diff --git a/README.md b/README.md
index 267d794e..8a3574fa 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,4 @@
-👉 推荐 [在线阅读](http://programmercarl.com/) (Github在国内访问经常不稳定)
+👉 推荐 [在线阅读](http://programmercarl.com/) (Github在国内访问经常不稳定)
👉 推荐 [Gitee同步](https://gitee.com/programmercarl/leetcode-master)
> 1. **介绍**:本项目是一套完整的刷题计划,旨在帮助大家少走弯路,循序渐进学算法,[关注作者](#关于作者)
@@ -494,6 +494,7 @@
## 图论
* [463.岛屿的周长](./problems/0463.岛屿的周长.md) (模拟)
* [841.钥匙和房间](./problems/0841.钥匙和房间.md) 【有向图】dfs,bfs都可以
+* [127.单词接龙](./problems/0127.单词接龙.md) 广搜
## 并查集
* [684.冗余连接](./problems/0684.冗余连接.md) 【并查集基础题目】
diff --git a/problems/0059.螺旋矩阵II.md b/problems/0059.螺旋矩阵II.md
index 228892de..4231fb39 100644
--- a/problems/0059.螺旋矩阵II.md
+++ b/problems/0059.螺旋矩阵II.md
@@ -191,33 +191,48 @@ class Solution {
python:
-```python
+```python3
class Solution:
+
def generateMatrix(self, n: int) -> List[List[int]]:
- left, right, up, down = 0, n-1, 0, n-1
- matrix = [ [0]*n for _ in range(n)]
- num = 1
- while left<=right and up<=down:
- # 填充左到右
- for i in range(left, right+1):
- matrix[up][i] = num
- num += 1
- up += 1
- # 填充上到下
- for i in range(up, down+1):
- matrix[i][right] = num
- num += 1
- right -= 1
- # 填充右到左
- for i in range(right, left-1, -1):
- matrix[down][i] = num
- num += 1
- down -= 1
- # 填充下到上
- for i in range(down, up-1, -1):
- matrix[i][left] = num
- num += 1
+ # 初始化要填充的正方形
+ matrix = [[0] * n for _ in range(n)]
+
+ left, right, up, down = 0, n - 1, 0, n - 1
+ number = 1 # 要填充的数字
+
+ while left < right and up < down:
+
+ # 从左到右填充上边
+ for x in range(left, right):
+ matrix[up][x] = number
+ number += 1
+
+ # 从上到下填充右边
+ for y in range(up, down):
+ matrix[y][right] = number
+ number += 1
+
+ # 从右到左填充下边
+ for x in range(right, left, -1):
+ matrix[down][x] = number
+ number += 1
+
+ # 从下到上填充左边
+ for y in range(down, up, -1):
+ matrix[y][left] = number
+ number += 1
+
+ # 缩小要填充的范围
left += 1
+ right -= 1
+ up += 1
+ down -= 1
+
+ # 如果阶数为奇数,额外填充一次中心
+ if n % 2:
+ matrix[n // 2][n // 2] = number
+
return matrix
```
diff --git a/problems/0127.单词接龙.md b/problems/0127.单词接龙.md
new file mode 100644
index 00000000..e38453ef
--- /dev/null
+++ b/problems/0127.单词接龙.md
@@ -0,0 +1,150 @@
+
+
+  +
+  +
+  +
+  +
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 127. 单词接龙
+
+[力扣题目链接](https://leetcode-cn.com/problems/word-ladder/)
+
+
+字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
+* 序列中第一个单词是 beginWord 。
+* 序列中最后一个单词是 endWord 。
+* 每次转换只能改变一个字母。
+* 转换过程中的中间单词必须是字典 wordList 中的单词。
+* 给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
+
+
+示例 1:
+
+* 输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
+* 输出:5
+* 解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
+
+示例 2:
+* 输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
+* 输出:0
+* 解释:endWord "cog" 不在字典中,所以无法进行转换。
+
+
+# 思路
+
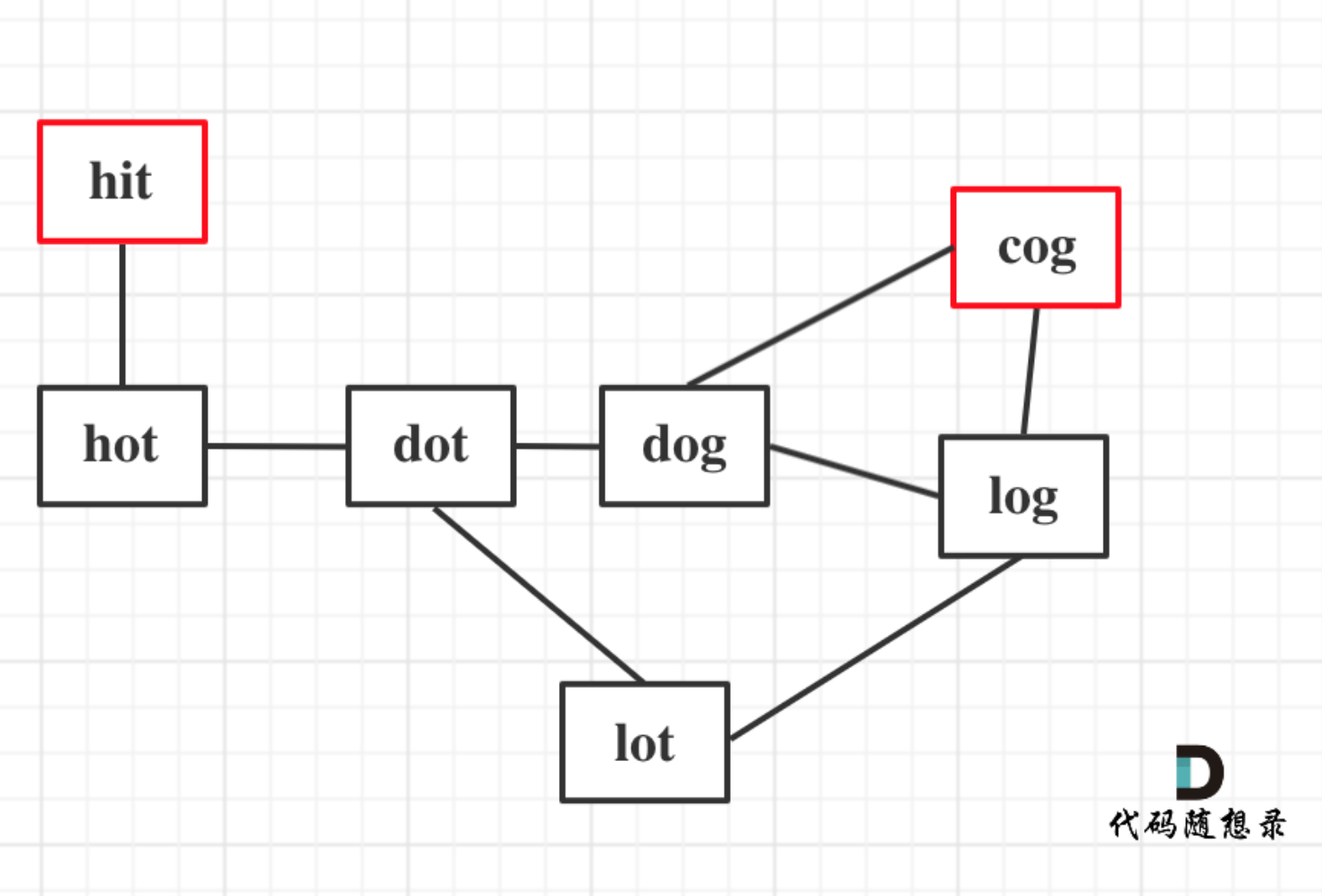
+以示例1为例,从这个图中可以看出 hit 到 cog的路线,不止一条,有三条,两条是最短的长度为5,一条长度为6。
+
+
+
+本题只需要求出最短长度就可以了,不用找出路径。
+
+所以这道题要解决两个问题:
+
+* 图中的线是如何连在一起的
+* 起点和终点的最短路径长度
+
+
+首先题目中并没有给出点与点之间的连线,而是要我们自己去连,条件是字符只能差一个,所以判断点与点之间的关系,要自己判断是不是差一个字符,如果差一个字符,那就是有链接。
+
+然后就是求起点和终点的最短路径长度,**这里无向图求最短路,广搜最为合适,广搜只要搜到了终点,那么一定是最短的路径**。因为广搜就是以起点中心向四周扩散的搜索。
+
+本题如果用深搜,会非常麻烦。
+
+另外需要有一个注意点:
+
+* 本题是一个无向图,需要用标记位,标记着节点是否走过,否则就会死循环!
+* 本题给出集合是数组型的,可以转成set结构,查找更快一些
+
+C++代码如下:(详细注释)
+
+```CPP
+class Solution {
+public:
+ int ladderLength(string beginWord, string endWord, vector& wordList) {
+ // 将vector转成unordered_set,提高查询速度
+ unordered_set wordSet(wordList.begin(), wordList.end());
+ // 如果endWord没有在wordSet出现,直接返回0
+ if (wordSet.find(endWord) == wordSet.end()) return 0;
+ // 记录word是否访问过
+ unordered_map visitMap; //
+ // 初始化队列
+ queue que;
+ que.push(beginWord);
+ // 初始化visitMap
+ visitMap.insert(pair(beginWord, 1));
+
+ while(!que.empty()) {
+ string word = que.front();
+ que.pop();
+ int path = visitMap[word]; // 这个word的路径长度
+ for (int i = 0; i < word.size(); i++) {
+ string newWord = word; // 用一个新单词替换word,因为每次置换一个字母
+ for (int j = 0 ; j < 26; j++) {
+ newWord[i] = j + 'a';
+ if (newWord == endWord) return path + 1; // 找到了end,返回path+1
+ // wordSet出现了newWord,并且newWord没有被访问过
+ if (wordSet.find(newWord) != wordSet.end()
+ && visitMap.find(newWord) == visitMap.end()) {
+ // 添加访问信息
+ visitMap.insert(pair(newWord, path + 1));
+ que.push(newWord);
+ }
+ }
+ }
+ }
+ return 0;
+ }
+};
+```
+
+# 其他语言版本
+
+## Java
+
+```java
+public int ladderLength(String beginWord, String endWord, List wordList) {
+ HashSet wordSet = new HashSet<>(wordList); //转换为hashset 加快速度
+ if (wordSet.size() == 0 || !wordSet.contains(endWord)) { //特殊情况判断
+ return 0;
+ }
+ Queue queue = new LinkedList<>(); //bfs 队列
+ queue.offer(beginWord);
+ Map map = new HashMap<>(); //记录单词对应路径长度
+ map.put(beginWord, 1);
+
+ while (!queue.isEmpty()) {
+ String word = queue.poll(); //取出队头单词
+ int path = map.get(word); //获取到该单词的路径长度
+ for (int i = 0; i < word.length(); i++) { //遍历单词的每个字符
+ char[] chars = word.toCharArray(); //将单词转换为char array,方便替换
+ for (char k = 'a'; k <= 'z'; k++) { //从'a' 到 'z' 遍历替换
+ chars[i] = k; //替换第i个字符
+ String newWord = String.valueOf(chars); //得到新的字符串
+ if (newWord.equals(endWord)) { //如果新的字符串值与endWord一致,返回当前长度+1
+ return path + 1;
+ }
+ if (wordSet.contains(newWord) && !map.containsKey(newWord)) { //如果新单词在set中,但是没有访问过
+ map.put(newWord, path + 1); //记录单词对应的路径长度
+ queue.offer(newWord);//加入队尾
+ }
+ }
+ }
+ }
+ return 0; //未找到
+}
+```
+
+## Python
+
+## Go
+
+## JavaScript
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+