mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-14 23:11:37 +08:00
根据身高重建队列~回溯总结更换连接
This commit is contained in:
@ -12,7 +12,7 @@
|
||||
|
||||
# 哈希表理论基础
|
||||
|
||||
在[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg)中,我们介绍了哈希表的基础理论知识,不同于枯燥的讲解,这里介绍了都是对刷题有帮助的理论知识点。
|
||||
在[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html)中,我们介绍了哈希表的基础理论知识,不同于枯燥的讲解,这里介绍了都是对刷题有帮助的理论知识点。
|
||||
|
||||
**一般来说哈希表都是用来快速判断一个元素是否出现集合里**。
|
||||
|
||||
@ -28,7 +28,7 @@
|
||||
* set(集合)
|
||||
* map(映射)
|
||||
|
||||
在C++语言中,set 和 map 都分别提供了三种数据结构,每种数据结构的底层实现和用途都有所不同,在[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg)中我给出了详细分析,这一知识点很重要!
|
||||
在C++语言中,set 和 map 都分别提供了三种数据结构,每种数据结构的底层实现和用途都有所不同,在[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html)中我给出了详细分析,这一知识点很重要!
|
||||
|
||||
例如什么时候用std::set,什么时候用std::multiset,什么时候用std::unordered_set,都是很有考究的。
|
||||
|
||||
@ -40,13 +40,13 @@
|
||||
|
||||
一些应用场景就是为数组量身定做的。
|
||||
|
||||
在[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)中,我们提到了数组就是简单的哈希表,但是数组的大小是受限的!
|
||||
在[242.有效的字母异位词](https://programmercarl.com/0242.有效的字母异位词.html)中,我们提到了数组就是简单的哈希表,但是数组的大小是受限的!
|
||||
|
||||
这道题目包含小写字母,那么使用数组来做哈希最合适不过。
|
||||
|
||||
在[383.赎金信](https://mp.weixin.qq.com/s/qAXqv--UERmiJNNpuphOUQ)中同样要求只有小写字母,那么就给我们浓浓的暗示,用数组!
|
||||
在[383.赎金信](https://programmercarl.com/0383.赎金信.html)中同样要求只有小写字母,那么就给我们浓浓的暗示,用数组!
|
||||
|
||||
本题和[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)很像,[242.有效的字母异位词](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)是求 字符串a 和 字符串b 是否可以相互组成,在[383.赎金信](https://mp.weixin.qq.com/s/qAXqv--UERmiJNNpuphOUQ)中是求字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
|
||||
本题和[242.有效的字母异位词](https://programmercarl.com/0242.有效的字母异位词.html)很像,[242.有效的字母异位词](https://programmercarl.com/0242.有效的字母异位词.html)是求 字符串a 和 字符串b 是否可以相互组成,在[383.赎金信](https://programmercarl.com/0383.赎金信.html)中是求字符串a能否组成字符串b,而不用管字符串b 能不能组成字符串a。
|
||||
|
||||
一些同学可能想,用数组干啥,都用map不就完事了。
|
||||
|
||||
@ -55,7 +55,7 @@
|
||||
|
||||
## set作为哈希表
|
||||
|
||||
在[349. 两个数组的交集](https://mp.weixin.qq.com/s/aMSA5zrp3jJcLjuSB0Es2Q)中我们给出了什么时候用数组就不行了,需要用set。
|
||||
在[349. 两个数组的交集](https://programmercarl.com/0349.两个数组的交集.html)中我们给出了什么时候用数组就不行了,需要用set。
|
||||
|
||||
这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
|
||||
|
||||
@ -66,7 +66,7 @@
|
||||
|
||||
所以此时一样的做映射的话,就可以使用set了。
|
||||
|
||||
关于set,C++ 给提供了如下三种可用的数据结构:(详情请看[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg))
|
||||
关于set,C++ 给提供了如下三种可用的数据结构:(详情请看[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html))
|
||||
|
||||
* std::set
|
||||
* std::multiset
|
||||
@ -74,12 +74,12 @@
|
||||
|
||||
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希, 使用unordered_set 读写效率是最高的,本题并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
|
||||
|
||||
在[202.快乐数](https://mp.weixin.qq.com/s/n5q0ujxxrjQS3xuh3dgqBQ)中,我们再次使用了unordered_set来判断一个数是否重复出现过。
|
||||
在[202.快乐数](https://programmercarl.com/0202.快乐数.html)中,我们再次使用了unordered_set来判断一个数是否重复出现过。
|
||||
|
||||
|
||||
## map作为哈希表
|
||||
|
||||
在[1.两数之和](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ)中map正式登场。
|
||||
在[1.两数之和](https://programmercarl.com/0001.两数之和.html)中map正式登场。
|
||||
|
||||
来说一说:使用数组和set来做哈希法的局限。
|
||||
|
||||
@ -88,7 +88,7 @@ std::set和std::multiset底层实现都是红黑树,std::unordered_set的底
|
||||
|
||||
map是一种`<key, value>`的结构,本题可以用key保存数值,用value在保存数值所在的下表。所以使用map最为合适。
|
||||
|
||||
C++提供如下三种map::(详情请看[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg))
|
||||
C++提供如下三种map::(详情请看[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html))
|
||||
|
||||
* std::map
|
||||
* std::multimap
|
||||
@ -96,19 +96,19 @@ C++提供如下三种map::(详情请看[关于哈希表,你该了解这
|
||||
|
||||
std::unordered_map 底层实现为哈希,std::map 和std::multimap 的底层实现是红黑树。
|
||||
|
||||
同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解),[1.两数之和](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ)中并不需要key有序,选择std::unordered_map 效率更高!
|
||||
同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解),[1.两数之和](https://programmercarl.com/0001.两数之和.html)中并不需要key有序,选择std::unordered_map 效率更高!
|
||||
|
||||
在[454.四数相加](https://mp.weixin.qq.com/s/12g_w6RzHuEpFts1pT6BWw)中我们提到了其实需要哈希的地方都能找到map的身影。
|
||||
在[454.四数相加](https://programmercarl.com/0454.四数相加II.html)中我们提到了其实需要哈希的地方都能找到map的身影。
|
||||
|
||||
本题咋眼一看好像和[18. 四数之和](https://mp.weixin.qq.com/s/SBU3THi1Kv6Sar7htqCB2Q),[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)差不多,其实差很多!
|
||||
本题咋眼一看好像和[18. 四数之和](https://programmercarl.com/0018.四数之和.html),[15.三数之和](https://programmercarl.com/0015.三数之和.html)差不多,其实差很多!
|
||||
|
||||
**关键差别是本题为四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑重复问题,而[18. 四数之和](https://mp.weixin.qq.com/s/SBU3THi1Kv6Sar7htqCB2Q),[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)是一个数组(集合)里找到和为0的组合,可就难很多了!**
|
||||
**关键差别是本题为四个独立的数组,只要找到A[i] + B[j] + C[k] + D[l] = 0就可以,不用考虑重复问题,而[18. 四数之和](https://programmercarl.com/0018.四数之和.html),[15.三数之和](https://programmercarl.com/0015.三数之和.html)是一个数组(集合)里找到和为0的组合,可就难很多了!**
|
||||
|
||||
用哈希法解决了两数之和,很多同学会感觉用哈希法也可以解决三数之和,四数之和。
|
||||
|
||||
其实是可以解决,但是非常麻烦,需要去重导致代码效率很低。
|
||||
|
||||
在[15.三数之和](https://mp.weixin.qq.com/s/QfTNEByq1YlNSXRKEumwHg)中我给出了哈希法和双指针两个解法,大家就可以体会到,使用哈希法还是比较麻烦的。
|
||||
在[15.三数之和](https://programmercarl.com/0015.三数之和.html)中我给出了哈希法和双指针两个解法,大家就可以体会到,使用哈希法还是比较麻烦的。
|
||||
|
||||
所以18. 四数之和,15.三数之和都推荐使用双指针法!
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
|
||||
关于回溯算法理论基础,我录了一期B站视频[带你学透回溯算法(理论篇)](https://www.bilibili.com/video/BV1cy4y167mM)如果对回溯算法还不了解的话,可以看一下。
|
||||
|
||||
在[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)中我们详细的介绍了回溯算法的理论知识,不同于教科书般的讲解,这里介绍的回溯法的效率,解决的问题以及模板都是在刷题的过程中非常实用!
|
||||
在[关于回溯算法,你该了解这些!](https://programmercarl.com/回溯算法理论基础.html)中我们详细的介绍了回溯算法的理论知识,不同于教科书般的讲解,这里介绍的回溯法的效率,解决的问题以及模板都是在刷题的过程中非常实用!
|
||||
|
||||
**回溯是递归的副产品,只要有递归就会有回溯**,所以回溯法也经常和二叉树遍历,深度优先搜索混在一起,因为这两种方式都是用了递归。
|
||||
|
||||
@ -32,7 +32,7 @@
|
||||
|
||||
回溯法确实不好理解,所以需要把回溯法抽象为一个图形来理解就容易多了,**在后面的每一道回溯法的题目我都将遍历过程抽象为树形结构方便大家的理解**。
|
||||
|
||||
在[关于回溯算法,你该了解这些!](https://mp.weixin.qq.com/s/gjSgJbNbd1eAA5WkA-HeWw)还用了回溯三部曲来分析回溯算法,并给出了回溯法的模板:
|
||||
在[关于回溯算法,你该了解这些!](https://programmercarl.com/回溯算法理论基础.html)还用了回溯三部曲来分析回溯算法,并给出了回溯法的模板:
|
||||
|
||||
```
|
||||
void backtracking(参数) {
|
||||
@ -55,7 +55,7 @@ void backtracking(参数) {
|
||||
|
||||
## 组合问题
|
||||
|
||||
在[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)中,我们开始用回溯法解决第一道题目:组合问题。
|
||||
在[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html)中,我们开始用回溯法解决第一道题目:组合问题。
|
||||
|
||||
我在文中开始的时候给大家列举k层for循环例子,进而得出都是同样是暴利解法,为什么要用回溯法!
|
||||
|
||||
@ -71,13 +71,13 @@ void backtracking(参数) {
|
||||
|
||||
**所以,录友们刚开始学回溯法,起跑姿势就很标准了!**
|
||||
|
||||
优化回溯算法只有剪枝一种方法,在[回溯算法:组合问题再剪剪枝](https://mp.weixin.qq.com/s/Ri7spcJMUmph4c6XjPWXQA)中把回溯法代码做了剪枝优化,树形结构如图:
|
||||
优化回溯算法只有剪枝一种方法,在[回溯算法:组合问题再剪剪枝](https://programmercarl.com/0077.组合优化.html)中把回溯法代码做了剪枝优化,树形结构如图:
|
||||
|
||||
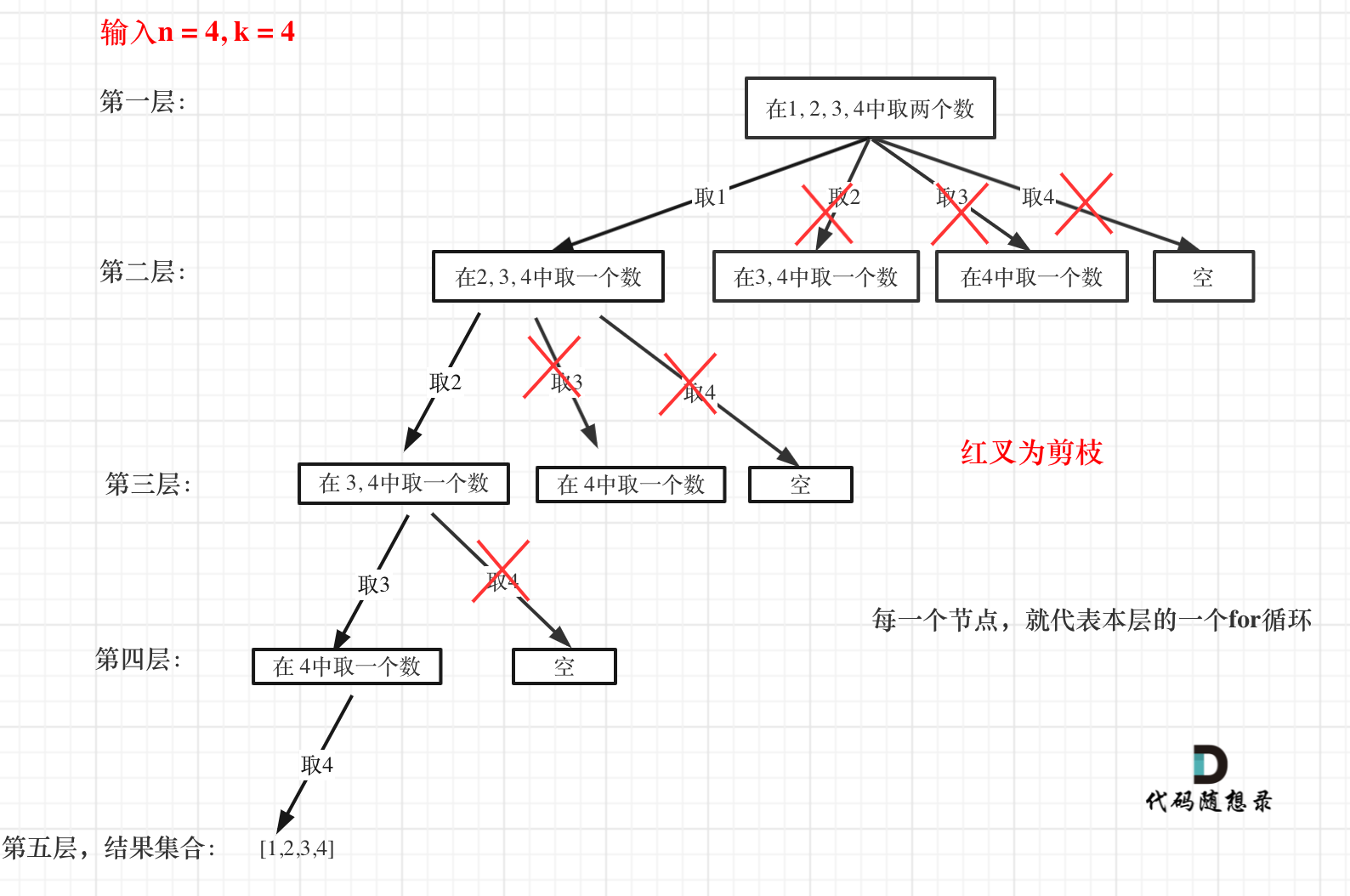
|
||||
|
||||
大家可以一目了然剪的究竟是哪里。
|
||||
|
||||
**[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)剪枝精髓是:for循环在寻找起点的时候要有一个范围,如果这个起点到集合终止之间的元素已经不够题目要求的k个元素了,就没有必要搜索了**。
|
||||
**[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html)剪枝精髓是:for循环在寻找起点的时候要有一个范围,如果这个起点到集合终止之间的元素已经不够题目要求的k个元素了,就没有必要搜索了**。
|
||||
|
||||
**在for循环上做剪枝操作是回溯法剪枝的常见套路!** 后面的题目还会经常用到。
|
||||
|
||||
@ -86,7 +86,7 @@ void backtracking(参数) {
|
||||
|
||||
### 组合总和(一)
|
||||
|
||||
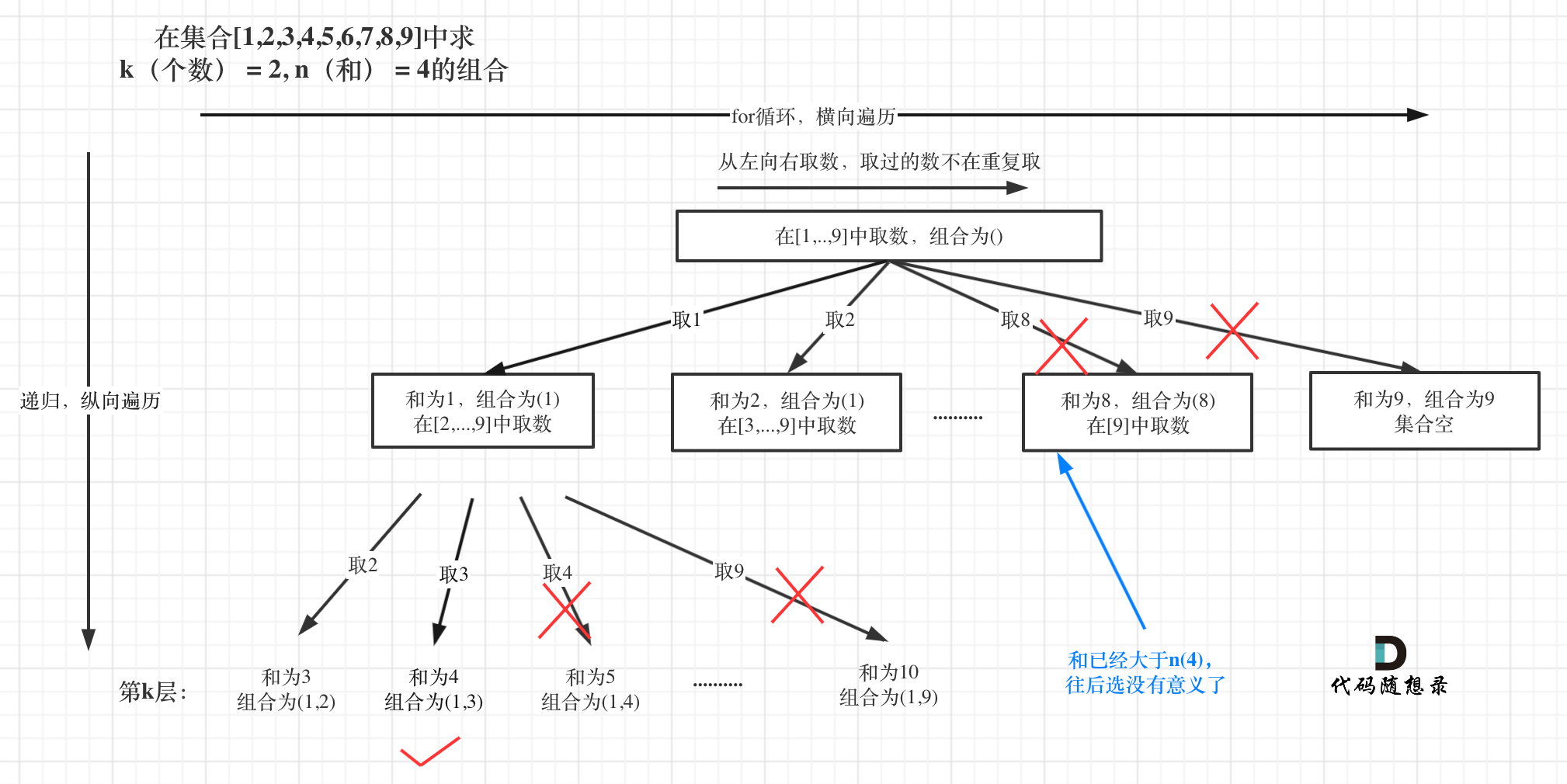
在[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)中,相当于 [回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)加了一个元素总和的限制。
|
||||
在[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)中,相当于 [回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html)加了一个元素总和的限制。
|
||||
|
||||
树形结构如图:
|
||||
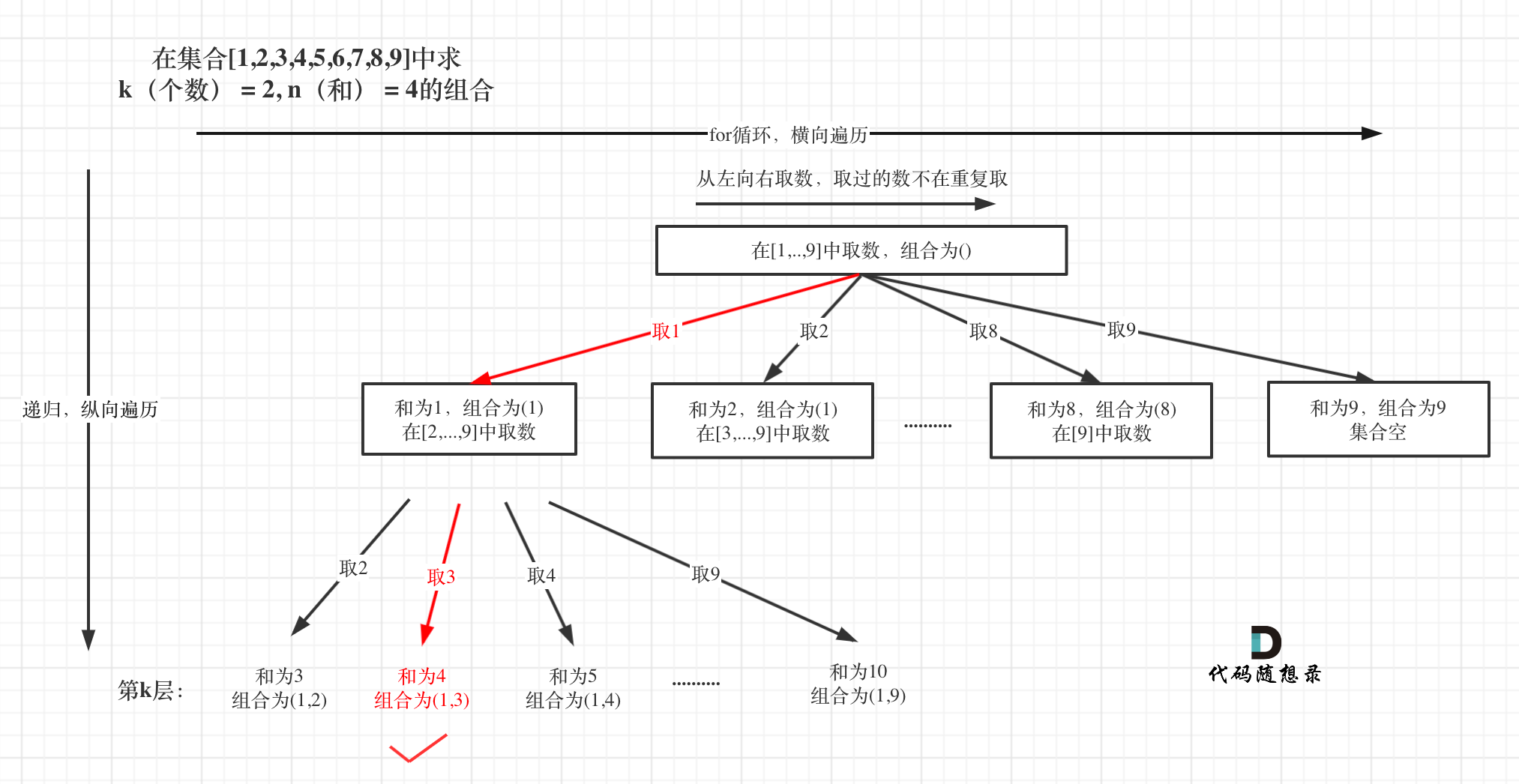
|
||||
@ -95,21 +95,21 @@ void backtracking(参数) {
|
||||
|
||||
|
||||
|
||||
在本题中,依然还可以有一个剪枝,就是[回溯算法:组合问题再剪剪枝](https://mp.weixin.qq.com/s/Ri7spcJMUmph4c6XjPWXQA)中提到的,对for循环选择的起始范围的剪枝。
|
||||
在本题中,依然还可以有一个剪枝,就是[回溯算法:组合问题再剪剪枝](https://programmercarl.com/0077.组合优化.html)中提到的,对for循环选择的起始范围的剪枝。
|
||||
|
||||
所以剪枝的代码可以在for循环加上 `i <= 9 - (k - path.size()) + 1` 的限制!
|
||||
|
||||
### 组合总和(二)
|
||||
|
||||
在[回溯算法:求组合总和(二)](https://mp.weixin.qq.com/s/FLg8G6EjVcxBjwCbzpACPw)中讲解的组合总和问题,和[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ),[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)和区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
|
||||
在[回溯算法:求组合总和(二)](https://programmercarl.com/0039.组合总和.html)中讲解的组合总和问题,和[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html),[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)和区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
|
||||
|
||||
不少同学都是看到可以重复选择,就义无反顾的把startIndex去掉了。
|
||||
|
||||
**本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?**
|
||||
|
||||
我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ),[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)。
|
||||
我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html),[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)。
|
||||
|
||||
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:[回溯算法:电话号码的字母组合](https://mp.weixin.qq.com/s/e2ua2cmkE_vpYjM3j6HY0A)
|
||||
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:[回溯算法:电话号码的字母组合](https://programmercarl.com/0017.电话号码的字母组合.html)
|
||||
|
||||
**注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路**。
|
||||
|
||||
@ -130,7 +130,7 @@ for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target;
|
||||
|
||||
### 组合总和(三)
|
||||
|
||||
在[回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)中集合元素会有重复,但要求解集不能包含重复的组合。
|
||||
在[回溯算法:求组合总和(三)](https://programmercarl.com/0040.组合总和II.html)中集合元素会有重复,但要求解集不能包含重复的组合。
|
||||
|
||||
**所以难就难在去重问题上了**。
|
||||
|
||||
@ -153,11 +153,11 @@ for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target;
|
||||
|
||||
## 多个集合求组合
|
||||
|
||||
在[回溯算法:电话号码的字母组合](https://mp.weixin.qq.com/s/e2ua2cmkE_vpYjM3j6HY0A)中,开始用多个集合来求组合,还是熟悉的模板题目,但是有一些细节。
|
||||
在[回溯算法:电话号码的字母组合](https://programmercarl.com/0017.电话号码的字母组合.html)中,开始用多个集合来求组合,还是熟悉的模板题目,但是有一些细节。
|
||||
|
||||
例如这里for循环,可不像是在 [回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)中从startIndex开始遍历的。
|
||||
例如这里for循环,可不像是在 [回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html)和[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)中从startIndex开始遍历的。
|
||||
|
||||
**因为本题每一个数字代表的是不同集合,也就是求不同集合之间的组合,而[回溯算法:求组合问题!](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ)和[回溯算法:求组合总和!](https://mp.weixin.qq.com/s/HX7WW6ixbFZJASkRnCTC3w)都是是求同一个集合中的组合!**
|
||||
**因为本题每一个数字代表的是不同集合,也就是求不同集合之间的组合,而[回溯算法:求组合问题!](https://programmercarl.com/0077.组合.html)和[回溯算法:求组合总和!](https://programmercarl.com/0216.组合总和III.html)都是是求同一个集合中的组合!**
|
||||
|
||||
树形结构如下:
|
||||
|
||||
@ -169,7 +169,7 @@ for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target;
|
||||
|
||||
# 切割问题
|
||||
|
||||
在[回溯算法:分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)中,我们开始讲解切割问题,虽然最后代码看起来好像是一道模板题,但是从分析到学会套用这个模板,是比较难的。
|
||||
在[回溯算法:分割回文串](https://programmercarl.com/0131.分割回文串.html)中,我们开始讲解切割问题,虽然最后代码看起来好像是一道模板题,但是从分析到学会套用这个模板,是比较难的。
|
||||
|
||||
我列出如下几个难点:
|
||||
|
||||
@ -196,7 +196,7 @@ for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target;
|
||||
|
||||
## 子集问题(一)
|
||||
|
||||
在[回溯算法:求子集问题!](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)中讲解了子集问题,**在树形结构中子集问题是要收集所有节点的结果,而组合问题是收集叶子节点的结果**。
|
||||
在[回溯算法:求子集问题!](https://programmercarl.com/0078.子集.html)中讲解了子集问题,**在树形结构中子集问题是要收集所有节点的结果,而组合问题是收集叶子节点的结果**。
|
||||
|
||||
如图:
|
||||
|
||||
@ -221,9 +221,9 @@ if (startIndex >= nums.size()) { // 终止条件可以不加
|
||||
|
||||
## 子集问题(二)
|
||||
|
||||
在[回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)中,开始针对子集问题进行去重。
|
||||
在[回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html)中,开始针对子集问题进行去重。
|
||||
|
||||
本题就是[回溯算法:求子集问题!](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA)的基础上加上了去重,去重我们在[回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)也讲过了,一样的套路。
|
||||
本题就是[回溯算法:求子集问题!](https://programmercarl.com/0078.子集.html)的基础上加上了去重,去重我们在[回溯算法:求组合总和(三)](https://programmercarl.com/0040.组合总和II.html)也讲过了,一样的套路。
|
||||
|
||||
树形结构如下:
|
||||
|
||||
@ -231,15 +231,15 @@ if (startIndex >= nums.size()) { // 终止条件可以不加
|
||||
|
||||
## 递增子序列
|
||||
|
||||
在[回溯算法:递增子序列](https://mp.weixin.qq.com/s/ePxOtX1ATRYJb2Jq7urzHQ)中,处处都能看到子集的身影,但处处是陷阱,值得好好琢磨琢磨!
|
||||
在[回溯算法:递增子序列](https://programmercarl.com/0491.递增子序列.html)中,处处都能看到子集的身影,但处处是陷阱,值得好好琢磨琢磨!
|
||||
|
||||
树形结构如下:
|
||||
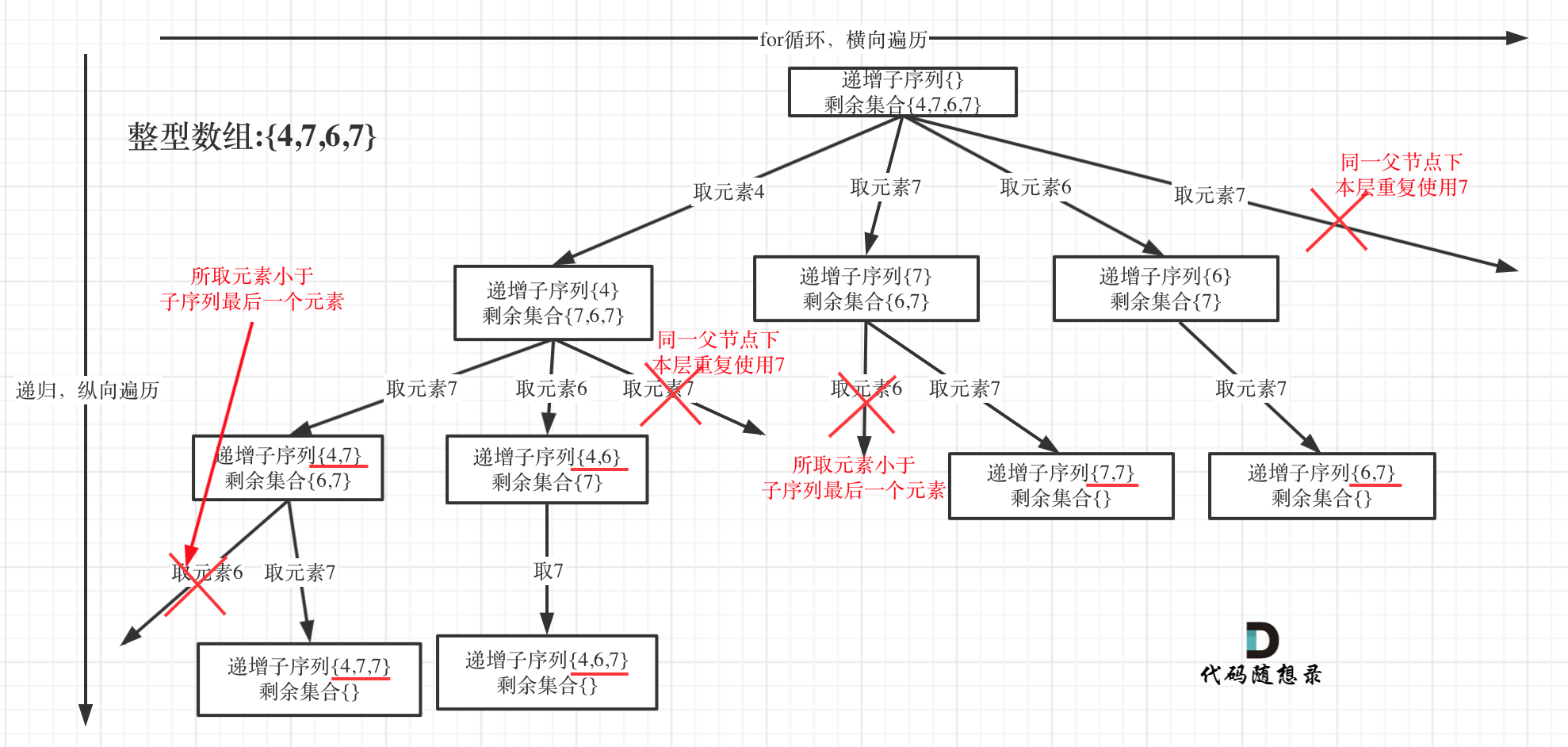
|
||||
|
||||
|
||||
很多同学都会把这道题目和[回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)混在一起。
|
||||
很多同学都会把这道题目和[回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html)混在一起。
|
||||
|
||||
**[回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)也可以使用set针对同一父节点本层去重,但子集问题一定要排序,为什么呢?**
|
||||
**[回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html)也可以使用set针对同一父节点本层去重,但子集问题一定要排序,为什么呢?**
|
||||
|
||||
我用没有排序的集合{2,1,2,2}来举个例子画一个图,如下:
|
||||
|
||||
@ -251,7 +251,7 @@ if (startIndex >= nums.size()) { // 终止条件可以不加
|
||||
|
||||
## 排列问题(一)
|
||||
|
||||
[回溯算法:排列问题!](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw) 又不一样了。
|
||||
[回溯算法:排列问题!](https://programmercarl.com/0046.全排列.html) 又不一样了。
|
||||
|
||||
排列是有序的,也就是说[1,2] 和[2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
|
||||
|
||||
@ -268,7 +268,7 @@ if (startIndex >= nums.size()) { // 终止条件可以不加
|
||||
|
||||
## 排列问题(二)
|
||||
|
||||
排列问题也要去重了,在[回溯算法:排列问题(二)](https://mp.weixin.qq.com/s/9L8h3WqRP_h8LLWNT34YlA)中又一次强调了“树层去重”和“树枝去重”。
|
||||
排列问题也要去重了,在[回溯算法:排列问题(二)](https://programmercarl.com/0047.全排列II.html)中又一次强调了“树层去重”和“树枝去重”。
|
||||
|
||||
树形结构如下:
|
||||
|
||||
@ -294,17 +294,17 @@ if (startIndex >= nums.size()) { // 终止条件可以不加
|
||||
|
||||
以上我都是统一使用used数组来去重的,其实使用set也可以用来去重!
|
||||
|
||||
在[本周小结!(回溯算法系列三)续集](https://mp.weixin.qq.com/s/kSMGHc_YpsqL2j-jb_E_Ag)中给出了子集、组合、排列问题使用set来去重的解法以及具体代码,并纠正一些同学的常见错误写法。
|
||||
在[本周小结!(回溯算法系列三)续集](https://programmercarl.com/回溯算法去重问题的另一种写法.html)中给出了子集、组合、排列问题使用set来去重的解法以及具体代码,并纠正一些同学的常见错误写法。
|
||||
|
||||
同时详细分析了 使用used数组去重 和 使用set去重 两种写法的性能差异:
|
||||
|
||||
**使用set去重的版本相对于used数组的版本效率都要低很多**,大家在leetcode上提交,能明显发现。
|
||||
|
||||
原因在[回溯算法:递增子序列](https://mp.weixin.qq.com/s/ePxOtX1ATRYJb2Jq7urzHQ)中也分析过,主要是因为程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且insert的时候其底层的符号表也要做相应的扩充,也是费时的。
|
||||
原因在[回溯算法:递增子序列](https://programmercarl.com/0491.递增子序列.html)中也分析过,主要是因为程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且insert的时候其底层的符号表也要做相应的扩充,也是费时的。
|
||||
|
||||
**而使用used数组在时间复杂度上几乎没有额外负担!**
|
||||
|
||||
**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://mp.weixin.qq.com/s/tLkt9PSo42X60w8i94ViiA)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了O(n^2),因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
|
||||
**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了O(n^2),因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
|
||||
|
||||
那有同学可能疑惑 用used数组也是占用O(n)的空间啊?
|
||||
|
||||
@ -314,7 +314,7 @@ used数组可是全局变量,每层与每层之间公用一个used数组,所
|
||||
|
||||
之前说过,有递归的地方就有回溯,深度优先搜索也是用递归来实现的,所以往往伴随着回溯。
|
||||
|
||||
在[回溯算法:重新安排行程](https://mp.weixin.qq.com/s/3kmbS4qDsa6bkyxR92XCTA)其实也算是图论里深搜的题目,但是我用回溯法的套路来讲解这道题目,算是给大家拓展一下思路,原来回溯法还可以这么玩!
|
||||
在[回溯算法:重新安排行程](https://programmercarl.com/0332.重新安排行程.html)其实也算是图论里深搜的题目,但是我用回溯法的套路来讲解这道题目,算是给大家拓展一下思路,原来回溯法还可以这么玩!
|
||||
|
||||
以输入:[["JFK", "KUL"], ["JFK", "NRT"], ["NRT", "JFK"]为例,抽象为树形结构如下:
|
||||
|
||||
@ -331,7 +331,7 @@ used数组可是全局变量,每层与每层之间公用一个used数组,所
|
||||
|
||||
## N皇后问题
|
||||
|
||||
在[回溯算法:N皇后问题](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg)中终于迎来了传说中的N皇后。
|
||||
在[回溯算法:N皇后问题](https://programmercarl.com/0051.N皇后.html)中终于迎来了传说中的N皇后。
|
||||
|
||||
下面我用一个3 * 3 的棋牌,将搜索过程抽象为一颗树,如图:
|
||||
|
||||
@ -345,19 +345,19 @@ used数组可是全局变量,每层与每层之间公用一个used数组,所
|
||||
|
||||
**这里我明确给出了棋盘的宽度就是for循环的长度,递归的深度就是棋盘的高度,这样就可以套进回溯法的模板里了**。
|
||||
|
||||
相信看完本篇[回溯算法:N皇后问题](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg)也没那么难了,传说已经不是传说了,哈哈。
|
||||
相信看完本篇[回溯算法:N皇后问题](https://programmercarl.com/0051.N皇后.html)也没那么难了,传说已经不是传说了,哈哈。
|
||||
|
||||
|
||||
|
||||
## 解数独问题
|
||||
|
||||
在[回溯算法:解数独](https://mp.weixin.qq.com/s/eWE9TapVwm77yW9Q81xSZQ)中要征服回溯法的最后一道山峰。
|
||||
在[回溯算法:解数独](https://programmercarl.com/0037.解数独.html)中要征服回溯法的最后一道山峰。
|
||||
|
||||
解数独应该是棋盘很难的题目了,比N皇后还要复杂一些,但只要理解 “二维递归”这个过程,其实发现就没那么难了。
|
||||
|
||||
大家已经跟着「代码随想录」刷过了如下回溯法题目,例如:[77.组合(组合问题)](https://mp.weixin.qq.com/s/OnBjbLzuipWz_u4QfmgcqQ),[131.分割回文串(分割问题)](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q),[78.子集(子集问题)](https://mp.weixin.qq.com/s/NNRzX-vJ_pjK4qxohd_LtA),[46.全排列(排列问题)](https://mp.weixin.qq.com/s/SCOjeMX1t41wcvJq49GhMw),以及[51.N皇后(N皇后问题)](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg),其实这些题目都是一维递归。
|
||||
大家已经跟着「代码随想录」刷过了如下回溯法题目,例如:[77.组合(组合问题)](https://programmercarl.com/0077.组合.html),[131.分割回文串(分割问题)](https://programmercarl.com/0131.分割回文串.html),[78.子集(子集问题)](https://programmercarl.com/0078.子集.html),[46.全排列(排列问题)](https://programmercarl.com/0046.全排列.html),以及[51.N皇后(N皇后问题)](https://programmercarl.com/0051.N皇后.html),其实这些题目都是一维递归。
|
||||
|
||||
其中[N皇后问题](https://mp.weixin.qq.com/s/lU_QwCMj6g60nh8m98GAWg)是因为每一行每一列只放一个皇后,只需要一层for循环遍历一行,递归来遍历列,然后一行一列确定皇后的唯一位置。
|
||||
其中[N皇后问题](https://programmercarl.com/0051.N皇后.html)是因为每一行每一列只放一个皇后,只需要一层for循环遍历一行,递归来遍历列,然后一行一列确定皇后的唯一位置。
|
||||
|
||||
本题就不一样了,**本题中棋盘的每一个位置都要放一个数字,并检查数字是否合法,解数独的树形结构要比N皇后更宽更深**。
|
||||
|
||||
@ -367,7 +367,7 @@ used数组可是全局变量,每层与每层之间公用一个used数组,所
|
||||
|
||||
解数独可以说是非常难的题目了,如果还一直停留在一维递归的逻辑中,这道题目可以让大家瞬间崩溃。
|
||||
|
||||
**所以我在[回溯算法:解数独](https://mp.weixin.qq.com/s/eWE9TapVwm77yW9Q81xSZQ)中开篇就提到了二维递归,这也是我自创词汇**,希望可以帮助大家理解解数独的搜索过程。
|
||||
**所以我在[回溯算法:解数独](https://programmercarl.com/0037.解数独.html)中开篇就提到了二维递归,这也是我自创词汇**,希望可以帮助大家理解解数独的搜索过程。
|
||||
|
||||
一波分析之后,在看代码会发现其实也不难,唯一难点就是理解**二维递归**的思维逻辑。
|
||||
|
||||
|
||||
@ -8,13 +8,13 @@
|
||||
|
||||
# 回溯算法去重问题的另一种写法
|
||||
|
||||
> 在 [本周小结!(回溯算法系列三)](https://mp.weixin.qq.com/s/tLkt9PSo42X60w8i94ViiA) 中一位录友对 整颗树的本层和同一节点的本层有疑问,也让我重新思考了一下,发现这里确实有问题,所以专门写一篇来纠正,感谢录友们的积极交流哈!
|
||||
> 在 [本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html) 中一位录友对 整颗树的本层和同一节点的本层有疑问,也让我重新思考了一下,发现这里确实有问题,所以专门写一篇来纠正,感谢录友们的积极交流哈!
|
||||
|
||||
接下来我再把这块再讲一下。
|
||||
|
||||
在[回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)中的去重和 [回溯算法:递增子序列](https://mp.weixin.qq.com/s/ePxOtX1ATRYJb2Jq7urzHQ)中的去重 都是 同一父节点下本层的去重。
|
||||
在[回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html)中的去重和 [回溯算法:递增子序列](https://programmercarl.com/0491.递增子序列.html)中的去重 都是 同一父节点下本层的去重。
|
||||
|
||||
[回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)也可以使用set针对同一父节点本层去重,但子集问题一定要排序,为什么呢?
|
||||
[回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html)也可以使用set针对同一父节点本层去重,但子集问题一定要排序,为什么呢?
|
||||
|
||||
我用没有排序的集合{2,1,2,2}来举例子画一个图,如图:
|
||||
|
||||
@ -22,11 +22,11 @@
|
||||
|
||||
图中,大家就很明显的看到,子集重复了。
|
||||
|
||||
那么下面我针对[回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ) 给出使用set来对本层去重的代码实现。
|
||||
那么下面我针对[回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html) 给出使用set来对本层去重的代码实现。
|
||||
|
||||
## 90.子集II
|
||||
|
||||
used数组去重版本: [回溯算法:求子集问题(二)](https://mp.weixin.qq.com/s/WJ4JNDRJgsW3eUN72Hh3uQ)
|
||||
used数组去重版本: [回溯算法:求子集问题(二)](https://programmercarl.com/0090.子集II.html)
|
||||
|
||||
使用set去重的版本如下:
|
||||
|
||||
@ -138,7 +138,7 @@ uset已经是全局变量,本层的uset记录了一个元素,然后进入下
|
||||
|
||||
## 40. 组合总和 II
|
||||
|
||||
使用used数组去重版本:[回溯算法:求组合总和(三)](https://mp.weixin.qq.com/s/_1zPYk70NvHsdY8UWVGXmQ)
|
||||
使用used数组去重版本:[回溯算法:求组合总和(三)](https://programmercarl.com/0040.组合总和II.html)
|
||||
|
||||
使用set去重的版本如下:
|
||||
|
||||
@ -179,7 +179,7 @@ public:
|
||||
|
||||
## 47. 全排列 II
|
||||
|
||||
使用used数组去重版本:[回溯算法:排列问题(二)](https://mp.weixin.qq.com/s/9L8h3WqRP_h8LLWNT34YlA)
|
||||
使用used数组去重版本:[回溯算法:排列问题(二)](https://programmercarl.com/0047.全排列II.html)
|
||||
|
||||
使用set去重的版本如下:
|
||||
|
||||
@ -224,11 +224,11 @@ public:
|
||||
|
||||
需要注意的是:**使用set去重的版本相对于used数组的版本效率都要低很多**,大家在leetcode上提交,能明显发现。
|
||||
|
||||
原因在[回溯算法:递增子序列](https://mp.weixin.qq.com/s/ePxOtX1ATRYJb2Jq7urzHQ)中也分析过,主要是因为程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且insert的时候其底层的符号表也要做相应的扩充,也是费时的。
|
||||
原因在[回溯算法:递增子序列](https://programmercarl.com/0491.递增子序列.html)中也分析过,主要是因为程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且insert的时候其底层的符号表也要做相应的扩充,也是费时的。
|
||||
|
||||
**而使用used数组在时间复杂度上几乎没有额外负担!**
|
||||
|
||||
**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://mp.weixin.qq.com/s/tLkt9PSo42X60w8i94ViiA)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了O(n^2),因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
|
||||
**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了O(n^2),因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
|
||||
|
||||
那有同学可能疑惑 用used数组也是占用O(n)的空间啊?
|
||||
|
||||
@ -236,7 +236,7 @@ used数组可是全局变量,每层与每层之间公用一个used数组,所
|
||||
|
||||
## 总结
|
||||
|
||||
本篇本打算是对[本周小结!(回溯算法系列三)](https://mp.weixin.qq.com/s/tLkt9PSo42X60w8i94ViiA)的一个点做一下纠正,没想到又写出来这么多!
|
||||
本篇本打算是对[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)的一个点做一下纠正,没想到又写出来这么多!
|
||||
|
||||
**这个点都源于一位录友的疑问,然后我思考总结了一下,就写着这一篇,所以还是得多交流啊!**
|
||||
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
|
||||
回溯法也可以叫做回溯搜索法,它是一种搜索的方式。
|
||||
|
||||
在二叉树系列中,我们已经不止一次,提到了回溯,例如[二叉树:以为使用了递归,其实还隐藏着回溯](https://mp.weixin.qq.com/s/ivLkHzWdhjQQD1rQWe6zWA)。
|
||||
在二叉树系列中,我们已经不止一次,提到了回溯,例如[二叉树:以为使用了递归,其实还隐藏着回溯](https://programmercarl.com/二叉树中递归带着回溯.html)。
|
||||
|
||||
回溯是递归的副产品,只要有递归就会有回溯。
|
||||
|
||||
@ -67,7 +67,7 @@
|
||||
|
||||
这里给出Carl总结的回溯算法模板。
|
||||
|
||||
在讲[二叉树的递归](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)中我们说了递归三部曲,这里我再给大家列出回溯三部曲。
|
||||
在讲[二叉树的递归](https://programmercarl.com/二叉树的递归遍历.html)中我们说了递归三部曲,这里我再给大家列出回溯三部曲。
|
||||
|
||||
* 回溯函数模板返回值以及参数
|
||||
|
||||
@ -87,7 +87,7 @@ void backtracking(参数)
|
||||
|
||||
* 回溯函数终止条件
|
||||
|
||||
既然是树形结构,那么我们在讲解[二叉树的递归](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)的时候,就知道遍历树形结构一定要有终止条件。
|
||||
既然是树形结构,那么我们在讲解[二叉树的递归](https://programmercarl.com/二叉树的递归遍历.html)的时候,就知道遍历树形结构一定要有终止条件。
|
||||
|
||||
所以回溯也有要终止条件。
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@
|
||||
<p align="center"><strong>欢迎大家<a href="https://mp.weixin.qq.com/s/tqCxrMEU-ajQumL1i8im9A">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!</strong></p>
|
||||
# 贪心算法:根据身高重建队列(续集)
|
||||
|
||||
在讲解[贪心算法:根据身高重建队列](https://mp.weixin.qq.com/s/-2TgZVdOwS-DvtbjjDEbfw)中,我们提到了使用vector(C++中的动态数组)来进行insert操作是费时的。
|
||||
在讲解[贪心算法:根据身高重建队列](https://programmercarl.com/0406.根据身高重建队列.html)中,我们提到了使用vector(C++中的动态数组)来进行insert操作是费时的。
|
||||
|
||||
但是在解释的过程中有不恰当的地方,所以来专门写一篇文章来详细说一说这个问题。
|
||||
|
||||
@ -99,9 +99,9 @@ for (int i = 0; i < vec.size(); i++) {
|
||||
|
||||
**同时也注意此时capicity和size的变化,关键的地方我都标红了**。
|
||||
|
||||
而在[贪心算法:根据身高重建队列](https://mp.weixin.qq.com/s/-2TgZVdOwS-DvtbjjDEbfw)中,我们使用vector来做insert的操作,此时大家可会发现,**虽然表面上复杂度是O(n^2),但是其底层都不知道额外做了多少次全量拷贝了,所以算上vector的底层拷贝,整体时间复杂度可以认为是O(n^2 + t * n)级别的,t是底层拷贝的次数**。
|
||||
而在[贪心算法:根据身高重建队列](https://programmercarl.com/0406.根据身高重建队列.html)中,我们使用vector来做insert的操作,此时大家可会发现,**虽然表面上复杂度是O(n^2),但是其底层都不知道额外做了多少次全量拷贝了,所以算上vector的底层拷贝,整体时间复杂度可以认为是O(n^2 + t * n)级别的,t是底层拷贝的次数**。
|
||||
|
||||
那么是不是可以直接确定好vector的大小,不让它在动态扩容了,例如在[贪心算法:根据身高重建队列](https://mp.weixin.qq.com/s/-2TgZVdOwS-DvtbjjDEbfw)中已经给出了有people.size这么多的人,可以定义好一个固定大小的vector,这样我们就可以控制vector,不让它底层动态扩容。
|
||||
那么是不是可以直接确定好vector的大小,不让它在动态扩容了,例如在[贪心算法:根据身高重建队列](https://programmercarl.com/0406.根据身高重建队列.html)中已经给出了有people.size这么多的人,可以定义好一个固定大小的vector,这样我们就可以控制vector,不让它底层动态扩容。
|
||||
|
||||
这种方法需要自己模拟插入的操作,不仅没有直接调用insert接口那么方便,需要手动模拟插入操作,而且效率也不高!
|
||||
|
||||
@ -147,7 +147,7 @@ public:
|
||||
|
||||
所以对于两种使用数组的方法一和方法三,也不好确定谁优,但一定都没有使用方法二链表的效率高!
|
||||
|
||||
一波分析之后,对于[贪心算法:根据身高重建队列](https://mp.weixin.qq.com/s/-2TgZVdOwS-DvtbjjDEbfw) ,大家就安心使用链表吧!别折腾了,哈哈,相当于我替大家折腾了一下。
|
||||
一波分析之后,对于[贪心算法:根据身高重建队列](https://programmercarl.com/0406.根据身高重建队列.html) ,大家就安心使用链表吧!别折腾了,哈哈,相当于我替大家折腾了一下。
|
||||
|
||||
## 总结
|
||||
|
||||
|
||||
Reference in New Issue
Block a user