mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-06 23:28:29 +08:00
Update
This commit is contained in:
337
problems/kamacoder/00.软件构建.md
Normal file
337
problems/kamacoder/00.软件构建.md
Normal file
@ -0,0 +1,337 @@
|
||||
|
||||
# 拓扑排序精讲
|
||||
|
||||
[卡码网:软件构建](https://kamacoder.com/problempage.php?pid=1191)
|
||||
|
||||
题目描述:
|
||||
|
||||
某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依赖于文件 B,则必须在处理文件 A 之前处理文件 B (0 <= A, B <= N - 1)。请编写一个算法,用于确定文件处理的顺序。
|
||||
|
||||
输入描述:
|
||||
|
||||
第一行输入两个正整数 M, N。表示 N 个文件之间拥有 M 条依赖关系。
|
||||
|
||||
后续 M 行,每行两个正整数 S 和 T,表示 T 文件依赖于 S 文件。
|
||||
|
||||
输出描述:
|
||||
|
||||
输出共一行,如果能处理成功,则输出文件顺序,用空格隔开。
|
||||
|
||||
如果不能成功处理(相互依赖),则输出 -1。
|
||||
|
||||
输入示例:
|
||||
|
||||
```
|
||||
5 4
|
||||
0 1
|
||||
0 2
|
||||
1 3
|
||||
2 4
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
0 1 2 3 4
|
||||
|
||||
提示信息:
|
||||
|
||||
文件依赖关系如下:
|
||||
|
||||
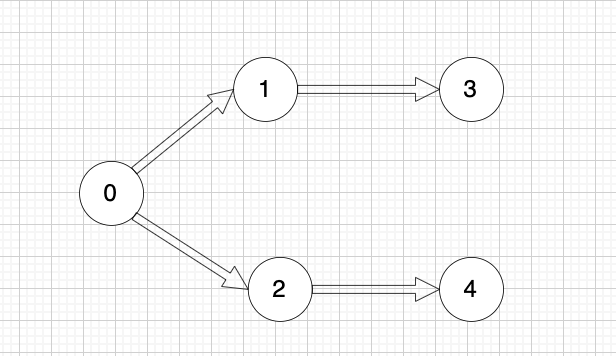
|
||||
|
||||
所以,文件处理的顺序除了示例中的顺序,还存在
|
||||
|
||||
0 2 4 1 3
|
||||
|
||||
0 2 1 3 4
|
||||
|
||||
等等合法的顺序。
|
||||
|
||||
数据范围:
|
||||
|
||||
* 0 <= N <= 10 ^ 5
|
||||
* 1 <= M <= 10 ^ 9
|
||||
|
||||
|
||||
## 拓扑排序的背景
|
||||
|
||||
本题是拓扑排序的经典题目。
|
||||
|
||||
一聊到 拓扑排序,一些录友可能会想这是排序,不会想到这是图论算法。
|
||||
|
||||
其实拓扑排序是经典的图论问题。
|
||||
|
||||
先说说 拓扑排序的应用场景。
|
||||
|
||||
大学排课,例如 先上A课,才能上B课,上了B课才能上C课,上了A课才能上D课,等等一系列这样的依赖顺序。 问给规划出一条 完整的上课顺序。
|
||||
|
||||
拓扑排序在文件处理上也有应用,我们在做项目安装文件包的时候,经常发现 复杂的文件依赖关系, A依赖B,B依赖C,B依赖D,C依赖E 等等。
|
||||
|
||||
如果给出一条线性的依赖顺序来下载这些文件呢?
|
||||
|
||||
有录友想上面的例子都很简单啊,我一眼能给排序出来。
|
||||
|
||||
那如果上面的依赖关系是一百对呢,一千对甚至上万个依赖关系,这些依赖关系中可能还有循环依赖,你如何发现循环依赖呢,又如果排出线性顺序呢。
|
||||
|
||||
所以 拓扑排序就是专门解决这类问题的。
|
||||
|
||||
概括来说,**给出一个 有向图,把这个有向图转成线性的排序 就叫拓扑排序**。
|
||||
|
||||
当然拓扑排序也要检测这个有向图 是否有环,即存在循环依赖的情况,因为这种情况是不能做线性排序的。
|
||||
|
||||
所以**拓扑排序也是图论中判断有向无环图的常用方法**。
|
||||
|
||||
------------
|
||||
|
||||
|
||||
## 拓扑排序的思路
|
||||
|
||||
拓扑排序指的是一种 解决问题的大体思路, 而具体算法,可能是广搜也可能是深搜。
|
||||
|
||||
大家可能发现 各式各样的解法,纠结哪个是拓扑排序?
|
||||
|
||||
其实只要能在把 有向无环图 进行线性排序 的算法 都可以叫做 拓扑排序。
|
||||
|
||||
实现拓扑排序的算法有两种:卡恩算法(BFS)和DFS
|
||||
|
||||
> 卡恩1962年提出这种解决拓扑排序的思路
|
||||
|
||||
一般来说我们只需要掌握 BFS (广度优先搜索)就可以了,清晰易懂,如果还想多了解一些,可以再去学一下 DFS 的思路,但 DFS 不是本篇重点。
|
||||
|
||||
接下来我们来讲解BFS的实现思路。
|
||||
|
||||
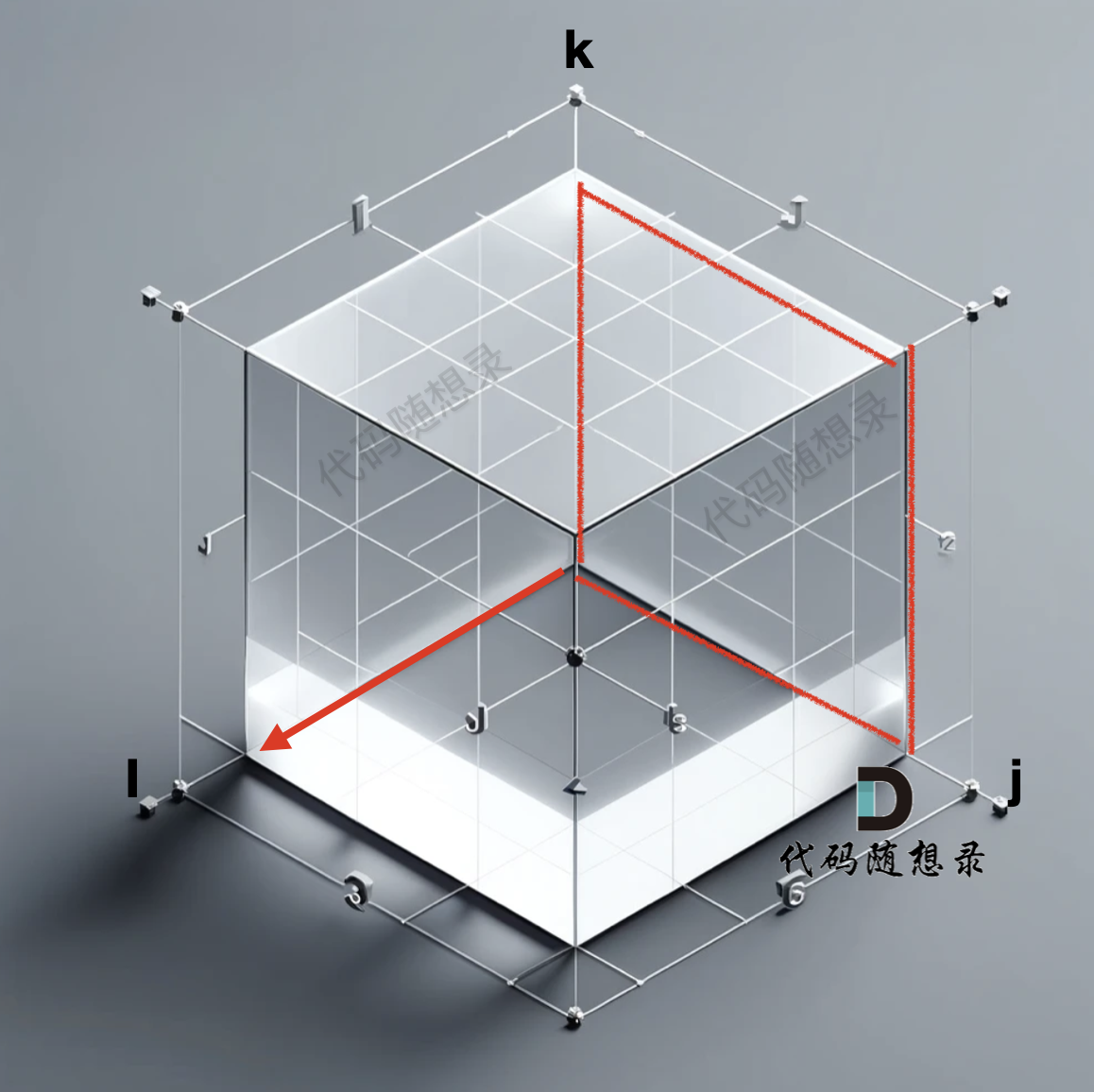
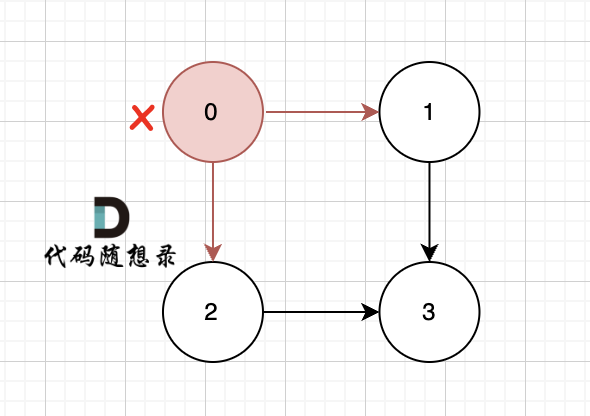
以题目中示例为例如图:
|
||||
|
||||
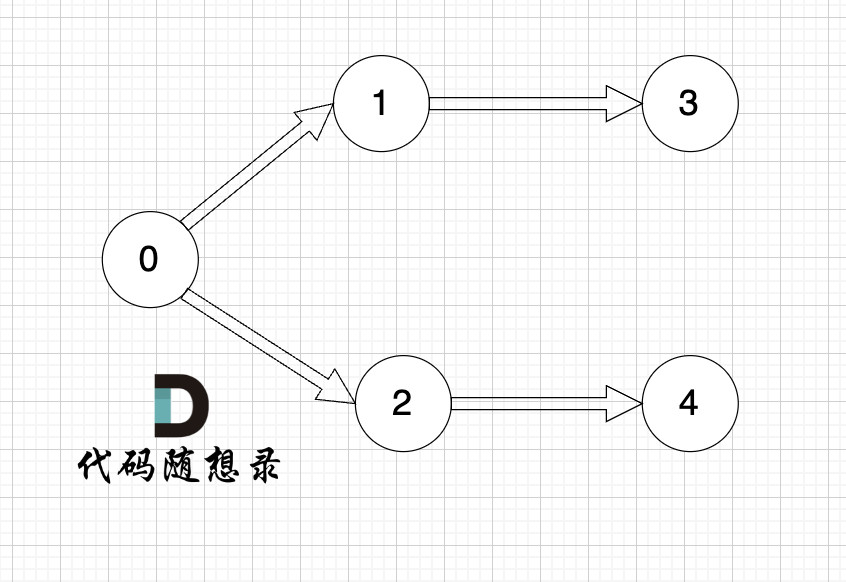
|
||||
|
||||
做拓扑排序的话,如果肉眼去找开头的节点,一定能找到 节点0 吧,都知道要从节点0 开始。
|
||||
|
||||
但为什么我们能找到 节点0呢,因为我们肉眼看着 这个图就是从 节点0出发的。
|
||||
|
||||
作为出发节点,它有什么特征?
|
||||
|
||||
你看节点0 的入度 为0 出度为2, 也就是 没有边指向它,而它有两条边是指出去的。
|
||||
|
||||
> 节点的入度表示 有多少条边指向它,节点的出度表示有多少条边 从该节点出发。
|
||||
|
||||
所以当我们做拓扑排序的时候,应该优先找 入度为 0 的节点,只有入度为0,它才是出发节点。
|
||||
**理解以上内容很重要**!
|
||||
|
||||
接下来我给出 拓扑排序的过程,其实就两步:
|
||||
|
||||
1. 找到入度为0 的节点,加入结果集
|
||||
2. 将该节点从图中移除
|
||||
|
||||
循环以上两步,直到 所有节点都在图中被移除了。
|
||||
|
||||
结果集的顺序,就是我们想要的拓扑排序顺序 (结果集里顺序可能不唯一)
|
||||
|
||||
## 模拟过程
|
||||
|
||||
用本题的示例来模拟一下这一过程:
|
||||
|
||||
|
||||
1、找到入度为0 的节点,加入结果集
|
||||
|
||||
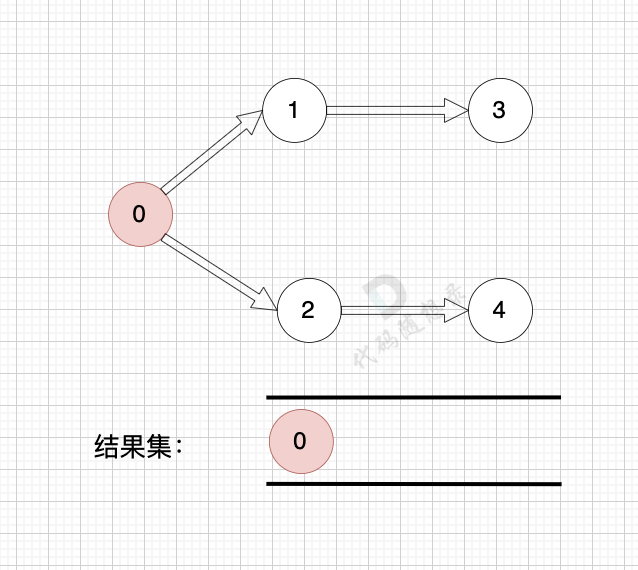
|
||||
|
||||
2、将该节点从图中移除
|
||||
|
||||
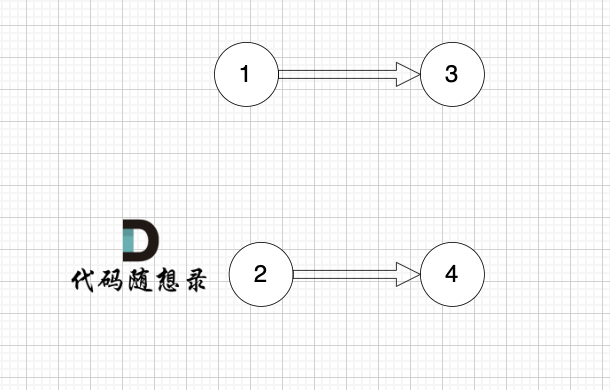
|
||||
|
||||
----------------
|
||||
|
||||
1、找到入度为0 的节点,加入结果集
|
||||
|
||||
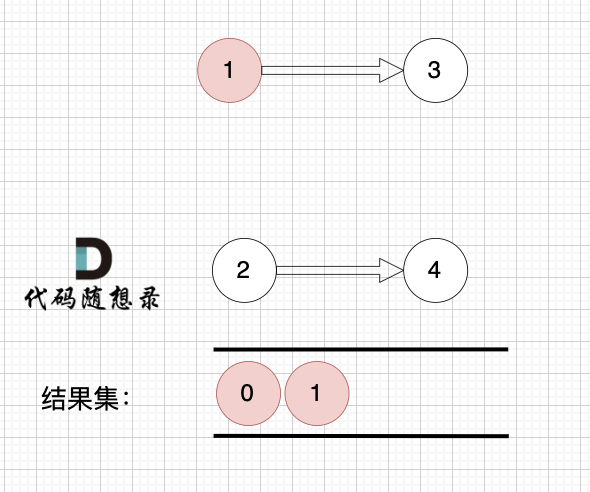
|
||||
|
||||
这里大家会发现,节点1 和 节点2 入度都为0, 选哪个呢?
|
||||
|
||||
选哪个都行,所以这也是为什么拓扑排序的结果是不唯一的。
|
||||
|
||||
2、将该节点从图中移除
|
||||
|
||||
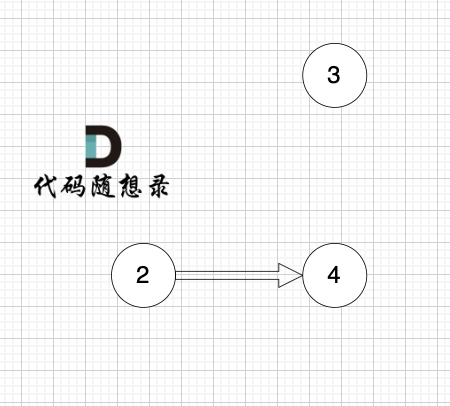
|
||||
|
||||
---------------
|
||||
|
||||
1、找到入度为0 的节点,加入结果集
|
||||
|
||||
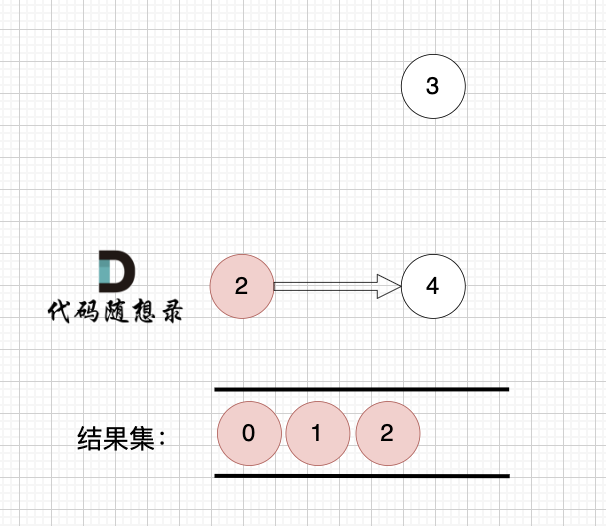
|
||||
|
||||
节点2 和 节点3 入度都为0,选哪个都行,这里选节点2
|
||||
|
||||
2、将该节点从图中移除
|
||||
|
||||

|
||||
|
||||
--------------
|
||||
|
||||
后面的过程一样的,节点3 和 节点4,入度都为0,选哪个都行。
|
||||
|
||||
最后结果集为: 0 1 2 3 4 。当然结果不唯一的。
|
||||
|
||||
## 判断有环
|
||||
|
||||
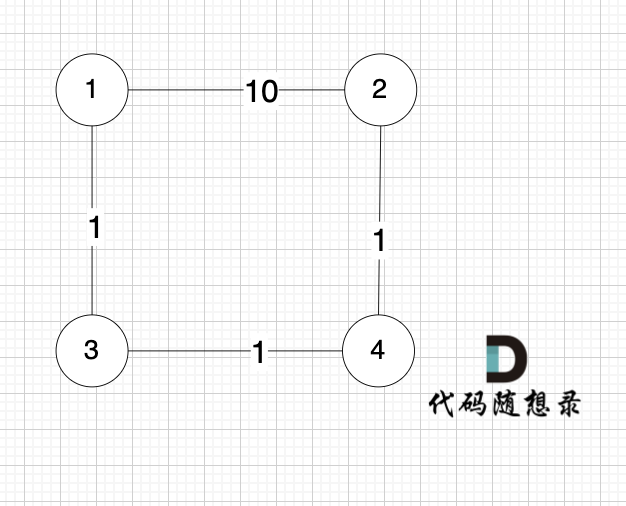
如果有 有向环怎么办呢?例如这个图:
|
||||
|
||||
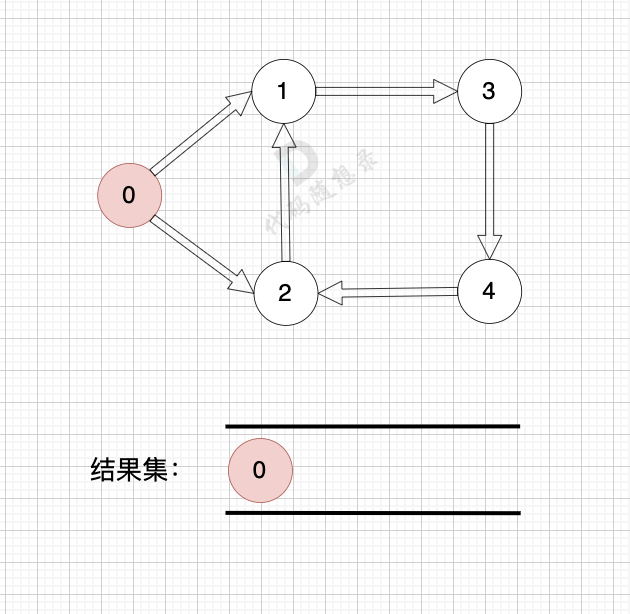
|
||||
|
||||
这个图,我们只能将入度为0 的节点0 接入结果集。
|
||||
|
||||
之后,节点1、2、3、4 形成了环,找不到入度为0 的节点了,所以此时结果集里只有一个元素。
|
||||
那么如果我们发现结果集元素个数 不等于 图中节点个数,我们就可以认定图中一定有 有向环!
|
||||
这也是拓扑排序判断有向环的方法。
|
||||
|
||||
通过以上过程的模拟大家会发现这个拓扑排序好像不难,还有点简单。
|
||||
|
||||
## 写代码
|
||||
|
||||
理解思想后,确实不难,但代码写起来也不容易。
|
||||
|
||||
为了每次可以找到所有节点的入度信息,我们要在初始话的时候,就把每个节点的入度 和 每个节点的依赖关系做统计。
|
||||
|
||||
代码如下:
|
||||
|
||||
```CPP
|
||||
cin >> n >> m;
|
||||
vector<int> inDegree(n, 0); // 记录每个文件的入度
|
||||
vector<int> result; // 记录结果
|
||||
unordered_map<int, vector<int>> umap; // 记录文件依赖关系
|
||||
|
||||
while (m--) {
|
||||
// s->t,先有s才能有t
|
||||
cin >> s >> t;
|
||||
inDegree[t]++; // t的入度加一
|
||||
umap[s].push_back(t); // 记录s指向哪些文件
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
找入度为0 的节点,我们需要用一个队列放存放。
|
||||
|
||||
因为每次寻找入度为0的节点,不一定只有一个节点,可能很多节点入度都为0,所以要将这些入度为0的节点放到队列里,依次去处理。
|
||||
|
||||
代码如下:
|
||||
|
||||
```CPP
|
||||
|
||||
queue<int> que;
|
||||
for (int i = 0; i < n; i++) {
|
||||
// 入度为0的节点,可以作为开头,先加入队列
|
||||
if (inDegree[i] == 0) que.push(i);
|
||||
}
|
||||
```
|
||||
|
||||
开始从队列里遍历入度为0 的节点,将其放入结果集。
|
||||
|
||||
```CPP
|
||||
|
||||
while (que.size()) {
|
||||
int cur = que.front(); // 当前选中的节点
|
||||
que.pop();
|
||||
result.push_back(cur);
|
||||
// 将该节点从图中移除
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
这里面还有一个很重要的过程,如何把这个入度为0的节点从图中移除呢?
|
||||
|
||||
首先我们为什么要把节点从图中移除?
|
||||
|
||||
为的是将 该节点作为出发点所连接的边删掉。
|
||||
|
||||
删掉的目的是什么呢?
|
||||
|
||||
要把 该节点作为出发点所连接的节点的 入度 减一。
|
||||
|
||||
如果这里不理解,看上面的模拟过程第一步:
|
||||
|
||||

|
||||
|
||||
这事节点1 和 节点2 的入度为 1。
|
||||
|
||||
将节点0删除后,图为这样:
|
||||
|
||||

|
||||
|
||||
那么 节点0 作为出发点 所连接的节点的入度 就都做了 减一 的操作。
|
||||
|
||||
此时 节点1 和 节点 2 的入度都为0, 这样才能作为下一轮选取的节点。
|
||||
|
||||
所以,我们在代码实现的过程中,本质是要将 该节点作为出发点所连接的节点的 入度 减一 就可以了,这样好能根据入度找下一个节点,不用真在图里把这个节点删掉。
|
||||
|
||||
该过程代码如下:
|
||||
|
||||
|
||||
```CPP
|
||||
|
||||
while (que.size()) {
|
||||
int cur = que.front(); // 当前选中的节点
|
||||
que.pop();
|
||||
result.push_back(cur);
|
||||
// 将该节点从图中移除
|
||||
vector<int> files = umap[cur]; //获取cur指向的节点
|
||||
if (files.size()) { // 如果cur有指向的节点
|
||||
for (int i = 0; i < files.size(); i++) { // 遍历cur指向的节点
|
||||
inDegree[files[i]] --; // cur指向的节点入度都做减一操作
|
||||
// 如果指向的节点减一之后,入度为0,说明是我们要选取的下一个节点,放入队列。
|
||||
if(inDegree[files[i]] == 0) que.push(files[i]);
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
最后代码如下:
|
||||
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <queue>
|
||||
#include <unordered_map>
|
||||
using namespace std;
|
||||
int main() {
|
||||
int m, n, s, t;
|
||||
cin >> n >> m;
|
||||
vector<int> inDegree(n, 0); // 记录每个节点的入度
|
||||
|
||||
unordered_map<int, vector<int>> umap;// 记录节点依赖关系
|
||||
vector<int> result; // 记录结果
|
||||
|
||||
while (m--) {
|
||||
// s->t,先有s才能有t
|
||||
cin >> s >> t;
|
||||
inDegree[t]++; // t的入度加一
|
||||
umap[s].push_back(t); // 记录s指向哪些节点
|
||||
}
|
||||
queue<int> que;
|
||||
for (int i = 0; i < n; i++) {
|
||||
// 入度为0的节点,可以作为开头,先加入队列
|
||||
if (inDegree[i] == 0) que.push(i);
|
||||
//cout << inDegree[i] << endl;
|
||||
}
|
||||
// int count = 0;
|
||||
while (que.size()) {
|
||||
int cur = que.front(); // 当前选中的节点
|
||||
que.pop();
|
||||
//count++;
|
||||
result.push_back(cur);
|
||||
vector<int> files = umap[cur]; //获取该节点指向的节点
|
||||
if (files.size()) { // cur有后续节点
|
||||
for (int i = 0; i < files.size(); i++) {
|
||||
inDegree[files[i]] --; // cur的指向的节点入度-1
|
||||
if(inDegree[files[i]] == 0) que.push(files[i]);
|
||||
}
|
||||
}
|
||||
}
|
||||
// 判断是否有有向环
|
||||
if (result.size() == n) {
|
||||
// 注意输出格式,最后一个元素后面没有空格
|
||||
for (int i = 0; i < n - 2; i++) cout << result[i] << " ";
|
||||
cout << result[n - 1];
|
||||
} else cout << -1 << endl;
|
||||
}
|
||||
```
|
||||
@ -1,18 +1,21 @@
|
||||
|
||||
# 94. 城市间货物运输 I
|
||||
# Bellman_ford 算法精讲
|
||||
|
||||
[卡码网: 94. 城市间货物运输 I](https://kamacoder.com/problempage.php?pid=1152)
|
||||
[卡码网:94. 城市间货物运输 I](https://kamacoder.com/problempage.php?pid=1152)
|
||||
|
||||
题目描述
|
||||
|
||||
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
|
||||
|
||||
|
||||
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
|
||||
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。
|
||||
|
||||
权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
|
||||
|
||||
|
||||
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。如果最低运输成本是一个负数,它表示在遵循最优路径的情况下,运输过程中反而能够实现盈利。
|
||||
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。
|
||||
|
||||
如果最低运输成本是一个负数,它表示在遵循最优路径的情况下,运输过程中反而能够实现盈利。
|
||||
|
||||
城市 1 到城市 n 之间可能会出现没有路径的情况,同时保证道路网络中不存在任何负权回路。
|
||||
|
||||
@ -41,17 +44,19 @@
|
||||
1 3 5
|
||||
```
|
||||
|
||||

|
||||
|
||||
## 思路
|
||||
|
||||
本题依然是最短路问题,求 从 节点1 到节点n 的最小费用。 但本题不同之处在于 边的权值是有负数的。
|
||||
本题依然是单源最短路问题,求 从 节点1 到节点n 的最小费用。 **但本题不同之处在于 边的权值是有负数了**。
|
||||
|
||||
从 节点1 到节点n 的最小费用也可以是负数,费用如果是负数 则表示 运输的过程中 政府补贴大于运输成本。
|
||||
|
||||
在求单源最短路的方法中,使用dijkstra 的话,则要求图中边的权值都为正数。
|
||||
|
||||
我们在 [kama47.参会dijkstra朴素](./kama47.参会dijkstra朴素.md) 中专门有讲解,为什么有边为负数 使用dijkstra就不行了。
|
||||
我们在 [dijkstra朴素版](./0047.参会dijkstra朴素.md) 中专门有讲解:为什么有边为负数 使用dijkstra就不行了。
|
||||
|
||||
本题是经典的带负权值的单源最短路问题,此时就轮到Bellman_ford登场了,接下来我们来详细介绍Bellman_ford 算法 如何解决这类问题。
|
||||
**本题是经典的带负权值的单源最短路问题,此时就轮到Bellman_ford登场了**,接下来我们来详细介绍Bellman_ford 算法 如何解决这类问题。
|
||||
|
||||
> 该算法是由 R.Bellman 和L.Ford 在20世纪50年代末期发明的算法,故称为Bellman_ford算法。
|
||||
|
||||
@ -67,7 +72,7 @@
|
||||
|
||||
所以大家翻译过来,就是 “放松” 或者 “松弛” 。
|
||||
|
||||
但《算法四》没有具体去讲这个 “放松” 究竟是个啥? 网上的题解也没有讲题解里的 “松弛这条边,松弛所有边”等等 里面的 “松弛” 究竟是什么意思?
|
||||
但《算法四》没有具体去讲这个 “放松” 究竟是个啥? 网上很多题解也没有讲题解里的 “松弛这条边,松弛所有边”等等 里面的 “松弛” 究竟是什么意思?
|
||||
|
||||
这里我给大家举一个例子,每条边有起点、终点和边的权值。例如一条边,节点A 到 节点B 权值为value,如图:
|
||||
|
||||
@ -76,13 +81,13 @@
|
||||
minDist[B] 表示 到达B节点 最小权值,minDist[B] 有哪些状态可以推出来?
|
||||
|
||||
状态一: minDist[A] + value 可以推出 minDist[B]
|
||||
状态二: minDist[B]本身就有权值 (可能是其他边链接的节点B 例如节点C,以至于 dp[B]记录了其他边到dp[B]的权值)
|
||||
状态二: minDist[B]本身就有权值 (可能是其他边链接的节点B 例如节点C,以至于 minDist[B]记录了其他边到minDist[B]的权值)
|
||||
|
||||
那么minDist[B] 应为如何取舍。
|
||||
minDist[B] 应为如何取舍。
|
||||
|
||||
本题我们要求最小权值,那么 这两个状态我们就取最小的
|
||||
|
||||
```
|
||||
```CPP
|
||||
if (minDist[B] > minDist[A] + value) minDist[B] = minDist[A] + value
|
||||
|
||||
```
|
||||
@ -108,7 +113,7 @@ if (minDist[B] > minDist[A] + value) minDist[B] = minDist[A] + value
|
||||
|
||||
**那么为什么是 n - 1次 松弛呢**?
|
||||
|
||||
这里要给大家模拟一遍 Bellman_ford 的算法才行,接下来我们来看看对所有边松弛 n -1 次的操作是什么样的。
|
||||
这里要给大家模拟一遍 Bellman_ford 的算法才行,接下来我们来看看对所有边松弛 n - 1 次的操作是什么样的。
|
||||
|
||||
我们依然使用**minDist数组来表达 起点到各个节点的最短距离**,例如minDist[3] = 5 表示起点到达节点3 的最小距离为5
|
||||
|
||||
@ -204,19 +209,18 @@ if (minDist[B] > minDist[A] + value) minDist[B] = minDist[A] + value
|
||||
|
||||
那么无论图是什么样的,边是什么样的顺序,我们对所有边松弛 n-1 次 就一定能得到 起点到达 终点的最短距离。
|
||||
|
||||
其实也同时计算出了,起点 到达 所有节点的最短距离,因为所有节点与起点连接的变数最多也就是 n-1条边。
|
||||
其实也同时计算出了,起点 到达 所有节点的最短距离,因为所有节点与起点连接的边数最多也就是 n-1 条边。
|
||||
|
||||
截止到这里,Bellman_ford 的核心算法思路,大家就了解的差不多了。
|
||||
|
||||
共有两个关键点。
|
||||
|
||||
* “松弛”究竟是个啥
|
||||
* 为什么要对所有边松弛 n - 1 次 (n为节点个数)
|
||||
* “松弛”究竟是个啥?
|
||||
* 为什么要对所有边松弛 n - 1 次 (n为节点个数) ?
|
||||
|
||||
那么Bellman_ford的解题解题过程其实就是对所有边松弛 n-1 次,然后得出得到终点的最短路径。
|
||||
|
||||
|
||||
|
||||
### 代码
|
||||
|
||||
理解上面讲解的内容,代码就更容易写了,本题代码如下:(详细注释)
|
||||
@ -271,7 +275,7 @@ int main() {
|
||||
|
||||
grid数组是用来存图的,这是题目描述中必须要使用的空间,而不是我们算法所使用的空间。
|
||||
|
||||
我们在讲空间复杂度的时候,一般都是说,我们这个算法的空间复杂度。
|
||||
我们在讲空间复杂度的时候,一般都是说,我们这个算法所用的空间复杂度。
|
||||
|
||||
|
||||
### 拓展
|
||||
@ -283,6 +287,7 @@ grid数组是用来存图的,这是题目描述中必须要使用的空间,
|
||||
那么我们只要松弛 n - 1次 就一定能得到结果,没必要在松弛更多次了。
|
||||
|
||||
这里有疑惑的录友,可以加上打印 minDist数组 的日志,尝试一下,看看松弛 n 次会怎么样。
|
||||
|
||||
你会发现 松弛 大于 n - 1次,minDist数组 就不会变化了。
|
||||
|
||||
这里我给出打印日志的代码:
|
||||
@ -336,9 +341,9 @@ int main() {
|
||||
|
||||
```
|
||||
|
||||
通过打日志,大家发现,怎么对所有边进行第二次松弛以后结果就 不再变化了,那根本就不用松弛 n - 1啊?
|
||||
通过打日志,大家发现,怎么对所有边进行第二次松弛以后结果就 不再变化了,那根本就不用松弛 n - 1 ?
|
||||
|
||||
这是本题的样例的特殊性, 松弛 n-1次 是保证对任何图 都能最后求得到终点的最小距离。
|
||||
这是本题的样例的特殊性, 松弛 n-1 次 是保证对任何图 都能最后求得到终点的最小距离。
|
||||
|
||||
如果还想不明白 我再举一个例子,用以下测试用例再跑一下。
|
||||
|
||||
@ -367,11 +372,11 @@ int main() {
|
||||
0 1 2 3 4 5
|
||||
```
|
||||
|
||||
你会发现到 n-1 次 打印出最后的最短路结果。
|
||||
你会发现到 n-1 次 才打印出最后的最短路结果。
|
||||
|
||||
关于上面的讲解,大家已经要多写代码去实验,验证自己的想法。
|
||||
关于上面的讲解,大家一定要多写代码去实验,验证自己的想法。
|
||||
|
||||
至于 负权回路 ,我在下一篇会专门讲解这种情况,大家有个印象就好。
|
||||
**至于 负权回路 ,我在下一篇会专门讲解这种情况,大家有个印象就好**。
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
|
||||
# 95. 城市间货物运输 II
|
||||
# bellman_ford之判断负权回路
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1153)
|
||||
[卡码网:95. 城市间货物运输 II](https://kamacoder.com/problempage.php?pid=1153)
|
||||
|
||||
【题目描述】
|
||||
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
|
||||
# 96. 城市间货物运输 III
|
||||
# bellman_ford之单源有限最短路
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1154)
|
||||
[卡码网:96. 城市间货物运输 III](https://kamacoder.com/problempage.php?pid=1154)
|
||||
|
||||
【题目描述】
|
||||
|
||||
@ -560,26 +560,73 @@ int main() {
|
||||
|
||||
这又是为什么呢?
|
||||
|
||||
可以发现耗时主要是在 第8组数据上:
|
||||
|
||||

|
||||
|
||||
其实第八组数据是我特别制作的一个 稠密大图,该图有250个节点和10000条边, 在这种情况下, SPFA 的时间复杂度 是接近与 bellman_ford的。
|
||||
对于后台数据,我特别制作的一个稠密大图,该图有250个节点和10000条边, 在这种情况下, SPFA 的时间复杂度 是接近与 bellman_ford的。
|
||||
|
||||
但因为 SPFA 节点的进出队列操作,耗时很大,所以相同的时间复杂度的情况下,SPFA 实际上更耗时了。
|
||||
|
||||
这一点我在 [0094.城市间货物运输I-SPFA](./0094.城市间货物运输I-SPFA.md) 有分析,感兴趣的录友再回头去看看。
|
||||
|
||||
## 拓展四(能否用dijkstra)
|
||||
|
||||
本题能否使用 dijkstra 算法呢?
|
||||
|
||||
dijkstra 是贪心的思路 每一次搜索都只会找距离源点最近的非访问过的节点。
|
||||
|
||||
如果限制最多访问k个节点,那么 dijkstra 未必能在有限次就能到达终点,即使在经过k个节点确实可以到达终点的情况下。
|
||||
|
||||
这么说大家会感觉有点抽象,我用 [dijkstra朴素版精讲](./0047.参会dijkstra朴素.md) 里的示例在举例说明: (如果没看过我讲的[dijkstra朴素版精讲](./0047.参会dijkstra朴素.md),建议去仔细看一下,否则下面讲解容易看不懂)
|
||||
|
||||
|
||||
在以下这个图中,求节点1 到 节点7 最多经过2个节点 的最短路是多少呢?
|
||||
|
||||

|
||||
|
||||
最短路显然是:
|
||||
|
||||

|
||||
|
||||
最多经过2个节点,也就是3条边相连的路线:节点1 -> 节点2 -> 节点6-> 节点7
|
||||
|
||||
如果是 dijkstra 求解的话,求解过程是这样的: (下面是dijkstra的模拟过程,我精简了很多,如果看不懂,一定要先看[dijkstra朴素版精讲](./0047.参会dijkstra朴素.md))
|
||||
|
||||
初始化如图所示:
|
||||
|
||||

|
||||
|
||||
找距离源点最近且没有被访问过的节点,先找节点1
|
||||
|
||||

|
||||
|
||||
|
||||
距离源点最近且没有被访问过的节点,找节点2:
|
||||
|
||||
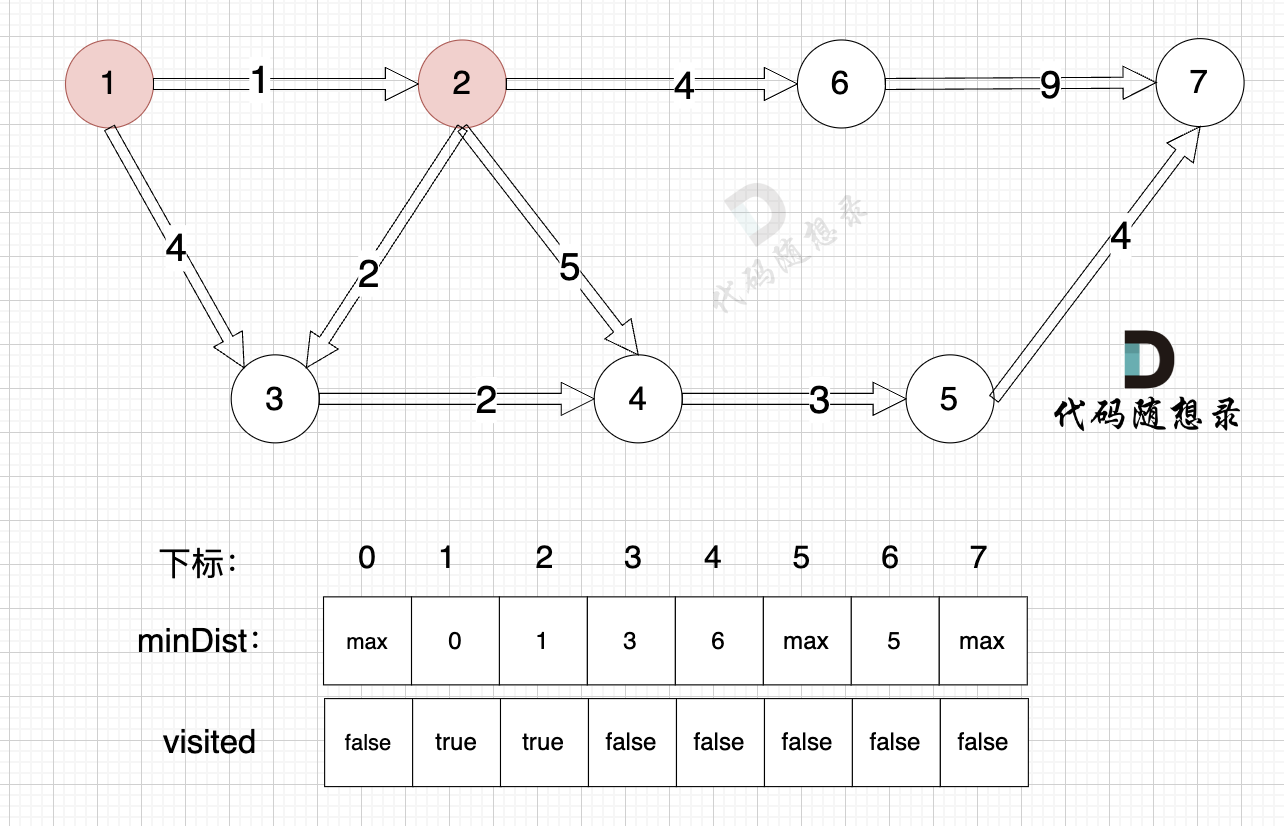
|
||||
|
||||
距离源点最近且没有被访问过的节点,找到节点3:
|
||||
|
||||

|
||||
|
||||
距离源点最近且没有被访问过的节点,找到节点4:
|
||||
|
||||
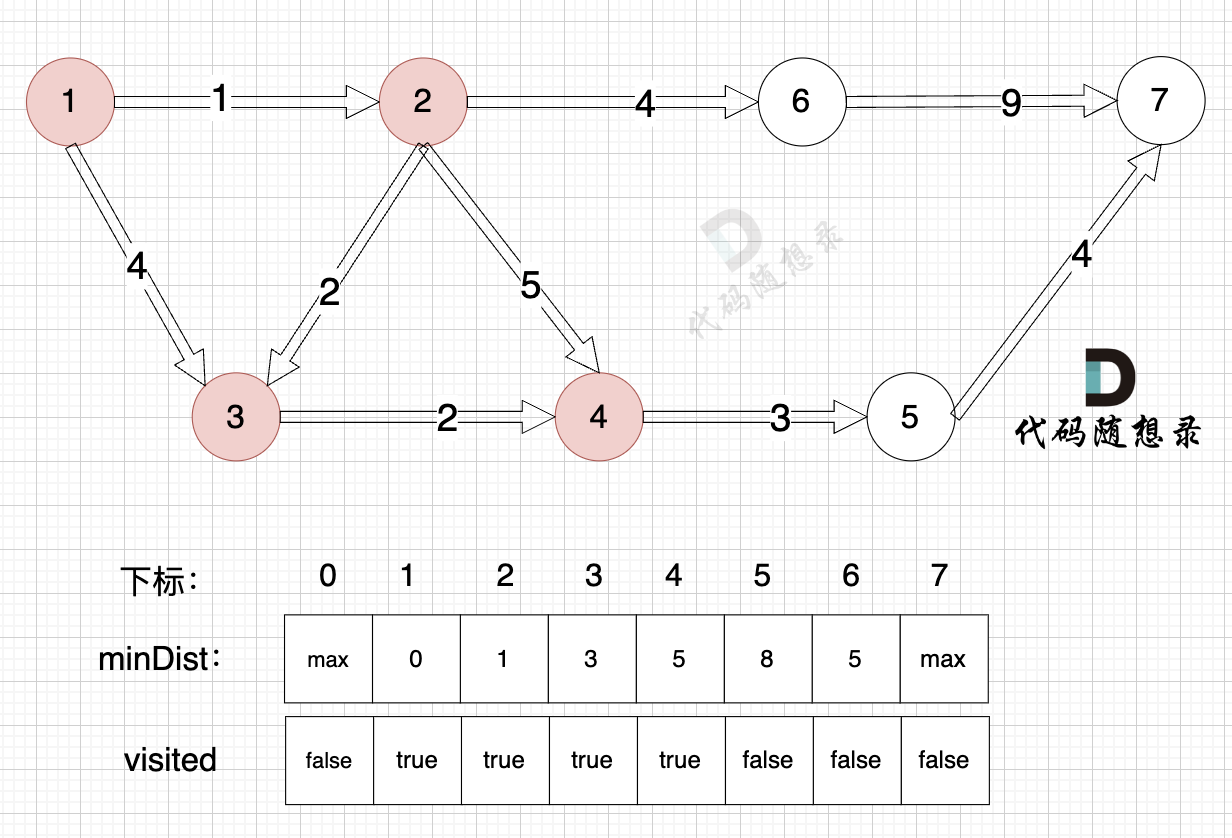
|
||||
|
||||
此时最多经过2个节点的搜索就完毕了,但结果中minDist[7] (即节点7的结果)并没有被更。
|
||||
|
||||
那么 dijkstra 会告诉我们 节点1 到 节点7 最多经过2个节点的情况下是不可到达的。
|
||||
|
||||
通过以上模拟过程,大家应该能感受到 dijkstra 贪心的过程,正是因为 贪心,所以 dijkstra 找不到 节点1 -> 节点2 -> 节点6-> 节点7 这条路径。
|
||||
|
||||
## 总结
|
||||
|
||||
本题是单源有限最短路问题,也是 bellman_ford的一个拓展问题,如果理解bellman_ford 其实思路比较容易理解,但有很多细节。
|
||||
|
||||
例如 为什么要用 minDist_copy 来记录上一轮 松弛的结果。 这也是本篇我为什么花了这么大篇幅讲解的关键所在。
|
||||
|
||||
接下来,还给大家多了三个拓展:
|
||||
接下来,还给大家做了四个拓展:
|
||||
|
||||
* 边的顺序的影响
|
||||
* 本题的本质
|
||||
* SPFA的解法
|
||||
* 能否用dijkstra
|
||||
|
||||
学透了以上三个拓展,相信大家会对bellman_ford有更深入的理解。
|
||||
学透了以上四个拓展,相信大家会对bellman_ford有更深入的理解。
|
||||
|
||||
@ -58,7 +58,7 @@
|
||||
|
||||
通过本题,我们来系统讲解一个新的最短路算法-Floyd 算法。
|
||||
|
||||
Floyd 算法对边的权值正负没有要求,都可以处理。
|
||||
**Floyd 算法对边的权值正负没有要求,都可以处理**。
|
||||
|
||||
Floyd算法核心思想是动态规划。
|
||||
|
||||
@ -76,7 +76,7 @@ Floyd算法核心思想是动态规划。
|
||||
|
||||
那么这样我们是不是就找到了,子问题推导求出整体最优方案的递归关系呢。
|
||||
|
||||
而节点1 到 节点9 的最短距离 可以由 节点1 到节点5的最短距离 + 节点5到节点9的最短距离组成, 也可以有 节点1 到节点7的最短距离 + 节点7 到节点9的最短距离的距离组成。
|
||||
节点1 到 节点9 的最短距离 可以由 节点1 到节点5的最短距离 + 节点5到节点9的最短距离组成, 也可以有 节点1 到节点7的最短距离 + 节点7 到节点9的最短距离的距离组成。
|
||||
|
||||
那么选哪个呢?
|
||||
|
||||
@ -100,11 +100,15 @@ Floyd算法核心思想是动态规划。
|
||||
|
||||
grid[i][j][k] = m,表示 节点i 到 节点j 以[1...k] 集合为中间节点的最短距离为m。
|
||||
|
||||
可能有录友会想: 节点i 到 节点j 的最短距离为m,这句话可以理解,但 以[1...k]集合为中间节点 理解不辽。
|
||||
可能有录友会想,凭什么就这么定义呢?
|
||||
|
||||
节点i 到 节点j 的最短路径中 一定是经过很多节点,那么这个集合用[1...k] 来表示。
|
||||
节点i 到 节点j 的最短距离为m,这句话可以理解,但 以[1...k]集合为中间节点就理解不辽了。
|
||||
|
||||
k不能单独指某个节点,因为谁说 节点i 到节点j的最短路径中 一定只有一个节点呢,所以k 一定要表示一个集合,即[1...k] ,表示节点1 到 节点k 一共k个节点的集合。
|
||||
节点i 到 节点j 的最短路径中 一定是经过很多节点,那么这个集合用[1...k] 来表示。
|
||||
|
||||
你可以反过来想,节点i 到 节点j 中间一定经过很多节点,那么你能用什么方式来表述中间这么多节点呢?
|
||||
|
||||
所以 这里的k不能单独指某个节点,k 一定要表示一个集合,即[1...k] ,表示节点1 到 节点k 一共k个节点的集合。
|
||||
|
||||
|
||||
2、确定递推公式
|
||||
@ -139,18 +143,20 @@ grid[i][j][k] = m,表示 节点i 到 节点j 以[1...k] 集合为中间节点
|
||||
|
||||
例如题目中只是输入边(节点2 -> 节点6,权值为3),那么grid[2][6][k] = 3,k需要填什么呢?
|
||||
|
||||
把k 填成1,那如何上来就知道 节点2 经过节点1 到达节点6的最短距离是3 呢。
|
||||
把k 填成1,那如何上来就知道 节点2 经过节点1 到达节点6的最短距离是多少 呢。
|
||||
|
||||
所以 只能 把k 赋值为 0,本题 节点0 是无意义的,节点是从1 到 n。
|
||||
|
||||
这样我们在下一轮计算的时候,就可以根据 grid[i][j][0] 来计算 grid[i][j][1],此时的 grid[i][j][1] 就是 节点i 经过节点1 到达 节点j 的最小距离了。
|
||||
|
||||
|
||||
grid数组是一个三维数组,那么我们初始化的数据在 i 与 j 构成的平层,如图:
|
||||
|
||||
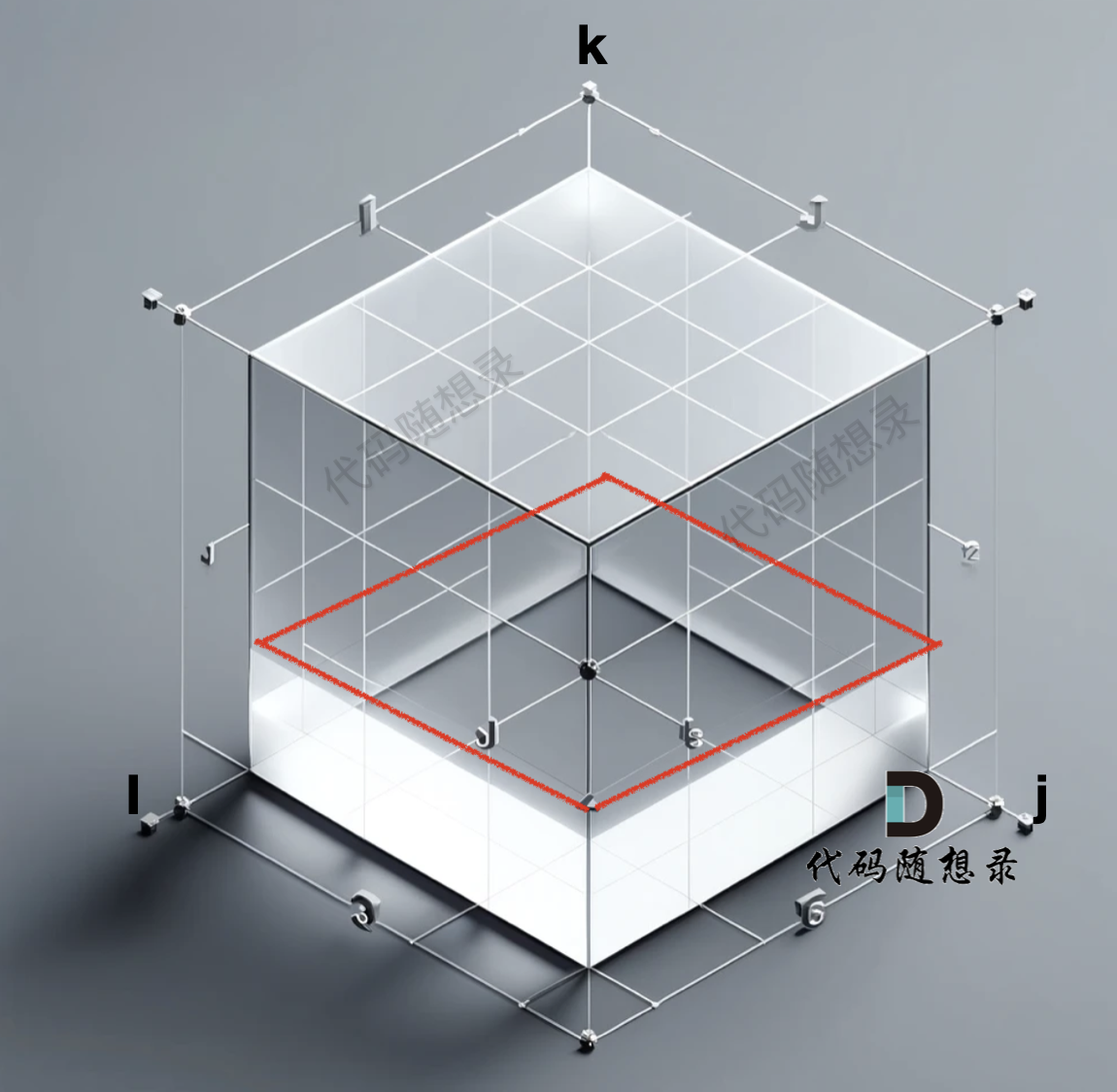
|
||||
|
||||
**初始化这里要画图,对后面的遍历顺序理解很重要**
|
||||
红色的 底部一层是我们初始化好的数据,注意:从三维角度去看初始化的数据很重要,下面我们在聊遍历顺序的时候还会再讲。
|
||||
|
||||
所以初始化:
|
||||
所以初始化代码:
|
||||
|
||||
```CPP
|
||||
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005))); // C++定义了一个三位数组,10005是因为边的最大距离是10^4
|
||||
@ -167,7 +173,7 @@ grid数组中其他元素数值应该初始化多少呢?
|
||||
|
||||
本题求的是最小值,所以输入数据没有涉及到的节点的情况都应该初始为一个最大数。
|
||||
|
||||
这样才不会影响,每次计算去最小值的时候,初始值对计算结果的影响。
|
||||
这样才不会影响,每次计算去最小值的时候 初始值对计算结果的影响。
|
||||
|
||||
所以grid数组的定义可以是:
|
||||
|
||||
@ -191,7 +197,7 @@ vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n
|
||||
|
||||
遍历的顺序是从底向上 一层一层去遍历。
|
||||
|
||||
所以遍历k 的for循环一定是在最外面,这样才能 水平方向一层一层去遍历。如图:
|
||||
所以遍历k 的for循环一定是在最外面,这样才能一层一层去遍历。如图:
|
||||
|
||||
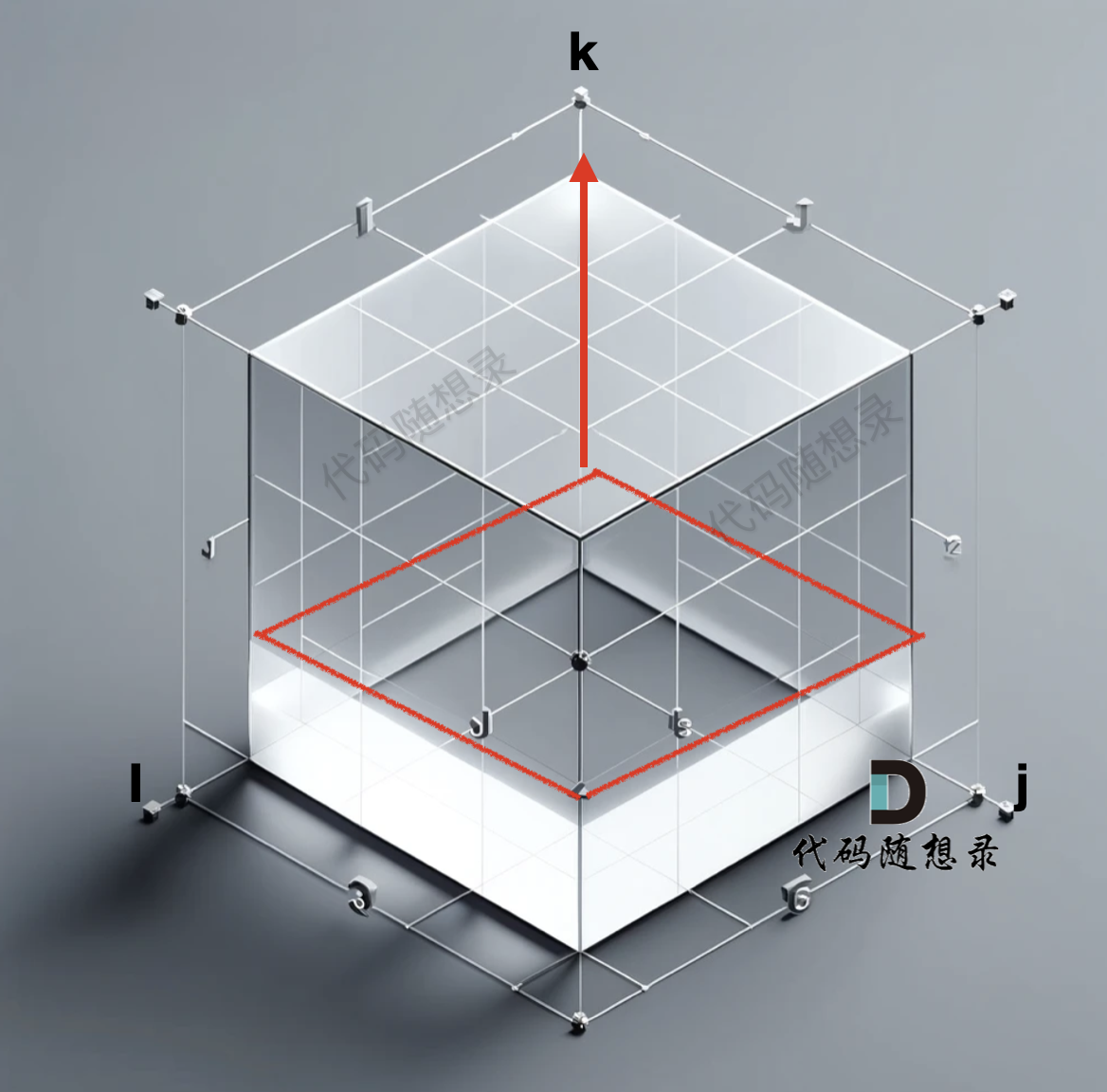
|
||||
|
||||
@ -228,7 +234,7 @@ for (int i = 1; i <= n; i++) {
|
||||
|
||||
|
||||
|
||||
而我们初始化,是 k 为0,然后 i 和 j 形成的平面做初始化,如果以 k 和 j 形成的平面去遍历,就造成了 递推公式 用不上上一轮计算的结果,从而导致结果不对(初始化的结果只能用上一部分,因为初始化是 i 与j 形成的平面)。
|
||||
而我们初始化的数据 是 k 为0, i 和 j 形成的平面做初始化,如果以 k 和 j 形成的平面去一层一层遍历,就造成了 递推公式 用不上上一轮计算的结果,从而导致结果不对(初始化的部分是 i 与j 形成的平面,在初始部分有讲过)。
|
||||
|
||||
我再给大家举一个测试用例
|
||||
|
||||
@ -246,23 +252,54 @@ for (int i = 1; i <= n; i++) {
|
||||
|
||||
|
||||
|
||||
就节点1 到 节点 2 的最短距离,运行结果是 10 ,但正确的结果很明显是3。
|
||||
求节点1 到 节点 2 的最短距离,运行结果是 10 ,但正确的结果很明显是3。
|
||||
|
||||
为什么呢?
|
||||
|
||||
因为 k 放在最里面,先就把 节点1 和 节点 2 的最短距离就确定了,后面再也不会计算节点 1 和 节点 2的距离,同时也不会基于 初始化或者之前计算过的结果来计算,即不会考虑 节点1 到 节点3, 节点3 到节点 4,节点4到节点2 的距离。
|
||||
因为 k 放在最里面,先就把 节点1 和 节点 2 的最短距离就确定了,后面再也不会计算节点 1 和 节点 2的距离,同时也不会基于 初始化或者之前计算过的结果来计算,即:不会考虑 节点1 到 节点3, 节点3 到节点 4,节点4到节点2 的距离。
|
||||
|
||||
|
||||
造成这一原因,是 在三维立体坐标中, 我们初始化的是 i 和 i 在k 为0 所构成的平面,但遍历的时候 是以 j 和 k构成的平面以 i 为垂直方向去层次遍历。
|
||||
|
||||
|
||||
而遍历k 的for循环如果放在中间呢,同样是 j 与k 行程一个平面,i 是纵面,遍历的也是这样:
|
||||
|
||||

|
||||
|
||||
|
||||
同样不能完全用上初始化 和 上一层计算的结果。
|
||||
|
||||
很多录友对于 floyd算法的遍历顺序搞不懂,其实 是没有从三维的角度去思考,同时我把三维立体图给大家画出来,遍历顺序标出来,大家就很容易想明白,为什么 k 放在最外层 才能用上 初始化和上一轮计算的结果了。
|
||||
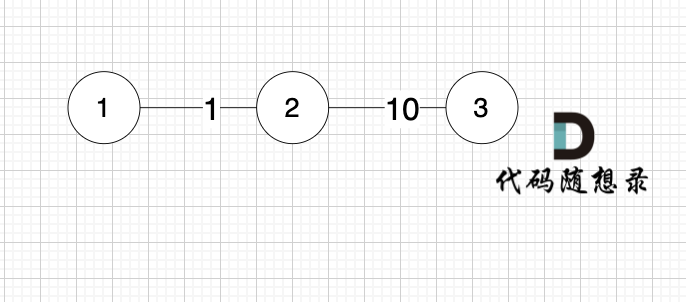
根据这个情况再举一个例子:
|
||||
|
||||
```
|
||||
5 2
|
||||
1 2 1
|
||||
2 3 10
|
||||
1
|
||||
1 3
|
||||
```
|
||||
|
||||
图:
|
||||
|
||||
|
||||
|
||||
求 节点1 到节点3 的最短距离,如果k循环放中间,程序的运行结果是 -1,也就是不能到达节点3。
|
||||
|
||||
在计算 grid[i][j][k] 的时候,需要基于 grid[i][k][k-1] 和 grid[k][j][k-1]的数值。
|
||||
|
||||
也就是 计算 grid[1][3][2] (表示节点1 到 节点3,经过节点2) 的时候,需要基于 grid[1][2][1] 和 grid[2][3][1]的数值,而 我们初始化,只初始化了 k为0 的那一层。
|
||||
|
||||
造成这一原因 依然是 在三维立体坐标中, 我们初始化的是 i 和 j 在k 为0 所构成的平面,但遍历的时候 是以 j 和 k构成的平面以 i 为垂直方向去层次遍历。
|
||||
|
||||
|
||||
很多录友对于 floyd算法的遍历顺序搞不懂,**其实 是没有从三维的角度去思考**,同时我把三维立体图给大家画出来,遍历顺序标出来,大家就很容易想明白,为什么 k 放在最外层 才能用上 初始化和上一轮计算的结果了。
|
||||
|
||||
5、举例推导dp数组
|
||||
|
||||
这里涉及到 三维矩阵,可以一层一层打印出来去分析,例如k=0 的这一层,k = 1的这一层,但一起把三维带数据的图画出来其实不太好画。
|
||||
|
||||
## 代码如下
|
||||
|
||||
以上分析完毕,最后代码如下:
|
||||
|
||||
|
||||
```CPP
|
||||
@ -300,42 +337,43 @@ int main() {
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
## 空间优化
|
||||
|
||||
这里 我们可以做一下 空间上的优化,从滚动数组的角度来看,我们定义一个 grid[n + 1][ n + 1][2] 这么大的数组就可以,因为k 只是依赖于 k-1的状态,并不需要记录k-2,k-3,k-4 等等这些状态。
|
||||
|
||||
那么我们只需要记录 grid[i][j][1] 和 grid[i][j][0] 就好,之后就是 grid[i][j][1] 和 grid[i][j][0] 交替滚动。
|
||||
|
||||
在进一步想,如果本层计算(本层计算即k相同,从三维角度来讲) gird[i][j] 用到了 本层中刚计算好的 grid[i][k] 会有什么问题吗?
|
||||
|
||||
如果 本层刚计算好的 grid[i][k] 比上一层 (即k-1层)计算的 grid[i][k] 小,说明确实有 i 到 k 的更短路径,那么基于 更小的 grid[i][k] 去计算 gird[i][j] 没有问题。
|
||||
|
||||
如果 本层刚计算好的 grid[i][k] 比上一层 (即k-1层)计算的 grid[i][k] 大, 这不可能,因为这样也不会做更新 grid[i][k]的操作。
|
||||
|
||||
所以本层计算中,使用了本层计算过的 grid[i][k] 和 grid[k][j] 是没问题的。
|
||||
|
||||
那么就没必要区分,grid[i][k] 和 grid[k][j] 是 属于 k - 1 层的呢,还是 k 层的。
|
||||
|
||||
所以递归公式可以为:
|
||||
|
||||
```CPP
|
||||
grid[i][j] = min(grid[i][j], grid[i][k] + grid[k][j]);
|
||||
```
|
||||
|
||||
基于二维数组的本题代码为:
|
||||
|
||||
|
||||
# 拓展 负权回路
|
||||
|
||||
本题可以有负数,但不能出现负权回路
|
||||
|
||||
---------
|
||||
|
||||
floyd n^3
|
||||
|
||||
同样多源汇最短路算法 Floyd 也是基于动态规划
|
||||
|
||||
Floyd 算法可以用来解决多源最短路径问题,它会计算图中每两个点之间的最短路径。
|
||||
|
||||
Floyd 算法对边权的正负没有限制要求(可处理正负权边的图),且能利用 Floyd 算法可能够对图中负环进行判定
|
||||
|
||||
LeetCode-1334. 阈值距离内邻居最少的城市
|
||||
|
||||
https://leetcode.cn/problems/find-the-city-with-the-smallest-number-of-neighbors-at-a-threshold-distance/description/
|
||||
|
||||
-----------
|
||||
|
||||
|
||||
```CPP
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m, p1, p2, val;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<vector<int>> grid(n, vector<int>(n, 10005)); // 因为边的最大距离是10^4
|
||||
vector<vector<int>> grid(n + 1, vector<int>(n + 1, 10005)); // 因为边的最大距离是10^4
|
||||
|
||||
for(int i = 0; i < m; i++){
|
||||
cin >> p1 >> p2 >> val;
|
||||
@ -344,10 +382,10 @@ int main() {
|
||||
|
||||
}
|
||||
// 开始 floyd
|
||||
for (int p = 0; p < n; p++) {
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < n; j++) {
|
||||
grid[i][j] = min(grid[i][j], grid[i][p] + grid[p][j]);
|
||||
for (int k = 1; k <= n; k++) {
|
||||
for (int i = 1; i <= n; i++) {
|
||||
for (int j = 1; j <= n; j++) {
|
||||
grid[i][j] = min(grid[i][j], grid[i][k] + grid[k][j]);
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -355,13 +393,31 @@ int main() {
|
||||
int z, start, end;
|
||||
cin >> z;
|
||||
while (z--) {
|
||||
cin >> start >> end;
|
||||
cin >> start >> end;
|
||||
if (grid[start][end] == 10005) cout << -1 << endl;
|
||||
else cout << grid[start][end] << endl;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
* 时间复杂度: O(n^3)
|
||||
* 空间复杂度:O(n^2)
|
||||
|
||||
## 总结
|
||||
|
||||
本期如果上来只用二维数组来讲的话,其实更容易,但遍历顺序那里用二维数组其实是讲不清楚的,所以我直接用三维数组来讲,目的是将遍历顺序这里讲清楚。
|
||||
|
||||
理解了遍历顺序才是floyd算法最精髓的地方。
|
||||
|
||||
|
||||
floyd算法的时间复杂度相对较高,适合 稠密图且源点较多的情况。
|
||||
|
||||
如果是稀疏图,floyd是从节点的角度去计算了,例如 图中节点数量是 1000,就一条边,那 floyd的时间复杂度依然是 O(n^3) 。
|
||||
|
||||
如果 源点少,其实可以 多次dijsktra 求源点到终点。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
471
problems/kamacoder/0098.所有可达路径.md
Normal file
471
problems/kamacoder/0098.所有可达路径.md
Normal file
@ -0,0 +1,471 @@
|
||||
|
||||
# 98. 所有可达路径
|
||||
|
||||
[卡码网题目链接(ACM模式)](https://kamacoder.com/problempage.php?pid=1170)
|
||||
|
||||
【题目描述】
|
||||
|
||||
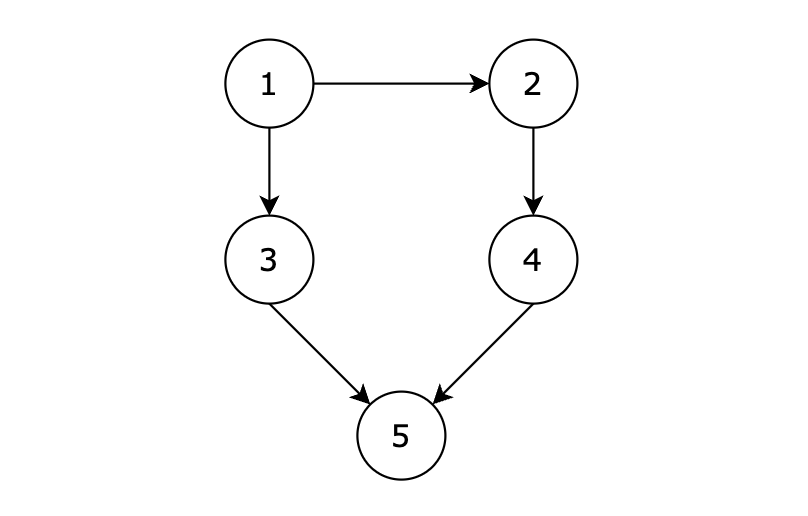
给定一个有 n 个节点的有向无环图,节点编号从 1 到 n。请编写一个函数,找出并返回所有从节点 1 到节点 n 的路径。每条路径应以节点编号的列表形式表示。
|
||||
|
||||
【输入描述】
|
||||
|
||||
第一行包含两个整数 N,M,表示图中拥有 N 个节点,M 条边
|
||||
|
||||
后续 M 行,每行包含两个整数 s 和 t,表示图中的 s 节点与 t 节点中有一条路径
|
||||
|
||||
【输出描述】
|
||||
|
||||
输出所有的可达路径,路径中所有节点的后面跟一个空格,每条路径独占一行,存在多条路径,路径输出的顺序可任意。
|
||||
|
||||
如果不存在任何一条路径,则输出 -1。
|
||||
|
||||
【输入示例】
|
||||
|
||||
```
|
||||
5 5
|
||||
1 3
|
||||
3 5
|
||||
1 2
|
||||
2 4
|
||||
4 5
|
||||
```
|
||||
|
||||
【输出示例】
|
||||
|
||||
```
|
||||
1 3 5
|
||||
1 2 4 5
|
||||
```
|
||||
|
||||
提示信息
|
||||
|
||||
|
||||
|
||||
用例解释:
|
||||
|
||||
有五个节点,其中的从 1 到达 5 的路径有两个,分别是 1 -> 3 -> 5 和 1 -> 2 -> 4 -> 5。
|
||||
|
||||
因为拥有多条路径,所以输出结果为:
|
||||
|
||||
```
|
||||
1 3 5
|
||||
1 2 4 5
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
1 2 4 5
|
||||
1 3 5
|
||||
```
|
||||
|
||||
都算正确。
|
||||
|
||||
数据范围:
|
||||
|
||||
* 图中不存在自环
|
||||
* 图中不存在平行边
|
||||
* 1 <= N <= 100
|
||||
* 1 <= M <= 500
|
||||
|
||||
|
||||
## 插曲
|
||||
|
||||
这道题目是深度优先搜索,比较好的入门题。
|
||||
|
||||
如果对深度优先搜索还不够了解,可以先看这里:[深度优先搜索的理论基础](https://programmercarl.com/图论深搜理论基础.html)
|
||||
|
||||
我依然总结了深搜三部曲,如果按照代码随想录刷题的录友,应该刷过 二叉树的递归三部曲,回溯三部曲。
|
||||
|
||||
**大家可能有疑惑,深搜 和 二叉树和回溯算法 有什么区别呢**? 什么时候用深搜 什么时候用回溯?
|
||||
|
||||
我在讲解[二叉树理论基础](https://programmercarl.com/二叉树理论基础.html)的时候,提到过,**二叉树的前中后序遍历其实就是深搜在二叉树这种数据结构上的应用**。
|
||||
|
||||
那么回溯算法呢,**其实 回溯算法就是 深搜,只不过 我们给他一个更细分的定义,叫做回溯算法**。
|
||||
|
||||
那有的录友可能说:那我以后称回溯算法为深搜,是不是没毛病?
|
||||
|
||||
理论上来说,没毛病,但 就像是 二叉树 你不叫它二叉树,叫它数据结构,有问题不? 也没问题对吧。
|
||||
|
||||
建议是 有细分的场景,还是称其细分场景的名称。 所以回溯算法可以独立出来,但回溯确实就是深搜。
|
||||
|
||||
## 图的存储
|
||||
|
||||
在[图论理论基础篇]()
|
||||
|
||||
|
||||
|
||||
## 深度优先搜索
|
||||
|
||||
接下来我们使用深搜三部曲来分析题目:
|
||||
|
||||
1. 确认递归函数,参数
|
||||
|
||||
首先我们dfs函数一定要存一个图,用来遍历的,还要存一个目前我们遍历的节点,定义为x
|
||||
|
||||
至于 单一路径,和路径集合可以放在全局变量,那么代码是这样的:
|
||||
|
||||
```CPP
|
||||
vector<vector<int>> result; // 收集符合条件的路径
|
||||
vector<int> path; // 0节点到终点的路径
|
||||
// x:目前遍历的节点
|
||||
// graph:存当前的图
|
||||
void dfs (vector<vector<int>>& graph, int x)
|
||||
```
|
||||
|
||||
2. 确认终止条件
|
||||
|
||||
什么时候我们就找到一条路径了?
|
||||
|
||||
当目前遍历的节点 为 最后一个节点的时候 就找到了一条 从出发点到终止点的路径。
|
||||
|
||||
-----------
|
||||
当前遍历的节点,我们定义为x,最后一点节点 就是 graph.size() - 1(因为题目描述是找出所有从节点 0 到节点 n-1 的路径并输出)。
|
||||
|
||||
所以 但 x 等于 graph.size() - 1 的时候就找到一条有效路径。 代码如下:
|
||||
|
||||
-------
|
||||
|
||||
```CPP
|
||||
// 要求从节点 0 到节点 n-1 的路径并输出,所以是 graph.size() - 1
|
||||
if (x == graph.size() - 1) { // 找到符合条件的一条路径
|
||||
result.push_back(path); // 收集有效路径
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
3. 处理目前搜索节点出发的路径
|
||||
|
||||
接下来是走 当前遍历节点x的下一个节点。
|
||||
|
||||
首先是要找到 x节点链接了哪些节点呢? 遍历方式是这样的:
|
||||
|
||||
```c++
|
||||
for (int i = 0; i < graph[x].size(); i++) { // 遍历节点n链接的所有节点
|
||||
```
|
||||
|
||||
接下来就是将 选中的x所连接的节点,加入到 单一路径来。
|
||||
|
||||
```C++
|
||||
path.push_back(graph[x][i]); // 遍历到的节点加入到路径中来
|
||||
|
||||
```
|
||||
|
||||
一些录友可以疑惑这里如果找到x 链接的节点的,例如如果x目前是节点0,那么目前的过程就是这样的:
|
||||
|
||||
|
||||
|
||||
二维数组中,graph[x][i] 都是x链接的节点,当前遍历的节点就是 `graph[x][i]` 。
|
||||
|
||||
进入下一层递归
|
||||
|
||||
```CPP
|
||||
dfs(graph, graph[x][i]); // 进入下一层递归
|
||||
```
|
||||
|
||||
最后就是回溯的过程,撤销本次添加节点的操作。 该过程整体代码:
|
||||
|
||||
```CPP
|
||||
for (int i = 0; i < graph[x].size(); i++) { // 遍历节点n链接的所有节点
|
||||
path.push_back(graph[x][i]); // 遍历到的节点加入到路径中来
|
||||
dfs(graph, graph[x][i]); // 进入下一层递归
|
||||
path.pop_back(); // 回溯,撤销本节点
|
||||
}
|
||||
```
|
||||
|
||||
本题整体代码如下:
|
||||
|
||||
```CPP
|
||||
class Solution {
|
||||
private:
|
||||
vector<vector<int>> result; // 收集符合条件的路径
|
||||
vector<int> path; // 0节点到终点的路径
|
||||
// x:目前遍历的节点
|
||||
// graph:存当前的图
|
||||
void dfs (vector<vector<int>>& graph, int x) {
|
||||
// 要求从节点 0 到节点 n-1 的路径并输出,所以是 graph.size() - 1
|
||||
if (x == graph.size() - 1) { // 找到符合条件的一条路径
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i = 0; i < graph[x].size(); i++) { // 遍历节点n链接的所有节点
|
||||
path.push_back(graph[x][i]); // 遍历到的节点加入到路径中来
|
||||
dfs(graph, graph[x][i]); // 进入下一层递归
|
||||
path.pop_back(); // 回溯,撤销本节点
|
||||
}
|
||||
}
|
||||
public:
|
||||
vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) {
|
||||
path.push_back(0); // 无论什么路径已经是从0节点出发
|
||||
dfs(graph, 0); // 开始遍历
|
||||
return result;
|
||||
}
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
本题是比较基础的深度优先搜索模板题,这种有向图路径问题,最合适使用深搜,当然本题也可以使用广搜,但广搜相对来说就麻烦了一些,需要记录一下路径。
|
||||
|
||||
而深搜和广搜都适合解决颜色类的问题,例如岛屿系列,其实都是 遍历+标记,所以使用哪种遍历都是可以的。
|
||||
|
||||
至于广搜理论基础,我们在下一篇在好好讲解,敬请期待!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
### Java
|
||||
|
||||
```Java
|
||||
// 深度优先遍历
|
||||
class Solution {
|
||||
List<List<Integer>> ans; // 用来存放满足条件的路径
|
||||
List<Integer> cnt; // 用来保存 dfs 过程中的节点值
|
||||
|
||||
public void dfs(int[][] graph, int node) {
|
||||
if (node == graph.length - 1) { // 如果当前节点是 n - 1,那么就保存这条路径
|
||||
ans.add(new ArrayList<>(cnt));
|
||||
return;
|
||||
}
|
||||
for (int index = 0; index < graph[node].length; index++) {
|
||||
int nextNode = graph[node][index];
|
||||
cnt.add(nextNode);
|
||||
dfs(graph, nextNode);
|
||||
cnt.remove(cnt.size() - 1); // 回溯
|
||||
}
|
||||
}
|
||||
|
||||
public List<List<Integer>> allPathsSourceTarget(int[][] graph) {
|
||||
ans = new ArrayList<>();
|
||||
cnt = new ArrayList<>();
|
||||
cnt.add(0); // 注意,0 号节点要加入 cnt 数组中
|
||||
dfs(graph, 0);
|
||||
return ans;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Python
|
||||
|
||||
```python
|
||||
class Solution:
|
||||
def __init__(self):
|
||||
self.result = []
|
||||
self.path = [0]
|
||||
|
||||
def allPathsSourceTarget(self, graph: List[List[int]]) -> List[List[int]]:
|
||||
if not graph: return []
|
||||
|
||||
self.dfs(graph, 0)
|
||||
return self.result
|
||||
|
||||
def dfs(self, graph, root: int):
|
||||
if root == len(graph) - 1: # 成功找到一条路径时
|
||||
# ***Python的list是mutable类型***
|
||||
# ***回溯中必须使用Deep Copy***
|
||||
self.result.append(self.path[:])
|
||||
return
|
||||
|
||||
for node in graph[root]: # 遍历节点n的所有后序节点
|
||||
self.path.append(node)
|
||||
self.dfs(graph, node)
|
||||
self.path.pop() # 回溯
|
||||
```
|
||||
|
||||
|
||||
### JavaScript
|
||||
```javascript
|
||||
var allPathsSourceTarget = function(graph) {
|
||||
let res=[],path=[]
|
||||
|
||||
function dfs(graph,start){
|
||||
if(start===graph.length-1){
|
||||
res.push([...path])
|
||||
return;
|
||||
}
|
||||
for(let i=0;i<graph[start].length;i++){
|
||||
path.push(graph[start][i])
|
||||
dfs(graph,graph[start][i])
|
||||
path.pop()
|
||||
}
|
||||
}
|
||||
path.push(0)
|
||||
dfs(graph,0)
|
||||
return res
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
### Go
|
||||
|
||||
```go
|
||||
func allPathsSourceTarget(graph [][]int) [][]int {
|
||||
result := make([][]int, 0)
|
||||
|
||||
var dfs func(path []int, step int)
|
||||
dfs = func(path []int, step int){
|
||||
// 从0遍历到length-1
|
||||
if step == len(graph) - 1{
|
||||
tmp := make([]int, len(path))
|
||||
copy(tmp, path)
|
||||
result = append(result, tmp)
|
||||
return
|
||||
}
|
||||
|
||||
for i := 0; i < len(graph[step]); i++{
|
||||
next := append(path, graph[step][i])
|
||||
dfs(next, graph[step][i])
|
||||
}
|
||||
}
|
||||
// 从0开始,开始push 0进去
|
||||
dfs([]int{0}, 0)
|
||||
return result
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### Rust
|
||||
|
||||
|
||||
```rust
|
||||
impl Solution {
|
||||
pub fn all_paths_source_target(graph: Vec<Vec<i32>>) -> Vec<Vec<i32>> {
|
||||
let (mut res, mut path) = (vec![], vec![0]);
|
||||
Self::dfs(&graph, &mut path, &mut res, 0);
|
||||
res
|
||||
}
|
||||
|
||||
pub fn dfs(graph: &Vec<Vec<i32>>, path: &mut Vec<i32>, res: &mut Vec<Vec<i32>>, node: usize) {
|
||||
if node == graph.len() - 1 {
|
||||
res.push(path.clone());
|
||||
return;
|
||||
}
|
||||
for &v in &graph[node] {
|
||||
path.push(v);
|
||||
Self::dfs(graph, path, res, v as usize);
|
||||
path.pop();
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
邻接矩阵
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
using namespace std;
|
||||
vector<vector<int>> result; // 收集符合条件的路径
|
||||
vector<int> path; // 1节点到终点的路径
|
||||
|
||||
void dfs (const vector<vector<int>>& graph, int x, int n) {
|
||||
|
||||
// 要求从节点 1 到节点 n 的路径并输出,所以是 graph.size()
|
||||
if (x == n) { // 找到符合条件的一条路径
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
|
||||
for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点
|
||||
if (graph[x][i] == 1) { // 找到 x链接的节点
|
||||
path.push_back(i); // 遍历到的节点加入到路径中来
|
||||
dfs(graph, i, n); // 进入下一层递归
|
||||
path.pop_back(); // 回溯,撤销本节点
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
|
||||
int n, m, s, t;
|
||||
|
||||
cin >> n >> m;
|
||||
|
||||
// 节点编号从1到n,所以申请 n+1 这么大的数组
|
||||
vector<vector<int>> graph(n + 1, vector<int>(n + 1, 0));
|
||||
|
||||
while (m--) {
|
||||
cin >> s >> t;
|
||||
// 使用临近矩阵 表示无线图,1 表示 s 与 t 是相连的
|
||||
graph[s][t] = 1;
|
||||
}
|
||||
path.push_back(1); // 无论什么路径已经是从0节点出发
|
||||
|
||||
dfs(graph, 1, n); // 开始遍历
|
||||
|
||||
// 输出结果
|
||||
if (result.size() == 0) cout << -1 << endl;
|
||||
for (const vector<int> &pa : result) {
|
||||
for (int i = 0; i < pa.size(); i++) {
|
||||
cout << pa[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
邻接表
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <list>
|
||||
using namespace std;
|
||||
|
||||
vector<vector<int>> result; // 收集符合条件的路径
|
||||
vector<int> path; // 1节点到终点的路径
|
||||
|
||||
void dfs (const vector<list<int>>& graph, int x, int n) {
|
||||
|
||||
// 要求从节点 1 到节点 n 的路径并输出,所以是 graph.size()
|
||||
if (x == n) { // 找到符合条件的一条路径
|
||||
result.push_back(path);
|
||||
return;
|
||||
}
|
||||
for (int i : graph[x]) { // 找到 x链接的节点
|
||||
path.push_back(i); // 遍历到的节点加入到路径中来
|
||||
dfs(graph, i, n); // 进入下一层递归
|
||||
path.pop_back(); // 回溯,撤销本节点
|
||||
}
|
||||
}
|
||||
|
||||
int main() {
|
||||
|
||||
|
||||
int n, m, s, t;
|
||||
|
||||
cin >> n >> m;
|
||||
|
||||
// 节点编号从1到n,所以申请 n+1 这么大的数组
|
||||
vector<list<int>> graph(n + 1); // 邻接表
|
||||
while (m--) {
|
||||
cin >> s >> t;
|
||||
// 使用邻接表 ,表示 s -> t 是相连的
|
||||
graph[s].push_back(t);
|
||||
|
||||
}
|
||||
|
||||
path.push_back(1); // 无论什么路径已经是从0节点出发
|
||||
|
||||
dfs(graph, 1, n); // 开始遍历
|
||||
|
||||
//输出结果
|
||||
if (result.size() == 0) cout << -1 << endl;
|
||||
for (const vector<int> &pa : result) {
|
||||
for (int i = 0; i < pa.size(); i++) {
|
||||
cout << pa[i] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
467
problems/kamacoder/图论并查集理论基础.md
Normal file
467
problems/kamacoder/图论并查集理论基础.md
Normal file
@ -0,0 +1,467 @@
|
||||
<p align="center">
|
||||
<a href="https://www.programmercarl.com/xunlian/xunlianying.html" target="_blank">
|
||||
<img src="../pics/训练营.png" width="1000"/>
|
||||
</a>
|
||||
<p align="center"><strong><a href="./qita/join.md">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们受益!</strong></p>
|
||||
|
||||
# 并查集理论基础
|
||||
|
||||
接下来我们来讲一下并查集,首先当然是并查集理论基础。
|
||||
|
||||
## 背景
|
||||
|
||||
首先要知道并查集可以解决什么问题呢?
|
||||
|
||||
并查集常用来解决连通性问题。
|
||||
|
||||
大白话就是当我们需要判断两个元素是否在同一个集合里的时候,我们就要想到用并查集。
|
||||
|
||||
并查集主要有两个功能:
|
||||
|
||||
* 将两个元素添加到一个集合中。
|
||||
* 判断两个元素在不在同一个集合
|
||||
|
||||
接下来围绕并查集的这两个功能来展开讲解。
|
||||
|
||||
## 原理讲解
|
||||
|
||||
从代码层面,我们如何将两个元素添加到同一个集合中呢。
|
||||
|
||||
此时有录友会想到:可以把他放到同一个数组里或者set 或者 map 中,这样就表述两个元素在同一个集合。
|
||||
|
||||
那么问题来了,对这些元素分门别类,可不止一个集合,可能是很多集合,成百上千,那么要定义这么多个数组吗?
|
||||
|
||||
有录友想,那可以定义一个二维数组。
|
||||
|
||||
但如果我们要判断两个元素是否在同一个集合里的时候 我们又能怎么办? 只能把而二维数组都遍历一遍。
|
||||
|
||||
而且每当想添加一个元素到某集合的时候,依然需要把把二维数组组都遍历一遍,才知道要放在哪个集合里。
|
||||
|
||||
这仅仅是一个粗略的思路,如果沿着这个思路去实现代码,非常复杂,因为管理集合还需要很多逻辑。
|
||||
|
||||
那么我们来换一个思路来看看。
|
||||
|
||||
我们将三个元素A,B,C (分别是数字)放在同一个集合,其实就是将三个元素连通在一起,如何连通呢。
|
||||
|
||||
只需要用一个一维数组来表示,即:father[A] = B,father[B] = C 这样就表述 A 与 B 与 C连通了(有向连通图)。
|
||||
|
||||
代码如下:
|
||||
|
||||
``` CPP
|
||||
// 将v,u 这条边加入并查集
|
||||
void join(int u, int v) {
|
||||
u = find(u); // 寻找u的根
|
||||
v = find(v); // 寻找v的根
|
||||
if (u == v) return; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
|
||||
father[v] = u;
|
||||
}
|
||||
```
|
||||
|
||||
可能有录友想,这样我可以知道 A 连通 B,因为 A 是索引下标,根据 father[A]的数值就知道 A 连通 B。那怎么知道 B 连通 A呢?
|
||||
|
||||
我们的目的是判断这三个元素是否在同一个集合里,知道 A 连通 B 就已经足够了。
|
||||
|
||||
这里要讲到寻根思路,只要 A ,B,C 在同一个根下就是同一个集合。
|
||||
|
||||
给出A元素,就可以通过 father[A] = B,father[B] = C,找到根为 C。
|
||||
|
||||
给出B元素,就可以通过 father[B] = C,找到根也为为 C,说明 A 和 B 是在同一个集合里。
|
||||
大家会想第一段代码里find函数是如何实现的呢?其实就是通过数组下标找到数组元素,一层一层寻根过程,代码如下:
|
||||
|
||||
```CPP
|
||||
// 并查集里寻根的过程
|
||||
int find(int u) {
|
||||
if (u == father[u]) return u; // 如果根就是自己,直接返回
|
||||
else return find(father[u]); // 如果根不是自己,就根据数组下标一层一层向下找
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
如何表示 C 也在同一个元素里呢? 我们需要 father[C] = C,即C的根也为C,这样就方便表示 A,B,C 都在同一个集合里了。
|
||||
|
||||
所以father数组初始化的时候要 father[i] = i,默认自己指向自己。
|
||||
|
||||
代码如下:
|
||||
|
||||
```CPP
|
||||
// 并查集初始化
|
||||
void init() {
|
||||
for (int i = 0; i < n; ++i) {
|
||||
father[i] = i;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
最后我们如何判断两个元素是否在同一个集合里,如果通过 find函数 找到 两个元素属于同一个根的话,那么这两个元素就是同一个集合,代码如下:
|
||||
|
||||
|
||||
```CPP
|
||||
// 判断 u 和 v是否找到同一个根
|
||||
bool isSame(int u, int v) {
|
||||
u = find(u);
|
||||
v = find(v);
|
||||
return u == v;
|
||||
}
|
||||
```
|
||||
|
||||
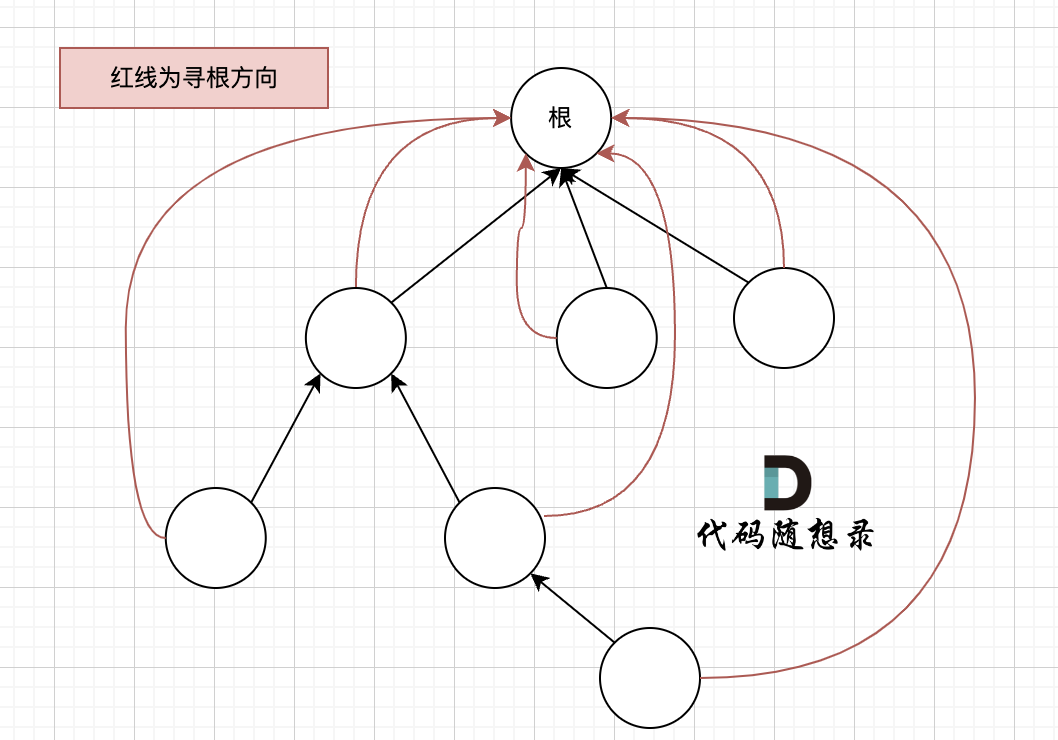
## 路径压缩
|
||||
|
||||
在实现 find 函数的过程中,我们知道,通过递归的方式,不断获取father数组下标对应的数值,最终找到这个集合的根。
|
||||
|
||||
搜索过程像是一个多叉树中从叶子到根节点的过程,如图:
|
||||
|
||||
|
||||
|
||||
如果这棵多叉树高度很深的话,每次find函数 去寻找根的过程就要递归很多次。
|
||||
|
||||
我们的目的只需要知道这些节点在同一个根下就可以,所以对这棵多叉树的构造只需要这样就可以了,如图:
|
||||
|
||||
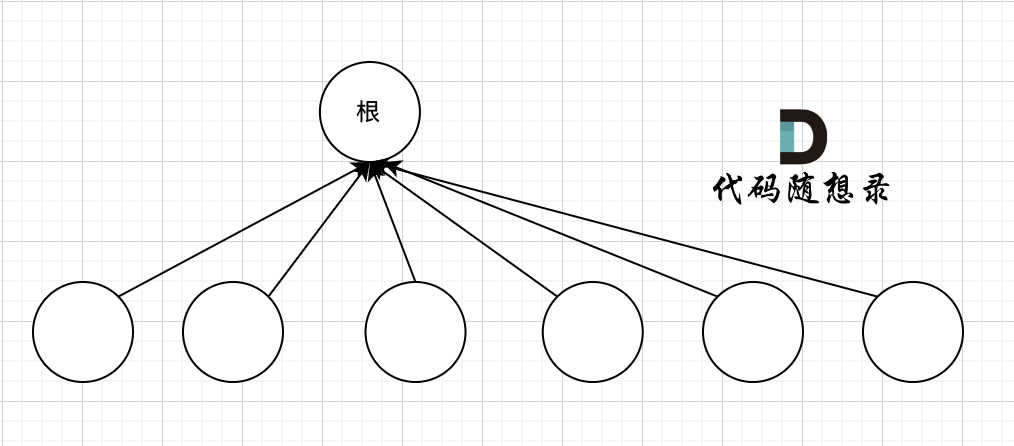
|
||||
|
||||
除了根节点其他所有节点都挂载根节点下,这样我们在寻根的时候就很快,只需要一步,
|
||||
|
||||
如果我们想达到这样的效果,就需要 **路径压缩**,将非根节点的所有节点直接指向根节点。
|
||||
那么在代码层面如何实现呢?
|
||||
|
||||
我们只需要在递归的过程中,让 father[u] 接住 递归函数 find(father[u]) 的返回结果。
|
||||
|
||||
因为 find 函数向上寻找根节点,father[u] 表述 u 的父节点,那么让 father[u] 直接获取 find函数 返回的根节点,这样就让节点 u 的父节点 变成根节点。
|
||||
|
||||
代码如下,注意看注释,路径压缩就一行代码:
|
||||
|
||||
```CPP
|
||||
// 并查集里寻根的过程
|
||||
int find(int u) {
|
||||
if (u == father[u]) return u;
|
||||
else return father[u] = find(father[u]); // 路径压缩
|
||||
}
|
||||
```
|
||||
|
||||
以上代码在C++中,可以用三元表达式来精简一下,代码如下:
|
||||
|
||||
```CPP
|
||||
int find(int u) {
|
||||
return u == father[u] ? u : father[u] = find(father[u]);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
相信不少录友在学习并查集的时候,对上面这三行代码实现的 find函数 很熟悉,但理解上却不够深入,仅仅知道这行代码很好用,不知道这里藏着路径压缩的过程。
|
||||
|
||||
所以对于算法初学者来说,直接看精简代码学习是不太友好的,往往忽略了很多细节。
|
||||
|
||||
## 代码模板
|
||||
|
||||
那么此时并查集的模板就出来了, 整体模板C++代码如下:
|
||||
|
||||
```CPP
|
||||
int n = 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好
|
||||
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构
|
||||
|
||||
// 并查集初始化
|
||||
void init() {
|
||||
for (int i = 0; i < n; ++i) {
|
||||
father[i] = i;
|
||||
}
|
||||
}
|
||||
// 并查集里寻根的过程
|
||||
int find(int u) {
|
||||
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
|
||||
}
|
||||
|
||||
// 判断 u 和 v是否找到同一个根
|
||||
bool isSame(int u, int v) {
|
||||
u = find(u);
|
||||
v = find(v);
|
||||
return u == v;
|
||||
}
|
||||
|
||||
// 将v->u 这条边加入并查集
|
||||
void join(int u, int v) {
|
||||
u = find(u); // 寻找u的根
|
||||
v = find(v); // 寻找v的根
|
||||
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
|
||||
father[v] = u;
|
||||
}
|
||||
```
|
||||
通过模板,我们可以知道,并查集主要有三个功能。
|
||||
|
||||
1. 寻找根节点,函数:find(int u),也就是判断这个节点的祖先节点是哪个
|
||||
2. 将两个节点接入到同一个集合,函数:join(int u, int v),将两个节点连在同一个根节点上
|
||||
3. 判断两个节点是否在同一个集合,函数:isSame(int u, int v),就是判断两个节点是不是同一个根节点
|
||||
|
||||
## 常见误区
|
||||
|
||||
这里估计有录友会想,模板中的 join 函数里的这段代码:
|
||||
|
||||
```CPP
|
||||
u = find(u); // 寻找u的根
|
||||
v = find(v); // 寻找v的根
|
||||
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
|
||||
|
||||
```
|
||||
|
||||
与 isSame 函数的实现是不是重复了? 如果抽象一下呢,代码如下:
|
||||
|
||||
```CPP
|
||||
// 判断 u 和 v是否找到同一个根
|
||||
bool isSame(int u, int v) {
|
||||
u = find(u);
|
||||
v = find(v);
|
||||
return u == v;
|
||||
}
|
||||
|
||||
// 将v->u 这条边加入并查集
|
||||
void join(int u, int v) {
|
||||
if (isSame) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
|
||||
father[v] = u;
|
||||
}
|
||||
```
|
||||
|
||||
这样写可以吗? 好像看出去没问题,而且代码更精简了。
|
||||
|
||||
**其实这么写是有问题的**,在join函数中 我们需要寻找 u 和 v 的根,然后再进行连线在一起,而不是直接 用 u 和 v 连线在一起。
|
||||
|
||||
举一个例子:
|
||||
|
||||
```
|
||||
join(1, 2);
|
||||
join(3, 2);
|
||||
```
|
||||
|
||||
此时构成的图是这样的:
|
||||
|
||||
|
||||
|
||||
此时问 1,3是否在同一个集合,我们调用 `join(1, 2); join(3, 2);` 很明显本意要表示 1,3是在同一个集合。
|
||||
|
||||
但我们来看一下代码逻辑,当我们调用 `isSame(1, 3)`的时候,find(1) 返回的是1,find(3)返回的是3。 `return 1 == 3` 返回的是false,代码告诉我们 1 和 3 不在同一个集合,这明显不符合我们的预期,所以问题出在哪里?
|
||||
|
||||
问题出在我们精简的代码上,即 join 函数 一定要先 通过find函数寻根再进行关联。
|
||||
|
||||
如果find函数是这么实现,再来看一下逻辑过程。
|
||||
|
||||
```CPP
|
||||
void join(int u, int v) {
|
||||
u = find(u); // 寻找u的根
|
||||
v = find(v); // 寻找v的根
|
||||
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
|
||||
father[v] = u;
|
||||
}
|
||||
```
|
||||
|
||||
分别将 这两对元素加入集合。
|
||||
|
||||
```CPP
|
||||
join(1, 2);
|
||||
join(3, 2);
|
||||
```
|
||||
|
||||
当执行`join(3, 2)`的时候,会先通过find函数寻找 3的根为3,2的根为1 (第一个`join(1, 2)`,将2的根设置为1),所以最后是将1 指向 3。
|
||||
|
||||
构成的图是这样的:
|
||||
|
||||
|
||||
|
||||
因为在join函数里,我们有find函数进行寻根的过程,这样就保证元素 1,2,3在这个有向图里是强连通的。
|
||||
|
||||
此时我们在调用 `isSame(1, 3)`的时候,find(1) 返回的是3,find(3) 返回的也是3,`return 3 == 3` 返回的是true,即告诉我们 元素 1 和 元素3 是 在同一个集合里的。
|
||||
|
||||
|
||||
|
||||
|
||||
## 模拟过程
|
||||
|
||||
(**凸显途径合并的过程,每一个join都要画图**)
|
||||
|
||||
不少录友在接触并查集模板之后,用起来很娴熟,因为模板确实相对固定,但是对并查集内部数据组织方式以及如何判断是否是同一个集合的原理很模糊。
|
||||
|
||||
通过以上讲解之后,我在带大家一步一步去画一下,并查集内部数据连接方式。
|
||||
|
||||
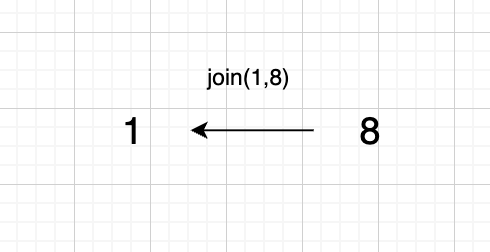
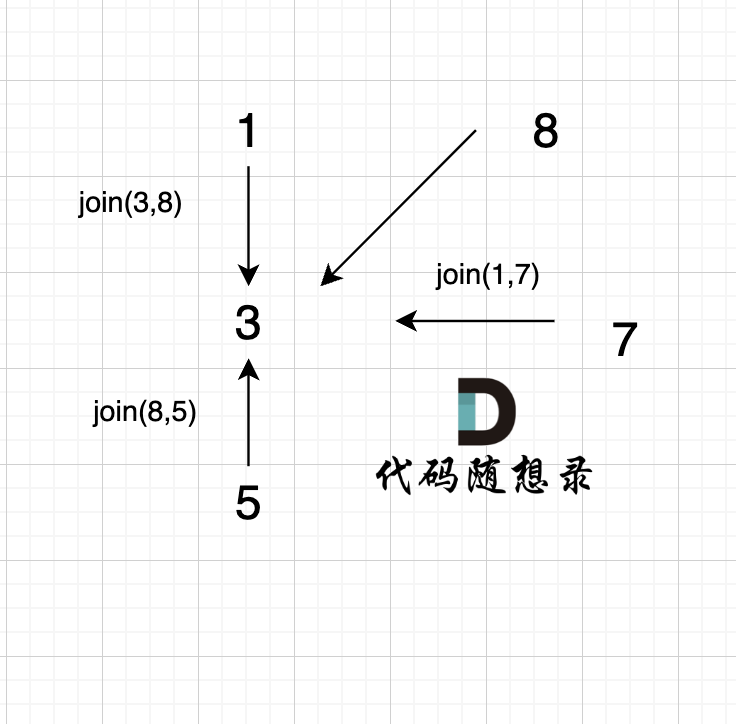
1、`join(1, 8);`
|
||||
|
||||
|
||||
|
||||
|
||||
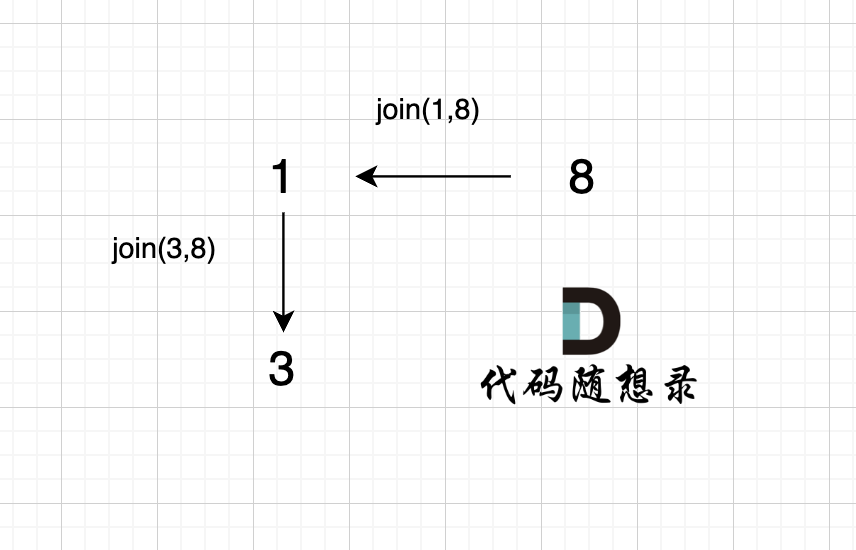
2、`join(3, 8);`
|
||||
|
||||
|
||||
|
||||
有录友可能想,`join(3, 8)` 在图中为什么 将 元素1 连向元素 3 而不是将 元素 8 连向 元素 3 呢?
|
||||
|
||||
这一点 我在 「常见误区」标题下已经详细讲解了,因为在`join(int u, int v)`函数里 要分别对 u 和 v 寻根之后再进行关联。
|
||||
|
||||
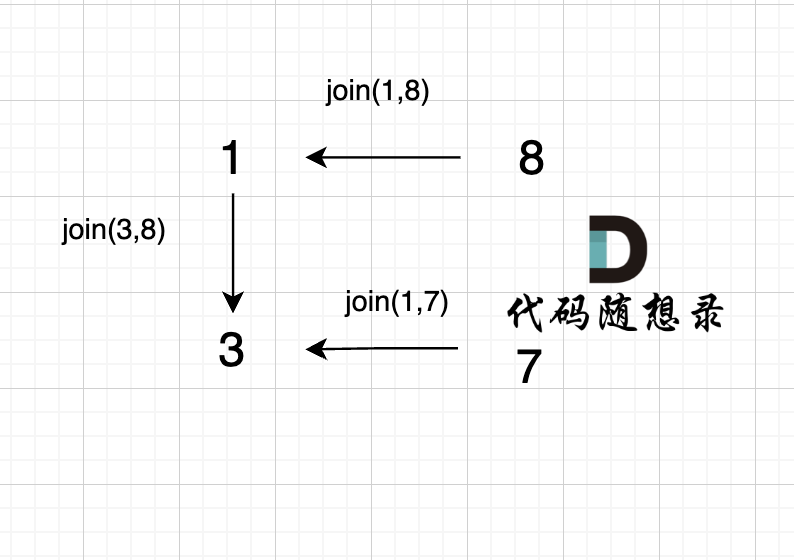
3、`join(1, 7);`
|
||||
|
||||
|
||||
|
||||
|
||||
4、`join(8, 5);`
|
||||
|
||||
|
||||
|
||||
这里8的根是3,那么 5 应该指向 8 的根 3,这里的原因,我们在上面「常见误区」已经讲过了。 但 为什么 图中 8 又直接指向了 3 了呢?
|
||||
|
||||
**因为路经压缩了**
|
||||
|
||||
即如下代码在寻找根的过程中,会有路径压缩,减少 下次查询的路径长度。
|
||||
|
||||
```
|
||||
// 并查集里寻根的过程
|
||||
int find(int u) {
|
||||
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
|
||||
}
|
||||
```
|
||||
|
||||
5、`join(2, 9);`
|
||||
|
||||
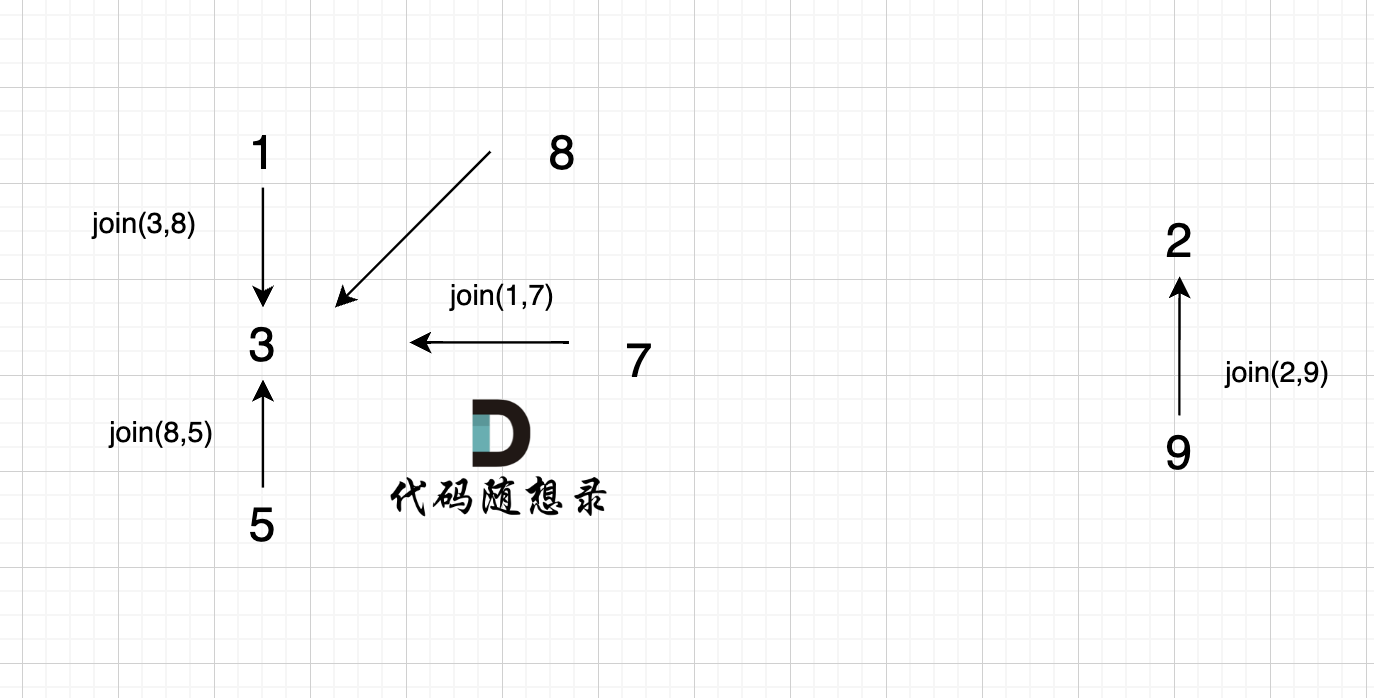
|
||||
|
||||
6、`join(6, 9);`
|
||||
|
||||
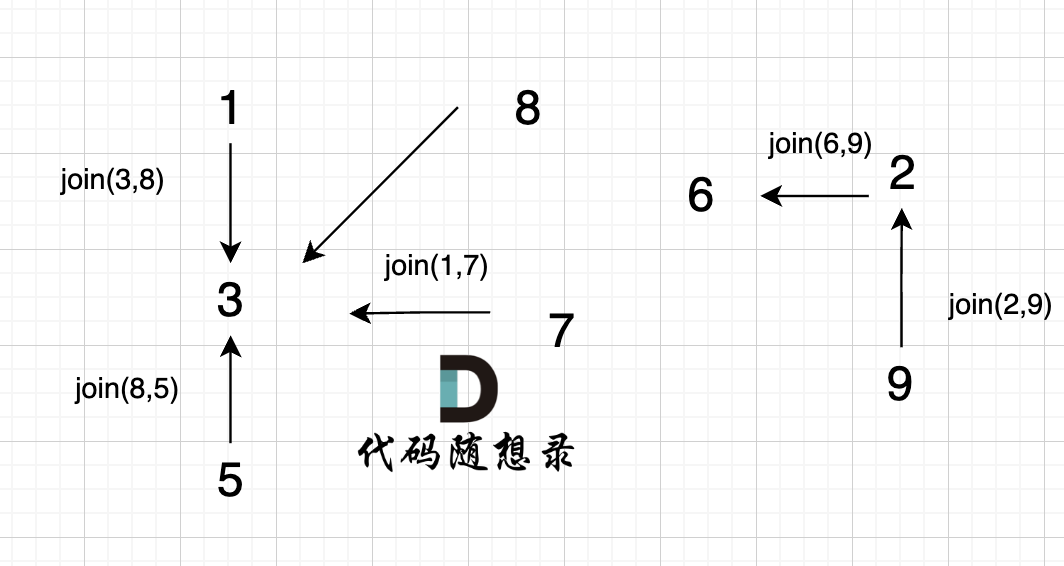
|
||||
|
||||
这里为什么是 2 指向了 6,因为 9的根为 2,所以用2指向6。
|
||||
|
||||
|
||||
|
||||
大家看懂这个有向图后,相信应该知道如下函数的返回值了。
|
||||
|
||||
```CPP
|
||||
cout << isSame(8, 7) << endl;
|
||||
cout << isSame(7, 2) << endl;
|
||||
```
|
||||
|
||||
返回值分别如下,表示,8 和 7 是同一个集合,而 7 和 2 不是同一个集合。
|
||||
|
||||
```
|
||||
true
|
||||
false
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 拓展
|
||||
|
||||
|
||||
在「路径压缩」讲解中,我们知道如何靠压缩路径来缩短查询根节点的时间。
|
||||
|
||||
其实还有另一种方法:按秩(rank)合并。
|
||||
|
||||
rank表示树的高度,即树中结点层次的最大值。
|
||||
|
||||
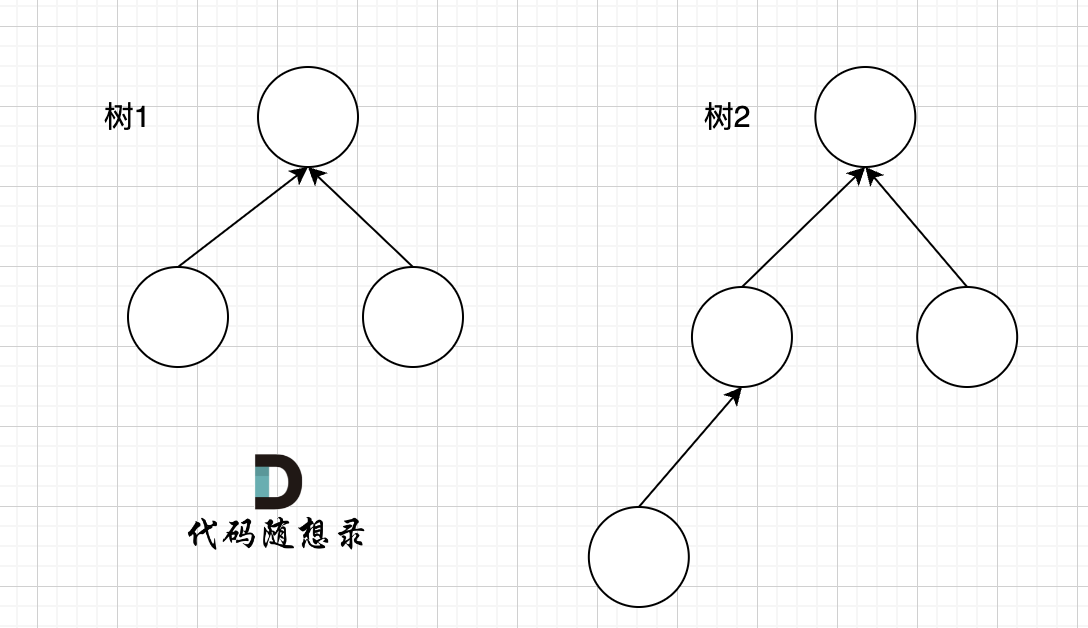
例如两个集合(多叉树)需要合并,如图所示:
|
||||
|
||||
|
||||
|
||||
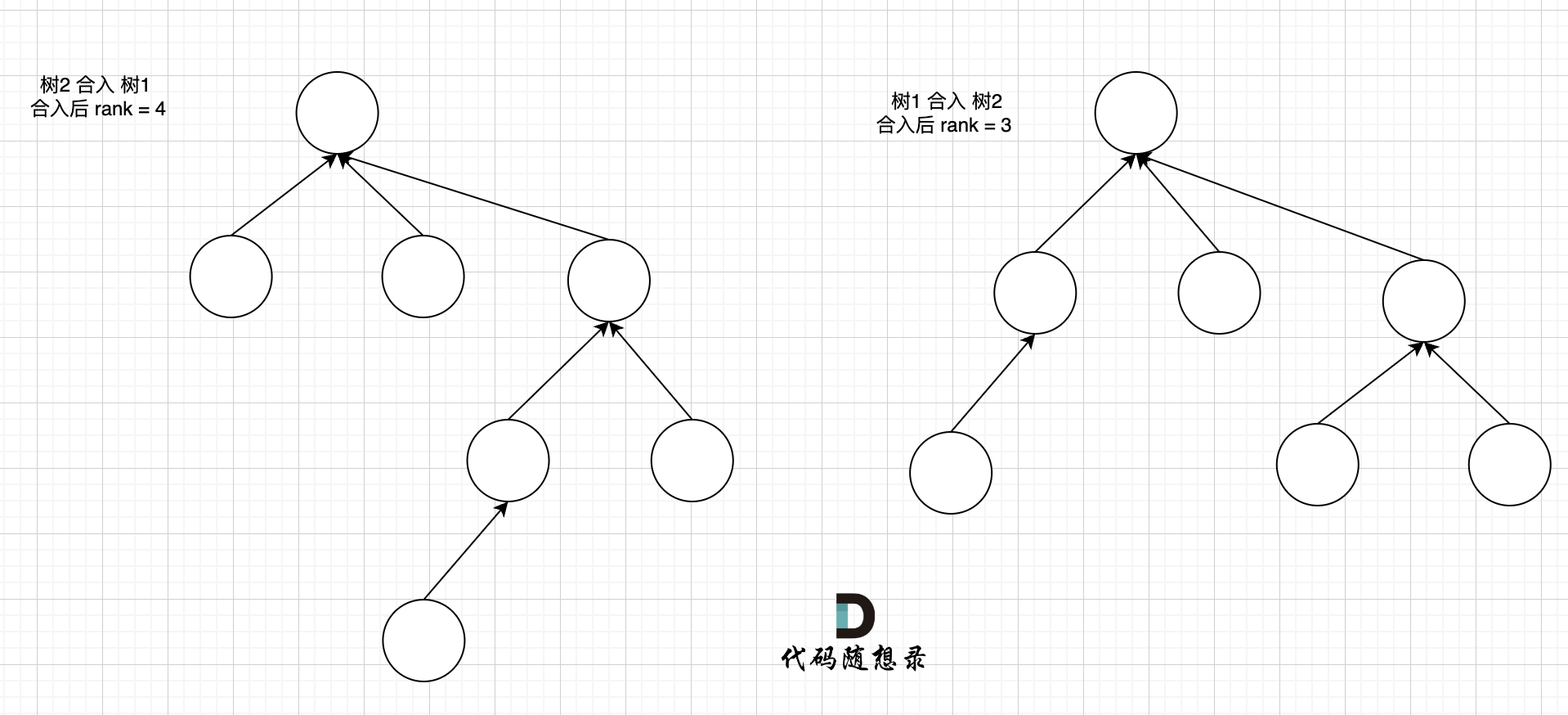
树1 rank 为2,树2 rank 为 3。那么合并两个集合,是 树1 合入 树2,还是 树2 合入 树1呢?
|
||||
|
||||
我们来看两个不同方式合入的效果。
|
||||
|
||||
|
||||
|
||||
这里可以看出,树2 合入 树1 会导致整棵树的高度变的更高,而 树1 合入 树2 整棵树的高度 和 树2 保持一致。
|
||||
|
||||
所以在 join函数中如何合并两棵树呢?
|
||||
|
||||
一定是 rank 小的树合入 到 rank大 的树,这样可以保证最后合成的树rank 最小,降低在树上查询的路径长度。
|
||||
|
||||
按秩合并的代码如下:
|
||||
|
||||
```CPP
|
||||
int n = 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好
|
||||
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构
|
||||
vector<int> rank = vector<int> (n, 1); // 初始每棵树的高度都为1
|
||||
|
||||
// 并查集初始化
|
||||
void init() {
|
||||
for (int i = 0; i < n; ++i) {
|
||||
father[i] = i;
|
||||
rank[i] = 1; // 也可以不写
|
||||
}
|
||||
}
|
||||
// 并查集里寻根的过程
|
||||
int find(int u) {
|
||||
return u == father[u] ? u : find(father[u]);// 注意这里不做路径压缩
|
||||
}
|
||||
|
||||
// 判断 u 和 v是否找到同一个根
|
||||
bool isSame(int u, int v) {
|
||||
u = find(u);
|
||||
v = find(v);
|
||||
return u == v;
|
||||
}
|
||||
|
||||
// 将v->u 这条边加入并查集
|
||||
void join(int u, int v) {
|
||||
u = find(u); // 寻找u的根
|
||||
v = find(v); // 寻找v的根
|
||||
|
||||
if (rank[u] <= rank[v]) father[u] = v; // rank小的树合入到rank大的树
|
||||
else father[v] = u;
|
||||
|
||||
if (rank[u] == rank[v] && u != v) rank[v]++; // 如果两棵树高度相同,则v的高度+1,因为上面 if (rank[u] <= rank[v]) father[u] = v; 注意是 <=
|
||||
}
|
||||
```
|
||||
|
||||
可以注意到在上面的模板代码中,我是没有做路径压缩的,因为一旦做路径压缩,rank记录的高度就不准了,根据rank来判断如何合并就没有意义。
|
||||
|
||||
也可以在 路径压缩的时候,再去实时修生rank的数值,但这样在代码实现上麻烦了不少,关键是收益很小。
|
||||
|
||||
其实我们在优化并查集查询效率的时候,只用路径压缩的思路就够了,不仅代码实现精简,而且效率足够高。
|
||||
|
||||
按秩合并的思路并没有将树形结构尽可能的扁平化,所以在整理效率上是没有路径压缩高的。
|
||||
|
||||
说到这里可能有录友会想,那在路径压缩的代码中,只有查询的过程 即 find 函数的执行过程中会有路径压缩,如果一直没有使用find函数,是不是相当于这棵树就没有路径压缩,导致查询效率依然很低呢?
|
||||
|
||||
大家可以再去回顾使用路径压缩的 并查集模板,在isSame函数 和 join函数中,我们都调用了 find 函数来进行寻根操作。
|
||||
|
||||
也就是说,无论使用并查集模板里哪一个函数(除了init函数),都会有路径压缩的过程,第二次访问相同节点的时候,这个节点就是直连根节点的,即 第一次访问的时候它的路径就被压缩了。
|
||||
|
||||
**所以这里推荐大家直接使用路径压缩的并查集模板就好**,但按秩合并的优化思路我依然给大家讲清楚,有助于更深一步理解并查集的优化过程。
|
||||
|
||||
## 复杂度分析
|
||||
|
||||
|
||||
这里对路径压缩版并查集来做分析。
|
||||
|
||||
空间复杂度: O(n) ,申请一个father数组。
|
||||
|
||||
关于时间复杂度,如果想精确表达出来需要繁琐的数学证明,就不在本篇讲解范围内了,大家感兴趣可以自己去深入研究。
|
||||
|
||||
这里做一个简单的分析思路。
|
||||
|
||||
路径压缩后的并查集时间复杂度在O(logn)与O(1)之间,且随着查询或者合并操作的增加,时间复杂度会越来越趋于O(1)。
|
||||
|
||||
了解到这个程度对于求职面试来说就够了。
|
||||
|
||||
在第一次查询的时候,相当于是n叉树上从叶子节点到根节点的查询过程,时间复杂度是logn,但路径压缩后,后面的查询操作都是O(1),而 join 函数 和 isSame函数 里涉及的查询操作也是一样的过程。
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
本篇我们讲解了并查集的背景、原理、两种优化方式(路径压缩,按秩合并),代码模板,常见误区,以及模拟过程。
|
||||
|
||||
要知道并查集解决什么问题,在什么场景下我们要想到使用并查集。
|
||||
|
||||
|
||||
接下来进一步优化并查集的执行效率,重点介绍了路径压缩的方式,另一种方法:按秩合并,我们在 「拓展」中讲解。
|
||||
|
||||
通过一步一步的原理讲解,最后给出并查集的模板,所有的并查集题目都在这个模板的基础上进行操作或者适当修改。
|
||||
|
||||
但只给出模板还是不够的,针对大家学习并查集的常见误区,详细讲解了模板代码的细节。
|
||||
|
||||
为了让录友们进一步了解并查集的运行过程,我们再通过具体用例模拟一遍代码过程并画出对应的内部数据连接图(有向图)。
|
||||
|
||||
这里也建议大家去模拟一遍才能对并查集理解的更到位。
|
||||
|
||||
如果对模板代码还是有点陌生,不用担心,接下来我会讲解对应LeetCode上的并查集题目,通过一系列题目练习,大家就会感受到这套模板有多么的好用!
|
||||
|
||||
敬请期待 并查集题目精讲系列。
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
163
problems/kamacoder/图论广搜理论基础.md
Normal file
163
problems/kamacoder/图论广搜理论基础.md
Normal file
@ -0,0 +1,163 @@
|
||||
<p align="center">
|
||||
<a href="https://www.programmercarl.com/xunlian/xunlianying.html" target="_blank">
|
||||
<img src="../pics/训练营.png" width="1000"/>
|
||||
</a>
|
||||
<p align="center"><strong><a href="./qita/join.md">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们受益!</strong></p>
|
||||
|
||||
# 广度优先搜索理论基础
|
||||
|
||||
|
||||
在[深度优先搜索](https://programmercarl.com/图论深搜理论基础.html)的讲解中,我们就讲过深度优先搜索和广度优先搜索的区别。
|
||||
|
||||
广搜(bfs)是一圈一圈的搜索过程,和深搜(dfs)是一条路跑到黑然后再回溯。
|
||||
|
||||
## 广搜的使用场景
|
||||
|
||||
广搜的搜索方式就适合于解决两个点之间的最短路径问题。
|
||||
|
||||
因为广搜是从起点出发,以起始点为中心一圈一圈进行搜索,一旦遇到终点,记录之前走过的节点就是一条最短路。
|
||||
|
||||
当然,也有一些问题是广搜 和 深搜都可以解决的,例如岛屿问题,**这类问题的特征就是不涉及具体的遍历方式,只要能把相邻且相同属性的节点标记上就行**。 (我们会在具体题目讲解中详细来说)
|
||||
|
||||
## 广搜的过程
|
||||
|
||||
上面我们提过,BFS是一圈一圈的搜索过程,但具体是怎么一圈一圈来搜呢。
|
||||
|
||||
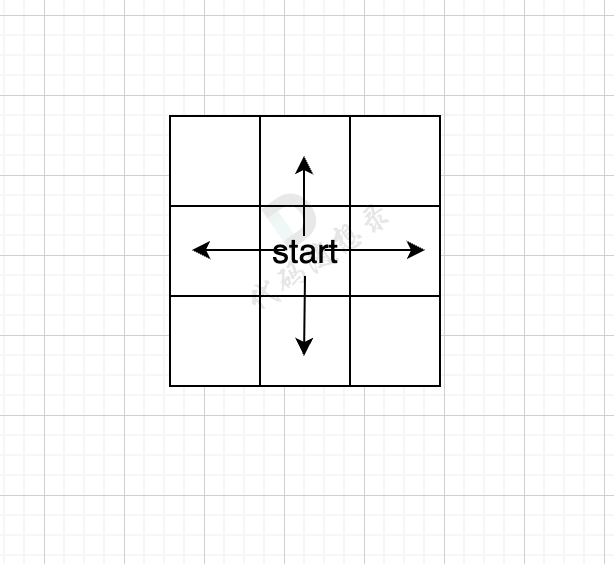
我们用一个方格地图,假如每次搜索的方向为 上下左右(不包含斜上方),那么给出一个start起始位置,那么BFS就是从四个方向走出第一步。
|
||||
|
||||
|
||||
|
||||
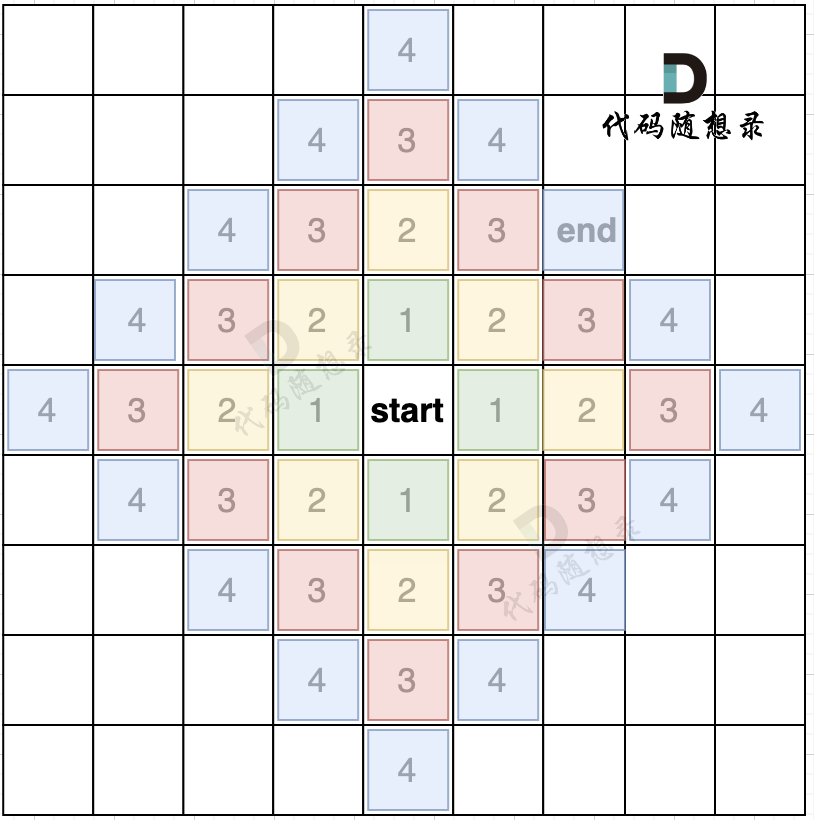
如果加上一个end终止位置,那么使用BFS的搜索过程如图所示:
|
||||
|
||||
|
||||
|
||||
我们从图中可以看出,从start起点开始,是一圈一圈,向外搜索,方格编号1为第一步遍历的节点,方格编号2为第二步遍历的节点,第四步的时候我们找到终止点end。
|
||||
|
||||
正是因为BFS一圈一圈的遍历方式,所以一旦遇到终止点,那么一定是一条最短路径。
|
||||
|
||||
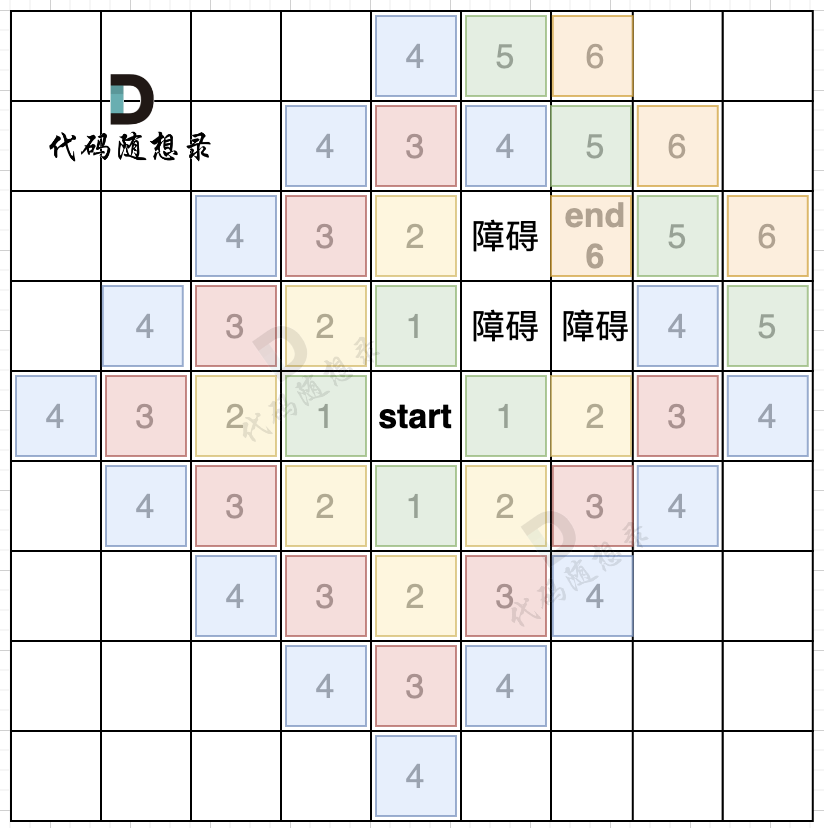
而且地图还可以有障碍,如图所示:
|
||||
|
||||
|
||||
|
||||
在第五步,第六步 我只把关键的节点染色了,其他方向周边没有去染色,大家只要关注关键地方染色的逻辑就可以。
|
||||
|
||||
从图中可以看出,如果添加了障碍,我们是第六步才能走到end终点。
|
||||
|
||||
只要BFS只要搜到终点一定是一条最短路径,大家可以参考上面的图,自己再去模拟一下。
|
||||
|
||||
## 代码框架
|
||||
|
||||
大家应该好奇,这一圈一圈的搜索过程是怎么做到的,是放在什么容器里,才能这样去遍历。
|
||||
|
||||
很多网上的资料都是直接说用队列来实现。
|
||||
|
||||
其实,我们仅仅需要一个容器,能保存我们要遍历过的元素就可以,**那么用队列,还是用栈,甚至用数组,都是可以的**。
|
||||
|
||||
**用队列的话,就是保证每一圈都是一个方向去转,例如统一顺时针或者逆时针**。
|
||||
|
||||
因为队列是先进先出,加入元素和弹出元素的顺序是没有改变的。
|
||||
|
||||
**如果用栈的话,就是第一圈顺时针遍历,第二圈逆时针遍历,第三圈有顺时针遍历**。
|
||||
|
||||
因为栈是先进后出,加入元素和弹出元素的顺序改变了。
|
||||
|
||||
那么广搜需要注意 转圈搜索的顺序吗? 不需要!
|
||||
|
||||
所以用队列,还是用栈都是可以的,但大家都习惯用队列了,**所以下面的讲解用我也用队列来讲,只不过要给大家说清楚,并不是非要用队列,用栈也可以**。
|
||||
|
||||
下面给出广搜代码模板,该模板针对的就是,上面的四方格的地图: (详细注释)
|
||||
|
||||
```CPP
|
||||
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向
|
||||
// grid 是地图,也就是一个二维数组
|
||||
// visited标记访问过的节点,不要重复访问
|
||||
// x,y 表示开始搜索节点的下标
|
||||
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
|
||||
queue<pair<int, int>> que; // 定义队列
|
||||
que.push({x, y}); // 起始节点加入队列
|
||||
visited[x][y] = true; // 只要加入队列,立刻标记为访问过的节点
|
||||
while(!que.empty()) { // 开始遍历队列里的元素
|
||||
pair<int ,int> cur = que.front(); que.pop(); // 从队列取元素
|
||||
int curx = cur.first;
|
||||
int cury = cur.second; // 当前节点坐标
|
||||
for (int i = 0; i < 4; i++) { // 开始想当前节点的四个方向左右上下去遍历
|
||||
int nextx = curx + dir[i][0];
|
||||
int nexty = cury + dir[i][1]; // 获取周边四个方向的坐标
|
||||
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 坐标越界了,直接跳过
|
||||
if (!visited[nextx][nexty]) { // 如果节点没被访问过
|
||||
que.push({nextx, nexty}); // 队列添加该节点为下一轮要遍历的节点
|
||||
visited[nextx][nexty] = true; // 只要加入队列立刻标记,避免重复访问
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
以上模板代码,就是可以直接拿来做 [200.岛屿数量](https://leetcode.cn/problems/number-of-islands/solution/by-carlsun-2-n72a/) 这道题目,唯一区别是 针对地图 grid 中有数字1的地方去做一个遍历。
|
||||
|
||||
即:
|
||||
|
||||
```
|
||||
if (!visited[nextx][nexty]) { // 如果节点没被访问过
|
||||
```
|
||||
|
||||
改为
|
||||
|
||||
```
|
||||
if (!visited[nextx][nexty] && grid[nextx][nexty] == '1') { // 如果节点没被访问过且节点是可遍历的
|
||||
|
||||
```
|
||||
就可以通过 [200.岛屿数量](https://leetcode.cn/problems/number-of-islands/solution/by-carlsun-2-n72a/) 这道题目,大家可以去体验一下。
|
||||
|
||||
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
当然广搜还有很多细节需要注意的地方,后面我会针对广搜的题目还做针对性的讲解,因为在理论篇讲太多细节,可能会让刚学广搜的录友们越看越懵,所以细节方面针对具体题目在做讲解。
|
||||
|
||||
本篇我们重点讲解了广搜的使用场景,广搜的过程以及广搜的代码框架。
|
||||
|
||||
其实在二叉树章节的[层序遍历](https://programmercarl.com/0102.%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E5%B1%82%E5%BA%8F%E9%81%8D%E5%8E%86.html)中,我们也讲过一次广搜,相当于是广搜在二叉树这种数据结构上的应用。
|
||||
|
||||
这次则从图论的角度上再详细讲解一次广度优先遍历。
|
||||
|
||||
相信看完本篇,大家会对广搜有一个基础性的认识,后面再来做对应的题目就会得心应手一些。
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
### Python
|
||||
```python
|
||||
from collections import deque
|
||||
|
||||
dir = [(0, 1), (1, 0), (-1, 0), (0, -1)] # 创建方向元素
|
||||
|
||||
def bfs(grid, visited, x, y):
|
||||
|
||||
queue = deque() # 初始化队列
|
||||
queue.append((x, y)) # 放入第一个元素/起点
|
||||
visited[x][y] = True # 标记为访问过的节点
|
||||
|
||||
while queue: # 遍历队列里的元素
|
||||
|
||||
curx, cury = queue.popleft() # 取出第一个元素
|
||||
|
||||
for dx, dy in dir: # 遍历四个方向
|
||||
|
||||
nextx, nexty = curx + dx, cury + dy
|
||||
|
||||
if nextx < 0 or nextx >= len(grid) or nexty < 0 or nexty >= len(grid[0]): # 越界了,直接跳过
|
||||
continue
|
||||
|
||||
if not visited[nextx][nexty]: # 如果节点没被访问过
|
||||
queue.append((nextx, nexty)) # 加入队列
|
||||
visited[nextx][nexty] = True # 标记为访问过的节点
|
||||
|
||||
```
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
31
problems/kamacoder/图论总结篇.md
Normal file
31
problems/kamacoder/图论总结篇.md
Normal file
@ -0,0 +1,31 @@
|
||||
|
||||
# 图论总结篇
|
||||
|
||||
从深搜广搜 到并查集,从最小生成树到拓扑排序, 最后是最短路算法系列。
|
||||
|
||||
至此算上本篇,一共30篇文章,图论之旅就在此收官了。
|
||||
|
||||
|
||||
## 深搜与广搜
|
||||
|
||||
深搜与广搜是图论里基本的搜索方法,大家需要掌握三点:
|
||||
|
||||
* 搜索方式:深搜是可一个方向搜,不到黄河不回头。 广搜是围绕这起点一圈一圈的去搜。
|
||||
* 代码模板:需要熟练掌握深搜和广搜的基本写法。
|
||||
* 应用场景:图论题目基本上可以即用深搜也可以广搜,无疑是用哪个方便而已
|
||||
|
||||
深搜注意事项
|
||||
|
||||
广搜注意事项
|
||||
|
||||
## 并查集
|
||||
|
||||
## 最小生成树
|
||||
|
||||
## 拓扑排序
|
||||
|
||||
## 最短路算法
|
||||
|
||||
|
||||
|
||||
算法4,只讲解了 Dijkstra,SPFA (Bellman-Ford算法基于队列) 和 拓扑排序,
|
||||
205
problems/kamacoder/图论深搜理论基础.md
Normal file
205
problems/kamacoder/图论深搜理论基础.md
Normal file
@ -0,0 +1,205 @@
|
||||
<p align="center">
|
||||
<a href="https://www.programmercarl.com/xunlian/xunlianying.html" target="_blank">
|
||||
<img src="../pics/训练营.png" width="1000"/>
|
||||
</a>
|
||||
<p align="center"><strong><a href="./qita/join.md">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们受益!</strong></p>
|
||||
|
||||
# 深度优先搜索理论基础
|
||||
|
||||
录友们期待图论内容已久了,为什么鸽了这么久,主要是最近半年开始更新[代码随想录算法公开课](https://www.bilibili.com/video/BV1fA4y1o715/),是开源在B站的算法视频,已经帮助非常多基础不好的录友学习算法。
|
||||
|
||||
录视频其实是非常累的,也要花很多时间,所以图论这边就没抽出时间来。
|
||||
|
||||
后面计划先给大家讲图论里大家特别需要的深搜和广搜。
|
||||
|
||||
以下,开始讲解深度优先搜索理论基础:
|
||||
|
||||
## dfs 与 bfs 区别
|
||||
|
||||
提到深度优先搜索(dfs),就不得不说和广度优先搜索(bfs)有什么区别
|
||||
|
||||
先来了解dfs的过程,很多录友可能对dfs(深度优先搜索),bfs(广度优先搜索)分不清。
|
||||
|
||||
先给大家说一下两者大概的区别:
|
||||
|
||||
* dfs是可一个方向去搜,不到黄河不回头,直到遇到绝境了,搜不下去了,再换方向(换方向的过程就涉及到了回溯)。
|
||||
* bfs是先把本节点所连接的所有节点遍历一遍,走到下一个节点的时候,再把连接节点的所有节点遍历一遍,搜索方向更像是广度,四面八方的搜索过程。
|
||||
|
||||
当然以上讲的是,大体可以这么理解,接下来 我们详细讲解dfs,(bfs在用单独一篇文章详细讲解)
|
||||
|
||||
## dfs 搜索过程
|
||||
|
||||
上面说道dfs是可一个方向搜,不到黄河不回头。 那么我们来举一个例子。
|
||||
|
||||
如图一,是一个无向图,我们要搜索从节点1到节点6的所有路径。
|
||||
|
||||
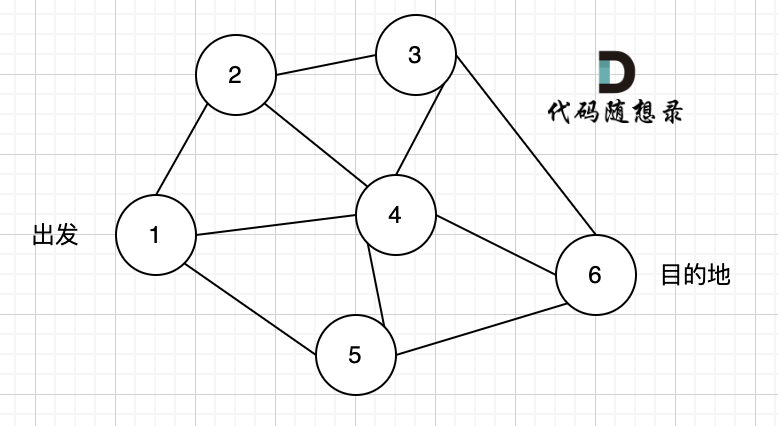
|
||||
|
||||
那么dfs搜索的第一条路径是这样的: (假设第一次延默认方向,就找到了节点6),图二
|
||||
|
||||
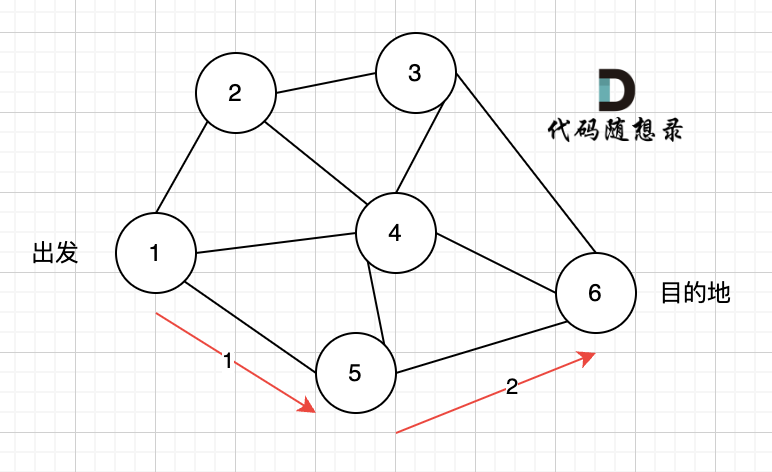
|
||||
|
||||
此时我们找到了节点6,(遇到黄河了,是不是应该回头了),那么应该再去搜索其他方向了。 如图三:
|
||||
|
||||
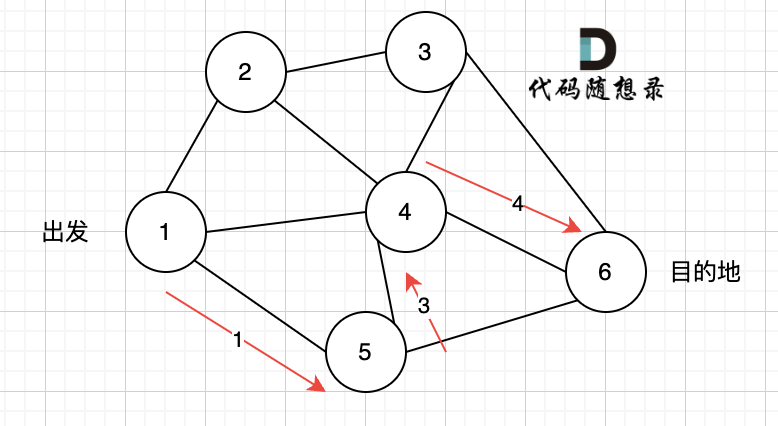
|
||||
|
||||
路径2撤销了,改变了方向,走路径3(红色线), 接着也找到终点6。 那么撤销路径2,改为路径3,在dfs中其实就是回溯的过程(这一点很重要,很多录友不理解dfs代码中回溯是用来干什么的)
|
||||
|
||||
又找到了一条从节点1到节点6的路径,又到黄河了,此时再回头,下图图四中,路径4撤销(回溯的过程),改为路径5。
|
||||
|
||||
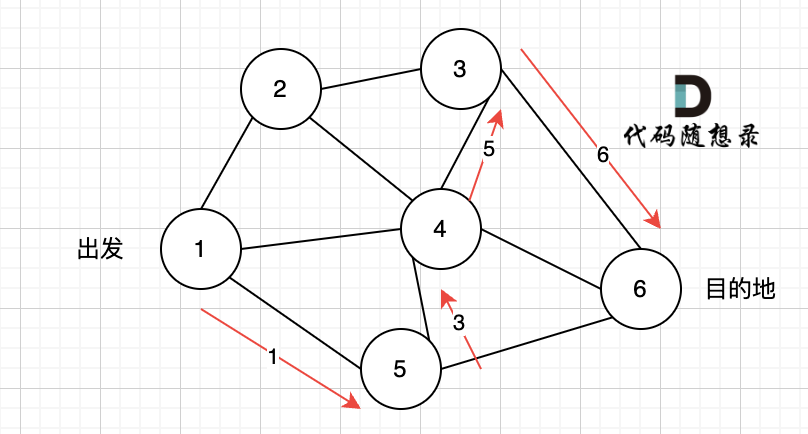
|
||||
|
||||
又找到了一条从节点1到节点6的路径,又到黄河了,此时再回头,下图图五,路径6撤销(回溯的过程),改为路径7,路径8 和 路径7,路径9, 结果发现死路一条,都走到了自己走过的节点。
|
||||
|
||||
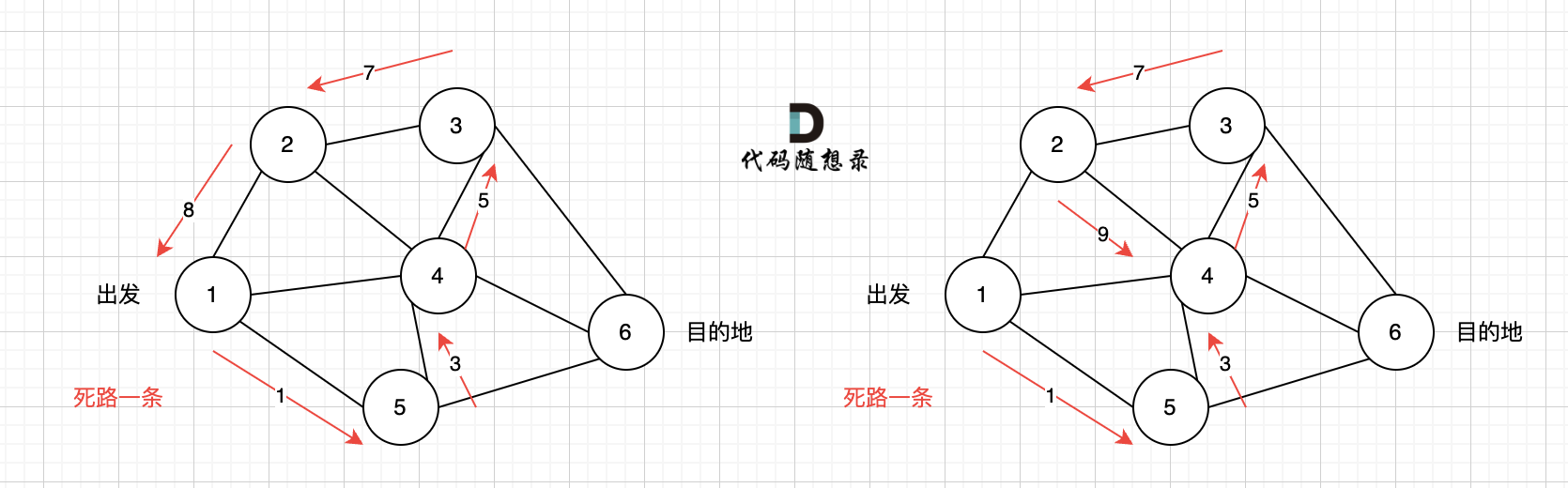
|
||||
|
||||
那么节点2所连接路径和节点3所链接的路径 都走过了,撤销路径只能向上回退,去选择撤销当初节点4的选择,也就是撤销路径5,改为路径10 。 如图图六:
|
||||
|
||||
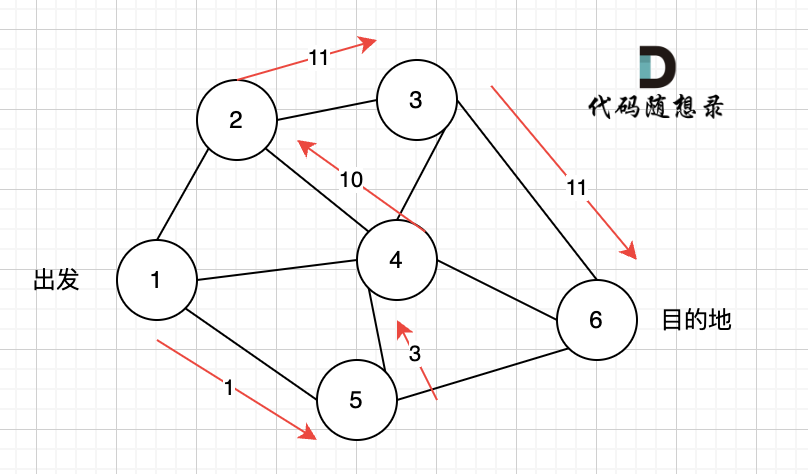
|
||||
|
||||
|
||||
上图演示中,其实我并没有把 所有的 从节点1 到节点6的dfs(深度优先搜索)的过程都画出来,那样太冗余了,但 已经把dfs 关键的地方都涉及到了,关键就两点:
|
||||
|
||||
* 搜索方向,是认准一个方向搜,直到碰壁之后再换方向
|
||||
* 换方向是撤销原路径,改为节点链接的下一个路径,回溯的过程。
|
||||
|
||||
## 代码框架
|
||||
|
||||
正是因为dfs搜索可一个方向,并需要回溯,所以用递归的方式来实现是最方便的。
|
||||
|
||||
很多录友对回溯很陌生,建议先看看代码随想录,[回溯算法章节](https://programmercarl.com/回溯算法理论基础.html)。
|
||||
|
||||
有递归的地方就有回溯,那么回溯在哪里呢?
|
||||
|
||||
就地递归函数的下面,例如如下代码:
|
||||
|
||||
```cpp
|
||||
void dfs(参数) {
|
||||
处理节点
|
||||
dfs(图,选择的节点); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
```
|
||||
|
||||
可以看到回溯操作就在递归函数的下面,递归和回溯是相辅相成的。
|
||||
|
||||
在讲解[二叉树章节](https://programmercarl.com/二叉树理论基础.html)的时候,二叉树的递归法其实就是dfs,而二叉树的迭代法,就是bfs(广度优先搜索)
|
||||
|
||||
所以**dfs,bfs其实是基础搜索算法,也广泛应用与其他数据结构与算法中**。
|
||||
|
||||
我们在回顾一下[回溯法](https://programmercarl.com/回溯算法理论基础.html)的代码框架:
|
||||
|
||||
```cpp
|
||||
void backtracking(参数) {
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
|
||||
处理节点;
|
||||
backtracking(路径,选择列表); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
回溯算法,其实就是dfs的过程,这里给出dfs的代码框架:
|
||||
|
||||
```cpp
|
||||
void dfs(参数) {
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
|
||||
for (选择:本节点所连接的其他节点) {
|
||||
处理节点;
|
||||
dfs(图,选择的节点); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
可以发现dfs的代码框架和回溯算法的代码框架是差不多的。
|
||||
|
||||
下面我在用 深搜三部曲,来解读 dfs的代码框架。
|
||||
|
||||
## 深搜三部曲
|
||||
|
||||
在 [二叉树递归讲解](https://programmercarl.com/%E4%BA%8C%E5%8F%89%E6%A0%91%E7%9A%84%E9%80%92%E5%BD%92%E9%81%8D%E5%8E%86.html)中,给出了递归三部曲。
|
||||
|
||||
[回溯算法](https://programmercarl.com/回溯算法理论基础.html)讲解中,给出了 回溯三部曲。
|
||||
|
||||
其实深搜也是一样的,深搜三部曲如下:
|
||||
|
||||
1. 确认递归函数,参数
|
||||
|
||||
```cpp
|
||||
void dfs(参数)
|
||||
```
|
||||
|
||||
通常我们递归的时候,我们递归搜索需要了解哪些参数,其实也可以在写递归函数的时候,发现需要什么参数,再去补充就可以。
|
||||
|
||||
一般情况,深搜需要 二维数组数组结构保存所有路径,需要一维数组保存单一路径,这种保存结果的数组,我们可以定义一个全局变量,避免让我们的函数参数过多。
|
||||
|
||||
例如这样:
|
||||
|
||||
```cpp
|
||||
vector<vector<int>> result; // 保存符合条件的所有路径
|
||||
vector<int> path; // 起点到终点的路径
|
||||
void dfs (图,目前搜索的节点)
|
||||
```
|
||||
|
||||
但这种写法看个人习惯,不强求。
|
||||
|
||||
2. 确认终止条件
|
||||
|
||||
终止条件很重要,很多同学写dfs的时候,之所以容易死循环,栈溢出等等这些问题,都是因为终止条件没有想清楚。
|
||||
|
||||
```cpp
|
||||
if (终止条件) {
|
||||
存放结果;
|
||||
return;
|
||||
}
|
||||
```
|
||||
|
||||
终止添加不仅是结束本层递归,同时也是我们收获结果的时候。
|
||||
|
||||
另外,其实很多dfs写法,没有写终止条件,其实终止条件写在了, 下面dfs递归的逻辑里了,也就是不符合条件,直接不会向下递归。这里如果大家不理解的话,没关系,后面会有具体题目来讲解。
|
||||
|
||||
3. 处理目前搜索节点出发的路径
|
||||
|
||||
一般这里就是一个for循环的操作,去遍历 目前搜索节点 所能到的所有节点。
|
||||
|
||||
```cpp
|
||||
for (选择:本节点所连接的其他节点) {
|
||||
处理节点;
|
||||
dfs(图,选择的节点); // 递归
|
||||
回溯,撤销处理结果
|
||||
}
|
||||
```
|
||||
|
||||
不少录友疑惑的地方,都是 dfs代码框架中for循环里分明已经处理节点了,那么 dfs函数下面 为什么还要撤销的呢。
|
||||
|
||||
如图七所示, 路径2 已经走到了 目的地节点6,那么 路径2 是如何撤销,然后改为 路径3呢? 其实这就是 回溯的过程,撤销路径2,走换下一个方向。
|
||||
|
||||
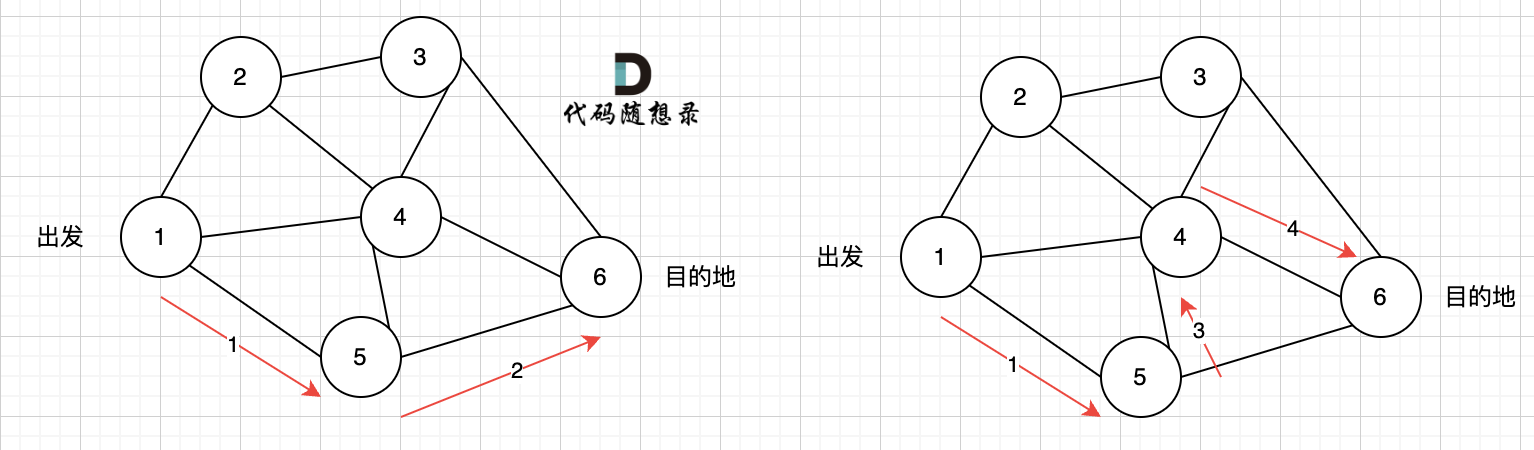
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
我们讲解了,dfs 和 bfs的大体区别(bfs详细过程下篇来讲),dfs的搜索过程以及代码框架。
|
||||
|
||||
最后还有 深搜三部曲来解读这份代码框架。
|
||||
|
||||
以上如果大家都能理解了,其实搜索的代码就很好写,具体题目套用具体场景就可以了。
|
||||
|
||||
后面我也会给大家安排具体练习的题目,依旧是代码随想录的风格,循序渐进由浅入深!
|
||||
|
||||
|
||||
<p align="center">
|
||||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
222
problems/kamacoder/图论理论基础.md
Normal file
222
problems/kamacoder/图论理论基础.md
Normal file
@ -0,0 +1,222 @@
|
||||
|
||||
# 图论理论基础
|
||||
|
||||
这一篇我们正式开始图论!
|
||||
|
||||
## 图的基本概念
|
||||
|
||||
二维坐标中,两点可以连成线,多个点连成的线就构成了图。
|
||||
|
||||
当然图也可以就一个节点,甚至没有节点(空图)
|
||||
|
||||
### 图的种类
|
||||
|
||||
整体上一般分为 有向图 和 无向图。
|
||||
|
||||
有向图是指 图中边是有方向的:
|
||||
|
||||
|
||||
|
||||
无向图是指 图中边没有方向:
|
||||
|
||||
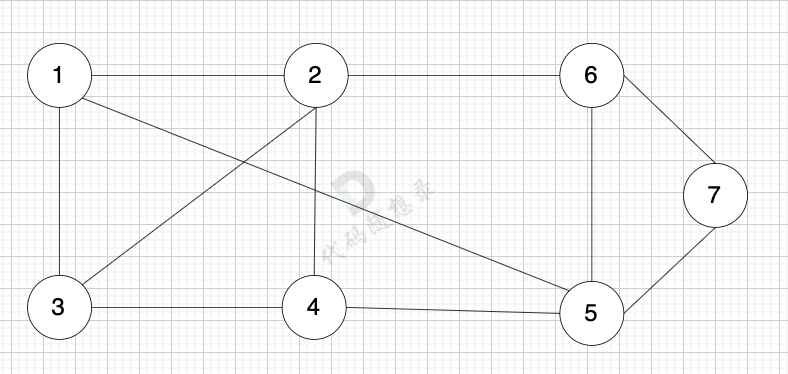
|
||||
|
||||
加权有向图,就是图中边是有权值的,例如:
|
||||
|
||||
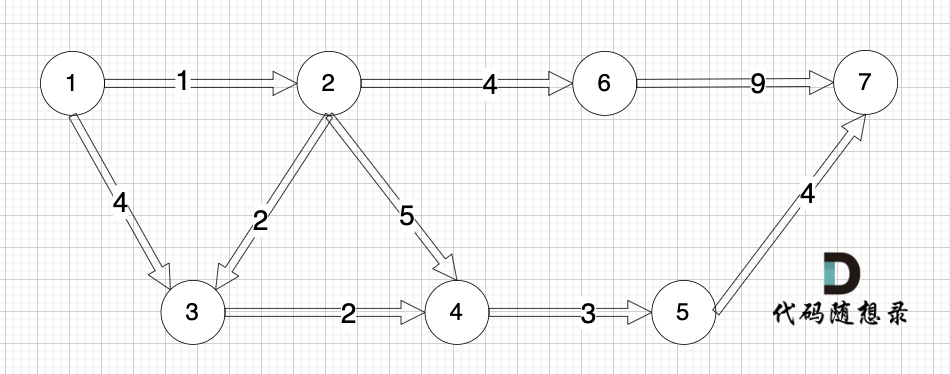
|
||||
|
||||
加权无向图也是同理。
|
||||
|
||||
### 度
|
||||
|
||||
无向图中有几条边连接该节点,该节点就有几度。
|
||||
|
||||
例如,该无向图中,节点4的度为5,节点6的度为3。
|
||||
|
||||
|
||||
|
||||
在有向图中,每个节点有出度和入度。
|
||||
|
||||
出度:从该节点出发的边的个数。
|
||||
|
||||
入度:指向该节点边的个数。
|
||||
|
||||
例如,该有向图中,节点3的入度为2,出度为1,节点1的入度为0,出度为2。
|
||||
|
||||
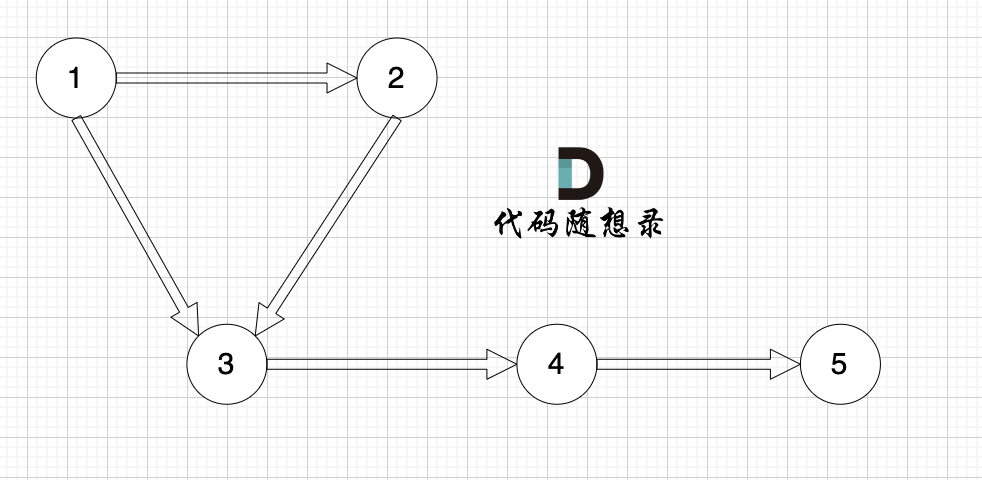
|
||||
|
||||
|
||||
## 连通性
|
||||
|
||||
在图中表示节点的连通情况,我们称之为连通性。
|
||||
|
||||
### 连通图
|
||||
|
||||
在无向图中,任何两个节点都是可以到达的,我们称之为连通图 ,如图:
|
||||
|
||||
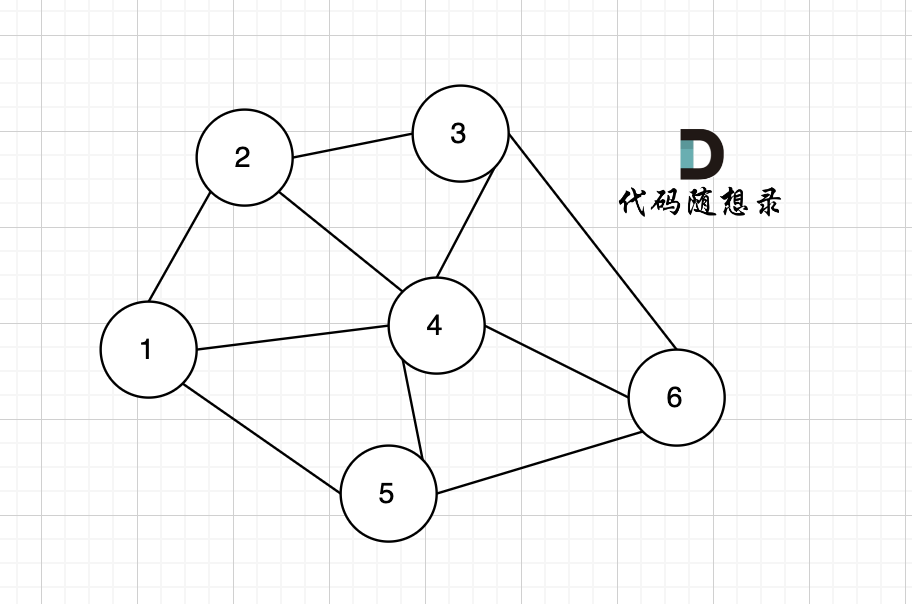
|
||||
|
||||
如果有节点不能到达其他节点,则为非连通图,如图:
|
||||
|
||||
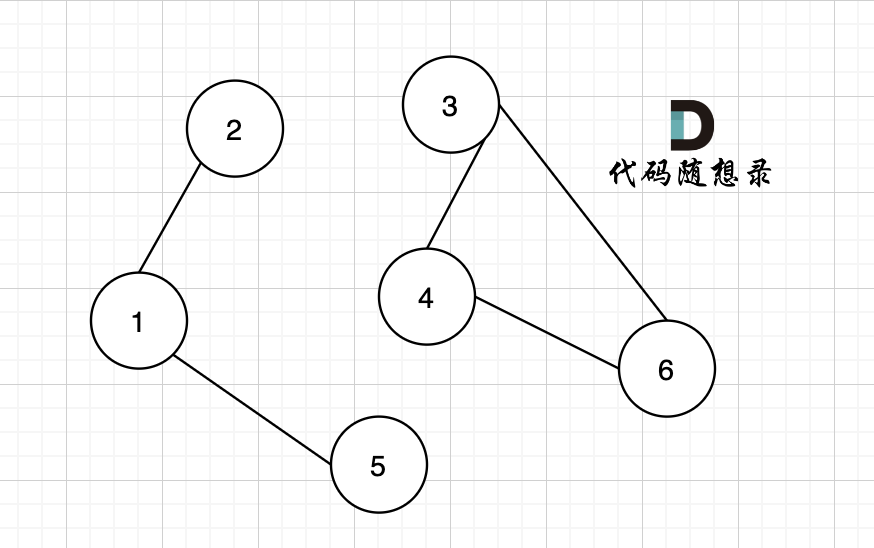
|
||||
|
||||
节点1 不能到达节点4。
|
||||
|
||||
### 强连通图
|
||||
|
||||
在有向图中,任何两个节点是可以相互到达的,我们称之为 强连通图。
|
||||
|
||||
这里有录友可能想,这和无向图中的连通图有什么区别,不是一样的吗?
|
||||
|
||||
我们来看这个有向图:
|
||||
|
||||
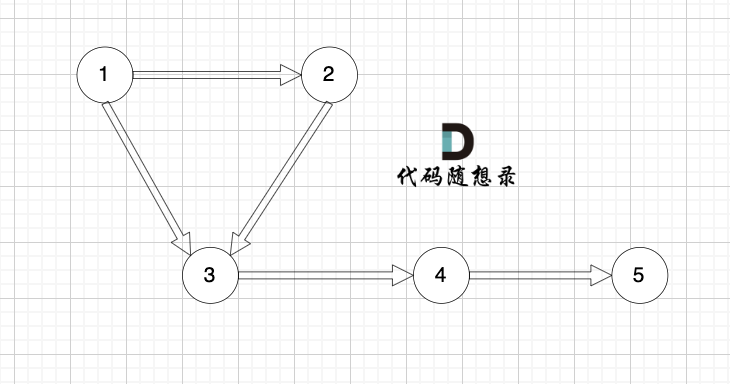
|
||||
|
||||
这个图是强连通图吗?
|
||||
|
||||
初步一看,好像这节点都连着呢,但这不是强连通图,节点1 可以到节点5,但节点5 不能到 节点1 。
|
||||
|
||||
强连通图是在有向图中**任何两个节点是可以相互到达**
|
||||
|
||||
下面这个有向图才是强连通图:
|
||||
|
||||
|
||||
|
||||
|
||||
### 连通分量
|
||||
|
||||
在无向图中的极大连通子图称之为该图的一个连通分量。
|
||||
|
||||
只看概念大家可能不理解,我来画个图:
|
||||
|
||||
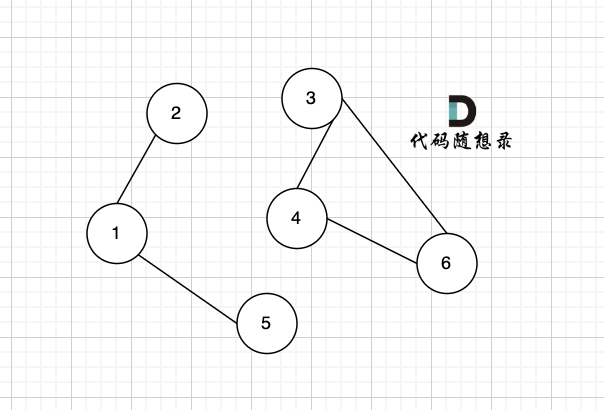
|
||||
|
||||
该无向图中 节点1、节点2、节点5 构成的子图就是 该无向图中的一个连通分量,该子图所有节点都是相互可达到的。
|
||||
|
||||
同理,节点3、节点4、节点6 构成的子图 也是该无向图中的一个连通分量。
|
||||
|
||||
那么无向图中 节点3 、节点4 构成的子图 是该无向图的联通分量吗?
|
||||
|
||||
不是!
|
||||
|
||||
因为必须是极大联通子图才能是连通分量,所以 必须是节点3、节点4、节点6 构成的子图才是连通分量。
|
||||
|
||||
在图论中,连通分量是一个很重要的概念,例如岛屿问题(后面章节会有专门讲解)其实就是求连通分量。
|
||||
|
||||
### 强连通分量
|
||||
|
||||
在有向图中极大强连通子图称之为该图的强连通分量。
|
||||
|
||||
如图:
|
||||
|
||||

|
||||
|
||||
节点1、节点2、节点3、节点4、节点5 构成的子图是强连通分量,因为这是强连通图,也是极大图。
|
||||
|
||||
节点6、节点7、节点8 构成的子图 不是强连通分量,因为这不是强连通图,节点8 不能达到节点6。
|
||||
|
||||
节点1、节点2、节点5 构成的子图 也不是 强连通分量,因为这不是极大图。
|
||||
|
||||
|
||||
## 图的构造
|
||||
|
||||
我们如何用代码来表示一个图呢?
|
||||
|
||||
一般使用邻接表、邻接矩阵 或者用类来表示。
|
||||
|
||||
主流是 邻接表和邻接矩阵。
|
||||
|
||||
### 邻接矩阵
|
||||
|
||||
邻接矩阵 使用 二维数组来表示图结构。 邻接矩阵是从节点的角度来表示图,有多少节点就申请多大的二维数组。
|
||||
|
||||
例如: grid[2][5] = 6,表示 节点 2 连接 节点5 为有向图,节点2 指向 节点5,边的权值为6。
|
||||
|
||||
如果想表示无向图,即:grid[2][5] = 6,grid[5][2] = 6,表示节点2 与 节点5 相互连通,权值为6。
|
||||
|
||||
如图:
|
||||
|
||||
|
||||
|
||||
在一个 n (节点数)为8 的图中,就需要申请 8 * 8 这么大的空间。
|
||||
|
||||
图中有一条双向边,即:grid[2][5] = 6,grid[5][2] = 6
|
||||
|
||||
这种表达方式(邻接矩阵) 在 边少,节点多的情况下,会导致申请过大的二维数组,造成空间浪费。
|
||||
|
||||
而且在寻找节点连接情况的时候,需要遍历整个矩阵,即 n * n 的时间复杂度,同样造成时间浪费。
|
||||
|
||||
邻接矩阵的优点:
|
||||
|
||||
* 表达方式简单,易于理解
|
||||
* 检查任意两个顶点间是否存在边的操作非常快
|
||||
* 适合稠密图,在边数接近顶点数平方的图中,邻接矩阵是一种空间效率较高的表示方法。
|
||||
|
||||
缺点:
|
||||
|
||||
* 遇到稀疏图,会导致申请过大的二维数组造成空间浪费 且遍历 边 的时候需要遍历整个n * n矩阵,造成时间浪费
|
||||
|
||||
### 邻接表
|
||||
|
||||
邻接表 使用 数组 + 链表的方式来表示。 邻接表是从边的数量来表示图,有多少边 才会申请对应大小的链表。
|
||||
|
||||
邻接表的构造如图:
|
||||
|
||||

|
||||
|
||||
这里表达的图是:
|
||||
|
||||
* 节点1 指向 节点3 和 节点5
|
||||
* 节点2 指向 节点4、节点3、节点5
|
||||
* 节点3 指向 节点4
|
||||
* 节点4指向节点1
|
||||
|
||||
有多少边 邻接表才会申请多少个对应的链表节点。
|
||||
|
||||
从图中可以直观看出 使用 数组 + 链表 来表达 边的连接情况 。
|
||||
|
||||
邻接表的优点:
|
||||
|
||||
* 对于稀疏图的存储,只需要存储边,空间利用率高
|
||||
* 遍历节点连接情况相对容易
|
||||
|
||||
缺点:
|
||||
|
||||
* 检查任意两个节点间是否存在边,效率相对低,需要 O(V)时间,V表示某节点连接其他节点的数量。
|
||||
* 实现相对复杂,不易理解
|
||||
|
||||
|
||||
**以上大家可能理解比较模糊,没关系**,因为大家还没做过图论的题目,对于图的表达没有概念。
|
||||
|
||||
这里我先不给出具体的实现代码,大家先有个初步印象,在后面算法题实战中,我还会讲到具体代码实现,等带大家做算法题,写了代码之后,自然就理解了。
|
||||
|
||||
## 图的遍历方式
|
||||
|
||||
图的遍历方式基本是两大类:
|
||||
|
||||
* 深度优先搜索(dfs)
|
||||
* 广度优先搜索(bfs)
|
||||
|
||||
在讲解二叉树章节的时候,其实就已经讲过这两种遍历方式。
|
||||
|
||||
二叉树的递归遍历,是dfs 在二叉树上的遍历方式。
|
||||
|
||||
二叉树的层序遍历,是bfs 在二叉树上的遍历方式。
|
||||
|
||||
dfs 和 bfs 一种搜索算法,可以在不同的数据结构上进行搜索,在二叉树章节里是在二叉树这样的数据结构上搜索。
|
||||
|
||||
而在图论章节,则是在图(邻接表或邻接矩阵)上进行搜索。
|
||||
|
||||
## 总结
|
||||
|
||||
以上知识点 大家先有个印象,上面提到的每个知识点,其实都需要大篇幅才能讲明白的。
|
||||
|
||||
我这里先给大家做一个概括,后面章节会针对每个知识点都会有对应的算法题和针对性的讲解,大家再去深入学习。
|
||||
|
||||
图论是非常庞大的知识体系,上面的内容还不足以概括图论内容,仅仅是理论基础而已。
|
||||
|
||||
在图论章节我会带大家深入讲解 深度优先搜索(DFS)、广度优先搜索(BFS)、并查集、拓扑排序、最小生成树系列、最短路算法系列等等。
|
||||
|
||||
敬请期待!
|
||||
|
||||
|
||||
48
problems/kamacoder/最短路问题总结篇.md
Normal file
48
problems/kamacoder/最短路问题总结篇.md
Normal file
@ -0,0 +1,48 @@
|
||||
|
||||
# 最短路算法总结篇
|
||||
|
||||
至此已经讲解了四大最短路算法,分别是Dijkstra、Bellman_ford、SPFA 和 Floyd。
|
||||
|
||||
针对这四大最短路算法,我用了七篇长文才彻底讲清楚,分别是:
|
||||
|
||||
* dijkstra朴素版
|
||||
* dijkstra堆优化版
|
||||
* Bellman_ford
|
||||
* Bellman_ford 队列优化算法(又名SPFA)
|
||||
* bellman_ford 算法判断负权回路
|
||||
* bellman_ford之单源有限最短路
|
||||
* Floyd 算法精讲
|
||||
|
||||
|
||||
最短路算法比较复杂,而且各自有各自的应用场景,我来用一张表把讲过的最短路算法的使用场景都展现出来:
|
||||
|
||||
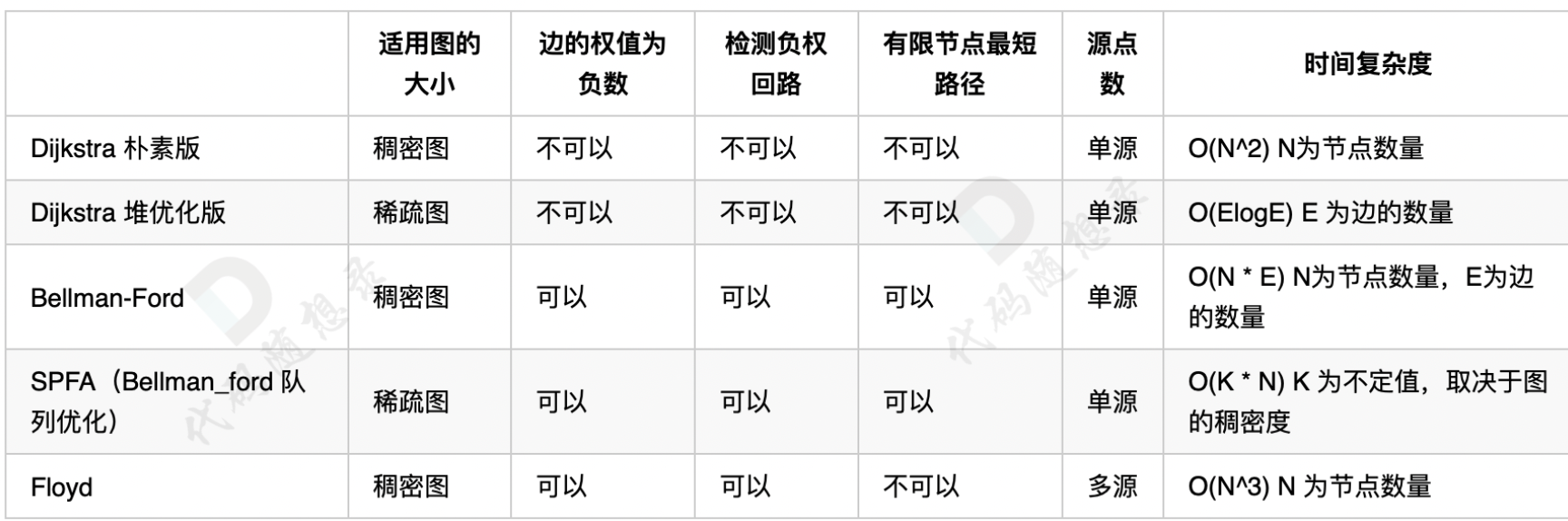
|
||||
|
||||
|
||||
可能有同学感觉:这个表太复杂了,我记也记不住。
|
||||
|
||||
其实记不住的原因还是对 这几个最短路算法没有深刻的理解。
|
||||
|
||||
这里我给大家一个大体使用场景的分析:
|
||||
|
||||
如果遇到单源且边为正数,直接Dijkstra。
|
||||
|
||||
至于 使用朴素版还是 堆优化版 还是取决于图的稠密度, 多少节点多少边算是稠密图,多少算是稀疏图,这个没有量化,如果想量化只能写出两个版本然后做实验去测试,不同的判题机得出的结果还不太一样。
|
||||
|
||||
一般情况下,可以直接用堆优化版本。
|
||||
|
||||
如果遇到单源边可为负数,直接 Bellman-Ford,同样 SPFA 还是 Bellman-Ford 取决于图的稠密度。
|
||||
|
||||
一般情况下,直接用 SPFA。
|
||||
|
||||
如果有负权回路,优先 Bellman-Ford, 如果是有限节点最短路 也优先 Bellman-Ford,理由是写代码比较方便。
|
||||
|
||||
如果是遇到多源点求最短路,直接 Floyd。
|
||||
|
||||
除非 源点特别少,且边都是正数,那可以 多次 Dijkstra 求出最短路径,但这种情况很少,一般出现多个源点了,就是想让你用 Floyd 了。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user