mirror of
https://github.com/youngyangyang04/leetcode-master.git
synced 2025-07-13 06:06:11 +08:00
Update
This commit is contained in:
@ -373,7 +373,7 @@
|
||||
|
||||
## 图论
|
||||
|
||||
通知:开始更新图论内容,图论部分还没有其他语言版本,欢迎录友们提交PR,成为contributor
|
||||
**[图论正式发布](./problems/qita/tulunfabu.md)**
|
||||
|
||||
1. [图论:理论基础](./problems/kamacoder/图论理论基础.md)
|
||||
2. [图论:深度优先搜索理论基础](./problems/kamacoder/图论深搜理论基础.md)
|
||||
|
||||
@ -244,56 +244,61 @@ int** fourSum(int* nums, int numsSize, int target, int* returnSize, int** return
|
||||
### Java:
|
||||
|
||||
```Java
|
||||
class Solution {
|
||||
import java.util.*;
|
||||
|
||||
public class Solution {
|
||||
public List<List<Integer>> fourSum(int[] nums, int target) {
|
||||
List<List<Integer>> result = new ArrayList<>();
|
||||
Arrays.sort(nums);
|
||||
|
||||
for (int i = 0; i < nums.length; i++) {
|
||||
|
||||
// nums[i] > target 直接返回, 剪枝操作
|
||||
if (nums[i] > 0 && nums[i] > target) {
|
||||
return result;
|
||||
Arrays.sort(nums); // 排序数组
|
||||
List<List<Integer>> result = new ArrayList<>(); // 结果集
|
||||
for (int k = 0; k < nums.length; k++) {
|
||||
// 剪枝处理
|
||||
if (nums[k] > target && nums[k] >= 0) {
|
||||
break;
|
||||
}
|
||||
|
||||
if (i > 0 && nums[i - 1] == nums[i]) { // 对nums[i]去重
|
||||
// 对nums[k]去重
|
||||
if (k > 0 && nums[k] == nums[k - 1]) {
|
||||
continue;
|
||||
}
|
||||
|
||||
for (int j = i + 1; j < nums.length; j++) {
|
||||
|
||||
// nums[i]+nums[j] > target 直接返回, 剪枝操作
|
||||
if (nums[i]+nums[j] > 0 && nums[i]+nums[j] > target) {
|
||||
return result;
|
||||
}
|
||||
|
||||
if (j > i + 1 && nums[j - 1] == nums[j]) { // 对nums[j]去重
|
||||
for (int i = k + 1; i < nums.length; i++) {
|
||||
// 第二级剪枝
|
||||
if (nums[k] + nums[i] > target && nums[k] + nums[i] >= 0) {
|
||||
break;
|
||||
}
|
||||
// 对nums[i]去重
|
||||
if (i > k + 1 && nums[i] == nums[i - 1]) {
|
||||
continue;
|
||||
}
|
||||
|
||||
int left = j + 1;
|
||||
int left = i + 1;
|
||||
int right = nums.length - 1;
|
||||
while (right > left) {
|
||||
// nums[k] + nums[i] + nums[left] + nums[right] > target int会溢出
|
||||
long sum = (long) nums[i] + nums[j] + nums[left] + nums[right];
|
||||
long sum = (long) nums[k] + nums[i] + nums[left] + nums[right];
|
||||
if (sum > target) {
|
||||
right--;
|
||||
} else if (sum < target) {
|
||||
left++;
|
||||
} else {
|
||||
result.add(Arrays.asList(nums[i], nums[j], nums[left], nums[right]));
|
||||
result.add(Arrays.asList(nums[k], nums[i], nums[left], nums[right]));
|
||||
// 对nums[left]和nums[right]去重
|
||||
while (right > left && nums[right] == nums[right - 1]) right--;
|
||||
while (right > left && nums[left] == nums[left + 1]) left++;
|
||||
|
||||
left++;
|
||||
right--;
|
||||
left++;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Solution solution = new Solution();
|
||||
int[] nums = {1, 0, -1, 0, -2, 2};
|
||||
int target = 0;
|
||||
List<List<Integer>> results = solution.fourSum(nums, target);
|
||||
for (List<Integer> result : results) {
|
||||
System.out.println(result);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -188,13 +188,13 @@ public:
|
||||
|
||||
开头为什么要加元素0?
|
||||
|
||||
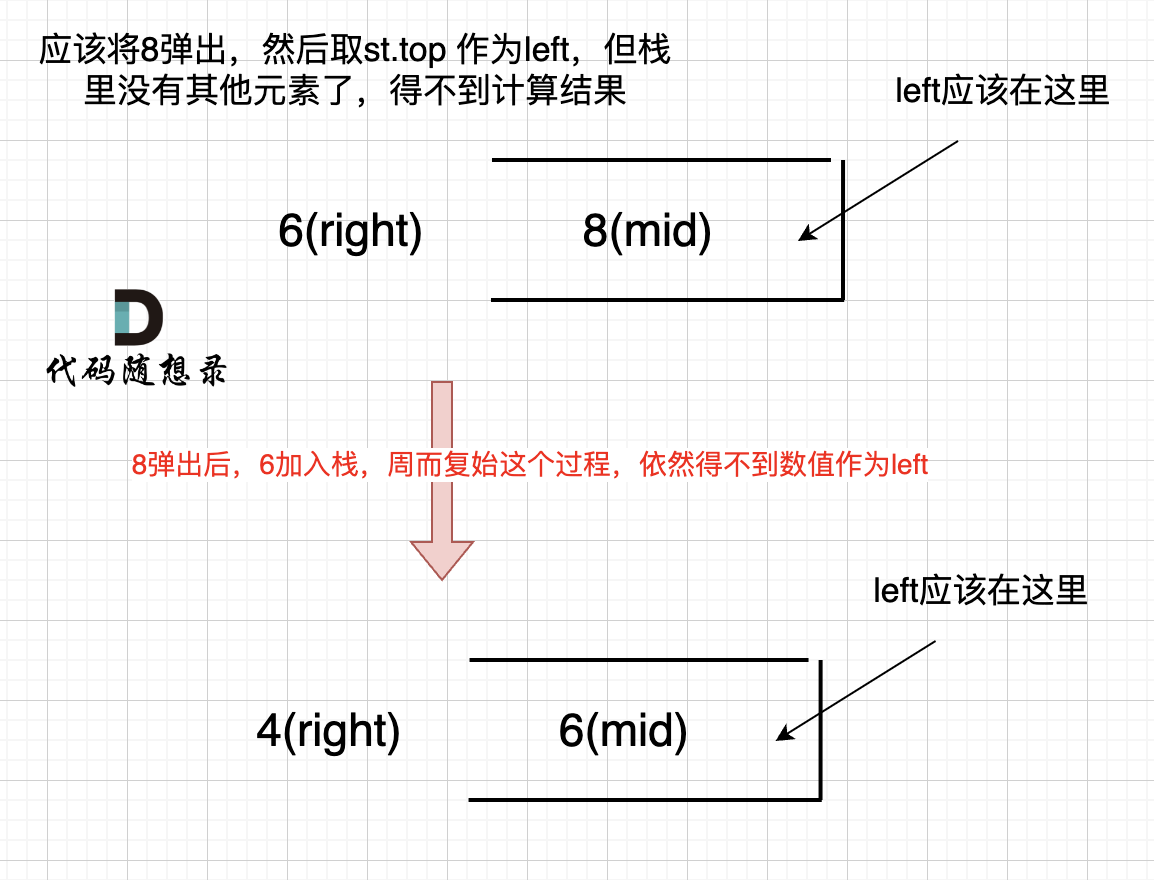
如果数组本身是降序的,例如 [8,6,4,2],在 8 入栈后,6 开始与8 进行比较,此时我们得到 mid(8),rigt(6),但是得不到 left。
|
||||
如果数组本身是降序的,例如 [8,6,4,2],在 8 入栈后,6 开始与8 进行比较,此时我们得到 mid(8),right(6),但是得不到 left。
|
||||
|
||||
(mid、left,right 都是对应版本一里的逻辑)
|
||||
|
||||
因为 将 8 弹出之后,栈里没有元素了,那么为了避免空栈取值,直接跳过了计算结果的逻辑。
|
||||
|
||||
之后又将6 加入栈(此时8已经弹出了),然后 就是 4 与 栈口元素 8 进行比较,周而复始,那么计算的最后结果resutl就是0。 如图所示:
|
||||
之后又将6 加入栈(此时8已经弹出了),然后 就是 4 与 栈口元素 6 进行比较,周而复始,那么计算的最后结果result就是0。 如图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
@ -243,7 +243,7 @@ public:
|
||||
|
||||
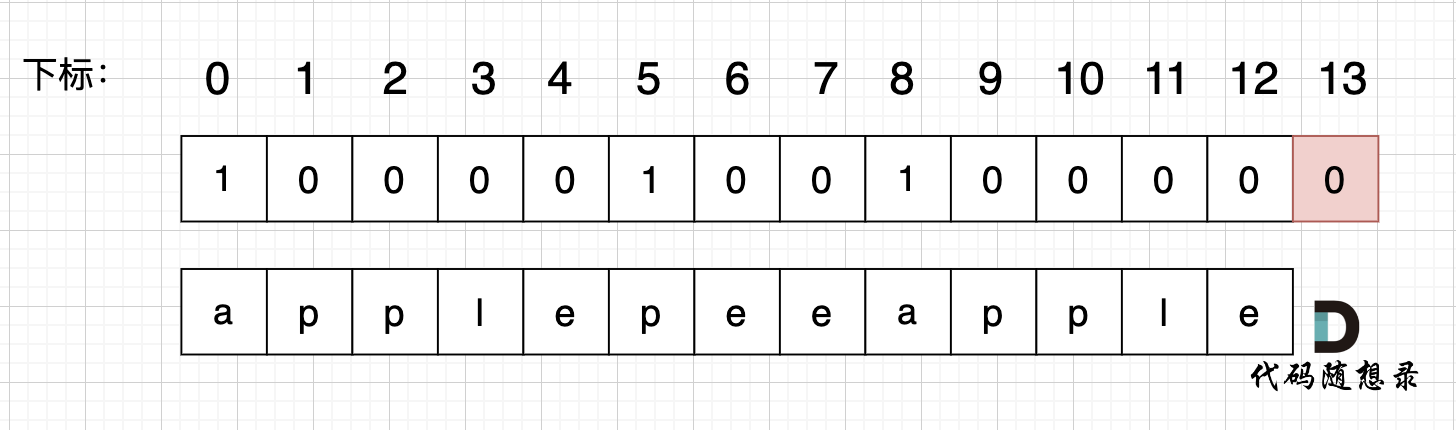
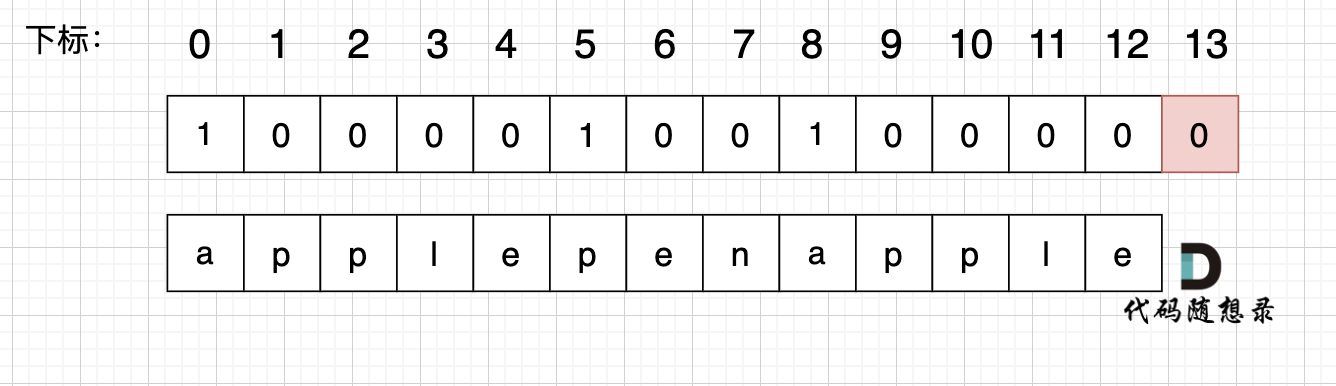
使用用例:s = "applepenapple", wordDict = ["apple", "pen"],对应的dp数组状态如下:
|
||||
|
||||
|
||||
|
||||
|
||||
最后dp[s.size()] = 0 即 dp[13] = 0 ,而不是1,因为先用 "apple" 去遍历的时候,dp[8]并没有被赋值为1 (还没用"pen"),所以 dp[13]也不能变成1。
|
||||
|
||||
|
||||
@ -131,7 +131,7 @@ public:
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度: pop为O(n),其他为O(1)
|
||||
* 时间复杂度: pop为O(n),top为O(n),其他为O(1)
|
||||
* 空间复杂度: O(n)
|
||||
|
||||
## 优化
|
||||
@ -147,17 +147,14 @@ class MyStack {
|
||||
public:
|
||||
queue<int> que;
|
||||
|
||||
/** Initialize your data structure here. */
|
||||
MyStack() {
|
||||
|
||||
}
|
||||
|
||||
/** Push element x onto stack. */
|
||||
void push(int x) {
|
||||
que.push(x);
|
||||
}
|
||||
|
||||
/** Removes the element on top of the stack and returns that element. */
|
||||
int pop() {
|
||||
int size = que.size();
|
||||
size--;
|
||||
@ -170,9 +167,6 @@ public:
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Get the top element.
|
||||
** Can not use back() direactly.
|
||||
*/
|
||||
int top(){
|
||||
int size = que.size();
|
||||
size--;
|
||||
@ -187,13 +181,12 @@ public:
|
||||
return result;
|
||||
}
|
||||
|
||||
/** Returns whether the stack is empty. */
|
||||
bool empty() {
|
||||
return que.empty();
|
||||
}
|
||||
};
|
||||
```
|
||||
* 时间复杂度: pop为O(n),其他为O(1)
|
||||
* 时间复杂度: pop为O(n),top为O(n),其他为O(1)
|
||||
* 空间复杂度: O(n)
|
||||
|
||||
|
||||
|
||||
@ -49,7 +49,7 @@
|
||||
* [动态规划:关于01背包问题,你该了解这些!](https://programmercarl.com/背包理论基础01背包-1.html)
|
||||
* [动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://programmercarl.com/背包理论基础01背包-2.html)
|
||||
|
||||
如果跟着「代码随想录」一起学过[回溯算法系列](https://programmercarl.com/回溯总结.html)的录友,看到这道题,应该有一种直觉,就是感觉好像回溯法可以爆搜出来。
|
||||
如果跟着「代码随想录」一起学过[回溯算法系列](https://programmercarl.com/回溯总结.html)的录友,看到这道题,应该有一种直觉,就是感觉好像回溯法可以暴搜出来。
|
||||
|
||||
事实确实如此,下面我也会给出相应的代码,只不过会超时。
|
||||
|
||||
@ -118,9 +118,7 @@ public:
|
||||
|
||||
也可以使用记忆化回溯,但这里我就不在回溯上下功夫了,直接看动规吧
|
||||
|
||||
### 动态规划
|
||||
|
||||
如何转化为01背包问题呢。
|
||||
### 动态规划 (二维dp数组)
|
||||
|
||||
假设加法的总和为x,那么减法对应的总和就是sum - x。
|
||||
|
||||
@ -132,7 +130,7 @@ x = (target + sum) / 2
|
||||
|
||||
这里的x,就是bagSize,也就是我们后面要求的背包容量。
|
||||
|
||||
大家看到(target + sum) / 2 应该担心计算的过程中向下取整有没有影响。
|
||||
大家看到`(target + sum) / 2` 应该担心计算的过程中向下取整有没有影响。
|
||||
|
||||
这么担心就对了,例如sum是5,target是2 的话其实就是无解的,所以:
|
||||
|
||||
@ -147,8 +145,6 @@ if ((target + sum) % 2 == 1) return 0; // 此时没有方案
|
||||
if (abs(target) > sum) return 0; // 此时没有方案
|
||||
```
|
||||
|
||||
再回归到01背包问题,为什么是01背包呢?
|
||||
|
||||
因为每个物品(题目中的1)只用一次!
|
||||
|
||||
这次和之前遇到的背包问题不一样了,之前都是求容量为j的背包,最多能装多少。
|
||||
@ -157,59 +153,260 @@ if (abs(target) > sum) return 0; // 此时没有方案
|
||||
|
||||
1. 确定dp数组以及下标的含义
|
||||
|
||||
dp[j] 表示:填满j(包括j)这么大容积的包,有dp[j]种方法
|
||||
先用 二维 dp数组求解本题,dp[i][j]:使用 下标为[0, i]的nums[i]能够凑满j(包括j)这么大容量的包,有dp[i][j]种方法。
|
||||
|
||||
其实也可以使用二维dp数组来求解本题,dp[i][j]:使用 下标为[0, i]的nums[i]能够凑满j(包括j)这么大容量的包,有dp[i][j]种方法。
|
||||
|
||||
下面我都是统一使用一维数组进行讲解, 二维降为一维(滚动数组),其实就是上一层拷贝下来,这个我在[动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://programmercarl.com/背包理论基础01背包-2.html)也有介绍。
|
||||
01背包为什么这么定义dp数组,我在[0-1背包理论基础](https://www.programmercarl.com/%E8%83%8C%E5%8C%85%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%8001%E8%83%8C%E5%8C%85-1.html)中 确定dp数组的含义里讲解过。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
有哪些来源可以推出dp[j]呢?
|
||||
我们先手动推导一下,这个二维数组里面的数值。
|
||||
|
||||
只要搞到nums[i],凑成dp[j]就有dp[j - nums[i]] 种方法。
|
||||
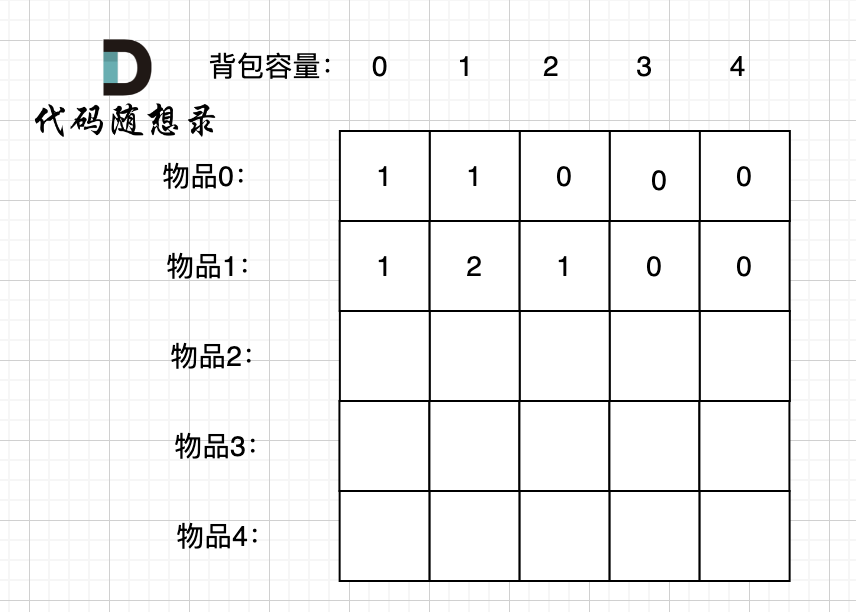
先只考虑物品0,如图:
|
||||
|
||||
例如:dp[j],j 为5,
|
||||

|
||||
|
||||
* 已经有一个1(nums[i]) 的话,有 dp[4]种方法 凑成 容量为5的背包。
|
||||
* 已经有一个2(nums[i]) 的话,有 dp[3]种方法 凑成 容量为5的背包。
|
||||
* 已经有一个3(nums[i]) 的话,有 dp[2]种方法 凑成 容量为5的背包
|
||||
* 已经有一个4(nums[i]) 的话,有 dp[1]种方法 凑成 容量为5的背包
|
||||
* 已经有一个5 (nums[i])的话,有 dp[0]种方法 凑成 容量为5的背包
|
||||
(这里的所有物品,都是题目中的数字1)。
|
||||
|
||||
那么凑整dp[5]有多少方法呢,也就是把 所有的 dp[j - nums[i]] 累加起来。
|
||||
装满背包容量为0 的方法个数是1,即 放0件物品。
|
||||
|
||||
所以求组合类问题的公式,都是类似这种:
|
||||
装满背包容量为1 的方法个数是1,即 放物品0。
|
||||
|
||||
装满背包容量为2 的方法个数是0,目前没有办法能装满容量为2的背包。
|
||||
|
||||
接下来 考虑 物品0 和 物品1,如图:
|
||||
|
||||
|
||||
|
||||
装满背包容量为0 的方法个数是1,即 放0件物品。
|
||||
|
||||
装满背包容量为1 的方法个数是2,即 放物品0 或者 放物品1。
|
||||
|
||||
装满背包容量为2 的方法个数是1,即 放物品0 和 放物品1。
|
||||
|
||||
其他容量都不能装满,所以方法是0。
|
||||
|
||||
接下来 考虑 物品0 、物品1 和 物品2 ,如图:
|
||||
|
||||
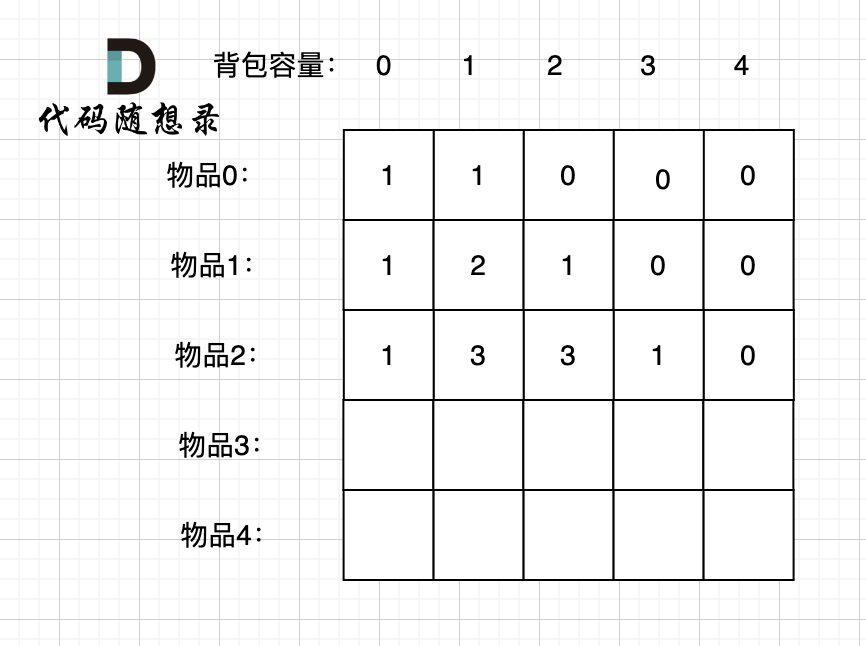
|
||||
|
||||
装满背包容量为0 的方法个数是1,即 放0件物品。
|
||||
|
||||
装满背包容量为1 的方法个数是3,即 放物品0 或者 放物品1 或者 放物品2。
|
||||
|
||||
装满背包容量为2 的方法个数是3,即 放物品0 和 放物品1、放物品0 和 物品 2、 放物品1 和 物品2。
|
||||
|
||||
装满背包容量为3的方法个数是1,即 放物品0 和 物品1 和 物品2。
|
||||
|
||||
通过以上举例,我们来看 dp[2][2] 可以有哪些方向推出来。
|
||||
|
||||
如图红色部分:
|
||||
|
||||
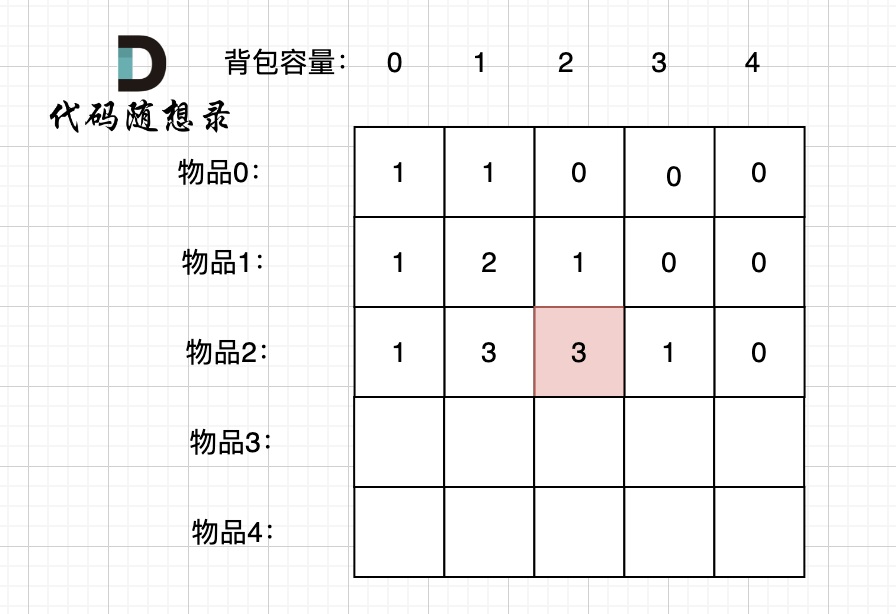
|
||||
|
||||
dp[2][2] = 3,即 放物品0 和 放物品1、放物品0 和 物品 2、放物品1 和 物品2, 如图所示,三种方法:
|
||||
|
||||
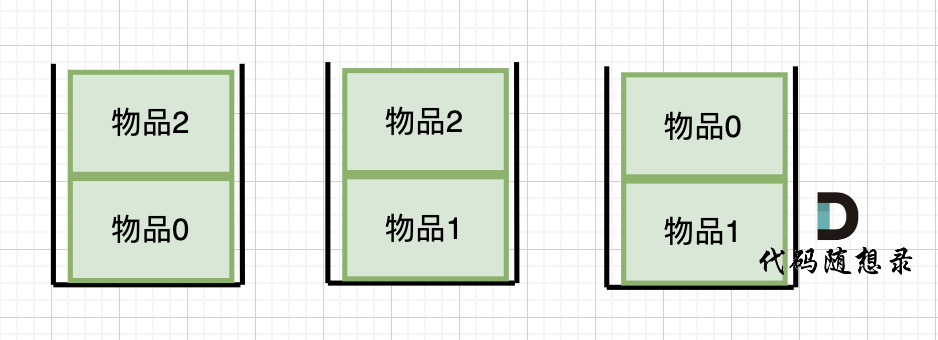
|
||||
|
||||
**容量为2 的背包,如果不放 物品2 有几种方法呢**?
|
||||
|
||||
有 dp[1][2] 种方法,即 背包容量为2,只考虑物品0 和 物品1 ,有 dp[1][2] 种方法,如图:
|
||||
|
||||
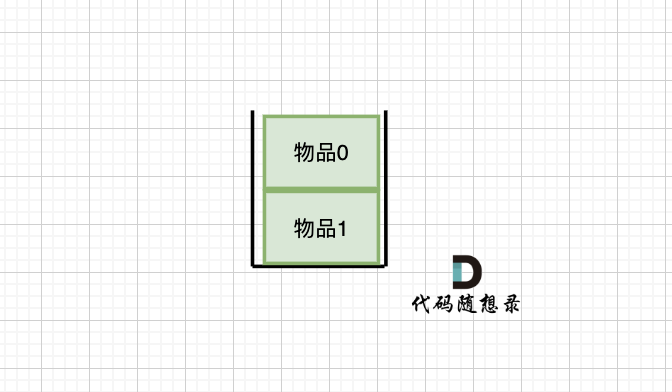
|
||||
|
||||
**容量为2 的背包, 如果放 物品2 有几种方法呢**?
|
||||
|
||||
首先 要在背包里 先把物品2的容量空出来, 装满 刨除物品2容量 的背包 有几种方法呢?
|
||||
|
||||
刨除物品2容量后的背包容量为 1。
|
||||
|
||||
此时装满背包容量为1 有 dp[1][1] 种方法,即: 不放物品2,背包容量为1,只考虑物品 0 和 物品 1,有 dp[1][1] 种方法。
|
||||
|
||||
如图:
|
||||
|
||||

|
||||
|
||||
有录友可能疑惑,这里计算的是放满 容量为2的背包 有几种方法,那物品2去哪了?
|
||||
|
||||
在上面图中,你把物品2补上就好,同样是两种方法。
|
||||
|
||||
dp[2][2] = 容量为2的背包不放物品2有几种方法 + 容量为2的背包不放物品2有几种方法
|
||||
|
||||
所以 dp[2][2] = dp[1][2] + dp[1][1] ,如图:
|
||||
|
||||

|
||||
|
||||
以上过程,抽象化如下:
|
||||
|
||||
* **不放物品i**:即背包容量为j,里面不放物品i,装满有dp[i - 1][j]中方法。
|
||||
|
||||
* **放物品i**: 即:先空出物品i的容量,背包容量为(j - 物品i容量),放满背包有 dp[i - 1][j - 物品i容量] 种方法。
|
||||
|
||||
本题中,物品i的容量是nums[i],价值也是nums[i]。
|
||||
|
||||
递推公式:dp[i][j] = dp[i - 1][j] + dp[i - 1][j - nums[i]];
|
||||
|
||||
考到这个递推公式,我们应该注意到,`j - nums[i]` 作为数组下标,如果 `j - nums[i]` 小于零呢?
|
||||
|
||||
说明背包容量装不下 物品i,所以此时装满背包的方法值 等于 不放物品i的装满背包的方法,即:dp[i][j] = dp[i - 1][j];
|
||||
|
||||
所以递推公式:
|
||||
|
||||
```CPP
|
||||
if (nums[i] > j) dp[i][j] = dp[i - 1][j];
|
||||
else dp[i][j] = dp[i - 1][j] + dp[i - 1][j - nums[i]];
|
||||
```
|
||||
dp[j] += dp[j - nums[i]]
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
先明确递推的方向,如图,求解 dp[2][2] 是由 上方和左上方推出。
|
||||
|
||||
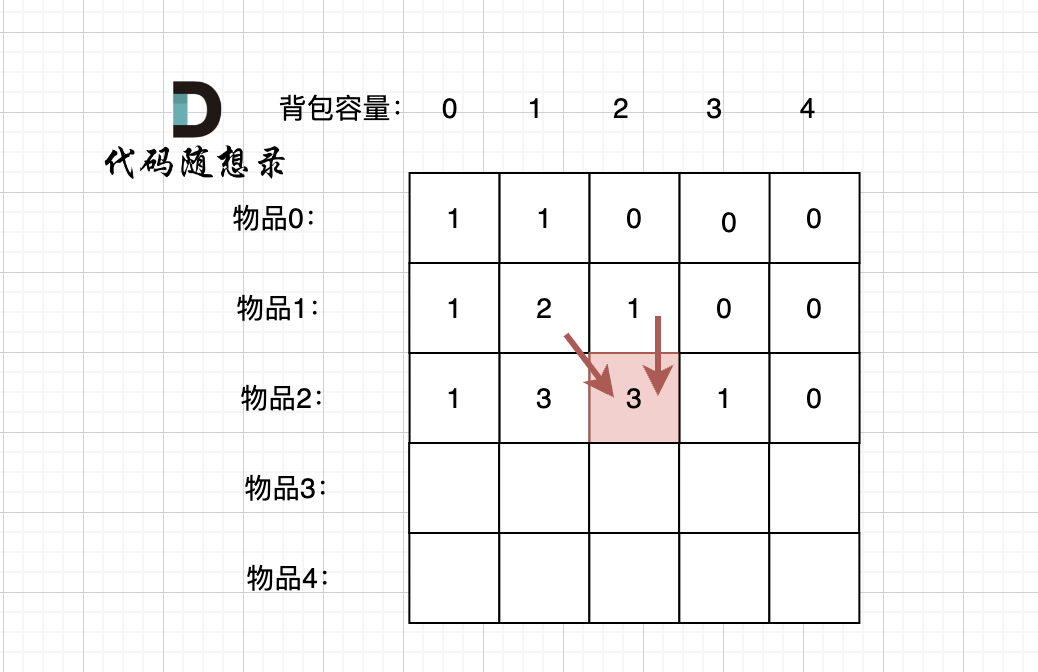
|
||||
|
||||
那么二维数组的最上行 和 最左列一定要初始化,这是递推公式推导的基础,如图红色部分:
|
||||
|
||||

|
||||
|
||||
关于dp[0][0]的值,在上面的递推公式讲解中已经讲过,装满背包容量为0 的方法数量是1,即 放0件物品。
|
||||
|
||||
那么最上行dp[0][j] 如何初始化呢?
|
||||
|
||||
dp[0][j]:只放物品0, 把容量为j的背包填满有几种方法。
|
||||
|
||||
只有背包容量为 物品0 的容量的时候,方法为1,正好装满。
|
||||
|
||||
其他情况下,要不是装不满,要不是装不下。
|
||||
|
||||
所以初始化:dp[0][nums[0]] = 1 ,其他均为0 。
|
||||
|
||||
表格最左列也要初始化,dp[i][0] : 背包容量为0, 放物品0 到 物品i,装满有几种方法。
|
||||
|
||||
都是有一种方法,就是放0件物品。
|
||||
|
||||
即 dp[i][0] = 1
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
在明确递推方向时,我们知道 当前值 是由上方和左上方推出。
|
||||
|
||||
那么我们的遍历顺序一定是 从上到下,从左到右。
|
||||
|
||||
因为只有这样,我们才能基于之前的数值做推导。
|
||||
|
||||
例如下图,如果上方没数值,左上方没数值,就无法推出 dp[2][2]。
|
||||
|
||||
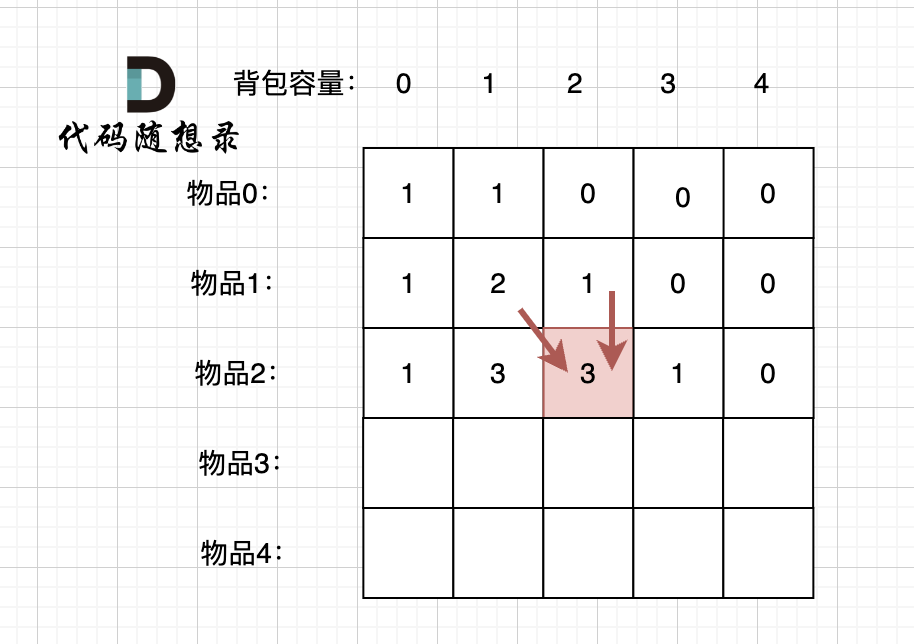
|
||||
|
||||
那么是先 从上到下 ,再从左到右遍历,例如这样:
|
||||
|
||||
```CPP
|
||||
for (int i = 1; i < nums.size(); i++) { // 行,遍历物品
|
||||
for (int j = 0; j <= bagSize; j++) { // 列,遍历背包
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
还是先 从左到右,再从上到下呢,例如这样:
|
||||
|
||||
```CPP
|
||||
for (int j = 0; j <= bagSize; j++) { // 列,遍历背包
|
||||
for (int i = 1; i < nums.size(); i++) { // 行,遍历物品
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**其实以上两种遍历都可以**! (但仅针对二维DP数组是这样的)
|
||||
|
||||
这一点我在 [01背包理论基础](https://www.programmercarl.com/%E8%83%8C%E5%8C%85%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%8001%E8%83%8C%E5%8C%85-1.html)中的 遍历顺序部分讲过。
|
||||
|
||||
这里我再画图讲一下,以求dp[2][2]为例,当先从上到下,再从左到右遍历,矩阵是这样:
|
||||
|
||||
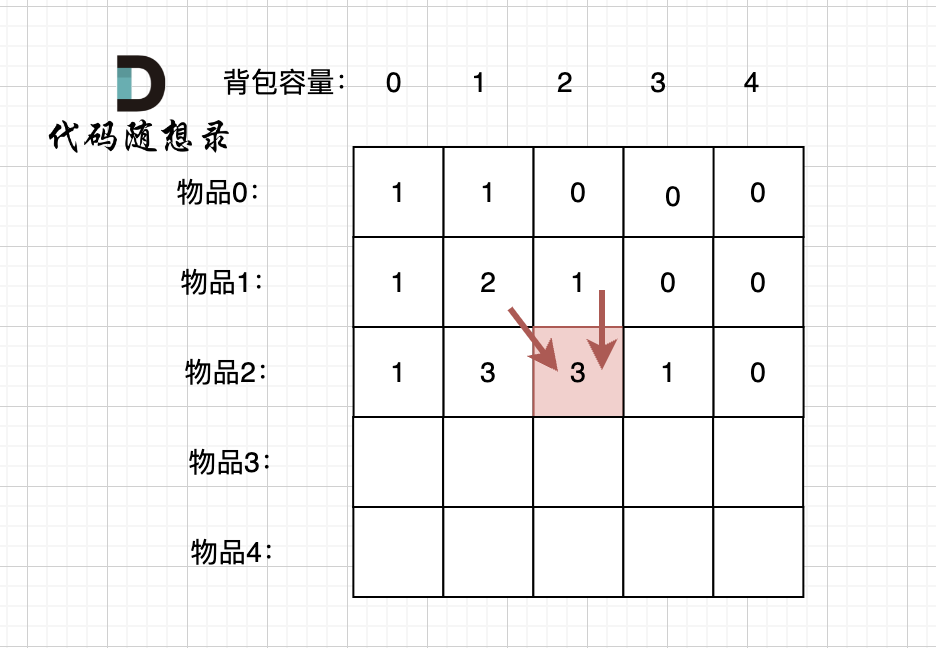
|
||||
|
||||
当先从左到右,再从上到下遍历,矩阵是这样:
|
||||
|
||||
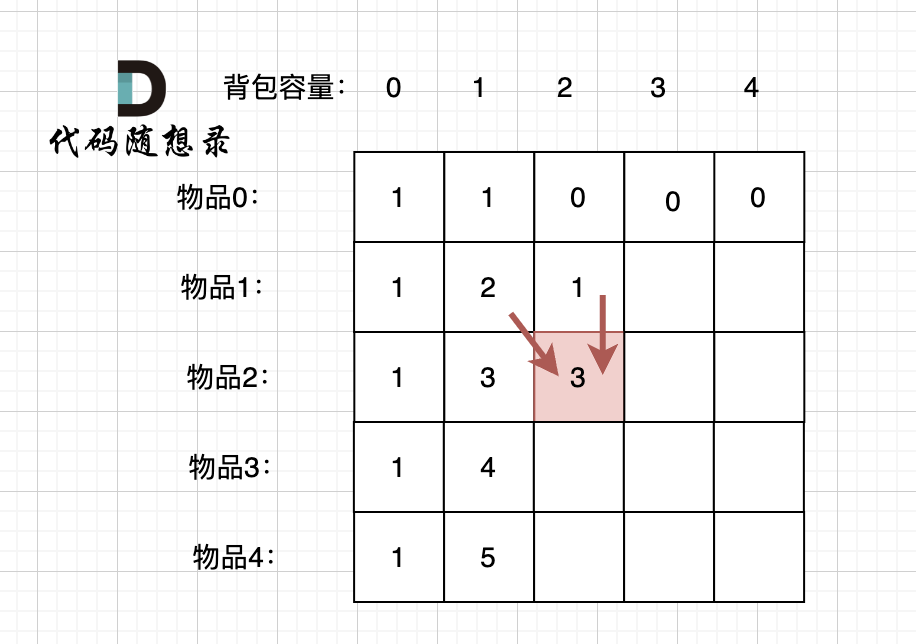
|
||||
|
||||
这里大家可以看出,无论是以上哪种遍历,都不影响 dp[2][2]的求值,用来 推导 dp[2][2] 的数值都在。
|
||||
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
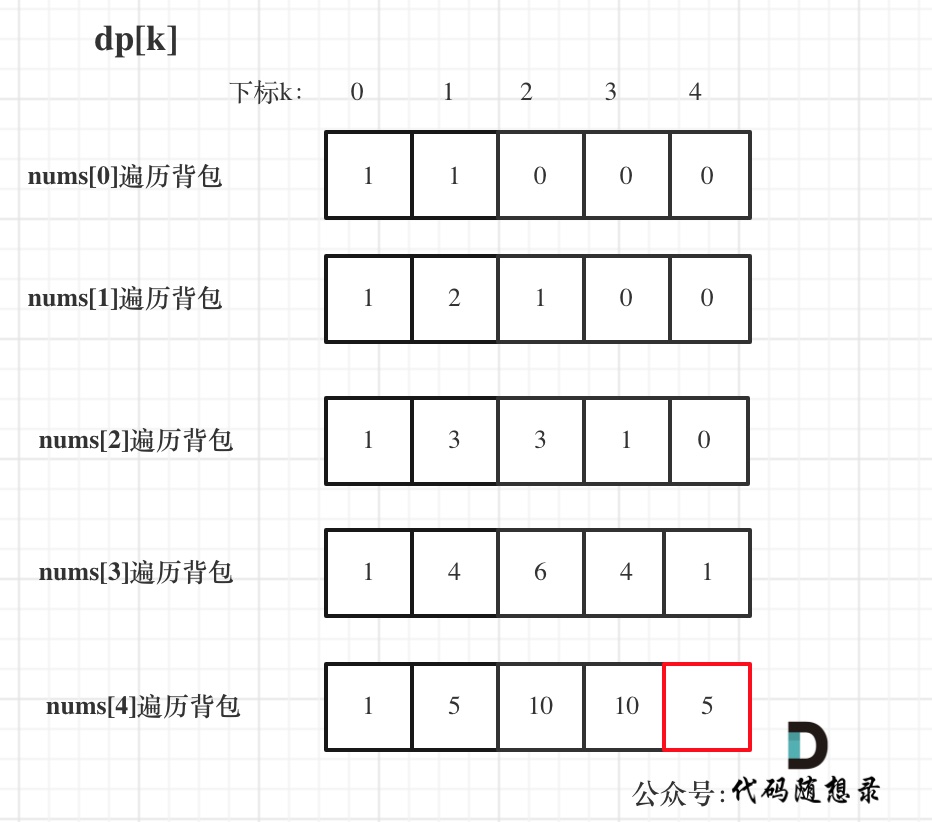
输入:nums: [1, 1, 1, 1, 1], target: 3
|
||||
|
||||
bagSize = (target + sum) / 2 = (3 + 5) / 2 = 4
|
||||
|
||||
dp数组状态变化如下:
|
||||
|
||||

|
||||
|
||||
这么大的矩阵,我们是可以自己手动模拟出来的。
|
||||
|
||||
在模拟的过程中,既可以帮我们寻找规律,也可以帮我们验证 递推公式加遍历顺序是不是按照我们想象的结果推进的。
|
||||
|
||||
|
||||
最后二维dp数组的C++代码如下:
|
||||
|
||||
```CPP
|
||||
class Solution {
|
||||
public:
|
||||
int findTargetSumWays(vector<int>& nums, int target) {
|
||||
int sum = 0;
|
||||
for (int i = 0; i < nums.size(); i++) sum += nums[i];
|
||||
if (abs(target) > sum) return 0; // 此时没有方案
|
||||
if ((target + sum) % 2 == 1) return 0; // 此时没有方案
|
||||
int bagSize = (target + sum) / 2;
|
||||
|
||||
vector<vector<int>> dp(nums.size(), vector<int>(bagSize + 1, 0));
|
||||
|
||||
// 初始化最上行
|
||||
if (nums[0] <= bagSize) dp[0][nums[0]] = 1;
|
||||
|
||||
// 初始化最左列,最左列其他数值在递推公式中就完成了赋值
|
||||
dp[0][0] = 1;
|
||||
|
||||
int numZero = 0;
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
if (nums[i] == 0) numZero++;
|
||||
dp[i][0] = (int) pow(2.0, numZero);
|
||||
}
|
||||
|
||||
// 以下遍历顺序行列可以颠倒
|
||||
for (int i = 1; i < nums.size(); i++) { // 行,遍历物品
|
||||
for (int j = 0; j <= bagSize; j++) { // 列,遍历背包
|
||||
if (nums[i] > j) dp[i][j] = dp[i - 1][j];
|
||||
else dp[i][j] = dp[i - 1][j] + dp[i - 1][j - nums[i]];
|
||||
}
|
||||
}
|
||||
return dp[nums.size() - 1][bagSize];
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
### 动态规划 (一维dp数组)
|
||||
|
||||
将二维dp数组压缩成一维dp数组,我们在 [01背包理论基础(滚动数组)](https://programmercarl.com/背包理论基础01背包-2.html) 讲过滚动数组,原理是一样的,即重复利用每一行的数值。
|
||||
|
||||
既然是重复利用每一行,就是将二维数组压缩成一行。
|
||||
|
||||
dp[i][j] 去掉 行的维度,即 dp[j],表示:填满j(包括j)这么大容积的包,有dp[j]种方法。
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
二维DP数组递推公式: `dp[i][j] = dp[i - 1][j] + dp[i - 1][j - nums[i]];`
|
||||
|
||||
去掉维度i 之后,递推公式:`dp[j] = dp[j] + dp[j - nums[i]]` ,即:`dp[j] += dp[j - nums[i]]`
|
||||
|
||||
**这个公式在后面在讲解背包解决排列组合问题的时候还会用到!**
|
||||
|
||||
3. dp数组如何初始化
|
||||
|
||||
从递推公式可以看出,在初始化的时候dp[0] 一定要初始化为1,因为dp[0]是在公式中一切递推结果的起源,如果dp[0]是0的话,递推结果将都是0。
|
||||
|
||||
这里有录友可能认为从dp数组定义来说 dp[0] 应该是0,也有录友认为dp[0]应该是1。
|
||||
|
||||
其实不要硬去解释它的含义,咱就把 dp[0]的情况带入本题看看应该等于多少。
|
||||
|
||||
如果数组[0] ,target = 0,那么 bagSize = (target + sum) / 2 = 0。 dp[0]也应该是1, 也就是说给数组里的元素 0 前面无论放加法还是减法,都是 1 种方法。
|
||||
|
||||
所以本题我们应该初始化 dp[0] 为 1。
|
||||
|
||||
可能有同学想了,那 如果是 数组[0,0,0,0,0] target = 0 呢。
|
||||
|
||||
其实 此时最终的dp[0] = 32,也就是这五个零 子集的所有组合情况,但此dp[0]非彼dp[0],dp[0]能算出32,其基础是因为dp[0] = 1 累加起来的。
|
||||
|
||||
dp[j]其他下标对应的数值也应该初始化为0,从递推公式也可以看出,dp[j]要保证是0的初始值,才能正确的由dp[j - nums[i]]推导出来。
|
||||
|
||||
在上面 二维dp数组中,我们讲解过 dp[0][0] 初始为1,这里dp[0] 同样初始为1 ,即装满背包为0的方法有一种,放0件物品。
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
在[动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://programmercarl.com/背包理论基础01背包-2.html)中,我们讲过对于01背包问题一维dp的遍历,nums放在外循环,target在内循环,且内循环倒序。
|
||||
在[动态规划:关于01背包问题,你该了解这些!(滚动数组)](https://programmercarl.com/背包理论基础01背包-2.html)中,我们系统讲过对于01背包问题一维dp的遍历。
|
||||
|
||||
遍历物品放在外循环,遍历背包在内循环,且内循环倒序(为了保证物品只使用一次)。
|
||||
|
||||
5. 举例推导dp数组
|
||||
|
||||
@ -221,7 +418,9 @@ dp数组状态变化如下:
|
||||
|
||||
|
||||
|
||||
C++代码如下:
|
||||
大家可以和 二维dp数组的打印结果做一下对比。
|
||||
|
||||
一维DP的C++代码如下:
|
||||
|
||||
```CPP
|
||||
class Solution {
|
||||
@ -248,23 +447,51 @@ public:
|
||||
* 空间复杂度:O(m),m为背包容量
|
||||
|
||||
|
||||
|
||||
### 拓展
|
||||
|
||||
关于一维dp数组的递推公式解释,也可以从以下维度来理解。 (**但还是从二维DP数组到一维DP数组这样更容易理解一些**)
|
||||
|
||||
2. 确定递推公式
|
||||
|
||||
有哪些来源可以推出dp[j]呢?
|
||||
|
||||
只要搞到nums[i],凑成dp[j]就有dp[j - nums[i]] 种方法。
|
||||
|
||||
例如:dp[j],j 为5,
|
||||
|
||||
* 已经有一个1(nums[i]) 的话,有 dp[4]种方法 凑成 容量为5的背包。
|
||||
* 已经有一个2(nums[i]) 的话,有 dp[3]种方法 凑成 容量为5的背包。
|
||||
* 已经有一个3(nums[i]) 的话,有 dp[2]种方法 凑成 容量为5的背包
|
||||
* 已经有一个4(nums[i]) 的话,有 dp[1]种方法 凑成 容量为5的背包
|
||||
* 已经有一个5 (nums[i])的话,有 dp[0]种方法 凑成 容量为5的背包
|
||||
|
||||
那么凑整dp[5]有多少方法呢,也就是把 所有的 dp[j - nums[i]] 累加起来。
|
||||
|
||||
所以求组合类问题的公式,都是类似这种:
|
||||
|
||||
```
|
||||
dp[j] += dp[j - nums[i]]
|
||||
```
|
||||
|
||||
|
||||
## 总结
|
||||
|
||||
此时 大家应该不禁想起,我们之前讲过的[回溯算法:39. 组合总和](https://programmercarl.com/0039.组合总和.html)是不是应该也可以用dp来做啊?
|
||||
|
||||
是的,如果仅仅是求个数的话,就可以用dp,但[回溯算法:39. 组合总和](https://programmercarl.com/0039.组合总和.html)要求的是把所有组合列出来,还是要使用回溯法爆搜的。
|
||||
是可以求的,如果仅仅是求个数的话,就可以用dp,但[回溯算法:39. 组合总和](https://programmercarl.com/0039.组合总和.html)要求的是把所有组合列出来,还是要使用回溯法暴搜的。
|
||||
|
||||
本题还是有点难度,大家也可以记住,在求装满背包有几种方法的情况下,递推公式一般为:
|
||||
本题还是有点难度,理解上从二维DP数组更容易理解,做题上直接用一维DP更简洁一些。
|
||||
|
||||
大家可以选择哪种方式自己更容易理解。
|
||||
|
||||
在后面得题目中,在求装满背包有几种方法的情况下,递推公式一般为:
|
||||
|
||||
```CPP
|
||||
dp[j] += dp[j - nums[i]];
|
||||
```
|
||||
|
||||
后面我们在讲解完全背包的时候,还会用到这个递推公式!
|
||||
|
||||
|
||||
|
||||
|
||||
我们在讲解完全背包的时候,还会用到这个递推公式!
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
@ -359,13 +586,6 @@ class Solution {
|
||||
}
|
||||
}
|
||||
|
||||
// 打印dp数组
|
||||
// for(int i = 0; i < nums.length; i++) {
|
||||
// for(int j = 0; j <= left; j++) {
|
||||
// System.out.print(dp[i][j] + " ");
|
||||
// }
|
||||
// System.out.println("");
|
||||
// }
|
||||
|
||||
return dp[nums.length - 1][left];
|
||||
|
||||
@ -656,51 +876,3 @@ public class Solution
|
||||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||||
</a>
|
||||
|
||||
|
||||
class Solution {
|
||||
public:
|
||||
int findTargetSumWays(vector<int>& nums, int target) {
|
||||
int sum = 0;
|
||||
for (int i = 0; i < nums.size(); i++) sum += nums[i];
|
||||
if (abs(target) > sum) return 0; // 此时没有方案
|
||||
if ((target + sum) % 2 == 1) return 0; // 此时没有方案
|
||||
int bagSize = (target + sum) / 2;
|
||||
|
||||
vector<vector<int>> dp(nums.size(), vector<int>(bagSize + 1, 0));
|
||||
|
||||
if (nums[0] <= bagSize) dp[0][nums[0]] = 1;
|
||||
|
||||
dp[0][0] = 1;
|
||||
|
||||
int numZero = 0;
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
if (nums[i] == 0) numZero++;
|
||||
dp[i][0] = (int) pow(2.0, numZero);
|
||||
}
|
||||
|
||||
for (int i = 1; i < nums.size(); i++) {
|
||||
for (int j = 0; j <= bagSize; j++) {
|
||||
if (nums[i] > j) dp[i][j] = dp[i - 1][j];
|
||||
else dp[i][j] = dp[i - 1][j] + dp[i - 1][j - nums[i]];
|
||||
}
|
||||
}
|
||||
for (int i = 0; i < nums.size(); i++) {
|
||||
for (int j = 0; j <= bagSize; j++) {
|
||||
cout << dp[i][j] << " ";
|
||||
}
|
||||
cout << endl;
|
||||
}
|
||||
return dp[nums.size() - 1][bagSize];
|
||||
}
|
||||
};
|
||||
|
||||
1 1 0 0 0
|
||||
1 2 1 0 0
|
||||
1 3 3 1 0
|
||||
1 4 6 4 1
|
||||
1 5 10 10 5
|
||||
|
||||
初始化 如果没有0, dp[i][0] = 1; 即所有元素都不取。
|
||||
|
||||
用元素 取与不取来举例
|
||||
|
||||
|
||||
@ -150,7 +150,7 @@ minDist数组数值初始化为int最大值。
|
||||
更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
|
||||
|
||||
* 源点到节点2的最短距离为1,小于原minDist[2]的数值max,更新minDist[2] = 1
|
||||
* 源点到节点3的最短距离为4,小于原minDist[3]的数值max,更新minDist[4] = 4
|
||||
* 源点到节点3的最短距离为4,小于原minDist[3]的数值max,更新minDist[3] = 4
|
||||
|
||||
可能有录友问:为啥和 minDist[2] 比较?
|
||||
|
||||
|
||||
@ -176,7 +176,7 @@ minDist 数组 里的数值初始化为 最大数,因为本题 节点距离不
|
||||
|
||||
所有非生成树的节点距离 最小生成树(节点1、节点2、节点3 )的距离都已经跟新了 。
|
||||
|
||||
* 节点 4 和 节点 3的距离为 1,和原先的距离值 2 小,所以更新minDist[3]为1。
|
||||
* 节点 4 和 节点 3的距离为 1,和原先的距离值 2 小,所以更新minDist[4]为1。
|
||||
|
||||
上面为什么我们只比较 节点4 和 节点3 的距离呢?
|
||||
|
||||
@ -213,7 +213,7 @@ minDist 数组 里的数值初始化为 最大数,因为本题 节点距离不
|
||||
|
||||
minDist数组已经更新了 所有非生成树的节点距离 最小生成树(节点1、节点2、节点3、节点4 )的距离 。
|
||||
|
||||
* 节点 5 和 节点 4的距离为 1,和原先的距离值 2 小,所以更新minDist[4]为1。
|
||||
* 节点 5 和 节点 4的距离为 1,和原先的距离值 2 小,所以更新minDist[5]为1。
|
||||
|
||||
### 6
|
||||
|
||||
|
||||
@ -247,6 +247,61 @@ int main() {
|
||||
|
||||
### Python
|
||||
|
||||
```python
|
||||
import sys
|
||||
|
||||
def main():
|
||||
input = sys.stdin.read
|
||||
data = input().split()
|
||||
index = 0
|
||||
|
||||
n = int(data[index])
|
||||
index += 1
|
||||
m = int(data[index])
|
||||
index += 1
|
||||
|
||||
grid = []
|
||||
for i in range(m):
|
||||
p1 = int(data[index])
|
||||
index += 1
|
||||
p2 = int(data[index])
|
||||
index += 1
|
||||
val = int(data[index])
|
||||
index += 1
|
||||
# p1 指向 p2,权值为 val
|
||||
grid.append([p1, p2, val])
|
||||
|
||||
start = 1 # 起点
|
||||
end = n # 终点
|
||||
|
||||
minDist = [float('inf')] * (n + 1)
|
||||
minDist[start] = 0
|
||||
flag = False
|
||||
|
||||
for i in range(1, n + 1): # 这里我们松弛n次,最后一次判断负权回路
|
||||
for side in grid:
|
||||
from_node = side[0]
|
||||
to = side[1]
|
||||
price = side[2]
|
||||
if i < n:
|
||||
if minDist[from_node] != float('inf') and minDist[to] > minDist[from_node] + price:
|
||||
minDist[to] = minDist[from_node] + price
|
||||
else: # 多加一次松弛判断负权回路
|
||||
if minDist[from_node] != float('inf') and minDist[to] > minDist[from_node] + price:
|
||||
flag = True
|
||||
|
||||
if flag:
|
||||
print("circle")
|
||||
elif minDist[end] == float('inf'):
|
||||
print("unconnected")
|
||||
else:
|
||||
print(minDist[end])
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
||||
```
|
||||
|
||||
### Go
|
||||
|
||||
### Rust
|
||||
|
||||
@ -192,50 +192,6 @@ int main() {
|
||||
|
||||
```java
|
||||
|
||||
import java.util.Scanner;
|
||||
|
||||
public class Main {
|
||||
static int[][] dir = { {0, 1}, {1, 0}, {-1, 0}, {0, -1} }; // 四个方向
|
||||
|
||||
public static void dfs(int[][] grid, boolean[][] visited, int x, int y) {
|
||||
for (int i = 0; i < 4; i++) {
|
||||
int nextx = x + dir[i][0];
|
||||
int nexty = y + dir[i][1];
|
||||
if (nextx < 0 || nextx >= grid.length || nexty < 0 || nexty >= grid[0].length) continue; // 越界了,直接跳过
|
||||
if (!visited[nextx][nexty] && grid[nextx][nexty] == 1) { // 没有访问过的 同时 是陆地的
|
||||
visited[nextx][nexty] = true;
|
||||
dfs(grid, visited, nextx, nexty);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Scanner scanner = new Scanner(System.in);
|
||||
int n = scanner.nextInt();
|
||||
int m = scanner.nextInt();
|
||||
int[][] grid = new int[n][m];
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
grid[i][j] = scanner.nextInt();
|
||||
}
|
||||
}
|
||||
|
||||
boolean[][] visited = new boolean[n][m];
|
||||
|
||||
int result = 0;
|
||||
for (int i = 0; i < n; i++) {
|
||||
for (int j = 0; j < m; j++) {
|
||||
if (!visited[i][j] && grid[i][j] == 1) {
|
||||
visited[i][j] = true;
|
||||
result++; // 遇到没访问过的陆地,+1
|
||||
dfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
System.out.println(result);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
@ -246,32 +202,6 @@ public class Main {
|
||||
|
||||
```python
|
||||
|
||||
def dfs(grid, visited, x, y):
|
||||
dir = [(0, 1), (1, 0), (-1, 0), (0, -1)] # 四个方向
|
||||
for d in dir:
|
||||
nextx, nexty = x + d[0], y + d[1]
|
||||
if 0 <= nextx < len(grid) and 0 <= nexty < len(grid[0]):
|
||||
if not visited[nextx][nexty] and grid[nextx][nexty] == 1: # 没有访问过的 同时 是陆地的
|
||||
visited[nextx][nexty] = True
|
||||
dfs(grid, visited, nextx, nexty)
|
||||
|
||||
def main():
|
||||
n, m = map(int, input().split())
|
||||
grid = [list(map(int, input().split())) for _ in range(n)]
|
||||
visited = [[False] * m for _ in range(n)]
|
||||
|
||||
result = 0
|
||||
for i in range(n):
|
||||
for j in range(m):
|
||||
if not visited[i][j] and grid[i][j] == 1:
|
||||
visited[i][j] = True
|
||||
result += 1 # 遇到没访问过的陆地,+1
|
||||
dfs(grid, visited, i, j) # 将与其链接的陆地都标记上 True
|
||||
|
||||
print(result)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
||||
|
||||
|
||||
|
||||
@ -17,7 +17,7 @@
|
||||
|
||||
输出描述:
|
||||
|
||||
输出一个整数,表示最大的岛屿面积。如果矩阵中不存在岛屿,则输出 0。
|
||||
输出一个整数,表示最大的岛屿面积。
|
||||
|
||||
输入示例:
|
||||
|
||||
|
||||
@ -7,16 +7,21 @@
|
||||
|
||||
题目描述
|
||||
|
||||
有向树指满足以下条件的有向图。该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。有向树拥有 n 个节点和 n - 1 条边。
|
||||
有一种有向树,该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。有向树拥有 n 个节点和 n - 1 条边。如图:
|
||||
|
||||
<img src="https://code-thinking-1253855093.file.myqcloud.com/pics/20240827152106.png" alt="" width="50%" />
|
||||
|
||||
输入一个有向图,该图由一个有着 n 个节点(节点编号 从 1 到 n),n 条边,请返回一条可以删除的边,使得删除该条边之后该有向图可以被当作一颗有向树。
|
||||
现在有一个有向图,有向图是在有向树中的两个没有直接链接的节点中间添加一条有向边。如图:
|
||||
|
||||
<img src="https://code-thinking-1253855093.file.myqcloud.com/pics/20240827152134.png" alt="" width="50%" />
|
||||
|
||||
输入一个有向图,该图由一个有着 n 个节点(节点编号 从 1 到 n),n 条边,请返回一条可以删除的边,使得删除该条边之后该有向图可以被当作一颗有向树。
|
||||
|
||||
输入描述
|
||||
|
||||
第一行输入一个整数 N,表示有向图中节点和边的个数。
|
||||
|
||||
后续 N 行,每行输入两个整数 s 和 t,代表 s 节点有一条连接 t 节点的单向边
|
||||
后续 N 行,每行输入两个整数 s 和 t,代表这是 s 节点连接并指向 t 节点的单向边
|
||||
|
||||
输出描述
|
||||
|
||||
@ -37,7 +42,7 @@
|
||||
|
||||
提示信息
|
||||
|
||||
|
||||
<img src="https://code-thinking-1253855093.file.myqcloud.com/pics/20240527112633.png" alt="" width="50%" />
|
||||
|
||||
在删除 2 3 后有向图可以变为一棵合法的有向树,所以输出 2 3
|
||||
|
||||
|
||||
95
problems/kamacoder/0153.权值优势路径计数.md
Normal file
95
problems/kamacoder/0153.权值优势路径计数.md
Normal file
@ -0,0 +1,95 @@
|
||||
|
||||
|
||||
# 权值优势路径计数
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1231)
|
||||
|
||||
1、构建二叉树:首先根据层序遍历的序列构建二叉树。这可以通过使用队列来实现,队列中存储当前节点及其索引,确保可以正确地将子节点添加到父节点下。
|
||||
|
||||
2、路径遍历:使用深度优先搜索(DFS)遍历所有从根到叶子的路径。在遍历过程中,维护一个计数器跟踪当前路径中权值为 1 和权值为 0 的节点的数量。
|
||||
|
||||
3、计数满足条件的路径:每当到达一个叶子节点时,检查当前路径的权值 1 的节点数量是否比权值 0 的节点数量多 1。如果满足,递增一个全局计数器。
|
||||
|
||||
|
||||
```CPP
|
||||
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <queue>
|
||||
|
||||
using namespace std;
|
||||
|
||||
struct TreeNode {
|
||||
int val;
|
||||
TreeNode *left, *right;
|
||||
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
|
||||
};
|
||||
|
||||
// DFS遍历二叉树,并计算满足条件的路径数量
|
||||
void countPaths(TreeNode* node, int count1, int count0, int& result) {
|
||||
if (!node) return;
|
||||
|
||||
// 更新当前路径中1和0的数量
|
||||
node->val == 1 ? count1++ : count0++;
|
||||
|
||||
// 检查当前节点是否为叶子节点
|
||||
if (!node->left && !node->right) {
|
||||
// 检查1的数量是否比0的数量多1
|
||||
if (count1 == count0 + 1) {
|
||||
result++;
|
||||
}
|
||||
return;
|
||||
}
|
||||
|
||||
// 递归访问左右子节点
|
||||
countPaths(node->left, count1, count0, result);
|
||||
countPaths(node->right, count1, count0, result);
|
||||
}
|
||||
|
||||
int main() {
|
||||
int N;
|
||||
cin >> N;
|
||||
|
||||
vector<int> nums(N);
|
||||
for (int i = 0; i < N; ++i) {
|
||||
cin >> nums[i];
|
||||
}
|
||||
|
||||
if (nums.empty()) {
|
||||
cout << 0 << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
// 根据层序遍历的输入构建二叉树
|
||||
queue<TreeNode*> q;
|
||||
TreeNode* root = new TreeNode(nums[0]);
|
||||
q.push(root);
|
||||
int index = 1;
|
||||
|
||||
while (!q.empty() && index < N) {
|
||||
TreeNode* node = q.front();
|
||||
q.pop();
|
||||
|
||||
if (index < N && nums[index] != -1) {
|
||||
node->left = new TreeNode(nums[index]);
|
||||
q.push(node->left);
|
||||
}
|
||||
index++;
|
||||
|
||||
if (index < N && nums[index] != -1) {
|
||||
node->right = new TreeNode(nums[index]);
|
||||
q.push(node->right);
|
||||
}
|
||||
index++;
|
||||
}
|
||||
|
||||
// 计算满足条件的路径数
|
||||
int result = 0;
|
||||
countPaths(root, 0, 0, result);
|
||||
|
||||
cout << result << endl;
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
68
problems/kamacoder/0154.序列中位数.md
Normal file
68
problems/kamacoder/0154.序列中位数.md
Normal file
@ -0,0 +1,68 @@
|
||||
|
||||
# 序列中位数
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1232)
|
||||
|
||||
注意给的数组默认不是有序的!
|
||||
|
||||
模拟题,排序之后,取中位数,然后按照b数组 删 a数组中元素,再取中位数。
|
||||
|
||||
```CPP
|
||||
#include<bits/stdc++.h>
|
||||
using namespace std;
|
||||
|
||||
// 计算并返回中位数
|
||||
double findMedian(vector<int>& nums) {
|
||||
int n = nums.size();
|
||||
if (n % 2 == 1) {
|
||||
return nums[n / 2]; // 奇数长度,返回中间的元素
|
||||
} else {
|
||||
// 偶数长度,返回中间两个元素的平均值
|
||||
return (nums[n / 2] + nums[n / 2 - 1]) / 2.0;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
int main(){
|
||||
int t;
|
||||
cin >> t;
|
||||
while(t--){
|
||||
int n;
|
||||
cin>> n;
|
||||
vector<int> a(n);
|
||||
vector<int> b(n - 1);
|
||||
for(int i = 0; i < n; i++){
|
||||
cin >> a[i];
|
||||
}
|
||||
for(int i = 0; i < n - 1; i++){
|
||||
cin >> b[i];
|
||||
}
|
||||
vector<int> nums = a;
|
||||
vector<double> answers;
|
||||
|
||||
sort(nums.begin(), nums.end());
|
||||
|
||||
// 把中位数放进结果集
|
||||
answers.push_back(findMedian(nums));
|
||||
|
||||
for(int i = 0; i < n - 1; i++){
|
||||
|
||||
int target = a[b[i]];
|
||||
// 删除目标值
|
||||
nums.erase(find(nums.begin(), nums.end(), target));
|
||||
// 把中位数放进结果集
|
||||
answers.push_back(findMedian(nums));
|
||||
|
||||
}
|
||||
|
||||
for(auto answer : answers){
|
||||
// 判断是否是整数
|
||||
if(answer == (int)answer) printf("%d ", (int)answer);
|
||||
else printf("%.1f ", answer);
|
||||
}
|
||||
cout << endl;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
106
problems/kamacoder/0155.最小化频率的删除代价.md
Normal file
106
problems/kamacoder/0155.最小化频率的删除代价.md
Normal file
@ -0,0 +1,106 @@
|
||||
|
||||
# 最小化频率的删除代价
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1233)
|
||||
|
||||
计数和排序:
|
||||
|
||||
* 使用 map 或 unordered_map 对数组 a 中每个元素出现的次数进行统计。
|
||||
* 将统计结果存入一个 vector<pair<int, int>>,其中 pair 的第一个元素是元素的出现次数,第二个元素是元素本身。
|
||||
* 按出现次数从大到小排序这个 vector。
|
||||
|
||||
确定最小 f(a):
|
||||
|
||||
* 从最大出现次数开始尝试减少 f(a)。为此,从最高频次的元素开始逐步向下考虑较少出现的元素,计算达到更低 f(a) 所需删除的元素数量。
|
||||
* 使用一个累加器 count 来记录需要删除的元素数量,直到这个数量超过允许的最大删除数量 k 或恰好等于 k。在此过程中,尽量使 f(a) 达到最小。
|
||||
|
||||
计算达到 f(a) 的代价:
|
||||
|
||||
* 计算完成后,需要确定达到最小 f(a) 的确切代价。首先,为每个元素确定在不超过 k 的前提下可以删除的最大数量,以使得 f(a) 最小。
|
||||
* 对于每个元素,如果它的数量超过了新的 f(a),则计算减少到 f(a) 所需删除的具体元素数,记录下来。
|
||||
|
||||
计算具体删除代价:
|
||||
|
||||
* 遍历原数组,对于每个需要删除的元素,根据其位置累加删除代价。每删除一个元素,相应地减少其在删除列表中的计数。当某元素需要删除的数量减至 0 时,从删除列表中移除该元素。
|
||||
|
||||
|
||||
```CPP
|
||||
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <unordered_map>
|
||||
#include <algorithm>
|
||||
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, k;
|
||||
cin >> n >> k;
|
||||
|
||||
vector<int> a(n);
|
||||
for (int i = 0; i < n; ++i) {
|
||||
cin >> a[i];
|
||||
}
|
||||
|
||||
unordered_map<int, int> umap; // 使用map来统计每个元素的出现频率
|
||||
for (int i = 0; i < n; ++i) {
|
||||
umap[a[i]]++; // 统计每个元素的出现次数
|
||||
}
|
||||
|
||||
vector<pair<int, int>> table;
|
||||
for (auto& pair : umap) {
|
||||
table.push_back({pair.second, pair.first}); // 将元素和其频率作为一个pair放入table中
|
||||
}
|
||||
|
||||
sort(table.begin(), table.end(), greater<>()); // 将table按照频率从大到小排序
|
||||
|
||||
int count = 0; // 用来计算已经删除的元素总数
|
||||
int minVal = table[0].first; // 从最高频率开始
|
||||
for (int i = 0; i < table.size(); ++i) {
|
||||
int freq = table[i].first;
|
||||
count += (minVal - freq) * i; // 累加删除元素的代价
|
||||
if (count > k) break; // 如果超过了k,停止循环
|
||||
else if (count == k) {
|
||||
minVal = freq;
|
||||
break;
|
||||
} else minVal = freq;
|
||||
}
|
||||
if (count < k) {
|
||||
int addDel = (k - count) / table.size(); // 如果删除的代价还没达到k,计算还可以进一步减少的频率
|
||||
minVal -= addDel; // 减少相应的频率
|
||||
}
|
||||
|
||||
if (minVal < 0) {
|
||||
minVal = 0; // 确保最小频率值不小于0
|
||||
}
|
||||
|
||||
unordered_map<int, int> deleteList; // 用来存储需要删除的元素及其数量
|
||||
for (auto& elem : table) {
|
||||
int num = elem.first;
|
||||
int ind = elem.second;
|
||||
if (num > minVal) {
|
||||
deleteList[ind] = num - minVal; // 如果元素频率大于最小值,计算需要删除的数量
|
||||
} else {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
int cost = 0; // 计算总的删除代价
|
||||
for (int i = 0; i < n; ++i) {
|
||||
if (deleteList.find(a[i]) != deleteList.end()) {
|
||||
cost += i + 1; // 删除的代价是元素的索引+1
|
||||
deleteList[a[i]]--; // 删除一个元素
|
||||
if (deleteList[a[i]] == 0) {
|
||||
deleteList.erase(a[i]); // 如果元素已经全部删除,从列表中移除
|
||||
if (deleteList.empty()) {
|
||||
break; // 如果没有元素需要删除了,结束循环
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
cout << minVal << " " << cost << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
68
problems/kamacoder/0156.勇敢牛牛战斗序列.md
Normal file
68
problems/kamacoder/0156.勇敢牛牛战斗序列.md
Normal file
@ -0,0 +1,68 @@
|
||||
|
||||
# 勇敢牛牛战斗序列
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1234)
|
||||
|
||||
贪心思路,对数组从小到大排序之后,先取最右边,再取最左边,循环反复。
|
||||
|
||||
```CPP
|
||||
#include<bits/stdc++.h>
|
||||
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n;
|
||||
cin >> n;
|
||||
vector<int> a(n); // 使用 vector 存储整数数组
|
||||
for (int i = 0; i < n; i++) {
|
||||
cin >> a[i]; // 读取数组
|
||||
}
|
||||
sort(a.begin(), a.end()); // 对数组进行排序
|
||||
|
||||
long long ans = 0; // 使用 long long 存储结果,以防溢出
|
||||
int cur = 0;
|
||||
int left = 0, right = n - 1;
|
||||
while (left <= right) {
|
||||
if (cur < a[right]) {
|
||||
ans += a[right] - cur;
|
||||
}
|
||||
cur = a[left];
|
||||
right--;
|
||||
left++;
|
||||
}
|
||||
cout << ans << endl; // 输出结果
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
```Java
|
||||
import java.util.Arrays;
|
||||
import java.util.Scanner;
|
||||
|
||||
public class Main {
|
||||
|
||||
public static void main(String[] args) {
|
||||
Scanner sc = new Scanner(System.in);
|
||||
int n = sc.nextInt();
|
||||
int[] a = new int[n];
|
||||
for (int i = 0; i < n; i++) {
|
||||
a[i] = sc.nextInt();
|
||||
}
|
||||
Arrays.sort(a);
|
||||
long ans = 0;
|
||||
int cur = 0;
|
||||
int left = 0, right = a.length - 1;
|
||||
while (left <= right) {
|
||||
if (cur < a[right]) {
|
||||
ans = ans + a[right] - cur;
|
||||
}
|
||||
cur = a[left];
|
||||
right--;
|
||||
left++;
|
||||
}
|
||||
System.out.println(ans);
|
||||
}
|
||||
}
|
||||
```
|
||||
59
problems/kamacoder/0157.最大化密码复杂度.md
Normal file
59
problems/kamacoder/0157.最大化密码复杂度.md
Normal file
@ -0,0 +1,59 @@
|
||||
|
||||
# 最大化密码复杂度
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1235)
|
||||
|
||||
注意**边界处理**,对于字符串的首尾位置,需要特别处理,因为它们只有一个相邻字符。
|
||||
* 遍历字符串 s,寻找 '?' 字符。
|
||||
* 对于每个 '?' 字符,选择一个字符填充,使其与前后字符都不同。这样做的目的是最大化密码的复杂度,即尽可能使相邻的字符不同。
|
||||
* 如果 '?' 是第一个或最后一个字符,或者无法找到与前后都不同的字符,选择与前一个或后一个字符不同的字符。
|
||||
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <algorithm>
|
||||
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m;
|
||||
string s;
|
||||
cin >> n >> m >> s;
|
||||
|
||||
if (n == 1) {
|
||||
cout << 0 << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
// 统一处理包括左右字符的情况
|
||||
for (int i = 0; i < n; ++i) {
|
||||
if (s[i] == '?') {
|
||||
bool found = false;
|
||||
for (char j = 'a'; j < 'a' + m; ++j) {
|
||||
// 避免第一个字符 和 最后一个字符,因为两个字符只有一个相邻字符,没有左右相邻字符
|
||||
if ((i == 0 || s[i - 1] != j) && (i == n - 1 || s[i + 1] != j)) {
|
||||
s[i] = j;
|
||||
found = true;
|
||||
break;
|
||||
}
|
||||
}
|
||||
// 如果没有找到合适的字符,就和附近字符保持一致
|
||||
if (!found) {
|
||||
if (i > 0) s[i] = s[i - 1];
|
||||
else s[i] = s[i + 1];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 计算结果
|
||||
int result = 0;
|
||||
for (int i = 0; i < n - 1; ++i) {
|
||||
if (s[i] != s[i + 1]) result++;
|
||||
}
|
||||
|
||||
cout << result << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
50
problems/kamacoder/0158.同余方程.md
Normal file
50
problems/kamacoder/0158.同余方程.md
Normal file
@ -0,0 +1,50 @@
|
||||
|
||||
# 同余方程
|
||||
|
||||
题目链接:https://kamacoder.com/problempage.php?pid=1236
|
||||
|
||||
我们需要求出满足以下条件的最小正整数 x:`ax≡1 (mod b)`
|
||||
|
||||
这意味着我们需要找到 x 使得 ax 除以 b 的余数是 1。这个问题实际上是一个典型的 模反元素 问题。
|
||||
|
||||
解题思路:
|
||||
|
||||
* 为了求出最小的 x,我们可以使用 扩展欧几里得算法 来求出 a 对模 b 的逆元。
|
||||
* 这个算法能够求解 ax + by = gcd(a, b) 的一组整数解 (x, y),而在 gcd(a, b) = 1 的情况下,x 即为所求的模逆元。
|
||||
* 扩展欧几里得算法:扩展欧几里得算法可以通过递归或者迭代的方式实现。
|
||||
|
||||
下面给出C++代码实现:
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
using namespace std;
|
||||
|
||||
// 扩展欧几里得:计算 ax + by = gcd(a, b) 的解
|
||||
long long extended_gcd(long long a, long long b, long long &x, long long &y) {
|
||||
if (b == 0) {
|
||||
x = 1;
|
||||
y = 0;
|
||||
return a;
|
||||
}
|
||||
long long x1, y1;
|
||||
long long gcd = extended_gcd(b, a % b, x1, y1);
|
||||
x = y1;
|
||||
y = x1 - (a / b) * y1;
|
||||
return gcd;
|
||||
}
|
||||
|
||||
int main() {
|
||||
long long a, b;
|
||||
cin >> a >> b;
|
||||
|
||||
long long x, y;
|
||||
long long gcd = extended_gcd(a, b, x, y);
|
||||
|
||||
// 由于我们只需要模 b 的正整数解,所以我们要保证 x 是正数
|
||||
x = (x % b + b) % b;
|
||||
|
||||
cout << x << endl;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
62
problems/kamacoder/0159.大整数乘法.md
Normal file
62
problems/kamacoder/0159.大整数乘法.md
Normal file
@ -0,0 +1,62 @@
|
||||
|
||||
# 大整数乘法
|
||||
|
||||
题目链接:https://kamacoder.com/problempage.php?pid=1237
|
||||
|
||||
思路:
|
||||
|
||||
我们可以使用模拟手算乘法的方法,即「逐位相乘累加」,对于每一位的乘法结果,我们将其加到相应的结果位置上。最终将累加的结果输出。
|
||||
|
||||
具体步骤:
|
||||
|
||||
* 初始化结果数组:结果数组的长度应该是两个数字长度之和,因为最大长度的结果不会超过这个长度。
|
||||
* 逐位相乘:从右往左遍历两个字符串的每一位,逐位相乘,并加到结果数组的相应位置。
|
||||
* 处理进位:在每一步累加之后处理进位,保证每个位置的值小于10。
|
||||
|
||||
将结果数组转化为字符串:从结果数组的最高位开始,忽略前导零,然后将数组转化为字符串。
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <string>
|
||||
|
||||
using namespace std;
|
||||
|
||||
string multiply(string num1, string num2) {
|
||||
int len1 = num1.size();
|
||||
int len2 = num2.size();
|
||||
vector<int> result(len1 + len2, 0);
|
||||
|
||||
// 逐位相乘
|
||||
for (int i = len1 - 1; i >= 0; i--) {
|
||||
for (int j = len2 - 1; j >= 0; j--) {
|
||||
int mul = (num1[i] - '0') * (num2[j] - '0');
|
||||
int sum = mul + result[i + j + 1];
|
||||
|
||||
result[i + j + 1] = sum % 10;
|
||||
result[i + j] += sum / 10;
|
||||
}
|
||||
}
|
||||
|
||||
// 将结果转换为字符串,跳过前导零
|
||||
string product;
|
||||
for (int num : result) {
|
||||
if (!(product.empty() && num == 0)) { // 跳过前导零
|
||||
product.push_back(num + '0');
|
||||
}
|
||||
}
|
||||
|
||||
return product.empty() ? "0" : product;
|
||||
}
|
||||
|
||||
int main() {
|
||||
string num1, num2;
|
||||
cin >> num1 >> num2;
|
||||
|
||||
string result = multiply(num1, num2);
|
||||
cout << result << endl;
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
88
problems/kamacoder/0160.二维平面上的折线段.md
Normal file
88
problems/kamacoder/0160.二维平面上的折线段.md
Normal file
@ -0,0 +1,88 @@
|
||||
|
||||
# 二维平面上的折线段
|
||||
|
||||
题目链接:https://kamacoder.com/problempage.php?pid=1238
|
||||
|
||||
这个问题要求我们在一条折线段上,根据移动的固定距离 s 进行标记点的计算。
|
||||
|
||||
为了实现这一点,我们需要对折线段进行分段处理,并根据每段的长度来确定标记点的位置。
|
||||
|
||||
解题思路:
|
||||
|
||||
1. 输入与初步处理:
|
||||
* 首先,读取所有点的坐标。
|
||||
* 计算每一段折线的长度,并逐段累积总长度。
|
||||
2. 确定标记点:
|
||||
* 从起点开始,每次沿着折线段前进 s 的距离,直到到达终点。
|
||||
* 对于每个标记点,根据当前段的起点和终点,计算出该点的精确坐标。
|
||||
3. 输出所有标记点的坐标,格式为 x, y。
|
||||
|
||||
```CPP
|
||||
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <cmath>
|
||||
#include <iomanip>
|
||||
|
||||
using namespace std;
|
||||
|
||||
// 定义一个点的结构体
|
||||
struct Point {
|
||||
double x, y;
|
||||
};
|
||||
|
||||
// 计算两点之间的距离
|
||||
double distance(const Point& a, const Point& b) {
|
||||
return sqrt((a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y));
|
||||
}
|
||||
|
||||
int main() {
|
||||
int n;
|
||||
cin >> n;
|
||||
|
||||
vector<Point> points(n);
|
||||
for (int i = 0; i < n; i++) {
|
||||
cin >> points[i].x >> points[i].y;
|
||||
}
|
||||
|
||||
double s;
|
||||
cin >> s;
|
||||
|
||||
double total_length = 0.0;
|
||||
vector<double> segment_lengths(n - 1);
|
||||
|
||||
// 计算每段长度和总长度
|
||||
for (int i = 0; i < n - 1; i++) {
|
||||
segment_lengths[i] = distance(points[i], points[i + 1]);
|
||||
total_length += segment_lengths[i];
|
||||
}
|
||||
|
||||
// 从起点开始标记
|
||||
Point current_point = points[0];
|
||||
double accumulated_distance = 0.0;
|
||||
|
||||
cout << fixed << setprecision(5);
|
||||
cout << current_point.x << ", " << current_point.y << endl;
|
||||
|
||||
while (accumulated_distance + s <= total_length) {
|
||||
accumulated_distance += s;
|
||||
double remaining_distance = accumulated_distance;
|
||||
|
||||
for (int i = 0; i < n - 1; i++) {
|
||||
if (remaining_distance <= segment_lengths[i]) {
|
||||
double ratio = remaining_distance / segment_lengths[i];
|
||||
double new_x = points[i].x + ratio * (points[i + 1].x - points[i].x);
|
||||
double new_y = points[i].y + ratio * (points[i + 1].y - points[i].y);
|
||||
current_point = {new_x, new_y};
|
||||
cout << current_point.x << ", " << current_point.y << endl;
|
||||
break;
|
||||
} else {
|
||||
remaining_distance -= segment_lengths[i];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
61
problems/kamacoder/0161.讨厌鬼的组合帖子.md
Normal file
61
problems/kamacoder/0161.讨厌鬼的组合帖子.md
Normal file
@ -0,0 +1,61 @@
|
||||
|
||||
# 讨厌鬼的组合帖子
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1239)
|
||||
|
||||
这个问题本质上是要找到两个数组的子集,使得这两个子集之间的差的绝对值最大。
|
||||
|
||||
问题可以简化为寻找两个数列之间最大可能的差的绝对值。
|
||||
|
||||
贪心思路如下:
|
||||
|
||||
计算差异,首先,我们可以计算每个帖子的点赞数和点踩数的差值 d[i] = a[i] - b[i]。这样问题就转化为选择这些差值的一个子集,使得子集中所有元素的和的绝对值最大。
|
||||
|
||||
遍历可能性,要使得一个数的绝对值尽可能大,可以尝试最大化这个数,或者最小化这个数(使其尽可能小于零)。我们可以分别尝试将所有正的差值加在一起,以及将所有负的差值加在一起。
|
||||
|
||||
计算最大吸引度:
|
||||
|
||||
* 将所有正的差值求和得到一个总和。
|
||||
* 将所有负的差值求和得到另一个总和。
|
||||
* 最后,吸引度即为这两个总和的绝对值中的较大者。
|
||||
|
||||
|
||||
```CPP
|
||||
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <cmath>
|
||||
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n;
|
||||
cin >> n;
|
||||
|
||||
vector<int> a(n), b(n);
|
||||
for (int i = 0; i < n; ++i) {
|
||||
cin >> a[i];
|
||||
}
|
||||
for (int i = 0; i < n; ++i) {
|
||||
cin >> b[i];
|
||||
}
|
||||
|
||||
long long positive_sum = 0;
|
||||
long long negative_sum = 0;
|
||||
|
||||
for (int i = 0; i < n; ++i) {
|
||||
int difference = a[i] - b[i];
|
||||
if (difference > 0) {
|
||||
positive_sum += difference;
|
||||
} else if (difference < 0) {
|
||||
negative_sum += difference;
|
||||
}
|
||||
}
|
||||
|
||||
// 最大吸引度是正总和或负总和的绝对值中的较大者
|
||||
cout << max(abs(positive_sum), abs(negative_sum)) << endl;
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
154
problems/kamacoder/0162.小红的第16版方案.md
Normal file
154
problems/kamacoder/0162.小红的第16版方案.md
Normal file
@ -0,0 +1,154 @@
|
||||
|
||||
# 小红的第16版方案
|
||||
|
||||
[题目链接](https://kamacoder.com/problempage.php?pid=1240)
|
||||
|
||||
暴力解法: (数据量已经出最大了,C++能过,java、python、go都过不了)
|
||||
|
||||
```CPP
|
||||
#include <bits/stdc++.h>
|
||||
using namespace std;
|
||||
int main() {
|
||||
int n, m;
|
||||
int l, r;
|
||||
cin >> n >> m;
|
||||
vector<int> a(n + 1);
|
||||
vector<int> angry(n + 1);
|
||||
for (int i = 1; i <= n; i++) cin >> a[i];
|
||||
for (int i = 1; i <= m; i++) {
|
||||
cin >> l >> r;
|
||||
for (int j = l; j <= r; j++) {
|
||||
angry[j]++;
|
||||
if (angry[j] > a[j]) {
|
||||
cout << i - 1 << endl;
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
}
|
||||
cout << m << endl;
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
使用 差分数组,代码如下:
|
||||
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<int> a(n + 1);
|
||||
for (int i = 1; i <= n; ++i) {
|
||||
cin >> a[i];
|
||||
}
|
||||
|
||||
vector<int> diff(n + 1, 0); // 差分数组,多一个元素用于处理边界情况
|
||||
|
||||
int l, r;
|
||||
for (int i = 1; i <= m; ++i) {
|
||||
cin >> l >> r;
|
||||
diff[l]++;
|
||||
if (r + 1 <= n) diff[r + 1]--;
|
||||
}
|
||||
|
||||
int current_anger = 0; // 当前的愤怒值
|
||||
for (int i = 1; i <= n; ++i) {
|
||||
current_anger += diff[i]; // 计算差分数组的前缀和,得到最终的愤怒值
|
||||
if (current_anger > a[i]) {
|
||||
cout << i - 1 << endl; // 如果当前的愤怒值超过阈值,输出最后一个没有问题的方案编号
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
|
||||
cout << m << endl; // 如果所有修改完成后都没有超过阈值,返回最后一个方案的编号
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
过不了,因为差分数组只能知道是哪个人超过了阈值,不能知道是第几次修改超过的
|
||||
|
||||
最后 优化思路:
|
||||
|
||||
* 差分数组(Difference Array):依然使用差分数组来处理区间更新。
|
||||
* 二分查找:通过二分查找来确定最早发生愤怒值超出阈值的操作,而不是逐次模拟每一次修改。
|
||||
|
||||
步骤:
|
||||
|
||||
* 创建一个差分数组 diff 用于处理区间增加操作。
|
||||
* 在 [1, m] 的范围内进行二分查找,确定导致某个人愤怒值超过阈值的最早的修改次数。
|
||||
* 对每个二分查找的中间值 mid,我们累积应用前 mid 次操作,然后检查是否有任何人的愤怒值超过了阈值。
|
||||
* 如果 mid 之前没有超标,则继续向右查找;否则向左缩小范围。
|
||||
* 在二分查找完成后,输出找到的第一个导致愤怒值超标的操作次数。
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <algorithm>
|
||||
|
||||
using namespace std;
|
||||
|
||||
bool isValid(const vector<int>& a, const vector<int>& diff, int n, int m) {
|
||||
vector<int> anger(n + 1, 0);
|
||||
int current_anger = 0;
|
||||
for (int i = 1; i <= n; ++i) {
|
||||
current_anger += diff[i];
|
||||
if (current_anger > a[i]) {
|
||||
return false; // 超出愤怒阈值
|
||||
}
|
||||
}
|
||||
return true; // 没有任何人超出愤怒阈值
|
||||
}
|
||||
|
||||
int main() {
|
||||
int n, m;
|
||||
cin >> n >> m;
|
||||
|
||||
vector<int> a(n + 1); // 愤怒阈值数组
|
||||
for (int i = 1; i <= n; ++i) {
|
||||
cin >> a[i];
|
||||
}
|
||||
|
||||
vector<pair<int, int>> operations(m + 1); // 保存每次操作的区间
|
||||
for (int i = 1; i <= m; ++i) {
|
||||
int l, r;
|
||||
cin >> l >> r;
|
||||
operations[i] = {l, r};
|
||||
}
|
||||
|
||||
int left = 1, right = m, result = m;
|
||||
|
||||
while (left <= right) {
|
||||
int mid = left + (right - left) / 2;
|
||||
|
||||
// 构建差分数组,只考虑前 mid 次操作
|
||||
vector<int> diff(n + 2, 0);
|
||||
for (int i = 1; i <= mid; ++i) {
|
||||
int l = operations[i].first;
|
||||
int r = operations[i].second;
|
||||
diff[l]++;
|
||||
if (r + 1 <= n) {
|
||||
diff[r + 1]--;
|
||||
}
|
||||
}
|
||||
|
||||
if (isValid(a, diff, n, mid)) {
|
||||
left = mid + 1; // 如果在mid次操作后没有超标,继续向右搜索
|
||||
} else {
|
||||
result = mid - 1; // 如果在mid次操作后超标,向左搜索
|
||||
right = mid - 1;
|
||||
}
|
||||
}
|
||||
|
||||
cout << result << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
* 时间复杂度:O(n + m * log m),其中 n 是成员数量,m 是操作次数。二分查找的时间复杂度为 O(log m),每次二分查找中通过差分数组检查愤怒值的复杂度为 O(n)。
|
||||
* 空间复杂度:O(n + m),主要用于存储差分数组和操作数组。
|
||||
85
problems/kamacoder/第一题.md
Normal file
85
problems/kamacoder/第一题.md
Normal file
@ -0,0 +1,85 @@
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
1、初始分析
|
||||
|
||||
- 给定一个排列 `p`,我们首先构建一个 `pos` 数组,使得 `pos[i]` 表示 `i` 在排列 `p` 中的位置。
|
||||
- 我们需要判断数组 `a` 是否是一个优秀数组,即 `pos[a[i]] < pos[a[i+1]] <= pos[a[i]] + d` 对于所有 `i` 都成立。
|
||||
- 我们的目标是通过最少的相邻元素交换,使得数组 `a` 不再是一个优秀数组。
|
||||
|
||||
2、思路
|
||||
|
||||
- 要使数组 `a` 不再是优秀数组,我们只需要打破条件 `pos[a[i]] < pos[a[i+1]] <= pos[a[i]] + d` 中的某一个。
|
||||
- 一种简单的做法是让 `pos[a[i]]` 和 `pos[a[i+1]]` 之间的距离超过 `d`,或者直接让 `pos[a[i]] >= pos[a[i+1]]`。
|
||||
|
||||
3、具体方法
|
||||
|
||||
- 只需要考虑 `a` 中相邻元素的顺序,并判断如何交换 `p` 中相邻元素使得其顺序被打破。
|
||||
- 假设我们需要在 `p` 中交换某些元素来实现上述目标,那么最小的交换次数是将 `a[i]` 和 `a[i+1]` 的位置交换。
|
||||
- 如果 `pos[a[i]] + 1 == pos[a[i+1]]`,则需要一步交换。
|
||||
|
||||
4、特别情况
|
||||
|
||||
- 还需要考虑,如果通过交换相邻元素无法解决问题的情况。比如 `pos[a[i+1]]` 的位置无法移到 `pos[a[i]]` 的前面或超过 `d`。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
|
||||
```cpp
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <algorithm>
|
||||
#include <climits>
|
||||
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int n, m, d;
|
||||
cin >> n >> m >> d;
|
||||
|
||||
vector<int> p(n + 1);
|
||||
vector<int> pos(n + 1);
|
||||
|
||||
// 读取排列 p,并构建位置数组 pos
|
||||
for (int i = 1; i <= n; i++) {
|
||||
cin >> p[i];
|
||||
pos[p[i]] = i;
|
||||
}
|
||||
|
||||
vector<int> a(m);
|
||||
for (int i = 0; i < m; i++) {
|
||||
cin >> a[i];
|
||||
}
|
||||
|
||||
int min_operations = INT_MAX;
|
||||
|
||||
// 遍历数组 a 的相邻元素
|
||||
for (int i = 0; i < m - 1; i++) {
|
||||
int current_pos = pos[a[i]];
|
||||
int next_pos = pos[a[i + 1]];
|
||||
|
||||
// 检查 pos[a[i]] < pos[a[i+1]] <= pos[a[i]] + d 是否成立
|
||||
if (current_pos < next_pos && next_pos <= current_pos + d) {
|
||||
// 计算需要的最少操作次数
|
||||
int distance = next_pos - current_pos;
|
||||
|
||||
// Case 1: 交换 current_pos 和 next_pos
|
||||
min_operations = min(min_operations, distance);
|
||||
|
||||
// Case 2: 如果 next_pos + d <= n,考虑使 pos[a[i+1]] 超过 pos[a[i]] + d
|
||||
if (current_pos + d + 1 <= n) {
|
||||
min_operations = min(min_operations, d + 1 - distance);
|
||||
}
|
||||
} else {
|
||||
min_operations = 0;
|
||||
}
|
||||
}
|
||||
|
||||
cout << min_operations << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
时间复杂度为 O(m)
|
||||
76
problems/kamacoder/第三题.md
Normal file
76
problems/kamacoder/第三题.md
Normal file
@ -0,0 +1,76 @@
|
||||
|
||||
|
||||
贪心思路
|
||||
|
||||
为了保证字典序最大,我们优先放置字母 `b`,然后再放置字母 `a`。在放置字符时,我们还需注意不能超过连续 `k` 次相同字符:
|
||||
|
||||
- 如果当前已经连续放置了 `k` 次相同字符,必须切换到另一个字符。
|
||||
- 每次放置字符后,相应的字符数量减少,同时更新当前字符的连续计数。
|
||||
|
||||
实现步骤:
|
||||
|
||||
- **初始化**:根据输入的 `x`, `y`, `k` 值,检查是否有可能构造出满足条件的字符串。初始化结果字符串的大小,并设置初始计数器。
|
||||
- **循环放置字符**:
|
||||
- 优先放置字符 `b`,如果 `b` 的数量已经足够,或者已经放置了 `k` 次字符 `b`,则放置字符 `a`。
|
||||
- 如果已经放置了 `k` 次相同字符,则强制切换到另一个字符。
|
||||
|
||||
C++代码如下:
|
||||
|
||||
```CPP
|
||||
#include<iostream>
|
||||
#include<string>
|
||||
using namespace std;
|
||||
|
||||
int main() {
|
||||
int countA, countB, maxRepeat;
|
||||
cin >> countA >> countB >> maxRepeat;
|
||||
|
||||
// 检查是否有可能生成满足条件的字符串
|
||||
if (countA > (countB + 1) * maxRepeat || countB > (countA + 1) * maxRepeat) {
|
||||
cout << -1 << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
string result(countA + countB, ' '); // 预先分配字符串大小
|
||||
int currentA = 0, currentB = 0; // 当前连续 'a' 和 'b' 的计数
|
||||
int pos = 0; // 当前填充位置
|
||||
|
||||
while (countA > 0 || countB > 0) {
|
||||
// 当可以继续添加 'a' 或 'b' 且没有超过最大连续限制时
|
||||
if (currentA < maxRepeat && currentB < maxRepeat) {
|
||||
if (countA <= countB * maxRepeat) {
|
||||
result[pos++] = 'b';
|
||||
countB--;
|
||||
currentB++;
|
||||
currentA = 0;
|
||||
} else {
|
||||
result[pos++] = 'a';
|
||||
countA--;
|
||||
currentA++;
|
||||
currentB = 0;
|
||||
}
|
||||
}
|
||||
|
||||
// 当当前字符达到最大连续限制时,切换到另一个字符
|
||||
if (currentA == maxRepeat || currentB == maxRepeat) {
|
||||
if (result[pos - 1] == 'a') {
|
||||
result[pos++] = 'b';
|
||||
countB--;
|
||||
currentB = 1;
|
||||
currentA = 0;
|
||||
} else {
|
||||
result[pos++] = 'a';
|
||||
countA--;
|
||||
currentA = 1;
|
||||
currentB = 0;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
cout << result << endl;
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
时间复杂度:O(n)
|
||||
78
problems/kamacoder/第二题.md
Normal file
78
problems/kamacoder/第二题.md
Normal file
@ -0,0 +1,78 @@
|
||||
|
||||
## 解题思路
|
||||
|
||||
贪心思路
|
||||
|
||||
- **计算相邻元素差值**:
|
||||
- 对于数组 `a`,计算每对相邻元素的差值 `diff[i] = a[i+1] - a[i]`。
|
||||
- 如果 `diff[i]` 为负数,意味着 `a[i+1]` 比 `a[i]` 小或相等,需要通过操作使 `a[i+1]` 变大。
|
||||
|
||||
- **确定最小操作次数**:
|
||||
- 计算所有相邻元素中的最小差值 `minDifference`,即 `minDifference = min(diff[i])`。
|
||||
- 如果 `minDifference` 为负数或零,则需要进行 `-minDifference + 1` 次操作,使得 `a[i+1]` 大于 `a[i]`,从而使数组严格递增。
|
||||
|
||||
- **实现细节**:
|
||||
- 遍历数组的每对相邻元素,找出最小的差值。
|
||||
- 根据最小差值,计算出最少的操作次数。
|
||||
|
||||
|
||||
|
||||
```CPP
|
||||
#include <iostream>
|
||||
#include <vector>
|
||||
#include <climits>
|
||||
|
||||
using namespace std;
|
||||
|
||||
int main()
|
||||
{
|
||||
int n;
|
||||
cin >> n;
|
||||
|
||||
vector<int> arr(n); // 用于存储输入数组
|
||||
vector<int> differences; // 用于存储相邻元素的差值
|
||||
|
||||
for(int i = 0; i < n; i++) {
|
||||
cin >> arr[i];
|
||||
if(i > 0) differences.push_back(arr[i] - arr[i - 1]);
|
||||
|
||||
}
|
||||
|
||||
int minDifference = INT_MAX;
|
||||
|
||||
// 寻找最小的差值
|
||||
for(int diff : differences) {
|
||||
if(diff < minDifference) {
|
||||
minDifference = diff;
|
||||
}
|
||||
}
|
||||
|
||||
// 如果最小差值是负数或零,计算所需的操作次数
|
||||
int minOperations = max(0, -minDifference + 1);
|
||||
|
||||
cout << minOperations << endl;
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
关于 `-minDifference + 1` 为什么要 + 1 解释:
|
||||
|
||||
对于数组 `a` 中相邻的两个元素 `a[i]` 和 `a[i+1]`,我们计算它们的差值 `diff = a[i+1] - a[i]`。
|
||||
|
||||
- **目标**:要使 `a[i] < a[i+1]`,需要 `diff > 0`。
|
||||
- 如果 `diff < 0`,说明 `a[i+1]` 比 `a[i]` 小,这时候 `a` 不是严格递增的。
|
||||
- 如果 `diff = 0`,说明 `a[i+1]` 和 `a[i]` 相等,这时也不满足严格递增。
|
||||
|
||||
解释 `-minDifference + 1`
|
||||
|
||||
1. **当 `minDifference < 0` 时**:
|
||||
- 假设 `minDifference` 是所有相邻差值中的最小值,并且它是一个负数。
|
||||
- 例如,`minDifference = -3`,表示 `a[i+1] - a[i] = -3`,也就是 `a[i+1]` 比 `a[i]` 小 `3`。
|
||||
- 要让 `a[i+1] > a[i]`,我们至少需要使 `a[i+1] - a[i]` 从 `-3` 增加到 `1`。因此需要增加 `4`,即 `(-(-3)) + 1 = 3 + 1 = 4` 次操作。
|
||||
|
||||
2. **当 `minDifference = 0` 时**:
|
||||
- `minDifference` 等于 `0`,表示 `a[i+1] - a[i] = 0`,即 `a[i+1]` 和 `a[i]` 相等。
|
||||
- 为了使 `a[i+1] > a[i]`,我们至少需要进行一次操作,使得 `a[i+1]` 大于 `a[i]`。
|
||||
|
||||
|
||||
239
problems/qita/tulunfabu.md
Normal file
239
problems/qita/tulunfabu.md
Normal file
@ -0,0 +1,239 @@
|
||||
|
||||
|
||||
# 图论正式发布!
|
||||
|
||||
录友们! 今天和大家正式宣布:大家期盼已久的「代码随想录图论」正式发布了。
|
||||
|
||||
**一年多来,日日夜夜,伏案编码、思考、写作,就为了今天给录友们一个交代**!
|
||||
|
||||
我知道录友们在等图论等太久了,其实我比大家都着急。
|
||||
|
||||
|
||||
|
||||
图论完整版目前已经开放在代码随想录网站:programmercarl.com
|
||||
|
||||
**「代码随想录图论」共分为 五大模块**,共有三十一篇长文讲解:
|
||||
|
||||
* 深搜与广搜
|
||||
* 并查集
|
||||
* 最小生成树
|
||||
* 拓扑排序
|
||||
* 最短路算法
|
||||
|
||||

|
||||
|
||||
**耗时一年之久,代码随想录图论 终于面世了**!
|
||||
|
||||
一年前 23年的3月份 我刚刚更新完了 [代码随想录算法公开课](https://mp.weixin.qq.com/s/xsKjrnB4GyWApm4BYxshvg) ,这是我亲自录制的 140期 算法视频讲解,目前口碑极佳。
|
||||
|
||||
录完公开课之后,我就开始筹划更新图论内容了,无奈图论内容真的很庞大。
|
||||
|
||||
关于图论章节,**可以说 是代码随想录所有章节里画图数量最多,工程量最大的一个章节**,整个图论 画图就400百多幅。
|
||||
|
||||
随便截一些图,大家感受一下:
|
||||
|
||||
|
||||
|
||||
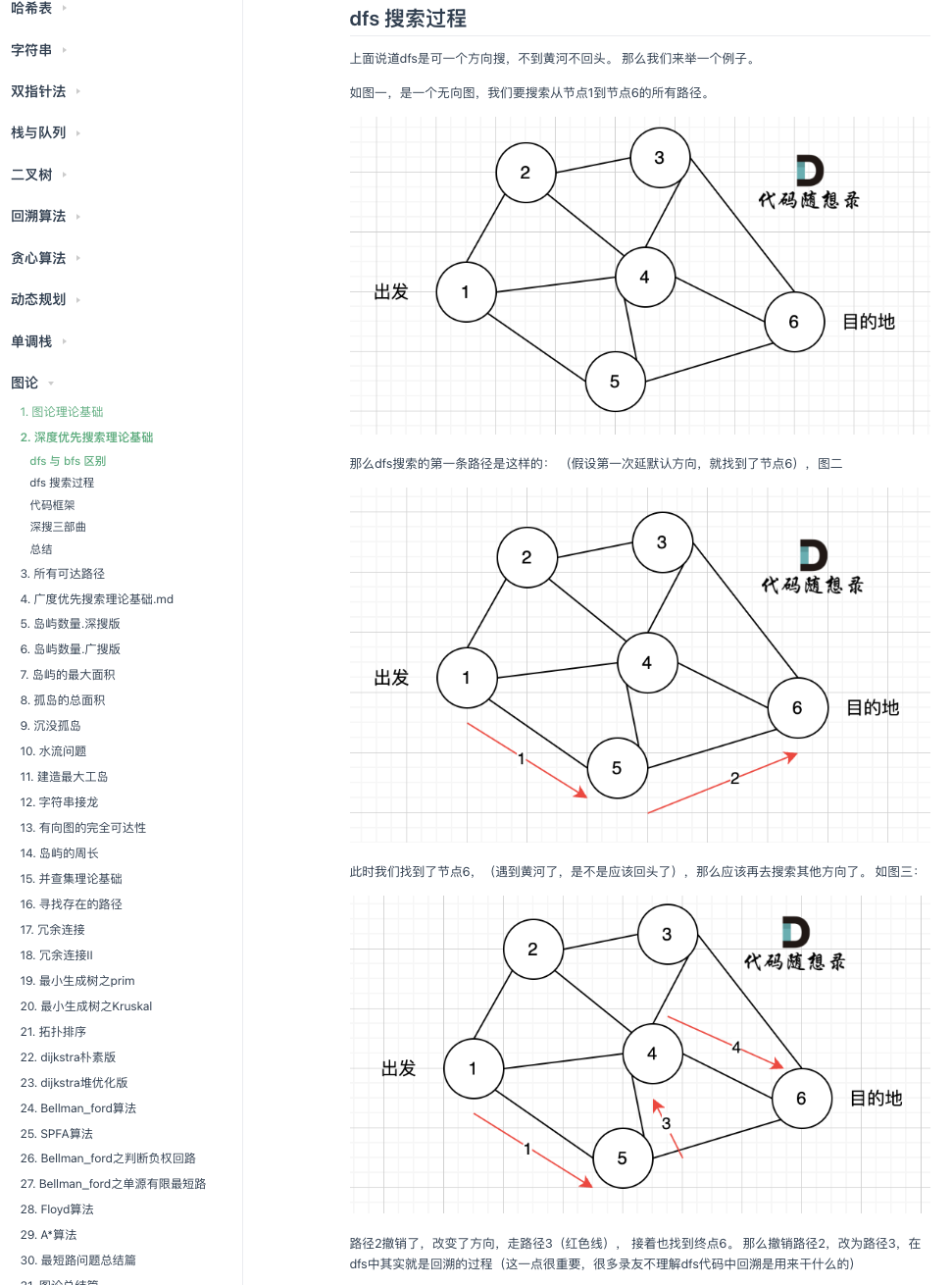
|
||||
|
||||
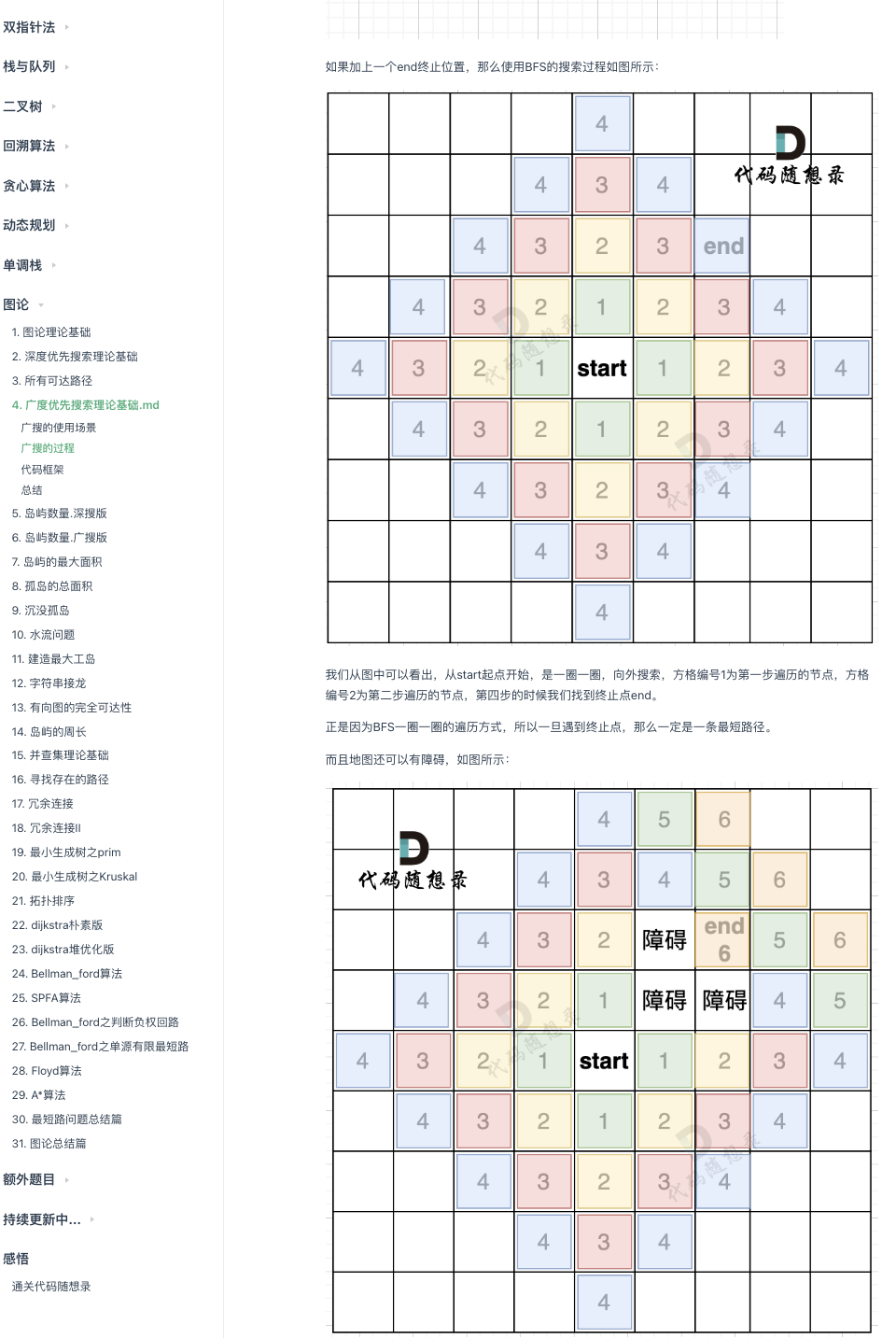
|
||||
|
||||

|
||||
|
||||
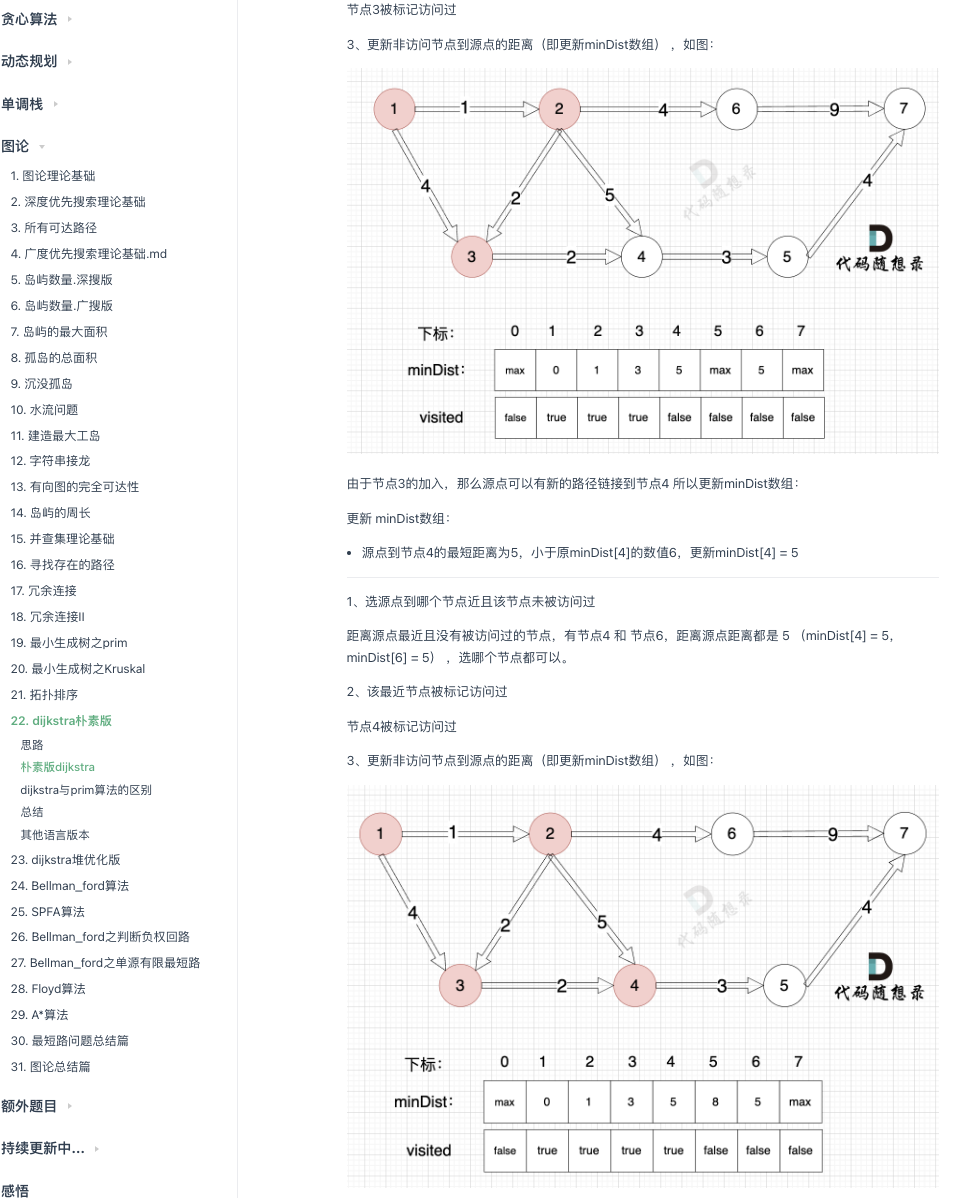
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
具体内容,大家可以去代码随想录网站(programmercarl.com)去看看,非常精彩!
|
||||
|
||||
期间有很多录友再催:**卡哥怎么不更新图论呢? 卡哥是不是不打算更新图论了**? 等等
|
||||
|
||||
每次我都要去解释一波。
|
||||
|
||||
如果我想 快速出图论章节,可以很快!
|
||||
|
||||
**但我不想做 降低 代码随想录整体质量和口碑的事情**。
|
||||
|
||||
所以关于现在发布的「代码随想录图论」,我可以很自信的说,**这是市面上大家能看到的,最全、最细致图论算法教程**。
|
||||
|
||||
**我在写作的时候没有避开任何雷区,完全遇雷排雷,然后让大家舒舒服服的走过去**。
|
||||
|
||||
什么是雷区?
|
||||
|
||||
很多知识点 ,大家去看资料的时候会发现是 没有讲解的或者一笔带过, 因为这种雷区知识点 很难讲清楚或者需要花费大量的时间去讲明白。
|
||||
|
||||
一些知识点是这样的:**自己一旦懂了就知道是那么回事,但要写出来,要给别人讲清楚,是很难的一件事**。
|
||||
|
||||
这些知识点同样是雷区,就是大家在看 教程或者算法讲解的时候,作者避而不谈的部分。
|
||||
|
||||
例如: 深搜为什么有两种写法,同样的广搜为什么有一种写法超时了,bellman_ford 为什么 要松弛 n - 1次,负权回路对最短路求解的影响 等等。
|
||||
|
||||
这一点大家在阅读代码随想录图论的时候,**可以感受到 我对细节讲解的把控程度**。
|
||||
|
||||
## 为什么要出图论
|
||||
|
||||
图论是很重要的章节,也是 大家求职笔试面试,无论是社招还是校招,都会考察的知识内容。
|
||||
|
||||
而且图论应用广泛,在大家做项目开发的时候,或多或少都会用到图论相关知识。
|
||||
|
||||
例如:通信网络(拓扑排序、最短路算法),社交网络(深搜、广搜),路径优化(最短路算法),任务调度(拓扑排序),生物信息学(基因为节点,基因关系为边),游戏开发(A * 算法等)等等
|
||||
|
||||
为了保质保量更新图论,**市面上所有的算法书籍,我都看过**!
|
||||
|
||||
**反复确认 思路正确性的同时,不仅感叹 市面上的算法书籍 在图论方面的 “缺斤少两**” 。
|
||||
|
||||
大名鼎鼎的《算法4》 以图论内容详细且图解多 而被大家好评,
|
||||
|
||||
以最短路算法为例,《算法4》,只讲解了 Dijkstra(堆优化)、SPFA (Bellman-Ford算法基于队列) 和 拓扑排序,
|
||||
|
||||
而 dijkstra朴素版、Bellman_ford 朴素版、bellman_ford之单源有限最短路、Floyd 、A * 算法 以及各个最短路算法的优劣,并没有讲解。
|
||||
|
||||
其他算法书籍 更是对图论的很多知识点一笔带过。
|
||||
|
||||
而在 代码随想录图论章节,**仅仅是 最短路算法方面,我就详细讲解了如下内容**:
|
||||
|
||||
* dijkstra朴素版
|
||||
* dijkstra堆优化版
|
||||
* Bellman_ford
|
||||
* Bellman_ford 队列优化算法(又名SPFA)
|
||||
* bellman_ford 算法判断负权回路
|
||||
* bellman_ford之单源有限最短路
|
||||
* Floyd 算法精讲
|
||||
* 启发式搜索:A * 算法
|
||||
|
||||
**常见最短路算法,我都没有落下**。
|
||||
|
||||
而且大家在看很多算法书籍是没有编程题目配合练习,这样学习效果大打折扣, 一些书籍有编程题目配合练习但知识点严重不全。
|
||||
|
||||
## 出题
|
||||
|
||||
我在讲解图论的时候,最头疼的就是找题,在力扣上 找题总是找不到符合思路且来完整表达算法精髓的题目。
|
||||
|
||||
特别是最短路算法相关的题目,例如 Bellman_ford系列 ,Floyd ,A * 等等总是找不到符合思路的题目。
|
||||
|
||||
所以我索性就自己出题吧,**这也是 卡码网(kamacoder.com)诞生的一个原因之一**。
|
||||
|
||||
**为了给大家带来极致的学习体验,我在很多细节上都下了功**夫。
|
||||
|
||||
卡码网专门给大家准备的ACM输入输出模式,**图论是在笔试还有面试中,通常都是以ACM模式来考察大家**,而大家习惯在力扣刷题(核心代码模式),核心代码模式对图的存储和输出都隐藏了。
|
||||
|
||||
**图论题目的输出输出相对其他章节的题目来说是最难处理的**。
|
||||
|
||||
### 输入的细节
|
||||
|
||||
图论的输入难在 图的存储结构,**如果没有练习过 邻接表和邻接矩阵 ,很多录友是写不出来的**。
|
||||
|
||||
而力扣上是直接给好现成的 数据结构,可以直接用,所以练习不到图的输入,也练习不到邻接表和邻接矩阵。
|
||||
|
||||
ACM输入输出模式是最考察候选人对代码细节把控程度。
|
||||
|
||||
如果熟练ACM模式,那么核心代码模式基本没问题,但反过来就不一定了。
|
||||
|
||||
### 输出的细节
|
||||
|
||||
同样,图论的输出也有细节,例如 求节点1 到节点5的所有路径, 输出可能是:
|
||||
|
||||
```
|
||||
1 2 4 5
|
||||
1 3 5
|
||||
```
|
||||
|
||||
表示有两条路可以到节点5, 那储存这个结果需要二维数组,最后在一起输出,力扣是直接return数组就好了,但 ACM模式要求我们自己输出,这里有就细节了。
|
||||
|
||||
就拿 只输出一行数据,输出 `1 2 4 5` 来说,
|
||||
|
||||
很多录友代码可能直接就这么写了:
|
||||
|
||||
```CPP
|
||||
for (int i = 0 ; i < result.size(); i++) {
|
||||
cout << result[i] << " ";
|
||||
}
|
||||
```
|
||||
|
||||
这么写输出的结果是 `1 2 4 5 `, 发现结果是对的,一提交,发现OJ返回 格式错误 或者 结果错误。
|
||||
|
||||
如果没练习过这种输出方式的录友,就开始怀疑了,这结果一样一样的,怎么就不对,我在力扣上提交都是对的!
|
||||
|
||||
**大家要注意,5 后面要不要有空格**!
|
||||
|
||||
上面这段代码输出,5后面是加上了空格了,如果判题机判断 结果的长度,标准答案`1 2 4 5`长度是7,而上面代码输出的长度是 8,很明显就是不对的。
|
||||
|
||||
所以正确的写法应该是:
|
||||
|
||||
```CPP
|
||||
for (int i = 0 ; i < result.size() - 1; i++) {
|
||||
cout << result[i] << " ";
|
||||
}
|
||||
cout << result[result.size() - 1];
|
||||
```
|
||||
|
||||
这么写,最后一个元素后面就没有空格了。
|
||||
|
||||
这是很多录友经常疏忽的,也是大家刷习惯了 力扣(核心代码模式)根本不会注意到的细节。
|
||||
|
||||
**同样在工程开发中,这些细节都是影响系统稳定运行的因素之一**。
|
||||
|
||||
**ACM模式 除了考验算法思路,也考验 大家对 代码的把控力度**, 而 核心代码模式 只注重算法的解题思路,所以输入输出这些就省略掉了。
|
||||
|
||||
## 情怀
|
||||
|
||||
大家可以发现,**现在 用心给大家更新硬核且免费资料的博主 已经不多了**。
|
||||
|
||||
这一年的空闲时间,如果我用来打磨付费课程或者付费项目,或者干脆把图论做成付费专栏 加上现在的影响力,一定可以 “狠狠赚一笔”。
|
||||
|
||||
对我来说,有些钱可以赚,有些钱不赚。
|
||||
|
||||
如果持续关注代码随想录的录友可以发现:代码随想录不仅仅优质题解和视频免费,还有 [ACM模版配套25题](https://mp.weixin.qq.com/s/ai_Br_jSayeV2ELIYvnMYQ)、 [设计模式精讲配套23题](https://mp.weixin.qq.com/s/Wmu8jW4ezCi4CQ0uT9v9iA)、[每周举办大厂笔试真题(制作真题是十分费时的)](https://mp.weixin.qq.com/s/ULTehoK4GbdbQIdauKYt1Q), 这些都是免费优质资源。
|
||||
|
||||
**在付费与免费之间,我一直都在努力寻找平衡**。
|
||||
|
||||
很多录友之所以付费加入 [知识星球](https://mp.weixin.qq.com/s/65Vrq6avJkuTqofnz361Rw) 或者 [算法训练营](https://mp.weixin.qq.com/s/vkbcihvdNvBu1W4-bExoXA) ,也是因为看了这些免费资源想支持我一下。
|
||||
|
||||
“不忘初心”,说出来很容易,**但真正能随着岁月的流淌 坚持初心,是非常非常难的事情**。
|
||||
|
||||
**诱惑太多!有惰性的诱惑,有利益的诱惑**。
|
||||
|
||||
正如我之前说的:“代码随想录” 这五个字,我是会用一生去经营。
|
||||
|
||||
**免费硬核的算法内容是 代码随想录的立身之本**,也是 大家为什么学算法学编程首选代码随想录的根本所在。
|
||||
|
||||
当大家通过 代码随想录 提升了编程与算法能力,考上研或者找到好工作的时候,于我来说已经是很幸福的事情:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
至此**图论内容 已完全免费开放在代码随想录网站(programmercarl.com),造福广大学习编程的录友们**!
|
||||
|
||||
Github 也已经同步 :https://github.com/youngyangyang04/leetcode-master ,关于其他语言版本,欢迎录友们去仓库提交PR
|
||||
|
||||
## 后序
|
||||
|
||||
关于图论PDF版本,我后面会整理出来,免费发放给大家。
|
||||
|
||||
关于图论视频版本,不出意外,应该在年底开始在B站更新,同样免费开放。
|
||||
|
||||
总之,代码随想录会持续更新下去,无论是文字版还是视频版。
|
||||
|
||||
希望大家 不用 非要到找工作的时候 或者要考研的时候 才想到代码随想录。
|
||||
|
||||
**代码是作品,算法更是艺术**,时不时来欣赏一段解决关键问题的优雅代码,也是一种享受。
|
||||
|
||||
最后,**愿录友们学有所成,归来仍看代码随想录**!
|
||||
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
|
||||
关于动态规划,在专题第一篇[关于动态规划,你该了解这些!](https://programmercarl.com/动态规划理论基础.html)就说了动规五部曲,**而且强调了五部对解动规题目至关重要!**
|
||||
|
||||
这是Carl做过一百多道动规题目总结出来的经验结晶啊,如果大家跟着「代码随想哦」刷过动规专题,一定会对这动规五部曲的作用感受极其深刻。
|
||||
这是Carl做过一百多道动规题目总结出来的经验结晶啊,如果大家跟着「代码随想录」刷过动规专题,一定会对这动规五部曲的作用感受极其深刻。
|
||||
|
||||
动规五部曲分别为:
|
||||
|
||||
|
||||
@ -29,7 +29,7 @@
|
||||
|
||||
而完全背包又是也是01背包稍作变化而来,即:完全背包的物品数量是无限的。
|
||||
|
||||
**所以背包问题的理论基础重中之重是01背包,一定要理解透!**
|
||||
**所以背包问题的理论基础重中之重是01背包,一定要理解透**!
|
||||
|
||||
leetcode上没有纯01背包的问题,都是01背包应用方面的题目,也就是需要转化为01背包问题。
|
||||
|
||||
@ -67,6 +67,7 @@ leetcode上没有纯01背包的问题,都是01背包应用方面的题目,
|
||||
|
||||
以下讲解和图示中出现的数字都是以这个例子为例。
|
||||
|
||||
(为了方便表述,下面描述 统一用 容量为XX的背包,放下容量(重量)为XX的物品,物品的价值是XX)
|
||||
|
||||
### 二维dp数组01背包
|
||||
|
||||
@ -76,7 +77,7 @@ leetcode上没有纯01背包的问题,都是01背包应用方面的题目,
|
||||
|
||||
我们需要使用二维数组,为什么呢?
|
||||
|
||||
因为有两个维度需要表示,分别是:物品 和 背包容量
|
||||
因为有两个维度需要分别表示:物品 和 背包容量
|
||||
|
||||
如图,二维数组为 dp[i][j]。
|
||||
|
||||
@ -110,13 +111,13 @@ i 来表示物品、j表示背包容量。
|
||||
|
||||
背包容量为 0,放不下物品0 或者物品1,此时背包里的价值为0。
|
||||
|
||||
背包容量为 1,只能放下物品1,背包里的价值为15。
|
||||
背包容量为 1,只能放下物品0,背包里的价值为15。
|
||||
|
||||
背包容量为 2,只能放下物品1,背包里的价值为15。
|
||||
背包容量为 2,只能放下物品0,背包里的价值为15。
|
||||
|
||||
背包容量为 3,上一行同一状态,背包只能放物品0,这次也可以选择物品1了,背包可以放物品2 或者 物品1,物品2价值更大,背包里的价值为20。
|
||||
背包容量为 3,上一行同一状态,背包只能放物品0,这次也可以选择物品1了,背包可以放物品1 或者 物品0,物品1价值更大,背包里的价值为20。
|
||||
|
||||
背包容量为 4,上一行同一状态,背包只能放物品0,这次也可以选择物品1了,背包都可都放下,背包价值为35。
|
||||
背包容量为 4,上一行同一状态,背包只能放物品0,这次也可以选择物品1了,背包可以放下物品0 和 物品1,背包价值为35。
|
||||
|
||||
以上举例,是比较容易看懂,我主要是通过这个例子,来帮助大家明确dp数组的含义。
|
||||
|
||||
@ -144,7 +145,10 @@ i 来表示物品、j表示背包容量。
|
||||
|
||||
这里我们dp[1][4]的状态来举例:
|
||||
|
||||
绝对 dp[1][4],就是放物品1 ,还是不放物品1。
|
||||
求取 dp[1][4] 有两种情况:
|
||||
|
||||
1. 放物品1
|
||||
2. 还是不放物品1
|
||||
|
||||
如果不放物品1, 那么背包的价值应该是 dp[0][4] 即 容量为4的背包,只放物品0的情况。
|
||||
|
||||
@ -152,24 +156,23 @@ i 来表示物品、j表示背包容量。
|
||||
|
||||
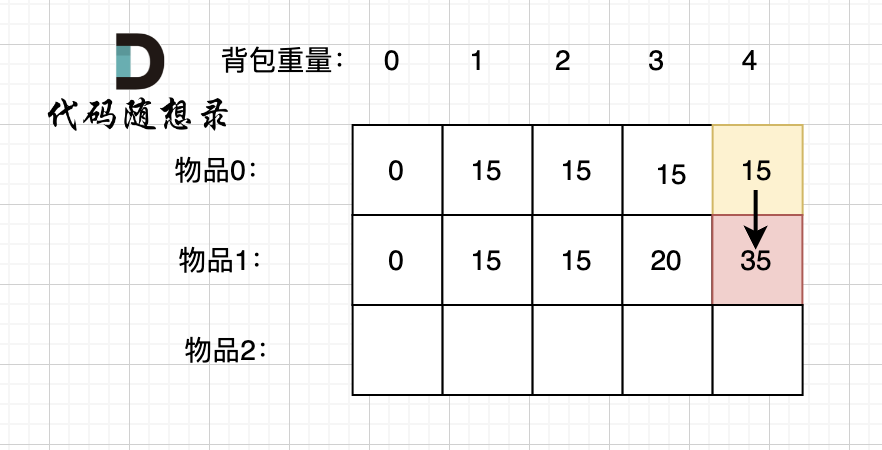
|
||||
|
||||
|
||||
如果放物品1, **那么背包要先留出物品1的容量**,目前容量是4,物品1 需要重量为3,此时背包剩下容量为1。
|
||||
如果放物品1, **那么背包要先留出物品1的容量**,目前容量是4,物品1 的容量(就是物品1的重量)为3,此时背包剩下容量为1。
|
||||
|
||||
容量为1,只考虑放物品0 的最大价值是 dp[0][1],这个值我们之前就计算过。
|
||||
|
||||
所以 放物品1 的情况 = dp[0][1] + 物品1 的重量,推导方向如图:
|
||||
所以 放物品1 的情况 = dp[0][1] + 物品1 的价值,推导方向如图:
|
||||
|
||||

|
||||
|
||||
两种情况,分别是放物品1 和 不放物品1,我们要取最大值(毕竟求的是最大价值)
|
||||
|
||||
`dp[1][4] = max(dp[0][4], dp[0][1] + 物品1 的重量) `
|
||||
`dp[1][4] = max(dp[0][4], dp[0][1] + 物品1 的价值) `
|
||||
|
||||
以上过程,抽象化如下:
|
||||
|
||||
* **不放物品i**:由dp[i - 1][j]推出,即背包容量为j,里面不放物品i的最大价值,此时dp[i][j]就是dp[i - 1][j]。
|
||||
* **不放物品i**:背包容量为j,里面不放物品i的最大价值是dp[i - 1][j]。
|
||||
|
||||
* **放物品i**:由dp[i - 1][j - weight[i]]推出,dp[i - 1][j - weight[i]] 为背包容量为j - weight[i]的时候不放物品i的最大价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值
|
||||
* **放物品i**:背包空出物品i的容量后,背包容量为j - weight[i],dp[i - 1][j - weight[i]] 为背包容量为j - weight[i]且不放物品i的最大价值,那么dp[i - 1][j - weight[i]] + value[i] (物品i的价值),就是背包放物品i得到的最大价值
|
||||
|
||||
递归公式: `dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);`
|
||||
|
||||
@ -235,7 +238,6 @@ for (int j = weight[0]; j <= bagweight; j++) {
|
||||
|
||||
4. 确定遍历顺序
|
||||
|
||||
|
||||
在如下图中,可以看出,有两个遍历的维度:物品与背包重量
|
||||
|
||||
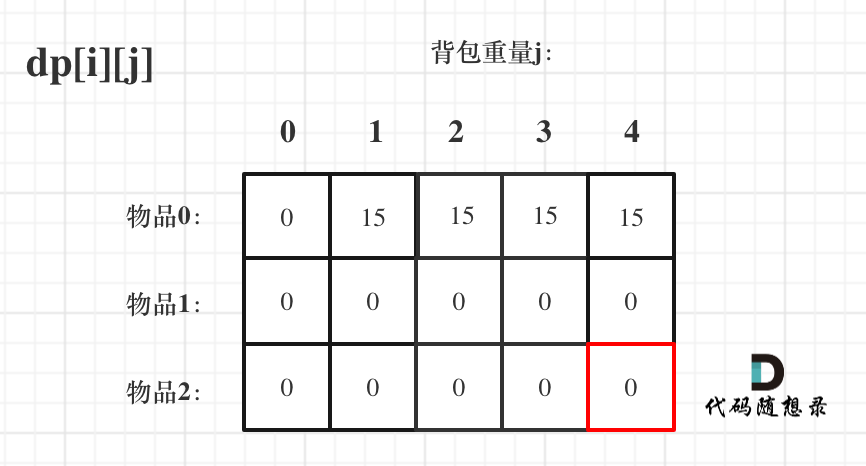
|
||||
@ -364,7 +366,6 @@ int main() {
|
||||
|
||||
|
||||
|
||||
|
||||
## 其他语言版本
|
||||
|
||||
### Java
|
||||
|
||||
Reference in New Issue
Block a user