diff --git a/README.md b/README.md
index cb55bbbc..0b3a5a3f 100644
--- a/README.md
+++ b/README.md
@@ -213,6 +213,7 @@
* [本周小结!(贪心算法系列二)](https://mp.weixin.qq.com/s/RiQri-4rP9abFmq_mlXNiQ)
* [贪心算法:加油站](https://mp.weixin.qq.com/s/aDbiNuEZIhy6YKgQXvKELw)
* [贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)
+ * [贪心算法:柠檬水找零](https://mp.weixin.qq.com/s/0kT4P-hzY7H6Ae0kjQqnZg)
* 动态规划
@@ -375,6 +376,7 @@
|[0701.二叉搜索树中的插入操作](https://github.com/youngyangyang04/leetcode/blob/master/problems/0701.二叉搜索树中的插入操作.md) |二叉搜索树 |简单|**递归** **迭代**|
|[0705.设计哈希集合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0705.设计哈希集合.md) |哈希表 |简单|**模拟**|
|[0707.设计链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0707.设计链表.md) |链表 |中等|**模拟**|
+|[0714.买卖股票的最佳时机含手续费](https://github.com/youngyangyang04/leetcode/blob/master/problems/0714.买卖股票的最佳时机含手续费.md) |贪心 动态规划 |中等|**贪心** **动态规划** 和122.买卖股票的最佳时机II类似,贪心的思路很巧妙|
|[0763.划分字母区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0763.划分字母区间.md) |贪心 |中等|**双指针/贪心** 体现贪心尽可能多的思想|
|[0738.单调递增的数字](https://github.com/youngyangyang04/leetcode/blob/master/problems/0738.单调递增的数字.md) |贪心算法 |中等|**贪心算法** 思路不错,贪心好题|
|[0739.每日温度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0739.每日温度.md) |栈 |中等|**单调栈** 适合单调栈入门|
@@ -388,7 +390,7 @@
|[0973.最接近原点的K个点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0973.最接近原点的K个点.md) |优先级队列 |中等|**优先级队列**|
|[0977.有序数组的平方](https://github.com/youngyangyang04/leetcode/blob/master/problems/0977.有序数组的平方.md) |数组 |中等|**双指针** 还是比较巧妙的|
|[1002.查找常用字符](https://github.com/youngyangyang04/leetcode/blob/master/problems/1002.查找常用字符.md) |栈 |简单|**栈**|
-|[1005.K次取反后最大化的数组和](https://github.com/youngyangyang04/leetcode/blob/master/problems/1005.K次取反后最大化的数组和.md) |贪心/排序 |**贪心算法** 贪心基础题目|
+|[1005.K次取反后最大化的数组和](https://github.com/youngyangyang04/leetcode/blob/master/problems/1005.K次取反后最大化的数组和.md) |贪心/排序 |简单|**贪心算法** 贪心基础题目|
|[1047.删除字符串中的所有相邻重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/1047.删除字符串中的所有相邻重复项.md) |哈希表 |简单|**哈希表/数组**|
|[1049.最后一块石头的重量II](https://github.com/youngyangyang04/leetcode/blob/master/problems/1049.最后一块石头的重量II.md) |动态规划 |中等|**01背包**|
|[1207.独一无二的出现次数](https://github.com/youngyangyang04/leetcode/blob/master/problems/1207.独一无二的出现次数.md) |哈希表 |简单|**哈希** 两层哈希|
diff --git a/pics/动态规划-背包问题1.png b/pics/动态规划-背包问题1.png
new file mode 100644
index 00000000..dd51c5a9
Binary files /dev/null and b/pics/动态规划-背包问题1.png differ
diff --git a/pics/动态规划-背包问题2.png b/pics/动态规划-背包问题2.png
new file mode 100644
index 00000000..6ea1863c
Binary files /dev/null and b/pics/动态规划-背包问题2.png differ
diff --git a/pics/动态规划-背包问题3.png b/pics/动态规划-背包问题3.png
new file mode 100644
index 00000000..568c7bd9
Binary files /dev/null and b/pics/动态规划-背包问题3.png differ
diff --git a/pics/动态规划-背包问题4.png b/pics/动态规划-背包问题4.png
new file mode 100644
index 00000000..97632993
Binary files /dev/null and b/pics/动态规划-背包问题4.png differ
diff --git a/problems/0027.移除元素.md b/problems/0027.移除元素.md
index 71f2af5c..637bd5ad 100644
--- a/problems/0027.移除元素.md
+++ b/problems/0027.移除元素.md
@@ -1,13 +1,21 @@
-> 笔者在BAT从事技术研发多年,利用工作之余重刷leetcode,更多原创文章请关注公众号「代码随想录」。
-
-# 题目地址
-
-https://leetcode-cn.com/problems/remove-element/
+
+ +
+
+
+  +
+  +
+  +
+  +
+  +
+  +
+
> 移除元素想要高效的话,不是很简单!
# 编号:27. 移除元素
+题目地址:https://leetcode-cn.com/problems/remove-element/
+
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并**原地**修改输入数组。
@@ -112,7 +120,8 @@ public:
};
```
-拓展: 也可以一个指向前面,一个指向后面,遇到需要删除的就交换,最后返回指针的位置加1,只不过这么做更改了数组元素的位置了,不算是移除元素。
-
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+**循序渐进学算法,认准「代码随想录」,Carl手把手带你过关斩将!**
+
+ +
+
diff --git a/problems/0035.搜索插入位置.md b/problems/0035.搜索插入位置.md
index 0cbe7be8..5c6a1545 100644
--- a/problems/0035.搜索插入位置.md
+++ b/problems/0035.搜索插入位置.md
@@ -44,7 +44,7 @@
这道题目,要在数组中插入目标值,无非是这四种情况。
- +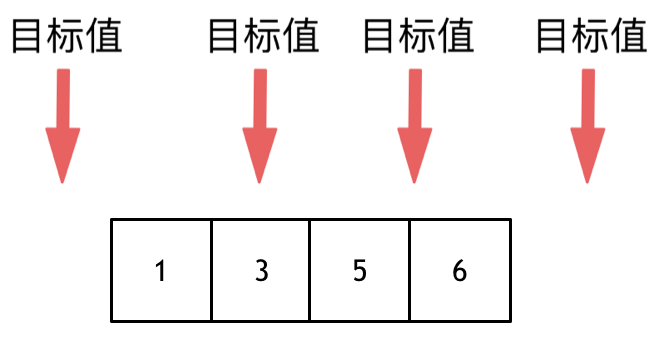
* 目标值在数组所有元素之前
* 目标值等于数组中某一个元素
@@ -85,13 +85,13 @@ public:
效率如下:
-
+
* 目标值在数组所有元素之前
* 目标值等于数组中某一个元素
@@ -85,13 +85,13 @@ public:
效率如下:
- +
## 二分法
既然暴力解法的时间复杂度是O(n),就要尝试一下使用二分查找法。
-
+
## 二分法
既然暴力解法的时间复杂度是O(n),就要尝试一下使用二分查找法。
- +
大家注意这道题目的前提是数组是有序数组,这也是使用二分查找的基础条件。
@@ -101,7 +101,7 @@ public:
大体讲解一下二分法的思路,这里来举一个例子,例如在这个数组中,使用二分法寻找元素为5的位置,并返回其下标。
-
+
大家注意这道题目的前提是数组是有序数组,这也是使用二分查找的基础条件。
@@ -101,7 +101,7 @@ public:
大体讲解一下二分法的思路,这里来举一个例子,例如在这个数组中,使用二分法寻找元素为5的位置,并返回其下标。
- +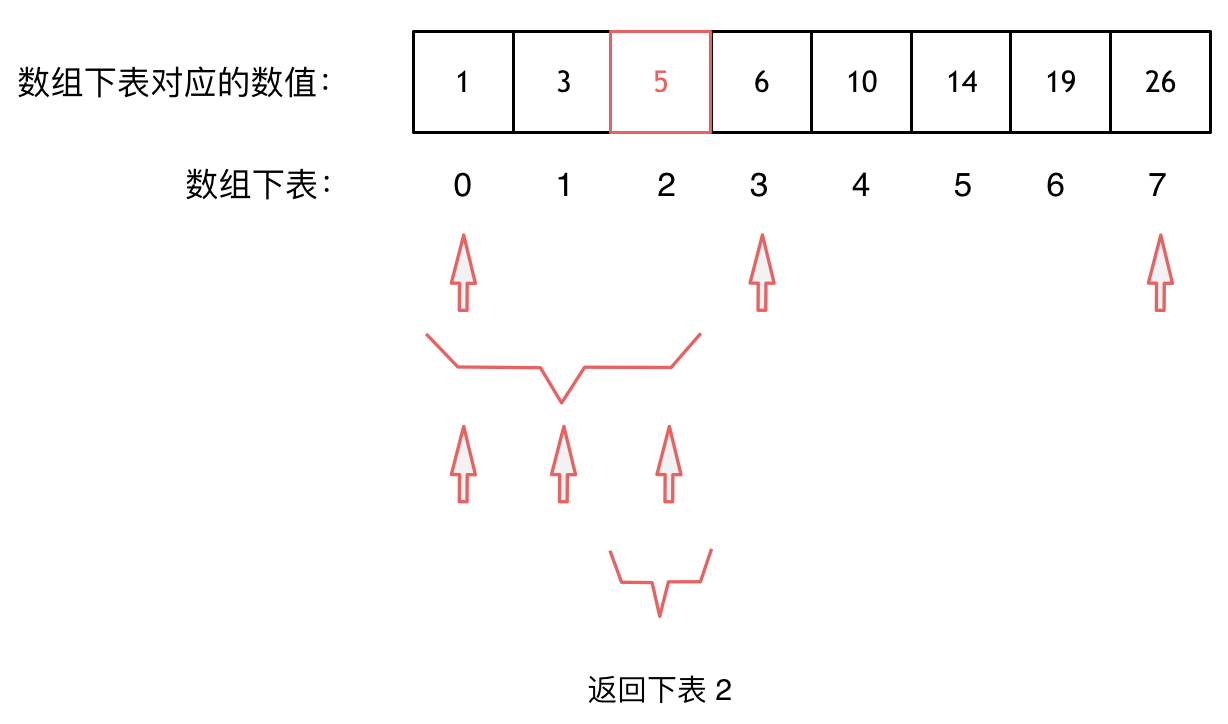
二分查找涉及的很多的边界条件,逻辑比较简单,就是写不好。
@@ -151,7 +151,7 @@ public:
时间复杂度:O(1)
效率如下:
-
+
二分查找涉及的很多的边界条件,逻辑比较简单,就是写不好。
@@ -151,7 +151,7 @@ public:
时间复杂度:O(1)
效率如下:
- +
## 二分法第二种写法
diff --git a/problems/0059.螺旋矩阵II.md b/problems/0059.螺旋矩阵II.md
index c5c3301a..111be4c4 100644
--- a/problems/0059.螺旋矩阵II.md
+++ b/problems/0059.螺旋矩阵II.md
@@ -1,12 +1,22 @@
-> 笔者在BAT从事技术研发多年,利用工作之余重刷leetcode,更多原创文章请关注公众号「代码随想录」。
-# 题目地址
-https://leetcode-cn.com/problems/spiral-matrix-ii/
+
+
## 二分法第二种写法
diff --git a/problems/0059.螺旋矩阵II.md b/problems/0059.螺旋矩阵II.md
index c5c3301a..111be4c4 100644
--- a/problems/0059.螺旋矩阵II.md
+++ b/problems/0059.螺旋矩阵II.md
@@ -1,12 +1,22 @@
-> 笔者在BAT从事技术研发多年,利用工作之余重刷leetcode,更多原创文章请关注公众号「代码随想录」。
-# 题目地址
-https://leetcode-cn.com/problems/spiral-matrix-ii/
+
+
+
+
+
+
+
+
+
+
+
+
> 一进循环深似海,从此offer是路人
# 题目59.螺旋矩阵II
+题目地址:https://leetcode-cn.com/problems/spiral-matrix-ii/
给定一个正整数 n,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。
示例:
@@ -48,7 +58,7 @@ https://leetcode-cn.com/problems/spiral-matrix-ii/
那么我按照左闭右开的原则,来画一圈,大家看一下:
- +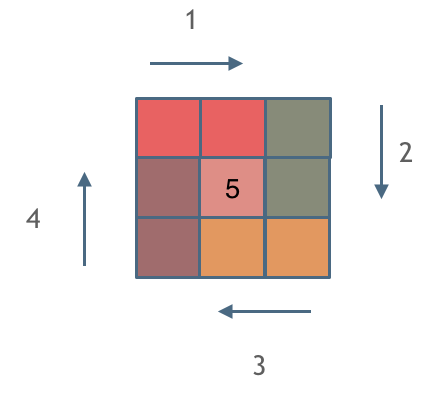
这里每一种颜色,代表一条边,我们遍历的长度,可以看出每一个拐角处的处理规则,拐角处让给新的一条边来继续画。
@@ -111,5 +121,9 @@ public:
}
};
```
-> 更过算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+**循序渐进学算法,认准「代码随想录」,Carl手把手带你过关斩将!**
+
+
+
这里每一种颜色,代表一条边,我们遍历的长度,可以看出每一个拐角处的处理规则,拐角处让给新的一条边来继续画。
@@ -111,5 +121,9 @@ public:
}
};
```
-> 更过算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+**循序渐进学算法,认准「代码随想录」,Carl手把手带你过关斩将!**
+
+
+
+
diff --git a/problems/0106.从中序与后序遍历序列构造二叉树.md b/problems/0106.从中序与后序遍历序列构造二叉树.md
index 9b8295b1..892f2167 100644
--- a/problems/0106.从中序与后序遍历序列构造二叉树.md
+++ b/problems/0106.从中序与后序遍历序列构造二叉树.md
@@ -1,7 +1,7 @@
## 题目地址
https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal/
-> 给出两个序列
+> 给出两个序列 (可以加unorder_map优化一下)
看完本文,可以一起解决如下两道题目
diff --git a/problems/0209.长度最小的子数组.md b/problems/0209.长度最小的子数组.md
index f206d641..1dd5ba15 100644
--- a/problems/0209.长度最小的子数组.md
+++ b/problems/0209.长度最小的子数组.md
@@ -1,10 +1,21 @@
-## 题目地址
-https://leetcode-cn.com/problems/minimum-size-subarray-sum/
+
+
+
+
+
+
+
+
+
+
+
> 滑动窗口拯救了你
# 题目209.长度最小的子数组
+题目链接: https://leetcode-cn.com/problems/minimum-size-subarray-sum/
+
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组,并返回其长度。如果不存在符合条件的子数组,返回 0。
示例:
@@ -107,5 +118,9 @@ public:
时间复杂度:O(n)
空间复杂度:O(1)
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+**循序渐进学算法,认准「代码随想录」,Carl手把手带你过关斩将!**
+
+
+
+
diff --git a/problems/0406.根据身高重建队列.md b/problems/0406.根据身高重建队列.md
index 64411010..fa7a3607 100644
--- a/problems/0406.根据身高重建队列.md
+++ b/problems/0406.根据身高重建队列.md
@@ -1,49 +1,147 @@
+
+
+
+
+
+
+
+
+
+
+
-## 思路
+> 就不能好好站个队
+
+# 406.根据身高重建队列
+
+题目链接:https://leetcode-cn.com/problems/queue-reconstruction-by-height/
+
+假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
+
+请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
+
+示例 1:
+输入:people = [[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
+输出:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
+解释:
+编号为 0 的人身高为 5 ,没有身高更高或者相同的人排在他前面。
+编号为 1 的人身高为 7 ,没有身高更高或者相同的人排在他前面。
+编号为 2 的人身高为 5 ,有 2 个身高更高或者相同的人排在他前面,即编号为 0 和 1 的人。
+编号为 3 的人身高为 6 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
+编号为 4 的人身高为 4 ,有 4 个身高更高或者相同的人排在他前面,即编号为 0、1、2、3 的人。
+编号为 5 的人身高为 7 ,有 1 个身高更高或者相同的人排在他前面,即编号为 1 的人。
+因此 [[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]] 是重新构造后的队列。
+
+示例 2:
+输入:people = [[6,0],[5,0],[4,0],[3,2],[2,2],[1,4]]
+输出:[[4,0],[5,0],[2,2],[3,2],[1,4],[6,0]]
+
+提示:
+
+* 1 <= people.length <= 2000
+* 0 <= hi <= 10^6
+* 0 <= ki < people.length
+
+题目数据确保队列可以被重建
+
+# 思路
本题有两个维度,h和k,看到这种题目一定要想如何确定一个维度,然后在按照另一个维度重新排列。
+其实如果大家认真做了[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ),就会发现和此题有点点的像。
+
+在[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)我就强调过一次,遇到两个维度权衡的时候,一定要先确定一个维度,再确定另一个维度。
+
**如果两个维度一起考虑一定会顾此失彼**。
-相信大家困惑的点是先确实k还是先确定h呢,也就是 究竟先按h排序呢,还先按照k排序呢?
+对于本题相信大家困惑的点是先确定k还是先确定h呢,也就是究竟先按h排序呢,还先按照k排序呢?
如果按照k来从小到大排序,排完之后,会发现k的排列并不符合条件,身高也不符合条件,两个维度哪一个都没确定下来。
-那么按照身高h来排序呢,身高一定是从大到小排(身高相同k小的站前面),让高个子在前面。
+那么按照身高h来排序呢,身高一定是从大到小排(身高相同的话则k小的站前面),让高个子在前面。
**此时我们可以确定一个维度了,就是身高,前面的节点一定都比本节点高!**
-此时只需要按照k为下表重新插入队列,就可以了呢,为什么呢?
+那么只需要按照k为下标重新插入队列就可以了,为什么呢?
以图中{5,2} 为例:
- +
-**都说用贪心算法,是贪心究竟贪在哪里呢?**
-贪心在优先按照身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列。
+按照身高排序之后,优先按身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列。
-局部最优:优先按照身高搞的people的k来插入。插入操作过后的people满足队列属性
+所以在按照身高从大到小排序后:
-全局最优:最后都做完插入操作,整个队列满足题目队列属性
+**局部最优:优先按身高高的people的k来插入。插入操作过后的people满足队列属性**
-局部最优可推出全局最优。
+**全局最优:最后都做完插入操作,整个队列满足题目队列属性**
-整个插入过程如下:
+局部最优可推出全局最优,找不出反例,那就试试贪心。
+
+一些同学可能也会疑惑,你怎么知道局部最优就可以推出全局最优呢? 有数学证明么?
+
+在贪心系列开篇词[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)中,我已经讲过了这个问题了。
+
+刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心,至于严格的数学证明,就不在讨论范围内了。
+
+如果没有读过[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)的同学建议读一下,相信对贪心就有初步的了解了。
+
+回归本题,整个插入过程如下:
+
+排序完的people:
+[[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
-排序完:
-[[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
插入的过程:
-插入[7,0]:[[7,0]]
-插入[7,1]:[[7,0],[7,1]]
-插入[6,1]:[[7,0],[6,1],[7,1]]
-插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
-插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
-插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
+插入[7,0]:[[7,0]]
+插入[7,1]:[[7,0],[7,1]]
+插入[6,1]:[[7,0],[6,1],[7,1]]
+插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
+插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
+插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
+此时就按照题目的要求完成了重新排列。
C++代码如下:
+
+```C++
+// 版本一
+class Solution {
+public:
+ static bool cmp(const vector a, const vector b) {
+ if (a[0] == b[0]) return a[1] < b[1];
+ return a[0] > b[0];
+ }
+ vector> reconstructQueue(vector>& people) {
+ sort (people.begin(), people.end(), cmp);
+ vector> que;
+ for (int i = 0; i < people.size(); i++) {
+ int position = people[i][1];
+ que.insert(que.begin() + position, people[i]);
+ }
+ return que;
+ }
+};
```
+* 时间复杂度O(nlogn + n^3)
+* 空间复杂度O(n)
+
+大家会发现这个n^3 是怎么来的?
+
+其实数组的插入操作复杂度是O(n^2):寻找插入元素位置O(1),插入元素O(n^2),因为插入元素后面的元素要整体向后移。
+
+如果对数组的增删时间复杂度不清楚的话,可以做做这道题目[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA),数组中插入元素和删除元素都是O(n^2)的复杂度。
+
+我们就是要模拟一个插入队列的行为,所以不应该使用数组,而是要使用链表!
+
+链表的插入操作复杂度是O(n):寻找插入元素位置O(n),插入元素O(1)。
+
+可以看出使用链表的插入效率要比普通数组高出一个数量级!
+
+改成链表之后,C++代码如下:
+
+```C++
+// 版本二
class Solution {
public:
// 身高从大到小排(身高相同k小的站前面)
@@ -53,16 +151,51 @@ public:
}
vector> reconstructQueue(vector>& people) {
sort (people.begin(), people.end(), cmp);
- list> que; // 使用list底层是链表实现,插入效率比vector高的多
+ list> que; // list底层是链表实现,插入效率比vector高的多
for (int i = 0; i < people.size(); i++) {
int position = people[i][1]; // 插入到下标为position的位置
std::list>::iterator it = que.begin();
- while (position--) {
- it++;
+ while (position--) { // 寻找在插入位置
+ it++;
}
- que.insert(it, people[i]);
+ que.insert(it, people[i]);
}
return vector>(que.begin(), que.end());
}
};
```
+
+* 时间复杂度O(nlogn + n^2)
+* 空间复杂度O(n)
+
+大家可以把两个版本的代码提交一下试试,就可以发现其差别了!
+
+# 总结
+
+关于出现两个维度一起考虑的情况,我们已经做过两道题目了,另一道就是[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)。
+
+**其技巧都是确定一边然后贪心另一边,两边一起考虑,就会顾此失彼**。
+
+这道题目可以说比[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)难不少,其贪心的策略也是比较巧妙。
+
+最后我给出了两个版本的代码,可以明显看是使用C++中的list(底层链表实现)比vector(数组)效率高得多。
+
+**对使用某一种语言容器的使用,特性的选择都会不同程度上影响效率**。
+
+所以很多人都说写算法题用什么语言都可以,主要体现在算法思维上,其实我是同意的但也不同意。
+
+对于看别人题解的同学,题解用什么语言其实影响不大,只要题解把所使用语言特性优化的点讲出来,大家都可以看懂,并使用自己语言的时候注意一下。
+
+对于写题解的同学,刷题用什么语言影响就非常大,如果自己语言没有学好而强调算法和编程语言没关系,其实是会误伤别人的。
+
+**这也是我为什么统一使用C++写题解的原因**,其实用其他语言java、python、php、go啥的,我也能写,我的Github上也有用这些语言写的小项目,但写题解的话,我就不能保证把语言特性这块讲清楚,所以我始终坚持使用最熟悉的C++写题解。
+
+**而且我在写题解的时候涉及语言特性,一般都会后面加上括号说明一下。没办法,认真负责就是我,哈哈**。
+
+就酱,「代码随想录」一直都是干货满满,值得介绍给身边的朋友同学们!
+
+**循序渐进学算法,认准「代码随想录」,Carl手把手带你过关斩将!**
+
+
+
-**都说用贪心算法,是贪心究竟贪在哪里呢?**
-贪心在优先按照身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列。
+按照身高排序之后,优先按身高高的people的k来插入,后序插入节点也不会影响前面已经插入的节点,最终按照k的规则完成了队列。
-局部最优:优先按照身高搞的people的k来插入。插入操作过后的people满足队列属性
+所以在按照身高从大到小排序后:
-全局最优:最后都做完插入操作,整个队列满足题目队列属性
+**局部最优:优先按身高高的people的k来插入。插入操作过后的people满足队列属性**
-局部最优可推出全局最优。
+**全局最优:最后都做完插入操作,整个队列满足题目队列属性**
-整个插入过程如下:
+局部最优可推出全局最优,找不出反例,那就试试贪心。
+
+一些同学可能也会疑惑,你怎么知道局部最优就可以推出全局最优呢? 有数学证明么?
+
+在贪心系列开篇词[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)中,我已经讲过了这个问题了。
+
+刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心,至于严格的数学证明,就不在讨论范围内了。
+
+如果没有读过[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)的同学建议读一下,相信对贪心就有初步的了解了。
+
+回归本题,整个插入过程如下:
+
+排序完的people:
+[[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
-排序完:
-[[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
插入的过程:
-插入[7,0]:[[7,0]]
-插入[7,1]:[[7,0],[7,1]]
-插入[6,1]:[[7,0],[6,1],[7,1]]
-插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
-插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
-插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
+插入[7,0]:[[7,0]]
+插入[7,1]:[[7,0],[7,1]]
+插入[6,1]:[[7,0],[6,1],[7,1]]
+插入[5,0]:[[5,0],[7,0],[6,1],[7,1]]
+插入[5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
+插入[4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
+此时就按照题目的要求完成了重新排列。
C++代码如下:
+
+```C++
+// 版本一
+class Solution {
+public:
+ static bool cmp(const vector a, const vector b) {
+ if (a[0] == b[0]) return a[1] < b[1];
+ return a[0] > b[0];
+ }
+ vector> reconstructQueue(vector>& people) {
+ sort (people.begin(), people.end(), cmp);
+ vector> que;
+ for (int i = 0; i < people.size(); i++) {
+ int position = people[i][1];
+ que.insert(que.begin() + position, people[i]);
+ }
+ return que;
+ }
+};
```
+* 时间复杂度O(nlogn + n^3)
+* 空间复杂度O(n)
+
+大家会发现这个n^3 是怎么来的?
+
+其实数组的插入操作复杂度是O(n^2):寻找插入元素位置O(1),插入元素O(n^2),因为插入元素后面的元素要整体向后移。
+
+如果对数组的增删时间复杂度不清楚的话,可以做做这道题目[数组:就移除个元素很难么?](https://mp.weixin.qq.com/s/wj0T-Xs88_FHJFwayElQlA),数组中插入元素和删除元素都是O(n^2)的复杂度。
+
+我们就是要模拟一个插入队列的行为,所以不应该使用数组,而是要使用链表!
+
+链表的插入操作复杂度是O(n):寻找插入元素位置O(n),插入元素O(1)。
+
+可以看出使用链表的插入效率要比普通数组高出一个数量级!
+
+改成链表之后,C++代码如下:
+
+```C++
+// 版本二
class Solution {
public:
// 身高从大到小排(身高相同k小的站前面)
@@ -53,16 +151,51 @@ public:
}
vector> reconstructQueue(vector>& people) {
sort (people.begin(), people.end(), cmp);
- list> que; // 使用list底层是链表实现,插入效率比vector高的多
+ list> que; // list底层是链表实现,插入效率比vector高的多
for (int i = 0; i < people.size(); i++) {
int position = people[i][1]; // 插入到下标为position的位置
std::list>::iterator it = que.begin();
- while (position--) {
- it++;
+ while (position--) { // 寻找在插入位置
+ it++;
}
- que.insert(it, people[i]);
+ que.insert(it, people[i]);
}
return vector>(que.begin(), que.end());
}
};
```
+
+* 时间复杂度O(nlogn + n^2)
+* 空间复杂度O(n)
+
+大家可以把两个版本的代码提交一下试试,就可以发现其差别了!
+
+# 总结
+
+关于出现两个维度一起考虑的情况,我们已经做过两道题目了,另一道就是[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)。
+
+**其技巧都是确定一边然后贪心另一边,两边一起考虑,就会顾此失彼**。
+
+这道题目可以说比[贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)难不少,其贪心的策略也是比较巧妙。
+
+最后我给出了两个版本的代码,可以明显看是使用C++中的list(底层链表实现)比vector(数组)效率高得多。
+
+**对使用某一种语言容器的使用,特性的选择都会不同程度上影响效率**。
+
+所以很多人都说写算法题用什么语言都可以,主要体现在算法思维上,其实我是同意的但也不同意。
+
+对于看别人题解的同学,题解用什么语言其实影响不大,只要题解把所使用语言特性优化的点讲出来,大家都可以看懂,并使用自己语言的时候注意一下。
+
+对于写题解的同学,刷题用什么语言影响就非常大,如果自己语言没有学好而强调算法和编程语言没关系,其实是会误伤别人的。
+
+**这也是我为什么统一使用C++写题解的原因**,其实用其他语言java、python、php、go啥的,我也能写,我的Github上也有用这些语言写的小项目,但写题解的话,我就不能保证把语言特性这块讲清楚,所以我始终坚持使用最熟悉的C++写题解。
+
+**而且我在写题解的时候涉及语言特性,一般都会后面加上括号说明一下。没办法,认真负责就是我,哈哈**。
+
+就酱,「代码随想录」一直都是干货满满,值得介绍给身边的朋友同学们!
+
+**循序渐进学算法,认准「代码随想录」,Carl手把手带你过关斩将!**
+
+
+
+
diff --git a/problems/0714.买卖股票的最佳时机含手续费.md b/problems/0714.买卖股票的最佳时机含手续费.md
new file mode 100644
index 00000000..3b5b6340
--- /dev/null
+++ b/problems/0714.买卖股票的最佳时机含手续费.md
@@ -0,0 +1,102 @@
+
+# 思路
+本题相对于[贪心算法:122.买卖股票的最佳时机II](https://mp.weixin.qq.com/s/VsTFA6U96l18Wntjcg3fcg),多添加了一个条件就是手续费。
+
+## 贪心算法
+
+在[贪心算法:122.买卖股票的最佳时机II](https://mp.weixin.qq.com/s/VsTFA6U96l18Wntjcg3fcg)中使用贪心策略不用关系具体什么时候买卖,只要收集每天的正利润,最后稳稳的就是最大利润了。
+
+而本题有了手续费,就要关系什么时候买卖了,因为只计算所获得利润,可能不足以手续费。
+
+如果使用贪心策略,就是最低值买,最高值(如果算上手续费还盈利)就卖。
+
+此时无非就是要找到两个点,买入日期,和卖出日期。
+
+* 买入日期:其实很好想,遇到更低点就记录一下。
+* 卖出日期:这个就不好算了,但也没有必要算出准确的卖出日期,只要当前价格大于(最低价格+费用),就可以收获利润,至于准确的卖出日期,就是连续收获利润区间里的最后一天。
+
+所以我们在做收获利润操作的时候其实有两种情况:
+
+* 情况一:收获利润的这一天并不是收获利润区间里的最后一天(不是真正的卖出,相当于持有股票),所以后面要继续收获利润。
+* 情况二:收获利润的这一天是收获利润区间里的最后一天(相当于真正的卖出了),后面要重新记录最小价格了。
+
+贪心算法C++代码如下:
+
+```C++
+class Solution {
+public:
+ int maxProfit(vector& prices, int fee) {
+ int result = 0;
+ int minPrice = prices[0]; // 记录最低价格
+ for (int i = 1; i < prices.size(); i++) {
+ // 买入
+ if (prices[i] < minPrice) minPrice = prices[i]; // 情况二
+
+ // 计算利润,可能有多次计算利润,最后一次计算利润才是真正意义的卖出
+ if (prices[i] > minPrice + fee) {
+ result += prices[i] - minPrice - fee;
+ minPrice = prices[i] - fee; // 情况一,这一步很关键
+ }
+ }
+ return result;
+ }
+};
+```
+
+从代码中可以看出对情况一的操作,因为如果还在收获利润的区间里,表示并不是真正的卖出,而计算利润每次都要减去手续费,
+**所以要让minPrice = prices[i] - fee;,这样在明天收获利润的时候,才不会多减一次手续费!**
+
+理解这里很关键,其实也是核心所在,很多题解关于这块都没有说清楚。
+
+## 动态规划
+
+我在「代码随想录」公众号里正在讲解贪心算法,将在下一个系列详细讲解动态规划,所以本题解先给出我的C++代码(带详细注释),感兴趣的同学可以自己先学习一下。
+
+相对于[贪心算法:122.买卖股票的最佳时机II](https://mp.weixin.qq.com/s/VsTFA6U96l18Wntjcg3fcg)的动态规划解法中,只需要在计算卖出操作的时候减去手续费就可以了,代码几乎是一样的。
+
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ int maxProfit(vector& prices, int fee) {
+ // dp[i][1]第i天持有的最多现金
+ // dp[i][0]第i天持有股票所剩的最多现金
+ int n = prices.size();
+ vector> dp(n, vector(2, 0));
+ dp[0][0] -= prices[0]; // 持股票
+ for (int i = 1; i < n; i++) {
+ // 第i天持股票所剩最多现金 = max(第i-1天持股票所剩现金, 第i-1天持现金-买第i天的股票)
+ dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
+ // 第i天持有最多现金 = max(第i-1天持有的最多现金,第i-1天持有股票所剩的最多现金+第i天卖出股票-手续费)
+ dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i] - fee);
+ }
+ return max(dp[n - 1][0], dp[n - 1][1]);
+ }
+};
+```
+
+当然可以对空间经行优化,因为当前状态只是依赖前一个状态。
+
+C++ 代码如下:
+
+```C++
+class Solution {
+public:
+ int maxProfit(vector& prices, int fee) {
+ int n = prices.size();
+ int holdStock = (-1) * prices[0]; // 持股票
+ int saleStock = 0; // 卖出股票
+ for (int i = 1; i < n; i++) {
+ int previousHoldStock = holdStock;
+ holdStock = max(holdStock, saleStock - prices[i]);
+ saleStock = max(saleStock, previousHoldStock + prices[i] - fee);
+ }
+ return saleStock;
+ }
+};
+```
+
+细心的同学可能发现,在计算saleStock的时候 使用的已经是最新的holdStock了,理论上应该使用上一个状态的holdStock即(i-1时候的holdstock),但是
+
+
diff --git a/problems/0860.柠檬水找零.md b/problems/0860.柠檬水找零.md
index ca11a168..21bc66bc 100644
--- a/problems/0860.柠檬水找零.md
+++ b/problems/0860.柠檬水找零.md
@@ -1,21 +1,78 @@
-> 如果对贪心算法理论基础还不了解的话,可以看看这篇:[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg) ,相信看完之后对贪心就有基本的了解了。
-这道题目我们需要维护三种金额的数量,5,10和20。
+> 给我来一杯柠檬水
+
+# 860.柠檬水找零
+
+题目链接:https://leetcode-cn.com/problems/lemonade-change/
+
+在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
+
+顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
+
+每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
+
+注意,一开始你手头没有任何零钱。
+
+如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
+
+示例 1:
+输入:[5,5,5,10,20]
+输出:true
+解释:
+前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
+第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
+第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
+由于所有客户都得到了正确的找零,所以我们输出 true。
+
+示例 2:
+输入:[5,5,10]
+输出:true
+
+示例 3:
+输入:[10,10]
+输出:false
+
+示例 4:
+输入:[5,5,10,10,20]
+输出:false
+解释:
+前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
+对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
+对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
+由于不是每位顾客都得到了正确的找零,所以答案是 false。
+
+提示:
+
+* 0 <= bills.length <= 10000
+* bills[i] 不是 5 就是 10 或是 20
+
+# 思路
+
+这是前几天的leetcode每日一题,感觉不错,给大家讲一下。
+
+这道题目刚一看,可能会有点懵,这要怎么找零才能保证完整全部账单的找零呢?
+
+**但仔细一琢磨就会发现,可供我们做判断的空间非常少!**
+
+只需要维护三种金额的数量,5,10和20。
有如下三种情况:
+
* 情况一:账单是5,直接收下。
* 情况二:账单是10,消耗一个5,增加一个10
-* 情况三:账单是20,优先消耗一个10和一个5,如果不够,在消耗三个5
+* 情况三:账单是20,优先消耗一个10和一个5,如果不够,再消耗三个5
-这道题大家可能感觉纯模拟就可以了,其实这里有贪心,就在情况三中。
+此时大家就发现 情况一,情况二,都是固定策略,都不用我们来做分析了,而唯一不确定的其实在情况三。
+
+而情况三逻辑也不复杂甚至感觉纯模拟就可以了,其实情况三这里是有贪心的。
账单是20的情况,为什么要优先消耗一个10和一个5呢?
**因为美元10只能给账单20找零,而美元5可以给账单10和账单20找零,美元5更万能!**
-局部最优:遇到账单20,优先消耗美元10,完成本次找零。全局最优:完成全部账单的找零。
+所以局部最优:遇到账单20,优先消耗美元10,完成本次找零。全局最优:完成全部账单的找零。
-局部最优可以推出全局最优,并找不出反例,那么就试试贪心。
+局部最优可以推出全局最优,并找不出反例,那么就试试贪心算法!
C++代码如下:
@@ -49,8 +106,19 @@ public:
return true;
}
};
-
```
+
+# 总结
+
+咋眼一看好像很复杂,分析清楚之后,会发现逻辑其实非常固定。
+
+这道题目可以告诉大家,遇到感觉没有思路的题目,可以静下心来把能遇到的情况分析一下,只要分析到具体情况了,一下子就豁然开朗了。
+
+如果一直陷入想从整体上寻找找零方案,就会把自己陷进去,各种情况一交叉,只会越想越复杂了。
+
+就酱,如果感觉「代码随想录」干货满满,就帮忙宣传一波吧,感激不尽!
+
+
> **我是[程序员Carl](https://github.com/youngyangyang04),可以找我[组队刷题](https://img-blog.csdnimg.cn/20201115103410182.png),也可以在[B站上找到我](https://space.bilibili.com/525438321),本文[leetcode刷题攻略](https://github.com/youngyangyang04/leetcode-master)已收录,更多[精彩算法文章](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzUxNjY5NTYxNA==&action=getalbum&album_id=1485825793120387074&scene=173#wechat_redirect)尽在公众号:[代码随想录](https://img-blog.csdnimg.cn/20201124161234338.png),关注后就会发现和「代码随想录」相见恨晚!**
**如果感觉题解对你有帮助,不要吝啬给一个👍吧!**
diff --git a/problems/1518.换酒问题.md b/problems/1518.换酒问题.md
index b72d7d2d..3dbd7739 100644
--- a/problems/1518.换酒问题.md
+++ b/problems/1518.换酒问题.md
@@ -1,4 +1,57 @@
+# 1518.换酒问题
+
+小区便利店正在促销,用 numExchange 个空酒瓶可以兑换一瓶新酒。你购入了 numBottles 瓶酒。
+
+如果喝掉了酒瓶中的酒,那么酒瓶就会变成空的。
+
+请你计算 最多 能喝到多少瓶酒。
+
+
+
+
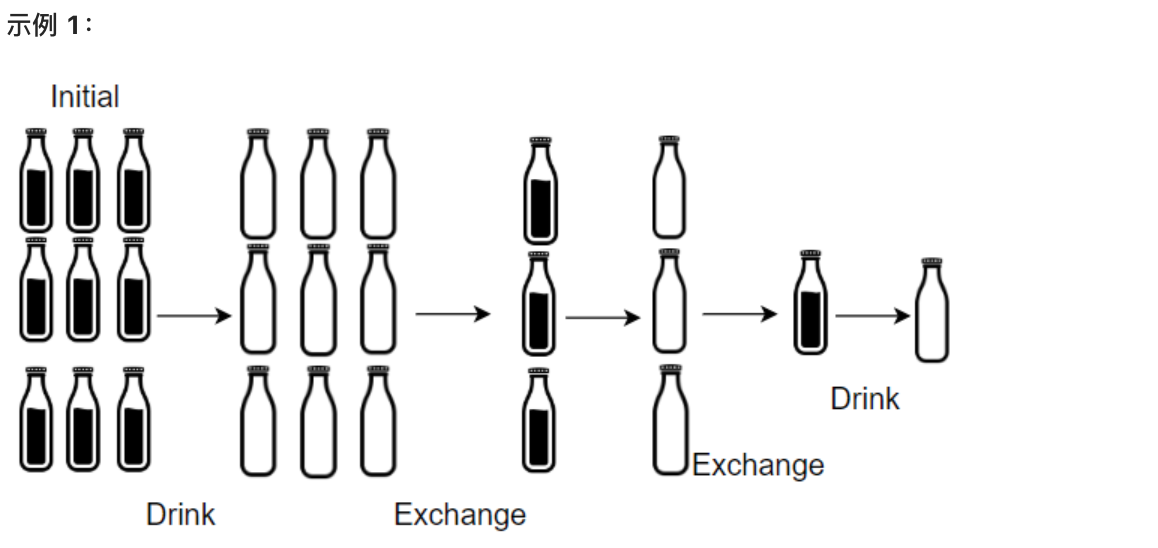
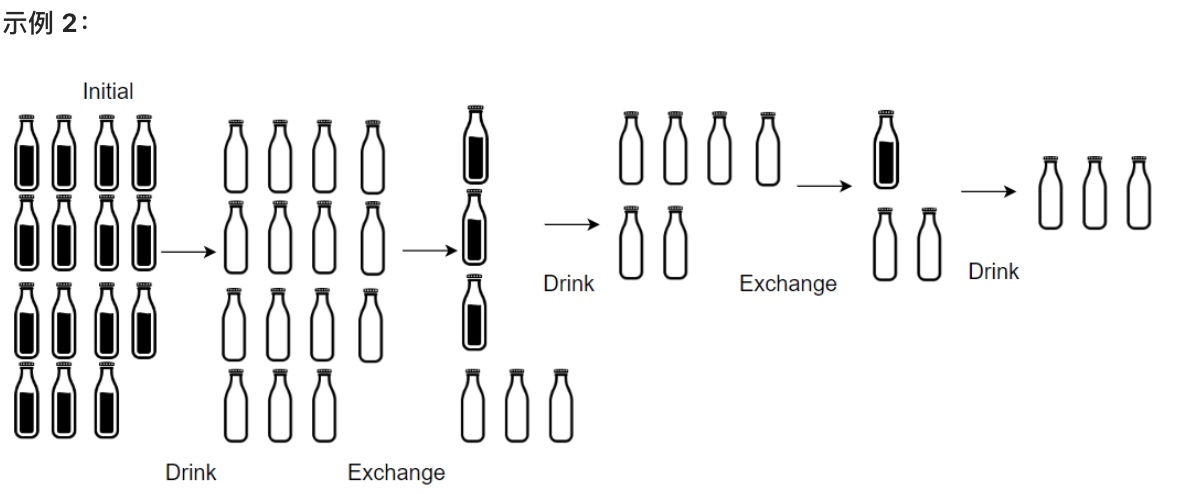
+输入:numBottles = 9, numExchange = 3
+输出:13
+解释:你可以用 3 个空酒瓶兑换 1 瓶酒。
+所以最多能喝到 9 + 3 + 1 = 13 瓶酒。
+
+
+
+输入:numBottles = 15, numExchange = 4
+输出:19
+解释:你可以用 4 个空酒瓶兑换 1 瓶酒。
+所以最多能喝到 15 + 3 + 1 = 19 瓶酒。
+
+示例 3:
+输入:numBottles = 5, numExchange = 5
+输出:6
+
+示例 4:
+输入:numBottles = 2, numExchange = 3
+输出:2
+
+提示:
+
+* 1 <= numBottles <= 100
+* 2 <= numExchange <= 100
+
+# 思路
+
+这道题目其实是很简单的了,简单到大家都不以为这是贪心算法,哈哈
+
+来分析一下:
+
+局部最优:每次换酒用尽可能多的酒瓶。全局最优:喝到最多的酒。
+
+局部最优可以推出全局最优,那么这就是贪心!
+
+本题其实
+
+
+每次环境
+
+其实思路是简单的,但本题在
+
```
// 这道题还是有陷阱啊,15 4 这个例子,答案应该是19 而不是18
class Solution {

