diff --git a/README.md b/README.md
index ad22aeab..40cd272f 100644
--- a/README.md
+++ b/README.md
@@ -71,7 +71,7 @@
**这里每一篇题解,都是精品,值得仔细琢磨**。
-我在题目讲解中统一用C++语言,但你会发现下面几乎每篇题解都配有其他语言版本,Java、Python、Go、JavaScript等等,这正是热心小伙们的贡献的代码,当然我也会严格把控代码质量。
+我在题目讲解中统一使用C++,但你会发现下面几乎每篇题解都配有其他语言版本,Java、Python、Go、JavaScript等等,正是这些[热心小伙们](https://github.com/youngyangyang04/leetcode-master/graphs/contributors)的贡献的代码,当然我也会严格把控代码质量。
**所以也欢迎大家参与进来,完善题解的各个语言版本,拥抱开源,让更多小伙伴们收益**。
@@ -133,6 +133,13 @@
9. [秋招和提前批都越来越提前了....](https://mp.weixin.qq.com/s/SNFiRDx8CKyjhTPlys6ywQ)
10. [你的简历里「专业技能」写的够专业么?](https://mp.weixin.qq.com/s/bp6y-e5FVN28H9qc8J9zrg)
11. [对于秋招,实习生也有烦恼....](https://mp.weixin.qq.com/s/ka07IPryFnfmIjByFFcXDg)
+12. [华为提前批已经开始了.....](https://mp.weixin.qq.com/s/OC35QDG8pn5OwLpCxieStw)
+13. [大厂新人培养体系应该是什么样的?](https://mp.weixin.qq.com/s/WBaPCosOljB5NEkFL2GhOQ)
+
+## 杂谈
+
+[大半年过去了......](https://mp.weixin.qq.com/s/lubfeistPxBLSQIe5XYg5g)
+
## 数组
@@ -161,14 +168,15 @@
1. [关于哈希表,你该了解这些!](./problems/哈希表理论基础.md)
2. [哈希表:可以拿数组当哈希表来用,但哈希值不要太大](./problems/0242.有效的字母异位词.md)
-3. [哈希表:哈希值太大了,还是得用set](./problems/0349.两个数组的交集.md)
-4. [哈希表:用set来判断快乐数](./problems/0202.快乐数.md)
-5. [哈希表:map等候多时了](./problems/0001.两数之和.md)
-6. [哈希表:其实需要哈希的地方都能找到map的身影](./problems/0454.四数相加II.md)
-7. [哈希表:这道题目我做过?](./problems/0383.赎金信.md)
-8. [哈希表:解决了两数之和,那么能解决三数之和么?](./problems/0015.三数之和.md)
-9. [双指针法:一样的道理,能解决四数之和](./problems/0018.四数之和.md)
-10. [哈希表:总结篇!(每逢总结必经典)](./problems/哈希表总结.md)
+3. [哈希表:查找常用字符](./problems/1002.查找常用字符.md)
+4. [哈希表:哈希值太大了,还是得用set](./problems/0349.两个数组的交集.md)
+5. [哈希表:用set来判断快乐数](./problems/0202.快乐数.md)
+6. [哈希表:map等候多时了](./problems/0001.两数之和.md)
+7. [哈希表:其实需要哈希的地方都能找到map的身影](./problems/0454.四数相加II.md)
+8. [哈希表:这道题目我做过?](./problems/0383.赎金信.md)
+9. [哈希表:解决了两数之和,那么能解决三数之和么?](./problems/0015.三数之和.md)
+10. [双指针法:一样的道理,能解决四数之和](./problems/0018.四数之和.md)
+11. [哈希表:总结篇!(每逢总结必经典)](./problems/哈希表总结.md)
## 字符串
@@ -444,7 +452,7 @@
# 贡献者
-你可以[点此链接](https://github.com/youngyangyang04/leetcode-master/graphs/contributors)查看LeetCode-Master的所有贡献者。感谢你们补充了LeetCode-Master的其他语言版本,让更多的读者收益于此项目。
+[点此这里](https://github.com/youngyangyang04/leetcode-master/graphs/contributors)查看LeetCode-Master的所有贡献者。感谢他们补充了LeetCode-Master的其他语言版本,让更多的读者收益于此项目。
# 关于作者
@@ -459,7 +467,7 @@
# 公众号
-更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:「666」可以获得所有算法专题原创PDF。
+更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:666,可以获得我的所有算法专题原创PDF。
**「代码随想录」每天准时为你推送一篇经典面试题目,帮你梳理算法知识体系,轻松学习算法!**,并且公众号里有大量学习资源,也有我自己的学习心得和方法总结,更有上万录友们在这里打卡学习。
diff --git a/problems/0028.实现strStr.md b/problems/0028.实现strStr.md
index aaa28d3d..69f8c9d6 100644
--- a/problems/0028.实现strStr.md
+++ b/problems/0028.实现strStr.md
@@ -651,7 +651,7 @@ class Solution {
}
```
-Python:
+Python3:
```python
// 方法一
diff --git a/problems/0042.接雨水.md b/problems/0042.接雨水.md
index 55a5c522..3f4d0123 100644
--- a/problems/0042.接雨水.md
+++ b/problems/0042.接雨水.md
@@ -1,4 +1,13 @@
+
+  +
+  +
+  +
+  +
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+> 这个图就是大厂面试经典题目,接雨水! 最常青藤的一道题,面试官百出不厌!
# 42. 接雨水
@@ -355,3 +364,38 @@ public:
## 其他语言版本
+Java:
+
+Python:
+
+双指针法
+```python3
+class Solution:
+ def trap(self, height: List[int]) -> int:
+ res = 0
+ for i in range(len(height)):
+ if i == 0 or i == len(height)-1: continue
+ lHight = height[i-1]
+ rHight = height[i+1]
+ for j in range(i-1):
+ if height[j] > lHight:
+ lHight = height[j]
+ for k in range(i+2,len(height)):
+ if height[k] > rHight:
+ rHight = height[k]
+ res1 = min(lHight,rHight) - height[i]
+ if res1 > 0:
+ res += res1
+ return res
+```
+
+Go:
+
+JavaScript:
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/0059.螺旋矩阵II.md b/problems/0059.螺旋矩阵II.md
index 6d8ec99c..90b74005 100644
--- a/problems/0059.螺旋矩阵II.md
+++ b/problems/0059.螺旋矩阵II.md
@@ -148,8 +148,6 @@ class Solution {
// 定义中间位置
int mid = n / 2;
-
-
while (loop > 0) {
int i = startX;
int j = startY;
@@ -182,7 +180,6 @@ class Solution {
offset += 2;
}
-
if (n % 2 == 1) {
res[mid][mid] = count;
}
diff --git a/problems/0101.对称二叉树.md b/problems/0101.对称二叉树.md
index 9717588a..241564e9 100644
--- a/problems/0101.对称二叉树.md
+++ b/problems/0101.对称二叉树.md
@@ -7,7 +7,7 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 101. 对称二叉树
+# 101. 对称二叉树
题目地址:https://leetcode-cn.com/problems/symmetric-tree/
@@ -15,7 +15,7 @@

-## 思路
+# 思路
**首先想清楚,判断对称二叉树要比较的是哪两个节点,要比较的可不是左右节点!**
@@ -73,7 +73,7 @@ bool compare(TreeNode* left, TreeNode* right)
此时左右节点不为空,且数值也不相同的情况我们也处理了。
代码如下:
-```
+```C++
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
@@ -84,7 +84,7 @@ else if (left->val != right->val) return false; // 注意这里我没有
3. 确定单层递归的逻辑
-此时才进入单层递归的逻辑,单层递归的逻辑就是处理 右节点都不为空,且数值相同的情况。
+此时才进入单层递归的逻辑,单层递归的逻辑就是处理 左右节点都不为空,且数值相同的情况。
* 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
@@ -93,7 +93,7 @@ else if (left->val != right->val) return false; // 注意这里我没有
代码如下:
-```
+```C++
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
bool isSame = outside && inside; // 左子树:中、 右子树:中(逻辑处理)
@@ -104,7 +104,7 @@ return isSame;
最后递归的C++整体代码如下:
-```
+```C++
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
@@ -137,7 +137,7 @@ public:
**盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。**
当然我可以把如上代码整理如下:
-```
+```C++
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
@@ -177,7 +177,7 @@ public:
代码如下:
-```
+```C++
class Solution {
public:
bool isSymmetric(TreeNode* root) {
@@ -212,7 +212,7 @@ public:
只要把队列原封不动的改成栈就可以了,我下面也给出了代码。
-```
+```C++
class Solution {
public:
bool isSymmetric(TreeNode* root) {
@@ -239,7 +239,7 @@ public:
};
```
-## 总结
+# 总结
这次我们又深度剖析了一道二叉树的“简单题”,大家会发现,真正的把题目搞清楚其实并不简单,leetcode上accept了和真正掌握了还是有距离的。
@@ -249,11 +249,14 @@ public:
如果已经做过这道题目的同学,读完文章可以再去看看这道题目,思考一下,会有不一样的发现!
+# 相关题目推荐
+* 100.相同的树
+* 572.另一个树的子树
-## 其他语言版本
+# 其他语言版本
-Java:
+## Java
```Java
/**
@@ -358,9 +361,9 @@ Java:
```
-Python:
+## Python
-> 递归法
+递归法:
```python
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
@@ -384,7 +387,7 @@ class Solution:
return isSame
```
-> 迭代法: 使用队列
+迭代法: 使用队列
```python
import collections
class Solution:
@@ -410,7 +413,7 @@ class Solution:
return True
```
-> 迭代法:使用栈
+迭代法:使用栈
```python
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
@@ -433,7 +436,7 @@ class Solution:
return True
```
-Go:
+## Go
```go
/**
@@ -484,22 +487,7 @@ func isSymmetric(root *TreeNode) bool {
```
-JavaScript
-```javascript
-var isSymmetric = function(root) {
- return check(root, root)
-};
-
-const check = (leftPtr, rightPtr) => {
- // 如果只有根节点,返回true
- if (!leftPtr && !rightPtr) return true
- // 如果左右节点只存在一个,则返回false
- if (!leftPtr || !rightPtr) return false
-
- return leftPtr.val === rightPtr.val && check(leftPtr.left, rightPtr.right) && check(leftPtr.right, rightPtr.left)
-}
-```
-JavaScript:
+## JavaScript
递归判断是否为对称二叉树:
```javascript
@@ -526,6 +514,7 @@ var isSymmetric = function(root) {
return compareNode(root.left,root.right);
};
```
+
队列实现迭代判断是否为对称二叉树:
```javascript
var isSymmetric = function(root) {
@@ -554,6 +543,7 @@ var isSymmetric = function(root) {
return true;
};
```
+
栈实现迭代判断是否为对称二叉树:
```javascript
var isSymmetric = function(root) {
diff --git a/problems/0102.二叉树的层序遍历.md b/problems/0102.二叉树的层序遍历.md
index b13fdd8d..8be3ac47 100644
--- a/problems/0102.二叉树的层序遍历.md
+++ b/problems/0102.二叉树的层序遍历.md
@@ -34,9 +34,10 @@
我们之前讲过了三篇关于二叉树的深度优先遍历的文章:
-* [二叉树:前中后序递归法](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)
-* [二叉树:前中后序迭代法](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)
-* [二叉树:前中后序迭代方式统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)
+* [二叉树:前中后序递归法](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)
+* [二叉树:前中后序迭代法](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)
+* [二叉树:前中后序迭代方式统一写法](https://mp.weixin.qq.com/s/ATQMPCpBlaAgrqdLDMVPZA)
+
接下来我们再来介绍二叉树的另一种遍历方式:层序遍历。
diff --git a/problems/0104.二叉树的最大深度.md b/problems/0104.二叉树的最大深度.md
index 463b55d9..218a966c 100644
--- a/problems/0104.二叉树的最大深度.md
+++ b/problems/0104.二叉树的最大深度.md
@@ -30,9 +30,13 @@
### 递归法
-本题其实也要后序遍历(左右中),依然是因为要通过递归函数的返回值做计算树的高度。
+本题可以使用前序(中左右),也可以使用后序遍历(左右中),使用前序求的就是深度,使用后序求的是高度。
-按照递归三部曲,来看看如何来写。
+**而根节点的高度就是二叉树的最大深度**,所以本题中我们通过后序求的根节点高度来求的二叉树最大深度。
+
+这一点其实是很多同学没有想清楚的,很多题解同样没有讲清楚。
+
+我先用后序遍历(左右中)来计算树的高度。
1. 确定递归函数的参数和返回值:参数就是传入树的根节点,返回就返回这棵树的深度,所以返回值为int类型。
@@ -92,6 +96,66 @@ public:
**精简之后的代码根本看不出是哪种遍历方式,也看不出递归三部曲的步骤,所以如果对二叉树的操作还不熟练,尽量不要直接照着精简代码来学。**
+本题当然也可以使用前序,代码如下:(**充分表现出求深度回溯的过程**)
+
+```C++
+class Solution {
+public:
+ int result;
+ void getDepth(TreeNode* node, int depth) {
+ result = depth > result ? depth : result; // 中
+
+ if (node->left == NULL && node->right == NULL) return ;
+
+ if (node->left) { // 左
+ depth++; // 深度+1
+ getDepth(node->left, depth);
+ depth--; // 回溯,深度-1
+ }
+ if (node->right) { // 右
+ depth++; // 深度+1
+ getDepth(node->right, depth);
+ depth--; // 回溯,深度-1
+ }
+ return ;
+ }
+ int maxDepth(TreeNode* root) {
+ result = 0;
+ if (root == 0) return result;
+ getDepth(root, 1);
+ return result;
+ }
+};
+```
+
+**可以看出使用了前序(中左右)的遍历顺序,这才是真正求深度的逻辑!**
+
+注意以上代码是为了把细节体现出来,简化一下代码如下:
+
+```C++
+class Solution {
+public:
+ int result;
+ void getDepth(TreeNode* node, int depth) {
+ result = depth > result ? depth : result; // 中
+ if (node->left == NULL && node->right == NULL) return ;
+ if (node->left) { // 左
+ getDepth(node->left, depth + 1);
+ }
+ if (node->right) { // 右
+ getDepth(node->right, depth + 1);
+ }
+ return ;
+ }
+ int maxDepth(TreeNode* root) {
+ result = 0;
+ if (root == 0) return result;
+ getDepth(root, 1);
+ return result;
+ }
+};
+```
+
### 迭代法
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
diff --git a/problems/0122.买卖股票的最佳时机II.md b/problems/0122.买卖股票的最佳时机II.md
index 4b878aa0..60d4591f 100644
--- a/problems/0122.买卖股票的最佳时机II.md
+++ b/problems/0122.买卖股票的最佳时机II.md
@@ -188,7 +188,40 @@ class Solution:
```
Go:
+```golang
+//贪心算法
+func maxProfit(prices []int) int {
+ var sum int
+ for i := 1; i < len(prices); i++ {
+ // 累加每次大于0的交易
+ if prices[i]-prices[i-1] > 0 {
+ sum += prices[i]-prices[i-1]
+ }
+ }
+ return sum
+}
+```
+```golang
+//确定售卖点
+func maxProfit(prices []int) int {
+ var result,buy int
+ prices=append(prices,0)//在price末尾加个0,防止price一直递增
+ /**
+ 思路:检查后一个元素是否大于当前元素,如果小于,则表明这是一个售卖点,当前元素的值减去购买时候的值
+ 如果不小于,说明后面有更好的售卖点,
+ **/
+ for i:=0;iprices[i+1]{
+ result+=prices[i]-prices[buy]
+ buy=i+1
+ }else if prices[buy]>prices[i]{//更改最低购买点
+ buy=i
+ }
+ }
+ return result
+}
+```
Javascript:
```Javascript
diff --git a/problems/0129.求根到叶子节点数字之和.md b/problems/0129.求根到叶子节点数字之和.md
new file mode 100644
index 00000000..f8c93382
--- /dev/null
+++ b/problems/0129.求根到叶子节点数字之和.md
@@ -0,0 +1,179 @@
+## 链接
+https://leetcode-cn.com/problems/sum-root-to-leaf-numbers/
+
+## 思路
+
+本题和[113.路径总和II](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)是类似的思路,做完这道题,可以顺便把[113.路径总和II](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg) 和 [112.路径总和](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg) 做了。
+
+结合112.路径总和 和 113.路径总和II,我在讲了[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg),如果大家对二叉树递归函数什么时候需要返回值很迷茫,可以看一下。
+
+接下来在看本题,就简单多了,本题其实需要使用回溯,但一些同学可能都不知道自己用了回溯,在[二叉树:以为使用了递归,其实还隐藏着回溯](https://mp.weixin.qq.com/s/ivLkHzWdhjQQD1rQWe6zWA)中,我详细讲解了二叉树的递归中,如何使用了回溯。
+
+接下来我们来看题:
+
+首先思路很明确,就是要遍历整个树把更节点到叶子节点组成的数字相加。
+
+那么先按递归三部曲来分析:
+
+### 递归三部曲
+
+如果对递归三部曲不了解的话,可以看这里:[二叉树:前中后递归详解](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)
+
+* 确定递归函数返回值及其参数
+
+这里我们要遍历整个二叉树,且需要要返回值做逻辑处理,所有返回值为void,在[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)中,详细讲解了返回值问题。
+
+参数只需要把根节点传入,此时还需要定义两个全局遍历,一个是result,记录最终结果,一个是vector path。
+
+**为什么用vector类型(就是数组)呢? 因为用vector方便我们做回溯!**
+
+所以代码如下:
+
+```
+int result;
+vector path;
+void traversal(TreeNode* cur)
+```
+
+* 确定终止条件
+
+递归什么时候终止呢?
+
+当然是遇到叶子节点,此时要收集结果了,通知返回本层递归,因为单条路径的结果使用vector,我们需要一个函数vectorToInt把vector转成int。
+
+终止条件代码如下:
+
+```
+if (!cur->left && !cur->right) { // 遇到了叶子节点
+ result += vectorToInt(path);
+ return;
+}
+```
+
+这里vectorToInt函数就是把数组转成int,代码如下:
+
+```C++
+int vectorToInt(const vector& vec) {
+ int sum = 0;
+ for (int i = 0; i < vec.size(); i++) {
+ sum = sum * 10 + vec[i];
+ }
+ return sum;
+}
+```
+
+
+* 确定递归单层逻辑
+
+本题其实采用前中后序都不无所谓, 因为也没有中间几点的处理逻辑。
+
+这里主要是当左节点不为空,path收集路径,并递归左孩子,右节点同理。
+
+**但别忘了回溯**。
+
+如图:
+
+
+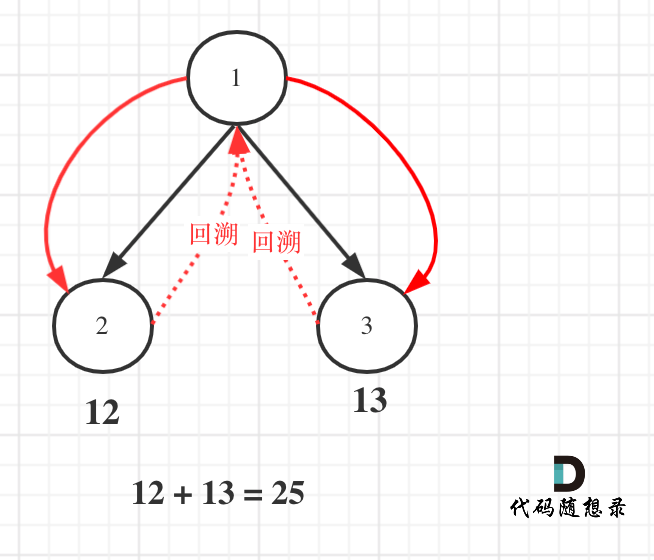 +
+代码如下:
+
+```C++
+ // 中
+if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val);
+ traversal(cur->left); // 递归
+ path.pop_back(); // 回溯
+}
+if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val);
+ traversal(cur->right); // 递归
+ path.pop_back(); // 回溯
+}
+```
+
+这里要注意回溯和递归要永远在一起,一个递归,对应一个回溯,是一对一的关系,有的同学写成如下代码:
+
+```C++
+if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val);
+ traversal(cur->left); // 递归
+}
+if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val);
+ traversal(cur->right); // 递归
+}
+path.pop_back(); // 回溯
+```
+**把回溯放在花括号外面了,世界上最遥远的距离,是你在花括号里,而我在花括号外!** 这就不对了。
+
+### 整体C++代码
+
+关键逻辑分析完了,整体C++代码如下:
+
+```C++
+class Solution {
+private:
+ int result;
+ vector path;
+ // 把vector转化为int
+ int vectorToInt(const vector& vec) {
+ int sum = 0;
+ for (int i = 0; i < vec.size(); i++) {
+ sum = sum * 10 + vec[i];
+ }
+ return sum;
+ }
+ void traversal(TreeNode* cur) {
+ if (!cur->left && !cur->right) { // 遇到了叶子节点
+ result += vectorToInt(path);
+ return;
+ }
+
+ if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val); // 处理节点
+ traversal(cur->left); // 递归
+ path.pop_back(); // 回溯,撤销
+ }
+ if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val); // 处理节点
+ traversal(cur->right); // 递归
+ path.pop_back(); // 回溯,撤销
+ }
+ return ;
+ }
+public:
+ int sumNumbers(TreeNode* root) {
+ path.clear();
+ if (root == nullptr) return 0;
+ path.push_back(root->val);
+ traversal(root);
+ return result;
+ }
+};
+```
+
+# 总结
+
+过于简洁的代码,很容易让初学者忽视了本题中回溯的精髓,甚至作者本身都没有想清楚自己用了回溯。
+
+**我这里提供的代码把整个回溯过程充分体现出来,希望可以帮助大家看的明明白白!**
+
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index ffa3446a..32d9deef 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -300,8 +300,9 @@ class Solution {
}
```
+python:
-```Python3
+```Python
class Solution:
#1.去除多余的空格
def trim_spaces(self,s):
@@ -349,7 +350,7 @@ class Solution:
return ''.join(l) #输出:blue is sky the
-'''
+```
Go:
@@ -407,6 +408,65 @@ func reverse(b *[]byte, left, right int) {
+javaScript:
+```js
+/**
+ * @param {string} s
+ * @return {string}
+ */
+ var reverseWords = function(s) {
+ // 字符串转数组
+ const strArr = Array.from(s);
+ // 移除多余空格
+ removeExtraSpaces(strArr);
+ // 翻转
+ reverse(strArr, 0, strArr.length - 1);
+
+ let start = 0;
+
+ for(let i = 0; i <= strArr.length; i++) {
+ if (strArr[i] === ' ' || i === strArr.length) {
+ // 翻转单词
+ reverse(strArr, start, i - 1);
+ start = i + 1;
+ }
+ }
+
+ return strArr.join('');
+};
+
+// 删除多余空格
+function removeExtraSpaces(strArr) {
+ let slowIndex = 0;
+ let fastIndex = 0;
+
+ while(fastIndex < strArr.length) {
+ // 移除开始位置和重复的空格
+ if (strArr[fastIndex] === ' ' && (fastIndex === 0 || strArr[fastIndex - 1] === ' ')) {
+ fastIndex++;
+ } else {
+ strArr[slowIndex++] = strArr[fastIndex++];
+ }
+ }
+
+ // 移除末尾空格
+ strArr.length = strArr[slowIndex - 1] === ' ' ? slowIndex - 1 : slowIndex;
+}
+
+// 翻转从 start 到 end 的字符
+function reverse(strArr, start, end) {
+ let left = start;
+ let right = end;
+
+ while(left < right) {
+ // 交换
+ [strArr[left], strArr[right]] = [strArr[right], strArr[left]];
+ left++;
+ right--;
+ }
+}
+```
+
diff --git a/problems/0225.用队列实现栈.md b/problems/0225.用队列实现栈.md
index 85b981e5..bcf82b84 100644
--- a/problems/0225.用队列实现栈.md
+++ b/problems/0225.用队列实现栈.md
@@ -200,14 +200,6 @@ class MyStack {
}
}
-/**
- * Your MyQueue object will be instantiated and called as such:
- * MyQueue obj = new MyQueue();
- * obj.push(x);
- * int param_2 = obj.pop();
- * int param_3 = obj.peek();
- * boolean param_4 = obj.empty();
- */
```
使用两个 Deque 实现
```java
@@ -350,12 +342,6 @@ class MyStack:
return False
-# Your MyStack object will be instantiated and called as such:
-# obj = MyStack()
-# obj.push(x)
-# param_2 = obj.pop()
-# param_3 = obj.top()
-# param_4 = obj.empty()
```
Go:
diff --git a/problems/0226.翻转二叉树.md b/problems/0226.翻转二叉树.md
index bb0d6d34..bba34766 100644
--- a/problems/0226.翻转二叉树.md
+++ b/problems/0226.翻转二叉树.md
@@ -7,7 +7,7 @@
+
+代码如下:
+
+```C++
+ // 中
+if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val);
+ traversal(cur->left); // 递归
+ path.pop_back(); // 回溯
+}
+if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val);
+ traversal(cur->right); // 递归
+ path.pop_back(); // 回溯
+}
+```
+
+这里要注意回溯和递归要永远在一起,一个递归,对应一个回溯,是一对一的关系,有的同学写成如下代码:
+
+```C++
+if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val);
+ traversal(cur->left); // 递归
+}
+if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val);
+ traversal(cur->right); // 递归
+}
+path.pop_back(); // 回溯
+```
+**把回溯放在花括号外面了,世界上最遥远的距离,是你在花括号里,而我在花括号外!** 这就不对了。
+
+### 整体C++代码
+
+关键逻辑分析完了,整体C++代码如下:
+
+```C++
+class Solution {
+private:
+ int result;
+ vector path;
+ // 把vector转化为int
+ int vectorToInt(const vector& vec) {
+ int sum = 0;
+ for (int i = 0; i < vec.size(); i++) {
+ sum = sum * 10 + vec[i];
+ }
+ return sum;
+ }
+ void traversal(TreeNode* cur) {
+ if (!cur->left && !cur->right) { // 遇到了叶子节点
+ result += vectorToInt(path);
+ return;
+ }
+
+ if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val); // 处理节点
+ traversal(cur->left); // 递归
+ path.pop_back(); // 回溯,撤销
+ }
+ if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val); // 处理节点
+ traversal(cur->right); // 递归
+ path.pop_back(); // 回溯,撤销
+ }
+ return ;
+ }
+public:
+ int sumNumbers(TreeNode* root) {
+ path.clear();
+ if (root == nullptr) return 0;
+ path.push_back(root->val);
+ traversal(root);
+ return result;
+ }
+};
+```
+
+# 总结
+
+过于简洁的代码,很容易让初学者忽视了本题中回溯的精髓,甚至作者本身都没有想清楚自己用了回溯。
+
+**我这里提供的代码把整个回溯过程充分体现出来,希望可以帮助大家看的明明白白!**
+
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index ffa3446a..32d9deef 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -300,8 +300,9 @@ class Solution {
}
```
+python:
-```Python3
+```Python
class Solution:
#1.去除多余的空格
def trim_spaces(self,s):
@@ -349,7 +350,7 @@ class Solution:
return ''.join(l) #输出:blue is sky the
-'''
+```
Go:
@@ -407,6 +408,65 @@ func reverse(b *[]byte, left, right int) {
+javaScript:
+```js
+/**
+ * @param {string} s
+ * @return {string}
+ */
+ var reverseWords = function(s) {
+ // 字符串转数组
+ const strArr = Array.from(s);
+ // 移除多余空格
+ removeExtraSpaces(strArr);
+ // 翻转
+ reverse(strArr, 0, strArr.length - 1);
+
+ let start = 0;
+
+ for(let i = 0; i <= strArr.length; i++) {
+ if (strArr[i] === ' ' || i === strArr.length) {
+ // 翻转单词
+ reverse(strArr, start, i - 1);
+ start = i + 1;
+ }
+ }
+
+ return strArr.join('');
+};
+
+// 删除多余空格
+function removeExtraSpaces(strArr) {
+ let slowIndex = 0;
+ let fastIndex = 0;
+
+ while(fastIndex < strArr.length) {
+ // 移除开始位置和重复的空格
+ if (strArr[fastIndex] === ' ' && (fastIndex === 0 || strArr[fastIndex - 1] === ' ')) {
+ fastIndex++;
+ } else {
+ strArr[slowIndex++] = strArr[fastIndex++];
+ }
+ }
+
+ // 移除末尾空格
+ strArr.length = strArr[slowIndex - 1] === ' ' ? slowIndex - 1 : slowIndex;
+}
+
+// 翻转从 start 到 end 的字符
+function reverse(strArr, start, end) {
+ let left = start;
+ let right = end;
+
+ while(left < right) {
+ // 交换
+ [strArr[left], strArr[right]] = [strArr[right], strArr[left]];
+ left++;
+ right--;
+ }
+}
+```
+
diff --git a/problems/0225.用队列实现栈.md b/problems/0225.用队列实现栈.md
index 85b981e5..bcf82b84 100644
--- a/problems/0225.用队列实现栈.md
+++ b/problems/0225.用队列实现栈.md
@@ -200,14 +200,6 @@ class MyStack {
}
}
-/**
- * Your MyQueue object will be instantiated and called as such:
- * MyQueue obj = new MyQueue();
- * obj.push(x);
- * int param_2 = obj.pop();
- * int param_3 = obj.peek();
- * boolean param_4 = obj.empty();
- */
```
使用两个 Deque 实现
```java
@@ -350,12 +342,6 @@ class MyStack:
return False
-# Your MyStack object will be instantiated and called as such:
-# obj = MyStack()
-# obj.push(x)
-# param_2 = obj.pop()
-# param_3 = obj.top()
-# param_4 = obj.empty()
```
Go:
diff --git a/problems/0226.翻转二叉树.md b/problems/0226.翻转二叉树.md
index bb0d6d34..bba34766 100644
--- a/problems/0226.翻转二叉树.md
+++ b/problems/0226.翻转二叉树.md
@@ -7,7 +7,7 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 226.翻转二叉树
+# 226.翻转二叉树
题目地址:https://leetcode-cn.com/problems/invert-binary-tree/
@@ -17,7 +17,7 @@
这道题目背后有一个让程序员心酸的故事,听说 Homebrew的作者Max Howell,就是因为没在白板上写出翻转二叉树,最后被Google拒绝了。(真假不做判断,权当一个乐子哈)
-## 题外话
+# 题外话
这道题目是非常经典的题目,也是比较简单的题目(至少一看就会)。
@@ -25,7 +25,7 @@
如果做过这道题的同学也建议认真看完,相信一定有所收获!
-## 思路
+# 思路
我们之前介绍的都是各种方式遍历二叉树,这次要翻转了,感觉还是有点懵逼。
@@ -49,7 +49,9 @@
## 递归法
-对于二叉树的递归法的前中后序遍历,已经在[二叉树:前中后序递归遍历](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)详细讲解了。
+
+
+对于二叉树的递归法的前中后序遍历,已经在[二叉树:前中后序递归遍历](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)详细讲解了。
我们下文以前序遍历为例,通过动画来看一下翻转的过程:
@@ -104,7 +106,8 @@ public:
### 深度优先遍历
-[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中给出了前中后序迭代方式的写法,所以本地可以很轻松的切出如下迭代法的代码:
+
+[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)中给出了前中后序迭代方式的写法,所以本地可以很轻松的切出如下迭代法的代码:
C++代码迭代法(前序遍历)
@@ -126,10 +129,10 @@ public:
}
};
```
-如果这个代码看不懂的话可以在回顾一下[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)。
+如果这个代码看不懂的话可以在回顾一下[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)。
-我们在[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)中介绍了统一的写法,所以,本题也只需将文中的代码少做修改便可。
+我们在[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/ATQMPCpBlaAgrqdLDMVPZA)中介绍了统一的写法,所以,本题也只需将文中的代码少做修改便可。
C++代码如下迭代法(前序遍历)
@@ -159,7 +162,7 @@ public:
};
```
-如果上面这个代码看不懂,回顾一下文章[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)。
+如果上面这个代码看不懂,回顾一下文章[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/ATQMPCpBlaAgrqdLDMVPZA)。
### 广度优先遍历
@@ -185,7 +188,7 @@ public:
}
};
```
-如果对以上代码不理解,或者不清楚二叉树的层序遍历,可以看这篇[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)
+如果对以上代码不理解,或者不清楚二叉树的层序遍历,可以看这篇[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)
## 总结
@@ -202,7 +205,7 @@ public:
## 其他语言版本
-Java:
+### Java:
```Java
//DFS递归
@@ -254,9 +257,9 @@ class Solution {
}
```
-Python:
+### Python
-> 递归法:前序遍历
+递归法:前序遍历:
```python
class Solution:
def invertTree(self, root: TreeNode) -> TreeNode:
@@ -268,7 +271,7 @@ class Solution:
return root
```
-> 迭代法:深度优先遍历(前序遍历)
+迭代法:深度优先遍历(前序遍历):
```python
class Solution:
def invertTree(self, root: TreeNode) -> TreeNode:
@@ -286,7 +289,7 @@ class Solution:
return root
```
-> 迭代法:广度优先遍历(层序遍历)
+迭代法:广度优先遍历(层序遍历):
```python
import collections
class Solution:
@@ -306,7 +309,8 @@ class Solution:
return root
```
-Go:
+### Go
+
```Go
func invertTree(root *TreeNode) *TreeNode {
if root ==nil{
@@ -323,7 +327,7 @@ func invertTree(root *TreeNode) *TreeNode {
}
```
-JavaScript:
+### JavaScript
使用递归版本的前序遍历
```javascript
diff --git a/problems/0232.用栈实现队列.md b/problems/0232.用栈实现队列.md
index be6e1df6..6890fc2b 100644
--- a/problems/0232.用栈实现队列.md
+++ b/problems/0232.用栈实现队列.md
@@ -385,15 +385,6 @@ func (this *MyQueue) Empty() bool {
return len(this.stack) == 0 && len(this.back) == 0
}
-/**
- * Your MyQueue object will be instantiated and called as such:
- * obj := Constructor();
- * obj.Push(x);
- * param_2 := obj.Pop();
- * param_3 := obj.Peek();
- * param_4 := obj.Empty();
- */
- ```
javaScript:
diff --git a/problems/0239.滑动窗口最大值.md b/problems/0239.滑动窗口最大值.md
index bb89a1ac..dedc3247 100644
--- a/problems/0239.滑动窗口最大值.md
+++ b/problems/0239.滑动窗口最大值.md
@@ -273,8 +273,8 @@ class Solution {
int[] res = new int[n - k + 1];
int idx = 0;
for(int i = 0; i < n; i++) {
- // 根据题意,i为nums下标,是要在[i - k + 1, k] 中选到最大值,只需要保证两点
- // 1.队列头结点需要在[i - k + 1, k]范围内,不符合则要弹出
+ // 根据题意,i为nums下标,是要在[i - k + 1, i] 中选到最大值,只需要保证两点
+ // 1.队列头结点需要在[i - k + 1, i]范围内,不符合则要弹出
while(!deque.isEmpty() && deque.peek() < i - k + 1){
deque.poll();
}
diff --git a/problems/0376.摆动序列.md b/problems/0376.摆动序列.md
index 4d283eb0..f64e0043 100644
--- a/problems/0376.摆动序列.md
+++ b/problems/0376.摆动序列.md
@@ -151,7 +151,24 @@ class Solution:
```
Go:
-
+```golang
+func wiggleMaxLength(nums []int) int {
+ var count,preDiff,curDiff int
+ count=1
+ if len(nums)<2{
+ return count
+ }
+ for i:=0;i 0 && preDiff <= 0) || (preDiff >= 0 && curDiff < 0){
+ preDiff=curDiff
+ count++
+ }
+ }
+ return count
+}
+```
Javascript:
```Javascript
diff --git a/problems/0455.分发饼干.md b/problems/0455.分发饼干.md
index 4814d414..6b121e36 100644
--- a/problems/0455.分发饼干.md
+++ b/problems/0455.分发饼干.md
@@ -146,6 +146,23 @@ class Solution:
return res
```
Go:
+```golang
+//排序后,局部最优
+func findContentChildren(g []int, s []int) int {
+ sort.Ints(g)
+ sort.Ints(s)
+
+ // 从小到大
+ child := 0
+ for sIdx := 0; child < len(g) && sIdx < len(s); sIdx++ {
+ if s[sIdx] >= g[child] {//如果饼干的大小大于或等于孩子的为空则给与,否则不给予,继续寻找选一个饼干是否符合
+ child++
+ }
+ }
+
+ return child
+}
+
Javascript:
```Javascript
diff --git a/problems/0459.重复的子字符串.md b/problems/0459.重复的子字符串.md
index 368489a5..f012811d 100644
--- a/problems/0459.重复的子字符串.md
+++ b/problems/0459.重复的子字符串.md
@@ -37,7 +37,7 @@ https://leetcode-cn.com/problems/repeated-substring-pattern/
如果KMP还不够了解,可以看我的B站:
-* [帮你把KMP算法学个通透!B站(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd/)
+* [帮你把KMP算法学个通透!(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd/)
* [帮你把KMP算法学个通透!(求next数组代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
diff --git a/problems/0463.岛屿的周长.md b/problems/0463.岛屿的周长.md
new file mode 100644
index 00000000..40378854
--- /dev/null
+++ b/problems/0463.岛屿的周长.md
@@ -0,0 +1,98 @@
+
+## 题目链接
+https://leetcode-cn.com/problems/island-perimeter/
+
+## 思路
+
+岛屿问题最容易让人想到BFS或者DFS,但是这道题还真的没有必要,别把简单问题搞复杂了。
+
+### 解法一:
+
+遍历每一个空格,遇到岛屿,计算其上下左右的情况,遇到水域或者出界的情况,就可以计算边了。
+
+如图:
+
+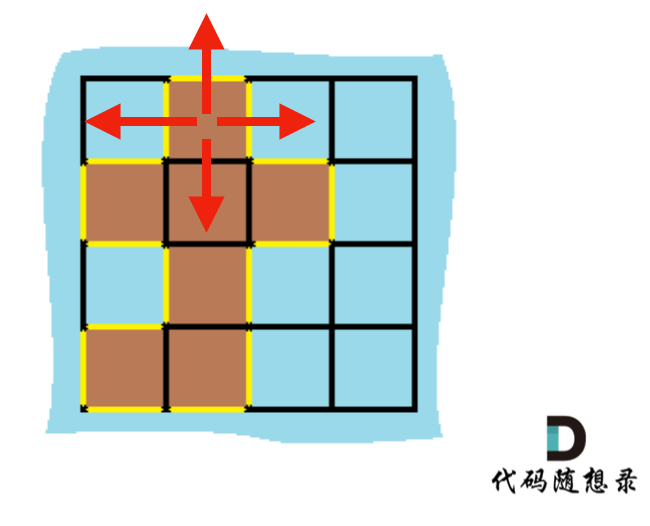 +
+C++代码如下:(详细注释)
+
+```C++
+class Solution {
+public:
+ int direction[4][2] = {0, 1, 1, 0, -1, 0, 0, -1};
+ int islandPerimeter(vector>& grid) {
+ int result = 0;
+ for (int i = 0; i < grid.size(); i++) {
+ for (int j = 0; j < grid[0].size(); j++) {
+ if (grid[i][j] == 1) {
+ for (int k = 0; k < 4; k++) { // 上下左右四个方向
+ int x = i + direction[k][0];
+ int y = j + direction[k][1]; // 计算周边坐标x,y
+ if (x < 0 // i在边界上
+ || x >= grid.size() // i在边界上
+ || y < 0 // j在边界上
+ || y >= grid[0].size() // j在边界上
+ || grid[x][y] == 0) { // x,y位置是水域
+ result++;
+ }
+ }
+ }
+ }
+ }
+ return result;
+ }
+};
+```
+
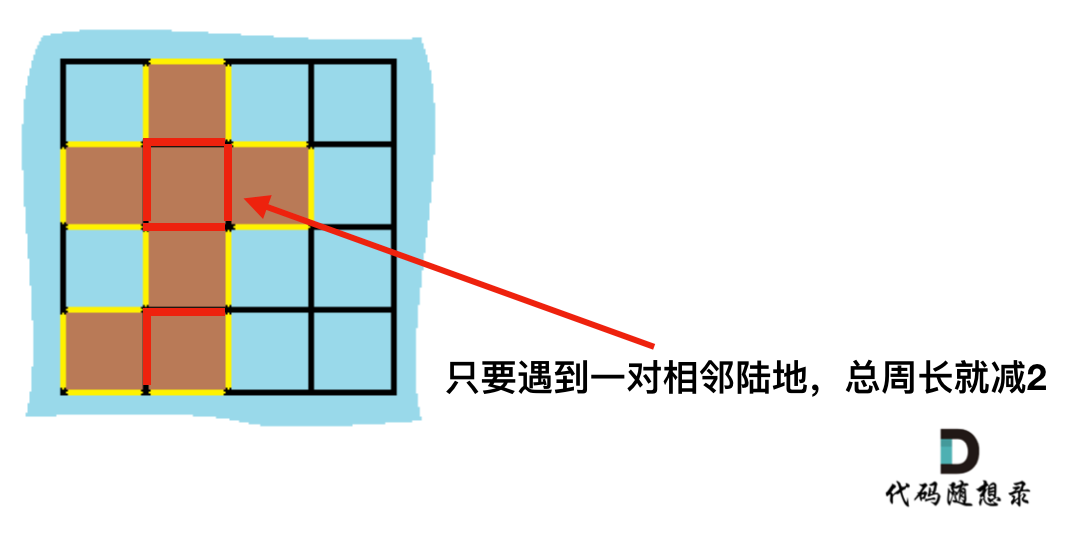
+### 解法二:
+
+计算出总的岛屿数量,因为有一对相邻两个陆地,边的总数就减2,那么在计算出相邻岛屿的数量就可以了。
+
+result = 岛屿数量 * 4 - cover * 2;
+
+如图:
+
+
+
+C++代码如下:(详细注释)
+
+```C++
+class Solution {
+public:
+ int direction[4][2] = {0, 1, 1, 0, -1, 0, 0, -1};
+ int islandPerimeter(vector>& grid) {
+ int result = 0;
+ for (int i = 0; i < grid.size(); i++) {
+ for (int j = 0; j < grid[0].size(); j++) {
+ if (grid[i][j] == 1) {
+ for (int k = 0; k < 4; k++) { // 上下左右四个方向
+ int x = i + direction[k][0];
+ int y = j + direction[k][1]; // 计算周边坐标x,y
+ if (x < 0 // i在边界上
+ || x >= grid.size() // i在边界上
+ || y < 0 // j在边界上
+ || y >= grid[0].size() // j在边界上
+ || grid[x][y] == 0) { // x,y位置是水域
+ result++;
+ }
+ }
+ }
+ }
+ }
+ return result;
+ }
+};
+```
+
+### 解法二:
+
+计算出总的岛屿数量,因为有一对相邻两个陆地,边的总数就减2,那么在计算出相邻岛屿的数量就可以了。
+
+result = 岛屿数量 * 4 - cover * 2;
+
+如图:
+
+ +
+C++代码如下:(详细注释)
+
+```C++
+class Solution {
+public:
+ int islandPerimeter(vector>& grid) {
+ int sum = 0; // 陆地数量
+ int cover = 0; // 相邻数量
+ for (int i = 0; i < grid.size(); i++) {
+ for (int j = 0; j < grid[0].size(); j++) {
+ if (grid[i][j] == 1) {
+ sum++;
+ // 统计上边相邻陆地
+ if(i - 1 >= 0 && grid[i - 1][j] == 1) cover++;
+ // 统计左边相邻陆地
+ if(j - 1 >= 0 && grid[i][j - 1] == 1) cover++;
+ // 为什么没统计下边和右边? 因为避免重复计算
+ }
+ }
+ }
+ return sum * 4 - cover * 2;
+ }
+};
+```
+
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+C++代码如下:(详细注释)
+
+```C++
+class Solution {
+public:
+ int islandPerimeter(vector>& grid) {
+ int sum = 0; // 陆地数量
+ int cover = 0; // 相邻数量
+ for (int i = 0; i < grid.size(); i++) {
+ for (int j = 0; j < grid[0].size(); j++) {
+ if (grid[i][j] == 1) {
+ sum++;
+ // 统计上边相邻陆地
+ if(i - 1 >= 0 && grid[i - 1][j] == 1) cover++;
+ // 统计左边相邻陆地
+ if(j - 1 >= 0 && grid[i][j - 1] == 1) cover++;
+ // 为什么没统计下边和右边? 因为避免重复计算
+ }
+ }
+ }
+ return sum * 4 - cover * 2;
+ }
+};
+```
+
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
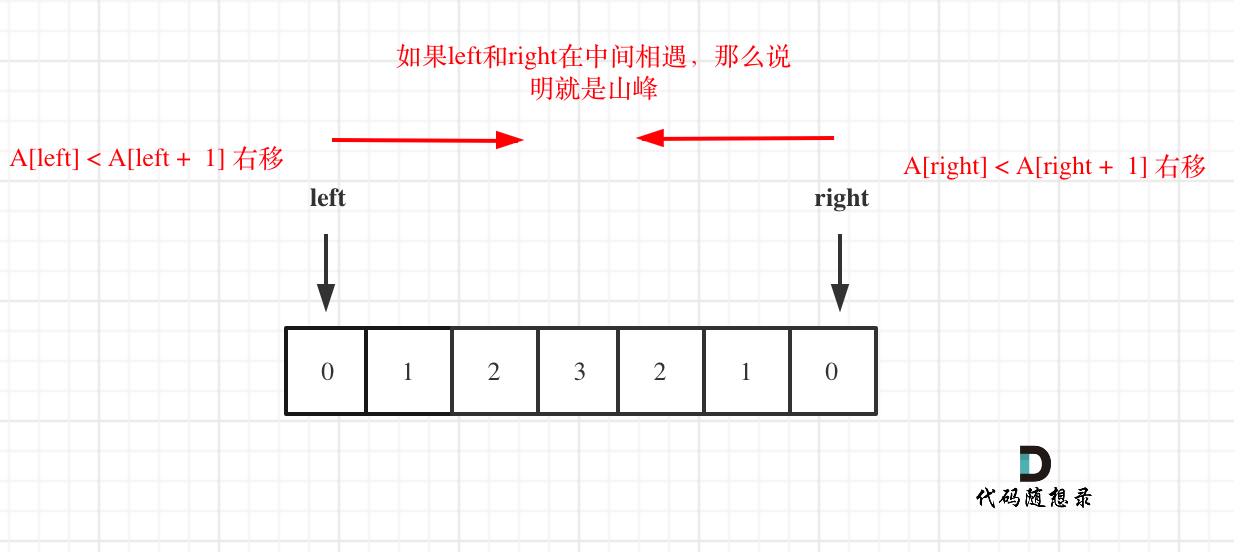 +
+**注意这里还是有一些细节,例如如下两点:**
+
+* 因为left和right是数组下表,移动的过程中注意不要数组越界
+* 如果left或者right没有移动,说明是一个单调递增或者递减的数组,依然不是山峰
+
+C++代码如下:
+
+```
+class Solution {
+public:
+ bool validMountainArray(vector& A) {
+ if (A.size() < 3) return false;
+ int left = 0;
+ int right = A.size() - 1;
+
+ // 注意防止越界
+ while (left < A.size() - 1 && A[left] < A[left + 1]) left++;
+
+ // 注意防止越界
+ while (right > 0 && A[right] < A[right - 1]) right--;
+
+ // 如果left或者right都在起始位置,说明不是山峰
+ if (left == right && left != 0 && right != A.size() - 1) return true;
+ return false;
+ }
+};
+```
+如果想系统学一学双指针的话, 可以看一下这篇[双指针法:总结篇!](https://mp.weixin.qq.com/s/_p7grwjISfMh0U65uOyCjA)
+
+
diff --git a/problems/1002.查找常用字符.md b/problems/1002.查找常用字符.md
new file mode 100644
index 00000000..875340c4
--- /dev/null
+++ b/problems/1002.查找常用字符.md
@@ -0,0 +1,177 @@
+
+
+
+**注意这里还是有一些细节,例如如下两点:**
+
+* 因为left和right是数组下表,移动的过程中注意不要数组越界
+* 如果left或者right没有移动,说明是一个单调递增或者递减的数组,依然不是山峰
+
+C++代码如下:
+
+```
+class Solution {
+public:
+ bool validMountainArray(vector& A) {
+ if (A.size() < 3) return false;
+ int left = 0;
+ int right = A.size() - 1;
+
+ // 注意防止越界
+ while (left < A.size() - 1 && A[left] < A[left + 1]) left++;
+
+ // 注意防止越界
+ while (right > 0 && A[right] < A[right - 1]) right--;
+
+ // 如果left或者right都在起始位置,说明不是山峰
+ if (left == right && left != 0 && right != A.size() - 1) return true;
+ return false;
+ }
+};
+```
+如果想系统学一学双指针的话, 可以看一下这篇[双指针法:总结篇!](https://mp.weixin.qq.com/s/_p7grwjISfMh0U65uOyCjA)
+
+
diff --git a/problems/1002.查找常用字符.md b/problems/1002.查找常用字符.md
new file mode 100644
index 00000000..875340c4
--- /dev/null
+++ b/problems/1002.查找常用字符.md
@@ -0,0 +1,177 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 1002. 查找常用字符
+
+https://leetcode-cn.com/problems/find-common-characters/
+
+给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表。例如,如果一个字符在每个字符串中出现 3 次,但不是 4 次,则需要在最终答案中包含该字符 3 次。
+
+你可以按任意顺序返回答案。
+
+【示例一】
+输入:["bella","label","roller"]
+输出:["e","l","l"]
+
+【示例二】
+输入:["cool","lock","cook"]
+输出:["c","o"]
+
+
+# 思路
+
+这道题意一起就有点绕,不是那么容易懂,其实就是26个小写字符中有字符 在所有字符串里都出现的话,就输出,重复的也算。
+
+例如:
+
+输入:["ll","ll","ll"]
+输出:["l","l"]
+
+这道题目一眼看上去,就是用哈希法,**“小写字符”,“出现频率”, 这些关键字都是为哈希法量身定做的啊**
+
+首先可以想到的是暴力解法,一个字符串一个字符串去搜,时间复杂度是O(n^m),n是字符串长度,m是有几个字符串。
+
+可以看出这是指数级别的时间复杂度,非常高,而且代码实现也不容易,因为要统计 重复的字符,还要适当的替换或者去重。
+
+那我们还是哈希法吧。如果对哈希法不了解,可以看这篇:[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg)。
+
+如果对用数组来做哈希法不了解的话,可以看这篇:[把数组当做哈希表来用,很巧妙!](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)。
+
+了解了哈希法,理解了数组在哈希法中的应用之后,可以来看解题思路了。
+
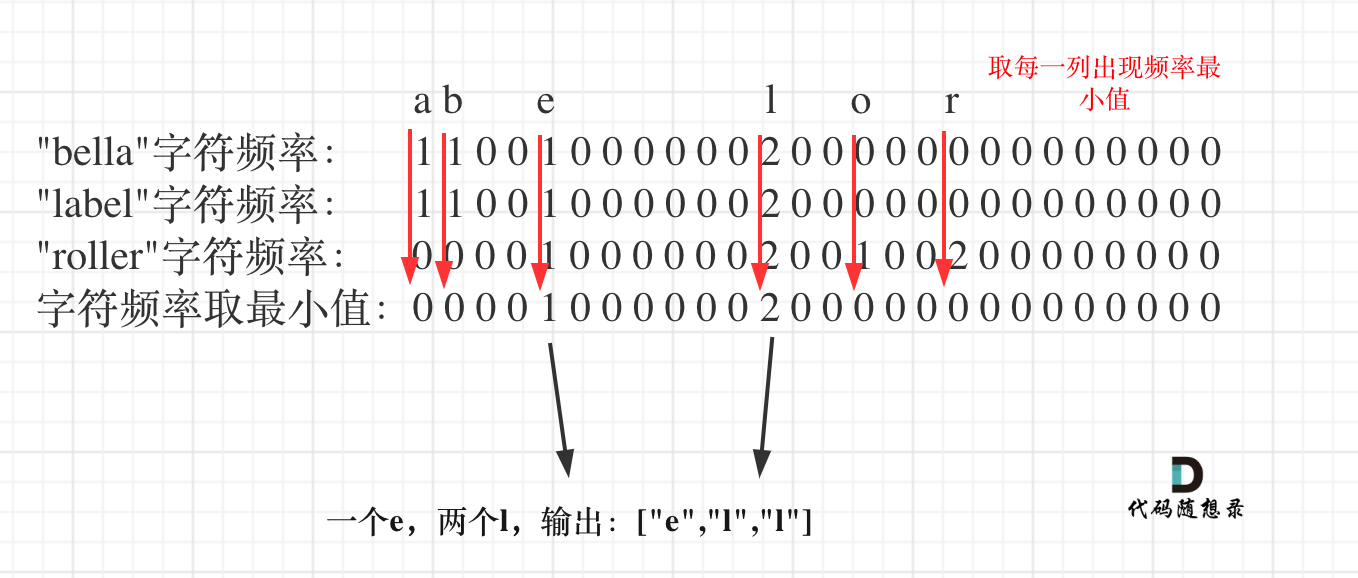
+整体思路就是统计出搜索字符串里26个字符的出现的频率,然后取每个字符频率最小值,最后转成输出格式就可以了。
+
+如图:
+
+
+
+先统计第一个字符串所有字符出现的次数,代码如下:
+
+```
+int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
+for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
+ hash[A[0][i] - 'a']++;
+}
+```
+
+接下来,把其他字符串里字符的出现次数也统计出来一次放在hashOtherStr中。
+
+然后hash 和 hashOtherStr 取最小值,这是本题关键所在,此时取最小值,就是 一个字符在所有字符串里出现的最小次数了。
+
+代码如下:
+
+```
+int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
+for (int i = 1; i < A.size(); i++) {
+ memset(hashOtherStr, 0, 26 * sizeof(int));
+ for (int j = 0; j < A[i].size(); j++) {
+ hashOtherStr[A[i][j] - 'a']++;
+ }
+ // 这是关键所在
+ for (int k = 0; k < 26; k++) { // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
+ hash[k] = min(hash[k], hashOtherStr[k]);
+ }
+}
+```
+此时hash里统计着字符在所有字符串里出现的最小次数,那么把hash转正题目要求的输出格式就可以了。
+
+代码如下:
+
+```
+// 将hash统计的字符次数,转成输出形式
+for (int i = 0; i < 26; i++) {
+ while (hash[i] != 0) { // 注意这里是while,多个重复的字符
+ string s(1, i + 'a'); // char -> string
+ result.push_back(s);
+ hash[i]--;
+ }
+}
+```
+
+整体C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector commonChars(vector& A) {
+ vector result;
+ if (A.size() == 0) return result;
+ int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
+ for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
+ hash[A[0][i] - 'a']++;
+ }
+
+ int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
+ for (int i = 1; i < A.size(); i++) {
+ memset(hashOtherStr, 0, 26 * sizeof(int));
+ for (int j = 0; j < A[i].size(); j++) {
+ hashOtherStr[A[i][j] - 'a']++;
+ }
+ // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
+ for (int k = 0; k < 26; k++) {
+ hash[k] = min(hash[k], hashOtherStr[k]);
+ }
+ }
+ // 将hash统计的字符次数,转成输出形式
+ for (int i = 0; i < 26; i++) {
+ while (hash[i] != 0) { // 注意这里是while,多个重复的字符
+ string s(1, i + 'a'); // char -> string
+ result.push_back(s);
+ hash[i]--;
+ }
+ }
+
+ return result;
+ }
+};
+```
+
+## 其他语言版本
+
+Java:
+
+```Java
+class Solution {
+ public List commonChars(String[] A) {
+ List result = new ArrayList<>();
+ if (A.length == 0) return result;
+ int[] hash= new int[26]; // 用来统计所有字符串里字符出现的最小频率
+ for (int i = 0; i < A[0].length(); i++) { // 用第一个字符串给hash初始化
+ hash[A[0].charAt(i)- 'a']++;
+ }
+ // 统计除第一个字符串外字符的出现频率
+ for (int i = 1; i < A.length; i++) {
+ int[] hashOtherStr= new int[26];
+ for (int j = 0; j < A[i].length(); j++) {
+ hashOtherStr[A[i].charAt(j)- 'a']++;
+ }
+ // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
+ for (int k = 0; k < 26; k++) {
+ hash[k] = Math.min(hash[k], hashOtherStr[k]);
+ }
+ }
+ // 将hash统计的字符次数,转成输出形式
+ for (int i = 0; i < 26; i++) {
+ while (hash[i] != 0) { // 注意这里是while,多个重复的字符
+ char c= (char) (i+'a');
+ result.add(String.valueOf(c));
+ hash[i]--;
+ }
+ }
+ return result;
+ }
+}
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/1356.根据数字二进制下1的数目排序.md b/problems/1356.根据数字二进制下1的数目排序.md
new file mode 100644
index 00000000..e8aee055
--- /dev/null
+++ b/problems/1356.根据数字二进制下1的数目排序.md
@@ -0,0 +1,89 @@
+
+## 题目链接
+https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
+
+## 思路
+
+这道题其实是考察如何计算一个数的二进制中1的数量。
+
+我提供两种方法:
+
+* 方法一:
+
+朴实无华挨个计算1的数量,最多就是循环n的二进制位数,32位。
+
+```C++
+int bitCount(int n) {
+ int count = 0; // 计数器
+ while (n > 0) {
+ if((n & 1) == 1) count++; // 当前位是1,count++
+ n >>= 1 ; // n向右移位
+ }
+ return count;
+}
+```
+
+* 方法二
+
+这种方法,只循环n的二进制中1的个数次,比方法一高效的多
+
+```C++
+int bitCount(int n) {
+ int count = 0;
+ while (n) {
+ n &= (n - 1); // 清除最低位的1
+ count++;
+ }
+ return count;
+}
+```
+以计算12的二进制1的数量为例,如图所示:
+
+ +
+下面我就使用方法二,来做这道题目:
+
+## C++代码
+
+```C++
+class Solution {
+private:
+ static int bitCount(int n) { // 计算n的二进制中1的数量
+ int count = 0;
+ while(n) {
+ n &= (n -1); // 清除最低位的1
+ count++;
+ }
+ return count;
+ }
+ static bool cmp(int a, int b) {
+ int bitA = bitCount(a);
+ int bitB = bitCount(b);
+ if (bitA == bitB) return a < b; // 如果bit中1数量相同,比较数值大小
+ return bitA < bitB; // 否则比较bit中1数量大小
+ }
+public:
+ vector sortByBits(vector& arr) {
+ sort(arr.begin(), arr.end(), cmp);
+ return arr;
+ }
+};
+```
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+下面我就使用方法二,来做这道题目:
+
+## C++代码
+
+```C++
+class Solution {
+private:
+ static int bitCount(int n) { // 计算n的二进制中1的数量
+ int count = 0;
+ while(n) {
+ n &= (n -1); // 清除最低位的1
+ count++;
+ }
+ return count;
+ }
+ static bool cmp(int a, int b) {
+ int bitA = bitCount(a);
+ int bitB = bitCount(b);
+ if (bitA == bitB) return a < b; // 如果bit中1数量相同,比较数值大小
+ return bitA < bitB; // 否则比较bit中1数量大小
+ }
+public:
+ vector sortByBits(vector& arr) {
+ sort(arr.begin(), arr.end(), cmp);
+ return arr;
+ }
+};
+```
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/1365.有多少小于当前数字的数字.md b/problems/1365.有多少小于当前数字的数字.md
new file mode 100644
index 00000000..3026dfca
--- /dev/null
+++ b/problems/1365.有多少小于当前数字的数字.md
@@ -0,0 +1,146 @@
+
+
+
+# 1365.有多少小于当前数字的数字
+
+题目链接:https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
+
+给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
+
+换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。
+
+以数组形式返回答案。
+
+
+示例 1:
+* 输入:nums = [8,1,2,2,3]
+* 输出:[4,0,1,1,3]
+* 解释:
+对于 nums[0]=8 存在四个比它小的数字:(1,2,2 和 3)。
+对于 nums[1]=1 不存在比它小的数字。
+对于 nums[2]=2 存在一个比它小的数字:(1)。
+对于 nums[3]=2 存在一个比它小的数字:(1)。
+对于 nums[4]=3 存在三个比它小的数字:(1,2 和 2)。
+
+示例 2:
+* 输入:nums = [6,5,4,8]
+* 输出:[2,1,0,3]
+
+示例 3:
+* 输入:nums = [7,7,7,7]
+* 输出:[0,0,0,0]
+
+提示:
+* 2 <= nums.length <= 500
+* 0 <= nums[i] <= 100
+
+# 思路
+
+两层for循环暴力查找,时间复杂度明显为O(n^2)。
+
+那么我们来看一下如何优化。
+
+首先要找小于当前数字的数字,那么从小到大排序之后,该数字之前的数字就都是比它小的了。
+
+所以可以定义一个新数组,将数组排个序。
+
+**排序之后,其实每一个数值的下标就代表这前面有几个比它小的了**。
+
+代码如下:
+
+```
+vector vec = nums;
+sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+```
+
+用一个哈希表hash(本题可以就用一个数组)来做数值和下标的映射。这样就可以通过数值快速知道下标(也就是前面有几个比它小的)。
+
+此时有一个情况,就是数值相同怎么办?
+
+例如,数组:1 2 3 4 4 4 ,第一个数值4的下标是3,第二个数值4的下标是4了。
+
+这里就需要一个技巧了,**在构造数组hash的时候,从后向前遍历,这样hash里存放的就是相同元素最左面的数值和下标了**。
+代码如下:
+
+```C++
+int hash[101];
+for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+}
+```
+
+最后在遍历原数组nums,用hash快速找到每一个数值 对应的 小于这个数值的个数。存放在将结果存放在另一个数组中。
+
+代码如下:
+
+```C++
+// 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+}
+```
+
+流程如图:
+
+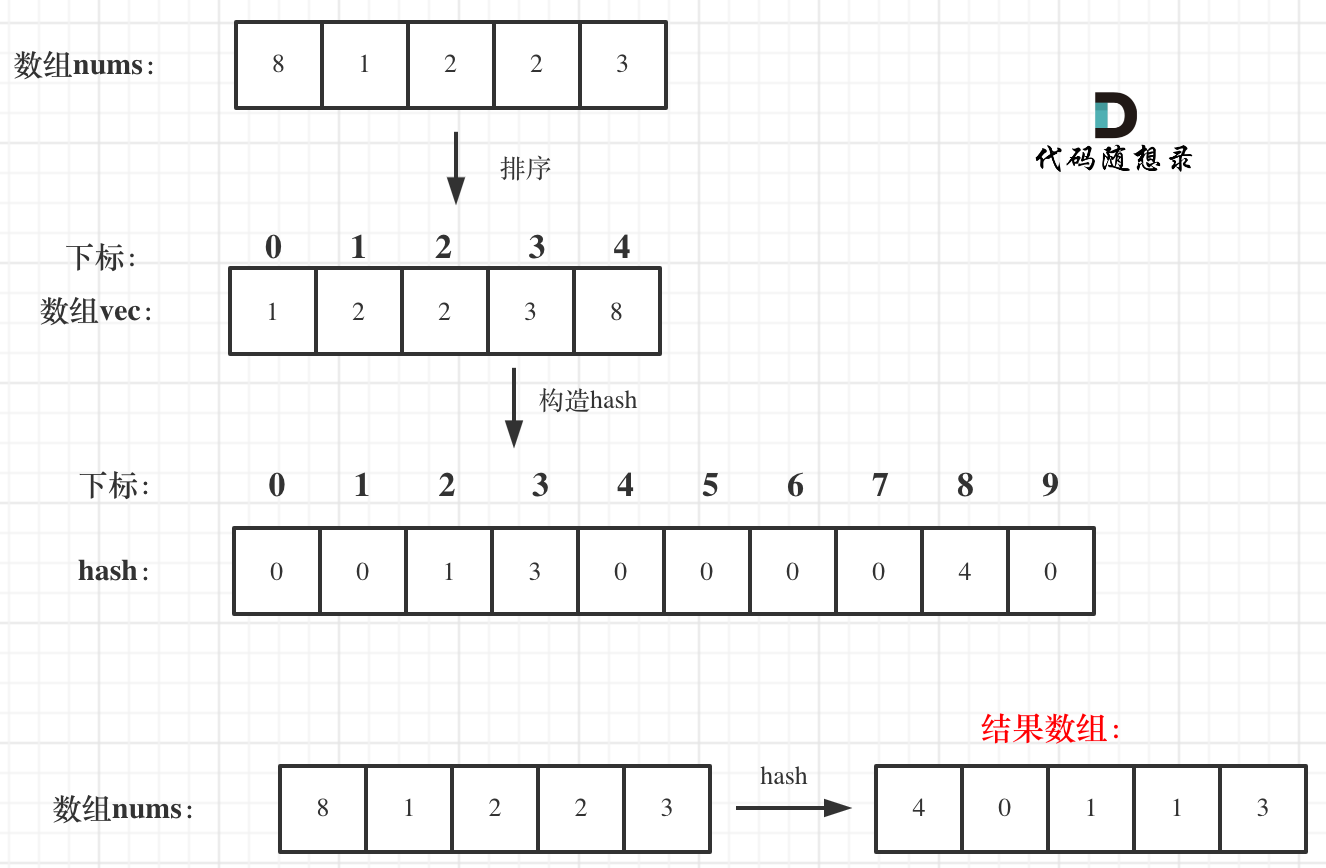 +
+关键地方讲完了,整体C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector smallerNumbersThanCurrent(vector& nums) {
+ vector vec = nums;
+ sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+ int hash[101];
+ for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+ }
+ // 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+ for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+ }
+ return vec;
+ }
+};
+```
+
+可以排序之后加哈希,时间复杂度为O(nlogn)
+
+
+# 其他语言版本
+
+Java:
+
+```Java
+public int[] smallerNumbersThanCurrent(int[] nums) {
+ Map map = new HashMap<>(); // 记录数字 nums[i] 有多少个比它小的数字
+ int[] res = Arrays.copyOf(nums, nums.length);
+ Arrays.sort(res);
+ for (int i = 0; i < res.length; i++) {
+ if (!map.containsKey(res[i])) { // 遇到了相同的数字,那么不需要更新该 number 的情况
+ map.put(res[i], i);
+ }
+ }
+
+ for (int i = 0; i < nums.length; i++) {
+ res[i] = map.get(nums[i]);
+ }
+
+ return res;
+ }
+```
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+关键地方讲完了,整体C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector smallerNumbersThanCurrent(vector& nums) {
+ vector vec = nums;
+ sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+ int hash[101];
+ for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+ }
+ // 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+ for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+ }
+ return vec;
+ }
+};
+```
+
+可以排序之后加哈希,时间复杂度为O(nlogn)
+
+
+# 其他语言版本
+
+Java:
+
+```Java
+public int[] smallerNumbersThanCurrent(int[] nums) {
+ Map map = new HashMap<>(); // 记录数字 nums[i] 有多少个比它小的数字
+ int[] res = Arrays.copyOf(nums, nums.length);
+ Arrays.sort(res);
+ for (int i = 0; i < res.length; i++) {
+ if (!map.containsKey(res[i])) { // 遇到了相同的数字,那么不需要更新该 number 的情况
+ map.put(res[i], i);
+ }
+ }
+
+ for (int i = 0; i < nums.length; i++) {
+ res[i] = map.get(nums[i]);
+ }
+
+ return res;
+ }
+```
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/二叉树理论基础.md b/problems/二叉树理论基础.md
index f4bb8fa9..a720672e 100644
--- a/problems/二叉树理论基础.md
+++ b/problems/二叉树理论基础.md
@@ -206,7 +206,13 @@ public class TreeNode {
Python:
-
+```python
+class TreeNode:
+ def __init__(self, value):
+ self.value = value
+ self.left = None
+ self.right = None
+```
Go:
```
diff --git a/problems/二叉树的统一迭代法.md b/problems/二叉树的统一迭代法.md
index 533bdfe7..9e24fef6 100644
--- a/problems/二叉树的统一迭代法.md
+++ b/problems/二叉树的统一迭代法.md
@@ -12,9 +12,9 @@
> 统一写法是一种什么感觉
-此时我们在[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)中用递归的方式,实现了二叉树前中后序的遍历。
+此时我们在[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)中用递归的方式,实现了二叉树前中后序的遍历。
-在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中用栈实现了二叉树前后中序的迭代遍历(非递归)。
+在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)中用栈实现了二叉树前后中序的迭代遍历(非递归)。
之后我们发现**迭代法实现的先中后序,其实风格也不是那么统一,除了先序和后序,有关联,中序完全就是另一个风格了,一会用栈遍历,一会又用指针来遍历。**
@@ -24,7 +24,7 @@
**重头戏来了,接下来介绍一下统一写法。**
-我们以中序遍历为例,在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中提到说使用栈的话,**无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况**。
+我们以中序遍历为例,在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)中提到说使用栈的话,**无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况**。
**那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。**
@@ -149,14 +149,13 @@ public:
-## 其他语言版本
+# 其他语言版本
Java:
- 迭代法前序遍历代码如下:
- ```java
- class Solution {
-
+迭代法前序遍历代码如下:
+```java
+class Solution {
public List preorderTraversal(TreeNode root) {
List result = new LinkedList<>();
Stack st = new Stack<>();
@@ -180,39 +179,39 @@ Java:
return result;
}
}
+```
- ```
- 迭代法中序遍历代码如下:
- ```java
- class Solution {
- public List inorderTraversal(TreeNode root) {
- List result = new LinkedList<>();
- Stack st = new Stack<>();
- if (root != null) st.push(root);
- while (!st.empty()) {
- TreeNode node = st.peek();
- if (node != null) {
- st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
- if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
- st.push(node); // 添加中节点
- st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
+迭代法中序遍历代码如下:
+```java
+class Solution {
+public List inorderTraversal(TreeNode root) {
+ List result = new LinkedList<>();
+ Stack st = new Stack<>();
+ if (root != null) st.push(root);
+ while (!st.empty()) {
+ TreeNode node = st.peek();
+ if (node != null) {
+ st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
+ if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
+ st.push(node); // 添加中节点
+ st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
- if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
- } else { // 只有遇到空节点的时候,才将下一个节点放进结果集
- st.pop(); // 将空节点弹出
- node = st.peek(); // 重新取出栈中元素
- st.pop();
- result.add(node.val); // 加入到结果集
- }
+ if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
+ } else { // 只有遇到空节点的时候,才将下一个节点放进结果集
+ st.pop(); // 将空节点弹出
+ node = st.peek(); // 重新取出栈中元素
+ st.pop();
+ result.add(node.val); // 加入到结果集
}
- return result;
}
+ return result;
}
- ```
- 迭代法后序遍历代码如下:
- ```java
- class Solution {
+}
+```
+迭代法后序遍历代码如下:
+```java
+class Solution {
public List postorderTraversal(TreeNode root) {
List result = new LinkedList<>();
Stack st = new Stack<>();
@@ -236,11 +235,11 @@ Java:
return result;
}
}
+```
- ```
Python:
-> 迭代法前序遍历
+迭代法前序遍历:
```python
class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
@@ -263,7 +262,7 @@ class Solution:
return result
```
-> 迭代法中序遍历
+迭代法中序遍历:
```python
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
@@ -288,7 +287,7 @@ class Solution:
return result
```
-> 迭代法后序遍历
+迭代法后序遍历:
```python
class Solution:
def postorderTraversal(self, root: TreeNode) -> List[int]:
diff --git a/problems/二叉树的迭代遍历.md b/problems/二叉树的迭代遍历.md
index 30b921ff..20397773 100644
--- a/problems/二叉树的迭代遍历.md
+++ b/problems/二叉树的迭代遍历.md
@@ -19,7 +19,7 @@
为什么可以用迭代法(非递归的方式)来实现二叉树的前后中序遍历呢?
-我们在[栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/eynAEbUbZoAWrk0ZlEugqg)中提到了,**递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中**,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
+我们在[栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/1-x6r1wGA9mqIHW5LrMvBg)中提到了,**递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中**,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
此时大家应该知道我们用栈也可以是实现二叉树的前后中序遍历了。
@@ -138,7 +138,7 @@ public:
```
-## 总结
+# 总结
此时我们用迭代法写出了二叉树的前后中序遍历,大家可以看出前序和中序是完全两种代码风格,并不想递归写法那样代码稍做调整,就可以实现前后中序。
@@ -153,7 +153,7 @@ public:
-## 其他语言版本
+# 其他语言版本
Java:
@@ -233,7 +233,8 @@ class Solution {
Python:
-```python3
+
+```python
# 前序遍历-迭代-LC144_二叉树的前序遍历
class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
diff --git a/problems/前序/关于时间复杂度,你不知道的都在这里!.md b/problems/前序/关于时间复杂度,你不知道的都在这里!.md
index 4ca9eede..d6471b99 100644
--- a/problems/前序/关于时间复杂度,你不知道的都在这里!.md
+++ b/problems/前序/关于时间复杂度,你不知道的都在这里!.md
@@ -7,12 +7,19 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+相信每一位录友都接触过时间复杂度,但又对时间复杂度的认识处于一种朦胧的状态,所以是时候对时间复杂度来一个深度的剖析了。
-Carl大胆断言:这可能是你见过对时间复杂度分析最通透的一篇文章了。
+本篇从如下六点进行分析:
-相信每一位录友都接触过时间复杂度,「代码随想录」已经也讲了一百多道经典题目了,是时候对时间复杂度来一个深度的剖析了,很早之前就写过一篇,当时文章还没有人看,Carl感觉有价值的东西值得让更多的人看到,哈哈。
+* 究竟什么是时间复杂度
+* 什么是大O
+* 不同数据规模的差异
+* 复杂表达式的化简
+* O(logn)中的log是以什么为底?
+* 举一个例子
-所以重新整理的时间复杂度文章,正式和大家见面啦!
+
+这可能是你见过对时间复杂度分析最通透的一篇文章。
## 究竟什么是时间复杂度
@@ -151,7 +158,7 @@ O(2 * n^2 + 10 * n + 1000) < O(3 * n^2),所以说最后省略掉常数项系
**当然这不是这道题目的最优解,我仅仅是用这道题目来讲解一下时间复杂度**。
-# 总结
+## 总结
本篇讲解了什么是时间复杂度,复杂度是用来干什么,以及数据规模对时间复杂度的影响。
@@ -161,12 +168,6 @@ O(2 * n^2 + 10 * n + 1000) < O(3 * n^2),所以说最后省略掉常数项系
相信看完本篇,大家对时间复杂度的认识会深刻很多!
-如果感觉「代码随想录」很不错,赶快推荐给身边的朋友同学们吧,他们发现和「代码随想录」相见恨晚!
-
-
-
-
-
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/前序/程序员简历.md b/problems/前序/程序员简历.md
index f9a226df..a9abcdc4 100644
--- a/problems/前序/程序员简历.md
+++ b/problems/前序/程序员简历.md
@@ -10,7 +10,6 @@
# 程序员的简历应该这么写!!(附简历模板)
-> Carl多年积累的简历技巧都在这里了
Carl校招社招都拿过大厂的offer,同时也看过很多应聘者的简历,这里把自己总结的简历技巧以及常见问题给大家梳理一下。
diff --git a/problems/剑指Offer05.替换空格.md b/problems/剑指Offer05.替换空格.md
index 49c2c223..3e4e3631 100644
--- a/problems/剑指Offer05.替换空格.md
+++ b/problems/剑指Offer05.替换空格.md
@@ -245,6 +245,45 @@ class Solution(object):
```
+javaScript:
+```js
+/**
+ * @param {string} s
+ * @return {string}
+ */
+ var replaceSpace = function(s) {
+ // 字符串转为数组
+ const strArr = Array.from(s);
+ let count = 0;
+
+ // 计算空格数量
+ for(let i = 0; i < strArr.length; i++) {
+ if (strArr[i] === ' ') {
+ count++;
+ }
+ }
+
+ let left = strArr.length - 1;
+ let right = strArr.length + count * 2 - 1;
+
+ while(left >= 0) {
+ if (strArr[left] === ' ') {
+ strArr[right--] = '0';
+ strArr[right--] = '2';
+ strArr[right--] = '%';
+ left--;
+ } else {
+ strArr[right--] = strArr[left--];
+ }
+ }
+
+ // 数组转字符串
+ return strArr.join('');
+};
+```
+
+
+
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
diff --git a/problems/剑指Offer58-II.左旋转字符串.md b/problems/剑指Offer58-II.左旋转字符串.md
index 1701086e..3c3eaef0 100644
--- a/problems/剑指Offer58-II.左旋转字符串.md
+++ b/problems/剑指Offer58-II.左旋转字符串.md
@@ -118,6 +118,8 @@ class Solution {
}
```
+python:
+
```python
# 方法一:可以使用切片方法
class Solution:
diff --git a/problems/周总结/20200927二叉树周末总结.md b/problems/周总结/20200927二叉树周末总结.md
index f983a929..a6d73c01 100644
--- a/problems/周总结/20200927二叉树周末总结.md
+++ b/problems/周总结/20200927二叉树周末总结.md
@@ -13,7 +13,7 @@
对于二叉树节点的定义,C++代码如下:
-```
+```C++
struct TreeNode {
int val;
TreeNode *left;
@@ -35,7 +35,7 @@ TreeNode* a = new TreeNode(9);
没有构造函数的话就要这么写:
-```
+```C++
TreeNode* a = new TreeNode();
a->val = 9;
a->left = NULL;
@@ -60,11 +60,35 @@ morris遍历是二叉树遍历算法的超强进阶算法,morris遍历可以
在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中我们开始用栈来实现递归的写法,也就是所谓的迭代法。
-细心的同学发现文中前后序遍历空节点是入栈的,其实空节点入不入栈都差不多,但感觉空节点不入栈确实清晰一些,符合文中动画的演示。
+细心的同学发现文中前后序遍历空节点是否入栈写法是不同的
-前序遍历空节点不入栈的代码:(注意注释部分,和文章中的区别)
+其实空节点入不入栈都差不多,但感觉空节点不入栈确实清晰一些,符合文中动画的演示。
+拿前序遍历来举例,空节点入栈:
+
+```C++
+class Solution {
+public:
+ vector preorderTraversal(TreeNode* root) {
+ stack st;
+ vector result;
+ st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top(); // 中
+ st.pop();
+ if (node != NULL) result.push_back(node->val);
+ else continue;
+ st.push(node->right); // 右
+ st.push(node->left); // 左
+ }
+ return result;
+ }
+};
```
+
+前序遍历空节点不入栈的代码:(注意注释部分和上文的区别)
+
+```C++
class Solution {
public:
vector preorderTraversal(TreeNode* root) {
@@ -82,32 +106,8 @@ public:
return result;
}
};
-
```
-后序遍历空节点不入栈的代码:(注意注释部分,和文章中的区别)
-
-```
-class Solution {
-public:
- vector postorderTraversal(TreeNode* root) {
- stack st;
- vector result;
- if (root == NULL) return result;
- st.push(root);
- while (!st.empty()) {
- TreeNode* node = st.top();
- st.pop();
- result.push_back(node->val);
- if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
- if (node->right) st.push(node->right); // 空节点不入栈
- }
- reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
- return result;
- }
-};
-
-```
在实现迭代法的过程中,有同学问了:递归与迭代究竟谁优谁劣呢?
diff --git a/problems/周总结/二叉树阶段总结系列一.md b/problems/周总结/二叉树阶段总结系列一.md
new file mode 100644
index 00000000..1527e9a1
--- /dev/null
+++ b/problems/周总结/二叉树阶段总结系列一.md
@@ -0,0 +1,209 @@
+# 本周小结!(二叉树)
+
+**周日我做一个针对本周的打卡留言疑问以及在刷题群里的讨论内容做一下梳理吧。**,这样也有助于大家补一补本周的内容,消化消化。
+
+**注意这个周末总结和系列总结还是不一样的(二叉树还远没有结束),这个总结是针对留言疑问以及刷题群里讨论内容的归纳。**
+
+1. [关于二叉树,你该了解这些!](https://mp.weixin.qq.com/s/q_eKfL8vmSbSFcptZ3aeRA)
+2. [二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)
+3. [二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)
+4. [二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/ATQMPCpBlaAgrqdLDMVPZA)
+5. [二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)
+6. [二叉树:你真的会翻转二叉树么?](https://mp.weixin.qq.com/s/jG0MgYR9DoUMYcRRF7magw)
+
+
+## [关于二叉树,你该了解这些!](https://mp.weixin.qq.com/s/q_eKfL8vmSbSFcptZ3aeRA)
+
+有同学会把红黑树和二叉平衡搜索树弄分开了,其实红黑树就是一种二叉平衡搜索树,这两个树不是独立的,所以C++中map、multimap、set、multiset的底层实现机制是二叉平衡搜索树,再具体一点是红黑树。
+
+对于二叉树节点的定义,C++代码如下:
+
+```C++
+struct TreeNode {
+ int val;
+ TreeNode *left;
+ TreeNode *right;
+ TreeNode(int x) : val(x), left(NULL), right(NULL) {}
+};
+```
+对于这个定义中`TreeNode(int x) : val(x), left(NULL), right(NULL) {}` 有同学不清楚干什么的。
+
+这是构造函数,这么说吧C语言中的结构体是C++中类的祖先,所以C++结构体也可以有构造函数。
+
+构造函数也可以不写,但是new一个新的节点的时候就比较麻烦。
+
+例如有构造函数,定义初始值为9的节点:
+
+```
+TreeNode* a = new TreeNode(9);
+```
+
+没有构造函数的话就要这么写:
+
+```C++
+TreeNode* a = new TreeNode();
+a->val = 9;
+a->left = NULL;
+a->right = NULL;
+```
+
+在介绍前中后序遍历的时候,有递归和迭代(非递归),还有一种牛逼的遍历方式:morris遍历。
+
+morris遍历是二叉树遍历算法的超强进阶算法,morris遍历可以将非递归遍历中的空间复杂度降为O(1),感兴趣大家就去查一查学习学习,比较小众,面试几乎不会考。我其实也没有研究过,就不做过多介绍了。
+
+## [二叉树的递归遍历](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)
+
+在[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)中讲到了递归三要素,以及前中后序的递归写法。
+
+文章中我给出了leetcode上三道二叉树的前中后序题目,但是看完[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA),依然可以解决n叉树的前后序遍历,在leetcode上分别是
+
+* 589. N叉树的前序遍历
+* 590. N叉树的后序遍历
+
+大家可以再去把这两道题目做了。
+
+## [二叉树的非递归遍历](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)
+
+细心的同学发现文中前后序遍历空节点是入栈的,其实空节点入不入栈都差不多,但感觉空节点不入栈确实清晰一些,符合文中动画的演示。
+
+前序遍历空节点不入栈的代码:(注意注释部分,和文章中的区别)
+
+```C++
+class Solution {
+public:
+ vector preorderTraversal(TreeNode* root) {
+ stack st;
+ vector result;
+ if (root == NULL) return result;
+ st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top(); // 中
+ st.pop();
+ result.push_back(node->val);
+ if (node->right) st.push(node->right); // 右(空节点不入栈)
+ if (node->left) st.push(node->left); // 左(空节点不入栈)
+ }
+ return result;
+ }
+};
+
+```
+
+后序遍历空节点不入栈的代码:(注意注释部分,和文章中的区别)
+
+```C++
+class Solution {
+public:
+ vector postorderTraversal(TreeNode* root) {
+ stack st;
+ vector result;
+ if (root == NULL) return result;
+ st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top();
+ st.pop();
+ result.push_back(node->val);
+ if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
+ if (node->right) st.push(node->right); // 空节点不入栈
+ }
+ reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
+ return result;
+ }
+};
+
+```
+
+在实现迭代法的过程中,有同学问了:递归与迭代究竟谁优谁劣呢?
+
+从时间复杂度上其实迭代法和递归法差不多(在不考虑函数调用开销和函数调用产生的堆栈开销),但是空间复杂度上,递归开销会大一些,因为递归需要系统堆栈存参数返回值等等。
+
+递归更容易让程序员理解,但收敛不好,容易栈溢出。
+
+这么说吧,递归是方便了程序员,难为了机器(各种保存参数,各种进栈出栈)。
+
+**在实际项目开发的过程中我们是要尽量避免递归!因为项目代码参数、调用关系都比较复杂,不容易控制递归深度,甚至会栈溢出。**
+
+## 周四
+
+在[二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)中我们使用空节点作为标记,给出了统一的前中后序迭代法。
+
+此时又多了一种前中后序的迭代写法,那么有同学问了:前中后序迭代法是不是一定要统一来写,这样才算是规范。
+
+其实没必要,还是自己感觉哪一种更好记就用哪种。
+
+但是**一定要掌握前中后序一种迭代的写法,并不因为某种场景的题目一定要用迭代,而是现场面试的时候,面试官看你顺畅的写出了递归,一般会进一步考察能不能写出相应的迭代。**
+
+## 周五
+
+在[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)中我们介绍了二叉树的另一种遍历方式(图论中广度优先搜索在二叉树上的应用)即:层序遍历。
+
+看完这篇文章,去leetcode上怒刷五题,文章中 编号107题目的样例图放错了(原谅我匆忙之间总是手抖),但不影响大家理解。
+
+只有同学发现leetcode上“515. 在每个树行中找最大值”,也是层序遍历的应用,依然可以分分钟解决,所以就是一鼓作气解决六道了,哈哈。
+
+**层序遍历遍历相对容易一些,只要掌握基本写法(也就是框架模板),剩下的就是在二叉树每一行遍历的时候做做逻辑修改。**
+
+## 周六
+
+在[二叉树:你真的会翻转二叉树么?](https://mp.weixin.qq.com/s/6gY1MiXrnm-khAAJiIb5Bg)中我们把翻转二叉树这么一道简单又经典的问题,充分的剖析了一波,相信就算做过这道题目的同学,看完本篇之后依然有所收获!
+
+
+**文中我指的是递归的中序遍历是不行的,因为使用递归的中序遍历,某些节点的左右孩子会翻转两次。**
+
+如果非要使用递归中序的方式写,也可以,如下代码就可以避免节点左右孩子翻转两次的情况:
+
+```
+class Solution {
+public:
+ TreeNode* invertTree(TreeNode* root) {
+ if (root == NULL) return root;
+ invertTree(root->left); // 左
+ swap(root->left, root->right); // 中
+ invertTree(root->left); // 注意 这里依然要遍历左孩子,因为中间节点已经翻转了
+ return root;
+ }
+};
+```
+
+代码虽然可以,但这毕竟不是真正的递归中序遍历了。
+
+但使用迭代方式统一写法的中序是可以的。
+
+代码如下:
+
+```
+class Solution {
+public:
+ TreeNode* invertTree(TreeNode* root) {
+ stack st;
+ if (root != NULL) st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top();
+ if (node != NULL) {
+ st.pop();
+ if (node->right) st.push(node->right); // 右
+ st.push(node); // 中
+ st.push(NULL);
+ if (node->left) st.push(node->left); // 左
+
+ } else {
+ st.pop();
+ node = st.top();
+ st.pop();
+ swap(node->left, node->right); // 节点处理逻辑
+ }
+ }
+ return root;
+ }
+};
+
+
+```
+
+为什么这个中序就是可以的呢,因为这是用栈来遍历,而不是靠指针来遍历,避免了递归法中翻转了两次的情况,大家可以画图理解一下,这里有点意思的。
+
+## 总结
+
+**本周我们都是讲解了二叉树,从理论基础到遍历方式,从递归到迭代,从深度遍历到广度遍历,最后再用了一个翻转二叉树的题目把我们之前讲过的遍历方式都串了起来。**
+
+
diff --git a/problems/背包理论基础01背包-1.md b/problems/背包理论基础01背包-1.md
index 0d376c92..3f603366 100644
--- a/problems/背包理论基础01背包-1.md
+++ b/problems/背包理论基础01背包-1.md
@@ -190,7 +190,7 @@ for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 递归公式中可以看出dp[i][j]是靠dp[i-1][j]和dp[i - 1][j - weight[i]]推导出来的。
-dp[i-1][j]和dp[i - 1][j - weight[i]] 都在dp[i][j]的左上角方向(包括正左和正上两个方向),那么先遍历物品,再遍历背包的过程如图所示:
+dp[i-1][j]和dp[i - 1][j - weight[i]] 都在dp[i][j]的左上角方向(包括正上方向),那么先遍历物品,再遍历背包的过程如图所示:
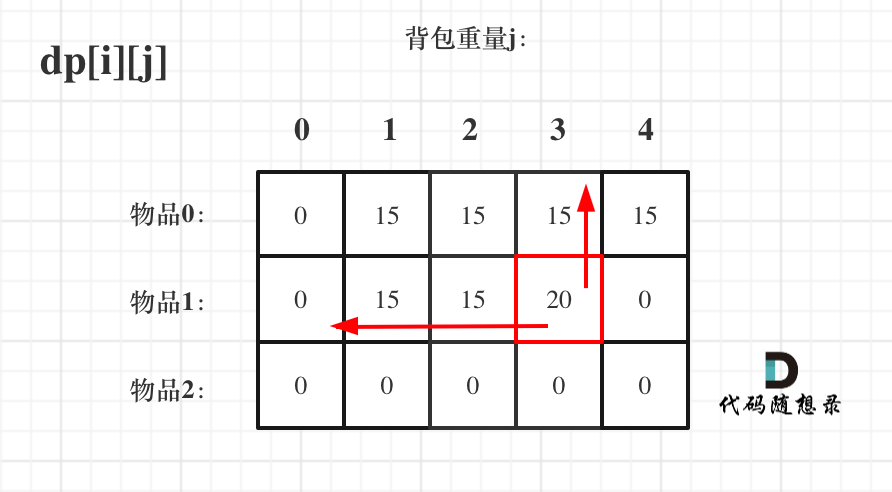
diff --git a/problems/背包理论基础01背包-2.md b/problems/背包理论基础01背包-2.md
index 36856cd6..ee2fb6d7 100644
--- a/problems/背包理论基础01背包-2.md
+++ b/problems/背包理论基础01背包-2.md
@@ -80,7 +80,7 @@ dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j],
看一下递归公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
-dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了,如果题目给的价值有负数,那么非0下标就要初始化为负无穷。
+dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了。
**这样才能让dp数组在递归公式的过程中取的最大的价值,而不是被初始值覆盖了**。