 -
-
-
-
-
-

 +
+
+
+
+
+
+
+

-
-

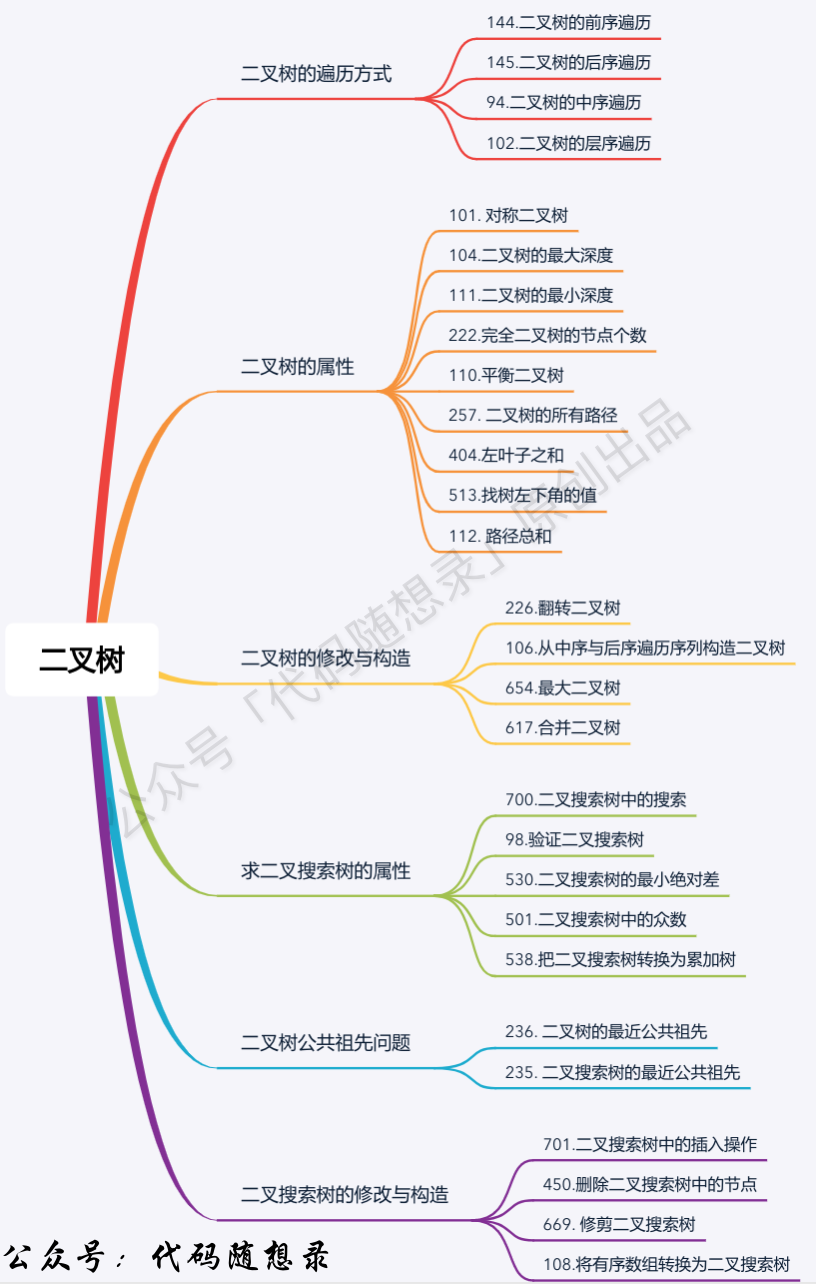 +
+1. [关于二叉树,你该了解这些!](./problems/二叉树理论基础.md)
+2. [二叉树:一入递归深似海,从此offer是路人](./problems/二叉树的递归遍历.md)
+3. [二叉树:听说递归能做的,栈也能做!](./problems/二叉树的迭代遍历.md)
+4. [二叉树:前中后序迭代方式的写法就不能统一一下么?](./problems/二叉树的统一迭代法.md)
+5. [二叉树:层序遍历登场!](./problems/0102.二叉树的层序遍历.md)
+6. [二叉树:你真的会翻转二叉树么?](./problems/0226.翻转二叉树.md)
+7. [本周小结!(二叉树)](./problems/周总结/20200927二叉树周末总结.md)
+8. [二叉树:我对称么?](./problems/0101.对称二叉树.md)
+9. [二叉树:看看这些树的最大深度](./problems/0104.二叉树的最大深度.md)
+10. [二叉树:看看这些树的最小深度](./problems/0111.二叉树的最小深度.md)
+11. [二叉树:我有多少个节点?](./problems/0222.完全二叉树的节点个数.md)
+12. [二叉树:我平衡么?](./problems/0110.平衡二叉树.md)
+13. [二叉树:找我的所有路径?](./problems/0257.二叉树的所有路径.md)
+14. [本周总结!二叉树系列二](./problems/周总结/20201003二叉树周末总结.md)
+15. [二叉树:以为使用了递归,其实还隐藏着回溯](./problems/二叉树中递归带着回溯.md)
+16. [二叉树:做了这么多题目了,我的左叶子之和是多少?](./problems/0404.左叶子之和.md)
+17. [二叉树:我的左下角的值是多少?](./problems/0513.找树左下角的值.md)
+18. [二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](./problems/0112.路径总和.md)
+19. [二叉树:构造二叉树登场!](./problems/0106.从中序与后序遍历序列构造二叉树.md)
+20. [二叉树:构造一棵最大的二叉树](./problems/0654.最大二叉树.md)
+21. [本周小结!(二叉树系列三)](./problems/周总结/20201010二叉树周末总结.md)
+22. [二叉树:合并两个二叉树](./problems/0617.合并二叉树.md)
+23. [二叉树:二叉搜索树登场!](./problems/0700.二叉搜索树中的搜索.md)
+24. [二叉树:我是不是一棵二叉搜索树](./problems/0098.验证二叉搜索树.md)
+25. [二叉树:搜索树的最小绝对差](./problems/0530.二叉搜索树的最小绝对差.md)
+26. [二叉树:我的众数是多少?](./problems/0501.二叉搜索树中的众数.md)
+27. [二叉树:公共祖先问题](./problems/0236.二叉树的最近公共祖先.md)
+28. [本周小结!(二叉树系列四)](./problems/周总结/20201017二叉树周末总结.md)
+29. [二叉树:搜索树的公共祖先问题](./problems/0235.二叉搜索树的最近公共祖先.md)
+30. [二叉树:搜索树中的插入操作](./problems/0701.二叉搜索树中的插入操作.md)
+31. [二叉树:搜索树中的删除操作](./problems/0450.删除二叉搜索树中的节点.md)
+32. [二叉树:修剪一棵搜索树](./problems/0669.修剪二叉搜索树.md)
+33. [二叉树:构造一棵搜索树](./problems/0108.将有序数组转换为二叉搜索树.md)
+34. [二叉树:搜索树转成累加树](./problems/0538.把二叉搜索树转换为累加树.md)
+35. [二叉树:总结篇!(需要掌握的二叉树技能都在这里了)](./problems/二叉树总结篇.md)
-* 回溯算法
- * [关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)
- * [回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)
- * [回溯算法:组合问题再剪剪枝](https://mp.weixin.qq.com/s/Ri7spcJMUmph4c6XjPWXQA)
- * [回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)
- * [回溯算法:电话号码的字母组合](https://mp.weixin.qq.com/s/e2ua2cmkE_vpYjM3j6HY0A)
- * [本周小结!(回溯算法系列一)](https://mp.weixin.qq.com/s/m2GnTJdkYhAamustbb6lmw)
- * [回溯算法:求组合总和(二)](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)
- * [回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)
- * [回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)
- * [回溯算法:复原IP地址](https://mp.weixin.qq.com/s/v--VmA8tp9vs4bXCqHhBuA)
- * [回溯算法:求子集问题!](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)
- * [本周小结!(回溯算法系列二)](https://mp.weixin.qq.com/s/uzDpjrrMCO8DOf-Tl5oBGw)
- * [回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)
- * [回溯算法:递增子序列](https://mp.weixin.qq.com/s/ePxOtX1ATRYJb2Jq7urzHQ)
- * [回溯算法:排列问题!](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw)
- * [回溯算法:排列问题(二)](https://mp.weixin.qq.com/s/9L8h3WqRP_h8LLWNT34YlA)
- * [本周小结!(回溯算法系列三)](https://mp.weixin.qq.com/s/tLkt9PSo42X60w8i94ViiA)
- * [本周小结!(回溯算法系列三)续集](https://mp.weixin.qq.com/s/kSMGHc_YpsqL2j-jb_E_Ag)
- * [视频来了!!带你学透回溯算法(理论篇)](https://mp.weixin.qq.com/s/wDd5azGIYWjbU0fdua_qBg)
- * [视频来了!!回溯算法:组合问题](https://mp.weixin.qq.com/s/a_r5JR93K_rBKSFplPGNAA)
- * [视频来了!!回溯算法:组合问题的剪枝操作](https://mp.weixin.qq.com/s/CK0kj9lq8-rFajxL4amyEg)
- * [视频来了!!回溯算法:组合总和](https://mp.weixin.qq.com/s/4M4Cr04uFOWosRMc_5--gg)
- * [回溯算法:重新安排行程](https://mp.weixin.qq.com/s/3kmbS4qDsa6bkyxR92XCTA)
- * [回溯算法:N皇后问题](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg)
- * [回溯算法:解数独](https://mp.weixin.qq.com/s/eWE9TapVwm77yW9Q81xSZQ)
- * [一篇总结带你彻底搞透回溯算法!](https://mp.weixin.qq.com/s/r73thpBnK1tXndFDtlsdCQ)
+## 回溯算法
-* 贪心算法
- * [关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)
- * [贪心算法:分发饼干](https://mp.weixin.qq.com/s/YSuLIAYyRGlyxbp9BNC1uw)
- * [贪心算法:摆动序列](https://mp.weixin.qq.com/s/Xytl05kX8LZZ1iWWqjMoHA)
- * [贪心算法:最大子序和](https://mp.weixin.qq.com/s/DrjIQy6ouKbpletQr0g1Fg)
- * [本周小结!(贪心算法系列一)](https://mp.weixin.qq.com/s/KQ2caT9GoVXgB1t2ExPncQ)
- * [贪心算法:买卖股票的最佳时机II](https://mp.weixin.qq.com/s/VsTFA6U96l18Wntjcg3fcg)
- * [贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)
- * [贪心算法:跳跃游戏II](https://mp.weixin.qq.com/s/kJBcsJ46DKCSjT19pxrNYg)
- * [贪心算法:K次取反后最大化的数组和](https://mp.weixin.qq.com/s/dMTzBBVllRm_Z0aaWvYazA)
- * [本周小结!(贪心算法系列二)](https://mp.weixin.qq.com/s/RiQri-4rP9abFmq_mlXNiQ)
- * [贪心算法:加油站](https://mp.weixin.qq.com/s/aDbiNuEZIhy6YKgQXvKELw)
- * [贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)
- * [贪心算法:柠檬水找零](https://mp.weixin.qq.com/s/0kT4P-hzY7H6Ae0kjQqnZg)
+题目分类大纲如下:
+
+
+1. [关于二叉树,你该了解这些!](./problems/二叉树理论基础.md)
+2. [二叉树:一入递归深似海,从此offer是路人](./problems/二叉树的递归遍历.md)
+3. [二叉树:听说递归能做的,栈也能做!](./problems/二叉树的迭代遍历.md)
+4. [二叉树:前中后序迭代方式的写法就不能统一一下么?](./problems/二叉树的统一迭代法.md)
+5. [二叉树:层序遍历登场!](./problems/0102.二叉树的层序遍历.md)
+6. [二叉树:你真的会翻转二叉树么?](./problems/0226.翻转二叉树.md)
+7. [本周小结!(二叉树)](./problems/周总结/20200927二叉树周末总结.md)
+8. [二叉树:我对称么?](./problems/0101.对称二叉树.md)
+9. [二叉树:看看这些树的最大深度](./problems/0104.二叉树的最大深度.md)
+10. [二叉树:看看这些树的最小深度](./problems/0111.二叉树的最小深度.md)
+11. [二叉树:我有多少个节点?](./problems/0222.完全二叉树的节点个数.md)
+12. [二叉树:我平衡么?](./problems/0110.平衡二叉树.md)
+13. [二叉树:找我的所有路径?](./problems/0257.二叉树的所有路径.md)
+14. [本周总结!二叉树系列二](./problems/周总结/20201003二叉树周末总结.md)
+15. [二叉树:以为使用了递归,其实还隐藏着回溯](./problems/二叉树中递归带着回溯.md)
+16. [二叉树:做了这么多题目了,我的左叶子之和是多少?](./problems/0404.左叶子之和.md)
+17. [二叉树:我的左下角的值是多少?](./problems/0513.找树左下角的值.md)
+18. [二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](./problems/0112.路径总和.md)
+19. [二叉树:构造二叉树登场!](./problems/0106.从中序与后序遍历序列构造二叉树.md)
+20. [二叉树:构造一棵最大的二叉树](./problems/0654.最大二叉树.md)
+21. [本周小结!(二叉树系列三)](./problems/周总结/20201010二叉树周末总结.md)
+22. [二叉树:合并两个二叉树](./problems/0617.合并二叉树.md)
+23. [二叉树:二叉搜索树登场!](./problems/0700.二叉搜索树中的搜索.md)
+24. [二叉树:我是不是一棵二叉搜索树](./problems/0098.验证二叉搜索树.md)
+25. [二叉树:搜索树的最小绝对差](./problems/0530.二叉搜索树的最小绝对差.md)
+26. [二叉树:我的众数是多少?](./problems/0501.二叉搜索树中的众数.md)
+27. [二叉树:公共祖先问题](./problems/0236.二叉树的最近公共祖先.md)
+28. [本周小结!(二叉树系列四)](./problems/周总结/20201017二叉树周末总结.md)
+29. [二叉树:搜索树的公共祖先问题](./problems/0235.二叉搜索树的最近公共祖先.md)
+30. [二叉树:搜索树中的插入操作](./problems/0701.二叉搜索树中的插入操作.md)
+31. [二叉树:搜索树中的删除操作](./problems/0450.删除二叉搜索树中的节点.md)
+32. [二叉树:修剪一棵搜索树](./problems/0669.修剪二叉搜索树.md)
+33. [二叉树:构造一棵搜索树](./problems/0108.将有序数组转换为二叉搜索树.md)
+34. [二叉树:搜索树转成累加树](./problems/0538.把二叉搜索树转换为累加树.md)
+35. [二叉树:总结篇!(需要掌握的二叉树技能都在这里了)](./problems/二叉树总结篇.md)
-* 回溯算法
- * [关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)
- * [回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)
- * [回溯算法:组合问题再剪剪枝](https://mp.weixin.qq.com/s/Ri7spcJMUmph4c6XjPWXQA)
- * [回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)
- * [回溯算法:电话号码的字母组合](https://mp.weixin.qq.com/s/e2ua2cmkE_vpYjM3j6HY0A)
- * [本周小结!(回溯算法系列一)](https://mp.weixin.qq.com/s/m2GnTJdkYhAamustbb6lmw)
- * [回溯算法:求组合总和(二)](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)
- * [回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)
- * [回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)
- * [回溯算法:复原IP地址](https://mp.weixin.qq.com/s/v--VmA8tp9vs4bXCqHhBuA)
- * [回溯算法:求子集问题!](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)
- * [本周小结!(回溯算法系列二)](https://mp.weixin.qq.com/s/uzDpjrrMCO8DOf-Tl5oBGw)
- * [回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)
- * [回溯算法:递增子序列](https://mp.weixin.qq.com/s/ePxOtX1ATRYJb2Jq7urzHQ)
- * [回溯算法:排列问题!](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw)
- * [回溯算法:排列问题(二)](https://mp.weixin.qq.com/s/9L8h3WqRP_h8LLWNT34YlA)
- * [本周小结!(回溯算法系列三)](https://mp.weixin.qq.com/s/tLkt9PSo42X60w8i94ViiA)
- * [本周小结!(回溯算法系列三)续集](https://mp.weixin.qq.com/s/kSMGHc_YpsqL2j-jb_E_Ag)
- * [视频来了!!带你学透回溯算法(理论篇)](https://mp.weixin.qq.com/s/wDd5azGIYWjbU0fdua_qBg)
- * [视频来了!!回溯算法:组合问题](https://mp.weixin.qq.com/s/a_r5JR93K_rBKSFplPGNAA)
- * [视频来了!!回溯算法:组合问题的剪枝操作](https://mp.weixin.qq.com/s/CK0kj9lq8-rFajxL4amyEg)
- * [视频来了!!回溯算法:组合总和](https://mp.weixin.qq.com/s/4M4Cr04uFOWosRMc_5--gg)
- * [回溯算法:重新安排行程](https://mp.weixin.qq.com/s/3kmbS4qDsa6bkyxR92XCTA)
- * [回溯算法:N皇后问题](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg)
- * [回溯算法:解数独](https://mp.weixin.qq.com/s/eWE9TapVwm77yW9Q81xSZQ)
- * [一篇总结带你彻底搞透回溯算法!](https://mp.weixin.qq.com/s/r73thpBnK1tXndFDtlsdCQ)
+## 回溯算法
-* 贪心算法
- * [关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg)
- * [贪心算法:分发饼干](https://mp.weixin.qq.com/s/YSuLIAYyRGlyxbp9BNC1uw)
- * [贪心算法:摆动序列](https://mp.weixin.qq.com/s/Xytl05kX8LZZ1iWWqjMoHA)
- * [贪心算法:最大子序和](https://mp.weixin.qq.com/s/DrjIQy6ouKbpletQr0g1Fg)
- * [本周小结!(贪心算法系列一)](https://mp.weixin.qq.com/s/KQ2caT9GoVXgB1t2ExPncQ)
- * [贪心算法:买卖股票的最佳时机II](https://mp.weixin.qq.com/s/VsTFA6U96l18Wntjcg3fcg)
- * [贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)
- * [贪心算法:跳跃游戏II](https://mp.weixin.qq.com/s/kJBcsJ46DKCSjT19pxrNYg)
- * [贪心算法:K次取反后最大化的数组和](https://mp.weixin.qq.com/s/dMTzBBVllRm_Z0aaWvYazA)
- * [本周小结!(贪心算法系列二)](https://mp.weixin.qq.com/s/RiQri-4rP9abFmq_mlXNiQ)
- * [贪心算法:加油站](https://mp.weixin.qq.com/s/aDbiNuEZIhy6YKgQXvKELw)
- * [贪心算法:分发糖果](https://mp.weixin.qq.com/s/8MwlgFfvaNYmjGwjuMlETQ)
- * [贪心算法:柠檬水找零](https://mp.weixin.qq.com/s/0kT4P-hzY7H6Ae0kjQqnZg)
+题目分类大纲如下:
+ -* 动态规划
+1. [关于回溯算法,你该了解这些!](./problems/回溯算法理论基础.md)
+2. [回溯算法:组合问题](./problems/0077.组合.md)
+3. [回溯算法:组合问题再剪剪枝](./problems/0077.组合优化.md)
+4. [回溯算法:求组合总和!](./problems/0216.组合总和III.md)
+5. [回溯算法:电话号码的字母组合](./problems/0017.电话号码的字母组合.md)
+6. [本周小结!(回溯算法系列一)](./problems/周总结/20201030回溯周末总结.md)
+7. [回溯算法:求组合总和(二)](./problems/0039.组合总和.md)
+8. [回溯算法:求组合总和(三)](./problems/0040.组合总和II.md)
+9. [回溯算法:分割回文串](./problems/0131.分割回文串.md)
+10. [回溯算法:复原IP地址](./problems/0093.复原IP地址.md)
+11. [回溯算法:求子集问题!](./problems/0078.子集.md)
+12. [本周小结!(回溯算法系列二)](./problems/周总结/20201107回溯周末总结.md)
+13. [回溯算法:求子集问题(二)](./problems/0090.子集II.md)
+14. [回溯算法:递增子序列](./problems/0491.递增子序列.md)
+15. [回溯算法:排列问题!](./problems/0046.全排列.md)
+16. [回溯算法:排列问题(二)](./problems/0047.全排列II.md)
+17. [本周小结!(回溯算法系列三)](./problems/周总结/20201112回溯周末总结.md)
+18. [回溯算法去重问题的另一种写法](./problems/回溯算法去重问题的另一种写法.md)
+23. [回溯算法:重新安排行程](./problems/0332.重新安排行程.md)
+24. [回溯算法:N皇后问题](./problems/0051.N皇后.md)
+25. [回溯算法:解数独](./problems/0037.解数独.md)
+26. [一篇总结带你彻底搞透回溯算法!](./problems/回溯总结.md)
-* 图论
+## 贪心算法
-* 数论
+题目分类大纲如下:
+
+
-* 动态规划
+1. [关于回溯算法,你该了解这些!](./problems/回溯算法理论基础.md)
+2. [回溯算法:组合问题](./problems/0077.组合.md)
+3. [回溯算法:组合问题再剪剪枝](./problems/0077.组合优化.md)
+4. [回溯算法:求组合总和!](./problems/0216.组合总和III.md)
+5. [回溯算法:电话号码的字母组合](./problems/0017.电话号码的字母组合.md)
+6. [本周小结!(回溯算法系列一)](./problems/周总结/20201030回溯周末总结.md)
+7. [回溯算法:求组合总和(二)](./problems/0039.组合总和.md)
+8. [回溯算法:求组合总和(三)](./problems/0040.组合总和II.md)
+9. [回溯算法:分割回文串](./problems/0131.分割回文串.md)
+10. [回溯算法:复原IP地址](./problems/0093.复原IP地址.md)
+11. [回溯算法:求子集问题!](./problems/0078.子集.md)
+12. [本周小结!(回溯算法系列二)](./problems/周总结/20201107回溯周末总结.md)
+13. [回溯算法:求子集问题(二)](./problems/0090.子集II.md)
+14. [回溯算法:递增子序列](./problems/0491.递增子序列.md)
+15. [回溯算法:排列问题!](./problems/0046.全排列.md)
+16. [回溯算法:排列问题(二)](./problems/0047.全排列II.md)
+17. [本周小结!(回溯算法系列三)](./problems/周总结/20201112回溯周末总结.md)
+18. [回溯算法去重问题的另一种写法](./problems/回溯算法去重问题的另一种写法.md)
+23. [回溯算法:重新安排行程](./problems/0332.重新安排行程.md)
+24. [回溯算法:N皇后问题](./problems/0051.N皇后.md)
+25. [回溯算法:解数独](./problems/0037.解数独.md)
+26. [一篇总结带你彻底搞透回溯算法!](./problems/回溯总结.md)
-* 图论
+## 贪心算法
-* 数论
+题目分类大纲如下:
+
+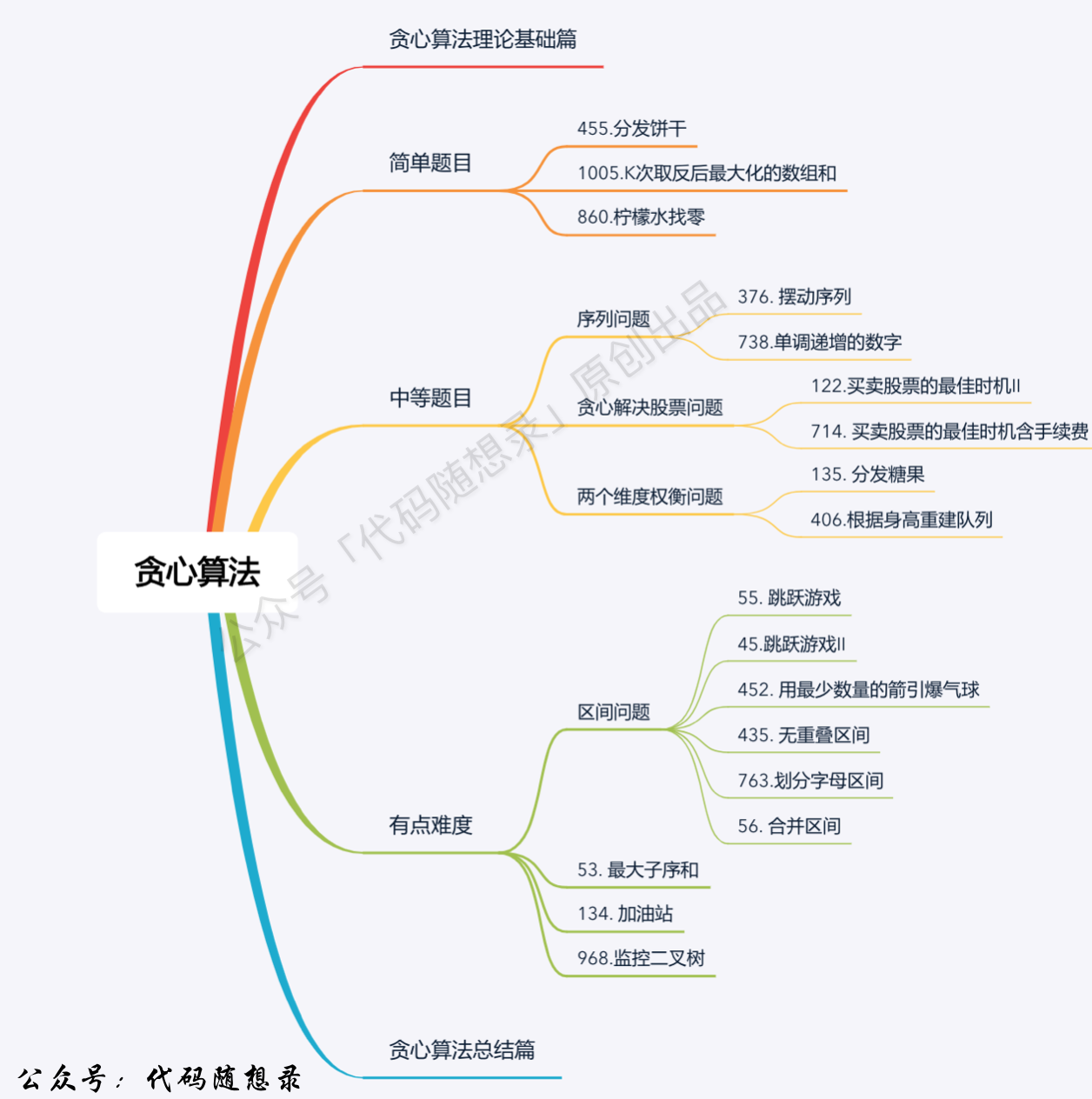 +
+1. [关于贪心算法,你该了解这些!](./problems/贪心算法理论基础.md)
+2. [贪心算法:分发饼干](./problems/0455.分发饼干.md)
+3. [贪心算法:摆动序列](./problems/0376.摆动序列.md)
+4. [贪心算法:最大子序和](./problems/0053.最大子序和.md)
+5. [本周小结!(贪心算法系列一)](./problems/周总结/20201126贪心周末总结.md)
+6. [贪心算法:买卖股票的最佳时机II](./problems/0122.买卖股票的最佳时机II.md)
+7. [贪心算法:跳跃游戏](./problems/0055.跳跃游戏.md)
+8. [贪心算法:跳跃游戏II](./problems/0045.跳跃游戏II.md)
+9. [贪心算法:K次取反后最大化的数组和](./problems/1005.K次取反后最大化的数组和.md)
+10. [本周小结!(贪心算法系列二)](./problems/周总结/20201203贪心周末总结.md)
+11. [贪心算法:加油站](./problems/0134.加油站.md)
+12. [贪心算法:分发糖果](./problems/0135.分发糖果.md)
+13. [贪心算法:柠檬水找零](./problems/0860.柠檬水找零.md)
+14. [贪心算法:根据身高重建队列](./problems/0406.根据身高重建队列.md)
+15. [本周小结!(贪心算法系列三)](./problems/周总结/20201217贪心周末总结.md)
+16. [贪心算法:根据身高重建队列(续集)](./problems/根据身高重建队列(vector原理讲解).md)
+17. [贪心算法:用最少数量的箭引爆气球](./problems/0452.用最少数量的箭引爆气球.md)
+18. [贪心算法:无重叠区间](./problems/0435.无重叠区间.md)
+19. [贪心算法:划分字母区间](./problems/0763.划分字母区间.md)
+20. [贪心算法:合并区间](./problems/0056.合并区间.md)
+21. [本周小结!(贪心算法系列四)](./problems/周总结/20201224贪心周末总结.md)
+22. [贪心算法:单调递增的数字](./problems/0738.单调递增的数字.md)
+23. [贪心算法:买卖股票的最佳时机含手续费](./problems/0714.买卖股票的最佳时机含手续费.md)
+24. [贪心算法:我要监控二叉树!](./problems/0968.监控二叉树.md)
+25. [贪心算法:总结篇!(每逢总结必经典)](./problems/贪心算法总结篇.md)
+
+## 动态规划
+
+动态规划专题已经开始啦,来不及解释了,小伙伴们上车别掉队!
+
+1. [关于动态规划,你该了解这些!](./problems/动态规划理论基础.md)
+2. [动态规划:斐波那契数](./problems/0509.斐波那契数.md)
+3. [动态规划:爬楼梯](./problems/0070.爬楼梯.md)
+4. [动态规划:使用最小花费爬楼梯](./problems/0746.使用最小花费爬楼梯.md)
+5. [本周小结!(动态规划系列一)](./problems/周总结/20210107动规周末总结.md)
+6. [动态规划:不同路径](./problems/0062.不同路径.md)
+7. [动态规划:不同路径还不够,要有障碍!](./problems/0063.不同路径II.md)
+8. [动态规划:整数拆分,你要怎么拆?](./problems/0343.整数拆分.md)
+9. [动态规划:不同的二叉搜索树](./problems/0096.不同的二叉搜索树.md)
+10. [本周小结!(动态规划系列二)](./problems/周总结/20210114动规周末总结.md)
+
+背包问题系列:
+
+
+
+1. [关于贪心算法,你该了解这些!](./problems/贪心算法理论基础.md)
+2. [贪心算法:分发饼干](./problems/0455.分发饼干.md)
+3. [贪心算法:摆动序列](./problems/0376.摆动序列.md)
+4. [贪心算法:最大子序和](./problems/0053.最大子序和.md)
+5. [本周小结!(贪心算法系列一)](./problems/周总结/20201126贪心周末总结.md)
+6. [贪心算法:买卖股票的最佳时机II](./problems/0122.买卖股票的最佳时机II.md)
+7. [贪心算法:跳跃游戏](./problems/0055.跳跃游戏.md)
+8. [贪心算法:跳跃游戏II](./problems/0045.跳跃游戏II.md)
+9. [贪心算法:K次取反后最大化的数组和](./problems/1005.K次取反后最大化的数组和.md)
+10. [本周小结!(贪心算法系列二)](./problems/周总结/20201203贪心周末总结.md)
+11. [贪心算法:加油站](./problems/0134.加油站.md)
+12. [贪心算法:分发糖果](./problems/0135.分发糖果.md)
+13. [贪心算法:柠檬水找零](./problems/0860.柠檬水找零.md)
+14. [贪心算法:根据身高重建队列](./problems/0406.根据身高重建队列.md)
+15. [本周小结!(贪心算法系列三)](./problems/周总结/20201217贪心周末总结.md)
+16. [贪心算法:根据身高重建队列(续集)](./problems/根据身高重建队列(vector原理讲解).md)
+17. [贪心算法:用最少数量的箭引爆气球](./problems/0452.用最少数量的箭引爆气球.md)
+18. [贪心算法:无重叠区间](./problems/0435.无重叠区间.md)
+19. [贪心算法:划分字母区间](./problems/0763.划分字母区间.md)
+20. [贪心算法:合并区间](./problems/0056.合并区间.md)
+21. [本周小结!(贪心算法系列四)](./problems/周总结/20201224贪心周末总结.md)
+22. [贪心算法:单调递增的数字](./problems/0738.单调递增的数字.md)
+23. [贪心算法:买卖股票的最佳时机含手续费](./problems/0714.买卖股票的最佳时机含手续费.md)
+24. [贪心算法:我要监控二叉树!](./problems/0968.监控二叉树.md)
+25. [贪心算法:总结篇!(每逢总结必经典)](./problems/贪心算法总结篇.md)
+
+## 动态规划
+
+动态规划专题已经开始啦,来不及解释了,小伙伴们上车别掉队!
+
+1. [关于动态规划,你该了解这些!](./problems/动态规划理论基础.md)
+2. [动态规划:斐波那契数](./problems/0509.斐波那契数.md)
+3. [动态规划:爬楼梯](./problems/0070.爬楼梯.md)
+4. [动态规划:使用最小花费爬楼梯](./problems/0746.使用最小花费爬楼梯.md)
+5. [本周小结!(动态规划系列一)](./problems/周总结/20210107动规周末总结.md)
+6. [动态规划:不同路径](./problems/0062.不同路径.md)
+7. [动态规划:不同路径还不够,要有障碍!](./problems/0063.不同路径II.md)
+8. [动态规划:整数拆分,你要怎么拆?](./problems/0343.整数拆分.md)
+9. [动态规划:不同的二叉搜索树](./problems/0096.不同的二叉搜索树.md)
+10. [本周小结!(动态规划系列二)](./problems/周总结/20210114动规周末总结.md)
+
+背包问题系列:
+
+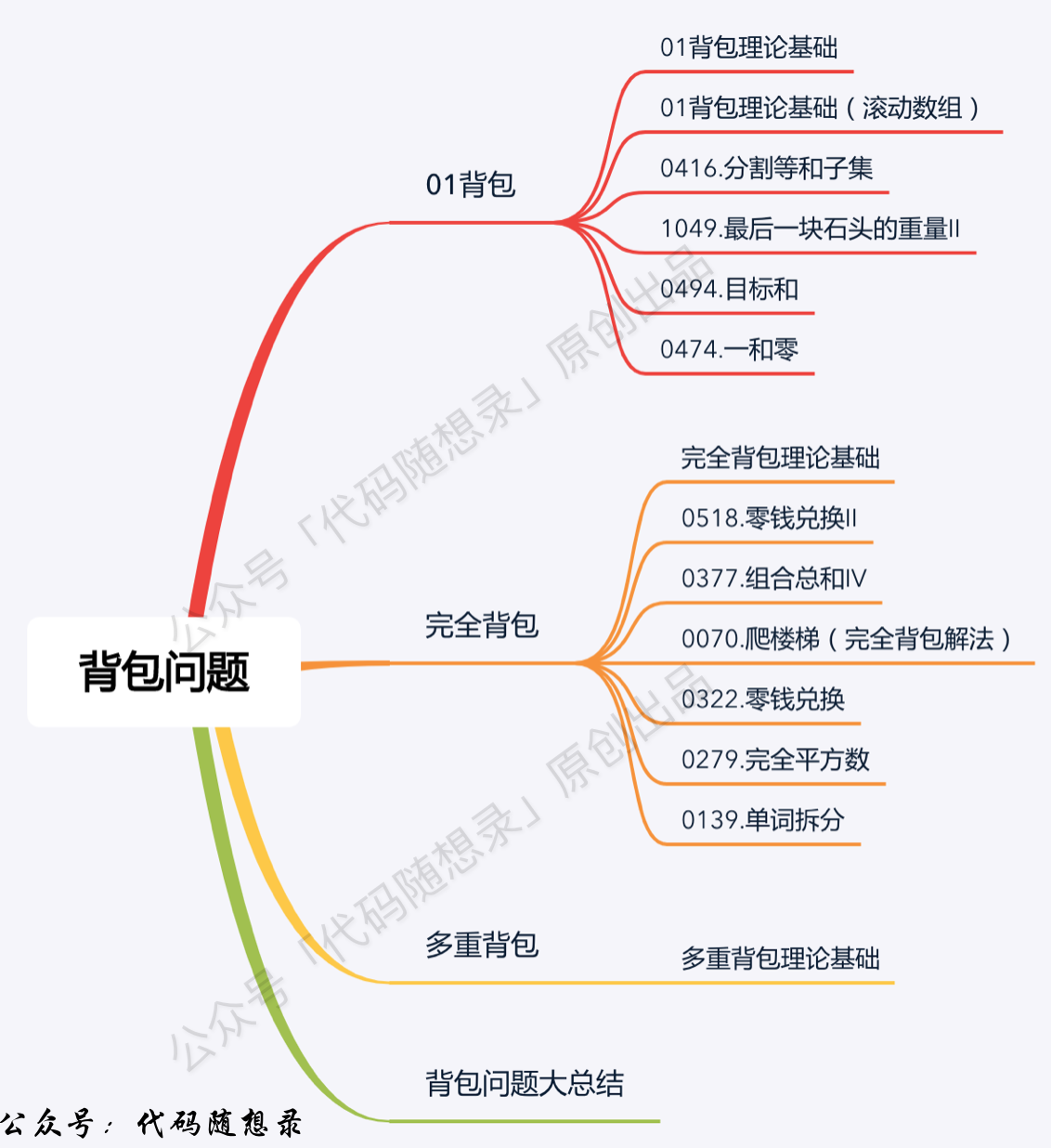 +
+11. [动态规划:关于01背包问题,你该了解这些!](./problems/背包理论基础01背包-1.md)
+12. [动态规划:关于01背包问题,你该了解这些!(滚动数组)](./problems/背包理论基础01背包-2.md)
+13. [动态规划:分割等和子集可以用01背包!](./problems/0416.分割等和子集.md)
+14. [动态规划:最后一块石头的重量 II](./problems/1049.最后一块石头的重量II.md)
+15. [本周小结!(动态规划系列三)](./problems/周总结/20210121动规周末总结.md)
+16. [动态规划:目标和!](./problems/0494.目标和.md)
+17. [动态规划:一和零!](./problems/0474.一和零.md)
+18. [动态规划:关于完全背包,你该了解这些!](./problems/背包问题理论基础完全背包.md)
+19. [动态规划:给你一些零钱,你要怎么凑?](./problems/0518.零钱兑换II.md)
+20. [本周小结!(动态规划系列四)](./problems/周总结/20210128动规周末总结.md)
+21. [动态规划:Carl称它为排列总和!](./problems/0377.组合总和Ⅳ.md)
+22. [动态规划:以前我没得选,现在我选择再爬一次!](./problems/0070.爬楼梯完全背包版本.md)
+23. [动态规划: 给我个机会,我再兑换一次零钱](./problems/0322.零钱兑换.md)
+24. [动态规划:一样的套路,再求一次完全平方数](./problems/0279.完全平方数.md)
+25. [本周小结!(动态规划系列五)](./problems/周总结/20210204动规周末总结.md)
+26. [动态规划:单词拆分](./problems/0139.单词拆分.md)
+27. [动态规划:关于多重背包,你该了解这些!](./problems/背包问题理论基础多重背包.md)
+28. [听说背包问题很难? 这篇总结篇来拯救你了](./problems/背包总结篇.md)
+
+打家劫舍系列:
+
+29. [动态规划:开始打家劫舍!](./problems/0198.打家劫舍.md)
+30. [动态规划:继续打家劫舍!](./problems/0213.打家劫舍II.md)
+31. [动态规划:还要打家劫舍!](./problems/0337.打家劫舍III.md)
+
+股票系列:
+
+
+
+11. [动态规划:关于01背包问题,你该了解这些!](./problems/背包理论基础01背包-1.md)
+12. [动态规划:关于01背包问题,你该了解这些!(滚动数组)](./problems/背包理论基础01背包-2.md)
+13. [动态规划:分割等和子集可以用01背包!](./problems/0416.分割等和子集.md)
+14. [动态规划:最后一块石头的重量 II](./problems/1049.最后一块石头的重量II.md)
+15. [本周小结!(动态规划系列三)](./problems/周总结/20210121动规周末总结.md)
+16. [动态规划:目标和!](./problems/0494.目标和.md)
+17. [动态规划:一和零!](./problems/0474.一和零.md)
+18. [动态规划:关于完全背包,你该了解这些!](./problems/背包问题理论基础完全背包.md)
+19. [动态规划:给你一些零钱,你要怎么凑?](./problems/0518.零钱兑换II.md)
+20. [本周小结!(动态规划系列四)](./problems/周总结/20210128动规周末总结.md)
+21. [动态规划:Carl称它为排列总和!](./problems/0377.组合总和Ⅳ.md)
+22. [动态规划:以前我没得选,现在我选择再爬一次!](./problems/0070.爬楼梯完全背包版本.md)
+23. [动态规划: 给我个机会,我再兑换一次零钱](./problems/0322.零钱兑换.md)
+24. [动态规划:一样的套路,再求一次完全平方数](./problems/0279.完全平方数.md)
+25. [本周小结!(动态规划系列五)](./problems/周总结/20210204动规周末总结.md)
+26. [动态规划:单词拆分](./problems/0139.单词拆分.md)
+27. [动态规划:关于多重背包,你该了解这些!](./problems/背包问题理论基础多重背包.md)
+28. [听说背包问题很难? 这篇总结篇来拯救你了](./problems/背包总结篇.md)
+
+打家劫舍系列:
+
+29. [动态规划:开始打家劫舍!](./problems/0198.打家劫舍.md)
+30. [动态规划:继续打家劫舍!](./problems/0213.打家劫舍II.md)
+31. [动态规划:还要打家劫舍!](./problems/0337.打家劫舍III.md)
+
+股票系列:
+
+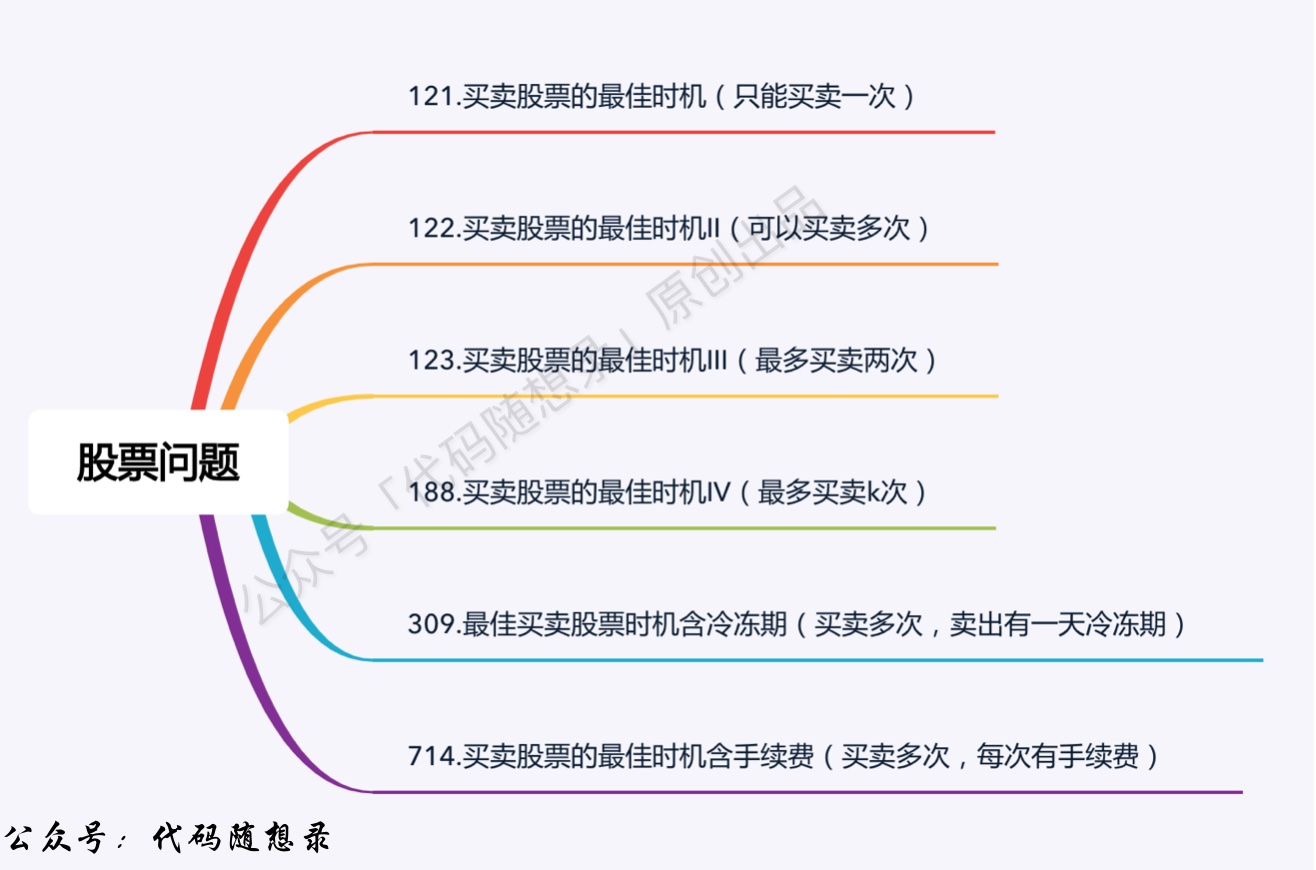 +
+32. [动态规划:买卖股票的最佳时机](./problems/0121.买卖股票的最佳时机.md)
+33. [动态规划:本周我们都讲了这些(系列六)](./problems/周总结/20210225动规周末总结.md)
+33. [动态规划:买卖股票的最佳时机II](./problems/0122.买卖股票的最佳时机II(动态规划).md)
+34. [动态规划:买卖股票的最佳时机III](./problems/0123.买卖股票的最佳时机III.md)
+35. [动态规划:买卖股票的最佳时机IV](./problems/0188.买卖股票的最佳时机IV.md)
+36. [动态规划:最佳买卖股票时机含冷冻期](./problems/0309.最佳买卖股票时机含冷冻期.md)
+37. [动态规划:本周我们都讲了这些(系列七)](./problems/周总结/20210304动规周末总结.md)
+38. [动态规划:买卖股票的最佳时机含手续费](./problems/0714.买卖股票的最佳时机含手续费(动态规划).md)
+39. [动态规划:股票系列总结篇](./problems/动态规划-股票问题总结篇.md)
+
+子序列系列:
+
+40. [动态规划:最长递增子序列](./problems/0300.最长上升子序列.md)
+41. [动态规划:最长连续递增序列](./problems/0674.最长连续递增序列.md)
+42. [动态规划:最长重复子数组](./problems/0718.最长重复子数组.md)
+43. [动态规划:最长公共子序列](./problems/1143.最长公共子序列.md)
+45. [动态规划:不相交的线](./problems/1035.不相交的线.md)
+46. [动态规划:最大子序和](./problems/0053.最大子序和(动态规划).md)
+47. [动态规划:判断子序列](./problems/0392.判断子序列.md)
+48. [动态规划:不同的子序列](./problems/0115.不同的子序列.md)
+49. [动态规划:两个字符串的删除操作](./problems/0583.两个字符串的删除操作.md)
+51. [动态规划:编辑距离](./problems/0072.编辑距离.md)
+52. [为了绝杀编辑距离,Carl做了三步铺垫,你都知道么?](./problems/为了绝杀编辑距离,卡尔做了三步铺垫.md)
+53. [动态规划:回文子串](./problems/0647.回文子串.md)
+54. [动态规划:最长回文子序列](./problems/0516.最长回文子序列.md)
-* 高级数据结构经典题目
- * 并查集
- * 最小生成树
- * 线段树
- * 树状数组
- * 字典树
-* 海量数据处理
(持续更新中....)
+## 图论
+
+## 十大排序
+
+## 数论
+
+## 高级数据结构经典题目
+
+* 并查集
+* 最小生成树
+* 线段树
+* 树状数组
+* 字典树
+
+## 海量数据处理
# 算法模板
[各类基础算法模板](https://github.com/youngyangyang04/leetcode/blob/master/problems/算法模板.md)
-# LeetCode 最强题解:
+# 备战秋招
-|题目 | 类型 | 难度 | 解题方法 |
-|---|---| ---| --- |
-|[0001.两数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0001.两数之和.md) | 数组|简单|**暴力** **哈希**|
-|[0015.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md) | 数组 |中等|**双指针** **哈希**|
-|[0017.电话号码的字母组合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0017.电话号码的字母组合.md) | 回溯 |中等|**回溯**|
-|[0018.四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md) | 数组 |中等|**双指针**|
-|[0019.删除链表的倒数第N个节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0019.删除链表的倒数第N个节点.md) | 链表 |中等|**双指针**|
-|[0020.有效的括号](https://github.com/youngyangyang04/leetcode/blob/master/problems/0020.有效的括号.md) | 栈 |简单|**栈**|
-|[0021.合并两个有序链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0021.合并两个有序链表.md) |链表 |简单|**模拟** |
-|[0024.两两交换链表中的节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0024.两两交换链表中的节点.md) |链表 |中等|**模拟** |
-|[0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md) |数组 |简单|**暴力** **快慢指针/快慢指针** |
-|[0027.移除元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0027.移除元素.md) |数组 |简单| **暴力** **双指针/快慢指针/双指针**|
-|[0028.实现strStr()](https://github.com/youngyangyang04/leetcode/blob/master/problems/0028.实现strStr().md) |字符串 |简单| **KMP** |
-|[0031.下一个排列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0031.下一个排列.md) |数组 |中等| **模拟** 这道题目还是有难度的|
-|[0034.在排序数组中查找元素的第一个和最后一个位置](https://github.com/youngyangyang04/leetcode/blob/master/problems/0031.下一个排列.md) |数组 |中等| **二分查找**比35.搜索插入位置难一些|
-|[0035.搜索插入位置](https://github.com/youngyangyang04/leetcode/blob/master/problems/0035.搜索插入位置.md) |数组 |简单| **暴力** **二分**|
-|[0037.解数独](https://github.com/youngyangyang04/leetcode/blob/master/problems/0037.解数独.md) |回溯 |困难| **回溯**|
-|[0039.组合总和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0039.组合总和.md) |数组/回溯 |中等| **回溯**|
-|[0040.组合总和II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0040.组合总和II.md) |数组/回溯 |中等| **回溯**|
-|[0042.接雨水](https://github.com/youngyangyang04/leetcode/blob/master/problems/0042.接雨水.md) |数组/栈/双指针 |困难| **双指针** **单调栈** **动态规划**|
-|[0045.跳跃游戏II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0045.跳跃游戏II.md) |贪心 |困难| **贪心**|
-|[0046.全排列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0046.全排列.md) |回溯|中等| **回溯**|
-|[0047.全排列II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0047.全排列II.md) |回溯|中等| **回溯**|
-|[0051.N皇后](https://github.com/youngyangyang04/leetcode/blob/master/problems/0051.N皇后.md) |回溯|困难| **回溯**|
-|[0052.N皇后II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0052.N皇后II.md) |回溯|困难| **回溯**|
-|[0053.最大子序和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0053.最大子序和.md) |数组 |简单|**暴力** **贪心** 动态规划 分治|
-|[0055.跳跃游戏](https://github.com/youngyangyang04/leetcode/blob/master/problems/0053.最大子序和.md) |数组 |中等| **贪心** 经典题目|
-|[0056.合并区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0056.合并区间.md) |数组 |中等| **贪心** 以为是模拟题,其实是贪心|
-|[0057.插入区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0057.插入区间.md) |数组 |困难| **模拟** 是一道数组难题|
-|[0059.螺旋矩阵II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0059.螺旋矩阵II.md) |数组 |中等|**模拟**|
-|[0062.不同路径](https://github.com/youngyangyang04/leetcode/blob/master/problems/0062.不同路径.md) |数组、动态规划 |中等|**深搜** **动态规划** **数论**|
-|[0070.爬楼梯](https://github.com/youngyangyang04/leetcode/blob/master/problems/0070.爬楼梯.md) |动态规划|简单|**动态规划** dp里求排列|
-|[0077.组合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0077.组合.md) |回溯 |中等|**回溯**|
-|[0078.子集](https://github.com/youngyangyang04/leetcode/blob/master/problems/0078.子集.md) |回溯/数组 |中等|**回溯**|
-|[0083.删除排序链表中的重复元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0083.删除排序链表中的重复元素.md) |链表 |简单|**模拟**|
-|[0084.柱状图中最大的矩形](https://github.com/youngyangyang04/leetcode/blob/master/problems/0084.柱状图中最大的矩形.md) |数组 |困难|**单调栈**|
-|[0090.子集II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0090.子集II.md) |回溯/数组 |中等|**回溯**|
-|[0093.复原IP地址](https://github.com/youngyangyang04/leetcode/blob/master/problems/0093.复原IP地址) |回溯 |中等|**回溯**|
-|[0094.二叉树的中序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0094.二叉树的中序遍历.md) |树 |中等|**递归** **迭代/栈**|
-|[0098.验证二叉搜索树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0098.验证二叉搜索树.md) |树 |中等|**递归**|
-|[0100.相同的树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0100.相同的树.md) |树 |简单|**递归** |
-|[0101.对称二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0101.对称二叉树.md) |树 |简单|**递归** **迭代/队列/栈** 和100. 相同的树 相似|
-|[0102.二叉树的层序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0102.二叉树的层序遍历.md) |树 |中等|**广度优先搜索/队列**|
-|[0104.二叉树的最大深度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0104.二叉树的最大深度.md) |树 |简单|**递归** **迭代/队列/BFS**|
-|[0105.从前序与中序遍历序列构造二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0105.从前序与中序遍历序列构造二叉树.md) |二叉树 |中等|**递归**|
-|[0106.从中序与后序遍历序列构造二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0106.从中序与后序遍历序列构造二叉树.md) |二叉树 |中等|**递归** 根据数组构造二叉树|
-|[0107.二叉树的层次遍历II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0107.二叉树的层次遍历II.md) |树 |简单|**广度优先搜索/队列/BFS**|
-|[0108.将有序数组转换为二叉搜索树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0108.将有序数组转换为二叉搜索树.md) |二叉搜索树 |中等|**递归** **迭代** 通过递归函数返回值构造树|
-|[0110.平衡二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0110.平衡二叉树.md) |二叉树 |简单|**递归**|
-|[0111.二叉树的最小深度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0111.二叉树的最小深度.md) |二叉树 |简单|**递归** **队列/BFS**|
-|[0112.路径总和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0112.路径总和.md) |二叉树树 |简单|**深度优先搜索/递归** **回溯** **栈** 思考递归函数什么时候需要返回值|
-|[0113.路径总和II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0113.路径总和II.md) |二叉树树 |简单|**深度优先搜索/递归** **回溯** **栈**|
-|[0116.填充每个节点的下一个右侧节点指针](https://github.com/youngyangyang04/leetcode/blob/master/problems/0116.填充每个节点的下一个右侧节点指针.md) |二叉树 |中等|**递归** **迭代/广度优先搜索**|
-|[0117.填充每个节点的下一个右侧节点指针II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0117.填充每个节点的下一个右侧节点指针II.md) |二叉树 |中等|**递归** **迭代/广度优先搜索**|
-|[0122.买卖股票的最佳时机II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0122.买卖股票的最佳时机II.md) |贪心 |简单|**贪心** |
-|[0127.单词接龙](https://github.com/youngyangyang04/leetcode/blob/master/problems/0127.单词接龙.md) |广度优先搜索 |中等|**广度优先搜索**|
-|[0129.求根到叶子节点数字之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0129.求根到叶子节点数字之和.md) |二叉树 |中等|**递归/回溯** 递归里隐藏着回溯,和113.路径总和II类似|
-|[0131.分割回文串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0131.分割回文串.md) |回溯 |中等|**回溯**|
-|[0135.分发糖果](https://github.com/youngyangyang04/leetcode/blob/master/problems/0135.分发糖果.md) |贪心 |困难|**贪心**好题目|
-|[0139.单词拆分](https://github.com/youngyangyang04/leetcode/blob/master/problems/0139.单词拆分.md) |动态规划 |中等|**完全背包** **回溯法**|
-|[0141.环形链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0141.环形链表.md) |链表 |简单|**快慢指针/双指针**|
-|[0142.环形链表II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0142.环形链表II.md) |链表 |中等|**快慢指针/双指针**|
-|[0143.重排链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0143.重排链表.md) |链表 |中等|**快慢指针/双指针** 也可以用数组,双向队列模拟,考察链表综合操作的好题|
-|[0144.二叉树的前序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0144.二叉树的前序遍历.md) |树 |中等|**递归** **迭代/栈**|
-|[0145.二叉树的后序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0145.二叉树的后序遍历.md) |树 |困难|**递归** **迭代/栈**|
-|[0147.对链表进行插入排序](https://github.com/youngyangyang04/leetcode/blob/master/problems/0147.对链表进行插入排序.md) |链表 |中等|**模拟** 考察链表综合操作|
-|[0150.逆波兰表达式求值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0150.逆波兰表达式求值.md) |栈 |中等|**栈**|
-|[0151.翻转字符串里的单词](https://github.com/youngyangyang04/leetcode/blob/master/problems/0151.翻转字符串里的单词.md) |字符串 |中等|**模拟/双指针**|
-|[0155.最小栈](https://github.com/youngyangyang04/leetcode/blob/master/problems/0155.最小栈.md) |栈 |简单|**栈**|
-|[0199.二叉树的右视图](https://github.com/youngyangyang04/leetcode/blob/master/problems/0199.二叉树的右视图.md) |二叉树 |中等|**广度优先遍历/队列**|
-|[0202.快乐数](https://github.com/youngyangyang04/leetcode/blob/master/problems/0202.快乐数.md) |哈希表 |简单|**哈希**|
-|[0203.移除链表元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0203.移除链表元素.md) |链表 |简单|**模拟** **虚拟头结点**|
-|[0205.同构字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0205.同构字符串.md) |哈希表 |简单| **哈希**|
-|[0206.翻转链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0206.翻转链表.md) |链表 |简单| **双指针法** **递归**|
-|[0209.长度最小的子数组](https://github.com/youngyangyang04/leetcode/blob/master/problems/0209.长度最小的子数组.md) |数组 |中等| **暴力** **滑动窗口**|
-|[0216.组合总和III](https://github.com/youngyangyang04/leetcode/blob/master/problems/0216.组合总和III.md) |数组/回溯 |中等| **回溯算法**|
-|[0219.存在重复元素II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0219.存在重复元素II.md) | 哈希表 |简单| **哈希** |
-|[0222.完全二叉树的节点个数](https://github.com/youngyangyang04/leetcode/blob/master/problems/0222.完全二叉树的节点个数.md) | 树 |简单| **递归** |
-|[0225.用队列实现栈](https://github.com/youngyangyang04/leetcode/blob/master/problems/0225.用队列实现栈.md) | 队列 |简单| **队列** |
-|[0226.翻转二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0226.翻转二叉树.md) |二叉树 |简单| **递归** **迭代**|
-|[0232.用栈实现队列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0232.用栈实现队列.md) | 栈 |简单| **栈** |
-|[0235.二叉搜索树的最近公共祖先](https://github.com/youngyangyang04/leetcode/blob/master/problems/0235.二叉搜索树的最近公共祖先.md) | 二叉搜索树 |简单| **递归** **迭代** |
-|[0236.二叉树的最近公共祖先](https://github.com/youngyangyang04/leetcode/blob/master/problems/0236.二叉树的最近公共祖先.md) | 二叉树 |中等| **递归/回溯** 与其说是递归,不如说是回溯|
-|[0237.删除链表中的节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0237.删除链表中的节点.md) |链表 |简单| **原链表移除** **添加虚拟节点** 递归|
-|[0239.滑动窗口最大值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0239.滑动窗口最大值.md) |滑动窗口/队列 |困难| **单调队列**|
-|[0242.有效的字母异位词](https://github.com/youngyangyang04/leetcode/blob/master/problems/0242.有效的字母异位词.md) |哈希表 |简单| **哈希**|
-|[0257.二叉树的所有路径](https://github.com/youngyangyang04/leetcode/blob/master/problems/0257.二叉树的所有路径.md) |树 |简单| **递归/回溯**|
-|[0283.移动零](https://github.com/youngyangyang04/leetcode/blob/master/problems/0283.移动零.md) |数组 |简单| **双指针** 和 27.移除元素 一个套路|
-|[0300.最长上升子序列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0300.最长上升子序列.md) |动态规划 |中等| **动态规划**|
-|[0316.去除重复字母](https://github.com/youngyangyang04/leetcode/blob/master/problems/0316.去除重复字母.md) |贪心/字符串 |中等| **单调栈** 这道题目处理的情况比较多,属于单调栈中的难题|
-|[0332.重新安排行程](https://github.com/youngyangyang04/leetcode/blob/master/problems/0332.重新安排行程.md) |深度优先搜索/回溯 |中等| **深度优先搜索/回溯算法**|
-|[0343.整数拆分](https://github.com/youngyangyang04/leetcode/blob/master/problems/0343.整数拆分.md) |动态规划/贪心 |中等| **动态规划**|
-|[0344.反转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0344.反转字符串.md) |字符串 |简单| **双指针**|
-|[0347.前K个高频元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0347.前K个高频元素.md) |哈希/堆/优先级队列 |中等| **哈希/优先级队列**|
-|[0349.两个数组的交集](https://github.com/youngyangyang04/leetcode/blob/master/problems/0349.两个数组的交集.md) |哈希表 |简单|**哈希**|
-|[0350.两个数组的交集II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0350.两个数组的交集II.md) |哈希表 |简单|**哈希**|
-|[0377.组合总和Ⅳ](https://github.com/youngyangyang04/leetcode/blob/master/problems/0377.组合总和Ⅳ.md) |动态规划 |中等|**完全背包** 求排列|
-|[0383.赎金信](https://github.com/youngyangyang04/leetcode/blob/master/problems/0383.赎金信.md) |数组 |简单|**暴力** **字典计数** **哈希**|
-|[0404.左叶子之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0404.左叶子之和.md) |树/二叉树 |简单|**递归** **迭代**|
-|[0406.根据身高重建队列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0406.根据身高重建队列.md) |树/二叉树 |简单|**递归** **迭代**|
-|[0416.分割等和子集](https://github.com/youngyangyang04/leetcode/blob/master/problems/0416.分割等和子集.md) |动态规划 |中等|**背包问题/01背包**|
-|[0429.N叉树的层序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0429.N叉树的层序遍历.md) |树 |简单|**队列/广度优先搜索**|
-|[0434.字符串中的单词数](https://github.com/youngyangyang04/leetcode/blob/master/problems/0434.字符串中的单词数.md) |字符串 |简单|**模拟**|
-|[0435.无重叠区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0435.无重叠区间.md) |贪心 |中等|**贪心** 经典题目,有点难|
-|[0450.删除二叉搜索树中的节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0450.删除二叉搜索树中的节点.md) |树 |中等|**递归**|
-|[0452.用最少数量的箭引爆气球](https://github.com/youngyangyang04/leetcode/blob/master/problems/0452.用最少数量的箭引爆气球.md) |贪心/排序 |中等|**贪心** 经典题目|
-|[0454.四数相加II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0454.四数相加II.md) |哈希表 |中等| **哈希**|
-|[0455.分发饼干](https://github.com/youngyangyang04/leetcode/blob/master/problems/0455.分发饼干.md) |贪心 |简单| **贪心**|
-|[0459.重复的子字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0459.重复的子字符串.md) |字符创 |简单| **KMP**|
-|[0473.火柴拼正方形](https://github.com/youngyangyang04/leetcode/blob/master/problems/0473.火柴拼正方形.md) |深度优先搜索|中等| **回溯算法** 和698.划分为k个相等的子集差不多|
-|[0474.一和零](https://github.com/youngyangyang04/leetcode/blob/master/problems/0474.一和零.md) |动态规划 |中等| **多重背包** 好题目|
-|[0486.预测赢家](https://github.com/youngyangyang04/leetcode/blob/master/problems/0486.预测赢家.md) |动态规划 |中等| **递归** **记忆递归** **动态规划**|
-|[0491.递增子序列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0491.递增子序列.md) |深度优先搜索 |中等|**深度优先搜索/回溯算法** 这个去重有意思|
-|[0496.下一个更大元素I](https://github.com/youngyangyang04/leetcode/blob/master/problems/0496.下一个更大元素I.md) |栈 |中等|**单调栈** 入门题目,但是两个数组还是有点绕的|
-|[0501.二叉搜索树中的众数](https://github.com/youngyangyang04/leetcode/blob/master/problems/0501.二叉搜索树中的众数.md) |二叉树 |简单|**递归/中序遍历**|
-|[0513.找树左下角的值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0513.找树左下角的值.md) |二叉树 |中等|**递归** **迭代**|
-|[0515.在每个树行中找最大值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0515.在每个树行中找最大值.md) |二叉树 |简单|**广度优先搜索/队列**|
-|[0518.零钱兑换II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0518.零钱兑换II.md) |动态规划 |中等|**动态规划** dp里求组合|
-|[0530.二叉搜索树的最小绝对差](https://github.com/youngyangyang04/leetcode/blob/master/problems/0530.二叉搜索树的最小绝对差.md) |二叉树搜索树 |简单|**递归** **迭代**|
-|[0538.把二叉搜索树转换为累加树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0538.把二叉搜索树转换为累加树.md) |二叉搜索树 |简单|**递归** **迭代**|
-|[0541.反转字符串II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0541.反转字符串II.md) |字符串 |简单| **模拟**|
-|[0559.N叉树的最大深度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0559.N叉树的最大深度.md) |N叉树 |简单| **递归**|
-|[0572.另一个树的子树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0572.另一个树的子树.md) |二叉树 |简单| **递归**|
-|[0575.分糖果](https://github.com/youngyangyang04/leetcode/blob/master/problems/0575.分糖果.md) |哈希表 |简单|**哈希**|
-|[0589.N叉树的前序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0589.N叉树的前序遍历.md) |N叉树 |简单|**递归** **栈/迭代**|
-|[0590.N叉树的后序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0590.N叉树的后序遍历.md) |N叉树 |简单|**递归** **栈/迭代**|
-|[0617.合并二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0617.合并二叉树.md) |树 |简单|**递归** **迭代**|
-|[0637.二叉树的层平均值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0637.二叉树的层平均值.md) |树 |简单|**广度优先搜索/队列**|
-|[0649.Dota2参议院](https://github.com/youngyangyang04/leetcode/blob/master/problems/0649.Dota2参议院.md) |贪心 |简单|**贪心算法** 简单的贪心策略但代码实现很有技巧|
-|[0654.最大二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0654.最大二叉树.md) |树 |中等|**递归**|
-|[0685.冗余连接II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0685.冗余连接II.md) | 并查集/树/图 |困难|**并查集**|
-|[0669.修剪二叉搜索树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0669.修剪二叉搜索树.md) | 二叉搜索树/二叉树 |简单|**递归** **迭代**|
-|[0698.划分为k个相等的子集](https://github.com/youngyangyang04/leetcode/blob/master/problems/0698.划分为k个相等的子集.md) |回溯算法|中等|动态规划 **回溯算法** 这其实是组合问题,使用了两次递归,好题|
-|[0700.二叉搜索树中的搜索](https://github.com/youngyangyang04/leetcode/blob/master/problems/0700.二叉搜索树中的搜索.md) |二叉搜索树 |简单|**递归** **迭代**|
-|[0701.二叉搜索树中的插入操作](https://github.com/youngyangyang04/leetcode/blob/master/problems/0701.二叉搜索树中的插入操作.md) |二叉搜索树 |简单|**递归** **迭代**|
-|[0705.设计哈希集合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0705.设计哈希集合.md) |哈希表 |简单|**模拟**|
-|[0707.设计链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0707.设计链表.md) |链表 |中等|**模拟**|
-|[0714.买卖股票的最佳时机含手续费](https://github.com/youngyangyang04/leetcode/blob/master/problems/0714.买卖股票的最佳时机含手续费.md) |贪心 动态规划 |中等|**贪心** **动态规划** 和122.买卖股票的最佳时机II类似,贪心的思路很巧妙|
-|[0763.划分字母区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0763.划分字母区间.md) |贪心 |中等|**双指针/贪心** 体现贪心尽可能多的思想|
-|[0738.单调递增的数字](https://github.com/youngyangyang04/leetcode/blob/master/problems/0738.单调递增的数字.md) |贪心算法 |中等|**贪心算法** 思路不错,贪心好题|
-|[0739.每日温度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0739.每日温度.md) |栈 |中等|**单调栈** 适合单调栈入门|
-|[0767.重构字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0767.重构字符串.md) |字符串 |中等|**字符串** + 排序+一点贪心|
-|[0841.钥匙和房间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0841.钥匙和房间.md) |孤岛问题 |中等|**bfs** **dfs**|
-|[0844.比较含退格的字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0844.比较含退格的字符串.md) |字符串 |简单|**栈** **双指针优化** 使用栈的思路但没有必要使用栈|
-|[0860.柠檬水找零](https://github.com/youngyangyang04/leetcode/blob/master/problems/0860.柠檬水找零.md) |贪心算法 |简单|**贪心算法** 基础题目|
-|[0925.长按键入](https://github.com/youngyangyang04/leetcode/blob/master/problems/0925.长按键入.md) |字符串 |简单|**双指针/模拟** 是一道模拟类型的题目|
-|[0941.有效的山脉数组](https://github.com/youngyangyang04/leetcode/blob/master/problems/0941.有效的山脉数组.md) |数组 |简单|**双指针**|
-|[0968.监控二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0968.监控二叉树.md) |二叉树 |困难|**贪心** 贪心与二叉树的结合|
-|[0973.最接近原点的K个点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0973.最接近原点的K个点.md) |优先级队列 |中等|**优先级队列**|
-|[0977.有序数组的平方](https://github.com/youngyangyang04/leetcode/blob/master/problems/0977.有序数组的平方.md) |数组 |中等|**双指针** 还是比较巧妙的|
-|[1002.查找常用字符](https://github.com/youngyangyang04/leetcode/blob/master/problems/1002.查找常用字符.md) |栈 |简单|**栈**|
-|[1005.K次取反后最大化的数组和](https://github.com/youngyangyang04/leetcode/blob/master/problems/1005.K次取反后最大化的数组和.md) |贪心/排序 |简单|**贪心算法** 贪心基础题目|
-|[1047.删除字符串中的所有相邻重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/1047.删除字符串中的所有相邻重复项.md) |哈希表 |简单|**哈希表/数组**|
-|[1049.最后一块石头的重量II](https://github.com/youngyangyang04/leetcode/blob/master/problems/1049.最后一块石头的重量II.md) |动态规划 |中等|**01背包**|
-|[1207.独一无二的出现次数](https://github.com/youngyangyang04/leetcode/blob/master/problems/1207.独一无二的出现次数.md) |哈希表 |简单|**哈希** 两层哈希|
-|[1221.分割平衡字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/1221.分割平衡字符串.md) |贪心 |简单|**贪心算法** 基础题目|
-|[1356.根据数字二进制下1的数目排序](https://github.com/youngyangyang04/leetcode/blob/master/problems/1356.根据数字二进制下1的数目排序.md) |位运算 |简单|**位运算** 巧妙的计算二进制中1的数量|
-|[1365.有多少小于当前数字的数字](https://github.com/youngyangyang04/leetcode/blob/master/problems/1365.有多少小于当前数字的数字.md) |数组、哈希表 |简单|**哈希** 从后遍历的技巧很不错|
-|[1382.将二叉搜索树变平衡](https://github.com/youngyangyang04/leetcode/blob/master/problems/1047.删除字符串中的所有相邻重复项.md) |二叉搜索树 |中等|**递归** **迭代** 98和108的组合题目|
-|[1403.非递增顺序的最小子序列](https://github.com/youngyangyang04/leetcode/blob/master/problems/1403.非递增顺序的最小子序列.md) | 贪心算法|简单|**贪心算法** 贪心基础题目|
-|[1518.换酒问题](https://github.com/youngyangyang04/leetcode/blob/master/problems/1518.换酒问题.md) | 贪心算法|简单|**贪心算法** 贪心基础题目|
-|[剑指Offer05.替换空格](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md) |字符串 |简单|**双指针**|
-|[ 剑指Offer58-I.翻转单词顺序](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md) |字符串 |简单|**模拟/双指针**|
-|[剑指Offer58-II.左旋转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer58-II.左旋转字符串.md) |字符串 |简单|**反转操作**|
-|[剑指Offer59-I.滑动窗口的最大值](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer59-I.滑动窗口的最大值.md) |滑动窗口/队列 |困难|**单调队列**|
-|[面试题02.07.链表相交](https://github.com/youngyangyang04/leetcode/blob/master/problems/面试题02.07.链表相交.md) |链表 |简单|**模拟**|
+1. [技术比较弱,也对技术不感兴趣,如何选择方向?](https://mp.weixin.qq.com/s/ZCzFiAHZHLqHPLJQXNm75g)
+2. [刷题就用库函数了,怎么了?](https://mp.weixin.qq.com/s/6K3_OSaudnHGq2Ey8vqYfg)
+3. [关于实习,大家可能有点迷茫!](https://mp.weixin.qq.com/s/xcxzi7c78kQGjvZ8hh7taA)
+4. [马上秋招了,慌得很!](https://mp.weixin.qq.com/s/7q7W8Cb2-a5U5atZdOnOFA)
-持续更新中....
+# B站算法视频讲解
+
+以下为[B站「代码随想录」](https://space.bilibili.com/525438321)算法讲解视频:
+
+* [KMP算法(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd)
+* [KMP算法(代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
+* [回溯算法理论基础](https://www.bilibili.com/video/BV1cy4y167mM)
+* [回溯算法之组合问题(力扣题目:77.组合)](https://www.bilibili.com/video/BV1ti4y1L7cv)
+* [组合问题的剪枝操作(对应力扣题目:77.组合)](https://www.bilibili.com/video/BV1wi4y157er)
+* [组合总和(对应力扣题目:39.组合总和)](https://www.bilibili.com/video/BV1KT4y1M7HJ/)
+* [分割回文串(对应力扣题目:131.分割回文串)](https://www.bilibili.com/video/BV1c54y1e7k6)
+* [二叉树理论基础](https://www.bilibili.com/video/BV1Hy4y1t7ij)
+* [二叉树的递归遍历](https://www.bilibili.com/video/BV1Wh411S7xt)
+* [二叉树的非递归遍历(一)](https://www.bilibili.com/video/BV15f4y1W7i2)
+
+(持续更新中....)
# 关于作者
大家好,我是程序员Carl,哈工大师兄,ACM 校赛、黑龙江省赛、东北四省赛金牌、亚洲区域赛铜牌获得者,先后在腾讯和百度从事后端技术研发,CSDN博客专家。对算法和C++后端技术有一定的见解,利用工作之余重新刷leetcode。
-**加我的微信,备注:「个人简单介绍」+「组队刷题」**, 拉你进刷题群,每天一道经典题目分析,而且题目不是孤立的,每一道题目之间都是有关系的,都是由浅入深一脉相承的,所以学习效果最好是每篇连续着看,也许之前你会某些知识点,但是一直没有把知识点串起来,这里每天一篇文章就会帮你把知识点串起来。
+加入刷题微信群,备注:「个人简单介绍」 + 组队刷题
+
+也欢迎与我交流,备注:「个人简单介绍」 + 交流,围观朋友圈,做点赞之交(备注没有自我介绍不通过哦)
+
+32. [动态规划:买卖股票的最佳时机](./problems/0121.买卖股票的最佳时机.md)
+33. [动态规划:本周我们都讲了这些(系列六)](./problems/周总结/20210225动规周末总结.md)
+33. [动态规划:买卖股票的最佳时机II](./problems/0122.买卖股票的最佳时机II(动态规划).md)
+34. [动态规划:买卖股票的最佳时机III](./problems/0123.买卖股票的最佳时机III.md)
+35. [动态规划:买卖股票的最佳时机IV](./problems/0188.买卖股票的最佳时机IV.md)
+36. [动态规划:最佳买卖股票时机含冷冻期](./problems/0309.最佳买卖股票时机含冷冻期.md)
+37. [动态规划:本周我们都讲了这些(系列七)](./problems/周总结/20210304动规周末总结.md)
+38. [动态规划:买卖股票的最佳时机含手续费](./problems/0714.买卖股票的最佳时机含手续费(动态规划).md)
+39. [动态规划:股票系列总结篇](./problems/动态规划-股票问题总结篇.md)
+
+子序列系列:
+
+40. [动态规划:最长递增子序列](./problems/0300.最长上升子序列.md)
+41. [动态规划:最长连续递增序列](./problems/0674.最长连续递增序列.md)
+42. [动态规划:最长重复子数组](./problems/0718.最长重复子数组.md)
+43. [动态规划:最长公共子序列](./problems/1143.最长公共子序列.md)
+45. [动态规划:不相交的线](./problems/1035.不相交的线.md)
+46. [动态规划:最大子序和](./problems/0053.最大子序和(动态规划).md)
+47. [动态规划:判断子序列](./problems/0392.判断子序列.md)
+48. [动态规划:不同的子序列](./problems/0115.不同的子序列.md)
+49. [动态规划:两个字符串的删除操作](./problems/0583.两个字符串的删除操作.md)
+51. [动态规划:编辑距离](./problems/0072.编辑距离.md)
+52. [为了绝杀编辑距离,Carl做了三步铺垫,你都知道么?](./problems/为了绝杀编辑距离,卡尔做了三步铺垫.md)
+53. [动态规划:回文子串](./problems/0647.回文子串.md)
+54. [动态规划:最长回文子序列](./problems/0516.最长回文子序列.md)
-* 高级数据结构经典题目
- * 并查集
- * 最小生成树
- * 线段树
- * 树状数组
- * 字典树
-* 海量数据处理
(持续更新中....)
+## 图论
+
+## 十大排序
+
+## 数论
+
+## 高级数据结构经典题目
+
+* 并查集
+* 最小生成树
+* 线段树
+* 树状数组
+* 字典树
+
+## 海量数据处理
# 算法模板
[各类基础算法模板](https://github.com/youngyangyang04/leetcode/blob/master/problems/算法模板.md)
-# LeetCode 最强题解:
+# 备战秋招
-|题目 | 类型 | 难度 | 解题方法 |
-|---|---| ---| --- |
-|[0001.两数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0001.两数之和.md) | 数组|简单|**暴力** **哈希**|
-|[0015.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md) | 数组 |中等|**双指针** **哈希**|
-|[0017.电话号码的字母组合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0017.电话号码的字母组合.md) | 回溯 |中等|**回溯**|
-|[0018.四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md) | 数组 |中等|**双指针**|
-|[0019.删除链表的倒数第N个节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0019.删除链表的倒数第N个节点.md) | 链表 |中等|**双指针**|
-|[0020.有效的括号](https://github.com/youngyangyang04/leetcode/blob/master/problems/0020.有效的括号.md) | 栈 |简单|**栈**|
-|[0021.合并两个有序链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0021.合并两个有序链表.md) |链表 |简单|**模拟** |
-|[0024.两两交换链表中的节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0024.两两交换链表中的节点.md) |链表 |中等|**模拟** |
-|[0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md) |数组 |简单|**暴力** **快慢指针/快慢指针** |
-|[0027.移除元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0027.移除元素.md) |数组 |简单| **暴力** **双指针/快慢指针/双指针**|
-|[0028.实现strStr()](https://github.com/youngyangyang04/leetcode/blob/master/problems/0028.实现strStr().md) |字符串 |简单| **KMP** |
-|[0031.下一个排列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0031.下一个排列.md) |数组 |中等| **模拟** 这道题目还是有难度的|
-|[0034.在排序数组中查找元素的第一个和最后一个位置](https://github.com/youngyangyang04/leetcode/blob/master/problems/0031.下一个排列.md) |数组 |中等| **二分查找**比35.搜索插入位置难一些|
-|[0035.搜索插入位置](https://github.com/youngyangyang04/leetcode/blob/master/problems/0035.搜索插入位置.md) |数组 |简单| **暴力** **二分**|
-|[0037.解数独](https://github.com/youngyangyang04/leetcode/blob/master/problems/0037.解数独.md) |回溯 |困难| **回溯**|
-|[0039.组合总和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0039.组合总和.md) |数组/回溯 |中等| **回溯**|
-|[0040.组合总和II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0040.组合总和II.md) |数组/回溯 |中等| **回溯**|
-|[0042.接雨水](https://github.com/youngyangyang04/leetcode/blob/master/problems/0042.接雨水.md) |数组/栈/双指针 |困难| **双指针** **单调栈** **动态规划**|
-|[0045.跳跃游戏II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0045.跳跃游戏II.md) |贪心 |困难| **贪心**|
-|[0046.全排列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0046.全排列.md) |回溯|中等| **回溯**|
-|[0047.全排列II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0047.全排列II.md) |回溯|中等| **回溯**|
-|[0051.N皇后](https://github.com/youngyangyang04/leetcode/blob/master/problems/0051.N皇后.md) |回溯|困难| **回溯**|
-|[0052.N皇后II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0052.N皇后II.md) |回溯|困难| **回溯**|
-|[0053.最大子序和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0053.最大子序和.md) |数组 |简单|**暴力** **贪心** 动态规划 分治|
-|[0055.跳跃游戏](https://github.com/youngyangyang04/leetcode/blob/master/problems/0053.最大子序和.md) |数组 |中等| **贪心** 经典题目|
-|[0056.合并区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0056.合并区间.md) |数组 |中等| **贪心** 以为是模拟题,其实是贪心|
-|[0057.插入区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0057.插入区间.md) |数组 |困难| **模拟** 是一道数组难题|
-|[0059.螺旋矩阵II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0059.螺旋矩阵II.md) |数组 |中等|**模拟**|
-|[0062.不同路径](https://github.com/youngyangyang04/leetcode/blob/master/problems/0062.不同路径.md) |数组、动态规划 |中等|**深搜** **动态规划** **数论**|
-|[0070.爬楼梯](https://github.com/youngyangyang04/leetcode/blob/master/problems/0070.爬楼梯.md) |动态规划|简单|**动态规划** dp里求排列|
-|[0077.组合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0077.组合.md) |回溯 |中等|**回溯**|
-|[0078.子集](https://github.com/youngyangyang04/leetcode/blob/master/problems/0078.子集.md) |回溯/数组 |中等|**回溯**|
-|[0083.删除排序链表中的重复元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0083.删除排序链表中的重复元素.md) |链表 |简单|**模拟**|
-|[0084.柱状图中最大的矩形](https://github.com/youngyangyang04/leetcode/blob/master/problems/0084.柱状图中最大的矩形.md) |数组 |困难|**单调栈**|
-|[0090.子集II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0090.子集II.md) |回溯/数组 |中等|**回溯**|
-|[0093.复原IP地址](https://github.com/youngyangyang04/leetcode/blob/master/problems/0093.复原IP地址) |回溯 |中等|**回溯**|
-|[0094.二叉树的中序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0094.二叉树的中序遍历.md) |树 |中等|**递归** **迭代/栈**|
-|[0098.验证二叉搜索树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0098.验证二叉搜索树.md) |树 |中等|**递归**|
-|[0100.相同的树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0100.相同的树.md) |树 |简单|**递归** |
-|[0101.对称二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0101.对称二叉树.md) |树 |简单|**递归** **迭代/队列/栈** 和100. 相同的树 相似|
-|[0102.二叉树的层序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0102.二叉树的层序遍历.md) |树 |中等|**广度优先搜索/队列**|
-|[0104.二叉树的最大深度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0104.二叉树的最大深度.md) |树 |简单|**递归** **迭代/队列/BFS**|
-|[0105.从前序与中序遍历序列构造二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0105.从前序与中序遍历序列构造二叉树.md) |二叉树 |中等|**递归**|
-|[0106.从中序与后序遍历序列构造二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0106.从中序与后序遍历序列构造二叉树.md) |二叉树 |中等|**递归** 根据数组构造二叉树|
-|[0107.二叉树的层次遍历II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0107.二叉树的层次遍历II.md) |树 |简单|**广度优先搜索/队列/BFS**|
-|[0108.将有序数组转换为二叉搜索树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0108.将有序数组转换为二叉搜索树.md) |二叉搜索树 |中等|**递归** **迭代** 通过递归函数返回值构造树|
-|[0110.平衡二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0110.平衡二叉树.md) |二叉树 |简单|**递归**|
-|[0111.二叉树的最小深度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0111.二叉树的最小深度.md) |二叉树 |简单|**递归** **队列/BFS**|
-|[0112.路径总和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0112.路径总和.md) |二叉树树 |简单|**深度优先搜索/递归** **回溯** **栈** 思考递归函数什么时候需要返回值|
-|[0113.路径总和II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0113.路径总和II.md) |二叉树树 |简单|**深度优先搜索/递归** **回溯** **栈**|
-|[0116.填充每个节点的下一个右侧节点指针](https://github.com/youngyangyang04/leetcode/blob/master/problems/0116.填充每个节点的下一个右侧节点指针.md) |二叉树 |中等|**递归** **迭代/广度优先搜索**|
-|[0117.填充每个节点的下一个右侧节点指针II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0117.填充每个节点的下一个右侧节点指针II.md) |二叉树 |中等|**递归** **迭代/广度优先搜索**|
-|[0122.买卖股票的最佳时机II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0122.买卖股票的最佳时机II.md) |贪心 |简单|**贪心** |
-|[0127.单词接龙](https://github.com/youngyangyang04/leetcode/blob/master/problems/0127.单词接龙.md) |广度优先搜索 |中等|**广度优先搜索**|
-|[0129.求根到叶子节点数字之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0129.求根到叶子节点数字之和.md) |二叉树 |中等|**递归/回溯** 递归里隐藏着回溯,和113.路径总和II类似|
-|[0131.分割回文串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0131.分割回文串.md) |回溯 |中等|**回溯**|
-|[0135.分发糖果](https://github.com/youngyangyang04/leetcode/blob/master/problems/0135.分发糖果.md) |贪心 |困难|**贪心**好题目|
-|[0139.单词拆分](https://github.com/youngyangyang04/leetcode/blob/master/problems/0139.单词拆分.md) |动态规划 |中等|**完全背包** **回溯法**|
-|[0141.环形链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0141.环形链表.md) |链表 |简单|**快慢指针/双指针**|
-|[0142.环形链表II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0142.环形链表II.md) |链表 |中等|**快慢指针/双指针**|
-|[0143.重排链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0143.重排链表.md) |链表 |中等|**快慢指针/双指针** 也可以用数组,双向队列模拟,考察链表综合操作的好题|
-|[0144.二叉树的前序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0144.二叉树的前序遍历.md) |树 |中等|**递归** **迭代/栈**|
-|[0145.二叉树的后序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0145.二叉树的后序遍历.md) |树 |困难|**递归** **迭代/栈**|
-|[0147.对链表进行插入排序](https://github.com/youngyangyang04/leetcode/blob/master/problems/0147.对链表进行插入排序.md) |链表 |中等|**模拟** 考察链表综合操作|
-|[0150.逆波兰表达式求值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0150.逆波兰表达式求值.md) |栈 |中等|**栈**|
-|[0151.翻转字符串里的单词](https://github.com/youngyangyang04/leetcode/blob/master/problems/0151.翻转字符串里的单词.md) |字符串 |中等|**模拟/双指针**|
-|[0155.最小栈](https://github.com/youngyangyang04/leetcode/blob/master/problems/0155.最小栈.md) |栈 |简单|**栈**|
-|[0199.二叉树的右视图](https://github.com/youngyangyang04/leetcode/blob/master/problems/0199.二叉树的右视图.md) |二叉树 |中等|**广度优先遍历/队列**|
-|[0202.快乐数](https://github.com/youngyangyang04/leetcode/blob/master/problems/0202.快乐数.md) |哈希表 |简单|**哈希**|
-|[0203.移除链表元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0203.移除链表元素.md) |链表 |简单|**模拟** **虚拟头结点**|
-|[0205.同构字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0205.同构字符串.md) |哈希表 |简单| **哈希**|
-|[0206.翻转链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0206.翻转链表.md) |链表 |简单| **双指针法** **递归**|
-|[0209.长度最小的子数组](https://github.com/youngyangyang04/leetcode/blob/master/problems/0209.长度最小的子数组.md) |数组 |中等| **暴力** **滑动窗口**|
-|[0216.组合总和III](https://github.com/youngyangyang04/leetcode/blob/master/problems/0216.组合总和III.md) |数组/回溯 |中等| **回溯算法**|
-|[0219.存在重复元素II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0219.存在重复元素II.md) | 哈希表 |简单| **哈希** |
-|[0222.完全二叉树的节点个数](https://github.com/youngyangyang04/leetcode/blob/master/problems/0222.完全二叉树的节点个数.md) | 树 |简单| **递归** |
-|[0225.用队列实现栈](https://github.com/youngyangyang04/leetcode/blob/master/problems/0225.用队列实现栈.md) | 队列 |简单| **队列** |
-|[0226.翻转二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0226.翻转二叉树.md) |二叉树 |简单| **递归** **迭代**|
-|[0232.用栈实现队列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0232.用栈实现队列.md) | 栈 |简单| **栈** |
-|[0235.二叉搜索树的最近公共祖先](https://github.com/youngyangyang04/leetcode/blob/master/problems/0235.二叉搜索树的最近公共祖先.md) | 二叉搜索树 |简单| **递归** **迭代** |
-|[0236.二叉树的最近公共祖先](https://github.com/youngyangyang04/leetcode/blob/master/problems/0236.二叉树的最近公共祖先.md) | 二叉树 |中等| **递归/回溯** 与其说是递归,不如说是回溯|
-|[0237.删除链表中的节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0237.删除链表中的节点.md) |链表 |简单| **原链表移除** **添加虚拟节点** 递归|
-|[0239.滑动窗口最大值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0239.滑动窗口最大值.md) |滑动窗口/队列 |困难| **单调队列**|
-|[0242.有效的字母异位词](https://github.com/youngyangyang04/leetcode/blob/master/problems/0242.有效的字母异位词.md) |哈希表 |简单| **哈希**|
-|[0257.二叉树的所有路径](https://github.com/youngyangyang04/leetcode/blob/master/problems/0257.二叉树的所有路径.md) |树 |简单| **递归/回溯**|
-|[0283.移动零](https://github.com/youngyangyang04/leetcode/blob/master/problems/0283.移动零.md) |数组 |简单| **双指针** 和 27.移除元素 一个套路|
-|[0300.最长上升子序列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0300.最长上升子序列.md) |动态规划 |中等| **动态规划**|
-|[0316.去除重复字母](https://github.com/youngyangyang04/leetcode/blob/master/problems/0316.去除重复字母.md) |贪心/字符串 |中等| **单调栈** 这道题目处理的情况比较多,属于单调栈中的难题|
-|[0332.重新安排行程](https://github.com/youngyangyang04/leetcode/blob/master/problems/0332.重新安排行程.md) |深度优先搜索/回溯 |中等| **深度优先搜索/回溯算法**|
-|[0343.整数拆分](https://github.com/youngyangyang04/leetcode/blob/master/problems/0343.整数拆分.md) |动态规划/贪心 |中等| **动态规划**|
-|[0344.反转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0344.反转字符串.md) |字符串 |简单| **双指针**|
-|[0347.前K个高频元素](https://github.com/youngyangyang04/leetcode/blob/master/problems/0347.前K个高频元素.md) |哈希/堆/优先级队列 |中等| **哈希/优先级队列**|
-|[0349.两个数组的交集](https://github.com/youngyangyang04/leetcode/blob/master/problems/0349.两个数组的交集.md) |哈希表 |简单|**哈希**|
-|[0350.两个数组的交集II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0350.两个数组的交集II.md) |哈希表 |简单|**哈希**|
-|[0377.组合总和Ⅳ](https://github.com/youngyangyang04/leetcode/blob/master/problems/0377.组合总和Ⅳ.md) |动态规划 |中等|**完全背包** 求排列|
-|[0383.赎金信](https://github.com/youngyangyang04/leetcode/blob/master/problems/0383.赎金信.md) |数组 |简单|**暴力** **字典计数** **哈希**|
-|[0404.左叶子之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0404.左叶子之和.md) |树/二叉树 |简单|**递归** **迭代**|
-|[0406.根据身高重建队列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0406.根据身高重建队列.md) |树/二叉树 |简单|**递归** **迭代**|
-|[0416.分割等和子集](https://github.com/youngyangyang04/leetcode/blob/master/problems/0416.分割等和子集.md) |动态规划 |中等|**背包问题/01背包**|
-|[0429.N叉树的层序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0429.N叉树的层序遍历.md) |树 |简单|**队列/广度优先搜索**|
-|[0434.字符串中的单词数](https://github.com/youngyangyang04/leetcode/blob/master/problems/0434.字符串中的单词数.md) |字符串 |简单|**模拟**|
-|[0435.无重叠区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0435.无重叠区间.md) |贪心 |中等|**贪心** 经典题目,有点难|
-|[0450.删除二叉搜索树中的节点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0450.删除二叉搜索树中的节点.md) |树 |中等|**递归**|
-|[0452.用最少数量的箭引爆气球](https://github.com/youngyangyang04/leetcode/blob/master/problems/0452.用最少数量的箭引爆气球.md) |贪心/排序 |中等|**贪心** 经典题目|
-|[0454.四数相加II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0454.四数相加II.md) |哈希表 |中等| **哈希**|
-|[0455.分发饼干](https://github.com/youngyangyang04/leetcode/blob/master/problems/0455.分发饼干.md) |贪心 |简单| **贪心**|
-|[0459.重复的子字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0459.重复的子字符串.md) |字符创 |简单| **KMP**|
-|[0473.火柴拼正方形](https://github.com/youngyangyang04/leetcode/blob/master/problems/0473.火柴拼正方形.md) |深度优先搜索|中等| **回溯算法** 和698.划分为k个相等的子集差不多|
-|[0474.一和零](https://github.com/youngyangyang04/leetcode/blob/master/problems/0474.一和零.md) |动态规划 |中等| **多重背包** 好题目|
-|[0486.预测赢家](https://github.com/youngyangyang04/leetcode/blob/master/problems/0486.预测赢家.md) |动态规划 |中等| **递归** **记忆递归** **动态规划**|
-|[0491.递增子序列](https://github.com/youngyangyang04/leetcode/blob/master/problems/0491.递增子序列.md) |深度优先搜索 |中等|**深度优先搜索/回溯算法** 这个去重有意思|
-|[0496.下一个更大元素I](https://github.com/youngyangyang04/leetcode/blob/master/problems/0496.下一个更大元素I.md) |栈 |中等|**单调栈** 入门题目,但是两个数组还是有点绕的|
-|[0501.二叉搜索树中的众数](https://github.com/youngyangyang04/leetcode/blob/master/problems/0501.二叉搜索树中的众数.md) |二叉树 |简单|**递归/中序遍历**|
-|[0513.找树左下角的值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0513.找树左下角的值.md) |二叉树 |中等|**递归** **迭代**|
-|[0515.在每个树行中找最大值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0515.在每个树行中找最大值.md) |二叉树 |简单|**广度优先搜索/队列**|
-|[0518.零钱兑换II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0518.零钱兑换II.md) |动态规划 |中等|**动态规划** dp里求组合|
-|[0530.二叉搜索树的最小绝对差](https://github.com/youngyangyang04/leetcode/blob/master/problems/0530.二叉搜索树的最小绝对差.md) |二叉树搜索树 |简单|**递归** **迭代**|
-|[0538.把二叉搜索树转换为累加树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0538.把二叉搜索树转换为累加树.md) |二叉搜索树 |简单|**递归** **迭代**|
-|[0541.反转字符串II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0541.反转字符串II.md) |字符串 |简单| **模拟**|
-|[0559.N叉树的最大深度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0559.N叉树的最大深度.md) |N叉树 |简单| **递归**|
-|[0572.另一个树的子树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0572.另一个树的子树.md) |二叉树 |简单| **递归**|
-|[0575.分糖果](https://github.com/youngyangyang04/leetcode/blob/master/problems/0575.分糖果.md) |哈希表 |简单|**哈希**|
-|[0589.N叉树的前序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0589.N叉树的前序遍历.md) |N叉树 |简单|**递归** **栈/迭代**|
-|[0590.N叉树的后序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0590.N叉树的后序遍历.md) |N叉树 |简单|**递归** **栈/迭代**|
-|[0617.合并二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0617.合并二叉树.md) |树 |简单|**递归** **迭代**|
-|[0637.二叉树的层平均值](https://github.com/youngyangyang04/leetcode/blob/master/problems/0637.二叉树的层平均值.md) |树 |简单|**广度优先搜索/队列**|
-|[0649.Dota2参议院](https://github.com/youngyangyang04/leetcode/blob/master/problems/0649.Dota2参议院.md) |贪心 |简单|**贪心算法** 简单的贪心策略但代码实现很有技巧|
-|[0654.最大二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0654.最大二叉树.md) |树 |中等|**递归**|
-|[0685.冗余连接II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0685.冗余连接II.md) | 并查集/树/图 |困难|**并查集**|
-|[0669.修剪二叉搜索树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0669.修剪二叉搜索树.md) | 二叉搜索树/二叉树 |简单|**递归** **迭代**|
-|[0698.划分为k个相等的子集](https://github.com/youngyangyang04/leetcode/blob/master/problems/0698.划分为k个相等的子集.md) |回溯算法|中等|动态规划 **回溯算法** 这其实是组合问题,使用了两次递归,好题|
-|[0700.二叉搜索树中的搜索](https://github.com/youngyangyang04/leetcode/blob/master/problems/0700.二叉搜索树中的搜索.md) |二叉搜索树 |简单|**递归** **迭代**|
-|[0701.二叉搜索树中的插入操作](https://github.com/youngyangyang04/leetcode/blob/master/problems/0701.二叉搜索树中的插入操作.md) |二叉搜索树 |简单|**递归** **迭代**|
-|[0705.设计哈希集合](https://github.com/youngyangyang04/leetcode/blob/master/problems/0705.设计哈希集合.md) |哈希表 |简单|**模拟**|
-|[0707.设计链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0707.设计链表.md) |链表 |中等|**模拟**|
-|[0714.买卖股票的最佳时机含手续费](https://github.com/youngyangyang04/leetcode/blob/master/problems/0714.买卖股票的最佳时机含手续费.md) |贪心 动态规划 |中等|**贪心** **动态规划** 和122.买卖股票的最佳时机II类似,贪心的思路很巧妙|
-|[0763.划分字母区间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0763.划分字母区间.md) |贪心 |中等|**双指针/贪心** 体现贪心尽可能多的思想|
-|[0738.单调递增的数字](https://github.com/youngyangyang04/leetcode/blob/master/problems/0738.单调递增的数字.md) |贪心算法 |中等|**贪心算法** 思路不错,贪心好题|
-|[0739.每日温度](https://github.com/youngyangyang04/leetcode/blob/master/problems/0739.每日温度.md) |栈 |中等|**单调栈** 适合单调栈入门|
-|[0767.重构字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0767.重构字符串.md) |字符串 |中等|**字符串** + 排序+一点贪心|
-|[0841.钥匙和房间](https://github.com/youngyangyang04/leetcode/blob/master/problems/0841.钥匙和房间.md) |孤岛问题 |中等|**bfs** **dfs**|
-|[0844.比较含退格的字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0844.比较含退格的字符串.md) |字符串 |简单|**栈** **双指针优化** 使用栈的思路但没有必要使用栈|
-|[0860.柠檬水找零](https://github.com/youngyangyang04/leetcode/blob/master/problems/0860.柠檬水找零.md) |贪心算法 |简单|**贪心算法** 基础题目|
-|[0925.长按键入](https://github.com/youngyangyang04/leetcode/blob/master/problems/0925.长按键入.md) |字符串 |简单|**双指针/模拟** 是一道模拟类型的题目|
-|[0941.有效的山脉数组](https://github.com/youngyangyang04/leetcode/blob/master/problems/0941.有效的山脉数组.md) |数组 |简单|**双指针**|
-|[0968.监控二叉树](https://github.com/youngyangyang04/leetcode/blob/master/problems/0968.监控二叉树.md) |二叉树 |困难|**贪心** 贪心与二叉树的结合|
-|[0973.最接近原点的K个点](https://github.com/youngyangyang04/leetcode/blob/master/problems/0973.最接近原点的K个点.md) |优先级队列 |中等|**优先级队列**|
-|[0977.有序数组的平方](https://github.com/youngyangyang04/leetcode/blob/master/problems/0977.有序数组的平方.md) |数组 |中等|**双指针** 还是比较巧妙的|
-|[1002.查找常用字符](https://github.com/youngyangyang04/leetcode/blob/master/problems/1002.查找常用字符.md) |栈 |简单|**栈**|
-|[1005.K次取反后最大化的数组和](https://github.com/youngyangyang04/leetcode/blob/master/problems/1005.K次取反后最大化的数组和.md) |贪心/排序 |简单|**贪心算法** 贪心基础题目|
-|[1047.删除字符串中的所有相邻重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/1047.删除字符串中的所有相邻重复项.md) |哈希表 |简单|**哈希表/数组**|
-|[1049.最后一块石头的重量II](https://github.com/youngyangyang04/leetcode/blob/master/problems/1049.最后一块石头的重量II.md) |动态规划 |中等|**01背包**|
-|[1207.独一无二的出现次数](https://github.com/youngyangyang04/leetcode/blob/master/problems/1207.独一无二的出现次数.md) |哈希表 |简单|**哈希** 两层哈希|
-|[1221.分割平衡字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/1221.分割平衡字符串.md) |贪心 |简单|**贪心算法** 基础题目|
-|[1356.根据数字二进制下1的数目排序](https://github.com/youngyangyang04/leetcode/blob/master/problems/1356.根据数字二进制下1的数目排序.md) |位运算 |简单|**位运算** 巧妙的计算二进制中1的数量|
-|[1365.有多少小于当前数字的数字](https://github.com/youngyangyang04/leetcode/blob/master/problems/1365.有多少小于当前数字的数字.md) |数组、哈希表 |简单|**哈希** 从后遍历的技巧很不错|
-|[1382.将二叉搜索树变平衡](https://github.com/youngyangyang04/leetcode/blob/master/problems/1047.删除字符串中的所有相邻重复项.md) |二叉搜索树 |中等|**递归** **迭代** 98和108的组合题目|
-|[1403.非递增顺序的最小子序列](https://github.com/youngyangyang04/leetcode/blob/master/problems/1403.非递增顺序的最小子序列.md) | 贪心算法|简单|**贪心算法** 贪心基础题目|
-|[1518.换酒问题](https://github.com/youngyangyang04/leetcode/blob/master/problems/1518.换酒问题.md) | 贪心算法|简单|**贪心算法** 贪心基础题目|
-|[剑指Offer05.替换空格](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md) |字符串 |简单|**双指针**|
-|[ 剑指Offer58-I.翻转单词顺序](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md) |字符串 |简单|**模拟/双指针**|
-|[剑指Offer58-II.左旋转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer58-II.左旋转字符串.md) |字符串 |简单|**反转操作**|
-|[剑指Offer59-I.滑动窗口的最大值](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer59-I.滑动窗口的最大值.md) |滑动窗口/队列 |困难|**单调队列**|
-|[面试题02.07.链表相交](https://github.com/youngyangyang04/leetcode/blob/master/problems/面试题02.07.链表相交.md) |链表 |简单|**模拟**|
+1. [技术比较弱,也对技术不感兴趣,如何选择方向?](https://mp.weixin.qq.com/s/ZCzFiAHZHLqHPLJQXNm75g)
+2. [刷题就用库函数了,怎么了?](https://mp.weixin.qq.com/s/6K3_OSaudnHGq2Ey8vqYfg)
+3. [关于实习,大家可能有点迷茫!](https://mp.weixin.qq.com/s/xcxzi7c78kQGjvZ8hh7taA)
+4. [马上秋招了,慌得很!](https://mp.weixin.qq.com/s/7q7W8Cb2-a5U5atZdOnOFA)
-持续更新中....
+# B站算法视频讲解
+
+以下为[B站「代码随想录」](https://space.bilibili.com/525438321)算法讲解视频:
+
+* [KMP算法(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd)
+* [KMP算法(代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
+* [回溯算法理论基础](https://www.bilibili.com/video/BV1cy4y167mM)
+* [回溯算法之组合问题(力扣题目:77.组合)](https://www.bilibili.com/video/BV1ti4y1L7cv)
+* [组合问题的剪枝操作(对应力扣题目:77.组合)](https://www.bilibili.com/video/BV1wi4y157er)
+* [组合总和(对应力扣题目:39.组合总和)](https://www.bilibili.com/video/BV1KT4y1M7HJ/)
+* [分割回文串(对应力扣题目:131.分割回文串)](https://www.bilibili.com/video/BV1c54y1e7k6)
+* [二叉树理论基础](https://www.bilibili.com/video/BV1Hy4y1t7ij)
+* [二叉树的递归遍历](https://www.bilibili.com/video/BV1Wh411S7xt)
+* [二叉树的非递归遍历(一)](https://www.bilibili.com/video/BV15f4y1W7i2)
+
+(持续更新中....)
# 关于作者
大家好,我是程序员Carl,哈工大师兄,ACM 校赛、黑龙江省赛、东北四省赛金牌、亚洲区域赛铜牌获得者,先后在腾讯和百度从事后端技术研发,CSDN博客专家。对算法和C++后端技术有一定的见解,利用工作之余重新刷leetcode。
-**加我的微信,备注:「个人简单介绍」+「组队刷题」**, 拉你进刷题群,每天一道经典题目分析,而且题目不是孤立的,每一道题目之间都是有关系的,都是由浅入深一脉相承的,所以学习效果最好是每篇连续着看,也许之前你会某些知识点,但是一直没有把知识点串起来,这里每天一篇文章就会帮你把知识点串起来。
+加入刷题微信群,备注:「个人简单介绍」 + 组队刷题
+
+也欢迎与我交流,备注:「个人简单介绍」 + 交流,围观朋友圈,做点赞之交(备注没有自我介绍不通过哦)
 # 我的公众号
-更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:「简历模板」「二叉树总结」「回溯算法总结」「栈与队列总结」等关键字就可以获得我整理的学习资料。
+更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:「666」可以获得所有算法专题原创PDF。
-**每天8:35准时为你推送一篇经典面试题目,帮你梳理算法知识体系,轻松学习算法!**,并且公众号里有大量学习资源,也有我自己的学习心得和方法总结,更有很多志同道合的好伙伴在这里打卡学习,来看看就你知道了,相信一定会有所收获!
+**「代码随想录」每天准时为你推送一篇经典面试题目,帮你梳理算法知识体系,轻松学习算法!**,并且公众号里有大量学习资源,也有我自己的学习心得和方法总结,更有上万录友们在这里打卡学习。
+
+**来看看就知道了,你会发现相见恨晚!**
-
# 我的公众号
-更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:「简历模板」「二叉树总结」「回溯算法总结」「栈与队列总结」等关键字就可以获得我整理的学习资料。
+更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:「666」可以获得所有算法专题原创PDF。
-**每天8:35准时为你推送一篇经典面试题目,帮你梳理算法知识体系,轻松学习算法!**,并且公众号里有大量学习资源,也有我自己的学习心得和方法总结,更有很多志同道合的好伙伴在这里打卡学习,来看看就你知道了,相信一定会有所收获!
+**「代码随想录」每天准时为你推送一篇经典面试题目,帮你梳理算法知识体系,轻松学习算法!**,并且公众号里有大量学习资源,也有我自己的学习心得和方法总结,更有上万录友们在这里打卡学习。
+
+**来看看就知道了,你会发现相见恨晚!**
- +
diff --git a/pics/100.相同的树.png b/pics/100.相同的树.png
deleted file mode 100644
index 88da7600..00000000
Binary files a/pics/100.相同的树.png and /dev/null differ
diff --git a/pics/1002.查找常用字符.png b/pics/1002.查找常用字符.png
deleted file mode 100644
index 23d75057..00000000
Binary files a/pics/1002.查找常用字符.png and /dev/null differ
diff --git a/pics/101. 对称二叉树.png b/pics/101. 对称二叉树.png
deleted file mode 100644
index 6485026d..00000000
Binary files a/pics/101. 对称二叉树.png and /dev/null differ
diff --git a/pics/101. 对称二叉树1.png b/pics/101. 对称二叉树1.png
deleted file mode 100644
index 98286136..00000000
Binary files a/pics/101. 对称二叉树1.png and /dev/null differ
diff --git a/pics/102.二叉树的层序遍历.png b/pics/102.二叉树的层序遍历.png
deleted file mode 100644
index dcfcf972..00000000
Binary files a/pics/102.二叉树的层序遍历.png and /dev/null differ
diff --git a/pics/104. 二叉树的最大深度.png b/pics/104. 二叉树的最大深度.png
deleted file mode 100644
index 74873c76..00000000
Binary files a/pics/104. 二叉树的最大深度.png and /dev/null differ
diff --git a/pics/1047.删除字符串中的所有相邻重复项.png b/pics/1047.删除字符串中的所有相邻重复项.png
deleted file mode 100644
index 57587100..00000000
Binary files a/pics/1047.删除字符串中的所有相邻重复项.png and /dev/null differ
diff --git a/pics/105. 从前序与中序遍历序列构造二叉树.png b/pics/105. 从前序与中序遍历序列构造二叉树.png
deleted file mode 100644
index 7430be27..00000000
Binary files a/pics/105. 从前序与中序遍历序列构造二叉树.png and /dev/null differ
diff --git a/pics/106. 从中序与后序遍历序列构造二叉树1.png b/pics/106. 从中序与后序遍历序列构造二叉树1.png
deleted file mode 100644
index ab8fa4b9..00000000
Binary files a/pics/106. 从中序与后序遍历序列构造二叉树1.png and /dev/null differ
diff --git a/pics/106.从中序与后序遍历序列构造二叉树.png b/pics/106.从中序与后序遍历序列构造二叉树.png
deleted file mode 100644
index 081a7813..00000000
Binary files a/pics/106.从中序与后序遍历序列构造二叉树.png and /dev/null differ
diff --git a/pics/106.从中序与后序遍历序列构造二叉树2.png b/pics/106.从中序与后序遍历序列构造二叉树2.png
deleted file mode 100644
index 8726f4ce..00000000
Binary files a/pics/106.从中序与后序遍历序列构造二叉树2.png and /dev/null differ
diff --git a/pics/107.二叉树的层次遍历II.png b/pics/107.二叉树的层次遍历II.png
deleted file mode 100644
index b4021c44..00000000
Binary files a/pics/107.二叉树的层次遍历II.png and /dev/null differ
diff --git a/pics/108.将有序数组转换为二叉搜索树.png b/pics/108.将有序数组转换为二叉搜索树.png
deleted file mode 100644
index 7d25f99d..00000000
Binary files a/pics/108.将有序数组转换为二叉搜索树.png and /dev/null differ
diff --git a/pics/110.平衡二叉树.png b/pics/110.平衡二叉树.png
deleted file mode 100644
index f227f1ad..00000000
Binary files a/pics/110.平衡二叉树.png and /dev/null differ
diff --git a/pics/110.平衡二叉树1.png b/pics/110.平衡二叉树1.png
deleted file mode 100644
index 36e0a09c..00000000
Binary files a/pics/110.平衡二叉树1.png and /dev/null differ
diff --git a/pics/110.平衡二叉树2.png b/pics/110.平衡二叉树2.png
deleted file mode 100644
index 53d46be6..00000000
Binary files a/pics/110.平衡二叉树2.png and /dev/null differ
diff --git a/pics/111.二叉树的最小深度.png b/pics/111.二叉树的最小深度.png
deleted file mode 100644
index b1980df8..00000000
Binary files a/pics/111.二叉树的最小深度.png and /dev/null differ
diff --git a/pics/111.二叉树的最小深度1.png b/pics/111.二叉树的最小深度1.png
deleted file mode 100644
index a0ac70cb..00000000
Binary files a/pics/111.二叉树的最小深度1.png and /dev/null differ
diff --git a/pics/112.路径总和.png b/pics/112.路径总和.png
deleted file mode 100644
index 2a1b5100..00000000
Binary files a/pics/112.路径总和.png and /dev/null differ
diff --git a/pics/112.路径总和1.png b/pics/112.路径总和1.png
deleted file mode 100644
index 4c6c0f60..00000000
Binary files a/pics/112.路径总和1.png and /dev/null differ
diff --git a/pics/113.路径总和II.png b/pics/113.路径总和II.png
deleted file mode 100644
index 931c2a9a..00000000
Binary files a/pics/113.路径总和II.png and /dev/null differ
diff --git a/pics/113.路径总和II1.png b/pics/113.路径总和II1.png
deleted file mode 100644
index e1d5a2d1..00000000
Binary files a/pics/113.路径总和II1.png and /dev/null differ
diff --git a/pics/116.填充每个节点的下一个右侧节点指针.png b/pics/116.填充每个节点的下一个右侧节点指针.png
deleted file mode 100644
index bec25c0a..00000000
Binary files a/pics/116.填充每个节点的下一个右侧节点指针.png and /dev/null differ
diff --git a/pics/1207.独一无二的出现次数.png b/pics/1207.独一无二的出现次数.png
deleted file mode 100644
index bbb036e6..00000000
Binary files a/pics/1207.独一无二的出现次数.png and /dev/null differ
diff --git a/pics/122.买卖股票的最佳时机II.png b/pics/122.买卖股票的最佳时机II.png
deleted file mode 100644
index 9799abfd..00000000
Binary files a/pics/122.买卖股票的最佳时机II.png and /dev/null differ
diff --git a/pics/127.单词接龙.png b/pics/127.单词接龙.png
deleted file mode 100644
index 581bb558..00000000
Binary files a/pics/127.单词接龙.png and /dev/null differ
diff --git a/pics/129.求根到叶子节点数字之和.png b/pics/129.求根到叶子节点数字之和.png
deleted file mode 100644
index 58288a9d..00000000
Binary files a/pics/129.求根到叶子节点数字之和.png and /dev/null differ
diff --git a/pics/131.分割回文串.png b/pics/131.分割回文串.png
deleted file mode 100644
index 0b50823f..00000000
Binary files a/pics/131.分割回文串.png and /dev/null differ
diff --git a/pics/134.加油站.png b/pics/134.加油站.png
deleted file mode 100644
index 120f714d..00000000
Binary files a/pics/134.加油站.png and /dev/null differ
diff --git a/pics/135.分发糖果.png b/pics/135.分发糖果.png
deleted file mode 100644
index cacd2cbe..00000000
Binary files a/pics/135.分发糖果.png and /dev/null differ
diff --git a/pics/135.分发糖果1.png b/pics/135.分发糖果1.png
deleted file mode 100644
index 27209df9..00000000
Binary files a/pics/135.分发糖果1.png and /dev/null differ
diff --git a/pics/1356.根据数字二进制下1的数目排序.png b/pics/1356.根据数字二进制下1的数目排序.png
deleted file mode 100644
index 0fca9fed..00000000
Binary files a/pics/1356.根据数字二进制下1的数目排序.png and /dev/null differ
diff --git a/pics/1365.有多少小于当前数字的数字.png b/pics/1365.有多少小于当前数字的数字.png
deleted file mode 100644
index 9d67d07b..00000000
Binary files a/pics/1365.有多少小于当前数字的数字.png and /dev/null differ
diff --git a/pics/142环形链表1.png b/pics/142环形链表1.png
deleted file mode 100644
index 7814be45..00000000
Binary files a/pics/142环形链表1.png and /dev/null differ
diff --git a/pics/142环形链表2.png b/pics/142环形链表2.png
deleted file mode 100644
index 86294647..00000000
Binary files a/pics/142环形链表2.png and /dev/null differ
diff --git a/pics/142环形链表3.png b/pics/142环形链表3.png
deleted file mode 100644
index 9bd96f6b..00000000
Binary files a/pics/142环形链表3.png and /dev/null differ
diff --git a/pics/142环形链表4.png b/pics/142环形链表4.png
deleted file mode 100644
index e37690d8..00000000
Binary files a/pics/142环形链表4.png and /dev/null differ
diff --git a/pics/142环形链表5.png b/pics/142环形链表5.png
deleted file mode 100644
index b99a79f1..00000000
Binary files a/pics/142环形链表5.png and /dev/null differ
diff --git a/pics/143.重排链表.png b/pics/143.重排链表.png
deleted file mode 100644
index 2fc94408..00000000
Binary files a/pics/143.重排链表.png and /dev/null differ
diff --git a/pics/147.对链表进行插入排序.png b/pics/147.对链表进行插入排序.png
deleted file mode 100644
index 807f66f4..00000000
Binary files a/pics/147.对链表进行插入排序.png and /dev/null differ
diff --git a/pics/151_翻转字符串里的单词.png b/pics/151_翻转字符串里的单词.png
deleted file mode 100644
index dc844950..00000000
Binary files a/pics/151_翻转字符串里的单词.png and /dev/null differ
diff --git a/pics/17. 电话号码的字母组合.jpeg b/pics/17. 电话号码的字母组合.jpeg
deleted file mode 100644
index f80ec767..00000000
Binary files a/pics/17. 电话号码的字母组合.jpeg and /dev/null differ
diff --git a/pics/17. 电话号码的字母组合.png b/pics/17. 电话号码的字母组合.png
deleted file mode 100644
index b11f7114..00000000
Binary files a/pics/17. 电话号码的字母组合.png and /dev/null differ
diff --git a/pics/19.删除链表的倒数第N个节点.png b/pics/19.删除链表的倒数第N个节点.png
deleted file mode 100644
index 6f6aa9c5..00000000
Binary files a/pics/19.删除链表的倒数第N个节点.png and /dev/null differ
diff --git a/pics/19.删除链表的倒数第N个节点1.png b/pics/19.删除链表的倒数第N个节点1.png
deleted file mode 100644
index cca947b4..00000000
Binary files a/pics/19.删除链表的倒数第N个节点1.png and /dev/null differ
diff --git a/pics/19.删除链表的倒数第N个节点2.png b/pics/19.删除链表的倒数第N个节点2.png
deleted file mode 100644
index 0d8144cd..00000000
Binary files a/pics/19.删除链表的倒数第N个节点2.png and /dev/null differ
diff --git a/pics/19.删除链表的倒数第N个节点3.png b/pics/19.删除链表的倒数第N个节点3.png
deleted file mode 100644
index d15d05e7..00000000
Binary files a/pics/19.删除链表的倒数第N个节点3.png and /dev/null differ
diff --git a/pics/199.二叉树的右视图.png b/pics/199.二叉树的右视图.png
deleted file mode 100644
index e5244117..00000000
Binary files a/pics/199.二叉树的右视图.png and /dev/null differ
diff --git a/pics/203_链表删除元素1.png b/pics/203_链表删除元素1.png
deleted file mode 100644
index b32aa50e..00000000
Binary files a/pics/203_链表删除元素1.png and /dev/null differ
diff --git a/pics/203_链表删除元素2.png b/pics/203_链表删除元素2.png
deleted file mode 100644
index 5519a69d..00000000
Binary files a/pics/203_链表删除元素2.png and /dev/null differ
diff --git a/pics/203_链表删除元素3.png b/pics/203_链表删除元素3.png
deleted file mode 100644
index cd50ce13..00000000
Binary files a/pics/203_链表删除元素3.png and /dev/null differ
diff --git a/pics/203_链表删除元素4.png b/pics/203_链表删除元素4.png
deleted file mode 100644
index 02aaf115..00000000
Binary files a/pics/203_链表删除元素4.png and /dev/null differ
diff --git a/pics/203_链表删除元素5.png b/pics/203_链表删除元素5.png
deleted file mode 100644
index e24ad3d3..00000000
Binary files a/pics/203_链表删除元素5.png and /dev/null differ
diff --git a/pics/203_链表删除元素6.png b/pics/203_链表删除元素6.png
deleted file mode 100644
index 13f9b6d6..00000000
Binary files a/pics/203_链表删除元素6.png and /dev/null differ
diff --git a/pics/206_反转链表.png b/pics/206_反转链表.png
deleted file mode 100644
index f26ad08f..00000000
Binary files a/pics/206_反转链表.png and /dev/null differ
diff --git a/pics/216.组合总和III.png b/pics/216.组合总和III.png
deleted file mode 100644
index 1b71e67c..00000000
Binary files a/pics/216.组合总和III.png and /dev/null differ
diff --git a/pics/216.组合总和III1.png b/pics/216.组合总和III1.png
deleted file mode 100644
index e495191d..00000000
Binary files a/pics/216.组合总和III1.png and /dev/null differ
diff --git a/pics/222.完全二叉树的节点个数.png b/pics/222.完全二叉树的节点个数.png
deleted file mode 100644
index 2eb1eb94..00000000
Binary files a/pics/222.完全二叉树的节点个数.png and /dev/null differ
diff --git a/pics/222.完全二叉树的节点个数1.png b/pics/222.完全二叉树的节点个数1.png
deleted file mode 100644
index 49e1772c..00000000
Binary files a/pics/222.完全二叉树的节点个数1.png and /dev/null differ
diff --git a/pics/226.翻转二叉树.png b/pics/226.翻转二叉树.png
deleted file mode 100644
index 1e3aec91..00000000
Binary files a/pics/226.翻转二叉树.png and /dev/null differ
diff --git a/pics/226.翻转二叉树1.png b/pics/226.翻转二叉树1.png
deleted file mode 100644
index 9435a12d..00000000
Binary files a/pics/226.翻转二叉树1.png and /dev/null differ
diff --git a/pics/234.回文链表.png b/pics/234.回文链表.png
deleted file mode 100644
index 285c73bb..00000000
Binary files a/pics/234.回文链表.png and /dev/null differ
diff --git a/pics/235.二叉搜索树的最近公共祖先.png b/pics/235.二叉搜索树的最近公共祖先.png
deleted file mode 100644
index 277b8165..00000000
Binary files a/pics/235.二叉搜索树的最近公共祖先.png and /dev/null differ
diff --git a/pics/236.二叉树的最近公共祖先.png b/pics/236.二叉树的最近公共祖先.png
deleted file mode 100644
index 023dd955..00000000
Binary files a/pics/236.二叉树的最近公共祖先.png and /dev/null differ
diff --git a/pics/236.二叉树的最近公共祖先1.png b/pics/236.二叉树的最近公共祖先1.png
deleted file mode 100644
index 4542ad5c..00000000
Binary files a/pics/236.二叉树的最近公共祖先1.png and /dev/null differ
diff --git a/pics/236.二叉树的最近公共祖先2.png b/pics/236.二叉树的最近公共祖先2.png
deleted file mode 100644
index 1681fbcc..00000000
Binary files a/pics/236.二叉树的最近公共祖先2.png and /dev/null differ
diff --git a/pics/239.滑动窗口最大值.png b/pics/239.滑动窗口最大值.png
deleted file mode 100644
index 49734e5d..00000000
Binary files a/pics/239.滑动窗口最大值.png and /dev/null differ
diff --git a/pics/24.两两交换链表中的节点.png b/pics/24.两两交换链表中的节点.png
deleted file mode 100644
index 3051c5a1..00000000
Binary files a/pics/24.两两交换链表中的节点.png and /dev/null differ
diff --git a/pics/24.两两交换链表中的节点1.png b/pics/24.两两交换链表中的节点1.png
deleted file mode 100644
index e79642c3..00000000
Binary files a/pics/24.两两交换链表中的节点1.png and /dev/null differ
diff --git a/pics/24.两两交换链表中的节点2.png b/pics/24.两两交换链表中的节点2.png
deleted file mode 100644
index e6dba912..00000000
Binary files a/pics/24.两两交换链表中的节点2.png and /dev/null differ
diff --git a/pics/24.两两交换链表中的节点3.png b/pics/24.两两交换链表中的节点3.png
deleted file mode 100644
index 7d706cd2..00000000
Binary files a/pics/24.两两交换链表中的节点3.png and /dev/null differ
diff --git a/pics/257.二叉树的所有路径.png b/pics/257.二叉树的所有路径.png
deleted file mode 100644
index 0a0683e0..00000000
Binary files a/pics/257.二叉树的所有路径.png and /dev/null differ
diff --git a/pics/257.二叉树的所有路径1.png b/pics/257.二叉树的所有路径1.png
deleted file mode 100644
index 97452f51..00000000
Binary files a/pics/257.二叉树的所有路径1.png and /dev/null differ
diff --git a/pics/26_封面.png b/pics/26_封面.png
deleted file mode 100644
index b8a2f1a1..00000000
Binary files a/pics/26_封面.png and /dev/null differ
diff --git a/pics/27_封面.png b/pics/27_封面.png
deleted file mode 100644
index a4a2b009..00000000
Binary files a/pics/27_封面.png and /dev/null differ
diff --git a/pics/31.下一个排列.png b/pics/31.下一个排列.png
deleted file mode 100644
index f88ef392..00000000
Binary files a/pics/31.下一个排列.png and /dev/null differ
diff --git a/pics/332.重新安排行程.png b/pics/332.重新安排行程.png
deleted file mode 100644
index 56f3ab02..00000000
Binary files a/pics/332.重新安排行程.png and /dev/null differ
diff --git a/pics/332.重新安排行程1.png b/pics/332.重新安排行程1.png
deleted file mode 100644
index 69d51882..00000000
Binary files a/pics/332.重新安排行程1.png and /dev/null differ
diff --git a/pics/347.前K个高频元素.png b/pics/347.前K个高频元素.png
deleted file mode 100644
index 54b1417d..00000000
Binary files a/pics/347.前K个高频元素.png and /dev/null differ
diff --git a/pics/35_封面.png b/pics/35_封面.png
deleted file mode 100644
index dc2971b5..00000000
Binary files a/pics/35_封面.png and /dev/null differ
diff --git a/pics/35_搜索插入位置.png b/pics/35_搜索插入位置.png
deleted file mode 100644
index 5fa65490..00000000
Binary files a/pics/35_搜索插入位置.png and /dev/null differ
diff --git a/pics/35_搜索插入位置2.png b/pics/35_搜索插入位置2.png
deleted file mode 100644
index 71fca151..00000000
Binary files a/pics/35_搜索插入位置2.png and /dev/null differ
diff --git a/pics/35_搜索插入位置3.png b/pics/35_搜索插入位置3.png
deleted file mode 100644
index ec1ce1eb..00000000
Binary files a/pics/35_搜索插入位置3.png and /dev/null differ
diff --git a/pics/35_搜索插入位置4.png b/pics/35_搜索插入位置4.png
deleted file mode 100644
index efb88e22..00000000
Binary files a/pics/35_搜索插入位置4.png and /dev/null differ
diff --git a/pics/35_搜索插入位置5.png b/pics/35_搜索插入位置5.png
deleted file mode 100644
index ec021c9d..00000000
Binary files a/pics/35_搜索插入位置5.png and /dev/null differ
diff --git a/pics/37.解数独.png b/pics/37.解数独.png
deleted file mode 100644
index 46b0a15a..00000000
Binary files a/pics/37.解数独.png and /dev/null differ
diff --git a/pics/376.摆动序列.png b/pics/376.摆动序列.png
deleted file mode 100644
index c6a06dfe..00000000
Binary files a/pics/376.摆动序列.png and /dev/null differ
diff --git a/pics/376.摆动序列1.png b/pics/376.摆动序列1.png
deleted file mode 100644
index 212e7722..00000000
Binary files a/pics/376.摆动序列1.png and /dev/null differ
diff --git a/pics/39.组合总和.png b/pics/39.组合总和.png
deleted file mode 100644
index 960cba69..00000000
Binary files a/pics/39.组合总和.png and /dev/null differ
diff --git a/pics/39.组合总和1.png b/pics/39.组合总和1.png
deleted file mode 100644
index d3557efc..00000000
Binary files a/pics/39.组合总和1.png and /dev/null differ
diff --git a/pics/40.组合总和II.png b/pics/40.组合总和II.png
deleted file mode 100644
index 104e5f4e..00000000
Binary files a/pics/40.组合总和II.png and /dev/null differ
diff --git a/pics/40.组合总和II1.png b/pics/40.组合总和II1.png
deleted file mode 100644
index 75fda6b3..00000000
Binary files a/pics/40.组合总和II1.png and /dev/null differ
diff --git a/pics/404.左叶子之和.png b/pics/404.左叶子之和.png
deleted file mode 100644
index 81b6d8c2..00000000
Binary files a/pics/404.左叶子之和.png and /dev/null differ
diff --git a/pics/404.左叶子之和1.png b/pics/404.左叶子之和1.png
deleted file mode 100644
index 8c050e04..00000000
Binary files a/pics/404.左叶子之和1.png and /dev/null differ
diff --git a/pics/406.根据身高重建队列.png b/pics/406.根据身高重建队列.png
deleted file mode 100644
index 9ea8f0b2..00000000
Binary files a/pics/406.根据身高重建队列.png and /dev/null differ
diff --git a/pics/416.分割等和子集.png b/pics/416.分割等和子集.png
deleted file mode 100644
index 8d1b9ef6..00000000
Binary files a/pics/416.分割等和子集.png and /dev/null differ
diff --git a/pics/416.分割等和子集1.png b/pics/416.分割等和子集1.png
deleted file mode 100644
index 6be70dc6..00000000
Binary files a/pics/416.分割等和子集1.png and /dev/null differ
diff --git a/pics/42.接雨水1.png b/pics/42.接雨水1.png
deleted file mode 100644
index 26624f4b..00000000
Binary files a/pics/42.接雨水1.png and /dev/null differ
diff --git a/pics/42.接雨水2.png b/pics/42.接雨水2.png
deleted file mode 100644
index 94eda97e..00000000
Binary files a/pics/42.接雨水2.png and /dev/null differ
diff --git a/pics/42.接雨水3.png b/pics/42.接雨水3.png
deleted file mode 100644
index 1e4b528a..00000000
Binary files a/pics/42.接雨水3.png and /dev/null differ
diff --git a/pics/42.接雨水4.png b/pics/42.接雨水4.png
deleted file mode 100644
index a18539ce..00000000
Binary files a/pics/42.接雨水4.png and /dev/null differ
diff --git a/pics/42.接雨水5.png b/pics/42.接雨水5.png
deleted file mode 100644
index 066792b0..00000000
Binary files a/pics/42.接雨水5.png and /dev/null differ
diff --git a/pics/429. N叉树的层序遍历.png b/pics/429. N叉树的层序遍历.png
deleted file mode 100644
index d28c543c..00000000
Binary files a/pics/429. N叉树的层序遍历.png and /dev/null differ
diff --git a/pics/435.无重叠区间.png b/pics/435.无重叠区间.png
deleted file mode 100644
index a45913c1..00000000
Binary files a/pics/435.无重叠区间.png and /dev/null differ
diff --git a/pics/45.跳跃游戏II.png b/pics/45.跳跃游戏II.png
deleted file mode 100644
index 77130cb2..00000000
Binary files a/pics/45.跳跃游戏II.png and /dev/null differ
diff --git a/pics/45.跳跃游戏II1.png b/pics/45.跳跃游戏II1.png
deleted file mode 100644
index 7850187f..00000000
Binary files a/pics/45.跳跃游戏II1.png and /dev/null differ
diff --git a/pics/45.跳跃游戏II2.png b/pics/45.跳跃游戏II2.png
deleted file mode 100644
index aa45f60a..00000000
Binary files a/pics/45.跳跃游戏II2.png and /dev/null differ
diff --git a/pics/452.用最少数量的箭引爆气球.png b/pics/452.用最少数量的箭引爆气球.png
deleted file mode 100644
index 64080914..00000000
Binary files a/pics/452.用最少数量的箭引爆气球.png and /dev/null differ
diff --git a/pics/455.分发饼干.png b/pics/455.分发饼干.png
deleted file mode 100644
index 17e15e09..00000000
Binary files a/pics/455.分发饼干.png and /dev/null differ
diff --git a/pics/459.重复的子字符串_1.png b/pics/459.重复的子字符串_1.png
deleted file mode 100644
index 2feddd6b..00000000
Binary files a/pics/459.重复的子字符串_1.png and /dev/null differ
diff --git a/pics/46.全排列.png b/pics/46.全排列.png
deleted file mode 100644
index d8c484ec..00000000
Binary files a/pics/46.全排列.png and /dev/null differ
diff --git a/pics/463.岛屿的周长.png b/pics/463.岛屿的周长.png
deleted file mode 100644
index 5b0fa013..00000000
Binary files a/pics/463.岛屿的周长.png and /dev/null differ
diff --git a/pics/463.岛屿的周长1.png b/pics/463.岛屿的周长1.png
deleted file mode 100644
index bb14dbd6..00000000
Binary files a/pics/463.岛屿的周长1.png and /dev/null differ
diff --git a/pics/47.全排列II1.png b/pics/47.全排列II1.png
deleted file mode 100644
index 8160dd86..00000000
Binary files a/pics/47.全排列II1.png and /dev/null differ
diff --git a/pics/47.全排列II2.png b/pics/47.全排列II2.png
deleted file mode 100644
index d2e096b1..00000000
Binary files a/pics/47.全排列II2.png and /dev/null differ
diff --git a/pics/47.全排列II3.png b/pics/47.全排列II3.png
deleted file mode 100644
index b6f5a862..00000000
Binary files a/pics/47.全排列II3.png and /dev/null differ
diff --git a/pics/486.预测赢家.png b/pics/486.预测赢家.png
deleted file mode 100644
index 03ddfaa8..00000000
Binary files a/pics/486.预测赢家.png and /dev/null differ
diff --git a/pics/486.预测赢家1.png b/pics/486.预测赢家1.png
deleted file mode 100644
index dbddef26..00000000
Binary files a/pics/486.预测赢家1.png and /dev/null differ
diff --git a/pics/486.预测赢家2.png b/pics/486.预测赢家2.png
deleted file mode 100644
index 7d26de9a..00000000
Binary files a/pics/486.预测赢家2.png and /dev/null differ
diff --git a/pics/486.预测赢家3.png b/pics/486.预测赢家3.png
deleted file mode 100644
index 506778c4..00000000
Binary files a/pics/486.预测赢家3.png and /dev/null differ
diff --git a/pics/486.预测赢家4.png b/pics/486.预测赢家4.png
deleted file mode 100644
index 8a679b74..00000000
Binary files a/pics/486.预测赢家4.png and /dev/null differ
diff --git a/pics/491. 递增子序列1.png b/pics/491. 递增子序列1.png
deleted file mode 100644
index 19da907e..00000000
Binary files a/pics/491. 递增子序列1.png and /dev/null differ
diff --git a/pics/491. 递增子序列2.png b/pics/491. 递增子序列2.png
deleted file mode 100644
index 24988010..00000000
Binary files a/pics/491. 递增子序列2.png and /dev/null differ
diff --git a/pics/491. 递增子序列3.png b/pics/491. 递增子序列3.png
deleted file mode 100644
index df293dd5..00000000
Binary files a/pics/491. 递增子序列3.png and /dev/null differ
diff --git a/pics/491. 递增子序列4.png b/pics/491. 递增子序列4.png
deleted file mode 100644
index 395fc515..00000000
Binary files a/pics/491. 递增子序列4.png and /dev/null differ
diff --git a/pics/501.二叉搜索树中的众数.png b/pics/501.二叉搜索树中的众数.png
deleted file mode 100644
index a7197b08..00000000
Binary files a/pics/501.二叉搜索树中的众数.png and /dev/null differ
diff --git a/pics/501.二叉搜索树中的众数1.png b/pics/501.二叉搜索树中的众数1.png
deleted file mode 100644
index 200bc2fa..00000000
Binary files a/pics/501.二叉搜索树中的众数1.png and /dev/null differ
diff --git a/pics/51.N皇后.png b/pics/51.N皇后.png
deleted file mode 100644
index 730b7cb8..00000000
Binary files a/pics/51.N皇后.png and /dev/null differ
diff --git a/pics/51.N皇后1.png b/pics/51.N皇后1.png
deleted file mode 100644
index e6c9c72d..00000000
Binary files a/pics/51.N皇后1.png and /dev/null differ
diff --git a/pics/513.找树左下角的值.png b/pics/513.找树左下角的值.png
deleted file mode 100644
index 67bda96f..00000000
Binary files a/pics/513.找树左下角的值.png and /dev/null differ
diff --git a/pics/513.找树左下角的值1.png b/pics/513.找树左下角的值1.png
deleted file mode 100644
index a5421ad6..00000000
Binary files a/pics/513.找树左下角的值1.png and /dev/null differ
diff --git a/pics/515.在每个树行中找最大值.png b/pics/515.在每个树行中找最大值.png
deleted file mode 100644
index e8f2f431..00000000
Binary files a/pics/515.在每个树行中找最大值.png and /dev/null differ
diff --git a/pics/530.二叉搜索树的最小绝对差.png b/pics/530.二叉搜索树的最小绝对差.png
deleted file mode 100644
index 04ca9a65..00000000
Binary files a/pics/530.二叉搜索树的最小绝对差.png and /dev/null differ
diff --git a/pics/538.把二叉搜索树转换为累加树.png b/pics/538.把二叉搜索树转换为累加树.png
deleted file mode 100644
index 27077f7b..00000000
Binary files a/pics/538.把二叉搜索树转换为累加树.png and /dev/null differ
diff --git a/pics/541_反转字符串II.png b/pics/541_反转字符串II.png
deleted file mode 100644
index 45f0ce6c..00000000
Binary files a/pics/541_反转字符串II.png and /dev/null differ
diff --git a/pics/55.跳跃游戏.png b/pics/55.跳跃游戏.png
deleted file mode 100644
index 012bb635..00000000
Binary files a/pics/55.跳跃游戏.png and /dev/null differ
diff --git a/pics/559.N叉树的最大深度.png b/pics/559.N叉树的最大深度.png
deleted file mode 100644
index d28c543c..00000000
Binary files a/pics/559.N叉树的最大深度.png and /dev/null differ
diff --git a/pics/56.合并区间.png b/pics/56.合并区间.png
deleted file mode 100644
index ff905c72..00000000
Binary files a/pics/56.合并区间.png and /dev/null differ
diff --git a/pics/57.插入区间.png b/pics/57.插入区间.png
deleted file mode 100644
index 67290167..00000000
Binary files a/pics/57.插入区间.png and /dev/null differ
diff --git a/pics/57.插入区间1.png b/pics/57.插入区间1.png
deleted file mode 100644
index 69835dee..00000000
Binary files a/pics/57.插入区间1.png and /dev/null differ
diff --git a/pics/59_封面.png b/pics/59_封面.png
deleted file mode 100644
index 795e8f04..00000000
Binary files a/pics/59_封面.png and /dev/null differ
diff --git a/pics/617.合并二叉树.png b/pics/617.合并二叉树.png
deleted file mode 100644
index 182f959c..00000000
Binary files a/pics/617.合并二叉树.png and /dev/null differ
diff --git a/pics/62.不同路径.png b/pics/62.不同路径.png
deleted file mode 100644
index d82c6ed0..00000000
Binary files a/pics/62.不同路径.png and /dev/null differ
diff --git a/pics/62.不同路径1.png b/pics/62.不同路径1.png
deleted file mode 100644
index 0d84838d..00000000
Binary files a/pics/62.不同路径1.png and /dev/null differ
diff --git a/pics/62.不同路径2.png b/pics/62.不同路径2.png
deleted file mode 100644
index 91984901..00000000
Binary files a/pics/62.不同路径2.png and /dev/null differ
diff --git a/pics/637.二叉树的层平均值.png b/pics/637.二叉树的层平均值.png
deleted file mode 100644
index 57018dab..00000000
Binary files a/pics/637.二叉树的层平均值.png and /dev/null differ
diff --git a/pics/654.最大二叉树.png b/pics/654.最大二叉树.png
deleted file mode 100644
index e8fc63aa..00000000
Binary files a/pics/654.最大二叉树.png and /dev/null differ
diff --git a/pics/657.机器人能否返回原点.png b/pics/657.机器人能否返回原点.png
deleted file mode 100644
index 6ea5b69b..00000000
Binary files a/pics/657.机器人能否返回原点.png and /dev/null differ
diff --git a/pics/669.修剪二叉搜索树.png b/pics/669.修剪二叉搜索树.png
deleted file mode 100644
index 89fe4104..00000000
Binary files a/pics/669.修剪二叉搜索树.png and /dev/null differ
diff --git a/pics/669.修剪二叉搜索树1.png b/pics/669.修剪二叉搜索树1.png
deleted file mode 100644
index 1b46e8d0..00000000
Binary files a/pics/669.修剪二叉搜索树1.png and /dev/null differ
diff --git a/pics/685.冗余连接II1.png b/pics/685.冗余连接II1.png
deleted file mode 100644
index ab833087..00000000
Binary files a/pics/685.冗余连接II1.png and /dev/null differ
diff --git a/pics/685.冗余连接II2.png b/pics/685.冗余连接II2.png
deleted file mode 100644
index 6dbb2ac7..00000000
Binary files a/pics/685.冗余连接II2.png and /dev/null differ
diff --git a/pics/700.二叉搜索树中的搜索.png b/pics/700.二叉搜索树中的搜索.png
deleted file mode 100644
index 1fd15466..00000000
Binary files a/pics/700.二叉搜索树中的搜索.png and /dev/null differ
diff --git a/pics/700.二叉搜索树中的搜索1.png b/pics/700.二叉搜索树中的搜索1.png
deleted file mode 100644
index 037627b1..00000000
Binary files a/pics/700.二叉搜索树中的搜索1.png and /dev/null differ
diff --git a/pics/763.划分字母区间.png b/pics/763.划分字母区间.png
deleted file mode 100644
index 0c1da0f3..00000000
Binary files a/pics/763.划分字母区间.png and /dev/null differ
diff --git a/pics/77.组合.png b/pics/77.组合.png
deleted file mode 100644
index 17cde493..00000000
Binary files a/pics/77.组合.png and /dev/null differ
diff --git a/pics/77.组合1.png b/pics/77.组合1.png
deleted file mode 100644
index a6a4a272..00000000
Binary files a/pics/77.组合1.png and /dev/null differ
diff --git a/pics/77.组合2.png b/pics/77.组合2.png
deleted file mode 100644
index 94e305b6..00000000
Binary files a/pics/77.组合2.png and /dev/null differ
diff --git a/pics/77.组合3.png b/pics/77.组合3.png
deleted file mode 100644
index 4ba73549..00000000
Binary files a/pics/77.组合3.png and /dev/null differ
diff --git a/pics/77.组合4.png b/pics/77.组合4.png
deleted file mode 100644
index b2519ccd..00000000
Binary files a/pics/77.组合4.png and /dev/null differ
diff --git a/pics/78.子集.png b/pics/78.子集.png
deleted file mode 100644
index 1700030f..00000000
Binary files a/pics/78.子集.png and /dev/null differ
diff --git a/pics/841.钥匙和房间.png b/pics/841.钥匙和房间.png
deleted file mode 100644
index 3bfdeea4..00000000
Binary files a/pics/841.钥匙和房间.png and /dev/null differ
diff --git a/pics/90.子集II.png b/pics/90.子集II.png
deleted file mode 100644
index 972010f6..00000000
Binary files a/pics/90.子集II.png and /dev/null differ
diff --git a/pics/90.子集II1.png b/pics/90.子集II1.png
deleted file mode 100644
index 92a18238..00000000
Binary files a/pics/90.子集II1.png and /dev/null differ
diff --git a/pics/90.子集II2.png b/pics/90.子集II2.png
deleted file mode 100644
index e42a56f7..00000000
Binary files a/pics/90.子集II2.png and /dev/null differ
diff --git a/pics/925.长按键入.png b/pics/925.长按键入.png
deleted file mode 100644
index c6bee552..00000000
Binary files a/pics/925.长按键入.png and /dev/null differ
diff --git a/pics/93.复原IP地址.png b/pics/93.复原IP地址.png
deleted file mode 100644
index 63d11f2e..00000000
Binary files a/pics/93.复原IP地址.png and /dev/null differ
diff --git a/pics/941.有效的山脉数组.png b/pics/941.有效的山脉数组.png
deleted file mode 100644
index e261242c..00000000
Binary files a/pics/941.有效的山脉数组.png and /dev/null differ
diff --git a/pics/968.监控二叉树1.png b/pics/968.监控二叉树1.png
deleted file mode 100644
index 7e6a75df..00000000
Binary files a/pics/968.监控二叉树1.png and /dev/null differ
diff --git a/pics/968.监控二叉树2.png b/pics/968.监控二叉树2.png
deleted file mode 100644
index 664a656e..00000000
Binary files a/pics/968.监控二叉树2.png and /dev/null differ
diff --git a/pics/968.监控二叉树3.png b/pics/968.监控二叉树3.png
deleted file mode 100644
index 0a3a9ea6..00000000
Binary files a/pics/968.监控二叉树3.png and /dev/null differ
diff --git a/pics/977.有序数组的平方.png b/pics/977.有序数组的平方.png
deleted file mode 100644
index cb9ccf6c..00000000
Binary files a/pics/977.有序数组的平方.png and /dev/null differ
diff --git a/pics/98.验证二叉搜索树.png b/pics/98.验证二叉搜索树.png
deleted file mode 100644
index 8a164140..00000000
Binary files a/pics/98.验证二叉搜索树.png and /dev/null differ
diff --git a/pics/leetcode_209.png b/pics/leetcode_209.png
deleted file mode 100644
index 2278be41..00000000
Binary files a/pics/leetcode_209.png and /dev/null differ
diff --git a/pics/公众号.png b/pics/公众号.png
new file mode 100644
index 00000000..eeec00ad
Binary files /dev/null and b/pics/公众号.png differ
diff --git a/pics/公众号二维码.jpg b/pics/公众号二维码.jpg
new file mode 100644
index 00000000..a91b2494
Binary files /dev/null and b/pics/公众号二维码.jpg differ
diff --git a/pics/剑指Offer05.替换空格.png b/pics/剑指Offer05.替换空格.png
deleted file mode 100644
index e4a2dfbc..00000000
Binary files a/pics/剑指Offer05.替换空格.png and /dev/null differ
diff --git a/pics/剑指Offer58-II.左旋转字符串.png b/pics/剑指Offer58-II.左旋转字符串.png
deleted file mode 100644
index 9b41754e..00000000
Binary files a/pics/剑指Offer58-II.左旋转字符串.png and /dev/null differ
diff --git a/pics/动态规划-背包问题1.png b/pics/动态规划-背包问题1.png
deleted file mode 100644
index dd51c5a9..00000000
Binary files a/pics/动态规划-背包问题1.png and /dev/null differ
diff --git a/pics/动态规划-背包问题2.png b/pics/动态规划-背包问题2.png
deleted file mode 100644
index 6ea1863c..00000000
Binary files a/pics/动态规划-背包问题2.png and /dev/null differ
diff --git a/pics/动态规划-背包问题3.png b/pics/动态规划-背包问题3.png
deleted file mode 100644
index 568c7bd9..00000000
Binary files a/pics/动态规划-背包问题3.png and /dev/null differ
diff --git a/pics/动态规划-背包问题4.png b/pics/动态规划-背包问题4.png
deleted file mode 100644
index 97632993..00000000
Binary files a/pics/动态规划-背包问题4.png and /dev/null differ
diff --git a/pics/回溯算法理论基础.png b/pics/回溯算法理论基础.png
deleted file mode 100644
index f8f2eb2f..00000000
Binary files a/pics/回溯算法理论基础.png and /dev/null differ
diff --git a/pics/微信搜一搜.png b/pics/微信搜一搜.png
new file mode 100644
index 00000000..62bee447
Binary files /dev/null and b/pics/微信搜一搜.png differ
diff --git a/pics/我要打十个.gif b/pics/我要打十个.gif
deleted file mode 100644
index c64eb70a..00000000
Binary files a/pics/我要打十个.gif and /dev/null differ
diff --git a/pics/知识星球.png b/pics/知识星球.png
new file mode 100644
index 00000000..43a5c6b3
Binary files /dev/null and b/pics/知识星球.png differ
diff --git a/pics/算法大纲.png b/pics/算法大纲.png
new file mode 100644
index 00000000..602f1d03
Binary files /dev/null and b/pics/算法大纲.png differ
diff --git a/pics/螺旋矩阵.png b/pics/螺旋矩阵.png
deleted file mode 100644
index 5148db46..00000000
Binary files a/pics/螺旋矩阵.png and /dev/null differ
diff --git a/pics/面试题02.07.链表相交_1.png b/pics/面试题02.07.链表相交_1.png
deleted file mode 100644
index 678311d1..00000000
Binary files a/pics/面试题02.07.链表相交_1.png and /dev/null differ
diff --git a/pics/面试题02.07.链表相交_2.png b/pics/面试题02.07.链表相交_2.png
deleted file mode 100644
index 97881bec..00000000
Binary files a/pics/面试题02.07.链表相交_2.png and /dev/null differ
diff --git a/problems/0001.两数之和.md b/problems/0001.两数之和.md
index b7c9831b..6c9d99dd 100644
--- a/problems/0001.两数之和.md
+++ b/problems/0001.两数之和.md
@@ -1,9 +1,15 @@
-# 题目地址
-https://leetcode-cn.com/problems/two-sum/
+
+
diff --git a/pics/100.相同的树.png b/pics/100.相同的树.png
deleted file mode 100644
index 88da7600..00000000
Binary files a/pics/100.相同的树.png and /dev/null differ
diff --git a/pics/1002.查找常用字符.png b/pics/1002.查找常用字符.png
deleted file mode 100644
index 23d75057..00000000
Binary files a/pics/1002.查找常用字符.png and /dev/null differ
diff --git a/pics/101. 对称二叉树.png b/pics/101. 对称二叉树.png
deleted file mode 100644
index 6485026d..00000000
Binary files a/pics/101. 对称二叉树.png and /dev/null differ
diff --git a/pics/101. 对称二叉树1.png b/pics/101. 对称二叉树1.png
deleted file mode 100644
index 98286136..00000000
Binary files a/pics/101. 对称二叉树1.png and /dev/null differ
diff --git a/pics/102.二叉树的层序遍历.png b/pics/102.二叉树的层序遍历.png
deleted file mode 100644
index dcfcf972..00000000
Binary files a/pics/102.二叉树的层序遍历.png and /dev/null differ
diff --git a/pics/104. 二叉树的最大深度.png b/pics/104. 二叉树的最大深度.png
deleted file mode 100644
index 74873c76..00000000
Binary files a/pics/104. 二叉树的最大深度.png and /dev/null differ
diff --git a/pics/1047.删除字符串中的所有相邻重复项.png b/pics/1047.删除字符串中的所有相邻重复项.png
deleted file mode 100644
index 57587100..00000000
Binary files a/pics/1047.删除字符串中的所有相邻重复项.png and /dev/null differ
diff --git a/pics/105. 从前序与中序遍历序列构造二叉树.png b/pics/105. 从前序与中序遍历序列构造二叉树.png
deleted file mode 100644
index 7430be27..00000000
Binary files a/pics/105. 从前序与中序遍历序列构造二叉树.png and /dev/null differ
diff --git a/pics/106. 从中序与后序遍历序列构造二叉树1.png b/pics/106. 从中序与后序遍历序列构造二叉树1.png
deleted file mode 100644
index ab8fa4b9..00000000
Binary files a/pics/106. 从中序与后序遍历序列构造二叉树1.png and /dev/null differ
diff --git a/pics/106.从中序与后序遍历序列构造二叉树.png b/pics/106.从中序与后序遍历序列构造二叉树.png
deleted file mode 100644
index 081a7813..00000000
Binary files a/pics/106.从中序与后序遍历序列构造二叉树.png and /dev/null differ
diff --git a/pics/106.从中序与后序遍历序列构造二叉树2.png b/pics/106.从中序与后序遍历序列构造二叉树2.png
deleted file mode 100644
index 8726f4ce..00000000
Binary files a/pics/106.从中序与后序遍历序列构造二叉树2.png and /dev/null differ
diff --git a/pics/107.二叉树的层次遍历II.png b/pics/107.二叉树的层次遍历II.png
deleted file mode 100644
index b4021c44..00000000
Binary files a/pics/107.二叉树的层次遍历II.png and /dev/null differ
diff --git a/pics/108.将有序数组转换为二叉搜索树.png b/pics/108.将有序数组转换为二叉搜索树.png
deleted file mode 100644
index 7d25f99d..00000000
Binary files a/pics/108.将有序数组转换为二叉搜索树.png and /dev/null differ
diff --git a/pics/110.平衡二叉树.png b/pics/110.平衡二叉树.png
deleted file mode 100644
index f227f1ad..00000000
Binary files a/pics/110.平衡二叉树.png and /dev/null differ
diff --git a/pics/110.平衡二叉树1.png b/pics/110.平衡二叉树1.png
deleted file mode 100644
index 36e0a09c..00000000
Binary files a/pics/110.平衡二叉树1.png and /dev/null differ
diff --git a/pics/110.平衡二叉树2.png b/pics/110.平衡二叉树2.png
deleted file mode 100644
index 53d46be6..00000000
Binary files a/pics/110.平衡二叉树2.png and /dev/null differ
diff --git a/pics/111.二叉树的最小深度.png b/pics/111.二叉树的最小深度.png
deleted file mode 100644
index b1980df8..00000000
Binary files a/pics/111.二叉树的最小深度.png and /dev/null differ
diff --git a/pics/111.二叉树的最小深度1.png b/pics/111.二叉树的最小深度1.png
deleted file mode 100644
index a0ac70cb..00000000
Binary files a/pics/111.二叉树的最小深度1.png and /dev/null differ
diff --git a/pics/112.路径总和.png b/pics/112.路径总和.png
deleted file mode 100644
index 2a1b5100..00000000
Binary files a/pics/112.路径总和.png and /dev/null differ
diff --git a/pics/112.路径总和1.png b/pics/112.路径总和1.png
deleted file mode 100644
index 4c6c0f60..00000000
Binary files a/pics/112.路径总和1.png and /dev/null differ
diff --git a/pics/113.路径总和II.png b/pics/113.路径总和II.png
deleted file mode 100644
index 931c2a9a..00000000
Binary files a/pics/113.路径总和II.png and /dev/null differ
diff --git a/pics/113.路径总和II1.png b/pics/113.路径总和II1.png
deleted file mode 100644
index e1d5a2d1..00000000
Binary files a/pics/113.路径总和II1.png and /dev/null differ
diff --git a/pics/116.填充每个节点的下一个右侧节点指针.png b/pics/116.填充每个节点的下一个右侧节点指针.png
deleted file mode 100644
index bec25c0a..00000000
Binary files a/pics/116.填充每个节点的下一个右侧节点指针.png and /dev/null differ
diff --git a/pics/1207.独一无二的出现次数.png b/pics/1207.独一无二的出现次数.png
deleted file mode 100644
index bbb036e6..00000000
Binary files a/pics/1207.独一无二的出现次数.png and /dev/null differ
diff --git a/pics/122.买卖股票的最佳时机II.png b/pics/122.买卖股票的最佳时机II.png
deleted file mode 100644
index 9799abfd..00000000
Binary files a/pics/122.买卖股票的最佳时机II.png and /dev/null differ
diff --git a/pics/127.单词接龙.png b/pics/127.单词接龙.png
deleted file mode 100644
index 581bb558..00000000
Binary files a/pics/127.单词接龙.png and /dev/null differ
diff --git a/pics/129.求根到叶子节点数字之和.png b/pics/129.求根到叶子节点数字之和.png
deleted file mode 100644
index 58288a9d..00000000
Binary files a/pics/129.求根到叶子节点数字之和.png and /dev/null differ
diff --git a/pics/131.分割回文串.png b/pics/131.分割回文串.png
deleted file mode 100644
index 0b50823f..00000000
Binary files a/pics/131.分割回文串.png and /dev/null differ
diff --git a/pics/134.加油站.png b/pics/134.加油站.png
deleted file mode 100644
index 120f714d..00000000
Binary files a/pics/134.加油站.png and /dev/null differ
diff --git a/pics/135.分发糖果.png b/pics/135.分发糖果.png
deleted file mode 100644
index cacd2cbe..00000000
Binary files a/pics/135.分发糖果.png and /dev/null differ
diff --git a/pics/135.分发糖果1.png b/pics/135.分发糖果1.png
deleted file mode 100644
index 27209df9..00000000
Binary files a/pics/135.分发糖果1.png and /dev/null differ
diff --git a/pics/1356.根据数字二进制下1的数目排序.png b/pics/1356.根据数字二进制下1的数目排序.png
deleted file mode 100644
index 0fca9fed..00000000
Binary files a/pics/1356.根据数字二进制下1的数目排序.png and /dev/null differ
diff --git a/pics/1365.有多少小于当前数字的数字.png b/pics/1365.有多少小于当前数字的数字.png
deleted file mode 100644
index 9d67d07b..00000000
Binary files a/pics/1365.有多少小于当前数字的数字.png and /dev/null differ
diff --git a/pics/142环形链表1.png b/pics/142环形链表1.png
deleted file mode 100644
index 7814be45..00000000
Binary files a/pics/142环形链表1.png and /dev/null differ
diff --git a/pics/142环形链表2.png b/pics/142环形链表2.png
deleted file mode 100644
index 86294647..00000000
Binary files a/pics/142环形链表2.png and /dev/null differ
diff --git a/pics/142环形链表3.png b/pics/142环形链表3.png
deleted file mode 100644
index 9bd96f6b..00000000
Binary files a/pics/142环形链表3.png and /dev/null differ
diff --git a/pics/142环形链表4.png b/pics/142环形链表4.png
deleted file mode 100644
index e37690d8..00000000
Binary files a/pics/142环形链表4.png and /dev/null differ
diff --git a/pics/142环形链表5.png b/pics/142环形链表5.png
deleted file mode 100644
index b99a79f1..00000000
Binary files a/pics/142环形链表5.png and /dev/null differ
diff --git a/pics/143.重排链表.png b/pics/143.重排链表.png
deleted file mode 100644
index 2fc94408..00000000
Binary files a/pics/143.重排链表.png and /dev/null differ
diff --git a/pics/147.对链表进行插入排序.png b/pics/147.对链表进行插入排序.png
deleted file mode 100644
index 807f66f4..00000000
Binary files a/pics/147.对链表进行插入排序.png and /dev/null differ
diff --git a/pics/151_翻转字符串里的单词.png b/pics/151_翻转字符串里的单词.png
deleted file mode 100644
index dc844950..00000000
Binary files a/pics/151_翻转字符串里的单词.png and /dev/null differ
diff --git a/pics/17. 电话号码的字母组合.jpeg b/pics/17. 电话号码的字母组合.jpeg
deleted file mode 100644
index f80ec767..00000000
Binary files a/pics/17. 电话号码的字母组合.jpeg and /dev/null differ
diff --git a/pics/17. 电话号码的字母组合.png b/pics/17. 电话号码的字母组合.png
deleted file mode 100644
index b11f7114..00000000
Binary files a/pics/17. 电话号码的字母组合.png and /dev/null differ
diff --git a/pics/19.删除链表的倒数第N个节点.png b/pics/19.删除链表的倒数第N个节点.png
deleted file mode 100644
index 6f6aa9c5..00000000
Binary files a/pics/19.删除链表的倒数第N个节点.png and /dev/null differ
diff --git a/pics/19.删除链表的倒数第N个节点1.png b/pics/19.删除链表的倒数第N个节点1.png
deleted file mode 100644
index cca947b4..00000000
Binary files a/pics/19.删除链表的倒数第N个节点1.png and /dev/null differ
diff --git a/pics/19.删除链表的倒数第N个节点2.png b/pics/19.删除链表的倒数第N个节点2.png
deleted file mode 100644
index 0d8144cd..00000000
Binary files a/pics/19.删除链表的倒数第N个节点2.png and /dev/null differ
diff --git a/pics/19.删除链表的倒数第N个节点3.png b/pics/19.删除链表的倒数第N个节点3.png
deleted file mode 100644
index d15d05e7..00000000
Binary files a/pics/19.删除链表的倒数第N个节点3.png and /dev/null differ
diff --git a/pics/199.二叉树的右视图.png b/pics/199.二叉树的右视图.png
deleted file mode 100644
index e5244117..00000000
Binary files a/pics/199.二叉树的右视图.png and /dev/null differ
diff --git a/pics/203_链表删除元素1.png b/pics/203_链表删除元素1.png
deleted file mode 100644
index b32aa50e..00000000
Binary files a/pics/203_链表删除元素1.png and /dev/null differ
diff --git a/pics/203_链表删除元素2.png b/pics/203_链表删除元素2.png
deleted file mode 100644
index 5519a69d..00000000
Binary files a/pics/203_链表删除元素2.png and /dev/null differ
diff --git a/pics/203_链表删除元素3.png b/pics/203_链表删除元素3.png
deleted file mode 100644
index cd50ce13..00000000
Binary files a/pics/203_链表删除元素3.png and /dev/null differ
diff --git a/pics/203_链表删除元素4.png b/pics/203_链表删除元素4.png
deleted file mode 100644
index 02aaf115..00000000
Binary files a/pics/203_链表删除元素4.png and /dev/null differ
diff --git a/pics/203_链表删除元素5.png b/pics/203_链表删除元素5.png
deleted file mode 100644
index e24ad3d3..00000000
Binary files a/pics/203_链表删除元素5.png and /dev/null differ
diff --git a/pics/203_链表删除元素6.png b/pics/203_链表删除元素6.png
deleted file mode 100644
index 13f9b6d6..00000000
Binary files a/pics/203_链表删除元素6.png and /dev/null differ
diff --git a/pics/206_反转链表.png b/pics/206_反转链表.png
deleted file mode 100644
index f26ad08f..00000000
Binary files a/pics/206_反转链表.png and /dev/null differ
diff --git a/pics/216.组合总和III.png b/pics/216.组合总和III.png
deleted file mode 100644
index 1b71e67c..00000000
Binary files a/pics/216.组合总和III.png and /dev/null differ
diff --git a/pics/216.组合总和III1.png b/pics/216.组合总和III1.png
deleted file mode 100644
index e495191d..00000000
Binary files a/pics/216.组合总和III1.png and /dev/null differ
diff --git a/pics/222.完全二叉树的节点个数.png b/pics/222.完全二叉树的节点个数.png
deleted file mode 100644
index 2eb1eb94..00000000
Binary files a/pics/222.完全二叉树的节点个数.png and /dev/null differ
diff --git a/pics/222.完全二叉树的节点个数1.png b/pics/222.完全二叉树的节点个数1.png
deleted file mode 100644
index 49e1772c..00000000
Binary files a/pics/222.完全二叉树的节点个数1.png and /dev/null differ
diff --git a/pics/226.翻转二叉树.png b/pics/226.翻转二叉树.png
deleted file mode 100644
index 1e3aec91..00000000
Binary files a/pics/226.翻转二叉树.png and /dev/null differ
diff --git a/pics/226.翻转二叉树1.png b/pics/226.翻转二叉树1.png
deleted file mode 100644
index 9435a12d..00000000
Binary files a/pics/226.翻转二叉树1.png and /dev/null differ
diff --git a/pics/234.回文链表.png b/pics/234.回文链表.png
deleted file mode 100644
index 285c73bb..00000000
Binary files a/pics/234.回文链表.png and /dev/null differ
diff --git a/pics/235.二叉搜索树的最近公共祖先.png b/pics/235.二叉搜索树的最近公共祖先.png
deleted file mode 100644
index 277b8165..00000000
Binary files a/pics/235.二叉搜索树的最近公共祖先.png and /dev/null differ
diff --git a/pics/236.二叉树的最近公共祖先.png b/pics/236.二叉树的最近公共祖先.png
deleted file mode 100644
index 023dd955..00000000
Binary files a/pics/236.二叉树的最近公共祖先.png and /dev/null differ
diff --git a/pics/236.二叉树的最近公共祖先1.png b/pics/236.二叉树的最近公共祖先1.png
deleted file mode 100644
index 4542ad5c..00000000
Binary files a/pics/236.二叉树的最近公共祖先1.png and /dev/null differ
diff --git a/pics/236.二叉树的最近公共祖先2.png b/pics/236.二叉树的最近公共祖先2.png
deleted file mode 100644
index 1681fbcc..00000000
Binary files a/pics/236.二叉树的最近公共祖先2.png and /dev/null differ
diff --git a/pics/239.滑动窗口最大值.png b/pics/239.滑动窗口最大值.png
deleted file mode 100644
index 49734e5d..00000000
Binary files a/pics/239.滑动窗口最大值.png and /dev/null differ
diff --git a/pics/24.两两交换链表中的节点.png b/pics/24.两两交换链表中的节点.png
deleted file mode 100644
index 3051c5a1..00000000
Binary files a/pics/24.两两交换链表中的节点.png and /dev/null differ
diff --git a/pics/24.两两交换链表中的节点1.png b/pics/24.两两交换链表中的节点1.png
deleted file mode 100644
index e79642c3..00000000
Binary files a/pics/24.两两交换链表中的节点1.png and /dev/null differ
diff --git a/pics/24.两两交换链表中的节点2.png b/pics/24.两两交换链表中的节点2.png
deleted file mode 100644
index e6dba912..00000000
Binary files a/pics/24.两两交换链表中的节点2.png and /dev/null differ
diff --git a/pics/24.两两交换链表中的节点3.png b/pics/24.两两交换链表中的节点3.png
deleted file mode 100644
index 7d706cd2..00000000
Binary files a/pics/24.两两交换链表中的节点3.png and /dev/null differ
diff --git a/pics/257.二叉树的所有路径.png b/pics/257.二叉树的所有路径.png
deleted file mode 100644
index 0a0683e0..00000000
Binary files a/pics/257.二叉树的所有路径.png and /dev/null differ
diff --git a/pics/257.二叉树的所有路径1.png b/pics/257.二叉树的所有路径1.png
deleted file mode 100644
index 97452f51..00000000
Binary files a/pics/257.二叉树的所有路径1.png and /dev/null differ
diff --git a/pics/26_封面.png b/pics/26_封面.png
deleted file mode 100644
index b8a2f1a1..00000000
Binary files a/pics/26_封面.png and /dev/null differ
diff --git a/pics/27_封面.png b/pics/27_封面.png
deleted file mode 100644
index a4a2b009..00000000
Binary files a/pics/27_封面.png and /dev/null differ
diff --git a/pics/31.下一个排列.png b/pics/31.下一个排列.png
deleted file mode 100644
index f88ef392..00000000
Binary files a/pics/31.下一个排列.png and /dev/null differ
diff --git a/pics/332.重新安排行程.png b/pics/332.重新安排行程.png
deleted file mode 100644
index 56f3ab02..00000000
Binary files a/pics/332.重新安排行程.png and /dev/null differ
diff --git a/pics/332.重新安排行程1.png b/pics/332.重新安排行程1.png
deleted file mode 100644
index 69d51882..00000000
Binary files a/pics/332.重新安排行程1.png and /dev/null differ
diff --git a/pics/347.前K个高频元素.png b/pics/347.前K个高频元素.png
deleted file mode 100644
index 54b1417d..00000000
Binary files a/pics/347.前K个高频元素.png and /dev/null differ
diff --git a/pics/35_封面.png b/pics/35_封面.png
deleted file mode 100644
index dc2971b5..00000000
Binary files a/pics/35_封面.png and /dev/null differ
diff --git a/pics/35_搜索插入位置.png b/pics/35_搜索插入位置.png
deleted file mode 100644
index 5fa65490..00000000
Binary files a/pics/35_搜索插入位置.png and /dev/null differ
diff --git a/pics/35_搜索插入位置2.png b/pics/35_搜索插入位置2.png
deleted file mode 100644
index 71fca151..00000000
Binary files a/pics/35_搜索插入位置2.png and /dev/null differ
diff --git a/pics/35_搜索插入位置3.png b/pics/35_搜索插入位置3.png
deleted file mode 100644
index ec1ce1eb..00000000
Binary files a/pics/35_搜索插入位置3.png and /dev/null differ
diff --git a/pics/35_搜索插入位置4.png b/pics/35_搜索插入位置4.png
deleted file mode 100644
index efb88e22..00000000
Binary files a/pics/35_搜索插入位置4.png and /dev/null differ
diff --git a/pics/35_搜索插入位置5.png b/pics/35_搜索插入位置5.png
deleted file mode 100644
index ec021c9d..00000000
Binary files a/pics/35_搜索插入位置5.png and /dev/null differ
diff --git a/pics/37.解数独.png b/pics/37.解数独.png
deleted file mode 100644
index 46b0a15a..00000000
Binary files a/pics/37.解数独.png and /dev/null differ
diff --git a/pics/376.摆动序列.png b/pics/376.摆动序列.png
deleted file mode 100644
index c6a06dfe..00000000
Binary files a/pics/376.摆动序列.png and /dev/null differ
diff --git a/pics/376.摆动序列1.png b/pics/376.摆动序列1.png
deleted file mode 100644
index 212e7722..00000000
Binary files a/pics/376.摆动序列1.png and /dev/null differ
diff --git a/pics/39.组合总和.png b/pics/39.组合总和.png
deleted file mode 100644
index 960cba69..00000000
Binary files a/pics/39.组合总和.png and /dev/null differ
diff --git a/pics/39.组合总和1.png b/pics/39.组合总和1.png
deleted file mode 100644
index d3557efc..00000000
Binary files a/pics/39.组合总和1.png and /dev/null differ
diff --git a/pics/40.组合总和II.png b/pics/40.组合总和II.png
deleted file mode 100644
index 104e5f4e..00000000
Binary files a/pics/40.组合总和II.png and /dev/null differ
diff --git a/pics/40.组合总和II1.png b/pics/40.组合总和II1.png
deleted file mode 100644
index 75fda6b3..00000000
Binary files a/pics/40.组合总和II1.png and /dev/null differ
diff --git a/pics/404.左叶子之和.png b/pics/404.左叶子之和.png
deleted file mode 100644
index 81b6d8c2..00000000
Binary files a/pics/404.左叶子之和.png and /dev/null differ
diff --git a/pics/404.左叶子之和1.png b/pics/404.左叶子之和1.png
deleted file mode 100644
index 8c050e04..00000000
Binary files a/pics/404.左叶子之和1.png and /dev/null differ
diff --git a/pics/406.根据身高重建队列.png b/pics/406.根据身高重建队列.png
deleted file mode 100644
index 9ea8f0b2..00000000
Binary files a/pics/406.根据身高重建队列.png and /dev/null differ
diff --git a/pics/416.分割等和子集.png b/pics/416.分割等和子集.png
deleted file mode 100644
index 8d1b9ef6..00000000
Binary files a/pics/416.分割等和子集.png and /dev/null differ
diff --git a/pics/416.分割等和子集1.png b/pics/416.分割等和子集1.png
deleted file mode 100644
index 6be70dc6..00000000
Binary files a/pics/416.分割等和子集1.png and /dev/null differ
diff --git a/pics/42.接雨水1.png b/pics/42.接雨水1.png
deleted file mode 100644
index 26624f4b..00000000
Binary files a/pics/42.接雨水1.png and /dev/null differ
diff --git a/pics/42.接雨水2.png b/pics/42.接雨水2.png
deleted file mode 100644
index 94eda97e..00000000
Binary files a/pics/42.接雨水2.png and /dev/null differ
diff --git a/pics/42.接雨水3.png b/pics/42.接雨水3.png
deleted file mode 100644
index 1e4b528a..00000000
Binary files a/pics/42.接雨水3.png and /dev/null differ
diff --git a/pics/42.接雨水4.png b/pics/42.接雨水4.png
deleted file mode 100644
index a18539ce..00000000
Binary files a/pics/42.接雨水4.png and /dev/null differ
diff --git a/pics/42.接雨水5.png b/pics/42.接雨水5.png
deleted file mode 100644
index 066792b0..00000000
Binary files a/pics/42.接雨水5.png and /dev/null differ
diff --git a/pics/429. N叉树的层序遍历.png b/pics/429. N叉树的层序遍历.png
deleted file mode 100644
index d28c543c..00000000
Binary files a/pics/429. N叉树的层序遍历.png and /dev/null differ
diff --git a/pics/435.无重叠区间.png b/pics/435.无重叠区间.png
deleted file mode 100644
index a45913c1..00000000
Binary files a/pics/435.无重叠区间.png and /dev/null differ
diff --git a/pics/45.跳跃游戏II.png b/pics/45.跳跃游戏II.png
deleted file mode 100644
index 77130cb2..00000000
Binary files a/pics/45.跳跃游戏II.png and /dev/null differ
diff --git a/pics/45.跳跃游戏II1.png b/pics/45.跳跃游戏II1.png
deleted file mode 100644
index 7850187f..00000000
Binary files a/pics/45.跳跃游戏II1.png and /dev/null differ
diff --git a/pics/45.跳跃游戏II2.png b/pics/45.跳跃游戏II2.png
deleted file mode 100644
index aa45f60a..00000000
Binary files a/pics/45.跳跃游戏II2.png and /dev/null differ
diff --git a/pics/452.用最少数量的箭引爆气球.png b/pics/452.用最少数量的箭引爆气球.png
deleted file mode 100644
index 64080914..00000000
Binary files a/pics/452.用最少数量的箭引爆气球.png and /dev/null differ
diff --git a/pics/455.分发饼干.png b/pics/455.分发饼干.png
deleted file mode 100644
index 17e15e09..00000000
Binary files a/pics/455.分发饼干.png and /dev/null differ
diff --git a/pics/459.重复的子字符串_1.png b/pics/459.重复的子字符串_1.png
deleted file mode 100644
index 2feddd6b..00000000
Binary files a/pics/459.重复的子字符串_1.png and /dev/null differ
diff --git a/pics/46.全排列.png b/pics/46.全排列.png
deleted file mode 100644
index d8c484ec..00000000
Binary files a/pics/46.全排列.png and /dev/null differ
diff --git a/pics/463.岛屿的周长.png b/pics/463.岛屿的周长.png
deleted file mode 100644
index 5b0fa013..00000000
Binary files a/pics/463.岛屿的周长.png and /dev/null differ
diff --git a/pics/463.岛屿的周长1.png b/pics/463.岛屿的周长1.png
deleted file mode 100644
index bb14dbd6..00000000
Binary files a/pics/463.岛屿的周长1.png and /dev/null differ
diff --git a/pics/47.全排列II1.png b/pics/47.全排列II1.png
deleted file mode 100644
index 8160dd86..00000000
Binary files a/pics/47.全排列II1.png and /dev/null differ
diff --git a/pics/47.全排列II2.png b/pics/47.全排列II2.png
deleted file mode 100644
index d2e096b1..00000000
Binary files a/pics/47.全排列II2.png and /dev/null differ
diff --git a/pics/47.全排列II3.png b/pics/47.全排列II3.png
deleted file mode 100644
index b6f5a862..00000000
Binary files a/pics/47.全排列II3.png and /dev/null differ
diff --git a/pics/486.预测赢家.png b/pics/486.预测赢家.png
deleted file mode 100644
index 03ddfaa8..00000000
Binary files a/pics/486.预测赢家.png and /dev/null differ
diff --git a/pics/486.预测赢家1.png b/pics/486.预测赢家1.png
deleted file mode 100644
index dbddef26..00000000
Binary files a/pics/486.预测赢家1.png and /dev/null differ
diff --git a/pics/486.预测赢家2.png b/pics/486.预测赢家2.png
deleted file mode 100644
index 7d26de9a..00000000
Binary files a/pics/486.预测赢家2.png and /dev/null differ
diff --git a/pics/486.预测赢家3.png b/pics/486.预测赢家3.png
deleted file mode 100644
index 506778c4..00000000
Binary files a/pics/486.预测赢家3.png and /dev/null differ
diff --git a/pics/486.预测赢家4.png b/pics/486.预测赢家4.png
deleted file mode 100644
index 8a679b74..00000000
Binary files a/pics/486.预测赢家4.png and /dev/null differ
diff --git a/pics/491. 递增子序列1.png b/pics/491. 递增子序列1.png
deleted file mode 100644
index 19da907e..00000000
Binary files a/pics/491. 递增子序列1.png and /dev/null differ
diff --git a/pics/491. 递增子序列2.png b/pics/491. 递增子序列2.png
deleted file mode 100644
index 24988010..00000000
Binary files a/pics/491. 递增子序列2.png and /dev/null differ
diff --git a/pics/491. 递增子序列3.png b/pics/491. 递增子序列3.png
deleted file mode 100644
index df293dd5..00000000
Binary files a/pics/491. 递增子序列3.png and /dev/null differ
diff --git a/pics/491. 递增子序列4.png b/pics/491. 递增子序列4.png
deleted file mode 100644
index 395fc515..00000000
Binary files a/pics/491. 递增子序列4.png and /dev/null differ
diff --git a/pics/501.二叉搜索树中的众数.png b/pics/501.二叉搜索树中的众数.png
deleted file mode 100644
index a7197b08..00000000
Binary files a/pics/501.二叉搜索树中的众数.png and /dev/null differ
diff --git a/pics/501.二叉搜索树中的众数1.png b/pics/501.二叉搜索树中的众数1.png
deleted file mode 100644
index 200bc2fa..00000000
Binary files a/pics/501.二叉搜索树中的众数1.png and /dev/null differ
diff --git a/pics/51.N皇后.png b/pics/51.N皇后.png
deleted file mode 100644
index 730b7cb8..00000000
Binary files a/pics/51.N皇后.png and /dev/null differ
diff --git a/pics/51.N皇后1.png b/pics/51.N皇后1.png
deleted file mode 100644
index e6c9c72d..00000000
Binary files a/pics/51.N皇后1.png and /dev/null differ
diff --git a/pics/513.找树左下角的值.png b/pics/513.找树左下角的值.png
deleted file mode 100644
index 67bda96f..00000000
Binary files a/pics/513.找树左下角的值.png and /dev/null differ
diff --git a/pics/513.找树左下角的值1.png b/pics/513.找树左下角的值1.png
deleted file mode 100644
index a5421ad6..00000000
Binary files a/pics/513.找树左下角的值1.png and /dev/null differ
diff --git a/pics/515.在每个树行中找最大值.png b/pics/515.在每个树行中找最大值.png
deleted file mode 100644
index e8f2f431..00000000
Binary files a/pics/515.在每个树行中找最大值.png and /dev/null differ
diff --git a/pics/530.二叉搜索树的最小绝对差.png b/pics/530.二叉搜索树的最小绝对差.png
deleted file mode 100644
index 04ca9a65..00000000
Binary files a/pics/530.二叉搜索树的最小绝对差.png and /dev/null differ
diff --git a/pics/538.把二叉搜索树转换为累加树.png b/pics/538.把二叉搜索树转换为累加树.png
deleted file mode 100644
index 27077f7b..00000000
Binary files a/pics/538.把二叉搜索树转换为累加树.png and /dev/null differ
diff --git a/pics/541_反转字符串II.png b/pics/541_反转字符串II.png
deleted file mode 100644
index 45f0ce6c..00000000
Binary files a/pics/541_反转字符串II.png and /dev/null differ
diff --git a/pics/55.跳跃游戏.png b/pics/55.跳跃游戏.png
deleted file mode 100644
index 012bb635..00000000
Binary files a/pics/55.跳跃游戏.png and /dev/null differ
diff --git a/pics/559.N叉树的最大深度.png b/pics/559.N叉树的最大深度.png
deleted file mode 100644
index d28c543c..00000000
Binary files a/pics/559.N叉树的最大深度.png and /dev/null differ
diff --git a/pics/56.合并区间.png b/pics/56.合并区间.png
deleted file mode 100644
index ff905c72..00000000
Binary files a/pics/56.合并区间.png and /dev/null differ
diff --git a/pics/57.插入区间.png b/pics/57.插入区间.png
deleted file mode 100644
index 67290167..00000000
Binary files a/pics/57.插入区间.png and /dev/null differ
diff --git a/pics/57.插入区间1.png b/pics/57.插入区间1.png
deleted file mode 100644
index 69835dee..00000000
Binary files a/pics/57.插入区间1.png and /dev/null differ
diff --git a/pics/59_封面.png b/pics/59_封面.png
deleted file mode 100644
index 795e8f04..00000000
Binary files a/pics/59_封面.png and /dev/null differ
diff --git a/pics/617.合并二叉树.png b/pics/617.合并二叉树.png
deleted file mode 100644
index 182f959c..00000000
Binary files a/pics/617.合并二叉树.png and /dev/null differ
diff --git a/pics/62.不同路径.png b/pics/62.不同路径.png
deleted file mode 100644
index d82c6ed0..00000000
Binary files a/pics/62.不同路径.png and /dev/null differ
diff --git a/pics/62.不同路径1.png b/pics/62.不同路径1.png
deleted file mode 100644
index 0d84838d..00000000
Binary files a/pics/62.不同路径1.png and /dev/null differ
diff --git a/pics/62.不同路径2.png b/pics/62.不同路径2.png
deleted file mode 100644
index 91984901..00000000
Binary files a/pics/62.不同路径2.png and /dev/null differ
diff --git a/pics/637.二叉树的层平均值.png b/pics/637.二叉树的层平均值.png
deleted file mode 100644
index 57018dab..00000000
Binary files a/pics/637.二叉树的层平均值.png and /dev/null differ
diff --git a/pics/654.最大二叉树.png b/pics/654.最大二叉树.png
deleted file mode 100644
index e8fc63aa..00000000
Binary files a/pics/654.最大二叉树.png and /dev/null differ
diff --git a/pics/657.机器人能否返回原点.png b/pics/657.机器人能否返回原点.png
deleted file mode 100644
index 6ea5b69b..00000000
Binary files a/pics/657.机器人能否返回原点.png and /dev/null differ
diff --git a/pics/669.修剪二叉搜索树.png b/pics/669.修剪二叉搜索树.png
deleted file mode 100644
index 89fe4104..00000000
Binary files a/pics/669.修剪二叉搜索树.png and /dev/null differ
diff --git a/pics/669.修剪二叉搜索树1.png b/pics/669.修剪二叉搜索树1.png
deleted file mode 100644
index 1b46e8d0..00000000
Binary files a/pics/669.修剪二叉搜索树1.png and /dev/null differ
diff --git a/pics/685.冗余连接II1.png b/pics/685.冗余连接II1.png
deleted file mode 100644
index ab833087..00000000
Binary files a/pics/685.冗余连接II1.png and /dev/null differ
diff --git a/pics/685.冗余连接II2.png b/pics/685.冗余连接II2.png
deleted file mode 100644
index 6dbb2ac7..00000000
Binary files a/pics/685.冗余连接II2.png and /dev/null differ
diff --git a/pics/700.二叉搜索树中的搜索.png b/pics/700.二叉搜索树中的搜索.png
deleted file mode 100644
index 1fd15466..00000000
Binary files a/pics/700.二叉搜索树中的搜索.png and /dev/null differ
diff --git a/pics/700.二叉搜索树中的搜索1.png b/pics/700.二叉搜索树中的搜索1.png
deleted file mode 100644
index 037627b1..00000000
Binary files a/pics/700.二叉搜索树中的搜索1.png and /dev/null differ
diff --git a/pics/763.划分字母区间.png b/pics/763.划分字母区间.png
deleted file mode 100644
index 0c1da0f3..00000000
Binary files a/pics/763.划分字母区间.png and /dev/null differ
diff --git a/pics/77.组合.png b/pics/77.组合.png
deleted file mode 100644
index 17cde493..00000000
Binary files a/pics/77.组合.png and /dev/null differ
diff --git a/pics/77.组合1.png b/pics/77.组合1.png
deleted file mode 100644
index a6a4a272..00000000
Binary files a/pics/77.组合1.png and /dev/null differ
diff --git a/pics/77.组合2.png b/pics/77.组合2.png
deleted file mode 100644
index 94e305b6..00000000
Binary files a/pics/77.组合2.png and /dev/null differ
diff --git a/pics/77.组合3.png b/pics/77.组合3.png
deleted file mode 100644
index 4ba73549..00000000
Binary files a/pics/77.组合3.png and /dev/null differ
diff --git a/pics/77.组合4.png b/pics/77.组合4.png
deleted file mode 100644
index b2519ccd..00000000
Binary files a/pics/77.组合4.png and /dev/null differ
diff --git a/pics/78.子集.png b/pics/78.子集.png
deleted file mode 100644
index 1700030f..00000000
Binary files a/pics/78.子集.png and /dev/null differ
diff --git a/pics/841.钥匙和房间.png b/pics/841.钥匙和房间.png
deleted file mode 100644
index 3bfdeea4..00000000
Binary files a/pics/841.钥匙和房间.png and /dev/null differ
diff --git a/pics/90.子集II.png b/pics/90.子集II.png
deleted file mode 100644
index 972010f6..00000000
Binary files a/pics/90.子集II.png and /dev/null differ
diff --git a/pics/90.子集II1.png b/pics/90.子集II1.png
deleted file mode 100644
index 92a18238..00000000
Binary files a/pics/90.子集II1.png and /dev/null differ
diff --git a/pics/90.子集II2.png b/pics/90.子集II2.png
deleted file mode 100644
index e42a56f7..00000000
Binary files a/pics/90.子集II2.png and /dev/null differ
diff --git a/pics/925.长按键入.png b/pics/925.长按键入.png
deleted file mode 100644
index c6bee552..00000000
Binary files a/pics/925.长按键入.png and /dev/null differ
diff --git a/pics/93.复原IP地址.png b/pics/93.复原IP地址.png
deleted file mode 100644
index 63d11f2e..00000000
Binary files a/pics/93.复原IP地址.png and /dev/null differ
diff --git a/pics/941.有效的山脉数组.png b/pics/941.有效的山脉数组.png
deleted file mode 100644
index e261242c..00000000
Binary files a/pics/941.有效的山脉数组.png and /dev/null differ
diff --git a/pics/968.监控二叉树1.png b/pics/968.监控二叉树1.png
deleted file mode 100644
index 7e6a75df..00000000
Binary files a/pics/968.监控二叉树1.png and /dev/null differ
diff --git a/pics/968.监控二叉树2.png b/pics/968.监控二叉树2.png
deleted file mode 100644
index 664a656e..00000000
Binary files a/pics/968.监控二叉树2.png and /dev/null differ
diff --git a/pics/968.监控二叉树3.png b/pics/968.监控二叉树3.png
deleted file mode 100644
index 0a3a9ea6..00000000
Binary files a/pics/968.监控二叉树3.png and /dev/null differ
diff --git a/pics/977.有序数组的平方.png b/pics/977.有序数组的平方.png
deleted file mode 100644
index cb9ccf6c..00000000
Binary files a/pics/977.有序数组的平方.png and /dev/null differ
diff --git a/pics/98.验证二叉搜索树.png b/pics/98.验证二叉搜索树.png
deleted file mode 100644
index 8a164140..00000000
Binary files a/pics/98.验证二叉搜索树.png and /dev/null differ
diff --git a/pics/leetcode_209.png b/pics/leetcode_209.png
deleted file mode 100644
index 2278be41..00000000
Binary files a/pics/leetcode_209.png and /dev/null differ
diff --git a/pics/公众号.png b/pics/公众号.png
new file mode 100644
index 00000000..eeec00ad
Binary files /dev/null and b/pics/公众号.png differ
diff --git a/pics/公众号二维码.jpg b/pics/公众号二维码.jpg
new file mode 100644
index 00000000..a91b2494
Binary files /dev/null and b/pics/公众号二维码.jpg differ
diff --git a/pics/剑指Offer05.替换空格.png b/pics/剑指Offer05.替换空格.png
deleted file mode 100644
index e4a2dfbc..00000000
Binary files a/pics/剑指Offer05.替换空格.png and /dev/null differ
diff --git a/pics/剑指Offer58-II.左旋转字符串.png b/pics/剑指Offer58-II.左旋转字符串.png
deleted file mode 100644
index 9b41754e..00000000
Binary files a/pics/剑指Offer58-II.左旋转字符串.png and /dev/null differ
diff --git a/pics/动态规划-背包问题1.png b/pics/动态规划-背包问题1.png
deleted file mode 100644
index dd51c5a9..00000000
Binary files a/pics/动态规划-背包问题1.png and /dev/null differ
diff --git a/pics/动态规划-背包问题2.png b/pics/动态规划-背包问题2.png
deleted file mode 100644
index 6ea1863c..00000000
Binary files a/pics/动态规划-背包问题2.png and /dev/null differ
diff --git a/pics/动态规划-背包问题3.png b/pics/动态规划-背包问题3.png
deleted file mode 100644
index 568c7bd9..00000000
Binary files a/pics/动态规划-背包问题3.png and /dev/null differ
diff --git a/pics/动态规划-背包问题4.png b/pics/动态规划-背包问题4.png
deleted file mode 100644
index 97632993..00000000
Binary files a/pics/动态规划-背包问题4.png and /dev/null differ
diff --git a/pics/回溯算法理论基础.png b/pics/回溯算法理论基础.png
deleted file mode 100644
index f8f2eb2f..00000000
Binary files a/pics/回溯算法理论基础.png and /dev/null differ
diff --git a/pics/微信搜一搜.png b/pics/微信搜一搜.png
new file mode 100644
index 00000000..62bee447
Binary files /dev/null and b/pics/微信搜一搜.png differ
diff --git a/pics/我要打十个.gif b/pics/我要打十个.gif
deleted file mode 100644
index c64eb70a..00000000
Binary files a/pics/我要打十个.gif and /dev/null differ
diff --git a/pics/知识星球.png b/pics/知识星球.png
new file mode 100644
index 00000000..43a5c6b3
Binary files /dev/null and b/pics/知识星球.png differ
diff --git a/pics/算法大纲.png b/pics/算法大纲.png
new file mode 100644
index 00000000..602f1d03
Binary files /dev/null and b/pics/算法大纲.png differ
diff --git a/pics/螺旋矩阵.png b/pics/螺旋矩阵.png
deleted file mode 100644
index 5148db46..00000000
Binary files a/pics/螺旋矩阵.png and /dev/null differ
diff --git a/pics/面试题02.07.链表相交_1.png b/pics/面试题02.07.链表相交_1.png
deleted file mode 100644
index 678311d1..00000000
Binary files a/pics/面试题02.07.链表相交_1.png and /dev/null differ
diff --git a/pics/面试题02.07.链表相交_2.png b/pics/面试题02.07.链表相交_2.png
deleted file mode 100644
index 97881bec..00000000
Binary files a/pics/面试题02.07.链表相交_2.png and /dev/null differ
diff --git a/problems/0001.两数之和.md b/problems/0001.两数之和.md
index b7c9831b..6c9d99dd 100644
--- a/problems/0001.两数之和.md
+++ b/problems/0001.两数之和.md
@@ -1,9 +1,15 @@
-# 题目地址
-https://leetcode-cn.com/problems/two-sum/
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 只用数组和set还是不够的! -# 第1题. 两数之和 +## 1. 两数之和 + +https://leetcode-cn.com/problems/two-sum/ 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。 @@ -18,7 +24,7 @@ https://leetcode-cn.com/problems/two-sum/ 所以返回 [0, 1] -# 思路 +## 思路 很明显暴力的解法是两层for循环查找,时间复杂度是O(n^2)。 @@ -51,11 +57,11 @@ std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底 解题思路动画如下: - + -# C++代码 +C++代码: -``` +```C++ class Solution { public: vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + > 用哈希表解决了[两数之和](https://mp.weixin.qq.com/s/uVAtjOHSeqymV8FeQbliJQ),那么三数之和呢? # 第15题. 三数之和 +https://leetcode-cn.com/problems/3sum/ + 给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。 **注意:** 答案中不可以包含重复的三元组。 @@ -20,7 +29,7 @@ https://leetcode-cn.com/problems/3sum/ ] -# 思路 +# 思路 **注意[0, 0, 0, 0] 这组数据** @@ -36,14 +45,14 @@ https://leetcode-cn.com/problems/3sum/ 大家可以尝试使用哈希法写一写,就知道其困难的程度了。 -## 哈希法C++代码 -``` +哈希法C++代码: +```C++ class Solution { public: vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 多个集合求组合问题。 # 17.电话号码的字母组合 @@ -9,29 +15,29 @@ 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 - + -示例: -输入:"23" -输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"]. +示例: +输入:"23" +输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"]. 说明:尽管上面的答案是按字典序排列的,但是你可以任意选择答案输出的顺序。 -# 思路 +# 思路 从示例上来说,输入"23",最直接的想法就是两层for循环遍历了吧,正好把组合的情况都输出了。 -如果输入"233"呢,那么就三层for循环,如果"2333"呢,就四层for循环....... +如果输入"233"呢,那么就三层for循环,如果"2333"呢,就四层for循环....... 大家应该感觉出和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)遇到的一样的问题,就是这for循环的层数如何写出来,此时又是回溯法登场的时候了。 理解本题后,要解决如下三个问题: -1. 数字和字母如何映射 -2. 两个字母就两个for循环,三个字符我就三个for循环,以此类推,然后发现代码根本写不出来 -3. 输入1 * #按键等等异常情况 +1. 数字和字母如何映射 +2. 两个字母就两个for循环,三个字符我就三个for循环,以此类推,然后发现代码根本写不出来 +3. 输入1 * #按键等等异常情况 -## 数字和字母如何映射 +## 数字和字母如何映射 可以使用map或者定义一个二位数组,例如:string letterMap[10],来做映射,我这里定义一个二维数组,代码如下: @@ -63,7 +69,7 @@ const string letterMap[10] = { 回溯三部曲: -* 确定回溯函数参数 +* 确定回溯函数参数 首先需要一个字符串s来收集叶子节点的结果,然后用一个字符串数组result保存起来,这两个变量我依然定义为全局。 @@ -78,10 +84,10 @@ const string letterMap[10] = { ``` vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ > 一样的道理,能解决四数之和 - > 那么五数之和、六数之和、N数之和呢? -# 第18题. 四数之和 +# 第18题. 四数之和 + +https://leetcode-cn.com/problems/4sum/ 题意:给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。 @@ -13,26 +20,26 @@ https://leetcode-cn.com/problems/4sum/ 答案中不可以包含重复的四元组。 -示例: -给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。 -满足要求的四元组集合为: +示例: +给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。 +满足要求的四元组集合为: [ [-1, 0, 0, 1], [-2, -1, 1, 2], [-2, 0, 0, 2] ] -# 思路 +# 思路 -四数之和,和[三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)是一个思路,都是使用双指针法, 基本解法就是在[三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A) 的基础上再套一层for循环。 +四数之和,和[三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)是一个思路,都是使用双指针法, 基本解法就是在[三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A) 的基础上再套一层for循环。 但是有一些细节需要注意,例如: 不要判断`nums[k] > target` 就返回了,三数之和 可以通过 `nums[i] > 0` 就返回了,因为 0 已经是确定的数了,四数之和这道题目 target是任意值。(大家亲自写代码就能感受出来) [三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)的双指针解法是一层for循环num[i]为确定值,然后循环内有left和right下表作为双指针,找到nums[i] + nums[left] + nums[right] == 0。 -四数之和的双指针解法是两层for循环nums[k] + nums[i]为确定值,依然是循环内有left和right下表作为双指针,找出nums[k] + nums[i] + nums[left] + nums[right] == target的情况,三数之和的时间复杂度是O(n^2),四数之和的时间复杂度是O(n^3) 。 +四数之和的双指针解法是两层for循环nums[k] + nums[i]为确定值,依然是循环内有left和right下表作为双指针,找出nums[k] + nums[i] + nums[left] + nums[right] == target的情况,三数之和的时间复杂度是O(n^2),四数之和的时间复杂度是O(n^3) 。 -那么一样的道理,五数之和、六数之和等等都采用这种解法。 +那么一样的道理,五数之和、六数之和等等都采用这种解法。 对于[三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)双指针法就是将原本暴力O(n^3)的解法,降为O(n^2)的解法,四数之和的双指针解法就是将原本暴力O(n^4)的解法,降为O(n^3)的解法。 @@ -57,15 +64,16 @@ https://leetcode-cn.com/problems/4sum/ 双指针法在数组和链表中还有很多应用,后面还会介绍到。 -# C++代码 -``` +C++代码 + +```C++ class Solution { public: vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 思路 + + +## 19.删除链表的倒数第N个节点 + +题目链接:https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list/ + +给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 + +进阶:你能尝试使用一趟扫描实现吗? + +示例 1: + + + +输入:head = [1,2,3,4,5], n = 2 +输出:[1,2,3,5] +示例 2: + +输入:head = [1], n = 1 +输出:[] +示例 3: + +输入:head = [1,2], n = 1 +输出:[1] + + +## 思路 双指针的经典应用,如果要删除倒数第n个节点,让fast移动n步,然后让fast和slow同时移动,直到fast指向链表末尾。删掉slow所指向的节点就可以了。 @@ -8,25 +41,24 @@ 分为如下几步: -* 首先这里我推荐大家使用虚拟头结点,这样方面处理删除实际头结点的逻辑,如果虚拟头结点不清楚,可以看这篇: [链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/slM1CH5Ew9XzK93YOQYSjA) - +* 首先这里我推荐大家使用虚拟头结点,这样方面处理删除实际头结点的逻辑,如果虚拟头结点不清楚,可以看这篇: [链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/L5aanfALdLEwVWGvyXPDqA) * 定义fast指针和slow指针,初始值为虚拟头结点,如图: - +
+ * fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作),如图:
-
* fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作),如图:
- +
+ -* fast和slow同时移动,之道fast指向末尾,如题:
-
-* fast和slow同时移动,之道fast指向末尾,如题:
- +* fast和slow同时移动,之道fast指向末尾,如题:
+
+* fast和slow同时移动,之道fast指向末尾,如题:
+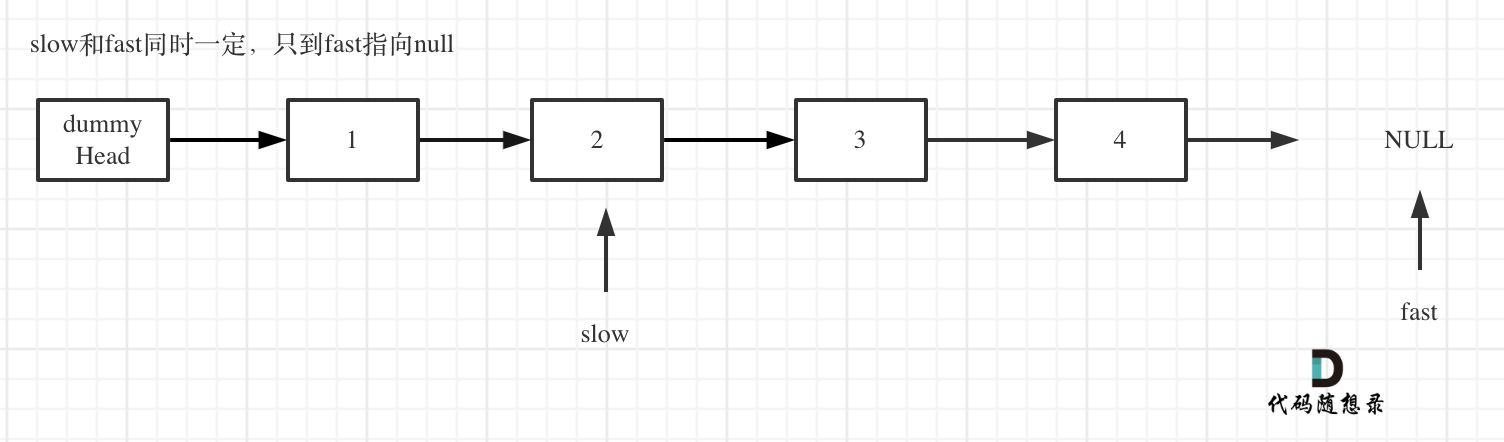 * 删除slow指向的下一个节点,如图:
-
* 删除slow指向的下一个节点,如图:
- +
+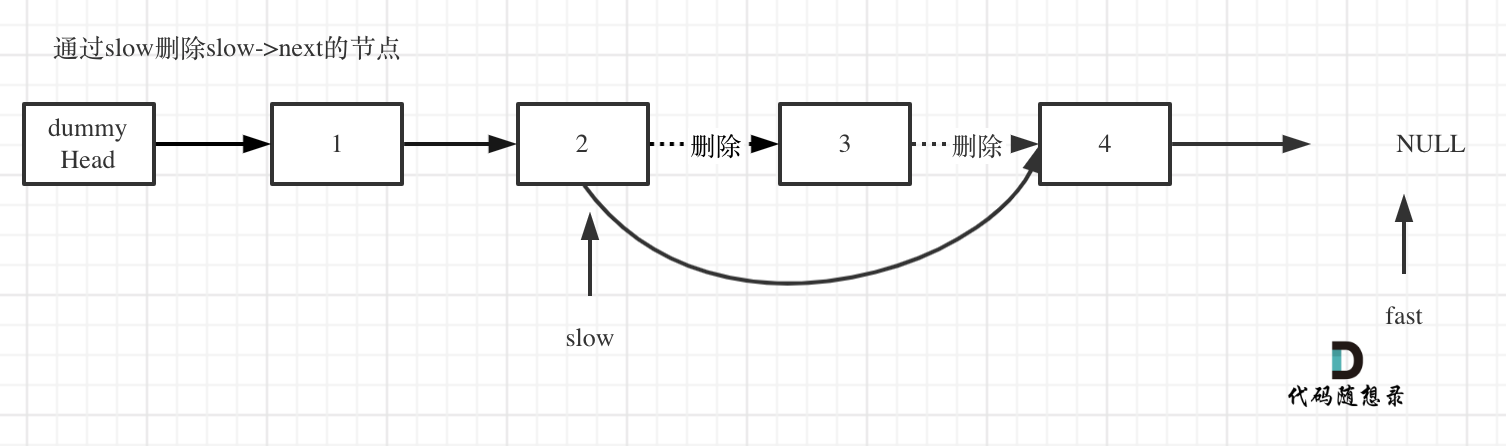 此时不难写出如下C++代码:
-```
+```C++
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
@@ -47,3 +79,43 @@ public:
}
};
```
+
+
+## 其他语言版本
+
+java:
+
+```java
+class Solution {
+ public ListNode removeNthFromEnd(ListNode head, int n) {
+ ListNode dummy = new ListNode(-1);
+ dummy.next = head;
+
+ ListNode slow = dummy;
+ ListNode fast = dummy;
+ while (n-- > 0) {
+ fast = fast.next;
+ }
+ // 记住 待删除节点slow 的上一节点
+ ListNode prev = null;
+ while (fast != null) {
+ prev = slow;
+ slow = slow.next;
+ fast = fast.next;
+ }
+ // 上一节点的next指针绕过 待删除节点slow 直接指向slow的下一节点
+ prev.next = slow.next;
+ // 释放 待删除节点slow 的next指针, 这句删掉也能AC
+ slow.next = null;
+
+ return dummy.next;
+ }
+}
+```
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
此时不难写出如下C++代码:
-```
+```C++
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
@@ -47,3 +79,43 @@ public:
}
};
```
+
+
+## 其他语言版本
+
+java:
+
+```java
+class Solution {
+ public ListNode removeNthFromEnd(ListNode head, int n) {
+ ListNode dummy = new ListNode(-1);
+ dummy.next = head;
+
+ ListNode slow = dummy;
+ ListNode fast = dummy;
+ while (n-- > 0) {
+ fast = fast.next;
+ }
+ // 记住 待删除节点slow 的上一节点
+ ListNode prev = null;
+ while (fast != null) {
+ prev = slow;
+ slow = slow.next;
+ fast = fast.next;
+ }
+ // 上一节点的next指针绕过 待删除节点slow 直接指向slow的下一节点
+ prev.next = slow.next;
+ // 释放 待删除节点slow 的next指针, 这句删掉也能AC
+ slow.next = null;
+
+ return dummy.next;
+ }
+}
+```
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 题目地址 -https://leetcode-cn.com/problems/valid-parentheses/ > 数据结构与算法应用往往隐藏在我们看不到的地方 -# 20. 有效的括号 +# 20. 有效的括号 + +https://leetcode-cn.com/problems/valid-parentheses/ 给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。 @@ -14,27 +21,27 @@ https://leetcode-cn.com/problems/valid-parentheses/ * 左括号必须以正确的顺序闭合。 * 注意空字符串可被认为是有效字符串。 -示例 1: -输入: "()" +示例 1: +输入: "()" 输出: true -示例 2: -输入: "()[]{}" -输出: true +示例 2: +输入: "()[]{}" +输出: true -示例 3: -输入: "(]" -输出: false +示例 3: +输入: "(]" +输出: false -示例 4: -输入: "([)]" -输出: false +示例 4: +输入: "([)]" +输出: false -示例 5: -输入: "{[]}" -输出: true +示例 5: +输入: "{[]}" +输出: true -# 思路 +# 思路 ## 题外话 @@ -52,9 +59,9 @@ cd a/b/c/../../ 这个命令最后进入a目录,系统是如何知道进入了a目录呢 ,这就是栈的应用(其实可以出一道相应的面试题了) -所以栈在计算机领域中应用是非常广泛的。 +所以栈在计算机领域中应用是非常广泛的。 -有的同学经常会想学的这些数据结构有什么用,也开发不了什么软件,大多数同学说的软件应该都是可视化的软件例如APP、网站之类的,那都是非常上层的应用了,底层很多功能的实现都是基础的数据结构和算法。 +有的同学经常会想学的这些数据结构有什么用,也开发不了什么软件,大多数同学说的软件应该都是可视化的软件例如APP、网站之类的,那都是非常上层的应用了,底层很多功能的实现都是基础的数据结构和算法。 **所以数据结构与算法的应用往往隐藏在我们看不到的地方!** @@ -66,9 +73,9 @@ cd a/b/c/../../ 首先要弄清楚,字符串里的括号不匹配有几种情况。 -**一些同学,在面试中看到这种题目上来就开始写代码,然后就越写越远。** +**一些同学,在面试中看到这种题目上来就开始写代码,然后就越写越乱。** -建议要写代码之前要分析好有哪几种不匹配的情况,如果不动手之前分析好,写出的代码也会有很多问题。 +建议要写代码之前要分析好有哪几种不匹配的情况,如果不动手之前分析好,写出的代码也会有很多问题。 先来分析一下 这里有三种不匹配的情况, @@ -83,7 +90,7 @@ cd a/b/c/../../ 动画如下: - +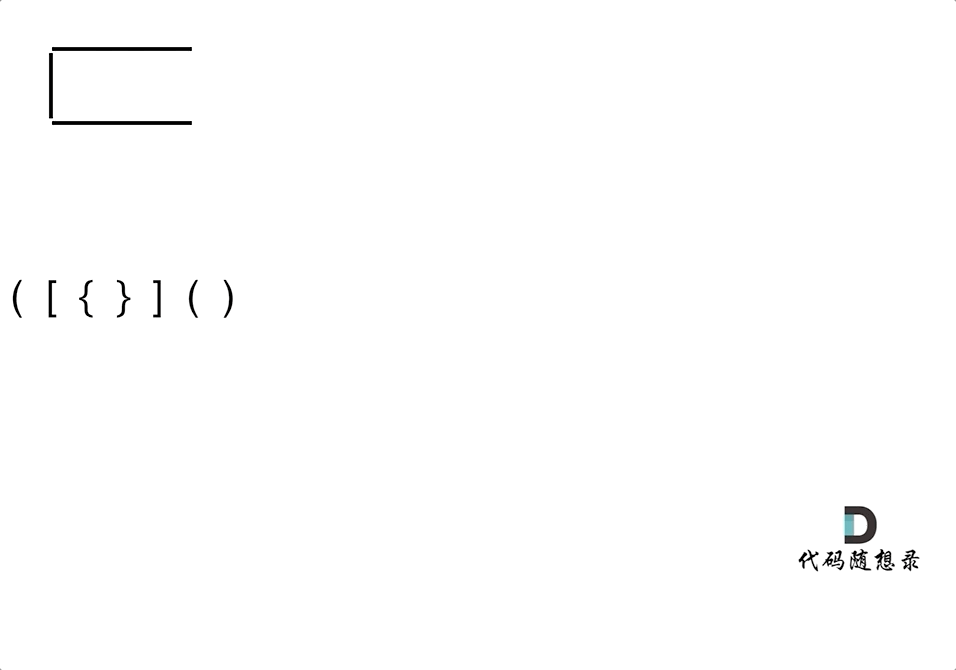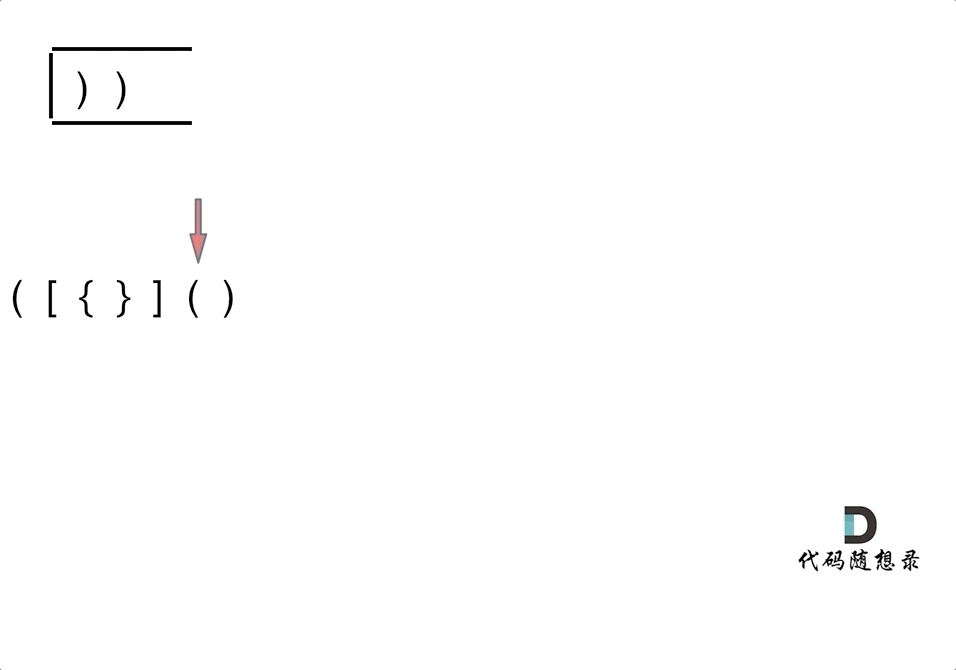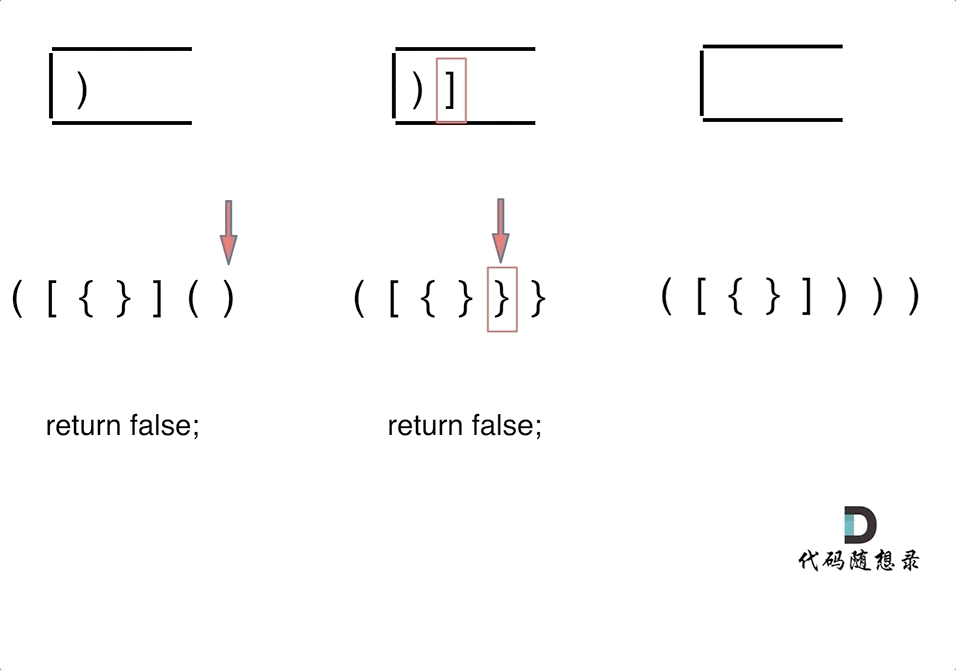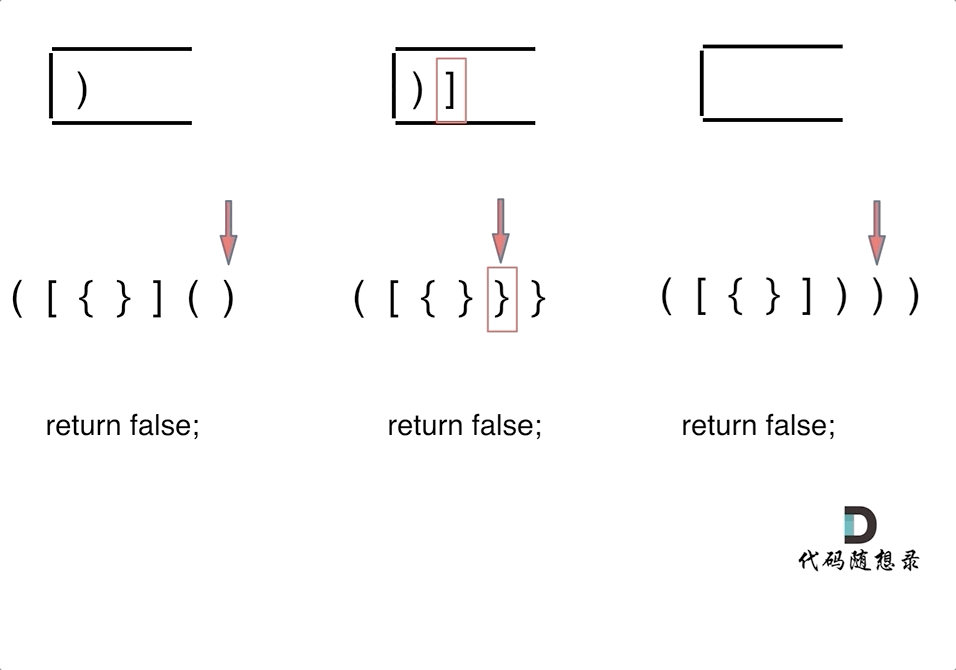 第一种情况:已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false @@ -98,12 +105,10 @@ cd a/b/c/../../ 但还有一些技巧,在匹配左括号的时候,右括号先入栈,就只需要比较当前元素和栈顶相不相等就可以了,比左括号先入栈代码实现要简单的多了! -实现代码如下: - -## C++代码 +实现C++代码如下: -``` +```C++ class Solution { public: bool isValid(string s) { @@ -124,5 +129,27 @@ public: ``` 技巧性的东西没有固定的学习方法,还是要多看多练,自己总灵活运用了。 -> 更过算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。 + + + + +## 其他语言版本 + + +Java: + + +Python: + + +Go: + + + + +----------------------- +* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw) +* B站视频:[代码随想录](https://space.bilibili.com/525438321) +* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) +  -
-操作之后,链表如下:
-
-
-
-
-操作之后,链表如下:
-
-
- -
-看这个可能就更直观一些了:
-
-
-
-
-看这个可能就更直观一些了:
-
-
- -
-对应的C++代码实现如下:
-
-```
-class Solution {
-public:
- ListNode* swapPairs(ListNode* head) {
- ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
- dummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作
- ListNode* cur = dummyHead;
- while(cur->next != nullptr && cur->next->next != nullptr) {
- ListNode* tmp = cur->next; // 记录临时节点
- ListNode* tmp1 = cur->next->next->next; // 记录临时节点
-
- cur->next = cur->next->next; // 步骤一
- cur->next->next = tmp; // 步骤二
- cur->next->next->next = tmp1; // 步骤三
-
- cur = cur->next->next; // cur移动两位,准备下一轮交换
- }
- return dummyHead->next;
- }
-};
-```
-时间复杂度:O(n)
-空间复杂度:O(1)
-
-## 拓展
-
-**这里还是说一下,大家不必太在意leetcode上执行用时,打败多少多少用户,这个就是一个玩具,非常不准确。**
-
-做题的时候自己能分析出来时间复杂度就可以了,至于leetcode上执行用时,大概看一下就行。
-
-上面的代码我第一次提交执行用时8ms,打败6.5%的用户,差点吓到我了。
-
-心想应该没有更好的方法了吧,也就O(n)的时间复杂度,重复提交几次,这样了:
-
-
-
-对应的C++代码实现如下:
-
-```
-class Solution {
-public:
- ListNode* swapPairs(ListNode* head) {
- ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
- dummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作
- ListNode* cur = dummyHead;
- while(cur->next != nullptr && cur->next->next != nullptr) {
- ListNode* tmp = cur->next; // 记录临时节点
- ListNode* tmp1 = cur->next->next->next; // 记录临时节点
-
- cur->next = cur->next->next; // 步骤一
- cur->next->next = tmp; // 步骤二
- cur->next->next->next = tmp1; // 步骤三
-
- cur = cur->next->next; // cur移动两位,准备下一轮交换
- }
- return dummyHead->next;
- }
-};
-```
-时间复杂度:O(n)
-空间复杂度:O(1)
-
-## 拓展
-
-**这里还是说一下,大家不必太在意leetcode上执行用时,打败多少多少用户,这个就是一个玩具,非常不准确。**
-
-做题的时候自己能分析出来时间复杂度就可以了,至于leetcode上执行用时,大概看一下就行。
-
-上面的代码我第一次提交执行用时8ms,打败6.5%的用户,差点吓到我了。
-
-心想应该没有更好的方法了吧,也就O(n)的时间复杂度,重复提交几次,这样了:
-
- -
-所以,不必过于在意leetcode上这个统计。
-
-
-
diff --git a/problems/0026.删除排序数组中的重复项.md b/problems/0026.删除排序数组中的重复项.md
deleted file mode 100644
index 114f2da2..00000000
--- a/problems/0026.删除排序数组中的重复项.md
+++ /dev/null
@@ -1,49 +0,0 @@
-## 题目地址
-https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/
-
-# 思路
-
-此题使用双指针法,O(n)的时间复杂度,拼速度的话,可以剪剪枝。
-
-注意题目中:不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
-
-双指针法,动画如下:
-
-
-
-其实**双指针法在在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法,可以将时间复杂度O(n^2)的解法优化为 O(n)的解法,例如:**
-
-* [0015.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md)
-* [0018.四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md)
-* [0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md)
-* [0206.翻转链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0206.翻转链表.md)
-* [0344.反转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0344.反转字符串.md)
-* [剑指Offer05.替换空格](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md)
-
-**还有链表找环,也用到双指针:**
-
-* [0142.环形链表II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0142.环形链表II.md)
-
-大家都可以去做一做,感受一下双指针法的内在逻辑!
-
-
-# C++ 代码
-
-
-```
-class Solution {
-public:
- int removeDuplicates(vector
-
-所以,不必过于在意leetcode上这个统计。
-
-
-
diff --git a/problems/0026.删除排序数组中的重复项.md b/problems/0026.删除排序数组中的重复项.md
deleted file mode 100644
index 114f2da2..00000000
--- a/problems/0026.删除排序数组中的重复项.md
+++ /dev/null
@@ -1,49 +0,0 @@
-## 题目地址
-https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/
-
-# 思路
-
-此题使用双指针法,O(n)的时间复杂度,拼速度的话,可以剪剪枝。
-
-注意题目中:不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
-
-双指针法,动画如下:
-
-
-
-其实**双指针法在在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法,可以将时间复杂度O(n^2)的解法优化为 O(n)的解法,例如:**
-
-* [0015.三数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0015.三数之和.md)
-* [0018.四数之和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0018.四数之和.md)
-* [0026.删除排序数组中的重复项](https://github.com/youngyangyang04/leetcode/blob/master/problems/0026.删除排序数组中的重复项.md)
-* [0206.翻转链表](https://github.com/youngyangyang04/leetcode/blob/master/problems/0206.翻转链表.md)
-* [0344.反转字符串](https://github.com/youngyangyang04/leetcode/blob/master/problems/0344.反转字符串.md)
-* [剑指Offer05.替换空格](https://github.com/youngyangyang04/leetcode/blob/master/problems/剑指Offer05.替换空格.md)
-
-**还有链表找环,也用到双指针:**
-
-* [0142.环形链表II](https://github.com/youngyangyang04/leetcode/blob/master/problems/0142.环形链表II.md)
-
-大家都可以去做一做,感受一下双指针法的内在逻辑!
-
-
-# C++ 代码
-
-
-```
-class Solution {
-public:
- int removeDuplicates(vector
-
-
-
-
+
-
-
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 移除元素想要高效的话,不是很简单! -# 编号:27. 移除元素 +## 27. 移除元素 题目地址:https://leetcode-cn.com/problems/remove-element/ @@ -22,38 +17,38 @@ 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。 -示例 1: -给定 nums = [3,2,2,3], val = 3, -函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。 -你不需要考虑数组中超出新长度后面的元素。 +示例 1: +给定 nums = [3,2,2,3], val = 3, +函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。 +你不需要考虑数组中超出新长度后面的元素。 -示例 2: -给定 nums = [0,1,2,2,3,0,4,2], val = 2, -函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。 +示例 2: +给定 nums = [0,1,2,2,3,0,4,2], val = 2, +函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。 **你不需要考虑数组中超出新长度后面的元素。** -# 思路 +## 思路 有的同学可能说了,多余的元素,删掉不就得了。 -**要知道数组的元素在内存地址中是连续的,不能单独删除数组中的某个元素,只能覆盖。** +**要知道数组的元素在内存地址中是连续的,不能单独删除数组中的某个元素,只能覆盖。** -数组的基础知识可以看这里[程序员算法面试中,必须掌握的数组理论知识](https://mp.weixin.qq.com/s/X7R55wSENyY62le0Fiawsg)。 +数组的基础知识可以看这里[程序员算法面试中,必须掌握的数组理论知识](https://mp.weixin.qq.com/s/c2KABb-Qgg66HrGf8z-8Og)。 -# 暴力解法 +### 暴力解法 -这个题目暴力的解法就是两层for循环,一个for循环遍历数组元素 ,第二个for循环更新数组。 +这个题目暴力的解法就是两层for循环,一个for循环遍历数组元素 ,第二个for循环更新数组。 删除过程如下: - +
很明显暴力解法的时间复杂度是O(n^2),这道题目暴力解法在leetcode上是可以过的。
-# 暴力解法C++代码
+代码如下:
-```
+```C++
// 时间复杂度:O(n^2)
// 空间复杂度:O(1)
class Solution {
@@ -75,53 +70,84 @@ public:
};
```
-# 双指针法
+* 时间复杂度:$O(n^2)$
+* 空间复杂度:$O(1)$
+
+### 双指针法
双指针法(快慢指针法): **通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。**
删除过程如下:
-
+
很明显暴力解法的时间复杂度是O(n^2),这道题目暴力解法在leetcode上是可以过的。
-# 暴力解法C++代码
+代码如下:
-```
+```C++
// 时间复杂度:O(n^2)
// 空间复杂度:O(1)
class Solution {
@@ -75,53 +70,84 @@ public:
};
```
-# 双指针法
+* 时间复杂度:$O(n^2)$
+* 空间复杂度:$O(1)$
+
+### 双指针法
双指针法(快慢指针法): **通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。**
删除过程如下:
- +
-**双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法。**
+**双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组、链表、字符串等操作的面试题,都使用双指针法。**
-我们来回顾一下,之前已经讲过有四道题目使用了双指针法。
+后序都会一一介绍到,本题代码如下:
-双指针法将时间复杂度O(n^2)的解法优化为 O(n)的解法。也就是降一个数量级,题目如下:
-
-* [15.三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)
-* [18.四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)
-
-双指针来记录前后指针实现链表反转:
-
-* [206.反转链表](https://mp.weixin.qq.com/s/pnvVP-0ZM7epB8y3w_Njwg)
-
-使用双指针来确定有环:
-
-* [142题.环形链表II](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)
-
-双指针法在数组和链表中还有很多应用,后面还会介绍到。
-
-# 双指针法C++代码:
-```
+```C++
// 时间复杂度:O(n)
// 空间复杂度:O(1)
class Solution {
public:
int removeElement(vector
+
-**双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组和链表操作的面试题,都使用双指针法。**
+**双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组、链表、字符串等操作的面试题,都使用双指针法。**
-我们来回顾一下,之前已经讲过有四道题目使用了双指针法。
+后序都会一一介绍到,本题代码如下:
-双指针法将时间复杂度O(n^2)的解法优化为 O(n)的解法。也就是降一个数量级,题目如下:
-
-* [15.三数之和](https://mp.weixin.qq.com/s/r5cgZFu0tv4grBAexdcd8A)
-* [18.四数之和](https://mp.weixin.qq.com/s/nQrcco8AZJV1pAOVjeIU_g)
-
-双指针来记录前后指针实现链表反转:
-
-* [206.反转链表](https://mp.weixin.qq.com/s/pnvVP-0ZM7epB8y3w_Njwg)
-
-使用双指针来确定有环:
-
-* [142题.环形链表II](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)
-
-双指针法在数组和链表中还有很多应用,后面还会介绍到。
-
-# 双指针法C++代码:
-```
+```C++
// 时间复杂度:O(n)
// 空间复杂度:O(1)
class Solution {
public:
int removeElement(vector
- -
-
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + +> 在一个串中查找是否出现过另一个串,这是KMP的看家本领。 + +# 28. 实现 strStr() -## 题目地址 https://leetcode-cn.com/problems/implement-strstr/ -> 在一个串中查找是否出现过另一个串,这是KMP的看家本领。 - -# 题目:28. 实现 strStr() - 实现 strStr() 函数。 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。 -示例 1: -输入: haystack = "hello", needle = "ll" -输出: 2 +示例 1: +输入: haystack = "hello", needle = "ll" +输出: 2 -示例 2: -输入: haystack = "aaaaa", needle = "bba" -输出: -1 +示例 2: +输入: haystack = "aaaaa", needle = "bba" +输出: -1 -说明: -当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。 -对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。 +说明: +当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。 +对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。 -# 思路 +# 思路 本题是KMP 经典题目。 @@ -108,7 +115,7 @@ next数组就是一个前缀表(prefix table)。 如动画所示: - +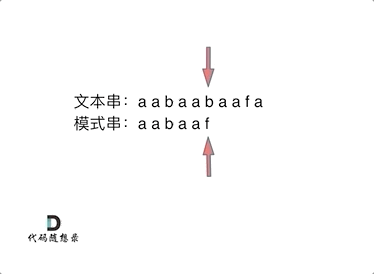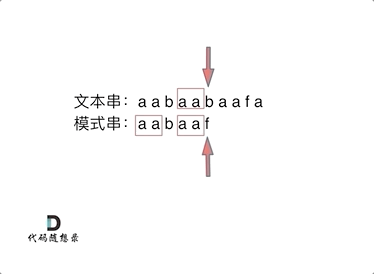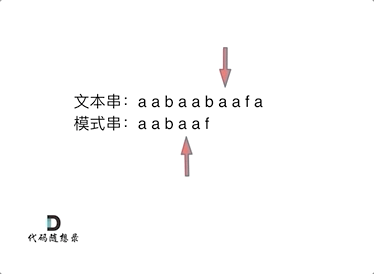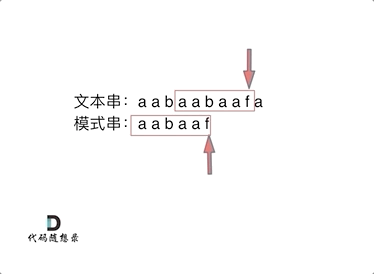
动画里,我特意把 子串`aa` 标记上了,这是有原因的,大家先注意一下,后面还会说道。
@@ -120,22 +127,45 @@ next数组就是一个前缀表(prefix table)。
首先要知道前缀表的任务是当前位置匹配失败,找到之前已经匹配上的位置,在重新匹配,此也意味着在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置。
-那么什么是前缀表:**记录下表i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
+那么什么是前缀表:**记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
+
+# 最长公共前后缀?
+
+文章中字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
+
+后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
+
+**正确理解什么是前缀什么是后缀很重要。**
+
+那么网上清一色都说 “kmp 最长公共前后缀” 又是什么回事呢?
+
+
+我查了一遍 算法导论 和 算法4里KMP的章节,都没有提到 “最长公共前后缀”这个词,也不知道从哪里来了,我理解是用“最长相等前后缀” 准确一些。
+
+**因为前缀表要求的就是相同前后缀的长度。**
+
+而最长公共前后缀里面的“公共”,更像是说前缀和后缀公共的长度。这其实并不是前缀表所需要的。
+
+所以字符串a的最长相等前后缀为0。
+字符串aa的最长相等前后缀为1。
+字符串aaa的最长相等前后缀为2。
+等等.....。
+
# 为什么一定要用前缀表
这就是前缀表那为啥就能告诉我们 上次匹配的位置,并跳过去呢?
-回顾一下,刚刚匹配的过程在下表5的地方遇到不匹配,模式串是指向f,如图:
-
+
动画里,我特意把 子串`aa` 标记上了,这是有原因的,大家先注意一下,后面还会说道。
@@ -120,22 +127,45 @@ next数组就是一个前缀表(prefix table)。
首先要知道前缀表的任务是当前位置匹配失败,找到之前已经匹配上的位置,在重新匹配,此也意味着在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置。
-那么什么是前缀表:**记录下表i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
+那么什么是前缀表:**记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
+
+# 最长公共前后缀?
+
+文章中字符串的前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
+
+后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
+
+**正确理解什么是前缀什么是后缀很重要。**
+
+那么网上清一色都说 “kmp 最长公共前后缀” 又是什么回事呢?
+
+
+我查了一遍 算法导论 和 算法4里KMP的章节,都没有提到 “最长公共前后缀”这个词,也不知道从哪里来了,我理解是用“最长相等前后缀” 准确一些。
+
+**因为前缀表要求的就是相同前后缀的长度。**
+
+而最长公共前后缀里面的“公共”,更像是说前缀和后缀公共的长度。这其实并不是前缀表所需要的。
+
+所以字符串a的最长相等前后缀为0。
+字符串aa的最长相等前后缀为1。
+字符串aaa的最长相等前后缀为2。
+等等.....。
+
# 为什么一定要用前缀表
这就是前缀表那为啥就能告诉我们 上次匹配的位置,并跳过去呢?
-回顾一下,刚刚匹配的过程在下表5的地方遇到不匹配,模式串是指向f,如图:
- +回顾一下,刚刚匹配的过程在下标5的地方遇到不匹配,模式串是指向f,如图:
+
+回顾一下,刚刚匹配的过程在下标5的地方遇到不匹配,模式串是指向f,如图:
+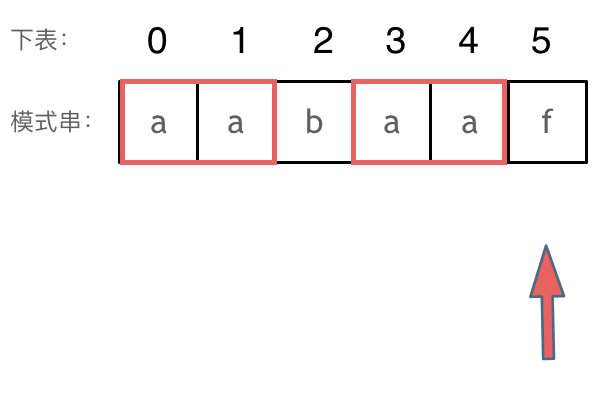 -然后就找到了下表2,指向b,继续匹配:如图:
-
-然后就找到了下表2,指向b,继续匹配:如图:
- +然后就找到了下标2,指向b,继续匹配:如图:
+
+然后就找到了下标2,指向b,继续匹配:如图:
+ 以下这句话,对于理解为什么使用前缀表可以告诉我们匹配失败之后跳到哪里重新匹配 非常重要!
-**下表5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面从新匹配就可以了。**
+**下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面从新匹配就可以了。**
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
@@ -147,14 +177,14 @@ next数组就是一个前缀表(prefix table)。
如图:
-
以下这句话,对于理解为什么使用前缀表可以告诉我们匹配失败之后跳到哪里重新匹配 非常重要!
-**下表5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面从新匹配就可以了。**
+**下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面从新匹配就可以了。**
所以前缀表具有告诉我们当前位置匹配失败,跳到之前已经匹配过的地方的能力。
@@ -147,14 +177,14 @@ next数组就是一个前缀表(prefix table)。
如图:
- +
+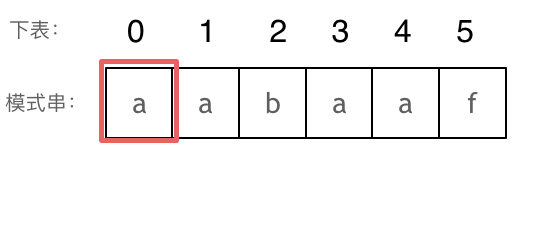 长度为前1个字符的子串`a`,最长相同前后缀的长度为0。(注意字符串的**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串**;**后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串**。)
-
长度为前1个字符的子串`a`,最长相同前后缀的长度为0。(注意字符串的**前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串**;**后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串**。)
- +
+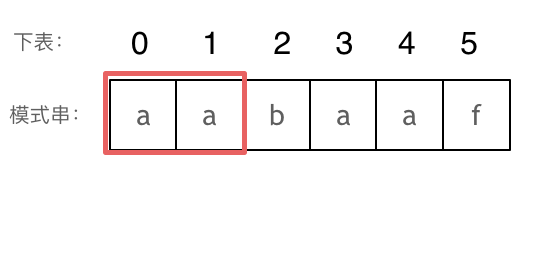 长度为前2个字符的子串`aa`,最长相同前后缀的长度为1。
-
长度为前2个字符的子串`aa`,最长相同前后缀的长度为1。
- +
+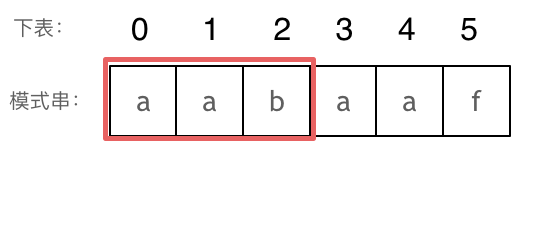 长度为前3个字符的子串`aab`,最长相同前后缀的长度为0。
以此类推:
@@ -163,13 +193,13 @@ next数组就是一个前缀表(prefix table)。
长度为前6个字符的子串`aabaaf`,最长相同前后缀的长度为0。
那么把求得的最长相同前后缀的长度就是对应前缀表的元素,如图:
-
长度为前3个字符的子串`aab`,最长相同前后缀的长度为0。
以此类推:
@@ -163,13 +193,13 @@ next数组就是一个前缀表(prefix table)。
长度为前6个字符的子串`aabaaf`,最长相同前后缀的长度为0。
那么把求得的最长相同前后缀的长度就是对应前缀表的元素,如图:
- +
+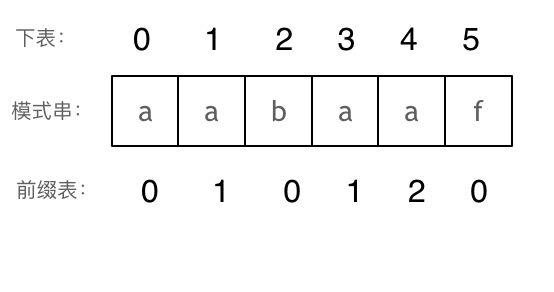 -可以看出模式串与前缀表对应位置的数字表示的就是:**下表i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
+可以看出模式串与前缀表对应位置的数字表示的就是:**下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
再来看一下如何利用 前缀表找到 当字符不匹配的时候应该指针应该移动的位置。如动画所示:
-
-可以看出模式串与前缀表对应位置的数字表示的就是:**下表i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
+可以看出模式串与前缀表对应位置的数字表示的就是:**下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。**
再来看一下如何利用 前缀表找到 当字符不匹配的时候应该指针应该移动的位置。如动画所示:
- +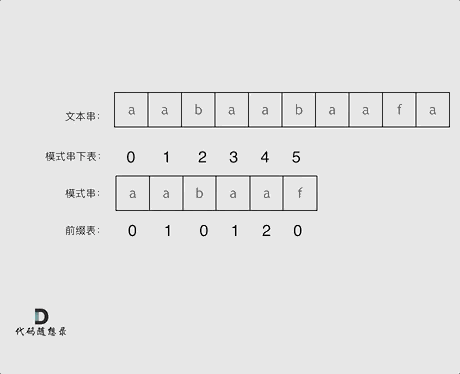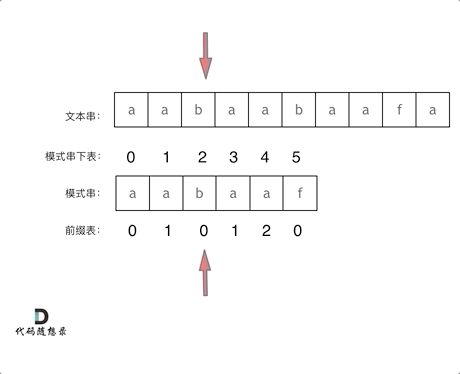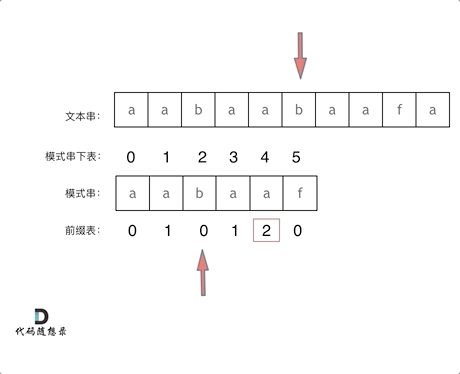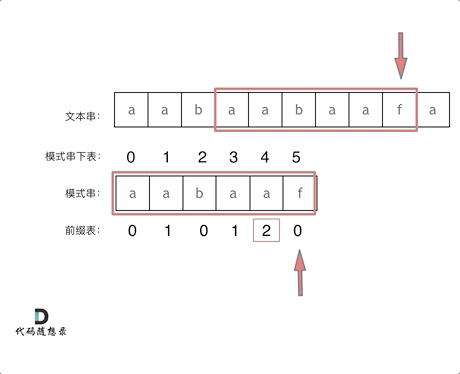
找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
@@ -177,7 +207,7 @@ next数组就是一个前缀表(prefix table)。
所以要看前一位的 前缀表的数值。
-前一个字符的前缀表的数值是2, 所有把下表移动到下表2的位置继续比配。 可以再反复看一下上面的动画。
+前一个字符的前缀表的数值是2, 所有把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
最后就在文本串中找到了和模式串匹配的子串了。
@@ -203,11 +233,10 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
匹配过程动画如下:
-
+
找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
@@ -177,7 +207,7 @@ next数组就是一个前缀表(prefix table)。
所以要看前一位的 前缀表的数值。
-前一个字符的前缀表的数值是2, 所有把下表移动到下表2的位置继续比配。 可以再反复看一下上面的动画。
+前一个字符的前缀表的数值是2, 所有把下标移动到下标2的位置继续比配。 可以再反复看一下上面的动画。
最后就在文本串中找到了和模式串匹配的子串了。
@@ -203,11 +233,10 @@ next数组就可以是前缀表,但是很多实现都是把前缀表统一减
匹配过程动画如下:
- +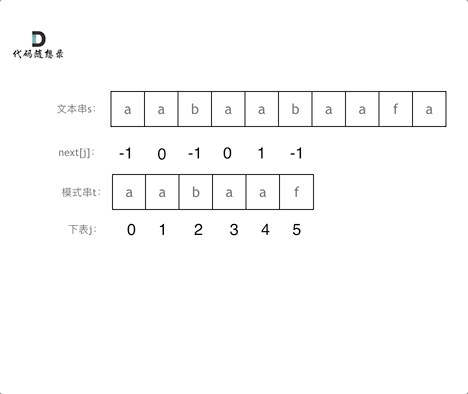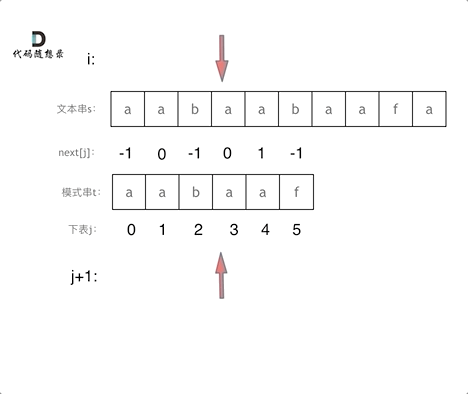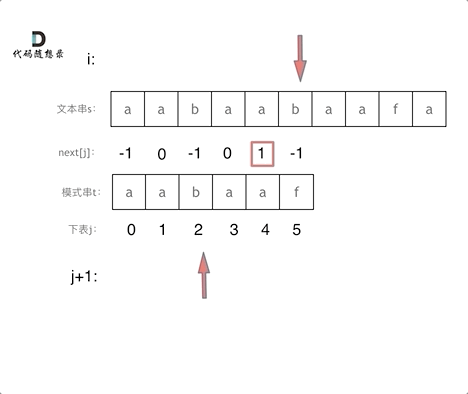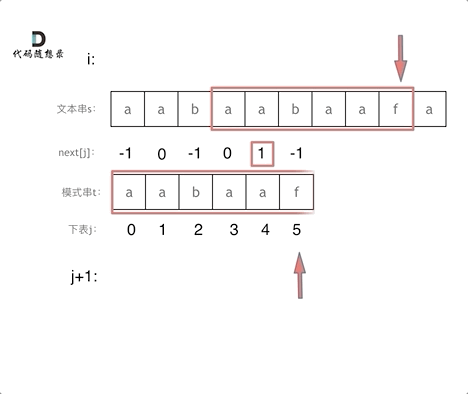
# 时间复杂度分析
-
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
暴力的解法显而易见是O(n * m),所以**KMP在字符串匹配中极大的提高的搜索的效率。**
@@ -234,7 +263,7 @@ void getNext(int* next, const string& s)
1. 初始化:
-定义两个指针i和j,j指向前缀终止位置(严格来说是终止位置减一的位置),i指向后缀终止位置(与j同理)。
+定义两个指针i和j,j指向前缀起始位置,i指向后缀起始位置。
然后还要对next数组进行初始化赋值,如下:
@@ -255,15 +284,15 @@ next[i] 表示 i(包括i)之前最长相等的前后缀长度(其实就是
因为j初始化为-1,那么i就从1开始,进行s[i] 与 s[j+1]的比较。
-所以遍历模式串s的循环下表i 要从 1开始,代码如下:
+所以遍历模式串s的循环下标i 要从 1开始,代码如下:
```
for(int i = 1; i < s.size(); i++) {
```
-如果 s[i] 与 s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回溯。
+如果 s[i] 与 s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回退。
-怎么回溯呢?
+怎么回退呢?
next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度。
@@ -273,7 +302,7 @@ next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度
```
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
- j = next[j]; // 向前回溯
+ j = next[j]; // 向前回退
}
```
@@ -292,13 +321,13 @@ next[i] = j;
最后整体构建next数组的函数代码如下:
-```
+```C++
void getNext(int* next, const string& s){
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
- j = next[j]; // 向前回溯
+ j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
@@ -311,8 +340,7 @@ void getNext(int* next, const string& s){
代码构造next数组的逻辑流程动画如下:
-
+
# 时间复杂度分析
-
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
暴力的解法显而易见是O(n * m),所以**KMP在字符串匹配中极大的提高的搜索的效率。**
@@ -234,7 +263,7 @@ void getNext(int* next, const string& s)
1. 初始化:
-定义两个指针i和j,j指向前缀终止位置(严格来说是终止位置减一的位置),i指向后缀终止位置(与j同理)。
+定义两个指针i和j,j指向前缀起始位置,i指向后缀起始位置。
然后还要对next数组进行初始化赋值,如下:
@@ -255,15 +284,15 @@ next[i] 表示 i(包括i)之前最长相等的前后缀长度(其实就是
因为j初始化为-1,那么i就从1开始,进行s[i] 与 s[j+1]的比较。
-所以遍历模式串s的循环下表i 要从 1开始,代码如下:
+所以遍历模式串s的循环下标i 要从 1开始,代码如下:
```
for(int i = 1; i < s.size(); i++) {
```
-如果 s[i] 与 s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回溯。
+如果 s[i] 与 s[j+1]不相同,也就是遇到 前后缀末尾不相同的情况,就要向前回退。
-怎么回溯呢?
+怎么回退呢?
next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度。
@@ -273,7 +302,7 @@ next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度
```
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
- j = next[j]; // 向前回溯
+ j = next[j]; // 向前回退
}
```
@@ -292,13 +321,13 @@ next[i] = j;
最后整体构建next数组的函数代码如下:
-```
+```C++
void getNext(int* next, const string& s){
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
- j = next[j]; // 向前回溯
+ j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
@@ -311,8 +340,7 @@ void getNext(int* next, const string& s){
代码构造next数组的逻辑流程动画如下:
- -
+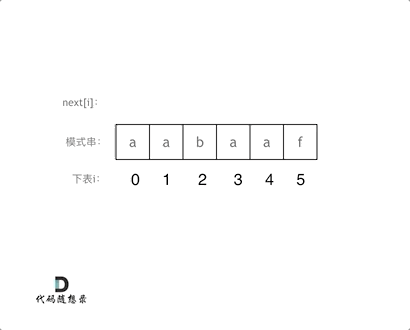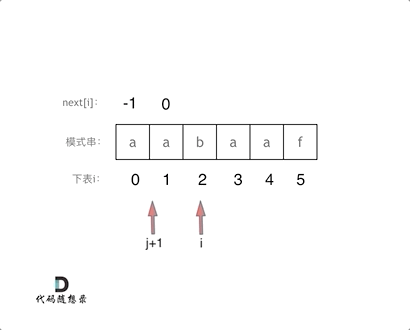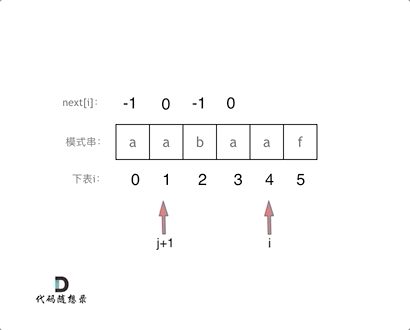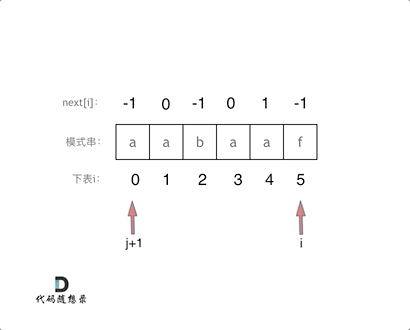
得到了next数组之后,就要用这个来做匹配了。
@@ -320,7 +348,7 @@ void getNext(int* next, const string& s){
在文本串s里 找是否出现过模式串t。
-定义两个下表j 指向模式串起始位置,i指向文本串起始位置。
+定义两个下标j 指向模式串起始位置,i指向文本串起始位置。
那么j初始值依然为-1,为什么呢? **依然因为next数组里记录的起始位置为-1。**
@@ -330,7 +358,7 @@ i就从0开始,遍历文本串,代码如下:
for (int i = 0; i < s.size(); i++)
```
-接下来就是 s[i] 与 t[j + 1] (因为j从-1开始的) 经行比较。
+接下来就是 s[i] 与 t[j + 1] (因为j从-1开始的) 进行比较。
如果 s[i] 与 t[j + 1] 不相同,j就要从next数组里寻找下一个匹配的位置。
@@ -364,7 +392,7 @@ if (j == (t.size() - 1) ) {
那么使用next数组,用模式串匹配文本串的整体代码如下:
-```
+```C++
int j = -1; // 因为next数组里记录的起始位置为-1
for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
while(j >= 0 && s[i] != t[j + 1]) { // 不匹配
@@ -383,7 +411,7 @@ for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
# 前缀表统一减一 C++代码实现
-```
+```C++
class Solution {
public:
void getNext(int* next, const string& s) {
@@ -391,7 +419,7 @@ public:
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
- j = next[j]; // 向前回溯
+ j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
@@ -410,11 +438,11 @@ public:
while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
- if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
+ if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t
- return (i - needle.size() + 1);
+ return (i - needle.size() + 1);
}
}
return -1;
@@ -433,13 +461,13 @@ public:
我给出的getNext的实现为:(前缀表统一减一)
-```
+```C++
void getNext(int* next, const string& s) {
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
- j = next[j]; // 向前回溯
+ j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
@@ -455,12 +483,12 @@ void getNext(int* next, const string& s) {
那么前缀表不减一来构建next数组,代码如下:
-```
+```C++
void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
- while (j > 0 && s[i] != s[j]) { // j要保证大于0,因为下面有取j-1作为数组下表的操作
+ while (j > 0 && s[i] != s[j]) { // j要保证大于0,因为下面有取j-1作为数组下标的操作
j = next[j - 1]; // 注意这里,是要找前一位的对应的回退位置了
}
if (s[i] == s[j]) {
@@ -478,20 +506,20 @@ void getNext(int* next, const string& s) {
实现代码如下:
-```
+```C++
class Solution {
public:
void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
- for(int i = 1; i < s.size(); i++) {
- while (j > 0 && s[i] != s[j]) {
- j = next[j - 1];
+ for(int i = 1; i < s.size(); i++) {
+ while (j > 0 && s[i] != s[j]) {
+ j = next[j - 1];
}
- if (s[i] == s[j]) {
+ if (s[i] == s[j]) {
j++;
}
- next[i] = j;
+ next[i] = j;
}
}
int strStr(string haystack, string needle) {
@@ -501,14 +529,14 @@ public:
int next[needle.size()];
getNext(next, needle);
int j = 0;
- for (int i = 0; i < haystack.size(); i++) {
- while(j > 0 && haystack[i] != needle[j]) {
- j = next[j - 1];
+ for (int i = 0; i < haystack.size(); i++) {
+ while(j > 0 && haystack[i] != needle[j]) {
+ j = next[j - 1];
}
- if (haystack[i] == needle[j]) {
+ if (haystack[i] == needle[j]) {
j++;
}
- if (j == needle.size() ) {
+ if (j == needle.size() ) {
return (i - needle.size() + 1);
}
}
@@ -532,7 +560,128 @@ public:
可以说把KMP的每一个细微的细节都扣了出来,毫无遮掩的展示给大家了!
+## 其他语言版本
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+Java:
+```java
+// 方法一
+class Solution {
+ public void getNext(int[] next, String s){
+ int j = -1;
+ next[0] = j;
+ for (int i = 1; i
diff --git a/problems/0031.下一个排列.md b/problems/0031.下一个排列.md
deleted file mode 100644
index 68665d6b..00000000
--- a/problems/0031.下一个排列.md
+++ /dev/null
@@ -1,58 +0,0 @@
-
-## 思路
-
-一些同学可能手动写排列的顺序,都没有写对,那么写程序的话思路一定是有问题的了,我这里以1234为例子,把全排列都列出来。可以参考一下规律所在:
-
-```
-1 2 3 4
-1 2 4 3
-1 3 2 4
-1 3 4 2
-1 4 2 3
-1 4 3 2
-2 1 3 4
-2 1 4 3
-2 3 1 4
-2 3 4 1
-2 4 1 3
-2 4 3 1
-3 1 2 4
-3 1 4 2
-3 2 1 4
-3 2 4 1
-3 4 1 2
-3 4 2 1
-4 1 2 3
-4 1 3 2
-4 2 1 3
-4 2 3 1
-4 3 1 2
-4 3 2 1
-```
-
-如图:
-
-以求1243为例,流程如图:
-
-
-
+
得到了next数组之后,就要用这个来做匹配了。
@@ -320,7 +348,7 @@ void getNext(int* next, const string& s){
在文本串s里 找是否出现过模式串t。
-定义两个下表j 指向模式串起始位置,i指向文本串起始位置。
+定义两个下标j 指向模式串起始位置,i指向文本串起始位置。
那么j初始值依然为-1,为什么呢? **依然因为next数组里记录的起始位置为-1。**
@@ -330,7 +358,7 @@ i就从0开始,遍历文本串,代码如下:
for (int i = 0; i < s.size(); i++)
```
-接下来就是 s[i] 与 t[j + 1] (因为j从-1开始的) 经行比较。
+接下来就是 s[i] 与 t[j + 1] (因为j从-1开始的) 进行比较。
如果 s[i] 与 t[j + 1] 不相同,j就要从next数组里寻找下一个匹配的位置。
@@ -364,7 +392,7 @@ if (j == (t.size() - 1) ) {
那么使用next数组,用模式串匹配文本串的整体代码如下:
-```
+```C++
int j = -1; // 因为next数组里记录的起始位置为-1
for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
while(j >= 0 && s[i] != t[j + 1]) { // 不匹配
@@ -383,7 +411,7 @@ for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
# 前缀表统一减一 C++代码实现
-```
+```C++
class Solution {
public:
void getNext(int* next, const string& s) {
@@ -391,7 +419,7 @@ public:
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
- j = next[j]; // 向前回溯
+ j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
@@ -410,11 +438,11 @@ public:
while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
- if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
+ if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t
- return (i - needle.size() + 1);
+ return (i - needle.size() + 1);
}
}
return -1;
@@ -433,13 +461,13 @@ public:
我给出的getNext的实现为:(前缀表统一减一)
-```
+```C++
void getNext(int* next, const string& s) {
int j = -1;
next[0] = j;
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
- j = next[j]; // 向前回溯
+ j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
@@ -455,12 +483,12 @@ void getNext(int* next, const string& s) {
那么前缀表不减一来构建next数组,代码如下:
-```
+```C++
void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
- while (j > 0 && s[i] != s[j]) { // j要保证大于0,因为下面有取j-1作为数组下表的操作
+ while (j > 0 && s[i] != s[j]) { // j要保证大于0,因为下面有取j-1作为数组下标的操作
j = next[j - 1]; // 注意这里,是要找前一位的对应的回退位置了
}
if (s[i] == s[j]) {
@@ -478,20 +506,20 @@ void getNext(int* next, const string& s) {
实现代码如下:
-```
+```C++
class Solution {
public:
void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
- for(int i = 1; i < s.size(); i++) {
- while (j > 0 && s[i] != s[j]) {
- j = next[j - 1];
+ for(int i = 1; i < s.size(); i++) {
+ while (j > 0 && s[i] != s[j]) {
+ j = next[j - 1];
}
- if (s[i] == s[j]) {
+ if (s[i] == s[j]) {
j++;
}
- next[i] = j;
+ next[i] = j;
}
}
int strStr(string haystack, string needle) {
@@ -501,14 +529,14 @@ public:
int next[needle.size()];
getNext(next, needle);
int j = 0;
- for (int i = 0; i < haystack.size(); i++) {
- while(j > 0 && haystack[i] != needle[j]) {
- j = next[j - 1];
+ for (int i = 0; i < haystack.size(); i++) {
+ while(j > 0 && haystack[i] != needle[j]) {
+ j = next[j - 1];
}
- if (haystack[i] == needle[j]) {
+ if (haystack[i] == needle[j]) {
j++;
}
- if (j == needle.size() ) {
+ if (j == needle.size() ) {
return (i - needle.size() + 1);
}
}
@@ -532,7 +560,128 @@ public:
可以说把KMP的每一个细微的细节都扣了出来,毫无遮掩的展示给大家了!
+## 其他语言版本
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+Java:
+```java
+// 方法一
+class Solution {
+ public void getNext(int[] next, String s){
+ int j = -1;
+ next[0] = j;
+ for (int i = 1; i
diff --git a/problems/0031.下一个排列.md b/problems/0031.下一个排列.md
deleted file mode 100644
index 68665d6b..00000000
--- a/problems/0031.下一个排列.md
+++ /dev/null
@@ -1,58 +0,0 @@
-
-## 思路
-
-一些同学可能手动写排列的顺序,都没有写对,那么写程序的话思路一定是有问题的了,我这里以1234为例子,把全排列都列出来。可以参考一下规律所在:
-
-```
-1 2 3 4
-1 2 4 3
-1 3 2 4
-1 3 4 2
-1 4 2 3
-1 4 3 2
-2 1 3 4
-2 1 4 3
-2 3 1 4
-2 3 4 1
-2 4 1 3
-2 4 3 1
-3 1 2 4
-3 1 4 2
-3 2 1 4
-3 2 4 1
-3 4 1 2
-3 4 2 1
-4 1 2 3
-4 1 3 2
-4 2 1 3
-4 2 3 1
-4 3 1 2
-4 3 2 1
-```
-
-如图:
-
-以求1243为例,流程如图:
-
- -
-对应的C++代码如下:
-
-```
-class Solution {
-public:
- void nextPermutation(vector
-
-对应的C++代码如下:
-
-```
-class Solution {
-public:
- void nextPermutation(vector
-
-
-
-
+
-
-
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 二分查找法是数组里的常用方法,彻底掌握它是十分必要的。 -# 编号35:搜索插入位置 + +# 35.搜索插入位置 题目地址:https://leetcode-cn.com/problems/search-insert-position/ @@ -22,23 +17,23 @@ 你可以假设数组中无重复元素。 -示例 1: -输入: [1,3,5,6], 5 -输出: 2 +示例 1: +输入: [1,3,5,6], 5 +输出: 2 -示例 2: -输入: [1,3,5,6], 2 -输出: 1 +示例 2: +输入: [1,3,5,6], 2 +输出: 1 -示例 3: -输入: [1,3,5,6], 7 +示例 3: +输入: [1,3,5,6], 7 输出: 4 -示例 4: -输入: [1,3,5,6], 0 -输出: 0 +示例 4: +输入: [1,3,5,6], 0 +输出: 0 -# 思路 +# 思路 这道题目不难,但是为什么通过率相对来说并不高呢,我理解是大家对边界处理的判断有所失误导致的。 @@ -68,20 +63,20 @@ public: for (int i = 0; i < nums.size(); i++) { // 分别处理如下三种情况 // 目标值在数组所有元素之前 - // 目标值等于数组中某一个元素 - // 目标值插入数组中的位置 + // 目标值等于数组中某一个元素 + // 目标值插入数组中的位置 if (nums[i] >= target) { // 一旦发现大于或者等于target的num[i],那么i就是我们要的结果 return i; } } - // 目标值在数组所有元素之后的情况 + // 目标值在数组所有元素之后的情况 return nums.size(); // 如果target是最大的,或者 nums为空,则返回nums的长度 } }; ``` -时间复杂度:O(n) -时间复杂度:O(1) +时间复杂度:O(n) +时间复杂度:O(1) 效率如下: @@ -89,7 +84,7 @@ public: ## 二分法 -既然暴力解法的时间复杂度是O(n),就要尝试一下使用二分查找法。 +既然暴力解法的时间复杂度是O(n),就要尝试一下使用二分查找法。  @@ -107,9 +102,9 @@ public: 相信很多同学对二分查找法中边界条件处理不好。 -例如到底是 `while(left < right)` 还是 `while(left <= right)`,到底是`right = middle`呢,还是要`right = middle - 1`呢? +例如到底是 `while(left < right)` 还是 `while(left <= right)`,到底是`right = middle`呢,还是要`right = middle - 1`呢? -这里弄不清楚主要是因为**对区间的定义没有想清楚,这就是不变量**。 +这里弄不清楚主要是因为**对区间的定义没有想清楚,这就是不变量**。 要在二分查找的过程中,保持不变量,这也就是**循环不变量** (感兴趣的同学可以查一查)。 @@ -127,7 +122,7 @@ public: int searchInsert(vector
-
-
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ 如果对回溯法理论还不清楚的同学,可以先看这个视频[视频来了!!带你学透回溯算法(理论篇)](https://mp.weixin.qq.com/s/wDd5azGIYWjbU0fdua_qBg) -# 37. 解数独 +## 37. 解数独 题目地址:https://leetcode-cn.com/problems/sudoku-solver/ 编写一个程序,通过填充空格来解决数独问题。 -一个数独的解法需遵循如下规则: -数字 1-9 在每一行只能出现一次。 -数字 1-9 在每一列只能出现一次。 -数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。 -空白格用 '.' 表示。 +一个数独的解法需遵循如下规则: +数字 1-9 在每一行只能出现一次。 +数字 1-9 在每一列只能出现一次。 +数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。 +空白格用 '.' 表示。 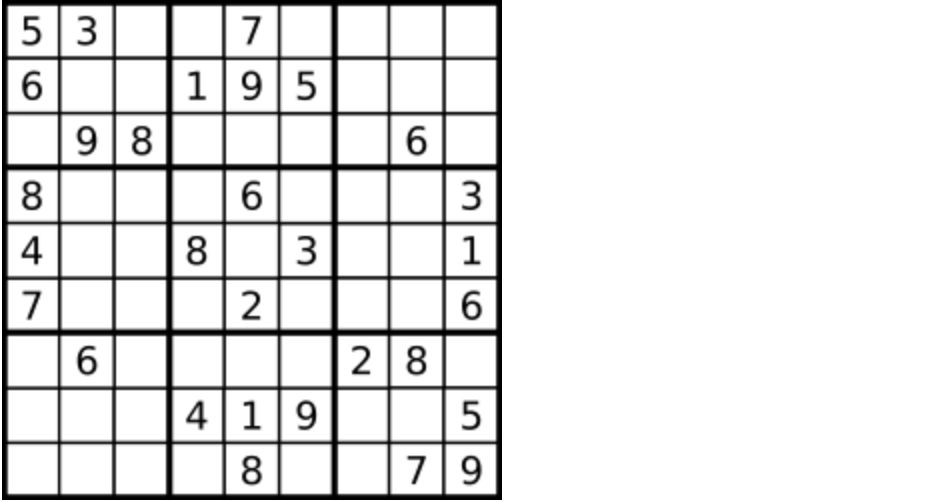 -一个数独。 +一个数独。 -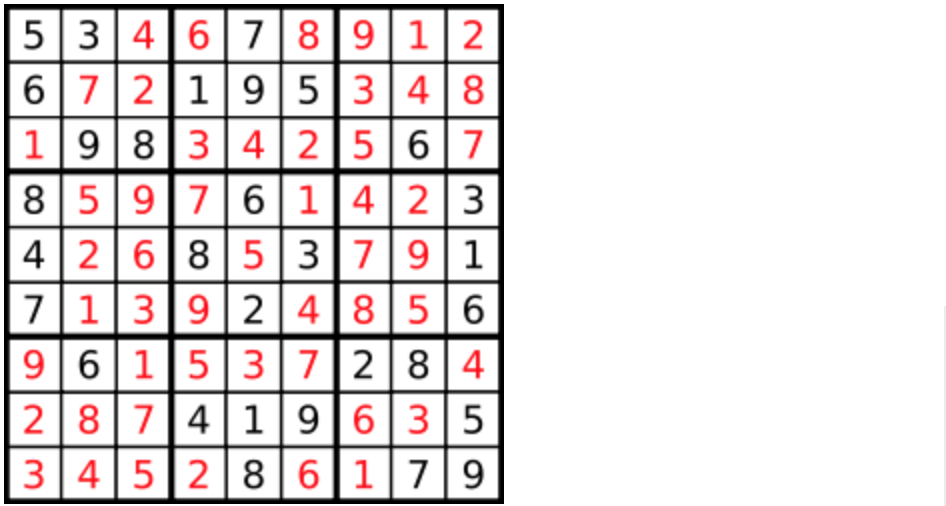 + -答案被标成红色。 +答案被标成红色。 -提示: +提示: * 给定的数独序列只包含数字 1-9 和字符 '.' 。 * 你可以假设给定的数独只有唯一解。 * 给定数独永远是 9x9 形式的。 -# 思路 +## 思路 -棋盘搜索问题可以使用回溯法暴力搜索,只不过这次我们要做的是**二维递归**。 +棋盘搜索问题可以使用回溯法暴力搜索,只不过这次我们要做的是**二维递归**。 怎么做二维递归呢? @@ -46,9 +53,9 @@ 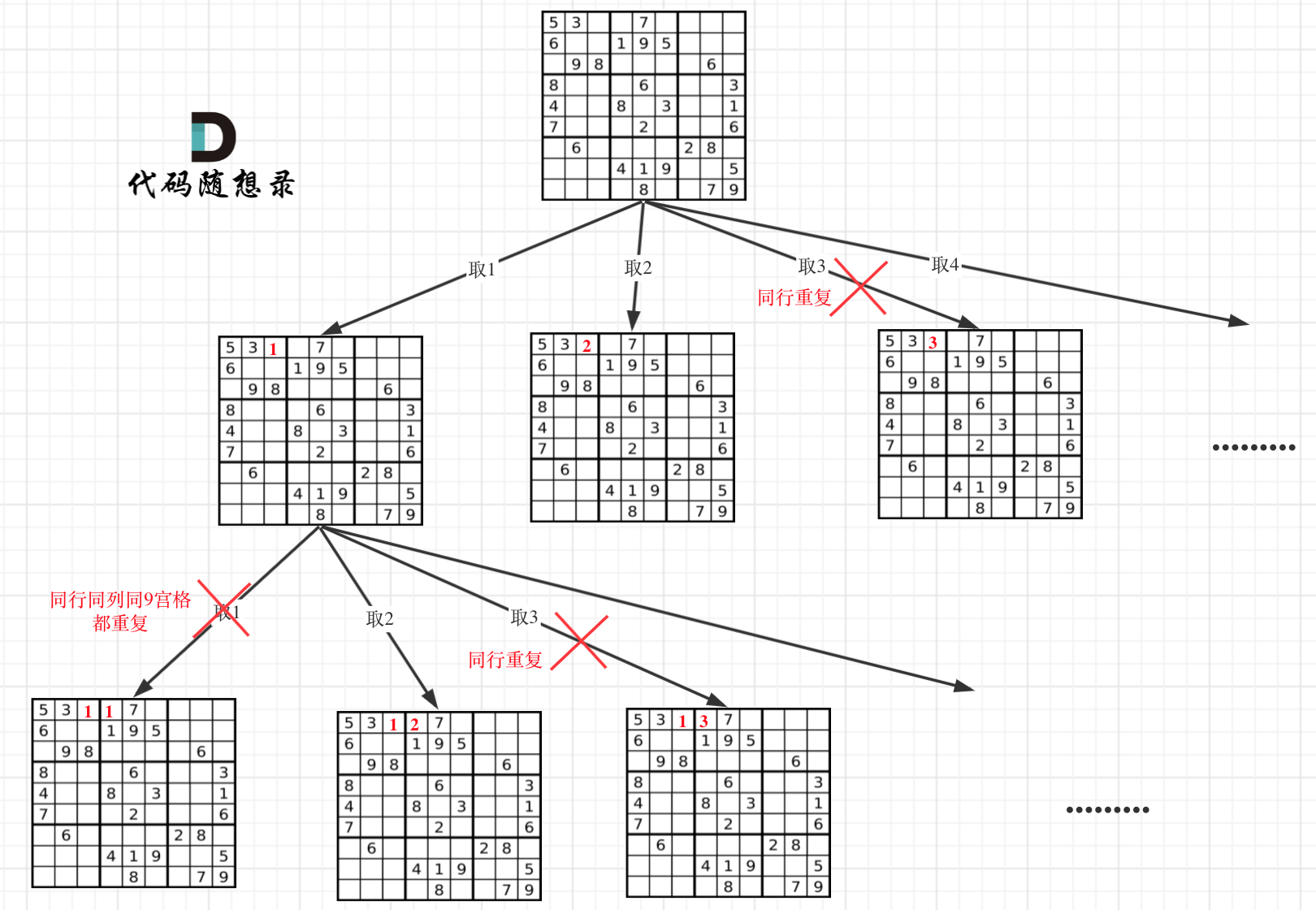 -## 回溯三部曲 +## 回溯三部曲 -* 递归函数以及参数 +* 递归函数以及参数 **递归函数的返回值需要是bool类型,为什么呢?** @@ -60,15 +67,15 @@ bool backtracking(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 看懂很容易,彻底掌握需要下功夫 -# 第39题. 组合总和 +## 39. 组合总和 题目链接:https://leetcode-cn.com/problems/combination-sum/ @@ -9,29 +15,32 @@ candidates 中的数字可以无限制重复被选取。 -说明: +说明: -* 所有数字(包括 target)都是正整数。 +* 所有数字(包括 target)都是正整数。 * 解集不能包含重复的组合。 -示例 1: -输入:candidates = [2,3,6,7], target = 7, -所求解集为: -[ - [7], - [2,2,3] -] +示例 1: +输入:candidates = [2,3,6,7], target = 7, +所求解集为: +[ + [7], + [2,2,3] +] -示例 2: -输入:candidates = [2,3,5], target = 8, -所求解集为: -[ - [2,2,2,2], - [2,3,3], - [3,5] -] +示例 2: +输入:candidates = [2,3,5], target = 8, +所求解集为: +[ + [2,2,2,2], + [2,3,3], + [3,5] +] + +## 思路 + +[B站视频讲解-组合总和](https://www.bilibili.com/video/BV1KT4y1M7HJ) -# 思路 题目中的**无限制重复被选取,吓得我赶紧想想 出现0 可咋办**,然后看到下面提示:1 <= candidates[i] <= 200,我就放心了。 @@ -39,15 +48,14 @@ candidates 中的数字可以无限制重复被选取。 本题搜索的过程抽象成树形结构如下: -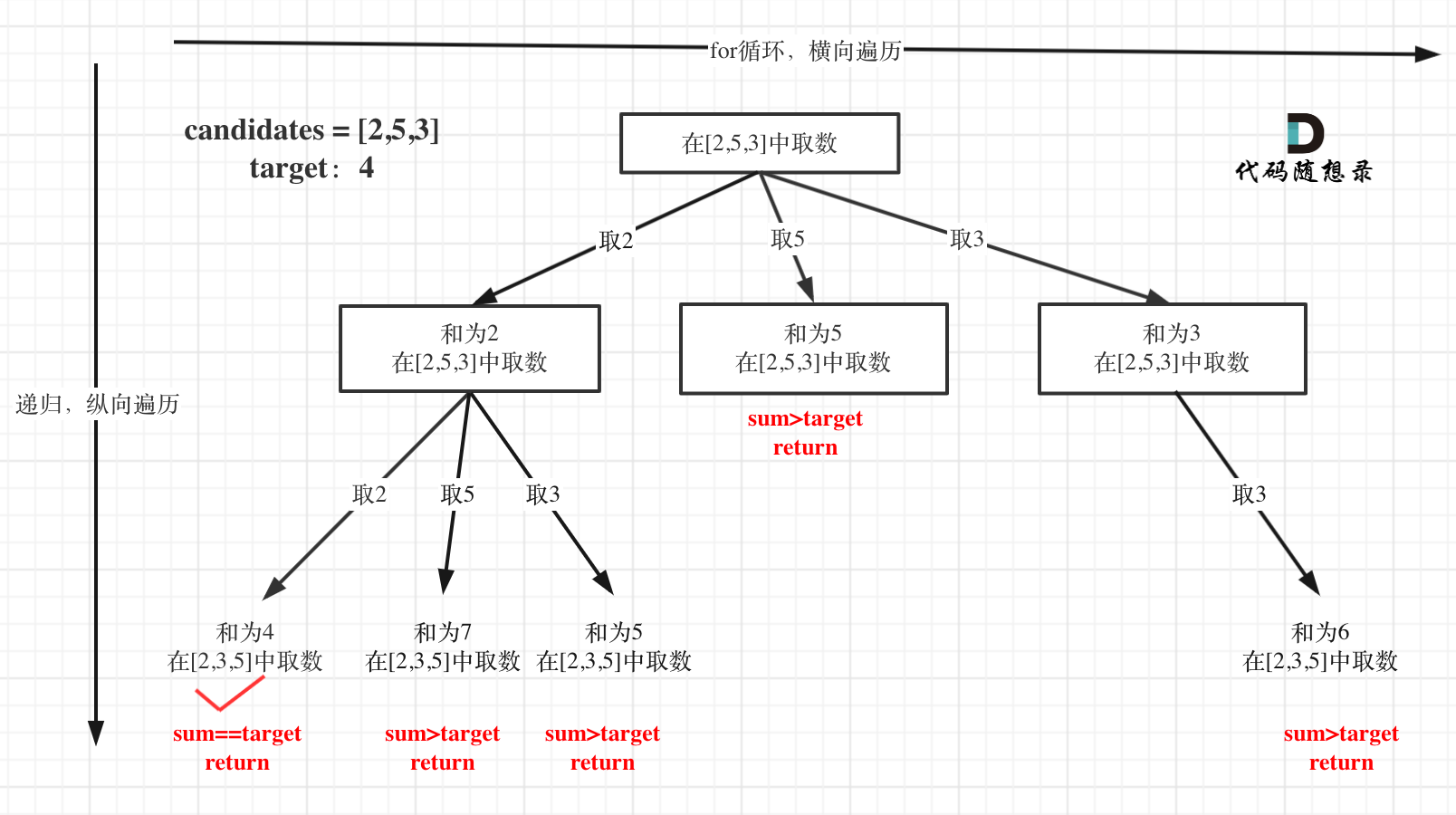 - +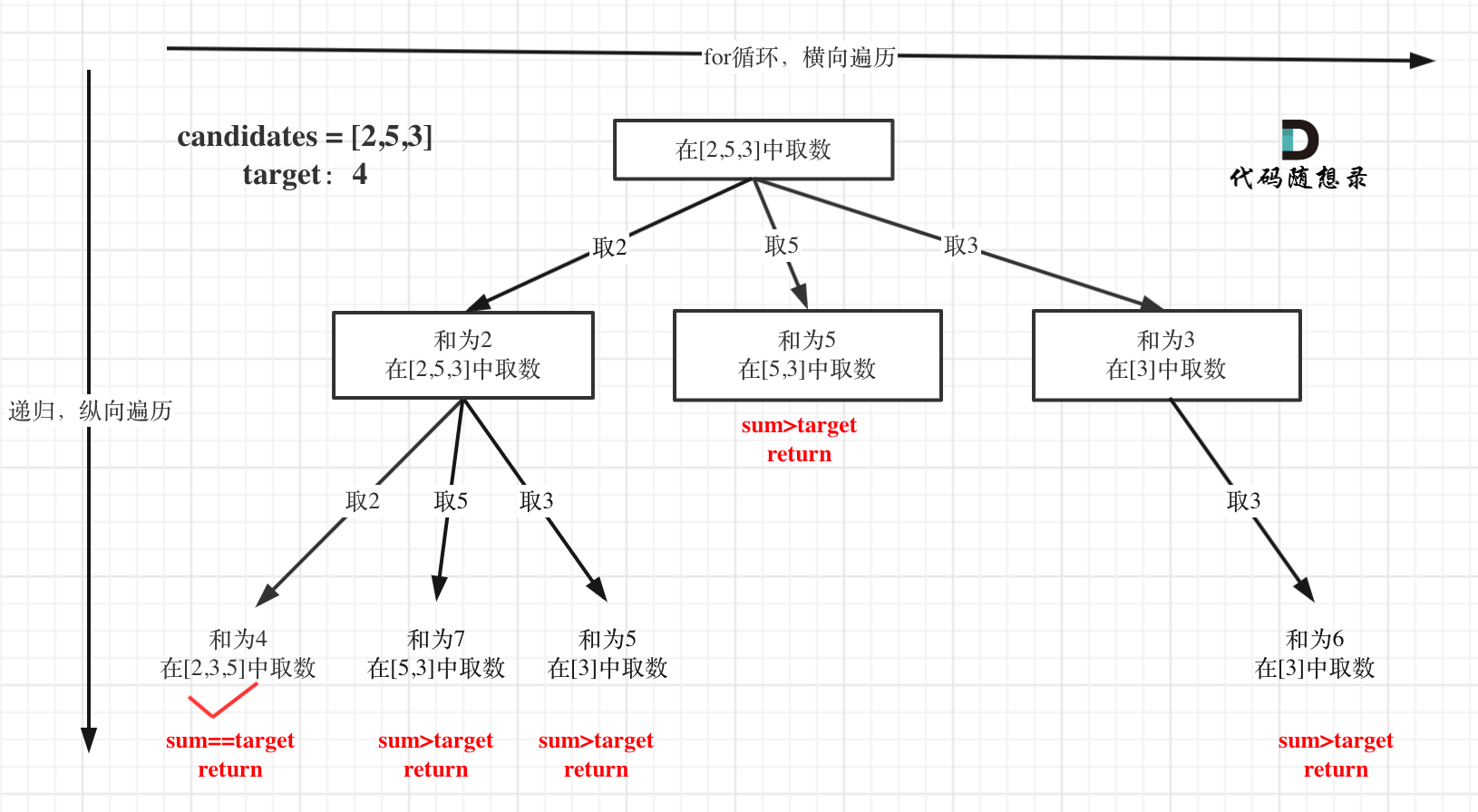 注意图中叶子节点的返回条件,因为本题没有组合数量要求,仅仅是总和的限制,所以递归没有层数的限制,只要选取的元素总和超过target,就返回! 而在[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w) 中都可以知道要递归K层,因为要取k个元素的组合。 ## 回溯三部曲 -* 递归函数参数 +* 递归函数参数 这里依然是定义两个全局变量,二维数组result存放结果集,数组path存放符合条件的结果。(这两个变量可以作为函数参数传入) @@ -65,23 +73,23 @@ candidates 中的数字可以无限制重复被选取。 代码如下: -``` +```C++ vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + > 这篇可以说是全网把组合问题如何去重,讲的最清晰的了! -# 40.组合总和II +## 40.组合总和II 题目链接:https://leetcode-cn.com/problems/combination-sum-ii/ @@ -8,42 +17,42 @@ candidates 中的每个数字在每个组合中只能使用一次。 -说明: -所有数字(包括目标数)都是正整数。 -解集不能包含重复的组合。 +说明: +所有数字(包括目标数)都是正整数。 +解集不能包含重复的组合。 -示例 1: -输入: candidates = [10,1,2,7,6,1,5], target = 8, -所求解集为: -[ - [1, 7], - [1, 2, 5], - [2, 6], - [1, 1, 6] -] - -示例 2: -输入: candidates = [2,5,2,1,2], target = 5, -所求解集为: -[ - [1,2,2], - [5] -] +示例 1: +输入: candidates = [10,1,2,7,6,1,5], target = 8, +所求解集为: +[ + [1, 7], + [1, 2, 5], + [2, 6], + [1, 1, 6] +] -# 思路 +示例 2: +输入: candidates = [2,5,2,1,2], target = 5, +所求解集为: +[ + [1,2,2], + [5] +] + +## 思路 这道题目和[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)如下区别: 1. 本题candidates 中的每个数字在每个组合中只能使用一次。 -2. 本题数组candidates的元素是有重复的,而[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)是无重复元素的数组candidates +2. 本题数组candidates的元素是有重复的,而[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)是无重复元素的数组candidates -最后本题和[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)要求一样,解集不能包含重复的组合。 +最后本题和[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)要求一样,解集不能包含重复的组合。 **本题的难点在于区别2中:集合(数组candidates)有重复元素,但还不能有重复的组合**。 一些同学可能想了:我把所有组合求出来,再用set或者map去重,这么做很容易超时! -所以要在搜索的过程中就去掉重复组合。 +所以要在搜索的过程中就去掉重复组合。 很多同学在去重的问题上想不明白,其实很多题解也没有讲清楚,反正代码是能过的,感觉是那么回事,稀里糊涂的先把题目过了。 @@ -68,17 +77,17 @@ candidates 中的每个数字在每个组合中只能使用一次。 可以看到图中,每个节点相对于 [39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)我多加了used数组,这个used数组下面会重点介绍。 -## 回溯三部曲 +## 回溯三部曲 -* **递归函数参数** +* **递归函数参数** -与[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)套路相同,此题还需要加一个bool型数组used,用来记录同一树枝上的元素是否使用过。 +与[39.组合总和](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)套路相同,此题还需要加一个bool型数组used,用来记录同一树枝上的元素是否使用过。 这个集合去重的重任就是used来完成的。 代码如下: -``` +```C++ vector  -
-
-
- -
-一些同学在实现暴力解法的时候,很容易一会按照行来计算一会按照列来计算,这样就会越写越乱。
-
-我个人倾向于按照列来计算,比较容易理解,接下来看一下按照列如何计算。
-
-首先,**如果按照列来计算的话,宽度一定是1了,我们再把每一列的雨水的高度求出来就可以了。**
-
-可以看出每一列雨水的高度,取决于,该列 左侧最高的柱子和右侧最高的柱子中最矮的那个柱子的高度。
-
-这句话可以有点绕,来举一个理解,例如求列4的雨水高度,如图:
-
-
-
-一些同学在实现暴力解法的时候,很容易一会按照行来计算一会按照列来计算,这样就会越写越乱。
-
-我个人倾向于按照列来计算,比较容易理解,接下来看一下按照列如何计算。
-
-首先,**如果按照列来计算的话,宽度一定是1了,我们再把每一列的雨水的高度求出来就可以了。**
-
-可以看出每一列雨水的高度,取决于,该列 左侧最高的柱子和右侧最高的柱子中最矮的那个柱子的高度。
-
-这句话可以有点绕,来举一个理解,例如求列4的雨水高度,如图:
-
- -
-列4 左侧最高的柱子是列3,高度为2(以下用lHeight表示)。
-
-列4 右侧最高的柱子是列7,高度为3(以下用rHeight表示)。
-
-列4 柱子的高度为1(以下用height表示)
-
-那么列4的雨水高度为 列3和列7的高度最小值减列4高度,即: min(lHeight, rHeight) - height。
-
-列4的雨水高度求出来了,宽度为1,相乘就是列4的雨水体积了。
-
-此时求出了列4的雨水体积。
-
-一样的方法,只要从头遍历一遍所有的列,然后求出每一列雨水的体积,相加之后就是总雨水的体积了。
-
-首先从头遍历所有的列,并且**要注意第一个柱子和最后一个柱子不接雨水**,代码如下:
-```
-for (int i = 0; i < height.size(); i++) {
- // 第一个柱子和最后一个柱子不接雨水
- if (i == 0 || i == height.size() - 1) continue;
-}
-```
-
-在for循环中求左右两边最高柱子,代码如下:
-
-```
-int rHeight = height[i]; // 记录右边柱子的最高高度
-int lHeight = height[i]; // 记录左边柱子的最高高度
-for (int r = i + 1; r < height.size(); r++) {
- if (height[r] > rHeight) rHeight = height[r];
-}
-for (int l = i - 1; l >= 0; l--) {
- if (height[l] > lHeight) lHeight = height[l];
-}
-```
-
-最后,计算该列的雨水高度,代码如下:
-
-```
-int h = min(lHeight, rHeight) - height[i];
-if (h > 0) sum += h; // 注意只有h大于零的时候,在统计到总和中
-```
-
-整体代码如下:
-
-```
-class Solution {
-public:
- int trap(vector
-
-知道这一点,后面的就可以理解了。
-
-2. 使用单调栈内元素的顺序
-
-从大到小还是从小打到呢?
-
-要从栈底到栈头(元素从栈头弹出)是从大到小的顺序。
-
-因为一旦发现添加的柱子高度大于栈头元素了,此时就出现凹槽了,栈头元素就是凹槽底部的柱子,栈头第二个元素就是凹槽左边的柱子,而添加的元素就是凹槽右边的柱子。
-
-如图:
-
-
-
-列4 左侧最高的柱子是列3,高度为2(以下用lHeight表示)。
-
-列4 右侧最高的柱子是列7,高度为3(以下用rHeight表示)。
-
-列4 柱子的高度为1(以下用height表示)
-
-那么列4的雨水高度为 列3和列7的高度最小值减列4高度,即: min(lHeight, rHeight) - height。
-
-列4的雨水高度求出来了,宽度为1,相乘就是列4的雨水体积了。
-
-此时求出了列4的雨水体积。
-
-一样的方法,只要从头遍历一遍所有的列,然后求出每一列雨水的体积,相加之后就是总雨水的体积了。
-
-首先从头遍历所有的列,并且**要注意第一个柱子和最后一个柱子不接雨水**,代码如下:
-```
-for (int i = 0; i < height.size(); i++) {
- // 第一个柱子和最后一个柱子不接雨水
- if (i == 0 || i == height.size() - 1) continue;
-}
-```
-
-在for循环中求左右两边最高柱子,代码如下:
-
-```
-int rHeight = height[i]; // 记录右边柱子的最高高度
-int lHeight = height[i]; // 记录左边柱子的最高高度
-for (int r = i + 1; r < height.size(); r++) {
- if (height[r] > rHeight) rHeight = height[r];
-}
-for (int l = i - 1; l >= 0; l--) {
- if (height[l] > lHeight) lHeight = height[l];
-}
-```
-
-最后,计算该列的雨水高度,代码如下:
-
-```
-int h = min(lHeight, rHeight) - height[i];
-if (h > 0) sum += h; // 注意只有h大于零的时候,在统计到总和中
-```
-
-整体代码如下:
-
-```
-class Solution {
-public:
- int trap(vector
-
-知道这一点,后面的就可以理解了。
-
-2. 使用单调栈内元素的顺序
-
-从大到小还是从小打到呢?
-
-要从栈底到栈头(元素从栈头弹出)是从大到小的顺序。
-
-因为一旦发现添加的柱子高度大于栈头元素了,此时就出现凹槽了,栈头元素就是凹槽底部的柱子,栈头第二个元素就是凹槽左边的柱子,而添加的元素就是凹槽右边的柱子。
-
-如图:
-
- -
-
-3. 遇到相同高度的柱子怎么办。
-
-遇到相同的元素,更新栈内下表,就是将栈里元素(旧下标)弹出,将新元素(新下标)加入栈中。
-
-例如 5 5 1 3 这种情况。如果添加第二个5的时候就应该将第一个5的下标弹出,把第二个5添加到栈中。
-
-因为我们要求宽度的时候 如果遇到相同高度的柱子,需要使用最右边的柱子来计算宽度。
-
-如图所示:
-
-
-
-
-
-3. 遇到相同高度的柱子怎么办。
-
-遇到相同的元素,更新栈内下表,就是将栈里元素(旧下标)弹出,将新元素(新下标)加入栈中。
-
-例如 5 5 1 3 这种情况。如果添加第二个5的时候就应该将第一个5的下标弹出,把第二个5添加到栈中。
-
-因为我们要求宽度的时候 如果遇到相同高度的柱子,需要使用最右边的柱子来计算宽度。
-
-如图所示:
-
-
- -
-
-4. 栈里要保存什么数值
-
-是用单调栈,其实是通过 长 * 宽 来计算雨水面积的。
-
-长就是通过柱子的高度来计算,宽是通过柱子之间的下表来计算,
-
-那么栈里有没有必要存一个pair
-
-取栈顶元素,将栈顶元素弹出,这个就是凹槽的底部,也就是中间位置,下表记为mid,对应的高度为height[mid](就是图中的高度1)。
-
-栈顶元素st.top(),就是凹槽的左边位置,下表为st.top(),对应的高度为height[st.top()](就是图中的高度2)。
-
-当前遍历的元素i,就是凹槽右边的位置,下表为i,对应的高度为height[i](就是图中的高度3)。
-
-那么雨水高度是 min(凹槽左边高度, 凹槽右边高度) - 凹槽底部高度,代码为:`int h = min(height[st.top()], height[i]) - height[mid];`
-
-雨水的宽度是 凹槽右边的下表 - 凹槽左边的下表 - 1(因为只求中间宽度),代码为:`int w = i - st.top() - 1 ;`
-
-当前凹槽雨水的体积就是:`h * w`。
-
-求当前凹槽雨水的体积代码如下:
-
-```
-while (!st.empty() && height[i] > height[st.top()]) { // 注意这里是while,持续跟新栈顶元素
- int mid = st.top();
- st.pop();
- if (!st.empty()) {
- int h = min(height[st.top()], height[i]) - height[mid];
- int w = i - st.top() - 1; // 注意减一,只求中间宽度
- sum += h * w;
- }
-}
-```
-
-关键部分讲完了,整体代码如下:
-
-```
-class Solution {
-public:
- int trap(vector
-
-
-4. 栈里要保存什么数值
-
-是用单调栈,其实是通过 长 * 宽 来计算雨水面积的。
-
-长就是通过柱子的高度来计算,宽是通过柱子之间的下表来计算,
-
-那么栈里有没有必要存一个pair
-
-取栈顶元素,将栈顶元素弹出,这个就是凹槽的底部,也就是中间位置,下表记为mid,对应的高度为height[mid](就是图中的高度1)。
-
-栈顶元素st.top(),就是凹槽的左边位置,下表为st.top(),对应的高度为height[st.top()](就是图中的高度2)。
-
-当前遍历的元素i,就是凹槽右边的位置,下表为i,对应的高度为height[i](就是图中的高度3)。
-
-那么雨水高度是 min(凹槽左边高度, 凹槽右边高度) - 凹槽底部高度,代码为:`int h = min(height[st.top()], height[i]) - height[mid];`
-
-雨水的宽度是 凹槽右边的下表 - 凹槽左边的下表 - 1(因为只求中间宽度),代码为:`int w = i - st.top() - 1 ;`
-
-当前凹槽雨水的体积就是:`h * w`。
-
-求当前凹槽雨水的体积代码如下:
-
-```
-while (!st.empty() && height[i] > height[st.top()]) { // 注意这里是while,持续跟新栈顶元素
- int mid = st.top();
- st.pop();
- if (!st.empty()) {
- int h = min(height[st.top()], height[i]) - height[mid];
- int w = i - st.top() - 1; // 注意减一,只求中间宽度
- sum += h * w;
- }
-}
-```
-
-关键部分讲完了,整体代码如下:
-
-```
-class Solution {
-public:
- int trap(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + > 相对于[贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)难了不少,做好心里准备! -# 45.跳跃游戏II +## 45.跳跃游戏II 题目地址:https://leetcode-cn.com/problems/jump-game-ii/ -给定一个非负整数数组,你最初位于数组的第一个位置。 +给定一个非负整数数组,你最初位于数组的第一个位置。 -数组中的每个元素代表你在该位置可以跳跃的最大长度。 - -你的目标是使用最少的跳跃次数到达数组的最后一个位置。 +数组中的每个元素代表你在该位置可以跳跃的最大长度。 -示例: -输入: [2,3,1,1,4] -输出: 2 -解释: 跳到最后一个位置的最小跳跃数是 2。从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。 +你的目标是使用最少的跳跃次数到达数组的最后一个位置。 -说明: -假设你总是可以到达数组的最后一个位置。 +示例: +输入: [2,3,1,1,4] +输出: 2 +解释: 跳到最后一个位置的最小跳跃数是 2。从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。 + +说明: +假设你总是可以到达数组的最后一个位置。 -# 思路 +## 思路 本题相对于[贪心算法:跳跃游戏](https://mp.weixin.qq.com/s/606_N9j8ACKCODoCbV1lSA)还是难了不少。 但思路是相似的,还是要看最大覆盖范围。 -本题要计算最小步数,那么就要想清楚什么时候步数才一定要加一呢? +本题要计算最小步数,那么就要想清楚什么时候步数才一定要加一呢? 贪心的思路,局部最优:当前可移动距离尽可能多走,如果还没到终点,步数再加一。整体最优:一步尽可能多走,从而达到最小步数。 @@ -50,7 +59,7 @@ 这里还是有个特殊情况需要考虑,当移动下标达到了当前覆盖的最远距离下标时 * 如果当前覆盖最远距离下标不是是集合终点,步数就加一,还需要继续走。 -* 如果当前覆盖最远距离下标就是是集合终点,步数不用加一,因为不能再往后走了。 +* 如果当前覆盖最远距离下标就是是集合终点,步数不用加一,因为不能再往后走了。 C++代码如下:(详细注释) @@ -76,7 +85,7 @@ public: return ans; } }; -``` +``` ## 方法二 @@ -103,8 +112,8 @@ class Solution { public: int jump(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 开始排列问题 -# 46.全排列 +## 46.全排列 题目链接:https://leetcode-cn.com/problems/permutations/ -给定一个 没有重复 数字的序列,返回其所有可能的全排列。 - -示例: -输入: [1,2,3] -输出: -[ - [1,2,3], - [1,3,2], - [2,1,3], - [2,3,1], - [3,1,2], - [3,2,1] -] +给定一个 没有重复 数字的序列,返回其所有可能的全排列。 -## 思路 +示例: +输入: [1,2,3] +输出: +[ + [1,2,3], + [1,3,2], + [2,1,3], + [2,3,1], + [3,1,2], + [3,2,1] +] + +## 思路 此时我们已经学习了[组合问题](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)、[切割问题](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)和[子集问题](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA),接下来看一看排列问题。 @@ -33,9 +39,9 @@ 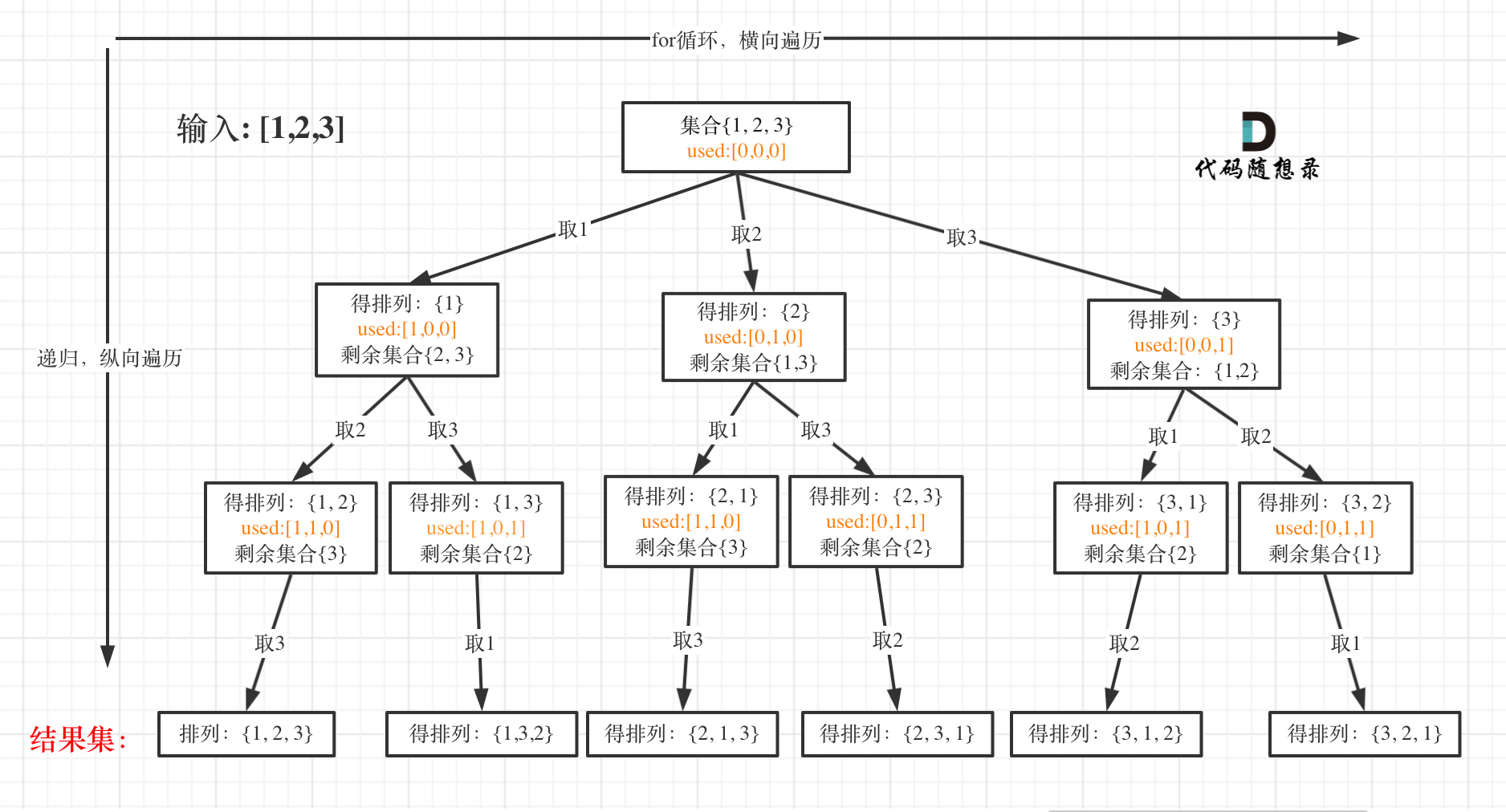 -## 回溯三部曲 +## 回溯三部曲 -* 递归函数参数 +* 递归函数参数 **首先排列是有序的,也就是说[1,2] 和[2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方**。 @@ -53,13 +59,13 @@ vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+# 排列问题(二) -> 排列也要去重了 - -# 47.全排列 II +## 47.全排列 II 题目链接:https://leetcode-cn.com/problems/permutations-ii/ 给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。 -示例 1: -输入:nums = [1,1,2] -输出: -[[1,1,2], - [1,2,1], - [2,1,1]] +示例 1: +输入:nums = [1,1,2] +输出: +[[1,1,2], + [1,2,1], + [2,1,1]] -示例 2: -输入:nums = [1,2,3] -输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] +示例 2: +输入:nums = [1,2,3] +输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 提示: * 1 <= nums.length <= 8 * -10 <= nums[i] <= 10 -## 思路 +## 思路 这道题目和[回溯算法:排列问题!](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw)的区别在与**给定一个可包含重复数字的序列**,要返回**所有不重复的全排列**。 @@ -91,14 +97,14 @@ public: 大家发现,去重最为关键的代码为: ``` -if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) { +if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) { continue; } ``` **如果改成 `used[i - 1] == true`, 也是正确的!**,去重代码如下: ``` -if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) { +if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) { continue; } ``` @@ -121,17 +127,17 @@ if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) { 大家应该很清晰的看到,树层上对前一位去重非常彻底,效率很高,树枝上对前一位去重虽然最后可以得到答案,但是做了很多无用搜索。 -# 总结 +## 总结 这道题其实还是用了我们之前讲过的去重思路,但有意思的是,去重的代码中,这么写: ``` -if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) { +if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) { continue; } ``` 和这么写: ``` -if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) { +if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) { continue; } ``` @@ -142,9 +148,83 @@ if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) { 是不是豁然开朗了!! -就酱,很多录友表示和「代码随想录」相见恨晚,那么大家帮忙多多宣传,让更多的同学知道这里,感谢啦! +## 其他语言版本 -> **我是[程序员Carl](https://github.com/youngyangyang04),可以找我[组队刷题](https://img-blog.csdnimg.cn/20201115103410182.png),也可以在[B站上找到我](https://space.bilibili.com/525438321),本文[leetcode刷题攻略](https://github.com/youngyangyang04/leetcode-master)已收录,更多[精彩算法文章](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzUxNjY5NTYxNA==&action=getalbum&album_id=1485825793120387074&scene=173#wechat_redirect)尽在公众号:[代码随想录](https://img-blog.csdnimg.cn/20200815195519696.png),关注后就会发现和「代码随想录」相见恨晚!** +java: -**如果感觉对你有帮助,不要吝啬给一个👍吧!** +```java +class Solution { + //存放结果 + List
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 第51题. N皇后 +## 第51题. N皇后 -题目链接: https://leetcode-cn.com/problems/n-queens/ +题目链接: https://leetcode-cn.com/problems/n-queens/ -n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。 +n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。 上图为 8 皇后问题的一种解法。 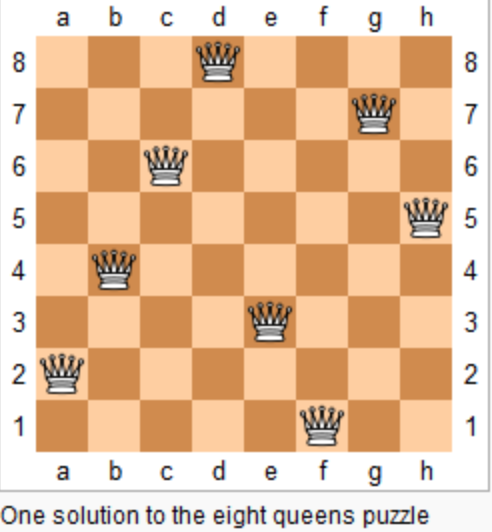 @@ -17,45 +21,45 @@ n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并 每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。 示例: -输入: 4 -输出: [ - [".Q..", // 解法 1 - "...Q", - "Q...", - "..Q."], - - ["..Q.", // 解法 2 - "Q...", - "...Q", - ".Q.."] -] -解释: 4 皇后问题存在两个不同的解法。 - -提示: +输入: 4 +输出: [ + [".Q..", // 解法 1 + "...Q", + "Q...", + "..Q."], + + ["..Q.", // 解法 2 + "Q...", + "...Q", + ".Q.."] +] +解释: 4 皇后问题存在两个不同的解法。 + +提示: > 皇后,是国际象棋中的棋子,意味着国王的妻子。皇后只做一件事,那就是“吃子”。当她遇见可以吃的棋子时,就迅速冲上去吃掉棋子。当然,她横、竖、斜都可走一到七步,可进可退。(引用自 百度百科 - 皇后 ) -# 思路 +## 思路 都知道n皇后问题是回溯算法解决的经典问题,但是用回溯解决多了组合、切割、子集、排列问题之后,遇到这种二位矩阵还会有点不知所措。 首先来看一下皇后们的约束条件: 1. 不能同行 -2. 不能同列 +2. 不能同列 3. 不能同斜线 确定完约束条件,来看看究竟要怎么去搜索皇后们的位置,其实搜索皇后的位置,可以抽象为一棵树。 下面我用一个3 * 3 的棋牌,将搜索过程抽象为一颗树,如图: -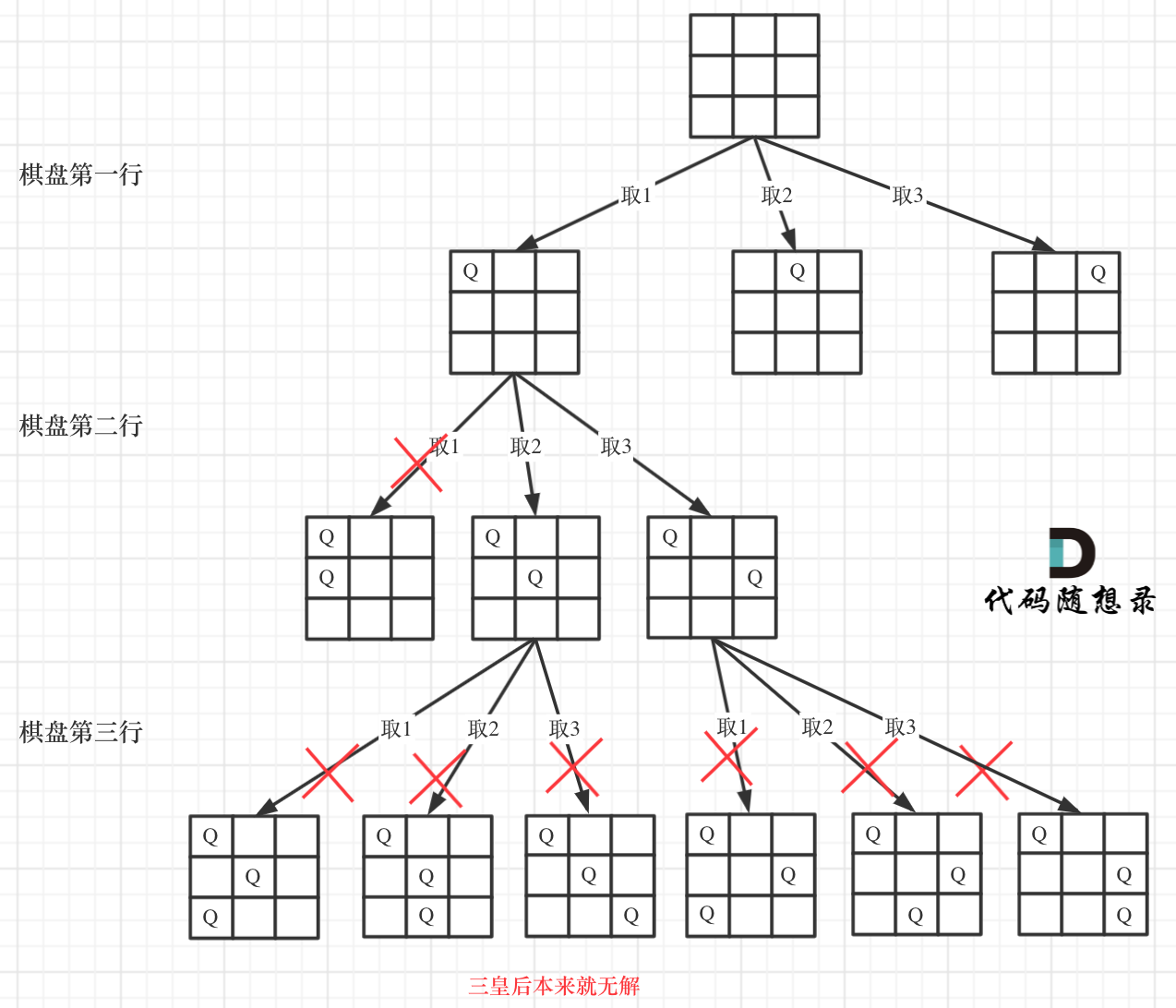 +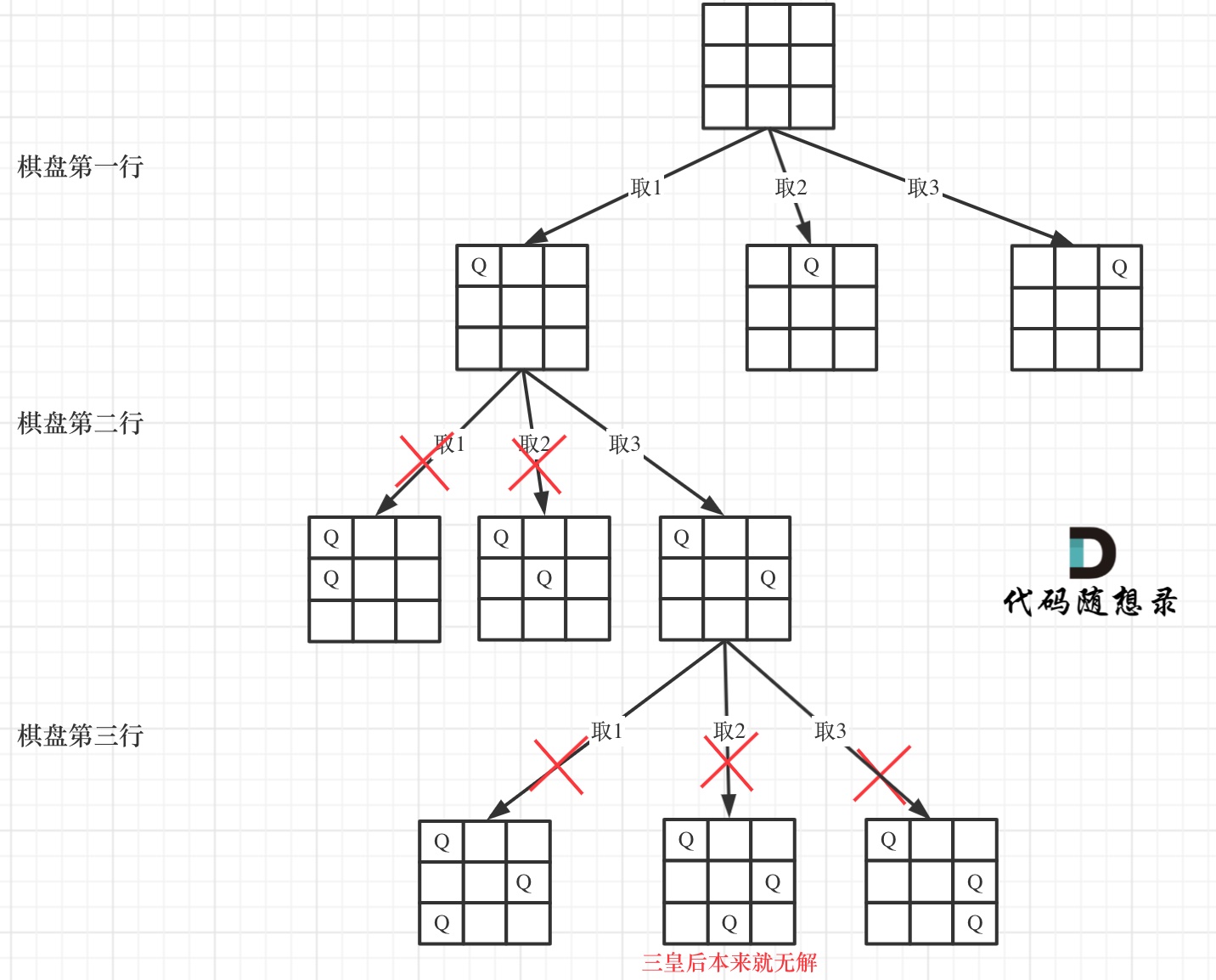 从图中,可以看出,二维矩阵中矩阵的高就是这颗树的高度,矩阵的宽就是树形结构中每一个节点的宽度。 -那么我们用皇后们的约束条件,来回溯搜索这颗树,**只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了**。 +那么我们用皇后们的约束条件,来回溯搜索这颗树,**只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了**。 -## 回溯三部曲 +## 回溯三部曲 按照我总结的如下回溯模板,我们来依次分析: @@ -73,11 +77,11 @@ void backtracking(参数) { } ``` -* 递归函数参数 +* 递归函数参数 我依然是定义全局变量二维数组result来记录最终结果。 -参数n是棋牌的大小,然后用row来记录当前遍历到棋盘的第几层了。 +参数n是棋牌的大小,然后用row来记录当前遍历到棋盘的第几层了。 代码如下: @@ -86,10 +90,11 @@ vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 从本题开始,贪心题目都比较难了! -通知:一些录友表示经常看不到每天的文章,现在公众号已经不按照发送时间推荐了,而是根据一些规则乱序推送,所以可能关注了「代码随想录」也一直看不到文章,建议把「代码随想录」设置星标哈,设置星标之后,每天就按发文时间推送了,我每天都是定时8:35发送的,嗷嗷准时! -# 53. 最大子序和 +## 53. 最大子序和 题目地址:https://leetcode-cn.com/problems/maximum-subarray/ 给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 -示例: -输入: [-2,1,-3,4,-1,2,1,-5,4] -输出: 6 -解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。 +示例: +输入: [-2,1,-3,4,-1,2,1,-5,4] +输出: 6 +解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。 -# 思路 -## 暴力解法 +## 暴力解法 -暴力解法的思路,第一层for 就是设置起始位置,第二层for循环遍历数组寻找最大值 +暴力解法的思路,第一层for 就是设置起始位置,第二层for循环遍历数组寻找最大值 -时间复杂度:O(n^2) +时间复杂度:O(n^2) 空间复杂度:O(1) -``` +```C++ class Solution { public: int maxSubArray(vector +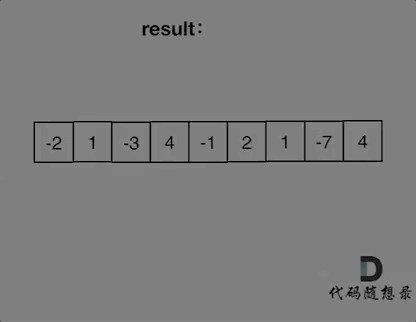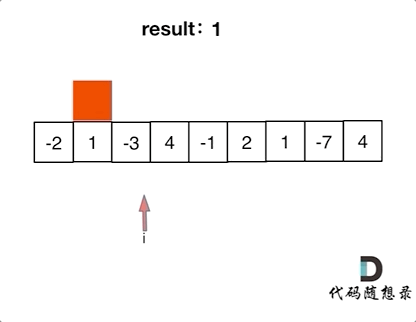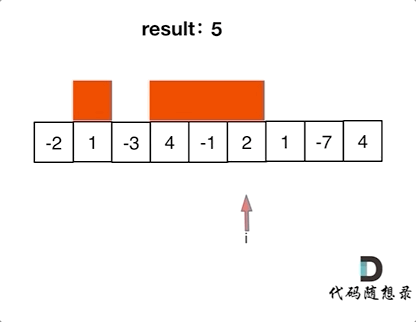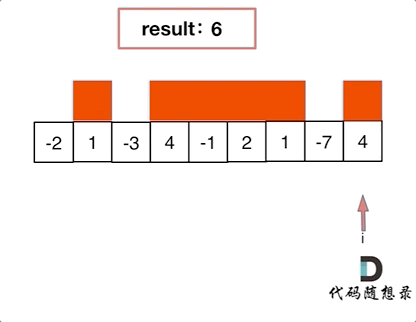
红色的起始位置就是贪心每次取count为正数的时候,开始一个区间的统计。
那么不难写出如下C++代码(关键地方已经注释)
-```
+```C++
class Solution {
public:
int maxSubArray(vector
+
红色的起始位置就是贪心每次取count为正数的时候,开始一个区间的统计。
那么不难写出如下C++代码(关键地方已经注释)
-```
+```C++
class Solution {
public:
int maxSubArray(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +## 53. 最大子序和 + +题目地址:https://leetcode-cn.com/problems/maximum-subarray/ + +给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 + +示例: +输入: [-2,1,-3,4,-1,2,1,-5,4] +输出: 6 +解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。 + +## 思路 + +这道题之前我们在讲解贪心专题的时候用贪心算法解决过一次,[贪心算法:最大子序和](https://mp.weixin.qq.com/s/DrjIQy6ouKbpletQr0g1Fg)。 + +这次我们用动态规划的思路再来分析一次。 + +动规五部曲如下: + +1. 确定dp数组(dp table)以及下标的含义 + +**dp[i]:包括下标i之前的最大连续子序列和为dp[i]**。 + +2. 确定递推公式 + +dp[i]只有两个方向可以推出来: + +* dp[i - 1] + nums[i],即:nums[i]加入当前连续子序列和 +* nums[i],即:从头开始计算当前连续子序列和 + +一定是取最大的,所以dp[i] = max(dp[i - 1] + nums[i], nums[i]); + +3. dp数组如何初始化 + +从递推公式可以看出来dp[i]是依赖于dp[i - 1]的状态,dp[0]就是递推公式的基础。 + +dp[0]应该是多少呢? + +更具dp[i]的定义,很明显dp[0]因为为nums[0]即dp[0] = nums[0]。 + +4. 确定遍历顺序 + +递推公式中dp[i]依赖于dp[i - 1]的状态,需要从前向后遍历。 + +5. 举例推导dp数组 + +以示例一为例,输入:nums = [-2,1,-3,4,-1,2,1,-5,4],对应的dp状态如下: +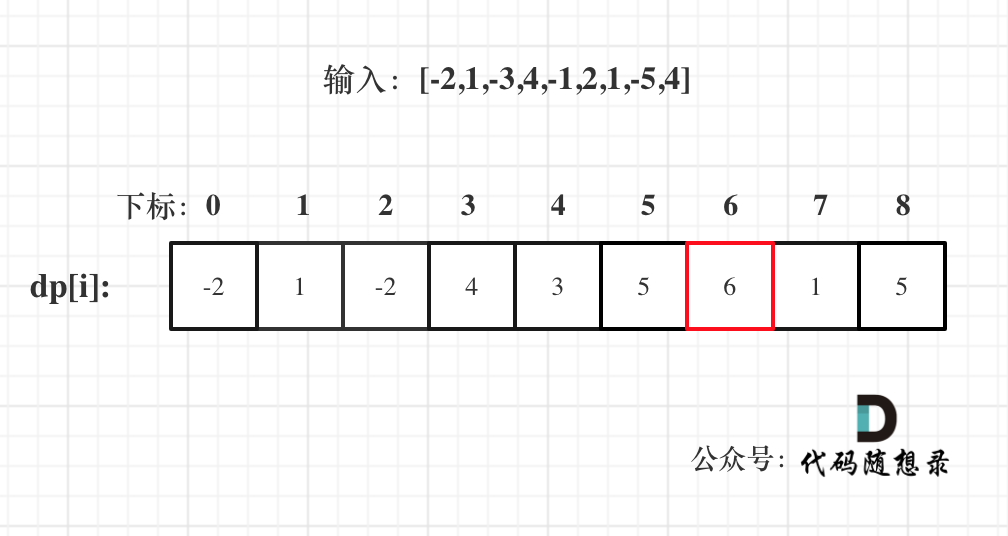 + +**注意最后的结果可不是dp[nums.size() - 1]!** ,而是dp[6]。 + +在回顾一下dp[i]的定义:包括下标i之前的最大连续子序列和为dp[i]。 + +那么我们要找最大的连续子序列,就应该找每一个i为终点的连续最大子序列。 + +所以在递推公式的时候,可以直接选出最大的dp[i]。 + +以上动规五部曲分析完毕,完整代码如下: + +```C++ +class Solution { +public: + int maxSubArray(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 通知 -# 55. 跳跃游戏 +## 55. 跳跃游戏 题目链接:https://leetcode-cn.com/problems/jump-game/ @@ -11,20 +17,20 @@ 判断你是否能够到达最后一个位置。 -示例 1: -输入: [2,3,1,1,4] -输出: true -解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。 +示例 1: +输入: [2,3,1,1,4] +输出: true +解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。 -示例 2: -输入: [3,2,1,0,4] -输出: false -解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。 +示例 2: +输入: [3,2,1,0,4] +输出: false +解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。 -## 思路 +## 思路 -刚看到本题一开始可能想:当前位置元素如果是3,我究竟是跳一步呢,还是两步呢,还是三步呢,究竟跳几步才是最优呢? +刚看到本题一开始可能想:当前位置元素如果是3,我究竟是跳一步呢,还是两步呢,还是三步呢,究竟跳几步才是最优呢? 其实跳几步无所谓,关键在于可跳的覆盖范围! @@ -32,9 +38,9 @@ 这个范围内,别管是怎么跳的,反正一定可以跳过来。 -**那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!** +**那么这个问题就转化为跳跃覆盖范围究竟可不可以覆盖到终点!** -每次移动取最大跳跃步数(得到最大的覆盖范围),每移动一个单位,就更新最大覆盖范围。 +每次移动取最大跳跃步数(得到最大的覆盖范围),每移动一个单位,就更新最大覆盖范围。 **贪心算法局部最优解:每次取最大跳跃步数(取最大覆盖范围),整体最优解:最后得到整体最大覆盖范围,看是否能到终点**。 @@ -66,7 +72,7 @@ public: } }; ``` -# 总结 +## 总结 这道题目关键点在于:不用拘泥于每次究竟跳跳几步,而是看覆盖范围,覆盖范围内一定是可以跳过来的,不用管是怎么跳的。 @@ -76,4 +82,22 @@ public: **是真的就是没什么联系,因为贪心无套路!**没有个整体的贪心框架解决一些列问题,只能是接触各种类型的题目锻炼自己的贪心思维! -就酱,「代码随想录」值得推荐给身边的朋友同学们! +## 其他语言版本 + + +Java: + + +Python: + + +Go: + + + + +----------------------- +* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw) +* B站视频:[代码随想录](https://space.bilibili.com/525438321) +* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) +
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 思路 -这道题目看起来就是一道模拟类的题,但其实是一道贪心题目! -按照左区间排序之后,每次合并都取最大的右区间,这样就可以合并更多的区间了。 +## 56. 合并区间 -那有同学问了,这不是废话么? 当然要取最大的右区间啊。 +题目链接:https://leetcode-cn.com/problems/merge-intervals/ -**是的,一想就是这么个道理,但它就是贪心的思想,局部最优推导出整体最优**。 +给出一个区间的集合,请合并所有重叠的区间。 -这也就是为什么很多同学刷题的时候都没有发现自己用了贪心。 +示例 1: +输入: intervals = [[1,3],[2,6],[8,10],[15,18]] +输出: [[1,6],[8,10],[15,18]] +解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6]. -合并思路:如果 `intervals[i][0] < intervals[i - 1][1]` 即intervals[i]起始位置 < intervals[i - 1]终止位置,则一定有重复,需要合并。 +示例 2: +输入: intervals = [[1,4],[4,5]] +输出: [[1,5]] +解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。 +注意:输入类型已于2019年4月15日更改。 请重置默认代码定义以获取新方法签名。 -如图所示: +提示: - +* intervals[i][0] <= intervals[i][1]
+
+## 思路
+
+大家应该都感觉到了,此题一定要排序,那么按照左边界排序,还是右边界排序呢?
+
+都可以!
+
+那么我按照左边界排序,排序之后局部最优:每次合并都取最大的右边界,这样就可以合并更多的区间了,整体最优:合并所有重叠的区间。
+
+局部最优可以推出全局最优,找不出反例,试试贪心。
+
+那有同学问了,本来不就应该合并最大右边界么,这和贪心有啥关系?
+
+有时候贪心就是常识!哈哈
+
+按照左边界从小到大排序之后,如果 `intervals[i][0] < intervals[i - 1][1]` 即intervals[i]左边界 < intervals[i - 1]右边界,则一定有重复,因为intervals[i]的左边界一定是大于等于intervals[i - 1]的左边界。
+
+即:intervals[i]的左边界在intervals[i - 1]左边界和右边界的范围内,那么一定有重复!
+
+这么说有点抽象,看图:(**注意图中区间都是按照左边界排序之后了**)
+
+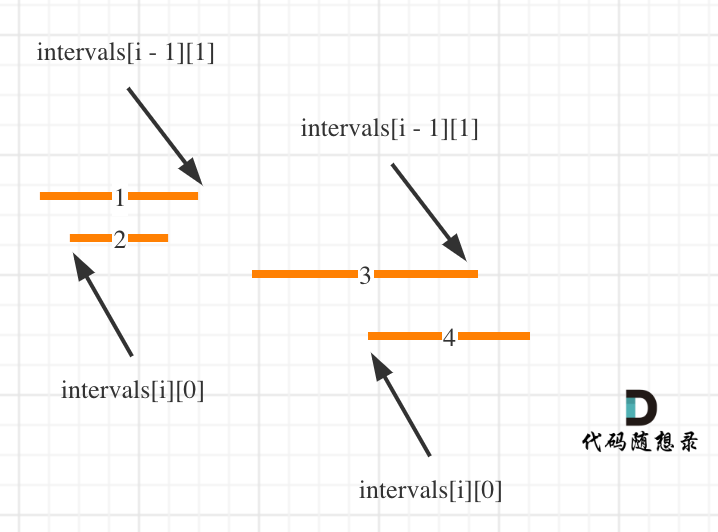
+
+知道如何判断重复之后,剩下的就是合并了,如何去模拟合并区间呢?
+
+其实就是用合并区间后左边界和右边界,作为一个新的区间,加入到result数组里就可以了。如果没有合并就把原区间加入到result数组。
C++代码如下:
-```
+```C++
class Solution {
public:
- // 按照区间左边界排序
+ // 按照区间左边界从小到大排序
static bool cmp (const vector
+* intervals[i][0] <= intervals[i][1]
+
+## 思路
+
+大家应该都感觉到了,此题一定要排序,那么按照左边界排序,还是右边界排序呢?
+
+都可以!
+
+那么我按照左边界排序,排序之后局部最优:每次合并都取最大的右边界,这样就可以合并更多的区间了,整体最优:合并所有重叠的区间。
+
+局部最优可以推出全局最优,找不出反例,试试贪心。
+
+那有同学问了,本来不就应该合并最大右边界么,这和贪心有啥关系?
+
+有时候贪心就是常识!哈哈
+
+按照左边界从小到大排序之后,如果 `intervals[i][0] < intervals[i - 1][1]` 即intervals[i]左边界 < intervals[i - 1]右边界,则一定有重复,因为intervals[i]的左边界一定是大于等于intervals[i - 1]的左边界。
+
+即:intervals[i]的左边界在intervals[i - 1]左边界和右边界的范围内,那么一定有重复!
+
+这么说有点抽象,看图:(**注意图中区间都是按照左边界排序之后了**)
+
+
+
+知道如何判断重复之后,剩下的就是合并了,如何去模拟合并区间呢?
+
+其实就是用合并区间后左边界和右边界,作为一个新的区间,加入到result数组里就可以了。如果没有合并就把原区间加入到result数组。
C++代码如下:
-```
+```C++
class Solution {
public:
- // 按照区间左边界排序
+ // 按照区间左边界从小到大排序
static bool cmp (const vector  -
-对于这种情况,只要是intervals[index]起始位置 <= newInterval终止位置,就要一直合并下去。
-
-代码如下:
-
-```
-while (index < intervals.size() && intervals[index][0] <= newInterval[1]) { // 注意防止越界
- newInterval[0] = min(intervals[index][0], newInterval[0]);
- newInterval[1] = max(intervals[index][1], newInterval[1]);
- index++;
-}
-```
-合并之后,将newInterval放入result就可以了
-
-2. intervals[index]不用合并,插入区间直接插入就行,如图:
-
-
-
-对于这种情况,只要是intervals[index]起始位置 <= newInterval终止位置,就要一直合并下去。
-
-代码如下:
-
-```
-while (index < intervals.size() && intervals[index][0] <= newInterval[1]) { // 注意防止越界
- newInterval[0] = min(intervals[index][0], newInterval[0]);
- newInterval[1] = max(intervals[index][1], newInterval[1]);
- index++;
-}
-```
-合并之后,将newInterval放入result就可以了
-
-2. intervals[index]不用合并,插入区间直接插入就行,如图:
-
- -
-对于这种情况,就直接把newInterval放入result就可以了
-
-## 步骤三:处理合并区间之后的区间
-
-合并之后,就应该把合并之后的区间,以此加入result中。
-
-代码如下:
-
-```
-while (index < intervals.size()) {
- result.push_back(intervals[index++]);
-}
-```
-
-# 整体C++代码
-
-```
-class Solution {
-public:
- vector
-
-对于这种情况,就直接把newInterval放入result就可以了
-
-## 步骤三:处理合并区间之后的区间
-
-合并之后,就应该把合并之后的区间,以此加入result中。
-
-代码如下:
-
-```
-while (index < intervals.size()) {
- result.push_back(intervals[index++]);
-}
-```
-
-# 整体C++代码
-
-```
-class Solution {
-public:
- vector
-
-
-
-
+
-
-
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 一进循环深似海,从此offer是路人 -# 题目59.螺旋矩阵II +## 59.螺旋矩阵II -题目地址:https://leetcode-cn.com/problems/spiral-matrix-ii/ +题目地址:https://leetcode-cn.com/problems/spiral-matrix-ii/ 给定一个正整数 n,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。 示例: @@ -29,7 +23,7 @@ [ 7, 6, 5 ] ] -# 思路 +## 思路 这道题目可以说在面试中出现频率较高的题目,**本题并不涉及到什么算法,就是模拟过程,但却十分考察对代码的掌控能力。** @@ -39,13 +33,13 @@ 结果运行的时候各种问题,然后开始各种修修补补,最后发现改了这里哪里有问题,改了那里这里又跑不起来了。 -大家还记得我们在这篇文章[数组:每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)中讲解了二分法,提到如果要写出正确的二分法一定要坚持**循环不变量原则**。 +大家还记得我们在这篇文章[数组:每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/4X-8VRgnYRGd5LYGZ33m4w)中讲解了二分法,提到如果要写出正确的二分法一定要坚持**循环不变量原则**。 而求解本题依然是要坚持循环不变量原则。 模拟顺时针画矩阵的过程: -* 填充上行从左到右 +* 填充上行从左到右 * 填充右列从上到下 * 填充下行从右到左 * 填充左列从下到上 @@ -64,13 +58,13 @@ 这也是坚持了每条边左闭右开的原则。 -一些同学做这道题目之所以一直写不好,代码越写越乱。 +一些同学做这道题目之所以一直写不好,代码越写越乱。 就是因为在画每一条边的时候,一会左开又闭,一会左闭右闭,一会又来左闭右开,岂能不乱。 代码如下,已经详细注释了每一步的目的,可以看出while循环里判断的情况是很多的,代码里处理的原则也是统一的左闭右开。 -# C++代码 +整体C++代码如下: ```C++ class Solution { @@ -122,8 +116,118 @@ public: }; ``` -**循序渐进学算法,认准「代码随想录」,Carl手把手带你过关斩将!** +## 类似题目 -
-
-
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 思路 +## 62.不同路径 -## 深搜 +题目链接:https://leetcode-cn.com/problems/unique-paths/ + +一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 + +机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 + +问总共有多少条不同的路径? + +示例 1: + + + +输入:m = 3, n = 7 +输出:28 + +示例 2: +输入:m = 2, n = 3 +输出:3 +解释: +从左上角开始,总共有 3 条路径可以到达右下角。 +1. 向右 -> 向右 -> 向下 +2. 向右 -> 向下 -> 向右 +3. 向下 -> 向右 -> 向右 + + +示例 3: +输入:m = 7, n = 3 +输出:28 + +示例 4: +输入:m = 3, n = 3 +输出:6 + +提示: +* 1 <= m, n <= 100 +* 题目数据保证答案小于等于 2 * 10^9 + +## 思路 + +### 深搜 这道题目,刚一看最直观的想法就是用图论里的深搜,来枚举出来有多少种路径。 @@ -28,27 +74,36 @@ public: }; ``` -大家如果提交了代码就会发现超时了! +**大家如果提交了代码就会发现超时了!** 来分析一下时间复杂度,这个深搜的算法,其实就是要遍历整个二叉树。 这颗树的深度其实就是m+n-1(深度按从1开始计算)。 -那二叉树的节点个数就是 2^(m + n - 1) - 1。可以理解深搜的算法就是遍历了整个满二叉树(其实没有把搜索节点都遍历到,只是近似而已) +那二叉树的节点个数就是 2^(m + n - 1) - 1。可以理解深搜的算法就是遍历了整个满二叉树(其实没有遍历整个满二叉树,只是近似而已) 所以上面深搜代码的时间复杂度为O(2^(m + n - 1) - 1),可以看出,这是指数级别的时间复杂度,是非常大的。 -## 动态规划 +### 动态规划 机器人从(0 , 0) 位置触发,到(m - 1, n - 1)终点。 -按照动规三部曲来分析: +按照动规五部曲来分析: -* dp数组表述啥 +1. 确定dp数组(dp table)以及下标的含义 -这里设计一个dp二维数组,dp[i][j] 表示从(0 ,0)出发,到(i, j) 有几条不同的路径。 +dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。 -* dp数组的初始化 + +2. 确定递推公式 + +想要求dp[i][j],只能有两个方向来推导出来,即dp[i - 1][j] 和 dp[i][j - 1]。 + +此时在回顾一下 dp[i - 1][j] 表示啥,是从(0, 0)的位置到(i - 1, j)有几条路径,dp[i][j - 1]同理。 + +那么很自然,dp[i][j] = dp[i - 1][j] + dp[i][j - 1],因为dp[i][j]只有这两个方向过来。 + +3. dp数组的初始化 如何初始化呢,首先dp[i][0]一定都是1,因为从(0, 0)的位置到(i, 0)的路径只有一条,那么dp[0][j]也同理。 @@ -59,19 +114,19 @@ for (int i = 0; i < m; i++) dp[i][0] = 1; for (int j = 0; j < n; j++) dp[0][j] = 1; ``` -* 递推公式 +4. 确定遍历顺序 -想要求dp[i][j],只能有两个方向来推导出来,即dp[i - 1][j] 和 dp[i][j - 1]。 +这里要看一下递归公式dp[i][j] = dp[i - 1][j] + dp[i][j - 1],dp[i][j]都是从其上方和左方推导而来,那么从左到右一层一层遍历就可以了。 -此时在回顾一下 dp[i-1][j] 表示啥,是从(0, 0)的位置到(i-1, j)有几条路径,dp[i][j - 1]同理。 +这样就可以保证推导dp[i][j]的时候,dp[i - 1][j] 和 dp[i][j - 1]一定是有数值的。 -那么很自然,dp[i][j] = dp[i-1][j] + dp[i][j - 1],因为dp[i][j]只有这两个方向过来。 +5. 举例推导dp数组 如图所示:  -C++代码如下: +以上动规五部曲分析完毕,C++代码如下: ```C++ class Solution { @@ -89,7 +144,7 @@ public: } }; ``` -* 时间复杂度:O(m * n) +* 时间复杂度:O(m * n) * 空间复杂度:O(m * n) 其实用一个一维数组(也可以理解是滚动数组)就可以了,但是不利于理解,可以优化点空间,建议先理解了二维,在理解一维,C++代码如下: @@ -109,12 +164,12 @@ public: } }; ``` -* 时间复杂度:O(m * n) +* 时间复杂度:O(m * n) * 空间复杂度:O(n) -# 数论方法 +### 数论方法 -在这个图中,可以看出一共 m,n的话,无论怎么走,走到终点都需要 m + n - 2 步。 +在这个图中,可以看出一共m,n的话,无论怎么走,走到终点都需要 m + n - 2 步。 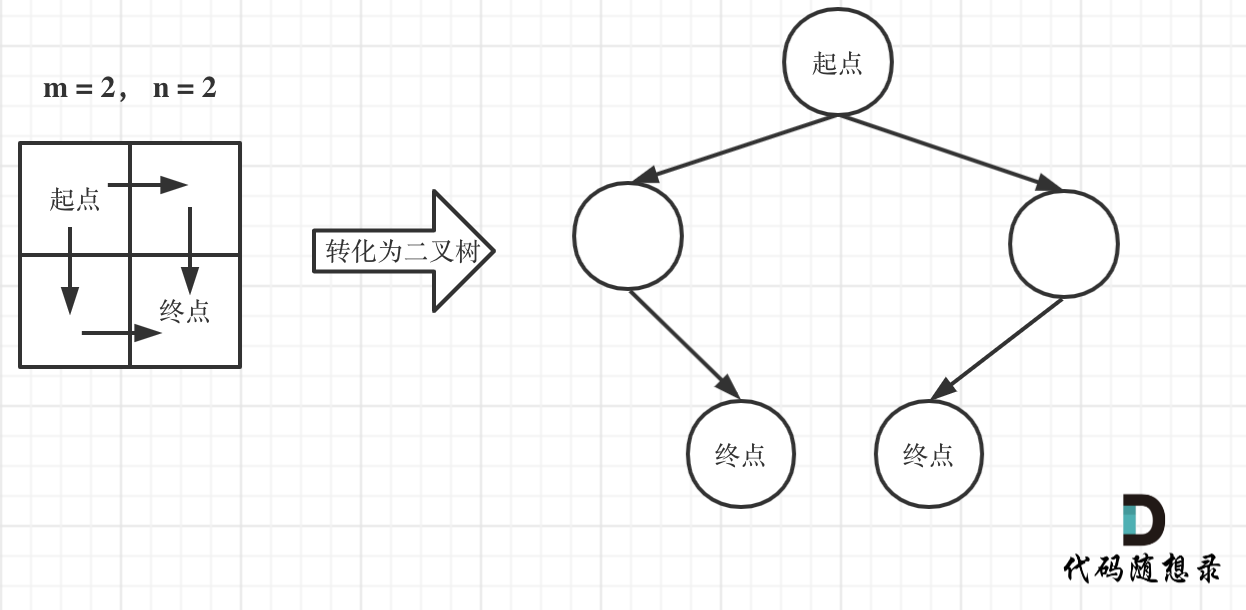 @@ -130,7 +185,9 @@ public: **求组合的时候,要防止两个int相乘溢出!** 所以不能把算式的分子都算出来,分母都算出来再做除法。 -``` +例如如下代码是不行的。 + +```C++ class Solution { public: int uniquePaths(int m, int n) { @@ -145,9 +202,9 @@ public: ``` -需要在计算分子的时候,不算除以分母,代码如下: +需要在计算分子的时候,不断除以分母,代码如下: -``` +```C++ class Solution { public: int uniquePaths(int m, int n) { @@ -167,10 +224,37 @@ public: }; ``` -计算组合问题的代码还是有难度的,特别是处理溢出的情况! +时间复杂度:O(m) +空间复杂度:O(1) -最后这个代码还有点复杂了,还是可以优化,我就不继续优化了,有空在整理一下,哈哈,就酱! +**计算组合问题的代码还是有难度的,特别是处理溢出的情况!** + +## 总结 + +本文分别给出了深搜,动规,数论三种方法。 + +深搜当然是超时了,顺便分析了一下使用深搜的时间复杂度,就可以看出为什么超时了。 + +然后在给出动规的方法,依然是使用动规五部曲,这次我们就要考虑如何正确的初始化了,初始化和遍历顺序其实也很重要! + +就酱,循序渐进学算法,认准「代码随想录」! + +## 其他语言版本 + + +Java: + + +Python: + + +Go: +----------------------- +* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw) +* B站视频:[代码随想录](https://space.bilibili.com/525438321) +* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) +
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +## 63. 不同路径 II + +题目链接:https://leetcode-cn.com/problems/unique-paths-ii/ + +一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。 + +机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。 + +现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径? + + + +网格中的障碍物和空位置分别用 1 和 0 来表示。 + +示例 1: + + + +输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]] +输出:2 +解释: +3x3 网格的正中间有一个障碍物。 +从左上角到右下角一共有 2 条不同的路径: +1. 向右 -> 向右 -> 向下 -> 向下 +2. 向下 -> 向下 -> 向右 -> 向右 + +示例 2: + + + +输入:obstacleGrid = [[0,1],[0,0]] +输出:1 + +提示: + +* m == obstacleGrid.length +* n == obstacleGrid[i].length +* 1 <= m, n <= 100 +* obstacleGrid[i][j] 为 0 或 1 + + +## 思路 + +这道题相对于[62.不同路径](https://mp.weixin.qq.com/s/MGgGIt4QCpFMROE9X9he_A) 就是有了障碍。 + +第一次接触这种题目的同学可能会有点懵,这有障碍了,应该怎么算呢? + +[62.不同路径](https://mp.weixin.qq.com/s/MGgGIt4QCpFMROE9X9he_A)中我们已经详细分析了没有障碍的情况,有障碍的话,其实就是标记对应的dp table(dp数组)保持初始值(0)就可以了。 + +动规五部曲: + +1. 确定dp数组(dp table)以及下标的含义 + +dp[i][j] :表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。 + +2. 确定递推公式 + +递推公式和62.不同路径一样,dp[i][j] = dp[i - 1][j] + dp[i][j - 1]。 + +但这里需要注意一点,因为有了障碍,(i, j)如果就是障碍的话应该就保持初始状态(初始状态为0)。 + +所以代码为: + +``` +if (obstacleGrid[i][j] == 0) { // 当(i, j)没有障碍的时候,再推导dp[i][j] + dp[i][j] = dp[i - 1][j] + dp[i][j - 1]; +} +``` + +3. dp数组如何初始化 + +在[62.不同路径](https://mp.weixin.qq.com/s/MGgGIt4QCpFMROE9X9he_A)不同路径中我们给出如下的初始化: + +``` +vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-dp里求排列,1 2 步 和 2 1 步都是上三个台阶,但不一样! +## 70. 爬楼梯 -这是求排列 +假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 + +每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? + +注意:给定 n 是一个正整数。 + +示例 1: +输入: 2 +输出: 2 +解释: 有两种方法可以爬到楼顶。 +1. 1 阶 + 1 阶 +2. 2 阶 + +示例 2: +输入: 3 +输出: 3 +解释: 有三种方法可以爬到楼顶。 +1. 1 阶 + 1 阶 + 1 阶 +2. 1 阶 + 2 阶 +3. 2 阶 + 1 阶 + + +## 思路 + +本题大家如果没有接触过的话,会感觉比较难,多举几个例子,就可以发现其规律。 + +爬到第一层楼梯有一种方法,爬到二层楼梯有两种方法。 + +那么第一层楼梯再跨两步就到第三层 ,第二层楼梯再跨一步就到第三层。 + +所以到第三层楼梯的状态可以由第二层楼梯 和 到第一层楼梯状态推导出来,那么就可以想到动态规划了。 + +我们来分析一下,动规五部曲: + +定义一个一维数组来记录不同楼层的状态 + +1. 确定dp数组以及下标的含义 + +dp[i]: 爬到第i层楼梯,有dp[i]种方法 + +2. 确定递推公式 + +如果可以推出dp[i]呢? + +从dp[i]的定义可以看出,dp[i] 可以有两个方向推出来。 + +首先是dp[i - 1],上i-1层楼梯,有dp[i - 1]种方法,那么再一步跳一个台阶不就是dp[i]了么。 + +还有就是dp[i - 2],上i-2层楼梯,有dp[i - 2]种方法,那么再一步跳两个台阶不就是dp[i]了么。 + +那么dp[i]就是 dp[i - 1]与dp[i - 2]之和! + +所以dp[i] = dp[i - 1] + dp[i - 2] 。 + +在推导dp[i]的时候,一定要时刻想着dp[i]的定义,否则容易跑偏。 + +这体现出确定dp数组以及下标的含义的重要性! + +3. dp数组如何初始化 + +在回顾一下dp[i]的定义:爬到第i层楼梯,有dp[i]中方法。 + +那么i为0,dp[i]应该是多少呢,这个可以有很多解释,但都基本是直接奔着答案去解释的。 + +例如强行安慰自己爬到第0层,也有一种方法,什么都不做也就是一种方法即:dp[0] = 1,相当于直接站在楼顶。 + +但总有点牵强的成分。 + +那还这么理解呢:我就认为跑到第0层,方法就是0啊,一步只能走一个台阶或者两个台阶,然而楼层是0,直接站楼顶上了,就是不用方法,dp[0]就应该是0. + +**其实这么争论下去没有意义,大部分解释说dp[0]应该为1的理由其实是因为dp[0]=1的话在递推的过程中i从2开始遍历本题就能过,然后就往结果上靠去解释dp[0] = 1**。 + +从dp数组定义的角度上来说,dp[0] = 0 也能说得通。 + +需要注意的是:题目中说了n是一个正整数,题目根本就没说n有为0的情况。 + +所以本题其实就不应该讨论dp[0]的初始化! + +我相信dp[1] = 1,dp[2] = 2,这个初始化大家应该都没有争议的。 + +所以我的原则是:不考虑dp[0]如果初始化,只初始化dp[1] = 1,dp[2] = 2,然后从i = 3开始递推,这样才符合dp[i]的定义。 + +4. 确定遍历顺序 + +从递推公式dp[i] = dp[i - 1] + dp[i - 2];中可以看出,遍历顺序一定是从前向后遍历的 + +5. 举例推导dp数组 + +举例当n为5的时候,dp table(dp数组)应该是这样的 + +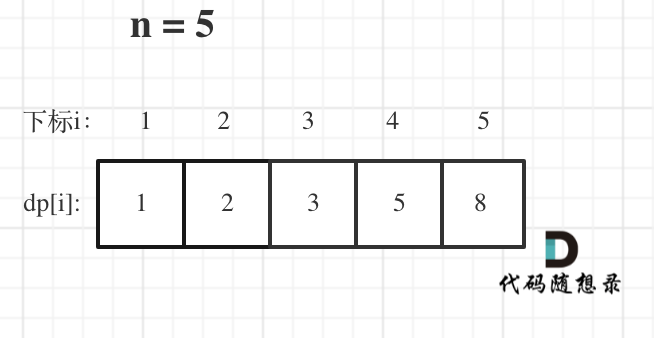 + +如果代码出问题了,就把dp table 打印出来,看看究竟是不是和自己推导的一样。 + +**此时大家应该发现了,这不就是斐波那契数列么!** + +唯一的区别是,没有讨论dp[0]应该是什么,因为dp[0]在本题没有意义! + +以上五部分析完之后,C++代码如下: + +```C++ +// 版本一 +class Solution { +public: + int climbStairs(int n) { + if (n <= 1) return n; // 因为下面直接对dp[2]操作了,防止空指针 + vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+# 动态规划:以前我没得选,现在我选择再爬一次! + +之前讲这道题目的时候,因为还没有讲背包问题,所以就只是讲了一下爬楼梯最直接的动规方法(斐波那契)。 + +**这次终于讲到了背包问题,我选择带录友们再爬一次楼梯!** + +## 70. 爬楼梯 + +链接:https://leetcode-cn.com/problems/climbing-stairs/ + +假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 + +每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? + +注意:给定 n 是一个正整数。 + +示例 1: +输入: 2 +输出: 2 +解释: 有两种方法可以爬到楼顶。 +1. 1 阶 + 1 阶 +2. 2 阶 + +示例 2: +输入: 3 +输出: 3 +解释: 有三种方法可以爬到楼顶。 +1. 1 阶 + 1 阶 + 1 阶 +2. 1 阶 + 2 阶 +3. 2 阶 + 1 阶 + +## 思路 + +这道题目 我们在[动态规划:爬楼梯](https://mp.weixin.qq.com/s/Ohop0jApSII9xxOMiFhGIw) 中已经讲过一次了,原题其实是一道简单动规的题目。 + +既然这么简单为什么还要讲呢,其实本题稍加改动就是一道面试好题。 + +**改为:一步一个台阶,两个台阶,三个台阶,.......,直到 m个台阶。问有多少种不同的方法可以爬到楼顶呢?** + +1阶,2阶,.... m阶就是物品,楼顶就是背包。 + +每一阶可以重复使用,例如跳了1阶,还可以继续跳1阶。 + +问跳到楼顶有几种方法其实就是问装满背包有几种方法。 + +**此时大家应该发现这就是一个完全背包问题了!** + +和昨天的题目[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)基本就是一道题了。 + +动规五部曲分析如下: + +1. 确定dp数组以及下标的含义 + +**dp[i]:爬到有i个台阶的楼顶,有dp[i]种方法**。 + +2. 确定递推公式 + +在[动态规划:494.目标和](https://mp.weixin.qq.com/s/2pWmaohX75gwxvBENS-NCw) 、 [动态规划:518.零钱兑换II](https://mp.weixin.qq.com/s/PlowDsI4WMBOzf3q80AksQ)、[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)中我们都讲过了,求装满背包有几种方法,递推公式一般都是dp[i] += dp[i - nums[j]]; + +本题呢,dp[i]有几种来源,dp[i - 1],dp[i - 2],dp[i - 3] 等等,即:dp[i - j] + +那么递推公式为:dp[i] += dp[i - j] + +3. dp数组如何初始化 + +既然递归公式是 dp[i] += dp[i - j],那么dp[0] 一定为1,dp[0]是递归中一切数值的基础所在,如果dp[0]是0的话,其他数值都是0了。 + +下标非0的dp[i]初始化为0,因为dp[i]是靠dp[i-j]累计上来的,dp[i]本身为0这样才不会影响结果 + +4. 确定遍历顺序 + +这是背包里求排列问题,即:**1、2 步 和 2、1 步都是上三个台阶,但是这两种方法不一样!** + +所以需将target放在外循环,将nums放在内循环。 + +每一步可以走多次,这是完全背包,内循环需要从前向后遍历。 + +5. 举例来推导dp数组 + +介于本题和[动态规划:377. 组合总和 Ⅳ](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)几乎是一样的,这里我就不再重复举例了。 + + +以上分析完毕,C++代码如下: +``` +class Solution { +public: + int climbStairs(int n) { + vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +## 72. 编辑距离 + +给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。 + +你可以对一个单词进行如下三种操作: + +* 插入一个字符 +* 删除一个字符 +* 替换一个字符 + +示例 1: +输入:word1 = "horse", word2 = "ros" +输出:3 +解释: +horse -> rorse (将 'h' 替换为 'r') +rorse -> rose (删除 'r') +rose -> ros (删除 'e') + +示例 2: +输入:word1 = "intention", word2 = "execution" +输出:5 +解释: +intention -> inention (删除 't') +inention -> enention (将 'i' 替换为 'e') +enention -> exention (将 'n' 替换为 'x') +exention -> exection (将 'n' 替换为 'c') +exection -> execution (插入 'u') + + +提示: + +* 0 <= word1.length, word2.length <= 500 +* word1 和 word2 由小写英文字母组成 + + +## 思路 + +编辑距离终于来了,这道题目如果大家没有了解动态规划的话,会感觉超级复杂。 + +编辑距离是用动规来解决的经典题目,这道题目看上去好像很复杂,但用动规可以很巧妙的算出最少编辑距离。 + +接下来我依然使用动规五部曲,对本题做一个详细的分析: + +1. 确定dp数组(dp table)以及下标的含义 + +**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。 + +这里在强调一下:为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢? + +用i来表示也可以! 但我统一以下标i-1为结尾的字符串,在下面的递归公式中会容易理解一点。 + +2. 确定递推公式 + +在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下: + +* if (word1[i - 1] == word2[j - 1]) + * 不操作 +* if (word1[i - 1] != word2[j - 1]) + * 增 + * 删 + * 换 + +也就是如上四种情况。 + +if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1]; + +此时可能有同学有点不明白,为啥要即dp[i][j] = dp[i - 1][j - 1]呢? + +那么就在回顾上面讲过的dp[i][j]的定义,word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1] 就是 dp[i][j]了。 + +在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。 + +**在整个动规的过程中,最为关键就是正确理解dp[i][j]的定义!** + +if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢? + +操作一:word1增加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-2为结尾的word1 与 i-1为结尾的word2的最近编辑距离 加上一个增加元素的操作。 + +即 dp[i][j] = dp[i - 1][j] + 1; + + +操作二:word2添加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个增加元素的操作。 + +即 dp[i][j] = dp[i][j - 1] + 1; + +这里有同学发现了,怎么都是添加元素,删除元素去哪了。 + +**word2添加一个元素,相当于word1删除一个元素**,例如 word1 = "ad" ,word2 = "a",word2添加一个元素d,也就是相当于word1删除一个元素d,操作数是一样! + +操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增加元素,那么以下标i-2为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个替换元素的操作。 + +即 dp[i][j] = dp[i - 1][j - 1] + 1; + +综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1; + +递归公式代码如下: + +```C++ +if (word1[i - 1] == word2[j - 1]) { + dp[i][j] = dp[i - 1][j - 1]; +} +else { + dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1; +} +``` + +3. dp数组如何初始化 + +在回顾一下dp[i][j]的定义。 + +**dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j]**。 + +那么dp[i][0] 和 dp[0][j] 表示什么呢? + +dp[i][0] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。 + +那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i; + +同理dp[0][j] = j; + +所以C++代码如下: + +```C++ +for (int i = 0; i <= word1.size(); i++) dp[i][0] = i; +for (int j = 0; j <= word2.size(); j++) dp[0][j] = j; +``` + +4. 确定遍历顺序 + +从如下四个递推公式: + +* dp[i][j] = dp[i - 1][j - 1] +* dp[i][j] = dp[i - 1][j - 1] + 1 +* dp[i][j] = dp[i][j - 1] + 1 +* dp[i][j] = dp[i - 1][j] + 1 + +可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图: + +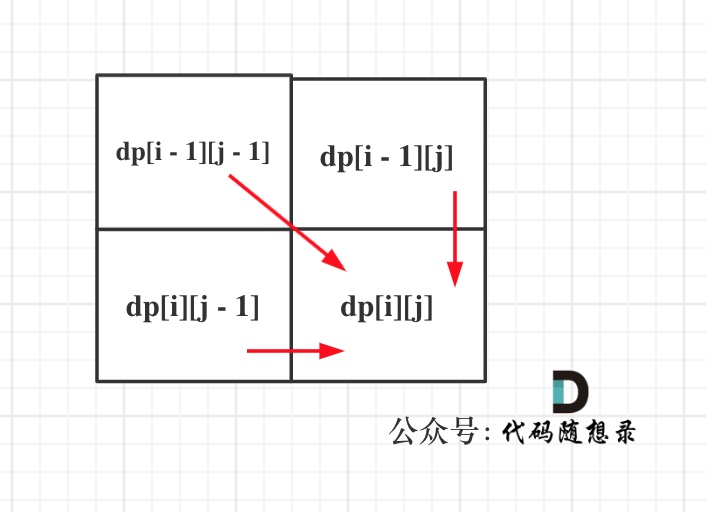 + +所以在dp矩阵中一定是从左到右从上到下去遍历。 + +代码如下: + +```C++ +for (int i = 1; i <= word1.size(); i++) { + for (int j = 1; j <= word2.size(); j++) { + if (word1[i - 1] == word2[j - 1]) { + dp[i][j] = dp[i - 1][j - 1]; + } + else { + dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1; + } + } +} +``` + +5. 举例推导dp数组 + +以示例1,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下: + +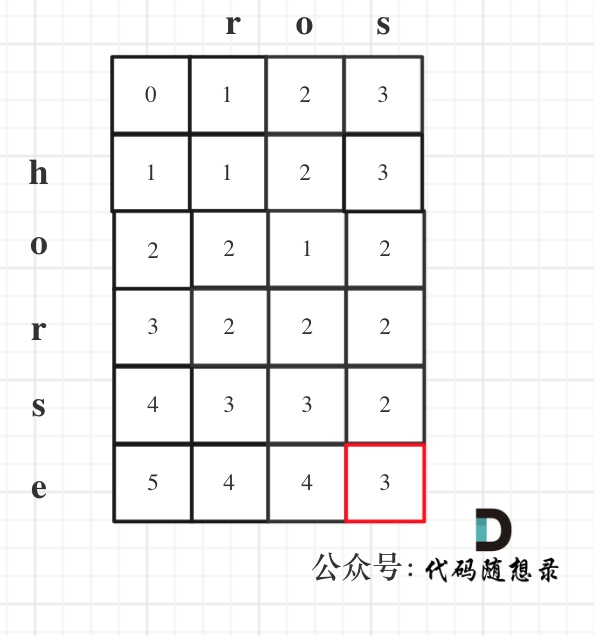 + +以上动规五部分析完毕,C++代码如下: + +```C++ +class Solution { +public: + int minDistance(string word1, string word2) { + vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + -> 回溯法的第一道题目,就不简单呀! # 第77题. 组合 @@ -21,7 +29,8 @@ 也可以直接看我的B站视频:[带你学透回溯算法-组合问题(对应力扣题目:77.组合)](https://www.bilibili.com/video/BV1ti4y1L7cv#reply3733925949) -# 思路 +## 思路 + 本题这是回溯法的经典题目。 @@ -164,7 +173,7 @@ for循环每次从startIndex开始遍历,然后用path保存取到的节点i 代码如下: -``` +```C++ for (int i = startIndex; i <= n; i++) { // 控制树的横向遍历 path.push_back(i); // 处理节点 backtracking(n, k, i + 1); // 递归:控制树的纵向遍历,注意下一层搜索要从i+1开始 @@ -179,7 +188,7 @@ backtracking的下面部分就是回溯的操作了,撤销本次处理的结 关键地方都讲完了,组合问题C++完整代码如下: -``` +```C++ class Solution { private: vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + -> 如果想在电脑上看文章的话,可以看这里:https://github.com/youngyangyang04/leetcode-master,已经按照顺序整理了「代码随想录」的所有文章,可以fork到自己仓库里,随时复习。**那么重点来了,来都来了,顺便给一个star吧,哈哈** 在[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)中,我们通过回溯搜索法,解决了n个数中求k个数的组合问题。 +> 可以直接看我的B栈视频讲解:[带你学透回溯算法-组合问题的剪枝操作](https://www.bilibili.com/video/BV1wi4y157er) + 文中的回溯法是可以剪枝优化的,本篇我们继续来看一下题目77. 组合。 链接:https://leetcode-cn.com/problems/combinations/ @@ -23,7 +33,7 @@ private: return; } for (int i = startIndex; i <= n; i++) { - path.push_back(i); // 处理节点 + path.push_back(i); // 处理节点 backtracking(n, k, i + 1); // 递归 path.pop_back(); // 回溯,撤销处理的节点 } @@ -38,17 +48,17 @@ public: }; ``` -## 剪枝优化 +# 剪枝优化 我们说过,回溯法虽然是暴力搜索,但也有时候可以有点剪枝优化一下的。 -在遍历的过程中有如下代码: +在遍历的过程中有如下代码: ``` -for (int i = startIndex; i <= n; i++) { - path.push_back(i); - backtracking(n, k, i + 1); - path.pop_back(); +for (int i = startIndex; i <= n; i++) { + path.push_back(i); + backtracking(n, k, i + 1); + path.pop_back(); } ``` @@ -58,9 +68,10 @@ for (int i = startIndex; i <= n; i++) { 这么说有点抽象,如图所示: - +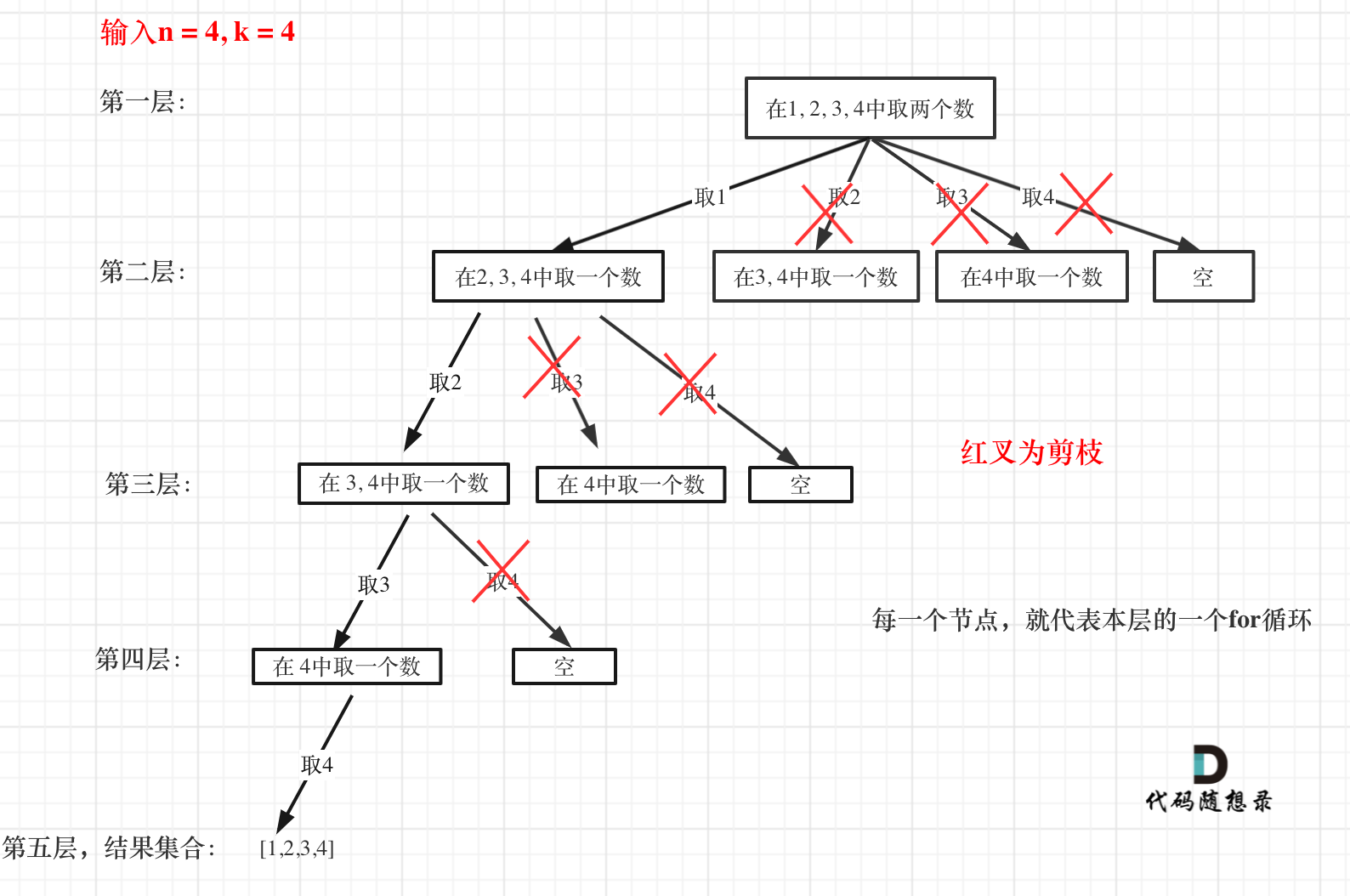
-图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
+
+图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
**所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置**。
@@ -68,7 +79,7 @@ for (int i = startIndex; i <= n; i++) {
注意代码中i,就是for循环里选择的起始位置。
```
-for (int i = startIndex; i <= n; i++) {
+for (int i = startIndex; i <= n; i++) {
```
接下来看一下优化过程如下:
@@ -81,7 +92,7 @@ for (int i = startIndex; i <= n; i++) {
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合。
-举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
+举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
从2开始搜索都是合理的,可以是组合[2, 3, 4]。
@@ -98,7 +109,7 @@ for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜
```
class Solution {
private:
- vector
+
-图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
+
+图中每一个节点(图中为矩形),就代表本层的一个for循环,那么每一层的for循环从第二个数开始遍历的话,都没有意义,都是无效遍历。
**所以,可以剪枝的地方就在递归中每一层的for循环所选择的起始位置**。
@@ -68,7 +79,7 @@ for (int i = startIndex; i <= n; i++) {
注意代码中i,就是for循环里选择的起始位置。
```
-for (int i = startIndex; i <= n; i++) {
+for (int i = startIndex; i <= n; i++) {
```
接下来看一下优化过程如下:
@@ -81,7 +92,7 @@ for (int i = startIndex; i <= n; i++) {
为什么有个+1呢,因为包括起始位置,我们要是一个左闭的集合。
-举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
+举个例子,n = 4,k = 3, 目前已经选取的元素为0(path.size为0),n - (k - 0) + 1 即 4 - ( 3 - 0) + 1 = 2。
从2开始搜索都是合理的,可以是组合[2, 3, 4]。
@@ -98,7 +109,7 @@ for (int i = startIndex; i <= n - (k - path.size()) + 1; i++) // i为本次搜
```
class Solution {
private:
- vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 第78题. 子集 -题目地址:https://leetcode-cn.com/problems/subsets/ +## 第78题. 子集 + +题目地址:https://leetcode-cn.com/problems/subsets/ 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。 说明:解集不能包含重复的子集。 示例: -输入: nums = [1,2,3] -输出: -[ - [3], - [1], - [2], - [1,2,3], - [1,3], - [2,3], - [1,2], - [] -] +输入: nums = [1,2,3] +输出: +[ + [3], + [1], + [2], + [1,2,3], + [1,3], + [2,3], + [1,2], + [] +] -# 思路 +## 思路 求子集问题和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[回溯算法:分割问题!](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)又不一样了。 -如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,**那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!** +如果把 子集问题、组合问题、分割问题都抽象为一棵树的话,**那么组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点!** -其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。 +其实子集也是一种组合问题,因为它的集合是无序的,子集{1,2} 和 子集{2,1}是一样的。 -**那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!** +**那么既然是无序,取过的元素不会重复取,写回溯算法的时候,for就要从startIndex开始,而不是从0开始!** 有同学问了,什么时候for可以从0开始呢? @@ -42,9 +49,9 @@ 从图中红线部分,可以看出**遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合**。 -## 回溯三部曲 +## 回溯三部曲 -* 递归函数参数 +* 递归函数参数 全局变量数组path为子集收集元素,二维数组result存放子集组合。(也可以放到递归函数参数里) @@ -58,13 +65,13 @@ vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 子集问题加去重! -# 第90题.子集II +## 第90题.子集II 题目链接:https://leetcode-cn.com/problems/subsets-ii/ @@ -9,20 +15,20 @@ 说明:解集不能包含重复的子集。 -示例: -输入: [1,2,2] -输出: -[ - [2], - [1], - [1,2,2], - [2,2], - [1,2], - [] -] +示例: +输入: [1,2,2] +输出: +[ + [2], + [1], + [1,2,2], + [2,2], + [1,2], + [] +] -# 思路 +## 思路 做本题之前一定要先做[78.子集](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)。 @@ -40,7 +46,7 @@ 本题就是其实就是[回溯算法:求子集问题!](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)的基础上加上了去重,去重我们在[回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)也讲过了,所以我就直接给出代码了: -# C++代码 +## C++代码 ``` class Solution { @@ -110,7 +116,45 @@ public: ``` -# 总结 +## 补充 + +本题也可以不适用used数组来去重,因为递归的时候下一个startIndex是i+1而不是0。 + +如果要是全排列的话,每次要从0开始遍历,为了跳过已入栈的元素,需要使用used。 + +代码如下: + +```C++ +class Solution { +private: + vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 93.复原IP地址 + + +## 93.复原IP地址 题目地址:https://leetcode-cn.com/problems/restore-ip-addresses/ @@ -10,32 +18,32 @@ 例如:"0.1.2.201" 和 "192.168.1.1" 是 有效的 IP 地址,但是 "0.011.255.245"、"192.168.1.312" 和 "192.168@1.1" 是 无效的 IP 地址。 -示例 1: -输入:s = "25525511135" -输出:["255.255.11.135","255.255.111.35"] +示例 1: +输入:s = "25525511135" +输出:["255.255.11.135","255.255.111.35"] -示例 2: -输入:s = "0000" -输出:["0.0.0.0"] +示例 2: +输入:s = "0000" +输出:["0.0.0.0"] 示例 3: -输入:s = "1111" -输出:["1.1.1.1"] +输入:s = "1111" +输出:["1.1.1.1"] -示例 4: -输入:s = "010010" -输出:["0.10.0.10","0.100.1.0"] +示例 4: +输入:s = "010010" +输出:["0.10.0.10","0.100.1.0"] -示例 5: -输入:s = "101023" -输出:["1.0.10.23","1.0.102.3","10.1.0.23","10.10.2.3","101.0.2.3"] +示例 5: +输入:s = "101023" +输出:["1.0.10.23","1.0.102.3","10.1.0.23","10.10.2.3","101.0.2.3"] -提示: -0 <= s.length <= 3000 -s 仅由数字组成 +提示: +0 <= s.length <= 3000 +s 仅由数字组成 -# 思路 +## 思路 做这道题目之前,最好先把[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)这个做了。 @@ -48,9 +56,9 @@ s 仅由数字组成  -## 回溯三部曲 +## 回溯三部曲 -* 递归参数 +* 递归参数 在[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)中我们就提到切割问题类似组合问题。 @@ -86,7 +94,7 @@ if (pointNum == 3) { // 逗点数量为3时,分隔结束 } ``` -* 单层搜索的逻辑 +* 单层搜索的逻辑 在[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)中已经讲过在循环遍历中如何截取子串。 @@ -118,14 +126,14 @@ for (int i = startIndex; i < s.size(); i++) { } ``` -## 判断子串是否合法 +## 判断子串是否合法 最后就是在写一个判断段位是否是有效段位了。 主要考虑到如下三点: * 段位以0为开头的数字不合法 -* 段位里有非正整数字符不合法 +* 段位里有非正整数字符不合法 * 段位如果大于255了不合法 代码如下: @@ -153,7 +161,7 @@ bool isValid(const string& s, int start, int end) { } ``` -## C++代码 +## C++代码 根据[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)给出的回溯算法模板: @@ -175,7 +183,7 @@ void backtracking(参数) { 可以写出如下回溯算法C++代码: -``` +```C++ class Solution { private: vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +## 96.不同的二叉搜索树 + +题目链接:https://leetcode-cn.com/problems/unique-binary-search-trees/ + +给定一个整数 n,求以 1 ... n 为节点组成的二叉搜索树有多少种? + +示例: + + + +## 思路 + +这道题目描述很简短,但估计大部分同学看完都是懵懵的状态,这得怎么统计呢? + +关于什么是二叉搜索树,我们之前在讲解二叉树专题的时候已经详细讲解过了,也可以看看这篇[二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)在回顾一波。 + +了解了二叉搜索树之后,我们应该先举几个例子,画画图,看看有没有什么规律,如图: + +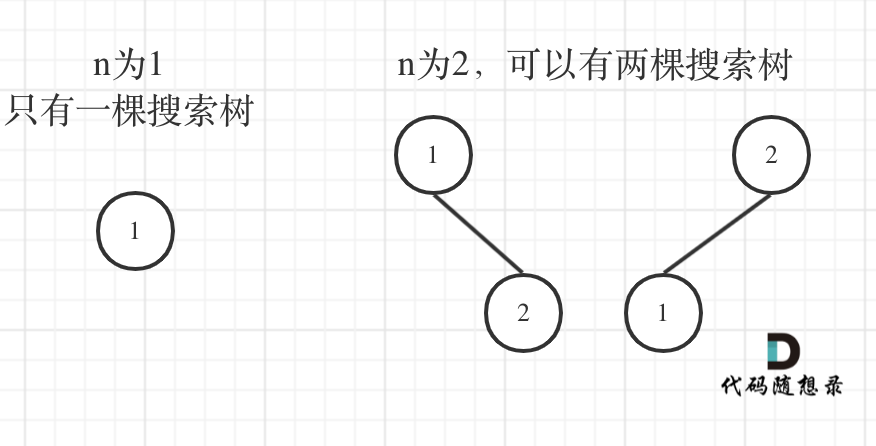 + +n为1的时候有一棵树,n为2有两棵树,这个是很直观的。 + +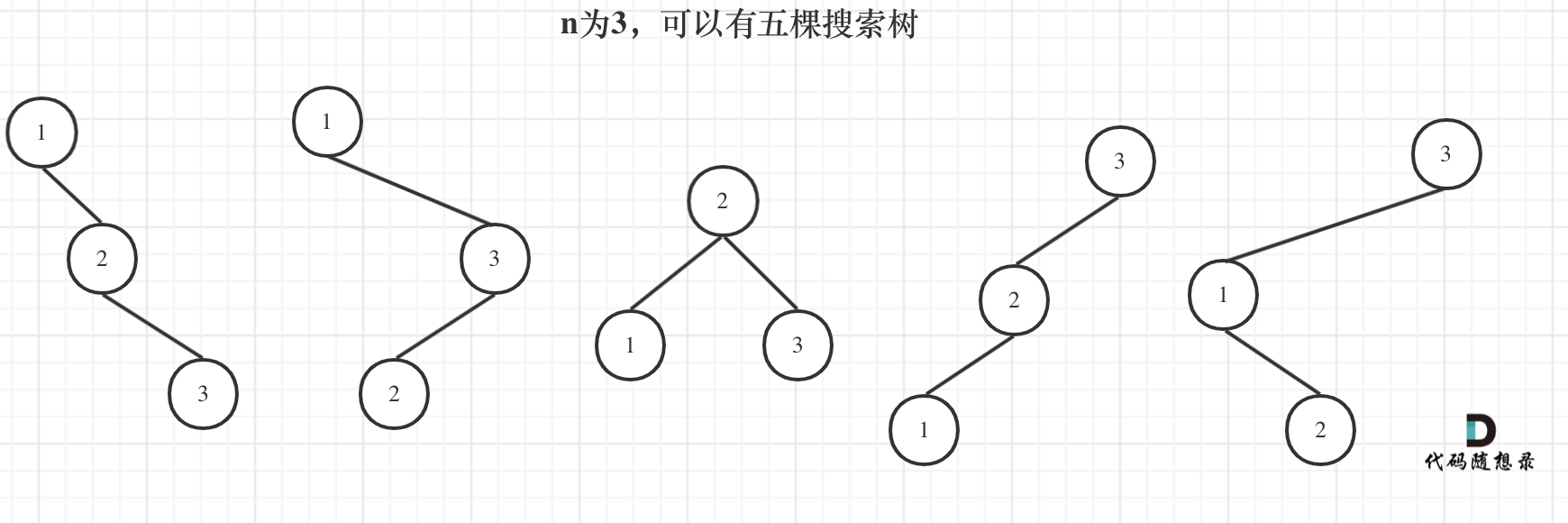 + +来看看n为3的时候,有哪几种情况。 + +当1为头结点的时候,其右子树有两个节点,看这两个节点的布局,是不是和 n 为2的时候两棵树的布局是一样的啊! + +(可能有同学问了,这布局不一样啊,节点数值都不一样。别忘了我们就是求不同树的数量,并不用把搜索树都列出来,所以不用关心其具体数值的差异) + +当3为头结点的时候,其左子树有两个节点,看这两个节点的布局,是不是和n为2的时候两棵树的布局也是一样的啊! + +当2位头结点的时候,其左右子树都只有一个节点,布局是不是和n为1的时候只有一棵树的布局也是一样的啊! + +发现到这里,其实我们就找到的重叠子问题了,其实也就是发现可以通过dp[1] 和 dp[2] 来推导出来dp[3]的某种方式。 + +思考到这里,这道题目就有眉目了。 + +dp[3],就是 元素1为头结点搜索树的数量 + 元素2为头结点搜索树的数量 + 元素3为头结点搜索树的数量 + +元素1为头结点搜索树的数量 = 右子树有2个元素的搜索树数量 * 左子树有0个元素的搜索树数量 + +元素2为头结点搜索树的数量 = 右子树有1个元素的搜索树数量 * 左子树有1个元素的搜索树数量 + +元素3为头结点搜索树的数量 = 右子树有0个元素的搜索树数量 * 左子树有2个元素的搜索树数量 + +有2个元素的搜索树数量就是dp[2]。 + +有1个元素的搜索树数量就是dp[1]。 + +有0个元素的搜索树数量就是dp[0]。 + +所以dp[3] = dp[2] * dp[0] + dp[1] * dp[1] + dp[0] * dp[2] + +如图所示: + +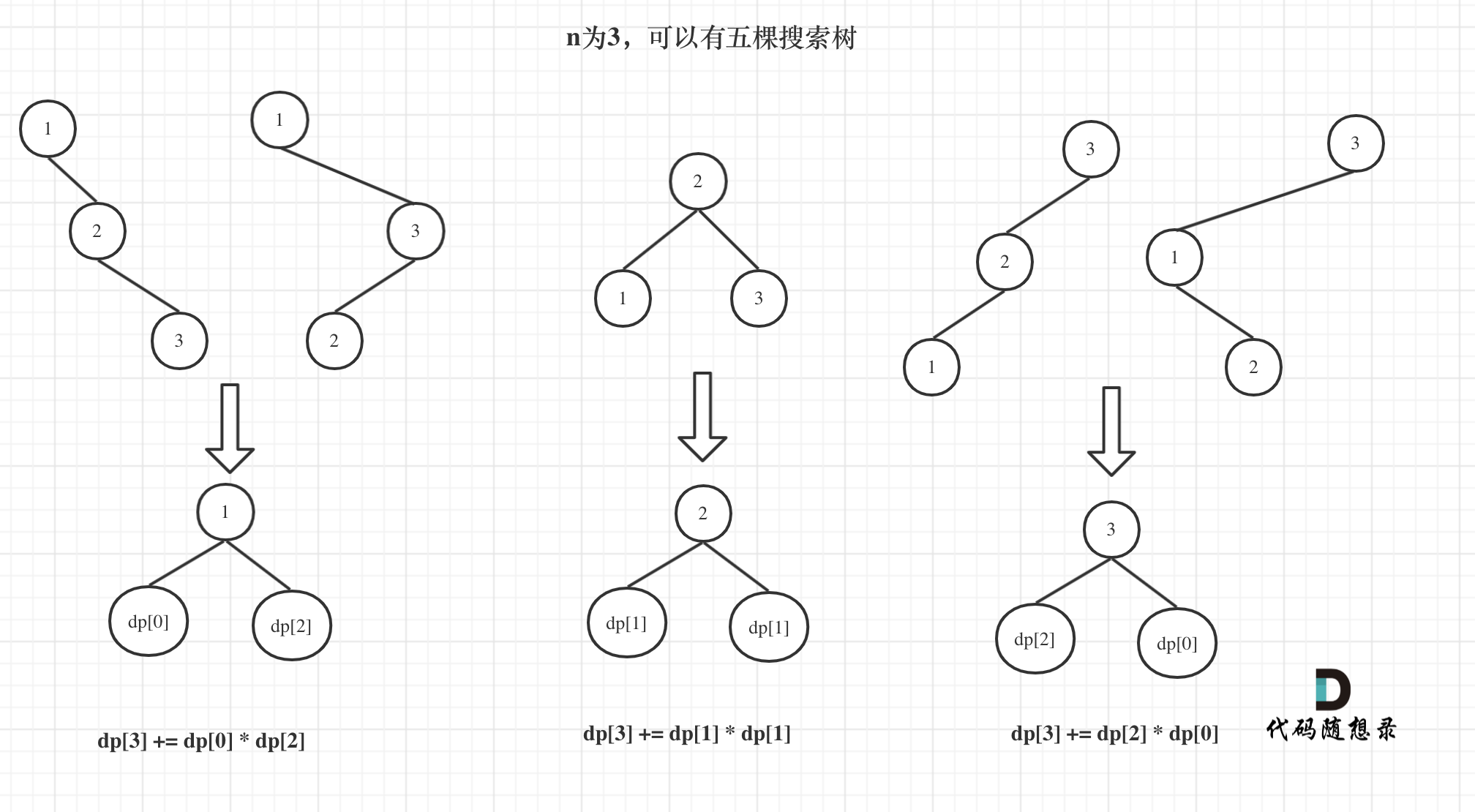 + + +此时我们已经找到的递推关系了,那么可以用动规五部曲在系统分析一遍。 + +1. 确定dp数组(dp table)以及下标的含义 + +**dp[i] : 1到i为节点组成的二叉搜索树的个数为dp[i]**。 + +也可以理解是i的不同元素节点组成的二叉搜索树的个数为dp[i] ,都是一样的。 + +以下分析如果想不清楚,就来回想一下dp[i]的定义 + +2. 确定递推公式 + +在上面的分析中,其实已经看出其递推关系, dp[i] += dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量] + +j相当于是头结点的元素,从1遍历到i为止。 + +所以递推公式:dp[i] += dp[j - 1] * dp[i - j]; ,j-1 为j为头结点左子树节点数量,i-j 为以j为头结点右子树节点数量 + +3. dp数组如何初始化 + +初始化,只需要初始化dp[0]就可以了,推导的基础,都是dp[0]。 + +那么dp[0]应该是多少呢? + +从定义上来讲,空节点也是一颗二叉树,也是一颗二叉搜索树,这是可以说得通的。 + +从递归公式上来讲,dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量] 中以j为头结点左子树节点数量为0,也需要dp[以j为头结点左子树节点数量] = 1, 否则乘法的结果就都变成0了。 + +所以初始化dp[0] = 1 + +4. 确定遍历顺序 + +首先一定是遍历节点数,从递归公式:dp[i] += dp[j - 1] * dp[i - j]可以看出,节点数为i的状态是依靠 i之前节点数的状态。 + +那么遍历i里面每一个数作为头结点的状态,用j来遍历。 + +代码如下: + +```C++ +for (int i = 1; i <= n; i++) { + for (int j = 1; j <= i; j++) { + dp[i] += dp[j - 1] * dp[i - j]; + } +} +``` + +5. 举例推导dp数组 + +n为5时候的dp数组状态如图: + +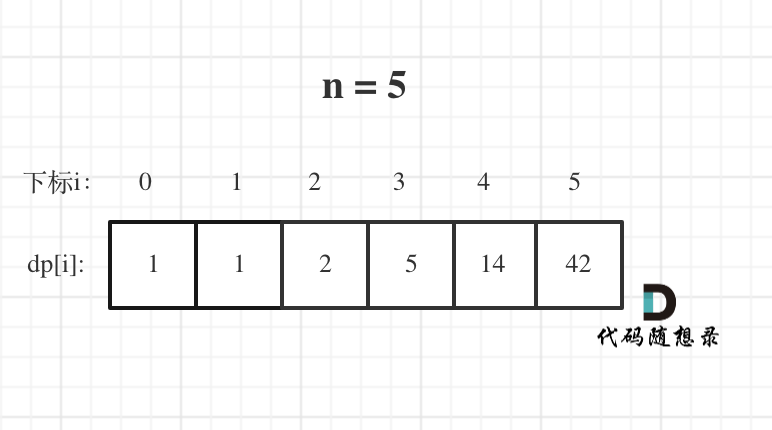 + +当然如果自己画图举例的话,基本举例到n为3就可以了,n为4的时候,画图已经比较麻烦了。 + +**我这里列到了n为5的情况,是为了方便大家 debug代码的时候,把dp数组打出来,看看哪里有问题**。 + +综上分析完毕,C++代码如下: + +```C++ +class Solution { +public: + int numTrees(int n) { + vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 学习完二叉搜索树的特性了,那么就验证一波 -# 98.验证二叉搜索树 +## 98.验证二叉搜索树 + +题目地址:https://leetcode-cn.com/problems/validate-binary-search-tree/ + 给定一个二叉树,判断其是否是一个有效的二叉搜索树。 @@ -12,9 +20,9 @@ * 节点的右子树只包含大于当前节点的数。 * 所有左子树和右子树自身必须也是二叉搜索树。 - +
-# 思路
+## 思路
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
@@ -75,9 +83,9 @@ public:
这道题目比较容易陷入两个陷阱:
-* 陷阱1
+* 陷阱1
-**不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了**。
+**不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了**。
写出了类似这样的代码:
@@ -97,7 +105,7 @@ if (root->val > root->left->val && root->val < root->right->val) {
节点10小于左节点5,大于右节点15,但右子树里出现了一个6 这就不符合了!
-* 陷阱2
+* 陷阱2
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
@@ -109,7 +117,7 @@ if (root->val > root->left->val && root->val < root->right->val) {
递归三部曲:
-* 确定递归函数,返回值以及参数
+* 确定递归函数,返回值以及参数
要定义一个longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。
@@ -117,14 +125,14 @@ if (root->val > root->left->val && root->val < root->right->val) {
其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
-代码如下:
+代码如下:
```
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
-bool isValidBST(TreeNode* root)
+bool isValidBST(TreeNode* root)
```
-* 确定终止条件
+* 确定终止条件
如果是空节点 是不是二叉搜索树呢?
@@ -136,11 +144,11 @@ bool isValidBST(TreeNode* root)
if (root == NULL) return true;
```
-* 确定单层递归的逻辑
+* 确定单层递归的逻辑
-中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
+中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
-代码如下:
+代码如下:
```
bool left = isValidBST(root->left); // 左
@@ -172,7 +180,7 @@ public:
};
```
-以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
+以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
如果测试数据中有 longlong的最小值,怎么办?
@@ -183,7 +191,7 @@ public:
```
class Solution {
public:
- TreeNode* pre = NULL; // 用来记录前一个节点
+ TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
@@ -199,7 +207,7 @@ public:
最后这份代码看上去整洁一些,思路也清晰。
-## 迭代法
+## 迭代法
可以用迭代法模拟二叉树中序遍历,对前中后序迭代法生疏的同学可以看这两篇[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg),[二叉树:前中后序迭代方式统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)
@@ -233,7 +241,7 @@ public:
在[二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)中我们分明写出了痛哭流涕的简洁迭代法,怎么在这里不行了呢,因为本题是要验证二叉搜索树啊。
-# 总结
+## 总结
这道题目是一个简单题,但对于没接触过的同学还是有难度的。
@@ -241,6 +249,23 @@ public:
只要把基本类型的题目都做过,总结过之后,思路自然就开阔了。
-**就酱,学到了的话,就转发给身边需要的同学吧!**
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
-# 思路
+## 思路
要知道中序遍历下,输出的二叉搜索树节点的数值是有序序列。
@@ -75,9 +83,9 @@ public:
这道题目比较容易陷入两个陷阱:
-* 陷阱1
+* 陷阱1
-**不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了**。
+**不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了**。
写出了类似这样的代码:
@@ -97,7 +105,7 @@ if (root->val > root->left->val && root->val < root->right->val) {
节点10小于左节点5,大于右节点15,但右子树里出现了一个6 这就不符合了!
-* 陷阱2
+* 陷阱2
样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
@@ -109,7 +117,7 @@ if (root->val > root->left->val && root->val < root->right->val) {
递归三部曲:
-* 确定递归函数,返回值以及参数
+* 确定递归函数,返回值以及参数
要定义一个longlong的全局变量,用来比较遍历的节点是否有序,因为后台测试数据中有int最小值,所以定义为longlong的类型,初始化为longlong最小值。
@@ -117,14 +125,14 @@ if (root->val > root->left->val && root->val < root->right->val) {
其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
-代码如下:
+代码如下:
```
long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值
-bool isValidBST(TreeNode* root)
+bool isValidBST(TreeNode* root)
```
-* 确定终止条件
+* 确定终止条件
如果是空节点 是不是二叉搜索树呢?
@@ -136,11 +144,11 @@ bool isValidBST(TreeNode* root)
if (root == NULL) return true;
```
-* 确定单层递归的逻辑
+* 确定单层递归的逻辑
-中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
+中序遍历,一直更新maxVal,一旦发现maxVal >= root->val,就返回false,注意元素相同时候也要返回false。
-代码如下:
+代码如下:
```
bool left = isValidBST(root->left); // 左
@@ -172,7 +180,7 @@ public:
};
```
-以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
+以上代码是因为后台数据有int最小值测试用例,所以都把maxVal改成了longlong最小值。
如果测试数据中有 longlong的最小值,怎么办?
@@ -183,7 +191,7 @@ public:
```
class Solution {
public:
- TreeNode* pre = NULL; // 用来记录前一个节点
+ TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
@@ -199,7 +207,7 @@ public:
最后这份代码看上去整洁一些,思路也清晰。
-## 迭代法
+## 迭代法
可以用迭代法模拟二叉树中序遍历,对前中后序迭代法生疏的同学可以看这两篇[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg),[二叉树:前中后序迭代方式统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)
@@ -233,7 +241,7 @@ public:
在[二叉树:二叉搜索树登场!](https://mp.weixin.qq.com/s/vsKrWRlETxCVsiRr8v_hHg)中我们分明写出了痛哭流涕的简洁迭代法,怎么在这里不行了呢,因为本题是要验证二叉搜索树啊。
-# 总结
+## 总结
这道题目是一个简单题,但对于没接触过的同学还是有难度的。
@@ -241,6 +249,23 @@ public:
只要把基本类型的题目都做过,总结过之后,思路自然就开阔了。
-**就酱,学到了的话,就转发给身边需要的同学吧!**
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+  -
-# 思路
-
-在[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)中,我们讲到对于二叉树是否对称,要比较的是根节点的左子树与右子树是不是相互翻转的,理解这一点就知道了**其实我们要比较的是两个树(这两个树是根节点的左右子树)**,所以在递归遍历的过程中,也是要同时遍历两棵树。
-
-理解这一本质之后,就会发现,求二叉树是否对称,和求二叉树是否相同几乎是同一道题目。
-
-**如果没有读过[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)这一篇,请认真读完再做这道题,就会有感觉了。**
-
-递归三部曲中:
-
-1. 确定递归函数的参数和返回值
-
-我们要比较的是两个树是否是相互相同的,参数也就是两个树的根节点。
-
-返回值自然是bool类型。
-
-代码如下:
-```
-bool compare(TreeNode* tree1, TreeNode* tree2)
-```
-
-分析过程同[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)。
-
-2. 确定终止条件
-
-**要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。**
-
-节点为空的情况有:
-
-* tree1为空,tree2不为空,不对称,return false
-* tree1不为空,tree2为空,不对称 return false
-* tree1,tree2都为空,对称,返回true
-
-此时已经排除掉了节点为空的情况,那么剩下的就是tree1和tree2不为空的时候:
-
-* tree1、tree2都不为空,比较节点数值,不相同就return false
-
-此时tree1、tree2节点不为空,且数值也不相同的情况我们也处理了。
-
-代码如下:
-```
-if (tree1 == NULL && tree2 != NULL) return false;
-else if (tree1 != NULL && tree2 == NULL) return false;
-else if (tree1 == NULL && tree2 == NULL) return true;
-else if (tree1->val != tree2->val) return false; // 注意这里我没有使用else
-```
-
-分析过程同[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)
-
-3. 确定单层递归的逻辑
-
-* 比较二叉树是否相同 :传入的是tree1的左孩子,tree2的右孩子。
-* 如果左右都相同就返回true ,有一侧不相同就返回false 。
-
-代码如下:
-
-```
-bool left = compare(tree1->left, tree2->left); // 左子树:左、 右子树:左
-bool right = compare(tree1->right, tree2->right); // 左子树:右、 右子树:右
-bool isSame = left && right; // 左子树:中、 右子树:中(逻辑处理)
-return isSame;
-```
-最后递归的C++整体代码如下:
-
-```
-class Solution {
-public:
- bool compare(TreeNode* tree1, TreeNode* tree2) {
- if (tree1 == NULL && tree2 != NULL) return false;
- else if (tree1 != NULL && tree2 == NULL) return false;
- else if (tree1 == NULL && tree2 == NULL) return true;
- else if (tree1->val != tree2->val) return false; // 注意这里我没有使用else
-
- // 此时就是:左右节点都不为空,且数值相同的情况
- // 此时才做递归,做下一层的判断
- bool left = compare(tree1->left, tree2->left); // 左子树:左、 右子树:左
- bool right = compare(tree1->right, tree2->right); // 左子树:右、 右子树:右
- bool isSame = left && right; // 左子树:中、 右子树:中(逻辑处理)
- return isSame;
-
- }
- bool isSameTree(TreeNode* p, TreeNode* q) {
- return compare(p, q);
- }
-};
-```
-
-
-**我给出的代码并不简洁,但是把每一步判断的逻辑都清楚的描绘出来了。**
-
-如果上来就看网上各种简洁的代码,看起来真的很简单,但是很多逻辑都掩盖掉了,而题解可能也没有把掩盖掉的逻辑说清楚。
-
-**盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。**
-
-当然我可以把如上代码整理如下:
-
-## 递归
-
-```
-class Solution {
-public:
- bool compare(TreeNode* left, TreeNode* right) {
- if (left == NULL && right != NULL) return false;
- else if (left != NULL && right == NULL) return false;
- else if (left == NULL && right == NULL) return true;
- else if (left->val != right->val) return false;
- else return compare(left->left, right->left) && compare(left->right, right->right);
-
- }
- bool isSameTree(TreeNode* p, TreeNode* q) {
- return compare(p, q);
- }
-};
-```
-
-## 迭代法
-
-```
-lass Solution {
-public:
-
- bool isSameTree(TreeNode* p, TreeNode* q) {
- if (p == NULL && q == NULL) return true;
- if (p == NULL || q == NULL) return false;
- queue
-
-# 思路
-
-在[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)中,我们讲到对于二叉树是否对称,要比较的是根节点的左子树与右子树是不是相互翻转的,理解这一点就知道了**其实我们要比较的是两个树(这两个树是根节点的左右子树)**,所以在递归遍历的过程中,也是要同时遍历两棵树。
-
-理解这一本质之后,就会发现,求二叉树是否对称,和求二叉树是否相同几乎是同一道题目。
-
-**如果没有读过[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)这一篇,请认真读完再做这道题,就会有感觉了。**
-
-递归三部曲中:
-
-1. 确定递归函数的参数和返回值
-
-我们要比较的是两个树是否是相互相同的,参数也就是两个树的根节点。
-
-返回值自然是bool类型。
-
-代码如下:
-```
-bool compare(TreeNode* tree1, TreeNode* tree2)
-```
-
-分析过程同[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)。
-
-2. 确定终止条件
-
-**要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。**
-
-节点为空的情况有:
-
-* tree1为空,tree2不为空,不对称,return false
-* tree1不为空,tree2为空,不对称 return false
-* tree1,tree2都为空,对称,返回true
-
-此时已经排除掉了节点为空的情况,那么剩下的就是tree1和tree2不为空的时候:
-
-* tree1、tree2都不为空,比较节点数值,不相同就return false
-
-此时tree1、tree2节点不为空,且数值也不相同的情况我们也处理了。
-
-代码如下:
-```
-if (tree1 == NULL && tree2 != NULL) return false;
-else if (tree1 != NULL && tree2 == NULL) return false;
-else if (tree1 == NULL && tree2 == NULL) return true;
-else if (tree1->val != tree2->val) return false; // 注意这里我没有使用else
-```
-
-分析过程同[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)
-
-3. 确定单层递归的逻辑
-
-* 比较二叉树是否相同 :传入的是tree1的左孩子,tree2的右孩子。
-* 如果左右都相同就返回true ,有一侧不相同就返回false 。
-
-代码如下:
-
-```
-bool left = compare(tree1->left, tree2->left); // 左子树:左、 右子树:左
-bool right = compare(tree1->right, tree2->right); // 左子树:右、 右子树:右
-bool isSame = left && right; // 左子树:中、 右子树:中(逻辑处理)
-return isSame;
-```
-最后递归的C++整体代码如下:
-
-```
-class Solution {
-public:
- bool compare(TreeNode* tree1, TreeNode* tree2) {
- if (tree1 == NULL && tree2 != NULL) return false;
- else if (tree1 != NULL && tree2 == NULL) return false;
- else if (tree1 == NULL && tree2 == NULL) return true;
- else if (tree1->val != tree2->val) return false; // 注意这里我没有使用else
-
- // 此时就是:左右节点都不为空,且数值相同的情况
- // 此时才做递归,做下一层的判断
- bool left = compare(tree1->left, tree2->left); // 左子树:左、 右子树:左
- bool right = compare(tree1->right, tree2->right); // 左子树:右、 右子树:右
- bool isSame = left && right; // 左子树:中、 右子树:中(逻辑处理)
- return isSame;
-
- }
- bool isSameTree(TreeNode* p, TreeNode* q) {
- return compare(p, q);
- }
-};
-```
-
-
-**我给出的代码并不简洁,但是把每一步判断的逻辑都清楚的描绘出来了。**
-
-如果上来就看网上各种简洁的代码,看起来真的很简单,但是很多逻辑都掩盖掉了,而题解可能也没有把掩盖掉的逻辑说清楚。
-
-**盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。**
-
-当然我可以把如上代码整理如下:
-
-## 递归
-
-```
-class Solution {
-public:
- bool compare(TreeNode* left, TreeNode* right) {
- if (left == NULL && right != NULL) return false;
- else if (left != NULL && right == NULL) return false;
- else if (left == NULL && right == NULL) return true;
- else if (left->val != right->val) return false;
- else return compare(left->left, right->left) && compare(left->right, right->right);
-
- }
- bool isSameTree(TreeNode* p, TreeNode* q) {
- return compare(p, q);
- }
-};
-```
-
-## 迭代法
-
-```
-lass Solution {
-public:
-
- bool isSameTree(TreeNode* p, TreeNode* q) {
- if (p == NULL && q == NULL) return true;
- if (p == NULL || q == NULL) return false;
- queue
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 又是一道“简单题” -# 101. 对称二叉树 +## 101. 对称二叉树 -给定一个二叉树,检查它是否是镜像对称的。 +题目地址:https://leetcode-cn.com/problems/symmetric-tree/ - +给定一个二叉树,检查它是否是镜像对称的。
-# 思路
+
-**首先想清楚,判断对称二叉树要比较的是哪两个节点,要比较的可不是左右节点!**
+## 思路
+
+**首先想清楚,判断对称二叉树要比较的是哪两个节点,要比较的可不是左右节点!**
对于二叉树是否对称,要比较的是根节点的左子树与右子树是不是相互翻转的,理解这一点就知道了**其实我们要比较的是两个树(这两个树是根节点的左右子树)**,所以在递归遍历的过程中,也是要同时遍历两棵树。
@@ -19,7 +25,7 @@ https://leetcode-cn.com/problems/symmetric-tree/
比较的是两个子树的里侧和外侧的元素是否相等。如图所示:
-
+给定一个二叉树,检查它是否是镜像对称的。
-# 思路
+
-**首先想清楚,判断对称二叉树要比较的是哪两个节点,要比较的可不是左右节点!**
+## 思路
+
+**首先想清楚,判断对称二叉树要比较的是哪两个节点,要比较的可不是左右节点!**
对于二叉树是否对称,要比较的是根节点的左子树与右子树是不是相互翻转的,理解这一点就知道了**其实我们要比较的是两个树(这两个树是根节点的左右子树)**,所以在递归遍历的过程中,也是要同时遍历两棵树。
@@ -19,7 +25,7 @@ https://leetcode-cn.com/problems/symmetric-tree/
比较的是两个子树的里侧和外侧的元素是否相等。如图所示:
- +
那么遍历的顺序应该是什么样的呢?
@@ -35,11 +41,11 @@ https://leetcode-cn.com/problems/symmetric-tree/
那么我们先来看看递归法的代码应该怎么写。
-## 递归法
+## 递归法
-### 递归三部曲
+递归三部曲
-1. 确定递归函数的参数和返回值
+1. 确定递归函数的参数和返回值
因为我们要比较的是根节点的两个子树是否是相互翻转的,进而判断这个树是不是对称树,所以要比较的是两个树,参数自然也是左子树节点和右子树节点。
@@ -50,15 +56,15 @@ https://leetcode-cn.com/problems/symmetric-tree/
bool compare(TreeNode* left, TreeNode* right)
```
-2. 确定终止条件
+2. 确定终止条件
要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。
节点为空的情况有:(**注意我们比较的其实不是左孩子和右孩子,所以如下我称之为左节点右节点**)
-* 左节点为空,右节点不为空,不对称,return false
+* 左节点为空,右节点不为空,不对称,return false
* 左不为空,右为空,不对称 return false
-* 左右都为空,对称,返回true
+* 左右都为空,对称,返回true
此时已经排除掉了节点为空的情况,那么剩下的就是左右节点不为空:
@@ -70,19 +76,19 @@ bool compare(TreeNode* left, TreeNode* right)
```
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
-else if (left == NULL && right == NULL) return true;
+else if (left == NULL && right == NULL) return true;
else if (left->val != right->val) return false; // 注意这里我没有使用else
```
注意上面最后一种情况,我没有使用else,而是elseif, 因为我们把以上情况都排除之后,剩下的就是 左右节点都不为空,且数值相同的情况。
-3. 确定单层递归的逻辑
+3. 确定单层递归的逻辑
此时才进入单层递归的逻辑,单层递归的逻辑就是处理 右节点都不为空,且数值相同的情况。
* 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
-* 比较内测是否对称,传入左节点的右孩子,右节点的左孩子。
+* 比较内测是否对称,传入左节点的右孩子,右节点的左孩子。
* 如果左右都对称就返回true ,有一侧不对称就返回false 。
代码如下:
@@ -153,7 +159,7 @@ public:
**所以建议大家做题的时候,一定要想清楚逻辑,每一步做什么。把道题目所有情况想到位,相应的代码写出来之后,再去追求简洁代码的效果。**
-## 迭代法
+## 迭代法
这道题目我们也可以使用迭代法,但要注意,这里的迭代法可不是前中后序的迭代写法,因为本题的本质是判断两个树是否是相互翻转的,其实已经不是所谓二叉树遍历的前中后序的关系了。
@@ -163,7 +169,8 @@ public:
通过队列来判断根节点的左子树和右子树的内侧和外侧是否相等,如动画所示:
-
+
那么遍历的顺序应该是什么样的呢?
@@ -35,11 +41,11 @@ https://leetcode-cn.com/problems/symmetric-tree/
那么我们先来看看递归法的代码应该怎么写。
-## 递归法
+## 递归法
-### 递归三部曲
+递归三部曲
-1. 确定递归函数的参数和返回值
+1. 确定递归函数的参数和返回值
因为我们要比较的是根节点的两个子树是否是相互翻转的,进而判断这个树是不是对称树,所以要比较的是两个树,参数自然也是左子树节点和右子树节点。
@@ -50,15 +56,15 @@ https://leetcode-cn.com/problems/symmetric-tree/
bool compare(TreeNode* left, TreeNode* right)
```
-2. 确定终止条件
+2. 确定终止条件
要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。
节点为空的情况有:(**注意我们比较的其实不是左孩子和右孩子,所以如下我称之为左节点右节点**)
-* 左节点为空,右节点不为空,不对称,return false
+* 左节点为空,右节点不为空,不对称,return false
* 左不为空,右为空,不对称 return false
-* 左右都为空,对称,返回true
+* 左右都为空,对称,返回true
此时已经排除掉了节点为空的情况,那么剩下的就是左右节点不为空:
@@ -70,19 +76,19 @@ bool compare(TreeNode* left, TreeNode* right)
```
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
-else if (left == NULL && right == NULL) return true;
+else if (left == NULL && right == NULL) return true;
else if (left->val != right->val) return false; // 注意这里我没有使用else
```
注意上面最后一种情况,我没有使用else,而是elseif, 因为我们把以上情况都排除之后,剩下的就是 左右节点都不为空,且数值相同的情况。
-3. 确定单层递归的逻辑
+3. 确定单层递归的逻辑
此时才进入单层递归的逻辑,单层递归的逻辑就是处理 右节点都不为空,且数值相同的情况。
* 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
-* 比较内测是否对称,传入左节点的右孩子,右节点的左孩子。
+* 比较内测是否对称,传入左节点的右孩子,右节点的左孩子。
* 如果左右都对称就返回true ,有一侧不对称就返回false 。
代码如下:
@@ -153,7 +159,7 @@ public:
**所以建议大家做题的时候,一定要想清楚逻辑,每一步做什么。把道题目所有情况想到位,相应的代码写出来之后,再去追求简洁代码的效果。**
-## 迭代法
+## 迭代法
这道题目我们也可以使用迭代法,但要注意,这里的迭代法可不是前中后序的迭代写法,因为本题的本质是判断两个树是否是相互翻转的,其实已经不是所谓二叉树遍历的前中后序的关系了。
@@ -163,7 +169,8 @@ public:
通过队列来判断根节点的左子树和右子树的内侧和外侧是否相等,如动画所示:
- +
+
如下的条件判断和递归的逻辑是一样的。
@@ -179,14 +186,14 @@ public:
que.push(root->left); // 将左子树头结点加入队列
que.push(root->right); // 将右子树头结点加入队列
while (!que.empty()) { // 接下来就要判断这这两个树是否相互翻转
- TreeNode* leftNode = que.front(); que.pop();
+ TreeNode* leftNode = que.front(); que.pop();
TreeNode* rightNode = que.front(); que.pop();
if (!leftNode && !rightNode) { // 左节点为空、右节点为空,此时说明是对称的
continue;
}
// 左右一个节点不为空,或者都不为空但数值不相同,返回false
- if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
+ if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
return false;
}
que.push(leftNode->left); // 加入左节点左孩子
@@ -232,7 +239,7 @@ public:
};
```
-# 总结
+## 总结
这次我们又深度剖析了一道二叉树的“简单题”,大家会发现,真正的把题目搞清楚其实并不简单,leetcode上accept了和真正掌握了还是有距离的。
@@ -243,4 +250,38 @@ public:
如果已经做过这道题目的同学,读完文章可以再去看看这道题目,思考一下,会有不一样的发现!
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+JavaScript
+```javascript
+var isSymmetric = function(root) {
+ return check(root, root)
+};
+
+const check = (leftPtr, rightPtr) => {
+ // 如果只有根节点,返回true
+ if (!leftPtr && !rightPtr) return true
+ // 如果左右节点只存在一个,则返回false
+ if (!leftPtr || !rightPtr) return false
+
+ return leftPtr.val === rightPtr.val && check(leftPtr.left, rightPtr.right) && check(leftPtr.right, rightPtr.left)
+}
+```
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
如下的条件判断和递归的逻辑是一样的。
@@ -179,14 +186,14 @@ public:
que.push(root->left); // 将左子树头结点加入队列
que.push(root->right); // 将右子树头结点加入队列
while (!que.empty()) { // 接下来就要判断这这两个树是否相互翻转
- TreeNode* leftNode = que.front(); que.pop();
+ TreeNode* leftNode = que.front(); que.pop();
TreeNode* rightNode = que.front(); que.pop();
if (!leftNode && !rightNode) { // 左节点为空、右节点为空,此时说明是对称的
continue;
}
// 左右一个节点不为空,或者都不为空但数值不相同,返回false
- if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
+ if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
return false;
}
que.push(leftNode->left); // 加入左节点左孩子
@@ -232,7 +239,7 @@ public:
};
```
-# 总结
+## 总结
这次我们又深度剖析了一道二叉树的“简单题”,大家会发现,真正的把题目搞清楚其实并不简单,leetcode上accept了和真正掌握了还是有距离的。
@@ -243,4 +250,38 @@ public:
如果已经做过这道题目的同学,读完文章可以再去看看这道题目,思考一下,会有不一样的发现!
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+JavaScript
+```javascript
+var isSymmetric = function(root) {
+ return check(root, root)
+};
+
+const check = (leftPtr, rightPtr) => {
+ // 如果只有根节点,返回true
+ if (!leftPtr && !rightPtr) return true
+ // 如果左右节点只存在一个,则返回false
+ if (!leftPtr || !rightPtr) return false
+
+ return leftPtr.val === rightPtr.val && check(leftPtr.left, rightPtr.right) && check(leftPtr.right, rightPtr.left)
+}
+```
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 我要打十个! +# 二叉树的层序遍历 看完这篇文章虽然不能打十个,但是可以迅速打八个!而且够快! @@ -13,17 +18,19 @@ https://leetcode-cn.com/problems/binary-tree-level-order-traversal/ * 637.二叉树的层平均值 * 429.N叉树的前序遍历 * 515.在每个树行中找最大值 -* 116. 填充每个节点的下一个右侧节点指针 +* 116. 填充每个节点的下一个右侧节点指针 * 117.填充每个节点的下一个右侧节点指针II -# 102.二叉树的层序遍历 +## 102.二叉树的层序遍历 + +题目地址:https://leetcode-cn.com/problems/binary-tree-level-order-traversal/ 给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。 - +
-## 思路
+思路:
我们之前讲过了三篇关于二叉树的深度优先遍历的文章:
@@ -41,14 +48,13 @@ https://leetcode-cn.com/problems/binary-tree-level-order-traversal/
使用队列实现二叉树广度优先遍历,动画如下:
-
-
+
这样就实现了层序从左到右遍历二叉树。
代码如下:**这份代码也可以作为二叉树层序遍历的模板,以后再打七个就靠它了**。
-## C++代码
+C++代码:
```
class Solution {
@@ -77,19 +83,21 @@ public:
**此时我们就掌握了二叉树的层序遍历了,那么如下五道leetcode上的题目,只需要修改模板的一两行代码(不能再多了),便可打倒!**
-# 107.二叉树的层次遍历 II
+## 107.二叉树的层次遍历 II
-给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
+题目链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal-ii/
-
+
-## 思路
+思路:
我们之前讲过了三篇关于二叉树的深度优先遍历的文章:
@@ -41,14 +48,13 @@ https://leetcode-cn.com/problems/binary-tree-level-order-traversal/
使用队列实现二叉树广度优先遍历,动画如下:
-
-
+
这样就实现了层序从左到右遍历二叉树。
代码如下:**这份代码也可以作为二叉树层序遍历的模板,以后再打七个就靠它了**。
-## C++代码
+C++代码:
```
class Solution {
@@ -77,19 +83,21 @@ public:
**此时我们就掌握了二叉树的层序遍历了,那么如下五道leetcode上的题目,只需要修改模板的一两行代码(不能再多了),便可打倒!**
-# 107.二叉树的层次遍历 II
+## 107.二叉树的层次遍历 II
-给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
+题目链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal-ii/
- +给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
-## 思路
+
-相对于102.二叉树的层序遍历,就是最后把result数组反转一下就可以了。
+思路:
-## C++代码
+相对于102.二叉树的层序遍历,就是最后把result数组反转一下就可以了。
-```
+C++代码:
+
+```C++
class Solution {
public:
vector
+给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
-## 思路
+
-相对于102.二叉树的层序遍历,就是最后把result数组反转一下就可以了。
+思路:
-## C++代码
+相对于102.二叉树的层序遍历,就是最后把result数组反转一下就可以了。
-```
+C++代码:
+
+```C++
class Solution {
public:
vector +
-## 思路
+思路:
层序遍历的时候,判断是否遍历到单层的最后面的元素,如果是,就放进result数组中,随后返回result就可以了。
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
vector
+
-## 思路
+思路:
层序遍历的时候,判断是否遍历到单层的最后面的元素,如果是,就放进result数组中,随后返回result就可以了。
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
vector +给定一个非空二叉树, 返回一个由每层节点平均值组成的数组。
-## 思路
+
+
+思路:
本题就是层序遍历的时候把一层求个总和在取一个均值。
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
vector
+给定一个非空二叉树, 返回一个由每层节点平均值组成的数组。
-## 思路
+
+
+思路:
本题就是层序遍历的时候把一层求个总和在取一个均值。
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
vector +
返回其层序遍历:
-[
- [1],
- [3,2,4],
- [5,6]
-]
+[
+ [1],
+ [3,2,4],
+ [5,6]
+]
-## 思路
+思路:
-这道题依旧是模板题,只不过一个节点有多个孩子了
+这道题依旧是模板题,只不过一个节点有多个孩子了
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
vector
+
返回其层序遍历:
-[
- [1],
- [3,2,4],
- [5,6]
-]
+[
+ [1],
+ [3,2,4],
+ [5,6]
+]
-## 思路
+思路:
-这道题依旧是模板题,只不过一个节点有多个孩子了
+这道题依旧是模板题,只不过一个节点有多个孩子了
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
vector +您需要在二叉树的每一行中找到最大的值。
-## 思路
+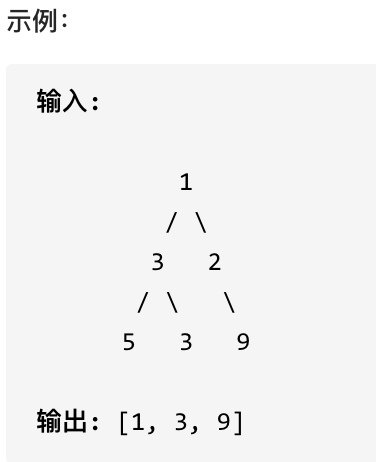
+
+思路:
层序遍历,取每一层的最大值
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
vector
+您需要在二叉树的每一行中找到最大的值。
-## 思路
+
+
+思路:
层序遍历,取每一层的最大值
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
vector +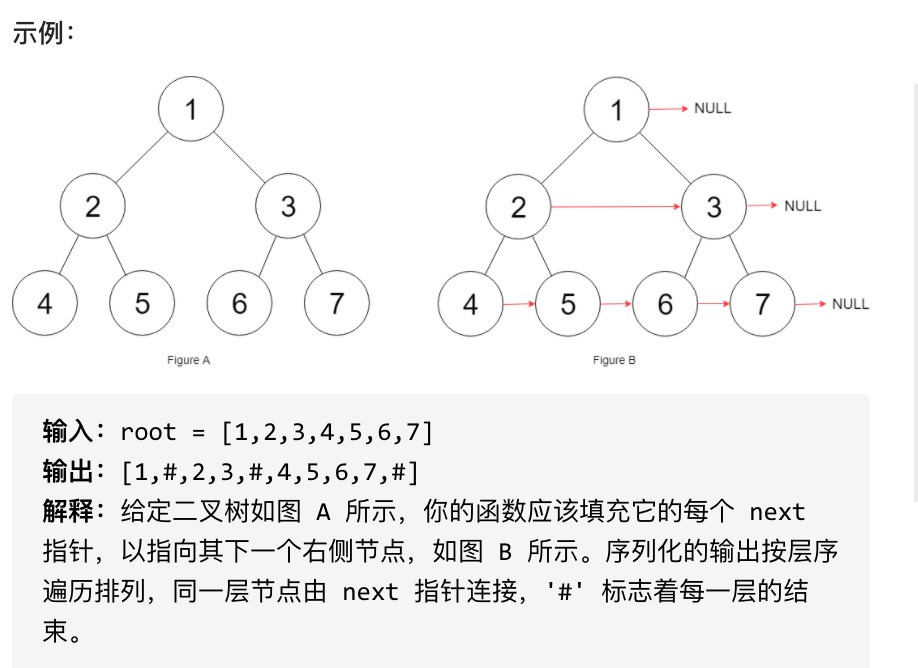
-## 思路
+思路:
本题依然是层序遍历,只不过在单层遍历的时候记录一下本层的头部节点,然后在遍历的时候让前一个节点指向本节点就可以了
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
Node* connect(Node* root) {
@@ -328,15 +349,17 @@ public:
};
```
-# 117.填充每个节点的下一个右侧节点指针II
+## 117.填充每个节点的下一个右侧节点指针II
-## 思路
+题目地址:https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node-ii/
+
+思路:
这道题目说是二叉树,但116题目说是完整二叉树,其实没有任何差别,一样的代码一样的逻辑一样的味道
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
Node* connect(Node* root) {
@@ -369,7 +392,7 @@ public:
```
-# 总结
+## 总结
二叉树的层序遍历,就是图论中的广度优先搜索在二叉树中的应用,需要借助队列来实现(此时是不是又发现队列的应用了)。
@@ -381,13 +404,32 @@ public:
* 637.二叉树的层平均值
* 429.N叉树的前序遍历
* 515.在每个树行中找最大值
-* 116. 填充每个节点的下一个右侧节点指针
+* 116. 填充每个节点的下一个右侧节点指针
* 117.填充每个节点的下一个右侧节点指针II
-如果非要打十个,还得找叶师傅!
+如果非要打十个,还得找叶师傅!
-
+
-## 思路
+思路:
本题依然是层序遍历,只不过在单层遍历的时候记录一下本层的头部节点,然后在遍历的时候让前一个节点指向本节点就可以了
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
Node* connect(Node* root) {
@@ -328,15 +349,17 @@ public:
};
```
-# 117.填充每个节点的下一个右侧节点指针II
+## 117.填充每个节点的下一个右侧节点指针II
-## 思路
+题目地址:https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node-ii/
+
+思路:
这道题目说是二叉树,但116题目说是完整二叉树,其实没有任何差别,一样的代码一样的逻辑一样的味道
-## C++代码
+C++代码:
-```
+```C++
class Solution {
public:
Node* connect(Node* root) {
@@ -369,7 +392,7 @@ public:
```
-# 总结
+## 总结
二叉树的层序遍历,就是图论中的广度优先搜索在二叉树中的应用,需要借助队列来实现(此时是不是又发现队列的应用了)。
@@ -381,13 +404,32 @@ public:
* 637.二叉树的层平均值
* 429.N叉树的前序遍历
* 515.在每个树行中找最大值
-* 116. 填充每个节点的下一个右侧节点指针
+* 116. 填充每个节点的下一个右侧节点指针
* 117.填充每个节点的下一个右侧节点指针II
-如果非要打十个,还得找叶师傅!
+如果非要打十个,还得找叶师傅!
- +
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 题目地址 -https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/ - -> “简单题”系列 看完本篇可以一起做了如下两道题目: * 104.二叉树的最大深度 * 559.N叉树的最大深度 -# 104.二叉树的最大深度 +## 104.二叉树的最大深度 + +题目地址:https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/ 给定一个二叉树,找出其最大深度。 @@ -17,16 +21,14 @@ https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/ 说明: 叶子节点是指没有子节点的节点。 -示例: -给定二叉树 [3,9,20,null,null,15,7], +示例: +给定二叉树 [3,9,20,null,null,15,7], - +
返回它的最大深度 3 。
-# 思路
-
-## 递归法
+### 递归法
本题其实也要后序遍历(左右中),依然是因为要通过递归函数的返回值做计算树的高度。
@@ -41,7 +43,7 @@ int getDepth(TreeNode* node)
2. 确定终止条件:如果为空节点的话,就返回0,表示高度为0。
-代码如下:
+代码如下:
```
if (node == NULL) return 0;
```
@@ -59,7 +61,7 @@ return depth;
所以整体C++代码如下:
-```
+```C++
class Solution {
public:
int getDepth(TreeNode* node) {
@@ -76,7 +78,7 @@ public:
```
代码精简之后C++代码如下:
-```
+```C++
class Solution {
public:
int maxDepth(TreeNode* root) {
@@ -90,7 +92,7 @@ public:
**精简之后的代码根本看不出是哪种遍历方式,也看不出递归三部曲的步骤,所以如果对二叉树的操作还不熟练,尽量不要直接照着精简代码来学。**
-## 迭代法
+### 迭代法
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
@@ -104,7 +106,7 @@ public:
C++代码如下:
-```
+```C++
class Solution {
public:
int maxDepth(TreeNode* root) {
@@ -127,10 +129,11 @@ public:
};
```
-那么我们可以顺便解决一下N叉树的最大深度问题
+那么我们可以顺便解决一下N叉树的最大深度问题
-# 559.N叉树的最大深度
-https://leetcode-cn.com/problems/maximum-depth-of-n-ary-tree/
+## 559.N叉树的最大深度
+
+题目地址:https://leetcode-cn.com/problems/maximum-depth-of-n-ary-tree/
给定一个 N 叉树,找到其最大深度。
@@ -138,19 +141,19 @@ https://leetcode-cn.com/problems/maximum-depth-of-n-ary-tree/
例如,给定一个 3叉树 :
-
+
返回它的最大深度 3 。
-# 思路
-
-## 递归法
+### 递归法
本题其实也要后序遍历(左右中),依然是因为要通过递归函数的返回值做计算树的高度。
@@ -41,7 +43,7 @@ int getDepth(TreeNode* node)
2. 确定终止条件:如果为空节点的话,就返回0,表示高度为0。
-代码如下:
+代码如下:
```
if (node == NULL) return 0;
```
@@ -59,7 +61,7 @@ return depth;
所以整体C++代码如下:
-```
+```C++
class Solution {
public:
int getDepth(TreeNode* node) {
@@ -76,7 +78,7 @@ public:
```
代码精简之后C++代码如下:
-```
+```C++
class Solution {
public:
int maxDepth(TreeNode* root) {
@@ -90,7 +92,7 @@ public:
**精简之后的代码根本看不出是哪种遍历方式,也看不出递归三部曲的步骤,所以如果对二叉树的操作还不熟练,尽量不要直接照着精简代码来学。**
-## 迭代法
+### 迭代法
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
@@ -104,7 +106,7 @@ public:
C++代码如下:
-```
+```C++
class Solution {
public:
int maxDepth(TreeNode* root) {
@@ -127,10 +129,11 @@ public:
};
```
-那么我们可以顺便解决一下N叉树的最大深度问题
+那么我们可以顺便解决一下N叉树的最大深度问题
-# 559.N叉树的最大深度
-https://leetcode-cn.com/problems/maximum-depth-of-n-ary-tree/
+## 559.N叉树的最大深度
+
+题目地址:https://leetcode-cn.com/problems/maximum-depth-of-n-ary-tree/
给定一个 N 叉树,找到其最大深度。
@@ -138,19 +141,19 @@ https://leetcode-cn.com/problems/maximum-depth-of-n-ary-tree/
例如,给定一个 3叉树 :
- +
我们应返回其最大深度,3。
-# 思路
+思路:
依然可以提供递归法和迭代法,来解决这个问题,思路是和二叉树思路一样的,直接给出代码如下:
-## 递归法
+### 递归法
C++代码:
-```
+```C++
class Solution {
public:
int maxDepth(Node* root) {
@@ -163,17 +166,17 @@ public:
}
};
```
-## 迭代法
+### 迭代法
依然是层序遍历,代码如下:
-```
+```C++
class Solution {
public:
int maxDepth(Node* root) {
queue
+
我们应返回其最大深度,3。
-# 思路
+思路:
依然可以提供递归法和迭代法,来解决这个问题,思路是和二叉树思路一样的,直接给出代码如下:
-## 递归法
+### 递归法
C++代码:
-```
+```C++
class Solution {
public:
int maxDepth(Node* root) {
@@ -163,17 +166,17 @@ public:
}
};
```
-## 迭代法
+### 迭代法
依然是层序遍历,代码如下:
-```
+```C++
class Solution {
public:
int maxDepth(Node* root) {
queue
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-> 给出两个序列 (可以加unorder_map优化一下) -看完本文,可以一起解决如下两道题目 +看完本文,可以一起解决如下两道题目 -* 106.从中序与后序遍历序列构造二叉树 +* 106.从中序与后序遍历序列构造二叉树 * 105.从前序与中序遍历序列构造二叉树 +## 106.从中序与后序遍历序列构造二叉树 -# 106.从中序与后序遍历序列构造二叉树 +题目地址:https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal/ 根据一棵树的中序遍历与后序遍历构造二叉树。 @@ -22,9 +27,9 @@ https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorde 后序遍历 postorder = [9,15,7,20,3] 返回如下的二叉树: - +
-## 思路
+### 思路
首先回忆一下如何根据两个顺序构造一个唯一的二叉树,相信理论知识大家应该都清楚,就是以 后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来在切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
@@ -32,7 +37,7 @@ https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorde
流程如图:
-
+
-## 思路
+### 思路
首先回忆一下如何根据两个顺序构造一个唯一的二叉树,相信理论知识大家应该都清楚,就是以 后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来在切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
@@ -32,7 +37,7 @@ https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorde
流程如图:
- +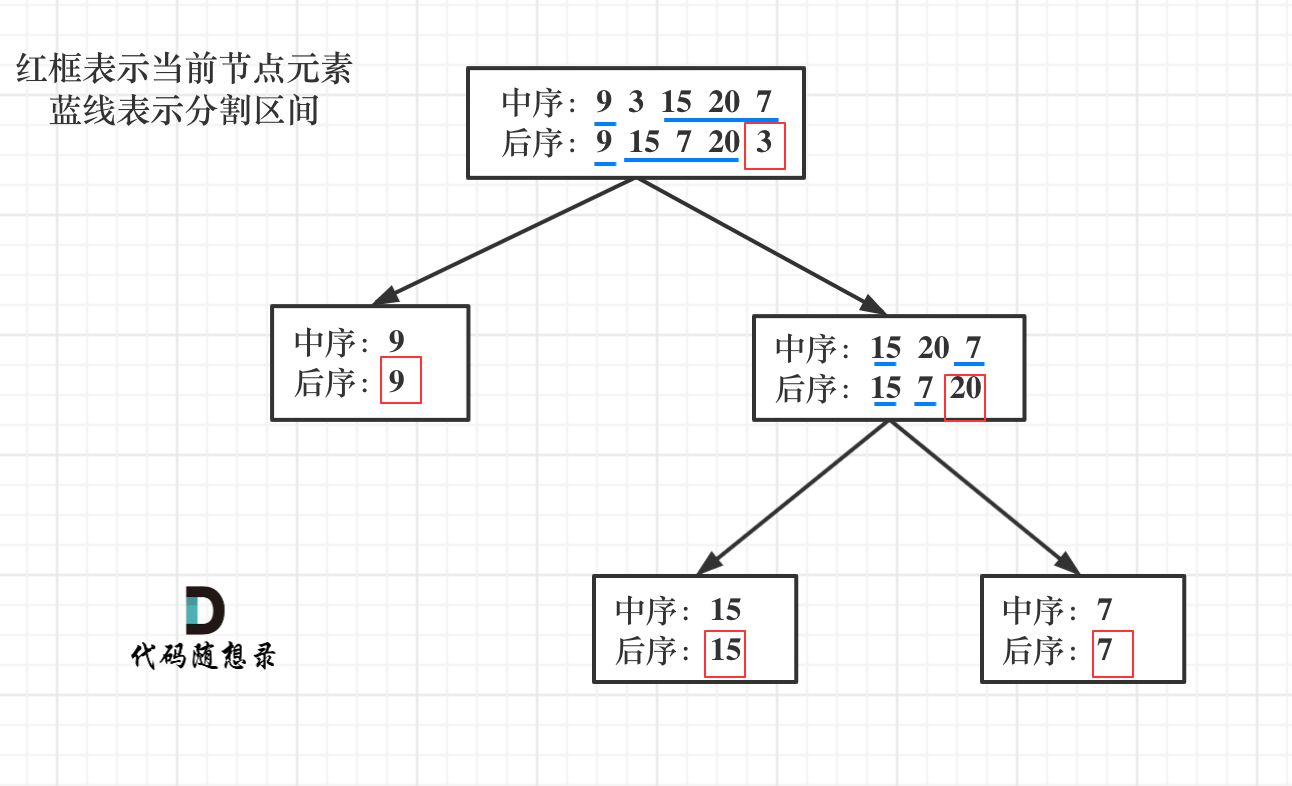
那么代码应该怎么写呢?
@@ -42,9 +47,9 @@ https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorde
* 第一步:如果数组大小为零的话,说明是空节点了。
-* 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
+* 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
-* 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
+* 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
* 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
@@ -54,34 +59,34 @@ https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorde
不难写出如下代码:(先把框架写出来)
-```
- TreeNode* traversal (vector
+
那么代码应该怎么写呢?
@@ -42,9 +47,9 @@ https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorde
* 第一步:如果数组大小为零的话,说明是空节点了。
-* 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
+* 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
-* 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
+* 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
* 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
@@ -54,34 +59,34 @@ https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorde
不难写出如下代码:(先把框架写出来)
-```
- TreeNode* traversal (vector +
-## 思路
+### 思路
本题和106是一样的道理。
@@ -412,7 +419,7 @@ public:
带日志的版本C++代码如下: (**带日志的版本仅用于调试,不要在leetcode上提交,会超时**)
-```
+```C++
class Solution {
private:
TreeNode* traversal (vector
+
-## 思路
+### 思路
本题和106是一样的道理。
@@ -412,7 +419,7 @@ public:
带日志的版本C++代码如下: (**带日志的版本仅用于调试,不要在leetcode上提交,会超时**)
-```
+```C++
class Solution {
private:
TreeNode* traversal (vector +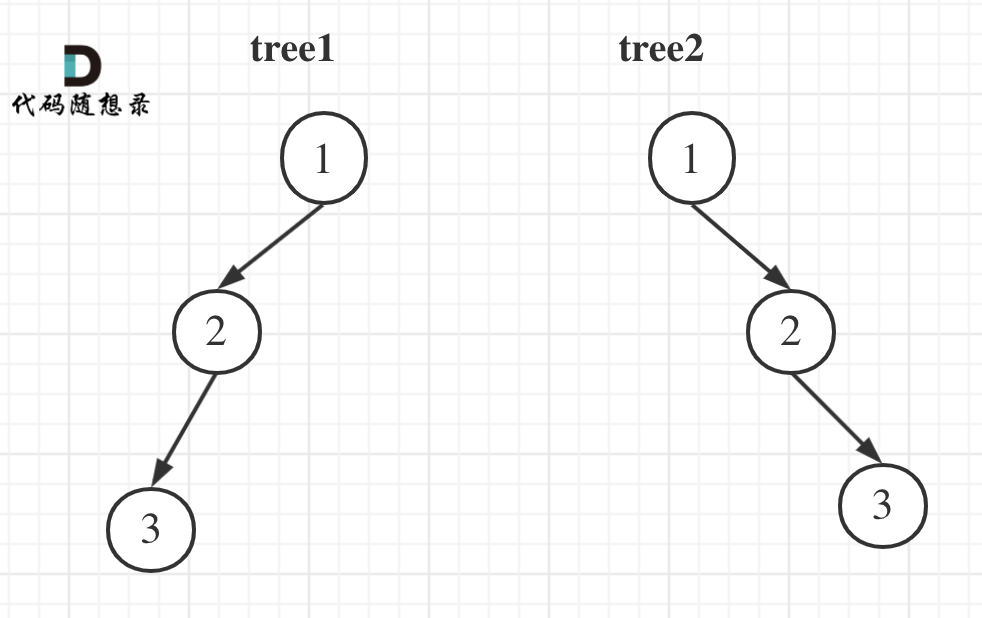
tree1 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
tree2 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
-那么tree1 和 tree2 的前序和后序完全相同,这是一棵树么,很明显是两棵树!
+那么tree1 和 tree2 的前序和后序完全相同,这是一棵树么,很明显是两棵树!
所以前序和后序不能唯一确定一颗二叉树!
-# 总结
+## 总结
之前我们讲的二叉树题目都是各种遍历二叉树,这次开始构造二叉树了,思路其实比较简单,但是真正代码实现出来并不容易。
@@ -569,8 +576,24 @@ tree2 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
认真研究完本篇,相信大家对二叉树的构造会清晰很多。
-如果学到了,就赶紧转发给身边需要的同学吧!
-
-加个油!
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
tree1 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
tree2 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
-那么tree1 和 tree2 的前序和后序完全相同,这是一棵树么,很明显是两棵树!
+那么tree1 和 tree2 的前序和后序完全相同,这是一棵树么,很明显是两棵树!
所以前序和后序不能唯一确定一颗二叉树!
-# 总结
+## 总结
之前我们讲的二叉树题目都是各种遍历二叉树,这次开始构造二叉树了,思路其实比较简单,但是真正代码实现出来并不容易。
@@ -569,8 +576,24 @@ tree2 的前序遍历是[1 2 3], 后序遍历是[3 2 1]。
认真研究完本篇,相信大家对二叉树的构造会清晰很多。
-如果学到了,就赶紧转发给身边需要的同学吧!
-
-加个油!
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 108.将有序数组转换为二叉搜索树 + +> 构造二叉搜索树,一不小心就平衡了 + +## 108.将有序数组转换为二叉搜索树 + +题目链接:https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree/ 将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。 @@ -10,13 +21,13 @@  -# 思路 +## 思路 做这道题目之前大家可以了解一下这几道: * [106.从中序与后序遍历序列构造二叉树](https://mp.weixin.qq.com/s/7r66ap2s-shvVvlZxo59xg) * [654.最大二叉树](https://mp.weixin.qq.com/s/1iWJV6Aov23A7xCF4nV88w)中其实已经讲过了,如果根据数组构造一颗二叉树。 -* [701.二叉搜索树中的插入操作](https://mp.weixin.qq.com/s/lwKkLQcfbCNX2W-5SOeZEA) +* [701.二叉搜索树中的插入操作](https://mp.weixin.qq.com/s/lwKkLQcfbCNX2W-5SOeZEA) * [450.删除二叉搜索树中的节点](https://mp.weixin.qq.com/s/-p-Txvch1FFk3ygKLjPAKw) @@ -39,21 +50,21 @@ 取哪一个都可以,只不过构成了不同的平衡二叉搜索树。 -例如:输入:[-10,-3,0,5,9] +例如:输入:[-10,-3,0,5,9] 如下两棵树,都是这个数组的平衡二叉搜索树: - +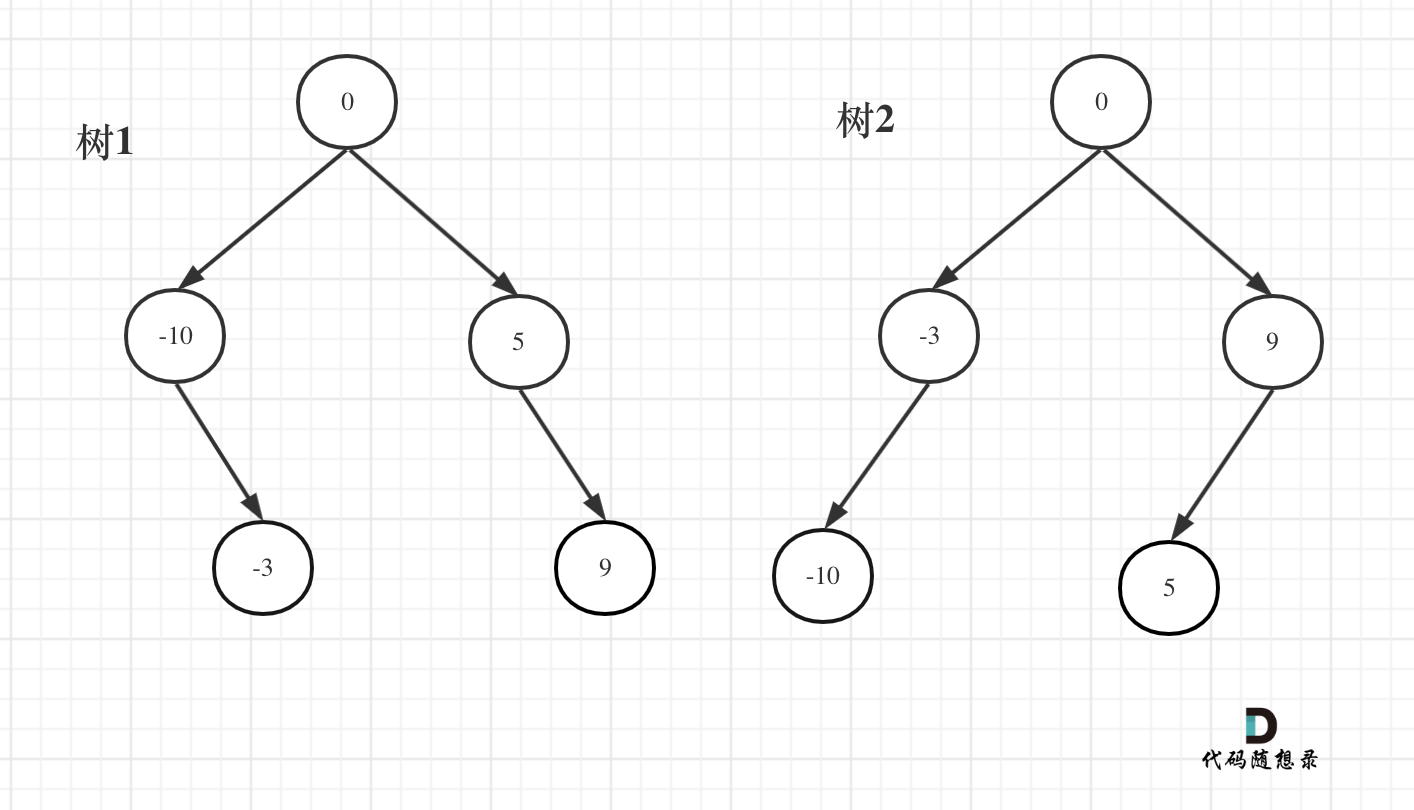
-如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
+如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
**这也是题目中强调答案不是唯一的原因。 理解这一点,这道题目算是理解到位了**。
-## 递归
+## 递归
递归三部曲:
-* 确定递归函数返回值及其参数
+* 确定递归函数返回值及其参数
删除二叉树节点,增加二叉树节点,都是用递归函数的返回值来完成,这样是比较方便的。
@@ -67,7 +78,7 @@
```
// 左闭右闭区间[left, right]
-TreeNode* traversal(vector
+
-如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
+如果要分割的数组长度为偶数的时候,中间元素为两个,是取左边元素 就是树1,取右边元素就是树2。
**这也是题目中强调答案不是唯一的原因。 理解这一点,这道题目算是理解到位了**。
-## 递归
+## 递归
递归三部曲:
-* 确定递归函数返回值及其参数
+* 确定递归函数返回值及其参数
删除二叉树节点,增加二叉树节点,都是用递归函数的返回值来完成,这样是比较方便的。
@@ -67,7 +78,7 @@
```
// 左闭右闭区间[left, right]
-TreeNode* traversal(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ > 求高度还是求深度,你搞懂了不? -# 110.平衡二叉树 +## 110.平衡二叉树 + +题目地址:https://leetcode-cn.com/problems/balanced-binary-tree/ 给定一个二叉树,判断它是否是高度平衡的二叉树。 @@ -13,7 +21,7 @@ https://leetcode-cn.com/problems/balanced-binary-tree/ 给定二叉树 [3,9,20,null,null,15,7] - +
返回 true 。
@@ -21,11 +29,11 @@ https://leetcode-cn.com/problems/balanced-binary-tree/
给定二叉树 [1,2,2,3,3,null,null,4,4]
-
+
返回 true 。
@@ -21,11 +29,11 @@ https://leetcode-cn.com/problems/balanced-binary-tree/
给定二叉树 [1,2,2,3,3,null,null,4,4]
- +
返回 false 。
-# 题外话
+## 题外话
咋眼一看这道题目和[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)很像,其实有很大区别。
@@ -36,7 +44,7 @@ https://leetcode-cn.com/problems/balanced-binary-tree/
但leetcode中强调的深度和高度很明显是按照节点来计算的,如图:
-
+
返回 false 。
-# 题外话
+## 题外话
咋眼一看这道题目和[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)很像,其实有很大区别。
@@ -36,7 +44,7 @@ https://leetcode-cn.com/problems/balanced-binary-tree/
但leetcode中强调的深度和高度很明显是按照节点来计算的,如图:
- +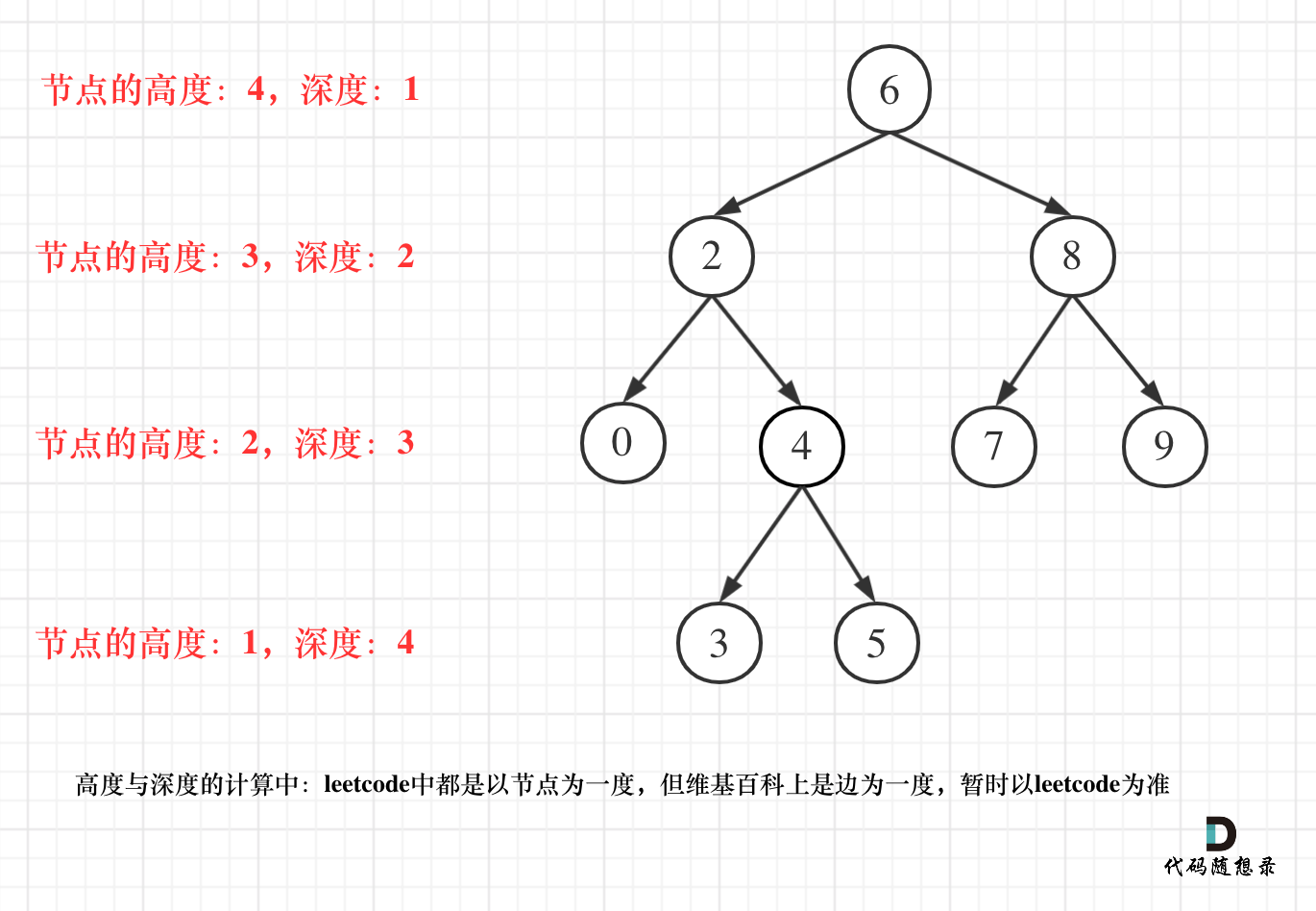
关于根节点的深度究竟是1 还是 0,不同的地方有不一样的标准,leetcode的题目中都是以节点为一度,即根节点深度是1。但维基百科上定义用边为一度,即根节点的深度是0,我们暂时以leetcode为准(毕竟要在这上面刷题)。
@@ -48,7 +56,7 @@ https://leetcode-cn.com/problems/balanced-binary-tree/
在[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)中,如果真正求取二叉树的最大深度,代码应该写成如下:(前序遍历)
-```
+```C++
class Solution {
public:
int result;
@@ -82,7 +90,7 @@ public:
注意以上代码是为了把细节体现出来,简化一下代码如下:
-```
+```C++
class Solution {
public:
int result;
@@ -106,15 +114,15 @@ public:
};
```
-# 本题思路
+## 本题思路
-## 递归
+### 递归
此时大家应该明白了既然要求比较高度,必然是要后序遍历。
递归三步曲分析:
-1. 明确递归函数的参数和返回值
+1. 明确递归函数的参数和返回值
参数的话为传入的节点指针,就没有其他参数需要传递了,返回值要返回传入节点为根节点树的深度。
@@ -132,9 +140,9 @@ public:
int getDepth(TreeNode* node)
```
-2. 明确终止条件
+2. 明确终止条件
-递归的过程中依然是遇到空节点了为终止,返回0,表示当前节点为根节点的书高度为0
+递归的过程中依然是遇到空节点了为终止,返回0,表示当前节点为根节点的书高度为0
代码如下:
@@ -144,7 +152,7 @@ if (node == NULL) {
}
```
-3. 明确单层递归的逻辑
+3. 明确单层递归的逻辑
如何判断当前传入节点为根节点的二叉树是否是平衡二叉树呢,当然是左子树高度和右子树高度相差。
@@ -154,7 +162,7 @@ if (node == NULL) {
```
int leftDepth = depth(node->left); // 左
-if (leftDepth == -1) return -1;
+if (leftDepth == -1) return -1;
int rightDepth = depth(node->right); // 右
if (rightDepth == -1) return -1;
@@ -172,7 +180,7 @@ return result;
```
int leftDepth = getDepth(node->left);
-if (leftDepth == -1) return -1;
+if (leftDepth == -1) return -1;
int rightDepth = getDepth(node->right);
if (rightDepth == -1) return -1;
return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
@@ -182,7 +190,7 @@ return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
getDepth整体代码如下:
-```
+```C++
int getDepth(TreeNode* node) {
if (node == NULL) {
return 0;
@@ -197,7 +205,7 @@ int getDepth(TreeNode* node) {
最后本题整体递归代码如下:
-```
+```C++
class Solution {
public:
// 返回以该节点为根节点的二叉树的高度,如果不是二叉搜索树了则返回-1
@@ -212,12 +220,12 @@ public:
return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
}
bool isBalanced(TreeNode* root) {
- return getDepth(root) == -1 ? false : true;
+ return getDepth(root) == -1 ? false : true;
}
};
```
-## 迭代
+### 迭代
在[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)中我们可以使用层序遍历来求深度,但是就不能直接用层序遍历来求高度了,这就体现出求高度和求深度的不同。
@@ -227,7 +235,7 @@ public:
代码如下:
-```
+```C++
// cur节点的最大深度,就是cur的高度
int getDepth(TreeNode* cur) {
stack
+
关于根节点的深度究竟是1 还是 0,不同的地方有不一样的标准,leetcode的题目中都是以节点为一度,即根节点深度是1。但维基百科上定义用边为一度,即根节点的深度是0,我们暂时以leetcode为准(毕竟要在这上面刷题)。
@@ -48,7 +56,7 @@ https://leetcode-cn.com/problems/balanced-binary-tree/
在[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)中,如果真正求取二叉树的最大深度,代码应该写成如下:(前序遍历)
-```
+```C++
class Solution {
public:
int result;
@@ -82,7 +90,7 @@ public:
注意以上代码是为了把细节体现出来,简化一下代码如下:
-```
+```C++
class Solution {
public:
int result;
@@ -106,15 +114,15 @@ public:
};
```
-# 本题思路
+## 本题思路
-## 递归
+### 递归
此时大家应该明白了既然要求比较高度,必然是要后序遍历。
递归三步曲分析:
-1. 明确递归函数的参数和返回值
+1. 明确递归函数的参数和返回值
参数的话为传入的节点指针,就没有其他参数需要传递了,返回值要返回传入节点为根节点树的深度。
@@ -132,9 +140,9 @@ public:
int getDepth(TreeNode* node)
```
-2. 明确终止条件
+2. 明确终止条件
-递归的过程中依然是遇到空节点了为终止,返回0,表示当前节点为根节点的书高度为0
+递归的过程中依然是遇到空节点了为终止,返回0,表示当前节点为根节点的书高度为0
代码如下:
@@ -144,7 +152,7 @@ if (node == NULL) {
}
```
-3. 明确单层递归的逻辑
+3. 明确单层递归的逻辑
如何判断当前传入节点为根节点的二叉树是否是平衡二叉树呢,当然是左子树高度和右子树高度相差。
@@ -154,7 +162,7 @@ if (node == NULL) {
```
int leftDepth = depth(node->left); // 左
-if (leftDepth == -1) return -1;
+if (leftDepth == -1) return -1;
int rightDepth = depth(node->right); // 右
if (rightDepth == -1) return -1;
@@ -172,7 +180,7 @@ return result;
```
int leftDepth = getDepth(node->left);
-if (leftDepth == -1) return -1;
+if (leftDepth == -1) return -1;
int rightDepth = getDepth(node->right);
if (rightDepth == -1) return -1;
return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
@@ -182,7 +190,7 @@ return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
getDepth整体代码如下:
-```
+```C++
int getDepth(TreeNode* node) {
if (node == NULL) {
return 0;
@@ -197,7 +205,7 @@ int getDepth(TreeNode* node) {
最后本题整体递归代码如下:
-```
+```C++
class Solution {
public:
// 返回以该节点为根节点的二叉树的高度,如果不是二叉搜索树了则返回-1
@@ -212,12 +220,12 @@ public:
return abs(leftDepth - rightDepth) > 1 ? -1 : 1 + max(leftDepth, rightDepth);
}
bool isBalanced(TreeNode* root) {
- return getDepth(root) == -1 ? false : true;
+ return getDepth(root) == -1 ? false : true;
}
};
```
-## 迭代
+### 迭代
在[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg)中我们可以使用层序遍历来求深度,但是就不能直接用层序遍历来求高度了,这就体现出求高度和求深度的不同。
@@ -227,7 +235,7 @@ public:
代码如下:
-```
+```C++
// cur节点的最大深度,就是cur的高度
int getDepth(TreeNode* cur) {
stack
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 题目地址 -https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/ > 和求最大深度一个套路? -# 111.二叉树的最小深度 +## 111.二叉树的最小深度 + +题目地址:https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/ 给定一个二叉树,找出其最小深度。 @@ -16,11 +23,11 @@ https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/ 给定二叉树 [3,9,20,null,null,15,7], - +
-返回它的最小深度 2.
+返回它的最小深度 2.
-# 思路
+## 思路
看完了这篇[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg),再来看看如何求最小深度。
@@ -28,13 +35,13 @@ https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/
遍历顺序上依然是后序遍历(因为要比较递归返回之后的结果),但在处理中间节点的逻辑上,最大深度很容易理解,最小深度可有一个误区,如图:
-
+
-返回它的最小深度 2.
+返回它的最小深度 2.
-# 思路
+## 思路
看完了这篇[二叉树:看看这些树的最大深度](https://mp.weixin.qq.com/s/guKwV-gSNbA1CcbvkMtHBg),再来看看如何求最小深度。
@@ -28,13 +35,13 @@ https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/
遍历顺序上依然是后序遍历(因为要比较递归返回之后的结果),但在处理中间节点的逻辑上,最大深度很容易理解,最小深度可有一个误区,如图:
- +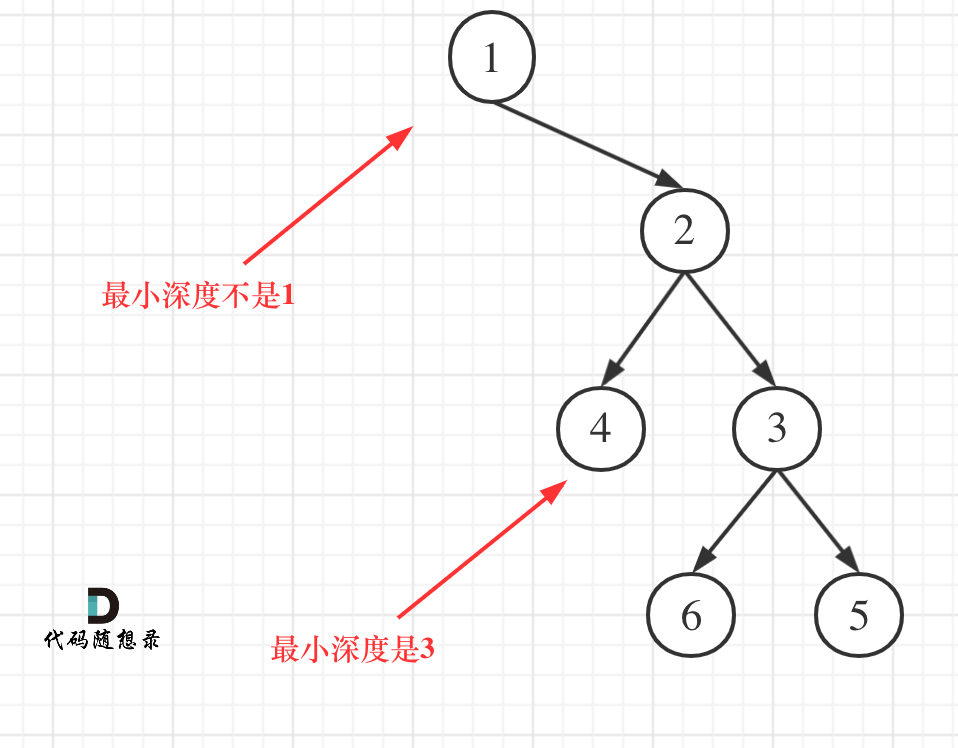
这就重新审题了,题目中说的是:**最小深度是从根节点到最近叶子节点的最短路径上的节点数量。**,注意是**叶子节点**。
什么是叶子节点,左右孩子都为空的节点才是叶子节点!
-## 递归法
+## 递归法
来来来,一起递归三部曲:
@@ -48,9 +55,9 @@ https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/
int getDepth(TreeNode* node)
```
-2. 确定终止条件
+2. 确定终止条件
-终止条件也是遇到空节点返回0,表示当前节点的高度为0。
+终止条件也是遇到空节点返回0,表示当前节点的高度为0。
代码如下:
@@ -58,7 +65,7 @@ int getDepth(TreeNode* node)
if (node == NULL) return 0;
```
-3. 确定单层递归的逻辑
+3. 确定单层递归的逻辑
这块和求最大深度可就不一样了,一些同学可能会写如下代码:
```
@@ -70,7 +77,7 @@ return result;
这个代码就犯了此图中的误区:
-
+
如果这么求的话,没有左孩子的分支会算为最短深度。
@@ -80,7 +87,7 @@ return result;
代码如下:
-```
+```C++
int leftDepth = getDepth(node->left); // 左
int rightDepth = getDepth(node->right); // 右
// 中
@@ -92,14 +99,14 @@ if (node->left == NULL && node->right != NULL) {
if (node->left != NULL && node->right == NULL) {
return 1 + leftDepth;
}
-int result = 1 + min(leftDepth, rightDepth);
+int result = 1 + min(leftDepth, rightDepth);
return result;
```
-遍历的顺序为后序(左右中),可以看出:**求二叉树的最小深度和求二叉树的最大深度的差别主要在于处理左右孩子不为空的逻辑。**
+遍历的顺序为后序(左右中),可以看出:**求二叉树的最小深度和求二叉树的最大深度的差别主要在于处理左右孩子不为空的逻辑。**
整体递归代码如下:
-```
+```C++
class Solution {
public:
int getDepth(TreeNode* node) {
@@ -115,7 +122,7 @@ public:
if (node->left != NULL && node->right == NULL) {
return 1 + leftDepth;
}
- int result = 1 + min(leftDepth, rightDepth);
+ int result = 1 + min(leftDepth, rightDepth);
return result;
}
@@ -127,7 +134,7 @@ public:
精简之后代码如下:
-```
+```C++
class Solution {
public:
int minDepth(TreeNode* root) {
@@ -155,7 +162,7 @@ public:
代码如下:(详细注释)
-```
+```C++
class Solution {
public:
@@ -182,4 +189,23 @@ public:
};
```
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
这就重新审题了,题目中说的是:**最小深度是从根节点到最近叶子节点的最短路径上的节点数量。**,注意是**叶子节点**。
什么是叶子节点,左右孩子都为空的节点才是叶子节点!
-## 递归法
+## 递归法
来来来,一起递归三部曲:
@@ -48,9 +55,9 @@ https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/
int getDepth(TreeNode* node)
```
-2. 确定终止条件
+2. 确定终止条件
-终止条件也是遇到空节点返回0,表示当前节点的高度为0。
+终止条件也是遇到空节点返回0,表示当前节点的高度为0。
代码如下:
@@ -58,7 +65,7 @@ int getDepth(TreeNode* node)
if (node == NULL) return 0;
```
-3. 确定单层递归的逻辑
+3. 确定单层递归的逻辑
这块和求最大深度可就不一样了,一些同学可能会写如下代码:
```
@@ -70,7 +77,7 @@ return result;
这个代码就犯了此图中的误区:
-
+
如果这么求的话,没有左孩子的分支会算为最短深度。
@@ -80,7 +87,7 @@ return result;
代码如下:
-```
+```C++
int leftDepth = getDepth(node->left); // 左
int rightDepth = getDepth(node->right); // 右
// 中
@@ -92,14 +99,14 @@ if (node->left == NULL && node->right != NULL) {
if (node->left != NULL && node->right == NULL) {
return 1 + leftDepth;
}
-int result = 1 + min(leftDepth, rightDepth);
+int result = 1 + min(leftDepth, rightDepth);
return result;
```
-遍历的顺序为后序(左右中),可以看出:**求二叉树的最小深度和求二叉树的最大深度的差别主要在于处理左右孩子不为空的逻辑。**
+遍历的顺序为后序(左右中),可以看出:**求二叉树的最小深度和求二叉树的最大深度的差别主要在于处理左右孩子不为空的逻辑。**
整体递归代码如下:
-```
+```C++
class Solution {
public:
int getDepth(TreeNode* node) {
@@ -115,7 +122,7 @@ public:
if (node->left != NULL && node->right == NULL) {
return 1 + leftDepth;
}
- int result = 1 + min(leftDepth, rightDepth);
+ int result = 1 + min(leftDepth, rightDepth);
return result;
}
@@ -127,7 +134,7 @@ public:
精简之后代码如下:
-```
+```C++
class Solution {
public:
int minDepth(TreeNode* root) {
@@ -155,7 +162,7 @@ public:
代码如下:(详细注释)
-```
+```C++
class Solution {
public:
@@ -182,4 +189,23 @@ public:
};
```
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+
+Go:
+
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ > 递归函数什么时候需要返回值 @@ -9,7 +16,9 @@ * 112. 路径总和 * 113. 路径总和II -# 112. 路径总和 +## 112. 路径总和 + +题目地址:https://leetcode-cn.com/problems/path-sum/ 给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。 @@ -18,16 +27,15 @@ 示例: 给定如下二叉树,以及目标和 sum = 22, - +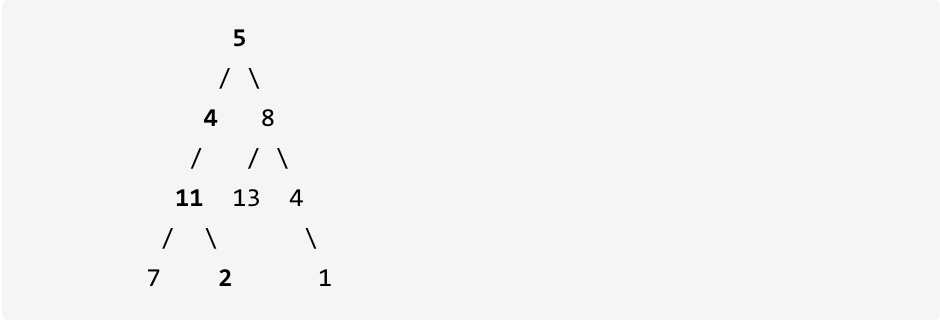
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
-# 思路
-
+### 思路
这道题我们要遍历从根节点到叶子节点的的路径看看总和是不是目标和。
-## 递归
+### 递归
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树
@@ -47,7 +55,7 @@
如图所示:
-
+
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
-# 思路
-
+### 思路
这道题我们要遍历从根节点到叶子节点的的路径看看总和是不是目标和。
-## 递归
+### 递归
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树
@@ -47,7 +55,7 @@
如图所示:
- +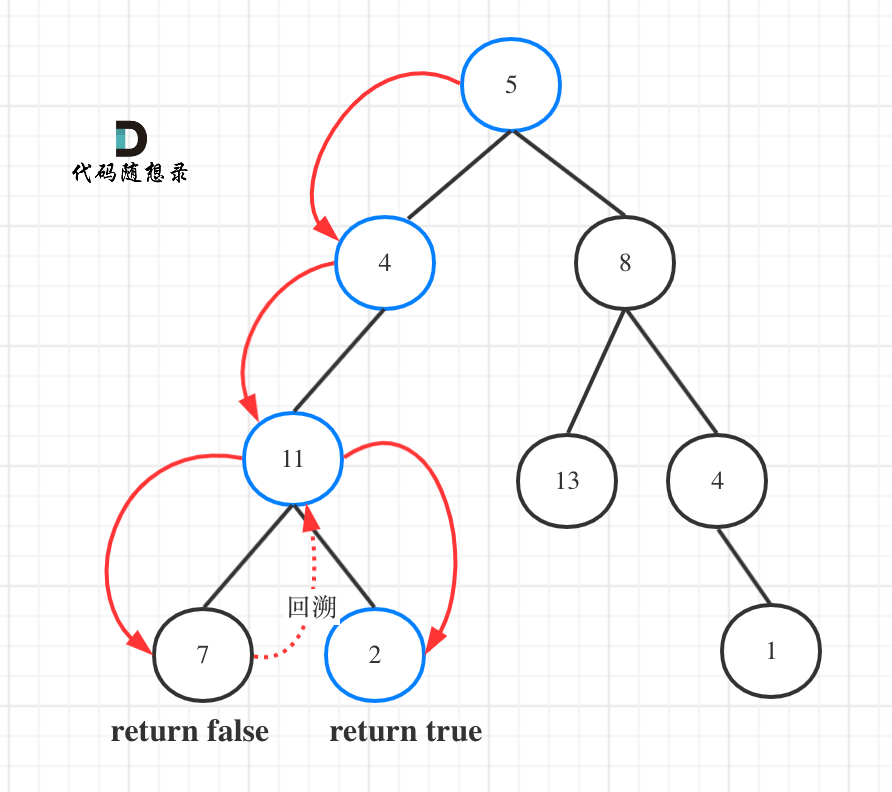
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。
@@ -58,7 +66,7 @@ bool traversal(TreeNode* cur, int count) // 注意函数的返回类型
```
-2. 确定终止条件
+2. 确定终止条件
首先计数器如何统计这一条路径的和呢?
@@ -75,15 +83,15 @@ if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点
if (!cur->left && !cur->right) return false; // 遇到叶子节点而没有找到合适的边,直接返回
```
-3. 确定单层递归的逻辑
+3. 确定单层递归的逻辑
-因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
+因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
代码如下:
-```
+```C++
if (cur->left) { // 左 (空节点不遍历)
// 遇到叶子节点返回true,则直接返回true
if (traversal(cur->left, count - cur->left->val)) return true; // 注意这里有回溯的逻辑
@@ -101,15 +109,15 @@ return false;
为了把回溯的过程体现出来,可以改为如下代码:
-```
+```C++
if (cur->left) { // 左
count -= cur->left->val; // 递归,处理节点;
if (traversal(cur->left, count)) return true;
count += cur->left->val; // 回溯,撤销处理结果
}
-if (cur->right) { // 右
+if (cur->right) { // 右
count -= cur->right->val;
- if (traversal(cur->right, count - cur->right->val)) return true;
+ if (traversal(cur->right, count - cur->right->val)) return true;
count += cur->right->val;
}
return false;
@@ -118,7 +126,7 @@ return false;
整体代码如下:
-```
+```C++
class Solution {
private:
bool traversal(TreeNode* cur, int count) {
@@ -146,9 +154,9 @@ public:
};
```
-以上代码精简之后如下:
+以上代码精简之后如下:
-```
+```C++
class Solution {
public:
bool hasPathSum(TreeNode* root, int sum) {
@@ -164,11 +172,11 @@ public:
**是不是发现精简之后的代码,已经完全看不出分析的过程了,所以我们要把题目分析清楚之后,在追求代码精简。** 这一点我已经强调很多次了!
-## 迭代
+### 迭代
-如果使用栈模拟递归的话,那么如果做回溯呢?
+如果使用栈模拟递归的话,那么如果做回溯呢?
-**此时栈里一个元素不仅要记录该节点指针,还要记录从头结点到该节点的路径数值总和。**
+**此时栈里一个元素不仅要记录该节点指针,还要记录从头结点到该节点的路径数值总和。**
C++就我们用pair结构来存放这个栈里的元素。
@@ -178,7 +186,7 @@ C++就我们用pair结构来存放这个栈里的元素。
如下代码是使用栈模拟的前序遍历,如下:(详细注释)
-```
+```C++
class Solution {
public:
@@ -210,7 +218,9 @@ public:
如果大家完全理解了本地的递归方法之后,就可以顺便把leetcode上113. 路径总和II做了。
-# 113. 路径总和II
+## 113. 路径总和II
+
+题目地址:https://leetcode-cn.com/problems/path-sum-ii/
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
@@ -220,27 +230,27 @@ public:
给定如下二叉树,以及目标和 sum = 22,
-
+
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。
@@ -58,7 +66,7 @@ bool traversal(TreeNode* cur, int count) // 注意函数的返回类型
```
-2. 确定终止条件
+2. 确定终止条件
首先计数器如何统计这一条路径的和呢?
@@ -75,15 +83,15 @@ if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点
if (!cur->left && !cur->right) return false; // 遇到叶子节点而没有找到合适的边,直接返回
```
-3. 确定单层递归的逻辑
+3. 确定单层递归的逻辑
-因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
+因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
代码如下:
-```
+```C++
if (cur->left) { // 左 (空节点不遍历)
// 遇到叶子节点返回true,则直接返回true
if (traversal(cur->left, count - cur->left->val)) return true; // 注意这里有回溯的逻辑
@@ -101,15 +109,15 @@ return false;
为了把回溯的过程体现出来,可以改为如下代码:
-```
+```C++
if (cur->left) { // 左
count -= cur->left->val; // 递归,处理节点;
if (traversal(cur->left, count)) return true;
count += cur->left->val; // 回溯,撤销处理结果
}
-if (cur->right) { // 右
+if (cur->right) { // 右
count -= cur->right->val;
- if (traversal(cur->right, count - cur->right->val)) return true;
+ if (traversal(cur->right, count - cur->right->val)) return true;
count += cur->right->val;
}
return false;
@@ -118,7 +126,7 @@ return false;
整体代码如下:
-```
+```C++
class Solution {
private:
bool traversal(TreeNode* cur, int count) {
@@ -146,9 +154,9 @@ public:
};
```
-以上代码精简之后如下:
+以上代码精简之后如下:
-```
+```C++
class Solution {
public:
bool hasPathSum(TreeNode* root, int sum) {
@@ -164,11 +172,11 @@ public:
**是不是发现精简之后的代码,已经完全看不出分析的过程了,所以我们要把题目分析清楚之后,在追求代码精简。** 这一点我已经强调很多次了!
-## 迭代
+### 迭代
-如果使用栈模拟递归的话,那么如果做回溯呢?
+如果使用栈模拟递归的话,那么如果做回溯呢?
-**此时栈里一个元素不仅要记录该节点指针,还要记录从头结点到该节点的路径数值总和。**
+**此时栈里一个元素不仅要记录该节点指针,还要记录从头结点到该节点的路径数值总和。**
C++就我们用pair结构来存放这个栈里的元素。
@@ -178,7 +186,7 @@ C++就我们用pair结构来存放这个栈里的元素。
如下代码是使用栈模拟的前序遍历,如下:(详细注释)
-```
+```C++
class Solution {
public:
@@ -210,7 +218,9 @@ public:
如果大家完全理解了本地的递归方法之后,就可以顺便把leetcode上113. 路径总和II做了。
-# 113. 路径总和II
+## 113. 路径总和II
+
+题目地址:https://leetcode-cn.com/problems/path-sum-ii/
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
@@ -220,27 +230,27 @@ public:
给定如下二叉树,以及目标和 sum = 22,
- +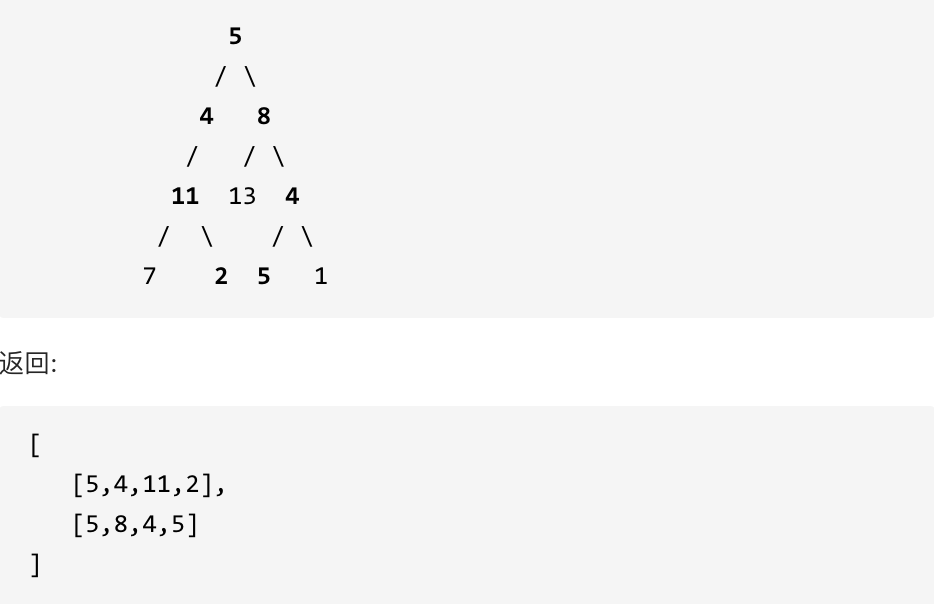
-## 思路
+### 思路
113.路径总和II要遍历整个树,找到所有路径,**所以递归函数不要返回值!**
如图:
-
+
-## 思路
+### 思路
113.路径总和II要遍历整个树,找到所有路径,**所以递归函数不要返回值!**
如图:
- +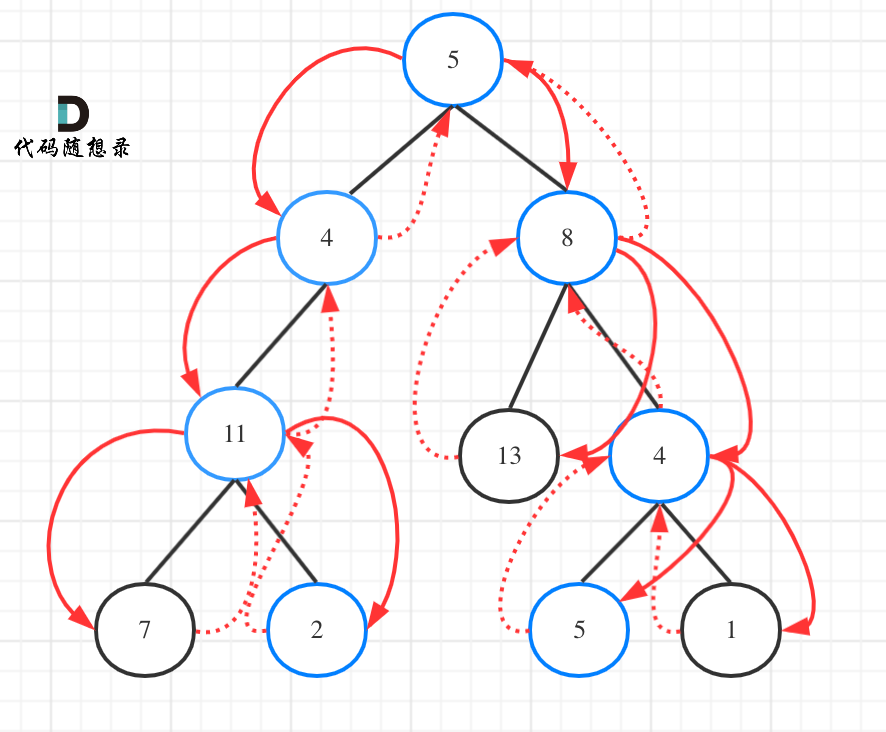
为了尽可能的把细节体现出来,我写出如下代码(**这份代码并不简洁,但是逻辑非常清晰**)
-```
+```C++
class Solution {
private:
vector
-
-
-这道题目其实比[112. 路径总和](https://leetcode-cn.com/problems/path-sum/)简单一些,大家做完了本题,可以在做[112. 路径总和](https://leetcode-cn.com/problems/path-sum/)。
-
-为了尽可能的把回溯过程体现出来,我写出如下代码(**这个代码一定不是最简洁的,但是比较清晰的,过于简洁的代码不方便读者理解**)
-
-
-## 回溯C++代码
-
-```
-class Solution {
-private:
- vector
+
为了尽可能的把细节体现出来,我写出如下代码(**这份代码并不简洁,但是逻辑非常清晰**)
-```
+```C++
class Solution {
private:
vector
-
-
-这道题目其实比[112. 路径总和](https://leetcode-cn.com/problems/path-sum/)简单一些,大家做完了本题,可以在做[112. 路径总和](https://leetcode-cn.com/problems/path-sum/)。
-
-为了尽可能的把回溯过程体现出来,我写出如下代码(**这个代码一定不是最简洁的,但是比较清晰的,过于简洁的代码不方便读者理解**)
-
-
-## 回溯C++代码
-
-```
-class Solution {
-private:
- vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +## 115.不同的子序列 + +题目链接:https://leetcode-cn.com/problems/distinct-subsequences/ + +给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。 + +字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是) + +题目数据保证答案符合 32 位带符号整数范围。 + + + +提示: + +0 <= s.length, t.length <= 1000 +s 和 t 由英文字母组成 + +## 思路 + +这道题目如果不是子序列,而是要求连续序列的,那就可以考虑用KMP。 + +这道题目相对于72. 编辑距离,简单了不少,因为本题相当于只有删除操作,不用考虑替换增加之类的。 + +但相对于刚讲过的[动态规划:392.判断子序列](https://mp.weixin.qq.com/s/2pjT4B4fjfOx5iB6N6xyng)就有难度了,这道题目双指针法可就做不了了,来看看动规五部曲分析如下: + +1. 确定dp数组(dp table)以及下标的含义 + +dp[i][j]:以i-1为结尾的s子序列中出现以j-1为结尾的t的个数为dp[i][j]。 + +2. 确定递推公式 + +这一类问题,基本是要分析两种情况 + +* s[i - 1] 与 t[j - 1]相等 +* s[i - 1] 与 t[j - 1] 不相等 + +当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。 + +一部分是用s[i - 1]来匹配,那么个数为dp[i - 1][j - 1]。 + +一部分是不用s[i - 1]来匹配,个数为dp[i - 1][j]。 + +这里可能有同学不明白了,为什么还要考虑 不用s[i - 1]来匹配,都相同了指定要匹配啊。 + +例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。 + +当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。 + +所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; + +当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配,即:dp[i - 1][j] + +所以递推公式为:dp[i][j] = dp[i - 1][j]; + +3. dp数组如何初始化 + +从递推公式dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]; 和 dp[i][j] = dp[i - 1][j]; 中可以看出dp[i][0] 和dp[0][j]是一定要初始化的。 + +每次当初始化的时候,都要回顾一下dp[i][j]的定义,不要凭感觉初始化。 + +dp[i][0]表示什么呢? + +dp[i][0] 表示:以i-1为结尾的s可以随便删除元素,出现空字符串的个数。 + +那么dp[i][0]一定都是1,因为也就是把以i-1为结尾的s,删除所有元素,出现空字符串的个数就是1。 + +再来看dp[0][j],dp[0][j]:空字符串s可以随便删除元素,出现以j-1为结尾的字符串t的个数。 + +那么dp[0][j]一定都是0,s如论如何也变成不了t。 + +最后就要看一个特殊位置了,即:dp[0][0] 应该是多少。 + +dp[0][0]应该是1,空字符串s,可以删除0个元素,变成空字符串t。 + +初始化分析完毕,代码如下: + +```C++ +vector
-
-最关键的点是可以通过上一层递归 搭出来的线,进行本次搭线。
-
-图中cur节点为元素4,那么搭线的逻辑代码:(**注意注释中操作1和操作2和图中的对应关系**)
-
-```
-if (cur->left) cur->left->next = cur->right; // 操作1
-if (cur->right) {
- if (cur->next) cur->right->next = cur->next->left; // 操作2
- else cur->right->next = NULL;
-}
-```
-
-理解到这里,使用前序遍历,那么不难写出如下代码:
-
-如果对二叉树的前中后序不了解看这篇:[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)
-
-
-```
-class Solution {
-private:
- void traversal(Node* cur) {
- if (cur == NULL) return;
- // 中
- if (cur->left) cur->left->next = cur->right; // 操作1
- if (cur->right) {
- if (cur->next) cur->right->next = cur->next->left; // 操作2
- else cur->right->next = NULL;
- }
- traversal(cur->left); // 左
- traversal(cur->right); // 右
- }
-public:
- Node* connect(Node* root) {
- traversal(root);
- return root;
- }
-};
-```
-
-### 迭代(层序遍历)
-
-本题使用层序遍历是最为直观的,如果对层序遍历不了解,看这篇:[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)。
-
-层序遍历本来就是一层一层的去遍历,记录一层的头结点(nodePre),然后让nodePre指向当前遍历的节点就可以了。
-
-代码如下:
-
-```
-
-class Solution {
-public:
- Node* connect(Node* root) {
- queue
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +## 121. 买卖股票的最佳时机 + +题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/ + +给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 + +你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 + +返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。 + +示例 1: +输入:[7,1,5,3,6,4] +输出:5 +解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。 + +示例 2: +输入:prices = [7,6,4,3,1] +输出:0 +解释:在这种情况下, 没有交易完成, 所以最大利润为 0。 + + +## 思路 + +### 暴力 + +这道题目最直观的想法,就是暴力,找最优间距了。 + +``` +class Solution { +public: + int maxProfit(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 122.买卖股票的最佳时机II + +## 122.买卖股票的最佳时机II 题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/ @@ -11,35 +18,35 @@ 注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 -示例 1: -输入: [7,1,5,3,6,4] -输出: 7 -解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。 +示例 1: +输入: [7,1,5,3,6,4] +输出: 7 +解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。 -示例 2: -输入: [1,2,3,4,5] -输出: 4 +示例 2: +输入: [1,2,3,4,5] +输出: 4 解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 -示例 3: -输入: [7,6,4,3,1] -输出: 0 -解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。 +示例 3: +输入: [7,6,4,3,1] +输出: 0 +解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。 -提示: +提示: * 1 <= prices.length <= 3 * 10 ^ 4 * 0 <= prices[i] <= 10 ^ 4 -# 思路 +## 思路 本题首先要清楚两点: * 只有一只股票! -* 当前只有买股票或者买股票的操作 +* 当前只有买股票或者买股票的操作 想获得利润至少要两天为一个交易单元。 -## 贪心算法 +## 贪心算法 这道题目可能我们只会想,选一个低的买入,在选个高的卖,在选一个低的买入.....循环反复。 @@ -88,7 +95,7 @@ public: * 时间复杂度O(n) * 空间复杂度O(1) -## 动态规划 +## 动态规划 动态规划将在下一个系列详细讲解,本题解先给出我的C++代码(带详细注释),感兴趣的同学可以自己先学习一下。 @@ -114,7 +121,7 @@ public: * 时间复杂度O(n) * 空间复杂度O(n) -# 总结 +## 总结 股票问题其实是一个系列的,属于动态规划的范畴,因为目前在讲解贪心系列,所以股票问题会在之后的动态规划系列中详细讲解。 @@ -122,13 +129,24 @@ public: **本题中理解利润拆分是关键点!** 不要整块的去看,而是把整体利润拆为每天的利润。 -一旦想到这里了,很自然就会想到贪心了,即:只收集每天的正利润,最后稳稳的就是最大利润了。 +一旦想到这里了,很自然就会想到贪心了,即:只收集每天的正利润,最后稳稳的就是最大利润了。 -就酱,「代码随想录」是技术公众号里的一抹清流,值得推荐给你的朋友同学们! +## 其他语言版本 -> **我是[程序员Carl](https://github.com/youngyangyang04),可以找我[组队刷题](https://img-blog.csdnimg.cn/20201115103410182.png),也可以在[B站上找到我](https://space.bilibili.com/525438321),本文[leetcode刷题攻略](https://github.com/youngyangyang04/leetcode-master)已收录,更多[精彩算法文章](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzUxNjY5NTYxNA==&action=getalbum&album_id=1485825793120387074&scene=173#wechat_redirect)尽在公众号:[代码随想录](https://img-blog.csdnimg.cn/20201124161234338.png),关注后就会发现和「代码随想录」相见恨晚!** -**如果感觉题解对你有帮助,不要吝啬给一个👍吧!** +Java: + + +Python: + + +Go: + +----------------------- +* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw) +* B站视频:[代码随想录](https://space.bilibili.com/525438321) +* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) +
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +## 122.买卖股票的最佳时机II + +题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/ + +给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。 + +设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。 + +注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 + + +示例 1: +输入: [7,1,5,3,6,4] +输出: 7 +解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。 + +示例 2: +输入: [1,2,3,4,5] +输出: 4 +解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 + +示例 3: +输入: [7,6,4,3,1] +输出: 0 +解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。 + +提示: +* 1 <= prices.length <= 3 * 10 ^ 4 +* 0 <= prices[i] <= 10 ^ 4 + +## 思路 + +本题我们在讲解贪心专题的时候就已经讲解过了[贪心算法:买卖股票的最佳时机II](https://mp.weixin.qq.com/s/VsTFA6U96l18Wntjcg3fcg),只不过没有深入讲解动态规划的解法,那么这次我们再好好分析一下动规的解法。 + + +本题和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)的唯一区别本题股票可以买卖多次了(注意只有一只股票,所以再次购买前要出售掉之前的股票) + +**在动规五部曲中,这个区别主要是体现在递推公式上,其他都和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)一样一样的**。 + +所以我们重点讲一讲递推公式。 + +这里重申一下dp数组的含义: + +* dp[i][0] 表示第i天持有股票所得现金。 +* dp[i][1] 表示第i天不持有股票所得最多现金 + + +如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来 +* 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0] +* 第i天买入股票,所得现金就是昨天不持有股票的所得现金减去 今天的股票价格 即:dp[i - 1][1] - prices[i] + + +**注意这里和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)唯一不同的地方,就是推导dp[i][0]的时候,第i天买入股票的情况**。 + +在[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)中,因为股票全程只能买卖一次,所以如果买入股票,那么第i天持有股票即dp[i][0]一定就是 -prices[i]。 + +而本题,因为一只股票可以买卖多次,所以当第i天买入股票的时候,所持有的现金可能有之前买卖过的利润。 + +那么第i天持有股票即dp[i][0],如果是第i天买入股票,所得现金就是昨天不持有股票的所得现金 减去 今天的股票价格 即:dp[i - 1][1] - prices[i]。 + +在来看看如果第i天不持有股票即dp[i][1]的情况, 依然可以由两个状态推出来 +* 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1] +* 第i天卖出股票,所得现金就是按照今天股票佳价格卖出后所得现金即:prices[i] + dp[i - 1][0] + +**注意这里和[121. 买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ)就是一样的逻辑,卖出股票收获利润(可能是负值)天经地义!** + +代码如下:(注意代码中的注释,标记了和121.买卖股票的最佳时机唯一不同的地方) + +```C++ +class Solution { +public: + int maxProfit(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ +## 123.买卖股票的最佳时机III + +题目链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-iii/ + + +给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。 + +设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。 + +注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 + +示例 1: +输入:prices = [3,3,5,0,0,3,1,4] +输出:6 +解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3。 + +示例 2: +输入:prices = [1,2,3,4,5] +输出:4 +解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 + +示例 3: +输入:prices = [7,6,4,3,1] +输出:0 +解释:在这个情况下, 没有交易完成, 所以最大利润为0。 + +示例 4: +输入:prices = [1] +输出:0 + +提示: + +* 1 <= prices.length <= 10^5 +* 0 <= prices[i] <= 10^5 + +## 思路 + + +这道题目相对 [121.买卖股票的最佳时机](https://mp.weixin.qq.com/s/keWo5qYJY4zmHn3amfXdfQ) 和 [122.买卖股票的最佳时机II](https://mp.weixin.qq.com/s/d4TRWFuhaY83HPa6t5ZL-w) 难了不少。 + +关键在于至多买卖两次,这意味着可以买卖一次,可以买卖两次,也可以不买卖。 + +接来下我用动态规划五部曲详细分析一下: + +1. 确定dp数组以及下标的含义 + +一天一共就有五个状态, +0. 没有操作 +1. 第一次买入 +2. 第一次卖出 +3. 第二次买入 +4. 第二次卖出 + +dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金。 + +2. 确定递推公式 + +需要注意:dp[i][1],**表示的是第i天,买入股票的状态,并不是说一定要第i天买入股票,这是很多同学容易陷入的误区**。 + +达到dp[i][1]状态,有两个具体操作: + +* 操作一:第i天买入股票了,那么dp[i][1] = dp[i-1][0] - prices[i] +* 操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1] + +那么dp[i][1]究竟选 dp[i-1][0] - prices[i],还是dp[i - 1][1]呢? + +一定是选最大的,所以 dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]); + +同理dp[i][2]也有两个操作: + +* 操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i] +* 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2] + +所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2]) + +同理可推出剩下状态部分: + +dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]); +dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]); + + +3. dp数组如何初始化 + +第0天没有操作,这个最容易想到,就是0,即:dp[0][0] = 0; + +第0天做第一次买入的操作,dp[0][1] = -prices[0]; + +第0天做第一次卖出的操作,这个初始值应该是多少呢? + +首先卖出的操作一定是收获利润,整个股票买卖最差情况也就是没有盈利即全程无操作现金为0, + +从递推公式中可以看出每次是取最大值,那么既然是收获利润如果比0还小了就没有必要收获这个利润了。 + +所以dp[0][2] = 0; + +第0天第二次买入操作,初始值应该是多少呢? + +不用管第几次,现在手头上没有现金,只要买入,现金就做相应的减少。 + +所以第二次买入操作,初始化为:dp[0][3] = -prices[0]; + +同理第二次卖出初始化dp[0][4] = 0; + +4. 确定遍历顺序 + +从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。 + +5. 举例推导dp数组 + +以输入[1,2,3,4,5]为例 + +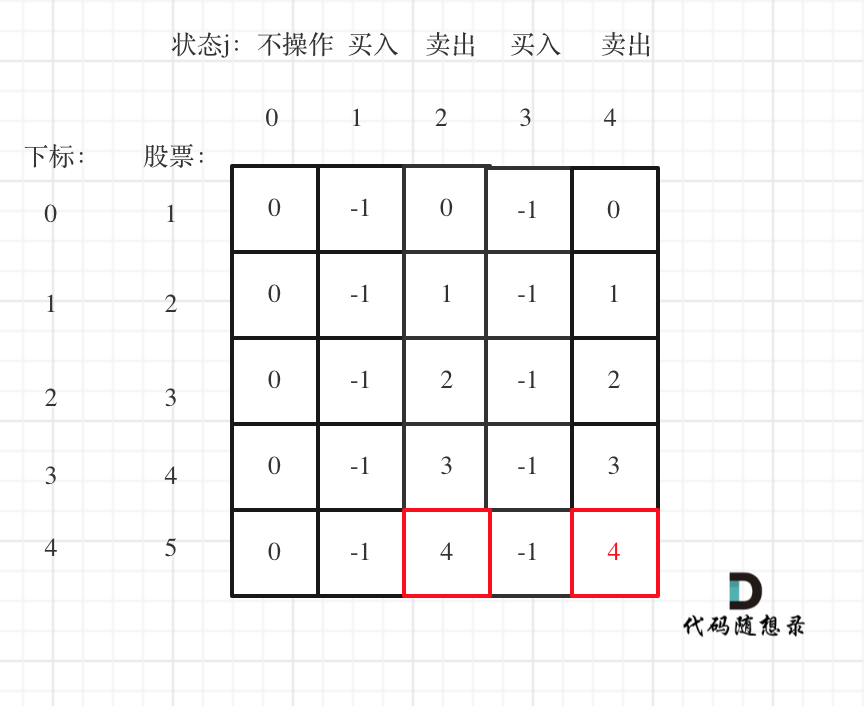 + +大家可以看到红色框为最后两次卖出的状态。 + +现在最大的时候一定是卖出的状态,而两次卖出的状态现金最大一定是最后一次卖出。 + +所以最终最大利润是dp[4][4] + +以上五部都分析完了,不难写出如下代码: + +```C++ +// 版本一 +class Solution { +public: + int maxProfit(vector  -
-本题只需要求出最短长度就可以了,不用找出路径。
-
-所以这道题要解决两个问题:
-
-* 图中的线是如何连在一起的
-* 起点和终点的最短路径长度
-
-
-首先题目中并没有给出点与点之间的连线,而是要我们自己去连,条件是字符只能差一个,所以判断点与点之间的关系,要自己判断是不是差一个字符,如果差一个字符,那就是有链接。
-
-然后就是求起点和终点的最短路径长度,**这里无向图求最短路,广搜最为合适,广搜只要搜到了终点,那么一定是最短的路径**。因为广搜就是以起点中心向四周扩散的搜索。
-
-本题如果用深搜,会非常麻烦。
-
-另外需要有一个注意点:
-
-* 本题是一个无向图,需要用标记位,标记着节点是否走过,否则就会死循环!
-* 本题给出集合是数组型的,可以转成set结构,查找更快一些
-
-C++代码如下:(详细注释)
-
-```
-class Solution {
-public:
- int ladderLength(string beginWord, string endWord, vector
-
-本题只需要求出最短长度就可以了,不用找出路径。
-
-所以这道题要解决两个问题:
-
-* 图中的线是如何连在一起的
-* 起点和终点的最短路径长度
-
-
-首先题目中并没有给出点与点之间的连线,而是要我们自己去连,条件是字符只能差一个,所以判断点与点之间的关系,要自己判断是不是差一个字符,如果差一个字符,那就是有链接。
-
-然后就是求起点和终点的最短路径长度,**这里无向图求最短路,广搜最为合适,广搜只要搜到了终点,那么一定是最短的路径**。因为广搜就是以起点中心向四周扩散的搜索。
-
-本题如果用深搜,会非常麻烦。
-
-另外需要有一个注意点:
-
-* 本题是一个无向图,需要用标记位,标记着节点是否走过,否则就会死循环!
-* 本题给出集合是数组型的,可以转成set结构,查找更快一些
-
-C++代码如下:(详细注释)
-
-```
-class Solution {
-public:
- int ladderLength(string beginWord, string endWord, vector -
-代码如下:
-
-```
- // 中
-if (cur->left) { // 左 (空节点不遍历)
- path.push_back(cur->left->val);
- traversal(cur->left); // 递归
- path.pop_back(); // 回溯
-}
-if (cur->right) { // 右 (空节点不遍历)
- path.push_back(cur->right->val);
- traversal(cur->right); // 递归
- path.pop_back(); // 回溯
-}
-```
-
-这里要注意回溯和递归要永远在一起,一个递归,对应一个回溯,是一对一的关系,有的同学写成如下代码:
-
-```
-if (cur->left) { // 左 (空节点不遍历)
- path.push_back(cur->left->val);
- traversal(cur->left); // 递归
-}
-if (cur->right) { // 右 (空节点不遍历)
- path.push_back(cur->right->val);
- traversal(cur->right); // 递归
-}
-path.pop_back(); // 回溯
-```
-**把回溯放在花括号外面了,世界上最遥远的距离,是你在花括号里,而我在花括号外!** 这就不对了。
-
-### 整体C++代码
-
-关键逻辑分析完了,整体C++代码如下:
-
-```
-class Solution {
-private:
- int result;
- vector
-
-代码如下:
-
-```
- // 中
-if (cur->left) { // 左 (空节点不遍历)
- path.push_back(cur->left->val);
- traversal(cur->left); // 递归
- path.pop_back(); // 回溯
-}
-if (cur->right) { // 右 (空节点不遍历)
- path.push_back(cur->right->val);
- traversal(cur->right); // 递归
- path.pop_back(); // 回溯
-}
-```
-
-这里要注意回溯和递归要永远在一起,一个递归,对应一个回溯,是一对一的关系,有的同学写成如下代码:
-
-```
-if (cur->left) { // 左 (空节点不遍历)
- path.push_back(cur->left->val);
- traversal(cur->left); // 递归
-}
-if (cur->right) { // 右 (空节点不遍历)
- path.push_back(cur->right->val);
- traversal(cur->right); // 递归
-}
-path.pop_back(); // 回溯
-```
-**把回溯放在花括号外面了,世界上最遥远的距离,是你在花括号里,而我在花括号外!** 这就不对了。
-
-### 整体C++代码
-
-关键逻辑分析完了,整体C++代码如下:
-
-```
-class Solution {
-private:
- int result;
- vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ > 切割问题其实是一种组合问题! -# 131.分割回文串 +## 131.分割回文串 题目链接:https://leetcode-cn.com/problems/palindrome-partitioning/ @@ -9,16 +17,18 @@ 返回 s 所有可能的分割方案。 -示例: -输入: "aab" -输出: -[ - ["aa","b"], - ["a","a","b"] -] +示例: +输入: "aab" +输出: +[ + ["aa","b"], + ["a","a","b"] +] -# 思路 +## 思路 + +关于本题,大家也可以看我在B站的视频讲解:[131.分割回文串(B站视频)](https://www.bilibili.com/video/BV1c54y1e7k6) 本题这涉及到两个关键问题: @@ -29,9 +39,9 @@ 这种题目,想用for循环暴力解法,可能都不那么容易写出来,所以要换一种暴力的方式,就是回溯。 -一些同学可能想不清楚 回溯究竟是如果切割字符串呢? +一些同学可能想不清楚 回溯究竟是如何切割字符串呢? -我们来分析一下切割,**其实切割问题类似组合问题**。 +我们来分析一下切割,**其实切割问题类似组合问题**。 例如对于字符串abcdef: @@ -42,15 +52,15 @@ 所以切割问题,也可以抽象为一颗树形结构,如图: -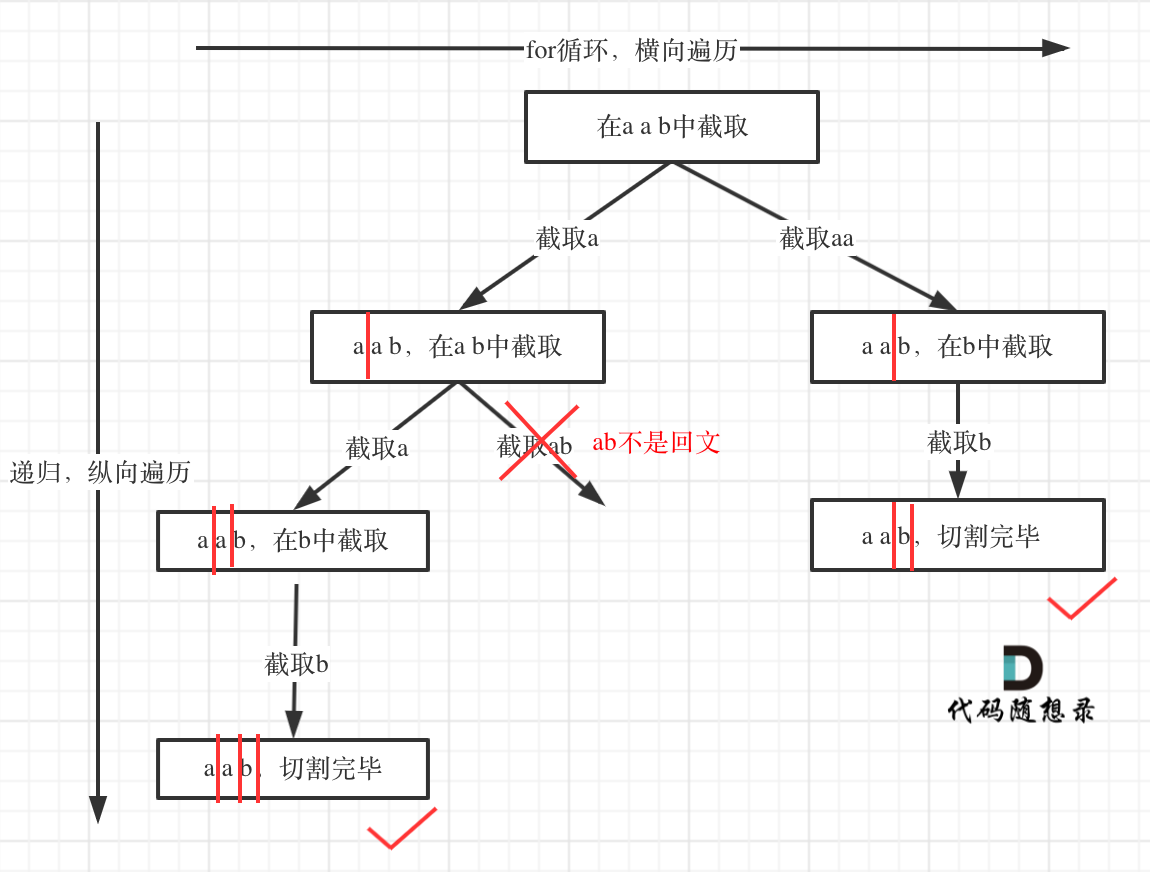 +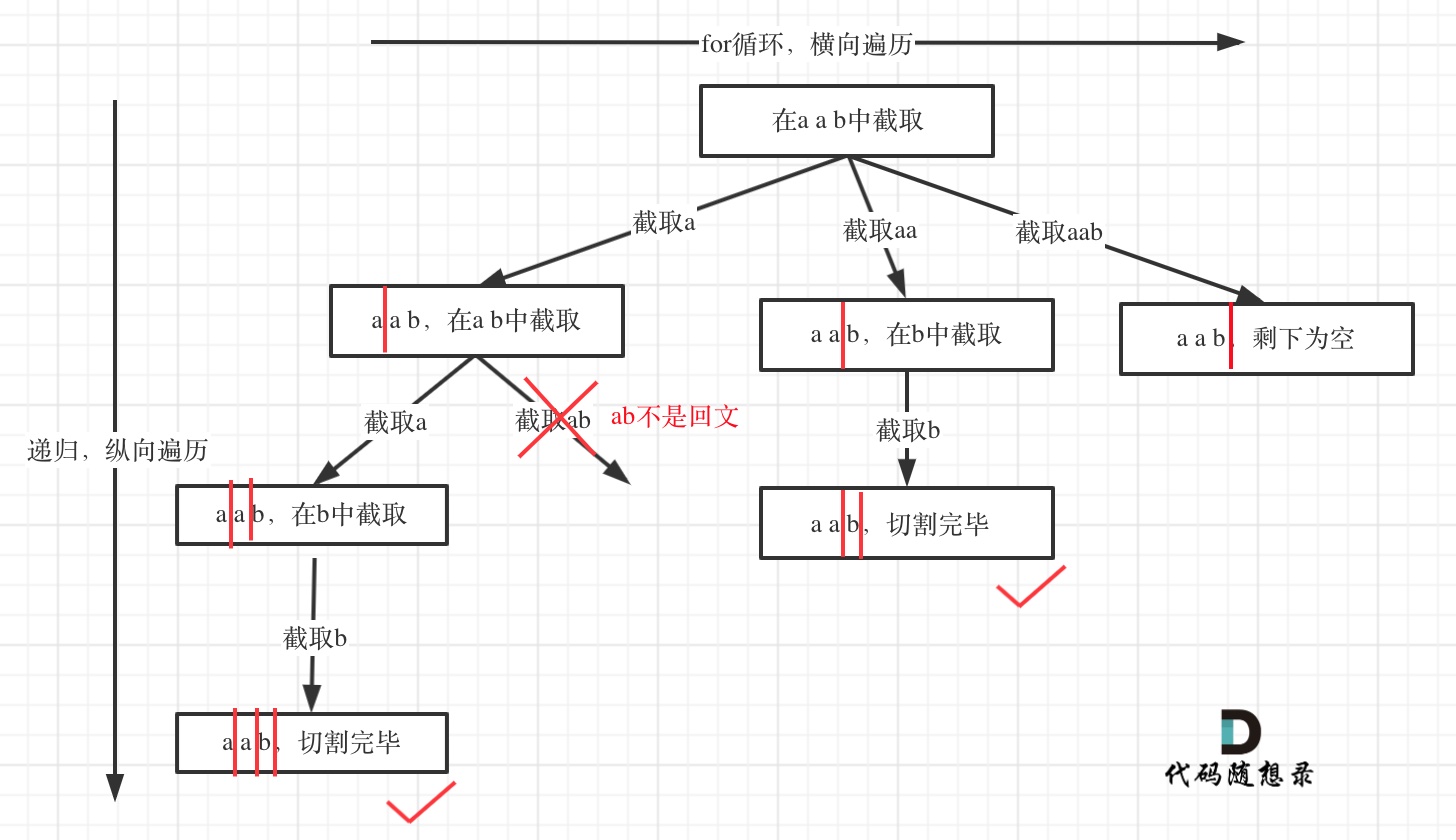 递归用来纵向遍历,for循环用来横向遍历,切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。 此时可以发现,切割问题的回溯搜索的过程和组合问题的回溯搜索的过程是差不多的。 -## 回溯三部曲 +## 回溯三部曲 -* 递归函数参数 +* 递归函数参数 全局变量数组path存放切割后回文的子串,二维数组result存放结果集。 (这两个参数可以放到函数参数里) @@ -60,7 +70,7 @@ 代码如下: -``` +```C++ vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 134. 加油站 + +## 134. 加油站 题目链接:https://leetcode-cn.com/problems/gas-station/ @@ -16,38 +23,37 @@ * 输入数组均为非空数组,且长度相同。 * 输入数组中的元素均为非负数。 -示例 1: -输入: -gas = [1,2,3,4,5] -cost = [3,4,5,1,2] +示例 1: +输入: +gas = [1,2,3,4,5] +cost = [3,4,5,1,2] -输出: 3 -解释: -从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 -开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 -开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 -开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 -开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 -开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。 -因此,3 可为起始索引。 +输出: 3 +解释: +从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 +开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 +开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 +开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 +开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 +开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。 +因此,3 可为起始索引。 -示例 2: -输入: -gas = [2,3,4] -cost = [3,4,3] +示例 2: +输入: +gas = [2,3,4] +cost = [3,4,3] -输出: -1 -解释: -你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。 -我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油 -开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油 -开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油 -你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。 -因此,无论怎样,你都不可能绕环路行驶一周。 +输出: -1 +解释: +你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。 +我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油 +开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油 +开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油 +你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。 +因此,无论怎样,你都不可能绕环路行驶一周。 -# 思路 -## 暴力方法 +## 暴力方法 暴力的方法很明显就是O(n^2)的,遍历每一个加油站为起点的情况,模拟一圈。 @@ -59,7 +65,7 @@ cost = [3,4,3] C++代码如下: -``` +```C++ class Solution { public: int canCompleteCircuit(vector
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 135. 分发糖果 +## 135. 分发糖果 -链接:https://leetcode-cn.com/problems/candy/ +链接:https://leetcode-cn.com/problems/candy/ 老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。 你需要按照以下要求,帮助老师给这些孩子分发糖果: -* 每个孩子至少分配到 1 个糖果。 +* 每个孩子至少分配到 1 个糖果。 * 相邻的孩子中,评分高的孩子必须获得更多的糖果。 那么这样下来,老师至少需要准备多少颗糖果呢? -示例 1: -输入: [1,0,2] -输出: 5 -解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。 +示例 1: +输入: [1,0,2] +输出: 5 +解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。 -示例 2: -输入: [1,2,2] -输出: 4 -解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。 -第三个孩子只得到 1 颗糖果,这已满足上述两个条件。 +示例 2: +输入: [1,2,2] +输出: 4 +解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。 +第三个孩子只得到 1 颗糖果,这已满足上述两个条件。 -# 思路 +## 思路 这道题目一定是要确定一边之后,再确定另一边,例如比较每一个孩子的左边,然后再比较右边,**如果两边一起考虑一定会顾此失彼**。 @@ -37,12 +43,12 @@ 局部最优可以推出全局最优。 -如果ratings[i] > ratings[i - 1] 那么[i]的糖 一定要比[i - 1]的糖多一个,所以贪心:candyVec[i] = candyVec[i - 1] + 1 +如果ratings[i] > ratings[i - 1] 那么[i]的糖 一定要比[i - 1]的糖多一个,所以贪心:candyVec[i] = candyVec[i - 1] + 1 代码如下: ```C++ -// 从前向后 +// 从前向后 for (int i = 1; i < ratings.size(); i++) { if (ratings[i] > ratings[i - 1]) candyVec[i] = candyVec[i - 1] + 1; } @@ -52,13 +58,13 @@ for (int i = 1; i < ratings.size(); i++) { 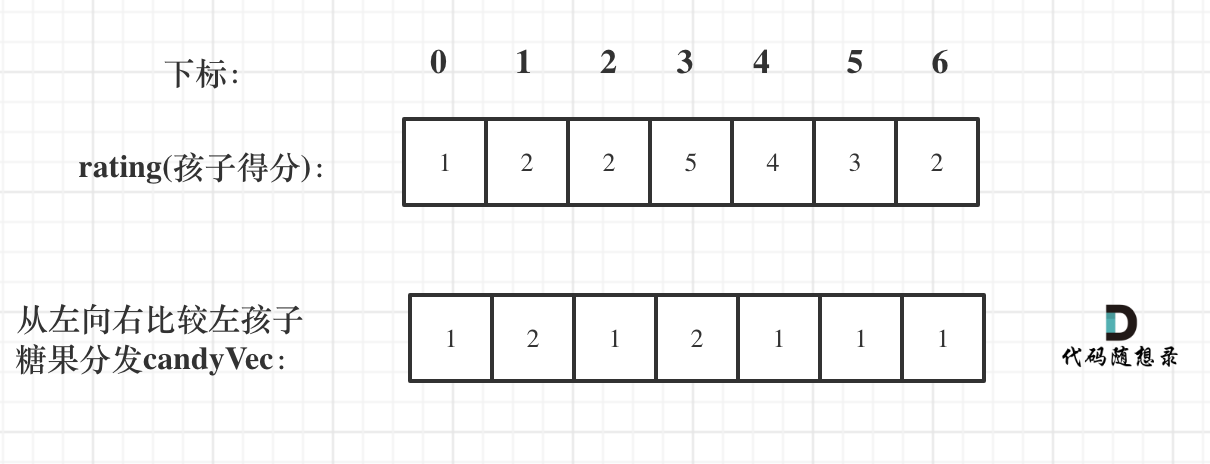 -再确定左孩子大于右孩子的情况(从后向前遍历) +再确定左孩子大于右孩子的情况(从后向前遍历) -遍历顺序这里有同学可能会有疑问,为什么不能从前向后遍历呢? +遍历顺序这里有同学可能会有疑问,为什么不能从前向后遍历呢? -因为如果从前向后遍历,根据 ratings[i + 1] 来确定 ratings[i] 对应的糖果,那么每次都不能利用上前一次的比较结果了。 +因为如果从前向后遍历,根据 ratings[i + 1] 来确定 ratings[i] 对应的糖果,那么每次都不能利用上前一次的比较结果了。 -**所以确定左孩子大于右孩子的情况一定要从后向前遍历!** +**所以确定左孩子大于右孩子的情况一定要从后向前遍历!** 如果 ratings[i] > ratings[i + 1],此时candyVec[i](第i个小孩的糖果数量)就有两个选择了,一个是candyVec[i + 1] + 1(从右边这个加1得到的糖果数量),一个是candyVec[i](之前比较右孩子大于左孩子得到的糖果数量)。 @@ -107,7 +113,7 @@ public: }; ``` -# 总结 +## 总结 这在leetcode上是一道困难的题目,其难点就在于贪心的策略,如果在考虑局部的时候想两边兼顾,就会顾此失彼。 @@ -118,11 +124,24 @@ public: 这样从局部最优推出了全局最优,即:相邻的孩子中,评分高的孩子获得更多的糖果。 -就酱,如果感觉「代码随想录」干货满满,就推荐给身边的朋友同学们吧,关注后就会发现相见恨晚! -> **我是[程序员Carl](https://github.com/youngyangyang04),[组队刷题](https://img-blog.csdnimg.cn/20201115103410182.png)可以找我,本文[leetcode刷题攻略](https://github.com/youngyangyang04/leetcode-master)已收录,更多[精彩算法文章](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzUxNjY5NTYxNA==&action=getalbum&album_id=1485825793120387074&scene=173#wechat_redirect)尽在:[代码随想录](https://img-blog.csdnimg.cn/20200815195519696.png),关注后就会发现和「代码随想录」相见恨晚!** - -**如果感觉题解对你有帮助,不要吝啬给一个👍吧!** +## 其他语言版本 +Java: + + +Python: + + +Go: + + + + +----------------------- +* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw) +* B站视频:[代码随想录](https://space.bilibili.com/525438321) +* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) +
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+# 动态规划:单词拆分 -// 如何往 完全背包上靠? -// 用多次倒是可以往 完全背包上靠一靠 -// 和单词分割的问题有点像 +## 139.单词拆分 -[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q) +题目链接:https://leetcode-cn.com/problems/word-break/ -回溯法代码: -``` +给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。 + +说明: + +拆分时可以重复使用字典中的单词。 + +你可以假设字典中没有重复的单词。 + +示例 1: +输入: s = "leetcode", wordDict = ["leet", "code"] +输出: true +解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。 + +示例 2: +输入: s = "applepenapple", wordDict = ["apple", "pen"] +输出: true +解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。 + 注意你可以重复使用字典中的单词。 + +示例 3: +输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] +输出: false + +## 思路 + +看到这道题目的时候,大家应该回想起我们之前讲解回溯法专题的时候,讲过的一道题目[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q),就是枚举字符串的所有分割情况。 + +[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q):是枚举分割后的所有子串,判断是否回文。 + +本道是枚举分割所有字符串,判断是否在字典里出现过。 + +那么这里我也给出回溯法C++代码: + +```C++ class Solution { private: bool backtracking (const string& s, const unordered_set  -
-fast和slow各自再走一步, fast和slow就相遇了
-
-这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
-
-动画如下:
-
-
-
-
-fast和slow各自再走一步, fast和slow就相遇了
-
-这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
-
-动画如下:
-
-
- -
-
-## C++代码如下
-
-```
-class Solution {
-public:
- bool hasCycle(ListNode *head) {
- ListNode* fast = head;
- ListNode* slow = head;
- while(fast != NULL && fast->next != NULL) {
- slow = slow->next;
- fast = fast->next->next;
- // 快慢指针相遇,说明有环
- if (slow == fast) return true;
- }
- return false;
- }
-};
-```
-## 扩展
-
-做完这道题目,可以在做做142.环形链表II,不仅仅要找环,还要找环的入口。
-
-142.环形链表II题解:[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)
diff --git a/problems/0142.环形链表II.md b/problems/0142.环形链表II.md
index 48aaed93..9622affc 100644
--- a/problems/0142.环形链表II.md
+++ b/problems/0142.环形链表II.md
@@ -1,11 +1,20 @@
+
-
-
-## C++代码如下
-
-```
-class Solution {
-public:
- bool hasCycle(ListNode *head) {
- ListNode* fast = head;
- ListNode* slow = head;
- while(fast != NULL && fast->next != NULL) {
- slow = slow->next;
- fast = fast->next->next;
- // 快慢指针相遇,说明有环
- if (slow == fast) return true;
- }
- return false;
- }
-};
-```
-## 扩展
-
-做完这道题目,可以在做做142.环形链表II,不仅仅要找环,还要找环的入口。
-
-142.环形链表II题解:[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)
diff --git a/problems/0142.环形链表II.md b/problems/0142.环形链表II.md
index 48aaed93..9622affc 100644
--- a/problems/0142.环形链表II.md
+++ b/problems/0142.环形链表II.md
@@ -1,11 +1,20 @@
+
+
+
+
+
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+ + + > 找到有没有环已经很不容易了,还要让我找到环的入口? -# 题目地址 + +## 142.环形链表II + https://leetcode-cn.com/problems/linked-list-cycle-ii/ - -# 第142题.环形链表II - 题意: 给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。 @@ -15,7 +24,7 @@ https://leetcode-cn.com/problems/linked-list-cycle-ii/ 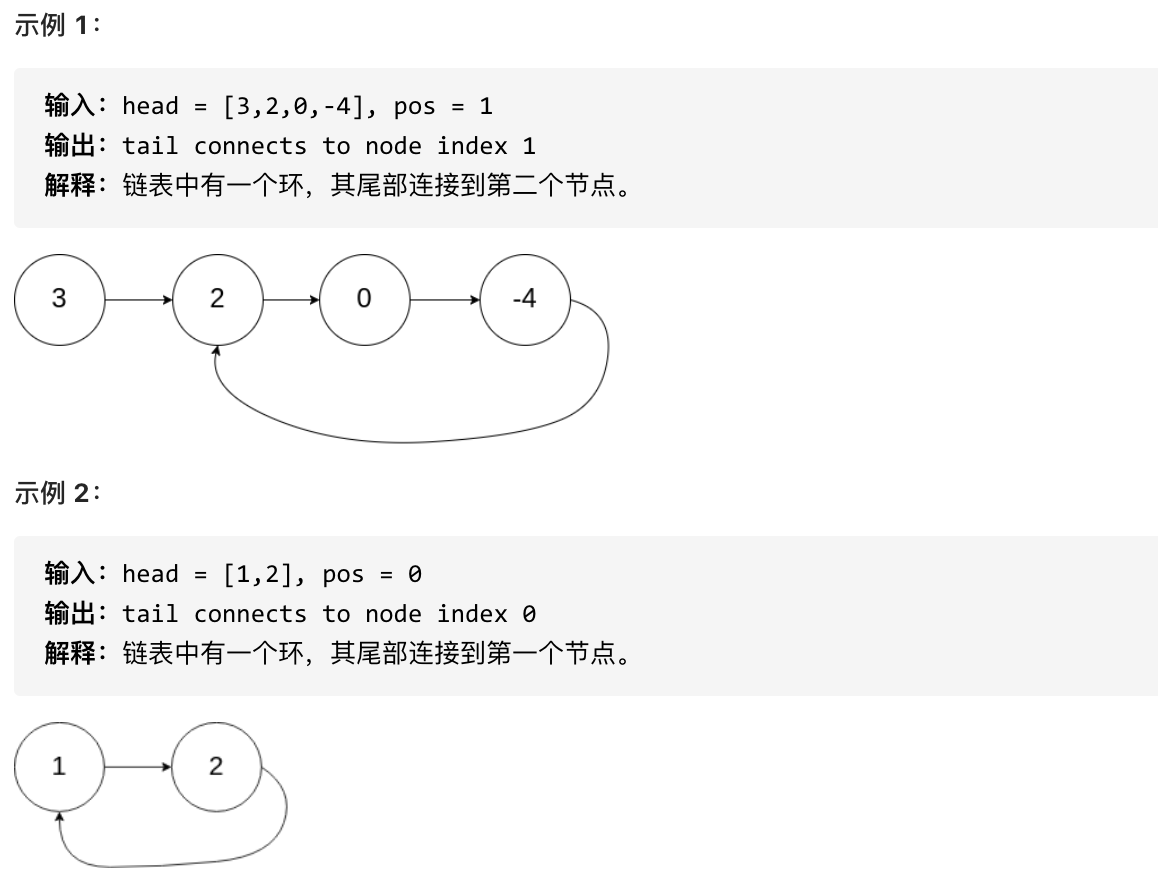 -# 思路 +## 思路 这道题目,不仅考察对链表的操作,而且还需要一些数学运算。 @@ -24,7 +33,7 @@ https://leetcode-cn.com/problems/linked-list-cycle-ii/ * 判断链表是否环 * 如果有环,如何找到这个环的入口 -## 判断链表是否有环 +### 判断链表是否有环 可以使用快慢指针法, 分别定义 fast 和 slow指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。 @@ -34,11 +43,12 @@ https://leetcode-cn.com/problems/linked-list-cycle-ii/ 那么来看一下,**为什么fast指针和slow指针一定会相遇呢?** -可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。 +可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。 会发现最终都是这种情况, 如下图: -
+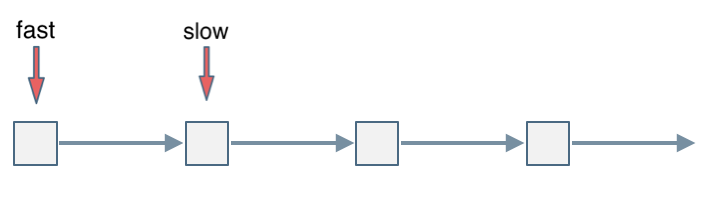
+
fast和slow各自再走一步, fast和slow就相遇了
@@ -46,11 +56,10 @@ fast和slow各自再走一步, fast和slow就相遇了
动画如下:
-
-
+
-## 如果有环,如何找到这个环的入口
+### 如果有环,如何找到这个环的入口
**此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。**
@@ -58,7 +67,7 @@ fast和slow各自再走一步, fast和slow就相遇了
环形入口节点到 fast指针与slow指针相遇节点 节点数为y。
从相遇节点 再到环形入口节点节点数为 z。 如图所示:
- +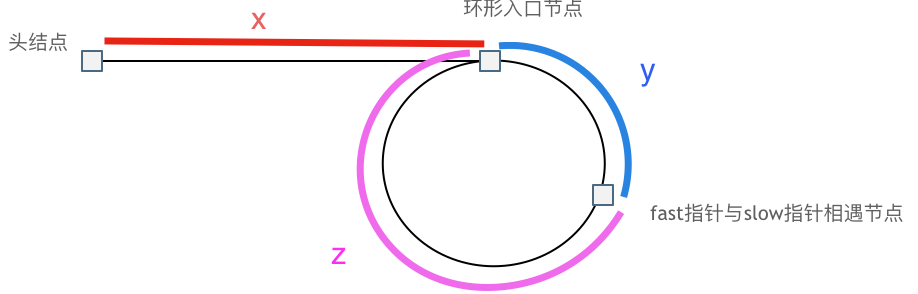
那么相遇时:
slow指针走过的节点数为: `x + y`,
@@ -68,9 +77,9 @@ fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走
`(x + y) * 2 = x + y + n (y + z)`
-两边消掉一个(x+y): `x + y = n (y + z) `
+两边消掉一个(x+y): `x + y = n (y + z) `
-因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
+因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
所以要求x ,将x单独放在左面:`x = n (y + z) - y` ,
@@ -78,7 +87,7 @@ fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走
这个公式说明什么呢?
-先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
+先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
当 n为1的时候,公式就化解为 `x = z`,
@@ -91,17 +100,16 @@ fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走
动画如下:
-
+
那么相遇时:
slow指针走过的节点数为: `x + y`,
@@ -68,9 +77,9 @@ fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走
`(x + y) * 2 = x + y + n (y + z)`
-两边消掉一个(x+y): `x + y = n (y + z) `
+两边消掉一个(x+y): `x + y = n (y + z) `
-因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
+因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
所以要求x ,将x单独放在左面:`x = n (y + z) - y` ,
@@ -78,7 +87,7 @@ fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走
这个公式说明什么呢?
-先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
+先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
当 n为1的时候,公式就化解为 `x = z`,
@@ -91,17 +100,16 @@ fast指针走过的节点数:` x + y + n (y + z)`,n为fast指针在环内走
动画如下:
-.gif) +
-那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
+那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
+代码如下:
-# C++代码
-
-```
+```C++
/**
* Definition for singly-linked list.
* struct ListNode {
@@ -136,32 +144,32 @@ public:
## 补充
-在推理过程中,大家可能有一个疑问就是:**为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y 呢?**
+在推理过程中,大家可能有一个疑问就是:**为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y 呢?**
即文章[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)中如下的地方:
-
+
-那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
+那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
+代码如下:
-# C++代码
-
-```
+```C++
/**
* Definition for singly-linked list.
* struct ListNode {
@@ -136,32 +144,32 @@ public:
## 补充
-在推理过程中,大家可能有一个疑问就是:**为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y 呢?**
+在推理过程中,大家可能有一个疑问就是:**为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y 呢?**
即文章[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)中如下的地方:
- +
首先slow进环的时候,fast一定是先进环来了。
如果slow进环入口,fast也在环入口,那么把这个环展开成直线,就是如下图的样子:
-
+
首先slow进环的时候,fast一定是先进环来了。
如果slow进环入口,fast也在环入口,那么把这个环展开成直线,就是如下图的样子:
- +
可以看出如果slow 和 fast同时在环入口开始走,一定会在环入口3相遇,slow走了一圈,fast走了两圈。
重点来了,slow进环的时候,fast一定是在环的任意一个位置,如图:
-
+
可以看出如果slow 和 fast同时在环入口开始走,一定会在环入口3相遇,slow走了一圈,fast走了两圈。
重点来了,slow进环的时候,fast一定是在环的任意一个位置,如图:
- +
那么fast指针走到环入口3的时候,已经走了k + n 个节点,slow相应的应该走了(k + n) / 2 个节点。
-因为k是小于n的(图中可以看出),所以(k + n) / 2 一定小于n。
+因为k是小于n的(图中可以看出),所以(k + n) / 2 一定小于n。
**也就是说slow一定没有走到环入口3,而fast已经到环入口3了**。
-这说明什么呢?
+这说明什么呢?
**在slow开始走的那一环已经和fast相遇了**。
@@ -169,9 +177,44 @@ public:
好了,这次把为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y ,用数学推理了一下,算是对[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)的补充。
-# 总结
+## 总结
这次可以说把环形链表这道题目的各个细节,完完整整的证明了一遍,说这是全网最详细讲解不为过吧,哈哈。
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+```python
+class Solution:
+ def detectCycle(self, head: ListNode) -> ListNode:
+ slow, fast = head, head
+ while fast and fast.next:
+ slow = slow.next
+ fast = fast.next.next
+ # 如果相遇
+ if slow == fast:
+ p = head
+ q = slow
+ while p!=q:
+ p = p.next
+ q = q.next
+ #你也可以return q
+ return p
+
+ return None
+```
+
+Go:
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
那么fast指针走到环入口3的时候,已经走了k + n 个节点,slow相应的应该走了(k + n) / 2 个节点。
-因为k是小于n的(图中可以看出),所以(k + n) / 2 一定小于n。
+因为k是小于n的(图中可以看出),所以(k + n) / 2 一定小于n。
**也就是说slow一定没有走到环入口3,而fast已经到环入口3了**。
-这说明什么呢?
+这说明什么呢?
**在slow开始走的那一环已经和fast相遇了**。
@@ -169,9 +177,44 @@ public:
好了,这次把为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y ,用数学推理了一下,算是对[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/_QVP3IkRZWx9zIpQRgajzA)的补充。
-# 总结
+## 总结
这次可以说把环形链表这道题目的各个细节,完完整整的证明了一遍,说这是全网最详细讲解不为过吧,哈哈。
-> 更多算法干货文章持续更新,可以微信搜索「代码随想录」第一时间围观,关注后,回复「Java」「C++」 「python」「简历模板」「数据结构与算法」等等,就可以获得我多年整理的学习资料。
+## 其他语言版本
+
+
+Java:
+
+
+Python:
+
+```python
+class Solution:
+ def detectCycle(self, head: ListNode) -> ListNode:
+ slow, fast = head, head
+ while fast and fast.next:
+ slow = slow.next
+ fast = fast.next.next
+ # 如果相遇
+ if slow == fast:
+ p = head
+ q = slow
+ while p!=q:
+ p = p.next
+ q = q.next
+ #你也可以return q
+ return p
+
+ return None
+```
+
+Go:
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+  -
-这种方法,比较难,平均切割链表,看上去很简单,真正代码写的时候有很多细节,同时两个链表最后拼装整一个新的链表也有一些细节需要注意!
-
-代码如下:
-
-```
-class Solution {
-private:
- // 反转链表
- ListNode* reverseList(ListNode* head) {
- ListNode* temp; // 保存cur的下一个节点
- ListNode* cur = head;
- ListNode* pre = NULL;
- while(cur) {
- temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
- cur->next = pre; // 翻转操作
- // 更新pre 和 cur指针
- pre = cur;
- cur = temp;
- }
- return pre;
- }
-
-public:
- void reorderList(ListNode* head) {
- if (head == nullptr) return;
- // 使用快慢指针法,将链表分成长度均等的两个链表head1和head2
- // 如果总链表长度为奇数,则head1相对head2多一个节点
- ListNode* fast = head;
- ListNode* slow = head;
- while (fast && fast->next && fast->next->next) {
- fast = fast->next->next;
- slow = slow->next;
- }
- ListNode* head1 = head;
- ListNode* head2;
- head2 = slow->next;
- slow->next = nullptr;
-
- // 对head2进行翻转
- head2 = reverseList(head2);
-
- // 将head1和head2交替生成新的链表head
- ListNode* cur1 = head1;
- ListNode* cur2 = head2;
- ListNode* cur = head;
- cur1 = cur1->next;
- int count = 0; // 偶数取head2的元素,奇数取head1的元素
- while (cur1 && cur2) {
- if (count % 2 == 0) {
- cur->next = cur2;
- cur2 = cur2->next;
- } else {
- cur->next = cur1;
- cur1 = cur1->next;
- }
- count++;
- cur = cur->next;
- }
- if (cur2 != nullptr) { // 处理结尾
- cur->next = cur2;
- }
- if (cur1 != nullptr) {
- cur->next = cur1;
- }
- }
-};
-```
diff --git a/problems/0144.二叉树的前序遍历.md b/problems/0144.二叉树的前序遍历.md
deleted file mode 100644
index 7e2e1260..00000000
--- a/problems/0144.二叉树的前序遍历.md
+++ /dev/null
@@ -1,387 +0,0 @@
-# 题目地址
-https://leetcode-cn.com/problems/binary-tree-preorder-traversal/
-
-# 思路
-这篇文章,**彻底讲清楚应该如何写递归,并给出了前中后序三种不同的迭代法,然后分析迭代法的代码风格为什么没有统一,最后给出统一的前中后序迭代法的代码,帮大家彻底吃透二叉树的深度优先遍历。**
-
-对二叉树基础理论还不清楚的话,可以看看这个[关于二叉树,你该了解这些!](https://mp.weixin.qq.com/s/_ymfWYvTNd2GvWvC5HOE4A)。
-
-[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)介绍了二叉树的前后中序的递归遍历方式。
-
-[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)介绍了二叉树的前后中序迭代写法。
-
-[二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg) 介绍了二叉树前中后迭代方式的统一写法。
-
-以下开始开始正文:
-
-* 二叉树深度优先遍历
- * 前序遍历: [0144.二叉树的前序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0144.二叉树的前序遍历.md)
- * 后序遍历: [0145.二叉树的后序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0145.二叉树的后序遍历.md)
- * 中序遍历: [0094.二叉树的中序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0094.二叉树的中序遍历.md)
-* 二叉树广度优先遍历
- * 层序遍历:[0102.二叉树的层序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0102.二叉树的层序遍历.md)
-
-这几道题目建议大家都做一下,本题解先只写二叉树深度优先遍历,二叉树广度优先遍历请看题解[0102.二叉树的层序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0102.二叉树的层序遍历.md)
-
-这里想帮大家一下,明确一下二叉树的遍历规则:
-
-
-
-以上述中,前中后序遍历顺序如下:
-
-* 前序遍历(中左右):5 4 1 2 6 7 8
-* 中序遍历(左中右):1 4 2 5 7 6 8
-* 后序遍历(左右中):1 2 4 7 8 6 5
-
-# 递归法
-
-接下来我们来好好谈一谈递归,为什么很多同学看递归算法都是“一看就会,一写就废”。主要是对递归不成体系,没有方法论,每次写递归算法 ,都是靠玄学来写代码,代码能不能编过都靠运气。
-
-这里帮助大家确定下来递归算法的三个要素。每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
-
-
-1. **确定递归函数的参数和返回值:**
-确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
-
-2. **确定终止条件:**
-写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
-
-3. **确定单层递归的逻辑:**
-确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
-
-好了,我们确认了递归的三要素,接下来就来练练手:
-
-**以下以前序遍历为例:**
-
-1. **确定递归函数的参数和返回值**:因为要打印出前序遍历节点的数值,所以参数里需要传入vector在放节点的数值,除了这一点就不需要在处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
-
-```
-void traversal(TreeNode* cur, vector
-
-这种方法,比较难,平均切割链表,看上去很简单,真正代码写的时候有很多细节,同时两个链表最后拼装整一个新的链表也有一些细节需要注意!
-
-代码如下:
-
-```
-class Solution {
-private:
- // 反转链表
- ListNode* reverseList(ListNode* head) {
- ListNode* temp; // 保存cur的下一个节点
- ListNode* cur = head;
- ListNode* pre = NULL;
- while(cur) {
- temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
- cur->next = pre; // 翻转操作
- // 更新pre 和 cur指针
- pre = cur;
- cur = temp;
- }
- return pre;
- }
-
-public:
- void reorderList(ListNode* head) {
- if (head == nullptr) return;
- // 使用快慢指针法,将链表分成长度均等的两个链表head1和head2
- // 如果总链表长度为奇数,则head1相对head2多一个节点
- ListNode* fast = head;
- ListNode* slow = head;
- while (fast && fast->next && fast->next->next) {
- fast = fast->next->next;
- slow = slow->next;
- }
- ListNode* head1 = head;
- ListNode* head2;
- head2 = slow->next;
- slow->next = nullptr;
-
- // 对head2进行翻转
- head2 = reverseList(head2);
-
- // 将head1和head2交替生成新的链表head
- ListNode* cur1 = head1;
- ListNode* cur2 = head2;
- ListNode* cur = head;
- cur1 = cur1->next;
- int count = 0; // 偶数取head2的元素,奇数取head1的元素
- while (cur1 && cur2) {
- if (count % 2 == 0) {
- cur->next = cur2;
- cur2 = cur2->next;
- } else {
- cur->next = cur1;
- cur1 = cur1->next;
- }
- count++;
- cur = cur->next;
- }
- if (cur2 != nullptr) { // 处理结尾
- cur->next = cur2;
- }
- if (cur1 != nullptr) {
- cur->next = cur1;
- }
- }
-};
-```
diff --git a/problems/0144.二叉树的前序遍历.md b/problems/0144.二叉树的前序遍历.md
deleted file mode 100644
index 7e2e1260..00000000
--- a/problems/0144.二叉树的前序遍历.md
+++ /dev/null
@@ -1,387 +0,0 @@
-# 题目地址
-https://leetcode-cn.com/problems/binary-tree-preorder-traversal/
-
-# 思路
-这篇文章,**彻底讲清楚应该如何写递归,并给出了前中后序三种不同的迭代法,然后分析迭代法的代码风格为什么没有统一,最后给出统一的前中后序迭代法的代码,帮大家彻底吃透二叉树的深度优先遍历。**
-
-对二叉树基础理论还不清楚的话,可以看看这个[关于二叉树,你该了解这些!](https://mp.weixin.qq.com/s/_ymfWYvTNd2GvWvC5HOE4A)。
-
-[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)介绍了二叉树的前后中序的递归遍历方式。
-
-[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)介绍了二叉树的前后中序迭代写法。
-
-[二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg) 介绍了二叉树前中后迭代方式的统一写法。
-
-以下开始开始正文:
-
-* 二叉树深度优先遍历
- * 前序遍历: [0144.二叉树的前序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0144.二叉树的前序遍历.md)
- * 后序遍历: [0145.二叉树的后序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0145.二叉树的后序遍历.md)
- * 中序遍历: [0094.二叉树的中序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0094.二叉树的中序遍历.md)
-* 二叉树广度优先遍历
- * 层序遍历:[0102.二叉树的层序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0102.二叉树的层序遍历.md)
-
-这几道题目建议大家都做一下,本题解先只写二叉树深度优先遍历,二叉树广度优先遍历请看题解[0102.二叉树的层序遍历](https://github.com/youngyangyang04/leetcode/blob/master/problems/0102.二叉树的层序遍历.md)
-
-这里想帮大家一下,明确一下二叉树的遍历规则:
-
-
-
-以上述中,前中后序遍历顺序如下:
-
-* 前序遍历(中左右):5 4 1 2 6 7 8
-* 中序遍历(左中右):1 4 2 5 7 6 8
-* 后序遍历(左右中):1 2 4 7 8 6 5
-
-# 递归法
-
-接下来我们来好好谈一谈递归,为什么很多同学看递归算法都是“一看就会,一写就废”。主要是对递归不成体系,没有方法论,每次写递归算法 ,都是靠玄学来写代码,代码能不能编过都靠运气。
-
-这里帮助大家确定下来递归算法的三个要素。每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
-
-
-1. **确定递归函数的参数和返回值:**
-确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
-
-2. **确定终止条件:**
-写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
-
-3. **确定单层递归的逻辑:**
-确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
-
-好了,我们确认了递归的三要素,接下来就来练练手:
-
-**以下以前序遍历为例:**
-
-1. **确定递归函数的参数和返回值**:因为要打印出前序遍历节点的数值,所以参数里需要传入vector在放节点的数值,除了这一点就不需要在处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
-
-```
-void traversal(TreeNode* cur, vector