diff --git a/README.md b/README.md
index 22b2103a..be72f97b 100644
--- a/README.md
+++ b/README.md
@@ -338,8 +338,8 @@ int countNodes(TreeNode* root) {
|[0018.四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md) | 数组 |中等|**双指针**|
|[0020.有效的括号](https://github.com/youngyangyang04/leetcode/blob/master/problems/0020.有效的括号.md) | 栈 |简单|**栈**|
|[0021.合并两个有序链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0021.合并两个有序链表.md) |链表 |简单|**模拟** |
-|[0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md) |数组 |简单|**暴力** **快慢指针** |
-|[0027.移除元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0027.移除元素.md) |数组 |简单| **暴力** **快慢指针/双指针**|
+|[0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md) |数组 |简单|**暴力** **快慢指针/快慢指针** |
+|[0027.移除元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0027.移除元素.md) |数组 |简单| **暴力** **双指针/快慢指针/双指针**|
|[0028.实现strStr()](https://github.com/youngyangyang04/leetcode/blob/master/problems/0028.实现strStr().md) |字符串 |简单| **KMP** |
|[0035.搜索插入位置](https://github.com/youngyangyang04/leetcode/blob/master/problems/0035.搜索插入位置.md) |数组 |简单| **暴力** **二分**|
|[0053.最大子序和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0053.最大子序和.md) |数组 |简单|**暴力** **贪心** 动态规划 分治|
diff --git a/problems/0015.三数之和.md b/problems/0015.三数之和.md
index 66265413..985cb76c 100644
--- a/problems/0015.三数之和.md
+++ b/problems/0015.三数之和.md
@@ -16,12 +16,23 @@ https://leetcode-cn.com/problems/3sum/
### 双指针
-推荐使用这个方法,排序后用双指针前后操作,比较容易达到去重的目的,但也有一些细节需要注意,我在如下代码详细注释了需要注意的点。
+**其实这道题目使用哈希法并不十分合适**,因为在去重的操作中有很多细节需要注意,在面试中很难直接写出没有bug的代码,而且是用哈希法 在使用两层for循环的时候,能做的剪枝操作很有限,虽然时间复杂度是O(n^2),也是可以在leetcode上通过,但是程序的执行时间依然比较长 。
+
+接下来我来介绍另一个解法:双指针法,**这道题目使用双指针法 要比哈希法高效一些**,那么来讲解一下具体实现的思路。
动画效果如下:
+拿这个nums数组来举例,首先将数组排序,然后 有一层for循环,i从下表0的地方开始,同时定一个下表left 定义在i+1的位置上,定义下表right 在数组结尾的位置上。
+
+我们依然还是在数组中找到 abc 使得a + b +c =0,我们这里相当于 a = nums[i] b = nums[left] c = nums[right]。
+
+接下来我们如何移动left 和right呢, 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下表就应该想左移动,这样才能让三数之和小一些。
+
+如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了, left 就向右移动,才能让三数之和大一些,直到left与right相遇为止。
+
+
时间复杂度:O(n^2)
## C++代码
diff --git a/problems/0018.四数之和.md b/problems/0018.四数之和.md
index 1130e802..2384ece1 100644
--- a/problems/0018.四数之和.md
+++ b/problems/0018.四数之和.md
@@ -4,7 +4,14 @@ https://leetcode-cn.com/problems/4sum/
## 思路
-四数之和,和[三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md)是一个思路,都是使用双指针法,但是有一些细节需要注意,例如: 不要判断`nums[k] > target` 就返回了,三数之和 可以通过 `nums[i] > 0` 就返回了,因为 0 已经是确定的数了,四数之和这道题目 target是任意值
+
+四数之和,和[三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md)是一个思路,都是使用双指针法,但是有一些细节需要注意,例如: 不要判断`nums[k] > target` 就返回了,三数之和 可以通过 `nums[i] > 0` 就返回了,因为 0 已经是确定的数了,四数之和这道题目 target是任意值。
+
+三数之和 我们是一层for循环,然后循环内有left和right下表作为指针,四数之和,就可以是两层for循环,依然是循环内有left和right下表作为指针,三数之和的时间复杂度是O(n^2),四数之和的时间复杂度是O(n^3) 。
+
+动画如下:
+
+
## C++代码
```
diff --git a/problems/0026.删除排序数组中的重复项.md b/problems/0026.删除排序数组中的重复项.md
index 220a5d12..114f2da2 100644
--- a/problems/0026.删除排序数组中的重复项.md
+++ b/problems/0026.删除排序数组中的重复项.md
@@ -1,12 +1,33 @@
## 题目地址
https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/
-## 思路
+# 思路
-此题就是O(n)的解法,拼速度的话,也就是剪剪枝
-注意题目中:你不需要考虑数组中超出新长度后面的元素。 说明是要对原数组进行操作的
+此题使用双指针法,O(n)的时间复杂度,拼速度的话,可以剪剪枝。
-## 解法
+注意题目中:不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
+
+双指针法,动画如下:
+
+
+
+其实**双指针法在在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法,可以将时间复杂度O(n^2)的解法优化为 O(n)的解法,例如:**
+
+* [0015.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md)
+* [0018.四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md)
+* [0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md)
+* [0206.翻转链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0206.翻转链表.md)
+* [0344.反转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0344.反转字符串.md)
+* [剑指Offer05.替换空格](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md)
+
+**还有链表找环,也用到双指针:**
+
+* [0142.环形链表II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0142.环形链表II.md)
+
+大家都可以去做一做,感受一下双指针法的内在逻辑!
+
+
+# C++ 代码
```
diff --git a/problems/0027.移除元素.md b/problems/0027.移除元素.md
index ec4e33b2..6c73881e 100644
--- a/problems/0027.移除元素.md
+++ b/problems/0027.移除元素.md
@@ -1,11 +1,90 @@
> 笔者在BAT从事技术研发多年,利用工作之余重刷leetcode,更多原创文章请关注公众号「代码随想录」。
-## 题目地址
+# 题目地址
https://leetcode-cn.com/problems/remove-element/
-建议做完这道题,接着再去做 26. 删除排序数组中的重复项, 对这种类型的题目就有有所感觉
+# 思路
+有的同学可能说了,多余的元素,删掉不就得了。
+
+**要清楚数组的元素在内存地址中是连续的,数组中的元素是不能删掉的,只能覆盖。**
+
+# 暴力解法
+
+这个题目暴力的解法就是两层for循环,一个for循环遍历数组元素 ,第二个for循环更新数组。
+
+如动画所示:
+
+
+
+很明显暴力解法的时间复杂度是O(n^2),这道题目暴力解法在leetcode上是可以过的。
+
+代码如下:
+
+```
+class Solution {
+public:
+ int removeElement(vector& nums, int val) {
+ int size = nums.size();
+ for (int i = 0; i < size; i++) {
+ if (nums[i] == val) { // 发现需要移除的元素,就将数组集体向前移动一位
+ for (int j = i + 1; j < size; j++) {
+ nums[j - 1] = nums[j];
+ }
+ i--; // 因为下表i以后的数值都向前移动了一位,所以i也向前移动一位
+ size--;// 此时数组的大小-1
+ }
+ }
+ return size;
+
+ }
+};
+```
+
+# 双指针法
+
+双指针法(快慢指针法): **说白了就是通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。**
+
+先看一下动画理解一下:
+
+
+
+
+代码如下:
+```
+// 时间复杂度:O(n)
+// 空间复杂度:O(1)
+class Solution {
+public:
+ int removeElement(vector& nums, int val) {
+ int slowIndex = 0; // index为 慢指针
+ for (int fastIndex = 0; fastIndex < nums.size(); fastIndex++) { // i 为快指针
+ if (val != nums[fastIndex]) { //将快指针对应的数值赋值给慢指针对应的数值
+ nums[slowIndex++] = nums[fastIndex]; 注意这里是slowIndex++ 而不是slowIndex--
+ }
+ }
+ return slowIndex;
+ }
+};
+```
+
+其实**双指针法(快慢指针法)在在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法,可以将时间复杂度O(n^2)的解法优化为 O(n)的解法,例如:**
+
+* [0015.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md)
+* [0018.四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md)
+* [0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md)
+* [0206.翻转链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0206.翻转链表.md)
+* [0344.反转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0344.反转字符串.md)
+* [剑指Offer05.替换空格](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md)
+
+**还有链表找环,也用到双指针:**
+
+* [0142.环形链表II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0142.环形链表II.md)
+
+大家都可以去做一做,感受一下双指针法的内在逻辑!
+
+# 本题C++代码
## 暴力解法
时间复杂度:O(n^2)
@@ -30,7 +109,7 @@ public:
};
```
-## 快慢指针解法
+## 双指针解法
时间复杂度:O(n)
空间复杂度:O(1)
```
diff --git a/problems/0142.环形链表II.md b/problems/0142.环形链表II.md
index 6aa90ebe..6abed001 100644
--- a/problems/0142.环形链表II.md
+++ b/problems/0142.环形链表II.md
@@ -1,7 +1,20 @@
-## 题目地址
+# 题目地址
https://leetcode-cn.com/problems/linked-list-cycle-ii/
-## 思路
+> 找到有没有环已经很不容易了,还要让我找到环的入口?
+
+# 第142题.环形链表II
+
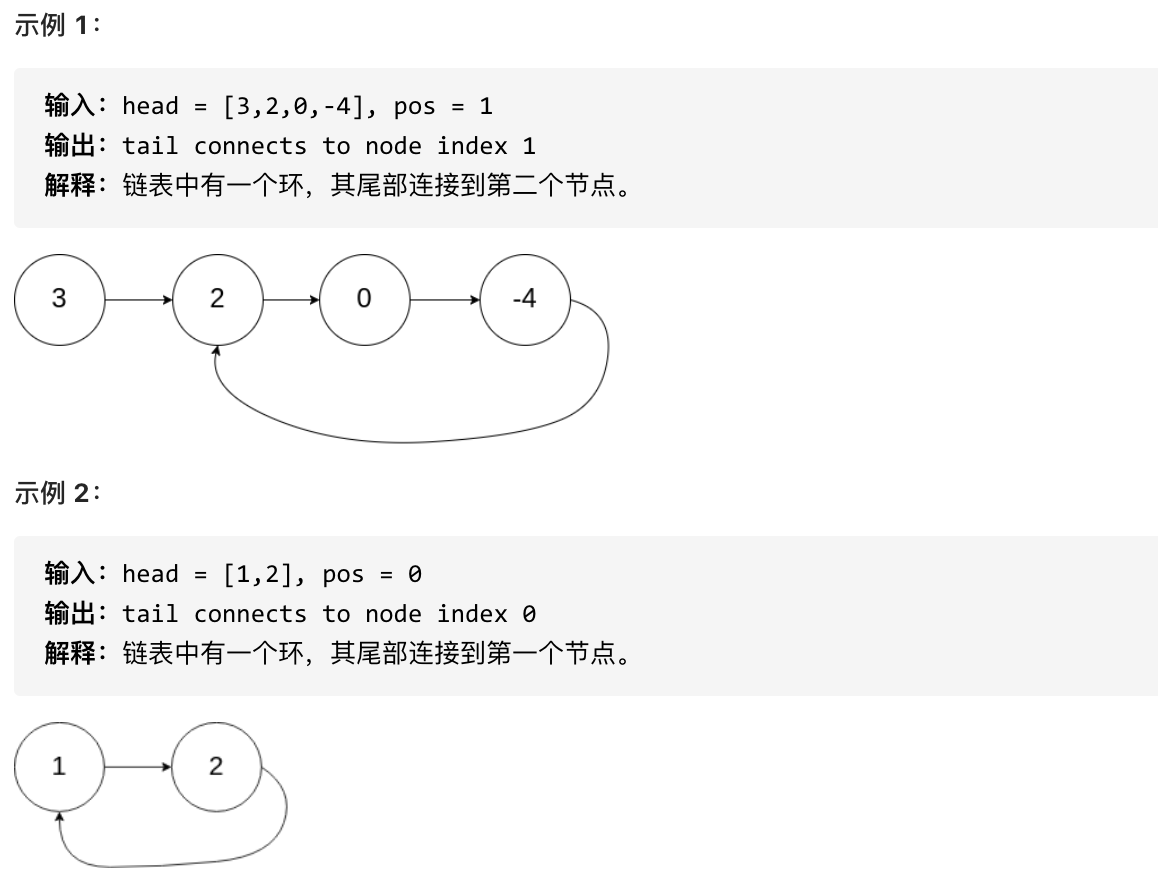
+题意:
+给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
+
+为了表示给定链表中的环,使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
+
+**说明**:不允许修改给定的链表。
+
+
+
+# 思路
这道题目,不仅考察对链表的操作,而且还需要一些数学运算。
@@ -10,7 +23,7 @@ https://leetcode-cn.com/problems/linked-list-cycle-ii/
* 判断链表是否环
* 如果有环,如何找到这个环的入口
-### 判断链表是否有环
+## 判断链表是否有环
可以使用快慢指针法, 分别定义 fast 和 slow指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
@@ -18,7 +31,7 @@ https://leetcode-cn.com/problems/linked-list-cycle-ii/
首先第一点: **fast指针一定先进入环中,如果fast 指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。**
-那么我们来看一下,**为什么fast指针和slow指针一定会相遇呢**
+那么来看一下,**为什么fast指针和slow指针一定会相遇呢?**
可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。
@@ -31,41 +44,39 @@ fast和slow各自再走一步, fast和slow就相遇了
这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
-### 如果有环,如何找到这个环的入口
-
-**此时我们已经可以判断链表是否有环了,那么接下来要找这个环的入口了**
+## 如果有环,如何找到这个环的入口
+**此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。**
假设从头结点到环形入口节点 的节点数为x。
环形入口节点到 fast指针与slow指针相遇节点 节点数为y。
从相遇节点 再到环形入口节点节点数为 z。 如图所示:
+
 那么相遇时:
-slow指针走过的节点数为: x + y
-fast指针走过的节点数: x + y + n (y + z),n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数
+slow指针走过的节点数为: `x + y`,
+fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。
-
-因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2
+因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
`(x + y) * 2 = x + y + n (y + z)`
两边消掉一个(x+y): `x + y = n (y + z) `
-因为我们要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
+因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
-所以我们要求x ,将x单独放在左面:`x = n (y + z) - y`
+所以要求x ,将x单独放在左面:`x = n (y + z) - y` ,
-在从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:`x = (n - 1) (y + z) + z ` 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针
+再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:`x = (n - 1) (y + z) + z ` 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。
-这个公式说明什么呢,
+这个公式说明什么呢?
先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
-当 n为1的时候,公式就化解为 `x = z`
+当 n为1的时候,公式就化解为 `x = z`,
-
-这就意味着,**从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点**
+这就意味着,**从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点**。
也就是在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
@@ -77,7 +88,7 @@ fast指针走过的节点数: x + y + n (y + z),n为fast指针在环内走
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
-## 代码
+# C++代码
```
/**
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index c4eed2e3..8f8454e4 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -16,6 +16,10 @@ https://leetcode-cn.com/problems/reverse-words-in-a-string/
* 将整个字符串反转
* 将每个单词反转
+如动画所示:
+
+
那么相遇时:
-slow指针走过的节点数为: x + y
-fast指针走过的节点数: x + y + n (y + z),n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数
+slow指针走过的节点数为: `x + y`,
+fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。
-
-因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2
+因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
`(x + y) * 2 = x + y + n (y + z)`
两边消掉一个(x+y): `x + y = n (y + z) `
-因为我们要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
+因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
-所以我们要求x ,将x单独放在左面:`x = n (y + z) - y`
+所以要求x ,将x单独放在左面:`x = n (y + z) - y` ,
-在从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:`x = (n - 1) (y + z) + z ` 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针
+再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:`x = (n - 1) (y + z) + z ` 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。
-这个公式说明什么呢,
+这个公式说明什么呢?
先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
-当 n为1的时候,公式就化解为 `x = z`
+当 n为1的时候,公式就化解为 `x = z`,
-
-这就意味着,**从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点**
+这就意味着,**从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点**。
也就是在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
@@ -77,7 +88,7 @@ fast指针走过的节点数: x + y + n (y + z),n为fast指针在环内走
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
-## 代码
+# C++代码
```
/**
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index c4eed2e3..8f8454e4 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -16,6 +16,10 @@ https://leetcode-cn.com/problems/reverse-words-in-a-string/
* 将整个字符串反转
* 将每个单词反转
+如动画所示:
+
+ +
这样我们就完成了翻转字符串里的单词。
## 代码
diff --git a/problems/0202.快乐数.md b/problems/0202.快乐数.md
index 0a5b6108..1ed65498 100644
--- a/problems/0202.快乐数.md
+++ b/problems/0202.快乐数.md
@@ -3,16 +3,22 @@ https://leetcode-cn.com/problems/happy-number/
# 思路
-这道题目重点是,题目中说了会 **无限循环**, 那么也就是说 求和的过程中,sum会重复出现,这对我们解题很重要,这样我们就可以使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止
+这道题目看上去貌似一道数学问题,其实它也需要使用哈希法!
-还有就是求和的过程,如果对 取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难
+这道题目重点是,题目中说了会 **无限循环**,那么也就是说**求和的过程中,sum会重复出现,这对解题很重要!**
+
+这样就可以使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
+
+判断sum是否重复出现就可以使用unordered_set。
+
+**还有一个难点就是求和的过程,如果对取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难。**
# C++代码
```
class Solution {
public:
- // 取和
+ // 取数值各个位上的单数之和
int getSum(int n) {
int sum = 0;
while (n) {
diff --git a/problems/0219.存在重复元素II.md b/problems/0219.存在重复元素II.md
index 17427b89..ddc67051 100644
--- a/problems/0219.存在重复元素II.md
+++ b/problems/0219.存在重复元素II.md
@@ -4,7 +4,7 @@ https://leetcode-cn.com/problems/contains-duplicate-ii/
## 思路
-使用哈希策略,map数据结构来记录数组元素和对应的元素所在下表
+使用哈希策略,map数据结构来记录数组元素和对应的元素所在下表,看代码,已经详细注释。
## C++代码
@@ -14,7 +14,8 @@ public:
bool containsNearbyDuplicate(vector& nums, int k) {
unordered_map map; // key: 数组元素, value:元素所在下表
for (int i = 0; i < nums.size(); i++) {
- if (map.find(nums[i]) != map.end()) { // 找到了在索引i之前就出现过nums[i]这个元素
+ // 找到了在索引i之前就出现过nums[i]这个元素
+ if (map.find(nums[i]) != map.end()) {
int distance = i - map[nums[i]];
if (distance <= k) {
return true;
diff --git a/problems/0242.有效的字母异位词.md b/problems/0242.有效的字母异位词.md
index cbb8bf86..e903ee44 100644
--- a/problems/0242.有效的字母异位词.md
+++ b/problems/0242.有效的字母异位词.md
@@ -4,25 +4,55 @@ https://leetcode-cn.com/problems/valid-anagram/
## 思路
-使用哈希法来判断 s 中的字母是否 都在t中,且t中的字符也都在s中
+先说一个特殊示例,输入:s = “car”, t= “car”,输出应该是什么呢? 后台判题逻辑返回的依然是true,其实这道题目真正题意是字符串s是否可以排练组合为字符串t。
-## 代码
+那么来看一下应该怎么做, 首先是暴力的解法,两层for循环,同时还要记录 字符是否重复出现,很明显时间复杂度是 O(n^2),暴力的方法这里就不做介绍了,直接看一下有没有更优的方式。
+
+数组其实就是一个简单哈希表,而且这道题目中字符串只有小写字符,那么就可以定义一个数组,来记录字符串s里字符出现的次数。
+
+需要定义一个多大的数组呢,定一个数组叫做record,大小为26 就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。
+
+为了方便举例,判断一下字符串s= "aee", t = "eae"。
+
+操作动画如下:
+
+
+
这样我们就完成了翻转字符串里的单词。
## 代码
diff --git a/problems/0202.快乐数.md b/problems/0202.快乐数.md
index 0a5b6108..1ed65498 100644
--- a/problems/0202.快乐数.md
+++ b/problems/0202.快乐数.md
@@ -3,16 +3,22 @@ https://leetcode-cn.com/problems/happy-number/
# 思路
-这道题目重点是,题目中说了会 **无限循环**, 那么也就是说 求和的过程中,sum会重复出现,这对我们解题很重要,这样我们就可以使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止
+这道题目看上去貌似一道数学问题,其实它也需要使用哈希法!
-还有就是求和的过程,如果对 取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难
+这道题目重点是,题目中说了会 **无限循环**,那么也就是说**求和的过程中,sum会重复出现,这对解题很重要!**
+
+这样就可以使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
+
+判断sum是否重复出现就可以使用unordered_set。
+
+**还有一个难点就是求和的过程,如果对取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难。**
# C++代码
```
class Solution {
public:
- // 取和
+ // 取数值各个位上的单数之和
int getSum(int n) {
int sum = 0;
while (n) {
diff --git a/problems/0219.存在重复元素II.md b/problems/0219.存在重复元素II.md
index 17427b89..ddc67051 100644
--- a/problems/0219.存在重复元素II.md
+++ b/problems/0219.存在重复元素II.md
@@ -4,7 +4,7 @@ https://leetcode-cn.com/problems/contains-duplicate-ii/
## 思路
-使用哈希策略,map数据结构来记录数组元素和对应的元素所在下表
+使用哈希策略,map数据结构来记录数组元素和对应的元素所在下表,看代码,已经详细注释。
## C++代码
@@ -14,7 +14,8 @@ public:
bool containsNearbyDuplicate(vector& nums, int k) {
unordered_map map; // key: 数组元素, value:元素所在下表
for (int i = 0; i < nums.size(); i++) {
- if (map.find(nums[i]) != map.end()) { // 找到了在索引i之前就出现过nums[i]这个元素
+ // 找到了在索引i之前就出现过nums[i]这个元素
+ if (map.find(nums[i]) != map.end()) {
int distance = i - map[nums[i]];
if (distance <= k) {
return true;
diff --git a/problems/0242.有效的字母异位词.md b/problems/0242.有效的字母异位词.md
index cbb8bf86..e903ee44 100644
--- a/problems/0242.有效的字母异位词.md
+++ b/problems/0242.有效的字母异位词.md
@@ -4,25 +4,55 @@ https://leetcode-cn.com/problems/valid-anagram/
## 思路
-使用哈希法来判断 s 中的字母是否 都在t中,且t中的字符也都在s中
+先说一个特殊示例,输入:s = “car”, t= “car”,输出应该是什么呢? 后台判题逻辑返回的依然是true,其实这道题目真正题意是字符串s是否可以排练组合为字符串t。
-## 代码
+那么来看一下应该怎么做, 首先是暴力的解法,两层for循环,同时还要记录 字符是否重复出现,很明显时间复杂度是 O(n^2),暴力的方法这里就不做介绍了,直接看一下有没有更优的方式。
+
+数组其实就是一个简单哈希表,而且这道题目中字符串只有小写字符,那么就可以定义一个数组,来记录字符串s里字符出现的次数。
+
+需要定义一个多大的数组呢,定一个数组叫做record,大小为26 就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。
+
+为了方便举例,判断一下字符串s= "aee", t = "eae"。
+
+操作动画如下:
+
+ +
+定义一个数组叫做record用来上记录字符串s里字符出现的次数。
+
+如何记录呢,需要把字符映射到数组也就是哈希表的索引下表上,那么**因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下表0,相应的字符z映射为下表25。**
+
+再遍历 字符串s的时候,**只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。** 这样就将字符串s中字符出现的次数,统计出来了。
+
+
+那看一下如何检查 字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
+
+那么最后检查一下,**record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符,return false。**
+
+最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
+
+时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
+
+## C++ 代码
```
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {0};
for (int i = 0; i < s.size(); i++) {
- record[s[i]-'a']++;
+ // 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
+ record[s[i] - 'a']++;
}
for (int i = 0; i < t.size(); i++) {
- record[t[i]-'a']--;
+ record[t[i] - 'a']--;
}
for (int i = 0; i < 26; i++) {
if (record[i] != 0) {
+ // record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return false;
}
}
+ // record数组所有元素都为零0,说明字符串s和t是字母异位词
return true;
}
};
diff --git a/problems/0349.两个数组的交集.md b/problems/0349.两个数组的交集.md
index 879f476c..2f36c503 100644
--- a/problems/0349.两个数组的交集.md
+++ b/problems/0349.两个数组的交集.md
@@ -8,7 +8,7 @@ https://leetcode-cn.com/problems/intersection-of-two-arrays/
注意题目特意说明:**输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序**
-这道题用暴力的解法时间复杂度是O(n^2),这种解法面试官一定不会满意,那我们看看使用哈希法进一步优化。
+这道题用暴力的解法时间复杂度是O(n^2),这种解法面试官一定不会满意,那看看使用哈希法进一步优化。
那么可以发现,貌似用数组做哈希表可以解决这道题目,把nums1的元素,映射到哈希数组的下表上,然后在遍历nums2的时候,判断是否出现过就可以了。
@@ -16,13 +16,13 @@ https://leetcode-cn.com/problems/intersection-of-two-arrays/
例如说:如果我的输入样例是这样的, 难道要定义一个2亿大小的数组来做哈希表么, 不同的语言对数组定义的大小都是有限制的, 即使有的语言可以定义这么大的数组,那也是对内存空间造成了非常大的浪费。
-此时我们就要使用另一种结构体了,set ,关于set,C++ 给我们提供了如下三种可用的数据结构
+此时就要使用另一种结构体了,set ,关于set,C++ 给提供了如下三种可用的数据结构
* std::set
* std::multiset
* std::unordered_set
-std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,我们并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
+std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
思路如图所示:

diff --git a/problems/0454.四数相加II.md b/problems/0454.四数相加II.md
index 8b3b049c..af10a130 100644
--- a/problems/0454.四数相加II.md
+++ b/problems/0454.四数相加II.md
@@ -3,13 +3,19 @@ https://leetcode-cn.com/problems/4sum-ii/
## 思路
-本题使用哈希表映射的方法
+本题咋眼一看好像和[第18题. 四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md),[第15题.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md)差不多,其实差很多。
-那么为什么18. 四数之和,0015.三数之和不适用哈希表映射的方法呢,感觉上 这道题目都是四个数之和都可以用哈希,三数之和怎么就用不了哈希呢
+**本题是使用哈希法的经典题目,而[第18题. 四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md),[第15题.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md) 并不合适使用哈希法**,因为使用哈希的方法在不超时的情况下做到对结果去重很困难。
-因为题目15.三数之和和18. 四数之和,使用哈希的方法在不超时的情况下做到对结果去重很困难
+**而这道题目相当于说不用考虑重复元素,是四个独立的数组,所以相对于题目18. 四数之和,题目15.三数之和,还是简单了不少!**
-而这道题目 相当于说 不用考虑重复元素,是四个独立的数组,所以相对于题目18. 四数之和,0015.三数之和,还是简单了不少
+解题步骤:
+
+1. 首先定义 一个unordered_map,key放a和b两数之和,value 放a和b两数之和出现的次数。
+2. 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中。
+3. 定义int变量count,用来统计a+b+c+d = 0 出现的次数。
+4. 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就用count把map中key对应的value也就是出现次数统计出来。
+5. 最后返回我们的统计值 count 就可以了
## C++代码
@@ -18,26 +24,25 @@ class Solution {
public:
int fourSumCount(vector& A, vector& B, vector& C, vector& D) {
unordered_map umap; //key:a+b的数值,value:a+b数值出现的次数
+ // 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
for (int a : A) {
for (int b : B) {
- if (umap.find(a + b) != umap.end()) {
- umap[a + b]++;
- } else {
- umap[a + b] = 1;
- }
+ umap[a + b]++;
}
}
- int count = 0;
+ int count = 0; // 统计a+b+c+d = 0 出现的次数
+ // 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
for (int c : C) {
for (int d : D) {
if (umap.find(0 - (c + d)) != umap.end()) {
- count += umap[0 - (c + d)];
+ count += umap[0 - (c + d)];
}
}
}
return count;
}
};
+
```
> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
diff --git a/video/151翻转字符串里的单词.gif b/video/151翻转字符串里的单词.gif
new file mode 100644
index 00000000..cd8a60fb
Binary files /dev/null and b/video/151翻转字符串里的单词.gif differ
diff --git a/video/242.有效的字母异位词.gif b/video/242.有效的字母异位词.gif
new file mode 100644
index 00000000..febc0bad
Binary files /dev/null and b/video/242.有效的字母异位词.gif differ
diff --git a/video/242.有效的字母异位词.mp4 b/video/242.有效的字母异位词.mp4
new file mode 100644
index 00000000..33504290
Binary files /dev/null and b/video/242.有效的字母异位词.mp4 differ
diff --git a/video/26.删除排序数组中的重复项.mp4 b/video/26.删除排序数组中的重复项.mp4
new file mode 100644
index 00000000..846d10ac
Binary files /dev/null and b/video/26.删除排序数组中的重复项.mp4 differ
diff --git a/video/27.移除元素-暴力解法.mp4 b/video/27.移除元素-暴力解法.mp4
new file mode 100644
index 00000000..5024f2d7
Binary files /dev/null and b/video/27.移除元素-暴力解法.mp4 differ
diff --git a/video/27.移除元素.mp4 b/video/27.移除元素.mp4
new file mode 100644
index 00000000..9dc869a1
Binary files /dev/null and b/video/27.移除元素.mp4 differ
+
+定义一个数组叫做record用来上记录字符串s里字符出现的次数。
+
+如何记录呢,需要把字符映射到数组也就是哈希表的索引下表上,那么**因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下表0,相应的字符z映射为下表25。**
+
+再遍历 字符串s的时候,**只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。** 这样就将字符串s中字符出现的次数,统计出来了。
+
+
+那看一下如何检查 字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
+
+那么最后检查一下,**record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符,return false。**
+
+最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
+
+时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
+
+## C++ 代码
```
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {0};
for (int i = 0; i < s.size(); i++) {
- record[s[i]-'a']++;
+ // 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
+ record[s[i] - 'a']++;
}
for (int i = 0; i < t.size(); i++) {
- record[t[i]-'a']--;
+ record[t[i] - 'a']--;
}
for (int i = 0; i < 26; i++) {
if (record[i] != 0) {
+ // record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return false;
}
}
+ // record数组所有元素都为零0,说明字符串s和t是字母异位词
return true;
}
};
diff --git a/problems/0349.两个数组的交集.md b/problems/0349.两个数组的交集.md
index 879f476c..2f36c503 100644
--- a/problems/0349.两个数组的交集.md
+++ b/problems/0349.两个数组的交集.md
@@ -8,7 +8,7 @@ https://leetcode-cn.com/problems/intersection-of-two-arrays/
注意题目特意说明:**输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序**
-这道题用暴力的解法时间复杂度是O(n^2),这种解法面试官一定不会满意,那我们看看使用哈希法进一步优化。
+这道题用暴力的解法时间复杂度是O(n^2),这种解法面试官一定不会满意,那看看使用哈希法进一步优化。
那么可以发现,貌似用数组做哈希表可以解决这道题目,把nums1的元素,映射到哈希数组的下表上,然后在遍历nums2的时候,判断是否出现过就可以了。
@@ -16,13 +16,13 @@ https://leetcode-cn.com/problems/intersection-of-two-arrays/
例如说:如果我的输入样例是这样的, 难道要定义一个2亿大小的数组来做哈希表么, 不同的语言对数组定义的大小都是有限制的, 即使有的语言可以定义这么大的数组,那也是对内存空间造成了非常大的浪费。
-此时我们就要使用另一种结构体了,set ,关于set,C++ 给我们提供了如下三种可用的数据结构
+此时就要使用另一种结构体了,set ,关于set,C++ 给提供了如下三种可用的数据结构
* std::set
* std::multiset
* std::unordered_set
-std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,我们并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
+std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
思路如图所示:

diff --git a/problems/0454.四数相加II.md b/problems/0454.四数相加II.md
index 8b3b049c..af10a130 100644
--- a/problems/0454.四数相加II.md
+++ b/problems/0454.四数相加II.md
@@ -3,13 +3,19 @@ https://leetcode-cn.com/problems/4sum-ii/
## 思路
-本题使用哈希表映射的方法
+本题咋眼一看好像和[第18题. 四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md),[第15题.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md)差不多,其实差很多。
-那么为什么18. 四数之和,0015.三数之和不适用哈希表映射的方法呢,感觉上 这道题目都是四个数之和都可以用哈希,三数之和怎么就用不了哈希呢
+**本题是使用哈希法的经典题目,而[第18题. 四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md),[第15题.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md) 并不合适使用哈希法**,因为使用哈希的方法在不超时的情况下做到对结果去重很困难。
-因为题目15.三数之和和18. 四数之和,使用哈希的方法在不超时的情况下做到对结果去重很困难
+**而这道题目相当于说不用考虑重复元素,是四个独立的数组,所以相对于题目18. 四数之和,题目15.三数之和,还是简单了不少!**
-而这道题目 相当于说 不用考虑重复元素,是四个独立的数组,所以相对于题目18. 四数之和,0015.三数之和,还是简单了不少
+解题步骤:
+
+1. 首先定义 一个unordered_map,key放a和b两数之和,value 放a和b两数之和出现的次数。
+2. 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中。
+3. 定义int变量count,用来统计a+b+c+d = 0 出现的次数。
+4. 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就用count把map中key对应的value也就是出现次数统计出来。
+5. 最后返回我们的统计值 count 就可以了
## C++代码
@@ -18,26 +24,25 @@ class Solution {
public:
int fourSumCount(vector& A, vector& B, vector& C, vector& D) {
unordered_map umap; //key:a+b的数值,value:a+b数值出现的次数
+ // 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中
for (int a : A) {
for (int b : B) {
- if (umap.find(a + b) != umap.end()) {
- umap[a + b]++;
- } else {
- umap[a + b] = 1;
- }
+ umap[a + b]++;
}
}
- int count = 0;
+ int count = 0; // 统计a+b+c+d = 0 出现的次数
+ // 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就把map中key对应的value也就是出现次数统计出来。
for (int c : C) {
for (int d : D) {
if (umap.find(0 - (c + d)) != umap.end()) {
- count += umap[0 - (c + d)];
+ count += umap[0 - (c + d)];
}
}
}
return count;
}
};
+
```
> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
diff --git a/video/151翻转字符串里的单词.gif b/video/151翻转字符串里的单词.gif
new file mode 100644
index 00000000..cd8a60fb
Binary files /dev/null and b/video/151翻转字符串里的单词.gif differ
diff --git a/video/242.有效的字母异位词.gif b/video/242.有效的字母异位词.gif
new file mode 100644
index 00000000..febc0bad
Binary files /dev/null and b/video/242.有效的字母异位词.gif differ
diff --git a/video/242.有效的字母异位词.mp4 b/video/242.有效的字母异位词.mp4
new file mode 100644
index 00000000..33504290
Binary files /dev/null and b/video/242.有效的字母异位词.mp4 differ
diff --git a/video/26.删除排序数组中的重复项.mp4 b/video/26.删除排序数组中的重复项.mp4
new file mode 100644
index 00000000..846d10ac
Binary files /dev/null and b/video/26.删除排序数组中的重复项.mp4 differ
diff --git a/video/27.移除元素-暴力解法.mp4 b/video/27.移除元素-暴力解法.mp4
new file mode 100644
index 00000000..5024f2d7
Binary files /dev/null and b/video/27.移除元素-暴力解法.mp4 differ
diff --git a/video/27.移除元素.mp4 b/video/27.移除元素.mp4
new file mode 100644
index 00000000..9dc869a1
Binary files /dev/null and b/video/27.移除元素.mp4 differ