mirror of
https://github.com/halfrost/LeetCode-Go.git
synced 2025-07-06 09:23:19 +08:00
Add solution 0609、0692、0890、1048、1442、1738
This commit is contained in:
@ -0,0 +1,23 @@
|
||||
package leetcode
|
||||
|
||||
import "strings"
|
||||
|
||||
func findDuplicate(paths []string) [][]string {
|
||||
cache := make(map[string][]string)
|
||||
for _, path := range paths {
|
||||
parts := strings.Split(path, " ")
|
||||
dir := parts[0]
|
||||
for i := 1; i < len(parts); i++ {
|
||||
bracketPosition := strings.IndexByte(parts[i], '(')
|
||||
content := parts[i][bracketPosition+1 : len(parts[i])-1]
|
||||
cache[content] = append(cache[content], dir+"/"+parts[i][:bracketPosition])
|
||||
}
|
||||
}
|
||||
res := make([][]string, 0, len(cache))
|
||||
for _, group := range cache {
|
||||
if len(group) >= 2 {
|
||||
res = append(res, group)
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
@ -0,0 +1,47 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question609 struct {
|
||||
para609
|
||||
ans609
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para609 struct {
|
||||
paths []string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans609 struct {
|
||||
one [][]string
|
||||
}
|
||||
|
||||
func Test_Problem609(t *testing.T) {
|
||||
|
||||
qs := []question609{
|
||||
|
||||
{
|
||||
para609{[]string{"root/a 1.txt(abcd) 2.txt(efgh)", "root/c 3.txt(abcd)", "root/c/d 4.txt(efgh)", "root 4.txt(efgh)"}},
|
||||
ans609{[][]string{{"root/a/2.txt", "root/c/d/4.txt", "root/4.txt"}, {"root/a/1.txt", "root/c/3.txt"}}},
|
||||
},
|
||||
|
||||
{
|
||||
para609{[]string{"root/a 1.txt(abcd) 2.txt(efgh)", "root/c 3.txt(abcd)", "root/c/d 4.txt(efgh)"}},
|
||||
ans609{[][]string{{"root/a/2.txt", "root/c/d/4.txt"}, {"root/a/1.txt", "root/c/3.txt"}}},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 609------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans609, q.para609
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, findDuplicate(p.paths))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
93
leetcode/0609.Find-Duplicate-File-in-System/README.md
Normal file
93
leetcode/0609.Find-Duplicate-File-in-System/README.md
Normal file
@ -0,0 +1,93 @@
|
||||
# [609. Find Duplicate File in System](https://leetcode.com/problems/find-duplicate-file-in-system/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given a list `paths` of directory info, including the directory path, and all the files with contents in this directory, return *all the duplicate files in the file system in terms of their paths*. You may return the answer in **any order**.
|
||||
|
||||
A group of duplicate files consists of at least two files that have the same content.
|
||||
|
||||
A single directory info string in the input list has the following format:
|
||||
|
||||
- `"root/d1/d2/.../dm f1.txt(f1_content) f2.txt(f2_content) ... fn.txt(fn_content)"`
|
||||
|
||||
It means there are `n` files `(f1.txt, f2.txt ... fn.txt)` with content `(f1_content, f2_content ... fn_content)` respectively in the directory "`root/d1/d2/.../dm"`. Note that `n >= 1` and `m >= 0`. If `m = 0`, it means the directory is just the root directory.
|
||||
|
||||
The output is a list of groups of duplicate file paths. For each group, it contains all the file paths of the files that have the same content. A file path is a string that has the following format:
|
||||
|
||||
- `"directory_path/file_name.txt"`
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: paths = ["root/a 1.txt(abcd) 2.txt(efgh)","root/c 3.txt(abcd)","root/c/d 4.txt(efgh)","root 4.txt(efgh)"]
|
||||
Output: [["root/a/2.txt","root/c/d/4.txt","root/4.txt"],["root/a/1.txt","root/c/3.txt"]]
|
||||
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: paths = ["root/a 1.txt(abcd) 2.txt(efgh)","root/c 3.txt(abcd)","root/c/d 4.txt(efgh)"]
|
||||
Output: [["root/a/2.txt","root/c/d/4.txt"],["root/a/1.txt","root/c/3.txt"]]
|
||||
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= paths.length <= 2 * 104`
|
||||
- `1 <= paths[i].length <= 3000`
|
||||
- `1 <= sum(paths[i].length) <= 5 * 105`
|
||||
- `paths[i]` consist of English letters, digits, `'/'`, `'.'`, `'('`, `')'`, and `' '`.
|
||||
- You may assume no files or directories share the same name in the same directory.
|
||||
- You may assume each given directory info represents a unique directory. A single blank space separates the directory path and file info.
|
||||
|
||||
**Follow up:**
|
||||
|
||||
- Imagine you are given a real file system, how will you search files? DFS or BFS?
|
||||
- If the file content is very large (GB level), how will you modify your solution?
|
||||
- If you can only read the file by 1kb each time, how will you modify your solution?
|
||||
- What is the time complexity of your modified solution? What is the most time-consuming part and memory-consuming part of it? How to optimize?
|
||||
- How to make sure the duplicated files you find are not false positive?
|
||||
|
||||
## 题目大意
|
||||
|
||||
给定一个目录信息列表,包括目录路径,以及该目录中的所有包含内容的文件,您需要找到文件系统中的所有重复文件组的路径。一组重复的文件至少包括二个具有完全相同内容的文件。输入列表中的单个目录信息字符串的格式如下:`"root/d1/d2/.../dm f1.txt(f1_content) f2.txt(f2_content) ... fn.txt(fn_content)"`。这意味着有 n 个文件(`f1.txt, f2.txt ... fn.txt` 的内容分别是 `f1_content, f2_content ... fn_content`)在目录 `root/d1/d2/.../dm` 下。注意:n>=1 且 m>=0。如果 m=0,则表示该目录是根目录。该输出是重复文件路径组的列表。对于每个组,它包含具有相同内容的文件的所有文件路径。文件路径是具有下列格式的字符串:`"directory_path/file_name.txt"`
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 这一题算简单题,考察的是字符串基本操作与 map 的使用。首先通过字符串操作获取目录路径、文件名和文件内容。再使用 map 来寻找重复文件,key 是文件内容,value 是存储路径和文件名的列表。遍历每一个文件,并把它加入 map 中。最后遍历 map,如果一个键对应的值列表的长度大于 1,说明找到了重复文件,可以把这个列表加入到最终答案中。
|
||||
- 这道题有价值的地方在 **Follow up** 中。感兴趣的读者可以仔细想想以下几个问题:
|
||||
1. 假设您有一个真正的文件系统,您将如何搜索文件?广度搜索还是宽度搜索?
|
||||
2. 如果文件内容非常大(GB级别),您将如何修改您的解决方案?
|
||||
3. 如果每次只能读取 1 kb 的文件,您将如何修改解决方案?
|
||||
4. 修改后的解决方案的时间复杂度是多少?其中最耗时的部分和消耗内存的部分是什么?如何优化?
|
||||
5. 如何确保您发现的重复文件不是误报?
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
import "strings"
|
||||
|
||||
func findDuplicate(paths []string) [][]string {
|
||||
cache := make(map[string][]string)
|
||||
for _, path := range paths {
|
||||
parts := strings.Split(path, " ")
|
||||
dir := parts[0]
|
||||
for i := 1; i < len(parts); i++ {
|
||||
bracketPosition := strings.IndexByte(parts[i], '(')
|
||||
content := parts[i][bracketPosition+1 : len(parts[i])-1]
|
||||
cache[content] = append(cache[content], dir+"/"+parts[i][:bracketPosition])
|
||||
}
|
||||
}
|
||||
res := make([][]string, 0, len(cache))
|
||||
for _, group := range cache {
|
||||
if len(group) >= 2 {
|
||||
res = append(res, group)
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,50 @@
|
||||
package leetcode
|
||||
|
||||
import "container/heap"
|
||||
|
||||
func topKFrequent(words []string, k int) []string {
|
||||
m := map[string]int{}
|
||||
for _, word := range words {
|
||||
m[word]++
|
||||
}
|
||||
pq := &PQ{}
|
||||
heap.Init(pq)
|
||||
for w, c := range m {
|
||||
heap.Push(pq, &wordCount{w, c})
|
||||
if pq.Len() > k {
|
||||
heap.Pop(pq)
|
||||
}
|
||||
}
|
||||
res := make([]string, k)
|
||||
for i := k - 1; i >= 0; i-- {
|
||||
wc := heap.Pop(pq).(*wordCount)
|
||||
res[i] = wc.word
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
type wordCount struct {
|
||||
word string
|
||||
cnt int
|
||||
}
|
||||
|
||||
type PQ []*wordCount
|
||||
|
||||
func (pq PQ) Len() int { return len(pq) }
|
||||
func (pq PQ) Swap(i, j int) { pq[i], pq[j] = pq[j], pq[i] }
|
||||
func (pq PQ) Less(i, j int) bool {
|
||||
if pq[i].cnt == pq[j].cnt {
|
||||
return pq[i].word > pq[j].word
|
||||
}
|
||||
return pq[i].cnt < pq[j].cnt
|
||||
}
|
||||
func (pq *PQ) Push(x interface{}) {
|
||||
tmp := x.(*wordCount)
|
||||
*pq = append(*pq, tmp)
|
||||
}
|
||||
func (pq *PQ) Pop() interface{} {
|
||||
n := len(*pq)
|
||||
tmp := (*pq)[n-1]
|
||||
*pq = (*pq)[:n-1]
|
||||
return tmp
|
||||
}
|
||||
@ -0,0 +1,48 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question692 struct {
|
||||
para692
|
||||
ans692
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para692 struct {
|
||||
words []string
|
||||
k int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans692 struct {
|
||||
one []string
|
||||
}
|
||||
|
||||
func Test_Problem692(t *testing.T) {
|
||||
|
||||
qs := []question692{
|
||||
|
||||
{
|
||||
para692{[]string{"i", "love", "leetcode", "i", "love", "coding"}, 2},
|
||||
ans692{[]string{"i", "love"}},
|
||||
},
|
||||
|
||||
{
|
||||
para692{[]string{"the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"}, 4},
|
||||
ans692{[]string{"the", "is", "sunny", "day"}},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 692------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans692, q.para692
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, topKFrequent(p.words, p.k))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
98
leetcode/0692.Top-K-Frequent-Words/README.md
Normal file
98
leetcode/0692.Top-K-Frequent-Words/README.md
Normal file
@ -0,0 +1,98 @@
|
||||
# [692. Top K Frequent Words](https://leetcode.com/problems/top-k-frequent-words/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given a non-empty list of words, return the k most frequent elements.
|
||||
|
||||
Your answer should be sorted by frequency from highest to lowest. If two words have the same frequency, then the word with the lower alphabetical order comes first.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: ["i", "love", "leetcode", "i", "love", "coding"], k = 2
|
||||
Output: ["i", "love"]
|
||||
Explanation: "i" and "love" are the two most frequent words.
|
||||
Note that "i" comes before "love" due to a lower alphabetical order.
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
|
||||
Output: ["the", "is", "sunny", "day"]
|
||||
Explanation: "the", "is", "sunny" and "day" are the four most frequent words,
|
||||
with the number of occurrence being 4, 3, 2 and 1 respectively.
|
||||
```
|
||||
|
||||
**Note:**
|
||||
|
||||
1. You may assume k is always valid, 1 ≤ k ≤ number of unique elements.
|
||||
2. Input words contain only lowercase letters.
|
||||
|
||||
**Follow up:**
|
||||
|
||||
1. Try to solve it in O(n log k) time and O(n) extra space.
|
||||
|
||||
## 题目大意
|
||||
|
||||
给一非空的单词列表,返回前 *k* 个出现次数最多的单词。返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 思路很简单的题。维护一个长度为 k 的最大堆,先按照频率排,如果频率相同再按照字母顺序排。最后输出依次将优先队列里面的元素 pop 出来即可。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
import "container/heap"
|
||||
|
||||
func topKFrequent(words []string, k int) []string {
|
||||
m := map[string]int{}
|
||||
for _, word := range words {
|
||||
m[word]++
|
||||
}
|
||||
pq := &PQ{}
|
||||
heap.Init(pq)
|
||||
for w, c := range m {
|
||||
heap.Push(pq, &wordCount{w, c})
|
||||
if pq.Len() > k {
|
||||
heap.Pop(pq)
|
||||
}
|
||||
}
|
||||
res := make([]string, k)
|
||||
for i := k - 1; i >= 0; i-- {
|
||||
wc := heap.Pop(pq).(*wordCount)
|
||||
res[i] = wc.word
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
type wordCount struct {
|
||||
word string
|
||||
cnt int
|
||||
}
|
||||
|
||||
type PQ []*wordCount
|
||||
|
||||
func (pq PQ) Len() int { return len(pq) }
|
||||
func (pq PQ) Swap(i, j int) { pq[i], pq[j] = pq[j], pq[i] }
|
||||
func (pq PQ) Less(i, j int) bool {
|
||||
if pq[i].cnt == pq[j].cnt {
|
||||
return pq[i].word > pq[j].word
|
||||
}
|
||||
return pq[i].cnt < pq[j].cnt
|
||||
}
|
||||
func (pq *PQ) Push(x interface{}) {
|
||||
tmp := x.(*wordCount)
|
||||
*pq = append(*pq, tmp)
|
||||
}
|
||||
func (pq *PQ) Pop() interface{} {
|
||||
n := len(*pq)
|
||||
tmp := (*pq)[n-1]
|
||||
*pq = (*pq)[:n-1]
|
||||
return tmp
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,32 @@
|
||||
package leetcode
|
||||
|
||||
func findAndReplacePattern(words []string, pattern string) []string {
|
||||
res := make([]string, 0)
|
||||
for _, word := range words {
|
||||
if match(word, pattern) {
|
||||
res = append(res, word)
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func match(w, p string) bool {
|
||||
if len(w) != len(p) {
|
||||
return false
|
||||
}
|
||||
m, used := make(map[uint8]uint8), make(map[uint8]bool)
|
||||
for i := 0; i < len(w); i++ {
|
||||
if v, ok := m[p[i]]; ok {
|
||||
if w[i] != v {
|
||||
return false
|
||||
}
|
||||
} else {
|
||||
if used[w[i]] {
|
||||
return false
|
||||
}
|
||||
m[p[i]] = w[i]
|
||||
used[w[i]] = true
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
@ -0,0 +1,48 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question890 struct {
|
||||
para890
|
||||
ans890
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para890 struct {
|
||||
words []string
|
||||
pattern string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans890 struct {
|
||||
one []string
|
||||
}
|
||||
|
||||
func Test_Problem890(t *testing.T) {
|
||||
|
||||
qs := []question890{
|
||||
|
||||
{
|
||||
para890{[]string{"abc", "deq", "mee", "aqq", "dkd", "ccc"}, "abb"},
|
||||
ans890{[]string{"mee", "aqq"}},
|
||||
},
|
||||
|
||||
{
|
||||
para890{[]string{"a", "b", "c"}, "a"},
|
||||
ans890{[]string{"a", "b", "c"}},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 890------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans890, q.para890
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, findAndReplacePattern(p.words, p.pattern))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
78
leetcode/0890.Find-and-Replace-Pattern/README.md
Normal file
78
leetcode/0890.Find-and-Replace-Pattern/README.md
Normal file
@ -0,0 +1,78 @@
|
||||
# [890. Find and Replace Pattern](https://leetcode.com/problems/find-and-replace-pattern/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given a list of strings `words` and a string `pattern`, return *a list of* `words[i]` *that match* `pattern`. You may return the answer in **any order**.
|
||||
|
||||
A word matches the pattern if there exists a permutation of letters `p` so that after replacing every letter `x` in the pattern with `p(x)`, we get the desired word.
|
||||
|
||||
Recall that a permutation of letters is a bijection from letters to letters: every letter maps to another letter, and no two letters map to the same letter.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: words = ["abc","deq","mee","aqq","dkd","ccc"], pattern = "abb"
|
||||
Output: ["mee","aqq"]
|
||||
Explanation: "mee" matches the pattern because there is a permutation {a -> m, b -> e, ...}.
|
||||
"ccc" does not match the pattern because {a -> c, b -> c, ...} is not a permutation, since a and b map to the same letter.
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: words = ["a","b","c"], pattern = "a"
|
||||
Output: ["a","b","c"]
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= pattern.length <= 20`
|
||||
- `1 <= words.length <= 50`
|
||||
- `words[i].length == pattern.length`
|
||||
- `pattern` and `words[i]` are lowercase English letters.
|
||||
|
||||
## 题目大意
|
||||
|
||||
你有一个单词列表 words 和一个模式 pattern,你想知道 words 中的哪些单词与模式匹配。如果存在字母的排列 p ,使得将模式中的每个字母 x 替换为 p(x) 之后,我们就得到了所需的单词,那么单词与模式是匹配的。(回想一下,字母的排列是从字母到字母的双射:每个字母映射到另一个字母,没有两个字母映射到同一个字母。)返回 words 中与给定模式匹配的单词列表。你可以按任何顺序返回答案。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 按照题目要求,分别映射两个字符串,words 字符串数组中的字符串与 pattern 字符串每个字母做映射。这里用 map 存储。题目还要求不存在 2 个字母映射到同一个字母的情况,所以再增加一个 map,用来判断当前字母是否已经被映射过了。以上 2 个条件都满足即代表模式匹配上了。最终将所有满足模式匹配的字符串输出即可。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func findAndReplacePattern(words []string, pattern string) []string {
|
||||
res := make([]string, 0)
|
||||
for _, word := range words {
|
||||
if match(word, pattern) {
|
||||
res = append(res, word)
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func match(w, p string) bool {
|
||||
if len(w) != len(p) {
|
||||
return false
|
||||
}
|
||||
m, used := make(map[uint8]uint8), make(map[uint8]bool)
|
||||
for i := 0; i < len(w); i++ {
|
||||
if v, ok := m[p[i]]; ok {
|
||||
if w[i] != v {
|
||||
return false
|
||||
}
|
||||
} else {
|
||||
if used[w[i]] {
|
||||
return false
|
||||
}
|
||||
m[p[i]] = w[i]
|
||||
used[w[i]] = true
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,49 @@
|
||||
package leetcode
|
||||
|
||||
import "sort"
|
||||
|
||||
func longestStrChain(words []string) int {
|
||||
sort.Slice(words, func(i, j int) bool { return len(words[i]) < len(words[j]) })
|
||||
poss, res := make([]int, 16+2), 0
|
||||
for i, w := range words {
|
||||
if poss[len(w)] == 0 {
|
||||
poss[len(w)] = i
|
||||
}
|
||||
}
|
||||
dp := make([]int, len(words))
|
||||
for i := len(words) - 1; i >= 0; i-- {
|
||||
dp[i] = 1
|
||||
for j := poss[len(words[i])+1]; j < len(words) && len(words[j]) == len(words[i])+1; j++ {
|
||||
if isPredecessor(words[j], words[i]) {
|
||||
dp[i] = max(dp[i], 1+dp[j])
|
||||
}
|
||||
}
|
||||
res = max(res, dp[i])
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func max(a, b int) int {
|
||||
if a > b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
|
||||
func isPredecessor(long, short string) bool {
|
||||
i, j := 0, 0
|
||||
wasMismatch := false
|
||||
for j < len(short) {
|
||||
if long[i] != short[j] {
|
||||
if wasMismatch {
|
||||
return false
|
||||
}
|
||||
wasMismatch = true
|
||||
i++
|
||||
continue
|
||||
}
|
||||
i++
|
||||
j++
|
||||
}
|
||||
return true
|
||||
}
|
||||
@ -0,0 +1,78 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question1048 struct {
|
||||
para1048
|
||||
ans1048
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para1048 struct {
|
||||
words []string
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans1048 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem1048(t *testing.T) {
|
||||
|
||||
qs := []question1048{
|
||||
|
||||
{
|
||||
para1048{[]string{"a", "b", "ab", "bac"}},
|
||||
ans1048{2},
|
||||
},
|
||||
|
||||
{
|
||||
para1048{[]string{"xbc", "pcxbcf", "xb", "cxbc", "pcxbc"}},
|
||||
ans1048{5},
|
||||
},
|
||||
|
||||
{
|
||||
para1048{[]string{"a", "b", "ba", "bca", "bda", "bdca"}},
|
||||
ans1048{4},
|
||||
},
|
||||
|
||||
{
|
||||
para1048{[]string{"qjcaeymang", "bqiq", "bcntqiqulagurhz", "lyctmomvis", "bdnhym", "crxrdlv", "wo", "kijftxssyqmui", "abtcrjs", "rceecupq", "crxrdclv", "tvwkxrev", "oc", "lrzzcl", "snpzuykyobci", "abbtczrjs", "rpqojpmv",
|
||||
"kbfbcjxgvnb", "uqvhuucupu", "fwoquoih", "ezsuqxunx", "biq", "crxrwdclv", "qoyfqhytzxfp", "aryqceercpaupqm", "tvwxrev", "gchusjxz", "uls", "whb", "natdmc", "jvidsf", "yhyz", "smvsitdbutamn", "gcfsghusjsxiz", "ijpyhk", "tzvqwkmzxruevs",
|
||||
"fwvjxaxrvmfm", "wscxklqmxhn", "velgcy", "lyctomvi", "smvsitbutam", "hfosz", "fuzubrpo", "dfdeidcepshvjn", "twqol", "rpqjpmv", "ijftxssyqmi", "dzuzsainzbsx", "qyzxfp", "tvwkmzxruev", "farfm", "bbwkizqhicip", "wqobtmamvpgluh", "rytspgy",
|
||||
"uqvheuucdupuw", "jcmang", "h", "kijfhtxssyqmui", "twqgolksq", "rtkgopofnykkrl", "smvstbutam", "xkbfbbcjxgvnbq", "feyq", "oyfqhytzxfp", "velgcby", "dmnioxbf", "kbx", "zx", "wscxkqlqmxbhn", "efvcjtgoiga", "jumttwxv", "zux", "z", "smvsitbutamn",
|
||||
"jftxssyqmi", "wnlhsaj", "bbwizqhcp", "yctomv", "oyqyzxfp", "wqhc", "jnnwp", "bcntqiquagurz", "qzx", "kbfbjxn", "dmnixbf", "ukqs", "fey", "ryqceecaupq", "smvlsitzdbutamn", "bdnhm", "lrhtwfosrzq", "nkptknldw", "crxrwdclvx", "abbtcwzrjs",
|
||||
"uqvheuucupu", "abjbtcwbzrjs", "nkmptknldw", "wnulhsbaj", "wnlhsbaj", "wqobtmamvgluh", "jvis", "pcd", "s", "kjuannelajc", "valas", "lrrzzcl", "kjuannelajct", "snyyoc", "jwp", "vbum", "ezuunx", "bcntqiquagur", "vals", "cov", "dfdidcepshvjn",
|
||||
"vvamlasl", "budnhym", "h", "fwxarvfm", "lrhwfosrz", "nkptnldw", "vjhse", "zzeb", "fubrpo", "fkla", "qjulm", "xpdcdxqia", "ucwxwdm", "jvidsfr", "exhc", "kbfbjx", "bcntqiquaur", "fwnoqjuoihe", "ezsruqxuinrpxc", "ec", "dzuzstuacinzbvsx",
|
||||
"cxkqmxhn", "egpveohyvq", "bkcv", "dzuzsaizbx", "jftxssymi", "ycov", "zbvbeai", "ch", "atcrjs", "qjcemang", "tvjhsed", "vamlas", "bundnhym", "li", "wnulfhsbaj", "o", "ijhtpyhkrif", "nyoc", "ov", "ryceecupq", "wjcrjnszipc", "lrhtwfosrz",
|
||||
"tbzngeqcz", "awfotfiqni", "azbw", "o", "gcfghusjsxiz", "uqvheuucdupu", "rypgy", "snpuykyobc", "ckhn", "kbfbcjxgnb", "xkeow", "jvids", "ubnsnusvgmqog", "endjbkjere", "fwarfm", "wvhb", "fwnoqtjuozihe", "jnwp", "awfotfmiyqni", "iv", "ryqceecupq",
|
||||
"y", "qjuelm", "qyzxp", "vsbum", "dnh", "fam", "snpuyyobc", "wqobtmamvglu", "gjpw", "jcemang", "ukqso", "evhlfz", "nad", "bucwxwdm", "xkabfbbcjxgvnbq", "fwnoqjuozihe", "smvsitzdbutamn", "vec", "fos", "abbtcwbzrjs", "uyifxeyq", "kbfbjxgnb",
|
||||
"nyyoc", "kcv", "fbundnhym", "tbzngpeqcz", "yekfvcjtgoiga", "rgjpw", "ezgvhsalfz", "yoc", "ezvhsalfz", "crxdlv", "chusjz", "fwxaxrvfm", "dzuzstuacinzbsx", "bwizqhc", "pdcdx", "dmnioxbmf", "zuunx", "oqyzxfp", "ezsruqxuinxc", "qjcaemang", "gcghusjsxiz", "nktnldw",
|
||||
"qoyfqhytxzxfp", "bwqhc", "btkcvj", "qxpdcdxqia", "kijofhtxssyqmui", "rypy", "helmi", "zkrlexhxbwt", "qobtmamgu", "vhlfz", "rqjpmv", "yhy", "zzembhy", "rjpmv", "jhse", "fosz", "twol", "qbtamu", "nawxxbslyhucqxb", "dzzsaizbx", "dmnijgoxsbmf",
|
||||
"ijhtpyhkr", "yp", "awfotfgmiyqni", "yctov", "hse", "azabw", "aryqceercaupqm", "fuzubrpoa", "ubnswnusvgmqog", "fafm", "i", "ezvhalfz", "aryxqceercpaupqm", "bwizqhcp", "pdcdxq", "wscxkqlqmxhn", "fuubrpo", "fwvxaxrvmfm", "abjbtcwbzrjas", "zx",
|
||||
"rxmiirbxemog", "dfdeidcepshvvjqn", "az", "velc", "zkrlexnhxbwt", "nawxbslyhucqxb", "qjugelm", "ijhtpdyhkrif", "dmixbf", "gcfsghtusjsxiz", "juannlajc", "uqvheuucdupmuw", "rpqojpmgxv", "rpqojpmxv", "xppph", "kjuannellajct", "lrhfosrz", "dmnijoxsbmf",
|
||||
"ckmxhn", "tvijhsed", "dzuzstuainzbsx", "exhvc", "tvwkxruev", "rxmiirbemog", "lhfosz", "fkyla", "tlwqgolksq", "velgcbpy", "bcqiqaur", "xkhfejow", "ezsuqunx", "dmnioxsbmf", "bqiqu", "ijhtpudyhkrif", "xpdcdxqi", "ckh", "nwxbslyhucqxb", "bbwkizqhcip", "pcdx",
|
||||
"dzuzsuainzbsx", "xkbfbcjxgvnbq", "smvsbutm", "ezsruqxuinrxc", "smvlsitzdbutamdn", "am", "tvwkzxruev", "scxkqmxhn", "snpzuykyobc", "ekfvcjtgoiga", "fuzsubrpoa", "trtkgopofnykkrl", "oyqhytzxfp", "kbjx", "ifeyq", "vhl", "xkfeow", "ezgvhsialfz", "velgc", "hb",
|
||||
"zbveai", "gcghusjxz", "twqgolkq", "btkcv", "ryqceercaupq", "bi", "vvamlas", "awfotfmiqni", "abbtcrjs", "jutkqesoh", "xkbfbcjxgvnb", "hli", "ryspgy", "endjjjbkjere", "mvsbum", "ckqmxhn", "ezsruqxunxc", "zzeby", "xhc", "ezvhlfz", "ezsruqxunx", "tzvwkmzxruev",
|
||||
"hlmi", "kbbjx", "uqvhuuupu", "scxklqmxhn", "wqobtmamglu", "xpdcdxq", "qjugelym", "ifxeyq", "bcnqiquaur", "qobtmamglu", "xkabfbbcjxbgvnbq", "fuuzsubrpoa", "tvibjhsed", "oyqhyzxfp", "ijhpyhk", "c", "gcghusjxiz", "exhvoc", "awfotfini", "vhlz", "rtgopofykkrl",
|
||||
"yh", "ypy", "azb", "bwiqhc", "fla", "dmnijgioxsbmf", "chusjxz", "jvjidsfr", "natddmc", "uifxeyq", "x", "tzvqwkmzxruev", "bucwxwdwm", "ckmhn", "zzemby", "rpmv", "bcntqiqulagurz", "fwoqjuoihe", "dzuzsainzbx", "zkrlehxbwt", "kv", "ucwxwm", "ubnswnusvgmdqog",
|
||||
"wol", "endjjbkjere", "natyddmc", "vl", "ukqsoh", "ezuqunx", "exhvovc", "bqiqau", "bqiqaur", "zunx", "pc", "snuyyoc", "a", "lrhfosz", "kbfbjxgn", "rtgopofnykkrl", "hehszegkvse", "smvsbum", "ijhpyhkr", "ijftxssyqmui", "lyctomvis", "juanlajc", "jukqesoh",
|
||||
"xptpph", "fwarvfm", "qbtmamu", "twqgolq", "aryqceercaupq", "qbtmamgu", "rtgopofykkr", "snpuyyoc", "qyzx", "fwvxaxrvfm", "juannelajc", "fwoquoihe", "nadmc", "jumttwxvx", "ijhtpyhkrf", "twqolq", "rpv", "hehszegkuvse", "ls", "tvjhse", "rxmiirbemg",
|
||||
"dfdeidcepshvvjn", "dnhm", "egpeohyvq", "rgnjpw", "bbwkizqhcp", "nadc", "bcqiquaur", "xkhfeow", "smvstbutm", "ukqesoh", "yctomvi"}},
|
||||
ans1048{15},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 1048------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans1048, q.para1048
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, longestStrChain(p.words))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
96
leetcode/1048.Longest-String-Chain/README.md
Normal file
96
leetcode/1048.Longest-String-Chain/README.md
Normal file
@ -0,0 +1,96 @@
|
||||
# [1048. Longest String Chain](https://leetcode.com/problems/longest-string-chain/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given a list of words, each word consists of English lowercase letters.
|
||||
|
||||
Let's say `word1` is a predecessor of `word2` if and only if we can add exactly one letter anywhere in `word1` to make it equal to `word2`. For example, `"abc"` is a predecessor of `"abac"`.
|
||||
|
||||
A *word chain* is a sequence of words `[word_1, word_2, ..., word_k]` with `k >= 1`, where `word_1` is a predecessor of `word_2`, `word_2` is a predecessor of `word_3`, and so on.
|
||||
|
||||
Return the longest possible length of a word chain with words chosen from the given list of `words`.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: words = ["a","b","ba","bca","bda","bdca"]
|
||||
Output: 4
|
||||
Explanation: One of the longest word chain is "a","ba","bda","bdca".
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: words = ["xbc","pcxbcf","xb","cxbc","pcxbc"]
|
||||
Output: 5
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= words.length <= 1000`
|
||||
- `1 <= words[i].length <= 16`
|
||||
- `words[i]` only consists of English lowercase letters.
|
||||
|
||||
## 题目大意
|
||||
|
||||
给出一个单词列表,其中每个单词都由小写英文字母组成。如果我们可以在 word1 的任何地方添加一个字母使其变成 word2,那么我们认为 word1 是 word2 的前身。例如,"abc" 是 "abac" 的前身。词链是单词 [word_1, word_2, ..., word_k] 组成的序列,k >= 1,其中 word_1 是 word_2 的前身,word_2 是 word_3 的前身,依此类推。从给定单词列表 words 中选择单词组成词链,返回词链的最长可能长度。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 从这题的数据规模上分析,可以猜出此题是 DFS 或者 DP 的题。简单暴力的方法是以每个字符串为链条的起点开始枚举之后的字符串,两两判断能否构成满足题意的前身字符串。这种做法包含很多重叠子问题,例如 a 和 b 能构成前身字符串,以 c 为起点的字符串链条可能用到 a 和 b,以 d 为起点的字符串链条也可能用到 a 和 b。顺其自然,考虑用 DP 的思路解题。
|
||||
- 先将 words 字符串数组排序,然后用 poss 数组记录下每种长度字符串的在排序数组中的起始下标。然后逆序往前递推。因为初始条件只能得到以最长字符串为起始的字符串链长度为 1 。每选择一个起始字符串,从它的长度 + 1 的每个字符串 j 开始比较,是否能为其前身字符串。如果能构成前身字符串,那么 dp[i] = max(dp[i], 1+dp[j])。最终递推到下标为 0 的字符串。最终输出整个递推过程中的最大长度即为所求。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
import "sort"
|
||||
|
||||
func longestStrChain(words []string) int {
|
||||
sort.Slice(words, func(i, j int) bool { return len(words[i]) < len(words[j]) })
|
||||
poss, res := make([]int, 16+2), 0
|
||||
for i, w := range words {
|
||||
if poss[len(w)] == 0 {
|
||||
poss[len(w)] = i
|
||||
}
|
||||
}
|
||||
dp := make([]int, len(words))
|
||||
for i := len(words) - 1; i >= 0; i-- {
|
||||
dp[i] = 1
|
||||
for j := poss[len(words[i])+1]; j < len(words) && len(words[j]) == len(words[i])+1; j++ {
|
||||
if isPredecessor(words[j], words[i]) {
|
||||
dp[i] = max(dp[i], 1+dp[j])
|
||||
}
|
||||
}
|
||||
res = max(res, dp[i])
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func max(a, b int) int {
|
||||
if a > b {
|
||||
return a
|
||||
}
|
||||
return b
|
||||
}
|
||||
|
||||
func isPredecessor(long, short string) bool {
|
||||
i, j := 0, 0
|
||||
wasMismatch := false
|
||||
for j < len(short) {
|
||||
if long[i] != short[j] {
|
||||
if wasMismatch {
|
||||
return false
|
||||
}
|
||||
wasMismatch = true
|
||||
i++
|
||||
continue
|
||||
}
|
||||
i++
|
||||
j++
|
||||
}
|
||||
return true
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,21 @@
|
||||
package leetcode
|
||||
|
||||
func countTriplets(arr []int) int {
|
||||
prefix, num, count, total := make([]int, len(arr)), 0, 0, 0
|
||||
for i, v := range arr {
|
||||
num ^= v
|
||||
prefix[i] = num
|
||||
}
|
||||
for i := 0; i < len(prefix)-1; i++ {
|
||||
for k := i + 1; k < len(prefix); k++ {
|
||||
total = prefix[k]
|
||||
if i > 0 {
|
||||
total ^= prefix[i-1]
|
||||
}
|
||||
if total == 0 {
|
||||
count += k - i
|
||||
}
|
||||
}
|
||||
}
|
||||
return count
|
||||
}
|
||||
@ -0,0 +1,62 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question1442 struct {
|
||||
para1442
|
||||
ans1442
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para1442 struct {
|
||||
arr []int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans1442 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem1442(t *testing.T) {
|
||||
|
||||
qs := []question1442{
|
||||
|
||||
{
|
||||
para1442{[]int{2, 3, 1, 6, 7}},
|
||||
ans1442{4},
|
||||
},
|
||||
|
||||
{
|
||||
para1442{[]int{1, 1, 1, 1, 1}},
|
||||
ans1442{10},
|
||||
},
|
||||
|
||||
{
|
||||
para1442{[]int{2, 3}},
|
||||
ans1442{0},
|
||||
},
|
||||
|
||||
{
|
||||
para1442{[]int{1, 3, 5, 7, 9}},
|
||||
ans1442{3},
|
||||
},
|
||||
|
||||
{
|
||||
para1442{[]int{7, 11, 12, 9, 5, 2, 7, 17, 22}},
|
||||
ans1442{8},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 1442------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans1442, q.para1442
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, countTriplets(p.arr))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
@ -0,0 +1,97 @@
|
||||
# [1442. Count Triplets That Can Form Two Arrays of Equal XOR](https://leetcode.com/problems/count-triplets-that-can-form-two-arrays-of-equal-xor/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
Given an array of integers `arr`.
|
||||
|
||||
We want to select three indices `i`, `j` and `k` where `(0 <= i < j <= k < arr.length)`.
|
||||
|
||||
Let's define `a` and `b` as follows:
|
||||
|
||||
- `a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]`
|
||||
- `b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]`
|
||||
|
||||
Note that **^** denotes the **bitwise-xor** operation.
|
||||
|
||||
Return *the number of triplets* (`i`, `j` and `k`) Where `a == b`.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: arr = [2,3,1,6,7]
|
||||
Output: 4
|
||||
Explanation: The triplets are (0,1,2), (0,2,2), (2,3,4) and (2,4,4)
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: arr = [1,1,1,1,1]
|
||||
Output: 10
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: arr = [2,3]
|
||||
Output: 0
|
||||
```
|
||||
|
||||
**Example 4:**
|
||||
|
||||
```
|
||||
Input: arr = [1,3,5,7,9]
|
||||
Output: 3
|
||||
```
|
||||
|
||||
**Example 5:**
|
||||
|
||||
```
|
||||
Input: arr = [7,11,12,9,5,2,7,17,22]
|
||||
Output: 8
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `1 <= arr.length <= 300`
|
||||
- `1 <= arr[i] <= 10^8`
|
||||
|
||||
## 题目大意
|
||||
|
||||
给你一个整数数组 arr 。现需要从数组中取三个下标 i、j 和 k ,其中 (0 <= i < j <= k < arr.length) 。a 和 b 定义如下:
|
||||
|
||||
- a = arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1]
|
||||
- b = arr[j] ^ arr[j + 1] ^ ... ^ arr[k]
|
||||
|
||||
注意:^ 表示 按位异或 操作。请返回能够令 a == b 成立的三元组 (i, j , k) 的数目。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 这一题需要用到 `x^x = 0` 这个异或特性。题目要求 `a == b`,可以等效转化为 `arr[i] ^ arr[i + 1] ^ ... ^ arr[j - 1] ^ arr[j] ^ arr[j + 1] ^ ... ^ arr[k] = 0`,这样 j 相当于可以“忽略”,专注找到所有元素异或结果为 0 的区间 [i,k] 即为答案。利用前缀和的思想,只不过此题非累加和,而是异或。又由 `x^x = 0` 这个异或特性,相同部分异或相当于消除,于是有 `prefix[i,k] = prefix[0,k] ^ prefix[0,i-1]`,找到每一个 `prefix[i,k] = 0` 的 i,k 组合,i < j <= k,那么满足条件的三元组 (i,j,k) 的个数完全取决于 j 的取值范围,(因为 i 和 k 已经固定了),j 的取值范围为 k-i,所以累加所有满足条件的 k-i,输出即为最终答案。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
func countTriplets(arr []int) int {
|
||||
prefix, num, count, total := make([]int, len(arr)), 0, 0, 0
|
||||
for i, v := range arr {
|
||||
num ^= v
|
||||
prefix[i] = num
|
||||
}
|
||||
for i := 0; i < len(prefix)-1; i++ {
|
||||
for k := i + 1; k < len(prefix); k++ {
|
||||
total = prefix[k]
|
||||
if i > 0 {
|
||||
total ^= prefix[i-1]
|
||||
}
|
||||
if total == 0 {
|
||||
count += k - i
|
||||
}
|
||||
}
|
||||
}
|
||||
return count
|
||||
}
|
||||
```
|
||||
@ -0,0 +1,36 @@
|
||||
package leetcode
|
||||
|
||||
import "sort"
|
||||
|
||||
// 解法一 压缩版的前缀和
|
||||
func kthLargestValue(matrix [][]int, k int) int {
|
||||
if len(matrix) == 0 || len(matrix[0]) == 0 {
|
||||
return 0
|
||||
}
|
||||
res, prefixSum := make([]int, 0, len(matrix)*len(matrix[0])), make([]int, len(matrix[0]))
|
||||
for i := range matrix {
|
||||
line := 0
|
||||
for j, v := range matrix[i] {
|
||||
line ^= v
|
||||
prefixSum[j] ^= line
|
||||
res = append(res, prefixSum[j])
|
||||
}
|
||||
}
|
||||
sort.Ints(res)
|
||||
return res[len(res)-k]
|
||||
}
|
||||
|
||||
// 解法二 前缀和
|
||||
func kthLargestValue1(matrix [][]int, k int) int {
|
||||
nums, prefixSum := []int{}, make([][]int, len(matrix)+1)
|
||||
prefixSum[0] = make([]int, len(matrix[0])+1)
|
||||
for i, row := range matrix {
|
||||
prefixSum[i+1] = make([]int, len(matrix[0])+1)
|
||||
for j, val := range row {
|
||||
prefixSum[i+1][j+1] = prefixSum[i+1][j] ^ prefixSum[i][j+1] ^ prefixSum[i][j] ^ val
|
||||
nums = append(nums, prefixSum[i+1][j+1])
|
||||
}
|
||||
}
|
||||
sort.Ints(nums)
|
||||
return nums[len(nums)-k]
|
||||
}
|
||||
@ -0,0 +1,58 @@
|
||||
package leetcode
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
)
|
||||
|
||||
type question1738 struct {
|
||||
para1738
|
||||
ans1738
|
||||
}
|
||||
|
||||
// para 是参数
|
||||
// one 代表第一个参数
|
||||
type para1738 struct {
|
||||
matrix [][]int
|
||||
k int
|
||||
}
|
||||
|
||||
// ans 是答案
|
||||
// one 代表第一个答案
|
||||
type ans1738 struct {
|
||||
one int
|
||||
}
|
||||
|
||||
func Test_Problem1738(t *testing.T) {
|
||||
|
||||
qs := []question1738{
|
||||
|
||||
{
|
||||
para1738{[][]int{{5, 2}, {1, 6}}, 1},
|
||||
ans1738{7},
|
||||
},
|
||||
|
||||
{
|
||||
para1738{[][]int{{5, 2}, {1, 6}}, 2},
|
||||
ans1738{5},
|
||||
},
|
||||
|
||||
{
|
||||
para1738{[][]int{{5, 2}, {1, 6}}, 3},
|
||||
ans1738{4},
|
||||
},
|
||||
|
||||
{
|
||||
para1738{[][]int{{5, 2}, {1, 6}}, 4},
|
||||
ans1738{0},
|
||||
},
|
||||
}
|
||||
|
||||
fmt.Printf("------------------------Leetcode Problem 1738------------------------\n")
|
||||
|
||||
for _, q := range qs {
|
||||
_, p := q.ans1738, q.para1738
|
||||
fmt.Printf("【input】:%v 【output】:%v\n", p, kthLargestValue(p.matrix, p.k))
|
||||
}
|
||||
fmt.Printf("\n\n\n")
|
||||
}
|
||||
111
leetcode/1738.Find-Kth-Largest-XOR-Coordinate-Value/README.md
Normal file
111
leetcode/1738.Find-Kth-Largest-XOR-Coordinate-Value/README.md
Normal file
@ -0,0 +1,111 @@
|
||||
# [1738. Find Kth Largest XOR Coordinate Value](https://leetcode.com/problems/find-kth-largest-xor-coordinate-value/)
|
||||
|
||||
|
||||
## 题目
|
||||
|
||||
You are given a 2D `matrix` of size `m x n`, consisting of non-negative integers. You are also given an integer `k`.
|
||||
|
||||
The **value** of coordinate `(a, b)` of the matrix is the XOR of all `matrix[i][j]` where `0 <= i <= a < m` and `0 <= j <= b < n` **(0-indexed)**.
|
||||
|
||||
Find the `kth` largest value **(1-indexed)** of all the coordinates of `matrix`.
|
||||
|
||||
**Example 1:**
|
||||
|
||||
```
|
||||
Input: matrix = [[5,2],[1,6]], k = 1
|
||||
Output: 7
|
||||
Explanation: The value of coordinate (0,1) is 5 XOR 2 = 7, which is the largest value.
|
||||
```
|
||||
|
||||
**Example 2:**
|
||||
|
||||
```
|
||||
Input: matrix = [[5,2],[1,6]], k = 2
|
||||
Output: 5
|
||||
Explanation:The value of coordinate (0,0) is 5 = 5, which is the 2nd largest value.
|
||||
```
|
||||
|
||||
**Example 3:**
|
||||
|
||||
```
|
||||
Input: matrix = [[5,2],[1,6]], k = 3
|
||||
Output: 4
|
||||
Explanation: The value of coordinate (1,0) is 5 XOR 1 = 4, which is the 3rd largest value.
|
||||
```
|
||||
|
||||
**Example 4:**
|
||||
|
||||
```
|
||||
Input: matrix = [[5,2],[1,6]], k = 4
|
||||
Output: 0
|
||||
Explanation: The value of coordinate (1,1) is 5 XOR 2 XOR 1 XOR 6 = 0, which is the 4th largest value.
|
||||
```
|
||||
|
||||
**Constraints:**
|
||||
|
||||
- `m == matrix.length`
|
||||
- `n == matrix[i].length`
|
||||
- `1 <= m, n <= 1000`
|
||||
- `0 <= matrix[i][j] <= 10^6`
|
||||
- `1 <= k <= m * n`
|
||||
|
||||
## 题目大意
|
||||
|
||||
给你一个二维矩阵 matrix 和一个整数 k ,矩阵大小为 m x n 由非负整数组成。矩阵中坐标 (a, b) 的 值 可由对所有满足 0 <= i <= a < m 且 0 <= j <= b < n 的元素 matrix[i][j](下标从 0 开始计数)执行异或运算得到。请你找出 matrix 的所有坐标中第 k 大的值(k 的值从 1 开始计数)。
|
||||
|
||||
## 解题思路
|
||||
|
||||
- 区间异或结果类比于区间二维前缀和。只不过需要注意 x^x = 0 这一性质。举例:
|
||||
|
||||
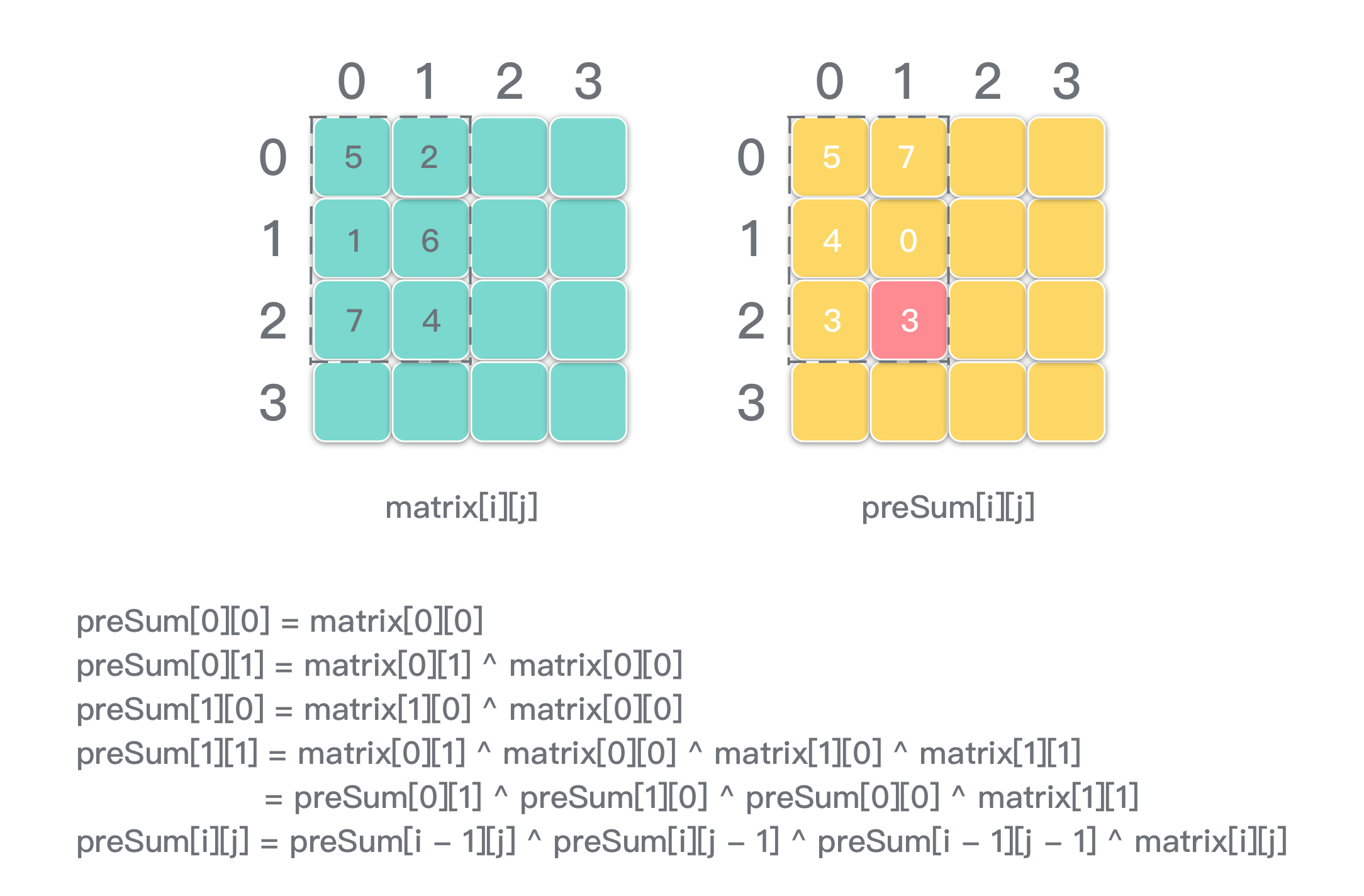
|
||||
|
||||
通过简单推理,可以得出区间二维前缀和 preSum 的递推式。具体代码见解法二。
|
||||
|
||||
- 上面的解法中,preSum 用二维数组计算的。能否再优化空间复杂度,降低成 O(n)?答案是可以的。通过观察可以发现。preSum 可以按照一行一行来生成。先生成 preSum 前一行,下一行生成过程中会用到前一行的信息,异或计算以后,可以覆盖原数据(前一行的信息),对之后的计算没有影响。这个优化空间复杂度的方法和优化 DP 空间复杂度是完全一样的思路和方法。
|
||||
|
||||
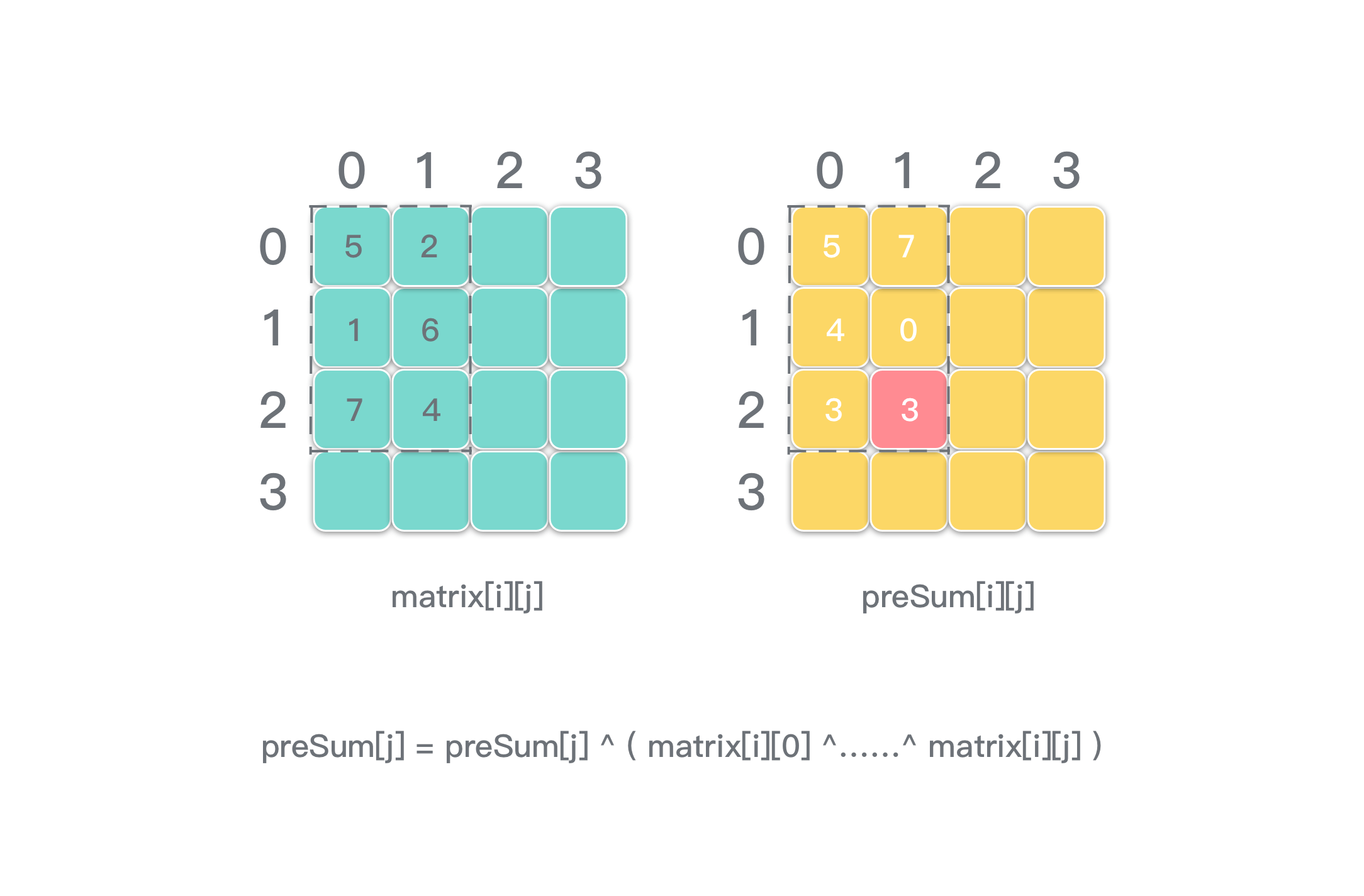
|
||||
|
||||
具体代码见解法一。
|
||||
|
||||
- 计算出了 preSum,还需要考虑如何输出第 k 大的值。有 3 种做法,第一种是排序,第二种是优先队列,第三种是第 215 题中的 O(n) 的 partition 方法。时间复杂度最低的当然是 O(n)。但是经过实际测试,runtime 最优的是排序的方法。所以笔者以下两种方法均采用了排序的方法。
|
||||
|
||||
## 代码
|
||||
|
||||
```go
|
||||
package leetcode
|
||||
|
||||
import "sort"
|
||||
|
||||
// 解法一 压缩版的前缀和
|
||||
func kthLargestValue(matrix [][]int, k int) int {
|
||||
if len(matrix) == 0 || len(matrix[0]) == 0 {
|
||||
return 0
|
||||
}
|
||||
res, prefixSum := make([]int, 0, len(matrix)*len(matrix[0])), make([]int, len(matrix[0]))
|
||||
for i := range matrix {
|
||||
line := 0
|
||||
for j, v := range matrix[i] {
|
||||
line ^= v
|
||||
prefixSum[j] ^= line
|
||||
res = append(res, prefixSum[j])
|
||||
}
|
||||
}
|
||||
sort.Ints(res)
|
||||
return res[len(res)-k]
|
||||
}
|
||||
|
||||
// 解法二 前缀和
|
||||
func kthLargestValue1(matrix [][]int, k int) int {
|
||||
nums, prefixSum := []int{}, make([][]int, len(matrix)+1)
|
||||
prefixSum[0] = make([]int, len(matrix[0])+1)
|
||||
for i, row := range matrix {
|
||||
prefixSum[i+1] = make([]int, len(matrix[0])+1)
|
||||
for j, val := range row {
|
||||
prefixSum[i+1][j+1] = prefixSum[i+1][j] ^ prefixSum[i][j+1] ^ prefixSum[i][j] ^ val
|
||||
nums = append(nums, prefixSum[i+1][j+1])
|
||||
}
|
||||
}
|
||||
sort.Ints(nums)
|
||||
return nums[len(nums)-k]
|
||||
}
|
||||
```
|
||||
Reference in New Issue
Block a user