
+ fiveCount += 1
+ } else if (bill === 10) {
+ if(fiveCount > 0) {
+ fiveCount -=1
+ tenCount += 1
+ } else {
+ return false
+ }
+ } else {
+ if(tenCount > 0 && fiveCount > 0) {
+ tenCount -= 1
+ fiveCount -= 1
+ } else if(fiveCount >= 3) {
+ fiveCount -= 3
+ } else {
+ return false
+ }
+ }
+ }
+ return true
+};
+
+```
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/0968.监控二叉树.md b/problems/0968.监控二叉树.md
index 8f1a3fdb..a0eb5883 100644
--- a/problems/0968.监控二叉树.md
+++ b/problems/0968.监控二叉树.md
@@ -369,7 +369,42 @@ class Solution:
```
Go:
+Javascript:
+```Javascript
+var minCameraCover = function(root) {
+ let result = 0
+ function traversal(cur) {
+ if(cur === null) {
+ return 2
+ }
+ let left = traversal(cur.left)
+ let right = traversal(cur.right)
+
+ if(left === 2 && right === 2) {
+ return 0
+ }
+
+ if(left === 0 || right === 0) {
+ result++
+ return 1
+ }
+
+ if(left === 1 || right === 1) {
+ return 2
+ }
+
+ return -1
+ }
+
+ if(traversal(root) === 0) {
+ result++
+ }
+
+ return result
+
+};
+```
-----------------------
diff --git a/problems/0977.有序数组的平方.md b/problems/0977.有序数组的平方.md
index b5d392e6..0f9007d7 100644
--- a/problems/0977.有序数组的平方.md
+++ b/problems/0977.有序数组的平方.md
@@ -96,8 +96,46 @@ public:
## 其他语言版本
-
Java:
+```Java
+class Solution {
+ public int[] sortedSquares(int[] nums) {
+ int right = nums.length - 1;
+ int left = 0;
+ int[] result = new int[nums.length];
+ int index = result.length - 1;
+ while (left <= right) {
+ if (nums[left] * nums[left] > nums[right] * nums[right]) {
+ result[index--] = nums[left] * nums[left];
+ ++left;
+ } else {
+ result[index--] = nums[right] * nums[right];
+ --right;
+ }
+ }
+ return result;
+ }
+}
+```
+
+```java
+class Solution {
+ public int[] sortedSquares(int[] nums) {
+ int l = 0;
+ int r = nums.length - 1;
+ int[] res = new int[nums.length];
+ int j = nums.length - 1;
+ while(l <= r){
+ if(nums[l] * nums[l] > nums[r] * nums[r]){
+ res[j--] = nums[l] * nums[l++];
+ }else{
+ res[j--] = nums[r] * nums[r--];
+ }
+ }
+ return res;
+ }
+}
+```
Python:
```Python
@@ -160,6 +198,31 @@ impl Solution {
}
}
```
+Javascript:
+```Javascript
+/**
+ * @desc two pointers solution
+ * @link https://leetcode-cn.com/problems/squares-of-a-sorted-array/
+ * @param nums Array e.g. [-4,-1,0,3,10]
+ * @return {array} e.g. [0,1,9,16,100]
+ */
+const sortedSquares = function (nums) {
+ let res = []
+ for (let i = 0, j = nums.length - 1; i <= j;) {
+ const left = Math.abs(nums[i])
+ const right = Math.abs(nums[j])
+ if (right > left) {
+ // push element to the front of the array
+ res.unshift(right * right)
+ j--
+ } else {
+ res.unshift(left * left)
+ i++
+ }
+ }
+ return res
+ }
+```
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/1005.K次取反后最大化的数组和.md b/problems/1005.K次取反后最大化的数组和.md
index 5539aff8..c3e99f7e 100644
--- a/problems/1005.K次取反后最大化的数组和.md
+++ b/problems/1005.K次取反后最大化的数组和.md
@@ -133,11 +133,35 @@ class Solution:
A[i] *= -1
K -= 1
if K > 0:
- A[len(A) - 1] *= ((-1)**K)
+ A[-1] *= (-1)**K #取A最后一个数只需要写-1
return sum(A)
```
Go:
+```Go
+func largestSumAfterKNegations(nums []int, K int) int {
+ sort.Slice(nums, func(i, j int) bool {
+ return math.Abs(float64(nums[i])) > math.Abs(float64(nums[j]))
+ })
+
+ for i := 0; i < len(nums); i++ {
+ if K > 0 && nums[i] < 0 {
+ nums[i] = -nums[i]
+ K--
+ }
+ }
+
+ if K%2 == 1 {
+ nums[len(nums)-1] = -nums[len(nums)-1]
+ }
+
+ result := 0
+ for i := 0; i < len(nums); i++ {
+ result += nums[i]
+ }
+ return result
+}
+```
Javascript:
diff --git a/problems/1035.不相交的线.md b/problems/1035.不相交的线.md
index 039030d2..be159543 100644
--- a/problems/1035.不相交的线.md
+++ b/problems/1035.不相交的线.md
@@ -93,7 +93,18 @@ Java:
```
Python:
-
+```python
+class Solution:
+ def maxUncrossedLines(self, A: List[int], B: List[int]) -> int:
+ dp = [[0] * (len(B)+1) for _ in range(len(A)+1)]
+ for i in range(1, len(A)+1):
+ for j in range(1, len(B)+1):
+ if A[i-1] == B[j-1]:
+ dp[i][j] = dp[i-1][j-1] + 1
+ else:
+ dp[i][j] = max(dp[i-1][j], dp[i][j-1])
+ return dp[-1][-1]
+```
Go:
diff --git a/problems/二叉树中递归带着回溯.md b/problems/二叉树中递归带着回溯.md
index 2adb826c..372dc40c 100644
--- a/problems/二叉树中递归带着回溯.md
+++ b/problems/二叉树中递归带着回溯.md
@@ -257,9 +257,190 @@ Java:
Python:
+100.相同的树
+> 递归法
+```python
+class Solution:
+ def isSameTree(self, p: TreeNode, q: TreeNode) -> bool:
+ return self.compare(p, q)
+
+ def compare(self, tree1, tree2):
+ if not tree1 and tree2:
+ return False
+ elif tree1 and not tree2:
+ return False
+ elif not tree1 and not tree2:
+ return True
+ elif tree1.val != tree2.val: #注意这里我没有使用else
+ return False
+
+ #此时就是:左右节点都不为空,且数值相同的情况
+ #此时才做递归,做下一层的判断
+ compareLeft = self.compare(tree1.left, tree2.left) #左子树:左、 右子树:左
+ compareRight = self.compare(tree1.right, tree2.right) #左子树:右、 右子树:右
+ isSame = compareLeft and compareRight #左子树:中、 右子树:中(逻辑处理)
+ return isSame
+```
+
+257.二叉的所有路径
+> 递归中隐藏着回溯
+```python
+class Solution:
+ def binaryTreePaths(self, root: TreeNode) -> List[str]:
+ result = []
+ path = []
+ if not root:
+ return result
+ self.traversal(root, path, result)
+ return result
+
+ def traversal(self, cur, path, result):
+ path.append(cur.val)
+ #这才到了叶子节点
+ if not cur.left and not cur.right:
+ sPath = ""
+ for i in range(len(path)-1):
+ sPath += str(path[i])
+ sPath += "->"
+ sPath += str(path[len(path)-1])
+ result.append(sPath)
+ return
+ if cur.left:
+ self.traversal(cur.left, path, result)
+ path.pop() #回溯
+ if cur.right:
+ self.traversal(cur.right, path, result)
+ path.pop() #回溯
+```
+
+> 精简版
+```python
+class Solution:
+ def binaryTreePaths(self, root: TreeNode) -> List[str]:
+ result = []
+ path = ""
+ if not root:
+ return result
+ self.traversal(root, path, result)
+ return result
+
+ def traversal(self, cur, path, result):
+ path += str(cur.val) #中
+ if not cur.left and not cur.right:
+ result.append(path)
+ return
+ if cur.left:
+ self.traversal(cur.left, path+"->", result) #左 回溯就隐藏在这里
+ if cur.right:
+ self.traversal(cur.right, path+"->", result) #右 回溯就隐藏在这里
+```
Go:
+100.相同的树
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func isSameTree(p *TreeNode, q *TreeNode) bool {
+ switch {
+ case p == nil && q == nil:
+ return true
+ case p == nil || q == nil:
+ fallthrough
+ case p.Val != q.Val:
+ return false
+ }
+ return isSameTree(p.Left, q.Left) && isSameTree(p.Right, q.Right)
+}
+```
+
+257.二叉的所有路径
+> 递归法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func binaryTreePaths(root *TreeNode) []string {
+ var result []string
+ traversal(root,&result,"")
+ return result
+}
+func traversal(root *TreeNode,result *[]string,pathStr string){
+ //判断是否为第一个元素
+ if len(pathStr)!=0{
+ pathStr=pathStr+"->"+strconv.Itoa(root.Val)
+ }else{
+ pathStr=strconv.Itoa(root.Val)
+ }
+ //判断是否为叶子节点
+ if root.Left==nil&&root.Right==nil{
+ *result=append(*result,pathStr)
+ return
+ }
+ //左右
+ if root.Left!=nil{
+ traversal(root.Left,result,pathStr)
+ }
+ if root.Right!=nil{
+ traversal(root.Right,result,pathStr)
+ }
+}
+```
+
+> 回溯法
+
+```go
+/**
+ * Definition for a binary tree node.
+ * type TreeNode struct {
+ * Val int
+ * Left *TreeNode
+ * Right *TreeNode
+ * }
+ */
+func binaryTreePaths(root *TreeNode) []string {
+ var result []string
+ var path []int
+ traversal(root,&result,&path)
+ return result
+}
+func traversal(root *TreeNode,result *[]string,path *[]int){
+ *path=append(*path,root.Val)
+ //判断是否为叶子节点
+ if root.Left==nil&&root.Right==nil{
+ pathStr:=strconv.Itoa((*path)[0])
+ for i:=1;i"+strconv.Itoa((*path)[i])
+ }
+ *result=append(*result,pathStr)
+ return
+ }
+ //左右
+ if root.Left!=nil{
+ traversal(root.Left,result,path)
+ *path=(*path)[:len(*path)-1]//回溯到上一个节点(因为traversal会加下一个节点值到path中)
+ }
+ if root.Right!=nil{
+ traversal(root.Right,result,path)
+ *path=(*path)[:len(*path)-1]//回溯
+ }
+}
+```
+
+
+
diff --git a/problems/二叉树的递归遍历.md b/problems/二叉树的递归遍历.md
index f2072e30..68f17257 100644
--- a/problems/二叉树的递归遍历.md
+++ b/problems/二叉树的递归遍历.md
@@ -221,12 +221,12 @@ class Solution:
Go:
前序遍历:
-```
+```go
func PreorderTraversal(root *TreeNode) (res []int) {
var traversal func(node *TreeNode)
traversal = func(node *TreeNode) {
if node == nil {
- return
+ return
}
res = append(res,node.Val)
traversal(node.Left)
@@ -239,12 +239,12 @@ func PreorderTraversal(root *TreeNode) (res []int) {
```
中序遍历:
-```
+```go
func InorderTraversal(root *TreeNode) (res []int) {
var traversal func(node *TreeNode)
traversal = func(node *TreeNode) {
if node == nil {
- return
+ return
}
traversal(node.Left)
res = append(res,node.Val)
@@ -256,12 +256,12 @@ func InorderTraversal(root *TreeNode) (res []int) {
```
后序遍历:
-```
+```go
func PostorderTraversal(root *TreeNode) (res []int) {
var traversal func(node *TreeNode)
traversal = func(node *TreeNode) {
if node == nil {
- return
+ return
}
traversal(node.Left)
traversal(node.Right)
diff --git a/problems/剑指Offer05.替换空格.md b/problems/剑指Offer05.替换空格.md
index 794f9ac5..f68d8e22 100644
--- a/problems/剑指Offer05.替换空格.md
+++ b/problems/剑指Offer05.替换空格.md
@@ -13,9 +13,9 @@ https://leetcode-cn.com/problems/ti-huan-kong-ge-lcof/
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
-示例 1:
-输入:s = "We are happy."
-输出:"We%20are%20happy."
+示例 1:
+输入:s = "We are happy."
+输出:"We%20are%20happy."
# 思路
@@ -42,9 +42,9 @@ i指向新长度的末尾,j指向旧长度的末尾。
时间复杂度,空间复杂度均超过100%的用户。
- +
+ -## C++代码
+C++代码如下:
```C++
class Solution {
@@ -76,17 +76,17 @@ public:
};
```
-时间复杂度:O(n)
-空间复杂度:O(1)
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
此时算上本题,我们已经做了七道双指针相关的题目了分别是:
-* [27.移除元素](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
-* [15.三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)
-* [18.四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)
-* [206.翻转链表](https://mp.weixin.qq.com/s/pnvVP-0ZM7epB8y3w_Njwg)
-* [142.环形链表II](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)
-* [344.反转字符串](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)
+* [27.移除元素](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)
+* [15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)
+* [18.四数之和](https://mp.weixin.qq.com/s/SBU3THi1Kv6Sar7htqCB2Q)
+* [206.翻转链表](https://mp.weixin.qq.com/s/ckEvIVGcNLfrz6OLOMoT0A)
+* [142.环形链表II](https://mp.weixin.qq.com/s/gt_VH3hQTqNxyWcl1ECSbQ)
+* [344.反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w)
# 拓展
@@ -121,10 +121,6 @@ for (int i = 0; i < a.size(); i++) {
所以想处理字符串,我们还是会定义一个string类型。
-
-
-
-
## 其他语言版本
@@ -150,11 +146,56 @@ public static String replaceSpace(StringBuffer str) {
}
```
-Python:
-
Go:
+```go
+// 遍历添加
+func replaceSpace(s string) string {
+ b := []byte(s)
+ result := make([]byte, 0)
+ for i := 0; i < len(b); i++ {
+ if b[i] == ' ' {
+ result = append(result, []byte("%20")...)
+ } else {
+ result = append(result, b[i])
+ }
+ }
+ return string(result)
+}
+// 原地修改
+func replaceSpace(s string) string {
+ b := []byte(s)
+ length := len(b)
+ spaceCount := 0
+ // 计算空格数量
+ for _, v := range b {
+ if v == ' ' {
+ spaceCount++
+ }
+ }
+ // 扩展原有切片
+ resizeCount := spaceCount * 2
+ tmp := make([]byte, resizeCount)
+ b = append(b, tmp...)
+ i := length - 1
+ j := len(b) - 1
+ for i >= 0 {
+ if b[i] != ' ' {
+ b[j] = b[i]
+ i--
+ j--
+ } else {
+ b[j] = '0'
+ b[j-1] = '2'
+ b[j-2] = '%'
+ i--
+ j = j - 3
+ }
+ }
+ return string(b)
+}
+```
diff --git a/problems/剑指Offer58-II.左旋转字符串.md b/problems/剑指Offer58-II.左旋转字符串.md
index 39c8382c..70c6f015 100644
--- a/problems/剑指Offer58-II.左旋转字符串.md
+++ b/problems/剑指Offer58-II.左旋转字符串.md
@@ -16,16 +16,16 @@ https://leetcode-cn.com/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof/
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
-示例 1:
-输入: s = "abcdefg", k = 2
-输出: "cdefgab"
+示例 1:
+输入: s = "abcdefg", k = 2
+输出: "cdefgab"
-示例 2:
-输入: s = "lrloseumgh", k = 6
-输出: "umghlrlose"
+示例 2:
+输入: s = "lrloseumgh", k = 6
+输出: "umghlrlose"
-限制:
-1 <= k < s.length <= 10000
+限制:
+1 <= k < s.length <= 10000
# 思路
@@ -34,7 +34,7 @@ https://leetcode-cn.com/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof/
不能使用额外空间的话,模拟在本串操作要实现左旋转字符串的功能还是有点困难的。
-那么我们可以想一下上一题目[字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)中讲过,使用整体反转+局部反转就可以实现,反转单词顺序的目的。
+那么我们可以想一下上一题目[字符串:花式反转还不够!](https://mp.weixin.qq.com/s/4j6vPFHkFAXnQhmSkq2X9g)中讲过,使用整体反转+局部反转就可以实现,反转单词顺序的目的。
这道题目也非常类似,依然可以通过局部反转+整体反转 达到左旋转的目的。
@@ -50,13 +50,13 @@ https://leetcode-cn.com/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof/
如图:
-
-## C++代码
+C++代码如下:
```C++
class Solution {
@@ -76,17 +76,17 @@ public:
};
```
-时间复杂度:O(n)
-空间复杂度:O(1)
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
此时算上本题,我们已经做了七道双指针相关的题目了分别是:
-* [27.移除元素](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA)
-* [15.三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)
-* [18.四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)
-* [206.翻转链表](https://mp.weixin.qq.com/s/pnvVP-0ZM7epB8y3w_Njwg)
-* [142.环形链表II](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)
-* [344.反转字符串](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA)
+* [27.移除元素](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)
+* [15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)
+* [18.四数之和](https://mp.weixin.qq.com/s/SBU3THi1Kv6Sar7htqCB2Q)
+* [206.翻转链表](https://mp.weixin.qq.com/s/ckEvIVGcNLfrz6OLOMoT0A)
+* [142.环形链表II](https://mp.weixin.qq.com/s/gt_VH3hQTqNxyWcl1ECSbQ)
+* [344.反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w)
# 拓展
@@ -121,10 +121,6 @@ for (int i = 0; i < a.size(); i++) {
所以想处理字符串,我们还是会定义一个string类型。
-
-
-
-
## 其他语言版本
@@ -150,11 +146,56 @@ public static String replaceSpace(StringBuffer str) {
}
```
-Python:
-
Go:
+```go
+// 遍历添加
+func replaceSpace(s string) string {
+ b := []byte(s)
+ result := make([]byte, 0)
+ for i := 0; i < len(b); i++ {
+ if b[i] == ' ' {
+ result = append(result, []byte("%20")...)
+ } else {
+ result = append(result, b[i])
+ }
+ }
+ return string(result)
+}
+// 原地修改
+func replaceSpace(s string) string {
+ b := []byte(s)
+ length := len(b)
+ spaceCount := 0
+ // 计算空格数量
+ for _, v := range b {
+ if v == ' ' {
+ spaceCount++
+ }
+ }
+ // 扩展原有切片
+ resizeCount := spaceCount * 2
+ tmp := make([]byte, resizeCount)
+ b = append(b, tmp...)
+ i := length - 1
+ j := len(b) - 1
+ for i >= 0 {
+ if b[i] != ' ' {
+ b[j] = b[i]
+ i--
+ j--
+ } else {
+ b[j] = '0'
+ b[j-1] = '2'
+ b[j-2] = '%'
+ i--
+ j = j - 3
+ }
+ }
+ return string(b)
+}
+```
diff --git a/problems/剑指Offer58-II.左旋转字符串.md b/problems/剑指Offer58-II.左旋转字符串.md
index 39c8382c..70c6f015 100644
--- a/problems/剑指Offer58-II.左旋转字符串.md
+++ b/problems/剑指Offer58-II.左旋转字符串.md
@@ -16,16 +16,16 @@ https://leetcode-cn.com/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof/
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
-示例 1:
-输入: s = "abcdefg", k = 2
-输出: "cdefgab"
+示例 1:
+输入: s = "abcdefg", k = 2
+输出: "cdefgab"
-示例 2:
-输入: s = "lrloseumgh", k = 6
-输出: "umghlrlose"
+示例 2:
+输入: s = "lrloseumgh", k = 6
+输出: "umghlrlose"
-限制:
-1 <= k < s.length <= 10000
+限制:
+1 <= k < s.length <= 10000
# 思路
@@ -34,7 +34,7 @@ https://leetcode-cn.com/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof/
不能使用额外空间的话,模拟在本串操作要实现左旋转字符串的功能还是有点困难的。
-那么我们可以想一下上一题目[字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)中讲过,使用整体反转+局部反转就可以实现,反转单词顺序的目的。
+那么我们可以想一下上一题目[字符串:花式反转还不够!](https://mp.weixin.qq.com/s/4j6vPFHkFAXnQhmSkq2X9g)中讲过,使用整体反转+局部反转就可以实现,反转单词顺序的目的。
这道题目也非常类似,依然可以通过局部反转+整体反转 达到左旋转的目的。
@@ -50,13 +50,13 @@ https://leetcode-cn.com/problems/zuo-xuan-zhuan-zi-fu-chuan-lcof/
如图:
-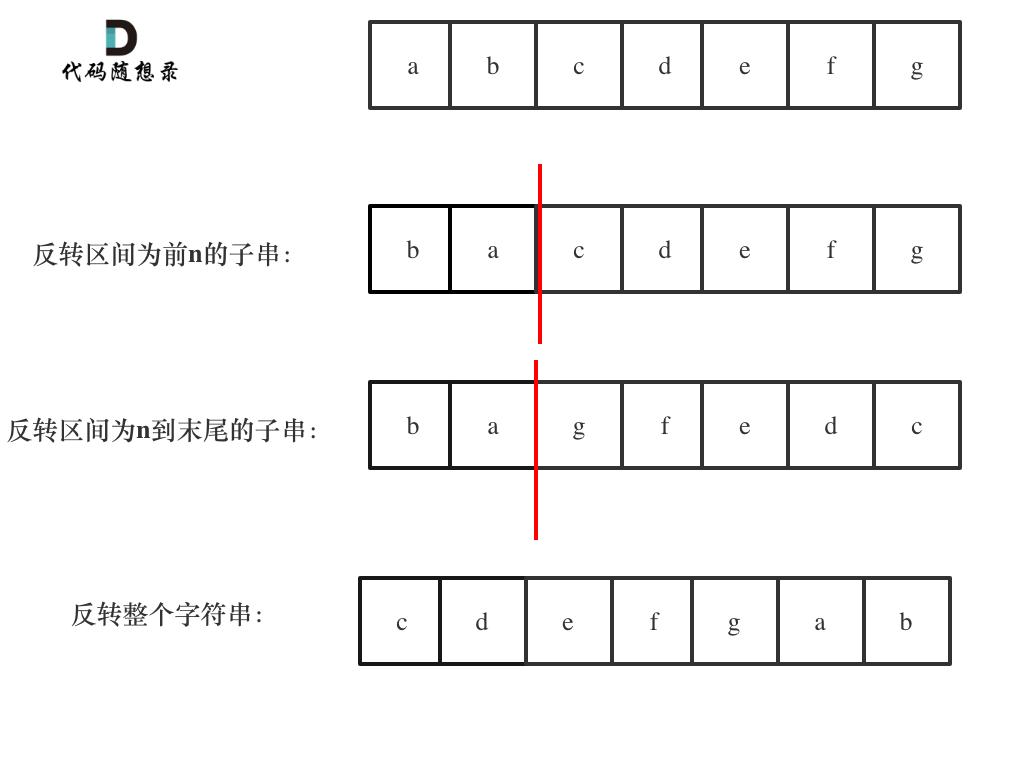 +
+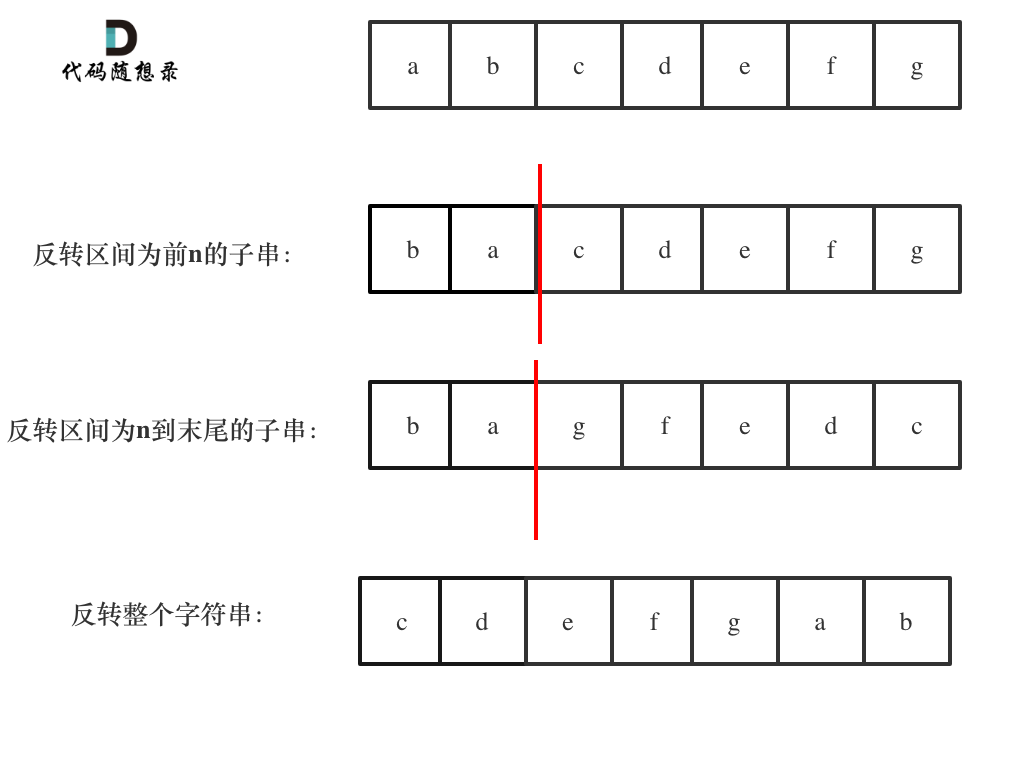 最终得到左旋2个单元的字符串:cdefgab
思路明确之后,那么代码实现就很简单了
-# C++代码
+C++代码如下:
```C++
class Solution {
@@ -73,15 +73,16 @@ public:
# 总结
+
此时我们已经反转好多次字符串了,来一起回顾一下吧。
-在这篇文章[字符串:这道题目,使用库函数一行代码搞定](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA),第一次讲到反转一个字符串应该怎么做,使用了双指针法。
+在这篇文章[344.反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w),第一次讲到反转一个字符串应该怎么做,使用了双指针法。
-然后发现[字符串:简单的反转还不够!](https://mp.weixin.qq.com/s/XGSk1GyPWhfqj2g7Cb1Vgw),这里开始给反转加上了一些条件,当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
+然后发现[541. 反转字符串II](https://mp.weixin.qq.com/s/pzXt6PQ029y7bJ9YZB2mVQ),这里开始给反转加上了一些条件,当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
-后来在[字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)中,要对一句话里的单词顺序进行反转,发现先整体反转再局部反转 是一个很妙的思路。
+后来在[151.翻转字符串里的单词](https://mp.weixin.qq.com/s/4j6vPFHkFAXnQhmSkq2X9g)中,要对一句话里的单词顺序进行反转,发现先整体反转再局部反转 是一个很妙的思路。
-最后再讲到本地,本题则是先局部反转再 整体反转,与[字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)类似,但是也是一种新的思路。
+最后再讲到本题,本题则是先局部反转再 整体反转,与[151.翻转字符串里的单词](https://mp.weixin.qq.com/s/4j6vPFHkFAXnQhmSkq2X9g)类似,但是也是一种新的思路。
好了,反转字符串一共就介绍到这里,相信大家此时对反转字符串的常见操作已经很了解了。
@@ -93,7 +94,6 @@ public:
**如果想让这套题目有意义,就不要申请额外空间。**
-
## 其他语言版本
Java:
@@ -117,7 +117,6 @@ class Solution {
}
}
```
-Python:
Go:
@@ -151,4 +150,4 @@ func reverse(b []byte, left, right int){
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
-
最终得到左旋2个单元的字符串:cdefgab
思路明确之后,那么代码实现就很简单了
-# C++代码
+C++代码如下:
```C++
class Solution {
@@ -73,15 +73,16 @@ public:
# 总结
+
此时我们已经反转好多次字符串了,来一起回顾一下吧。
-在这篇文章[字符串:这道题目,使用库函数一行代码搞定](https://mp.weixin.qq.com/s/X02S61WCYiCEhaik6VUpFA),第一次讲到反转一个字符串应该怎么做,使用了双指针法。
+在这篇文章[344.反转字符串](https://mp.weixin.qq.com/s/_rNm66OJVl92gBDIbGpA3w),第一次讲到反转一个字符串应该怎么做,使用了双指针法。
-然后发现[字符串:简单的反转还不够!](https://mp.weixin.qq.com/s/XGSk1GyPWhfqj2g7Cb1Vgw),这里开始给反转加上了一些条件,当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
+然后发现[541. 反转字符串II](https://mp.weixin.qq.com/s/pzXt6PQ029y7bJ9YZB2mVQ),这里开始给反转加上了一些条件,当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
-后来在[字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)中,要对一句话里的单词顺序进行反转,发现先整体反转再局部反转 是一个很妙的思路。
+后来在[151.翻转字符串里的单词](https://mp.weixin.qq.com/s/4j6vPFHkFAXnQhmSkq2X9g)中,要对一句话里的单词顺序进行反转,发现先整体反转再局部反转 是一个很妙的思路。
-最后再讲到本地,本题则是先局部反转再 整体反转,与[字符串:花式反转还不够!](https://mp.weixin.qq.com/s/X3qpi2v5RSp08mO-W5Vicw)类似,但是也是一种新的思路。
+最后再讲到本题,本题则是先局部反转再 整体反转,与[151.翻转字符串里的单词](https://mp.weixin.qq.com/s/4j6vPFHkFAXnQhmSkq2X9g)类似,但是也是一种新的思路。
好了,反转字符串一共就介绍到这里,相信大家此时对反转字符串的常见操作已经很了解了。
@@ -93,7 +94,6 @@ public:
**如果想让这套题目有意义,就不要申请额外空间。**
-
## 其他语言版本
Java:
@@ -117,7 +117,6 @@ class Solution {
}
}
```
-Python:
Go:
@@ -151,4 +150,4 @@ func reverse(b []byte, left, right int){
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
-
\ No newline at end of file
+
diff --git a/problems/哈希表总结.md b/problems/哈希表总结.md
index a578a203..c3fbde2b 100644
--- a/problems/哈希表总结.md
+++ b/problems/哈希表总结.md
@@ -9,11 +9,10 @@
> 哈希表总结篇如约而至
-哈希表系列也是早期讲解的时候没有写总结篇,所以选个周末给补上,毕竟「代码随想录」的系列怎么能没有总结篇呢[机智]。
# 哈希表理论基础
-在[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/g8N6WmoQmsCUw3_BaWxHZA)中,我们介绍了哈希表的基础理论知识,不同于枯燥的讲解,这里介绍了都是对刷题有帮助的理论知识点。
+在[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg)中,我们介绍了哈希表的基础理论知识,不同于枯燥的讲解,这里介绍了都是对刷题有帮助的理论知识点。
**一般来说哈希表都是用来快速判断一个元素是否出现集合里**。
@@ -29,7 +28,7 @@
* set(集合)
* map(映射)
-在C++语言中,set 和 map 都分别提供了三种数据结构,每种数据结构的底层实现和用途都有所不同,在[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/g8N6WmoQmsCUw3_BaWxHZA)中我给出了详细分析,这一知识点很重要!
+在C++语言中,set 和 map 都分别提供了三种数据结构,每种数据结构的底层实现和用途都有所不同,在[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg)中我给出了详细分析,这一知识点很重要!
例如什么时候用std::set,什么时候用std::multiset,什么时候用std::unordered_set,都是很有考究的。
@@ -41,13 +40,13 @@
一些应用场景就是为数组量身定做的。
-在[哈希表:有效的字母异位词](https://mp.weixin.qq.com/s/vM6OszkM6L1Mx2Ralm9Dig)中,我们提到了数组就是简单的哈希表,但是数组的大小是受限的!
+在[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)中,我们提到了数组就是简单的哈希表,但是数组的大小是受限的!
这道题目包含小写字母,那么使用数组来做哈希最合适不过。
-在[哈希表:赎金信](https://mp.weixin.qq.com/s/sYZIR4dFBrw_lr3eJJnteQ)中同样要求只有小写字母,那么就给我们浓浓的暗示,用数组!
+在[383.赎金信](https://mp.weixin.qq.com/s/qAXqv--UERmiJNNpuphOUQ)中同样要求只有小写字母,那么就给我们浓浓的暗示,用数组!
-本题和[哈希表:有效的字母异位词](https://mp.weixin.qq.com/s/vM6OszkM6L1Mx2Ralm9Dig)很像,[哈希表:有效的字母异位词](https://mp.weixin.qq.com/s/vM6OszkM6L1Mx2Ralm9Dig)是求 字符串a 和 字符串b 是否可以相互组成,在[哈希表:赎金信](https://mp.weixin.qq.com/s/sYZIR4dFBrw_lr3eJJnteQ)中是求字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
+本题和[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)很像,[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)是求 字符串a 和 字符串b 是否可以相互组成,在[383.赎金信](https://mp.weixin.qq.com/s/qAXqv--UERmiJNNpuphOUQ)中是求字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
一些同学可能想,用数组干啥,都用map不就完事了。
@@ -56,7 +55,7 @@
## set作为哈希表
-在[哈希表:两个数组的交集](https://mp.weixin.qq.com/s/N9iqAchXreSVW7zXUS4BVA)中我们给出了什么时候用数组就不行了,需要用set。
+在[349. 两个数组的交集](https://mp.weixin.qq.com/s/aMSA5zrp3jJcLjuSB0Es2Q)中我们给出了什么时候用数组就不行了,需要用set。
这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
@@ -67,7 +66,7 @@
所以此时一样的做映射的话,就可以使用set了。
-关于set,C++ 给提供了如下三种可用的数据结构:(详情请看[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/g8N6WmoQmsCUw3_BaWxHZA))
+关于set,C++ 给提供了如下三种可用的数据结构:(详情请看[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg))
* std::set
* std::multiset
@@ -75,12 +74,12 @@
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希, 使用unordered_set 读写效率是最高的,本题并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
-在[哈希表:快乐数](https://mp.weixin.qq.com/s/G4Q2Zfpfe706gLK7HpZHpA)中,我们再次使用了unordered_set来判断一个数是否重复出现过。
+在[202.快乐数](https://mp.weixin.qq.com/s/n5q0ujxxrjQS3xuh3dgqBQ)中,我们再次使用了unordered_set来判断一个数是否重复出现过。
## map作为哈希表
-在[哈希表:两数之和](https://mp.weixin.qq.com/s/uVAtjOHSeqymV8FeQbliJQ)中map正式登场。
+在[1.两数之和](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ)中map正式登场。
来说一说:使用数组和set来做哈希法的局限。
@@ -89,7 +88,7 @@ std::set和std::multiset底层实现都是红黑树,std::unordered_set的底
map是一种``的结构,本题可以用key保存数值,用value在保存数值所在的下表。所以使用map最为合适。
-C++提供如下三种map::(详情请看[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/g8N6WmoQmsCUw3_BaWxHZA))
+C++提供如下三种map::(详情请看[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg))
* std::map
* std::multimap
@@ -97,21 +96,21 @@ C++提供如下三种map::(详情请看[关于哈希表,你该了解这
std::unordered_map 底层实现为哈希,std::map 和std::multimap 的底层实现是红黑树。
-同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解),[哈希表:两数之和](https://mp.weixin.qq.com/s/uVAtjOHSeqymV8FeQbliJQ)中并不需要key有序,选择std::unordered_map 效率更高!
+同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解),[1.两数之和](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ)中并不需要key有序,选择std::unordered_map 效率更高!
-在[哈希表:四数相加II](https://mp.weixin.qq.com/s/Ue8pKKU5hw_m-jPgwlHcbA)中我们提到了其实需要哈希的地方都能找到map的身影。
+在[454.四数相加](https://mp.weixin.qq.com/s/12g_w6RzHuEpFts1pT6BWw)中我们提到了其实需要哈希的地方都能找到map的身影。
-本题咋眼一看好像和[18. 四数之](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A),[15.三数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)差不多,其实差很多!
+本题咋眼一看好像和[18. 四数之和](https://mp.weixin.qq.com/s/SBU3THi1Kv6Sar7htqCB2Q),[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)差不多,其实差很多!
-**关键差别是本题为四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑重复问题,而[18. 四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g),[15.三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)是一个数组(集合)里找到和为0的组合,可就难很多了!**
+**关键差别是本题为四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑重复问题,而[18. 四数之和](https://mp.weixin.qq.com/s/SBU3THi1Kv6Sar7htqCB2Q),[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)是一个数组(集合)里找到和为0的组合,可就难很多了!**
用哈希法解决了两数之和,很多同学会感觉用哈希法也可以解决三数之和,四数之和。
其实是可以解决,但是非常麻烦,需要去重导致代码效率很低。
-在[哈希表:解决了两数之和,那么能解决三数之和么?](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)中我给出了哈希法和双指针两个解法,大家就可以体会到,使用哈希法还是比较麻烦的。
+在[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)中我给出了哈希法和双指针两个解法,大家就可以体会到,使用哈希法还是比较麻烦的。
-所以[18. 四数之](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A),[15.三数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)都推荐使用双指针法!
+所以18. 四数之和,15.三数之和都推荐使用双指针法!
# 总结
@@ -127,19 +126,6 @@ std::unordered_map 底层实现为哈希,std::map 和std::multimap 的底层
-## 其他语言版本
-
-
-Java:
-
-
-Python:
-
-
-Go:
-
-
-
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/栈与队列理论基础.md b/problems/栈与队列理论基础.md
index 04f99981..db871a3c 100644
--- a/problems/栈与队列理论基础.md
+++ b/problems/栈与队列理论基础.md
@@ -85,20 +85,7 @@ std::queue> third; // 定义以list为底层容器的队列
所以STL 队列也不被归类为容器,而被归类为container adapter( 容器适配器)。
-我这里讲的都是(clck)C++ 语言中情况, 使用其他语言的同学也要思考栈与队列的底层实现问题, 不要对数据结构的使用浅尝辄止,而要深挖起内部原理,才能夯实基础。
-
-
-
-## 其他语言版本
-
-
-Java:
-
-
-Python:
-
-
-Go:
+我这里讲的都是C++ 语言中情况, 使用其他语言的同学也要思考栈与队列的底层实现问题, 不要对数据结构的使用浅尝辄止,而要深挖起内部原理,才能夯实基础。
diff --git a/problems/背包理论基础01背包-1.md b/problems/背包理论基础01背包-1.md
index a78d9232..1269d9c1 100644
--- a/problems/背包理论基础01背包-1.md
+++ b/problems/背包理论基础01背包-1.md
@@ -265,15 +265,120 @@ int main() {
## 其他语言版本
-
Java:
+```java
+ public static void main(String[] args) {
+ int[] weight = {1, 3, 4};
+ int[] value = {15, 20, 30};
+ int bagSize = 4;
+ testWeightBagProblem(weight, value, bagSize);
+ }
+
+ public static void testWeightBagProblem(int[] weight, int[] value, int bagSize){
+ int wLen = weight.length, value0 = 0;
+ //定义dp数组:dp[i][j]表示背包容量为j时,前i个物品能获得的最大价值
+ int[][] dp = new int[wLen + 1][bagSize + 1];
+ //初始化:背包容量为0时,能获得的价值都为0
+ for (int i = 0; i <= wLen; i++){
+ dp[i][0] = value0;
+ }
+ //遍历顺序:先遍历物品,再遍历背包容量
+ for (int i = 1; i <= wLen; i++){
+ for (int j = 1; j <= bagSize; j++){
+ if (j < weight[i - 1]){
+ dp[i][j] = dp[i - 1][j];
+ }else{
+ dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weight[i - 1]] + value[i - 1]);
+ }
+ }
+ }
+ //打印dp数组
+ for (int i = 0; i <= wLen; i++){
+ for (int j = 0; j <= bagSize; j++){
+ System.out.print(dp[i][j] + " ");
+ }
+ System.out.print("\n");
+ }
+ }
+```
+
+
+
Python:
+```python
+def test_2_wei_bag_problem1(bag_size, weight, value) -> int:
+ rows, cols = len(weight), bag_size + 1
+ dp = [[0 for _ in range(cols)] for _ in range(rows)]
+ res = 0
+
+ # 初始化dp数组.
+ for i in range(rows):
+ dp[i][0] = 0
+ first_item_weight, first_item_value = weight[0], value[0]
+ for j in range(1, cols):
+ if first_item_weight <= j:
+ dp[0][j] = first_item_value
+
+ # 更新dp数组: 先遍历物品, 再遍历背包.
+ for i in range(1, len(weight)):
+ cur_weight, cur_val = weight[i], value[i]
+ for j in range(1, cols):
+ if cur_weight > j: # 说明背包装不下当前物品.
+ dp[i][j] = dp[i - 1][j] # 所以不装当前物品.
+ else:
+ # 定义dp数组: dp[i][j] 前i个物品里,放进容量为j的背包,价值总和最大是多少。
+ dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - cur_weight]+ cur_val)
+ if dp[i][j] > res:
+ res = dp[i][j]
+
+ print(dp)
+
+
+if __name__ == "__main__":
+ bag_size = 4
+ weight = [1, 3, 4]
+ value = [15, 20, 30]
+ test_2_wei_bag_problem1(bag_size, weight, value)
+```
Go:
+```go
+func test_2_wei_bag_problem1(weight, value []int, bagWeight int) int {
+ // 定义dp数组
+ dp := make([][]int, len(weight))
+ for i, _ := range dp {
+ dp[i] = make([]int, bagWeight+1)
+ }
+ // 初始化
+ for j := bagWeight; j >= weight[0]; j-- {
+ dp[0][j] = dp[0][j-weight[0]] + value[0]
+ }
+ // 递推公式
+ for i := 1; i < len(weight); i++ {
+ //正序,也可以倒序
+ for j := weight[i];j<= bagWeight ; j++ {
+ dp[i][j] = max(dp[i-1][j], dp[i-1][j-weight[i]]+value[i])
+ }
+ }
+ return dp[len(weight)-1][bagWeight]
+}
+func max(a,b int) int {
+ if a > b {
+ return a
+ }
+ return b
+}
+
+func main() {
+ weight := []int{1,3,4}
+ value := []int{15,20,30}
+ test_2_wei_bag_problem1(weight,value,4)
+}
+```
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/背包理论基础01背包-2.md b/problems/背包理论基础01背包-2.md
index e831d88f..48275908 100644
--- a/problems/背包理论基础01背包-2.md
+++ b/problems/背包理论基础01背包-2.md
@@ -5,6 +5,7 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
# 动态规划:关于01背包问题,你该了解这些!(滚动数组)
昨天[动态规划:关于01背包问题,你该了解这些!](https://mp.weixin.qq.com/s/FwIiPPmR18_AJO5eiidT6w)中是用二维dp数组来讲解01背包。
@@ -35,7 +36,7 @@
**其实可以发现如果把dp[i - 1]那一层拷贝到dp[i]上,表达式完全可以是:dp[i][j] = max(dp[i][j], dp[i][j - weight[i]] + value[i]);**
-**于其把dp[i - 1]这一层拷贝到dp[i]上,不如只用一个一维数组了**,只用dp[j](一维数组,也可以理解是一个滚动数组)。
+**与其把dp[i - 1]这一层拷贝到dp[i]上,不如只用一个一维数组了**,只用dp[j](一维数组,也可以理解是一个滚动数组)。
这就是滚动数组的由来,需要满足的条件是上一层可以重复利用,直接拷贝到当前层。
@@ -211,15 +212,87 @@ int main() {
## 其他语言版本
-
Java:
+```java
+ public static void main(String[] args) {
+ int[] weight = {1, 3, 4};
+ int[] value = {15, 20, 30};
+ int bagWight = 4;
+ testWeightBagProblem(weight, value, bagWight);
+ }
+
+ public static void testWeightBagProblem(int[] weight, int[] value, int bagWeight){
+ int wLen = weight.length;
+ //定义dp数组:dp[j]表示背包容量为j时,能获得的最大价值
+ int[] dp = new int[bagWeight + 1];
+ //遍历顺序:先遍历物品,再遍历背包容量
+ for (int i = 0; i < wLen; i++){
+ for (int j = bagWeight; j >= weight[i]; j--){
+ dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]);
+ }
+ }
+ //打印dp数组
+ for (int j = 0; j <= bagWeight; j++){
+ System.out.print(dp[j] + " ");
+ }
+ }
+```
+
+
+
Python:
+```python
+def test_1_wei_bag_problem():
+ weight = [1, 3, 4]
+ value = [15, 20, 30]
+ bag_weight = 4
+ # 初始化: 全为0
+ dp = [0] * (bag_weight + 1)
+ # 先遍历物品, 再遍历背包容量
+ for i in range(len(weight)):
+ for j in range(bag_weight, weight[i] - 1, -1):
+ # 递归公式
+ dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
+
+ print(dp)
+
+test_1_wei_bag_problem()
+```
Go:
+```go
+func test_1_wei_bag_problem(weight, value []int, bagWeight int) int {
+ // 定义 and 初始化
+ dp := make([]int,bagWeight+1)
+ // 递推顺序
+ for i := 0 ;i < len(weight) ; i++ {
+ // 这里必须倒序,区别二维,因为二维dp保存了i的状态
+ for j:= bagWeight; j >= weight[i] ; j-- {
+ // 递推公式
+ dp[j] = max(dp[j], dp[j-weight[i]]+value[i])
+ }
+ }
+ //fmt.Println(dp)
+ return dp[bagWeight]
+}
+func max(a,b int) int {
+ if a > b {
+ return a
+ }
+ return b
+}
+
+
+func main() {
+ weight := []int{1,3,4}
+ value := []int{15,20,30}
+ test_1_wei_bag_problem(weight,value,4)
+}
+```
diff --git a/problems/背包问题理论基础多重背包.md b/problems/背包问题理论基础多重背包.md
index 26890a2b..e14575d4 100644
--- a/problems/背包问题理论基础多重背包.md
+++ b/problems/背包问题理论基础多重背包.md
@@ -147,9 +147,56 @@ int main() {
Java:
-
Python:
+```python
+def test_multi_pack1():
+ '''版本一:改变物品数量为01背包格式'''
+ weight = [1, 3, 4]
+ value = [15, 20, 30]
+ nums = [2, 3, 2]
+ bag_weight = 10
+ for i in range(len(nums)):
+ # 将物品展开数量为1
+ while nums[i] > 1:
+ weight.append(weight[i])
+ value.append(value[i])
+ nums[i] -= 1
+
+ dp = [0]*(bag_weight + 1)
+ # 遍历物品
+ for i in range(len(weight)):
+ # 遍历背包
+ for j in range(bag_weight, weight[i] - 1, -1):
+ dp[j] = max(dp[j], dp[j - weight[i]] + value[i])
+
+ print(" ".join(map(str, dp)))
+
+def test_multi_pack2():
+ '''版本:改变遍历个数'''
+ weight = [1, 3, 4]
+ value = [15, 20, 30]
+ nums = [2, 3, 2]
+ bag_weight = 10
+
+ dp = [0]*(bag_weight + 1)
+ for i in range(len(weight)):
+ for j in range(bag_weight, weight[i] - 1, -1):
+ # 以上是01背包,加上遍历个数
+ for k in range(1, nums[i] + 1):
+ if j - k*weight[i] >= 0:
+ dp[j] = max(dp[j], dp[j - k*weight[i]] + k*value[i])
+
+ print(" ".join(map(str, dp)))
+
+
+if __name__ == '__main__':
+ test_multi_pack1()
+ test_multi_pack2()
+```
+
+
+
Go:
diff --git a/problems/背包问题理论基础完全背包.md b/problems/背包问题理论基础完全背包.md
index 9997dff3..a5a708cf 100644
--- a/problems/背包问题理论基础完全背包.md
+++ b/problems/背包问题理论基础完全背包.md
@@ -220,7 +220,58 @@ if __name__ == '__main__':
Go:
+```go
+// test_CompletePack1 先遍历物品, 在遍历背包
+func test_CompletePack1(weight, value []int, bagWeight int) int {
+ // 定义dp数组 和初始化
+ dp := make([]int, bagWeight+1)
+ // 遍历顺序
+ for i := 0; i < len(weight); i++ {
+ // 正序会多次添加 value[i]
+ for j := weight[i]; j <= bagWeight; j++ {
+ // 推导公式
+ dp[j] = max(dp[j], dp[j-weight[i]]+value[i])
+ // debug
+ //fmt.Println(dp)
+ }
+ }
+ return dp[bagWeight]
+}
+
+// test_CompletePack2 先遍历背包, 在遍历物品
+func test_CompletePack2(weight, value []int, bagWeight int) int {
+ // 定义dp数组 和初始化
+ dp := make([]int, bagWeight+1)
+ // 遍历顺序
+ // j从0 开始
+ for j := 0; j <= bagWeight; j++ {
+ for i := 0; i < len(weight); i++ {
+ if j >= weight[i] {
+ // 推导公式
+ dp[j] = max(dp[j], dp[j-weight[i]]+value[i])
+ }
+ // debug
+ //fmt.Println(dp)
+ }
+ }
+ return dp[bagWeight]
+}
+
+func max(a, b int) int {
+ if a > b {
+ return a
+ }
+ return b
+}
+
+func main() {
+ weight := []int{1, 3, 4}
+ price := []int{15, 20, 30}
+ fmt.Println(test_CompletePack1(weight, price, 4))
+ fmt.Println(test_CompletePack2(weight, price, 4))
+}
+```
diff --git a/problems/面试题02.07.链表相交.md b/problems/面试题02.07.链表相交.md
index 78f34e71..c6779427 100644
--- a/problems/面试题02.07.链表相交.md
+++ b/problems/面试题02.07.链表相交.md
@@ -32,11 +32,11 @@
看如下两个链表,目前curA指向链表A的头结点,curB指向链表B的头结点:
-v
+
我们求出两个链表的长度,并求出两个链表长度的差值,然后让curA移动到,和curB 末尾对齐的位置,如图:
-
+
此时我们就可以比较curA和curB是否相同,如果不相同,同时向后移动curA和curB,如果遇到curA == curB,则找到焦点。