diff --git a/README.md b/README.md
index f976e12e..d235f96c 100644
--- a/README.md
+++ b/README.md
@@ -25,6 +25,10 @@
 +
+
+支持 Progressive Web Apps 的题解电子书《LeetCode Cookbook》在线阅读 地址
+
+
## Data Structures
> 标识了 ✅ 的专题是完成所有题目了的,没有标识的是还没有做完所有题目的
diff --git a/leetcode/0850.Rectangle-Area-II/README.md b/leetcode/0850.Rectangle-Area-II/README.md
index f21316d0..4bce0939 100755
--- a/leetcode/0850.Rectangle-Area-II/README.md
+++ b/leetcode/0850.Rectangle-Area-II/README.md
@@ -56,7 +56,7 @@ Find the total area covered by all `rectangles` in the plane. Since the answer
需要注意的一点是,**每次 query 的结果并不一定是连续线段**。如上图最右边的图,中间有一段是可能出现镂空的。这种情况看似复杂,其实很简单,因为每段线段树的线段代表的权值高度是不同的,每次 query 最大高度得到的结果已经考虑了中间可能有镂空的情况了。
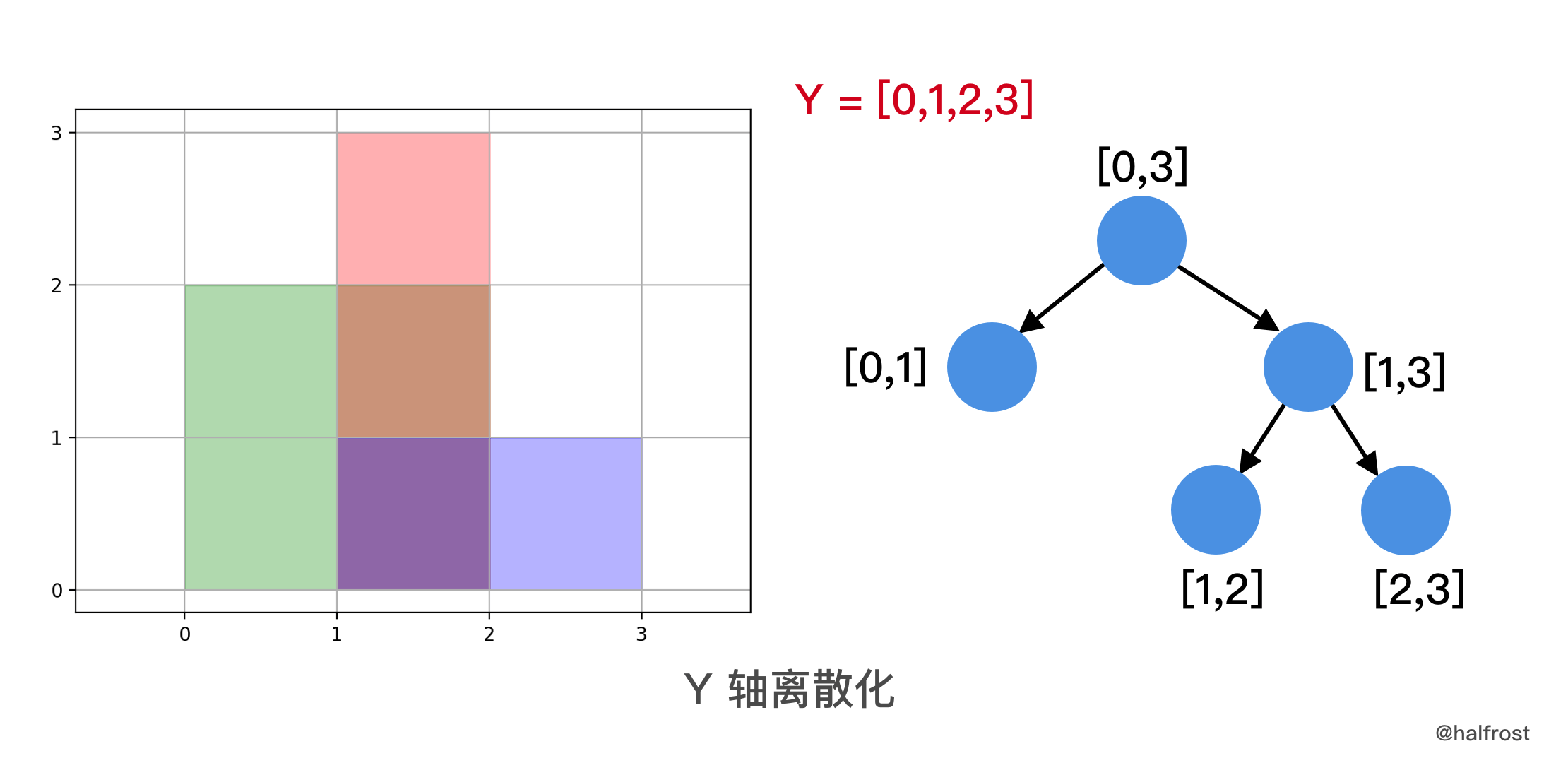
-- 具体做法,先把各个矩形在 Y 轴方向上离散化,这里的**线段树叶子节点不再是一个点了,而是一个区间长度为 1 的区间段。**
+- 具体做法,先把各个矩形在 Y 轴方向上离散化,这里的**线段树叶子节点不再是一个点了,而是一个区间长度为 1 的区间段**。
diff --git a/leetcode/1157.Online-Majority-Element-In-Subarray/README.md b/leetcode/1157.Online-Majority-Element-In-Subarray/README.md
index 6e63f4de..b4d14878 100755
--- a/leetcode/1157.Online-Majority-Element-In-Subarray/README.md
+++ b/leetcode/1157.Online-Majority-Element-In-Subarray/README.md
@@ -73,6 +73,6 @@ Each `query(...)` returns the element in `arr[left], arr[left+1], ..., arr[ri
return segmentItem{candidate: j.candidate, count: j.count - i.count}
}
- 直到根节点的 candidate 和 count 都填满。**注意,这里的 count 并不是元素出现的总次数,而是摩尔投票中坚持没有被投出去的轮数。**当线段树构建完成以后,就可以开始查询任意区间内的众数了,candidate 即为众数。接下来还要确定众数是否满足 `threshold` 的条件。
+ 直到根节点的 candidate 和 count 都填满。**注意,这里的 count 并不是元素出现的总次数,而是摩尔投票中坚持没有被投出去的轮数**。当线段树构建完成以后,就可以开始查询任意区间内的众数了,candidate 即为众数。接下来还要确定众数是否满足 `threshold` 的条件。
- 用一个字典记录每个元素在数组中出现位置的下标,例如上述这个例子,用 map 记录下标:count = map[1:[0 1 4 5] 2:[2 3]]。由于下标在记录过程中是递增的,所以满足二分查找的条件。利用这个字典就可以查出在任意区间内,指定元素出现的次数。例如这里要查找 1 在 [0,5] 区间内出现的个数,那么利用 2 次二分查找,分别找到 `lowerBound` 和 `upperBound`,在 [lowerBound,upperBound) 区间内,都是元素 1 ,那么区间长度即是该元素重复出现的次数,和 `threshold` 比较,如果 ≥ `threshold` 说明找到了答案,否则没有找到就输出 -1 。
diff --git a/website/content/ChapterFour/0850.Rectangle-Area-II.md b/website/content/ChapterFour/0850.Rectangle-Area-II.md
index 1dad9faf..29dbe94e 100755
--- a/website/content/ChapterFour/0850.Rectangle-Area-II.md
+++ b/website/content/ChapterFour/0850.Rectangle-Area-II.md
@@ -56,7 +56,7 @@ Find the total area covered by all `rectangles` in the plane. Since the answer
需要注意的一点是,**每次 query 的结果并不一定是连续线段**。如上图最右边的图,中间有一段是可能出现镂空的。这种情况看似复杂,其实很简单,因为每段线段树的线段代表的权值高度是不同的,每次 query 最大高度得到的结果已经考虑了中间可能有镂空的情况了。
-- 具体做法,先把各个矩形在 Y 轴方向上离散化,这里的**线段树叶子节点不再是一个点了,而是一个区间长度为 1 的区间段。**
+- 具体做法,先把各个矩形在 Y 轴方向上离散化,这里的**线段树叶子节点不再是一个点了,而是一个区间长度为 1 的区间段**。

diff --git a/website/content/ChapterFour/1157.Online-Majority-Element-In-Subarray.md b/website/content/ChapterFour/1157.Online-Majority-Element-In-Subarray.md
index 6d06c5ae..ac7d539b 100755
--- a/website/content/ChapterFour/1157.Online-Majority-Element-In-Subarray.md
+++ b/website/content/ChapterFour/1157.Online-Majority-Element-In-Subarray.md
@@ -73,7 +73,7 @@ Each `query(...)` returns the element in `arr[left], arr[left+1], ..., arr[ri
return segmentItem{candidate: j.candidate, count: j.count - i.count}
}
- 直到根节点的 candidate 和 count 都填满。**注意,这里的 count 并不是元素出现的总次数,而是摩尔投票中坚持没有被投出去的轮数。**当线段树构建完成以后,就可以开始查询任意区间内的众数了,candidate 即为众数。接下来还要确定众数是否满足 `threshold` 的条件。
+ 直到根节点的 candidate 和 count 都填满。**注意,这里的 count 并不是元素出现的总次数,而是摩尔投票中坚持没有被投出去的轮数**。当线段树构建完成以后,就可以开始查询任意区间内的众数了,candidate 即为众数。接下来还要确定众数是否满足 `threshold` 的条件。
- 用一个字典记录每个元素在数组中出现位置的下标,例如上述这个例子,用 map 记录下标:count = map[1:[0 1 4 5] 2:[2 3]]。由于下标在记录过程中是递增的,所以满足二分查找的条件。利用这个字典就可以查出在任意区间内,指定元素出现的次数。例如这里要查找 1 在 [0,5] 区间内出现的个数,那么利用 2 次二分查找,分别找到 `lowerBound` 和 `upperBound`,在 [lowerBound,upperBound) 区间内,都是元素 1 ,那么区间长度即是该元素重复出现的次数,和 `threshold` 比较,如果 ≥ `threshold` 说明找到了答案,否则没有找到就输出 -1 。
diff --git a/website/content/ChapterOne/_index.md b/website/content/ChapterOne/_index.md
index a3b07a15..e0c1e697 100644
--- a/website/content/ChapterOne/_index.md
+++ b/website/content/ChapterOne/_index.md
@@ -36,7 +36,7 @@ type: docs
笔者是一个刚刚入行一年半的 gopher 新人,还请各位大佬多多指点小弟我。大学参加了 3 年 ACM-ICPC,但是由于资质不高,没有拿到一块金牌。所以在算法方面,我对自己的评价算是新手吧。参加 ACM-ICPC 最大的收获是训练了思维能力,这种能力也会运用到生活中。其次是认识了很多国内很聪明的选手,看到了自己和他们的差距。最后,就是那 200 多页,有些自己都没有完全理解的,打印的密密麻麻的算法模板。知识学会了,终身都是自己的,没有学会,那些知识都是身外之物。
-笔者从 2019 年 3 月 25 号开始刷题,到 2020 年 3 月 25 号,整整一年的时间。原计划是每天一题。实际上每天有时候不止一题,最终完成了 500+:
+笔者从 2019 年 3 月 25 号开始刷题,到 2020 年 3 月 25 号,整整一年的时间。原计划是每天一题。实际上每天有时候不止一题,最终完成了 600+:

diff --git a/website/content/_index.md b/website/content/_index.md
index d265c7eb..9daa10df 100644
--- a/website/content/_index.md
+++ b/website/content/_index.md
@@ -36,7 +36,7 @@ type: docs
笔者是一个刚刚入行一年半的 gopher 新人,还请各位大佬多多指点小弟我。大学参加了 3 年 ACM-ICPC,但是由于资质不高,没有拿到一块金牌。所以在算法方面,我对自己的评价算是新手吧。参加 ACM-ICPC 最大的收获是训练了思维能力,这种能力也会运用到生活中。其次是认识了很多国内很聪明的选手,看到了自己和他们的差距。最后,就是那 200 多页,有些自己都没有完全理解的,打印的密密麻麻的算法模板。知识学会了,终身都是自己的,没有学会,那些知识都是身外之物。
-笔者从 2019 年 3 月 25 号开始刷题,到 2020 年 3 月 25 号,整整一年的时间。原计划是每天一题。实际上每天有时候不止一题,最终完成了 500+:
+笔者从 2019 年 3 月 25 号开始刷题,到 2020 年 3 月 25 号,整整一年的时间。原计划是每天一题。实际上每天有时候不止一题,最终完成了 600+:

diff --git a/website/themes/book/static/LeetCode_logo.png b/website/themes/book/static/LeetCode_logo.png
new file mode 100644
index 00000000..b57d2127
Binary files /dev/null and b/website/themes/book/static/LeetCode_logo.png differ
diff --git a/website/themes/book/static/favicon.svg b/website/themes/book/static/favicon.svg
index ab7c5225..2fbfd775 100644
--- a/website/themes/book/static/favicon.svg
+++ b/website/themes/book/static/favicon.svg
@@ -1,7 +1,7 @@
-