From 9bd3c4d3549516cd469e9b4ab8580c326741479a Mon Sep 17 00:00:00 2001
From: X-shuffle <53906918+X-shuffle@users.noreply.github.com>
Date: Wed, 21 Jul 2021 22:32:35 +0800
Subject: [PATCH 01/27] =?UTF-8?q?=E5=A2=9E=E5=8A=A00455.=E5=88=86=E5=8F=91?=
=?UTF-8?q?=E9=A5=BC=E5=B9=B2=20go=E7=89=88=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
增加0455.分发饼干 go版本
---
problems/0455.分发饼干.md | 17 +++++++++++++++++
1 file changed, 17 insertions(+)
diff --git a/problems/0455.分发饼干.md b/problems/0455.分发饼干.md
index 4814d414..6b121e36 100644
--- a/problems/0455.分发饼干.md
+++ b/problems/0455.分发饼干.md
@@ -146,6 +146,23 @@ class Solution:
return res
```
Go:
+```golang
+//排序后,局部最优
+func findContentChildren(g []int, s []int) int {
+ sort.Ints(g)
+ sort.Ints(s)
+
+ // 从小到大
+ child := 0
+ for sIdx := 0; child < len(g) && sIdx < len(s); sIdx++ {
+ if s[sIdx] >= g[child] {//如果饼干的大小大于或等于孩子的为空则给与,否则不给予,继续寻找选一个饼干是否符合
+ child++
+ }
+ }
+
+ return child
+}
+
Javascript:
```Javascript
From 802f421bd72c478167b4b68f4df08dac889f49d8 Mon Sep 17 00:00:00 2001
From: youngyangyang04 <826123027@qq.com>
Date: Thu, 22 Jul 2021 14:59:17 +0800
Subject: [PATCH 02/27] Update
---
README.md | 30 +--
problems/0028.实现strStr.md | 2 +-
problems/0042.接雨水.md | 15 ++
problems/0059.螺旋矩阵II.md | 3 -
problems/0102.二叉树的层序遍历.md | 7 +-
.../0129.求根到叶子节点数字之和.md | 179 ++++++++++++++++++
problems/0151.翻转字符串里的单词.md | 5 +-
problems/0225.用队列实现栈.md | 14 --
problems/0226.翻转二叉树.md | 36 ++--
problems/0232.用栈实现队列.md | 9 -
problems/0459.重复的子字符串.md | 2 +-
problems/0463.岛屿的周长.md | 98 ++++++++++
problems/0704.二分查找.md | 2 +-
problems/0707.设计链表.md | 4 +-
problems/0941.有效的山脉数组.md | 43 +++++
problems/1002.查找常用字符.md | 177 +++++++++++++++++
...��据数字二进制下1的数目排序.md | 89 +++++++++
problems/二叉树的统一迭代法.md | 77 ++++----
problems/二叉树的迭代遍历.md | 9 +-
...杂度,你不知道的都在这里!.md | 21 +-
.../剑指Offer58-II.左旋转字符串.md | 2 +
21 files changed, 708 insertions(+), 116 deletions(-)
create mode 100644 problems/0129.求根到叶子节点数字之和.md
create mode 100644 problems/0463.岛屿的周长.md
create mode 100644 problems/0941.有效的山脉数组.md
create mode 100644 problems/1002.查找常用字符.md
create mode 100644 problems/1356.根据数字二进制下1的数目排序.md
diff --git a/README.md b/README.md
index ad22aeab..40cd272f 100644
--- a/README.md
+++ b/README.md
@@ -71,7 +71,7 @@
**这里每一篇题解,都是精品,值得仔细琢磨**。
-我在题目讲解中统一用C++语言,但你会发现下面几乎每篇题解都配有其他语言版本,Java、Python、Go、JavaScript等等,这正是热心小伙们的贡献的代码,当然我也会严格把控代码质量。
+我在题目讲解中统一使用C++,但你会发现下面几乎每篇题解都配有其他语言版本,Java、Python、Go、JavaScript等等,正是这些[热心小伙们](https://github.com/youngyangyang04/leetcode-master/graphs/contributors)的贡献的代码,当然我也会严格把控代码质量。
**所以也欢迎大家参与进来,完善题解的各个语言版本,拥抱开源,让更多小伙伴们收益**。
@@ -133,6 +133,13 @@
9. [秋招和提前批都越来越提前了....](https://mp.weixin.qq.com/s/SNFiRDx8CKyjhTPlys6ywQ)
10. [你的简历里「专业技能」写的够专业么?](https://mp.weixin.qq.com/s/bp6y-e5FVN28H9qc8J9zrg)
11. [对于秋招,实习生也有烦恼....](https://mp.weixin.qq.com/s/ka07IPryFnfmIjByFFcXDg)
+12. [华为提前批已经开始了.....](https://mp.weixin.qq.com/s/OC35QDG8pn5OwLpCxieStw)
+13. [大厂新人培养体系应该是什么样的?](https://mp.weixin.qq.com/s/WBaPCosOljB5NEkFL2GhOQ)
+
+## 杂谈
+
+[大半年过去了......](https://mp.weixin.qq.com/s/lubfeistPxBLSQIe5XYg5g)
+
## 数组
@@ -161,14 +168,15 @@
1. [关于哈希表,你该了解这些!](./problems/哈希表理论基础.md)
2. [哈希表:可以拿数组当哈希表来用,但哈希值不要太大](./problems/0242.有效的字母异位词.md)
-3. [哈希表:哈希值太大了,还是得用set](./problems/0349.两个数组的交集.md)
-4. [哈希表:用set来判断快乐数](./problems/0202.快乐数.md)
-5. [哈希表:map等候多时了](./problems/0001.两数之和.md)
-6. [哈希表:其实需要哈希的地方都能找到map的身影](./problems/0454.四数相加II.md)
-7. [哈希表:这道题目我做过?](./problems/0383.赎金信.md)
-8. [哈希表:解决了两数之和,那么能解决三数之和么?](./problems/0015.三数之和.md)
-9. [双指针法:一样的道理,能解决四数之和](./problems/0018.四数之和.md)
-10. [哈希表:总结篇!(每逢总结必经典)](./problems/哈希表总结.md)
+3. [哈希表:查找常用字符](./problems/1002.查找常用字符.md)
+4. [哈希表:哈希值太大了,还是得用set](./problems/0349.两个数组的交集.md)
+5. [哈希表:用set来判断快乐数](./problems/0202.快乐数.md)
+6. [哈希表:map等候多时了](./problems/0001.两数之和.md)
+7. [哈希表:其实需要哈希的地方都能找到map的身影](./problems/0454.四数相加II.md)
+8. [哈希表:这道题目我做过?](./problems/0383.赎金信.md)
+9. [哈希表:解决了两数之和,那么能解决三数之和么?](./problems/0015.三数之和.md)
+10. [双指针法:一样的道理,能解决四数之和](./problems/0018.四数之和.md)
+11. [哈希表:总结篇!(每逢总结必经典)](./problems/哈希表总结.md)
## 字符串
@@ -444,7 +452,7 @@
# 贡献者
-你可以[点此链接](https://github.com/youngyangyang04/leetcode-master/graphs/contributors)查看LeetCode-Master的所有贡献者。感谢你们补充了LeetCode-Master的其他语言版本,让更多的读者收益于此项目。
+[点此这里](https://github.com/youngyangyang04/leetcode-master/graphs/contributors)查看LeetCode-Master的所有贡献者。感谢他们补充了LeetCode-Master的其他语言版本,让更多的读者收益于此项目。
# 关于作者
@@ -459,7 +467,7 @@
# 公众号
-更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:「666」可以获得所有算法专题原创PDF。
+更多精彩文章持续更新,微信搜索:「代码随想录」第一时间围观,关注后回复:666,可以获得我的所有算法专题原创PDF。
**「代码随想录」每天准时为你推送一篇经典面试题目,帮你梳理算法知识体系,轻松学习算法!**,并且公众号里有大量学习资源,也有我自己的学习心得和方法总结,更有上万录友们在这里打卡学习。
diff --git a/problems/0028.实现strStr.md b/problems/0028.实现strStr.md
index aaa28d3d..69f8c9d6 100644
--- a/problems/0028.实现strStr.md
+++ b/problems/0028.实现strStr.md
@@ -651,7 +651,7 @@ class Solution {
}
```
-Python:
+Python3:
```python
// 方法一
diff --git a/problems/0042.接雨水.md b/problems/0042.接雨水.md
index 55a5c522..70a4e07c 100644
--- a/problems/0042.接雨水.md
+++ b/problems/0042.接雨水.md
@@ -1,4 +1,13 @@
+
+  +
+  +
+  +
+  +
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+> 这个图就是大厂面试经典题目,接雨水! 最常青藤的一道题,面试官百出不厌!
# 42. 接雨水
@@ -355,3 +364,9 @@ public:
## 其他语言版本
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
 +
+代码如下:
+
+```C++
+ // 中
+if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val);
+ traversal(cur->left); // 递归
+ path.pop_back(); // 回溯
+}
+if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val);
+ traversal(cur->right); // 递归
+ path.pop_back(); // 回溯
+}
+```
+
+这里要注意回溯和递归要永远在一起,一个递归,对应一个回溯,是一对一的关系,有的同学写成如下代码:
+
+```C++
+if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val);
+ traversal(cur->left); // 递归
+}
+if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val);
+ traversal(cur->right); // 递归
+}
+path.pop_back(); // 回溯
+```
+**把回溯放在花括号外面了,世界上最遥远的距离,是你在花括号里,而我在花括号外!** 这就不对了。
+
+### 整体C++代码
+
+关键逻辑分析完了,整体C++代码如下:
+
+```C++
+class Solution {
+private:
+ int result;
+ vector path;
+ // 把vector转化为int
+ int vectorToInt(const vector& vec) {
+ int sum = 0;
+ for (int i = 0; i < vec.size(); i++) {
+ sum = sum * 10 + vec[i];
+ }
+ return sum;
+ }
+ void traversal(TreeNode* cur) {
+ if (!cur->left && !cur->right) { // 遇到了叶子节点
+ result += vectorToInt(path);
+ return;
+ }
+
+ if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val); // 处理节点
+ traversal(cur->left); // 递归
+ path.pop_back(); // 回溯,撤销
+ }
+ if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val); // 处理节点
+ traversal(cur->right); // 递归
+ path.pop_back(); // 回溯,撤销
+ }
+ return ;
+ }
+public:
+ int sumNumbers(TreeNode* root) {
+ path.clear();
+ if (root == nullptr) return 0;
+ path.push_back(root->val);
+ traversal(root);
+ return result;
+ }
+};
+```
+
+## 总结
+
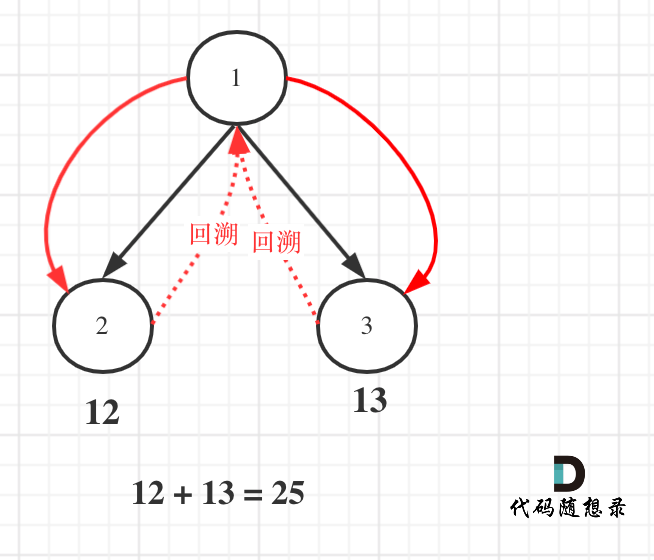
+过于简洁的代码,很容易让初学者忽视了本题中回溯的精髓,甚至作者本身都没有想清楚自己用了回溯。
+
+**我这里提供的代码把整个回溯过程充分体现出来,希望可以帮助大家看的明明白白!**
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index ffa3446a..acdf84fc 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -300,8 +300,9 @@ class Solution {
}
```
+python:
-```Python3
+```Python
class Solution:
#1.去除多余的空格
def trim_spaces(self,s):
@@ -349,7 +350,7 @@ class Solution:
return ''.join(l) #输出:blue is sky the
-'''
+```
Go:
diff --git a/problems/0225.用队列实现栈.md b/problems/0225.用队列实现栈.md
index 85b981e5..bcf82b84 100644
--- a/problems/0225.用队列实现栈.md
+++ b/problems/0225.用队列实现栈.md
@@ -200,14 +200,6 @@ class MyStack {
}
}
-/**
- * Your MyQueue object will be instantiated and called as such:
- * MyQueue obj = new MyQueue();
- * obj.push(x);
- * int param_2 = obj.pop();
- * int param_3 = obj.peek();
- * boolean param_4 = obj.empty();
- */
```
使用两个 Deque 实现
```java
@@ -350,12 +342,6 @@ class MyStack:
return False
-# Your MyStack object will be instantiated and called as such:
-# obj = MyStack()
-# obj.push(x)
-# param_2 = obj.pop()
-# param_3 = obj.top()
-# param_4 = obj.empty()
```
Go:
diff --git a/problems/0226.翻转二叉树.md b/problems/0226.翻转二叉树.md
index bb0d6d34..bba34766 100644
--- a/problems/0226.翻转二叉树.md
+++ b/problems/0226.翻转二叉树.md
@@ -7,7 +7,7 @@
+
+代码如下:
+
+```C++
+ // 中
+if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val);
+ traversal(cur->left); // 递归
+ path.pop_back(); // 回溯
+}
+if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val);
+ traversal(cur->right); // 递归
+ path.pop_back(); // 回溯
+}
+```
+
+这里要注意回溯和递归要永远在一起,一个递归,对应一个回溯,是一对一的关系,有的同学写成如下代码:
+
+```C++
+if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val);
+ traversal(cur->left); // 递归
+}
+if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val);
+ traversal(cur->right); // 递归
+}
+path.pop_back(); // 回溯
+```
+**把回溯放在花括号外面了,世界上最遥远的距离,是你在花括号里,而我在花括号外!** 这就不对了。
+
+### 整体C++代码
+
+关键逻辑分析完了,整体C++代码如下:
+
+```C++
+class Solution {
+private:
+ int result;
+ vector path;
+ // 把vector转化为int
+ int vectorToInt(const vector& vec) {
+ int sum = 0;
+ for (int i = 0; i < vec.size(); i++) {
+ sum = sum * 10 + vec[i];
+ }
+ return sum;
+ }
+ void traversal(TreeNode* cur) {
+ if (!cur->left && !cur->right) { // 遇到了叶子节点
+ result += vectorToInt(path);
+ return;
+ }
+
+ if (cur->left) { // 左 (空节点不遍历)
+ path.push_back(cur->left->val); // 处理节点
+ traversal(cur->left); // 递归
+ path.pop_back(); // 回溯,撤销
+ }
+ if (cur->right) { // 右 (空节点不遍历)
+ path.push_back(cur->right->val); // 处理节点
+ traversal(cur->right); // 递归
+ path.pop_back(); // 回溯,撤销
+ }
+ return ;
+ }
+public:
+ int sumNumbers(TreeNode* root) {
+ path.clear();
+ if (root == nullptr) return 0;
+ path.push_back(root->val);
+ traversal(root);
+ return result;
+ }
+};
+```
+
+## 总结
+
+过于简洁的代码,很容易让初学者忽视了本题中回溯的精髓,甚至作者本身都没有想清楚自己用了回溯。
+
+**我这里提供的代码把整个回溯过程充分体现出来,希望可以帮助大家看的明明白白!**
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index ffa3446a..acdf84fc 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -300,8 +300,9 @@ class Solution {
}
```
+python:
-```Python3
+```Python
class Solution:
#1.去除多余的空格
def trim_spaces(self,s):
@@ -349,7 +350,7 @@ class Solution:
return ''.join(l) #输出:blue is sky the
-'''
+```
Go:
diff --git a/problems/0225.用队列实现栈.md b/problems/0225.用队列实现栈.md
index 85b981e5..bcf82b84 100644
--- a/problems/0225.用队列实现栈.md
+++ b/problems/0225.用队列实现栈.md
@@ -200,14 +200,6 @@ class MyStack {
}
}
-/**
- * Your MyQueue object will be instantiated and called as such:
- * MyQueue obj = new MyQueue();
- * obj.push(x);
- * int param_2 = obj.pop();
- * int param_3 = obj.peek();
- * boolean param_4 = obj.empty();
- */
```
使用两个 Deque 实现
```java
@@ -350,12 +342,6 @@ class MyStack:
return False
-# Your MyStack object will be instantiated and called as such:
-# obj = MyStack()
-# obj.push(x)
-# param_2 = obj.pop()
-# param_3 = obj.top()
-# param_4 = obj.empty()
```
Go:
diff --git a/problems/0226.翻转二叉树.md b/problems/0226.翻转二叉树.md
index bb0d6d34..bba34766 100644
--- a/problems/0226.翻转二叉树.md
+++ b/problems/0226.翻转二叉树.md
@@ -7,7 +7,7 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 226.翻转二叉树
+# 226.翻转二叉树
题目地址:https://leetcode-cn.com/problems/invert-binary-tree/
@@ -17,7 +17,7 @@
这道题目背后有一个让程序员心酸的故事,听说 Homebrew的作者Max Howell,就是因为没在白板上写出翻转二叉树,最后被Google拒绝了。(真假不做判断,权当一个乐子哈)
-## 题外话
+# 题外话
这道题目是非常经典的题目,也是比较简单的题目(至少一看就会)。
@@ -25,7 +25,7 @@
如果做过这道题的同学也建议认真看完,相信一定有所收获!
-## 思路
+# 思路
我们之前介绍的都是各种方式遍历二叉树,这次要翻转了,感觉还是有点懵逼。
@@ -49,7 +49,9 @@
## 递归法
-对于二叉树的递归法的前中后序遍历,已经在[二叉树:前中后序递归遍历](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)详细讲解了。
+
+
+对于二叉树的递归法的前中后序遍历,已经在[二叉树:前中后序递归遍历](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)详细讲解了。
我们下文以前序遍历为例,通过动画来看一下翻转的过程:
@@ -104,7 +106,8 @@ public:
### 深度优先遍历
-[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中给出了前中后序迭代方式的写法,所以本地可以很轻松的切出如下迭代法的代码:
+
+[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)中给出了前中后序迭代方式的写法,所以本地可以很轻松的切出如下迭代法的代码:
C++代码迭代法(前序遍历)
@@ -126,10 +129,10 @@ public:
}
};
```
-如果这个代码看不懂的话可以在回顾一下[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)。
+如果这个代码看不懂的话可以在回顾一下[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)。
-我们在[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)中介绍了统一的写法,所以,本题也只需将文中的代码少做修改便可。
+我们在[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/ATQMPCpBlaAgrqdLDMVPZA)中介绍了统一的写法,所以,本题也只需将文中的代码少做修改便可。
C++代码如下迭代法(前序遍历)
@@ -159,7 +162,7 @@ public:
};
```
-如果上面这个代码看不懂,回顾一下文章[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)。
+如果上面这个代码看不懂,回顾一下文章[二叉树:前中后序迭代方式的统一写法](https://mp.weixin.qq.com/s/ATQMPCpBlaAgrqdLDMVPZA)。
### 广度优先遍历
@@ -185,7 +188,7 @@ public:
}
};
```
-如果对以上代码不理解,或者不清楚二叉树的层序遍历,可以看这篇[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)
+如果对以上代码不理解,或者不清楚二叉树的层序遍历,可以看这篇[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)
## 总结
@@ -202,7 +205,7 @@ public:
## 其他语言版本
-Java:
+### Java:
```Java
//DFS递归
@@ -254,9 +257,9 @@ class Solution {
}
```
-Python:
+### Python
-> 递归法:前序遍历
+递归法:前序遍历:
```python
class Solution:
def invertTree(self, root: TreeNode) -> TreeNode:
@@ -268,7 +271,7 @@ class Solution:
return root
```
-> 迭代法:深度优先遍历(前序遍历)
+迭代法:深度优先遍历(前序遍历):
```python
class Solution:
def invertTree(self, root: TreeNode) -> TreeNode:
@@ -286,7 +289,7 @@ class Solution:
return root
```
-> 迭代法:广度优先遍历(层序遍历)
+迭代法:广度优先遍历(层序遍历):
```python
import collections
class Solution:
@@ -306,7 +309,8 @@ class Solution:
return root
```
-Go:
+### Go
+
```Go
func invertTree(root *TreeNode) *TreeNode {
if root ==nil{
@@ -323,7 +327,7 @@ func invertTree(root *TreeNode) *TreeNode {
}
```
-JavaScript:
+### JavaScript
使用递归版本的前序遍历
```javascript
diff --git a/problems/0232.用栈实现队列.md b/problems/0232.用栈实现队列.md
index be6e1df6..6890fc2b 100644
--- a/problems/0232.用栈实现队列.md
+++ b/problems/0232.用栈实现队列.md
@@ -385,15 +385,6 @@ func (this *MyQueue) Empty() bool {
return len(this.stack) == 0 && len(this.back) == 0
}
-/**
- * Your MyQueue object will be instantiated and called as such:
- * obj := Constructor();
- * obj.Push(x);
- * param_2 := obj.Pop();
- * param_3 := obj.Peek();
- * param_4 := obj.Empty();
- */
- ```
javaScript:
diff --git a/problems/0459.重复的子字符串.md b/problems/0459.重复的子字符串.md
index 368489a5..f012811d 100644
--- a/problems/0459.重复的子字符串.md
+++ b/problems/0459.重复的子字符串.md
@@ -37,7 +37,7 @@ https://leetcode-cn.com/problems/repeated-substring-pattern/
如果KMP还不够了解,可以看我的B站:
-* [帮你把KMP算法学个通透!B站(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd/)
+* [帮你把KMP算法学个通透!(理论篇)](https://www.bilibili.com/video/BV1PD4y1o7nd/)
* [帮你把KMP算法学个通透!(求next数组代码篇)](https://www.bilibili.com/video/BV1M5411j7Xx)
diff --git a/problems/0463.岛屿的周长.md b/problems/0463.岛屿的周长.md
new file mode 100644
index 00000000..40378854
--- /dev/null
+++ b/problems/0463.岛屿的周长.md
@@ -0,0 +1,98 @@
+
+## 题目链接
+https://leetcode-cn.com/problems/island-perimeter/
+
+## 思路
+
+岛屿问题最容易让人想到BFS或者DFS,但是这道题还真的没有必要,别把简单问题搞复杂了。
+
+### 解法一:
+
+遍历每一个空格,遇到岛屿,计算其上下左右的情况,遇到水域或者出界的情况,就可以计算边了。
+
+如图:
+
+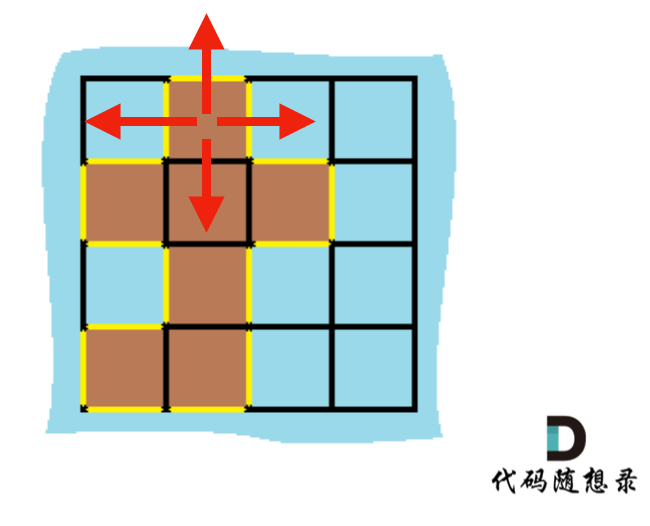 +
+C++代码如下:(详细注释)
+
+```C++
+class Solution {
+public:
+ int direction[4][2] = {0, 1, 1, 0, -1, 0, 0, -1};
+ int islandPerimeter(vector>& grid) {
+ int result = 0;
+ for (int i = 0; i < grid.size(); i++) {
+ for (int j = 0; j < grid[0].size(); j++) {
+ if (grid[i][j] == 1) {
+ for (int k = 0; k < 4; k++) { // 上下左右四个方向
+ int x = i + direction[k][0];
+ int y = j + direction[k][1]; // 计算周边坐标x,y
+ if (x < 0 // i在边界上
+ || x >= grid.size() // i在边界上
+ || y < 0 // j在边界上
+ || y >= grid[0].size() // j在边界上
+ || grid[x][y] == 0) { // x,y位置是水域
+ result++;
+ }
+ }
+ }
+ }
+ }
+ return result;
+ }
+};
+```
+
+### 解法二:
+
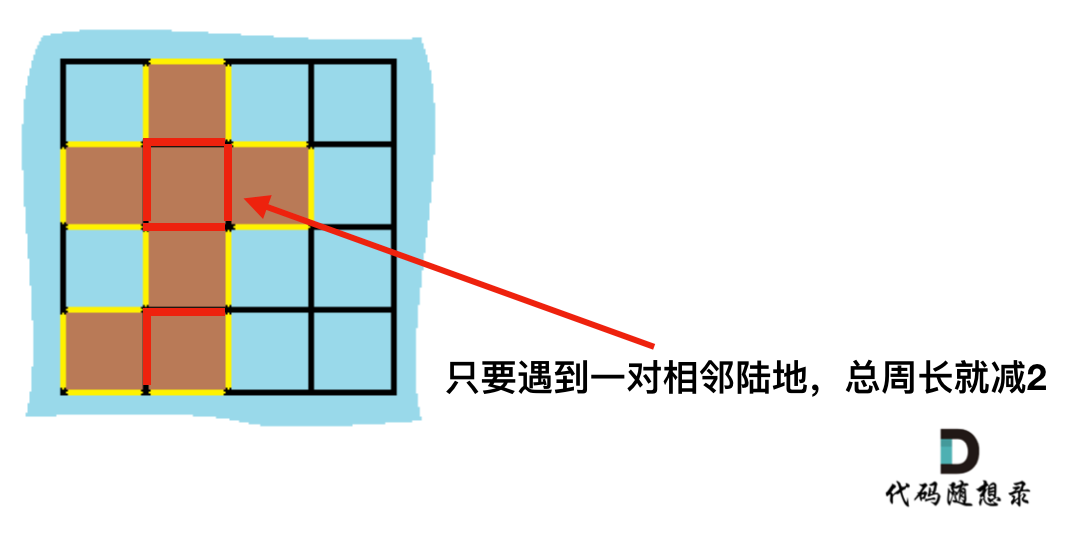
+计算出总的岛屿数量,因为有一对相邻两个陆地,边的总数就减2,那么在计算出相邻岛屿的数量就可以了。
+
+result = 岛屿数量 * 4 - cover * 2;
+
+如图:
+
+
+
+C++代码如下:(详细注释)
+
+```C++
+class Solution {
+public:
+ int direction[4][2] = {0, 1, 1, 0, -1, 0, 0, -1};
+ int islandPerimeter(vector>& grid) {
+ int result = 0;
+ for (int i = 0; i < grid.size(); i++) {
+ for (int j = 0; j < grid[0].size(); j++) {
+ if (grid[i][j] == 1) {
+ for (int k = 0; k < 4; k++) { // 上下左右四个方向
+ int x = i + direction[k][0];
+ int y = j + direction[k][1]; // 计算周边坐标x,y
+ if (x < 0 // i在边界上
+ || x >= grid.size() // i在边界上
+ || y < 0 // j在边界上
+ || y >= grid[0].size() // j在边界上
+ || grid[x][y] == 0) { // x,y位置是水域
+ result++;
+ }
+ }
+ }
+ }
+ }
+ return result;
+ }
+};
+```
+
+### 解法二:
+
+计算出总的岛屿数量,因为有一对相邻两个陆地,边的总数就减2,那么在计算出相邻岛屿的数量就可以了。
+
+result = 岛屿数量 * 4 - cover * 2;
+
+如图:
+
+ +
+C++代码如下:(详细注释)
+
+```C++
+class Solution {
+public:
+ int islandPerimeter(vector>& grid) {
+ int sum = 0; // 陆地数量
+ int cover = 0; // 相邻数量
+ for (int i = 0; i < grid.size(); i++) {
+ for (int j = 0; j < grid[0].size(); j++) {
+ if (grid[i][j] == 1) {
+ sum++;
+ // 统计上边相邻陆地
+ if(i - 1 >= 0 && grid[i - 1][j] == 1) cover++;
+ // 统计左边相邻陆地
+ if(j - 1 >= 0 && grid[i][j - 1] == 1) cover++;
+ // 为什么没统计下边和右边? 因为避免重复计算
+ }
+ }
+ }
+ return sum * 4 - cover * 2;
+ }
+};
+```
+
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+C++代码如下:(详细注释)
+
+```C++
+class Solution {
+public:
+ int islandPerimeter(vector>& grid) {
+ int sum = 0; // 陆地数量
+ int cover = 0; // 相邻数量
+ for (int i = 0; i < grid.size(); i++) {
+ for (int j = 0; j < grid[0].size(); j++) {
+ if (grid[i][j] == 1) {
+ sum++;
+ // 统计上边相邻陆地
+ if(i - 1 >= 0 && grid[i - 1][j] == 1) cover++;
+ // 统计左边相邻陆地
+ if(j - 1 >= 0 && grid[i][j - 1] == 1) cover++;
+ // 为什么没统计下边和右边? 因为避免重复计算
+ }
+ }
+ }
+ return sum * 4 - cover * 2;
+ }
+};
+```
+
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/0704.二分查找.md b/problems/0704.二分查找.md
index 931e6e5c..cce471ae 100644
--- a/problems/0704.二分查找.md
+++ b/problems/0704.二分查找.md
@@ -139,7 +139,7 @@ public:
## 相关题目推荐
-* [35.搜索插入位置](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)
+* [35.搜索插入位置](./0035.搜索插入位置.md)
* 34.在排序数组中查找元素的第一个和最后一个位置
* 69.x 的平方根
* 367.有效的完全平方数
diff --git a/problems/0707.设计链表.md b/problems/0707.设计链表.md
index b67a36eb..8be28f88 100644
--- a/problems/0707.设计链表.md
+++ b/problems/0707.设计链表.md
@@ -28,9 +28,9 @@ https://leetcode-cn.com/problems/design-linked-list/
# 思路
-如果对链表的基础知识还不太懂,可以看这篇文章:[关于链表,你该了解这些!](https://mp.weixin.qq.com/s/ntlZbEdKgnFQKZkSUAOSpQ)
+如果对链表的基础知识还不太懂,可以看这篇文章:[关于链表,你该了解这些!](https://mp.weixin.qq.com/s/fDGMmLrW7ZHlzkzlf_dZkw)
-如果对链表的虚拟头结点不清楚,可以看这篇文章:[链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/slM1CH5Ew9XzK93YOQYSjA)
+如果对链表的虚拟头结点不清楚,可以看这篇文章:[链表:听说用虚拟头节点会方便很多?](https://mp.weixin.qq.com/s/L5aanfALdLEwVWGvyXPDqA)
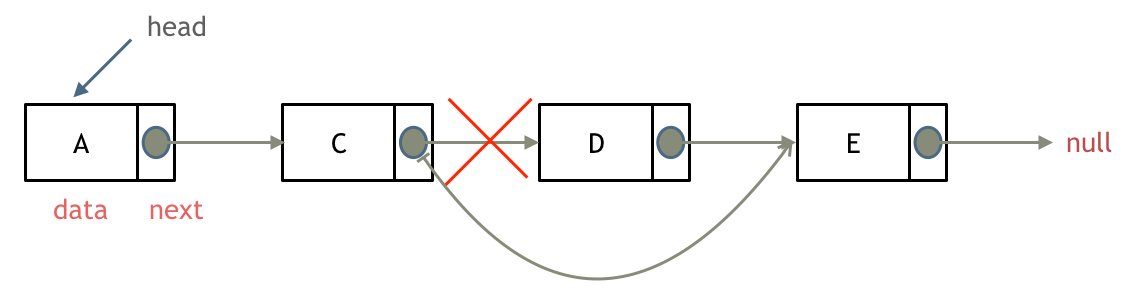
删除链表节点:
diff --git a/problems/0941.有效的山脉数组.md b/problems/0941.有效的山脉数组.md
new file mode 100644
index 00000000..6dbc3da2
--- /dev/null
+++ b/problems/0941.有效的山脉数组.md
@@ -0,0 +1,43 @@
+
+## 题目链接
+
+https://leetcode-cn.com/problems/valid-mountain-array/
+
+## 思路
+
+判断是山峰,主要就是要严格的保存左边到中间,和右边到中间是递增的。
+
+这样可以使用两个指针,left和right,让其按照如下规则移动,如图:
+
+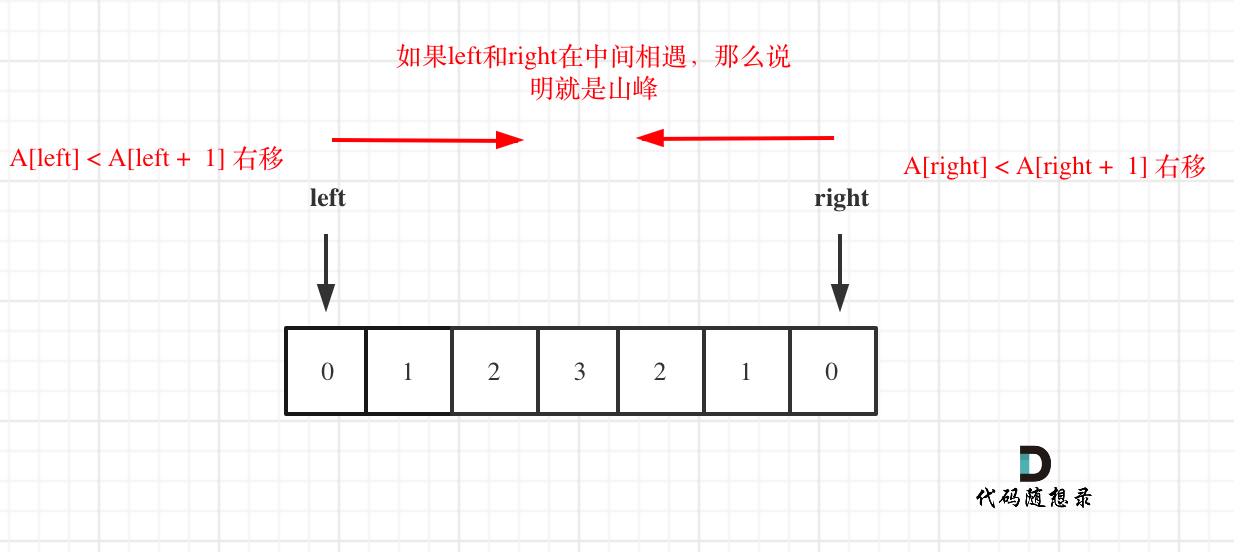 +
+**注意这里还是有一些细节,例如如下两点:**
+
+* 因为left和right是数组下表,移动的过程中注意不要数组越界
+* 如果left或者right没有移动,说明是一个单调递增或者递减的数组,依然不是山峰
+
+C++代码如下:
+
+```
+class Solution {
+public:
+ bool validMountainArray(vector& A) {
+ if (A.size() < 3) return false;
+ int left = 0;
+ int right = A.size() - 1;
+
+ // 注意防止越界
+ while (left < A.size() - 1 && A[left] < A[left + 1]) left++;
+
+ // 注意防止越界
+ while (right > 0 && A[right] < A[right - 1]) right--;
+
+ // 如果left或者right都在起始位置,说明不是山峰
+ if (left == right && left != 0 && right != A.size() - 1) return true;
+ return false;
+ }
+};
+```
+如果想系统学一学双指针的话, 可以看一下这篇[双指针法:总结篇!](https://mp.weixin.qq.com/s/_p7grwjISfMh0U65uOyCjA)
+
+
diff --git a/problems/1002.查找常用字符.md b/problems/1002.查找常用字符.md
new file mode 100644
index 00000000..875340c4
--- /dev/null
+++ b/problems/1002.查找常用字符.md
@@ -0,0 +1,177 @@
+
+
+
+**注意这里还是有一些细节,例如如下两点:**
+
+* 因为left和right是数组下表,移动的过程中注意不要数组越界
+* 如果left或者right没有移动,说明是一个单调递增或者递减的数组,依然不是山峰
+
+C++代码如下:
+
+```
+class Solution {
+public:
+ bool validMountainArray(vector& A) {
+ if (A.size() < 3) return false;
+ int left = 0;
+ int right = A.size() - 1;
+
+ // 注意防止越界
+ while (left < A.size() - 1 && A[left] < A[left + 1]) left++;
+
+ // 注意防止越界
+ while (right > 0 && A[right] < A[right - 1]) right--;
+
+ // 如果left或者right都在起始位置,说明不是山峰
+ if (left == right && left != 0 && right != A.size() - 1) return true;
+ return false;
+ }
+};
+```
+如果想系统学一学双指针的话, 可以看一下这篇[双指针法:总结篇!](https://mp.weixin.qq.com/s/_p7grwjISfMh0U65uOyCjA)
+
+
diff --git a/problems/1002.查找常用字符.md b/problems/1002.查找常用字符.md
new file mode 100644
index 00000000..875340c4
--- /dev/null
+++ b/problems/1002.查找常用字符.md
@@ -0,0 +1,177 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 1002. 查找常用字符
+
+https://leetcode-cn.com/problems/find-common-characters/
+
+给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表。例如,如果一个字符在每个字符串中出现 3 次,但不是 4 次,则需要在最终答案中包含该字符 3 次。
+
+你可以按任意顺序返回答案。
+
+【示例一】
+输入:["bella","label","roller"]
+输出:["e","l","l"]
+
+【示例二】
+输入:["cool","lock","cook"]
+输出:["c","o"]
+
+
+# 思路
+
+这道题意一起就有点绕,不是那么容易懂,其实就是26个小写字符中有字符 在所有字符串里都出现的话,就输出,重复的也算。
+
+例如:
+
+输入:["ll","ll","ll"]
+输出:["l","l"]
+
+这道题目一眼看上去,就是用哈希法,**“小写字符”,“出现频率”, 这些关键字都是为哈希法量身定做的啊**
+
+首先可以想到的是暴力解法,一个字符串一个字符串去搜,时间复杂度是O(n^m),n是字符串长度,m是有几个字符串。
+
+可以看出这是指数级别的时间复杂度,非常高,而且代码实现也不容易,因为要统计 重复的字符,还要适当的替换或者去重。
+
+那我们还是哈希法吧。如果对哈希法不了解,可以看这篇:[关于哈希表,你该了解这些!](https://mp.weixin.qq.com/s/RSUANESA_tkhKhYe3ZR8Jg)。
+
+如果对用数组来做哈希法不了解的话,可以看这篇:[把数组当做哈希表来用,很巧妙!](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)。
+
+了解了哈希法,理解了数组在哈希法中的应用之后,可以来看解题思路了。
+
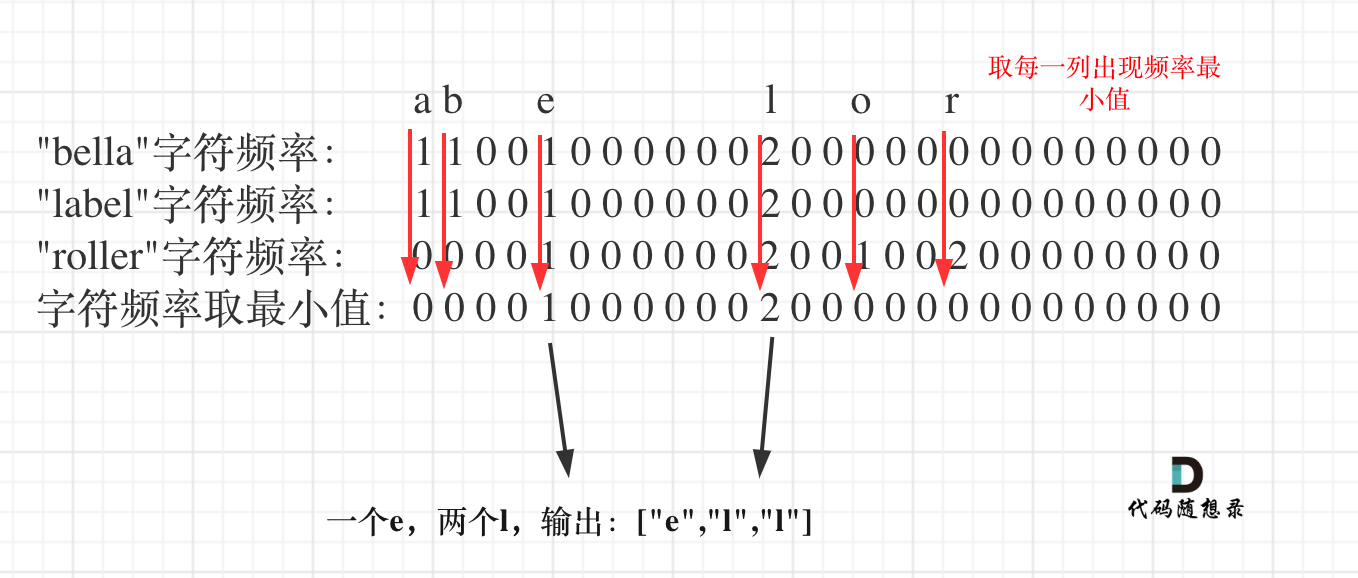
+整体思路就是统计出搜索字符串里26个字符的出现的频率,然后取每个字符频率最小值,最后转成输出格式就可以了。
+
+如图:
+
+
+
+先统计第一个字符串所有字符出现的次数,代码如下:
+
+```
+int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
+for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
+ hash[A[0][i] - 'a']++;
+}
+```
+
+接下来,把其他字符串里字符的出现次数也统计出来一次放在hashOtherStr中。
+
+然后hash 和 hashOtherStr 取最小值,这是本题关键所在,此时取最小值,就是 一个字符在所有字符串里出现的最小次数了。
+
+代码如下:
+
+```
+int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
+for (int i = 1; i < A.size(); i++) {
+ memset(hashOtherStr, 0, 26 * sizeof(int));
+ for (int j = 0; j < A[i].size(); j++) {
+ hashOtherStr[A[i][j] - 'a']++;
+ }
+ // 这是关键所在
+ for (int k = 0; k < 26; k++) { // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
+ hash[k] = min(hash[k], hashOtherStr[k]);
+ }
+}
+```
+此时hash里统计着字符在所有字符串里出现的最小次数,那么把hash转正题目要求的输出格式就可以了。
+
+代码如下:
+
+```
+// 将hash统计的字符次数,转成输出形式
+for (int i = 0; i < 26; i++) {
+ while (hash[i] != 0) { // 注意这里是while,多个重复的字符
+ string s(1, i + 'a'); // char -> string
+ result.push_back(s);
+ hash[i]--;
+ }
+}
+```
+
+整体C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector commonChars(vector& A) {
+ vector result;
+ if (A.size() == 0) return result;
+ int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
+ for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
+ hash[A[0][i] - 'a']++;
+ }
+
+ int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
+ for (int i = 1; i < A.size(); i++) {
+ memset(hashOtherStr, 0, 26 * sizeof(int));
+ for (int j = 0; j < A[i].size(); j++) {
+ hashOtherStr[A[i][j] - 'a']++;
+ }
+ // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
+ for (int k = 0; k < 26; k++) {
+ hash[k] = min(hash[k], hashOtherStr[k]);
+ }
+ }
+ // 将hash统计的字符次数,转成输出形式
+ for (int i = 0; i < 26; i++) {
+ while (hash[i] != 0) { // 注意这里是while,多个重复的字符
+ string s(1, i + 'a'); // char -> string
+ result.push_back(s);
+ hash[i]--;
+ }
+ }
+
+ return result;
+ }
+};
+```
+
+## 其他语言版本
+
+Java:
+
+```Java
+class Solution {
+ public List commonChars(String[] A) {
+ List result = new ArrayList<>();
+ if (A.length == 0) return result;
+ int[] hash= new int[26]; // 用来统计所有字符串里字符出现的最小频率
+ for (int i = 0; i < A[0].length(); i++) { // 用第一个字符串给hash初始化
+ hash[A[0].charAt(i)- 'a']++;
+ }
+ // 统计除第一个字符串外字符的出现频率
+ for (int i = 1; i < A.length; i++) {
+ int[] hashOtherStr= new int[26];
+ for (int j = 0; j < A[i].length(); j++) {
+ hashOtherStr[A[i].charAt(j)- 'a']++;
+ }
+ // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
+ for (int k = 0; k < 26; k++) {
+ hash[k] = Math.min(hash[k], hashOtherStr[k]);
+ }
+ }
+ // 将hash统计的字符次数,转成输出形式
+ for (int i = 0; i < 26; i++) {
+ while (hash[i] != 0) { // 注意这里是while,多个重复的字符
+ char c= (char) (i+'a');
+ result.add(String.valueOf(c));
+ hash[i]--;
+ }
+ }
+ return result;
+ }
+}
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/1356.根据数字二进制下1的数目排序.md b/problems/1356.根据数字二进制下1的数目排序.md
new file mode 100644
index 00000000..e8aee055
--- /dev/null
+++ b/problems/1356.根据数字二进制下1的数目排序.md
@@ -0,0 +1,89 @@
+
+## 题目链接
+https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
+
+## 思路
+
+这道题其实是考察如何计算一个数的二进制中1的数量。
+
+我提供两种方法:
+
+* 方法一:
+
+朴实无华挨个计算1的数量,最多就是循环n的二进制位数,32位。
+
+```C++
+int bitCount(int n) {
+ int count = 0; // 计数器
+ while (n > 0) {
+ if((n & 1) == 1) count++; // 当前位是1,count++
+ n >>= 1 ; // n向右移位
+ }
+ return count;
+}
+```
+
+* 方法二
+
+这种方法,只循环n的二进制中1的个数次,比方法一高效的多
+
+```C++
+int bitCount(int n) {
+ int count = 0;
+ while (n) {
+ n &= (n - 1); // 清除最低位的1
+ count++;
+ }
+ return count;
+}
+```
+以计算12的二进制1的数量为例,如图所示:
+
+ +
+下面我就使用方法二,来做这道题目:
+
+## C++代码
+
+```C++
+class Solution {
+private:
+ static int bitCount(int n) { // 计算n的二进制中1的数量
+ int count = 0;
+ while(n) {
+ n &= (n -1); // 清除最低位的1
+ count++;
+ }
+ return count;
+ }
+ static bool cmp(int a, int b) {
+ int bitA = bitCount(a);
+ int bitB = bitCount(b);
+ if (bitA == bitB) return a < b; // 如果bit中1数量相同,比较数值大小
+ return bitA < bitB; // 否则比较bit中1数量大小
+ }
+public:
+ vector sortByBits(vector& arr) {
+ sort(arr.begin(), arr.end(), cmp);
+ return arr;
+ }
+};
+```
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+下面我就使用方法二,来做这道题目:
+
+## C++代码
+
+```C++
+class Solution {
+private:
+ static int bitCount(int n) { // 计算n的二进制中1的数量
+ int count = 0;
+ while(n) {
+ n &= (n -1); // 清除最低位的1
+ count++;
+ }
+ return count;
+ }
+ static bool cmp(int a, int b) {
+ int bitA = bitCount(a);
+ int bitB = bitCount(b);
+ if (bitA == bitB) return a < b; // 如果bit中1数量相同,比较数值大小
+ return bitA < bitB; // 否则比较bit中1数量大小
+ }
+public:
+ vector sortByBits(vector& arr) {
+ sort(arr.begin(), arr.end(), cmp);
+ return arr;
+ }
+};
+```
+
+## 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/二叉树的统一迭代法.md b/problems/二叉树的统一迭代法.md
index 533bdfe7..9e24fef6 100644
--- a/problems/二叉树的统一迭代法.md
+++ b/problems/二叉树的统一迭代法.md
@@ -12,9 +12,9 @@
> 统一写法是一种什么感觉
-此时我们在[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/PwVIfxDlT3kRgMASWAMGhA)中用递归的方式,实现了二叉树前中后序的遍历。
+此时我们在[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)中用递归的方式,实现了二叉树前中后序的遍历。
-在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中用栈实现了二叉树前后中序的迭代遍历(非递归)。
+在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)中用栈实现了二叉树前后中序的迭代遍历(非递归)。
之后我们发现**迭代法实现的先中后序,其实风格也不是那么统一,除了先序和后序,有关联,中序完全就是另一个风格了,一会用栈遍历,一会又用指针来遍历。**
@@ -24,7 +24,7 @@
**重头戏来了,接下来介绍一下统一写法。**
-我们以中序遍历为例,在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中提到说使用栈的话,**无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况**。
+我们以中序遍历为例,在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)中提到说使用栈的话,**无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况**。
**那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。**
@@ -149,14 +149,13 @@ public:
-## 其他语言版本
+# 其他语言版本
Java:
- 迭代法前序遍历代码如下:
- ```java
- class Solution {
-
+迭代法前序遍历代码如下:
+```java
+class Solution {
public List preorderTraversal(TreeNode root) {
List result = new LinkedList<>();
Stack st = new Stack<>();
@@ -180,39 +179,39 @@ Java:
return result;
}
}
+```
- ```
- 迭代法中序遍历代码如下:
- ```java
- class Solution {
- public List inorderTraversal(TreeNode root) {
- List result = new LinkedList<>();
- Stack st = new Stack<>();
- if (root != null) st.push(root);
- while (!st.empty()) {
- TreeNode node = st.peek();
- if (node != null) {
- st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
- if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
- st.push(node); // 添加中节点
- st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
+迭代法中序遍历代码如下:
+```java
+class Solution {
+public List inorderTraversal(TreeNode root) {
+ List result = new LinkedList<>();
+ Stack st = new Stack<>();
+ if (root != null) st.push(root);
+ while (!st.empty()) {
+ TreeNode node = st.peek();
+ if (node != null) {
+ st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
+ if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
+ st.push(node); // 添加中节点
+ st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
- if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
- } else { // 只有遇到空节点的时候,才将下一个节点放进结果集
- st.pop(); // 将空节点弹出
- node = st.peek(); // 重新取出栈中元素
- st.pop();
- result.add(node.val); // 加入到结果集
- }
+ if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
+ } else { // 只有遇到空节点的时候,才将下一个节点放进结果集
+ st.pop(); // 将空节点弹出
+ node = st.peek(); // 重新取出栈中元素
+ st.pop();
+ result.add(node.val); // 加入到结果集
}
- return result;
}
+ return result;
}
- ```
- 迭代法后序遍历代码如下:
- ```java
- class Solution {
+}
+```
+迭代法后序遍历代码如下:
+```java
+class Solution {
public List postorderTraversal(TreeNode root) {
List result = new LinkedList<>();
Stack st = new Stack<>();
@@ -236,11 +235,11 @@ Java:
return result;
}
}
+```
- ```
Python:
-> 迭代法前序遍历
+迭代法前序遍历:
```python
class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
@@ -263,7 +262,7 @@ class Solution:
return result
```
-> 迭代法中序遍历
+迭代法中序遍历:
```python
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
@@ -288,7 +287,7 @@ class Solution:
return result
```
-> 迭代法后序遍历
+迭代法后序遍历:
```python
class Solution:
def postorderTraversal(self, root: TreeNode) -> List[int]:
diff --git a/problems/二叉树的迭代遍历.md b/problems/二叉树的迭代遍历.md
index 30b921ff..20397773 100644
--- a/problems/二叉树的迭代遍历.md
+++ b/problems/二叉树的迭代遍历.md
@@ -19,7 +19,7 @@
为什么可以用迭代法(非递归的方式)来实现二叉树的前后中序遍历呢?
-我们在[栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/eynAEbUbZoAWrk0ZlEugqg)中提到了,**递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中**,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
+我们在[栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/1-x6r1wGA9mqIHW5LrMvBg)中提到了,**递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中**,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
此时大家应该知道我们用栈也可以是实现二叉树的前后中序遍历了。
@@ -138,7 +138,7 @@ public:
```
-## 总结
+# 总结
此时我们用迭代法写出了二叉树的前后中序遍历,大家可以看出前序和中序是完全两种代码风格,并不想递归写法那样代码稍做调整,就可以实现前后中序。
@@ -153,7 +153,7 @@ public:
-## 其他语言版本
+# 其他语言版本
Java:
@@ -233,7 +233,8 @@ class Solution {
Python:
-```python3
+
+```python
# 前序遍历-迭代-LC144_二叉树的前序遍历
class Solution:
def preorderTraversal(self, root: TreeNode) -> List[int]:
diff --git a/problems/前序/关于时间复杂度,你不知道的都在这里!.md b/problems/前序/关于时间复杂度,你不知道的都在这里!.md
index 4ca9eede..d6471b99 100644
--- a/problems/前序/关于时间复杂度,你不知道的都在这里!.md
+++ b/problems/前序/关于时间复杂度,你不知道的都在这里!.md
@@ -7,12 +7,19 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+相信每一位录友都接触过时间复杂度,但又对时间复杂度的认识处于一种朦胧的状态,所以是时候对时间复杂度来一个深度的剖析了。
-Carl大胆断言:这可能是你见过对时间复杂度分析最通透的一篇文章了。
+本篇从如下六点进行分析:
-相信每一位录友都接触过时间复杂度,「代码随想录」已经也讲了一百多道经典题目了,是时候对时间复杂度来一个深度的剖析了,很早之前就写过一篇,当时文章还没有人看,Carl感觉有价值的东西值得让更多的人看到,哈哈。
+* 究竟什么是时间复杂度
+* 什么是大O
+* 不同数据规模的差异
+* 复杂表达式的化简
+* O(logn)中的log是以什么为底?
+* 举一个例子
-所以重新整理的时间复杂度文章,正式和大家见面啦!
+
+这可能是你见过对时间复杂度分析最通透的一篇文章。
## 究竟什么是时间复杂度
@@ -151,7 +158,7 @@ O(2 * n^2 + 10 * n + 1000) < O(3 * n^2),所以说最后省略掉常数项系
**当然这不是这道题目的最优解,我仅仅是用这道题目来讲解一下时间复杂度**。
-# 总结
+## 总结
本篇讲解了什么是时间复杂度,复杂度是用来干什么,以及数据规模对时间复杂度的影响。
@@ -161,12 +168,6 @@ O(2 * n^2 + 10 * n + 1000) < O(3 * n^2),所以说最后省略掉常数项系
相信看完本篇,大家对时间复杂度的认识会深刻很多!
-如果感觉「代码随想录」很不错,赶快推荐给身边的朋友同学们吧,他们发现和「代码随想录」相见恨晚!
-
-
-
-
-
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/剑指Offer58-II.左旋转字符串.md b/problems/剑指Offer58-II.左旋转字符串.md
index 1701086e..3c3eaef0 100644
--- a/problems/剑指Offer58-II.左旋转字符串.md
+++ b/problems/剑指Offer58-II.左旋转字符串.md
@@ -118,6 +118,8 @@ class Solution {
}
```
+python:
+
```python
# 方法一:可以使用切片方法
class Solution:
From 59755d57f28cedc466110fd2c6075f30bcfe0cd0 Mon Sep 17 00:00:00 2001
From: SkyLazy <627770537@qq.com>
Date: Thu, 22 Jul 2021 17:19:15 +0800
Subject: [PATCH 03/27] =?UTF-8?q?Update=200239.=E6=BB=91=E5=8A=A8=E7=AA=97?=
=?UTF-8?q?=E5=8F=A3=E6=9C=80=E5=A4=A7=E5=80=BC.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0239.滑动窗口最大值.md | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/problems/0239.滑动窗口最大值.md b/problems/0239.滑动窗口最大值.md
index bb89a1ac..dedc3247 100644
--- a/problems/0239.滑动窗口最大值.md
+++ b/problems/0239.滑动窗口最大值.md
@@ -273,8 +273,8 @@ class Solution {
int[] res = new int[n - k + 1];
int idx = 0;
for(int i = 0; i < n; i++) {
- // 根据题意,i为nums下标,是要在[i - k + 1, k] 中选到最大值,只需要保证两点
- // 1.队列头结点需要在[i - k + 1, k]范围内,不符合则要弹出
+ // 根据题意,i为nums下标,是要在[i - k + 1, i] 中选到最大值,只需要保证两点
+ // 1.队列头结点需要在[i - k + 1, i]范围内,不符合则要弹出
while(!deque.isEmpty() && deque.peek() < i - k + 1){
deque.poll();
}
From 1176b756a9b82c282c5aa05c539402f6805d9f85 Mon Sep 17 00:00:00 2001
From: X-shuffle <53906918+X-shuffle@users.noreply.github.com>
Date: Fri, 23 Jul 2021 10:55:16 +0800
Subject: [PATCH 04/27] =?UTF-8?q?=E5=A2=9E=E5=8A=A0=200376.=E6=91=86?=
=?UTF-8?q?=E5=8A=A8=E5=BA=8F=E5=88=97=20go=E7=89=88=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
增加 0376.摆动序列 go版本
---
problems/0376.摆动序列.md | 19 ++++++++++++++++++-
1 file changed, 18 insertions(+), 1 deletion(-)
diff --git a/problems/0376.摆动序列.md b/problems/0376.摆动序列.md
index 4d283eb0..f64e0043 100644
--- a/problems/0376.摆动序列.md
+++ b/problems/0376.摆动序列.md
@@ -151,7 +151,24 @@ class Solution:
```
Go:
-
+```golang
+func wiggleMaxLength(nums []int) int {
+ var count,preDiff,curDiff int
+ count=1
+ if len(nums)<2{
+ return count
+ }
+ for i:=0;i 0 && preDiff <= 0) || (preDiff >= 0 && curDiff < 0){
+ preDiff=curDiff
+ count++
+ }
+ }
+ return count
+}
+```
Javascript:
```Javascript
From 65363329f02cefb67909e781c326bffc7fe5b1eb Mon Sep 17 00:00:00 2001
From: X-shuffle <53906918+X-shuffle@users.noreply.github.com>
Date: Fri, 23 Jul 2021 14:00:03 +0800
Subject: [PATCH 05/27] =?UTF-8?q?=E5=A2=9E=E5=8A=A0=200122.=E4=B9=B0?=
=?UTF-8?q?=E5=8D=96=E8=82=A1=E7=A5=A8=E7=9A=84=E6=9C=80=E4=BD=B3=E6=97=B6?=
=?UTF-8?q?=E6=9C=BAII=20go=E7=89=88=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
增加 0122.买卖股票的最佳时机II go版本
---
.../0122.买卖股票的最佳时机II.md | 33 +++++++++++++++++++
1 file changed, 33 insertions(+)
diff --git a/problems/0122.买卖股票的最佳时机II.md b/problems/0122.买卖股票的最佳时机II.md
index 4b878aa0..60d4591f 100644
--- a/problems/0122.买卖股票的最佳时机II.md
+++ b/problems/0122.买卖股票的最佳时机II.md
@@ -188,7 +188,40 @@ class Solution:
```
Go:
+```golang
+//贪心算法
+func maxProfit(prices []int) int {
+ var sum int
+ for i := 1; i < len(prices); i++ {
+ // 累加每次大于0的交易
+ if prices[i]-prices[i-1] > 0 {
+ sum += prices[i]-prices[i-1]
+ }
+ }
+ return sum
+}
+```
+```golang
+//确定售卖点
+func maxProfit(prices []int) int {
+ var result,buy int
+ prices=append(prices,0)//在price末尾加个0,防止price一直递增
+ /**
+ 思路:检查后一个元素是否大于当前元素,如果小于,则表明这是一个售卖点,当前元素的值减去购买时候的值
+ 如果不小于,说明后面有更好的售卖点,
+ **/
+ for i:=0;iprices[i+1]{
+ result+=prices[i]-prices[buy]
+ buy=i+1
+ }else if prices[buy]>prices[i]{//更改最低购买点
+ buy=i
+ }
+ }
+ return result
+}
+```
Javascript:
```Javascript
From 7ae65550db141a1bb6f3e537d027d25b5b24b1d6 Mon Sep 17 00:00:00 2001
From: SwordsmanYao
Date: Fri, 23 Jul 2021 15:26:04 +0800
Subject: [PATCH 06/27] =?UTF-8?q?[=E5=89=91=E6=8C=87Offer05.=E6=9B=BF?=
=?UTF-8?q?=E6=8D=A2=E7=A9=BA=E6=A0=BC]=20=E6=B7=BB=E5=8A=A0=20javaScript?=
=?UTF-8?q?=20=E4=BB=A3=E7=A0=81?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/剑指Offer05.替换空格.md | 39 ++++++++++++++++++++++++++
1 file changed, 39 insertions(+)
diff --git a/problems/剑指Offer05.替换空格.md b/problems/剑指Offer05.替换空格.md
index 49c2c223..3e4e3631 100644
--- a/problems/剑指Offer05.替换空格.md
+++ b/problems/剑指Offer05.替换空格.md
@@ -245,6 +245,45 @@ class Solution(object):
```
+javaScript:
+```js
+/**
+ * @param {string} s
+ * @return {string}
+ */
+ var replaceSpace = function(s) {
+ // 字符串转为数组
+ const strArr = Array.from(s);
+ let count = 0;
+
+ // 计算空格数量
+ for(let i = 0; i < strArr.length; i++) {
+ if (strArr[i] === ' ') {
+ count++;
+ }
+ }
+
+ let left = strArr.length - 1;
+ let right = strArr.length + count * 2 - 1;
+
+ while(left >= 0) {
+ if (strArr[left] === ' ') {
+ strArr[right--] = '0';
+ strArr[right--] = '2';
+ strArr[right--] = '%';
+ left--;
+ } else {
+ strArr[right--] = strArr[left--];
+ }
+ }
+
+ // 数组转字符串
+ return strArr.join('');
+};
+```
+
+
+
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
From cd951923386f70662dd27f793008658433a0595e Mon Sep 17 00:00:00 2001
From: SwordsmanYao
Date: Fri, 23 Jul 2021 15:36:03 +0800
Subject: [PATCH 07/27] =?UTF-8?q?Update=200151.=E7=BF=BB=E8=BD=AC=E5=AD=97?=
=?UTF-8?q?=E7=AC=A6=E4=B8=B2=E9=87=8C=E7=9A=84=E5=8D=95=E8=AF=8D.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0151.翻转字符串里的单词.md | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index ffa3446a..4b1778c8 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -301,6 +301,7 @@ class Solution {
```
+Python
```Python3
class Solution:
#1.去除多余的空格
@@ -349,7 +350,7 @@ class Solution:
return ''.join(l) #输出:blue is sky the
-'''
+```
Go:
From dc8f9fbde59e6e891e047d1721ba8ecf1c3a6ff7 Mon Sep 17 00:00:00 2001
From: SwordsmanYao
Date: Fri, 23 Jul 2021 17:09:43 +0800
Subject: [PATCH 08/27] =?UTF-8?q?[0151.=E7=BF=BB=E8=BD=AC=E5=AD=97?=
=?UTF-8?q?=E7=AC=A6=E4=B8=B2=E9=87=8C=E7=9A=84=E5=8D=95=E8=AF=8D]=20?=
=?UTF-8?q?=E5=A2=9E=E5=8A=A0=20javaScript=20=E7=89=88=E6=9C=AC=E4=BB=A3?=
=?UTF-8?q?=E7=A0=81?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0151.翻转字符串里的单词.md | 59 ++++++++++++++++++++
1 file changed, 59 insertions(+)
diff --git a/problems/0151.翻转字符串里的单词.md b/problems/0151.翻转字符串里的单词.md
index ffa3446a..95222d2e 100644
--- a/problems/0151.翻转字符串里的单词.md
+++ b/problems/0151.翻转字符串里的单词.md
@@ -407,6 +407,65 @@ func reverse(b *[]byte, left, right int) {
+javaScript:
+```js
+/**
+ * @param {string} s
+ * @return {string}
+ */
+ var reverseWords = function(s) {
+ // 字符串转数组
+ const strArr = Array.from(s);
+ // 移除多余空格
+ removeExtraSpaces(strArr);
+ // 翻转
+ reverse(strArr, 0, strArr.length - 1);
+
+ let start = 0;
+
+ for(let i = 0; i <= strArr.length; i++) {
+ if (strArr[i] === ' ' || i === strArr.length) {
+ // 翻转单词
+ reverse(strArr, start, i - 1);
+ start = i + 1;
+ }
+ }
+
+ return strArr.join('');
+};
+
+// 删除多余空格
+function removeExtraSpaces(strArr) {
+ let slowIndex = 0;
+ let fastIndex = 0;
+
+ while(fastIndex < strArr.length) {
+ // 移除开始位置和重复的空格
+ if (strArr[fastIndex] === ' ' && (fastIndex === 0 || strArr[fastIndex - 1] === ' ')) {
+ fastIndex++;
+ } else {
+ strArr[slowIndex++] = strArr[fastIndex++];
+ }
+ }
+
+ // 移除末尾空格
+ strArr.length = strArr[slowIndex - 1] === ' ' ? slowIndex - 1 : slowIndex;
+}
+
+// 翻转从 start 到 end 的字符
+function reverse(strArr, start, end) {
+ let left = start;
+ let right = end;
+
+ while(left < right) {
+ // 交换
+ [strArr[left], strArr[right]] = [strArr[right], strArr[left]];
+ left++;
+ right--;
+ }
+}
+```
+
From 60f61199853b5de43994ecf482643a855cafb0ee Mon Sep 17 00:00:00 2001
From: kok-s0s <2694308562@qq.com>
Date: Fri, 23 Jul 2021 19:14:29 +0800
Subject: [PATCH 09/27] =?UTF-8?q?=E6=8F=90=E4=BE=9BJavaScript=E7=89=88?=
=?UTF-8?q?=E6=9C=AC=E7=9A=84=E3=80=8A=E5=B7=A6=E6=97=8B=E8=BD=AC=E5=AD=97?=
=?UTF-8?q?=E7=AC=A6=E4=B8=B2=E3=80=8B?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../剑指Offer58-II.左旋转字符串.md | 20 +++++++++++++++++++
1 file changed, 20 insertions(+)
diff --git a/problems/剑指Offer58-II.左旋转字符串.md b/problems/剑指Offer58-II.左旋转字符串.md
index 1701086e..1f57b4af 100644
--- a/problems/剑指Offer58-II.左旋转字符串.md
+++ b/problems/剑指Offer58-II.左旋转字符串.md
@@ -162,7 +162,27 @@ func reverse(b []byte, left, right int){
}
```
+JavaScript版本
+```javascript
+/**
+ * @param {string} s
+ * @param {number} n
+ * @return {string}
+ */
+var reverseLeftWords = function (s, n) {
+ const reverse = (str, left, right) => {
+ let strArr = str.split("");
+ for (; left < right; left++, right--) {
+ [strArr[left], strArr[right]] = [strArr[right], strArr[left]];
+ }
+ return strArr.join("");
+ }
+ s = reverse(s, 0, n - 1);
+ s = reverse(s, n, s.length - 1);
+ return reverse(s, 0, s.length - 1);
+};
+```
From 7b263b445d4ba5f7bc98f8b574cea17ebc1209b3 Mon Sep 17 00:00:00 2001
From: jojoo15 <75017412+jojoo15@users.noreply.github.com>
Date: Fri, 23 Jul 2021 23:13:36 +0200
Subject: [PATCH 10/27] =?UTF-8?q?=E6=B7=BB=E5=8A=A0=200042=E6=8E=A5?=
=?UTF-8?q?=E9=9B=A8=E6=B0=B4=20python3=E7=89=88=E6=9C=AC=20=E5=8F=8C?=
=?UTF-8?q?=E6=8C=87=E9=92=88=E6=B3=95?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
添加 0042接雨水 python3版本 双指针法
---
problems/0042.接雨水.md | 22 +++++++++++++++++++++-
1 file changed, 21 insertions(+), 1 deletion(-)
diff --git a/problems/0042.接雨水.md b/problems/0042.接雨水.md
index 55a5c522..33a90e4e 100644
--- a/problems/0042.接雨水.md
+++ b/problems/0042.接雨水.md
@@ -354,4 +354,24 @@ public:
## 其他语言版本
-
+python 版本
+双指针法
+```python3
+class Solution:
+ def trap(self, height: List[int]) -> int:
+ res = 0
+ for i in range(len(height)):
+ if i == 0 or i == len(height)-1: continue
+ lHight = height[i-1]
+ rHight = height[i+1]
+ for j in range(i-1):
+ if height[j] > lHight:
+ lHight = height[j]
+ for k in range(i+2,len(height)):
+ if height[k] > rHight:
+ rHight = height[k]
+ res1 = min(lHight,rHight) - height[i]
+ if res1 > 0:
+ res += res1
+ return res
+```
From b29529120be5d646700773824c43e9ace450dfd9 Mon Sep 17 00:00:00 2001
From: Andy <2311566266@qq.com>
Date: Mon, 26 Jul 2021 10:10:44 +0800
Subject: [PATCH 11/27] =?UTF-8?q?Update=200225.=E7=94=A8=E9=98=9F=E5=88=97?=
=?UTF-8?q?=E5=AE=9E=E7=8E=B0=E6=A0=88.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
fix typo.
---
problems/0225.用队列实现栈.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/problems/0225.用队列实现栈.md b/problems/0225.用队列实现栈.md
index 85b981e5..03c24132 100644
--- a/problems/0225.用队列实现栈.md
+++ b/problems/0225.用队列实现栈.md
@@ -38,7 +38,7 @@ https://leetcode-cn.com/problems/implement-stack-using-queues/
**队列模拟栈,其实一个队列就够了**,那么我们先说一说两个队列来实现栈的思路。
-**队列是先进先出的规则,把一个队列中的数据导入另一个队列中,数据的顺序并没有变,并有变成先进后出的顺序。**
+**队列是先进先出的规则,把一个队列中的数据导入另一个队列中,数据的顺序并没有变,并没有变成先进后出的顺序。**
所以用栈实现队列, 和用队列实现栈的思路还是不一样的,这取决于这两个数据结构的性质。
From f1b862c8144c5fa23c7728c1e6e9b34de695f119 Mon Sep 17 00:00:00 2001
From: youngyangyang04 <826123027@qq.com>
Date: Mon, 26 Jul 2021 11:18:29 +0800
Subject: [PATCH 12/27] Update
---
problems/0042.接雨水.md | 8 +
problems/0101.对称二叉树.md | 56 ++---
problems/0104.二叉树的最大深度.md | 68 +++++-
.../0129.求根到叶子节点数字之和.md | 16 +-
...65.有多少小于当前数字的数字.md | 146 ++++++++++++
problems/前序/程序员简历.md | 1 -
.../20200927二叉树周末总结.md | 56 ++---
.../二叉树阶段总结系列一.md | 209 ++++++++++++++++++
problems/背包理论基础01背包-1.md | 2 +-
problems/背包理论基础01背包-2.md | 2 +-
10 files changed, 490 insertions(+), 74 deletions(-)
create mode 100644 problems/1365.有多少小于当前数字的数字.md
create mode 100644 problems/周总结/二叉树阶段总结系列一.md
diff --git a/problems/0042.接雨水.md b/problems/0042.接雨水.md
index 70a4e07c..b0af2c26 100644
--- a/problems/0042.接雨水.md
+++ b/problems/0042.接雨水.md
@@ -364,6 +364,14 @@ public:
## 其他语言版本
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
diff --git a/problems/0101.对称二叉树.md b/problems/0101.对称二叉树.md
index 9717588a..241564e9 100644
--- a/problems/0101.对称二叉树.md
+++ b/problems/0101.对称二叉树.md
@@ -7,7 +7,7 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 101. 对称二叉树
+# 101. 对称二叉树
题目地址:https://leetcode-cn.com/problems/symmetric-tree/
@@ -15,7 +15,7 @@

-## 思路
+# 思路
**首先想清楚,判断对称二叉树要比较的是哪两个节点,要比较的可不是左右节点!**
@@ -73,7 +73,7 @@ bool compare(TreeNode* left, TreeNode* right)
此时左右节点不为空,且数值也不相同的情况我们也处理了。
代码如下:
-```
+```C++
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
@@ -84,7 +84,7 @@ else if (left->val != right->val) return false; // 注意这里我没有
3. 确定单层递归的逻辑
-此时才进入单层递归的逻辑,单层递归的逻辑就是处理 右节点都不为空,且数值相同的情况。
+此时才进入单层递归的逻辑,单层递归的逻辑就是处理 左右节点都不为空,且数值相同的情况。
* 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
@@ -93,7 +93,7 @@ else if (left->val != right->val) return false; // 注意这里我没有
代码如下:
-```
+```C++
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
bool isSame = outside && inside; // 左子树:中、 右子树:中(逻辑处理)
@@ -104,7 +104,7 @@ return isSame;
最后递归的C++整体代码如下:
-```
+```C++
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
@@ -137,7 +137,7 @@ public:
**盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。**
当然我可以把如上代码整理如下:
-```
+```C++
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
@@ -177,7 +177,7 @@ public:
代码如下:
-```
+```C++
class Solution {
public:
bool isSymmetric(TreeNode* root) {
@@ -212,7 +212,7 @@ public:
只要把队列原封不动的改成栈就可以了,我下面也给出了代码。
-```
+```C++
class Solution {
public:
bool isSymmetric(TreeNode* root) {
@@ -239,7 +239,7 @@ public:
};
```
-## 总结
+# 总结
这次我们又深度剖析了一道二叉树的“简单题”,大家会发现,真正的把题目搞清楚其实并不简单,leetcode上accept了和真正掌握了还是有距离的。
@@ -249,11 +249,14 @@ public:
如果已经做过这道题目的同学,读完文章可以再去看看这道题目,思考一下,会有不一样的发现!
+# 相关题目推荐
+* 100.相同的树
+* 572.另一个树的子树
-## 其他语言版本
+# 其他语言版本
-Java:
+## Java
```Java
/**
@@ -358,9 +361,9 @@ Java:
```
-Python:
+## Python
-> 递归法
+递归法:
```python
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
@@ -384,7 +387,7 @@ class Solution:
return isSame
```
-> 迭代法: 使用队列
+迭代法: 使用队列
```python
import collections
class Solution:
@@ -410,7 +413,7 @@ class Solution:
return True
```
-> 迭代法:使用栈
+迭代法:使用栈
```python
class Solution:
def isSymmetric(self, root: TreeNode) -> bool:
@@ -433,7 +436,7 @@ class Solution:
return True
```
-Go:
+## Go
```go
/**
@@ -484,22 +487,7 @@ func isSymmetric(root *TreeNode) bool {
```
-JavaScript
-```javascript
-var isSymmetric = function(root) {
- return check(root, root)
-};
-
-const check = (leftPtr, rightPtr) => {
- // 如果只有根节点,返回true
- if (!leftPtr && !rightPtr) return true
- // 如果左右节点只存在一个,则返回false
- if (!leftPtr || !rightPtr) return false
-
- return leftPtr.val === rightPtr.val && check(leftPtr.left, rightPtr.right) && check(leftPtr.right, rightPtr.left)
-}
-```
-JavaScript:
+## JavaScript
递归判断是否为对称二叉树:
```javascript
@@ -526,6 +514,7 @@ var isSymmetric = function(root) {
return compareNode(root.left,root.right);
};
```
+
队列实现迭代判断是否为对称二叉树:
```javascript
var isSymmetric = function(root) {
@@ -554,6 +543,7 @@ var isSymmetric = function(root) {
return true;
};
```
+
栈实现迭代判断是否为对称二叉树:
```javascript
var isSymmetric = function(root) {
diff --git a/problems/0104.二叉树的最大深度.md b/problems/0104.二叉树的最大深度.md
index 463b55d9..218a966c 100644
--- a/problems/0104.二叉树的最大深度.md
+++ b/problems/0104.二叉树的最大深度.md
@@ -30,9 +30,13 @@
### 递归法
-本题其实也要后序遍历(左右中),依然是因为要通过递归函数的返回值做计算树的高度。
+本题可以使用前序(中左右),也可以使用后序遍历(左右中),使用前序求的就是深度,使用后序求的是高度。
-按照递归三部曲,来看看如何来写。
+**而根节点的高度就是二叉树的最大深度**,所以本题中我们通过后序求的根节点高度来求的二叉树最大深度。
+
+这一点其实是很多同学没有想清楚的,很多题解同样没有讲清楚。
+
+我先用后序遍历(左右中)来计算树的高度。
1. 确定递归函数的参数和返回值:参数就是传入树的根节点,返回就返回这棵树的深度,所以返回值为int类型。
@@ -92,6 +96,66 @@ public:
**精简之后的代码根本看不出是哪种遍历方式,也看不出递归三部曲的步骤,所以如果对二叉树的操作还不熟练,尽量不要直接照着精简代码来学。**
+本题当然也可以使用前序,代码如下:(**充分表现出求深度回溯的过程**)
+
+```C++
+class Solution {
+public:
+ int result;
+ void getDepth(TreeNode* node, int depth) {
+ result = depth > result ? depth : result; // 中
+
+ if (node->left == NULL && node->right == NULL) return ;
+
+ if (node->left) { // 左
+ depth++; // 深度+1
+ getDepth(node->left, depth);
+ depth--; // 回溯,深度-1
+ }
+ if (node->right) { // 右
+ depth++; // 深度+1
+ getDepth(node->right, depth);
+ depth--; // 回溯,深度-1
+ }
+ return ;
+ }
+ int maxDepth(TreeNode* root) {
+ result = 0;
+ if (root == 0) return result;
+ getDepth(root, 1);
+ return result;
+ }
+};
+```
+
+**可以看出使用了前序(中左右)的遍历顺序,这才是真正求深度的逻辑!**
+
+注意以上代码是为了把细节体现出来,简化一下代码如下:
+
+```C++
+class Solution {
+public:
+ int result;
+ void getDepth(TreeNode* node, int depth) {
+ result = depth > result ? depth : result; // 中
+ if (node->left == NULL && node->right == NULL) return ;
+ if (node->left) { // 左
+ getDepth(node->left, depth + 1);
+ }
+ if (node->right) { // 右
+ getDepth(node->right, depth + 1);
+ }
+ return ;
+ }
+ int maxDepth(TreeNode* root) {
+ result = 0;
+ if (root == 0) return result;
+ getDepth(root, 1);
+ return result;
+ }
+};
+```
+
### 迭代法
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
diff --git a/problems/0129.求根到叶子节点数字之和.md b/problems/0129.求根到叶子节点数字之和.md
index a54ebf59..f8c93382 100644
--- a/problems/0129.求根到叶子节点数字之和.md
+++ b/problems/0129.求根到叶子节点数字之和.md
@@ -1,10 +1,9 @@
-
-## 链接
+## 链接
https://leetcode-cn.com/problems/sum-root-to-leaf-numbers/
## 思路
-本题和[113.路径总和II](https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0113.%E8%B7%AF%E5%BE%84%E6%80%BB%E5%92%8CII.md)是类似的思路,做完这道题,可以顺便把[113.路径总和II](https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0113.%E8%B7%AF%E5%BE%84%E6%80%BB%E5%92%8CII.md) 和 [112.路径总和](https://github.com/youngyangyang04/leetcode/blob/master/problems/0112.路径总和.md) 做了。
+本题和[113.路径总和II](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg)是类似的思路,做完这道题,可以顺便把[113.路径总和II](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg) 和 [112.路径总和](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg) 做了。
结合112.路径总和 和 113.路径总和II,我在讲了[二叉树:递归函数究竟什么时候需要返回值,什么时候不要返回值?](https://mp.weixin.qq.com/s/6TWAVjxQ34kVqROWgcRFOg),如果大家对二叉树递归函数什么时候需要返回值很迷茫,可以看一下。
@@ -26,19 +25,19 @@ https://leetcode-cn.com/problems/sum-root-to-leaf-numbers/
参数只需要把根节点传入,此时还需要定义两个全局遍历,一个是result,记录最终结果,一个是vector path。
-**为什么用vector类型(就是数组)呢? 因为用vector方便我们做回溯!**
+**为什么用vector类型(就是数组)呢? 因为用vector方便我们做回溯!**
所以代码如下:
```
int result;
vector path;
-void traversal(TreeNode* cur)
+void traversal(TreeNode* cur)
```
-* 确定终止条件
+* 确定终止条件
-递归什么时候终止呢?
+递归什么时候终止呢?
当然是遇到叶子节点,此时要收集结果了,通知返回本层递归,因为单条路径的结果使用vector,我们需要一个函数vectorToInt把vector转成int。
@@ -154,12 +153,13 @@ public:
};
```
-## 总结
+# 总结
过于简洁的代码,很容易让初学者忽视了本题中回溯的精髓,甚至作者本身都没有想清楚自己用了回溯。
**我这里提供的代码把整个回溯过程充分体现出来,希望可以帮助大家看的明明白白!**
+
## 其他语言版本
Java:
diff --git a/problems/1365.有多少小于当前数字的数字.md b/problems/1365.有多少小于当前数字的数字.md
new file mode 100644
index 00000000..3026dfca
--- /dev/null
+++ b/problems/1365.有多少小于当前数字的数字.md
@@ -0,0 +1,146 @@
+
+
+
+# 1365.有多少小于当前数字的数字
+
+题目链接:https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
+
+给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
+
+换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。
+
+以数组形式返回答案。
+
+
+示例 1:
+* 输入:nums = [8,1,2,2,3]
+* 输出:[4,0,1,1,3]
+* 解释:
+对于 nums[0]=8 存在四个比它小的数字:(1,2,2 和 3)。
+对于 nums[1]=1 不存在比它小的数字。
+对于 nums[2]=2 存在一个比它小的数字:(1)。
+对于 nums[3]=2 存在一个比它小的数字:(1)。
+对于 nums[4]=3 存在三个比它小的数字:(1,2 和 2)。
+
+示例 2:
+* 输入:nums = [6,5,4,8]
+* 输出:[2,1,0,3]
+
+示例 3:
+* 输入:nums = [7,7,7,7]
+* 输出:[0,0,0,0]
+
+提示:
+* 2 <= nums.length <= 500
+* 0 <= nums[i] <= 100
+
+# 思路
+
+两层for循环暴力查找,时间复杂度明显为O(n^2)。
+
+那么我们来看一下如何优化。
+
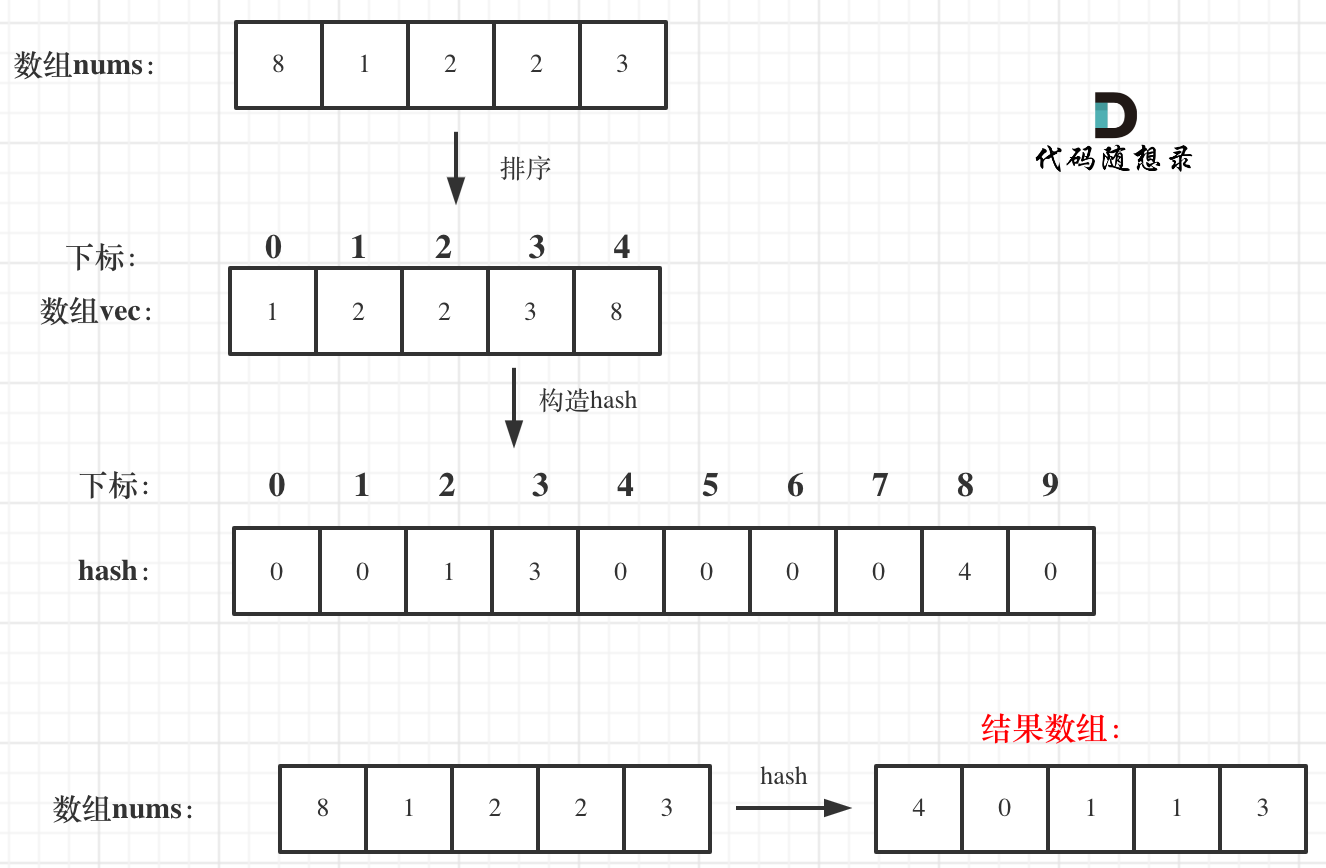
+首先要找小于当前数字的数字,那么从小到大排序之后,该数字之前的数字就都是比它小的了。
+
+所以可以定义一个新数组,将数组排个序。
+
+**排序之后,其实每一个数值的下标就代表这前面有几个比它小的了**。
+
+代码如下:
+
+```
+vector vec = nums;
+sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+```
+
+用一个哈希表hash(本题可以就用一个数组)来做数值和下标的映射。这样就可以通过数值快速知道下标(也就是前面有几个比它小的)。
+
+此时有一个情况,就是数值相同怎么办?
+
+例如,数组:1 2 3 4 4 4 ,第一个数值4的下标是3,第二个数值4的下标是4了。
+
+这里就需要一个技巧了,**在构造数组hash的时候,从后向前遍历,这样hash里存放的就是相同元素最左面的数值和下标了**。
+代码如下:
+
+```C++
+int hash[101];
+for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+}
+```
+
+最后在遍历原数组nums,用hash快速找到每一个数值 对应的 小于这个数值的个数。存放在将结果存放在另一个数组中。
+
+代码如下:
+
+```C++
+// 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+}
+```
+
+流程如图:
+
+ +
+关键地方讲完了,整体C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector smallerNumbersThanCurrent(vector& nums) {
+ vector vec = nums;
+ sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+ int hash[101];
+ for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+ }
+ // 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+ for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+ }
+ return vec;
+ }
+};
+```
+
+可以排序之后加哈希,时间复杂度为O(nlogn)
+
+
+# 其他语言版本
+
+Java:
+
+```Java
+public int[] smallerNumbersThanCurrent(int[] nums) {
+ Map map = new HashMap<>(); // 记录数字 nums[i] 有多少个比它小的数字
+ int[] res = Arrays.copyOf(nums, nums.length);
+ Arrays.sort(res);
+ for (int i = 0; i < res.length; i++) {
+ if (!map.containsKey(res[i])) { // 遇到了相同的数字,那么不需要更新该 number 的情况
+ map.put(res[i], i);
+ }
+ }
+
+ for (int i = 0; i < nums.length; i++) {
+ res[i] = map.get(nums[i]);
+ }
+
+ return res;
+ }
+```
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+关键地方讲完了,整体C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector smallerNumbersThanCurrent(vector& nums) {
+ vector vec = nums;
+ sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+ int hash[101];
+ for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+ }
+ // 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+ for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+ }
+ return vec;
+ }
+};
+```
+
+可以排序之后加哈希,时间复杂度为O(nlogn)
+
+
+# 其他语言版本
+
+Java:
+
+```Java
+public int[] smallerNumbersThanCurrent(int[] nums) {
+ Map map = new HashMap<>(); // 记录数字 nums[i] 有多少个比它小的数字
+ int[] res = Arrays.copyOf(nums, nums.length);
+ Arrays.sort(res);
+ for (int i = 0; i < res.length; i++) {
+ if (!map.containsKey(res[i])) { // 遇到了相同的数字,那么不需要更新该 number 的情况
+ map.put(res[i], i);
+ }
+ }
+
+ for (int i = 0; i < nums.length; i++) {
+ res[i] = map.get(nums[i]);
+ }
+
+ return res;
+ }
+```
+
+Python:
+
+Go:
+
+JavaScript:
+
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
diff --git a/problems/前序/程序员简历.md b/problems/前序/程序员简历.md
index f9a226df..a9abcdc4 100644
--- a/problems/前序/程序员简历.md
+++ b/problems/前序/程序员简历.md
@@ -10,7 +10,6 @@
# 程序员的简历应该这么写!!(附简历模板)
-> Carl多年积累的简历技巧都在这里了
Carl校招社招都拿过大厂的offer,同时也看过很多应聘者的简历,这里把自己总结的简历技巧以及常见问题给大家梳理一下。
diff --git a/problems/周总结/20200927二叉树周末总结.md b/problems/周总结/20200927二叉树周末总结.md
index f983a929..a6d73c01 100644
--- a/problems/周总结/20200927二叉树周末总结.md
+++ b/problems/周总结/20200927二叉树周末总结.md
@@ -13,7 +13,7 @@
对于二叉树节点的定义,C++代码如下:
-```
+```C++
struct TreeNode {
int val;
TreeNode *left;
@@ -35,7 +35,7 @@ TreeNode* a = new TreeNode(9);
没有构造函数的话就要这么写:
-```
+```C++
TreeNode* a = new TreeNode();
a->val = 9;
a->left = NULL;
@@ -60,11 +60,35 @@ morris遍历是二叉树遍历算法的超强进阶算法,morris遍历可以
在[二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/c_zCrGHIVlBjUH_hJtghCg)中我们开始用栈来实现递归的写法,也就是所谓的迭代法。
-细心的同学发现文中前后序遍历空节点是入栈的,其实空节点入不入栈都差不多,但感觉空节点不入栈确实清晰一些,符合文中动画的演示。
+细心的同学发现文中前后序遍历空节点是否入栈写法是不同的
-前序遍历空节点不入栈的代码:(注意注释部分,和文章中的区别)
+其实空节点入不入栈都差不多,但感觉空节点不入栈确实清晰一些,符合文中动画的演示。
+拿前序遍历来举例,空节点入栈:
+
+```C++
+class Solution {
+public:
+ vector preorderTraversal(TreeNode* root) {
+ stack st;
+ vector result;
+ st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top(); // 中
+ st.pop();
+ if (node != NULL) result.push_back(node->val);
+ else continue;
+ st.push(node->right); // 右
+ st.push(node->left); // 左
+ }
+ return result;
+ }
+};
```
+
+前序遍历空节点不入栈的代码:(注意注释部分和上文的区别)
+
+```C++
class Solution {
public:
vector preorderTraversal(TreeNode* root) {
@@ -82,32 +106,8 @@ public:
return result;
}
};
-
```
-后序遍历空节点不入栈的代码:(注意注释部分,和文章中的区别)
-
-```
-class Solution {
-public:
- vector postorderTraversal(TreeNode* root) {
- stack st;
- vector result;
- if (root == NULL) return result;
- st.push(root);
- while (!st.empty()) {
- TreeNode* node = st.top();
- st.pop();
- result.push_back(node->val);
- if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
- if (node->right) st.push(node->right); // 空节点不入栈
- }
- reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
- return result;
- }
-};
-
-```
在实现迭代法的过程中,有同学问了:递归与迭代究竟谁优谁劣呢?
diff --git a/problems/周总结/二叉树阶段总结系列一.md b/problems/周总结/二叉树阶段总结系列一.md
new file mode 100644
index 00000000..1527e9a1
--- /dev/null
+++ b/problems/周总结/二叉树阶段总结系列一.md
@@ -0,0 +1,209 @@
+# 本周小结!(二叉树)
+
+**周日我做一个针对本周的打卡留言疑问以及在刷题群里的讨论内容做一下梳理吧。**,这样也有助于大家补一补本周的内容,消化消化。
+
+**注意这个周末总结和系列总结还是不一样的(二叉树还远没有结束),这个总结是针对留言疑问以及刷题群里讨论内容的归纳。**
+
+1. [关于二叉树,你该了解这些!](https://mp.weixin.qq.com/s/q_eKfL8vmSbSFcptZ3aeRA)
+2. [二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)
+3. [二叉树:听说递归能做的,栈也能做!](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)
+4. [二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/ATQMPCpBlaAgrqdLDMVPZA)
+5. [二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)
+6. [二叉树:你真的会翻转二叉树么?](https://mp.weixin.qq.com/s/jG0MgYR9DoUMYcRRF7magw)
+
+
+## [关于二叉树,你该了解这些!](https://mp.weixin.qq.com/s/q_eKfL8vmSbSFcptZ3aeRA)
+
+有同学会把红黑树和二叉平衡搜索树弄分开了,其实红黑树就是一种二叉平衡搜索树,这两个树不是独立的,所以C++中map、multimap、set、multiset的底层实现机制是二叉平衡搜索树,再具体一点是红黑树。
+
+对于二叉树节点的定义,C++代码如下:
+
+```C++
+struct TreeNode {
+ int val;
+ TreeNode *left;
+ TreeNode *right;
+ TreeNode(int x) : val(x), left(NULL), right(NULL) {}
+};
+```
+对于这个定义中`TreeNode(int x) : val(x), left(NULL), right(NULL) {}` 有同学不清楚干什么的。
+
+这是构造函数,这么说吧C语言中的结构体是C++中类的祖先,所以C++结构体也可以有构造函数。
+
+构造函数也可以不写,但是new一个新的节点的时候就比较麻烦。
+
+例如有构造函数,定义初始值为9的节点:
+
+```
+TreeNode* a = new TreeNode(9);
+```
+
+没有构造函数的话就要这么写:
+
+```C++
+TreeNode* a = new TreeNode();
+a->val = 9;
+a->left = NULL;
+a->right = NULL;
+```
+
+在介绍前中后序遍历的时候,有递归和迭代(非递归),还有一种牛逼的遍历方式:morris遍历。
+
+morris遍历是二叉树遍历算法的超强进阶算法,morris遍历可以将非递归遍历中的空间复杂度降为O(1),感兴趣大家就去查一查学习学习,比较小众,面试几乎不会考。我其实也没有研究过,就不做过多介绍了。
+
+## [二叉树的递归遍历](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)
+
+在[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA)中讲到了递归三要素,以及前中后序的递归写法。
+
+文章中我给出了leetcode上三道二叉树的前中后序题目,但是看完[二叉树:一入递归深似海,从此offer是路人](https://mp.weixin.qq.com/s/Ww60X5mIKWdMQV4cN3ejOA),依然可以解决n叉树的前后序遍历,在leetcode上分别是
+
+* 589. N叉树的前序遍历
+* 590. N叉树的后序遍历
+
+大家可以再去把这两道题目做了。
+
+## [二叉树的非递归遍历](https://mp.weixin.qq.com/s/OH7aCVJ5-Gi32PkNCoZk4A)
+
+细心的同学发现文中前后序遍历空节点是入栈的,其实空节点入不入栈都差不多,但感觉空节点不入栈确实清晰一些,符合文中动画的演示。
+
+前序遍历空节点不入栈的代码:(注意注释部分,和文章中的区别)
+
+```C++
+class Solution {
+public:
+ vector preorderTraversal(TreeNode* root) {
+ stack st;
+ vector result;
+ if (root == NULL) return result;
+ st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top(); // 中
+ st.pop();
+ result.push_back(node->val);
+ if (node->right) st.push(node->right); // 右(空节点不入栈)
+ if (node->left) st.push(node->left); // 左(空节点不入栈)
+ }
+ return result;
+ }
+};
+
+```
+
+后序遍历空节点不入栈的代码:(注意注释部分,和文章中的区别)
+
+```C++
+class Solution {
+public:
+ vector postorderTraversal(TreeNode* root) {
+ stack st;
+ vector result;
+ if (root == NULL) return result;
+ st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top();
+ st.pop();
+ result.push_back(node->val);
+ if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
+ if (node->right) st.push(node->right); // 空节点不入栈
+ }
+ reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
+ return result;
+ }
+};
+
+```
+
+在实现迭代法的过程中,有同学问了:递归与迭代究竟谁优谁劣呢?
+
+从时间复杂度上其实迭代法和递归法差不多(在不考虑函数调用开销和函数调用产生的堆栈开销),但是空间复杂度上,递归开销会大一些,因为递归需要系统堆栈存参数返回值等等。
+
+递归更容易让程序员理解,但收敛不好,容易栈溢出。
+
+这么说吧,递归是方便了程序员,难为了机器(各种保存参数,各种进栈出栈)。
+
+**在实际项目开发的过程中我们是要尽量避免递归!因为项目代码参数、调用关系都比较复杂,不容易控制递归深度,甚至会栈溢出。**
+
+## 周四
+
+在[二叉树:前中后序迭代方式的写法就不能统一一下么?](https://mp.weixin.qq.com/s/WKg0Ty1_3SZkztpHubZPRg)中我们使用空节点作为标记,给出了统一的前中后序迭代法。
+
+此时又多了一种前中后序的迭代写法,那么有同学问了:前中后序迭代法是不是一定要统一来写,这样才算是规范。
+
+其实没必要,还是自己感觉哪一种更好记就用哪种。
+
+但是**一定要掌握前中后序一种迭代的写法,并不因为某种场景的题目一定要用迭代,而是现场面试的时候,面试官看你顺畅的写出了递归,一般会进一步考察能不能写出相应的迭代。**
+
+## 周五
+
+在[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/Gb3BjakIKGNpup2jYtTzog)中我们介绍了二叉树的另一种遍历方式(图论中广度优先搜索在二叉树上的应用)即:层序遍历。
+
+看完这篇文章,去leetcode上怒刷五题,文章中 编号107题目的样例图放错了(原谅我匆忙之间总是手抖),但不影响大家理解。
+
+只有同学发现leetcode上“515. 在每个树行中找最大值”,也是层序遍历的应用,依然可以分分钟解决,所以就是一鼓作气解决六道了,哈哈。
+
+**层序遍历遍历相对容易一些,只要掌握基本写法(也就是框架模板),剩下的就是在二叉树每一行遍历的时候做做逻辑修改。**
+
+## 周六
+
+在[二叉树:你真的会翻转二叉树么?](https://mp.weixin.qq.com/s/6gY1MiXrnm-khAAJiIb5Bg)中我们把翻转二叉树这么一道简单又经典的问题,充分的剖析了一波,相信就算做过这道题目的同学,看完本篇之后依然有所收获!
+
+
+**文中我指的是递归的中序遍历是不行的,因为使用递归的中序遍历,某些节点的左右孩子会翻转两次。**
+
+如果非要使用递归中序的方式写,也可以,如下代码就可以避免节点左右孩子翻转两次的情况:
+
+```
+class Solution {
+public:
+ TreeNode* invertTree(TreeNode* root) {
+ if (root == NULL) return root;
+ invertTree(root->left); // 左
+ swap(root->left, root->right); // 中
+ invertTree(root->left); // 注意 这里依然要遍历左孩子,因为中间节点已经翻转了
+ return root;
+ }
+};
+```
+
+代码虽然可以,但这毕竟不是真正的递归中序遍历了。
+
+但使用迭代方式统一写法的中序是可以的。
+
+代码如下:
+
+```
+class Solution {
+public:
+ TreeNode* invertTree(TreeNode* root) {
+ stack st;
+ if (root != NULL) st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top();
+ if (node != NULL) {
+ st.pop();
+ if (node->right) st.push(node->right); // 右
+ st.push(node); // 中
+ st.push(NULL);
+ if (node->left) st.push(node->left); // 左
+
+ } else {
+ st.pop();
+ node = st.top();
+ st.pop();
+ swap(node->left, node->right); // 节点处理逻辑
+ }
+ }
+ return root;
+ }
+};
+
+
+```
+
+为什么这个中序就是可以的呢,因为这是用栈来遍历,而不是靠指针来遍历,避免了递归法中翻转了两次的情况,大家可以画图理解一下,这里有点意思的。
+
+## 总结
+
+**本周我们都是讲解了二叉树,从理论基础到遍历方式,从递归到迭代,从深度遍历到广度遍历,最后再用了一个翻转二叉树的题目把我们之前讲过的遍历方式都串了起来。**
+
+
diff --git a/problems/背包理论基础01背包-1.md b/problems/背包理论基础01背包-1.md
index 0d376c92..3f603366 100644
--- a/problems/背包理论基础01背包-1.md
+++ b/problems/背包理论基础01背包-1.md
@@ -190,7 +190,7 @@ for(int j = 0; j <= bagWeight; j++) { // 遍历背包容量
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]); 递归公式中可以看出dp[i][j]是靠dp[i-1][j]和dp[i - 1][j - weight[i]]推导出来的。
-dp[i-1][j]和dp[i - 1][j - weight[i]] 都在dp[i][j]的左上角方向(包括正左和正上两个方向),那么先遍历物品,再遍历背包的过程如图所示:
+dp[i-1][j]和dp[i - 1][j - weight[i]] 都在dp[i][j]的左上角方向(包括正上方向),那么先遍历物品,再遍历背包的过程如图所示:
diff --git a/problems/背包理论基础01背包-2.md b/problems/背包理论基础01背包-2.md
index 36856cd6..ee2fb6d7 100644
--- a/problems/背包理论基础01背包-2.md
+++ b/problems/背包理论基础01背包-2.md
@@ -80,7 +80,7 @@ dp[j]表示:容量为j的背包,所背的物品价值可以最大为dp[j],
看一下递归公式:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
-dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了,如果题目给的价值有负数,那么非0下标就要初始化为负无穷。
+dp数组在推导的时候一定是取价值最大的数,如果题目给的价值都是正整数那么非0下标都初始化为0就可以了。
**这样才能让dp数组在递归公式的过程中取的最大的价值,而不是被初始值覆盖了**。
From c08686cc6b26fdd92bb4726080edd0a4ee1e434e Mon Sep 17 00:00:00 2001
From: X-shuffle <53906918+X-shuffle@users.noreply.github.com>
Date: Tue, 27 Jul 2021 10:48:11 +0800
Subject: [PATCH 13/27] =?UTF-8?q?=E6=B7=BB=E5=8A=A0=200135.=E5=88=86?=
=?UTF-8?q?=E5=8F=91=E7=B3=96=E6=9E=9C=20GO=E7=89=88=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
添加 0135.分发糖果 GO版本
---
problems/0135.分发糖果.md | 38 ++++++++++++++++++++++++++++++++++-
1 file changed, 37 insertions(+), 1 deletion(-)
diff --git a/problems/0135.分发糖果.md b/problems/0135.分发糖果.md
index fd791277..2d3fca84 100644
--- a/problems/0135.分发糖果.md
+++ b/problems/0135.分发糖果.md
@@ -175,7 +175,43 @@ class Solution:
```
Go:
-
+```golang
+func candy(ratings []int) int {
+ /**先确定一边,再确定另外一边
+ 1.先从左到右,当右边的大于左边的就加1
+ 2.再从右到左,当左边的大于右边的就再加1
+ **/
+ need:=make([]int,len(ratings))
+ sum:=0
+ //初始化(每个人至少一个糖果)
+ for i:=0;i0;i--{
+ if ratings[i-1]>ratings[i]{
+ need[i-1]=findMax(need[i-1],need[i]+1)
+ }
+ }
+ //计算总共糖果
+ for i:=0;inum2{
+ return num1
+ }
+ return num2
+}
+```
Javascript:
```Javascript
var candy = function(ratings) {
From 600f82d9166a5b1a3adb3fa84a4421a979fafec7 Mon Sep 17 00:00:00 2001
From: X-shuffle <53906918+X-shuffle@users.noreply.github.com>
Date: Tue, 27 Jul 2021 13:07:18 +0800
Subject: [PATCH 14/27] =?UTF-8?q?=E6=B7=BB=E5=8A=A0=200860.=E6=9F=A0?=
=?UTF-8?q?=E6=AA=AC=E6=B0=B4=E6=89=BE=E9=9B=B6=20GO=E7=89=88=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
添加 0860.柠檬水找零 GO版本
---
problems/0860.柠檬水找零.md | 39 ++++++++++++++++++++++++++++++++
1 file changed, 39 insertions(+)
diff --git a/problems/0860.柠檬水找零.md b/problems/0860.柠檬水找零.md
index a18c008d..0d5a7075 100644
--- a/problems/0860.柠檬水找零.md
+++ b/problems/0860.柠檬水找零.md
@@ -183,6 +183,45 @@ class Solution:
Go:
+```golang
+func lemonadeChange(bills []int) bool {
+ //left表示还剩多少 下表0位5元的个数 ,下表1为10元的个数
+ left:=[2]int{0,0}
+ //第一个元素不为5,直接退出
+ if bills[0]!=5{
+ return false
+ }
+ for i:=0;i0{
+ left[0]-=1
+ }else {
+ return false
+ }
+ }
+ if tmp==15{
+ if left[1]>0&&left[0]>0{
+ left[0]-=1
+ left[1]-=1
+ }else if left[1]==0&&left[0]>2{
+ left[0]-=3
+ }else{
+ return false
+ }
+ }
+ }
+ return true
+}
+```
Javascript:
```Javascript
From 45e996805b4ce94676abb1d5a2e43098403a6a6c Mon Sep 17 00:00:00 2001
From: SwordsmanYao
Date: Tue, 27 Jul 2021 16:44:04 +0800
Subject: [PATCH 15/27] =?UTF-8?q?[=E5=89=91=E6=8C=87Offer58-II.=E5=B7=A6?=
=?UTF-8?q?=E6=97=8B=E8=BD=AC=E5=AD=97=E7=AC=A6=E4=B8=B2]=20=E6=B7=BB?=
=?UTF-8?q?=E5=8A=A0js=E7=89=88=E6=9C=AC=E4=BB=A3=E7=A0=81?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../剑指Offer58-II.左旋转字符串.md | 31 +++++++++++++++++++
1 file changed, 31 insertions(+)
diff --git a/problems/剑指Offer58-II.左旋转字符串.md b/problems/剑指Offer58-II.左旋转字符串.md
index 3c3eaef0..8a60252c 100644
--- a/problems/剑指Offer58-II.左旋转字符串.md
+++ b/problems/剑指Offer58-II.左旋转字符串.md
@@ -165,6 +165,37 @@ func reverse(b []byte, left, right int){
```
+javaScript:
+
+```js
+/**
+ * @param {string} s
+ * @param {number} n
+ * @return {string}
+ */
+ var reverseLeftWords = function(s, n) {
+ const strArr = Array.from(s);
+ reverse(strArr, 0, n - 1);
+ reverse(strArr, n, strArr.length - 1);
+ reverse(strArr, 0, strArr.length - 1);
+ return strArr.join('');
+};
+
+// 翻转从 start 到 end 的字符
+function reverse(strArr, start, end) {
+ let left = start;
+ let right = end;
+
+ while(left < right) {
+ // 交换
+ [strArr[left], strArr[right]] = [strArr[right], strArr[left]];
+ left++;
+ right--;
+ }
+}
+```
+
+
From 1c601fe7223a3669635d43dfdf20b3a88d66e788 Mon Sep 17 00:00:00 2001
From: youngyangyang04 <826123027@qq.com>
Date: Tue, 27 Jul 2021 17:47:31 +0800
Subject: [PATCH 16/27] Update
---
README.md | 65 +++-
problems/0005.最长回文子串.md | 291 ++++++++++++++++++
problems/0031.下一个排列.md | 124 ++++++++
...元素的第一个和最后一个位置.md | 199 ++++++++++++
problems/0100.相同的树.md | 186 +++++++++++
...个节点的下一个右侧节点指针.md | 155 ++++++++++
problems/0132.分割回文串II.md | 256 +++++++++++++++
problems/0139.单词拆分.md | 3 +-
problems/0141.环形链表.md | 109 +++++++
problems/0143.重排链表.md | 190 ++++++++++++
problems/0189.旋转数组.md | 142 +++++++++
problems/0205.同构字符串.md | 93 ++++++
problems/0226.翻转二叉树.md | 55 ++++
problems/0234.回文链表.md | 170 ++++++++++
problems/0283.移动零.md | 89 ++++++
problems/0649.Dota2参议院.md | 140 +++++++++
problems/0657.机器人能否返回原点.md | 96 ++++++
.../0673.最长递增子序列的个数.md | 249 +++++++++++++++
problems/0684.冗余连接.md | 171 ++++++++++
problems/0685.冗余连接II.md | 229 ++++++++++++++
problems/0724.寻找数组的中心索引.md | 93 ++++++
problems/0841.钥匙和房间.md | 135 ++++++++
problems/0844.比较含退格的字符串.md | 174 +++++++++++
problems/0922.按奇偶排序数组II.md | 146 +++++++++
problems/0925.长按键入.md | 113 +++++++
problems/1207.独一无二的出现次数.md | 92 ++++++
...��据数字二进制下1的数目排序.md | 165 ++++++----
...65.有多少小于当前数字的数字.md | 9 +-
problems/1382.将二叉搜索树变平衡.md | 92 ++++++
.../二叉树阶段总结系列一.md | 5 +-
30 files changed, 3975 insertions(+), 61 deletions(-)
create mode 100644 problems/0005.最长回文子串.md
create mode 100644 problems/0031.下一个排列.md
create mode 100644 problems/0034.在排序数组中查找元素的第一个和最后一个位置.md
create mode 100644 problems/0100.相同的树.md
create mode 100644 problems/0116.填充每个节点的下一个右侧节点指针.md
create mode 100644 problems/0132.分割回文串II.md
create mode 100644 problems/0141.环形链表.md
create mode 100644 problems/0143.重排链表.md
create mode 100644 problems/0189.旋转数组.md
create mode 100644 problems/0205.同构字符串.md
create mode 100644 problems/0234.回文链表.md
create mode 100644 problems/0283.移动零.md
create mode 100644 problems/0649.Dota2参议院.md
create mode 100644 problems/0657.机器人能否返回原点.md
create mode 100644 problems/0673.最长递增子序列的个数.md
create mode 100644 problems/0684.冗余连接.md
create mode 100644 problems/0685.冗余连接II.md
create mode 100644 problems/0724.寻找数组的中心索引.md
create mode 100644 problems/0841.钥匙和房间.md
create mode 100644 problems/0844.比较含退格的字符串.md
create mode 100644 problems/0922.按奇偶排序数组II.md
create mode 100644 problems/0925.长按键入.md
create mode 100644 problems/1207.独一无二的出现次数.md
create mode 100644 problems/1382.将二叉搜索树变平衡.md
diff --git a/README.md b/README.md
index 40cd272f..2d1d57a3 100644
--- a/README.md
+++ b/README.md
@@ -139,8 +139,7 @@
## 杂谈
[大半年过去了......](https://mp.weixin.qq.com/s/lubfeistPxBLSQIe5XYg5g)
-
-
+[一万录友在B站学算法!](https://mp.weixin.qq.com/s/Vzq4zkMZY7erKeu0fqGLgw)
## 数组
@@ -427,6 +426,68 @@
## 海量数据处理
+# 补充题目
+
+以上题目是重中之重,大家至少要刷两遍以上才能彻底理解,如果熟练以上题目之后还在找其他题目练手,可以再刷以下题目:
+
+这些题解,是我平时随便写的,题目很不错,但有的题解我未必写的很详细,后面还会适当补充,所以我还没有将其纳入刷题攻略。等日后我再完善一下,再纳入到刷题攻略。
+
+## 数组
+
+* [1365.有多少小于当前数字的数字](./problems/1365.有多少小于当前数字的数字.md)
+* [941.有效的山脉数组](./problems/0941.有效的山脉数组.md) (双指针)
+* [1207.独一无二的出现次数](./problems/1207.独一无二的出现次数.md) 数组在哈希法中的经典应用
+* [283.移动零](./problems/0283.移动零.md) 【数组】【双指针】
+* [189.旋转数组](./problems/0189.旋转数组.md)
+* [724.寻找数组的中心索引](./problems/0724.寻找数组的中心索引.md)
+* [34.在排序数组中查找元素的第一个和最后一个位置](./problems/0034.在排序数组中查找元素的第一个和最后一个位置.md) (二分法)
+* [922.按奇偶排序数组II](./problems/0922.按奇偶排序数组II.md)
+
+## 链表
+
+* [24.两两交换链表中的节点](./problems/0024.两两交换链表中的节点.md)
+* [234.回文链表](./problems/0234.回文链表.md)
+* [143.重排链表](./problems/0143.重排链表.md)【数组】【双向队列】【直接操作链表】
+* [234.回文链表](./problems/0234.回文链表.md)
+* [141.环形链表](./problems/0141.环形链表.md)
+
+## 哈希表
+* [205.同构字符串](./problems/0205.同构字符串.md):【哈希表的应用】
+
+## 字符串
+* [925.长按键入](./problems/0925.长按键入.md) 模拟匹配
+* [0844.比较含退格的字符串](./problems/0844.比较含退格的字符串.md)【栈模拟】【空间更优的双指针】
+
+## 二叉树
+* [129.求根到叶子节点数字之和](./problems/0129.求根到叶子节点数字之和.md)
+* [1382.将二叉搜索树变平衡](./problems/1382.将二叉搜索树变平衡.md) 构造平衡二叉搜索树
+* [100.相同的树](./problems/0100.相同的树.md) 同101.对称二叉树 一个思路
+* [116.填充每个节点的下一个右侧节点指针](./problems/0116.填充每个节点的下一个右侧节点指针.md)
+
+## 贪心
+* [649.Dota2参议院](./problems/0649.Dota2参议院.md) 有难度
+
+## 动态规划
+* [5.最长回文子串](./problems/0005.最长回文子串.md) 和[647.回文子串](https://mp.weixin.qq.com/s/2WetyP6IYQ6VotegepVpEw) 差不多是一样的
+* [132.分割回文串II](./problems/0132.分割回文串II.md) 与647.回文子串和 5.最长回文子串 很像
+* [673.最长递增子序列的个数](./problems/0673.最长递增子序列的个数.md)
+
+## 图论
+* [463.岛屿的周长](./problems/0463.岛屿的周长.md) (模拟)
+* [841.钥匙和房间](./problems/0841.钥匙和房间.md) 【有向图】dfs,bfs都可以
+
+## 并查集
+* [684.冗余连接](./problems/0684.冗余连接.md) 【并查集基础题目】
+* [685.冗余连接II](./problems/0685.冗余连接II.md)【并查集的应用】
+
+## 模拟
+* [657.机器人能否返回原点](./problems/0657.机器人能否返回原点.md)
+* [31.下一个排列](./problems/0031.下一个排列.md)
+
+## 位运算
+* [1356.根据数字二进制下1的数目排序](./problems/1356.根据数字二进制下1的数目排序.md)
+
+
# 算法模板
[各类基础算法模板](https://github.com/youngyangyang04/leetcode/blob/master/problems/算法模板.md)
diff --git a/problems/0005.最长回文子串.md b/problems/0005.最长回文子串.md
new file mode 100644
index 00000000..0063b358
--- /dev/null
+++ b/problems/0005.最长回文子串.md
@@ -0,0 +1,291 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 5.最长回文子串
+
+题目链接:https://leetcode-cn.com/problems/longest-palindromic-substring/
+
+给你一个字符串 s,找到 s 中最长的回文子串。
+
+示例 1:
+* 输入:s = "babad"
+* 输出:"bab"
+* 解释:"aba" 同样是符合题意的答案。
+
+示例 2:
+* 输入:s = "cbbd"
+* 输出:"bb"
+
+示例 3:
+* 输入:s = "a"
+* 输出:"a"
+
+示例 4:
+* 输入:s = "ac"
+* 输出:"a"
+
+
+# 思路
+
+本题和[647.回文子串](https://mp.weixin.qq.com/s/2WetyP6IYQ6VotegepVpEw) 差不多是一样的,但647.回文子串更基本一点,建议可以先做647.回文子串
+
+## 暴力解法
+
+两层for循环,遍历区间起始位置和终止位置,然后判断这个区间是不是回文。
+
+时间复杂度:O(n^3)
+
+## 动态规划
+
+动规五部曲:
+
+1. 确定dp数组(dp table)以及下标的含义
+
+布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
+
+
+2. 确定递推公式
+
+在确定递推公式时,就要分析如下几种情况。
+
+整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。
+
+当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。
+
+当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况
+
+* 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串
+* 情况二:下标i 与 j相差为1,例如aa,也是文子串
+* 情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。
+
+以上三种情况分析完了,那么递归公式如下:
+
+```C++
+if (s[i] == s[j]) {
+ if (j - i <= 1) { // 情况一 和 情况二
+ dp[i][j] = true;
+ } else if (dp[i + 1][j - 1]) { // 情况三
+ dp[i][j] = true;
+ }
+}
+```
+
+注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。
+
+在得到[i,j]区间是否是回文子串的时候,直接保存最长回文子串的左边界和右边界,代码如下:
+
+```C++
+if (s[i] == s[j]) {
+ if (j - i <= 1) { // 情况一 和 情况二
+ dp[i][j] = true;
+ } else if (dp[i + 1][j - 1]) { // 情况三
+ dp[i][j] = true;
+ }
+}
+if (dp[i][j] && j - i + 1 > maxlenth) {
+ maxlenth = j - i + 1;
+ left = i;
+ right = j;
+}
+```
+
+3. dp数组如何初始化
+
+dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。
+
+所以dp[i][j]初始化为false。
+
+4. 确定遍历顺序
+
+遍历顺序可有有点讲究了。
+
+首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。
+
+dp[i + 1][j - 1] 在 dp[i][j]的左下角,如图:
+
+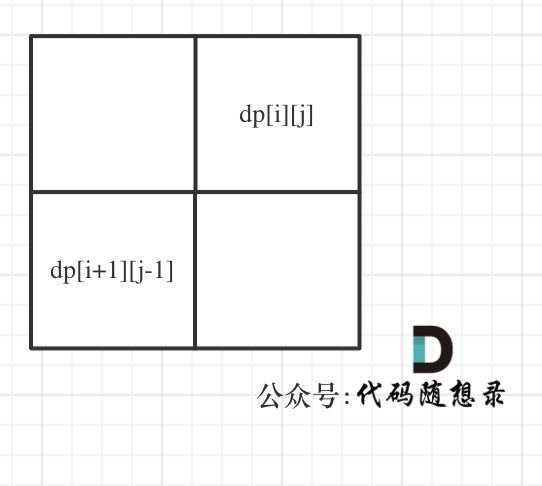
+
+如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。
+
+**所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的**。
+
+有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。
+
+代码如下:
+
+```C++
+for (int i = s.size() - 1; i >= 0; i--) { // 注意遍历顺序
+ for (int j = i; j < s.size(); j++) {
+ if (s[i] == s[j]) {
+ if (j - i <= 1) { // 情况一 和 情况二
+ dp[i][j] = true;
+ } else if (dp[i + 1][j - 1]) { // 情况三
+ dp[i][j] = true;
+ }
+ }
+ if (dp[i][j] && j - i + 1 > maxlenth) {
+ maxlenth = j - i + 1;
+ left = i;
+ right = j;
+ }
+ }
+
+}
+```
+
+5. 举例推导dp数组
+
+举例,输入:"aaa",dp[i][j]状态如下:
+
+
+
+**注意因为dp[i][j]的定义,所以j一定是大于等于i的,那么在填充dp[i][j]的时候一定是只填充右上半部分**。
+
+以上分析完毕,C++代码如下:
+
+```C++
+class Solution {
+public:
+ string longestPalindrome(string s) {
+ vector> dp(s.size(), vector(s.size(), 0));
+ int maxlenth = 0;
+ int left = 0;
+ int right = 0;
+ for (int i = s.size() - 1; i >= 0; i--) {
+ for (int j = i; j < s.size(); j++) {
+ if (s[i] == s[j]) {
+ if (j - i <= 1) { // 情况一 和 情况二
+ dp[i][j] = true;
+ } else if (dp[i + 1][j - 1]) { // 情况三
+ dp[i][j] = true;
+ }
+ }
+ if (dp[i][j] && j - i + 1 > maxlenth) {
+ maxlenth = j - i + 1;
+ left = i;
+ right = j;
+ }
+ }
+
+ }
+ return s.substr(left, right - left + 1);
+ }
+};
+```
+以上代码是为了凸显情况一二三,当然是可以简洁一下的,如下:
+
+```C++
+class Solution {
+public:
+ string longestPalindrome(string s) {
+ vector> dp(s.size(), vector(s.size(), 0));
+ int maxlenth = 0;
+ int left = 0;
+ int right = 0;
+ for (int i = s.size() - 1; i >= 0; i--) {
+ for (int j = i; j < s.size(); j++) {
+ if (s[i] == s[j] && (j - i <= 1 || dp[i + 1][j - 1])) {
+ dp[i][j] = true;
+ }
+ if (dp[i][j] && j - i + 1 > maxlenth) {
+ maxlenth = j - i + 1;
+ left = i;
+ right = j;
+ }
+ }
+ }
+ return s.substr(left, maxlenth);
+ }
+};
+
+```
+
+* 时间复杂度:O(n^2)
+* 空间复杂度:O(n^2)
+
+## 双指针
+
+动态规划的空间复杂度是偏高的,我们再看一下双指针法。
+
+首先确定回文串,就是找中心然后想两边扩散看是不是对称的就可以了。
+
+**在遍历中心点的时候,要注意中心点有两种情况**。
+
+一个元素可以作为中心点,两个元素也可以作为中心点。
+
+那么有人同学问了,三个元素还可以做中心点呢。其实三个元素就可以由一个元素左右添加元素得到,四个元素则可以由两个元素左右添加元素得到。
+
+所以我们在计算的时候,要注意一个元素为中心点和两个元素为中心点的情况。
+
+**这两种情况可以放在一起计算,但分别计算思路更清晰,我倾向于分别计算**,代码如下:
+
+```C++
+class Solution {
+public:
+ int left = 0;
+ int right = 0;
+ int maxLength = 0;
+ string longestPalindrome(string s) {
+ int result = 0;
+ for (int i = 0; i < s.size(); i++) {
+ extend(s, i, i, s.size()); // 以i为中心
+ extend(s, i, i + 1, s.size()); // 以i和i+1为中心
+ }
+ return s.substr(left, maxLength);
+ }
+ void extend(const string& s, int i, int j, int n) {
+ while (i >= 0 && j < n && s[i] == s[j]) {
+ if (j - i + 1 > maxLength) {
+ left = i;
+ right = j;
+ maxLength = j - i + 1;
+ }
+ i--;
+ j++;
+ }
+ }
+};
+
+```
+
+* 时间复杂度:O(n^2)
+* 空间复杂度:O(1)
+
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/0031.下一个排列.md b/problems/0031.下一个排列.md
new file mode 100644
index 00000000..fbe31eb3
--- /dev/null
+++ b/problems/0031.下一个排列.md
@@ -0,0 +1,124 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+
+# 31.下一个排列
+
+链接:https://leetcode-cn.com/problems/next-permutation/
+
+实现获取 下一个排列 的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
+
+如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
+
+必须 原地 修改,只允许使用额外常数空间。
+
+示例 1:
+* 输入:nums = [1,2,3]
+* 输出:[1,3,2]
+
+示例 2:
+* 输入:nums = [3,2,1]
+* 输出:[1,2,3]
+
+示例 3:
+* 输入:nums = [1,1,5]
+* 输出:[1,5,1]
+
+示例 4:
+* 输入:nums = [1]
+* 输出:[1]
+
+
+# 思路
+
+一些同学可能手动写排列的顺序,都没有写对,那么写程序的话思路一定是有问题的了,我这里以1234为例子,把全排列都列出来。可以参考一下规律所在:
+
+```
+1 2 3 4
+1 2 4 3
+1 3 2 4
+1 3 4 2
+1 4 2 3
+1 4 3 2
+2 1 3 4
+2 1 4 3
+2 3 1 4
+2 3 4 1
+2 4 1 3
+2 4 3 1
+3 1 2 4
+3 1 4 2
+3 2 1 4
+3 2 4 1
+3 4 1 2
+3 4 2 1
+4 1 2 3
+4 1 3 2
+4 2 1 3
+4 2 3 1
+4 3 1 2
+4 3 2 1
+```
+
+如图:
+
+以求1243为例,流程如图:
+
+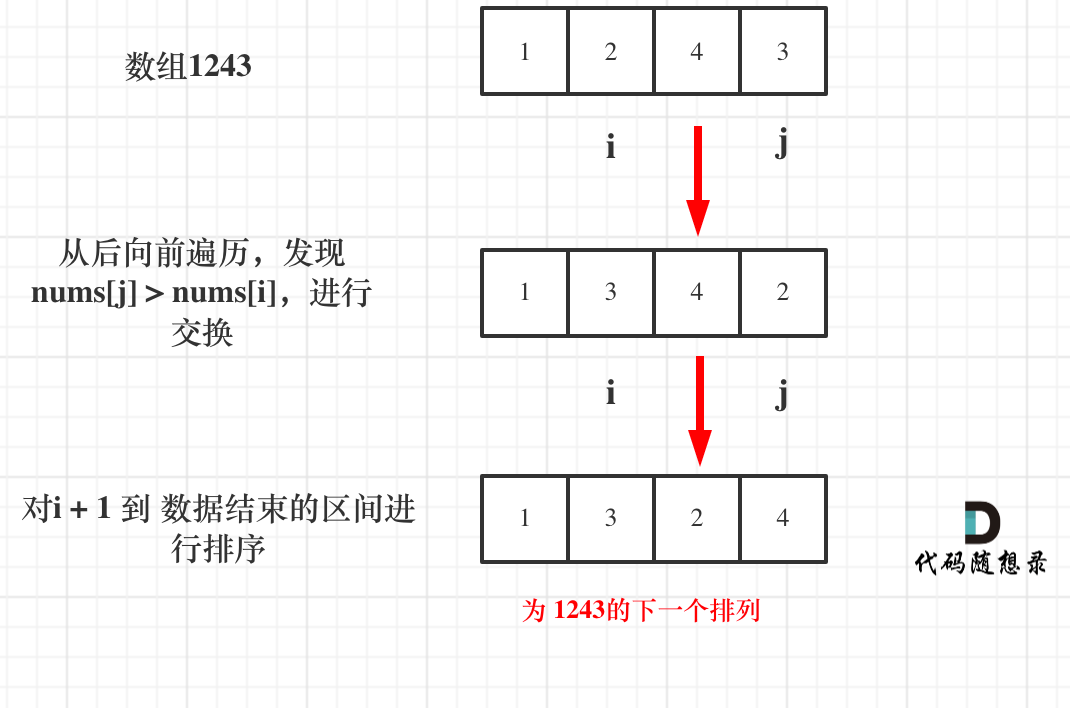 +
+对应的C++代码如下:
+
+```C++
+class Solution {
+public:
+ void nextPermutation(vector& nums) {
+ for (int i = nums.size() - 1; i >= 0; i--) {
+ for (int j = nums.size() - 1; j > i; j--) {
+ if (nums[j] > nums[i]) {
+ swap(nums[j], nums[i]);
+ sort(nums.begin() + i + 1, nums.end());
+ return;
+ }
+ }
+ }
+ // 到这里了说明整个数组都是倒叙了,反转一下便可
+ reverse(nums.begin(), nums.end());
+ }
+};
+```
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md b/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md
new file mode 100644
index 00000000..04f5eaf7
--- /dev/null
+++ b/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md
@@ -0,0 +1,199 @@
+
+
+
+对应的C++代码如下:
+
+```C++
+class Solution {
+public:
+ void nextPermutation(vector& nums) {
+ for (int i = nums.size() - 1; i >= 0; i--) {
+ for (int j = nums.size() - 1; j > i; j--) {
+ if (nums[j] > nums[i]) {
+ swap(nums[j], nums[i]);
+ sort(nums.begin() + i + 1, nums.end());
+ return;
+ }
+ }
+ }
+ // 到这里了说明整个数组都是倒叙了,反转一下便可
+ reverse(nums.begin(), nums.end());
+ }
+};
+```
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md b/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md
new file mode 100644
index 00000000..04f5eaf7
--- /dev/null
+++ b/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md
@@ -0,0 +1,199 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 34. 在排序数组中查找元素的第一个和最后一个位置
+
+给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
+
+如果数组中不存在目标值 target,返回 [-1, -1]。
+
+进阶:你可以设计并实现时间复杂度为 O(log n) 的算法解决此问题吗?
+
+
+示例 1:
+* 输入:nums = [5,7,7,8,8,10], target = 8
+* 输出:[3,4]
+
+示例 2:
+* 输入:nums = [5,7,7,8,8,10], target = 6
+* 输出:[-1,-1]
+
+示例 3:
+* 输入:nums = [], target = 0
+* 输出:[-1,-1]
+
+
+# 思路
+
+这道题目如果基础不是很好,不建议大家看简短的代码,简短的代码隐藏了太多逻辑,结果就是稀里糊涂把题AC了,但是没有想清楚具体细节!
+
+对二分还不了解的同学先做这两题:
+
+* [704.二分查找](https://mp.weixin.qq.com/s/4X-8VRgnYRGd5LYGZ33m4w)
+* [35.搜索插入位置](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)
+
+下面我来把所有情况都讨论一下。
+
+寻找target在数组里的左右边界,有如下三种情况:
+
+* 情况一:target 在数组范围的右边或者左边,例如数组{3, 4, 5},target为2或者数组{3, 4, 5},target为6,此时应该返回{-1, -1}
+* 情况二:target 在数组范围中,且数组中不存在target,例如数组{3,6,7},target为5,此时应该返回{-1, -1}
+* 情况三:target 在数组范围中,且数组中存在target,例如数组{3,6,7},target为6,此时应该返回{1, 1}
+
+这三种情况都考虑到,说明就想的很清楚了。
+
+接下来,在去寻找左边界,和右边界了。
+
+采用二分法来取寻找左右边界,为了让代码清晰,我分别写两个二分来寻找左边界和右边界。
+
+**刚刚接触二分搜索的同学不建议上来就像如果用一个二分来查找左右边界,很容易把自己绕进去,建议扎扎实实的写两个二分分别找左边界和右边界**
+
+## 寻找右边界
+
+先来寻找右边界,至于二分查找,如果看过[为什么每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)就会知道,二分查找中什么时候用while (left <= right),有什么时候用while (left < right),其实只要清楚**循环不变量**,很容易区分两种写法。
+
+那么这里我采用while (left <= right)的写法,区间定义为[left, right],即左闭又闭的区间(如果这里有点看不懂了,强烈建议把[为什么每次遇到二分法,都是一看就会,一写就废](https://mp.weixin.qq.com/s/fCf5QbPDtE6SSlZ1yh_q8Q)这篇文章先看了,在把「leetcode:35.搜索插入位置」做了之后在做这道题目就好很多了)
+
+确定好:计算出来的右边界是不包好target的右边界,左边界同理。
+
+可以写出如下代码
+
+```C++
+// 二分查找,寻找target的右边界(不包括target)
+// 如果rightBorder为没有被赋值(即target在数组范围的左边,例如数组[3,3],target为2),为了处理情况一
+int getRightBorder(vector& nums, int target) {
+ int left = 0;
+ int right = nums.size() - 1; // 定义target在左闭右闭的区间里,[left, right]
+ int rightBorder = -2; // 记录一下rightBorder没有被赋值的情况
+ while (left <= right) { // 当left==right,区间[left, right]依然有效
+ int middle = left + ((right - left) / 2);// 防止溢出 等同于(left + right)/2
+ if (nums[middle] > target) {
+ right = middle - 1; // target 在左区间,所以[left, middle - 1]
+ } else { // 当nums[middle] == target的时候,更新left,这样才能得到target的右边界
+ left = middle + 1;
+ rightBorder = left;
+ }
+ }
+ return rightBorder;
+}
+```
+
+## 寻找左边界
+
+```C++
+// 二分查找,寻找target的左边界leftBorder(不包括target)
+// 如果leftBorder没有被赋值(即target在数组范围的右边,例如数组[3,3],target为4),为了处理情况一
+int getLeftBorder(vector& nums, int target) {
+ int left = 0;
+ int right = nums.size() - 1; // 定义target在左闭右闭的区间里,[left, right]
+ int leftBorder = -2; // 记录一下leftBorder没有被赋值的情况
+ while (left <= right) {
+ int middle = left + ((right - left) / 2);
+ if (nums[middle] >= target) { // 寻找左边界,就要在nums[middle] == target的时候更新right
+ right = middle - 1;
+ leftBorder = right;
+ } else {
+ left = middle + 1;
+ }
+ }
+ return leftBorder;
+}
+```
+
+## 处理三种情况
+
+左右边界计算完之后,看一下主体代码,这里把上面讨论的三种情况,都覆盖了
+
+```C++
+class Solution {
+public:
+ vector searchRange(vector& nums, int target) {
+ int leftBorder = getLeftBorder(nums, target);
+ int rightBorder = getRightBorder(nums, target);
+ // 情况一
+ if (leftBorder == -2 || rightBorder == -2) return {-1, -1};
+ // 情况三
+ if (rightBorder - leftBorder > 1) return {leftBorder + 1, rightBorder - 1};
+ // 情况二
+ return {-1, -1};
+ }
+private:
+ int getRightBorder(vector& nums, int target) {
+ int left = 0;
+ int right = nums.size() - 1;
+ int rightBorder = -2; // 记录一下rightBorder没有被赋值的情况
+ while (left <= right) {
+ int middle = left + ((right - left) / 2);
+ if (nums[middle] > target) {
+ right = middle - 1;
+ } else { // 寻找右边界,nums[middle] == target的时候更新left
+ left = middle + 1;
+ rightBorder = left;
+ }
+ }
+ return rightBorder;
+ }
+ int getLeftBorder(vector& nums, int target) {
+ int left = 0;
+ int right = nums.size() - 1;
+ int leftBorder = -2; // 记录一下leftBorder没有被赋值的情况
+ while (left <= right) {
+ int middle = left + ((right - left) / 2);
+ if (nums[middle] >= target) { // 寻找左边界,nums[middle] == target的时候更新right
+ right = middle - 1;
+ leftBorder = right;
+ } else {
+ left = middle + 1;
+ }
+ }
+ return leftBorder;
+ }
+};
+```
+
+这份代码在简洁性很有大的优化空间,例如把寻找左右区间函数合并一起。
+
+但拆开更清晰一些,而且把三种情况以及对应的处理逻辑完整的展现出来了。
+
+# 总结
+
+初学者建议大家一块一块的去分拆这道题目,正如本题解描述,想清楚三种情况之后,先专注于寻找右区间,然后专注于寻找左区间,左右根据左右区间做最后判断。
+
+不要上来就想如果一起寻找左右区间,搞着搞着就会顾此失彼,绕进去拔不出来了。
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/0100.相同的树.md b/problems/0100.相同的树.md
new file mode 100644
index 00000000..b536ffe3
--- /dev/null
+++ b/problems/0100.相同的树.md
@@ -0,0 +1,186 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 100. 相同的树
+
+题目地址:https://leetcode-cn.com/problems/same-tree/
+
+给定两个二叉树,编写一个函数来检验它们是否相同。
+
+如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
+
+
+
+
+
+
+# 思路
+
+在[101.对称二叉树](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)中,我们讲到对于二叉树是否对称,要比较的是根节点的左子树与右子树是不是相互翻转的,理解这一点就知道了**其实我们要比较的是两个树(这两个树是根节点的左右子树)**,所以在递归遍历的过程中,也是要同时遍历两棵树。
+
+理解这一本质之后,就会发现,求二叉树是否对称,和求二叉树是否相同几乎是同一道题目。
+
+**如果没有读过[二叉树:我对称么?](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)这一篇,请认真读完再做这道题,就会有感觉了。**
+
+递归三部曲中:
+
+1. 确定递归函数的参数和返回值
+
+我们要比较的是两个树是否是相互相同的,参数也就是两个树的根节点。
+
+返回值自然是bool类型。
+
+代码如下:
+```
+bool compare(TreeNode* tree1, TreeNode* tree2)
+```
+
+分析过程同[101.对称二叉树](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)。
+
+2. 确定终止条件
+
+**要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。**
+
+节点为空的情况有:
+
+* tree1为空,tree2不为空,不对称,return false
+* tree1不为空,tree2为空,不对称 return false
+* tree1,tree2都为空,对称,返回true
+
+此时已经排除掉了节点为空的情况,那么剩下的就是tree1和tree2不为空的时候:
+
+* tree1、tree2都不为空,比较节点数值,不相同就return false
+
+此时tree1、tree2节点不为空,且数值也不相同的情况我们也处理了。
+
+代码如下:
+```C++
+if (tree1 == NULL && tree2 != NULL) return false;
+else if (tree1 != NULL && tree2 == NULL) return false;
+else if (tree1 == NULL && tree2 == NULL) return true;
+else if (tree1->val != tree2->val) return false; // 注意这里我没有使用else
+```
+
+分析过程同[101.对称二叉树](https://mp.weixin.qq.com/s/Kgf0gjvlDlNDfKIH2b1Oxg)
+
+3. 确定单层递归的逻辑
+
+* 比较二叉树是否相同 :传入的是tree1的左孩子,tree2的右孩子。
+* 如果左右都相同就返回true ,有一侧不相同就返回false 。
+
+代码如下:
+
+```C++
+bool left = compare(tree1->left, tree2->left); // 左子树:左、 右子树:左
+bool right = compare(tree1->right, tree2->right); // 左子树:右、 右子树:右
+bool isSame = left && right; // 左子树:中、 右子树:中(逻辑处理)
+return isSame;
+```
+最后递归的C++整体代码如下:
+
+```C++
+class Solution {
+public:
+ bool compare(TreeNode* tree1, TreeNode* tree2) {
+ if (tree1 == NULL && tree2 != NULL) return false;
+ else if (tree1 != NULL && tree2 == NULL) return false;
+ else if (tree1 == NULL && tree2 == NULL) return true;
+ else if (tree1->val != tree2->val) return false; // 注意这里我没有使用else
+
+ // 此时就是:左右节点都不为空,且数值相同的情况
+ // 此时才做递归,做下一层的判断
+ bool left = compare(tree1->left, tree2->left); // 左子树:左、 右子树:左
+ bool right = compare(tree1->right, tree2->right); // 左子树:右、 右子树:右
+ bool isSame = left && right; // 左子树:中、 右子树:中(逻辑处理)
+ return isSame;
+
+ }
+ bool isSameTree(TreeNode* p, TreeNode* q) {
+ return compare(p, q);
+ }
+};
+```
+
+
+**我给出的代码并不简洁,但是把每一步判断的逻辑都清楚的描绘出来了。**
+
+如果上来就看网上各种简洁的代码,看起来真的很简单,但是很多逻辑都掩盖掉了,而题解可能也没有把掩盖掉的逻辑说清楚。
+
+**盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。**
+
+当然我可以把如上代码整理如下:
+
+## 递归
+
+```C++
+class Solution {
+public:
+ bool compare(TreeNode* left, TreeNode* right) {
+ if (left == NULL && right != NULL) return false;
+ else if (left != NULL && right == NULL) return false;
+ else if (left == NULL && right == NULL) return true;
+ else if (left->val != right->val) return false;
+ else return compare(left->left, right->left) && compare(left->right, right->right);
+
+ }
+ bool isSameTree(TreeNode* p, TreeNode* q) {
+ return compare(p, q);
+ }
+};
+```
+
+## 迭代法
+
+```C++
+lass Solution {
+public:
+
+ bool isSameTree(TreeNode* p, TreeNode* q) {
+ if (p == NULL && q == NULL) return true;
+ if (p == NULL || q == NULL) return false;
+ queue que;
+ que.push(p); //
+ que.push(q); //
+ while (!que.empty()) { //
+ TreeNode* leftNode = que.front(); que.pop();
+ TreeNode* rightNode = que.front(); que.pop();
+ if (!leftNode && !rightNode) { //
+ continue;
+ }
+ //
+ if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
+ return false;
+ }
+ que.push(leftNode->left); //
+ que.push(rightNode->left); //
+ que.push(leftNode->right); //
+ que.push(rightNode->right); //
+ }
+ return true;
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0116.填充每个节点的下一个右侧节点指针.md b/problems/0116.填充每个节点的下一个右侧节点指针.md
new file mode 100644
index 00000000..28e6f645
--- /dev/null
+++ b/problems/0116.填充每个节点的下一个右侧节点指针.md
@@ -0,0 +1,155 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 116. 填充每个节点的下一个右侧节点指针
+
+链接:https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node/
+
+给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
+
+```
+struct Node {
+ int val;
+ Node *left;
+ Node *right;
+ Node *next;
+}
+```
+
+填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
+
+初始状态下,所有 next 指针都被设置为 NULL。
+
+进阶:
+* 你只能使用常量级额外空间。
+* 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
+
+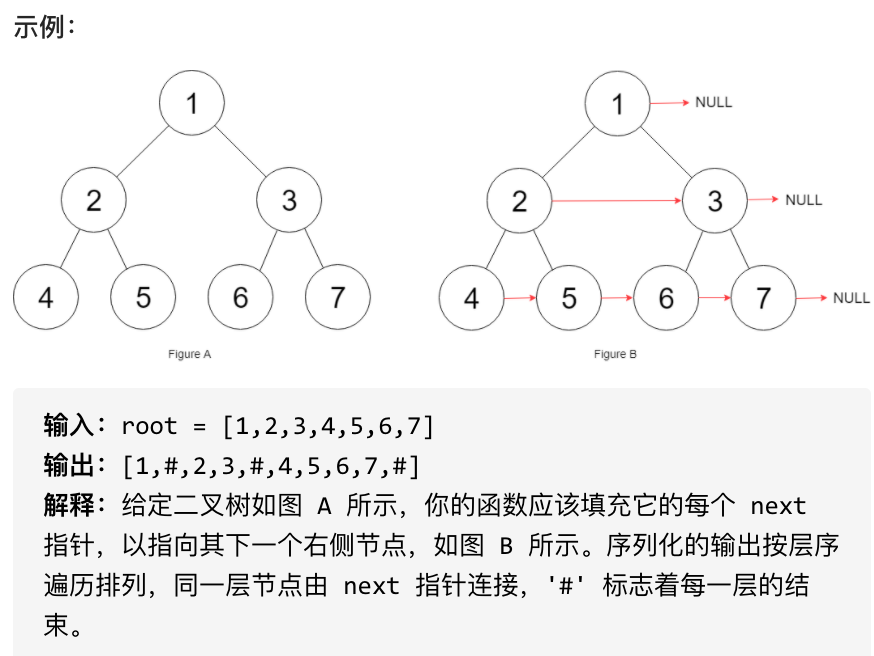
+
+# 思路
+
+注意题目提示内容,:
+* 你只能使用常量级额外空间。
+* 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。
+
+基本上就是要求使用递归了,迭代的方式一定会用到栈或者队列。
+
+## 递归
+
+一想用递归怎么做呢,虽然层序遍历是最直观的,但是递归的方式确实不好想。
+
+如图,假如当前操作的节点是cur:
+
+ +
+最关键的点是可以通过上一层递归 搭出来的线,进行本次搭线。
+
+图中cur节点为元素4,那么搭线的逻辑代码:(**注意注释中操作1和操作2和图中的对应关系**)
+
+```C++
+if (cur->left) cur->left->next = cur->right; // 操作1
+if (cur->right) {
+ if (cur->next) cur->right->next = cur->next->left; // 操作2
+ else cur->right->next = NULL;
+}
+```
+
+理解到这里,使用前序遍历,那么不难写出如下代码:
+
+
+```C++
+class Solution {
+private:
+ void traversal(Node* cur) {
+ if (cur == NULL) return;
+ // 中
+ if (cur->left) cur->left->next = cur->right; // 操作1
+ if (cur->right) {
+ if (cur->next) cur->right->next = cur->next->left; // 操作2
+ else cur->right->next = NULL;
+ }
+ traversal(cur->left); // 左
+ traversal(cur->right); // 右
+ }
+public:
+ Node* connect(Node* root) {
+ traversal(root);
+ return root;
+ }
+};
+```
+
+## 迭代(层序遍历)
+
+本题使用层序遍历是最为直观的,如果对层序遍历不了解,看这篇:[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)。
+
+层序遍历本来就是一层一层的去遍历,记录一层的头结点(nodePre),然后让nodePre指向当前遍历的节点就可以了。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ Node* connect(Node* root) {
+ queue que;
+ if (root != NULL) que.push(root);
+ while (!que.empty()) {
+ int size = que.size();
+ vector vec;
+ Node* nodePre;
+ Node* node;
+ for (int i = 0; i < size; i++) { // 开始每一层的遍历
+ if (i == 0) {
+ nodePre = que.front(); // 记录一层的头结点
+ que.pop();
+ node = nodePre;
+ } else {
+ node = que.front();
+ que.pop();
+ nodePre->next = node; // 本层前一个节点next指向本节点
+ nodePre = nodePre->next;
+ }
+ if (node->left) que.push(node->left);
+ if (node->right) que.push(node->right);
+ }
+ nodePre->next = NULL; // 本层最后一个节点指向NULL
+ }
+ return root;
+ }
+};
+```
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0132.分割回文串II.md b/problems/0132.分割回文串II.md
new file mode 100644
index 00000000..856262d6
--- /dev/null
+++ b/problems/0132.分割回文串II.md
@@ -0,0 +1,256 @@
+
+
+
+最关键的点是可以通过上一层递归 搭出来的线,进行本次搭线。
+
+图中cur节点为元素4,那么搭线的逻辑代码:(**注意注释中操作1和操作2和图中的对应关系**)
+
+```C++
+if (cur->left) cur->left->next = cur->right; // 操作1
+if (cur->right) {
+ if (cur->next) cur->right->next = cur->next->left; // 操作2
+ else cur->right->next = NULL;
+}
+```
+
+理解到这里,使用前序遍历,那么不难写出如下代码:
+
+
+```C++
+class Solution {
+private:
+ void traversal(Node* cur) {
+ if (cur == NULL) return;
+ // 中
+ if (cur->left) cur->left->next = cur->right; // 操作1
+ if (cur->right) {
+ if (cur->next) cur->right->next = cur->next->left; // 操作2
+ else cur->right->next = NULL;
+ }
+ traversal(cur->left); // 左
+ traversal(cur->right); // 右
+ }
+public:
+ Node* connect(Node* root) {
+ traversal(root);
+ return root;
+ }
+};
+```
+
+## 迭代(层序遍历)
+
+本题使用层序遍历是最为直观的,如果对层序遍历不了解,看这篇:[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)。
+
+层序遍历本来就是一层一层的去遍历,记录一层的头结点(nodePre),然后让nodePre指向当前遍历的节点就可以了。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ Node* connect(Node* root) {
+ queue que;
+ if (root != NULL) que.push(root);
+ while (!que.empty()) {
+ int size = que.size();
+ vector vec;
+ Node* nodePre;
+ Node* node;
+ for (int i = 0; i < size; i++) { // 开始每一层的遍历
+ if (i == 0) {
+ nodePre = que.front(); // 记录一层的头结点
+ que.pop();
+ node = nodePre;
+ } else {
+ node = que.front();
+ que.pop();
+ nodePre->next = node; // 本层前一个节点next指向本节点
+ nodePre = nodePre->next;
+ }
+ if (node->left) que.push(node->left);
+ if (node->right) que.push(node->right);
+ }
+ nodePre->next = NULL; // 本层最后一个节点指向NULL
+ }
+ return root;
+ }
+};
+```
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0132.分割回文串II.md b/problems/0132.分割回文串II.md
new file mode 100644
index 00000000..856262d6
--- /dev/null
+++ b/problems/0132.分割回文串II.md
@@ -0,0 +1,256 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 132. 分割回文串 II
+
+链接:https://leetcode-cn.com/problems/palindrome-partitioning-ii/
+
+给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。
+
+返回符合要求的 最少分割次数 。
+
+示例 1:
+
+输入:s = "aab"
+输出:1
+解释:只需一次分割就可将 s 分割成 ["aa","b"] 这样两个回文子串。
+
+示例 2:
+输入:s = "a"
+输出:0
+
+示例 3:
+输入:s = "ab"
+输出:1
+
+
+提示:
+
+* 1 <= s.length <= 2000
+* s 仅由小写英文字母组成
+
+# 思路
+
+我们在讲解回溯法系列的时候,讲过了这道题目[回溯算法:131.分割回文串](https://mp.weixin.qq.com/s/Pb1epUTbU8fHIht-g_MS5Q)。
+
+本题呢其实也可以使用回溯法,只不过会超时!(通过记忆化回溯,也可以过,感兴趣的同学可以自行研究一下)
+
+我们来讲一讲如何使用动态规划,来解决这道题目。
+
+关于回文子串,两道题目题目大家是一定要掌握的。
+
+* [动态规划:647. 回文子串](https://mp.weixin.qq.com/s/2WetyP6IYQ6VotegepVpEw)
+* 5.最长回文子串 和 647.回文子串基本一样的
+
+这两道题目是回文子串的基础题目,本题也要用到相关的知识点。
+
+动规五部曲分析如下:
+
+1. 确定dp数组(dp table)以及下标的含义
+
+dp[i]:范围是[0, i]的回文子串,最少分割次数是dp[i]。
+
+2. 确定递推公式
+
+来看一下由什么可以推出dp[i]。
+
+如果要对长度为[0, i]的子串进行分割,分割点为j。
+
+那么如果分割后,区间[j + 1, i]是回文子串,那么dp[i] 就等于 dp[j] + 1。
+
+这里可能有同学就不明白了,为什么只看[j + 1, i]区间,不看[0, j]区间是不是回文子串呢?
+
+那么在回顾一下dp[i]的定义: 范围是[0, i]的回文子串,最少分割次数是dp[i]。
+
+[0, j]区间的最小切割数量,我们已经知道了就是dp[j]。
+
+此时就找到了递推关系,当切割点j在[0, i] 之间时候,dp[i] = dp[j] + 1;
+
+本题是要找到最少分割次数,所以遍历j的时候要取最小的dp[i]。
+
+**所以最后递推公式为:dp[i] = min(dp[i], dp[j] + 1);**
+
+注意这里不是要 dp[j] + 1 和 dp[i]去比较,而是要在遍历j的过程中取最小的dp[i]!
+
+可以有dp[j] + 1推出,当[j + 1, i] 为回文子串
+
+3. dp数组如何初始化
+
+首先来看一下dp[0]应该是多少。
+
+dp[i]: 范围是[0, i]的回文子串,最少分割次数是dp[i]。
+
+那么dp[0]一定是0,长度为1的字符串最小分割次数就是0。这个是比较直观的。
+
+在看一下非零下标的dp[i]应该初始化为多少?
+
+在递推公式dp[i] = min(dp[i], dp[j] + 1) 中我们可以看出每次要取最小的dp[i]。
+
+那么非零下标的dp[i]就应该初始化为一个最大数,这样递推公式在计算结果的时候才不会被初始值覆盖!
+
+如果非零下标的dp[i]初始化为0,在那么在递推公式中,所有数值将都是零。
+
+非零下标的dp[i]初始化为一个最大数。
+
+代码如下:
+
+```C++
+vector dp(s.size(), INT_MAX);
+dp[0] = 0;
+```
+
+其实也可以这样初始化,更具dp[i]的定义,dp[i]的最大值其实就是i,也就是把每个字符分割出来。
+
+所以初始化代码也可以为:
+```C++
+vector dp(s.size());
+for (int i = 0; i < s.size(); i++) dp[i] = i;
+```
+
+4. 确定遍历顺序
+
+根据递推公式:dp[i] = min(dp[i], dp[j] + 1);
+
+j是在[0,i]之间,所以遍历i的for循环一定在外层,这里遍历j的for循环在内层才能通过 计算过的dp[j]数值推导出dp[i]。
+
+代码如下:
+
+```C++
+for (int i = 1; i < s.size(); i++) {
+ if (isPalindromic[0][i]) { // 判断是不是回文子串
+ dp[i] = 0;
+ continue;
+ }
+ for (int j = 0; j < i; j++) {
+ if (isPalindromic[j + 1][i]) {
+ dp[i] = min(dp[i], dp[j] + 1);
+ }
+ }
+}
+```
+
+大家会发现代码里有一个isPalindromic函数,这是一个二维数组isPalindromic[i][j],记录[i, j]是不是回文子串。
+
+那么这个isPalindromic[i][j]是怎么的代码的呢?
+
+就是其实这两道题目的代码:
+
+* 647.回文子串
+* 5.最长回文子串
+
+所以先用一个二维数组来保存整个字符串的回文情况。
+
+代码如下:
+
+```C++
+vector> isPalindromic(s.size(), vector(s.size(), false));
+for (int i = s.size() - 1; i >= 0; i--) {
+ for (int j = i; j < s.size(); j++) {
+ if (s[i] == s[j] && (j - i <= 1 || isPalindromic[i + 1][j - 1])) {
+ isPalindromic[i][j] = true;
+ }
+ }
+}
+```
+
+5. 举例推导dp数组
+
+以输入:"aabc" 为例:
+
+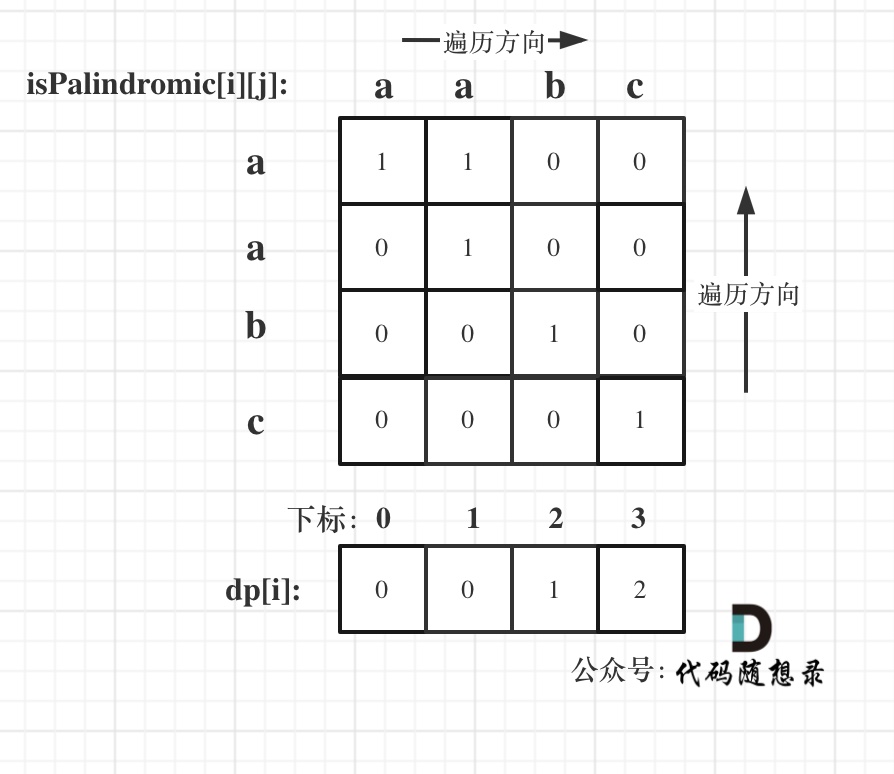
+
+以上分析完毕,代码如下:
+
+```C++
+class Solution {
+public:
+ int minCut(string s) {
+ vector> isPalindromic(s.size(), vector(s.size(), false));
+ for (int i = s.size() - 1; i >= 0; i--) {
+ for (int j = i; j < s.size(); j++) {
+ if (s[i] == s[j] && (j - i <= 1 || isPalindromic[i + 1][j - 1])) {
+ isPalindromic[i][j] = true;
+ }
+ }
+ }
+ // 初始化
+ vector dp(s.size(), 0);
+ for (int i = 0; i < s.size(); i++) dp[i] = i;
+
+ for (int i = 1; i < s.size(); i++) {
+ if (isPalindromic[0][i]) {
+ dp[i] = 0;
+ continue;
+ }
+ for (int j = 0; j < i; j++) {
+ if (isPalindromic[j + 1][i]) {
+ dp[i] = min(dp[i], dp[j] + 1);
+ }
+ }
+ }
+ return dp[s.size() - 1];
+
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+class Solution:
+ def minCut(self, s: str) -> int:
+
+ isPalindromic=[[False]*len(s) for _ in range(len(s))]
+
+ for i in range(len(s)-1,-1,-1):
+ for j in range(i,len(s)):
+ if s[i]!=s[j]:
+ isPalindromic[i][j] = False
+ elif j-i<=1 or isPalindromic[i+1][j-1]:
+ isPalindromic[i][j] = True
+
+ # print(isPalindromic)
+ dp=[sys.maxsize]*len(s)
+ dp[0]=0
+
+ for i in range(1,len(s)):
+ if isPalindromic[0][i]:
+ dp[i]=0
+ continue
+ for j in range(0,i):
+ if isPalindromic[j+1][i]==True:
+ dp[i]=min(dp[i], dp[j]+1)
+ return dp[-1]
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0139.单词拆分.md b/problems/0139.单词拆分.md
index 59892ef9..4ba08aa9 100644
--- a/problems/0139.单词拆分.md
+++ b/problems/0139.单词拆分.md
@@ -5,7 +5,8 @@
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-# 动态规划:单词拆分
+
+
## 139.单词拆分
diff --git a/problems/0141.环形链表.md b/problems/0141.环形链表.md
new file mode 100644
index 00000000..4a40f953
--- /dev/null
+++ b/problems/0141.环形链表.md
@@ -0,0 +1,109 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 141. 环形链表
+
+给定一个链表,判断链表中是否有环。
+
+如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
+
+如果链表中存在环,则返回 true 。 否则,返回 false 。
+
+
+
+# 思路
+
+可以使用快慢指针法, 分别定义 fast 和 slow指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
+
+为什么fast 走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢?
+
+首先第一点: **fast指针一定先进入环中,如果fast 指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。**
+
+那么来看一下,**为什么fast指针和slow指针一定会相遇呢?**
+
+可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。
+
+会发现最终都是这种情况, 如下图:
+
+ +
+fast和slow各自再走一步, fast和slow就相遇了
+
+这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
+
+动画如下:
+
+
+
+
+
+C++代码如下
+
+```C++
+class Solution {
+public:
+ bool hasCycle(ListNode *head) {
+ ListNode* fast = head;
+ ListNode* slow = head;
+ while(fast != NULL && fast->next != NULL) {
+ slow = slow->next;
+ fast = fast->next->next;
+ // 快慢指针相遇,说明有环
+ if (slow == fast) return true;
+ }
+ return false;
+ }
+};
+```
+
+# 扩展
+
+做完这道题目,可以在做做142.环形链表II,不仅仅要找环,还要找环的入口。
+
+142.环形链表II题解:[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/gt_VH3hQTqNxyWcl1ECSbQ)
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+class Solution:
+ def hasCycle(self, head: ListNode) -> bool:
+ if not head: return False
+ slow, fast = head, head
+ while fast and fast.next:
+ slow = slow.next
+ fast = fast.next.next
+ if fast == slow:
+ return True
+ return False
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0143.重排链表.md b/problems/0143.重排链表.md
new file mode 100644
index 00000000..c4e8d8f7
--- /dev/null
+++ b/problems/0143.重排链表.md
@@ -0,0 +1,190 @@
+
+
+
+fast和slow各自再走一步, fast和slow就相遇了
+
+这是因为fast是走两步,slow是走一步,**其实相对于slow来说,fast是一个节点一个节点的靠近slow的**,所以fast一定可以和slow重合。
+
+动画如下:
+
+
+
+
+
+C++代码如下
+
+```C++
+class Solution {
+public:
+ bool hasCycle(ListNode *head) {
+ ListNode* fast = head;
+ ListNode* slow = head;
+ while(fast != NULL && fast->next != NULL) {
+ slow = slow->next;
+ fast = fast->next->next;
+ // 快慢指针相遇,说明有环
+ if (slow == fast) return true;
+ }
+ return false;
+ }
+};
+```
+
+# 扩展
+
+做完这道题目,可以在做做142.环形链表II,不仅仅要找环,还要找环的入口。
+
+142.环形链表II题解:[链表:环找到了,那入口呢?](https://mp.weixin.qq.com/s/gt_VH3hQTqNxyWcl1ECSbQ)
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+class Solution:
+ def hasCycle(self, head: ListNode) -> bool:
+ if not head: return False
+ slow, fast = head, head
+ while fast and fast.next:
+ slow = slow.next
+ fast = fast.next.next
+ if fast == slow:
+ return True
+ return False
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0143.重排链表.md b/problems/0143.重排链表.md
new file mode 100644
index 00000000..c4e8d8f7
--- /dev/null
+++ b/problems/0143.重排链表.md
@@ -0,0 +1,190 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 143.重排链表
+
+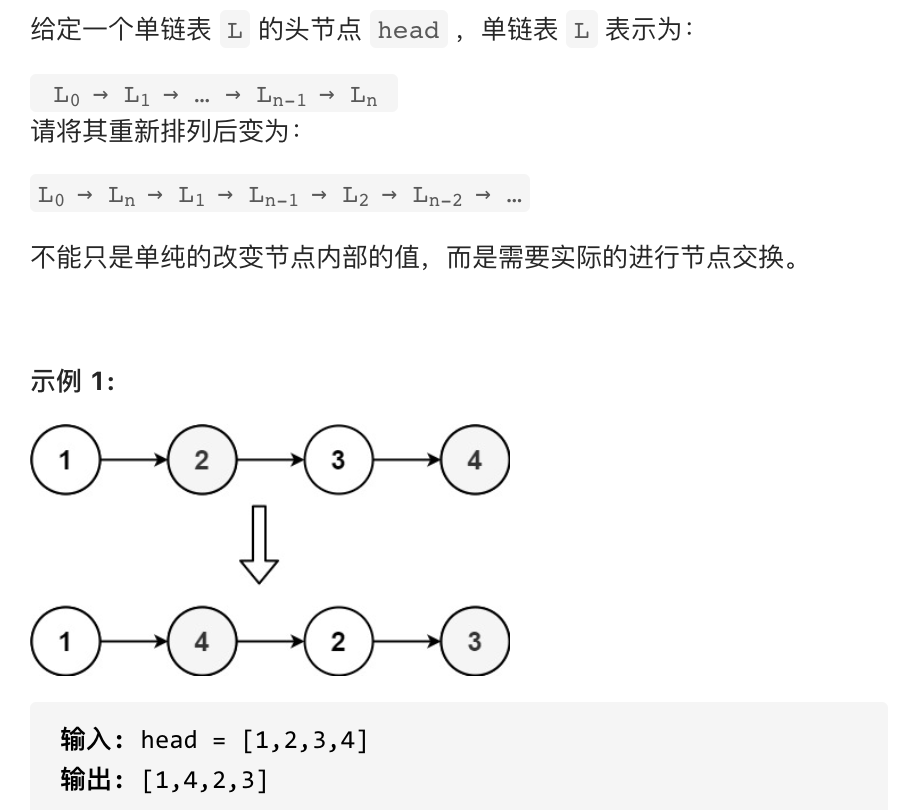
+
+# 思路
+
+本篇将给出三种C++实现的方法
+
+* 数组模拟
+* 双向队列模拟
+* 直接分割链表
+
+## 方法一
+
+把链表放进数组中,然后通过双指针法,一前一后,来遍历数组,构造链表。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ void reorderList(ListNode* head) {
+ vector vec;
+ ListNode* cur = head;
+ if (cur == nullptr) return;
+ while(cur != nullptr) {
+ vec.push_back(cur);
+ cur = cur->next;
+ }
+ cur = head;
+ int i = 1;
+ int j = vec.size() - 1; // i j为之前前后的双指针
+ int count = 0; // 计数,偶数去后面,奇数取前面
+ while (i <= j) {
+ if (count % 2 == 0) {
+ cur->next = vec[j];
+ j--;
+ } else {
+ cur->next = vec[i];
+ i++;
+ }
+ cur = cur->next;
+ count++;
+ }
+ if (vec.size() % 2 == 0) { // 如果是偶数,还要多处理中间的一个
+ cur->next = vec[i];
+ cur = cur->next;
+ }
+ cur->next = nullptr; // 注意结尾
+ }
+};
+```
+
+## 方法二
+
+把链表放进双向队列,然后通过双向队列一前一后弹出数据,来构造新的链表。这种方法比操作数组容易一些,不用双指针模拟一前一后了
+```C++
+class Solution {
+public:
+ void reorderList(ListNode* head) {
+ deque que;
+ ListNode* cur = head;
+ if (cur == nullptr) return;
+
+ while(cur->next != nullptr) {
+ que.push_back(cur->next);
+ cur = cur->next;
+ }
+
+ cur = head;
+ int count = 0; // 计数,偶数去后面,奇数取前面
+ ListNode* node;
+ while(que.size()) {
+ if (count % 2 == 0) {
+ node = que.back();
+ que.pop_back();
+ } else {
+ node = que.front();
+ que.pop_front();
+ }
+ count++;
+ cur->next = node;
+ cur = cur->next;
+ }
+ cur->next = nullptr; // 注意结尾
+ }
+};
+```
+
+## 方法三
+
+将链表分割成两个链表,然后把第二个链表反转,之后在通过两个链表拼接成新的链表。
+
+如图:
+
+ +
+这种方法,比较难,平均切割链表,看上去很简单,真正代码写的时候有很多细节,同时两个链表最后拼装整一个新的链表也有一些细节需要注意!
+
+代码如下:
+
+```C++
+class Solution {
+private:
+ // 反转链表
+ ListNode* reverseList(ListNode* head) {
+ ListNode* temp; // 保存cur的下一个节点
+ ListNode* cur = head;
+ ListNode* pre = NULL;
+ while(cur) {
+ temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
+ cur->next = pre; // 翻转操作
+ // 更新pre 和 cur指针
+ pre = cur;
+ cur = temp;
+ }
+ return pre;
+ }
+
+public:
+ void reorderList(ListNode* head) {
+ if (head == nullptr) return;
+ // 使用快慢指针法,将链表分成长度均等的两个链表head1和head2
+ // 如果总链表长度为奇数,则head1相对head2多一个节点
+ ListNode* fast = head;
+ ListNode* slow = head;
+ while (fast && fast->next && fast->next->next) {
+ fast = fast->next->next;
+ slow = slow->next;
+ }
+ ListNode* head1 = head;
+ ListNode* head2;
+ head2 = slow->next;
+ slow->next = nullptr;
+
+ // 对head2进行翻转
+ head2 = reverseList(head2);
+
+ // 将head1和head2交替生成新的链表head
+ ListNode* cur1 = head1;
+ ListNode* cur2 = head2;
+ ListNode* cur = head;
+ cur1 = cur1->next;
+ int count = 0; // 偶数取head2的元素,奇数取head1的元素
+ while (cur1 && cur2) {
+ if (count % 2 == 0) {
+ cur->next = cur2;
+ cur2 = cur2->next;
+ } else {
+ cur->next = cur1;
+ cur1 = cur1->next;
+ }
+ count++;
+ cur = cur->next;
+ }
+ if (cur2 != nullptr) { // 处理结尾
+ cur->next = cur2;
+ }
+ if (cur1 != nullptr) {
+ cur->next = cur1;
+ }
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0189.旋转数组.md b/problems/0189.旋转数组.md
new file mode 100644
index 00000000..9f565c1d
--- /dev/null
+++ b/problems/0189.旋转数组.md
@@ -0,0 +1,142 @@
+
+
+
+这种方法,比较难,平均切割链表,看上去很简单,真正代码写的时候有很多细节,同时两个链表最后拼装整一个新的链表也有一些细节需要注意!
+
+代码如下:
+
+```C++
+class Solution {
+private:
+ // 反转链表
+ ListNode* reverseList(ListNode* head) {
+ ListNode* temp; // 保存cur的下一个节点
+ ListNode* cur = head;
+ ListNode* pre = NULL;
+ while(cur) {
+ temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
+ cur->next = pre; // 翻转操作
+ // 更新pre 和 cur指针
+ pre = cur;
+ cur = temp;
+ }
+ return pre;
+ }
+
+public:
+ void reorderList(ListNode* head) {
+ if (head == nullptr) return;
+ // 使用快慢指针法,将链表分成长度均等的两个链表head1和head2
+ // 如果总链表长度为奇数,则head1相对head2多一个节点
+ ListNode* fast = head;
+ ListNode* slow = head;
+ while (fast && fast->next && fast->next->next) {
+ fast = fast->next->next;
+ slow = slow->next;
+ }
+ ListNode* head1 = head;
+ ListNode* head2;
+ head2 = slow->next;
+ slow->next = nullptr;
+
+ // 对head2进行翻转
+ head2 = reverseList(head2);
+
+ // 将head1和head2交替生成新的链表head
+ ListNode* cur1 = head1;
+ ListNode* cur2 = head2;
+ ListNode* cur = head;
+ cur1 = cur1->next;
+ int count = 0; // 偶数取head2的元素,奇数取head1的元素
+ while (cur1 && cur2) {
+ if (count % 2 == 0) {
+ cur->next = cur2;
+ cur2 = cur2->next;
+ } else {
+ cur->next = cur1;
+ cur1 = cur1->next;
+ }
+ count++;
+ cur = cur->next;
+ }
+ if (cur2 != nullptr) { // 处理结尾
+ cur->next = cur2;
+ }
+ if (cur1 != nullptr) {
+ cur->next = cur1;
+ }
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0189.旋转数组.md b/problems/0189.旋转数组.md
new file mode 100644
index 00000000..9f565c1d
--- /dev/null
+++ b/problems/0189.旋转数组.md
@@ -0,0 +1,142 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 189. 旋转数组
+
+给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
+
+进阶:
+
+尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。
+你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
+
+示例 1:
+
+* 输入: nums = [1,2,3,4,5,6,7], k = 3
+* 输出: [5,6,7,1,2,3,4]
+* 解释:
+向右旋转 1 步: [7,1,2,3,4,5,6]。
+向右旋转 2 步: [6,7,1,2,3,4,5]。
+向右旋转 3 步: [5,6,7,1,2,3,4]。
+
+示例 2:
+* 输入:nums = [-1,-100,3,99], k = 2
+* 输出:[3,99,-1,-100]
+* 解释:
+向右旋转 1 步: [99,-1,-100,3]。
+向右旋转 2 步: [3,99,-1,-100]。
+
+
+# 思路
+
+这道题目在字符串里其实很常见,我把字符串反转相关的题目列一下:
+
+* [字符串:力扣541.反转字符串II](https://mp.weixin.qq.com/s/pzXt6PQ029y7bJ9YZB2mVQ)
+* [字符串:力扣151.翻转字符串里的单词](https://mp.weixin.qq.com/s/4j6vPFHkFAXnQhmSkq2X9g)
+* [字符串:剑指Offer58-II.左旋转字符串](https://mp.weixin.qq.com/s/Px_L-RfT2b_jXKcNmccPsw)
+
+本题其实和[字符串:剑指Offer58-II.左旋转字符串](https://mp.weixin.qq.com/s/Px_L-RfT2b_jXKcNmccPsw)就非常像了,剑指offer上左旋转,本题是右旋转。
+
+注意题目要求是**要求使用空间复杂度为 O(1) 的 原地 算法**
+
+那么我来提供一种旋转的方式哈。
+
+在[字符串:剑指Offer58-II.左旋转字符串](https://mp.weixin.qq.com/s/Px_L-RfT2b_jXKcNmccPsw)中,我们提到,如下步骤就可以坐旋转字符串:
+
+1. 反转区间为前n的子串
+2. 反转区间为n到末尾的子串
+3. 反转整个字符串
+
+本题是右旋转,其实就是反转的顺序改动一下,优先反转整个字符串,步骤如下:
+
+1. 反转整个字符串
+2. 反转区间为前k的子串
+3. 反转区间为k到末尾的子串
+
+**需要注意的是,本题还有一个小陷阱,题目输入中,如果k大于nums.size了应该怎么办?**
+
+举个例子,比较容易想,
+
+例如,1,2,3,4,5,6,7 如果右移动15次的话,是 7 1 2 3 4 5 6 。
+
+所以其实就是右移 k % nums.size() 次,即:15 % 7 = 1
+
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ void rotate(vector& nums, int k) {
+ k = k % nums.size();
+ reverse(nums.begin(), nums.end());
+ reverse(nums.begin(), nums.begin() + k);
+ reverse(nums.begin() + k, nums.end());
+
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+class Solution {
+ private void reverse(int[] nums, int start, int end) {
+ for (int i = start, j = end; i < j; i++, j--) {
+ int temp = nums[j];
+ nums[j] = nums[i];
+ nums[i] = temp;
+ }
+ }
+ public void rotate(int[] nums, int k) {
+ int n = nums.length;
+ k %= n;
+ reverse(nums, 0, n - 1);
+ reverse(nums, 0, k - 1);
+ reverse(nums, k, n - 1);
+ }
+}
+```
+
+## Python
+
+```python
+class Solution:
+ def rotate(self, A: List[int], k: int) -> None:
+ def reverse(i, j):
+ while i < j:
+ A[i], A[j] = A[j], A[i]
+ i += 1
+ j -= 1
+ n = len(A)
+ k %= n
+ reverse(0, n - 1)
+ reverse(0, k - 1)
+ reverse(k, n - 1)
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/0205.同构字符串.md b/problems/0205.同构字符串.md
new file mode 100644
index 00000000..4e963ece
--- /dev/null
+++ b/problems/0205.同构字符串.md
@@ -0,0 +1,93 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 205. 同构字符串
+
+题目地址:https://leetcode-cn.com/problems/isomorphic-strings/
+
+给定两个字符串 s 和 t,判断它们是否是同构的。
+
+如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。
+
+每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
+
+示例 1:
+* 输入:s = "egg", t = "add"
+* 输出:true
+
+示例 2:
+* 输入:s = "foo", t = "bar"
+* 输出:false
+
+示例 3:
+* 输入:s = "paper", t = "title"
+* 输出:true
+
+提示:可以假设 s 和 t 长度相同。
+
+# 思路
+
+字符串没有说都是小写字母之类的,所以用数组不合适了,用map来做映射。
+
+使用两个map 保存 s[i] 到 t[j] 和 t[j] 到 s[i] 的映射关系,如果发现对应不上,立刻返回 false
+
+C++代码 如下:
+
+```C++
+class Solution {
+public:
+ bool isIsomorphic(string s, string t) {
+ unordered_map map1;
+ unordered_map map2;
+ for (int i = 0, j = 0; i < s.size(); i++, j++) {
+ if (map1.find(s[i]) == map1.end()) { // map1保存s[i] 到 t[j]的映射
+ map1[s[i]] = t[j];
+ }
+ if (map2.find(t[j]) == map2.end()) { // map2保存t[j] 到 s[i]的映射
+ map2[t[j]] = s[i];
+ }
+ // 发现映射 对应不上,立刻返回false
+ if (map1[s[i]] != t[j] || map2[t[j]] != s[i]) {
+ return false;
+ }
+ }
+ return true;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0226.翻转二叉树.md b/problems/0226.翻转二叉树.md
index bba34766..44f0d3b4 100644
--- a/problems/0226.翻转二叉树.md
+++ b/problems/0226.翻转二叉树.md
@@ -190,6 +190,61 @@ public:
```
如果对以上代码不理解,或者不清楚二叉树的层序遍历,可以看这篇[二叉树:层序遍历登场!](https://mp.weixin.qq.com/s/4-bDKi7SdwfBGRm9FYduiA)
+## 拓展
+
+**文中我指的是递归的中序遍历是不行的,因为使用递归的中序遍历,某些节点的左右孩子会翻转两次。**
+
+如果非要使用递归中序的方式写,也可以,如下代码就可以避免节点左右孩子翻转两次的情况:
+
+```C++
+class Solution {
+public:
+ TreeNode* invertTree(TreeNode* root) {
+ if (root == NULL) return root;
+ invertTree(root->left); // 左
+ swap(root->left, root->right); // 中
+ invertTree(root->left); // 注意 这里依然要遍历左孩子,因为中间节点已经翻转了
+ return root;
+ }
+};
+```
+
+代码虽然可以,但这毕竟不是真正的递归中序遍历了。
+
+但使用迭代方式统一写法的中序是可以的。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ TreeNode* invertTree(TreeNode* root) {
+ stack st;
+ if (root != NULL) st.push(root);
+ while (!st.empty()) {
+ TreeNode* node = st.top();
+ if (node != NULL) {
+ st.pop();
+ if (node->right) st.push(node->right); // 右
+ st.push(node); // 中
+ st.push(NULL);
+ if (node->left) st.push(node->left); // 左
+
+ } else {
+ st.pop();
+ node = st.top();
+ st.pop();
+ swap(node->left, node->right); // 节点处理逻辑
+ }
+ }
+ return root;
+ }
+};
+
+```
+
+为什么这个中序就是可以的呢,因为这是用栈来遍历,而不是靠指针来遍历,避免了递归法中翻转了两次的情况,大家可以画图理解一下,这里有点意思的。
+
## 总结
针对二叉树的问题,解题之前一定要想清楚究竟是前中后序遍历,还是层序遍历。
diff --git a/problems/0234.回文链表.md b/problems/0234.回文链表.md
new file mode 100644
index 00000000..945d2ef4
--- /dev/null
+++ b/problems/0234.回文链表.md
@@ -0,0 +1,170 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 234.回文链表
+
+题目链接:https://leetcode-cn.com/problems/palindrome-linked-list/
+
+请判断一个链表是否为回文链表。
+
+示例 1:
+* 输入: 1->2
+* 输出: false
+
+示例 2:
+* 输入: 1->2->2->1
+* 输出: true
+
+
+# 思路
+
+## 数组模拟
+
+最直接的想法,就是把链表装成数组,然后再判断是否回文。
+
+代码也比较简单。如下:
+
+```C++
+class Solution {
+public:
+ bool isPalindrome(ListNode* head) {
+ vector vec;
+ ListNode* cur = head;
+ while (cur) {
+ vec.push_back(cur->val);
+ cur = cur->next;
+ }
+ // 比较数组回文
+ for (int i = 0, j = vec.size() - 1; i < j; i++, j--) {
+ if (vec[i] != vec[j]) return false;
+ }
+ return true;
+ }
+};
+```
+
+上面代码可以在优化,就是先求出链表长度,然后给定vector的初始长度,这样避免vector每次添加节点重新开辟空间
+
+```C++
+class Solution {
+public:
+ bool isPalindrome(ListNode* head) {
+
+ ListNode* cur = head;
+ int length = 0;
+ while (cur) {
+ length++;
+ cur = cur->next;
+ }
+ vector vec(length, 0); // 给定vector的初始长度,这样避免vector每次添加节点重新开辟空间
+ cur = head;
+ int index = 0;
+ while (cur) {
+ vec[index++] = cur->val;
+ cur = cur->next;
+ }
+ // 比较数组回文
+ for (int i = 0, j = vec.size() - 1; i < j; i++, j--) {
+ if (vec[i] != vec[j]) return false;
+ }
+ return true;
+ }
+};
+
+```
+
+## 反转后半部分链表
+
+分为如下几步:
+
+* 用快慢指针,快指针有两步,慢指针走一步,快指针遇到终止位置时,慢指针就在链表中间位置
+* 同时用pre记录慢指针指向节点的前一个节点,用来分割链表
+* 将链表分为前后均等两部分,如果链表长度是奇数,那么后半部分多一个节点
+* 将后半部分反转 ,得cur2,前半部分为cur1
+* 按照cur1的长度,一次比较cur1和cur2的节点数值
+
+如图所示:
+
+ +
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool isPalindrome(ListNode* head) {
+ if (head == nullptr || head->next == nullptr) return true;
+ ListNode* slow = head; // 慢指针,找到链表中间分位置,作为分割
+ ListNode* fast = head;
+ ListNode* pre = head; // 记录慢指针的前一个节点,用来分割链表
+ while (fast && fast->next) {
+ pre = slow;
+ slow = slow->next;
+ fast = fast->next->next;
+ }
+ pre->next = nullptr; // 分割链表
+
+ ListNode* cur1 = head; // 前半部分
+ ListNode* cur2 = reverseList(slow); // 反转后半部分,总链表长度如果是奇数,cur2比cur1多一个节点
+
+ // 开始两个链表的比较
+ while (cur1) {
+ if (cur1->val != cur2->val) return false;
+ cur1 = cur1->next;
+ cur2 = cur2->next;
+ }
+ return true;
+ }
+ // 反转链表
+ ListNode* reverseList(ListNode* head) {
+ ListNode* temp; // 保存cur的下一个节点
+ ListNode* cur = head;
+ ListNode* pre = nullptr;
+ while(cur) {
+ temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
+ cur->next = pre; // 翻转操作
+ // 更新pre 和 cur指针
+ pre = cur;
+ cur = temp;
+ }
+ return pre;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0283.移动零.md b/problems/0283.移动零.md
new file mode 100644
index 00000000..56f96b2f
--- /dev/null
+++ b/problems/0283.移动零.md
@@ -0,0 +1,89 @@
+
+
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool isPalindrome(ListNode* head) {
+ if (head == nullptr || head->next == nullptr) return true;
+ ListNode* slow = head; // 慢指针,找到链表中间分位置,作为分割
+ ListNode* fast = head;
+ ListNode* pre = head; // 记录慢指针的前一个节点,用来分割链表
+ while (fast && fast->next) {
+ pre = slow;
+ slow = slow->next;
+ fast = fast->next->next;
+ }
+ pre->next = nullptr; // 分割链表
+
+ ListNode* cur1 = head; // 前半部分
+ ListNode* cur2 = reverseList(slow); // 反转后半部分,总链表长度如果是奇数,cur2比cur1多一个节点
+
+ // 开始两个链表的比较
+ while (cur1) {
+ if (cur1->val != cur2->val) return false;
+ cur1 = cur1->next;
+ cur2 = cur2->next;
+ }
+ return true;
+ }
+ // 反转链表
+ ListNode* reverseList(ListNode* head) {
+ ListNode* temp; // 保存cur的下一个节点
+ ListNode* cur = head;
+ ListNode* pre = nullptr;
+ while(cur) {
+ temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
+ cur->next = pre; // 翻转操作
+ // 更新pre 和 cur指针
+ pre = cur;
+ cur = temp;
+ }
+ return pre;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0283.移动零.md b/problems/0283.移动零.md
new file mode 100644
index 00000000..56f96b2f
--- /dev/null
+++ b/problems/0283.移动零.md
@@ -0,0 +1,89 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+# 动态规划:一样的套路,再求一次完全平方数
+
+# 283. 移动零
+
+题目链接:https://leetcode-cn.com/problems/move-zeroes/
+
+给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
+
+示例:
+
+输入: [0,1,0,3,12]
+输出: [1,3,12,0,0]
+说明:
+
+必须在原数组上操作,不能拷贝额外的数组。
+尽量减少操作次数。
+
+
+# 思路
+
+做这道题目之前,大家可以做一做[27.移除元素](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)
+
+这道题目,使用暴力的解法,可以两层for循环,模拟数组删除元素(也就是向前覆盖)的过程。
+
+好了,我们说一说双指针法,大家如果对双指针还不熟悉,可以看我的这篇总结[双指针法:总结篇!](https://mp.weixin.qq.com/s/PLfYLuUIGDR6xVRQ_jTrmg)。
+
+双指针法在数组移除元素中,可以达到O(n)的时间复杂度,在[27.移除元素](https://mp.weixin.qq.com/s/RMkulE4NIb6XsSX83ra-Ww)里已经详细讲解了,那么本题和移除元素其实是一个套路。
+
+**相当于对整个数组移除元素0,然后slowIndex之后都是移除元素0的冗余元素,把这些元素都赋值为0就可以了**。
+
+如动画所示:
+
+
+
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ void moveZeroes(vector& nums) {
+ int slowIndex = 0;
+ for (int fastIndex = 0; fastIndex < nums.size(); fastIndex++) {
+ if (nums[fastIndex] != 0) {
+ nums[slowIndex++] = nums[fastIndex];
+ }
+ }
+ // 将slowIndex之后的冗余元素赋值为0
+ for (int i = slowIndex; i < nums.size(); i++) {
+ nums[i] = 0;
+ }
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+```python
+ def moveZeroes(self, nums: List[int]) -> None:
+ slow = 0
+ for fast in range(len(nums)):
+ if nums[fast] != 0:
+ nums[slow] = nums[fast]
+ slow += 1
+ for i in range(slow, len(nums)):
+ nums[i] = 0
+```
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0649.Dota2参议院.md b/problems/0649.Dota2参议院.md
new file mode 100644
index 00000000..696124d6
--- /dev/null
+++ b/problems/0649.Dota2参议院.md
@@ -0,0 +1,140 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 649. Dota2 参议院
+
+Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
+
+Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的一项:
+
+1. 禁止一名参议员的权利:参议员可以让另一位参议员在这一轮和随后的几轮中丧失所有的权利。
+
+2. 宣布胜利:如果参议员发现有权利投票的参议员都是同一个阵营的,他可以宣布胜利并决定在游戏中的有关变化。
+
+给定一个字符串代表每个参议员的阵营。字母 “R” 和 “D” 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。
+
+以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
+
+假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 Radiant 或 Dire。
+
+
+
+示例 1:
+* 输入:"RD"
+* 输出:"Radiant"
+* 解释:第一个参议员来自 Radiant 阵营并且他可以使用第一项权利让第二个参议员失去权力,因此第二个参议员将被跳过因为他没有任何权利。然后在第二轮的时候,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人
+
+示例 2:
+* 输入:"RDD"
+* 输出:"Dire"
+* 解释:
+第一轮中,第一个来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利,
+第二个来自 Dire 阵营的参议员会被跳过因为他的权利被禁止,
+第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利,
+因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利。
+
+
+# 思路
+
+这道题 题意太绕了,我举一个更形象的例子给大家捋顺一下。
+
+例如输入"RRDDD",执行过程应该是什么样呢?
+
+* 第一轮:senate[0]的R消灭senate[2]的D,senate[1]的R消灭senate[3]的D,senate[4]的D消灭senate[0]的R,此时剩下"RD",第一轮结束!
+* 第二轮:senate[0]的R消灭senate[1]的D,第二轮结束
+* 第三轮:只有R了,R胜利
+
+估计不少同学都困惑,R和D数量相同怎么办,究竟谁赢,**其实这是一个持续消灭的过程!** 即:如果同时存在R和D就继续进行下一轮消灭,轮数直到只剩下R或者D为止!
+
+那么每一轮消灭的策略应该是什么呢?
+
+例如:RDDRD
+
+第一轮:senate[0]的R消灭senate[1]的D,那么senate[2]的D,是消灭senate[0]的R还是消灭senate[3]的R呢?
+
+当然是消灭senate[3]的R,因为当轮到这个R的时候,它可以消灭senate[4]的D。
+
+**所以消灭的策略是,尽量消灭自己后面的对手,因为前面的对手已经使用过权利了,而后序的对手依然可以使用权利消灭自己的同伴!**
+
+那么局部最优:有一次权利机会,就消灭自己后面的对手。全局最优:为自己的阵营赢取最大利益。
+
+局部最优可以退出全局最优,举不出反例,那么试试贪心。
+
+如果对贪心算法理论基础还不了解的话,可以看看这篇:[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/O935TaoHE9Eexwe_vSbRAg) ,相信看完之后对贪心就有基本的了解了。
+
+# 代码实现
+
+实现代码,在每一轮循环的过程中,去过模拟优先消灭身后的对手,其实是比较麻烦的。
+
+这里有一个技巧,就是用一个变量记录当前参议员之前有几个敌对对手了,进而判断自己是否被消灭了。这个变量我用flag来表示。
+
+C++代码如下:
+
+
+```C++
+class Solution {
+public:
+ string predictPartyVictory(string senate) {
+ // R = true表示本轮循环结束后,字符串里依然有R。D同理
+ bool R = true, D = true;
+ // 当flag大于0时,R在D前出现,R可以消灭D。当flag小于0时,D在R前出现,D可以消灭R
+ int flag = 0;
+ while (R && D) { // 一旦R或者D为false,就结束循环,说明本轮结束后只剩下R或者D了
+ R = false;
+ D = false;
+ for (int i = 0; i < senate.size(); i++) {
+ if (senate[i] == 'R') {
+ if (flag < 0) senate[i] = 0; // 消灭R,R此时为false
+ else R = true; // 如果没被消灭,本轮循环结束有R
+ flag++;
+ }
+ if (senate[i] == 'D') {
+ if (flag > 0) senate[i] = 0;
+ else D = true;
+ flag--;
+ }
+ }
+ }
+ // 循环结束之后,R和D只能有一个为true
+ return R == true ? "Radiant" : "Dire";
+ }
+};
+```
+
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0657.机器人能否返回原点.md b/problems/0657.机器人能否返回原点.md
new file mode 100644
index 00000000..cd26836c
--- /dev/null
+++ b/problems/0657.机器人能否返回原点.md
@@ -0,0 +1,96 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 657. 机器人能否返回原点
+
+题目地址:https://leetcode-cn.com/problems/robot-return-to-origin/
+
+在二维平面上,有一个机器人从原点 (0, 0) 开始。给出它的移动顺序,判断这个机器人在完成移动后是否在 (0, 0) 处结束。
+
+移动顺序由字符串表示。字符 move[i] 表示其第 i 次移动。机器人的有效动作有 R(右),L(左),U(上)和 D(下)。如果机器人在完成所有动作后返回原点,则返回 true。否则,返回 false。
+
+注意:机器人“面朝”的方向无关紧要。 “R” 将始终使机器人向右移动一次,“L” 将始终向左移动等。此外,假设每次移动机器人的移动幅度相同。
+
+
+
+示例 1:
+* 输入: "UD"
+* 输出: true
+* 解释:机器人向上移动一次,然后向下移动一次。所有动作都具有相同的幅度,因此它最终回到它开始的原点。因此,我们返回 true。
+
+示例 2:
+* 输入: "LL"
+* 输出: false
+* 解释:机器人向左移动两次。它最终位于原点的左侧,距原点有两次 “移动” 的距离。我们返回 false,因为它在移动结束时没有返回原点。
+
+
+
+# 思路
+
+这道题目还是挺简单的,大家不要想复杂了,一波哈希法又一波图论算法啥的,哈哈。
+
+其实就是,x,y坐标,初始为0,然后:
+* if (moves[i] == 'U') y++;
+* if (moves[i] == 'D') y--;
+* if (moves[i] == 'L') x--;
+* if (moves[i] == 'R') x++;
+
+最后判断一下x,y是否回到了(0, 0)位置就可以了。
+
+如图所示:
+ +
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ bool judgeCircle(string moves) {
+ int x = 0, y = 0;
+ for (int i = 0; i < moves.size(); i++) {
+ if (moves[i] == 'U') y++;
+ if (moves[i] == 'D') y--;
+ if (moves[i] == 'L') x--;
+ if (moves[i] == 'R') x++;
+ }
+ if (x == 0 && y == 0) return true;
+ return false;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0673.最长递增子序列的个数.md b/problems/0673.最长递增子序列的个数.md
new file mode 100644
index 00000000..da0be740
--- /dev/null
+++ b/problems/0673.最长递增子序列的个数.md
@@ -0,0 +1,249 @@
+
+
+
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ bool judgeCircle(string moves) {
+ int x = 0, y = 0;
+ for (int i = 0; i < moves.size(); i++) {
+ if (moves[i] == 'U') y++;
+ if (moves[i] == 'D') y--;
+ if (moves[i] == 'L') x--;
+ if (moves[i] == 'R') x++;
+ }
+ if (x == 0 && y == 0) return true;
+ return false;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0673.最长递增子序列的个数.md b/problems/0673.最长递增子序列的个数.md
new file mode 100644
index 00000000..da0be740
--- /dev/null
+++ b/problems/0673.最长递增子序列的个数.md
@@ -0,0 +1,249 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 673.最长递增子序列的个数
+
+给定一个未排序的整数数组,找到最长递增子序列的个数。
+
+示例 1:
+* 输入: [1,3,5,4,7]
+* 输出: 2
+* 解释: 有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, 3, 5, 7]。
+
+示例 2:
+* 输入: [2,2,2,2,2]
+* 输出: 5
+* 解释: 最长递增子序列的长度是1,并且存在5个子序列的长度为1,因此输出5。
+
+
+# 思路
+
+这道题可以说是 300.最长上升子序列 的进阶版本
+
+1. 确定dp数组(dp table)以及下标的含义
+
+这道题目我们要一起维护两个数组。
+
+dp[i]:i之前(包括i)最长递增子序列的长度为dp[i]
+
+count[i]:以nums[i]为结尾的字符串,最长递增子序列的个数为count[i]
+
+2. 确定递推公式
+
+在300.最长上升子序列 中,我们给出的状态转移是:
+
+if (nums[i] > nums[j]) dp[i] = max(dp[i], dp[j] + 1);
+
+即:位置i的最长递增子序列长度 等于j从0到i-1各个位置的最长升序子序列 + 1的最大值。
+
+本题就没那么简单了,我们要考虑两个维度,一个是dp[i]的更新,一个是count[i]的更新。
+
+那么如何更新count[i]呢?
+
+以nums[i]为结尾的字符串,最长递增子序列的个数为count[i]。
+
+那么在nums[i] > nums[j]前提下,如果在[0, i-1]的范围内,找到了j,使得dp[j] + 1 > dp[i],说明找到了一个更长的递增子序列。
+
+那么以j为结尾的子串的最长递增子序列的个数,就是最新的以i为结尾的子串的最长递增子序列的个数,即:count[i] = count[j]。
+
+在nums[i] > nums[j]前提下,如果在[0, i-1]的范围内,找到了j,使得dp[j] + 1 == dp[i],说明找到了两个相同长度的递增子序列。
+
+那么以i为结尾的子串的最长递增子序列的个数 就应该加上以j为结尾的子串的最长递增子序列的个数,即:count[i] += count[j];
+
+代码如下:
+
+```C++
+if (nums[i] > nums[j]) {
+ if (dp[j] + 1 > dp[i]) {
+ count[i] = count[j];
+ } else if (dp[j] + 1 == dp[i]) {
+ count[i] += count[j];
+ }
+ dp[i] = max(dp[i], dp[j] + 1);
+}
+```
+
+当然也可以这么写:
+
+```C++
+if (nums[i] > nums[j]) {
+ if (dp[j] + 1 > dp[i]) {
+ dp[i] = dp[j] + 1; // 更新dp[i]放在这里,就不用max了
+ count[i] = count[j];
+ } else if (dp[j] + 1 == dp[i]) {
+ count[i] += count[j];
+ }
+}
+```
+
+这里count[i]记录了以nums[i]为结尾的字符串,最长递增子序列的个数。dp[i]记录了i之前(包括i)最长递增序列的长度。
+
+题目要求最长递增序列的长度的个数,我们应该把最长长度记录下来。
+
+代码如下:
+
+```C++
+for (int i = 1; i < nums.size(); i++) {
+ for (int j = 0; j < i; j++) {
+ if (nums[i] > nums[j]) {
+ if (dp[j] + 1 > dp[i]) {
+ count[i] = count[j];
+ } else if (dp[j] + 1 == dp[i]) {
+ count[i] += count[j];
+ }
+ dp[i] = max(dp[i], dp[j] + 1);
+ }
+ if (dp[i] > maxCount) maxCount = dp[i]; // 记录最长长度
+ }
+}
+```
+
+3. dp数组如何初始化
+
+再回顾一下dp[i]和count[i]的定义
+
+count[i]记录了以nums[i]为结尾的字符串,最长递增子序列的个数。
+
+那么最少也就是1个,所以count[i]初始为1。
+
+dp[i]记录了i之前(包括i)最长递增序列的长度。
+
+最小的长度也是1,所以dp[i]初始为1。
+
+代码如下:
+
+```
+vector dp(nums.size(), 1);
+vector count(nums.size(), 1);
+```
+
+**其实动规的题目中,初始化很有讲究,也很考察对dp数组定义的理解**。
+
+4. 确定遍历顺序
+
+dp[i] 是由0到i-1各个位置的最长升序子序列 推导而来,那么遍历i一定是从前向后遍历。
+
+j其实就是0到i-1,遍历i的循环里外层,遍历j则在内层,代码如下:
+
+```C++
+for (int i = 1; i < nums.size(); i++) {
+ for (int j = 0; j < i; j++) {
+ if (nums[i] > nums[j]) {
+ if (dp[j] + 1 > dp[i]) {
+ count[i] = count[j];
+ } else if (dp[j] + 1 == dp[i]) {
+ count[i] += count[j];
+ }
+ dp[i] = max(dp[i], dp[j] + 1);
+ }
+ if (dp[i] > maxCount) maxCount = dp[i];
+ }
+}
+```
+
+
+最后还有再遍历一遍dp[i],把最长递增序列长度对应的count[i]累计下来就是结果了。
+
+代码如下:
+
+```C++
+for (int i = 1; i < nums.size(); i++) {
+ for (int j = 0; j < i; j++) {
+ if (nums[i] > nums[j]) {
+ if (dp[j] + 1 > dp[i]) {
+ count[i] = count[j];
+ } else if (dp[j] + 1 == dp[i]) {
+ count[i] += count[j];
+ }
+ dp[i] = max(dp[i], dp[j] + 1);
+ }
+ if (dp[i] > maxCount) maxCount = dp[i];
+ }
+}
+int result = 0; // 统计结果
+for (int i = 0; i < nums.size(); i++) {
+ if (maxCount == dp[i]) result += count[i];
+}
+```
+
+统计结果,可能有的同学又有点看懵了,那么就再回顾一下dp[i]和count[i]的定义。
+
+5. 举例推导dp数组
+
+输入:[1,3,5,4,7]
+
+
+
+**如果代码写出来了,怎么改都通过不了,那么把dp和count打印出来看看对不对!**
+
+以上分析完毕,C++整体代码如下:
+
+```C++
+class Solution {
+public:
+ int findNumberOfLIS(vector& nums) {
+ if (nums.size() <= 1) return nums.size();
+ vector dp(nums.size(), 1);
+ vector count(nums.size(), 1);
+ int maxCount = 0;
+ for (int i = 1; i < nums.size(); i++) {
+ for (int j = 0; j < i; j++) {
+ if (nums[i] > nums[j]) {
+ if (dp[j] + 1 > dp[i]) {
+ dp[i] = dp[j] + 1;
+ count[i] = count[j];
+ } else if (dp[j] + 1 == dp[i]) {
+ count[i] += count[j];
+ }
+ }
+ if (dp[i] > maxCount) maxCount = dp[i];
+ }
+ }
+ int result = 0;
+ for (int i = 0; i < nums.size(); i++) {
+ if (maxCount == dp[i]) result += count[i];
+ }
+ return result;
+ }
+};
+```
+
+* 时间复杂度O(n^2)
+* 空间复杂度O(n)
+
+还有O(nlogn)的解法,使用树状数组,今天有点忙就先不写了,感兴趣的同学可以自行学习一下,这里有我之前写的树状数组系列博客:https://blog.csdn.net/youngyangyang04/category_871105.html (十年前的陈年老文了)
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0684.冗余连接.md b/problems/0684.冗余连接.md
new file mode 100644
index 00000000..9215af5f
--- /dev/null
+++ b/problems/0684.冗余连接.md
@@ -0,0 +1,171 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 684.冗余连接
+
+树可以看成是一个连通且 无环 的 无向 图。
+
+给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
+
+请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的边。
+
+
+
+提示:
+* n == edges.length
+* 3 <= n <= 1000
+* edges[i].length == 2
+* 1 <= ai < bi <= edges.length
+* ai != bi
+* edges 中无重复元素
+* 给定的图是连通的
+
+# 思路
+
+这道题目也是并查集基础题目。
+
+首先要知道并查集可以解决什么问题呢?
+
+主要就是集合问题,两个节点在不在一个集合,也可以将两个节点添加到一个集合中。
+
+这里整理出我的并查集模板如下:
+
+```C++
+int n = 1005; // 节点数量3 到 1000
+int father[1005];
+
+// 并查集初始化
+void init() {
+ for (int i = 0; i < n; ++i) {
+ father[i] = i;
+ }
+}
+// 并查集里寻根的过程
+int find(int u) {
+ return u == father[u] ? u : father[u] = find(father[u]);
+}
+// 将v->u 这条边加入并查集
+void join(int u, int v) {
+ u = find(u);
+ v = find(v);
+ if (u == v) return ;
+ father[v] = u;
+}
+// 判断 u 和 v是否找到同一个根
+bool same(int u, int v) {
+ u = find(u);
+ v = find(v);
+ return u == v;
+}
+```
+
+以上模板汇总,只要修改 n 和father数组的大小就可以了。
+
+并查集主要有三个功能。
+
+1. 寻找根节点,函数:find(int u),也就是判断这个节点的祖先节点是哪个
+2. 将两个节点接入到同一个集合,函数:join(int u, int v),将两个节点连在同一个根节点上
+3. 判断两个节点是否在同一个集合,函数:same(int u, int v),就是判断两个节点是不是同一个根节点
+
+简单介绍并查集之后,我们再来看一下这道题目。
+
+题目说是无向图,返回一条可以删去的边,使得结果图是一个有着N个节点的树。
+
+如果有多个答案,则返回二维数组中最后出现的边。
+
+那么我们就可以从前向后遍历每一条边,边的两个节点如果不在同一个集合,就加入集合(即:同一个根节点)。
+
+如果边的两个节点已经出现在同一个集合里,说明着边的两个节点已经连在一起了,如果再加入这条边一定就出现环了。
+
+这个思路清晰之后,代码就很好写了。
+
+并查集C++代码如下:
+
+```C++
+class Solution {
+private:
+ int n = 1005; // 节点数量3 到 1000
+ int father[1005];
+
+ // 并查集初始化
+ void init() {
+ for (int i = 0; i < n; ++i) {
+ father[i] = i;
+ }
+ }
+ // 并查集里寻根的过程
+ int find(int u) {
+ return u == father[u] ? u : father[u] = find(father[u]);
+ }
+ // 将v->u 这条边加入并查集
+ void join(int u, int v) {
+ u = find(u);
+ v = find(v);
+ if (u == v) return ;
+ father[v] = u;
+ }
+ // 判断 u 和 v是否找到同一个根,本题用不上
+ bool same(int u, int v) {
+ u = find(u);
+ v = find(v);
+ return u == v;
+ }
+public:
+ vector findRedundantConnection(vector>& edges) {
+ init();
+ for (int i = 0; i < edges.size(); i++) {
+ if (same(edges[i][0], edges[i][1])) return edges[i];
+ else join(edges[i][0], edges[i][1]);
+ }
+ return {};
+ }
+};
+
+```
+
+可以看出,主函数的代码很少,就判断一下边的两个节点在不在同一个集合就可以了。
+
+这里对并查集就不展开过多的讲解了,翻到了自己十年前写过了一篇并查集的文章[并查集学习](https://blog.csdn.net/youngyangyang04/article/details/6447435),哈哈,那时候还太年轻,写不咋地,有空我会重写并查集基础篇!
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
+
+
+
+
+
diff --git a/problems/0685.冗余连接II.md b/problems/0685.冗余连接II.md
new file mode 100644
index 00000000..b744c831
--- /dev/null
+++ b/problems/0685.冗余连接II.md
@@ -0,0 +1,229 @@
+
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 685.冗余连接II
+
+题目地址:https://leetcode-cn.com/problems/redundant-connection-ii/
+
+在本问题中,有根树指满足以下条件的 有向 图。该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。
+
+输入一个有向图,该图由一个有着 n 个节点(节点值不重复,从 1 到 n)的树及一条附加的有向边构成。附加的边包含在 1 到 n 中的两个不同顶点间,这条附加的边不属于树中已存在的边。
+
+结果图是一个以边组成的二维数组 edges 。 每个元素是一对 [ui, vi],用以表示 有向 图中连接顶点 ui 和顶点 vi 的边,其中 ui 是 vi 的一个父节点。
+
+返回一条能删除的边,使得剩下的图是有 n 个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。
+
+
+
+
+
+
+提示:
+
+* n == edges.length
+* 3 <= n <= 1000
+* edges[i].length == 2
+* 1 <= ui, vi <= n
+
+## 思路
+
+先重点读懂题目中的这句**该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。**
+
+**这说明题目中的图原本是是一棵树,只不过在不增加节点的情况下多加了一条边!**
+
+还有**若有多个答案,返回最后出现在给定二维数组的答案。**这说明在两天边都可以删除的情况下,要删顺序靠后的!
+
+
+那么有如下三种情况,前两种情况是出现入度为2的点,如图:
+
+ +
+且只有一个节点入度为2,为什么不看出度呢,出度没有意义,一颗树中随便一个父节点就有多个出度。
+
+
+第三种情况是没有入度为2的点,那么图中一定出现了有向环(**注意这里强调是有向环!**)
+
+如图:
+
+
+
+且只有一个节点入度为2,为什么不看出度呢,出度没有意义,一颗树中随便一个父节点就有多个出度。
+
+
+第三种情况是没有入度为2的点,那么图中一定出现了有向环(**注意这里强调是有向环!**)
+
+如图:
+
+ +
+
+首先先计算节点的入度,代码如下:
+
+```C++
+int inDegree[N] = {0}; // 记录节点入度
+n = edges.size(); // 边的数量
+for (int i = 0; i < n; i++) {
+ inDegree[edges[i][1]]++; // 统计入度
+}
+```
+
+前两种入度为2的情况,一定是删除指向入度为2的节点的两条边其中的一条,如果删了一条,判断这个图是一个树,那么这条边就是答案,同时注意要从后向前遍历,因为如果两天边删哪一条都可以成为树,就删最后那一条。
+
+代码如下:
+
+```C++
+vector vec; // 记录入度为2的边(如果有的话就两条边)
+// 找入度为2的节点所对应的边,注意要倒叙,因为优先返回最后出现在二维数组中的答案
+for (int i = n - 1; i >= 0; i--) {
+ if (inDegree[edges[i][1]] == 2) {
+ vec.push_back(i);
+ }
+}
+// 处理图中情况1 和 情况2
+// 如果有入度为2的节点,那么一定是两条边里删一个,看删哪个可以构成树
+if (vec.size() > 0) {
+ if (isTreeAfterRemoveEdge(edges, vec[0])) {
+ return edges[vec[0]];
+ } else {
+ return edges[vec[1]];
+ }
+}
+```
+
+在来看情况三,明确没有入度为2的情况,那么一定有有向环,找到构成环的边就是要删除的边。
+
+可以定义一个函数,代码如下:
+
+```
+// 在有向图里找到删除的那条边,使其变成树,返回值就是要删除的边
+vector getRemoveEdge(const vector>& edges)
+```
+
+此时 大家应该知道了,我们要实现两个最为关键的函数:
+
+* `isTreeAfterRemoveEdge()` 判断删一个边之后是不是树了
+* `getRemoveEdge` 确定图中一定有了有向环,那么要找到需要删除的那条边
+
+此时应该是用到**并查集**了,并查集为什么可以判断 一个图是不是树呢?
+
+**因为如果两个点所在的边在添加图之前如果就可以在并查集里找到了相同的根,那么这条边添加上之后 这个图一定不是树了**
+
+这里对并查集就不展开过多的讲解了,翻到了自己十年前写过了一篇并查集的文章[并查集学习](https://blog.csdn.net/youngyangyang04/article/details/6447435),哈哈,那时候还太年轻,写不咋地,有空我会重写一篇!
+
+本题C++代码如下:(详细注释了)
+
+
+```C++
+class Solution {
+private:
+ static const int N = 1010; // 如题:二维数组大小的在3到1000范围内
+ int father[N];
+ int n; // 边的数量
+ // 并查集初始化
+ void init() {
+ for (int i = 1; i <= n; ++i) {
+ father[i] = i;
+ }
+ }
+ // 并查集里寻根的过程
+ int find(int u) {
+ return u == father[u] ? u : father[u] = find(father[u]);
+ }
+ // 将v->u 这条边加入并查集
+ void join(int u, int v) {
+ u = find(u);
+ v = find(v);
+ if (u == v) return ;
+ father[v] = u;
+ }
+ // 判断 u 和 v是否找到同一个根
+ bool same(int u, int v) {
+ u = find(u);
+ v = find(v);
+ return u == v;
+ }
+ // 在有向图里找到删除的那条边,使其变成树
+ vector getRemoveEdge(const vector>& edges) {
+ init(); // 初始化并查集
+ for (int i = 0; i < n; i++) { // 遍历所有的边
+ if (same(edges[i][0], edges[i][1])) { // 构成有向环了,就是要删除的边
+ return edges[i];
+ }
+ join(edges[i][0], edges[i][1]);
+ }
+ return {};
+ }
+
+ // 删一条边之后判断是不是树
+ bool isTreeAfterRemoveEdge(const vector>& edges, int deleteEdge) {
+ init(); // 初始化并查集
+ for (int i = 0; i < n; i++) {
+ if (i == deleteEdge) continue;
+ if (same(edges[i][0], edges[i][1])) { // 构成有向环了,一定不是树
+ return false;
+ }
+ join(edges[i][0], edges[i][1]);
+ }
+ return true;
+ }
+public:
+
+ vector findRedundantDirectedConnection(vector>& edges) {
+ int inDegree[N] = {0}; // 记录节点入度
+ n = edges.size(); // 边的数量
+ for (int i = 0; i < n; i++) {
+ inDegree[edges[i][1]]++; // 统计入度
+ }
+ vector vec; // 记录入度为2的边(如果有的话就两条边)
+ // 找入度为2的节点所对应的边,注意要倒叙,因为优先返回最后出现在二维数组中的答案
+ for (int i = n - 1; i >= 0; i--) {
+ if (inDegree[edges[i][1]] == 2) {
+ vec.push_back(i);
+ }
+ }
+ // 处理图中情况1 和 情况2
+ // 如果有入度为2的节点,那么一定是两条边里删一个,看删哪个可以构成树
+ if (vec.size() > 0) {
+ if (isTreeAfterRemoveEdge(edges, vec[0])) {
+ return edges[vec[0]];
+ } else {
+ return edges[vec[1]];
+ }
+ }
+ // 处理图中情况3
+ // 明确没有入度为2的情况,那么一定有有向环,找到构成环的边返回就可以了
+ return getRemoveEdge(edges);
+
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/0724.寻找数组的中心索引.md b/problems/0724.寻找数组的中心索引.md
new file mode 100644
index 00000000..bf989979
--- /dev/null
+++ b/problems/0724.寻找数组的中心索引.md
@@ -0,0 +1,93 @@
+
+
+
+
+首先先计算节点的入度,代码如下:
+
+```C++
+int inDegree[N] = {0}; // 记录节点入度
+n = edges.size(); // 边的数量
+for (int i = 0; i < n; i++) {
+ inDegree[edges[i][1]]++; // 统计入度
+}
+```
+
+前两种入度为2的情况,一定是删除指向入度为2的节点的两条边其中的一条,如果删了一条,判断这个图是一个树,那么这条边就是答案,同时注意要从后向前遍历,因为如果两天边删哪一条都可以成为树,就删最后那一条。
+
+代码如下:
+
+```C++
+vector vec; // 记录入度为2的边(如果有的话就两条边)
+// 找入度为2的节点所对应的边,注意要倒叙,因为优先返回最后出现在二维数组中的答案
+for (int i = n - 1; i >= 0; i--) {
+ if (inDegree[edges[i][1]] == 2) {
+ vec.push_back(i);
+ }
+}
+// 处理图中情况1 和 情况2
+// 如果有入度为2的节点,那么一定是两条边里删一个,看删哪个可以构成树
+if (vec.size() > 0) {
+ if (isTreeAfterRemoveEdge(edges, vec[0])) {
+ return edges[vec[0]];
+ } else {
+ return edges[vec[1]];
+ }
+}
+```
+
+在来看情况三,明确没有入度为2的情况,那么一定有有向环,找到构成环的边就是要删除的边。
+
+可以定义一个函数,代码如下:
+
+```
+// 在有向图里找到删除的那条边,使其变成树,返回值就是要删除的边
+vector getRemoveEdge(const vector>& edges)
+```
+
+此时 大家应该知道了,我们要实现两个最为关键的函数:
+
+* `isTreeAfterRemoveEdge()` 判断删一个边之后是不是树了
+* `getRemoveEdge` 确定图中一定有了有向环,那么要找到需要删除的那条边
+
+此时应该是用到**并查集**了,并查集为什么可以判断 一个图是不是树呢?
+
+**因为如果两个点所在的边在添加图之前如果就可以在并查集里找到了相同的根,那么这条边添加上之后 这个图一定不是树了**
+
+这里对并查集就不展开过多的讲解了,翻到了自己十年前写过了一篇并查集的文章[并查集学习](https://blog.csdn.net/youngyangyang04/article/details/6447435),哈哈,那时候还太年轻,写不咋地,有空我会重写一篇!
+
+本题C++代码如下:(详细注释了)
+
+
+```C++
+class Solution {
+private:
+ static const int N = 1010; // 如题:二维数组大小的在3到1000范围内
+ int father[N];
+ int n; // 边的数量
+ // 并查集初始化
+ void init() {
+ for (int i = 1; i <= n; ++i) {
+ father[i] = i;
+ }
+ }
+ // 并查集里寻根的过程
+ int find(int u) {
+ return u == father[u] ? u : father[u] = find(father[u]);
+ }
+ // 将v->u 这条边加入并查集
+ void join(int u, int v) {
+ u = find(u);
+ v = find(v);
+ if (u == v) return ;
+ father[v] = u;
+ }
+ // 判断 u 和 v是否找到同一个根
+ bool same(int u, int v) {
+ u = find(u);
+ v = find(v);
+ return u == v;
+ }
+ // 在有向图里找到删除的那条边,使其变成树
+ vector getRemoveEdge(const vector>& edges) {
+ init(); // 初始化并查集
+ for (int i = 0; i < n; i++) { // 遍历所有的边
+ if (same(edges[i][0], edges[i][1])) { // 构成有向环了,就是要删除的边
+ return edges[i];
+ }
+ join(edges[i][0], edges[i][1]);
+ }
+ return {};
+ }
+
+ // 删一条边之后判断是不是树
+ bool isTreeAfterRemoveEdge(const vector>& edges, int deleteEdge) {
+ init(); // 初始化并查集
+ for (int i = 0; i < n; i++) {
+ if (i == deleteEdge) continue;
+ if (same(edges[i][0], edges[i][1])) { // 构成有向环了,一定不是树
+ return false;
+ }
+ join(edges[i][0], edges[i][1]);
+ }
+ return true;
+ }
+public:
+
+ vector findRedundantDirectedConnection(vector>& edges) {
+ int inDegree[N] = {0}; // 记录节点入度
+ n = edges.size(); // 边的数量
+ for (int i = 0; i < n; i++) {
+ inDegree[edges[i][1]]++; // 统计入度
+ }
+ vector vec; // 记录入度为2的边(如果有的话就两条边)
+ // 找入度为2的节点所对应的边,注意要倒叙,因为优先返回最后出现在二维数组中的答案
+ for (int i = n - 1; i >= 0; i--) {
+ if (inDegree[edges[i][1]] == 2) {
+ vec.push_back(i);
+ }
+ }
+ // 处理图中情况1 和 情况2
+ // 如果有入度为2的节点,那么一定是两条边里删一个,看删哪个可以构成树
+ if (vec.size() > 0) {
+ if (isTreeAfterRemoveEdge(edges, vec[0])) {
+ return edges[vec[0]];
+ } else {
+ return edges[vec[1]];
+ }
+ }
+ // 处理图中情况3
+ // 明确没有入度为2的情况,那么一定有有向环,找到构成环的边返回就可以了
+ return getRemoveEdge(edges);
+
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/0724.寻找数组的中心索引.md b/problems/0724.寻找数组的中心索引.md
new file mode 100644
index 00000000..bf989979
--- /dev/null
+++ b/problems/0724.寻找数组的中心索引.md
@@ -0,0 +1,93 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 724.寻找数组的中心下标
+
+给你一个整数数组 nums ,请计算数组的 中心下标 。
+
+数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
+
+如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
+
+如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
+
+示例 1:
+* 输入:nums = [1, 7, 3, 6, 5, 6]
+* 输出:3
+* 解释:中心下标是 3。左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 ,右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。
+
+示例 2:
+* 输入:nums = [1, 2, 3]
+* 输出:-1
+* 解释:数组中不存在满足此条件的中心下标。
+
+示例 3:
+* 输入:nums = [2, 1, -1]
+* 输出:0
+* 解释:中心下标是 0。左侧数之和 sum = 0 ,(下标 0 左侧不存在元素),右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
+
+
+# 思路
+
+这道题目还是比较简单直接啊哈哈
+
+1. 遍历一遍求出总和sum
+2. 遍历第二遍求中心索引左半和leftSum
+ * 同时根据sum和leftSum 计算中心索引右半和rightSum
+ * 判断leftSum和rightSum是否相同
+
+C++代码如下:
+```C++
+class Solution {
+public:
+ int pivotIndex(vector& nums) {
+ int sum = 0;
+ for (int num : nums) sum += num; // 求和
+ int leftSum = 0; // 中心索引左半和
+ int rightSum = 0; // 中心索引右半和
+ for (int i = 0; i < nums.size(); i++) {
+ leftSum += nums[i];
+ rightSum = sum - leftSum + nums[i];
+ if (leftSum == rightSum) return i;
+ }
+ return -1;
+ }
+};
+```
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/0841.钥匙和房间.md b/problems/0841.钥匙和房间.md
new file mode 100644
index 00000000..1b3c4a95
--- /dev/null
+++ b/problems/0841.钥匙和房间.md
@@ -0,0 +1,135 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+# 841.钥匙和房间
+
+题目地址:https://leetcode-cn.com/problems/keys-and-rooms/
+
+有 N 个房间,开始时你位于 0 号房间。每个房间有不同的号码:0,1,2,...,N-1,并且房间里可能有一些钥匙能使你进入下一个房间。
+
+在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i],每个钥匙 rooms[i][j] 由 [0,1,...,N-1] 中的一个整数表示,其中 N = rooms.length。 钥匙 rooms[i][j] = v 可以打开编号为 v 的房间。
+
+最初,除 0 号房间外的其余所有房间都被锁住。
+
+你可以自由地在房间之间来回走动。
+
+如果能进入每个房间返回 true,否则返回 false。
+
+示例 1:
+* 输入: [[1],[2],[3],[]]
+* 输出: true
+* 解释:
+我们从 0 号房间开始,拿到钥匙 1。
+之后我们去 1 号房间,拿到钥匙 2。
+然后我们去 2 号房间,拿到钥匙 3。
+最后我们去了 3 号房间。
+由于我们能够进入每个房间,我们返回 true。
+
+示例 2:
+* 输入:[[1,3],[3,0,1],[2],[0]]
+* 输出:false
+* 解释:我们不能进入 2 号房间。
+
+
+## 思
+
+其实这道题的本质就是判断各个房间所连成的有向图,说明不用访问所有的房间。
+
+如图所示:
+
+ +
+示例1就可以访问所有的房间,因为通过房间里的key将房间连在了一起。
+
+示例2中,就不能访问所有房间,从图中就可以看出,房间2是一个孤岛,我们从0出发,无论怎么遍历,都访问不到房间2。
+
+认清本质问题之后,**使用 广度优先搜索(BFS) 还是 深度优先搜索(DFS) 都是可以的。**
+
+BFS C++代码代码如下:
+
+```C++
+class Solution {
+bool bfs(const vector>& rooms) {
+ vector visited(rooms.size(), 0); // 标记房间是否被访问过
+ visited[0] = 1; // 0 号房间开始
+ queue que;
+ que.push(0); // 0 号房间开始
+
+ // 广度优先搜索的过程
+ while (!que.empty()) {
+ int key = que.front(); que.pop();
+ vector keys = rooms[key];
+ for (int key : keys) {
+ if (!visited[key]) {
+ que.push(key);
+ visited[key] = 1;
+ }
+ }
+ }
+ // 检查房间是不是都遍历过了
+ for (int i : visited) {
+ if (i == 0) return false;
+ }
+ return true;
+
+}
+public:
+ bool canVisitAllRooms(vector>& rooms) {
+ return bfs(rooms);
+ }
+};
+```
+
+DFS C++代码如下:
+
+```C++
+class Solution {
+private:
+ void dfs(int key, const vector>& rooms, vector& visited) {
+ if (visited[key]) {
+ return;
+ }
+ visited[key] = 1;
+ vector keys = rooms[key];
+ for (int key : keys) {
+ // 深度优先搜索遍历
+ dfs(key, rooms, visited);
+ }
+ }
+public:
+ bool canVisitAllRooms(vector>& rooms) {
+ vector visited(rooms.size(), 0);
+ dfs(0, rooms, visited);
+ //检查是否都访问到了
+ for (int i : visited) {
+ if (i == 0) return false;
+ }
+ return true;
+ }
+};
+```
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0844.比较含退格的字符串.md b/problems/0844.比较含退格的字符串.md
new file mode 100644
index 00000000..9f37959d
--- /dev/null
+++ b/problems/0844.比较含退格的字符串.md
@@ -0,0 +1,174 @@
+
+
+
+示例1就可以访问所有的房间,因为通过房间里的key将房间连在了一起。
+
+示例2中,就不能访问所有房间,从图中就可以看出,房间2是一个孤岛,我们从0出发,无论怎么遍历,都访问不到房间2。
+
+认清本质问题之后,**使用 广度优先搜索(BFS) 还是 深度优先搜索(DFS) 都是可以的。**
+
+BFS C++代码代码如下:
+
+```C++
+class Solution {
+bool bfs(const vector>& rooms) {
+ vector visited(rooms.size(), 0); // 标记房间是否被访问过
+ visited[0] = 1; // 0 号房间开始
+ queue que;
+ que.push(0); // 0 号房间开始
+
+ // 广度优先搜索的过程
+ while (!que.empty()) {
+ int key = que.front(); que.pop();
+ vector keys = rooms[key];
+ for (int key : keys) {
+ if (!visited[key]) {
+ que.push(key);
+ visited[key] = 1;
+ }
+ }
+ }
+ // 检查房间是不是都遍历过了
+ for (int i : visited) {
+ if (i == 0) return false;
+ }
+ return true;
+
+}
+public:
+ bool canVisitAllRooms(vector>& rooms) {
+ return bfs(rooms);
+ }
+};
+```
+
+DFS C++代码如下:
+
+```C++
+class Solution {
+private:
+ void dfs(int key, const vector>& rooms, vector& visited) {
+ if (visited[key]) {
+ return;
+ }
+ visited[key] = 1;
+ vector keys = rooms[key];
+ for (int key : keys) {
+ // 深度优先搜索遍历
+ dfs(key, rooms, visited);
+ }
+ }
+public:
+ bool canVisitAllRooms(vector>& rooms) {
+ vector visited(rooms.size(), 0);
+ dfs(0, rooms, visited);
+ //检查是否都访问到了
+ for (int i : visited) {
+ if (i == 0) return false;
+ }
+ return true;
+ }
+};
+```
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0844.比较含退格的字符串.md b/problems/0844.比较含退格的字符串.md
new file mode 100644
index 00000000..9f37959d
--- /dev/null
+++ b/problems/0844.比较含退格的字符串.md
@@ -0,0 +1,174 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 844.比较含退格的字符串
+
+题目链接:https://leetcode-cn.com/problems/backspace-string-compare/
+
+给定 S 和 T 两个字符串,当它们分别被输入到空白的文本编辑器后,判断二者是否相等,并返回结果。 # 代表退格字符。
+
+注意:如果对空文本输入退格字符,文本继续为空。
+
+示例 1:
+* 输入:S = "ab#c", T = "ad#c"
+* 输出:true
+* 解释:S 和 T 都会变成 “ac”。
+
+示例 2:
+* 输入:S = "ab##", T = "c#d#"
+* 输出:true
+* 解释:S 和 T 都会变成 “”。
+
+示例 3:
+* 输入:S = "a##c", T = "#a#c"
+* 输出:true
+* 解释:S 和 T 都会变成 “c”。
+
+示例 4:
+* 输入:S = "a#c", T = "b"
+* 输出:false
+* 解释:S 会变成 “c”,但 T 仍然是 “b”。
+
+
+# 思路
+
+本文将给出 空间复杂度O(n)的栈模拟方法 以及空间复杂度是O(1)的双指针方法。
+
+## 普通方法(使用栈的思路)
+
+这道题目一看就是要使用栈的节奏,这种匹配(消除)问题也是栈的擅长所在,跟着一起刷题的同学应该知道,在[栈与队列:匹配问题都是栈的强项](https://mp.weixin.qq.com/s/1-x6r1wGA9mqIHW5LrMvBg),我就已经提过了一次使用栈来做类似的事情了。
+
+**那么本题,确实可以使用栈的思路,但是没有必要使用栈,因为最后比较的时候还要比较栈里的元素,有点麻烦**。
+
+这里直接使用字符串string,来作为栈,末尾添加和弹出,string都有相应的接口,最后比较的时候,只要比较两个字符串就可以了,比比较栈里的元素方便一些。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool backspaceCompare(string S, string T) {
+ string s; // 当栈来用
+ string t; // 当栈来用
+ for (int i = 0; i < S.size(); i++) {
+ if (S[i] != '#') s += S[i];
+ else if (!s.empty()) {
+ s.pop_back();
+
+ }
+ for (int i = 0; i < T.size(); i++) {
+ if (T[i] != '#') t += T[i];
+ else if (!t.empty()) {
+ t.pop_back();
+ }
+ }
+ if (s == t) return true; // 直接比较两个字符串是否相等,比用栈来比较方便多了
+ return false;
+ }
+};
+```
+* 时间复杂度:O(n + m), n为S的长度,m为T的长度 ,也可以理解是O(n)的时间复杂度
+* 空间复杂度:O(n + m)
+
+当然以上代码,大家可以发现有重复的逻辑处理S,处理T,可以把这块公共逻辑抽离出来,代码精简如下:
+
+```C++
+class Solution {
+private:
+string getString(const string& S) {
+ string s;
+ for (int i = 0; i < S.size(); i++) {
+ if (S[i] != '#') s += S[i];
+ else if (!s.empty()) {
+ s.pop_back();
+ }
+ }
+ return s;
+}
+public:
+ bool backspaceCompare(string S, string T) {
+ return getString(S) == getString(T);
+ }
+};
+```
+性能依然是:
+* 时间复杂度:O(n + m)
+* 空间复杂度:O(n + m)
+
+## 优化方法(从后向前双指针)
+
+当然还可以有使用 O(1) 的空间复杂度来解决该问题。
+
+同时从后向前遍历S和T(i初始为S末尾,j初始为T末尾),记录#的数量,模拟消除的操作,如果#用完了,就开始比较S[i]和S[j]。
+
+动画如下:
+
+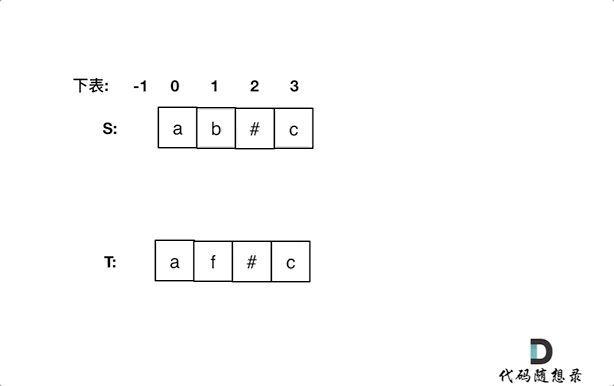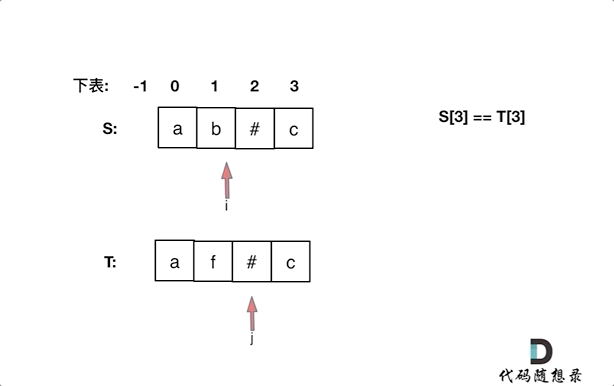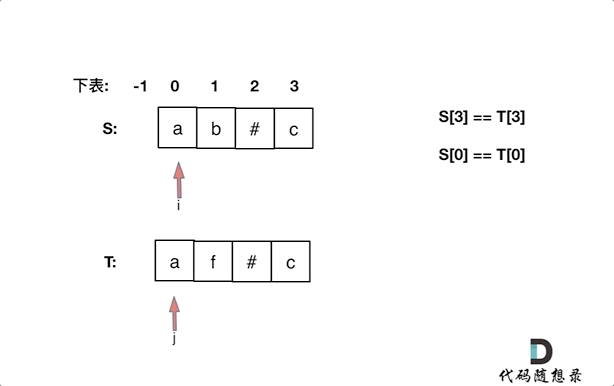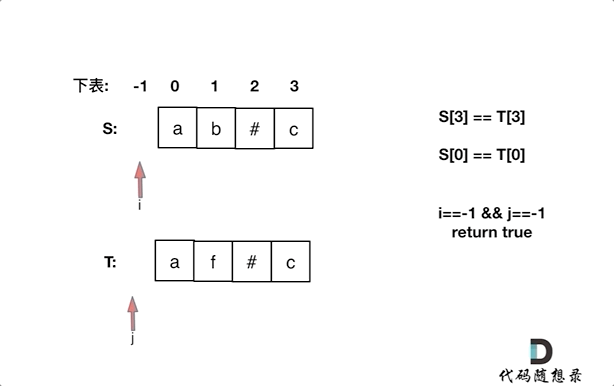 +
+如果S[i]和S[j]不相同返回false,如果有一个指针(i或者j)先走到的字符串头部位置,也返回false。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool backspaceCompare(string S, string T) {
+ int sSkipNum = 0; // 记录S的#数量
+ int tSkipNum = 0; // 记录T的#数量
+ int i = S.size() - 1;
+ int j = T.size() - 1;
+ while (1) {
+ while (i >= 0) { // 从后向前,消除S的#
+ if (S[i] == '#') sSkipNum++;
+ else {
+ if (sSkipNum > 0) sSkipNum--;
+ else break;
+ }
+ i--;
+ }
+ while (j >= 0) { // 从后向前,消除T的#
+ if (T[j] == '#') tSkipNum++;
+ else {
+ if (tSkipNum > 0) tSkipNum--;
+ else break;
+ }
+ j--;
+ }
+ // 后半部分#消除完了,接下来比较S[i] != T[j]
+ if (i < 0 || j < 0) break; // S 或者T 遍历到头了
+ if (S[i] != T[j]) return false;
+ i--;j--;
+ }
+ // 说明S和T同时遍历完毕
+ if (i == -1 && j == -1) return true;
+ return false;
+ }
+};
+```
+
+* 时间复杂度:O(n + m)
+* 空间复杂度:O(1)
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0922.按奇偶排序数组II.md b/problems/0922.按奇偶排序数组II.md
new file mode 100644
index 00000000..bb609c12
--- /dev/null
+++ b/problems/0922.按奇偶排序数组II.md
@@ -0,0 +1,146 @@
+
+
+
+如果S[i]和S[j]不相同返回false,如果有一个指针(i或者j)先走到的字符串头部位置,也返回false。
+
+代码如下:
+
+```C++
+class Solution {
+public:
+ bool backspaceCompare(string S, string T) {
+ int sSkipNum = 0; // 记录S的#数量
+ int tSkipNum = 0; // 记录T的#数量
+ int i = S.size() - 1;
+ int j = T.size() - 1;
+ while (1) {
+ while (i >= 0) { // 从后向前,消除S的#
+ if (S[i] == '#') sSkipNum++;
+ else {
+ if (sSkipNum > 0) sSkipNum--;
+ else break;
+ }
+ i--;
+ }
+ while (j >= 0) { // 从后向前,消除T的#
+ if (T[j] == '#') tSkipNum++;
+ else {
+ if (tSkipNum > 0) tSkipNum--;
+ else break;
+ }
+ j--;
+ }
+ // 后半部分#消除完了,接下来比较S[i] != T[j]
+ if (i < 0 || j < 0) break; // S 或者T 遍历到头了
+ if (S[i] != T[j]) return false;
+ i--;j--;
+ }
+ // 说明S和T同时遍历完毕
+ if (i == -1 && j == -1) return true;
+ return false;
+ }
+};
+```
+
+* 时间复杂度:O(n + m)
+* 空间复杂度:O(1)
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/0922.按奇偶排序数组II.md b/problems/0922.按奇偶排序数组II.md
new file mode 100644
index 00000000..bb609c12
--- /dev/null
+++ b/problems/0922.按奇偶排序数组II.md
@@ -0,0 +1,146 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+
+
+# 922. 按奇偶排序数组II
+
+给定一个非负整数数组 A, A 中一半整数是奇数,一半整数是偶数。
+
+对数组进行排序,以便当 A[i] 为奇数时,i 也是奇数;当 A[i] 为偶数时, i 也是偶数。
+
+你可以返回任何满足上述条件的数组作为答案。
+
+示例:
+
+* 输入:[4,2,5,7]
+* 输出:[4,5,2,7]
+* 解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。
+
+
+# 思路
+
+这道题目直接的想法可能是两层for循环再加上used数组表示使用过的元素。这样的的时间复杂度是O(n^2)。
+
+## 方法一
+
+其实这道题可以用很朴实的方法,时间复杂度就就是O(n)了,C++代码如下:
+
+```C++
+class Solution {
+public:
+ vector sortArrayByParityII(vector& A) {
+ vector even(A.size() / 2); // 初始化就确定数组大小,节省开销
+ vector odd(A.size() / 2);
+ vector result(A.size());
+ int evenIndex = 0;
+ int oddIndex = 0;
+ int resultIndex = 0;
+ // 把A数组放进偶数数组,和奇数数组
+ for (int i = 0; i < A.size(); i++) {
+ if (A[i] % 2 == 0) even[evenIndex++] = A[i];
+ else odd[oddIndex++] = A[i];
+ }
+ // 把偶数数组,奇数数组分别放进result数组中
+ for (int i = 0; i < evenIndex; i++) {
+ result[resultIndex++] = even[i];
+ result[resultIndex++] = odd[i];
+ }
+ return result;
+ }
+};
+```
+
+时间复杂度:O(n)
+空间复杂度:O(n)
+
+## 方法二
+
+以上代码我是建了两个辅助数组,而且A数组还相当于遍历了两次,用辅助数组的好处就是思路清晰,优化一下就是不用这两个辅助树,代码如下:
+
+```C++
+class Solution {
+public:
+ vector sortArrayByParityII(vector& A) {
+ vector result(A.size());
+ int evenIndex = 0; // 偶数下表
+ int oddIndex = 1; // 奇数下表
+ for (int i = 0; i < A.size(); i++) {
+ if (A[i] % 2 == 0) {
+ result[evenIndex] = A[i];
+ evenIndex += 2;
+ }
+ else {
+ result[oddIndex] = A[i];
+ oddIndex += 2;
+ }
+ }
+ return result;
+ }
+};
+```
+
+时间复杂度O(n)
+空间复杂度O(n)
+
+## 方法三
+
+当然还可以在原数组上修改,连result数组都不用了。
+
+```C++
+class Solution {
+public:
+ vector sortArrayByParityII(vector& A) {
+ int oddIndex = 1;
+ for (int i = 0; i < A.size(); i += 2) {
+ if (A[i] % 2 == 1) { // 在偶数位遇到了奇数
+ while(A[oddIndex] % 2 != 0) oddIndex += 2; // 在奇数位找一个偶数
+ swap(A[i], A[oddIndex]); // 替换
+ }
+ }
+ return A;
+ }
+};
+```
+
+时间复杂度:O(n)
+空间复杂度:O(1)
+
+这里时间复杂度并不是O(n^2),因为偶数位和奇数位都只操作一次,不是n/2 * n/2的关系,而是n/2 + n/2的关系!
+
+
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/0925.长按键入.md b/problems/0925.长按键入.md
new file mode 100644
index 00000000..95b6325a
--- /dev/null
+++ b/problems/0925.长按键入.md
@@ -0,0 +1,113 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 925.长按键入
+
+你的朋友正在使用键盘输入他的名字 name。偶尔,在键入字符 c 时,按键可能会被长按,而字符可能被输入 1 次或多次。
+
+你将会检查键盘输入的字符 typed。如果它对应的可能是你的朋友的名字(其中一些字符可能被长按),那么就返回 True。
+
+示例 1:
+* 输入:name = "alex", typed = "aaleex"
+* 输出:true
+* 解释:'alex' 中的 'a' 和 'e' 被长按。
+
+示例 2:
+* 输入:name = "saeed", typed = "ssaaedd"
+* 输出:false
+* 解释:'e' 一定需要被键入两次,但在 typed 的输出中不是这样。
+
+
+示例 3:
+
+* 输入:name = "leelee", typed = "lleeelee"
+* 输出:true
+
+示例 4:
+
+* 输入:name = "laiden", typed = "laiden"
+* 输出:true
+* 解释:长按名字中的字符并不是必要的。
+
+# 思路
+
+这道题目一看以为是哈希,仔细一看不行,要有顺序。
+
+所以模拟同时遍历两个数组,进行对比就可以了。
+
+对比的时候需要一下几点:
+
+* name[i] 和 typed[j]相同,则i++,j++ (继续向后对比)
+* name[i] 和 typed[j]不相同
+ * 看是不是第一位就不相同了,也就是j如果等于0,那么直接返回false
+ * 不是第一位不相同,就让j跨越重复项,移动到重复项之后的位置,再次比较name[i] 和typed[j]
+ * 如果 name[i] 和 typed[j]相同,则i++,j++ (继续向后对比)
+ * 不相同,返回false
+* 对比完之后有两种情况
+ * name没有匹配完,例如name:"pyplrzzzzdsfa" type:"ppyypllr"
+ * type没有匹配完,例如name:"alex" type:"alexxrrrrssda"
+
+动画如下:
+
+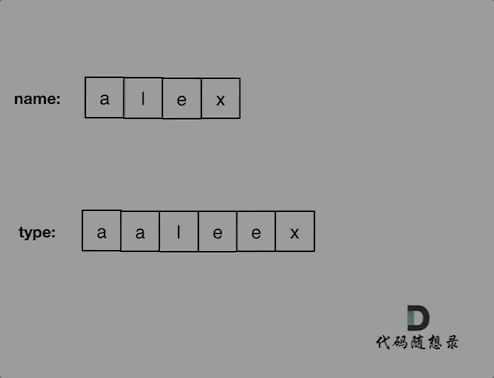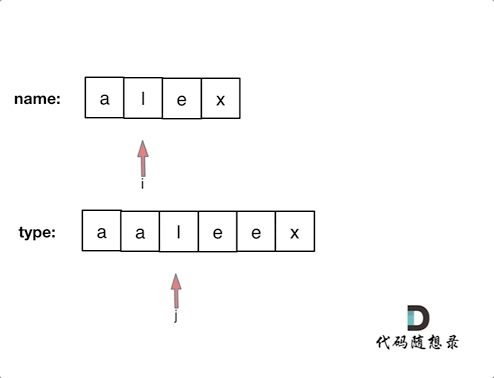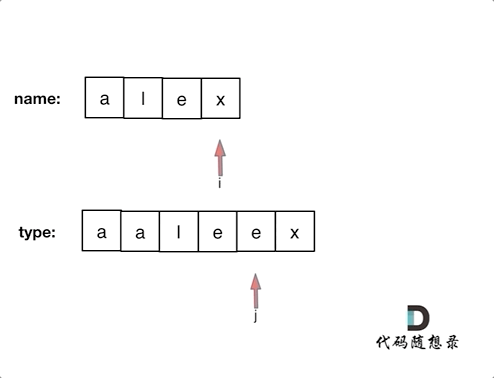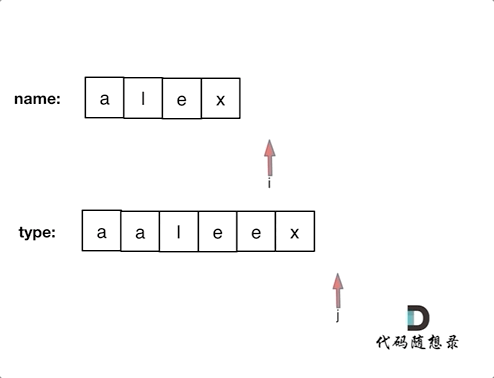 +
+上面的逻辑想清楚了,不难写出如下C++代码:
+
+```C++
+class Solution {
+public:
+ bool isLongPressedName(string name, string typed) {
+ int i = 0, j = 0;
+ while (i < name.size() && j < typed.size()) {
+ if (name[i] == typed[j]) { // 相同则同时向后匹配
+ j++; i++;
+ } else { // 不相同
+ if (j == 0) return false; // 如果是第一位就不相同直接返回false
+ // j跨越重复项,向后移动,同时防止j越界
+ while(j < typed.size() && typed[j] == typed[j - 1]) j++;
+ if (name[i] == typed[j]) { // j跨越重复项之后再次和name[i]匹配
+ j++; i++; // 相同则同时向后匹配
+ }
+ else return false;
+ }
+ }
+ // 说明name没有匹配完,例如 name:"pyplrzzzzdsfa" type:"ppyypllr"
+ if (i < name.size()) return false;
+
+ // 说明type没有匹配完,例如 name:"alex" type:"alexxrrrrssda"
+ while (j < typed.size()) {
+ if (typed[j] == typed[j - 1]) j++;
+ else return false;
+ }
+ return true;
+ }
+};
+
+```
+
+时间复杂度:O(n)
+空间复杂度:O(1)
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/1207.独一无二的出现次数.md b/problems/1207.独一无二的出现次数.md
new file mode 100644
index 00000000..377d9ebf
--- /dev/null
+++ b/problems/1207.独一无二的出现次数.md
@@ -0,0 +1,92 @@
+
+
+上面的逻辑想清楚了,不难写出如下C++代码:
+
+```C++
+class Solution {
+public:
+ bool isLongPressedName(string name, string typed) {
+ int i = 0, j = 0;
+ while (i < name.size() && j < typed.size()) {
+ if (name[i] == typed[j]) { // 相同则同时向后匹配
+ j++; i++;
+ } else { // 不相同
+ if (j == 0) return false; // 如果是第一位就不相同直接返回false
+ // j跨越重复项,向后移动,同时防止j越界
+ while(j < typed.size() && typed[j] == typed[j - 1]) j++;
+ if (name[i] == typed[j]) { // j跨越重复项之后再次和name[i]匹配
+ j++; i++; // 相同则同时向后匹配
+ }
+ else return false;
+ }
+ }
+ // 说明name没有匹配完,例如 name:"pyplrzzzzdsfa" type:"ppyypllr"
+ if (i < name.size()) return false;
+
+ // 说明type没有匹配完,例如 name:"alex" type:"alexxrrrrssda"
+ while (j < typed.size()) {
+ if (typed[j] == typed[j - 1]) j++;
+ else return false;
+ }
+ return true;
+ }
+};
+
+```
+
+时间复杂度:O(n)
+空间复杂度:O(1)
+
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/1207.独一无二的出现次数.md b/problems/1207.独一无二的出现次数.md
new file mode 100644
index 00000000..377d9ebf
--- /dev/null
+++ b/problems/1207.独一无二的出现次数.md
@@ -0,0 +1,92 @@
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 1207.独一无二的出现次数
+
+链接:https://leetcode-cn.com/problems/unique-number-of-occurrences/
+
+给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。
+
+如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。
+
+示例 1:
+* 输入:arr = [1,2,2,1,1,3]
+* 输出:true
+* 解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。
+
+示例 2:
+* 输入:arr = [1,2]
+* 输出:false
+
+示例 3:
+* 输入:arr = [-3,0,1,-3,1,1,1,-3,10,0]
+* 输出:true
+
+提示:
+
+* 1 <= arr.length <= 1000
+* -1000 <= arr[i] <= 1000
+
+
+# 思路
+
+这道题目数组在是哈希法中的经典应用,如果对数组在哈希法中的使用还不熟悉的同学可以看这两篇:[数组在哈希法中的应用](https://mp.weixin.qq.com/s/ffS8jaVFNUWyfn_8T31IdA)和[哈希法:383. 赎金信](https://mp.weixin.qq.com/s/qAXqv--UERmiJNNpuphOUQ)
+
+进而可以学习一下[set在哈希法中的应用](https://mp.weixin.qq.com/s/aMSA5zrp3jJcLjuSB0Es2Q),以及[map在哈希法中的应用](https://mp.weixin.qq.com/s/vaMsLnH-f7_9nEK4Cuu3KQ)
+
+回归本题,**本题强调了-1000 <= arr[i] <= 1000**,那么就可以用数组来做哈希,arr[i]作为哈希表(数组)的下标,那么arr[i]可以是负数,怎么办?负数不能做数组下标。
+
+
+**此时可以定义一个2000大小的数组,例如int count[2002];**,统计的时候,将arr[i]统一加1000,这样就可以统计arr[i]的出现频率了。
+
+题目中要求的是是否有相同的频率出现,那么需要再定义一个哈希表(数组)用来记录频率是否重复出现过,bool fre[1002]; 定义布尔类型的就可以了,**因为题目中强调1 <= arr.length <= 1000,所以哈希表大小为1000就可以了**。
+
+如图所示:
+
+
+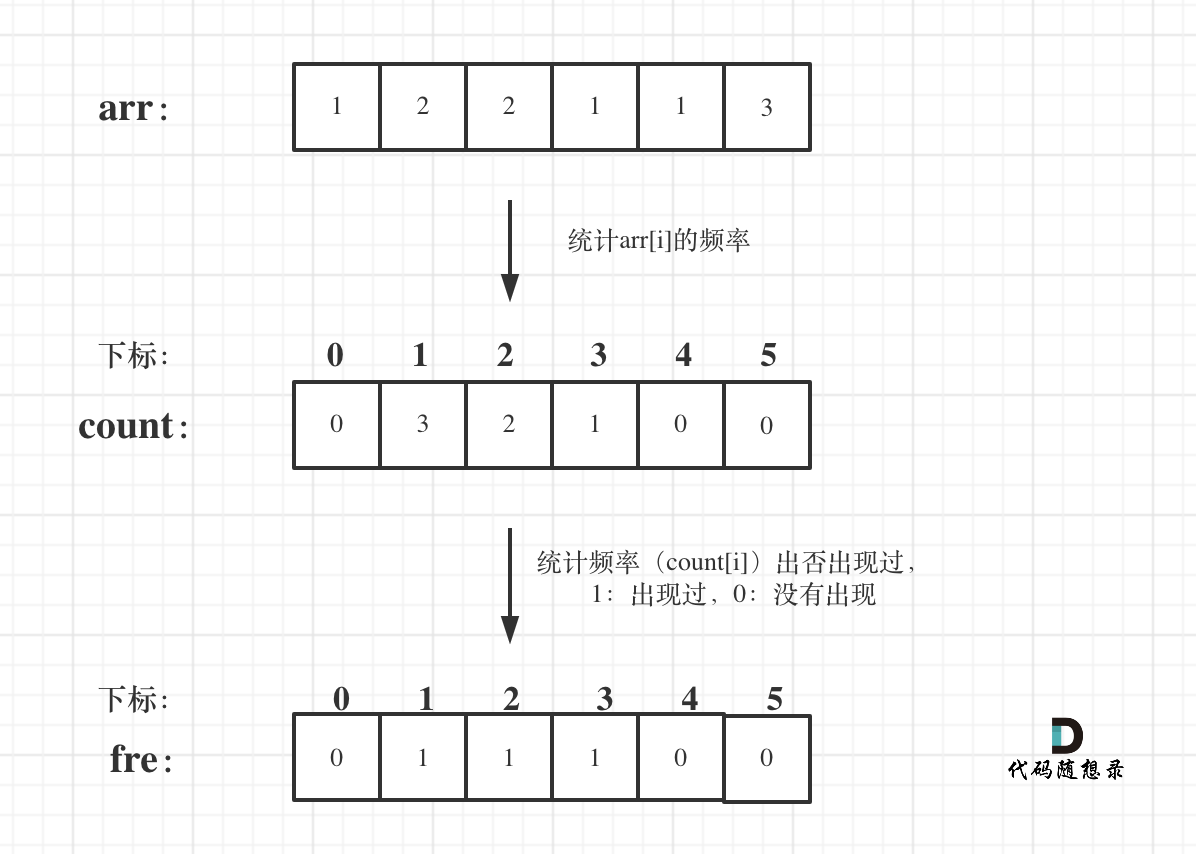 +
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ bool uniqueOccurrences(vector& arr) {
+ int count[2002] = {0}; // 统计数字出现的频率
+ for (int i = 0; i < arr.size(); i++) {
+ count[arr[i] + 1000]++;
+ }
+ bool fre[1002] = {false}; // 看相同频率是否重复出现
+ for (int i = 0; i <= 2000; i++) {
+ if (count[i]) {
+ if (fre[count[i]] == false) fre[count[i]] = true;
+ else return false;
+ }
+ }
+ return true;
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/1356.根据数字二进制下1的数目排序.md b/problems/1356.根据数字二进制下1的数目排序.md
index e8aee055..e464f716 100644
--- a/problems/1356.根据数字二进制下1的数目排序.md
+++ b/problems/1356.根据数字二进制下1的数目排序.md
@@ -1,89 +1,146 @@
-## 题目链接
-https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
+
+
+C++代码如下:
+
+```C++
+class Solution {
+public:
+ bool uniqueOccurrences(vector& arr) {
+ int count[2002] = {0}; // 统计数字出现的频率
+ for (int i = 0; i < arr.size(); i++) {
+ count[arr[i] + 1000]++;
+ }
+ bool fre[1002] = {false}; // 看相同频率是否重复出现
+ for (int i = 0; i <= 2000; i++) {
+ if (count[i]) {
+ if (fre[count[i]] == false) fre[count[i]] = true;
+ else return false;
+ }
+ }
+ return true;
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/1356.根据数字二进制下1的数目排序.md b/problems/1356.根据数字二进制下1的数目排序.md
index e8aee055..e464f716 100644
--- a/problems/1356.根据数字二进制下1的数目排序.md
+++ b/problems/1356.根据数字二进制下1的数目排序.md
@@ -1,89 +1,146 @@
-## 题目链接
-https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 思路
+# 1365.有多少小于当前数字的数字
-这道题其实是考察如何计算一个数的二进制中1的数量。
+题目链接:https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
-我提供两种方法:
+给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
-* 方法一:
+换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。
-朴实无华挨个计算1的数量,最多就是循环n的二进制位数,32位。
+以数组形式返回答案。
+
+
+示例 1:
+输入:nums = [8,1,2,2,3]
+输出:[4,0,1,1,3]
+解释:
+对于 nums[0]=8 存在四个比它小的数字:(1,2,2 和 3)。
+对于 nums[1]=1 不存在比它小的数字。
+对于 nums[2]=2 存在一个比它小的数字:(1)。
+对于 nums[3]=2 存在一个比它小的数字:(1)。
+对于 nums[4]=3 存在三个比它小的数字:(1,2 和 2)。
+
+示例 2:
+输入:nums = [6,5,4,8]
+输出:[2,1,0,3]
+
+示例 3:
+输入:nums = [7,7,7,7]
+输出:[0,0,0,0]
+
+提示:
+* 2 <= nums.length <= 500
+* 0 <= nums[i] <= 100
+
+# 思路
+
+两层for循环暴力查找,时间复杂度明显为O(n^2)。
+
+那么我们来看一下如何优化。
+
+首先要找小于当前数字的数字,那么从小到大排序之后,该数字之前的数字就都是比它小的了。
+
+所以可以定义一个新数组,将数组排个序。
+
+**排序之后,其实每一个数值的下标就代表这前面有几个比它小的了**。
+
+代码如下:
+
+```
+vector vec = nums;
+sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+```
+
+此时用一个哈希表hash(本题可以就用一个数组)来做数值和下标的映射。这样就可以通过数值快速知道下标(也就是前面有几个比它小的)。
+
+此时有一个情况,就是数值相同怎么办?
+
+例如,数组:1 2 3 4 4 4 ,第一个数值4的下标是3,第二个数值4的下标是4了。
+
+这里就需要一个技巧了,**在构造数组hash的时候,从后向前遍历,这样hash里存放的就是相同元素最左面的数值和下标了**。
+代码如下:
```C++
-int bitCount(int n) {
- int count = 0; // 计数器
- while (n > 0) {
- if((n & 1) == 1) count++; // 当前位是1,count++
- n >>= 1 ; // n向右移位
- }
- return count;
+int hash[101];
+for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
}
```
-* 方法二
+最后在遍历原数组nums,用hash快速找到每一个数值 对应的 小于这个数值的个数。存放在将结果存放在另一个数组中。
-这种方法,只循环n的二进制中1的个数次,比方法一高效的多
+代码如下:
```C++
-int bitCount(int n) {
- int count = 0;
- while (n) {
- n &= (n - 1); // 清除最低位的1
- count++;
- }
- return count;
+// 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
}
```
-以计算12的二进制1的数量为例,如图所示:
-
+流程如图:
-下面我就使用方法二,来做这道题目:
+
-## C++代码
+关键地方讲完了,整体C++代码如下:
```C++
class Solution {
-private:
- static int bitCount(int n) { // 计算n的二进制中1的数量
- int count = 0;
- while(n) {
- n &= (n -1); // 清除最低位的1
- count++;
- }
- return count;
- }
- static bool cmp(int a, int b) {
- int bitA = bitCount(a);
- int bitB = bitCount(b);
- if (bitA == bitB) return a < b; // 如果bit中1数量相同,比较数值大小
- return bitA < bitB; // 否则比较bit中1数量大小
- }
public:
- vector sortByBits(vector& arr) {
- sort(arr.begin(), arr.end(), cmp);
- return arr;
+ vector smallerNumbersThanCurrent(vector& nums) {
+ vector vec = nums;
+ sort(vec.begin(), vec.end()); // 从小到大排序之后,元素下标就是小于当前数字的数字
+ int hash[101];
+ for (int i = vec.size() - 1; i >= 0; i--) { // 从后向前,记录 vec[i] 对应的下标
+ hash[vec[i]] = i;
+ }
+ // 此时hash里保存的每一个元素数值 对应的 小于这个数值的个数
+ for (int i = 0; i < nums.size(); i++) {
+ vec[i] = hash[nums[i]];
+ }
+ return vec;
}
};
```
-## 其他语言版本
-
-Java:
-
-Python:
-
-Go:
-
-JavaScript:
+可以排序之后加哈希,时间复杂度为O(nlogn)
+# 其他语言版本
+
+## Java
+
+```java
+```
+
+## Python
+
+```python
+```
+
+## Go
+
+```go
+```
+
+## JavaScript
+
+```js
+```
+
-----------------------
* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
* B站视频:[代码随想录](https://space.bilibili.com/525438321)
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
diff --git a/problems/1365.有多少小于当前数字的数字.md b/problems/1365.有多少小于当前数字的数字.md
index 3026dfca..6324329c 100644
--- a/problems/1365.有多少小于当前数字的数字.md
+++ b/problems/1365.有多少小于当前数字的数字.md
@@ -1,9 +1,16 @@
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
# 1365.有多少小于当前数字的数字
-题目链接:https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits/
+题目链接:https://leetcode-cn.com/problems/how-many-numbers-are-smaller-than-the-current-number/
给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
diff --git a/problems/1382.将二叉搜索树变平衡.md b/problems/1382.将二叉搜索树变平衡.md
new file mode 100644
index 00000000..268f21c5
--- /dev/null
+++ b/problems/1382.将二叉搜索树变平衡.md
@@ -0,0 +1,92 @@
+
+
+
+
+
+
+
+欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
+
+# 1382.将二叉搜索树变平衡
+
+题目地址:https://leetcode-cn.com/problems/balance-a-binary-search-tree/
+
+给你一棵二叉搜索树,请你返回一棵 平衡后 的二叉搜索树,新生成的树应该与原来的树有着相同的节点值。
+
+如果一棵二叉搜索树中,每个节点的两棵子树高度差不超过 1 ,我们就称这棵二叉搜索树是 平衡的 。
+
+如果有多种构造方法,请你返回任意一种。
+
+示例:
+
+
+
+* 输入:root = [1,null,2,null,3,null,4,null,null]
+* 输出:[2,1,3,null,null,null,4]
+* 解释:这不是唯一的正确答案,[3,1,4,null,2,null,null] 也是一个可行的构造方案。
+
+提示:
+
+* 树节点的数目在 1 到 10^4 之间。
+* 树节点的值互不相同,且在 1 到 10^5 之间。
+
+# 思路
+
+这道题目,可以中序遍历把二叉树转变为有序数组,然后在根据有序数组构造平衡二叉搜索树。
+
+建议做这道题之前,先看如下两篇题解:
+* [98.验证二叉搜索树](https://mp.weixin.qq.com/s/8odY9iUX5eSi0eRFSXFD4Q) 学习二叉搜索树的特性
+* [108.将有序数组转换为二叉搜索树](https://mp.weixin.qq.com/s/sy3ygnouaZVJs8lhFgl9mw) 学习如何通过有序数组构造二叉搜索树
+
+这两道题目做过之后,本题分分钟就可以做出来了。
+
+代码如下:
+
+```C++
+class Solution {
+private:
+ vector vec;
+ // 有序树转成有序数组
+ void traversal(TreeNode* cur) {
+ if (cur == nullptr) {
+ return;
+ }
+ traversal(cur->left);
+ vec.push_back(cur->val);
+ traversal(cur->right);
+ }
+ 有序数组转平衡二叉树
+ TreeNode* getTree(vector& nums, int left, int right) {
+ if (left > right) return nullptr;
+ int mid = left + ((right - left) / 2);
+ TreeNode* root = new TreeNode(nums[mid]);
+ root->left = getTree(nums, left, mid - 1);
+ root->right = getTree(nums, mid + 1, right);
+ return root;
+ }
+
+public:
+ TreeNode* balanceBST(TreeNode* root) {
+ traversal(root);
+ return getTree(vec, 0, vec.size() - 1);
+ }
+};
+```
+
+# 其他语言版本
+
+Java:
+
+Python:
+
+Go:
+
+JavaScript:
+
+-----------------------
+* 作者微信:[程序员Carl](https://mp.weixin.qq.com/s/b66DFkOp8OOxdZC_xLZxfw)
+* B站视频:[代码随想录](https://space.bilibili.com/525438321)
+* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+
+
+
diff --git a/problems/周总结/二叉树阶段总结系列一.md b/problems/周总结/二叉树阶段总结系列一.md
index 1527e9a1..dc73672d 100644
--- a/problems/周总结/二叉树阶段总结系列一.md
+++ b/problems/周总结/二叉树阶段总结系列一.md
@@ -152,7 +152,7 @@ public:
如果非要使用递归中序的方式写,也可以,如下代码就可以避免节点左右孩子翻转两次的情况:
-```
+```C++
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
@@ -171,7 +171,7 @@ public:
代码如下:
-```
+```C++
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
@@ -197,7 +197,6 @@ public:
}
};
-
```
为什么这个中序就是可以的呢,因为这是用栈来遍历,而不是靠指针来遍历,避免了递归法中翻转了两次的情况,大家可以画图理解一下,这里有点意思的。
From 877c8ca4188c59e792e78ee8619f7dc1657b0666 Mon Sep 17 00:00:00 2001
From: ylzou
Date: Tue, 27 Jul 2021 16:37:17 +0100
Subject: [PATCH 17/27] =?UTF-8?q?Update=200435.=E6=97=A0=E9=87=8D=E5=8F=A0?=
=?UTF-8?q?=E5=8C=BA=E9=97=B4.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
Java,按左边排序,不管右边顺序。相交的时候取最小的右边。
---
problems/0435.无重叠区间.md | 23 +++++++++++++++++++++++
1 file changed, 23 insertions(+)
diff --git a/problems/0435.无重叠区间.md b/problems/0435.无重叠区间.md
index 37bb0b5d..d32c2ebb 100644
--- a/problems/0435.无重叠区间.md
+++ b/problems/0435.无重叠区间.md
@@ -211,6 +211,29 @@ class Solution {
}
```
+Java:
+按左边排序,不管右边顺序。相交的时候取最小的右边。
+```java
+class Solution {
+ public int eraseOverlapIntervals(int[][] intervals) {
+
+ Arrays.sort(intervals,(a,b)->{
+ return Integer.compare(a[0],b[0]);
+ });
+ int remove = 0;
+ int pre = intervals[0][1];
+ for(int i=1;iintervals[i][0]) {
+ remove++;
+ pre = Math.min(pre,intervals[i][1]);
+ }
+ else pre = intervals[i][1];
+ }
+ return remove;
+ }
+}
+```
+
Python:
```python
class Solution:
From 888eb6b9325e1a9c6c741360b545f5b347a3d93b Mon Sep 17 00:00:00 2001
From: youngyangyang04 <826123027@qq.com>
Date: Wed, 28 Jul 2021 00:49:54 +0800
Subject: [PATCH 18/27] Update
---
README.md | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 2d1d57a3..7a45e233 100644
--- a/README.md
+++ b/README.md
@@ -89,6 +89,7 @@
* [C++面试&C++学习指南知识点整理](https://github.com/youngyangyang04/TechCPP)
* 项目
* [基于跳表的轻量级KV存储引擎](https://github.com/youngyangyang04/Skiplist-CPP)
+ * [Nosql数据库注入攻击系统](https://github.com/youngyangyang04/NoSQLAttack)
* 编程素养
* [看了这么多代码,谈一谈代码风格!](./problems/前序/代码风格.md)
@@ -430,7 +431,8 @@
以上题目是重中之重,大家至少要刷两遍以上才能彻底理解,如果熟练以上题目之后还在找其他题目练手,可以再刷以下题目:
-这些题解,是我平时随便写的,题目很不错,但有的题解我未必写的很详细,后面还会适当补充,所以我还没有将其纳入刷题攻略。等日后我再完善一下,再纳入到刷题攻略。
+这些题目很不错,但有的题目是和刷题攻略类似的,有的题解后面还会适当补充,所以我还没有将其纳入到刷题攻略。一些题解等日后我完善一下,再纳入到刷题攻略。
+
## 数组
From b8b8865c697b0a5c66c36f6bd25a4af4b869e8ad Mon Sep 17 00:00:00 2001
From: youngyangyang04 <826123027@qq.com>
Date: Wed, 28 Jul 2021 12:04:43 +0800
Subject: [PATCH 19/27] Update
---
README.md | 5 +++--
1 file changed, 3 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index 7a45e233..c006fd6b 100644
--- a/README.md
+++ b/README.md
@@ -139,8 +139,9 @@
## 杂谈
-[大半年过去了......](https://mp.weixin.qq.com/s/lubfeistPxBLSQIe5XYg5g)
-[一万录友在B站学算法!](https://mp.weixin.qq.com/s/Vzq4zkMZY7erKeu0fqGLgw)
+* [LeetCode-Master上榜了](https://mp.weixin.qq.com/s/wZRTrA9Rbvgq1yEkSw4vfQ)
+* [大半年过去了......](https://mp.weixin.qq.com/s/lubfeistPxBLSQIe5XYg5g)
+* [一万录友在B站学算法!](https://mp.weixin.qq.com/s/Vzq4zkMZY7erKeu0fqGLgw)
## 数组
From 79fd10a6c498b5a3313738da41e653ccb1ab4580 Mon Sep 17 00:00:00 2001
From: posper
Date: Wed, 28 Jul 2021 14:13:51 +0800
Subject: [PATCH 20/27] =?UTF-8?q?283.=20=E7=A7=BB=E5=8A=A8=E9=9B=B6=20?=
=?UTF-8?q?=E6=B7=BB=E5=8A=A0Java=E7=89=88=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0283.移动零.md | 15 +++++++++++++++
1 file changed, 15 insertions(+)
diff --git a/problems/0283.移动零.md b/problems/0283.移动零.md
index 56f96b2f..8db42a0a 100644
--- a/problems/0283.移动零.md
+++ b/problems/0283.移动零.md
@@ -64,6 +64,21 @@ public:
Java:
+```java
+public void moveZeroes(int[] nums) {
+ int slow = 0;
+ for (int fast = 0; fast < nums.length; fast++) {
+ if (nums[fast] != 0) {
+ nums[slow++] = nums[fast];
+ }
+ }
+ // 后面的元素全变成 0
+ for (int j = slow; j < nums.length; j++) {
+ nums[j] = 0;
+ }
+ }
+```
+
Python:
```python
From 8b15ec147c2027f48f4d211d0f7e1c8c1d26d7c6 Mon Sep 17 00:00:00 2001
From: posper
Date: Wed, 28 Jul 2021 14:21:34 +0800
Subject: [PATCH 21/27] =?UTF-8?q?141.=20=E7=8E=AF=E5=BD=A2=E9=93=BE?=
=?UTF-8?q?=E8=A1=A8=20=E6=B7=BB=E5=8A=A0Java=E7=89=88=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0141.环形链表.md | 17 ++++++++++++++++-
1 file changed, 16 insertions(+), 1 deletion(-)
diff --git a/problems/0141.环形链表.md b/problems/0141.环形链表.md
index 4a40f953..0871202d 100644
--- a/problems/0141.环形链表.md
+++ b/problems/0141.环形链表.md
@@ -14,7 +14,7 @@
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
如果链表中存在环,则返回 true 。 否则,返回 false 。
-
+

# 思路
@@ -74,6 +74,21 @@ public:
## Java
```java
+public class Solution {
+ public boolean hasCycle(ListNode head) {
+ ListNode fast = head;
+ ListNode slow = head;
+ // 空链表、单节点链表一定不会有环
+ while (fast != null && fast.next != null) {
+ fast = fast.next.next; // 快指针,一次移动两步
+ slow = slow.next; // 慢指针,一次移动一步
+ if (fast == slow) { // 快慢指针相遇,表明有环
+ return true;
+ }
+ }
+ return false; // 正常走到链表末尾,表明没有环
+ }
+}
```
## Python
From 3be442c833eb21e1d7084cc44a898bf4ef951627 Mon Sep 17 00:00:00 2001
From: posper
Date: Wed, 28 Jul 2021 14:47:26 +0800
Subject: [PATCH 22/27] =?UTF-8?q?0941.=E6=9C=89=E6=95=88=E7=9A=84=E5=B1=B1?=
=?UTF-8?q?=E8=84=89=E6=95=B0=E7=BB=84=20=E6=B7=BB=E5=8A=A0Java=E7=89=88?=
=?UTF-8?q?=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0941.有效的山脉数组.md | 31 ++++++++++++++++++++++++--
1 file changed, 29 insertions(+), 2 deletions(-)
diff --git a/problems/0941.有效的山脉数组.md b/problems/0941.有效的山脉数组.md
index 6dbc3da2..167cfb1a 100644
--- a/problems/0941.有效的山脉数组.md
+++ b/problems/0941.有效的山脉数组.md
@@ -18,7 +18,7 @@ https://leetcode-cn.com/problems/valid-mountain-array/
C++代码如下:
-```
+```c++
class Solution {
public:
bool validMountainArray(vector& A) {
@@ -38,6 +38,33 @@ public:
}
};
```
+Java 版本如下:
+
+```java
+class Solution {
+ public boolean validMountainArray(int[] arr) {
+ if (arr.length < 3) { // 此时,一定不是有效的山脉数组
+ return false;
+ }
+ // 双指针
+ int left = 0;
+ int right = arr.length - 1;
+ // 注意防止指针越界
+ while (left + 1 < arr.length && arr[left] < arr[left + 1]) {
+ left++;
+ }
+ // 注意防止指针越界
+ while (right > 0 && arr[right] < arr[right - 1]) {
+ right--;
+ }
+ // 如果left或者right都在起始位置,说明不是山峰
+ if (left == right && left != 0 && right != arr.length - 1) {
+ return true;
+ }
+ return false;
+ }
+}
+```
+
如果想系统学一学双指针的话, 可以看一下这篇[双指针法:总结篇!](https://mp.weixin.qq.com/s/_p7grwjISfMh0U65uOyCjA)
-
From 32ffbe028816905ea510472d72d40aae7bd4fb4f Mon Sep 17 00:00:00 2001
From: posper
Date: Wed, 28 Jul 2021 15:08:14 +0800
Subject: [PATCH 23/27] =?UTF-8?q?34.=20=E5=9C=A8=E6=8E=92=E5=BA=8F?=
=?UTF-8?q?=E6=95=B0=E7=BB=84=E4=B8=AD=E6=9F=A5=E6=89=BE=E5=85=83=E7=B4=A0?=
=?UTF-8?q?=E7=9A=84=E7=AC=AC=E4=B8=80=E4=B8=AA=E5=92=8C=E6=9C=80=E5=90=8E?=
=?UTF-8?q?=E4=B8=80=E4=B8=AA=E4=BD=8D=E7=BD=AE=EF=BC=8C=E6=B7=BB=E5=8A=A0?=
=?UTF-8?q?Java=E7=89=88=E6=9C=AC&=E8=A7=A3=E6=B3=952?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
...元素的第一个和最后一个位置.md | 100 +++++++++++++++++-
1 file changed, 98 insertions(+), 2 deletions(-)
diff --git a/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md b/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md
index 04f5eaf7..97b9a9b6 100644
--- a/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md
+++ b/problems/0034.在排序数组中查找元素的第一个和最后一个位置.md
@@ -14,7 +14,7 @@
如果数组中不存在目标值 target,返回 [-1, -1]。
进阶:你可以设计并实现时间复杂度为 O(log n) 的算法解决此问题吗?
-
+
示例 1:
* 输入:nums = [5,7,7,8,8,10], target = 8
@@ -173,8 +173,105 @@ private:
## Java
```java
+class Solution {
+ int[] searchRange(int[] nums, int target) {
+ int leftBorder = getLeftBorder(nums, target);
+ int rightBorder = getRightBorder(nums, target);
+ // 情况一
+ if (leftBorder == -2 || rightBorder == -2) return new int[]{-1, -1};
+ // 情况三
+ if (rightBorder - leftBorder > 1) return new int[]{leftBorder + 1, rightBorder - 1};
+ // 情况二
+ return new int[]{-1, -1};
+ }
+
+ int getRightBorder(int[] nums, int target) {
+ int left = 0;
+ int right = nums.length - 1;
+ int rightBorder = -2; // 记录一下rightBorder没有被赋值的情况
+ while (left <= right) {
+ int middle = left + ((right - left) / 2);
+ if (nums[middle] > target) {
+ right = middle - 1;
+ } else { // 寻找右边界,nums[middle] == target的时候更新left
+ left = middle + 1;
+ rightBorder = left;
+ }
+ }
+ return rightBorder;
+ }
+
+ int getLeftBorder(int[] nums, int target) {
+ int left = 0;
+ int right = nums.length - 1;
+ int leftBorder = -2; // 记录一下leftBorder没有被赋值的情况
+ while (left <= right) {
+ int middle = left + ((right - left) / 2);
+ if (nums[middle] >= target) { // 寻找左边界,nums[middle] == target的时候更新right
+ right = middle - 1;
+ leftBorder = right;
+ } else {
+ left = middle + 1;
+ }
+ }
+ return leftBorder;
+ }
+}
```
+```java
+// 解法2
+// 1、首先,在 nums 数组中二分查找 target;
+// 2、如果二分查找失败,则 binarySearch 返回 -1,表明 nums 中没有 target。此时,searchRange 直接返回 {-1, -1};
+// 3、如果二分查找失败,则 binarySearch 返回 nums 中 为 target 的一个下标。然后,通过左右滑动指针,来找到符合题意的区间
+
+class Solution {
+ public int[] searchRange(int[] nums, int target) {
+ int index = binarySearch(nums, target); // 二分查找
+
+ if (index == -1) { // nums 中不存在 target,直接返回 {-1, -1}
+ return new int[] {-1, -1}; // 匿名数组
+ }
+ // nums 中存在 targe,则左右滑动指针,来找到符合题意的区间
+ int left = index;
+ int right = index;
+ // 向左滑动,找左边界
+ while (left - 1 >= 0 && nums[left - 1] == nums[index]) { // 防止数组越界。逻辑短路,两个条件顺序不能换
+ left--;
+ }
+ // 向左滑动,找右边界
+ while (right + 1 < nums.length && nums[right + 1] == nums[index]) { // 防止数组越界。
+ right++;
+ }
+ return new int[] {left, right};
+ }
+
+ /**
+ * 二分查找
+ * @param nums
+ * @param target
+ */
+ public int binarySearch(int[] nums, int target) {
+ int left = 0;
+ int right = nums.length - 1; // 不变量:左闭右闭区间
+
+ while (left <= right) { // 不变量:左闭右闭区间
+ int mid = left + (right - left) / 2;
+ if (nums[mid] == target) {
+ return mid;
+ } else if (nums[mid] < target) {
+ left = mid + 1;
+ } else {
+ right = mid - 1; // 不变量:左闭右闭区间
+ }
+ }
+ return -1; // 不存在
+ }
+}
+```
+
+
+
## Python
```python
@@ -196,4 +293,3 @@ private:
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
-
From b6424893b3bfc25b8f4824f5ba994641e708b176 Mon Sep 17 00:00:00 2001
From: posper
Date: Wed, 28 Jul 2021 15:25:16 +0800
Subject: [PATCH 24/27] =?UTF-8?q?1207.=E7=8B=AC=E4=B8=80=E6=97=A0=E4=BA=8C?=
=?UTF-8?q?=E7=9A=84=E5=87=BA=E7=8E=B0=E6=AC=A1=E6=95=B0=20=E6=B7=BB?=
=?UTF-8?q?=E5=8A=A0Java=E7=89=88=E6=9C=AC?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/1207.独一无二的出现次数.md | 23 +++++++++++++++++++-
1 file changed, 22 insertions(+), 1 deletion(-)
diff --git a/problems/1207.独一无二的出现次数.md b/problems/1207.独一无二的出现次数.md
index 377d9ebf..c1720430 100644
--- a/problems/1207.独一无二的出现次数.md
+++ b/problems/1207.独一无二的出现次数.md
@@ -77,6 +77,28 @@ public:
Java:
+```java
+class Solution {
+ public boolean uniqueOccurrences(int[] arr) {
+ int[] count = new int[2002];
+ for (int i = 0; i < arr.length; i++) {
+ count[arr[i] + 1000]++; // 防止负数作为下标
+ }
+ boolean[] flag = new boolean[1002]; // 标记相同频率是否重复出现
+ for (int i = 0; i <= 2000; i++) {
+ if (count[i] > 0) {
+ if (flag[count[i]] == false) {
+ flag[count[i]] = true;
+ } else {
+ return false;
+ }
+ }
+ }
+ return true;
+ }
+}
+```
+
Python:
Go:
@@ -89,4 +111,3 @@ JavaScript:
* 知识星球:[代码随想录](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
-
From e7f772afb4425f65d6821667ba78aa3edb52f2fc Mon Sep 17 00:00:00 2001
From: fixme
Date: Wed, 28 Jul 2021 22:49:01 +0800
Subject: [PATCH 25/27] =?UTF-8?q?=E5=A2=9E=E5=8A=A0c=E5=AE=9E=E7=8E=B0?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0203.移除链表元素.md | 31 +++++++++++++++++++++++++++++
1 file changed, 31 insertions(+)
diff --git a/problems/0203.移除链表元素.md b/problems/0203.移除链表元素.md
index cac9f233..ea1d705a 100644
--- a/problems/0203.移除链表元素.md
+++ b/problems/0203.移除链表元素.md
@@ -146,8 +146,39 @@ public:
## 其他语言版本
+C:
+```c
+/**
+ * Definition for singly-linked list.
+ * struct ListNode {
+ * int val;
+ * struct ListNode *next;
+ * };
+ */
+struct ListNode* removeElements(struct ListNode* head, int val){
+ typedef struct ListNode ListNode;
+ ListNode *shead;
+ shead = (ListNode *)malloc(sizeof(ListNode));
+ shead->next = head;
+ ListNode *cur = shead;
+ while(cur->next != NULL){
+ if (cur->next->val == val){
+ ListNode *tmp = cur->next;
+ cur->next = cur->next->next;
+ free(tmp);
+ }
+ else{
+ cur = cur->next;
+ }
+ }
+ head = shead->next;
+ free(shead);
+ return head;
+}
+```
+
Java:
```java
/**
From c75b29bc04c71063266cfbcec97c3398e1d3ef98 Mon Sep 17 00:00:00 2001
From: kok-s0s <2694308562@qq.com>
Date: Wed, 28 Jul 2021 23:46:46 +0800
Subject: [PATCH 26/27] =?UTF-8?q?=E6=8F=90=E4=BE=9BJavaScript=E7=89=88?=
=?UTF-8?q?=E6=9C=AC=E7=9A=84=E3=80=8A=E5=AE=9E=E7=8E=B0strStr()=E3=80=8B?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0028.实现strStr.md | 86 +++++++++++++++++++++++++++++++++++
1 file changed, 86 insertions(+)
diff --git a/problems/0028.实现strStr.md b/problems/0028.实现strStr.md
index 69f8c9d6..fc14a34a 100644
--- a/problems/0028.实现strStr.md
+++ b/problems/0028.实现strStr.md
@@ -808,7 +808,93 @@ func strStr(haystack string, needle string) int {
}
```
+JavaScript版本
+> 前缀表统一减一
+
+```javascript
+/**
+ * @param {string} haystack
+ * @param {string} needle
+ * @return {number}
+ */
+var strStr = function (haystack, needle) {
+ if (needle.length === 0)
+ return 0;
+
+ const getNext = (needle) => {
+ let next = [];
+ let j = -1;
+ next.push(j);
+
+ for (let i = 1; i < needle.length; ++i) {
+ while (j >= 0 && needle[i] !== needle[j + 1])
+ j = next[j];
+ if (needle[i] === needle[j + 1])
+ j++;
+ next.push(j);
+ }
+
+ return next;
+ }
+
+ let next = getNext(needle);
+ let j = -1;
+ for (let i = 0; i < haystack.length; ++i) {
+ while (j >= 0 && haystack[i] !== needle[j + 1])
+ j = next[j];
+ if (haystack[i] === needle[j + 1])
+ j++;
+ if (j === needle.length - 1)
+ return (i - needle.length + 1);
+ }
+
+ return -1;
+};
+```
+
+> 前缀表统一不减一
+
+```javascript
+/**
+ * @param {string} haystack
+ * @param {string} needle
+ * @return {number}
+ */
+var strStr = function (haystack, needle) {
+ if (needle.length === 0)
+ return 0;
+
+ const getNext = (needle) => {
+ let next = [];
+ let j = 0;
+ next.push(j);
+
+ for (let i = 1; i < needle.length; ++i) {
+ while (j > 0 && needle[i] !== needle[j])
+ j = next[j - 1];
+ if (needle[i] === needle[j])
+ j++;
+ next.push(j);
+ }
+
+ return next;
+ }
+
+ let next = getNext(needle);
+ let j = 0;
+ for (let i = 0; i < haystack.length; ++i) {
+ while (j > 0 && haystack[i] !== needle[j])
+ j = next[j - 1];
+ if (haystack[i] === needle[j])
+ j++;
+ if (j === needle.length)
+ return (i - needle.length + 1);
+ }
+
+ return -1;
+};
+```
From 3dcaa43ffe0e6b585e0eb2c372ea7786c1e7cca6 Mon Sep 17 00:00:00 2001
From: kok-s0s <2694308562@qq.com>
Date: Wed, 28 Jul 2021 23:48:27 +0800
Subject: [PATCH 27/27] =?UTF-8?q?=E6=8F=90=E4=BE=9BJavaScript=E7=89=88?=
=?UTF-8?q?=E6=9C=AC=E7=9A=84=E3=80=8A=E9=87=8D=E5=A4=8D=E7=9A=84=E5=AD=90?=
=?UTF-8?q?=E5=AD=97=E7=AC=A6=E4=B8=B2=E3=80=8B?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
problems/0459.重复的子字符串.md | 71 ++++++++++++++++++++++++++
1 file changed, 71 insertions(+)
diff --git a/problems/0459.重复的子字符串.md b/problems/0459.重复的子字符串.md
index f012811d..25b52e86 100644
--- a/problems/0459.重复的子字符串.md
+++ b/problems/0459.重复的子字符串.md
@@ -289,8 +289,79 @@ func repeatedSubstringPattern(s string) bool {
}
```
+JavaScript版本
+> 前缀表统一减一
+```javascript
+/**
+ * @param {string} s
+ * @return {boolean}
+ */
+var repeatedSubstringPattern = function (s) {
+ if (s.length === 0)
+ return false;
+
+ const getNext = (s) => {
+ let next = [];
+ let j = -1;
+
+ next.push(j);
+
+ for (let i = 1; i < s.length; ++i) {
+ while (j >= 0 && s[i] !== s[j + 1])
+ j = next[j];
+ if (s[i] === s[j + 1])
+ j++;
+ next.push(j);
+ }
+
+ return next;
+ }
+
+ let next = getNext(s);
+
+ if (next[next.length - 1] !== -1 && s.length % (s.length - (next[next.length - 1] + 1)) === 0)
+ return true;
+ return false;
+};
+```
+
+> 前缀表统一不减一
+
+```javascript
+/**
+ * @param {string} s
+ * @return {boolean}
+ */
+var repeatedSubstringPattern = function (s) {
+ if (s.length === 0)
+ return false;
+
+ const getNext = (s) => {
+ let next = [];
+ let j = 0;
+
+ next.push(j);
+
+ for (let i = 1; i < s.length; ++i) {
+ while (j > 0 && s[i] !== s[j])
+ j = next[j - 1];
+ if (s[i] === s[j])
+ j++;
+ next.push(j);
+ }
+
+ return next;
+ }
+
+ let next = getNext(s);
+
+ if (next[next.length - 1] !== 0 && s.length % (s.length - next[next.length - 1]) === 0)
+ return true;
+ return false;
+};
+```